一种针对塔吊驾驶员危险行为的目标检测方法
文献发布时间:2024-04-18 20:02:40
技术领域
本发明属于计算机视觉技术领域,具体是一种针对塔吊驾驶员危险行为的目标检测方法。
背景技术
在建筑施工行业,塔式起重机(塔机、塔吊)是大部分建筑工地必备的设备。塔吊具有运行效率很高、操作比较灵活、运转速度比较快等特点,对建筑工地节省建设成本、工地进展效率的提高以及建筑质量等方面都起到巨大的作用。然而,由于塔吊违规超限作业等引起的安全事故频繁发生,造成生命财产的巨大损失。这些安全事故的发生大部分都是因为塔吊驾驶员违规行为,比如在操作过程中抽烟、打电话等。
由于塔吊操作室面积小、位置高等问题,传统的工地安全管理只能通过在地面设计安全条例等方法对驾驶员的行为进行规范。但是这类方法管理成本高、效率低、且无法有效监督驾驶员达到降低事故发生率的目的。
近年来,摄像头[1]、深度学习[2]等新技术的发展为降低事故发生率提供了新的可能。通过在塔吊操作室加装摄像头,工地管理人员在地面上可以对塔吊驾驶员的行为进行监控,对于危险行为持续检测。
目前基于深度学习的目标检测算法分为两大类:通过神经网络产生候选区域,再对候选区域的目标进行分类的二阶段(two stage)算法,比如Fast R-CNN[3]、Faster R-RCNN[4]等;还有通过一个神经网络直接输出目标的位置和类别信息的一阶段(one stage)算法,比如YOLO[5][6]系列和SDD[7]等。
对于工地危险行为,赵江河等[8]在center网络中引入Ciou损失函数解决安全帽定位不准,通过残差链接特征网络和上采样的特征图充分利用推理过程特征图信息,提高安全帽检测的准确度;宋志瑶[9]引入迁移学习实现对工地中遗留物的识别分类,建立工地遗留物识别的模型有效检测出工地遗留物,自动进行报警、提示;但同样在工地安全领域,利用机器学习对于塔吊操作人员是否在操作过程中抽烟、接打电话的研究还是很少。
参考文献:
[1]张静.基于深度学习的目标检测系统在工地中的研究与应用[D].浙江科技学院,2022.DOI:10.27840/d.cnki.gzjkj.2022.000204;
[2]DONG S,WANG P,ABBAS K.A survey on deep learning and itsapplications[J].Computer Science Review,2021,40:100379;
[3]GIRSHICK R.Fast R-CNN[C]//Proceedings of the IEEE InternationalConferenceon Computer Vision,Chile,Dec 13-16,2015.New York:IEEE,2015:1440-1448;
[4]REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-timeobject detection with region proposal networks[J].IEEE Transactions onPattern Analysis and Machine Intelligence,2017,39(6):1137-1149;
[5]Bochkovskiy,A.,Wang,C.,&Liao,H.M.(2020).YOLOv4:Optimal Speed andAccuracy of Object Detection.ArXiv,abs/2004.10934;
[6]Wang,C.,Bochkovskiy,A.,&Liao,H.M.(2022).YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.ArXiv,abs/2207.02696;
[7]LIU W,ANGUELOV D,ERHAN D,et al.SSD:single shot multibox detector[C]//Proceedings of the European Conference on Computer Vision,Netherlands,Oct 10-16,2016.Berlin,Heidelberg:Springer-Verlag,2016:21-37;
[8]赵江河,王海瑞,朱贵富等.改进CenterNet的小目标安全帽检测算法[J].陕西理工大学学报(自然科学版),2023,39(03):40-47;
[9]宋志瑶.面向智慧工地的遗留物检测与识别研究[D].重庆理工大学,2022.DOI:10.27753/d.cnki.gcqgx.2022.000458。
发明内容
本发明针对塔吊驾驶员驾驶场景,公开一种针对塔吊驾驶员危险行为的目标检测方法。该方法通过改进YOLOv7目标检测算法,结合多种成熟的方法,从而达到对塔吊驾驶员危险行为更好的检测效果。
本发明一种针对塔吊驾驶员危险行为的目标检测方法,包括如下步骤:
步骤1:收集塔吊驾驶室操作人员行为图像样本数据,制作数据集;
步骤2:对图像数据进行预处理;
步骤3:通过改进YOLOv7主干网络,输入处理后的图像数据,并对输入图像进行特征提取;
步骤4:通过改进YOLOv7增强网络,融合主干网络提取的图像特征;
步骤5:通过改进YOLOv7预测网络,对塔吊驾驶场景下危险行为小目标(如烟和电话)进行分类和边界框回归;
步骤6:对预测网络的检测结果进行分类和位置预测,输出最终检测结果。
本发明方法中,步骤1所述制作数据集,数据一部分挑选kaggle的cigarettesmoker detection数据集以及阿里天池的吸烟、打电话行为图片数据集,一部分为采集的塔吊驾驶室监控图像,命名为2C(cigarette and cell phone)数据集,并按照6:2:2的比例划分为训练集、测试集、验证集;
数据集中对象包含两类物体,分别是烟头和电话,对应塔吊驾驶员的抽烟和打电话这两类危险行为。
收集到的数据集大部分是小目标,同时分辨率不统一;塔吊驾驶室监控图像由于塔吊驾驶室条件受限,图像存在尺度变化的情况。
步骤2所述图像数据预处理,包括获取图像样本数据,读取图像并进行图像裁剪以及图像去噪,并在YOLOv7原有的mosaic高阶数据增强策略和自适应图像调整策略的基础上加入MixUp数据增强方法。
针对模型检测的塔吊驾驶员危险行为的小目标对象,通过在训练过程中合成新的训练样本,增加训练数据的多样性,提高了模型对小目标的泛化能力。
YOLOv7的主干网络采用独特的ELAN模块和MPC模块提取特征信息。MPC模块将最大池化层和卷积层获得的信息进行拼接。ELAN模块侧重于通过聚合网络加深网络深度,实现在不破坏原始梯度路径的情况下,提高网络的学习能力。这样设计是为了在获得更多的信息的同时简化网络结构。这也导致增加网络对于特征图的计算量,还减弱了网络的表达能力。
本发明方法中,步骤3所述图像特征提取,是改进YOLOv7模型的主干网络实现的,改进模型包括在每次卷积提取特征后嵌入卷积注意力模块和采用四尺度检测。
本发明方法使用卷积注意力模块,其包含两个注意力机制:通道注意力模块CAM和空间注意力模块SAM。
CAM对特征图的不同通道进行建模,计算每个通道的全局平均池化和全局最大池化获取通道级别的信息,然后使用全连接层和激活函数学习通道的权重。
SAM使用多个卷积核对特征图进行不同尺度的卷积操作,然后利用全局平均池化和全局最大池化来捕捉每个位置的空间信息。这些信息经过一系列的操作后被融合在一起,得到最终的空间注意力图,从而提高模型对重要特征的关注度,从而改善模型在检测塔吊驾驶员危险行为小目标任务中的性能,使得网络更能够适应不同的输入数据并提高泛化能力。
所述采用四尺度检测,是在YOLOv7主干网络上添加一个4倍的下采样过程,输入图片经过4倍下采样操作后,得到一个尺寸较大的浅层特征图。
由于网络的层数相对较少,该特征图具有较高的空间分辨率,能够保留输入图像中的细节信息;同时保留了较高分辨率的信息,有助于模型更好地理解输入图像的局部结构,进而提高了模型对于塔吊驾驶员危险行为小目标的检测效果。
本发明方法中,步骤4所述通过改进增强网络,融合主干网络提取的图像特征,具体是,对于塔吊驾驶员危险行为小目标检测的数据集中具有不同尺度的目标或在图像中存在尺度变化的情况,引入数据驱动的金字塔特征融合方式,自适应空间特征融合(ASFF)。
本发明方法中,步骤5所述通过改进YOLOv7预测网络,具体是2C数据集偏向塔吊驾驶员危险行为小目标,同时有部分图片分辨率较低,采用传统卷积易忽略全局信息导致图像边界信息丢失;为提升模型检测性能,引入SPD-Conv层对网络输出部分进行改进,从而减少网络中信息的丢失,提升了对小目标的检测精度;
SPD-Conv由一个空间到深度层SPD跟一个非跨步卷积层(non-stridedconvolution,Conv)构成;
SPD层将原始图像转换技术推广到对CNN内部和整个CNN中的特征图进行下采样;非跨步卷积层尽可能地保留所有判别信息。
本发明方法中,步骤6所述对检测结果进行分类和位置预测,引入SIOU损失函数,通过添加角惩罚成本,减少损失的总自由度,让预测框更快地移动到最近的轴。
本发明目标检测方法,通过改进YOLOv7目标检测算法,结合多种成熟的方法,构建新的目标检测模型,该模型达到更好的检测效果。本发明方法能够有效提高检测效果,方法简单易用,应用性强,尤其在工地安全领域检测塔吊驾驶员危险行为的方面将会有很大的应用。
附图说明
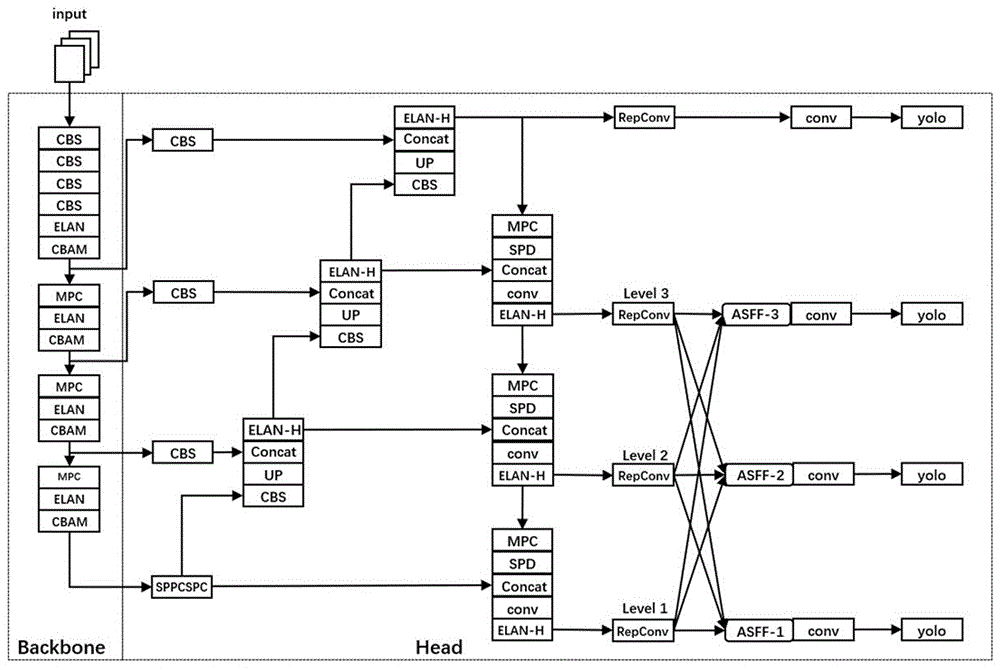
图1是本发明目标检测模型示意图。
具体实施方式
下面结合实施例和附图对本发明内容作进一步的说明,但不是对本发明的限定。
实施例
一种针对塔吊驾驶员危险行为的目标检测方法,检测模型如图1所示,在模型的主干网络引入卷积注意力模块并使用四尺度检测获取图片特征,在模型的预测网络引入SPD-Conv模块提高检测精度,在模型的增强网络引入自适应空间融合策略进行特征融合,检测方法包括如下步骤:
步骤1:收集塔吊驾驶室操作人员行为图像样本数据,制作数据集;
步骤2:对图像数据进行预处理;
步骤3:通过改进YOLOv7主干网络,输入处理后的图像数据,并对输入图像进行特征提取;
步骤4:通过改进YOLOv7增强网络,融合主干网络提取的图像特征;
步骤5:通过改进YOLOv7预测网络,对塔吊驾驶场景下危险行为小目标(如烟和电话)进行分类和边界框回归;
步骤6:对预测网络的检测结果进行分类和位置预测,输出最终检测结果。
步骤1步所述制作数据集,数据一部分挑选kaggle的cigarette smokerdetection数据集以及阿里天池的吸烟打电话行为图片数据集,一部分为采集的塔吊驾驶室监控图像,共计12381张图片,命名为2C(cigarette and cell phone)数据集,按照6:2:2的比例划分为训练集7429张、测试集2476张、验证集2476张;数据集中对象包含两类物体,分别是烟头和电话,对应塔吊驾驶员的抽烟和打电话这两类危险行为。收集到的数据集大部分是小目标,同时分辨率不统一;塔吊驾驶室监控图像由于塔吊驾驶室条件受限,图像存在尺度变化的情况。
步骤2所述图像数据预处理,包括获取图像样本数据,读取图像并按常规方法进行图像去噪、裁剪,并在YOLOv7原有的mosaic高阶数据增强策略和自适应图像调整策略的基础上加入MixUp数据增强方法。
MixUp对于输入的两个样本(例如图像和对应的标签)会随机选择一个权重因子lambda(取值范围为0到1),然后对两个样本的特征和标签进行线性插值,MixUp通过对样本之间进行插值,引入样本之间的相互关系,扩展模型在输入空间中的有效范围;
MixUp的计算公式为:
(x
针对模型检测的塔吊驾驶员危险行为的小目标对象,通过在训练过程中合成新的训练样本,增加训练数据的多样性,提高了模型对小目标的泛化能力。
步骤3所述图像特征提取,是改进YOLOv7模型的主干网络实现的,改进模型包括在每次卷积提取特征后嵌入卷积注意力模块和采用四尺度检测。
本发明方法使用卷积注意力模块,其包含两个注意力机制:通道注意力模块CAM和空间注意力模块SAM。
通道注意力权重M
M
空间注意力权重M
M
其中,F、F
CAM使用平均池化和最大池化来聚合特征图F的空间信息,收集更细的目标特征;随后经过池化操作的两个一维向量进入到全连接层,并使用1×1卷积核进行特征向量间的权值共享;最后,将生成的两个特征向量进行加和操作和sigmoid激活,得到通道注意力M
SAM使用平均池化和最大池化在通道维度上做压缩操作,并将生成的两个二维特征图Concat在一起,得到一个通道数为2的特征图;然后,对拼接后的特征图进行卷积操作;最后经sigmoid激活生成空间注意力权重M
采用四尺度检测,是在YOLOv7主干网络上添加一个4倍的下采样过程,输入图片经过4倍下采样操作后,得到一个尺寸较大的浅层特征图。
由于网络的层数相对较少,该特征图具有较高的空间分辨率,能够保留输入图像中的细节信息;同时保留了较高分辨率的信息,有助于模型更好地理解输入图像的局部结构,进而提高了模型对于塔吊驾驶员危险行为小目标的检测效果。
本发明方法中,步骤4所述通过改进增强网络,融合主干网络提取的图像特征,具体是,对于塔吊驾驶员危险行为小目标检测的数据集中具有不同尺度的目标或在图像中存在尺度变化的情况,引入数据驱动的金字塔特征融合方式,自适应空间特征融合(ASFF)。
引入的ASFF算法结构包括特征缩放和自适应融合两个步骤。ASFF首先对输入图像进行多尺度的卷积处理,得到不同尺度的特征图;然后,针对每个尺度的特征图,ASFF引入一个权重模块,该模块通过学习动态权重来控制特征图的融合比例。ASFF自适应地调整每个尺度特征图的重要性,更好地适应不同的图像内容和任务。
以某一个新的融合特征ASFF-3为例,其中X1,X2,X3分别为来自level1,level2,level3的特征,与为来自不同层的特征乘上权重参数α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,公式为:
对于权重参数α,β和γ,则是通过resize后的level1~level3的特征图经过卷积得到的,并且参数α,β和γ经过concat之后通过softmax使得他们的范围都在[0,1]内并且和为1,参数α计算如公式(6)所示,其他两个参数相似,
通过ASFF处理多尺度信息,提高了塔吊驾驶员危险行为小目标定位的准确性;同时提供更细致的特征表示,改善了模型对小目标的检测性能。
由于在主干网络阶段采用四尺度检测,在现有的4个不同尺度的预测分支进行自适应空间融合会导致算法开销过大,只在原有的3个尺度的预测分支上使用ASFF自适应空间特征融合策略。
本发明方法中,步骤5所述通过改进预测网络,是对YOLOv7的预测网络进行改进,具体是2C数据集偏向塔吊驾驶员危险行为小目标,同时有部分图片分辨率较低,采用传统卷积易忽略全局信息导致图像边界信息丢失;为提升模型检测性能,引入SPD-Conv层对预测网络输出部分进行改进,从而减少网络中信息的丢失,提升了对小目标的检测精度。
对任意给定一个大小为(S,S,C
f
f
…
f
如scale=2时,则获得4个子特征图,每个子映射形状都为f
为了使中间特征层的鉴别特征信息尽可能保留,将SPD层的输出经过含有卷积层C
由于在主干网络阶段增加一个检测分支,用来得到一个大尺寸的浅层特征图,整个网络拥有四个检测分支。这四个分支得到的不同尺寸的特征图在处理过程中需要进行3次concat操作。在这3个concat操作中使用了SPD-Conv构建块进行替代原有的卷积方法,提高了模型对低分辨率图像和小型物体的检测性能。
本发明方法中,步骤6所述对检测结果进行分类和位置预测,引入SIOU损失函数,通过添加角惩罚成本,减少损失的总自由度,让预测框更快地移动到最近的轴。
SIOU损失函数由4个Cost函数组成:IoU损失IoU cost、距离损失distance cost、角度损失Angle cost和形状损失Shape cost;
回归损失函数L
L=W
其中,IoU指的是IoU cost,Δ是指Distance cost,Ω是指Shape cost,L
Focal Loss解决了类别不平衡问题,总损失函数L包含了边界框损失和分类概率损失,在边界框损失部分通过引入角度、距离和形状三个参数,解决了预测框与真实框不匹配的问题,角度向量以矫正预测框的偏差角度,距离相关变量用来解决预测框与真实框的位置偏移问题,引入形状相关变量以规制边界框形状。
本发明针对塔吊驾驶员危险行为的目标检测方法,能够有效提高检测效果。实施例将图像输入尺寸都设置为640×640,所有对比模型均使用2C数据集进行训练、测试和验证。用精确率(Rrecision,P)、召回率(Recall,R)、平均精度(Average Precision,AP)和平均精度均值(mAP)等指标来评估改进YOLOv7模型的性能,以上指标的具体含义如下:
P表示预测出的真实正例占所有预测为正确的比例,用以衡量预测结果中,正例被预测正确的概率。
R表示预测出的真实正例占实际正样本总量的比例,用来反映漏检情况。
mAP表示不同召回率下的精度均值。
在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR曲线,进而计算出一个AP值,而多个类别的AP值的平均就是mAP。
对目标检测效果见下表,表中实验均使用2C数据集。
从表中可以看出,本发明模型在保证持续检测的基础上,检测精度优于其他算法。相较于原始的YOLOv7,准确度提高了4个百分点,mAP也提高了4.6个百分点;相较于目前最新的YOLOv8,准确度也提高了0.7个百分点,mAP提高了1.4个百分点。综合来看,本发明模型能够在检测塔吊驾驶员危险行为目标检测任务中具有更大优势。
本发明目标检测方法简单易用,应用性强,尤其在工地安全领域检测塔吊驾驶员危险行为的方面将会有很大的应用。