一种驾驶员加速意图建模方法及识别方法
文献发布时间:2023-06-19 11:19:16
技术领域
本发明涉及车辆领域,特别涉及一种驾驶员加速意图建模方法和识别方法。
背景技术
加速策略是车辆运动控制策略的重要组成部分,它直接影响到车辆行驶安全性和乘坐舒适性。然而,由于驾驶员的加速意图是随着周围环境的变化而变化的,车辆的加速策略必须将驾驶员加速意图纳入考虑之中方可为用户带来更好的驾驶感受,提高产品竞争力。然而,驾驶员的加速意图建模是一个很复杂的问题。刘海江等发表的论文《基于GM-HMM的DCT车辆驾驶员起步意图辨识研究》(《汽车技术》2020年第01期,作者:刘海江;苏博炜)仅研究了针对DCT车辆驾驶员的起步意图建模问题,而非驾驶员加速意图建模,且其未将加速踏板行程导数纳入考虑之中,得到的聚类结果可信度值得怀疑。目前,尚无关于驾驶员加速意图建模方法相关的专利。
发明内容
本发明的主要目的在于提供一种驾驶员加速意图建模方法和识别方法,以使用模拟驾驶器进行模拟驾驶试验所得到的车辆行驶相关数据,得到基于GM-HMM的驾驶员加速意图模型,根据该模型进行驾驶员加速意图的识别。
为了达到上述目的,本发明首先提供一种驾驶员加速意图建模方法,主要包括以下步骤:
进行模拟驾驶试验并采集数据:驾驶员使用模拟驾驶器进行模拟驾驶试验,采集多组试验数据,每组试验数据包括加速踏板行程、加速踏板行程导数和纵向加速度;
试验数据预处理:对原始试验数据进行归一化处理后进行聚类,得到3个群落及3个中心点,包括:缓慢加速中心点、正常加速中心点和激进加速中心点;其中,中心点坐标值为加速踏板行程、加速踏板行程导数和纵向加速度;
划分数据集:根据多个中心点坐标,将属于相同加速意图的数据放入同一数据集,得到缓慢加速数据集、正常加速数据集和激进加速数据集;根据时间连续性,将属于同一数据集的数据按照时间连续性进行切分,得到切分后的数据集;并将切分后的所有数据组划分为训练数据集和测试数据集;
训练并测试驾驶员加速意图模型:采用缓慢加速意图状态、正常加速意图状态和激进加速意图状态这3种加速意图状态类型,对不同时间段的驾驶员驾驶状态进行分类,将拥有相同加速意图状态类型的数据组逐组输入GM-HMM模型,GM-HMM模型的输入变量为数据所属群落编号,输出变量为加速意图状态类型;训练得到基于GM-HMM算法的驾驶员加速意图模型;训练结束后进行模型测试。
进一步地,进行模拟驾驶试验时,虚拟环境为包含有随机交通流的1:1城市道路,数据采集频率为100Hz。
进一步地,试验数据预处理步骤中:模拟驾驶试验后提取出加速踏板行程连续增加时间段的数据作为原始试验数据,并根据以下公式对原始试验数据进行归一化处理,得到归一化后试验数据:
其中,i为数据点编号;j为变量编号;X表示变量值;Y表示归一化后的变量值;max为相关数据的最大值;min为相关数据的最小值;参与归一化的变量包括加速踏板行程、加速踏板行程导数和纵向加速度。
更进一步地,归一化后试验数据聚类使用K-Medoids算法。聚类后得到3个加速意图的中心点,即缓慢加速中心点,正常加速中心点、激进加速中心点。3个中心点坐标值,即加速踏板行程、加速踏板行程导数、纵向加速度。更进一步地,K-Medoids算法的工作步骤如下:
(1)确定所需群落个数k。
(2)在待聚类的数据集中随机选择k个数据点作为k个类群的中心点。
(3)计算所有非中心点的数据点到上一步确定的k个中心点的欧氏距离,与数据点距离最近的中心点对应的群落就是该数据点所属群落。
(4)在每个群落中,依次选取一点,并计算该点与当前所在群落中所有其它点的欧氏距离之和,所得欧氏距离之和最小的点即可视为该群落新的中心点。
(5)重复(2),(3)步骤,直到各个聚簇的中心点不再改变。
本发明中,k=3,3个聚类群落对应3种可观测状态。
进一步地,划分数据集步骤还包括:从切分后的缓慢加速数据集、切分后的正常加速数据集和切分后的激进加速数据集中分别随机抽取一定数量比例的拥有连续时间序列的数据作为测试数据集,剩余的数据作为训练数据集;
训练驾驶员加速意图模型时,使用所述训练数据集中的数据对GM-HMM模型进行训练;模型测试时,使用所述测试数据集中的数据对训练得到的基于GM-HMM算法的驾驶员加速意图模型进行测试。
优选地,所述数量比例为三分之一。
进一步地,训练驾驶员加速意图模型时,将数据所属群落的编号作为可观测状态,可观测状态数量取k,k为大于等于3的自然数;将数据对应的加速意图状态作为隐含状态,隐含状态数量为3;高斯混合度取10。优选地,使用Baum-Welch算法进行迭代优化得到模型参数。
更进一步地,HMM(隐马尔可夫)模型可简写为下式:
λ=(N,M,π,A,B)
其中,N为隐含意图个数,M为可观测状态数,π为初始概率矢量,A为隐含状态的变化过程,B表示可观测状态的变化过程。
假设存在N个隐含状态,分别为θ
q
假设存在M个可观测状态数,分别为V
O
初始概率矢量π为一矢量,其包含第一个时刻各个隐含状态出现的概率,即:
意图转移概率矩阵A的计算方式为:
式中a
输出概率矩阵B=(b
b
式中,b
在GM-HMM模型中,模型的观测概率b
式中,C
更进一步地,使用测试数据集测试基于GM-HMM算法的加速意图模型时,按照时序将测试数据集中测试数据点所属群落的编号输入加速意图模型,得到相应测试数据点对应的预测加速意图状态类型;若一组数据中,预测加速意图类型与实际加速意图类型相同的数据点比例超过该组数据总量的90%,则表示该组预测成功,否则该组预测失败;若预测成功的测试数据组占测试数据组总量的比例超过90%,则该基于GM-HMM算法的加速意图模型可接受,否则需要重新进行模拟驾驶试验。
本发明还提供一种驾驶员加速意图识别方法,其特征在于,使用权利要求1-8任意一项得到的基于GM-HMM算法的加速意图模型对行驶中车辆的驾驶员加速意图进行识别。
进一步地,使用基于GM-HMM算法的加速意图模型的步骤包括:
1)实时地检测车辆的加速踏板行程、加速踏板行程导数和纵向加速度,并进行归一化;
2)计算归一化后的加速踏板行程、加速踏板行程导数和纵向加速度组成的数据点与3个中心点坐标的欧氏距离,其中欧氏距离最小的中心点坐标对应的群落编号即为当前的可观测状态;
3)将当前的可观测状态输入与之对应的基于GM-HMM算法的加速意图模型中,计算得到当前加速意图状态类型。
当识别出驾驶员的加速意图状态后,车辆控制系统可根据当前驾驶员加速意图实时地调整加速策略,从而可以提升用户的驾驶感受。
由于采用上述技术方案,本发明达到以下有益效果:以模拟驾驶器试验获得的车辆行驶相关数据,基于GM-HMM算法建立高可信度的驾驶员加速意图模型,建模过程实施简单,数据采集方便,所得模型运算速度快、精度高、实时性好,且该建模方法将加速踏板行程导数考虑在内,模型预测结果更接近真实驾驶员的加速意图;根据该加速意图模型,可以实时地识别驾驶员加速意图,车辆的加速策略可以及时地随之调整,从而为用户带来更好的驾驶感受。
附图说明
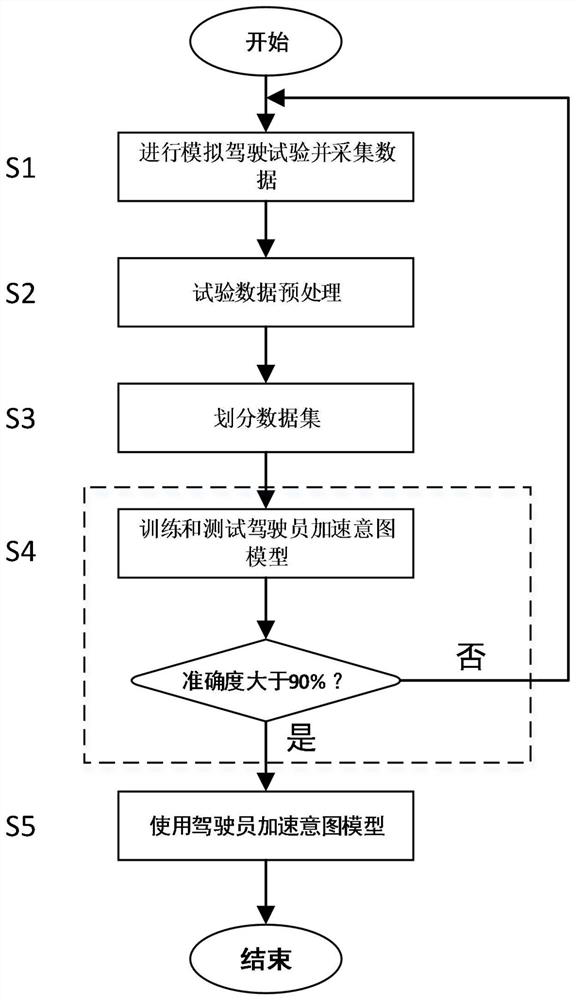
图1为根据本发明的驾驶员加速意图建模方法的步骤流程示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明,下面将结合实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所做的等效变化与修饰前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
请结合图1,本实施例提供一种驾驶员加速意图建模方法和识别方法,其中建模方法包括步骤S1-S4,根据所得的加速意图模型对驾驶员加速意图进行识别的步骤为S5。以下对各步骤做详细说明。
S1.进行模拟驾驶试验并采集数据:
驾驶员使用模拟驾驶器进行模拟驾驶试验,试验中的虚拟环境为1:1城市道路,且包含有随机交通流,试验中采集多组试验数据,每组试验数据包括加速踏板行程、加速踏板行程导数和纵向加速度,数据采集频率为100Hz,共采集约365400000组试验数据。
S2.试验数据预处理:
试验数据预处理包括原始实验数据归一化、聚类。
试验后提取出加速踏板连续增加时间段的数据,即原始试验数据。将原始试验数据归一化,得到归一化试验数据,归一化方式如下式所示:
其中,i为数据点编号;j为变量编号;X表示变量值;Y表示归一化后的变量值;max为相关数据的最大值;min为相关数据的最小值;参与归一化的变量包括加速踏板行程、加速踏板行程导数和纵向加速度。
归一化后试验数据聚类使用K-Medoids算法。聚类后得到3个加速意图的中心点,即缓慢加速中心点,正常加速中心点、激进加速中心点。3个中心点坐标值,即加速踏板行程、加速踏板行程导数、纵向加速度。
K-Medoids算法的工作步骤如下:
(1)确定所需群落个数k。本实施例中,k=3。
(2)在待聚类的数据集中随机选择k个数据点作为k个类群的中心点。
(3)计算所有非中心点的数据点到上一步确定的k个中心点的欧氏距离,与数据点距离最近的中心点对应的群落就是该数据点所属群落。
(4)在每个群落中,依次选取一点,并计算该点与当前所在群落中所有其它点的欧氏距离之和,所得欧氏距离之和最小的点即可视为该群落新的中心点。
(5)重复(2),(3)步骤,直到各个聚簇的中心点不再改变。
S3.划分数据集:
划分数据集时,使用K-Medoids聚类结果,即3个中心点坐标,将属于相同意图的数据放入同一数据集,得到缓慢加速数据集、正常加速数据集和激进加速数据集。根据时间连续性,将属于同一数据集的数据按照时间连续性进行切分,得到切分后的数据集,即切分后的缓慢加速数据集、切分后的正常加速数据集和切分后的激进加速数据集激进加速数据集。从每个切分后的数据集中随机取三分之一组拥有连续时间序列的数据作为测试数据集,剩余的三分之二组数据作为训练数据集。
S4.训练和测试驾驶员加速意图模型:
训练加速意图模型时,根据专家意见对不同时间段的驾驶员驾驶状态进行分类,即缓慢加速意图状态、正常加速意图状态和激进加速意图状态。将拥有相同加速意图类型的训练数据逐组输入GM-HMM模型中。
本实施例中,训练驾驶员加速意图模型时,将数据所属群落的编号作为可观测状态,可观测状态数量取k=3;将数据对应的加速意图状态作为隐含状态,隐含状态数量为3;高斯混合度取10。优选地,使用Baum-Welch算法进行迭代优化得到模型参数。
更进一步地,HMM(隐马尔可夫)模型可简写为下式:
λ=(N,M,π,A,B)
其中,N为隐含意图个数,M为可观测状态数,π为初始概率矢量,A为隐含状态的变化过程,B表示可观测状态的变化过程。
假设存在N个隐含状态,分别为θ
q
假设存在M个可观测状态数,分别为V
O
初始概率矢量π为一矢量,其包含第一个时刻各个隐含状态出现的概率,即:
意图转移概率矩阵A的计算方式为:
式中a
输出概率矩阵B=(b
b
式中,b
在GM-HMM模型中,模型的观测概率b
式中,C
本实施例使用惠普Z1G6工作站进行训练,驾驶员加速意图模型的训练总耗时为36分钟48秒。
使用测试数据测试基于GM-HMM算法的加速意图模型时,将测试数据按照时序输入测试数据所述群落的编号,即可观测状态输入意图模型中,得到相应组对应的预测加速意图类型。若一组数据中,预测加速类型与实际加速意图类型相同的数据点比例超过该组数据总量的90%,则表示该组预测成功,否则该组预测失败。
若预测成功的测试数据组占测试数据组总量的比例超过90%,则该基于GM-HMM算法的加速意图模型可接受,否则需要重新进行模拟驾驶试验。本实例中预测成功比例为96.3%,模型可接受。
S5.使用驾驶员加速意图模型:
使用由步骤S1-S4建模得到的基于GM-HMM算法的加速意图模型对行驶中车辆的驾驶员加速意图进行识别。步骤包括:
1)实时地检测车辆的加速踏板行程、加速踏板行程导数和纵向加速度,并进行归一化;
2)计算归一化后的加速踏板行程、加速踏板行程导数和纵向加速度组成的数据点与k个中心点坐标的欧氏距离,其中欧氏距离最小的中心点坐标对应的群落编号即为当前的可观测状态;
3)将当前的可观测状态输入与之对应的基于GM-HMM算法的加速意图模型中,计算得到当前加速意图状态类型。
当识别出驾驶员的加速意图状态后,车辆控制系统可根据当前驾驶员加速意图实时地调整加速策略,从而可以提升用户的驾驶感受。
通过本实施例的建模方法获得的基于K-Medoids和GM-HMM的驾驶员加速意图识别模型,建模成本低廉,且考虑了加速意图时序变化,预测结果更接近驾驶员真实的加速意图,模型具有高精度、实时性好的特点,使用该模型识别驾驶员加速意图更加准确,结合车辆加速策略,可为用户带来更好的驾驶感受。
以上所述仅为本发明较佳的实施方式,并非用以限定本发明的保护范围;同时,以上的描述对于相关技术领域中具有通常知识者应可明了并据以实施,因此其他未脱离本发明所揭露概念下所完成之等效改变或修饰,都应涵盖在本发明的保护范围之内。
- 一种驾驶员加速意图建模方法及识别方法
- 一种驾驶员加速意图识别方法及其装置