基于深度强化学习的柔性作业车间调度策略训练方法
文献发布时间:2024-04-18 19:53:33
技术领域
本发明涉及轨面状态识别技术领域,特别是涉及一种基于改进深度学习网络的轨面状态识别方法。
背景技术
DQN算法使用深度神经网络来逼近Q函数,网络训练可能会受到梯度爆炸或消失等问题的影响,现有技术中采用DQN算法在进行柔性作业车间调度策略训练时容易出现训练不稳定和难以收敛的问题,除此之外,DQN算法中使用了深度神经网络,在柔性作业车间调度策略训练过程中需要大量的计算资源,因此经过DQN算法训练的调度策略在求解不同规模的柔性作业车间调度问题实例时泛化性差且求解效率低。另外,现有技术中PPO算法在进行柔性作业车间调度策略训练时相对于DQN算法而言训练相对稳定且收敛性更好,但是PPO算法中存在多个超参数影响算法的性能和稳定性,而调整这些超参数需要进行大量的试验和调优,除此之外,经过PPO算法训练的调度策略在求解不同规模的柔性作业车间调度问题实例时表现非常不稳定。
申请号为CN202310433751.1的发明公开了一种基于深度强化学习的关于能耗的多目标动态柔性作业车间调度的方法,所述方法构建了双DQN算法的高层次深度强化学习网络和低层次深度强化学习网络,高层次网络可控制低层次网络的决策;将高层次的优化目标和状态特征输入到低层次的网络中,并优化网络中参数;根据所得优化目标值选择合适工件和加工机器,使得最终调度优化目标达到要求;此发明方法中采用了DQN算法,DQN算法中使用了深度神经网络,经过此发明DQN算法训练的调度策略在求解不同规模的柔性作业车间调度问题实例时泛化性差且求解效率低。
发明内容
针对上述存在的技术问题,本发明提供了一种基于深度强化学习的柔性作业车间调度策略训练方法。
本发明采用以下具体的技术方案:
基于深度强化学习的柔性作业车间调度策略训练方法,所述方法采用SDAC算法模型并进行迭代训练,其方法的步骤如下:
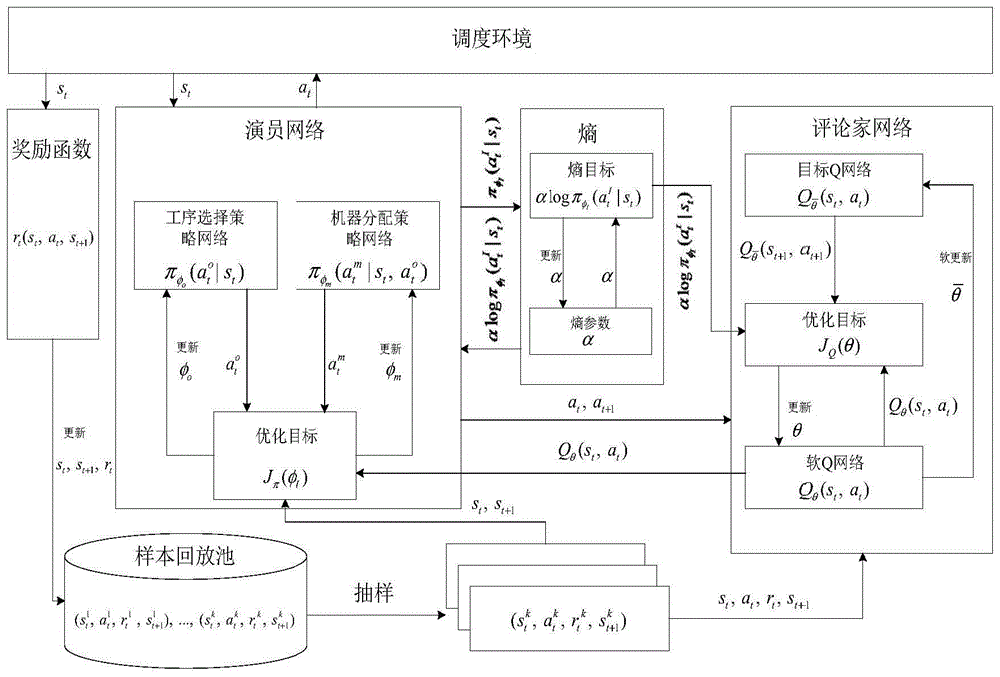
S1:构建SDAC算法模型,所述SDAC算法模型包括演员网络、评论家网络、熵目标函数以及样本存放池D;
S2:在演员网络中设计工序选择策略网络和机器分配策略网络来分别训练工序选择策略和机器分配策略,并通过最小化目标函数J
所述演员网络中的最小化目标函数J
其中I∈{o,m},o表示工序,m表示机器,φ
S3:采用熵目标函数平衡动作a和奖励r的相对重要性,以控制最优策略的随机性;
S4:运用评论家网络中设计的目标Q函数和软Q函数,计算当前调度策略下某个状态-动作对的Q值,通过最小化目标损失函数来更新评论家网络;
所述评论家网络的目标损失函数J
θ表示软Q网络的参数,通过软Q网络训练获得,Q
S5:使用评论家网络来控制演员网络的训练,经过多次迭代训练后输出最终的工序选择策略网络和机器分配策略网络。
进一步地,所述迭代训练的步骤如下:
S1.1:输入SDAC算法模型的训练参数,初始化评论家网络中的目标Q网络参数
S1.2:在迭代训练开始前,重置柔性作业车间调度环境状态为s
S1.3:在时间步t,使用工序选择策略网络和机器分配策略网络来分别选择动作
S1.4:当前状态从s
S1.5:判断当前状态s
S1.6:更新软Q网络的参数θ、策略网络的参数φ
S1.7:判断是否已经学习完B个样本,如果B个样本全部学习完毕,则执行步骤S1.8,否则,跳转到步骤S1.7;
S1.8:判断K个柔性作业车间调度实例是否全部求解完毕,若K个实例已经全部求解完毕,则执行步骤S1.9,否则跳转到步骤S1.3;
S1.9:判断整个训练迭代过程是否达到了最大迭代次数
S1.10:输出训练好的工序选择策略网络和机器分配策略网络用以生成最终的调度策略。
进一步地,所述步骤S1.1中输入SDAC算法模型的训练参数包括最大迭代次数
进一步地,所述步骤S1.6中软Q网络参数通过计算评论家网络中的目标损失函数的J
进一步地,所述步骤S1.6中熵参数α的更新通过熵目标函数的最小化目标函数J(a)。
进一步地,所述步骤S1.6中策略网络的参数通过计算演员网络中的最小化目标函数的梯度J
进一步地,步骤S1.6中熵参数α的更新通过熵目标函数的最小化目标函数J(α),所述J(α)的公式表达式为:
其中
熵目标函数中
进一步地,所述评论家网络的目标损失函数J
其中
进一步地,所述目标Q网络的参数
其中ζ是一个软更新权重参数。
进一步地,即时奖励r
进一步地,所述方法采用实验验证其可行性。
本发明的有益效果为:
本发明提出基于深度强化学习的柔性作业车间调度策略训练方法,模型使用SDAC算法模型作为深度强化学习模型,本发明方法通过设计工序选择策略网络和机器分配策略网络分别对工序选择策略和机器分配策略进行训练,提高了策略训练的效率,并且本发明设计的目标Q网络和软Q网络,有效提高算法的性能以及算法的收敛性和稳定性,除此之外,本发明设计的熵目标函数使得在进行调度策略训练时增加了动作的探索性,有利于学习更多的调度策略。综上所述,本发明不仅提高了调度策略的训练效率,而且经过本发明所训练的调度策略能高效求解各个规模大小的柔性作业车间调度问题实例。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为SDAC算法的训练流程图;
图2为演员网络的简单示意图;
图3为在不同规模的柔性作业车间调度问题实例上使用SDAC算法进行策略训练得到的最大完工时间收敛曲线。
下面结合实施例进一步解释和阐明,但具体实施例并不对本发明有任何形式的限定。
实施例1
如图1~3所示,本发明实施例公开了一种基于深度强化学习的柔性作业车间调度策略训练方法,包括以下步骤:
基于深度强化学习的柔性作业车间调度策略训练方法,所述方法采用SDAC算法模型并进行迭代训练,其方法的步骤如下:
S1:构建SDAC算法模型,所述SDAC算法模型包括演员网络、评论家网络、熵目标函数以及样本存放池D;
S2:在演员网络中设计工序选择策略网络和机器分配策略网络来分别训练工序选择策略和机器分配策略,并通过最小化目标函数J
S3:采用熵目标函数平衡动作a和奖励r的相对重要性,以控制最优策略的随机性;
S4:运用评论家网络中设计的目标Q函数和软Q函数,计算当前调度策略下某个状态-动作对的Q值,通过最小化目标损失函数来更新评论家网络;
S5:使用评论家网络来控制演员网络的训练,经过多次迭代训练后输出最终的工序选择策略网络和机器分配策略网络。
进一步地,采用SDAC算法模型进行迭代训练的步骤如下:
S1.1:输入最大迭代次数
S1.2:在迭代训练开始前,重置柔性作业车间调度环境状态为s
S1.3:在时间步t,使用工序选择策略网络和机器分配策略网络来分别选择动作
S1.4:当前状态从s
S1.5:判断当前状态s
S1.6:更新软Q网络的参数θ、策略网络的参数φ
软Q网络参数θ通过计算评论家网络中的目标损失函数的J
其中
θ表示软Q网络的参数,通过软Q网络训练获得,
熵参数α的更新通过熵目标函数的最小化目标函数J(α),J(α)的计算公式如下:
其中
策略网络的参数φ
其中I∈{o,m}、φ
S1.7:判断是否已经学习完B个样本,如果B个样本全部学习完毕,则执行步骤S1.8,否则,跳转到步骤S1.7;
S1.8:判断K个柔性作业车间调度实例是否全部求解完毕,若K个实例已经全部求解完毕,则执行步骤S1.9,否则跳转到步骤S1.3;
S1.9:判断整个训练迭代过程是否达到了最大迭代次数
S1.10:输出训练好的工序选择策略网络和机器分配策略网络用以生成最终的调度策略。
进一步地,目标Q网络的参数
其公式(5)中ζ为一个软更新权重参数。
进一步地,样本存放池用于将在调度环境中的使用的训练样本进行存储和重用。
进一步地,使用SDAC算法进行策略训练时,使用随机生成的六种不同规模的柔性作业车间调度(FJSP)实例来进行策略训练,包括6×6、10×5、10×10、15×15、20×10和30×10,如图3所示,图3展示了在随机生成的六种不同规模的FJSP实例上进行策略训练得到的最大完工时间的收敛曲线。从图2中可以看出,经过大约50次迭代之后,最大完工时间收敛曲线的波动变得较小,这表明使用SDAC算法进行策略训练能快速收敛。
本发明的有益效果为:
本发明提出基于深度强化学习的柔性作业车间调度策略训练方法,模型使用SDAC算法模型作为深度强化学习模型,本发明方法通过设计工序选择策略网络和机器分配策略网络分别对工序选择策略和机器分配策略进行训练,提高了策略训练的效率,并且本发明设计的目标Q网络和软Q网络,有效提高算法的性能以及算法的收敛性和稳定性,除此之外,本发明设计的熵目标函数使得在进行调度策略训练时增加了动作的探索性,有利于学习更多的调度策略。综上,本发明不仅提高了调度策略的训练效率,而且经过本发明所训练的调度策略能高效求解各个规模大小的柔性作业车间调度问题实例。
实施例2
在实施例1的基础上,为了验证SDAC算法模型的可行性,本实验将本发明采用的SDAC算法与DQN算法和PPO算法,应用在同一数据集,对本发明采用的SDAC算法与DQN算法和PPO算法的求解质量进行比较。
从Behnke数据集上抽取了10个不同规模的FJSP实例,分别使用SDAC算法、DQN算法和PPO算法对这10个不同规模的实例进行求解,通过分别对比求解质量(即最大完工时间)和求解时间(即在同一设备上运行这三种算法的运行时间)来凸显出所提出的SDAC算法的优越性,如表1所示,表1展示了在上述抽取的Behnke数据集上SDAC算法、DQN算法和PPO算法的求解质量比较。表1中C
从下表1中可以看出,在所有的FJSP实例上使用SDAC算法得出的最大完工时间C
表1
实施例3
在实施例1的基础上,为了验证SDAC算法模型的可行性,本实验将本发明采用的SDAC算法与DQN算法和PPO算法,应用在同一数据集,对本发明采用的SDAC算法与DQN算法和PPO算法的求解时间进行比较。
表2列出了在同一设备上分别使用SDAC算法、DQN算法和PPO算法求解10个不同规模的FJSP实例的求解时间(即求解FJSP实例时算法的运行时间),求解时间越短表示该算法的求解速度越快。在表1中可以看出,在所有的FJSP实例上SDAC算法的求解时间都小于DQN算法和PPO算法的求解时间,说明本发明提出的用于柔性作业车间调度策略训练的方法有效减少了求解不同规模柔性作业车间调度问题实例的求解时间。
表2
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。