分布式水文模型的优化、水文数据的确定方法及装置
文献发布时间:2024-07-23 01:35:21
技术领域
本申请涉及水文技术领域,具体涉及一种分布式水文模型的优化、水文数据的确定方法及装置。
背景技术
陆地水循环在陆地和大气之间进行水分和能量交换,其与人类生存、生态系统演变和社会经济发展密切相关。在全球变化的背景下,气候变化和人类活动对水文循环及水资源产生了重大影响,水文研究正面临诸多挑战。因此,准确模拟变化环境下中国陆地水循环演变规律及时空分布格局对水资源管理及干旱或洪水预警预报和风险评估有重要意义。
分布式水文模型是分析变化环境下陆地水循环响应的关键工具,可以对径流及其他水循环变量进行定量模拟和预测,是人类生活、农业、工业和环境水资源管理的基础,在洪水预报、水资源评价、干旱预警等方面发挥关键作用。
然而,传统的水文模型通常不会考虑季节性的植被动态过程对流域的水循环过程的影响,流域的水循环模拟不够准确。
发明内容
本申请实施例提供一种分布式水文模型的优化、水文数据的确定方法及装置、介质,旨在提高流域的水循环模拟的准确性。
一方面,本申请提供一种分布式水文模型的优化方法,所述方法包括:
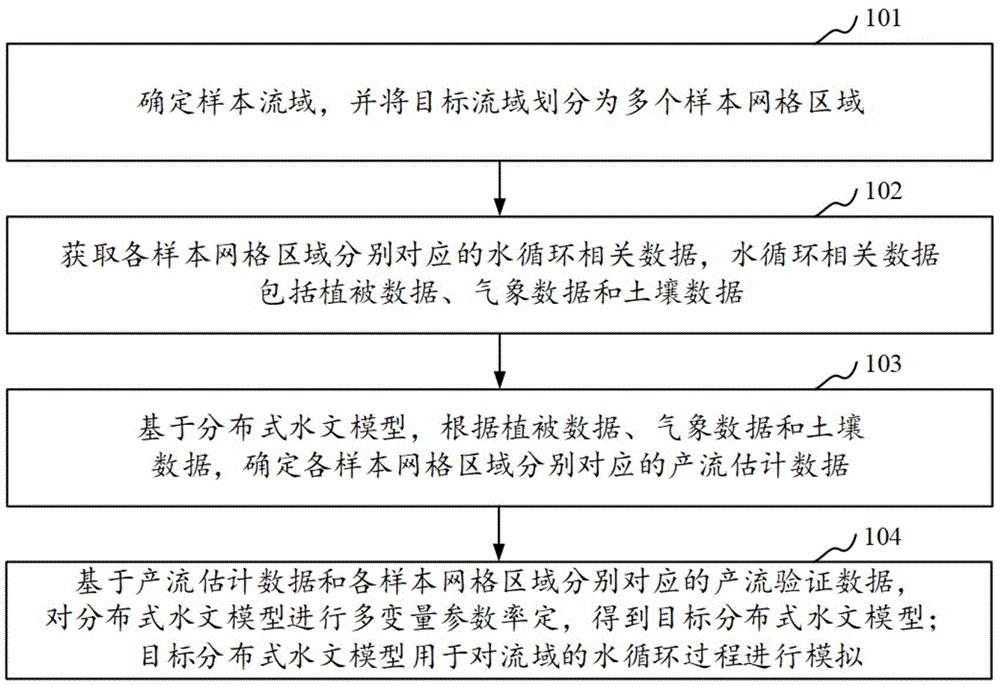
确定样本流域,并将所述样本流域划分为多个样本网格区域;
获取各样本网格区域分别对应的水循环相关数据,所述水循环相关数据包括植被数据、气象数据和土壤数据;
基于分布式水文模型,根据所述植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据;
基于所述产流估计数据和各样本网格区域分别对应的产流验证数据,对所述分布式水文模型进行多变量参数率定,得到目标分布式水文模型;所述目标分布式水文模型用于对流域的水循环过程进行模拟以得到水文数据。
另一方面,本申请实施例提供一种水文数据的确定方法,所述方法包括:
确定待模拟流域,并将所述待模拟流域划分为多个目标网格区域;
针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据;所述输入数据至少包括气象输入数据;
将所述输入数据输入至目标分布式水文模型,以供所述目标分布式水文模型根据所述输入数据对所述待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据;
基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到所述待模拟流域的水文数据。
另一方面,本申请实施例提供一种分布式水文模型的优化装置,所述装置包括:
划分模块,用于确定样本流域,并将所述样本流域划分为多个样本网格区域;
第一获取模块,用于获取各样本网格区域分别对应的水循环相关数据,所述水循环相关数据包括植被数据、气象数据和土壤数据;
估计模块,用于基于分布式水文模型,根据所述植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据;
率定模块,用于基于所述产流估计数据和各样本网格区域分别对应的产流验证数据,对所述分布式水文模型进行多变量参数率定,得到目标分布式水文模型;所述目标分布式水文模型用于对流域的水循环过程进行模拟以得到水文数据。
另一方面,本申请实施例提供一种水文数据的确定装置,所述装置包括:
确定模块,用于确定待模拟流域,并将所述待模拟流域划分为多个目标网格区域;
第二获取模块,用于针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据;所述输入数据至少包括气象输入数据;
模拟模块,用于将所述输入数据输入至目标分布式水文模型,以供所述目标分布式水文模型根据所述输入数据对所述待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据;
汇流模块,用于基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到所述待模拟流域的水文数据。
另一方面,本申请还提供一种计算机设备,所述计算机设备包括:
一个或多个处理器;
存储器;以及
一个或多个应用程序,其中所述一个或多个应用程序被存储于所述存储器中,并配置为由所述处理器执行以实现任一项所述的方法中的步骤。
另一方面,本申请还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器进行加载,以执行任一项所述的方法中的步骤。
另一方面,本申请实施例还提供一种计算机程序产品,包括计算机程序或指令,计算机程序或指令被处理器执行时实现本申请实施例所提供的任一种方法中的步骤。
本申请实施例了提供一种分布式水文模型的优化、水文数据的确定方法及装置、介质及计算机程序产品。其中,分布式水文模型的优化方法包括:确定样本流域,并将样本流域划分为多个样本网格区域;获取各样本网格区域分别对应的水循环相关数据,并基于分布式水文模型,根据上述数据确定各样本网格区域分别对应的产流估计数据,再基于产流估计数据和产流验证数据进行多变量参数率定,得到目标分布式水文模型,由此能够基于目标分布式水文模型对流域的水循环过程进行模拟以得到水文数据。本申请实施例通过提出一种耦合植被动态信息的分布式水文模型优化方法,将基于样本流域的数据输入至分布式水文模型中,通过考虑季节性的植被动态过程对水循环过程的影响,将植被动态信息纳入水文模拟中,为植被变化下的水文响应研究提供了新的工具,从而使得水循环模拟过程更加真实,进而得到更加准确的水文数据。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例中流域的水循环过程在一个实施例中的场景示意图;
图2为本申请实施例中提供的分布式水文模型的优化方法在一个实施例中的流程示意图;
图3为本申请实施例中提供的水文数据的确定方法在一个实施例中的流程示意图;
图4为本申请实施例中提供的分布式水文模型的优化方法和水文数据的确定方法整体流程在一个实施例中的示意图;
图5为本申请实施例中提供的水文数据的确定方法在另一个实施例中的流程示意图;
图6A为本申请实施例中提供的分布式水文模型在一个实施例中的准确性实验结果示意图;
图6B为本申请实施例中提供的分布式水文模型在另一个实施例中的准确性实验结果示意图;
图6C为本申请实施例中提供的分布式水文模型在另一个实施例中的准确性实验结果示意图;
图6D为本申请实施例中提供的分布式水文模型在又一个实施例中的准确性实验结果示意图;
图6E为本申请实施例中提供的分布式水文模型在再一个实施例中的准确性实验结果示意图;
图6F为本申请实施例中提供的分布式水文模型在再一个实施例中的准确性实验结果示意图;
图7为本申请实施例中提供的分布式水文模型在一个实施例中的性能示意图;
图8为本申请实施例中提供的分布式水文模型的优化装置在一个实施例中的结构示意图;
图9为本申请实施例中提供的水文数据的确定装置在一个实施例中的结构示意图;
图10为本申请实施例中提供的计算机设备在一个实施例中的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。在本申请的描述中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个所述特征。在本申请的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。在本申请中,“一些实施例中”一词用来表示“用作例子、例证或说明”。本申请中被描述为“一些实施例中”的任何实施例不一定被解释为比其它实施例更优选或更具优势。
需要说明的是,本申请实施例系统由于是在计算机设备中执行,各计算机设备的处理对象均以数据或信息的形式存在,例如时间,实质为时间信息,可以理解的是,后续实施例中若提及尺寸、数量、位置等,均为对应的数据存在,以便计算机设备进行处理,具体此处不作赘述。
相关技术中,水文模型通常将蒸散发作为一个整体进行计算。但实际上,蒸散发包括了土壤蒸发和植物蒸腾,这两个过程对环境因素有不同的敏感性。其次,传统的水文模型没有考虑植被变化对蒸散发过程的影响,季节性的植被动态过程会在植被冠层和土壤表面之间重新分配能量,从而引起实际蒸散发及其组分的变化。
有鉴于此,本申请实施例提供一种分布式水文模型的优化方法、装置及计算机存储介质,以及水文数据的确定方法、装置及计算机存储介质,通过将分布式水文模型耦合植被动态信息,并细化蒸散发过程,分别对蒸腾过程和蒸发过程进行模拟,并考虑季节因素的影响,从而使得水循环模拟过程更加准确,进而得到更加准确的水文数据。
其中,流域是陆地系统中比较重要的自然集水区域。流域的水循环主要包括降水、植物冠层截留、径流(地表流、壤中流和地下径流)、下渗、蒸发(土壤蒸发、水面蒸发、植物蒸发)等若干环节。这几个环节伴随着水量的转化和能量交换,同时还受到气候变化和季节因素影响。
请参照图1,流域的水循环过程可以描述为:在降水(包括降雨或者降雪)后,水分一部分被植物冠层截留,一部分被植物吸收并通过蒸腾作用散发,还有一部分穿过冠层落入土壤。落入土壤的部分一部分留在地表,形成坡面流并汇入河流,一部分通过土壤蒸发作用蒸发,还有一部分在土壤中进一步下渗,形成地表下的壤中流。而地表下还存在有地下水补给,这部分形成了河流的基流。最终,地表产流、壤中流和基流共同形成了河流的产流。
参照图2,在一些实施例中,分布式水文模型的优化方法包括:
步骤201,确定样本流域,并将样本流域划分为多个样本网格区域。
具体地,在分布式水文模型的构建与优化阶段,计算机设备通过选择一些流域的数据进行模型率定。其中,在此阶段所选取的流域称为样本流域。样本流域可以从已有的流域进行选择,包括但不限于长江流域、松花江流域、珠江流域、黄河流域、内陆河流域、或者淮河流域等中的一种或多种。
计算机设备将样本流域划分为多个网格区域,称为样本网格区域。每个样本网格区域具有独立的水文过程,由此,通过这种划分方式能够使得分布式水文模型能够更好地反应流域内降雨和下垫面要素(如地形、土壤、植被等)控件变化对流域的水循环过程的影响,进而能够使得分布式水文模型更准确地模拟和分析流域内的水文过程。示例性地,计算机设备利用DEM(Digital Elevation Model,数据高程模型)提取流域地图,进而将样本流域划分为多个样本网格区域。
步骤202,获取各样本网格区域分别对应的水循环相关数据,水循环相关数据包括植被数据、气象数据和土壤数据。
具体地,计算机设备可以基于雷达、卫星遥感、地理信息系统(GeographicInformation System,GIS)等系统,获取样本流域对应的测量数据,以作为用于对分布式水文模型进行优化的水循环相关数据。例如,计算机设备获取降水量、降雨量、降雪量、气温等测量数据,并从中进行筛选出部分数据作为水循环相关数据。
其中,水循环相关数据指的是与流域的水循环过程有关的数据,主要分为三大类数据,包括植被数据、气象数据和土壤数据等。其中,植被数据指的是流域水循环过程中与植被有关的数据,通常与降雨过程中穿过植物冠层和被植物冠层截留的雨水量有关。植被数据包括但不限于植被覆盖率、冠层湿润时的降雨阈值、冠层覆盖面积比例、冠层最大蓄水容量、单位叶面积的蓄水容量、单位冠层的平均蒸发率、遥感叶面积指数、参考叶面积指数、地表反照率等中的一种或多种。气象数据指的是流域水循环过程中与气象因素有关的数据,通常包括了影响水的来源、水的流动以及水的流失的相关数据。气象数据包括但不限于空气密度、空气定压比热、水汽压、降雨强度、降水量、降雨量、平均降雨强度、降雪量、气温、风速、大气辐射等中的一种或多种。土壤数据指的是流域水循环过程中与土壤有关的数据,通常与土壤吸收包括但不限于土壤辐射、土壤热通量、土壤含水量、土壤蓄水容量等中的一种或多种。
步骤203,基于分布式水文模型,根据植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据。
具体地,计算机设备将所确定的植被数据、气象数据和土壤数据,输入至预先构建的分布式水文模型中,在耦合有植被动态信息的同时,整合蒸散发过程、截留过程、融雪过程、以及产流过程,能够提高分布式水文模型对流域的水循环过程进行模拟的准确性。
其中,针对任一样本网格区域,计算机设备获取该样本网格区域对应的植被数据、气象数据和土壤数据,并基于分布式水文模型对所输入的数据进行处理,从而输出该样本网格区域对应的产流估计数据。其中,产流估计数据通过由分布式水文模型对位于样本网格区域的流域的产流数据进行估计得到。产流数据包括但不限于地表产流数据、壤中流数据、或者基流数据等中的一种或多种。
步骤204,基于产流估计数据和各样本网格区域分别对应的产流验证数据,对分布式水文模型进行多变量参数率定,得到目标分布式水文模型。
具体地,针对任一样本网格区域,计算机设备获取与该样本网格区域对应的产流验证数据。其中,产流验证数据指的是位于样本网格区域的流域经过实际测量得到的产流数据。产流验证数据包括但不限于来自水文站的径流测量数据、网格实际产流数据等中的一种或多种。
针对任一样本网格区域,计算机设备将该样本网格区域对应的产流估计数据和产流验证数据进行比对,进而根据比对结果对该分布式水文模型进行参数率定,得到率定好的分布式水分模型,称为目标分布式水文模型。
在一些实施例中,计算机设备基于产流估计数据和各样本网格区域分别对应的产流验证数据,对分布式水文模型进行多变量参数率定,得到目标分布式水文模型,包括:针对任一样本网格区域,获取所针对的样本网格区域对应的产流估计数据与产流验证数据之间的数据差值;数据差值至少包括分别对应于地表产流类型、壤中流类型、或者基流类型中一种的数据差值;调整分布式水文模型的模型参数,并返回至步骤203执行,直至数据差值小于预设阈值,得到目标分布式水文模型。
示例性地,计算机设备采用多变量率定方式对分布式水文模型进行多变量参数率定,以得到目标分布式水文模型。在一些实施例中,计算机设备对分布式水文模型进行多变量参数率定之前,还包括:确定每类水循环相关数据分别对应的目标关键系数。每类水循环相关数据的关键系数表示了该类水文数据对分布式水文模型进行流域的水循环模拟过程的重要程度。对应地,计算机设备基于分布式水文模型,根据植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据,包括:基于分布式水文模型,根据植被数据、气象数据、土壤数据、以及每类水循环相关数据各自对应的目标关键系数,确定各样本网格区域分别对应的产流估计数据。
在一些实施例中,针对任一样本网格区域,计算机设备确定每类水循环相关数据分别对应的关键系数,包括:针对任一类水循环相关数据,确定所针对的类别对应的初始关键系数;基于分布式水文模型,根据植被数据、气象数据、土壤数据、以及初始关键系数,确定所针对的样本网格区域的产流估计数据;获取产流估计数据与产流验证数据之间的数据差值;对所针对的类别对应的关键系数进行调整,并重新计算得到数据差值;根据数据差值在关键系数调整前后的变化幅度,确定所针对的类别对应的目标关键系数。其中,数据差值在关键系数调整前后的变化幅度越大,所针对的类别对应的目标关键系数越大。示例性地,每类水循环相关数据的初始的关键系数相同。
本申请实施例提供的分布式水文模型的优化方法,通过确定样本流域,并将样本流域划分为多个样本网格区域,再分别获取各样本网格区域各自对应的植被数据、气象数据和土壤数据,基于分布式水文模型对这些数据进行处理,进而输出各样本网格区域分别对应的产流估计数据,进而根据产流估计数据和产流验证数据,对分布式水文模型进行多变量参数率定,最终得到目标分布式水文模型。由此,即可将目标分布式水文模型用于对水循环过程进行模拟以得到水文数据。本申请实施例通过提出一种耦合植被动态信息的分布式水文模型优化方法,将基于样本流域的数据输入至分布式水文模型中,通过考虑季节性的植被动态过程对水循环过程的影响,将植被动态信息纳入水文模拟中,为植被变化下的水文响应研究提供了新的工具,从而使得水循环模拟过程更加真实,进而得到更加准确的水文数据。此外,上述目标分布式水文模型可以应用在各种水文模拟场景中,适用性较广。
在一些实施例中,基于分布式水文模型,根据植被数据、气象数据和土壤数据,确定各网格区域分别对应的产流估计数据,包括:
步骤2031,基于分布式水文模型,针对任一样本网格区域,根据所对应的植被数据、气象数据和土壤数据,对植物蒸腾和土壤蒸发过程进行模拟,得到蒸散发数据。
具体地,计算机设备针对任一样本网格区域,根据该样本网格区域对应的植被数据、气象数据和土壤数据,将其输入至分布式水文模型中,由分布式水分模型对水循环过程进行模拟,从而得到该样本网格区域对应的产流估计数据。其中,水循环过程包括但不限于降雨过程、降雪过程、植物蒸腾过程、以及土壤蒸发过程等中的一种或多种。
针对任一样本网格区域,计算机设备根据该样本网格区域对应的植被数据、气象数据和土壤数据,通过对植物蒸腾和土壤蒸发过程进行模拟,得到蒸散发数据。蒸散发数据包括蒸散发量等。蒸散发量可以表示为植物蒸腾量和土壤蒸发量之和。示例性地,蒸散发量可以通过如下公式(1)表示:
ET=E
其中,ET表示蒸散发量;E
步骤2032,在目标处理模式下对气象数据进行处理,得到雨雪数据;目标处理模式为降雨模式或降雪模式。
考虑到季节因素对水循环过程带来的影响,本申请实施例中提供了降雨模式和降雪模式两种处理模式。具体地,计算机设备根据气象数据,确定目标处理模式,并在该目标处理模式下,对气象数据进行处理,得到雨雪数据。雨雪数据包括穿过冠层的降雨量、融雪量、冻结量等。其中,目标处理模式为降雨模式或降雪模式中的至少一种。则计算机设备分别确定在不同处理模式下的雨雪数据。
在一些实施例中,上述步骤2032之前还包括:从气象数据中提取得到平均气温;当平均气温不低于气温阈值时,确定目标处理模式为降雨模式;当平均气温低于气温阈值时,确定目标处理模式为降雪模式。
具体地,计算机设备从气象数据中,提取得到平均气温
进而,在一些实施例中,在目标处理模式下对气象数据进行处理,得到雨雪数据,包括:当目标处理模式为降雨模式时,根据植被数据、气象数据和降雨阈值,计算截留蒸发量,并根据截留蒸发量确定穿过冠层降雨量;当目标处理模式为降雪模式时,根据气象数据和气温阈值,计算得到融雪量;将穿过冠层降雨量和/或融雪量作为雨雪数据。
其中,降雪量和降雨量的总和可以表示为降水量。具体可如下公式(2)表示:
(2)
其中,
(3)
即,在平均气温不低于气温阈值的情况下,比如春季、夏季、秋季等,此时降水的主要来源为下雨,因此这种情况下计算机设备可以确定降雪量为0。而在平均气温低于气温阈值的情况下,比如冬季气温下,降水的主要来源为下雪,计算机设备可以将降水量作为降雪量。
具体地,计算机设备在降雨模式下,根据植被数据、气象数据和降雨阈值,计算得到截留蒸发量,再根据截留蒸发量和降雨量,计算得到穿过冠层降雨量。具体公式可如下公式(4)~(5)所示:
(4)
(5)
其中,E
由此,计算机设备即可根据如下公式(6)得到穿过冠层降雨量:
P
其中,
计算机设备在降雪模式下,根据度日因子并结合气象数据中的平均气温和气温阈值之间的差异,计算得到融雪量和冻结量中的至少一种。
其中,计算机设备确定融雪量的步骤可按照如下公式(7)进行计算:
(7)
其中,
(8)
其中,
步骤2033,基于蒸散发数据和雨雪数据,得到所针对的样本网格区域对应的产流估计数据。
具体地,计算机设备基于蒸散发数据和雨雪数据,进一步模拟土壤表面水分汇集成的河流等过程,进而得到所针对的样本网格区域对应的产流估计数据。
在一些实施例中,计算机设备基于蒸散发数据和雨雪数据,得到所针对的样本网格区域对应的产流估计数据,包括:基于雨雪数据和相对土壤含水量,确定地表产流数据、壤中流数据和基流数据;将地表产流数据、壤中流数据以及基流数据进行汇总,得到所针对的样本网格区域对应的产流估计数据。地表产流数据包括地表产流量。壤中流数据包括壤中流量。基流数据包括基流量。
具体地,计算机设备基于雨雪数据和相对土壤含水量,确定地表产流数据;基于雨雪数据和地表产流量,得到土壤下渗量;基于土壤下渗量和相对土壤含水量,确定壤中流量;基于土壤下渗量和壤中流量,得到地下水补给量;基于地下水补给量,确定基流量。上述过程可通过如下公式表示:
假设地表产流增益因子与土壤含水量存在一个幂指数关系,具体公式可如下公式(9)所示:
(9)
其中,
发生地表产流后,剩余的水量结合融雪量下渗进入土壤。即下渗量可以通过如下公式(10)表示:
(10)
其中,
进入土壤的水,首先形成壤中流,假设其与相对土壤含水量(也称为土壤湿润度)存在线性关系,则可以根据如下公式(11)表示:
(11)
其中,
土壤水部分蒸发掉,当剩下的土壤水超过土壤水蓄水容量,多余部分补给地下水,补给量也可利用相对土壤含水量计算,即可以根据如下公式(12)表示:
(12)
其中,
土壤水补给地下水后,如果土壤含水量大于土壤水蓄水容量时,该部分在模型中也作为壤中流的一部分考虑。对于基流的计算,采用经验公式,即地下水蓄水量乘以流域退水系数,可以表示为如下公式(13):
(13)
其中,
土壤含水量的变化等于下渗量减去壤中流、补给量和蒸发量之和,地下水蓄水量的变化则等于补给量减去基流量。具体可以参照如下公式(14)~(15):
(14)
(15)
其中,Δ
计算机设备将地表产流数据、壤中流数据以及基流数据进行汇总,得到产流估计数据。示例性地,产流估计数据为地表产流数据、壤中流数据以及基流数据之和。具体公式可如下公式(16)所示:
(16)
其中,
上述实施例中,通过以分布式时变增益水文模型为基础,耦合植被动态信息,并耦合基于物理过程的蒸散发方程,改进了蒸散发模块的物理机制描述,通过同化遥感植被动态输入,发展了考虑植被动态信息的大尺度分布式水文模型,有效提高了变化环境下的水文模拟精度。
其中,水分的蒸散发过程包括了植物蒸腾过程和土壤蒸发过程。对应地,蒸散发数据也应包括植物蒸腾量和土壤蒸发量。在一些实施例中,基于分布式水文模型,根据所对应的植被数据、气象数据和土壤数据,对植物蒸腾和土壤蒸发过程进行模拟,得到蒸散发数据,包括:根据所对应的植被数据、气象数据和土壤数据,确定当前可用能量;当前可用能量的类型包括自植物冠层吸收能量和土壤吸收能量;基于遥感叶面积指数,确定自植物冠层吸收能量和土壤吸收能量在当前可用能量中的占比;基于当前可用能量计算蒸散发总量,并根据蒸散发总量和占比确定植物蒸腾量和土壤蒸发量。
其中,针对任一样本网格区域,计算机设备基于分布式水文模型,根据所对应的植被数据、气象数据和土壤数据中的一种或多种,提取数据从而确定出当前可用能量。其中,当前可用能量的类型包括自植物冠层吸收能量和土壤吸收能量。
进而,计算机设备基于遥感叶面积指数,确定自植物冠层吸收能量和土壤吸收能量分别在当前可用能量中的占比。遥感叶面积指数(Leaf Area Index,LAI)为现有的函数。进而,计算机设备即可基于当前可用能量计算蒸散发总量,并根据蒸散发总量和占比确定植物蒸腾量和土壤蒸发量。示例性地,计算机设备可以利用蒸散发(Penman-Monteith-Leuning)方程计算蒸散发总量,并进一步确定根据蒸散发总量和占比确定植物蒸腾量和土壤蒸发量。
示例性地,分布式水文模型中的蒸散发方程可如下公式(17)所示:
(17)
其中,
其中,蒸散发(ET)可表示为植物蒸腾(E
(18)
(19)
其中,
基于相同的发明构思,利用所优化得到的目标分布式水文模型,本申请实施例还提供一种水文数据的确定方法。请参见图3,该方法包括如下步骤:
步骤301,确定待模拟流域,并将待模拟流域划分为多个目标网格区域。
具体地,计算机设备确定待模拟流域,并将该待模拟流域划分成多个网格区域,为了与上述实施例中的网格区域进行区分,此处称为目标网格区域。
步骤302,针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据;输入数据至少包括气象输入数据。
具体地,针对任一目标网格流域,计算机设备获取所针对的目标网格区域对应的输入数据。该输入数据用于作为目标分布式水文模型的输入,通过目标分布式水文模型的运行来输出模拟的结果。输入数据至少包括气象输入数据,气象输入数据与模型率定阶段的气象数据为相同类型的数据。气象输入数据比如为当天的气温、降雨量等。计算机设备获取输入数据的过程,与上述实施例类似,此处不再赘述。
步骤303,将输入数据输入至目标分布式水文模型,以供目标分布式水文模型根据输入数据对待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据。
具体地,计算机设备利用优化得到的分布式水文模型,即目标分布式水文模型,将上述获取的输入数据输入至该目标分布式水文模型中,由该目标分布式水文模型进行处理后,输出得到该目标网格区域对应的产流模拟数据。其中,产流模拟数据是对位于目标网格区域的流域的产流数据进行模拟的结果。
步骤304,基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到待模拟流域的水文数据。
具体地,计算机设备在得到各个目标网格区域分别对应的产流模拟数据之后,基于这些数据进行汇流处理,从而得到该待模拟流域的水文数据。示例性地,水文数据包括径流数据等。
示例性地,计算机设备可以通过Lohmann汇流方法(罗曼汇流方法)等对地表产流数据、壤中流数据以及基流数据进行汇流处理,从而将各个目标网格区域对应模拟得到的产流数据进行汇总,进而得到待模拟流域的水文数据。待模拟流域的水文数据例如为假设其在某一水文站或断面的径流数据,该径流数据基于各个目标网格区域对应的产流数据汇流得到。
本申请实施例提供的水文数据的确定方法,通过确定待模拟流域,并将待模拟流域划分为多个目标网格区域,再针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据,并将输入数据输入至目标分布式水文模型,以供目标分布式水文模型根据输入数据对待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据,最后基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到待模拟流域的水文数据,通过考虑植被动态过程对水循环过程的影响,将植被动态信息纳入水文模拟中,提高了水循环模拟过程的真实性,水文数据的模拟结果更加准确。
下面以一个具体的示例阐述上述方法的步骤。请参阅图4,整体流程包括基础数据准备、模型构建与率定、以及产汇流模拟三大步骤。
步骤1:基础数据准备。
该步骤中,计算机设备获取植被数据、气象数据和土壤数据,作为基础数据。同时,计算机设备还获取实际测量得到的各类型数据,用以构建数据验证集。数据验证集例如包括水文站径流数据、网格产流、蒸散发、土壤含水量数据等。计算机设备还可以根据DEM数据进行网格划分,以及结合植被数据和LUCC(land use-cover change)数据综合确定植被覆盖率等。
步骤2:模型构建与率定。
该步骤中,计算机设备将植被动态输入的蒸散发模块与分布式时变增益水文模型耦合,再整合融雪模块、产流模块和汇流模块,模块化构建耦合植被动态信息的分布式水文模型。
计算机设备以网格产流、蒸散发等数据为基准,基于多变量率定框架采用优化算法对分布式水文模型进行参数率定。其中,蒸散发模块的具体方程可见上述实施例。截留模块假定湿润冠层蒸发与降雨的比率在不同暴雨事件中保持不变,具体公式可见上述实施例。融雪模块首先基于一个气温阈值,来判断降水模式为降雨还是降雪。当温度高于阈值时,以降雨形式输入至模型,当温度低于阈值时,以降雪形式输入至模型。基于度日因子来计算融雪量,假设日融雪量与日差温(日气温与气温阈值之差)之间为简单的线性关系。在没有超过一定水当量(一般为10%)的雪时,降雨和融雪可以保持在积雪中。产流模块采用水文非线性时变增益理论,假设地表产流增益因子与土壤含水量存在一个幂指数关系,具体公式可见上述实施例。汇流模块采用Lohmann汇流方法将模拟输出的网格产流量汇流至流域出口网格控制水文站点。
步骤3:产汇流模拟。
该步骤中,计算机设备根据已率定的模型参数,利用率定好的分布式水文模型,分别计算每个网格的蒸散发、产流、土壤含水量等变量,再通过坡面汇流和河道汇流计算汇流过程,得到区域和控制断面的水文过程。
示例性地,如图5所示,产汇流模拟的过程可以包括:根据植被数据(图中仅示出LAI、反照率等植被数据,其余未示出)、气象数据和土壤数据,首先进行雨雪分割,即根据是降雨模式还是降雪模式确定目标处理模式,当为降雨模式时,计算机设备根据截留模块计算得到截留蒸发量E
如图6A~图6F所示,根据对长江流域(图6A)、松花江流域(图6B)、珠江流域(图6C)、内陆河流域(图6D)、黄河流域(图6E)、淮河流域(图6F)的水文站的径流数据进行实测,并将本申请实施例提供的分布式水文模型模拟得到的模拟径流数据和实际测量得到的实测径流数据进行比较,显示本申请实施例提供的分布式水文模型输出的模拟径流数据与实测径流数据高度拟合,水文数据的模拟准确性高。
示例性地,计算机设备将本申请实施例提供的考虑植被动态信息的水文模型与未考虑植被动态信息水文模型各自的模拟性能进行比较,比较结果如图7所示,图7中的(a)为产流KGE对比,图7中的(b)为产流PBIAS对比,图7中的(c)为蒸散发KGE对比,图7中的(d)为蒸散发PBIAS对比。如图7所示,本申请实施例提供的考虑植被动态信息的水文模型模拟精度有明显提升,表现在产流KGE(Kling-Gupta efficiency coefficient,克林-古普塔效率系数)增大,蒸散发PBIAS(Percent bias,百分比偏差)减小。其中,PBIAS表示测量模拟的水流的百分比偏差大于或小于相应的推断的自然水流,越接近0模型效果越好。
为了更好实施本申请实施例中分布式水文模型的优化方法,在分布式水文模型的优化方法的基础之上,本申请实施例中还提供一种分布式水文模型的优化装置,如图8所示,分布式水文模型的优化装置包括划分模块801、第一获取模块802、估计模块803和率定模块804,具体如下:
划分模块801,用于确定样本流域,并将样本流域划分为多个样本网格区域。
第一获取模块802,用于获取各样本网格区域分别对应的水循环相关数据,水循环相关数据包括植被数据、气象数据和土壤数据。
估计模块803,用于基于分布式水文模型,根据植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据。
率定模块804,用于基于产流估计数据和各样本网格区域分别对应的产流验证数据,对分布式水文模型进行多变量参数率定,得到目标分布式水文模型;目标分布式水文模型用于对流域的水循环过程进行模拟以得到水文数据。
在一些实施例中,估计模块803还用于基于分布式水文模型,针对任一样本网格区域,根据所对应的植被数据、气象数据和土壤数据,对植物蒸腾和土壤蒸发过程进行模拟,得到蒸散发数据;在目标处理模式下对气象数据进行处理,得到雨雪数据;目标处理模式为降雨模式或降雪模式;基于蒸散发数据和雨雪数据,得到所针对的样本网格区域对应的产流估计数据。
在一些实施例中,估计模块803还用于根据所对应的植被数据、气象数据和土壤数据,确定当前可用能量;当前可用能量的类型包括自植物冠层吸收能量和土壤吸收能量;基于遥感叶面积指数,确定自植物冠层吸收能量和土壤吸收能量分别在当前可用能量中的占比;基于当前可用能量计算蒸散发总量,并根据蒸散发总量和占比确定植物蒸腾量和土壤蒸发量。
在一些实施例中,估计模块803还用于当目标处理模式为降雨模式时,根据植被数据、气象数据和降雨阈值,计算截留蒸发量,并根据截留蒸发量确定穿过冠层降雨量;当目标处理模式为降雪模式时,根据气象数据和气温阈值,计算得到融雪量;将穿过冠层降雨量和/或融雪量作为雨雪数据。
在一些实施例中,估计模块803还用于基于雨雪数据和相对土壤含水量,确定地表产流数据、壤中流数据和基流数据;将地表产流数据、壤中流数据以及基流数据进行汇总,得到所针对的样本网格区域对应的产流估计数据。
本申请实施例通过提出一种耦合植被动态信息的分布式水文模型优化装置,将基于样本流域的数据输入至分布式水文模型中,通过考虑季节性的植被动态过程对水循环过程的影响,将植被动态信息纳入水文模拟中,为植被变化下的水文响应研究提供了新的工具,从而使得水循环模拟过程更加真实,进而得到更加准确的水文数据。
为了更好实施本申请实施例中水文数据的确定方法,在水文数据的确定方法的基础之上,本申请实施例中还提供一种水文数据的确定装置,如图9所示,水文数据的确定装置包括确定模块901、第二获取模块902、模拟模块903和汇流模块904,具体如下:
确定模块901,用于确定待模拟流域,并将待模拟流域划分为多个目标网格区域。
第二获取模块902,用于针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据;输入数据至少包括气象输入数据。
模拟模块903,用于将输入数据输入至目标分布式水文模型,以供目标分布式水文模型根据输入数据对待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据。
汇流模块904,用于基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到待模拟流域的水文数据。
本申请实施例还提供一种计算机设备,其集成了本申请实施例所提供的任一种分布式水文模型的优化装置或者水文数据的确定装置。如图10所示,其示出了本申请实施例所涉及的计算机设备的结构示意图,具体来讲:
该计算机设备可以包括一个或者一个以上处理核心的处理器1001、一个或一个以上计算机可读存储介质的存储器1002、电源1003和输入单元1004等部件。本领域技术人员可以理解,图10中示出的计算机设备结构并不以构建对计算机设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。其中:
处理器1001是该计算机设备的控制中心,利用各种接口和线路连接整个计算机设备的各个部分,通过运行或执行存储在存储器1002内的软件程序和/或模块,以及调用存储在存储器1002内的数据,执行计算机设备的各种功能和处理数据,从而对计算机设备进行整体监控。可选地,处理器1001可包括一个或多个处理核心;优选的,处理器1001可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器1001中。
存储器1002可用于存储软件程序以及模块,处理器1001通过运行存储在存储器1002的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器1002可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据计算机设备的使用所创建的数据等。此外,存储器1002可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。相应地,存储器1002还可以包括存储器控制器,以提供处理器1001对存储器1002的访问。
计算机设备还包括给各个部件供电的电源1003,优选的,电源1003可以通过电源管理系统与处理器1001逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。电源1003还可以包括一个或一个以上的直流或交流电源、再充电系统、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。
该计算机设备还可包括输入单元1004,该输入单元1004可用于接收输入的数字或字符信息,以及产生与用户设置以及功能控制有关的键盘、鼠标、操作杆、光学或者轨迹球信号输入。
尽管未示出,计算机设备还可以包括显示单元等,在此不再赘述。具体在一些实施例中,计算机设备中的处理器1001会按照如下的指令,将一个或一个以上的应用程序的进程对应的可执行文件加载到存储器1002中,并由处理器1001来运行存储在存储器1002中的应用程序,从而实现各种功能,如下:确定样本流域,并将样本流域划分为多个样本网格区域;获取各样本网格区域分别对应的水循环相关数据,水循环相关数据包括植被数据、气象数据和土壤数据;基于分布式水文模型,根据植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据;基于产流估计数据和各样本网格区域分别对应的产流验证数据,对分布式水文模型进行多变量参数率定,得到目标分布式水文模型;目标分布式水文模型用于对流域的水循环过程进行模拟以得到水文数据。
在一些实施例中,处理器1001运行存储在存储器1002中的应用程序,从而执行并实现如下步骤:基于分布式水文模型,针对任一样本网格区域,根据所对应的植被数据、气象数据和土壤数据,对植物蒸腾和土壤蒸发过程进行模拟,得到蒸散发数据;在目标处理模式下对气象数据进行处理,得到雨雪数据;目标处理模式为降雨模式或降雪模式;基于蒸散发数据和雨雪数据,得到所针对的样本网格区域对应的产流估计数据。
在一些实施例中,处理器1001运行存储在存储器1002中的应用程序,从而执行并实现如下步骤:根据所对应的植被数据、气象数据和土壤数据,确定当前可用能量;当前可用能量的类型包括自植物冠层吸收能量和土壤吸收能量;基于遥感叶面积指数,确定自植物冠层吸收能量和土壤吸收能量分别在当前可用能量中的占比;基于当前可用能量计算蒸散发总量,并根据蒸散发总量和占比确定植物蒸腾量和土壤蒸发量。
在一些实施例中,处理器1001运行存储在存储器1002中的应用程序,从而执行并实现如下步骤:当目标处理模式为降雨模式时,根据植被数据、气象数据和降雨阈值,计算截留蒸发量,并根据截留蒸发量确定穿过冠层降雨量;当目标处理模式为降雪模式时,根据气象数据和气温阈值,计算得到融雪量;将穿过冠层降雨量和/或融雪量作为雨雪数据。
在一些实施例中,处理器1001运行存储在存储器1002中的应用程序,从而执行并实现如下步骤:基于雨雪数据和相对土壤含水量,确定地表产流数据、壤中流数据和基流数据;将地表产流数据、壤中流数据以及基流数据进行汇总,得到所针对的样本网格区域对应的产流估计数据。
或者,在另一些实施例中,计算机设备中的处理器1001会按照如下的指令,将一个或一个以上的应用程序的进程对应的可执行文件加载到存储器1002中,并由处理器1001来运行存储在存储器1002中的应用程序,从而实现各种功能,如下:确定待模拟流域,并将待模拟流域划分为多个目标网格区域;针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据;输入数据至少包括气象输入数据;将输入数据输入至目标分布式水文模型,以供目标分布式水文模型根据输入数据对待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据;基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到待模拟流域的水文数据。
本领域普通技术人员可以理解,上述实施例的各种方法中的全部或部分步骤可以通过指令来完成,或通过指令控制相关的硬件来完成,该指令可以存储于一计算机可读存储介质中,并由处理器进行加载和执行。
为此,本申请实施例提供一种计算机可读存储介质,该存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取记忆体(RAM,Random Access Memory)、磁盘或光盘等。其上存储有计算机程序,所述计算机程序被处理器进行加载,以执行本申请实施例所提供的任一种分布式水文模型的优化方法或者水文数据的确定方法中的步骤。例如,所述计算机程序被处理器进行加载可以执行如下步骤:确定样本流域,并将所述样本流域划分为多个样本网格区域;获取各样本网格区域分别对应的水循环相关数据,所述水循环相关数据包括植被数据、气象数据和土壤数据;基于分布式水文模型,根据所述植被数据、气象数据和土壤数据,确定各样本网格区域分别对应的产流估计数据;基于所述产流估计数据和各样本网格区域分别对应的产流验证数据,对所述分布式水文模型进行多变量参数率定,得到目标分布式水文模型;所述目标分布式水文模型用于对流域的水循环过程进行模拟以得到水文数据。
在一些实施例中,计算机程序被处理器进行加载还可以执行如下步骤:基于分布式水文模型,针对任一样本网格区域,根据所对应的植被数据、气象数据和土壤数据,对植物蒸腾和土壤蒸发过程进行模拟,得到蒸散发数据;在目标处理模式下对气象数据进行处理,得到雨雪数据;目标处理模式为降雨模式或降雪模式;基于蒸散发数据和雨雪数据,得到所针对的样本网格区域对应的产流估计数据。
在一些实施例中,计算机程序被处理器进行加载还可以执行如下步骤:根据所对应的植被数据、气象数据和土壤数据,确定当前可用能量;当前可用能量的类型包括自植物冠层吸收能量和土壤吸收能量;基于遥感叶面积指数,确定自植物冠层吸收能量和土壤吸收能量分别在当前可用能量中的占比;基于当前可用能量计算蒸散发总量,并根据蒸散发总量和占比确定植物蒸腾量和土壤蒸发量。
在一些实施例中,计算机程序被处理器进行加载还可以执行如下步骤:当目标处理模式为降雨模式时,根据植被数据、气象数据和降雨阈值,计算截留蒸发量,并根据截留蒸发量确定穿过冠层降雨量;当目标处理模式为降雪模式时,根据气象数据和气温阈值,计算得到融雪量;将穿过冠层降雨量和/或融雪量作为雨雪数据。
在一些实施例中,计算机程序被处理器进行加载还可以执行如下步骤:基于雨雪数据和相对土壤含水量,确定地表产流数据、壤中流数据和基流数据;将地表产流数据、壤中流数据以及基流数据进行汇总,得到所针对的样本网格区域对应的产流估计数据。
又如,计算机程序被处理器进行加载可以执行如下步骤:确定待模拟流域,并将待模拟流域划分为多个目标网格区域;针对任一目标网格区域,获取所针对的目标网格区域对应的输入数据;输入数据至少包括气象输入数据;将输入数据输入至目标分布式水文模型,以供目标分布式水文模型根据输入数据对待模拟流域的水循环过程进行模拟,输出所针对的目标网格区域对应的产流模拟数据;基于各目标网格区域分别对应的产流模拟数据进行汇流处理,得到待模拟流域的水文数据。
根据本申请的一个方面,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。电子设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该电子设备执行上述实施例中的各种可选实现方式中提供的方法的步骤。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见上文针对其他实施例的详细描述,此处不再赘述。
以上各个操作的具体实施可参见前面的实施例,在此不再赘述。
以上对本申请实施例所提供的一种分布式水文模型的优化方法、装置、设备及介质,以及水文数据的确定方法、装置、设备及介质进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 基于分布式水文模型的室内水文实验模型比例尺确定方法
- 基于分布式水文模型的室内水文实验模型比例尺确定方法