一种针对新闻场景的标题字幕提取方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及电视新闻制作领域,涉及图像处理和分析,更为具体的,涉及一种针对新闻场景的标题字幕提取方法。
背景技术
随着网络技术的发展,数字视频的普及,融媒体的兴起,视频数据的处理和分析技术变得越来越重要。
在新闻视频中,每个新闻事件展开前会有相应的标题字幕的展示,该标题字幕对整个新闻事件进行了概括,通过标题人们可以大致了解事件的内容。同时,标题字幕的内容通常非常生动形象,从而提升观众对新闻事件的兴趣。因此对新闻视频中的标题字幕进行提取,可形成对新闻视频的概括。
在电视新闻制作中,有时希望对一档新闻进行拆条,即从整档新闻视频中将每个独立的新闻事件拆分出来。在这个过程中,标题字幕可以提供很强的先验信息,通过标题字幕进行初步的切分后可显著地减少所需的工作量。
由于电视新闻制作过程中有大量的素材,若通过人工的方式对标题字幕进行提取需要很高的人力成本。因此,提供一种针对电视新闻制作过程中的标题字幕提取方法,可以大大节省人力成本。
发明内容
本发明的目的在于克服现有技术的不足,提供一种针对新闻场景的标题字幕提取方法,可用于不同的新闻栏目,可有效地提升新闻视频的编辑效率,减少人工成本等。
本发明的目的是通过以下方案实现的:
一种针对新闻场景的标题字幕提取方法,包括步骤:
S1,提取待处理新闻视频中的文本并进行位置编码和内容编码;
S2,基于所述位置编码和内容编码对文本进行预处理;
S3,构建一致性约束并从预处理后的文本中选出部分文本作为标题字幕的候选文本;
S4,对所述标题字幕的候选文本进行视觉特征和语义特征提取并将两者融合,得到文本融合特征;
S5,基于所述文本融合特征,使用聚类算法对标题字幕的候选文本进行聚类,从而得到标题字幕集合;
S6,对所述标题字幕集合进行后处理。
进一步地,步骤S1中,所述位置编码包括子步骤:使用文本检测算法对视频进行处理,检测各帧画面中的文本内容的文本位置,检测到的文本位置作为对应画面的文本位置编码:所述内容编码包括子步骤:使用文本识别算法对各帧画面中的文本位置的图像进行识别,识别出的文本内容作为文本内容编码。
进一步地,步骤S2中,所述预处理包括基于位置编码将相邻文本重新合成一条文本;和/或,所述预处理包括设定阈值去掉同帧中字号较标题字幕小的文本。
进一步地,步骤S3中包括子步骤:基于标题字幕出现在视频中时位置固定、内容固定、持续时间较长的特性构建一致性约束,通过构建的一致性约束过滤掉非标题字幕的文本,过滤掉非标题字幕文本后得到剩余的文本作为标题字幕的候选文本。
进一步地,步骤S4中,对所述候选文本进行视觉特征和语义特征提取包括子步骤:基于所述候选文本的位置编码信息,从视频中获取包含该标题字幕的候选文本的图像,使用图像分类模型对文本图像进行视觉特征提取;同时,使用语言模型对所述候选文本的内容进行语义特征提取。
进一步地,步骤S5中,所述聚类包括聚为两类;并在聚为两类后,包括子步骤:分别计算两类的类内距离,取类内距离小的一类作为标题字幕所在类别即得到所述标题字幕集合。
进一步地,步骤S6中,所述后处理包括子步骤:基于标题字幕的先验信息,对所述标题字幕集合进行过滤处理。
进一步地,在识别出文本位置编码和文本内容编码后,包括子步骤:。
进一步地,所述构建一致性约束,通过构建的一致性约束过滤掉非标题字幕的文本包括子步骤:
S31,基于位置编码和内容编码信息,对矩形框左上角相同位置、连续出现的文本进行合并,得到一个包含文起止时间点、位置编码集合、内容编码集合的文本集合;
S32,在步骤S31的基础上,若SS中存在某文本内容,其出现次数与文本总条数m的比例大于设定值k,则视为满足内容一致性。
本发明的有益效果是:
本发明针对新闻视频场景,提供一种通用的新闻视频标题提取的解决方案。通过对新闻视频中标题字幕的通用特征进行分析,构建了一致性约束,该一致性约束适用于不同新闻栏目,保证了本发明的通用性。使用视觉特征和语义特征对标题候选文本进行表征,并进一步地通过无监督的方法提升了对标题字幕提取的准确性。综上,本发明可用于不同的新闻栏目,可有效地提升新闻视频的编辑效率,减少人工成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
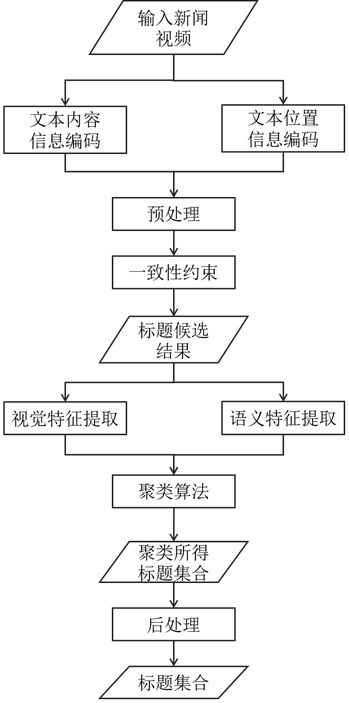
图1为本发明实施例的整体流程图;
图2为本发明实施例中基于文本的位置和内容编码进行预处理的流程图;
图3为本发明实施例中一致性约束的流程图。
具体实施方式
本说明书中所有实施例公开的所有特征,或隐含公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合和/或扩展、替换。
本发明实施例中,包含图1~图3。
实施例1:如图1所示,一种针对新闻场景的标题字幕提取方法,
一种针对新闻场景的标题字幕提取方法,包括步骤:
S1,提取待处理新闻视频中的文本并进行位置编码和内容编码;
S2,基于位置编码和内容编码对文本进行预处理;
S3,构建一致性约束并从预处理后的文本中选出部分文本作为标题字幕的候选文本;
S4,对标题字幕的候选文本进行视觉特征和语义特征提取并将两者融合,得到文本融合特征;
S5,基于文本融合特征,使用聚类算法对标题字幕的候选文本进行聚类,从而得到标题字幕集合;
S6,对标题字幕集合进行后处理。
在实施例1具体应用时,通过对新闻视频中标题字幕的通用特征进行分析,构建了一致性约束,该一致性约束适用于不同新闻栏目,保证了本实施例的通用性。使用视觉特征和语义特征对标题候选文本进行表征,并进一步地通过无监督的方法提升了对标题字幕提取的准确性。综上,本实施例可用于不同的新闻栏目,可有效地提升新闻视频的编辑效率,减少人工成本。
实施例2:在实施例1的基础上,举例说明:步骤S1中,具体包括子步骤:
步骤101:使用文本检测算法模型DB对视频以10帧为步长进行文本检测,该算法模型针对画面中每条文本输出一个文本矩形框。具体的,针对第
其中,
其中
步骤102:使用文本识别算法模型CRNN对各帧画面中已知的文本矩形框中的图像内容进行识别,识别出的文本内容作为文本内容编码。具体的,针对第
其中,
在本实施例中,可选的,包括子步骤:
步骤103:将新闻视频中各视频帧的编号及其中包含的文本位置和内容编码按一定格式存放,作为该视频文本内容的位置和内容编码。具体的,第i帧的存储格式为
实施例3:在实施例1的基础上,举例说明:步骤S2中,如图2所示,具体包括子步骤:
步骤201:由于文本检测模块可能将本该连在一起的文本检测为两条文本,因此需要基于位置编码对横向相邻的文本进行合并。具体的,针对第
步骤202:针对第
由于标题字幕为同一帧画面中字号较大的文本,因此去掉文本矩形框高度小于
实施例4:在实施例1的基础上,举例说明:步骤S3中,如图3所示,具体包括子步骤:
步骤301:基于标题字幕出现在视频中时位置固定、内容固定、持续时间较长的特性,构建一致性约束。具体的,基于位置编码和内容编码信息,对矩形框左上角相同位置、连续出现的文本进行合并,最终得到一个文本集合的起止时间点、位置编码集合、内容编码集合。具体的,该文本集合可表示为
其中,
步骤302:在步骤301的基础上,若文本内容SS中存在某文本内容,其出现次数与文本总条数m的比例大于k,则视为满足内容一致性,具体的,k可以取0.8,可将对应TS记为标题字幕的候选文本集合CT:
其中,
实施例5:在实施例4的基础上,举例说明:步骤S4中,包括子步骤:
步骤401:针对步骤302中每个标题字幕的候选文本,基于候选文本的位置编码信息,从视频画面中获取包含候选标题的图像。
步骤402:使用在ImageNet图像分类数据集上训练得到的模型Resnet50对步骤401中的包含候选标题的图像进行视觉特征提取:
其中
步骤403:使用预训练的语言模型Bert对文本内容进行语义特征提取:
其中,
步骤404:将视觉特征与语义特征结合,作为该文本的融合特征,具体的可朴素地将视觉特征和语义特征进行拼接:
其中,
实施例6:在实施例5的基础上,包括子步骤:
步骤501:基于步骤404中所得的融合特征F,使用层次聚类算法将步骤302所述标题字幕的候选文本集合聚为两类。具体地,由于标题字幕的视觉特征和语义特征都应很相近,因此分别计算两类的类内距离
其中N为类中样本个数;F代表融合特征。
步骤502:取类内距离小的一类作为标题字幕所在类别,从而得到该视频中标题字幕的集合。
本发明功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,在一台计算机设备(可以是个人计算机,服务器,或者网络设备等)以及相应的软件中执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、或者光盘等各种可以存储程序代码的介质,进行测试或者实际的数据在程序实现中存在于只读存储器(Random Access Memory,RAM)、随机存取存储器(Random Access Memory,RAM)等。