一种文本标注的数据处理系统
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及数据处理技术领域,尤其涉及一种文本标注的数据处理系统。
背景技术
随着时代的发展和无纸化办公技术的不断进步,人们生活中需要处理的电子文档越来越多,纸质文档占比则在渐渐降低。企业内的文档处理如果借助NLP相关技术则往往需要大量的文本标注工作用于模型训练,而在电子文档上完成这些操作则需要一种操作便捷、使用方便的标注系统。
当下热门的标注方式中,针对不同标注原对问题理解不一致的情况,通常采用多个标注员对同一数据进行反复标注,再通过投票的方式,决定出数据的标注结果,并且在标注时采取基于PDF文档解析后在文字上划选来完成标注,会导致多种弊端情况出现,例如无法在单层PDF上划选、无法对印章水印等内容进行标记、无法在文档上进行表格标注等,同时,也会出现标注错误或者漏标注的情况,并且影响到文本标注效率,此外,也无法对不同标注人员的准确性和差异性进行确定,因此,如何准确的对文本进行标注,提高文本标注的准确性和效率成为亟待解决的技术问题。
发明内容
本发明目的在于,提供一种文本标注的数据处理系统,通过对主动学习模型的训练,能够无需人员进行标注且对文本进行标注,提高文本标注的准确性和效率。
本发明一方面提供了一种文本标注的数据处理系统,所述系统包括:数据库、处理器和存储有计算机程序的存储器,其中,所述数据库包括N个文本和M个标注端ID,当所述计算机程序被处理器执行时,实现以下步骤:
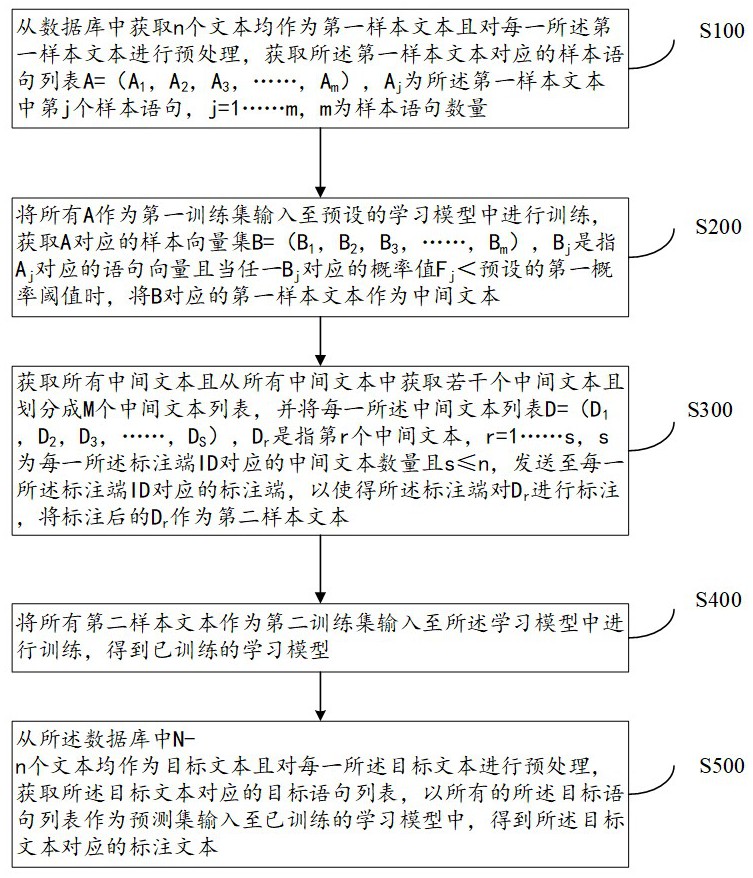
S100、从数据库中获取n个文本均作为第一样本文本且对每一所述第一样本文本进行预处理,获取所述第一样本文本对应的样本语句列表A=(A
S200、将所有A作为第一训练集输入至预设的学习模型中进行训练,获取A对应的样本向量集B=(B
S300、获取所有中间文本且从所有中间文本中获取若干个中间文本且划分成M个中间文本列表,并将每一所述中间文本列表D=(D
S400、将所有第二样本文本作为第二训练集输入至所述学习模型中进行训练,得到已训练的学习模型;
S500、从所述数据库中N-n个文本均作为目标文本且对每一所述目标文本进行预处理,获取所述目标文本对应的目标语句列表,以所有的所述目标语句列表作为预测集输入至已训练的学习模型中,得到所述目标文本对应的标注文本。
本发明与现有技术相比具有明显的优点和有益效果。借由上述技术方案,本发明提供的一种文本标注的数据处理系统可达到相当的技术进步性及实用性,并具有产业上的广泛利用价值,其至少具有下列优点:
本发明通过获取不同的样本对标注端进行标注,进而获取准确的函数插入至学习模型中,能够避免了标注端出现的异常标注或者漏标注的情况,提高了文本标注的准确性;
同时通过获取若干个关键文本列表实现不同标注端ID对同一关键文本和不同关键文本进行标注,进而获取标注端对应的共性函数和差异函数,且插入至学习模型中,能够有效的提高了学习模型的准确性和效率,避免了出现标注端出现的异常标注或者漏标注的情况,提高了文本标注的准确性,且能够无需对同一数据进行反复标注,提高了标注的准确性
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1为本发明实施例一提供的文本标注的数据处理系统执行的数据处理方法的流程图;
图2为本发明实施例二提供的文本标注的数据处理系统执行的数据处理方法的流程图。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种获取目标位置的数据处理系统的具体实施方式及其功效,详细说明如后。
本发明实施例提供了一种文本标注的数据处理系统,所述系统包括:数据库、处理器和存储有计算机程序的存储器,其中,所述数据库包括N个文本和M个标注端ID,当所述计算机程序被处理器执行时,实现以下步骤,如图1所示:
S100、从数据库中获取n个文本均作为第一样本文本且对每一所述第一样本文本进行预处理,获取所述第一样本文本对应的样本语句列表A=(A
具体地,在S100步骤中,所述样本语句是指将所述第一样本文本按照预设规则进行语句划分处理生成的语句,其中,预设规则可为现有技术中任一规则,例如,所述第一样本文本按照标点符号进行语句划分处理生成的语句。
S200、将所有A作为第一训练集输入至预设的学习模型中进行训练,获取A对应的样本向量集B=(B
具体地,在S200步骤中,还包括如下步骤确定B
S201、获取A
S203、将任一A
S205、当F
S207、当F
S209、根据所有A
具体地,所述第二概率阈值的范围为50~60%,优选地,所述第二概率阈值为50%。
在一些实施例中,S205步骤和S207步骤中,当F
优选地,在S300步骤之前,还包括:
当任一B
当F<预设的第三概率阈值时,将F对应的所述第一样本文本作为中间文本。
上述实施例中在S300步骤之前实施的步骤:根据B
S300、获取所有中间文本且从所有中间文本中获取若干个中间文本且划分成M个中间文本列表,并将每一所述中间文本列表D=(D
具体地,在S300步骤中,每一所述标注端ID对应的标注端接收到的D中的中间文本数量一致;其中,所述标注端ID是指标注端的唯一识别码,所述标注端是指用于标注文本的用户端。
S400、将所有第二样本文本作为第二训练集输入至所述学习模型中进行训练,得到已训练的学习模型,能够基于标注后的文件对模型进行训练,避免了标注端出现的异常标注或者漏标注的情况,提高了文本标注的准确性。
具体地,在S400步骤中,还包括如下步骤:
S401、对每一所述第二样本文本进行预处理,获取所述第二样本文本对应的目标 语句列表
S403、获取`A
S405、将任一
具体地,在S401步骤中,可以理解为:同一所述第二样本文本是有不同的所述标注端ID对应的标注端进行标注生成的文本。
优先地,第二样本文本和第一样本文本采取相同的预设规则进行语句划分,在此不再赘述。
优先地,h
S500、从所述数据库中N-n个文本均作为目标文本且对每一所述目标文本进行预处理,获取所述目标文本对应的目标语句列表,以所有的所述目标语句列表作为预测集输入至已训练的学习模型中,得到所述目标文本对应的标注文本。
具体地,所述目标文本为数据库中除第一样本文本之外的文本,所述目标文本与所述第一样本文本采取相同的预设规则进行语句划分,在此不再赘述。
实施例一提供了一种文本标注的数据处理系统,通过获取不同的样本对标注端进行标注,进而获取准确的函数插入至学习模型中,能够避免了标注端出现的异常标注或者漏标注的情况,提高了文本标注的准确性。
在另一个具体的实施例中,当所述计算机程序被处理器执行时,实现以下步骤,如图2所示:
S1、获取第一关键文本列表a=(a
具体地,所述第二关键文本是指在所有样本中除所述第一关键文本之外的其他关键文本,其中,所述第一关键文本和所述第二关键文本从数据库存储的关键文本中获取的,可以理解为,所述关键文本是基于实施例一中S100-S200步骤进行确定的中间文本,在此不再赘述。
S3、将a发送至所有标注端ID对应的标注端进行标注,获取a
具体地,不同所述标注端ID对应的b中所有第二关键文本不相同,可以理解为:任一所述标注端ID对应的b中所有第二关键文本,与其他的M-1个所述标注端ID对应的b中所有第二关键文本均不一致,能够获取不同标注端对文本进行标注的差异特征,有利于训练模型,进而提高文本标注的准确性和效率。
S5、将第一关键训练集输入至预设的学习模型中,获取所有标注端ID的第一目标函数T(x),可以理解为:T(x)用于表征标注端差异的函数。
S7、将第二关键训练集输入至预设的学习模型中,获取每一所述标注端ID的第二目标函数H
具体地,S5中T(x)和S7中H
S9、根据T(x)和H
具体地,所述目标关键文本是指在数据库中除第一关键文本和第二关键文本之外的其他关键文本。
在一些具体的实施例中,对T(x)和H
S11、获取目标文本且对每一所述目标文本进行预处理,得到所述目标文本对应的目标语句列表,以将所述目标语句列表输入至已训练的目标学习模型中,获取所述目标文本对应的标注文本。
具体地,所述目标文本的预处理参照实施例一中S600步骤,在此不再赘述。
具体地,在S11步骤中,当所述目标文本对应的目标语句列表输入至所述已训练的目标学习模型时,所述已训练的目标学习模型中只具有H
实施例二提供通过获取若干个关键文本列表实现不同标注端ID对同一关键文本和不同关键文本进行标注,进而获取标注端对应的共性函数和差异函数,且插入至学习模型中,能够有效的提高了学习模型的准确性和效率,避免了出现标注端出现的异常标注或者漏标注的情况,提高了文本标注的准确性,且能够无需对同一数据进行反复标注,提高了标注的准确性。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。