一种智能算力动态优化调度的分布式模型训练装置及方法
文献发布时间:2024-04-18 20:02:40
技术领域
本发明涉及分布式模型训练技术领域,具体涉及一种智能算力动态优化调度的分布式模型训练装置及方法。
背景技术
当前,在推进工业制造数字化升级、实施智能制造的过程中,其关键问题之一就是对于生产线上所制造工业产品的质量,如何用自动化的技术对其进行质量检测,从而实现从原料加工、生产到后端质量检测的端到端的自动化生产线。随着计算机视觉技术的发展,有很多企业已经开始通过图像检测的方法来自动发现产品的缺陷并进行分拣。近几年来,随着深度学习技术的发展和广泛应用,大量的图像检测技术都是基于深度学习模型的,在深度学习模型进行检测时,很重要的就是需要对模型进行持续不断的优化训练。模型的训练过程是一个非常耗费硬件设备算力和时间的过程,当前,在实际训练时,往往会采用分布式训练的技术来加快模型的训练速度,缩短训练时间。对于一个公司来说,往往会存在多个算法工程师在同时使用训练集群,因此这里就存在一个多人协作过程如何提高GPU利用率,加快模型训练速度的问题。
当前对于多个人共享GPU集群进行训练时,一般的做法是两个:1、每个人都可以共享整个集群的所有GPU卡,每次训练时,可以由工程师自行选择要使用的GPU卡数量,后边工程师一旦提交训练后,发现GPU卡不够时,训练作业就会进入等待,一直等到有空闲的GPU卡时才能够进行训练;2、提前给每个算法工程师划分一个固定的专用GPU工作区,该工作区中包含了该算法工程师所能够使用的所有GPU卡,并且只能该工程师才有权限使用该工作区。针对这两种方式,对于方式1,由于所有工程师都能够使用所有的GPU卡,在实际使用时,就会导致不同工程师之间互相冲突的情况,先使用的工程师可以优先使用所有的GPU卡,后使用的工程师只能等待,影响了后续工程师的工作效率和体验。所以在实际应用中,更多的会使用方式2,而对于方式2,则因为每个工程师也不是一直都会占用其所分配的GPU卡的,对于比较昂贵的GPU卡资源,在实际使用时,会造成资源的浪费,无法充分发挥GPU卡的价值。
发明内容
本发明的目的是针对现有技术存在的不足,提供一种智能算力动态优化调度的分布式模型训练装置及方法。
为实现上述目的,在第一方面,本发明提供了一种智能算力动态优化调度的分布式模型训练方法,包括:
预先为每位算法工程师分配分布式训练集群中的GPU卡的允许使用数量,并形成GPU卡分配信息进行存储;
当算法工程师创建模型训练任务时,读取存储的GPU卡分配信息以及当前分布式训练集群中的GPU卡使用情况,若分布式训练集群中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,则仅预先分配给该算法工程师允许使用数量的GUP卡允许被该算法工程师选择使用;若分布式训练集群中处于空闲状态的GPU卡的数量在预先分配给该算法工程师允许使用数量之上时,则所有处于空闲状态的GPU卡均允许被该算法工程师选择使用;
当某一算法工程师选择训练任务所需的GPU卡时,根据选择的GPU卡执行训练作业调度,并根据该算法工程师选择的GPU卡的数量判断是否缩减其他算法工程师正在训练任务的GPU卡的数量,若需缩减正在训练任务的GPU卡的数量,则通过动态调度当前正在训练的任务,将其他算法工程师多占用的GPU卡还给将要启动的新的训练任务,然后启动新的训练任务,若无需缩减其他算法工程师正在训练任务的GPU卡的数量,直接启动新的训练任务;
根据新的训练任务生成作业启动命令,并根据作业启动命令执行对应的训练任务,在训练过程中,实时获取各个GPU卡使用情况并进行存储。
进一步的,判断是否缩减正在训练任务的GPU卡的数量的方式如下:
若分布式训练集群中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,且算法工程师选择的GPU卡的数量大于分布式训练集群中处于空闲状态的GPU卡的数量,则需缩减正在训练任务的GPU卡数量。
进一步的,将多占用的GPU卡还给当前训练任务的方式如下:
发送缩减的GPU卡数量以及对应的作业id至分布式训练集群的训练作业管理模块;
分布式训练集群的训练作业管理模块在当前批次训练结束后回收相应数量的GPU卡,并将回收的GPU卡分配至新的训练任务。
进一步的,所述GPU卡分配信息和获取的各个GPU卡的状态存储在数据库或文件系统中。
在第二方面,本发明提供了一种智能算力动态优化调度的分布式模型训练装置,包括:
GPU资源管理模块,用以预先为每位算法工程师分配分布式训练集群中的GPU卡的允许使用数量,并控制形成GPU卡分配信息进行存储;
模型训练任务管理模块,用以供算法工程师创建模型训练任务,并在算法工程师创建模型训练任务时,读取存储的GPU卡分配信息以及当前分布式训练集群中的GPU卡使用情况,若分布式训练集群中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,则仅预先分配给该算法工程师允许使用数量的GUP卡允许被该算法工程师选择使用;若分布式训练集群中处于空闲状态的GPU卡的数量在预先分配给该算法工程师允许使用数量之上时,则所有处于空闲状态的GPU卡均允许被该算法工程师选择使用;
分布式算力资源调度模块,用以在某一算法工程师选择训练任务所需的GPU卡时,根据选择的GPU卡执行训练作业调度,并根据该算法工程师选择的GPU卡的数量判断是否缩减其他算法工程师正在训练任务的GPU卡的数量,若需缩减正在训练任务的GPU卡的数量,则通过动态调度当前正在训练的任务,将其他算法工程师多占用的GPU卡还给将要启动的新的训练任务,然后启动新的训练任务,若无需缩减其他算法工程师正在训练任务的GPU卡的数量,直接启动新的训练任务;
训练作业管理模块,用以根据新的训练任务生成作业启动命令;
训练作业执行器,用以根据作业启动命令执行对应的训练任务,所述分布式算力资源调度模块还用以在训练过程中实时获取各个GPU卡使用情况并进行存储。
进一步的,判断是否缩减正在训练任务的GPU卡的数量的方式如下:
若分布式训练集群中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,且算法工程师选择的GPU卡的数量大于分布式训练集群中处于空闲状态的GPU卡的数量,则需缩减正在训练任务的GPU卡数量。
进一步的,将多占用的GPU卡还给当前训练任务的方式如下:
发送缩减的GPU卡数量以及对应的作业id至分布式训练集群的训练作业管理模块;
分布式训练集群的训练作业管理模块在当前批次训练结束后回收相应数量的GPU卡,并将回收的GPU卡分配至新的训练任务。
进一步的,所述GPU卡分配信息和获取的各个GPU卡的状态存储在数据库或文件系统中。
有益效果:本发明可满足每个算法工程师立即的模型训练需求,提高算法工程师个人的工作效率;在资源可用的情况下,为算法工程师提供尽可能多的GPU训练资源,提高资源利用率的同时,也加快模型的训练速度,进一步提高算法工程师的工作效率。
附图说明
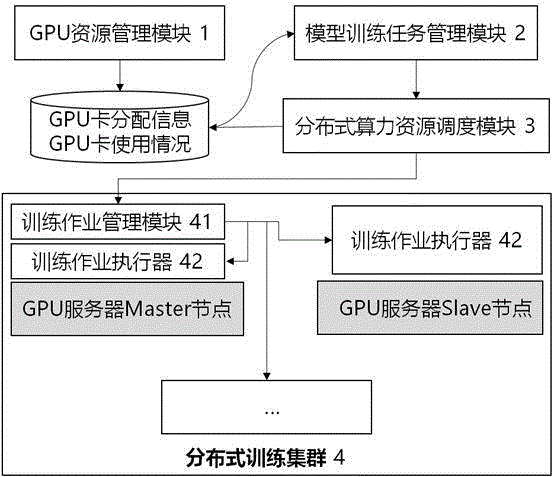
图1是一种智能算力动态优化调度的分布式模型训练装置的原理图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,本实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
本发明实施例提供了一种智能算力动态优化调度的分布式模型训练方法,包括:
预先为每位算法工程师分配分布式训练集群中的GPU卡的允许使用数量,并形成GPU卡分配信息进行存储。其中,GPU卡分配信息可以存储在数据库或文件系统中。上述分布式训练集群是由一台或者多台GPU服务器(一台GPU服务器会包含一个或者多个GPU卡,当GPU服务器为一台时,一台GPU服务器会包含多个GPU卡)组成的。
当算法工程师创建模型训练任务时,读取存储的GPU卡分配信息以及当前分布式训练集群中的GPU卡使用情况,GPU卡使用情况可分为被使用中和空闲状态。若分布式训练集群中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,则仅预先分配给该算法工程师允许使用数量的GUP卡允许被该算法工程师选择使用。若分布式训练集群中处于空闲状态的GPU卡的数量在预先分配给该算法工程师允许使用数量之上时,则所有处于空闲状态的GPU卡均允许被该算法工程师选择使用。算法工程师可以选择被允许使用数量的全部或者部分GPU卡来进行模型训练。
当某一算法工程师选择训练任务所需的GPU卡时,根据选择的GPU卡执行训练作业调度,并根据该算法工程师选择的GPU卡的数量判断是否缩减其他算法工程师正在训练任务的GPU卡的数量,若需缩减正在训练任务的GPU卡的数量,则通过动态调度当前正在训练的任务,将其他算法工程师多占用的GPU卡还给将要启动的新的训练任务,然后启动新的训练任务。若无需缩减其他算法工程师正在训练任务的GPU卡的数量,直接启动新的训练任务。具体的,判断是否缩减正在训练任务的GPU卡的数量的方式如下:
若分布式训练集群中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,且算法工程师选择的GPU卡的数量大于分布式训练集群中处于空闲状态的GPU卡的数量,则需缩减正在训练任务的GPU卡数量。
将多占用的GPU卡还给当前训练任务的方式如下:
发送缩减的GPU卡数量以及对应的作业id至分布式训练集群的训练作业管理模块,由分布式训练集群的训练作业管理模块在当前批次训练结束后回收相应数量的GPU卡,并将回收的GPU卡分配至新的训练任务。需要说明的是,分布式训练集群包括两类节点,GPU服务器master节点和GPU服务器slave节点(当训练集群只有一台机器时,就只有一个master节点),在master节点上会有训练作业执行器和训练作业管理模块,上述缩减的GPU卡数量以及对应的作业id即发送至master节点的训练作业管理模块上,在slave节点上会有训练作业执行器。深度学习的训练过程是按照迭代进行的,每一轮的迭代会在比较短的时间内完成。在每一轮训练完成后,都会由训练作业管理模块重新向每一颗GPU重新发送训练任务。
根据新的训练任务生成作业启动命令,并根据作业启动命令执行对应的训练任务,在训练过程中,实时获取各个GPU卡使用情况并进行存储。上述GPU卡使用情况也可以存储在数据库或文件系统中。
参见图1,基于以上实施例,本领域技术人员可以轻易理解,本发明还提供了一种智能算力动态优化调度的分布式模型训练装置,包括GPU资源管理模块1、模型训练任务管理模块2、分布式算力资源调度模块3和分布式训练集群4等。
GPU资源管理模块1用以预先为每位算法工程师分配分布式训练集群4中的GPU卡的允许使用数量,并控制形成GPU卡分配信息进行存储。其中,GPU卡分配信息可以存储在数据库或文件系统中。上述分布式训练集群4是由一台或者多台GPU服务器(一台GPU服务器会包含一个或者多个GPU卡,当GPU服务器为一台时,一台GPU服务器会包含多个GPU卡)组成的。
模型训练任务管理模块2用以供算法工程师创建模型训练任务,并在算法工程师创建模型训练任务时,读取存储的GPU卡分配信息以及当前分布式训练集群4中的GPU卡使用情况,若分布式训练集群4中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,则仅预先分配给该算法工程师允许使用数量的GUP卡允许被该算法工程师选择使用;若分布式训练集群4中处于空闲状态的GPU卡的数量在预先分配给该算法工程师允许使用数量之上时,则所有处于空闲状态的GPU卡均允许被该算法工程师选择使用。算法工程师可以选择被允许使用数量的全部或者部分GPU卡来进行模型训练。
分布式算力资源调度模块3用以在某一算法工程师选择训练任务所需的GPU卡时,根据选择的GPU卡执行训练作业调度,并根据该算法工程师选择的GPU卡的数量判断是否缩减其他算法工程师正在训练任务的GPU卡的数量,若需缩减正在训练任务的GPU卡的数量,则通过动态调度当前正在训练的任务,将其他算法工程师多占用的GPU卡还给将要启动的新的训练任务,然后启动新的训练任务。需缩减其他算法工程师正在训练任务的GPU卡的数量,直接启动新的训练任务。具体的,判断是否缩减正在训练任务的GPU卡的数量的方式如下:
若分布式训练集群4中的处于空闲状态的GPU卡的数量小于预先分配给该算法工程师允许使用数量,且算法工程师选择的GPU卡的数量大于分布式训练集群4中处于空闲状态的GPU卡的数量,则需缩减正在训练任务的GPU卡数量。
将多占用的GPU卡还给当前训练任务的方式如下:
分布式算力资源调度模块3发送缩减的GPU卡数量以及对应的作业id至分布式训练集群4的训练作业管理模块41,由分布式训练集群4的训练作业管理模块41在当前批次训练结束后回收相应数量的GPU卡,并将回收的GPU卡分配至新的训练任务。需要说明的是,分布式训练集群4包括两类节点,GPU服务器master节点和GPU服务器slave节点(当分布式训练集群4只有一台GPU服务器时,就只有一个master节点),在master节点上会有训练作业执行器42和训练作业管理模块41,上述缩减的GPU卡数量以及对应的作业id即发送至master节点的训练作业管理模块41上,在slave节点上会有训练作业执行器42。深度学习的训练过程是按照迭代进行的,每一轮的迭代会在比较短的时间内完成。在每一轮训练完成后,都会由训练作业管理模块重新向每一颗GPU重新发送训练任务。
上述训练作业管理模块41用以根据新的训练任务生成作业启动命令。训练作业执行器42用以根据作业启动命令执行对应的训练任务。分布式算力资源调度模块3还用以在训练过程中实时获取各个GPU卡使用情况并控制进行存储,上述GPU卡使用情况也可以存储在数据库或文件系统中。
例如,预先为A、B两个算法工程师分配分布式训练集群4中的GPU卡的允许使用数量为8个,A算法工程师在创建模型训练任务时,分布式训练集群4中的处于空闲状态的GPU卡的数量为16个,A算法工程师先选择了10个GPU卡进行模型训练任务,在A算法工程师训练期间,B算法工程师也开始了模型训练工作,此时分布式训练集群4中的处于空闲状态的GPU卡的数量为6个,那么分布式算力资源调度模块3发送缩减的GPU卡数量为2以及对应的作业id至训练作业管理模块41,由训练作业管理模块41完成回收A算法工程师多占用的2个GPU卡,然后把这2个回收的GPU卡分配至B算法工程师新的训练任务。另外,从A算法工程师使用的10个GPU卡回收的2个可以是随机回收,可设定为回收当前批次训练先结束的2个GPU卡。另外,当有多个算法工程师均占用空闲状态的GPU卡时,回收的GPU卡可以是被不同的算法工程师占用的GPU卡。
综上所述,本发明可以为每为算法工程师预先分配允许其使用的GPU卡数量,在实际训练中,当分布式训练集群4中有多余空闲的GPU卡时,算法工程师可以优先使用超出其被分配数量的GPU卡,但是当别的算法工程师也需要训练时,会自动缩减前边算法工程师多占用的GPU卡,将其还给后续需要的算法工程师。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,其它未具体描述的部分,属于现有技术或公知常识。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 算力资源调度方法、算力资源调度模型的训练方法和系统
- 用于分布式视频智能分析平台的算力负载调度方法及装置