一种事件日志的批量迹与过程模型的多视角对齐方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及业务过程管理技术领域,具体涉及一种事件日志的批量迹与过程模型的多视角对齐方法。
背景技术
大数据时代背景下,企业的各种信息系统日益庞大与复杂,给业务过程管理带来了新的挑战。从事件日志中提取业务过程的需求逐渐增加,过程挖掘在业务过程管理中发挥着越来越重要的作用。过程挖掘研究对于实施新的业务过程以及分析、改进已实施的业务过程具有重要的意义,是近年来业务过程管理领域的研究热点。过程挖掘主要包括过程发现、一致性检测、过程改进等应用类型。其中,一致性检测将事件日志的事件和过程模型中的变迁进行关联,并且将二者进行比对,目标是找到观察的业务过程行为和业务过程的建模行为之间的共性和差异。
Rozinat等人提出一种基于托肯重演的一致性检测方法。该方法能用来评价事件日志与过程模型的拟合情况,但不能准确定位导致不一致性的偏差。Adriansyah等人提出对齐方法来发现事件日志与过程模型间的偏差。所有对齐中偏差最少的对齐被称为最优对齐。此后,对齐方法迅速成为一致性检测的标准技术。Adriansyah等人提出一种计算迹与过程模型间的最优对齐方法,但一次只能获得一条迹与过程模型的最优对齐。由于业务过程的事件日志包含多条迹,这就需要反复多次构造搜索空间进行求解,以致效率低而且时间和空间复杂度高。为此,田银花等人提出一种基于Petri网模型的批量迹与过程模型对齐方法,构造一次搜索空间可以获取多条迹与过程模型的最优对齐,提高了事件日志中迹与过程模型之间的一致性检测效率。以上对齐方法主要关注了业务过程的控制流,只能检查控制流视角的一致性,并不能检测数据流和资源视角的一致性。
Leoni等人从控制流、数据和资源这3个视角进行迹与过程模型的对齐;先进行控制流视角对齐,再考虑数据和资源视角的对齐。该方法主要关注控制流视角,因而可能会将控制流视角的偏差诊断为数据和资源视角的偏差,导致错误的判断。为此,Mannhardt等人提出一种同时考虑控制流、数据和资源视角的对齐方法,为控制流、数据和资源视角设置相同的权重,从而获得更准确的对齐。Zhang等人使用模糊集合来评估数据视角偏差的严重程度,对数据视角偏差进行更细粒的评估,提高了对数据视角偏差的分析能力。现有的多视角对齐方法只能一次获得一条迹与过程模型的最优对齐,效率低且时间和空间复杂度高。
发明内容
本发明针对获取批量迹的多视角最优对齐时,内存空间过大和提高计算多视角最优对齐的速度这一需求,提供了一种事件日志的批量迹与过程模型的多视角对齐方法。该方法可以在同一个批量迹的搜索空间中获取批量迹的多视角最优对齐,降低了搜索过程中占用的内存空间,也提高了计算多视角最优对齐的速度。
实现本发明目的的技术方案是:
一种事件日志的批量迹与过程模型的多视角对齐方法,包括如下步骤:
1)从过程感知信息系统中的多个数据源中收集数据,组成事件日志,使用基于区域的迭代挖掘算法得到事件日志中批量迹的活动序列的Petri网模型,称为日志模型,Petri网模型是一个元组SN=(P,T,F,α,m
2)由步骤1)所得的日志模型通过日志模型与过程模型的乘积运算,将事件日志中观察到的活动和过程模型中变迁对应活动之间的比对结果展现在乘积模型的变迁上,日志模型与过程模型的乘积模型定义如下:
给定日志模型SN=(P
①P=P
②
-T
-T
-T
③F={(p,(t
④
⑤
第①-⑤步分别为获取乘积模型的库所集合、变迁集合、有向弧集合、初始标识集合和结束标识集合;根据日志模型SN和过程模型TN两个Petri网模型乘积的定义,可知乘积模型ST中保留了Petri网SN、TN中所有的库所、变迁和弧关系,若日志模型SN和过程模型TN两个Petri网模型中具有相同标签的变迁,不可见变迁除外,则相应地生成一个新的变迁,则新的变迁继承日志模型SN和过程模型TN两个Petri网模型中变迁上的标签以及它们的弧关系,从而得到乘积模型;
3)步骤2)所得的乘积模型为一个Perti网ST=(P,T,F,α,m
4)考虑同时从控制流、数据和资源这3个视角进行迹与过程模型的对齐,由于标准多视角代价函数为数据和资源视角分配相同权重,不能根据过程模型的实际业务需求为二者分配不同的权重,因此求得的最优对齐不能符合过程模型业务需求,于是提出了一个新的多视角代价函数,如公式(1)所示:
多视角代价函数c(b)表示为移动分配代价值,其中b=(a,t)是迹与过程模型的对齐中的一个任意移动:
其中,p为变迁t对应的数据和资源约束变量的个数,
根据公式(1)所示的代价函数,迹与过程模型之间对齐的代价值,即所有移动的代价之和的最小的对齐,即为最优对齐;
计算迹与过程模型的最优对齐建模为在有向图中搜索代价最小路径的问题,一般的思路为:首先根据公式(1),为变迁系统的边加上权值,构成加权有向图,然后,在加权有向图的基础上,使用A*算法快速地找出初始标识结点v
g:S→R
h:S→R
若启发函数h(v)估计代价总是小于等于真实代价,A*算法能保证找到总体代价最小的路径;
启发函数h(v)的定义能采用不同的策略,给出Peri网标识结点的变迁序列集合的定义,用变迁序列集合与剩余迹,即迹与过程模型对齐过程中剩余迹待对齐的活动序列的最小编辑距离构造启发函数;
5)使用多视角代价函数,在乘积模型的变迁系统上分别求解批量迹中每条迹与过程模型多视角的单个最优对齐:
5-1)多视角的单个最优对齐方法:针对批量迹中的某条迹,从乘积模型的变迁系统的初始标识结点开始,依据标识结点的评价函数f(v)的最小原则前搜索,直到当前标识结点属于结束标识结点集,搜索结束;在当前标识结点所记录的移动序列中,对移动序列的第1行中的活动所对应的事件属性和第2行中的变迁的约束变量进行赋值,即为该迹与过程模型的单个最优对齐。为了加快搜索当前标识结点的速度,使用优先队列的数据结构存储最优对齐中的候选标识结点集canNodeSet,并按照标识结点的f(v)值降序排序,在O(1)的时间内从canNodeSet中选出当前标识结点。
所述步骤5-1)中多视角的单个最优对齐方法设计了MA1算法,下面给出MA1算法的伪代码,MA1所需的变量和函数的说明如下:
(1)变量定义
srnode:初始标识结点;tgtNodeSet:结束标识结点集;curnode:当前访问标识结点;
sucnode:后继标识结点;pre(σ
selNodeSet:已选标识结点集;canNodeSet:候选标识结点集;
(2)函数定义
g(node):从初始标识结到标识结点node的最小代价;
h(node):标识结点node到结束标识结点最短路径的估计代价;f(node):标识结点node的评价代价;
mv(node1,node2):标识结点node1和node2之间的移动;mv_seq(node):初始标识结点到node标识结点路径上的移动序列;sucNodeSet(node):node标识结点的后继标识结点集;
align(mv_seq(node)):对node标识结点的移动序列,其移动序列的第1行活动对应事件的属性与第2行变迁的约束变量进行赋值,得到当前迹与过程模型多视角的单个最优对齐;
cmin_seq(mv_seq(node)):使用整数混合线性规划模型,求得当前移动序列的最小代价值;
在算法1中,第2行用于初始化已选标识结点集、候选标识结点集、初始结点的移动序列;第5--7行,在当前标识结点属于结束标识结点集时,返回当前迹的多视角单个最优对齐;第8--19行对当前标识结点的后继标识结点进行处理。
本技术方案同时从多视角和批量对齐两个方面出发,研究迹与过程模型间的对齐问题,通过构造一次批量迹与过程模型的搜索空间来实现批量迹与过程模型的多视角对齐,以提高最优对齐的计算效率。首先,使用基于区域的迭代挖掘算法获取事件日志中批量迹的活动序列对应的日志模型,接着获取日志模型与过程模型的乘积模型、以及乘积模型对应的变迁系统。然后,改造标准A*算法,提出一种变迁序列集合与剩余迹的最小编辑距离方法,用于A*算法中启发函数的计算,可提高启发函数的计算速度。最后,在该变迁系统基础上,针对不同的业务过程需要,本技术方案使用自定义多视角代价函数,提出了批量迹中每条迹与过程模型的多视角单个最优对齐的计算方法。与现有多视角对齐方法相比,本技术方案多视角的批量迹对齐方法可以在同一个批量迹的搜索空间中获取批量迹的多视角最优对齐,降低了搜索过程中占用的内存空间,也提高了计算多视角最优对齐的速度。
有益效果:
(1)提出了一种结合控制流、数据和资源视角的多视角代价函数。
(2)设计了一种基于变迁序列集合与剩余迹的最小编辑距离的启发式函数,以此来加快A*算法的计算。
(3)为了满足迹与过程模型的不同对齐需求,设计了计算批量迹中每条迹与过程模型多视角的单个最优对齐算法。
(4)实验结果表明,本技术方案的多视角批量迹对齐方法占用更少的内存空间和使用更少的运行时间。
这种方法可以在同一个批量迹的搜索空间中获取批量迹的多视角最优对齐,降低了搜索过程中占用的内存空间,也提高了计算多视角最优对齐的速度。
附图说明
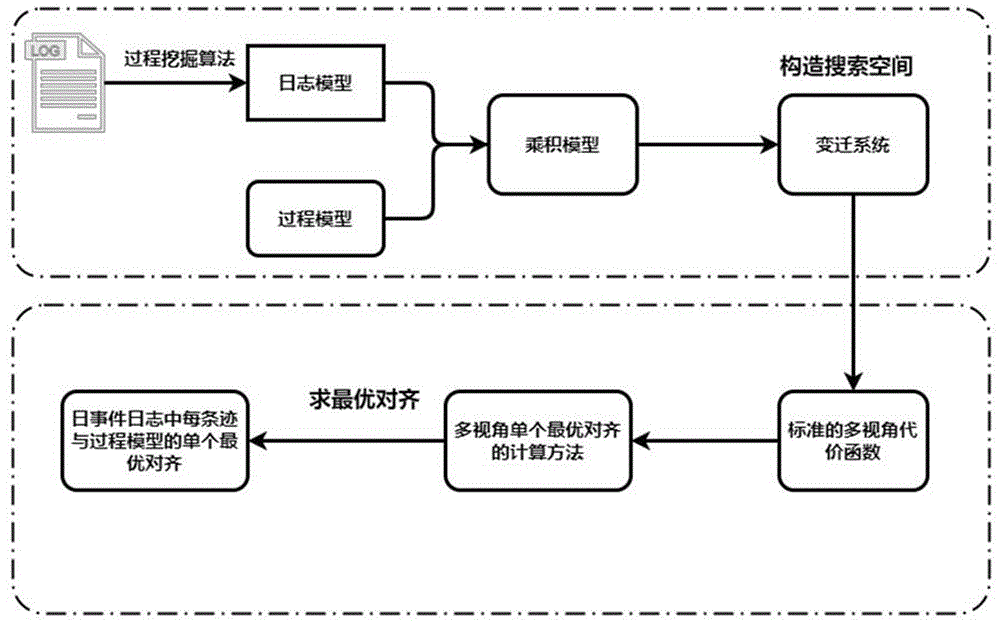
图1为实施例中批量迹与过程模型的多视角对齐的流程示意图;
图2为实施例中迹与过程模型的移动序列示意图;
图3为实施例中过程模型TN的示意图;
图4为实施例中数据和资源约束示意图;
图5为实施例中事件日志L示意图;
图6为实施例中日志模型SN示意图;
图7为实施例中日志模型SN和过程模型TN的乘积模型ST示意图;
图8为实施例中乘积模型ST的变迁系统TS示意图;
图9为实施例中迹σ与过程模型TN间的多视角单个最优对齐的查找过程示意图;
图10为实施例中迹σ与过程模型TN的多视角单个最优对齐的查找标识结点属性示意图。
具体实施方式
下面结合附图和实施例对本发明内容做进一步阐述,但不是对本发明的限定。
实施例:
本例提出的批量迹与过程模型的多视角对齐方法的流程如图1所示。该方法可分为2个模块:构造搜索空间模块、求解最优对齐模块。
首先,使用挖掘算法获取事件日志中批量迹的活动序列的日志模型。然后,获取日志模型与过程模型的乘积模型及其变迁系统。最后,使用多视角代价函数,在乘积模型的变迁系统上分别求解批量迹中每条迹与过程模型多视角的单个最优对齐。具体方法包括如下步骤:
1)对事件日志使用基于区域的迭代挖掘算法得到事件日志中批量迹的活动序列的Petri网模型,称为日志模型,Petri网模型是一个元组SN=(P,T,F,α,m
2)由步骤1)所得的日志模型通过日志模型与过程模型的乘积运算,将事件日志中观察到的活动和过程模型中变迁对应活动之间的比对结果展现在乘积模型的变迁上,日志模型与过程模型的乘积模型定义如下:
给定日志模型SN=(P
①P=P
②
-T
-T
-T
③F={(p,(t
④
⑤
第①-⑤步分别为获取乘积模型的库所集合、变迁集合、有向弧集合、初始标识集合和结束标识集合;根据日志模型SN和过程模型TN两个Petri网模型乘积的定义,可知乘积模型ST中保留了Petri网SN、TN中所有的库所、变迁和弧关系,若日志模型SN和过程模型TN两个Petri网模型中具有相同标签的变迁,不可见变迁除外,则相应地生成一个新的变迁,则新的变迁继承日志模型SN和过程模型TN两个Petri网模型中变迁上的标签以及它们的弧关系,从而得到乘积模型;
3)步骤2)所得的乘积模型为一个Perti网ST=(P,T,F,α,m
本例记业务过程的事件日志为L,首先,本例使用基于区域的迭代挖掘算法挖掘事件日志L的所有迹的活动序列的日志模型,记为SN,该挖掘算法可以保证从事件日志中得到完全拟合迹的日志模型,即SN能够重演事件日志L的任意一条迹,然后,计算得出日志模型SN和过程模型TN的乘积模型ST,最后,获得乘积模型的变迁系统TS,TS即为事件日志中L中所有迹与过程模型TN的搜索空间,现有的多视角对齐方法每次求解一条迹的最优对齐都要构造一次搜索空间,本例方法构造一次搜索空间就可以实现批量迹(即多条迹)与过程模型的多视角对齐,减少了搜索空间所占用的内存空间;
步骤4)本例考虑同时从控制流、数据和资源这3个视角进行迹与过程模型的对齐,由于标准多视角代价函数为数据和资源视角分配相同权重,不能根据过程模型的实际业务需求为二者分配不同的权重,因此有时求得的最优对齐不能符合过程模型业务需求,于是,本例提出了一个新的多视角代价函数,如公式(1)所示:
多视角代价函数c(b)可以表示为移动分配代价值,其中b=(a,t)是迹与过程模型的对齐中的一个任意移动;
其中,p为变迁t对应的数据和资源约束变量的个数,
根据公式(1)所示的代价函数,迹与过程模型之间对齐的代价值(即所有移动的代价之和)最小的对齐,即为最优对齐;
计算迹与过程模型的最优对齐可以建模为在有向图中搜索代价最小路径的问题,一般的思路为:首先根据公式(1),为变迁系统的边加上权值,构成加权有向图,然后,在加权有向图的基础上,使用A*算法可以较快地找出初始标识结点v
g:S→R
h:S→R
如果启发函数h(v)估计代价总是小于等于真实代价,A*算法可以保证找到总体代价最小的路径;
启发函数h(v)的定义可以采用不同的策略,为此,本例给出Peri网标识结点的变迁序列集合的定义,用变迁序列集合与剩余迹(即为迹与过程模型对齐过程中迹剩余待对齐的活动序列)的最小编辑距离构造启发函数;
TN=(P,T,F,α,m
基于Petri网标识结点的变迁序列集合与剩余迹最小编辑距离的启发函数,首先获得过程模型标识结点的变迁序列集合,其变迁序列长度均小于等于2*max+min,然后在变迁系统上进行最优对齐时,计算当前迹剩余的活动序列与过程模型对应的标识结点的变迁序列集合中每条变迁序列的编辑距离,并选出最小值作为当前启发函数h(v)的值,其中,max表示日志中迹的最大长度,min表示过程模型生成变迁序列的最小长度。
经分析,本例方法的时间复杂度O(nlk),其中,n表示过程模型对应的标识结点的变迁序列集合中变迁序列的个数,l表示变迁序列集合中变迁序列的平均长度,k表示迹剩余的活动序列长度,其时间复杂度是多项式级的,相比指数级时间复杂度,降低了求取启发函数h(v)值的时间复杂度;
5)使用多视角代价函数,在乘积模型的变迁系统上分别求解批量迹中每条迹与过程模型多视角的单个最优对齐:
5-1)多视角的单个最优对齐方法,本例方法的主要思路是针对批量迹中的某条迹,从乘积模型的变迁系统的初始标识结点开始,依据标识结点的评价函数f(v)的最小原则前搜索,直到当前标识结点属于结束标识结点集,搜索结束;在当前标识结点所记录的移动序列中,对移动序列的第1行中的活动所对应的事件属性和第2行中的变迁的约束变量进行赋值,即为该迹与过程模型的单个最优对齐;迹与过程模型的移动序列的形式如图3所示,其中第1行为活动序列 步骤5-1-1)多视角对齐中过程模型变迁的约束变量处理方法基于公式(1)的自定义多视角代价函数,在乘积模型的变迁系统上搜索批量迹与过程模型的多视角最优对齐时,标识结点所记录的移动序列就是批量迹中每条迹与过程模型的控制流视角的前缀对齐,这需要计算移动序列的第2行元素对应变迁的约束变量值,使得移动序列的代价值最小,为了解决这个问题,本例对、变迁的约束变量值处理方法进行改进,提出根据过程模型的不同业务需求,可以给数据和资源约束设置不同的权重; 移动序列的第2行元素对应变迁的约束变量值的处理方法可以分为如下2步: ①将移动序列第2行元素对应变迁中的数据约束变量记为d ②根据过程模型中变迁的数据约束和资源约束,分别为数据约束变量和资源约束变量确定约束条件t min w s.t.t 其中,w 步骤5-1-2)多视角的单个最优对齐算法,本例为多视角的单个最优对齐方法设计了MA1算法,下面给出MA1算法的伪代码,MA1所需的变量和函数的说明如下: srnode:初始标识结点;tgtNodeSet:结束标识结点集;curnode:当前访问标识结点; sucnode:后继标识结点;pre(σ selNodeSet:已选标识结点集;canNodeSet:候选标识结点集; g(node):从初始标识结到标识结点node的最小代价; h(node):标识结点node到结束标识结点最短路径的估计代价;f(node):标识结点node的评价代价; mv(node1,node2):标识结点node1和node2之间的移动;mv_seq(node):初始标识结点到node标识结点路径上的移动序列;sucNodeSet(node):node标识结点的后继标识结点集; align(mv_seq(node)):对node标识结点的移动序列,其移动序列的第1行活动对应事件的属性与第2行变迁的约束变量进行赋值,得到当前迹与过程模型多视角的单个最优对齐; cmin_seq(mv_seq(node)):使用整数混合线性规划模型,求得当前移动序列的最小代价值; 上述函数功能明确,不再细介绍。 在算法1中,第2行用于初始化已选标识结点集、候选标识结点集、初始结点的移动序列;第5--7行,在当前标识结点属于结束标识结点集时,返回当前迹的多视角单个最优对齐;第8--19行对当前标识结点的后继标识结点进行处理; 本例的候选标记结点集canNodeSet使用优先队列存储,并按照标识结点的评价函数f(v)降序排序,这样可以在O(1)的时间内从canNodeSet中选出当前标识结点,从而加快查找当前标识结点的速度; 单个最优对齐方法的计算实例: 本例使用实例展示算法MA1的执行过程,给定如图3所示银行贷款金额业务过程模型TN。如果申请人的贷款金额大于等于一千元执行活动a审查,否则执行活动b审查,最后活动c记录贷款信息; 变迁的数据和资源约束如图4所示,其中,贷款金额数据约束变量为Amount,执行人的约束变量为E 给定该行贷款金额业务过程模型TN的事件日志L如图5所示,针对L中所有迹的活动序列,使用基于区域的迭代挖掘算法,可以得到如图6所示的工作流网SN,SN即为日志模型; 计算日志模型SN和过程模型TN的乘积模型ST,如图7所示; 乘积模型ST的变迁系统TS如图8所示,其中设A是一个活动集合且ST=(P,T,F,α,m 现在以迹σ=<(a,{R=Sue,A=900}),(c,{E=Pete})>和图8的变迁系统TS为例,展示算法1的执行过程,其中,即迹σ表示贷款金额为900元,审查人为Sue,记录人Pete。使用公式(1)的自定义多视角代价函数,为了计算方便设置公式(1)中的权重系数w 算法MA1的执行过程如下: ①首先,确定变迁系统TS的初始标识为[p ②将canNodeSet中的标识结点v ③此时,canNodeSet中标识结点排列顺序为v ④canNodeSet中标识结点排列顺序为v