一种计算顺序优化的图注意力网络算法及其硬件加速器
文献发布时间:2024-07-23 01:35:21
技术领域
本发明涉及机器学习技术领域,特别涉及一种计算顺序优化的图注意力网络算法及其硬件加速器。
背景技术
图神经网络已成为处理图数据这种非欧几里得域的数据结构的有效方法,在社交网络、交通网络、化学分子结构等多种应用场景中发挥了传统神经网络难以比拟的优势。图神经网络:Graph Neural Network,简称GNN。其中,图注意力网络引入了注意力机制,通过注意力系数来区分某节点的不同邻居的重要性,以关注数据中最突出、最重要的部分,并使用加权和来进行特征聚合,拥有更好的表征能力。
图注意力网络算法由三个主要阶段组成:组合阶段、注意力阶段和聚合阶段。图注意力网络算法:Graph Attention Networks,简称GAT。与其他GNN算法一样,GAT有着混合的计算特点,在组合阶段,特征变换和相似度常数计算是规则且密集的。而注意力阶段和聚合阶段的运算在很大程度上依赖于图数据的邻接信息,这两个阶段的执行涉及大量不规则的、稀疏的访存操作。此外,注意力阶段还包含了一些复杂的运算,如softmax等。
图注意力网络的算法特点使得CPU和GPU这两种最常用的计算架构无法高效地进行GAT的正向推理过程。CPU在面对组合阶段的密集运算时缺乏足够的算力,计算延迟很大;而GPU在面对注意力阶段和聚合阶段的不规则的、稀疏的访存和运算时,计算效率低下,功耗很高。而先进的FPGA集成了丰富的存储、计算、逻辑和总线资源,其兼具强大的并行计算能力和灵活性,因此适于作为GAT硬件加速器架构的平台。
现有技术方案下的硬件加速器仍然存在推理延迟高和存储资源消耗大的缺陷,没有解决并GAT的算法特点带来的计算复杂度高、计算并行性、推理延迟高和存储资源消耗大的问题。
发明内容
为了解决现有技术中存在GAT的算法特点带来的计算复杂度高的问题,提出了一种计算顺序优化的图注意力网络算法及其硬件加速器,通过优化图注意力网络算法的计算顺序,减少运算次数,降低计算复杂度。
本发明的技术方案如下:
一种计算顺序优化的图注意力网络算法,包括:
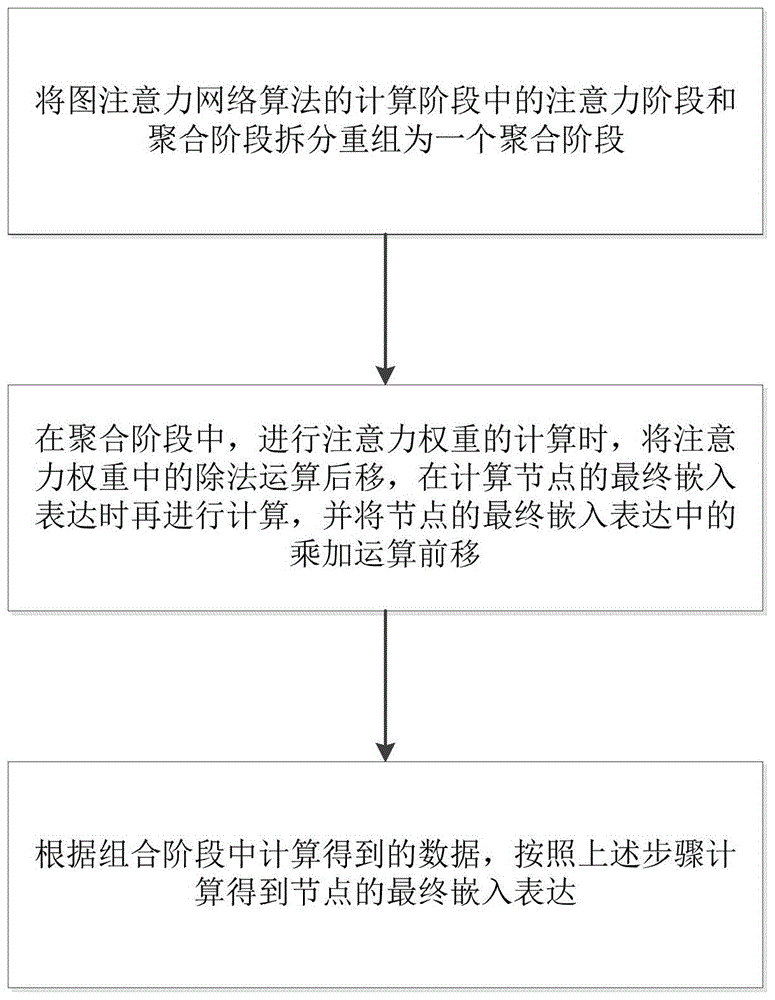
图注意力网络算法的计算阶段包括组合阶段、注意力阶段、聚合阶段;
将注意力阶段和聚合阶段拆分重组为一个聚合阶段;
在拆分重组后的聚合阶段中,进行注意力权重的计算时,将注意力权重中的除法运算后移,在计算节点的最终嵌入表达z
根据组合阶段中计算得到的数据,按照拆分重组后的聚合阶段的步骤计算得到节点的最终嵌入表达。
进一步地,单个注意力头下的拆分重组后的图注意力网络算法的计算过程包括如下:
首先将不同类型节点的特征投影到同一特征空间,即进行组合运算;通过对应的权重矩阵W对节点原始特征向量h
h′
然后进行注意力权重a
最后计算节点的最终嵌入表达z
其中e
对注意力权重计算的(2)式进行拆解,将其中的密集运算部分抽离出来,并使用矩阵形式表示组合运算,则将单个注意力头下的算法过程用下(3)至(7)式表示;
H′=HW (3)
H′(a
e
其中,H表示特征矩阵,H′表示所有节点的组合结果,p表示左相似度常数,q表示右相似度常数,W为权重矩阵,a
由于(6)式的注意力权重计算中,分母部分需要累加所有节点对的注意力系数e
将上述(6)式代入(7)式中,然后通过乘法分配律将分式
e′
其中,e′
上述(3)、(4)式表示图注意力网络算法的组合阶段,而上述(8)、(9)、(10)和(18)式表示聚合阶段。
进一步地,在图注意力网络算法中,每个注意力头的组合运算都得到与之对应的组合结果、左相似度常数和右相似度常数;
当注意力头的数量为k时,存在k个不同的组合结果H′、左相似度常数p和右相似度常数q。
更进一步地,在多个注意力头下,节点的最终嵌入表达的计算方式如下:
在中间层拼接K个注意力头的计算结果,使用
中间层:
输出层:
图注意力网络算法是多层结构,看作是多次运算过程,输出层即为最后一次运算过程,而中间层为除输出层外的每次运算过程。
一种计算顺序优化的图注意力网络算法的硬件加速器,采用所述的一种计算顺序优化的图注意力网络算法,包括:
外部存储器、主控制器、组合模块、聚合模块;
所述外部存储器用于存储图数据、聚合模块输出的计算结果;
所述主控制器用于将外部存储器中的图数据的切片加载到FPGA的片上存储中、控制计算任务的切换;
所述组合模块用于完成图注意力网络算法的组合阶段运算,并将结果传入聚合模块中;
所述聚合模块用于完成图注意力网络算法的聚合阶段运算,得到节点的最终嵌入表达作为输出的计算结果。
更进一步地,所述聚合模块包括若干个聚合计算模块、聚合结果同步模块;
所述聚合计算模块用于索引片上缓存并完成聚合计算任务;
所述聚合结果同步模块用于接收各个聚合计算模块的计算结果后计算节点的最终嵌入表达z
更进一步地,所述聚合计算模块包括索引子模块、计算子模块;
所述的索引子模块包括索引控制器、左相似度常数缓存块、右相似度常数缓存块、组合结果缓存块、邻接信息缓存块;
计算子模块包括第一计算阵列、系数寄存器、乘积寄存器;
所述索引控制器用于根据输入的源节点号读取各片上缓存的数据,并将数据传输至计算子模块;
所述左相似度常数缓存块、右相似度常数缓存块、组合结果缓存块、邻接信息缓存块均用于缓存其对应的数据;
所述第一计算阵列包括第一计算单元;所述第一计算阵列用于接收索引控制器输出的数据;
所述第一计算单元包括向量处理单元;所述向量处理单元用于接收索引控制器输出的数据计算后得到注意力系数、乘积;
所述系数寄存器用于缓存注意力系数;所述乘积寄存器用于缓存乘积寄存器;
计算单元通过系数寄存器、乘积寄存器累加向量处理单元计算得到的注意力系数、乘积;
当完成索引子模块中的邻接信息缓存中所有邻居节点的计算后,计算子模块将系数寄存器、乘积寄存器中存储的部分和数据输出到聚合结果同步模块。
更进一步地,所述聚合结果同步模块包括第二计算阵列、拼接计算单元、聚合结果缓存块;
所述第二计算阵列包括第二计算单元;第二计算单元用于接收并叠加来自各个聚合计算模块的部分和,然后计算节点的嵌入表达;
所述拼接计算单元用于拼接或平均各第二计算单元的结果,得到节点的最终嵌入表达;
所述聚合结果缓存块用于存储一组源节点的最终嵌入表达。
更进一步地,针对k个不同的组合结果H′、左相似度常数p和右相似度常数q,分别对应k个对应的缓存,k个对应的索引控制器,并使用k个计算单元组成的计算阵列进行并行运算,拼接运算单元则负责拼接或平均k个注意力头下的计算结果获得节点的最终嵌入表达;
每个聚合计算模块均设置若干块片上缓存,并且根据不同注意力头拆分片上缓存,使每块片上缓存对应一个注意力头。
进一步地,所述聚合计算模块采用流水线设计方式;
索引子模块作为第一个流水级;
所述第一计算单元包括第二流水级、第三流水级、第四流水级;
第二流水级包括一个加法运算器、一个非线性运算器;
第三流水级包括一个指数运算器;
第四流水级包括一个乘法运算器、两个累加运算器;
第二流水级、第三流水级、第四流水级中均设置一个寄存器,用于存储对应的流水级正在处理的源节点的编号i,使得各流水级并行处理不同源节点的计算。
本发明的有益效果:
1.通过改变图注意力网络的计算顺序,提出的计算顺序优化的算法减少了对应硬件加速器中的除法运算次数,降低了计算的复杂程度。
2.通过硬件加速器的聚合模块,各聚合计算模块能够并行的聚合任务,解决计算并行性低下的问题。
附图说明
图1为实施例提供的计算顺序优化的图注意力网络算法的步骤示意图。
图2为实施例提供的计算顺序优化的图注意力网络算法的硬件加速器的结构框图。
图3为实施例提供的聚合模块的结构框图。
图4为实施例提供的聚合结果同步模块的结构框图。
图5为实施例提供的计算任务划分和计算任务顺序的示意图。
图6为实施例提供的聚合计算模块中计算过程的示意图。
图7为实施例提供的聚合计算任务的示意图。
图8为实施例提供的聚合计算模块的流水线的示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做详细描述。
实施例1
在本实施例中,如图1所示,一种计算顺序优化的图注意力网络算法,包括如下:图注意力网络算法的计算阶段包括组合阶段、注意力阶段、聚合阶段;
将注意力阶段和聚合阶段拆分重组为一个聚合阶段;
在拆分重组后的聚合阶段中,进行注意力权重的计算时,将注意力权重中的除法运算后移,在计算节点的最终嵌入表达z
根据组合阶段中计算得到的数据,按照拆分重组后的聚合阶段的步骤计算得到节点的最终嵌入表达。
在本实施例中,所述组合阶段包括:将权重数据、特征数据、注意力核值进行密集计算,得到所有节点的组合结果H′、左相似度常数p和右相似度常数q。
密集计算指的是:由于权重矩阵和注意力核是密集的,即矩阵中没有0值,且特征矩阵数据相较于邻接矩阵数据也更稠密,因此组合阶段需要的计算次数多,是计算密集型的运算阶段。
更具体的,单个注意力头下的拆分重组后的图注意力网络算法的计算过程包括如下:
首先将不同类型节点的特征投影到同一特征空间,即进行组合运算;通过对应的权重矩阵W对节点原始特征向量h
h′
然后进行注意力权重a
最后计算节点的最终嵌入表达z
其中e
对注意力权重计算的(2)式进行拆解,将其中的密集运算部分抽离出来,并使用矩阵形式表示组合运算,则将单个注意力头下的算法过程用下(3)至(7)式表示;
H′=HW(3)
h′(a
e
其中,H表示特征矩阵,H′表示所有节点的组合结果,p表示左相似度常数,q表示右相似度常数,W为权重矩阵,a
由于(6)式的注意力权重计算中,分母部分需要累加所有节点对的注意力系数e
原有的计算顺序下,硬件设计仅能在注意力权重计算阶段和聚合阶段间形成阶段级的流水,无法进行节点对级别的流水线设计,延迟较大,且由于对每个节点对都需要计算一次除法,对应的硬件设计将包含大量的除法运算。
为解决以上问题,将上述(6)式代入(7)式中,然后通过乘法分配律将分式
e′
其中,e′
上述(3)、(4)式表示图注意力网络算法的组合阶段,而上述(8)、(9)、(10)和(18)式表示聚合阶段。
更具体的,在图注意力网络算法中,每个注意力头的组合运算都得到与之对应的组合结果、左相似度常数和右相似度常数;
当注意力头的数量为k时,存在k个不同的组合结果H′、左相似度常数p和右相似度常数q。
在多个注意力头下,节点的最终嵌入表达的计算方式如下:
在中间层拼接K个注意力头的计算结果,使用
中间层:
输出层:
图注意力网络算法是多层结构,看作是多次运算过程,输出层即为最后一次运算过程,而中间层为除输出层外的每次运算过程。
实施例2
在本实施例中,一种计算顺序优化的图注意力网络算法的硬件加速器,采用如实施例1所述的一种计算顺序优化的图注意力网络算法,包括:
外部存储器、主控制器、组合模块、聚合模块;
所述外部存储器用于存储图数据、聚合模块输出的计算结果;
所述主控制器用于将外部存储器中的图数据的切片加载到FPGA的片上存储中、控制计算任务的切换;
所述组合模块用于完成图注意力网络算法的组合阶段运算,并将结果传入聚合模块中;
所述聚合模块用于完成图注意力网络算法的聚合阶段运算,得到节点的最终嵌入表达z
所述聚合模块包括若干个聚合计算模块、聚合结果同步模块;
所述聚合计算模块用于索引片上缓存并完成聚合计算任务;
所述聚合结果同步模块用于接收各个聚合计算模块的计算结果后计算节点的最终嵌入表达z
由于图数据通常较大,FPGA中的片上存储只能存储部分图数据,即图数据的切片,因此需要借助外部存储器来存储一张完整的图。主控制器从外部存储器将图数据的切片加载到FPGA的片上存储中,当加速器将该切片计算完成后,主控制器将加速器得到的计算结果传回外部存储器中,并加载新的一个切片到FPGA片上存储中。此外,主控制器控制硬件电路中计算任务的切换。
所述聚合计算模块包括索引子模块、计算子模块;
所述的索引子模块包括索引控制器、左相似度常数缓存块、右相似度常数缓存块、组合结果缓存块、邻接信息缓存块;
计算子模块包括第一计算阵列、系数寄存器、乘积寄存器;
所述索引控制器用于根据输入的源节点号读取各片上缓存的数据,并将数据传输至计算子模块;
所述左相似度常数缓存块、右相似度常数缓存块、组合结果缓存块、邻接信息缓存块均用于缓存其对应的数据;
所述第一计算阵列包括第一计算单元;所述第一计算阵列用于接收索引控制器输出的数据;
所述第一计算单元包括向量处理单元;所述向量处理单元用于接收索引控制器输出的数据计算后得到注意力系数、乘积;向量处理单元:Vector Process Unit,简称VPU。
所述系数寄存器用于缓存注意力系数;所述乘积寄存器用于缓存乘积寄存器;
第一计算单元通过系数寄存器、乘积寄存器累加向量处理单元计算得到的注意力系数、乘积;
当完成索引子模块中的邻接信息缓存中所有邻居节点的计算后,计算子模块将系数寄存器、乘积寄存器中存储的部分和数据输出到聚合结果同步模块。
所述聚合结果同步模块包括第二计算阵列、拼接计算单元、聚合结果缓存块;
所述第二计算阵列包括第二计算单元;第二计算单元用于接收并叠加来自各个聚合计算模块的部分和,然后计算节点的嵌入表达;
所述拼接计算单元用于拼接或平均各第二计算单元的结果,得到节点的最终嵌入表达;
所述聚合结果缓存块用于存储一组源节点的最终嵌入表达,即聚合结果。聚合结果缓存存储一组源节点的聚合结果。
更具体的,针对k个不同的组合结果H′、左相似度常数p和右相似度常数q,分别对应k个对应的缓存,k个对应的索引控制器,并使用k个计算单元组成的计算阵列进行并行运算,拼接运算单元则负责拼接或平均k个注意力头下的计算结果获得节点的最终嵌入表达;
每个聚合计算模块均设置若干块片上缓存,并且根据不同注意力头拆分片上缓存,使每块片上缓存对应一个注意力头。
在该硬件加速器架构中,采用了一种分布式的细粒度的存储方案,消除了存储访存冲突,从而保证了计算的并行性,同时限制了片上存储资源消耗的成倍增长。
图注意力网络的聚合阶段需要的数据包括左相似度常数、右相似度常数、邻接信息以及组合结果共四种。若使用四个粗粒度的片上缓存存储一个图数据切片中的这四种数据,则各聚合计算模块需要共用这四个片上缓存,此时数据传输的带宽需求很高,且不同聚合计算模块访问存储中同一个地址的数据时,存在访存冲突问题,各聚合计算模块无法并行工作。若将这四个片上缓存复制多次,每块对应一个聚合计算模块,可以消除访存冲突,但由于GAT的算法特点,聚合所需的数据量很大,使得该方案将消耗大量的片上存储资源。
因此采用一种分布式的细粒度的存储方案,在每个聚合计算模块中都设置对上述四个数据的片上缓存,并根据各聚合计算模块的不同计算任务对数据进行拆分,具体来说,将数据按目标节点分为多组,每组对应于一个聚合计算模块的计算任务。拆分后的数据分别存储在各聚合计算模块的片上缓存中,使各聚合计算模块能够并行处理同一组源节点与不同组邻居目标节点的聚合任务。此外,根据不同注意力头进一步拆分片上缓存,使每块片上缓存对应一个注意力头,使得各注意力头下的聚合运算也可以并行执行,而不存在访存冲突问题。该存储方案根据各聚合计算模块的计算任务来划分数据的片上存储,而并非对数据进行简单复制,因此能在保证运算并行性的同时,控制片上存储资源的消耗,使其不随聚合计算模块数量的增加而成倍增长。
更具体的,所述聚合计算模块采用流水线设计方式;
索引子模块作为第一个流水级;
所述第一计算单元包括第二流水级、第三流水级、第四流水级;
第二流水级包括一个加法运算器、一个非线性运算器;
第三流水级包括一个指数运算器;
第四流水级包括一个乘法运算器、两个累加运算器;
各流水级的硬件电路可以同时工作,并行完成不同节点对的索引或各级运算任务。
第二流水级、第三流水级、第四流水级中均设置一个寄存器,用于存储对应的流水级正在处理的源节点的编号i,使得各流水级并行处理不同源节点的计算,流水线在切换不同源节点的计算任务时不会发生堵塞。
当节点对数量为M,节点数量为N时,原计算顺序下的算法过程的除法次数为M,而优化计算顺序下的算法过程的除法次数为N,减少了M/N倍。
实施例3
在本实施例中,根据实施例2所述的计算顺序优化的图注意力网络算法的硬件加速器,主控制器从外部存储器将图数据的切片加载到FPGA的片上存储中,并控制加速器开始进行计算。组合模块通过传入的权重数据、特征数据和注意力核值,完成算法中(3)、(4)式的组合阶段密集运算,计算得到了所有节点的组合结果H′、左相似度常数p和右相似度常数q,主控制器将这些数据传入聚合模块中。聚合模块根据计算顺序优化后的GAT算法,完成聚合阶段的(8)至(10)式,得到节点的最终嵌入表达。当加速器将该切片计算完成后,主控制器将加速器得到的计算结果传回外部存储器中,并加载一个新的切片到FPGA片上存储中。
如图3所示,结合计算顺序优化后的算法过程,以一个源节点的计算过程,详解聚合模块的工作流。
主控制器将组合模块的计算结果传入聚合模块中存储,如图中的组合结果缓存、左相似度常数缓存和右相似度常数缓存,并将外部存储器的邻接信息传入聚合模块中存储,如图中的邻接信息缓存。
在运算所需的各数据就绪后,执行索引操作。索引控制器首先从左相似度常数缓存中取出一个源节点的左相似度常数p
然后执行计算操作。计算阵列中的一个计算单元中的VPU首先执行式(5)、式(8),完成该节点对的注意力系数e′
当邻接信息缓存中该源节点i的所有邻居目标节点都已经完成了上述运算,就得到了属于该聚合计算模块的系数部分和以及乘积部分和,将这两个部分和以及对应的源节点编号i输入到聚合结果同步模块,并清空系数寄存器以及乘积寄存器。
聚合结果同步模块接收所有聚合计算模块得到的部分和,完成剩余运算,并得到聚合结果。具体而言,如图4所示,计算单元叠加来自各聚合计算模块的系数部分和,就得到了(10)式中分式的分母
如图5所示,为各聚合计算模块的计算任务划分方法,以及聚合模块的计算顺序。
图5最左侧的矩阵表示一张完整图的邻接矩阵,其纵坐标表示源节点号i,横坐标表示目标节点号j,箭头表示各切片的计算顺序。
图5中间的矩形表示一个图数据切片,当聚合计算模块数为N时,一个切片被划分为N个子切片,一个子切片对应一个聚合计算模块的计算任务,这些子切片在不同聚合计算模块中被并行计算;子切片中的计算任务也被分为多个源节点组,箭头表示各组的计算顺序。
具体而言,主控制器根据各聚合计算模块的计算任务,将组合结果、右相似度常数和邻接信息按目标节点编号分成各子切片,并分别存在不同聚合计算模块的分立的片上存储中;目标节点编号为邻接矩阵横坐标。在其中一个子切片中,主控制器将组合模块的计算得到的左相似度常数按源节点分成各组,每次将其中的一组传入不同聚合计算模块的左相似度常数缓存中;源节点为邻接矩阵列坐标。如图5中间的矩形的箭头所示,当一个聚合计算模块完成了子切片中一组源节点的运算后,主控制器顺序地将子切片中下一组源节点的左相似度常数传入聚合模块,开始执行下一组源节点的运算。
图5右侧的矩形表示某子切片中的一组计算任务,其中的白色正方形则代表节点间不存在连接关系,深色正方形代表节点间存在连接关系,即代表一个源节点与邻居目标节点构成的节点对。计算顺序如图中的箭头所示。其中的实线箭头表示顺序地计算一个源节点在该子切片中的所有节点对的运算。实线箭头到达矩阵中一行的末尾,代表当前子切片中该源节点的所有邻居目标节点都已经完成了聚合计算模块中的运算。随后,虚线箭头指向下一行的开头,表示索引控制器从左相似度常数缓存取出下一个源节点的左相似度常数及其节点编号,开始执行下一个源节点的运算。
如图6所示,为聚合计算模块中计算部分的详细框图。计算部分被分为三个流水级;阶段1为第二流水级,阶段2为第三流水级,阶段3为第四流水级。
阶段1接收输入的左、右相似度常数,执行算法式(5)中的加法运算和非线性激活运算;非线性激活运算:LeakyReLU;阶段2执行算法(8)式中的指数运算,得到的注意力系数e′
如图7所示,为聚合计算模块中一组计算任务的例图,其中白色方格代表对应的两个节点之间不存在连接关系,有字母的格子代表对应的两个节点之间存在连接关系,即对应的节点对存在聚合的计算任务。相同深浅程度的格子为相同源节点的计算任务。
如图8所示,为聚合计算模块的流水线执行过程的示意图。横轴表示计算所需的时间,纵轴表示各流水级。在每个流水级中,方块代表对应流水级的硬件电路处于工作状态,方块内的字母与图8中方格内的字母相对应,表示该方块所属的节点对。由于各流水级之间可能存在执行时间的差异,因此方块的长度可能不同,执行时间较短的阶段需要等待执行时间最长的流水级执行完毕后才能开始执行下一个节点对的任务,因此方块之间可能存在空隙,表示对应流水级的硬件电路处于空闲状态。
结合图6、7、8,阐述聚合计算模块的流水线执行过程。图7所示的计算任务的计算顺序是按照字母排序的。
首先,索引部分根据源节点1的节点号进行索引,得到邻居目标节点1的相关数据,即完成了节点对a的索引任务。
阶段1的执行依赖于索引结果,因此在a的索引完成后,阶段1才能开始a的计算。在阶段1计算a时,索引部分同时进行下一个节点对的索引任务。这里的下一个节点对指的是节点对b。
阶段2的执行依赖于阶段1的结果,因此在a的阶段1的计算完成后,阶段2才能开始a的计算。在阶段2计算a时,阶段1同时进行下一个节点对的计算任务。这里的下一个节点对指的是节点对b。
同理,在a的阶段2的计算完成后,阶段3才能开始a的计算,阶段2的硬件电路同时开始下一个节点对的计算任务。这里的下一个节点对指的是节点对b。a之后的任务执行过程与上述过程同理。
如图8所示,在时刻4,阶段3完成a的计算,此时聚合计算模块的流水线被填满,从此时直至时刻11,聚合计算模块在每个时刻都输出一个节点对的计算结果。时刻0至4之间的时间为流水线的通过时间,对应于第一个任务a进入流水线到其完成计算的时间。时刻4至7之间的时间为流水线的稳定工作时间,在该时间段内,四个流水级的硬件电路都处于工作状态,并行地处理不同节点对的不同阶段任务。时刻7至11之间的时间为流水线的排空时间,对应于最后一个任务h进入流水线到其完成计算的时间。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种算法与硬件协同优化的混合精度存内计算加速器
- 基于Winograd算法的卷积神经网络硬件加速器及计算方法