一个Cas9蛋白拆分得到的蛋白组及其应用
文献发布时间:2023-06-19 10:46:31
技术领域
本发明涉及生物技术领域,更具体地,涉及一个Cas9蛋白拆分得到的蛋白组及其应用。
背景技术
CRISPR/Cas(Clustered regularly interspaced short palindromic repeats/CRI SPR-associated protein)系统是一种源于细菌和古细菌的抗病毒获得性免疫机制。CRISPR/Cas系统以RNA蛋白质复合体的形式发挥免疫作用,其中效应蛋白包括Cas9,Cas12a,Cas12b,CasX等。经科学家改造将crRNA和tracrRNA合二为一形成单链引导RNA(guide RNA,gRNA)。Cas蛋白首先识别基因组上的PA M(Protospacer adjacement motif)序列,然后gRNA特异性识别并与靶位点互补配对,从而激活Cas蛋白发挥核酸内切酶的功能切割DNA双链,实现特定位点的基因编辑。自开发成为有效的基因编辑工具以来在各种生物体中得到了广泛的应用,来自化脓链球菌(Streptococcus pyogenes,Sp)的CRISPR/Cas9系统是其中应用最广泛的基因编辑工具。然而,由于已知的致病性人类遗传变异多为点突变、插入或缺失,而CRISPR/Cas9系统通过同源重组的方式实现精确的碱基修复的效率低下,且在修复过程中会导致双链损伤,限制了CRISPR/Cas9系统在精确的碱基修复领域的应用。
在Cas9 H840A切口酶(Cas9n-H840A切口酶)的C端融合逆转录酶,并向导RNA(sgRNA)的基础上进行改造,使其还包含一段含有目标碱基突变的RT模板以及引物结合位点(primer binding site,PBS),得到引导编辑技术向导RNA(pri me editing guide RNA,pegRNA,,可得到Prime editing(PE)系统。PE系统通过pegRNA靶向基因组内特定位点,被Cas9n-H840A切口酶切断的非互补链与pegRNA携带的primer binding site(PBS)结合,在逆转录酶作用下,沿着逆转录模板(RT template)延伸,从而在靶位点实现特定碱基的转换、插入和缺失。
然而,质粒越大越难以转染,编码序列或蛋白序列越长越难转运,未算上启动子序列和poly(A)序列,Cas9蛋白编码序列就已4.1kb,其延伸出来的PE蛋白编码序列更是长达6.2kb,这使得在不同的场景应用Cas9系统及其进化出的Prim e editing系统时常常遇到运载的问题,特别是当想利用广为应用的腺相关病毒(a deno-associated virus,AAV)作为运载体时,遇到了AAV的装载容量仅为4.7k b的障碍。
Cas9蛋白是Prime editing系统和Cas9系统的核心组成模块。因此,如果能成功地把Cas9蛋白拆分为两段,分开运载到靶器官或靶细胞内,再利用蛋白剪接机制使其融合成完整的蛋白,则可解决转运障碍,提高转运效率,扩大编辑系统运载体的选择范围和编辑系统的应用范围。并且,因只有Cas9的N端和C端同时表达才会实现其功能,所以可以通过调控拆分后的Cas9蛋白进行Cas9系统或Prime editing系统的调控。
拆分位点常常极大地影响蛋白拼接的效率。同时,不同的拆分位点,形成了不同长度的Cas9N和Cas9C,而Cas9N和Cas9C的长度是影响其转运效率的关键因素。因此,找到合适的拆分位点是拆分方法的关键。
合适的拆分位点常常能与多种常见的蛋白拼接技术结合,形成高效的拆分和拼接系统。其中一种可行的拼接技术是利用蛋白内含肽(Intein)介导的蛋白剪接作用而发展起来的。内含肽的作用类似于RNA剪接中的内含子,是一类可以介导翻译后的蛋白进行剪接的内部蛋白原件。内含肽位于多肽序列的中间,经过加工后切除,并催化两端的蛋白质外显子(Extein)连接为成熟的蛋白质分子。一般来说,内含肽可以分开为N端段(InteinN)和C端段(InteinC)两个编码蛋白的基因片段,同时,可以在适当的位点将目的基因拆分成N端段和C端段两个编码蛋白的基因片段,其中目的基因N端段与位于C端的InteinN连接,而目的基因C端段则在N端连接InteinC,分别形成融合基因,翻译后形成融合蛋白。单独存在的融合蛋白不具备目的蛋白的活性,只有当N端部分和C端部分两融合蛋白相遇时,拆分的前体蛋白中的Intein作用域催化一系列反应,将其自身从前体蛋白中移去,并将两侧称为Extein的蛋白片段以正常的肽键连接起来形成成熟蛋白,即发生蛋白剪接,才能形成有功能的目的蛋白。
目前已有研究人员尝试利用内含肽或者在雷帕霉素诱导下FRB与FKBP形成的异源二聚体拆分包括Cas9蛋白在内的多种蛋白,效率参差不齐。同时在偶联了脱氨酶模块和效率增强模块得到更大的单碱基编辑系统后,蛋白长度有所改变,部分拆分位点因造成了过长的Cas9N或Cas9C而拼接效率大大降低甚至不再适用。因此,急需在新的条件下寻找新的可高效拆分和剪接Cas9蛋白的位点,并且是基因编辑系统临床转化的研究重点。
发明内容
本发明的目的是为了克服现有技术的不足,提供一个Cas9蛋白拆分得到的蛋白组及其应用。
为了实现上述目的,本发明是通过以下技术方案予以实现的:
本发明的第一个目的是提供一个Cas9蛋白拆分得到的蛋白组。
本发明的第二个目的是提供一个融合蛋白组。
本发明的第三个目的是提供一个核苷酸序列组。
本发明的第四个目的是提供一个载体组。
本发明的第五个目的是提供一个工程菌株或基因工程细胞。
本发明的第六个目的是提供所述的蛋白组、所述的融合蛋白组、所述的核苷酸序列组、所述的载体组、或所述的工程菌株或基因工程细胞中的任意一个或几个在制备基因编辑、靶向定位、基因表达转录激活或基因表达转录抑制制剂或试剂盒中的应用。
本发明的第七个目的是提供一种用于基因编辑、靶向定位、基因表达转录激活或基因表达转录抑制的制剂。
本发明要求保护一个Cas9蛋白拆分得到的蛋白组,包括将Cas9蛋白的氨基酸序列从N端至C端的以下位点拆分而得到的位于N端的N端蛋白和位于C端的C端蛋白,所述位点为第994~995个氨基酸之间、第1005~1006个氨基酸之间、第1024~1025个氨基酸之间或第1032~1033个氨基酸之间;
所述Cas9蛋白为(1)氨基酸序列如SEQ ID NO.1所示的蛋白(spCas9(H840A)蛋白),
或(2)氨基酸序列与SEQ ID NO.1所示的氨基酸序列具有至少90%同源性,且蛋白具有靶向目的基因、结合目的基因、切割目的基因功能的蛋白。
优选地,所述Cas9蛋白为(1)氨基酸序列如SEQ ID NO.1所示的蛋白,
或(2)氨基酸序列与SEQ ID NO.1所示的氨基酸序列具有至少95%同源性,且蛋白具有靶向目的基因、结合目的基因、切割目的基因功能的蛋白。
更优选地,所述Cas9蛋白为(1)氨基酸序列如SEQ ID NO.1所示的蛋白,
或(2)氨基酸序列与SEQ ID NO.1所示的氨基酸序列具有至少99%同源性,且蛋白具有靶向目的基因、结合目的基因、切割目的基因功能的蛋白。
进一步优选地,所述氨基酸序列与SEQ ID NO.1所示的氨基酸序列具有至少99%同源性,且蛋白具有靶向目的基因、结合目的基因、切割目的基因功能的蛋白为XCas9(含有突变A262T、R324L、S409I、E480K、E543D、M694I、E1219V)、Cas9-NG(含有突变L1111R、D1135V、G1218R、E1219F、A1322R、R1335V,T1337R)、Cas9-HF1(含有突变N497A、R661A、Q695A、Q926A)、Cas9-HF2(含有突变N497A、R661A、Q695A、Q926A、D1135E)、Cas9-HF3(含有突变L169A、N497A、R661A、Q695A、Q926A)、Cas9-HF4(含有突变Y450A、N497A、R661A、Q695A、Q926A)、eSpCas9(含有突变K848A、K1003A、R1060A)、Cas9-VQR(含有突变D1135V、R1335Q、T1337R)、Cas9-EQR(含有突变D1135E、R1335Q、T1337R)、Cas9-VRER(含有突变D1135V、G1218R、R1335E、T1337R),或HypaCas9(含有突变N692A、M694A、Q695A、H698A)任一。
优选地,所述位点为第1024~1025个氨基酸之间。
根据所述拆分方法,可得到N端的Cas9N蛋白和C端的Cas9C蛋白的蛋白组。
在该位点对Cas9蛋白进行拆分,并与逆转录酶以及拼接组件等组成融合蛋白组,在体内的重组效率高。
本发明在适当的位置把Cas9蛋白拆分为不同的部分,拆分后的Cas9不具有活性,但可通过与内含肽(intein)、光诱导二聚化蛋白、FKBP-RAP-FRB等拼接组件连接,在细胞内将其重新组合成具有活性的Cas9蛋白,由于拆分后的蛋白相对于原蛋白更小,更容易导入生物体内,从而能够有效提高编辑效率。同时,单独存在的Cas9N或Cas9C不具有完整的功能,通过调控Cas9N和Cas9C加入的时间先后顺序或调节Cas9N和Cas9C的比例,可以起到调控Cas9蛋白功能的作用。
因此,本发明还要求保护一个融合蛋白组,包括第一融合蛋白和第二融合蛋白,
所示第一融合蛋白从N端至C端依次为所述的N端蛋白和拼接组件N端的氨基酸序列,N端蛋白和拼接组件通过连接肽或连接键连接;
所示第二融合蛋白从N端至C端依次为拼接组件的C端的氨基酸序列和中所述的C端蛋白,拼接组件的C端的氨基酸序列和中所述的C端蛋白通过连接肽或连接键连接;
所述N端蛋白和所述C端蛋白为Cas9蛋白以同一个位点拆分而得到的;
所述拼接组件N端的氨基酸序列和拼接组件的C端的氨基酸序列为同一个拼接组件拆分得到;
所述拼接组件为内含肽、光诱导二聚化蛋白、FRB/FKBP、DmC/FKBP、ABI/PLY中的一种。
PE蛋白通过pegRNA靶向基因组内特定位点,被Cas9n-H840A切口酶切断的非互补链与pegRNA携带的primer binding site(PBS)结合,逆转录酶可以特异性地沿着pegRNA携带的逆转录模板(RT template)延伸,从而在靶位点实现特定碱基的转换、插入和缺失,理论上可以实现几乎所有碱基位点的特异性修饰,应用范围更广。
融合蛋白组在细胞内利用内含肽的反式剪接作用,可得到含有全长、具有gRNA识别作用的Cas9蛋白的蛋白;内含肽为Rhodothermus marinus DnaB intein(以下简称Rmaintein)。
所以优选地,所述拼接组件为内含肽Rma intein,
其氨基酸序列(1)如SEQ ID NO.6所示,
或(2)与SEQ ID NO.6所示氨基酸序列具有至少90%相似性,并与SEQ ID NO.6所示氨基酸序列具有相同功能。
所述具有相同功能指氨基酸序列具有经过加工后切除,并催化两端的蛋白质多肽连接为成熟的蛋白质分子的功能。
更优选地,拼接组件的C端氨基酸序列为SEQ ID NO.6所示氨基酸序列的第1~102个氨基酸序列,拼接组件的N端氨基酸序列为SEQ ID NO.6所示氨基酸序列的第103~154个氨基酸序列。
优选地,所述第一融合蛋白的从N端至C端依次为核定位信号的氨基酸序列、所述的N端蛋白和拼接组件N端的氨基酸序列,各段氨基酸序列通过连接肽或连接键连接。
核定位信号能够帮助蛋白更容易进入细胞核内,进一步提高编辑效率。
优选地,所述第二融合蛋白的从N端至C端依次为拼接组件的C端的氨基酸序列、所述的C端蛋白、逆转录酶的氨基酸序列和/或核定位信号的氨基酸序列,各段氨基酸序列通过连接肽或连接键连接。
更优选地,所述逆转录酶为M-MLV。
进一步优选地,所述逆转录酶的氨基酸序列如SEQ ID NO.3所示。
核定位信号能够帮助蛋白更容易进入细胞核内,进一步提高编辑效率。
更优选地,所述连接肽为XTEN、SGGS、(SGGS)
更优选地,所述核定位信号为SV40 NLS或nucleoplasmin NLS。
进一步优选地,SV40 NLS的氨基酸序列如SEQ ID NO.4所示。
进一步优选地,nucleoplasmin NLS的氨基酸序列如SEQ ID NO.5所示。
本发明还要保护一个核苷酸序列组,包括第一核苷酸序列和第二核苷酸序列,
所述第一核苷酸序列从5’端到3’端依次为启动子核苷酸序列、编码所述第一融合蛋白的核苷酸序列、和poly(A)的核苷酸序列;
所述第二核苷酸序列从5’端到3’端依次为启动子核苷酸序列、编码所述第一融合蛋白的核苷酸序列、和poly(A)的核苷酸序列;
各段核苷酸序列之间通过编码连接肽的核苷酸序列或连接键。
核苷酸序列组的第一核苷酸序列和第二核苷酸序列,转至体内可转录成RNA,并经翻译得到所述融合蛋白组,所述融合蛋白组在拼接组件作用下重新组装得到全长Cas9或PE蛋白。
优选地,所述poly(A)为bGH poly(A)。
更优选地,所述bGH poly(A)的核苷酸序列如SEQ ID NO.9所示。
优选地,所述启动子序列为EF1α启动子序列。
更优选地,所述EF1α启动子的核苷酸序列如SEQ ID NO.8所示。
优选地,所述连接肽为XTEN、SGGS、(SGGS)
本发明还要保护一个载体组,包含第一载体和第二载体,分别为含有所述的核苷酸序列组中的第一核苷酸序列和第二核苷酸序列的载体。
优选地,所述载体组的两个载体分别还含有pegRNA或gRNA序列。
优选地,所述载体为病毒载体。
更优选地,所述载体为腺相关病毒AAV载体。
腺相关病毒(adeno-associated virus,AAV)是一类单链DNA病毒,属于细小病毒科(parvoviridae)。改造后的重组腺相关病毒载体(rAAV)工具具有免疫原性低、宿主范围广、安全性高并能介导基因在动物体内长期稳定表达等特点,是一种重要的携带外源基因转染生物个体的病毒工具,已被广泛的应用在动物水平的基因表达、基因操作和基因治疗。rAAV所包含的DNA一般是用外源基因表达元件替换AAV的编码基因,仅保留了病毒复制和包装所需的ITR序列。通过反式补偿Rep基因、Cap基因和辅助病毒功能因子,可以包装产生携带外源DNA的rAAV。但AAV的装载容量有限,仅为约4.7kb,因此全长的PE蛋白无法使用该载体进行运载。本发明将Cas9拆分为不同的两端,构建得到含有逆转录酶以及分段Cas9的融合蛋白组,突破了AAV装载容量的限制,分开包装病毒并运载到靶器官或靶细胞内,再利用内含肽的蛋白自剪接机制使其融合成完整的PE蛋白,从而解决转运障碍,并提高了转运效率,扩大运载体的选择范围和应用范围。
本发明还要保护一个工程菌株或基因工程细胞,表达有任一所述的融合蛋白组或其中的一个,或者被所述的载体组或其中的一个转化或转染得到,或者携带有所述的核苷酸序列组或其中的一个核苷酸序列。
本发明还要求保护所述的蛋白组、所述的融合蛋白组、所述的核苷酸序列组、所述的载体组、或所述的工程菌株或基因工程细胞中的任意一个或几个在制备基因编辑、靶向定位、基因表达转录激活或基因表达转录抑制制剂或试剂盒中的应用。
本发明还要求保护一种用于基因编辑、靶向定位、基因表达转录激活或基因表达转录抑制的制剂,包括所述的蛋白组、所述的融合蛋白组、所述的核苷酸序列组、所述的载体组、或所述的工程菌株或基因工程细胞中的任意一个或几个;或者利用所述的蛋白组、所述的融合蛋白组、所述的核苷酸序列组、所述的载体组、或所述的工程菌株或基因工程细胞中的任意一个或几个制备得到。
所述制剂为试剂盒中的试剂或药物制剂。
优选地,所述药物制剂为于眼睛、造血干细胞、内耳细胞或肝脏细胞的基因编辑的药物制剂。
本发明还提供了一种基因编辑的方法,包括如下步骤:将靶序列或靶基因与所述融合蛋白组或所述核苷酸序列组或所述载体组导入细胞内。
与现有技术相比,本发明具有如下有益效果:
本发明提供了多种Cas9拆分的方法,在这些位置对Cas9进行拆分得到的蛋白肽段可通过内含肽等多种拼接方法,在靶细胞或器官内重新组装成具有功能活性的Cas9蛋白;本发明提供的新的断裂位点部分优于已报导位点,体内重组后的Cas9活性更高,脱靶率更低。另外,由于拆分后的蛋白更小,受AAV等载体的运载量限制更小,载体的选择范围更多,应用范围更广,可有效提高基因编辑效率和安全性;另外,单独存在的Cas9N或Cas9C不具有完整的功能,进一步通过调控Cas9N和Cas9C加入的时间先后顺序或调节Cas9N和Cas9C的比例,可起到调控Cas9蛋白功能的作用,对CRISPR的进一步应用具有重要的意义。
附图说明
图1为用于表达含有逆转录酶的split-cas9蛋白的表达载体组图谱。
图2为用于表达split-cas9蛋白的核酸构建物组的结构示意图。
图3为pegRNA和gRNA的表达载体图谱。
图4为稳转细胞系GFP-A的检测原理示意图。
图5为含有未拆分的全长spCas9的pAAV-EF1α-PE载体图谱。
图6为各组PE2s处理GFP-A细胞后的GFP阳性细胞数和平均荧光强度。
图7为各组PE3s处理GFP-A细胞后的GFP阳性细胞数和平均荧光强度。
图8为split-PE系统在人类细胞内源基因位点的基因编辑和脱靶情况。
图9为含有U6-pegRNA和U6-gRNA的pAAV-EF1α-split-PE载体图谱。
图10为利用AAV运载的split-PE进行基因编辑的编辑效率情况。
具体实施方式
下面结合说明书附图和具体实施例对本发明作出进一步地详细阐述,所述实施例只用于解释本发明,并非用于限定本发明的范围。下述实施例中所使用的试验方法如无特殊说明,均为常规方法;所使用的材料、试剂等,如无特殊说明,为可从商业途径得到的试剂和材料。
实施例1 Cas9蛋白的拆分
将Cas9蛋白拆分成两段不同的氨基酸序列Cas9N(N端)和Cas9C(C端)。其中,Cas9蛋白为spCas9(H840A)蛋白,其氨基酸序列如SEQ ID NO.1所示,编码核苷酸序列如SEQ IDNO.2所示。
拆分位置分别为:第994~995位之间、第1005~1006位之间、第1024~1025位之间、和第1032~1033位之间,得到的各拆分片段组合的氨基酸序列和编码其的核苷酸序列如表1所示。
表1:
实施例2 AAV载体的构建
一、实验方法
1、将内含肽Rma intein基因进行拆分(其核苷酸序列如SEQ ID NO.7所示,其编码的氨基酸序列如SEQ ID NO.6所示)得到两个核苷酸片段RmaN和RmaC,序列分别为如SEQ IDNO.7所示核苷酸序列的第1~306位的核苷酸序列片段和第307~462位的核苷酸序列(对应的氨基酸片段分别如SEQ ID NO.6所示的氨基酸序列的1~102的氨基酸片段和第103~154的氨基酸片段)。
2、根据表1的Cas9拆分方法,构建prime editor(PE),其核苷酸序列如SEQ IDNO.10所示,其中第1~27个碱基的序列为编码核定位信号肽的核苷酸序列(编码的氨基端序列如SEQ ID NO.4所示),第28~4128个碱基的序列为编码Cas9(H840A)的核苷酸序列(不含起始密码子ATG),第4228~6300个碱基的序列为编码逆转录酶M-MLV的核苷酸序列(编码的氨基端序列如SEQ ID NO.3所示),第6301~6324个碱基的序列为编码核定位信号的核苷酸序列(编码的氨基端序列如SEQ ID NO.4所示),其余第4129~4227个碱基为编码连接肽的核苷酸序列。
3、按照实施例1的给出的拆分Cas9蛋白的方式,对应的,将核苷酸序列如SEQ IDNO.10所示的编码Cas9(H840A)的核苷酸序列进行拆分
当Cas9蛋白的在994~995之间进行拆分,则核苷酸序列如SEQ ID NO.10所示的prime editor的拆分为1~3006个碱基的PEN核苷酸序列和3007~6324个碱基的PEC核苷酸序列。
当Cas9蛋白的在1005~1006之间进行拆分,则核苷酸序列如SEQ ID NO.10所示的prime editor的拆分为1~3039个碱基的PEN的核苷酸序列和3040~6324个碱基的PEC的核苷酸序列。
当Cas9蛋白的在1024~1025之间进行拆分,则核苷酸序列如SEQ ID NO.10所示的prime editor的拆分为1~3096个碱基的PEN的核苷酸序列和3097~6324个碱基的PEC的核苷酸序列。
当Cas9蛋白的在1032~1033之间进行拆分,则核苷酸序列如SEQ ID NO.10所示的prime editor的拆分为1~3120个碱基的PEN的核苷酸序列和3121~6324个碱基的PEC的核苷酸序列。
4、通过在引物上引入限制性内切酶(TypeⅡS型)酶切位点,扩增核苷酸序列如SEQID NO.10所示的prime editor的两段PEC和PEN,酶切。然后将PEC与编码内含肽C端的RmaC核苷酸序列连接,将PEN与编码内含肽N端的RmaN核苷酸序列连接,将得到两个待接入载体的核酸序列,准备后续分别的序列;其中,PEC的5’端与所述内含肽C端序列的3’端连接;PEN的3’端与所述内含肽N端序列的5’端连接。
5、改造pX601-AAV-CMV::NLS-SaCas9-NLS-3xHA-bGHpA;U6::BsaI-sgRNA(购于addgene,编号#61591,):
(1)将其启动子改为EF1α启动子(其核苷酸序列如SEQ ID NO.8所示);
(2)删除U6-sagRNA序列,将上面的到的两个待接入载体的序列通过酶切、连接,连入pX601载体,替换掉原来载体中的SaCas9编码序列;
(3)转入工程菌中,扩大培养后,提取质粒。
二、实验结果
提取质粒经过测序后,得到如图1所示的含有逆转录酶的表达载体组pAAV-EF1α-PEN-InteinN(含有PEN和RmaN)和pAAV-EF1α-InteinC-PEC(含有PEC是在RmaC),所述载体组的图谱示意图如图1,表达的相关核酸如图2所示结构)。其中,a为不含逆转录酶模块的PE N端的核酸构建物组结构;b为含有逆转录酶M-MLV的PEC端的核酸构建物组结构;nCas9(H840A)N、nCas9(H840A)C为拆分后的Cas9N、CasC;RmaN、RmaC对应内含肽拆分后的N端和C端部分。
实施例3拆分的PE系统可以有效的进行基因特定位点的编辑
一、实验方法
拆分的split-PE系统为实施例2的方法构建的含有逆转录酶的表达载体组:pAAV-EF1α-PEN-InteinN和pAAV-EF1α-InteinC-PEC,其中表达载体组分别为spCas9蛋白分别按照从以下四个位点进行拆分:第994~995位之间、第1005~1006位之间、第1024~1025位之间或第1032~1033位之间;内含肽为Rma intein。
构建含有m1EmGFP稳转表达的HEK293T细胞,m1EmGFP为EmGFP(核苷酸序列如SEQID NO.11所示)序列第70个氨基酸的密码子CAG突变为TAG,由于EmGFP的突变导致翻译提前终止,只有当TAG被编辑为CAG,才能恢复GFP的正常表达,因此可以通过统计GFP阳性细胞的数目和亮度准确便捷地检测基因编辑的能力(原理示意图如图4)。
取6孔板,每孔接种约7×10
表2:
其中,pLenti-U6-GFP-A-pegRNA1或pLenti-U6-GFP-A-pegRNA2为按实施例2的方法构建的靶向m1EmGFP突变位点的两条pegRNAs的表达载体,序列分为:gcttcatgtggtcggggtagc和gcttcatgtggtcggggtag;
pAAV-EF1α-PE为将PE(其核苷酸序列如SEQ ID NO.10所示)连入pX601得到,其载体图谱如图5所示;pX601-empty-vector,用于保障每组转染质粒总量和组内质粒间的摩尔比一致的空载体(下同)。
转染8小时后更换培养基,转染后的第72小时利用流式细胞术统计各组GFP阳性细胞数和平均荧光强度。
二、实验结果
检测结果如图6(a为GFP阳性细胞数,b为平均荧光强度,Rma指内含肽为Rmaintein)。由检测结果可得,阳性对照组PE2全长载体转入细胞后,可实现目标位点的编辑,点亮GFP;部分split-PE表达载体组转入后同样实现了基因组的编辑,成功检测到一定比例的GFP阳性细胞,其中1024~1025断裂位点展现出和全长PE2相同的荧光强度和略低的GFP阳性细胞比例。因此,证明利用拆分的PE系统可以有效的进行基因特定位点的编辑。
实施例4拆分的PE3可以有效的进行基因特定位点的编辑
一、实验方法
PE3系统为:实施例2的方法构建的含有逆转录酶的表达载体组:pAAV-EF1α-PEN-InteinN和pAAV-EF1α-InteinC-PEC,其中表达载体组分别为spCas9蛋白分别按照从以下四个位点进行拆分:第994~995位之间、第1005~1006位之间、第1024~1025位之间或第1032~1033位之间;内含肽为Rma intein。
进行细胞水平验证,应用前文所述含有m1EmGFP稳转表达的HEK293T细胞,取6孔板,每孔接种约7×10
表3
其中,pLenti-U6-PE3-gRNA1和pLenti-U6-PE3-gRNA2为根据实施例2方法构建的靶向m1EmGFP突变位点上下游的gRNA表达载体,gRNA序列分别为:ctcgtgaccaccttcaccta和catgcccgaaggctacgtcc。
转染8小时后更换培养基,72小时后利用流式细胞术统计各组GFP阳性细胞数和平均荧光强度。
二、实验结果
检测结果如图7(a为GFP阳性细胞数,b为平均荧光强度)。由检测结果可得,各实验组载体转入细胞后,可实现目标位点的编辑,点亮GFP;部分split-PE表达载体组转入后的平均荧光强度甚至超越了直接转入完整的PE,特别是拆分位点为第1024~1025位之间,nick-gRNA为PE3-g1时,内含肽为Rma intein时,其GFP平均荧光强度和GFP阳性细胞比例,都优于其它组,显示这个位点与Rma intein内含肽的组合得到了高效组合、高效编辑的split-PE系统。因此,证明利用拆分的PE3系统可以有效的进行基因特定位点的编辑。
实施例5 split-PE系统进行基因编辑的活性检测
一、实验方法
进一步检测split-PE系统进行基因组基因编辑的能力,实施例2制备得到的表达载体组(pAAV-EF1α-PEN-InteinN和pAAV-EF1α-InteinC-PEC)分别为spCas9蛋白从以下位置中其中一种拆分得到:第1005~1006位之间、第1024~1025位之间;内含肽为Rmaintein。
根据实施例2方法分别构建靶向RNF2、VEGFA、HEK3和PRNP的pegRNA和gRNA表达载体pLenti-U6-RNF2–pegRNA、pLenti-U6-VEGFA–pegRNA、pLenti-U6-HEK3–pegRNA、pLenti-U6-PRNP–pegRNA和pLenti-U6-RNF2–gRNA、pLenti-U6-VEGFA–gRNA、pLenti-U6-HEK3–gRNA、pLenti-U6-PRNP–gRNA。各载体的pegRNA和gRNA序列如表4所述:
表4:4个内源位点pegRNA和gRNA序列
培养野生型HEK293T细胞,铺入6孔板中,每孔铺入约7×10
表5:各组转染情况
注:总质粒加入量为3微克;其中,pLenti-U6-pegRNA-target-gene分别为:pLenti-U6-RNF2–pegRNA、pLenti-U6-VEGFA–pegRNA、pLenti-U6-HEK3–pegRNA、pLenti-U6-PRNP–pegRNA中的一种。pLenti-U6-gRNA-target gene分别为:pLenti-U6-RNF2–gRNA、pLenti-U6-VEGFA–gRNA、pLenti-U6-HEK3–gRNA、pLenti-U6-PRNP–gRNA中的一种,对应基因的pegRNA和gRNA两两组合共转染。
转染8小时后更换培养基,72小时后提细胞基因组,PCR后通过二代测序法(扩增子测序)检测不同靶位点的编辑效率或脱靶情况.
二、实验结果
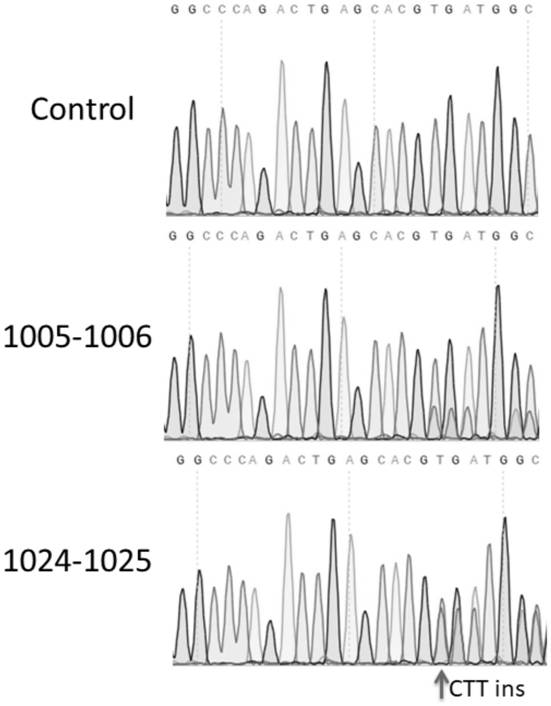
结果如图8所示。深度测序分析结果显示,相较于阴性对照组,全长的PE和Split-PEs(1005~1006和1024~1025)在4个人类基因内源位点都有显著的基因组编辑发生。包括碱基的插入(RNF2+1GAT ins和HEK3+1CTT ins)和单碱基的替换(VEGFA+5G to T和PRNP+6Gto T)。并发现在RNF2基因位点,1005~1006和1024~1025两个断裂位点的Split-PEs介导的基因组编辑效率相较全长的PE蛋白无显著性地降低。在HEK3和VEGFA两个位点表现出约60-~70%的全长编辑效率,并在上述VEGFA和RNF2两个基因位点都有较低的indels水平,保持了较低的脱靶效率。总体而言,本发明提供的拆分的Split-PEs系统成功地在人类细胞系中靶向内源基因位点实现了较高效率的基因组编辑,证明本发明提供的Split-PEs系统可以安全有效的进行人类基因组内源位点的编辑。
实施例6利用AAV运载的split-PE进行基因编辑的活性检测
一、实验方法
克隆pX330-U6-Chimeric_BB-CBh-hSpCas9(购于addgene,编号#42230)上的U6-spgRNA,在split-PE系统的表达载体中选择序列较短的载体,在其poly(A)序列后面加上U6-spgRNA序列,得到gRNA表达载体pAAV-EF1α-PEN-InteinN-U6-chimeric和pAAV-EF1α-InteinC-PEC-U6-chimeric,表达的gRNA序列为ggtcttcgagaagacct,不靶向任何目的基因,作为阴性对照。
连入目旳pegRNA和gRNA:分别克隆pLenti-U6-pegRNA和pLenti-U6-gRNA的U6-pegRNA和U6-gRNA DNA片段,通过NotI核酸内切酶位点分别连入实施例2方法制备的表达载体组(pAAV-EF1α-PEN-InteinN和pAAV-EF1α-InteinC-PEC)的载体的poly(A)序列后面,分别得到pegRNA和gRNA表达载体pAAV-EF1α-PEN-InteinN-U6-pegRNA和pAAV-EF1α-InteinC-PEC-U6-gRNA,连入含有U6-pegRNA和U6-gRNA的载体组图谱如图9(a为pAAV-EF1α-PEN-InteinN-U6-pegRNA,b为pAAV-EF1α-InteinC-PEC-U6-gRNA)。
所述表达载体组分别为spCas9蛋白从以下位置中其中一种拆分后构建得到:第1005~1006位之间和第1024~1025位之间;内含肽为Rma intein。
构建靶向HEK3的pegRNA和gRNA表达载体,其pegRNA和gRNA序列如表4所示。
用三质粒转染法(如表6)生产AAV-split-PE病毒,血清型为AAV1,并用Q-PCR测滴度。
表6:各组转染情况
其中,RepCap和pHelper是病毒生产中需要用到的辅助质粒,RepCap用于表达腺相关病毒的Rep蛋白(Rep78,Rep68,Rep52,Rep40)和Cap蛋白(VP1,VP2,VP3),pHelper用于表达腺病毒helper基因,包括E1A,E1B,E2A,E4和VA等;质粒总加入量为每7×10
转染96小时后回收细胞,用超声裂解细胞,PEG8000沉淀病毒,利用碘克沙醇密度梯度超速离心进行病毒纯化,利用超滤进行缓冲液交换和病毒浓缩,分装后-80℃冻存。
实验组病毒总用量为1×10
二、实验结果
编辑效率如图10所示。由检测结果可得,AAV可以有效运载split-PE系统进入HEK293T细胞内,并表达split-PE蛋白、pegRNA和gRNA,在内含肽的可变剪接作用下,splitPE系统可以较为高效地编辑目的基因,在HEK3内源基因位点成功插入CTT碱基对。特别是拆分位点为第1024-1025位之间,内含肽为Rma intein时,编辑效率高。总体而言,各split PE系统都具有良好的编辑效率和安全性,这说明可利用AAV运载split-PE系统安全有效地进行基因特定位点的编辑。
序列表
<110> 中山大学
<120> 一个Cas9蛋白拆分得到的蛋白组及其应用
<160> 11
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1368
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 1
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
Arg His Lys Pro Glu Asn Ile Val Ile Glu Met Ala Arg Glu Asn Gln
755 760 765
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
Leu Ser Asp Tyr Asp Val Asp His Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
Asp Asp Ser Ile Asp Asn Lys Val Leu Thr Arg Ser Asp Lys Asn Arg
850 855 860
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
Glu Ile Asn Asn Tyr His His Ala His Asp Ala Tyr Leu Asn Ala Val
980 985 990
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala Lys
1010 1015 1020
Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser
1025 1030 1035 1040
Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu
1045 1050 1055
Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile
1060 1065 1070
Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser
1075 1080 1085
Met Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1090 1095 1100
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu Ile
1105 1110 1115 1120
Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe Asp Ser
1125 1130 1135
Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val Glu Lys Gly
1140 1145 1150
Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu Gly Ile Thr Ile
1155 1160 1165
Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala
1170 1175 1180
Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys
1185 1190 1195 1200
Tyr Ser Leu Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser
1205 1210 1215
Ala Gly Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr
1220 1225 1230
Val Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys His
1250 1255 1260
Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val
1265 1270 1275 1280
Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys
1285 1290 1295
His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu
1300 1305 1310
Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp
1315 1320 1325
Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1330 1335 1340
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg Ile
1345 1350 1355 1360
Asp Leu Ser Gln Leu Gly Gly Asp
1365
<210> 2
<211> 4104
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
atggacaaga agtacagcat cggcctggac atcggcacca actctgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gcccagcaag aaattcaagg tgctgggcaa caccgaccgg 120
cacagcatca agaagaacct gatcggagcc ctgctgttcg acagcggcga aacagccgag 180
gccacccggc tgaagagaac cgccagaaga agatacacca gacggaagaa ccggatctgc 240
tatctgcaag agatcttcag caacgagatg gccaaggtgg acgacagctt cttccacaga 300
ctggaagagt ccttcctggt ggaagaggat aagaagcacg agcggcaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgagaaag 420
aaactggtgg acagcaccga caaggccgac ctgcggctga tctatctggc cctggcccac 480
atgatcaagt tccggggcca cttcctgatc gagggcgacc tgaaccccga caacagcgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggaaaacccc 600
atcaacgcca gcggcgtgga cgccaaggcc atcctgtctg ccagactgag caagagcaga 660
cggctggaaa atctgatcgc ccagctgccc ggcgagaaga agaatggcct gttcggaaac 720
ctgattgccc tgagcctggg cctgaccccc aacttcaaga gcaacttcga cctggccgag 780
gatgccaaac tgcagctgag caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttt ctggccgcca agaacctgtc cgacgccatc 900
ctgctgagcg acatcctgag agtgaacacc gagatcacca aggcccccct gagcgcctct 960
atgatcaaga gatacgacga gcaccaccag gacctgaccc tgctgaaagc tctcgtgcgg 1020
cagcagctgc ctgagaagta caaagagatt ttcttcgacc agagcaagaa cggctacgcc 1080
ggctacattg acggcggagc cagccaggaa gagttctaca agttcatcaa gcccatcctg 1140
gaaaagatgg acggcaccga ggaactgctc gtgaagctga acagagagga cctgctgcgg 1200
aagcagcgga ccttcgacaa cggcagcatc ccccaccaga tccacctggg agagctgcac 1260
gccattctgc ggcggcagga agatttttac ccattcctga aggacaaccg ggaaaagatc 1320
gagaagatcc tgaccttccg catcccctac tacgtgggcc ctctggccag gggaaacagc 1380
agattcgcct ggatgaccag aaagagcgag gaaaccatca ccccctggaa cttcgaggaa 1440
gtggtggaca agggcgcttc cgcccagagc ttcatcgagc ggatgaccaa cttcgataag 1500
aacctgccca acgagaaggt gctgcccaag cacagcctgc tgtacgagta cttcaccgtg 1560
tataacgagc tgaccaaagt gaaatacgtg accgagggaa tgagaaagcc cgccttcctg 1620
agcggcgagc agaaaaaggc catcgtggac ctgctgttca agaccaaccg gaaagtgacc 1680
gtgaagcagc tgaaagagga ctacttcaag aaaatcgagt gcttcgactc cgtggaaatc 1740
tccggcgtgg aagatcggtt caacgcctcc ctgggcacat accacgatct gctgaaaatt 1800
atcaaggaca aggacttcct ggacaatgag gaaaacgagg acattctgga agatatcgtg 1860
ctgaccctga cactgtttga ggacagagag atgatcgagg aacggctgaa aacctatgcc 1920
cacctgttcg acgacaaagt gatgaagcag ctgaagcggc ggagatacac cggctggggc 1980
aggctgagcc ggaagctgat caacggcatc cgggacaagc agtccggcaa gacaatcctg 2040
gatttcctga agtccgacgg cttcgccaac agaaacttca tgcagctgat ccacgacgac 2100
agcctgacct ttaaagagga catccagaaa gcccaggtgt ccggccaggg cgatagcctg 2160
cacgagcaca ttgccaatct ggccggcagc cccgccatta agaagggcat cctgcagaca 2220
gtgaaggtgg tggacgagct cgtgaaagtg atgggccggc acaagcccga gaacatcgtg 2280
atcgaaatgg ccagagagaa ccagaccacc cagaagggac agaagaacag ccgcgagaga 2340
atgaagcgga tcgaagaggg catcaaagag ctgggcagcc agatcctgaa agaacacccc 2400
gtggaaaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaatgggcgg 2460
gatatgtacg tggaccagga actggacatc aaccggctgt ccgactacga tgtggaccat 2520
atcgtgcctc agagctttct gaaggacgac tccatcgaca acaaggtgct gaccagaagc 2580
gacaagaacc ggggcaagag cgacaacgtg ccctccgaag aggtcgtgaa gaagatgaag 2640
aactactggc ggcagctgct gaacgccaag ctgattaccc agagaaagtt cgacaatctg 2700
accaaggccg agagaggcgg cctgagcgaa ctggataagg ccggcttcat caagagacag 2760
ctggtggaaa cccggcagat cacaaagcac gtggcacaga tcctggactc ccggatgaac 2820
actaagtacg acgagaatga caagctgatc cgggaagtga aagtgatcac cctgaagtcc 2880
aagctggtgt ccgatttccg gaaggatttc cagttttaca aagtgcgcga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtcgtgg gaaccgccct gatcaaaaag 3000
taccctaagc tggaaagcga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag 3060
atgatcgcca agagcgagca ggaaatcggc aaggctaccg ccaagtactt cttctacagc 3120
aacatcatga actttttcaa gaccgagatt accctggcca acggcgagat ccggaagcgg 3180
cctctgatcg agacaaacgg cgaaaccggg gagatcgtgt gggataaggg ccgggatttt 3240
gccaccgtgc ggaaagtgct gagcatgccc caagtgaata tcgtgaaaaa gaccgaggtg 3300
cagacaggcg gcttcagcaa agagtctatc ctgcccaaga ggaacagcga taagctgatc 3360
gccagaaaga aggactggga ccctaagaag tacggcggct tcgacagccc caccgtggcc 3420
tattctgtgc tggtggtggc caaagtggaa aagggcaagt ccaagaaact gaagagtgtg 3480
aaagagctgc tggggatcac catcatggaa agaagcagct tcgagaagaa tcccatcgac 3540
tttctggaag ccaagggcta caaagaagtg aaaaaggacc tgatcatcaa gctgcctaag 3600
tactccctgt tcgagctgga aaacggccgg aagagaatgc tggcctctgc cggcgaactg 3660
cagaagggaa acgaactggc cctgccctcc aaatatgtga acttcctgta cctggccagc 3720
cactatgaga agctgaaggg ctcccccgag gataatgagc agaaacagct gtttgtggaa 3780
cagcacaagc actacctgga cgagatcatc gagcagatca gcgagttctc caagagagtg 3840
atcctggccg acgctaatct ggacaaagtg ctgtccgcct acaacaagca ccgggataag 3900
cccatcagag agcaggccga gaatatcatc cacctgttta ccctgaccaa tctgggagcc 3960
cctgccgcct tcaagtactt tgacaccacc atcgaccgga agaggtacac cagcaccaaa 4020
gaggtgctgg acgccaccct gatccaccag agcatcaccg gcctgtacga gacacggatc 4080
gacctgtctc agctgggagg cgac 4104
<210> 3
<211> 691
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 3
Thr Leu Asn Ile Glu Asp Glu Tyr Arg Leu His Glu Thr Ser Lys Glu
1 5 10 15
Pro Asp Val Ser Leu Gly Ser Thr Trp Leu Ser Asp Phe Pro Gln Ala
20 25 30
Trp Ala Glu Thr Gly Gly Met Gly Leu Ala Val Arg Gln Ala Pro Leu
35 40 45
Ile Ile Pro Leu Lys Ala Thr Ser Thr Pro Val Ser Ile Lys Gln Tyr
50 55 60
Pro Met Ser Gln Glu Ala Arg Leu Gly Ile Lys Pro His Ile Gln Arg
65 70 75 80
Leu Leu Asp Gln Gly Ile Leu Val Pro Cys Gln Ser Pro Trp Asn Thr
85 90 95
Pro Leu Leu Pro Val Lys Lys Pro Gly Thr Asn Asp Tyr Arg Pro Val
100 105 110
Gln Asp Leu Arg Glu Val Asn Lys Arg Val Glu Asp Ile His Pro Thr
115 120 125
Val Pro Asn Pro Tyr Asn Leu Leu Ser Gly Leu Pro Pro Ser His Gln
130 135 140
Trp Tyr Thr Val Leu Asp Leu Lys Asp Ala Phe Phe Cys Leu Arg Leu
145 150 155 160
His Pro Thr Ser Gln Pro Leu Phe Ala Phe Glu Trp Arg Asp Pro Glu
165 170 175
Met Gly Ile Ser Gly Gln Leu Thr Trp Thr Arg Leu Pro Gln Gly Phe
180 185 190
Lys Asn Ser Pro Thr Leu Phe Asn Glu Ala Leu His Arg Asp Leu Ala
195 200 205
Asp Phe Arg Ile Gln His Pro Asp Leu Ile Leu Leu Gln Tyr Val Asp
210 215 220
Asp Leu Leu Leu Ala Ala Thr Ser Glu Leu Asp Cys Gln Gln Gly Thr
225 230 235 240
Arg Ala Leu Leu Gln Thr Leu Gly Asn Leu Gly Tyr Arg Ala Ser Ala
245 250 255
Lys Lys Ala Gln Ile Cys Gln Lys Gln Val Lys Tyr Leu Gly Tyr Leu
260 265 270
Leu Lys Glu Gly Gln Arg Trp Leu Thr Glu Ala Arg Lys Glu Thr Val
275 280 285
Met Gly Gln Pro Thr Pro Lys Thr Pro Arg Gln Leu Arg Glu Phe Leu
290 295 300
Gly Lys Ala Gly Phe Cys Arg Leu Phe Ile Pro Gly Phe Ala Glu Met
305 310 315 320
Ala Ala Pro Leu Tyr Pro Leu Thr Lys Pro Gly Thr Leu Phe Asn Trp
325 330 335
Gly Pro Asp Gln Gln Lys Ala Tyr Gln Glu Ile Lys Gln Ala Leu Leu
340 345 350
Thr Ala Pro Ala Leu Gly Leu Pro Asp Leu Thr Lys Pro Phe Glu Leu
355 360 365
Phe Val Asp Glu Lys Gln Gly Tyr Ala Lys Gly Val Leu Thr Gln Lys
370 375 380
Leu Gly Pro Trp Arg Arg Pro Val Ala Tyr Leu Ser Lys Lys Leu Asp
385 390 395 400
Pro Val Ala Ala Gly Trp Pro Pro Cys Leu Arg Met Val Ala Ala Ile
405 410 415
Ala Val Leu Thr Lys Asp Ala Gly Lys Leu Thr Met Gly Gln Pro Leu
420 425 430
Val Ile Leu Ala Pro His Ala Val Glu Ala Leu Val Lys Gln Pro Pro
435 440 445
Asp Arg Trp Leu Ser Asn Ala Arg Met Thr His Tyr Gln Ala Leu Leu
450 455 460
Leu Asp Thr Asp Arg Val Gln Phe Gly Pro Val Val Ala Leu Asn Pro
465 470 475 480
Ala Thr Leu Leu Pro Leu Pro Glu Glu Gly Leu Gln His Asn Cys Leu
485 490 495
Asp Ile Leu Ala Glu Ala His Gly Thr Arg Pro Asp Leu Thr Asp Gln
500 505 510
Pro Leu Pro Asp Ala Asp His Thr Trp Tyr Thr Asp Gly Ser Ser Leu
515 520 525
Leu Gln Glu Gly Gln Arg Lys Ala Gly Ala Ala Val Thr Thr Glu Thr
530 535 540
Glu Val Ile Trp Ala Lys Ala Leu Pro Ala Gly Thr Ser Ala Gln Arg
545 550 555 560
Ala Glu Leu Ile Ala Leu Thr Gln Ala Leu Lys Met Ala Glu Gly Lys
565 570 575
Lys Leu Asn Val Tyr Thr Asp Ser Arg Tyr Ala Phe Ala Thr Ala His
580 585 590
Ile His Gly Glu Ile Tyr Arg Arg Arg Gly Trp Leu Thr Ser Glu Gly
595 600 605
Lys Glu Ile Lys Asn Lys Asp Glu Ile Leu Ala Leu Leu Lys Ala Leu
610 615 620
Phe Leu Pro Lys Arg Leu Ser Ile Ile His Cys Pro Gly His Gln Lys
625 630 635 640
Gly His Ser Ala Glu Ala Arg Gly Asn Arg Met Ala Asp Gln Ala Ala
645 650 655
Arg Lys Ala Ala Ile Thr Glu Thr Pro Asp Thr Ser Thr Leu Leu Ile
660 665 670
Glu Asn Ser Ser Pro Ser Gly Gly Ser Lys Arg Thr Ala Asp Gly Ser
675 680 685
Glu Phe Glu
690
<210> 4
<211> 7
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 4
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 5
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 5
Lys Arg Thr Ala Asp Gly Ser Glu Phe Glu Pro Lys Lys Lys Arg Lys
1 5 10 15
Val
<210> 6
<211> 154
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 6
Cys Leu Ala Gly Asp Thr Leu Ile Thr Leu Ala Asp Gly Arg Arg Val
1 5 10 15
Pro Ile Arg Glu Leu Val Ser Gln Gln Asn Phe Ser Val Trp Ala Leu
20 25 30
Asn Pro Gln Thr Tyr Arg Leu Glu Arg Ala Arg Val Ser Arg Ala Phe
35 40 45
Cys Thr Gly Ile Lys Pro Val Tyr Arg Leu Thr Thr Arg Leu Gly Arg
50 55 60
Ser Ile Arg Ala Thr Ala Asn His Arg Phe Leu Thr Pro Gln Gly Trp
65 70 75 80
Lys Arg Val Asp Glu Leu Gln Pro Gly Asp Tyr Leu Ala Leu Pro Arg
85 90 95
Arg Ile Pro Thr Ala Ser Met Ala Ala Ala Cys Pro Glu Leu Arg Gln
100 105 110
Leu Ala Gln Ser Asp Val Tyr Trp Asp Pro Ile Val Ser Ile Glu Pro
115 120 125
Asp Gly Val Glu Glu Val Phe Asp Leu Thr Val Pro Gly Pro His Asn
130 135 140
Phe Val Ala Asn Asp Ile Ile Ala His Asn
145 150
<210> 7
<211> 462
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 7
tgtctggctg gcgatactct cattaccctg gccgatggac gacgagtgcc tattagagaa 60
ctggtgtcac agcagaattt ttccgtgtgg gctctgaatc ctcagactta ccgcctggag 120
agggctagag tgagtagagc tttctgtacc ggcatcaaac ctgtgtaccg cctcaccact 180
agactgggga gatccattag ggccactgcc aaccaccgat ttctcacacc tcagggctgg 240
aaacgagtcg atgaactcca gcctggagat tacctggctc tgcctaggag aatccctact 300
gcctccatgg cggcggcgtg cccggaactg cgtcagctgg cgcagagcga tgtgtattgg 360
gacccgattg tgagcattga accggatggc gtggaagaag tgtttgatct gaccgtgccg 420
ggcccgcata actttgtggc gaacgatatt attgcgcata ac 462
<210> 8
<211> 212
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 8
gggcagagcg cacatcgccc acagtccccg agaagttggg gggaggggtc ggcaattgat 60
ccggtgccta gagaaggtgg cgcggggtaa actgggaaag tgatgtcgtg tactggctcc 120
gcctttttcc cgagggtggg ggagaaccgt atataagtgc agtagtcgcc gtgaacgttc 180
tttttcgcaa cgggtttgcc gccagaacac ag 212
<210> 9
<211> 208
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 9
ctgtgccttc tagttgccag ccatctgttg tttgcccctc ccccgtgcct tccttgaccc 60
tggaaggtgc cactcccact gtcctttcct aataaaatga ggaaattgca tcgcattgtc 120
tgagtaggtg tcattctatt ctggggggtg gggtggggca ggacagcaag ggggaggatt 180
gggaagagaa tagcaggcat gctgggga 208
<210> 10
<211> 6324
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 10
atgggcccaa agaagaagcg gaaagtcgac aagaagtaca gcatcggcct ggacatcggc 60
accaactctg tgggctgggc cgtgatcacc gacgagtaca aggtgcccag caagaaattc 120
aaggtgctgg gcaacaccga ccggcacagc atcaagaaga acctgatcgg agccctgctg 180
ttcgacagcg gcgaaacagc cgaggccacc cggctgaaga gaaccgccag aagaagatac 240
accagacgga agaaccggat ctgctatctg caagagatct tcagcaacga gatggccaag 300
gtggacgaca gcttcttcca cagactggaa gagtccttcc tggtggaaga ggataagaag 360
cacgagcggc accccatctt cggcaacatc gtggacgagg tggcctacca cgagaagtac 420
cccaccatct accacctgag aaagaaactg gtggacagca ccgacaaggc cgacctgcgg 480
ctgatctatc tggccctggc ccacatgatc aagttccggg gccacttcct gatcgagggc 540
gacctgaacc ccgacaacag cgacgtggac aagctgttca tccagctggt gcagacctac 600
aaccagctgt tcgaggaaaa ccccatcaac gccagcggcg tggacgccaa ggccatcctg 660
tctgccagac tgagcaagag cagacggctg gaaaatctga tcgcccagct gcccggcgag 720
aagaagaatg gcctgttcgg aaacctgatt gccctgagcc tgggcctgac ccccaacttc 780
aagagcaact tcgacctggc cgaggatgcc aaactgcagc tgagcaagga cacctacgac 840
gacgacctgg acaacctgct ggcccagatc ggcgaccagt acgccgacct gtttctggcc 900
gccaagaacc tgtccgacgc catcctgctg agcgacatcc tgagagtgaa caccgagatc 960
accaaggccc ccctgagcgc ctctatgatc aagagatacg acgagcacca ccaggacctg 1020
accctgctga aagctctcgt gcggcagcag ctgcctgaga agtacaaaga gattttcttc 1080
gaccagagca agaacggcta cgccggctac attgacggcg gagccagcca ggaagagttc 1140
tacaagttca tcaagcccat cctggaaaag atggacggca ccgaggaact gctcgtgaag 1200
ctgaacagag aggacctgct gcggaagcag cggaccttcg acaacggcag catcccccac 1260
cagatccacc tgggagagct gcacgccatt ctgcggcggc aggaagattt ttacccattc 1320
ctgaaggaca accgggaaaa gatcgagaag atcctgacct tccgcatccc ctactacgtg 1380
ggccctctgg ccaggggaaa cagcagattc gcctggatga ccagaaagag cgaggaaacc 1440
atcaccccct ggaacttcga ggaagtggtg gacaagggcg cttccgccca gagcttcatc 1500
gagcggatga ccaacttcga taagaacctg cccaacgaga aggtgctgcc caagcacagc 1560
ctgctgtacg agtacttcac cgtgtataac gagctgacca aagtgaaata cgtgaccgag 1620
ggaatgagaa agcccgcctt cctgagcggc gagcagaaaa aggccatcgt ggacctgctg 1680
ttcaagacca accggaaagt gaccgtgaag cagctgaaag aggactactt caagaaaatc 1740
gagtgcttcg actccgtgga aatctccggc gtggaagatc ggttcaacgc ctccctgggc 1800
acataccacg atctgctgaa aattatcaag gacaaggact tcctggacaa tgaggaaaac 1860
gaggacattc tggaagatat cgtgctgacc ctgacactgt ttgaggacag agagatgatc 1920
gaggaacggc tgaaaaccta tgcccacctg ttcgacgaca aagtgatgaa gcagctgaag 1980
cggcggagat acaccggctg gggcaggctg agccggaagc tgatcaacgg catccgggac 2040
aagcagtccg gcaagacaat cctggatttc ctgaagtccg acggcttcgc caacagaaac 2100
ttcatgcagc tgatccacga cgacagcctg acctttaaag aggacatcca gaaagcccag 2160
gtgtccggcc agggcgatag cctgcacgag cacattgcca atctggccgg cagccccgcc 2220
attaagaagg gcatcctgca gacagtgaag gtggtggacg agctcgtgaa agtgatgggc 2280
cggcacaagc ccgagaacat cgtgatcgaa atggccagag agaaccagac cacccagaag 2340
ggacagaaga acagccgcga gagaatgaag cggatcgaag agggcatcaa agagctgggc 2400
agccagatcc tgaaagaaca ccccgtggaa aacacccagc tgcagaacga gaagctgtac 2460
ctgtactacc tgcagaatgg gcgggatatg tacgtggacc aggaactgga catcaaccgg 2520
ctgtccgact acgatgtgga cgctatcgtg cctcagagct ttctgaagga cgactccatc 2580
gacaacaagg tgctgaccag aagcgacaag aaccggggca agagcgacaa cgtgccctcc 2640
gaagaggtcg tgaagaagat gaagaactac tggcggcagc tgctgaacgc caagctgatt 2700
acccagagaa agttcgacaa tctgaccaag gccgagagag gcggcctgag cgaactggat 2760
aaggccggct tcatcaagag acagctggtg gaaacccggc agatcacaaa gcacgtggca 2820
cagatcctgg actcccggat gaacactaag tacgacgaga atgacaagct gatccgggaa 2880
gtgaaagtga tcaccctgaa gtccaagctg gtgtccgatt tccggaagga tttccagttt 2940
tacaaagtgc gcgagatcaa caactaccac cacgcccacg acgcctacct gaacgccgtc 3000
gtgggaaccg ccctgatcaa aaagtaccct aagctggaaa gcgagttcgt gtacggcgac 3060
tacaaggtgt acgacgtgcg gaagatgatc gccaagagcg agcaggaaat cggcaaggct 3120
accgccaagt acttcttcta cagcaacatc atgaactttt tcaagaccga gattaccctg 3180
gccaacggcg agatccggaa gcggcctctg atcgagacaa acggcgaaac cggggagatc 3240
gtgtgggata agggccggga ttttgccacc gtgcggaaag tgctgagcat gccccaagtg 3300
aatatcgtga aaaagaccga ggtgcagaca ggcggcttca gcaaagagtc tatcctgccc 3360
aagaggaaca gcgataagct gatcgccaga aagaaggact gggaccctaa gaagtacggc 3420
ggcttcgaca gccccaccgt ggcctattct gtgctggtgg tggccaaagt ggaaaagggc 3480
aagtccaaga aactgaagag tgtgaaagag ctgctgggga tcaccatcat ggaaagaagc 3540
agcttcgaga agaatcccat cgactttctg gaagccaagg gctacaaaga agtgaaaaag 3600
gacctgatca tcaagctgcc taagtactcc ctgttcgagc tggaaaacgg ccggaagaga 3660
atgctggcct ctgccggcga actgcagaag ggaaacgaac tggccctgcc ctccaaatat 3720
gtgaacttcc tgtacctggc cagccactat gagaagctga agggctcccc cgaggataat 3780
gagcagaaac agctgtttgt ggaacagcac aagcactacc tggacgagat catcgagcag 3840
atcagcgagt tctccaagag agtgatcctg gccgacgcta atctggacaa agtgctgtcc 3900
gcctacaaca agcaccggga taagcccatc agagagcagg ccgagaatat catccacctg 3960
tttaccctga ccaatctggg agcccctgcc gccttcaagt actttgacac caccatcgac 4020
cggaagaggt acaccagcac caaagaggtg ctggacgcca ccctgatcca ccagagcatc 4080
accggcctgt acgagacacg gatcgacctg tctcagctgg gaggtgactc tggaggatct 4140
agcggaggat cctctggcag cgagacacca ggaacaagcg agtcagcaac accagagagc 4200
agtggcggca gcagcggcgg cagcagcacc ctaaatatag aagatgagta tcggctacat 4260
gagacctcaa aagagccaga tgtttctcta gggtccacat ggctgtctga ttttcctcag 4320
gcctgggcgg aaaccggggg catgggactg gcagttcgcc aagctcctct gatcatacct 4380
ctgaaagcaa cctctacccc cgtgtccata aaacaatacc ccatgtcaca agaagccaga 4440
ctggggatca agccccacat acagagactg ttggaccagg gaatactggt accctgccag 4500
tccccctgga acacgcccct gctacccgtt aagaaaccag ggactaatga ttataggcct 4560
gtccaggatc tgagagaagt caacaagcgg gtggaagaca tccaccccac cgtgcccaac 4620
ccttacaacc tcttgagcgg gctcccaccg tcccaccagt ggtacactgt gcttgattta 4680
aaggatgcct ttttctgcct gagactccac cccaccagtc agcctctctt cgcctttgag 4740
tggagagatc cagagatggg aatctcagga caattgacct ggaccagact cccacagggt 4800
ttcaaaaaca gtcccaccct gtttaatgag gcactgcaca gagacctagc agacttccgg 4860
atccagcacc cagacttgat cctgctacag tacgtggatg acttactgct ggccgccact 4920
tctgagctag actgccaaca aggtactcgg gccctgttac aaaccctagg gaacctcggg 4980
tatcgggcct cggccaagaa agcccaaatt tgccagaaac aggtcaagta tctggggtat 5040
cttctaaaag agggtcagag atggctgact gaggccagaa aagagactgt gatggggcag 5100
cctactccga agacccctcg acaactaagg gagttcctag ggaaggcagg cttctgtcgc 5160
ctcttcatcc ctgggtttgc agaaatggca gcccccctgt accctctcac caaaccgggg 5220
actctgttta attggggccc agaccaacaa aaggcctatc aagaaatcaa gcaagctctt 5280
ctaactgccc cagccctggg gttgccagat ttgactaagc cctttgaact ctttgtcgac 5340
gagaagcagg gctacgccaa aggtgtccta acgcaaaaac tgggaccttg gcgtcggccg 5400
gtggcctacc tgtccaaaaa gctagaccca gtagcagctg ggtggccccc ttgcctacgg 5460
atggtagcag ccattgccgt actgacaaag gatgcaggca agctaaccat gggacagcca 5520
ctagtcattc tggcccccca tgcagtagag gcactagtca aacaaccccc cgaccgctgg 5580
ctttccaacg cccggatgac tcactatcag gccttgcttt tggacacgga ccgggtccag 5640
ttcggaccgg tggtagccct gaacccggct acgctgctcc cactgcctga ggaagggctg 5700
caacacaact gccttgatat cctggccgaa gcccacggaa cccgacccga cctaacggac 5760
cagccgctcc cagacgccga ccacacctgg tacacggatg gaagcagtct cttacaagag 5820
ggacagcgta aggcgggagc tgcggtgacc accgagaccg aggtaatctg ggctaaagcc 5880
ctgccagccg ggacatccgc tcagcgggct gaactgatag cactcaccca ggccctaaag 5940
atggcagaag gtaagaagct aaatgtttat actgatagcc gttatgcttt tgctactgcc 6000
catatccatg gagaaatata cagaaggcgt gggtggctca catcagaagg caaagagatc 6060
aaaaataaag acgagatctt ggccctacta aaagccctct ttctgcccaa aagacttagc 6120
ataatccatt gtccaggaca tcaaaaggga cacagcgccg aggctagagg caaccggatg 6180
gctgaccaag cggcccgaaa ggcagccatc acagagactc cagacacctc taccctcctc 6240
atagaaaatt catcaccctc tggcggctca aaaagaaccg ccgacggcag cgaattcgag 6300
cccaagaaga agaggaaagt ctaa 6324
<210> 11
<211> 717
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 11
atggtgagca agggcgagga gctgttcacc ggggtggtgc ccatcctggt cgagctggac 60
ggcgacgtaa acggccacaa gttcagcgtg tccggcgagg gcgagggcga tgccacctac 120
ggcaagctga ccctgaagtt catctgcacc accggcaagc tgcccgtgcc ctggcccacc 180
ctcgtgacca ccttcaccta cggcgtgtag tgcttcgccc gctaccccga ccacatgaag 240
cagcacgact tcttcaagtc cgccatgccc gaaggctacg tccaggagcg caccatcttc 300
ttcaaggacg acggcaacta caagacccgc gccgaggtga agttcgaggg cgacaccctg 360
gtgaaccgca tcgagctgaa gggcatcgac ttcaaggagg acggcaacat cctggggcac 420
aagctggagt acaactacaa cagccacaag gtctatatca ccgccgacaa gcagaagaac 480
ggcatcaagg tgaacttcaa gacccgccac aacatcgagg acggcagcgt gcagctcgcc 540
gaccactacc agcagaacac ccccatcggc gacggccccg tgctgctgcc cgacaaccac 600
tacctgagca cccagtccgc cctgagcaaa gaccccaacg agaagcgcga tcacatggtc 660
ctgctggagt tcgtgaccgc cgccgggatc actctcggca tggacgagct gtacaag 717
- 一个Cas9蛋白拆分得到的蛋白组及其应用
- 水性醇溶蛋白组合物、制备水性醇溶蛋白组合物的方法及其应用