生物催化产生萜烯化合物的方法
文献发布时间:2023-06-19 09:47:53
技术领域
本文提供了通过应用新型的磷酸酶来产生萜烯化合物的生物催化方法。该方法允许完全生化合成萜烯化合物,例如柯巴醇(copalol)和赖百当烯二醇(labdendiol),以及它们的衍生物,它们用作产生香料成分例如降龙涎香醚(ambrox)或γ-ambrol的有价值的中间体。还提供了用于产生此类化合物的新颖的完全生化多步骤方法,以及新颖的磷酸酶以及由其衍生的突变体和变体。
背景技术
萜烯存在于大多数生物(微生物、动物和植物)中。这些化合物由称为异戊二烯单元的五碳单元构成并且通过存在于它们结构中的这些单元的数目进行分类。因此,单萜、倍半萜和二萜是分别含有10、15和20个碳原子的萜烯。例如,在植物界中广泛地存在有倍半萜。许多倍半萜分子因为它们的风味和芳香特性以及它们的美容、医疗和抗菌效果而众所周知。已经鉴定出许多倍半萜烃和倍半萜类化合物。
萜烯的生物合成产生涉及称为萜合酶的酶。这些酶将无环萜烯前体转化成一种或多种萜烯产物。具体而言,二萜合酶通过前体香叶基香叶基二磷酸(GGPP)的环化产生二萜。GGPP的环化通常需要两种酶多肽,即在两个连续的酶促反应中组合起作用的I型和II型二萜合酶。II型二萜合酶催化由GGPP的末端双键质子化引发的GGPP的环化/重排,导致环状二萜二磷酸中间体。然后该中间体被催化电离引发的环化的I型二萜合酶进一步转化。
二萜合酶存在于植物和其他生物中,并使用底物如GGPP,但它们具有不同的产物特征。编码二萜合酶的基因和cDNA已经被克隆,并且表征了相应的重组酶。
到目前为止,还没有描述过从萜烯二磷酸中间体,特别是从环状萜烯二磷酸中间体,例如二萜柯巴基二磷酸(酯)(CPP)或赖百当烯二醇二磷酸(酯)(LPP),特异性或优先裂解或除去二磷酸酯基的酶。为了进行所述裂解,将需要磷酸酯键的化学裂解。
本发明要解决的问题是提供一种显示出磷酸酶的酶促活性的多肽,该磷酸酶可用于萜烯基二磷酸键的酶促裂解,并允许生物催化产生萜烯醇。
发明内容
上述问题可以出乎意料地通过提供一类新的酶来解决,该酶显示萜烯基二磷酸磷酸酶活性,其选自大蛋白质酪氨酸磷酸酶家族的二磷酸去除酶的亚组。现有技术中没有描述过蛋白质酪氨酸磷酸酶家族的这种酶作为磷酸酶的应用,其利用萜烯基二磷酸作为底物,特别是诸如CPP和LPP的这种复杂的双环化合物。
这种方法可以提供更具成本效益的产生萜烯中间体(例如柯巴醇和赖百当烯二醇)的方法,它们是制备高价值香料成分(例如Ambrox)的基础材料。
在本发明的一些实施方案中,还提供了从相应的二磷酸前体的生物催化产生非环状萜烯醇,例如法尼醇或香叶基香叶醇。
所述生物催化步骤可以与其他几个先前的或连续的酶促步骤偶联,并允许提供生物催化的多步法,用于从它们各自的前体完全酶促合成有价值的复杂萜烯分子。
附图说明
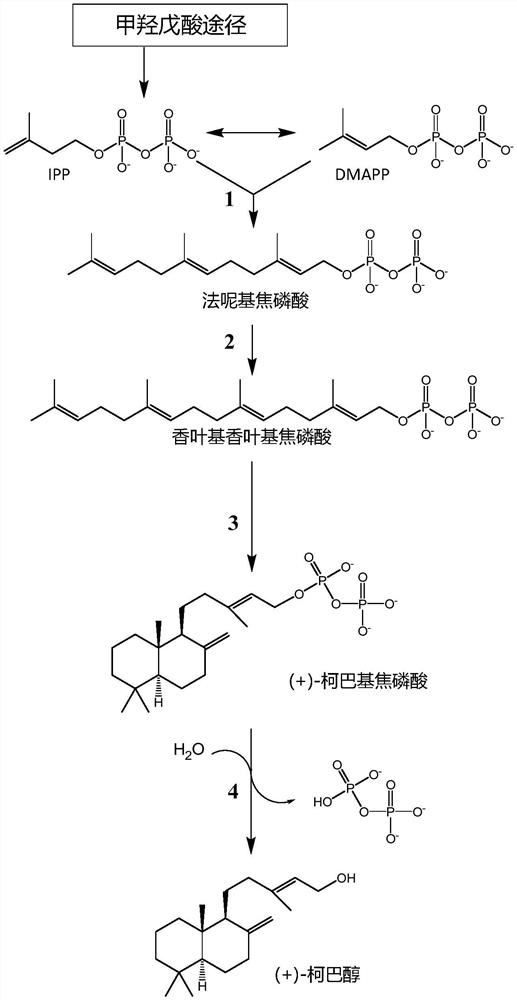
图1.柯巴醇的生物合成途径。1,法呢基焦磷酸合酶。2,香叶基香叶基焦磷酸合酶。3,柯巴基焦磷酸合酶。4,磷酸酶。
图2a.大肠杆菌细胞产生的柯巴醇的GC-MS分析色谱图。上色谱图:大肠杆菌细胞,产生甲羟戊酸途径的重组酶,CPP合酶和AspWeTPP。中色谱图:大肠杆菌细胞,产生甲羟戊酸途径的重组酶,CPP合酶和TalVeTPP。下色谱图:用大肠杆菌细胞产生甲羟戊酸途径的重组酶和CPP合酶进行的对照。
图2b.大肠杆菌细胞产生的柯巴醇的质谱图(在图1a中保留时间为16.7的峰)(A)和真实的柯巴醇的质谱图(B)。
图3.使用TalVeTPP和AspWeTPP在工程化大肠杆菌细胞中产生柯巴醇。
图4.使用TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1在工程化大肠杆菌细胞中产生柯巴醇。
图5.赖百当烯二醇的生物合成途径。1,法呢基焦磷酸合酶。2,香叶基香叶基焦磷酸合酶。3,赖百当烯二醇焦磷酸合酶。4,磷酸酶。
图6.使用TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1在工程化大肠杆菌细胞中产生赖百当烯二醇。
图7a.大肠杆菌细胞产生的赖百当烯二醇的GC-MS分析色谱图。上色谱图:大肠杆菌细胞,产生甲羟戊酸途径的重组酶,LPP合酶和HelGriTPP1。下色谱图:用大肠杆菌产生甲羟戊酸途径的重组酶和LPP合酶进行的对照。
图7b.大肠杆菌细胞产生的赖百当烯二醇的质谱图(在图6a中保留时间为18.2的峰)(A)和真实的柯巴醇的质谱图(B)。
图8.法尼醇和香叶基香叶醇的生物合成途径。1,法呢基焦磷酸合酶。2,香叶基香叶基焦磷酸合酶。3,磷酸酶。
图9.使用TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1在工程化大肠杆菌细胞中产生法尼醇和香叶基香叶醇。
图10.使用TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1在工程化大肠杆菌细胞中产生法尼醇、香叶基香叶醇、柯巴醇和赖百当烯二醇的比较。值是相对于每种化合物的最大产量设置为100而言的。
图11.用质粒CPOL-2和LOH-2转化的工程化大肠杆菌细胞中萜烯化合物的产生,并与产生LPP和CPP而不表达重组磷酸酶的细胞进行比较。
图12.在工程化细胞中产生的柯巴醇。该图显示了大肠杆菌细胞产生的柯巴醇的GC-MS分析色谱图。这些细胞经过工程改造,可以从甲羟戊酸途径中产生柯巴基二磷酸(酯),并表达蛋白质酪氨酸磷酸酶和ADH酶。每个色谱图均标明了细胞中表达的不同ADH。
图13.GCMS色谱图,显示了在经过工程改造以产生甲羟戊酸途径的重组酶,CPP合酶,蛋白质酪氨酸磷酸酶和ADH的细胞中从法呢醇形成法呢醛。
图14.大肠杆菌细胞中的赖百当烯二醇氧化产物的产生的GCMS分析,该细胞经工程改造以产生甲羟戊酸途径的重组酶,LPP合酶,蛋白质酪氨酸磷酸酶和ADH。每个色谱图均标明了细胞中表达的不同ADH。赖百当烯二醇及其氧化产物的峰分别标记为1和2。
图15.编码甲羟戊酸途径酶的基因的染色体整合和两个合成基因操纵子的组织的示意图。mvaK1,一种来自肺炎链球菌(S.pneumoniae)的编码甲羟戊酸激酶的基因;mvaD,一种来自肺炎链球菌的编码磷酸甲羟戊酸脱羧酶的基因;mvaK2,一种来自肺炎链球菌的编码磷酸甲羟戊酸激酶的基因;fni,一种来自肺炎链球菌的编码异戊烯基二磷酸异构酶的基因;mvaA,一种来自金黄色葡萄球菌(S.aureus)的编码HMG-CoA合酶的基因;mvaS,一种来自金黄色葡萄球菌的编码HMG-CoA还原酶的基因;atoB,一种来自大肠杆菌(E.coli)的编码乙酰乙酰辅酶A硫解酶的基因;ERG20,一种来自酿酒酵母(S.cerevisiae)的编码FPP合酶的基因。
图16a.萜烯基二磷酸磷酸酶的保守基序区的氨基酸序列与推导的共有序列的比对。保守残基以黑色背景上的白色字母表示。
图16b.萜烯基二磷酸磷酸酶的保守基序区的氨基酸序列与推导的共有序列的比对。保守残基以黑色背景上的白色字母表示。
图17.18,13-环氧-赖百当-15-醛的生物合成途径。虚线箭头表示多个酶促步骤。1,磷酸酶;2,醇脱氢酶。以下步骤是非酶重排反应。
图18.使用表达GGPP合酶CrtE,CPP合酶SmCPS2,CPP磷酸酶TalVeTPP和以下醇脱氢酶之一的经修饰的酿酒酵母菌株产生的柯巴醇和柯巴醇的GC-MS分析:AzTolADH1,PsAeroADH1,SCH23-ADH1或SCH24-ADH1。
具体实施方式
ADH 醇脱氢酶
bp 碱基对
kb 千碱基
CPP 柯巴基二磷酸(酯)
CPS 柯巴基二磷酸合酶
DNA 脱氧核糖核酸
cDNA 互补DNA
DMAPP 二甲基烯丙基二磷酸(酯)
DTT 二硫苏糖醇
FPP 法呢基二磷酸(酯)
GPP 香叶基二磷酸(酯)
GGPP 香叶基香叶基二磷酸(酯)
GGPS 香叶基香叶基二磷酸合酶
GC 气相色谱
IPP 异戊烯基二磷酸(酯)
LPP 赖百当烯二醇二磷酸(酯)
LPS 赖百当烯二醇二磷酸合酶
MS 质谱仪/质谱法
MVA 甲羟戊酸
PP 二磷酸(酯),焦磷酸(酯)
PCR 聚合酶链反应
RNA 核糖核酸
mRNA 信使核糖核酸
miRNA 微RNA
siRNA 小干扰RNA
rRNA 核糖体RNA
tRNA 转移RNA
TPP 萜烯基二磷酸(酯)
本文所用的“二磷酸(酯)”与“焦磷酸(酯)”是同义词。
“萜烯基”表示衍生自C5结构单元异戊二烯的非环状和环状化学烃基残基,并且特别地含有一个或更多个这样的结构单元。
“双环萜烯”或“双环萜烯基”或“双环二萜烯”或“双环二萜烯基”是指在其结构中包含两个碳环,优选两个碳环稠合环的萜烯化合物或萜烯基残基。
“烃基”残基是基本上由碳和氢原子组成的化学基团,并且可以是环状(例如单环或多环)或非环状,直链或支链的饱和或不饱和部分。它包含多于一个,例如2、3、4或5个,但特别是5个或更多个碳原子,例如5至30个,5至25个,5至20个,5至15个或5至10个碳原子。所述烃基可以是未取代的,或可以带有至少一个,例如1至5个,优选0、1或2个取代基。取代基含一个杂原子,例如O或N。优选地,取代基独立地选自-OH、C=O或-COOH。最优选地,所述取代基是-OH。
“单环或多环烃基残基”包含1、2或3个稠合的(稠环化anellated)或非稠合的,可选有取代基的、饱和或不饱和烃环基团(或“碳环”基团)。每个环可彼此独立地包含3至8个,特别是5至7个,更特别地6个环碳原子。作为单环残基的例子,可以提及的是具有3至7个环碳原子的碳环基团的“环烷基”,例如环丙基,环丁基,环戊基,环己基,环庚基和环辛基;和相应的“环烯基”基团。“环烯基”(或“单或多不饱和环烷基”)特别代表具有5至8个,优选至多6个碳环成员的单环,单或多不饱和碳环基团,例如单不饱和环戊烯基,环己烯基,环庚烯基和环辛烯基。
作为多环残基的例子,可以提及的基团是这样的基团,其中,1、2或3个这样的环烷基和/或环烯基连接在一起,例如稠环化,以形成多环环烷基或环烯基环。作为非限制性例子,可提及由两个稠环化6元碳环组成的双环十氢化萘基(decalinyl)残基。
这样的单环或多环烃基残基中的取代基的数目可以为1至10个,特别是1至5个取代基。这种环状残基的合适的取代基选自低级烷基,低级烯基,烷亚基(alkylidene),烯亚基(alkenylidene),或含有一个杂原子如O或N的残基,例如-OH或-COOH。特别地,取代基独立地选自-OH,-COOH,甲基和甲亚基(methylidene)。
术语“低级烷基”或“短链烷基”表示具有1至4个,1至5个,1至6个或1至7个,特别是1至4个碳原子的饱和的直链或支链的烃基。作为例子,可以提及的是:甲基,乙基,正丙基,1-甲基乙基,正丁基,1-甲基丙基,2-甲基丙基,1,1-二甲基乙基,正戊基,1-甲基丁基,2-甲基丁基,3-甲基丁基,2,2-二甲基丙基,1-乙基丙基,正己基,1,1-二甲基丙基,1,2-二甲基丙基,1-甲基戊基,2-甲基戊基,3-甲基戊基,4-甲基戊基,1,1-二甲基丁基,1,2-二甲基丁基,1,3-二甲基丁基,2,2-二甲基丁基,2,3-二甲基丁基,3,3-二甲基丁基,1-乙基丁基,2-乙基丁基,1,1,2-三甲基丙基,1,2,2-三甲基丙基,1-乙基-1-甲基丙基和1-乙基-2-甲基丙基;以及正庚基,以及它们的单或多分支类似物。
“短链烯基”或“低级烯基”表示具有2至4个,2至6个或2至7个碳原子和在任何位置的一个双键的单或多不饱和,特别是单不饱和的直链或支链烃基,例如C
“烷亚基(alkylidene)”基团表示通过双键连接至分子主体的直链或支链烃取代基。它包含1至6个碳原子。作为此类“C
“烯亚基(alkenylidene)”表示具有超过2个碳原子的上述烷亚基的单不饱和类似物,并且可以称为“C
不饱和环状基团可以包含1个或多个,例如1、2或3个C=C键,并且是芳族的,或者特别是非芳族的。
环状残基的具体例子是式Cyc-A-的基团,其中A代表直链或支链的C
含有此类残基的化合物的典型例子是以下式(1)的那些,特别是柯巴醇和赖百当烯二醇以及它们的立体异构体。
C
C
C
C
本文所述的目标化合物的“前体”分子优选通过对所述前体分子进行至少一个结构改变的合适多肽的酶促作用而转化为所述目标化合物。例如,借助磷酸酶,通过酶促去除二磷酸部分,例如通过去除单磷酸酯或二磷酸酯基团,将“二磷酸酯前体”(例如“萜烯基二磷酸酯前体”)转化为所述目标化合物(例如萜烯醇)。例如,可以通过环化酶或合酶的作用,以一个或多个步骤,将“非环状前体”(如非环状萜烯前体”)转化为环状目标分子(如环状萜烯化合物),而与这种酶的特定的酶促机理无关。
“萜烯合酶”表示一种多肽,其将萜烯前体分子转化为相应的萜烯目标分子,例如特别是经加工的目标萜烯醇。此类萜烯前体分子的非限制性例子为例如非环化合物,其选自法呢基焦磷酸(FPP),香叶基香叶基焦磷酸(GGPP),或者异戊烯基焦磷酸(IPP)与二甲基烯丙基焦磷酸(DMAPP)的混合物。在所获得的萜烯含有二磷酸部分的情况下,合酶被称为“萜烯基二磷酸合酶”
术语“萜烯基二磷酸合酶”或“具有萜烯基二磷酸合酶活性的多肽”或“萜烯基二磷酸合酶蛋白(质)”或“具有产生萜烯基二磷酸的能力”涉及一种多肽,其能够催化任何立体异构体或其混合物的形式的萜烯基二磷酸的合成,该合成从无环萜烯焦磷酸,特别是GPP、FPP或GGPP或IPP开始与DMAPP一起进行。萜烯基二磷酸可能是唯一的产物,或者可能是萜烯基磷酸酯混合物的一部分。所述混合物可以包含萜烯基单磷酸酯和/或萜烯醇。上面的定义也适用于“双环二萜烯基二磷酸合酶”,它可产生双环萜烯基二磷酸,如CPP或LPP。
作为此类“萜烯基二磷酸合酶”或“二萜烯基二磷酸合酶”的例子,可以提及柯巴基二磷酸合酶(CPS)。柯巴基二磷酸可能是唯一的产物,或者可能是柯巴基磷酸酯混合物的一部分。所述混合物可以包含柯巴基单磷酸酯和/或其他萜烯基二磷酸。
作为此类“萜烯基二磷酸合酶”或“二萜烯基二磷酸合酶”的例子,可以列举出赖百当烯二醇二磷酸合酶(LPS)。赖百当烯二醇二磷酸可能是唯一的产物,或者可能是赖百当烯二醇磷酸酯混合物的一部分。所述混合物可以包含赖百当烯二醇单磷酸酯和/或萜烯基二磷酸。
在如下所述的“标准条件”下测定“萜烯基二磷酸合酶活性”或“二萜烯基二磷酸合酶活性”(如CPS或LPS活性):可以使用重组萜烯基二磷酸合酶表达宿主细胞,经破坏的萜烯基二磷酸合酶表达细胞,它们的级分或富集或纯化的萜烯基二磷酸合酶来确定它们,条件是在大约20至45℃,例如大约25至40℃,优选25至32℃的温度下,在pH值为6至11,优选为7至9的培养基或反应介质(优选经缓冲的)中,并在存在参考底物(此处特别是GGPP)的情况下,以1至100μM,优选5至50μM,尤其是30至40μM的初始浓度添加,或由细胞宿主内源产生。形成萜烯基二磷酸的转化反应进行10分钟至5小时,优选约1至2小时。如果不存在内源性磷酸酶,则将一种或多种外源性磷酸酶,例如碱性磷酸酶加入到反应混合物中,以将由合酶形成的萜烯基二磷酸转化为相应的萜烯醇。然后可以用常规方法,例如在用有机溶剂如乙酸乙酯萃取后确定萜烯醇。
术语“蛋白质酪氨酸磷酸酶”表示通常已知从蛋白质上的磷酸化酪氨酸残基去除磷酸基团的一组酶。本文所述的所述家族的特定亚组是用于使磷酸化的萜烯分子去磷酸化的酶。
具有萜烯基二磷酸磷酸酶活性的本发明的多肽被鉴定为蛋白质酪氨酸磷酸酶家族的成员,特别是具有Pfam ID号PF13350的Y_磷酸酶3(Y_phosphatase3)家族的成员。可以使用例如以下网站来扫描多肽与Pfam蛋白质家族特征数据库,尤其是Pfam 32.0数据库版本(2018年9月)的匹配:
http://pfam.xfam.org/search#tabview=tab0,
https://www.ebi.ac.uk/Tools/hmmer/search/hmmscan或
https://www.ebi.ac.uk/Tools/pfa/pfamscan/。
术语“Pfam”是指由Pfam联盟维护的蛋白质结构域和蛋白质家族大型集合,可在多个赞助的万维网站点上获得,这些网站包括:pfam.sanger.ac.uk/(Welcome Trust,SangerInstitute);pfam.sbc.su.se/(Stockholm Bioinformatics Center)和pfam.janelia.org/(Janelia Farm,Howard Hughes Medical Institute)。Pfam的最新版本是Pfam 32.0(2018年9月),基于UniProt Reference Proteomes(El-Gebali S.et al,2019,Nucleic Acids Res.47,Database issue D427–D432)。Pfam结构域和家族通过使用多个序列比对和隐马尔可夫模型(HMM)来识别。Pfam-A家族或结构域分配是使用蛋白质家族的代表性成员通过策划的种子比对和基于种子比对的特征谱(profile)隐马尔可夫模型产生的高质量分配(除非另有说明,否则所查询的蛋白质与Pfam结构域或家族的匹配为Pfam-A匹配)。然后使用属于该家族的所有已鉴定序列自动生成该家族的完全比对(Sonnhammer(1998)Nucleic Acids Research 26,320-322;Bateman(2000)Nucleic AcidsResearch 26,263-266;Bateman(2004)Nucleic Acids Research 32,Database Issue,D138-D141;Finn(2006)Nucleic Acids Research Database Issue34,D247-251;Finn(2010)Nucleic Acids Research Database Issue 38,D211-222)。例如,通过使用任何上述参考网站访问Pfam数据库,可以使用HMMER同源性搜索软件(例如HMMER2,HMMER3或更高版本hmmer.janelia.org/)针对HMM查询蛋白质序列。将所查询的蛋白质标识为pfam家族(或具有特定的Pfam结构域)的重要匹配是位得分(bit score)大于或等于Pfam结构域的收集阈值的匹配。期望值(e值)也可以用作在Pfam中包含所查询的蛋白质或确定所查询的蛋白质是否具有特定的Pfam结构域的标准,其中e值低,远小于1.0,例如小于0.1或更小。
“E值”(期望值)是指仅凭偶然机会预期得分等于或高于该值的命中数。这意味着能给出可靠预测的良好E值远小于1。E值在1附近是偶然的期望。因此,E值越低,对域的搜索就越具体。只允许使用正数(由Pfam定义)。术语“萜烯基二磷酸磷酸酶”或“具有萜烯基二磷酸磷酸酶活性的多肽”或“萜烯基二磷酸磷酸酶蛋白(质)”或“具有产生萜烯醇的能力”涉及一种多肽,其能够催化二磷酸部分或单磷酸部分的去除(无论特定酶促机理如何),以形成去磷酸化的化合物,特别是所述萜烯基部分的相应醇化合物。萜烯醇可以其任何立体异构体或其混合物的形式存在于产物中。萜烯醇可能是唯一的产物,或者可能是与其他萜烯化合物(例如所述萜烯基二磷酸的各个(例如非环状)萜烯基二磷酸酯前体的去磷酸化类似物)的混合物的一部分。上面的定义也适用于“双环萜烯基二磷酸磷酸酶”,其产生双环萜烯醇,如柯巴醇或赖百当烯二醇。上述磷酸酶中的每一个均举例说明了“二磷酸去除酶”。
作为此类“萜烯基二磷酸磷酸酶”的例子,可以提及的是柯巴基二磷酸磷酸酶(CPP磷酸酶)。柯巴醇可能是唯一的产品,或者可能是与去磷酸化前体(例如法尼醇和/或香叶基香叶醇)的混合物的一部分;和/或由反应混合物中的酶促副反应产生的副产物,例如此类醇或其他环状或非环状二萜的酯或醛。
作为此类“萜烯基二磷酸磷酸酶”的酶的另一个例子,可以提及的是赖百当烯二醇二磷酸磷酸酶(LPP磷酸酶)。赖百当烯二醇可能是唯一的产品,或者可能是与去磷酸化前体(例如法尼醇和/或香叶基香叶醇)的混合物的一部分;和/或由反应混合物中的酶促副反应产生的副产物,例如此类醇或其他环状或非环状二萜的酯或醛。
在如下所述的“标准条件”下测定“萜烯基二磷酸
合适的标准条件的特定例子可取自以下的实验部分。
在本发明的语境中,“醇脱氢酶”(ADH)是指一种多肽,其在NAD
本文所用的“柯巴醇”是指(E)-5-[(1S,4aS,8aS)-5,5,8a-三甲基-2-甲亚基-3,4,4a,6,7,8-六氢-1H-萘-1-基]-3-甲基戊-2-烯-1-醇;CAS注册号10395-43-4。
本文所用的“柯巴醛”是指(2E)-3-甲基-5-[(1S,4aS,8aS)-5,5,8a-三甲基-2-亚甲基十氢-1-萘基]-2-戊烯醛。
本文所用的“赖百当烯二醇”是指(1R,2R,4aS,8aS)-1-[(E)-5-羟基-3-甲基戊-3-烯基]-2,5,5,8a-四甲基-3,4,4a,6,7,8-六氢-1H-萘-2-醇;CAS注册号10267-31-9。
本文所用的“迈诺醇”是指5-[(1S,4aS,8aS)-5,5,8a-三甲基-2-甲亚基-3,4,4a,6,7,8-六氢-1H-萘-1-基]-3-甲基戊-1-烯-3-醇。
本文所用的(+)-迈诺醇氧基((+)-manooloxy)是指4-[(1S,4aS,8aS)-5,5,8a-三甲基-2-亚甲基十氢-1-萘基]-2-丁酮,
本文所用的“Z-11”是指(3S,5aR,7aS,11aS,11bR)-3,8,8,11a-四甲基十二氢-3,5a-环氧萘并[2,1-c]氧杂
本文所用的“γ-ambrol”是指2-[(1S,4aS,8aS)-5,5,5a-三甲基-2-亚甲基十氢-1-萘基]乙醇。和
本文所用的
本文所用的“香紫苏内酯”是指3a,6,6,9a-四甲基十氢萘并[2,1-b]呋喃-2(1H)-酮。
本文所用的“DOL”是指(1R,2R,4aS,8aS)-1-(2-羟乙基)-2,5,5,8a-四甲基-3,4,4a,6,7,8-六氢-1H-萘-2-醇…CAS号38419-75-9
本文所用的“法尼醇”是指(2E,6E)-3,7,11-三甲基十二碳-2,6,10-三烯-1-醇
本文所用的“香叶基香叶醇”是指(2E,6E,10E)-3,7,11,15-四甲基十六碳-2,6,10,14-四烯-1-醇。
一般而言,以下含义适用:
对于类似Z11的化合物:通式为8,13:13,20-二环氧-15,16-二降赖百当烷(或二环氧-二降赖百当烷(dinorlabdane)):
对于类似
术语萜烯合酶的“生物学功能”、“功能”、“生物学活性”或“活性”是指本文所述的萜烯基二磷酸合酶催化从相应的前体萜烯形成至少一种萜烯基二磷酸的能力。
术语萜烯基二磷酸磷酸酶的“生物学功能”、“功能”、“生物学活性”或“活性”是指如本文所述的萜烯基二磷酸磷酸酶催化从所述萜烯基化合物中去除二磷酸基团以形成相应的萜烯醇的能力。
“甲羟戊酸途径”(也称为“异戊二烯途径”或“HMG-CoA还原酶途径”)是真核生物、古菌和某些细菌中必不可少的代谢途径。甲羟戊酸途径始于乙酰辅酶A,产生两个五碳结构单元,称为异戊烯基焦磷酸(IPP)和二甲基烯丙基焦磷酸(DMAPP)。关键酶是乙酰乙酰基-CoA硫解酶(atoB),HMG-CoA合酶(mvaS),HMG-CoA还原酶(mvaA),甲羟戊酸激酶(MvaK1),磷酸甲羟戊酸激酶(MvaK2),甲羟戊酸二磷酸脱羧酶(MvaD)和异戊烯基焦磷酸异构酶(idi)。将甲羟戊酸途径与酶活性结合以产生萜烯前体GPP、FPP或GGPP,特别是FPP合酶(ERG20),允许重组细胞生产萜烯。
如本文所用,术语“宿主细胞”或“经转化的细胞”是指一种细胞(或生物),其被改变以携带(harbor)至少一个核酸分子,例如,编码所需蛋白质或核酸序列的重组基因,其在转录时产生本发明的功能性多肽,即,上文定义的萜烯基二磷酸合酶蛋白或萜烯基二磷酸磷酸酶。宿主细胞特别是细菌细胞、真菌细胞或植物细胞或植物。宿主细胞可含有已整合到宿主细胞的核或细胞器基因组中的重组基因或几个基因,例如被组织为操纵子的基因。或者,宿主可以在染色体外含有重组基因。
术语“生物”是指任何非人的多细胞或单细胞生物,例如植物或微生物。特别地,微生物是细菌、酵母、藻类或真菌。
术语“植物”可互换使用以包括植物细胞,包括植物原生质体,植物组织,产生再生植物或植物部分的植物细胞组织培养物,或植物器官诸如根、茎、叶、花、花粉、胚珠、胚、果实等。任何植物均可以用来实施本文实施方案的方法。
当特定的生物或细胞天然地产生FPP或当其不天然地产生FPP但是用本文所述的核酸转化以产生FPP时意味着“能够产生FPP”。经转化以比天然存在的生物或细胞产生更高量的FPP的生物或细胞也被“能够产生FPP的生物或细胞”所涵盖。
当特定的生物或细胞天然地产生GGPP或当其不天然地产生GGPP但是用本文所述的核酸转化以产生GGPP时意味着“能够产生GGPP”。经转化以比天然存在的生物或细胞产生更高量的GGPP的生物或细胞也被“能够产生GGPP的生物或细胞”所涵盖。
当特定的生物或细胞天然地产生如本文所定义的萜烯基二磷酸或当其不天然地产生所述二磷酸酯但是用本文所述的核酸转化以产生所述二磷酸酯时意味着“能够产生萜烯基二磷酸”。经转化以比天然存在的生物或细胞产生更高量的萜烯基二磷酸的生物或细胞也被“能够产生萜烯基二磷酸的生物或细胞”所涵盖。
当特定的生物或细胞天然地产生本文所定义的萜烯醇或当其不天然地产生所述醇但是用本文所述的核酸转化以产生所述醇时意味着“能够产生萜烯醇”。经转化以比天然存在的生物或细胞产生更高量的萜烯醇的生物或细胞也被“能够产生萜烯醇的生物或细胞”所涵盖。
对于本文的说明书和所附权利要求,除非另有说明,否则“或”的使用意味着“和/或”。类似地,各种时态的“含”、“含有”、“包含”和“包括”是可互换的而不是限制性的。
应进一步理解,在各种实施方案的描述使用术语“包含”的情况下,本领域技术人员将理解,在一些特定情况下,可以使用“基本上由……组成”或“由……组成”的语言来替代地描述实施方案。
本文所用的术语“纯化的”、“基本上纯化的”和“分离的”是指不含其他不同化合物(本发明化合物通常以其天然状态与其缔合)的状态,因此“纯化的”、“基本上纯化的”和“分离的”物品占给定样品质量按重量计至少0.5%、1%、5%、10%或20%,或至少50%或75%。在一个实施方案中,这些术语是指本发明的化合物占给定样品质量按重量计至少95%、96%、97%、98%、99%或100%。如本文所用,当提及核酸或蛋白质时,核酸或蛋白质的术语“纯化的”、“基本上纯化的”和“分离的”也指一种纯化或浓缩状态,其不同于天然存在于例如原核或真核环境中,例如在细菌或真菌细胞中,或哺乳动物特别是人体中的状态。任何纯化程度或浓度,只要大于天然存在的纯化或浓缩程度,包括(1)从其他相关结构或化合物中的纯化,或(2)与在所述原核或真核环境中通常不相关的结构或化合物的缔合,都在“分离的”含义内。根据本领域技术人员已知的各种方法和工艺,本文所述的核酸、蛋白质或核酸或蛋白质的类别可以是分离的,或如若不然与它们通常在性质上不相关的结构或化合物相缔合。
术语“约”表示所述值的±25%的可能变化,特别是±15%、±10%、更特别是±5%、±2%或±1%。
术语“基本上”描述的值范围为约80至100%,例如85至99.9%,特别是90至99.9%,更特别是95至99.9%,或98至99.9%,尤其是99至99.9%。
“主要地”是指大于50%的范围内的比例,例如在51%至100%的范围内,特别是在75%至99.9%的范围内;尤其是85至98.5%,例如95至99%。
在本发明的上下文中,“主要产物”表示单一化合物或一组至少2种化合物,例如2、3、4、5或更多种,特别是2或3种化合物,该单一化合物或一组化合物“主要”是通过本文所述的反应制备的,并且基于由所述反应形成的产物的成分的总量,以主要比例包含在所述反应中。所述比例可以是摩尔比例,重量比例,或者优选基于色谱分析,由反应产物的相应色谱图计算的面积比例。
在本发明的上下文中,“副产物”表示单一化合物或一组至少2种化合物,例如2、3、4、5或更多种,特别是2或3种化合物,该单一化合物或一组化合物并非“主要”是通过本文所述的反应制备的。
由于酶促反应的可逆性,除非另有说明,否则本发明涉及在两个反应方向上本文所述的酶促或生物催化反应。
本文描述的多肽的“功能突变体”包括如下定义的此类多肽的“功能等同物”。
术语“立体异构体”包括构象异构体,特别是构型异构体。
根据本发明,通常包括本文所述化合物的所有“立体异构形式”,例如“结构异构体”和“立体异构体”。
“立体异构形式”特别地包括“立体异构体”及其混合物,例如。构型异构体(光学异构体),例如对映异构体,或几何异构体(非对映异构体),例如E-和Z-异构体,及其组合。如果在一个分子中存在一个或多个不对称中心,则本发明包括这些不对称中心的不同构象的所有组合,例如对映异构体对。
“立体选择性”描述了产生立体异构纯形式的化合物的特定立体异构体的能力或以本文所述的酶催化方法从多种立体异构体中特异性转化特定立体异构体的能力。更具体而言,这意味着本发明的产物相对于特定的立体异构体富集,或者离析物相对于特定的立体异构体可以贫化。这可以通过根据下式计算的纯度%ee参数进行量化:
%ee=[X
其中X
术语“有选择地转化”或“增加选择性”通常是指,在所述反应的整个过程期间(即在反应的起始和终止之间),在所述反应的某个时间点,或在所述反应的“一段”期间,特定的立体异构形式例如E-形式的不饱和烃以比相应的其他立体异构体形式例如Z-形式更高的比例或量(以摩尔为基准对比)被转化。特别地,在“一段”期间可以观察到所述选择性对应于底物初始量的1至99%,2至95%,3至90%,5至85%,10至80%,15至75%,20至70%,25至65%,30至60%,或40至50%的转化率。所述更高的比例或量可以例如以以下方式表示:
-在整个反应过程或其所述一段期间观察到的较高的异构体最大收率;
-在确定的底物转化率值百分比下,较高的异构体相对含量;和/或
-在较高的转化率值百分比下,相同的异构体相对含量;
其中的每一种优选相对于参考方法来观察,所述参考方法在其他相同条件下用已知化学或生物化学方法进行。
根据本发明,通常包括本文描述的化合物的所有“异构体形式”,例如结构异构体,尤其是立体异构体及其混合物,例如旋光异构体或几何异构体,例如E-和Z-异构体,以及它们的组合。如果在一个分子中存在几个不对称中心,则本发明包括这些不对称中心的不同构象的所有组合,例如对映异构体对,或立体异构体形式的任何混合形式。
根据本发明的反应的“收率”和/或“转化率”是在例如4、6、8、10、12、16、20、24、36或48小时的规定时间段内(反应在该段时间内进行)确定的。特别地,反应在精确定义的条件下进行,例如在本文定义的“标准条件”下进行。
不同的收率参数(“收率”或YP/S;“比生产率收率”;或时空收率(STY))在本领域中是众所周知的,并且如文献所述进行测定。
“收率”和“YP/S”(均以所生产的产品质量/所消耗的材料质量表示)在本文中用作同义词。
比生产率收率(specific productivity-yield)描述了每小时每L发酵液每克生物质所生产的产物的量。用WCW表示的湿细胞重量描述了生化反应中具有生物活性的微生物的数量。该值以每g WCW每小时的产品g数给出(即g/gWCW
术语“发酵产生”或“发酵”是指微生物(由所述微生物所包含或由其产生的酶活性辅助)在细胞培养物中利用添加到温育中的至少一种碳源产生化合物的能力。
术语“发酵液”应理解为是指一种液体,特别是水性溶液或水性/有机溶液,其基于发酵工艺并且未进行或进行了例如本文所述的后处理(work up)。
“酶催化”或“生物催化”方法是指所述方法在酶(包括本文所定义的酶突变体)的催化作用下进行。因此,该方法可以在分离形式的(纯化的、富集的)或粗制形式的所述酶的存在下,或者在细胞系统的存在下进行,特别是包含活性形式的所述酶并具有如本文所公开的催化转化反应能力的天然或重组微生物细胞。
如果本公开涉及不同优先程度的特征、参数及其范围(包括上位的,非明确优选的特征、参数及其范围),则除非另有说明,否则这些特征、参数和范围中的两个或更多个的任意组合与它们各自的优选程度无关地涵盖在本发明的公开内容中。
a.本发明的特定实施方案
本发明具体涉及以下实施方案:
1.第一个主要实施方案涉及一种产生通式1的萜烯醇化合物的生物催化方法,
其中
R代表H,或更特别地是环状或非环状、直链或支链、饱和或不饱和的、可选有取代基的烃基残基,优选具有能被5整除,特别是能被5、10、15或20整除,更特别是能被10或15整除的总碳原子数,
该方法包括以下步骤:
(1)使所述式(1)的萜烯化合物的相应的萜烯基二磷酸前体与具有萜烯基二磷酸磷酸酶活性,例如具有单萜烯基-、倍半萜烯基-或二萜烯基-二磷酸磷酸酶活性的多肽接触,以形成所述萜烯醇;和
(2)可选地,将步骤(1)的萜烯醇分离。
其中所述具有萜烯基二磷酸磷酸酶活性的多肽选自蛋白质酪氨酸磷酸酶家族的二磷酸去除酶成员。
具有“萜烯基二磷酸磷酸酶活性”的该实施方案的多肽被鉴定为蛋白质酪氨酸磷酸酶家族的成员,特别是具有Pfam ID号PF13350的Y_磷酸酶3家族的成员。
2.本发明的第二个主要实施方案涉及一种产生双环二萜醇化合物的生物催化方法,
包括以下步骤:
a)使所述双环二萜化合物的相应双环二萜烯基二磷酸前体与具有萜烯基二磷酸磷酸酶活性,例如具有二萜烯基二磷酸磷酸酶活性或更特别是双环二萜烯基二磷酸磷酸酶活性的多肽接触,以形成所述双环二萜醇;和
b)可选地,将步骤(1)的双环二萜醇分离。
具有“萜烯基二磷酸磷酸酶活性”的该实施方案的多肽被鉴定为蛋白质酪氨酸磷酸酶家族的成员,特别是具有Pfam ID号PF13350的Y_磷酸酶3家族的成员。
3.实施方案2的方法,其中所述具有萜烯基二磷酸磷酸酶活性的多肽选自蛋白质酪氨酸磷酸酶家族的二磷酸去除酶成员。
4.实施方案1或3的方法,其中所述具有萜烯基二磷酸磷酸酶活性的多肽选自一类二磷酸去除酶,该二磷酸去除酶的特征在于具有以下活性位点签名基序的氨基酸序列:
HCxxGxxR (SEQ ID NO:57)
其中
每个x彼此独立地代表任何天然氨基酸残基。
5.实施方案4的方法,其中所述活性位点签名基序是:
HC(T/S)xGKDRTG (SEQ ID NO:58)
其中
x代表任何天然氨基酸残基,并且例如选自残基L,A,G和V。
在另一个实施方案中,所述具有萜烯基二磷酸磷酸酶活性的多肽包含如图16b所示的氨基酸共有序列基序。
6.前述实施方案中任一项的方法,其中所述具有萜烯基二磷酸磷酸酶活性的多肽从由以下多肽构成的群组中选出:
a)TalVeTPP,其包含根据SEQ ID NO:2的氨基酸序列
b)AspWeTPP,其包含根据SEQ ID NO:6的氨基酸序列
c)HelGriTPP,其包含根据SEQ ID NO:10的氨基酸序列,
d)UmbPiTPP1,其包含根据SEQ ID NO:13的氨基酸序列
e)TalVeTPP2,其包含根据SEQ ID NO:16的氨基酸序列
f)HydPiTPP1,其包含根据SEQ ID NO:19的氨基酸序列,
g)TalCeTPP1,其包含根据SEQ ID NO:22的氨基酸序列,
h)TalMaTPP1,其包含根据SEQ ID NO:25的氨基酸序列,
i)TalAstroTPP1,其包含根据SEQ ID NO:28的氨基酸序列,和
j)PeSubTPP1,其包含根据SEQ ID NO:31的氨基酸序列,和
k)一种多肽,其具有萜烯基二磷酸磷酸酶活性并且包含与根据a)至j)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
7.实施方案1和4至6中任一项的方法,其中制备了通式1的萜烯醇化合物,其中R代表H,或更特别地是非环状、直链或支链、饱和或不饱和的烃基残基,优选具有能被5整除,特别是能被5、10、15或20整除的总碳原子数。
8.实施方案7的方法,其中式1的萜烯醇选自法尼醇和香叶基香叶醇。
9.实施方案2至6中任一项的方法,其中步骤(1)还包括使非环状萜烯基二磷酸前体与具有双环二萜烯基二磷酸合酶活性的多肽接触以形成所述双环二萜烯基二磷酸前体。
10.实施方案9的方法,其中所述双环二萜烯基二磷酸合酶选自:
a)SmCPS2,其包含根据SEQ ID NO:34的氨基酸序列,
b)TaTps1-del59,其包含根据SEQ ID NO:40的氨基酸序列,
c)SsLPS,其包含根据SEQ ID NO:38的氨基酸序列,和
d)一种多肽,其具有双环二萜烯基二磷酸合酶活性并且包含与根据a)、b)和c)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
11.实施方案2至6、9和10中任一项的方法,其中所述生物催化产生的双环二萜醇选自柯巴醇,特别是(+)-柯巴醇和赖百当烯二醇,它们各自为实质上纯的立体异构体形式或至少两种立体异构体的混合物形式。
12.前述实施方案中任一项的方法,其还包括使用化学或生物催化合成或两者的组合将步骤(1)或步骤(2)的萜烯醇加工成醇衍生物作为步骤(3)。
13.实施方案12的方法,其中该衍生物是烃,醇,二醇,三醇,缩醛,缩酮,醛,酸,醚,酰胺,酮,内酯,环氧化物,乙酸酯,糖苷和/或酯。
14.实施方案12或13的方法,其中所述萜烯醇以生物催化的方式氧化。
15.实施方案14的方法,其中所述萜烯醇通过与醇脱氢酶(ADH)接触而转化。
16.实施方案15的方法,其中所述ADH选自:
a)CymB,其包含根据SEQ ID NO:42的氨基酸序列;
b)AspWeADH1,其包含根据SEQ ID NO:44的氨基酸序列;
c)PsAeroADH1,其包含根据SEQ ID NO:46的氨基酸序列;
d)AzTolADH1,其包含根据SEQ ID NO:48的氨基酸序列;
e)AroAroADH1,其包含根据SEQ ID NO:50的氨基酸序列;
f)ThTerpADH1,其包含根据SEQ ID NO:52的氨基酸序列;
g)CdGeoA,其包含根据SEQ ID NO:54的氨基酸序列;
h)VoADH1,其包含根据SEQ ID NO:56的氨基酸序列;和
i)一种多肽,其具有ADH活性并且包含与根据a)至h)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
17.实施方案2至6和9至11中任一项的方法,用于生物催化产生柯巴醇,包括以下步骤:
(1)使柯巴基二磷酸与具有柯巴基二磷酸(CPP)磷酸酶活性的多肽接触以形成基本上纯的立体异构体形式的柯巴醇,特别是(+)-柯巴醇,或者形成至少两种立体异构体的混合物形式的柯巴醇;和
(2)可选地,将步骤(1)的柯巴醇分离。
18.实施方案17的方法,其中所述具有柯巴基二磷酸磷酸酶活性的多肽从由以下多肽构成的群组中选出:
a)TalVeTPP,其包含根据SEQ ID NO:2的氨基酸序列
b)AspWeTPP,其包含根据SEQ ID NO:6的氨基酸序列
c)HelGriTPP,其包含根据SEQ ID NO:10的氨基酸序列,
d)UmbPiTPP1,其包含根据SEQ ID NO:13的氨基酸序列
e)TalVeTPP2,其包含根据SEQ ID NO:16的氨基酸序列
f)HydPiTPP1,其包含根据SEQ ID NO:19的氨基酸序列,
g)TalCeTPP1,其包含根据SEQ ID NO:22的氨基酸序列,
h)TalMaTPP1,其包含根据SEQ ID NO:25的氨基酸序列,
i)TalAstroTPP1,其包含根据SEQ ID NO:28的氨基酸序列,和
j)PeSubTPP1,其包含根据SEQ ID NO:31的氨基酸序列,和
k)一种多肽,其具有柯巴基二磷酸磷酸酶活性并且包含与根据a)至j)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
19.实施方案17和18中任一项的方法,其中步骤(1)还包括萜烯焦磷酸(例如,香叶基香叶基焦磷酸(GGPP),或异戊烯基焦磷酸(IPP)和二甲基烯丙基焦磷酸(DMAPP)的混合物)的生物催化转化,其通过柯巴基焦磷酸合酶(CPS)的催化作用,转化为柯巴基二异丙酯(CPP)。
20.实施方案19的方法,其中,所述CPS选自:
a)SmCPS2,其包含根据SEQ ID NO:34的氨基酸序列,
b)TaTps1-del59,其包含根据SEQ ID NO:40的氨基酸序列,和
c)一种多肽,其具有柯巴基焦磷酸合酶活性并且包含与根据a)和b)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
21.实施方案17至20中任一项的方法,其进一步包括使用化学或生物催化合成或两者的组合将步骤(1)或步骤(2)的柯巴醇加工成柯巴醇衍生物作为步骤(3)。
22.实施方案21的方法,其中该衍生物是烃,醇,二醇,三醇,缩醛,缩酮,醛,酸,醚,酰胺,酮,内酯,环氧化物,乙酸酯,糖苷和/或酯。
23.实施方案21或22的方法,其中柯巴醇以生物催化的方式氧化。
24.实施方案23的方法,其中柯巴醇通过与醇脱氢酶(ADH)接触而氧化。
25.实施方案24的方法,其中所述ADH选自:
a)CymB,其包含根据SEQ ID NO:42的氨基酸序列;
b)AspWeADH1,其包含根据SEQ ID NO:44的氨基酸序列;
c)PsAeroADH1,其包含根据SEQ ID NO:46的氨基酸序列;
d)AzTolADH1,其包含根据SEQ ID NO:48的氨基酸序列;
e)AroAroADH1,其包含根据SEQ ID NO:50的氨基酸序列;
f)ThTerpADH1,其包含根据SEQ ID NO:52的氨基酸序列;
g)CdGeoA,其包含根据SEQ ID NO:54的氨基酸序列;
h)VoADH1,其包含根据SEQ ID NO:56的氨基酸序列;和
i)一种多肽,其具有ADH活性并且包含与根据a)至h)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
26.实施方案1的方法,用于生物催化产生赖百当烯二醇,包括以下步骤:
(1)使赖百当烯二醇二磷酸(也称为赖百当-13-烯-8-醇二磷酸酯或8α-羟基柯巴基二磷酸)与具有赖百当烯二醇二磷酸(LPP)磷酸酶活性的多肽接触以形成基本上纯的立体异构形式或者形成至少两种立体异构体的混合物形式的赖百当烯二醇;和
(2)可选地,将步骤(1)的赖百当烯二醇分离。
27.实施方案26的方法,其中所述具有LPP磷酸酶活性的多肽从由以下多肽构成的群组中选出:
a)TalVeTPP,其包含根据SEQ ID NO:2的氨基酸序列
b)AspWeTPP,其包含根据SEQ ID NO:6的氨基酸序列
c)HelGriTPP,其包含根据SEQ ID NO:10的氨基酸序列,
d)UmbPiTPP1,其包含根据SEQ ID NO:13的氨基酸序列
e)TalVeTPP2,其包含根据SEQ ID NO:16的氨基酸序列
f)HydPiTPP1,其包含根据SEQ ID NO:19的氨基酸序列,
g)TalCeTPP1,其包含根据SEQ ID NO:22的氨基酸序列,
h)TalMaTPP1,其包含根据SEQ ID NO:25的氨基酸序列,
i)TalAstroTPP1,其包含根据SEQ ID NO:28的氨基酸序列,和
j)PeSubTPP1,其包含根据SEQ ID NO:31的氨基酸序列,和
k)一种多肽,其具有LPP磷酸酶活性并且包含与根据a)至j)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
28.实施方案26和27中任一项的方法,其中步骤(1)还包括萜烯焦磷酸(例如,香叶基香叶基焦磷酸(GGPP),或异戊烯基焦磷酸(IPP)和二甲基烯丙基焦磷酸(DMAPP)的混合物)的生物催化转化,其通过赖百当烯二醇焦磷酸合酶(LPS)的催化作用,转化为赖百当烯二醇二磷酸(LPP)。
29.实施方案28的方法,其中,所述LPS选自:
a)SsLPS,其包含根据SEQ ID NO:38的氨基酸序列,和
b)一种多肽,其具有赖百当烯二醇焦磷酸合酶活性并且包含与根据a)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
30.实施方案26至29中任一项的方法,其进一步包括使用化学或生物催化合成或两者的组合将步骤(1)或步骤(2)的赖百当烯二醇加工成赖百当烯二醇衍生物作为步骤(3)。
31.实施方案30的方法,其中该衍生物是烃,醇,二醇,三醇,缩醛,缩酮,醛,酸,醚,酰胺,酮,内酯,环氧化物,乙酸酯,糖苷和/或酯。
32.实施方案30或31的方法,其中赖百当烯二醇以生物催化的方式氧化。
33.实施方案32的方法,其中赖百当烯二醇通过与醇脱氢酶(ADH)接触而氧化。
34.实施方案33的方法,其中所述ADH选自:
a)CymB,其包含根据SEQ ID NO:42的氨基酸序列;
b)AspWeADH1,其包含根据SEQ ID NO:44的氨基酸序列;
c)PsAeroADH1,其包含根据SEQ ID NO:46的氨基酸序列;
d)AzTolADH1,其包含根据SEQ ID NO:48的氨基酸序列;
e)AroAroADH1,其包含根据SEQ ID NO:50的氨基酸序列;
f)ThTerpADH1,其包含根据SEQ ID NO:52的氨基酸序列;
g)CdGeoA,其包含根据SEQ ID NO:54的氨基酸序列;
h)VoADH1,其包含根据SEQ ID NO:56的氨基酸序列;
i)SCH23-ADH1,其包含根据SEQ ID NO:68的氨基酸序列
j)SCH24-ADH1a,其包含根据SEQ ID NO:70的氨基酸序列;和
k)一种多肽,其具有ADH活性并且包含与根据a)至j)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
35.实施方案19和28中任一项的方法,其中所述方法还包括通过香叶基香叶基焦磷酸合酶(GGPS)的催化作用,从法呢基焦磷酸(FPP)生物催化形成GGPP。
36.实施方案35的方法,其中,所述GGPS选自:
a)一种多肽,其包含根据SEQ ID NO:36的氨基酸序列,和
b)一种多肽,其具有香叶基香叶基焦磷酸合酶活性并且包含与根据a)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
37.前述实施方案中任一项的方法,该方法在体外或体内进行。
38.前述实施方案中任一项的方法,该方法在体内进行,其包括在步骤(1)之前将一种或多种核酸分子引入到非人宿主生物或细胞中,并且可选地稳定地整合至各自的基因组中;该核酸分子编码一种或多种多肽,该多肽具有执行相应的一个或多个生物催化转化步骤所需的酶活性。
39.实施方案38的方法,其中引入到所述非人宿主生物或细胞中的所述核酸编码:
a)至少一种具有萜烯基二磷酸磷酸酶活性,特别是双环二萜烯基二磷酸磷酸酶活性的多肽;以及可选的
b)至少一种具有萜烯基二磷酸合酶活性,特别是双环二萜烯基二磷酸合酶活性的多肽,和/或
c)至少一种具有ADH活性的多肽;和/或
d)至少一种具有无环萜烯基二磷酸合酶活性,特别是无环二萜烯基二磷酸合酶活性的多肽。
40.实施方案39的方法,其中引入到所述非人宿主生物或细胞中的所述核酸编码:
a)至少一种具有双环二萜烯基二磷酸酶活性的多肽,其选自实施方案6中定义的多肽;或由选自SEQ ID NO:1、3、4、5、7、8、9、11、12、14、15、17、18、20、21、23、24、26、27、29、30和32的核苷酸序列编码;或与所述序列中任一者具有至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性的核苷酸序列;以及可选的以下中的至少一者:
b)至少一种具有双环二萜烯基二磷酸合酶活性的多肽,其选自实施方案10中定义的多肽;或由选自SEQ ID NO:33、37和39的核苷酸序列编码;或与所述序列中任一者具有至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性的核苷酸序列;
c)至少一种具有ADH活性的多肽,其选自实施方案16中定义的多肽;或由选自SEQID NO:41、43、45、47、49、51、53和55的核苷酸序列编码;或与所述序列中任一者具有至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性的核苷酸序列;
d)至少一种如实施方案36中所定义的具有无环二萜烯基二磷酸合酶活性的多肽;或由选自SEQ ID NO:35的核苷酸序列编码,或与所述序列具有至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%的序列同一性。
41.实施方案38至40中任一项的方法,其通过施加内源性产生FPP和/或GGPP,或者IPP与DMAPP的混合物的非人宿主生物或细胞来进行;或通过施加经过基因修饰以产生增加量的FPP和/或GGPP,和/或IPP与DMAPP混合物的非人宿主生物来进行。
这些宿主细胞或生物中的某些不能天然地产生FPP或GGPP或者IPP与DMAPP的混合物,也不能以认为过低因此应增加的量来内源性产生FPP或GGPP或者IPP与DMAPP的混合物。为了适合于实施本文所述的实施方案的方法,不天然地产生无环萜烯焦磷酸前体(例如FPP或GGPP或者IPP与DMAPP的混合物)或以次优量产生所述化合物的生物或细胞通常进行遗传修饰以产生所述前体。例如,它们可以在用根据以上任何一个实施方案所述的核酸修饰之前或同时如此转化。转化生物体以使其产生无环萜烯焦磷酸前体(例如FPP或GGPP或者IPP与DMAPP的混合物)的方法在本领域中是已知的。例如,引入甲羟戊酸途径、异戊二烯途径或MEP途径,特别是甲羟戊酸途径的酶活性是使生物体产生FPP或GGPP或者IPP与DMAPP的混合物的合适策略。
42.实施方案38至41中任一项的方法,其中所述非人宿主生物或细胞是真核生物或原核生物,特别是植物、细菌或真菌,特别是酵母。
43.实施方案42的方法,其中所述细菌是埃希氏菌(Escherichia)属,特别是大肠杆菌(E.coli),并且所述酵母是酵母(Saccharomyces)属,特别是酿酒酵母(S.cerevisiae)。
44.实施方案42的方法,其中所述细胞是植物细胞。
45.实施方案38至44中任一项所定义的非人宿主生物或细胞。
46.一种重组核酸构建体,其包含至少一种实施方案38至44中任一项所定义的核酸分子。
47.一种表达载体,其包含至少一种实施方案46的核酸构建体。
48.实施方案47的表达载体,其中该载体是原核载体、病毒载体、真核载体或一种或多种质粒。
49.实施方案45中定义的重组非人宿主生物或细胞,其经实施方案46的至少一种核酸构建体转化或经实施方案47或48的至少一种载体转化。
50.一种多肽,其具有萜烯基二磷酸磷酸酶活性,特别是双环二萜烯基二磷酸磷酸酶活性,其选自蛋白质酪氨酸磷酸酶家族的二磷酸去除酶成员及其突变体或变体;其中所述多肽优选以>50%,例如>60%、70%、80%、90%、95%或99%的选择性催化萜烯基二磷酸转化为相应的萜烯醇。特别地,其优选以>50%,例如>60%、70%、80%、90%、95%或99%的选择性催化选自CPP和LPP的至少一种萜烯基二磷酸转化为相应的萜烯醇柯巴醇和赖百当烯二醇。
具有“萜烯基二磷酸磷酸酶活性”的该实施方案的多肽被鉴定为蛋白质酪氨酸磷酸酶家族的成员,特别是具有Pfam ID号PF13350的Y_磷酸酶3家族的成员。
尤其是,如果位得分(bit score)大于或等于Pfam结构域的收集阈值,则将具有“萜烯基二磷酸磷酸酶活性”的本发明的多肽鉴定为蛋白质酪氨酸磷酸酶家族的成员,尤其是具有Pfam ID号为PF13350的Y_磷酸酶3家族的成员。期望值(e值)也可以用作在Pfam家族中包含所查询的蛋白质或确定所查询的蛋白质是否具有特定的Pfam结构域的标准。与所述域的匹配的e值小于1x10
例如,可以将以下网站应用于搜索和计算此类e值:https://pfam.xfam.org/search#tabview=tab0或https://www.ebi.ac.uk/Tools/hmmer/。
在一个优选的替代方案中,此类磷酸酶还将FPP和/或GGPP转化为相应的醇法呢醇和香叶基香叶醇。
在另一个优选的替代方案中,此类磷酸酶不将FPP和/或GGPP转化为相应的醇法呢醇和香叶基香叶醇,而保留了将选自CPP和LPP的至少一种双环二萜烯基二磷酸转化为相应的萜烯醇柯巴醇和赖百当烯二醇的能力。
在另一个优选的替代方案中,此类磷酸酶产生至少一种选自柯巴醇和赖百当烯二醇的醇作为主要产物。在该种情况下,与将至少一种选自CPP和LPP的双环二萜烯基二磷酸转化为相应的萜烯醇柯巴醇和赖百当烯二醇的能力相比,此类酶确实以较低的摩尔收率将FPP和/或GGPP转化为相应的醇法呢醇和香叶基香叶醇。与对于至少一种非环状萜烯醇法尼醇和香叶基香叶醇的收率相比,至少一种选自柯巴醇和赖百当烯二醇的双环二萜醇的相对摩尔收率可以高至等于或大于2倍,例如为2至1,000倍或5至100倍或10至50倍。
51.实施方案50的多肽,其特征在于具有以下活性位点签名基序的氨基酸序列:
HCxxGxxR (SEQ ID NO:57)
其中
每个x彼此独立地代表任何天然氨基酸残基。
52.实施方案51的多肽,其中所述活性位点签名基序是:
HC(T/S)xGKDRTG (SEQ ID NO:58)
其中
x代表任何天然氨基酸残基。
53.实施方案50至52中任一项的多肽,其中所述具有双环二萜烯基二磷酸磷酸酶活性的多肽从由以下多肽构成的群组中选出:
a)TalVeTPP,其包含根据SEQ ID NO:2的氨基酸序列
b)AspWeTPP,其包含根据SEQ ID NO:6的氨基酸序列
c)HelGriTPP,其包含根据SEQ ID NO:10的氨基酸序列,
d)UmbPiTPP1,其包含根据SEQ ID NO:13的氨基酸序列
e)TalVeTPP2,其包含根据SEQ ID NO:16的氨基酸序列
f)HydPiTPP1,其包含根据SEQ ID NO:19的氨基酸序列,
g)TalCeTPP1,其包含根据SEQ ID NO:22的氨基酸序列,
h)TalMaTPP1,其包含根据SEQ ID NO:25的氨基酸序列,
i)TalAstroTPP1,其包含根据SEQ ID NO:28的氨基酸序列,
j)PeSubTPP1,其包含根据SEQ ID NO:31的氨基酸序列,和
k)一种多肽,其具有二萜烯基二磷酸磷酸酶活性并且包含与根据a)至j)的所述氨基酸序列中的至少一个显示出至少60%,65%,70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性程度的氨基酸序列。
另一个特定的实施方案涉及具有双环二萜烯基二磷酸磷酸酶活性的本发明的新型多肽的多肽变体,其如上文由SEQ ID NO:2、6、10、13、16、19、22、25、28和31的任何特定氨基酸序列所鉴定,并且其中多肽变体选自与SEQ ID NO:2、6、10、13、16、19、22、25、28和31中任何一者具有至少70%,75%,80%,85%,90%,95%,96%,97%,98%或99%序列同一性的氨基酸序列,并且相对于任何未修饰的SEQ ID NO:2、6、10、13、16、19、22、25、28和31中的任何一者,含有至少一个取代修饰。
54.一种核酸分子,其包含:
a)编码实施方案50至53中任一项的多肽的核酸序列;
b)a)的互补核酸序列;或
c)在严格条件下与a)或b)的核酸序列杂交的核酸序列。
55.一种表达构建体,其包含至少一种权利要求54的核酸分子。
56.一种载体,其包含至少一种权利要求54的核酸分子。
57.权利要求56的载体,其中该载体是原核、病毒或真核载体。
58.实施方案56或57的载体,其中该载体是表达载体。
59.实施方案56至58中任一项的载体,其是质粒载体。
60.一种重组宿主细胞或重组非人宿主生物,其包含:
a)至少一种实施方案54的分离的核酸分子,其可选地稳定地整合到基因组中;或
b)至少一种实施方案55的表达构建体,其可选地稳定地整合到基因组中;或
c)实施方案56至59中任一项的至少一种载体。
61.实施方案60的宿主细胞或宿主生物,其选自原核或真核微生物,或由其衍生的细胞。
62.实施方案61的宿主细胞或宿主生物,其选自细菌、真菌和植物细胞或植物。
63.实施方案62的宿主细胞或宿主生物,其中所述真菌细胞是酵母细胞。
64.实施方案63的宿主细胞或宿主生物,其中所述细菌细胞选自埃希氏菌(Escherichia)属,特别是大肠杆菌(E.coli)种,并且所述酵母选自酵母(Saccharomyces)属或毕赤酵母(Pichia)属,特别是选自酿酒酵母(Saccharomyces cerevisiae)或巴斯德毕赤酵母(Pichia pastoris)种。
65.一种用于产生根据实施方案50至53中任一项的至少一种催化活性多肽的方法,包括:
(1)培养权利要求60至64中任一项的非人宿主生物或宿主细胞以表达或过表达至少一种根据实施方案50至53中任一项的多肽;和
(2)可选地,从步骤(1)中培养的非人宿主细胞或生物中分离多肽。
66.实施方案65的方法,其还包括在步骤a)之前,用至少一种根据实施方案54的核酸,或至少一种实施方案55的构建体,或至少一种实施方案56至59中任一项的载体来转化非人宿主生物或细胞,从而其表达或过表达根据实施方案50至53中任一项的多肽。
67.一种制备具有萜烯合酶活性,特别是萜烯基二磷酸合酶活性的突变多肽的方法,该方法包括以下步骤:
(1)选择实施方案54的核酸分子;
(2)修饰所选择的核酸分子以获得至少一种突变核酸分子;
(3)用该突变核酸序列转化宿主细胞或单细胞宿主生物,以表达由该突变核酸序列编码的多肽。
(4)筛选表达产物中至少一种具有萜烯合酶活性,特别是萜烯基二磷酸合酶活性的突变体;
(5)可选地,如果该多肽不具有所需的突变活性,则重复步骤(1)至(4),直到获得具有所需突变活性的多肽为止;和
(6)可选地,如果在步骤(4)中鉴定了具有所需突变活性的多肽,则分离在步骤(3)中获得的相应的突变核酸。
68.实施方案22的方法,其中该柯巴醇衍生物从由以下构成的群组中选出:柯巴醇,迈诺醇,(+)-迈诺醇氧基,Z-11,γ-ambrol和降龙涎香醚(ambrox)和结构上相关的化合物,该化合物特别地在立体化学方面与其不同。
69.实施方案31的方法,其中该赖百当烯二醇衍生物从由以下构成的群组中选出:香紫苏内酯,DOL和降龙涎香醚和结构上相关的化合物,该化合物特别地在立体化学方面与其不同。
70.一种制备如上所定义的降龙涎香醚或类降龙涎香醚化合物的方法,该方法包括:
a)通过进行实施方案1至44中任一项所定义的生物催化方法提供赖百当烯二醇或柯巴醇化合物,可选地,分离所述赖百当烯二醇或柯巴醇化合物;和
b)使用化学合成和/或生化合成将步骤(1)的所述赖百当烯二醇或柯巴醇化合物转化为降龙涎香醚或类降龙涎香醚化合物。
71.本发明进一步涉及以上实施方案中任一项所定义的多肽用于制备气味剂、调味剂或芳香剂成分,特别是Ambrox的用途;以及根据上述实施方案中任一项制备的萜烯醇用于制备气味剂、调味剂或芳香剂成分,特别是Ambrox的用途。
b.根据本发明适用的多肽
在本文语境中,以下定义适用:
可以互换使用的通用术语“多肽”或“肽”是指天然的或合成的,连续的、肽方式连接的氨基酸残基的线性链或序列,其包含约10个至多于1000个残基。具有最多30个残基的短链多肽也被称为“寡肽”。
术语“蛋白(质)”是指由一种或多种多肽组成的大分子结构。其多肽的氨基酸序列代表蛋白质的“一级结构”。氨基酸序列还通过形成特殊的结构元素(例如在多肽链中形成的α-螺旋和β-折叠结构)来预先确定蛋白质的“二级结构”。多个这样的二级结构元件的排列定义了蛋白质的“三级结构”或空间排列。如果蛋白质包含多于一个的多肽链,则所述链在空间上排列形成蛋白质的“四级结构”。蛋白质正确的空间排列或“折叠”是蛋白质功能的前提。变性或展开会破坏蛋白质功能。如果这种破坏是可逆的,则可以通过重新折叠来恢复蛋白质功能。
本文所指的典型的蛋白质功能是“酶功能”,即蛋白质在底物例如化合物上充当生物催化剂,并催化所述底物向产物的转化。酶可以显示高或低程度的底物和/或产物特异性。
因此,本文中被称为具有特定“活性”的“多肽”隐含地是指正确折叠的蛋白质,其显示出所指示的活性,例如特定的酶活性。
因此,除非另有说明,否则术语“多肽”也涵盖术语“蛋白质”和“酶”。
类似地,术语“多肽片段”涵盖术语“蛋白质片段”和“酶片段”。
术语“分离的多肽”是指通过本领域已知的任何方法或这些方法(包括重组、生物化学和合成法)的组合从其天然环境中取出的氨基酸序列。
“靶肽”是指一种氨基酸序列,其将蛋白质或多肽靶向细胞内细胞器(即,线粒体或质体)或细胞外空间(分泌信号肽)。编码靶肽的核酸序列可以被融合到编码蛋白或多肽的氨基末端(例如N-末端)的核酸序列,或者可以被用来替换天然靶向多肽。
本发明还涉及本文具体描述的多肽的“功能等同物”(也称为“类似物”或“功能突变”)。
例如,“功能等同物”是指一种多肽,其在用于确定酶促萜烯基二磷酸合酶活性或萜烯基二磷酸磷酸酶活性的测试中,显示与本文具体描述的多肽相比,至少高或低1至10%、或至少20%、或至少50%、或至少75%、或至少90%的活性。
根据本发明,“功能等同物”还涵盖特定的突变体,其在本文所述的氨基酸序列的至少一个序列位置中具有与具体陈述的氨基酸不同的氨基酸,但是仍然具有上述生物活性之一,例如酶活性。因此,“功能等同物”包括可通过一个或多个,例如1至20个、1至15个或5至10个氨基酸的添加、取代特别是保守取代、缺失和/或倒置而获得的突变体,其中所述变化可以在任何序列位置上发生,只要它们导致突变体具有本发明特性的概貌。还特别地提供功能等同性,如果活性模式与在突变体和未改变的多肽之间定性地重合,即,如果例如观察到与相同的激动剂或拮抗剂或底物的相互作用,但是速率不同(即,通过EC
上述意义上的“功能等同物”也是本文所述多肽的“前体”,以及所述多肽的“功能衍生物”和“盐”。
在该情况下,“前体”是具有或不具有所期望生物活性的多肽的天然或合成前体。
表述“盐”是指根据本发明的蛋白质分子的羧基的盐以及氨基的酸加成的盐。羧基的盐可以已知的方式生产,包括无机盐,例如钠、钙、铵、铁和锌盐,以及与有机碱例如胺,如三乙醇胺、精氨酸、赖氨酸、哌啶等形成的盐。酸加成的盐,例如与无机酸例如盐酸或硫酸形成的盐,以及与有机酸例如乙酸和草酸形成的盐,也被本发明所涵盖。
根据本发明的多肽的“功能衍生物”还可以使用已知技术在功能性氨基酸侧基或它们的N末端或C末端产生。这样的衍生物包括例如:羧酸基的脂族酯,羧酸基的酰胺,它们可通过与氨或与伯或仲胺反应获得;游离氨基的N-酰基衍生物,其通过与酰基反应生成;或游离羟基的O-酰基衍生物,其通过与酰基反应生成。
“功能等同物”自然也包括可以从其他生物体获得的多肽以及天然存在的变体。例如,可以通过序列比较来确定同源序列区域的面积,并且等同的多肽可以基于本发明的具体参数来确定。
“功能等同物”还包含根据本发明的多肽的“片段”,例如单个结构域或序列基序,或N末端和/或C末端截短的形式,其可以显示或可以不显示期望的生物学功能。优选地,这样的“片段”至少定性地保持期望的生物学功能。
此外,“功能等同物”是融合蛋白,其具有本文所述的多肽序列之一或由其衍生的功能等同物,以及在功能性N-末端或C-末端缔合(即,没有融合蛋白部分的实质性相互功能受损)中具有至少一个另外的功能不同的异源序列。这些异源序列的非限制性例子是例如信号肽、组氨酸锚或酶。
根据本发明还包括的“功能等同物”是与具体公开的多肽的同源物。它们与具体公开的氨基酸序列具有至少60%,优选至少75%,特别是至少80或85%,例如90、91、92、93、94、95、96、97、98或99%的同源性(或同一性),其通过Pearson and Lipman,Proc.Natl.Acad,Sci.(USA)85(8),1988,2444-2448的算法计算。根据本发明的同源多肽的以百分比表示的同源性或同一性尤其是指基于本文具体描述的氨基酸序列之一的总长度,以氨基酸残基的百分比表示的同一性。
以百分比表示的同一性数据也可以借助于BLAST比对,算法blastp(蛋白质-蛋白质BLAST)或通过应用本文下面详述的Clustal设置来确定。
在可能的蛋白质糖基化的情况下,根据本发明的“功能等同物”包括本文所述的去糖基化或糖基化形式的多肽,以及可以通过改变糖基化模式获得的经修饰形式。
根据本发明的多肽的功能等同物或同源物可以通过诱变产生,例如通过点突变,延长或缩短蛋白质或如下文更详细描述。
根据本发明的多肽的功能等同物或同源物可以通过筛选突变体例如缩短的突变体的组合数据库来鉴定。例如,蛋白质变体的多样性数据库可以通过在核酸水平上的组合诱变,例如通过合成寡核苷酸混合物的酶促连接来产生。有许多方法可用于从简并寡核苷酸序列产生潜在同源物的数据库。简并基因序列的化学合成可以在自动DNA合成仪中进行,然后可以将合成基因连接在合适的表达载体中。简并基因组的使用使得可以提供混合物中的所有序列,其编码所需的潜在蛋白质序列集合。简并寡核苷酸的合成方法是本领域技术人员已知的。
在现有技术中,已知几种技术用于筛选通过点突变或缩短产生的组合数据库的基因产物,以及用于筛选具有选定性质的基因产物的cDNA文库。这些技术可以适用于快速筛选通过根据本发明的同源物的组合诱变产生的基因库。最常用于筛选大型基因库的基于高通量分析的技术包括在可复制的表达载体中克隆基因库,用所得载体数据库转化合适的细胞,以及在特定条件下表达组合基因,在所述条件下,所需活性的检测促进编码基因(其产物被检测)的载体的分离。递归整合诱变(REM)是一种提高数据库中功能突变体频率的技术,其可以与筛选测试结合使用,以鉴定同源物。
本文提供的实施方案提供了本文公开的多肽的直系同源物和旁系同源物,以及用于鉴定和分离此类直系同源物和旁系同源物的方法。术语“直系同源物”和“旁系同源物”的定义在下面给出,并适用于氨基酸和核酸序列。
c.根据本发明适用的编码核酸序列
在本文语境中,以下定义适用:
术语“核酸序列”、“核酸”、“核酸分子”和“多核苷酸”可互换使用,是指核苷酸的序列。核酸序列可以是任意长度的单链或双链脱氧核糖核苷酸或核糖核苷酸,并且包括基因的编码和非编码序列、外显子、内含子、有义和反义互补序列、基因组DNA、cDNA、miRNA、siRNA、mRNA、rRNA、tRNA、重组核酸序列、分离的和纯化的天然产生的DNA和/或RNA序列、合成的DNA和RNA序列、片段、引物和核酸探针。技术人员了解RNA的核酸序列与DNA序列相同,差异在于胸腺嘧啶(T)被替代为尿嘧啶(U)。术语“核苷酸序列”也应理解为包含单独的片段形式或作为较大核酸组分的多核苷酸分子或寡核苷酸分子。
“分离的核酸”或“分离的核酸序列”是指一种核酸或核酸序列,其所处的环境与天然产生的核酸或核酸序列所处的环境不同,并且可以包括基本上不含污染内源性物质的那些。
如本文使用的应用于核酸的术语“天然产生的”是指一种核酸,其在自然界的生物的细胞中发现,并且未经人类在实验室中进行有意的修饰。
多核苷酸或核酸序列的“片段”是指连续的核苷酸,其特别是本文一个实施方案的多核苷酸长度的至少15bp,至少30bp,至少40bp,至少50bp和/或至少60bp。特别地,多核苷酸的片段包含本文一个实施方案的多核苷酸的至少25个,更特别是至少50个,更特别是至少75个,更特别是至少100个,更特别是至少150个,更特别是至少200个,更特别是至少300个,更特别是至少400个,更特别是至少500个,更特别是至少600个,更特别是至少700个,更特别是至少800个,更特别是至少900个,更特别是至少1000个连续核苷酸。不受限制,本文的多核苷酸的片段可以用作PCR引物和/或探针,或用于反义基因沉默或RNAi。
如本文所用,术语“杂交”或在一定条件下杂交旨在描述杂交和洗涤的条件,在所述条件下彼此显著相同或同源的核苷酸序列保持彼此结合。该条件可以使得至少约70%、例如至少约80%、和例如至少约85%、90%或95%同一性的序列保持彼此结合。下文提供了低严格度、中等和高严格度杂交条件的定义。本领域技术人员可以通过例如Ausubel等人(1995,Current Protocols in Molecular Biology,John Wiley&Sons,sections 2,4,and6)所举例说明的那样以最少的实验来选择合适的杂交条件。另外,严格条件在Sambrook等人(1989,Molecular Cloning:A Laboratory Manual,2nd ed.,Cold Spring HarborPress,chapters 7,9,and 11)中描述。
“重组核酸序列”是通过使用实验室方法(例如分子克隆)将来自多于一个源的遗传物质组合在一起所生成的核酸序列,由此创造出或修饰出不是天然产生并且不能以其他方式在生物有机体中发现的核酸序列。
“重组DNA技术”是指用于制备重组核酸序列的分子生物学方法,例如描述于由Weigel和Glazebrook编辑的Laboratory Manuals,2002,Cold Spring Harbor Lab Press;和Sambrook等,1989Cold Spring Harbor,NY:Cold Spring Harbor Laboratory Press。
术语“基因”是指一种DNA序列,其包含可操作地连接到适当调控区域(例如启动子)的被转录为RNA分子(例如细胞中的mRNA)的区域。因此,基因可以包含几个可操作地连接的序列,诸如启动子、5’前导序列(包含例如参与翻译初始化的序列)、cDNA或基因组DNA的编码区、内含子、外显子和/或3’非翻译序列(包含例如转录终止位点)。
“多顺反子”是指可以在同一核酸分子内分别编码多于一个多肽的核酸分子,特别是mRNA。
“嵌合基因”是指通常不能在自然界的物种中发现的任何基因,特别是这样一种基因,其中核酸序列存在一个或多个部分在性质上彼此不相关联。例如,启动子在性质上与转录区的部分或全部或与另一调控区不相关联。术语“嵌合基因”应当被理解为包括表达构建体,其中启动子或转录调控序列被可操作地连接到一个或多个编码序列或反义(即有义链的反向互补链)或反向重复序列(有义和反义,由此RNA转录物在转录后形成双链RNA)。术语“嵌合基因”还包括通过组合一个或多个编码序列的部分以产生新基因而获得的基因。
“3’URT”或“3’非翻译序列”(也称为“3’未翻译区”或“3’末端”)是指在基因编码序列的下游发现的核酸序列,其包含例如转录终止位点和(在大多数但非全部的真核mRNA中)多聚腺苷酸化信号,例如AAUAAA或其变体。在转录终止后,mRNA转录物可以在多聚腺苷酸化信号的下游切去,并且可以添加poly(A)尾,其参与了mRNA向翻译位点例如细胞质的转运。
术语“引物”是指短的核酸序列,其被杂交到模板核酸序列并且被用于与该模板互补的核酸序列的聚合。
术语“可选择标记”是指在表达后能够被用来选择包括该可选择标记的一种或多种细胞的任何基因。以下描述了可选择标记的例子。本领域技术人员了解不同的抗生素、杀真菌剂、营养缺陷型或除草剂可选择标记可适用于不同的目标物种。
本发明还涉及编码如本文定义的多肽的核酸序列。
特别地,本发明还涉及编码上述多肽之一及其功能等同物的核酸序列(单链和双链DNA和RNA序列,例如cDNA、基因组DNA和mRNA),其可以通过例如使用人工核苷酸类似物来获得。
本发明既涉及分离的核酸分子,其编码根据本发明的多肽或其生物学活性区段,又涉及核酸片段,其可用作例如鉴定或扩增根据本发明的编码核酸的杂交探针或引物。
本发明还涉及与本文具体公开的序列具有一定程度的“同一性”的核酸。两个核酸之间的“同一性”是指在每种情况下在核酸的整个长度上核苷酸的同一性。
两个核苷酸序列(同样适用于肽或氨基酸序列)之间的“同一性”是当产生这两个序列的比对时,核苷酸残基(或氨基酸残基)的数目的函数,或两个序列中相同的残基数目。相同的残基被定义为两个序列中在比对的给定位置的相同的残基。本文使用的序列同一性的百分比是从最佳比对中通过将两个序列之间相同的残基数除以最短序列中的残基总数并乘以100计算得到的。最佳比对是同一性百分比最高可能性的比对。可以将空位引入到一个或两个序列中的比对的一个或多个位置中以获得最佳比对。然后将这些空位考虑为用于计算序列同一性百分比的不相同的残基。用于确定氨基酸或核酸序列同一性百分比的比对可以使用计算机程序以及例如在互联网上可公开获得的计算机程序以多种方式实现。
特别地,可使用可从National Center for Biotechnology Information(美国国家生物技术信息中心)(NCBI)于http://www.ncbi.nlm.nih.gov/BLAST/bl2seq/wblast2.cgi获得的设定为默认参数的BLAST程序(Tatiana等,FEMS Microbiol Lett.,1999,174:247-250,1999)来获得蛋白或核酸序列的最佳比对并计算序列同一性的百分比。
在另一个例子中,同一性可以通过Informax公司(美国)的Vector NTI Suite 7.1程序使用Clustal方法(Higgins DG,Sharp PM.((1989)))通过以下设置来计算:
多重比对参数:
成对比对参数:
或者,同一性可以根据Chenna et al.(2003),网页:http://www.ebi.ac.uk/Tools/clustalw/index.html#的方法和以下设置来确定:
本文提及的所有核酸序列(单链和双链DNA和RNA序列,例如cDNA和mRNA)可以以已知方式通过化学合成从核苷酸结构单元产生,例如通过双螺旋的各个重叠的互补核酸结构单元的片段缩合来实现。寡核苷酸的化学合成例如可以通过磷酰胺法(Voet,Voet,2ndedition,Wiley Press,New York,pages 896-897)以已知的方式进行。合成寡核苷酸的积累,和借助于DNA聚合酶的Klenow片段和连接反应的空位的填补,以及一般的克隆技术描述于Sambrook et al.(1989),请参阅下文。
另外,根据本发明的核酸分子可以另外包含来自编码遗传区域的3'和/或5'末端的非翻译序列。
本发明进一步涉及与具体描述的核苷酸序列或其区段互补的核酸分子。
根据本发明的核苷酸序列使得可以产生可用于鉴定和/或克隆其他细胞类型和生物体中的同源序列的探针和引物。此类探针或引物通常包含在“严格”条件下(如本文其他部分所定义)与根据本发明的核酸序列的有义链或相应的反义链的至少约12个,优选至少约25个,例如约40、50或75个连续核苷酸杂交的核苷酸序列区域。
“同源”序列包括直系同源或旁系同源序列。鉴别直系同源物或旁系同源物的方法包括现有技术中已知且在本文中描述的系统发生学方法、序列相似性和杂交方法。
“旁系同源物”或旁系同源序列来源于基因复制,其产生具有相似序列和相似功能的两种或更多种基因。旁系同源物通常聚簇在一起并且通过在相关植物物种内基因的复制而形成。使用成对Blast分析或在基因家族的系统发生分析过程中使用程序诸如CLUSTAL在类似基因的组中发现旁系同源物。在旁系同源物中,共有序列可被鉴定为其特征在于相关基因中的序列并且具有基因的类似功能。
“直系同源物”或直系同源序列是彼此相似的序列,因为它们发现于由共同的祖先传下的物种中。例如,已知具有共同祖先的植物物种含有许多具有相似序列和功能的酶。例如通过使用CLUSTAL或BLAST程序构建一个物种的基因族的系统发生树,技术人员能够鉴定直系同源序列并预测直系同源物的功能。一种用于鉴定或确认同源序列间的相似功能的方法是通过比较过表达或缺乏(在基因敲除/敲减中)相关多肽的宿主细胞或生物体(如植物或微生物)中的转录物概况。技术人员能够理解,具有相似转录物概况的基因(具有大于50%调控的共同转录物,或具有大于70%调控的共同转录物,或大于90%调控的共同转录物)会具有相似的功能。通过使宿主细胞,生物体例如植物或微生物产生萜合酶蛋白,本文所述序列的同源物、旁系同源物、直系同源物以及任何其他变体预期以类似的方式发挥作用。
术语“可选择标记”是指在表达后能够被用来选择包括该可选择标记的一种或多种细胞的任何基因。以下描述了可选择标记的例子。本领域技术人员了解不同的抗生素、杀真菌剂、营养缺陷型或除草剂可选择标记可适用于不同的目标物种。
“分离的”核酸分子与存在于核酸天然来源中的其他核酸分子分离,并且如果通过重组技术生产,则可以基本上不含其他细胞材料或培养基,或者如果通过化学合成,则可以不含化学前体或其他化学物质。
可以借助于分子生物学的标准技术和根据本发明提供的序列信息来分离根据本发明的核酸分子。例如,可以使用具体公开的完整序列之一或其片段作为杂交探针和标准杂交技术(例如,描述于Sambrook,(1989))从合适的cDNA文库中分离cDNA。
另外,包含所公开的序列之一或其片段的核酸分子可以使用基于该序列构建的寡核苷酸引物,通过聚合酶链反应来分离。以此方式扩增的核酸可以克隆到合适的载体中,并可以通过DNA测序来表征。根据本发明的寡核苷酸也可以通过标准的合成方法,例如使用自动DNA合成仪制备。
根据本发明的核酸序列或其衍生物,这些序列的同源物或部分可以例如通过常规的杂交技术或PCR技术从其他细菌中,例如通过基因组或cDNA文库分离出来。这些DNA序列在标准条件下与根据本发明的序列杂交。
“杂交”是指多核苷酸或寡核苷酸在标准条件下结合几乎互补的序列的能力,而在这些条件下非互补配对者之间不发生非特异性结合。为此,序列可以是90~100%互补的。能够彼此特异性结合的互补序列的性质被用于例如Northern印迹或Southern印迹或PCR或RT-PCR中的引物结合。
保守区的短寡核苷酸有利地用于杂交。然而,也可能使用更长的本发明核酸片段或完整序列进行杂交。这些“标准条件”取决于所使用的核酸(寡核苷酸,更长的片段或完整序列)或用于杂交的核酸类型(DNA或RNA)而有所不同。例如,DNA:DNA杂交种的解链温度比相同长度的DNA:RNA杂交种低约10℃。
例如,根据特定核酸的不同,标准条件是指温度在42至58℃,在浓度为0.1至5xSSC(1X SSC=0.15M NaCl,15mM柠檬酸钠,pH 7.2)的缓冲水溶液中,或另外在50%甲酰胺(例如42℃,5x SSC,50%甲酰胺)的存在下。有利地,用于DNA:DNA杂交种的杂交条件是0.1×SSC,温度为约20℃至45℃,优选约30℃至45℃。对于DNA:RNA杂交种,杂交条件有利地为0.1×SSC,并且温度为约30℃至55℃,优选约45℃至55℃。这些所述的杂交温度是对于长度约100个核苷酸的核酸,以及在不存在甲酰胺的情况下G+C含量为50%的经计算的解链温度值的例子。DNA杂交的实验条件已在相关的遗传学教科书(例如Sambrook et al.,1989)中进行了描述,并且可以使用本领域技术人员已知的分子式来计算,例如取决于核酸的长度,杂交种的类型或G+C含量。本领域技术人员可以从以下教科书中获得有关杂交的更多信息:Ausubel et al.(eds),(1985),Brown(ed)(1991)。
“杂交”尤其可以在严格条件下进行。这样的杂交条件例如描述于Sambrook(1989),或Current Protocols in Molecular Biology,John Wiley&Sons,N.Y.(1989),6.3.1-6.3.6。
如本文所用,术语“杂交或在一定条件下杂交”旨在描述杂交和洗涤的条件,在所述条件下彼此显著相同或同源的核苷酸序列保持彼此结合。该条件可以使得至少约70%,例如至少约80%和例如至少约85%、90%或95%同一性的序列保持彼此结合。本文提供了低严格度、中等和高严格度杂交条件的定义。
本领域技术人员可以通过例如Ausubel等人(1995,Current Protocols inMolecular Biology,John Wiley&Sons,sections 2,4,and 6)所举例说明的那样以最少的实验来选择合适的杂交条件。另外,严格条件在Sambrook等人(1989,Molecular Cloning:ALaboratory Manual,2nd ed.,Cold Spring Harbor Press,chapters 7,9,and 11)中描述。
如本文所用,所限定的低严格度条件如下。含有DNA的滤膜在含有35%甲酰胺,5xSSC,50mM Tris-HCl(pH 7.5),5mM EDTA,0.1%PVP,0.1%Ficoll,1%BSA和500μg/ml变性鲑鱼精子DNA的溶液中于40℃预处理6小时。杂交在相同的溶液中进行,并进行以下修改:0.02%PVP,0.02%Ficoll,0.2%BSA,100μg/ml鲑鱼精子DNA,10%(wt/vol)硫酸葡聚糖,并使用5-20x10
如本文所用,所限定的中等严格度条件如下。含有DNA的滤膜在含有35%甲酰胺,5x SSC,50mM Tris-HCl(pH 7.5),5mM EDTA,0.1%PVP,0.1%Ficoll,1%BSA和500μg/ml变性鲑鱼精子DNA的溶液中于50℃预处理7小时。杂交在相同的溶液中进行,并进行以下修改:0.02%PVP,0.02%Ficoll,0.2%BSA,100μg/ml鲑鱼精子DNA,10%(wt/vol)硫酸葡聚糖,并使用5-20x10
如本文所用,所限定的高严格度条件如下。含DNA的滤膜在由6x SSC,50mM Tris-HCl(pH 7.5),1mM EDTA,0.02%PVP,0.02%Ficoll,0.02%BSA和500μg/ml变性鲑鱼精子DNA组成的缓冲液中于65℃下预杂交8小时至过夜。在含有100μg/ml变性鲑鱼精子DNA和5-20x10
如果上述条件不合适(例如,如用于种间杂交),则可以使用本领域众所周知的其他低、中等和高严格度条件(例如,用于种间杂交)。
用于编码本发明多肽的核酸序列的检测试剂盒可以包括对编码该多肽的核酸序列具有特异性的引物和/或探针,以及使用该引物和/或探针来检测样品中编码该多肽的核酸序列的相关方案。此种检测试剂盒可用于确定植物、生物、微生物或细胞是否已被修饰,即是否已用编码多肽的序列转化。
为了测试根据本文一个实施方案的变体DNA序列的功能,将目标序列可操作地连接到可选择的或可筛选的标记基因,并且在使用微生物或原生质体进行的瞬时表达分析中或在稳定转化的植物中测试报告基因的表达。
本发明还涉及具体公开的或可衍生的核酸序列的衍生物。
因此,根据本发明的另外的核酸序列可以衍生自本文具体公开的序列,并且可以通过一个或几个(例如1至10个)核苷酸的一个或多个,例如1至20个,特别是1至15个或5至10个添加、取代、插入或缺失而与之不同,并且还编码具有所期望特性的多肽。
本发明还包括与具体陈述的序列相比,根据特定原始或宿主生物的密码子使用而包含所谓的沉默突变或已被改变的核酸序列。
根据本发明的特定实施方案,可以制备变体核酸以使其核苷酸序列适应特定的表达系统。例如,如果氨基酸由特定的密码子编码,则已知细菌表达系统可更有效地表达多肽。由于遗传密码的简并性,多于一个密码子可以编码相同的氨基酸序列,多个核酸序列能够编码相同的蛋白或多肽,所有这些DNA序列均被涵盖在本文一个实施方案中。在适当的情况下,编码本文所述多肽的核酸序列可以被优化以增加在宿主细胞中的表达。例如,可以使用宿主特异性的密码子合成本文一个实施方案的核酸以改善表达。
本发明还涵盖本文描述的序列的天然存在的变体,例如剪接变体或等位基因变体。
等位基因变体在所衍生的氨基酸水平上,具有在整个氨基酸范围至少60%的同源性,优选至少80%的同源性,非常特别优选至少90%的同源性(关于氨基酸水平的同源性,应参考以上对于多肽给出的详细信息)。有利地,同源性可以在序列的部分区域上更高。
本发明还涉及可通过保守核苷酸取代(即,由于其结果,所讨论的氨基酸被具有相同电荷、大小、极性和/或溶解度的氨基酸取代)获得的序列。
本发明还涉及通过序列多态性从具体公开的核酸衍生的分子。由于天然等位基因变异,这种遗传多态性可能存在于来自不同群体的细胞或来自一个群体内的细胞中。等位基因变体还可包括功能等同物。这些自然变异通常会在基因的核苷酸序列中产生1~5%的变化。所述多态性可以导致本文公开的多肽的氨基酸序列的改变。等位基因变体还可包括功能等同物。
此外,衍生物也应理解为根据本发明的核酸序列的同源物,例如动物、植物、真菌或细菌的同源物,缩短的序列,编码和非编码DNA序列的单链DNA或RNA。例如,在DNA水平上,同源物在本文具体公开的序列中给定的整个DNA区域中具有至少40%,优选至少60%,特别优选至少70%,非常特别优选至少80%的同源性。
此外,衍生物应理解为例如与启动子的融合体。尽管不损害启动子的功能或功效,添加至所述核苷酸序列的启动子可以通过至少一种核苷酸交换、至少一种插入、倒置和/或缺失来修饰。而且,启动子的功效可以通过改变它们的序列来增加,或者可以与更有效的启动子甚至是不同属的生物体的启动子完全交换。
d.功能性多肽突变体的产生
此外,本领域技术人员熟悉用于产生功能性突变体的方法,也就是说,一种核苷酸序列,其编码多肽,该多肽与本文公开的任何与氨基酸相关的SEQ ID NO具有至少40%,45%,50%,55%,60%,65%,70%,75%,80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的序列同一性;和/或由核酸分子编码,该核酸分子包含与本文公开的任何与核苷酸相关的SEQ ID NO具有至少70%序列同一性的核苷酸序列。
取决于所使用的技术,本领域技术人员可以将完全随机的或更有针对性的突变引入到基因或非编码核酸区域(例如对于调节表达很重要)中,并随后产生遗传文库。为此目的所需的分子生物学方法是技术人员已知的,例如描述于Sambrook and Russell,Molecular Cloning.3rd Edition,Cold Spring Harbor Laboratory Press 2001。
修饰基因并由此修饰由其编码的多肽的方法是本领域技术人员长期已知的,举例而言例如:
-位点特异性诱变,其中基因的单个或多个核苷酸以定向方式被替换(Trower MK(Ed.)1996;In vitro mutagenesis protocols.Humana Press,New Jersey),
-饱和诱变,其中任何氨基酸的密码子都可以在基因的任何位点交换或添加(Kegler-Ebo DM,Docktor CM,DiMaio D(1994)Nucleic Acids Res 22:1593;BarettinoD,Feigenbutz M,Valcárel R,Stunnenberg HG(1994)Nucleic Acids Res 22:541;BarikS(1995)Mol Biotechnol 3:1),
-易错聚合酶链反应,其中核苷酸序列被易错DNA聚合酶突变(Eckert KA,KunkelTA(1990)Nucleic Acids Res 18:3739);
-SeSaM法(序列饱和法),其中优选的交换被聚合酶阻止。Schenk et al.,Biospektrum,Vol.3,2006,277-279,
-突变株中的基因传代,其中例如由于DNA修复机制缺陷,核苷酸序列的突变率增加(Greener A,Callahan M,Jerpseth B(1996)An efficient random mutagenesistechnique using an E.coli mutator strain.In:Trower MK(Ed.)In vitromutagenesis protocols.Humana Press,New Jersey),或
-DNA改组,其中形成并消化一组密切相关的基因,并将这些片段用作聚合酶链反应的模板,其中通过重复的链分离和重新结合,最终生成了全长的镶嵌基因(Stemmer WPC(1994)Nature 370:389;Stemmer WPC(1994)Proc Natl Acad Sci USA 91:10747)。
使用所谓的定向进化(尤其描述于Reetz MT and Jaeger K-E(1999),TopicsCurr Chem 200:31;Zhao H,Moore JC,Volkov AA,Arnold FH(1999),Methods foroptimizing industrial polypeptides by directed evolution,In:Demain AL,DaviesJE(Ed.)Manual of industrial microbiology and biotechnology.American Societyfor Microbiology),熟练的工人可以以定向的方式大规模生产功能性突变体。为此,在第一步中,首先,例如使用上文给出的方法,产生各自多肽的基因文库。基因文库以合适的方式表达,例如通过细菌或噬菌体展示系统来表达。
表达功能性突变体的宿主生物的相关基因(其功能在很大程度上与所需的特性相对应)可以提交给另一个突变周期。突变和选择或筛选的步骤可以迭代地重复,直到本发明的功能性突变体具有足够程度的所需特性。使用该迭代过程,可以分阶段进行有限数量的突变,例如1、2、3、4或5个突变,并评估和选择它们对所研究活性的影响。然后可以以相同的方式将所选择的突变体进行进一步的突变步骤。这样,可以显著减少待研究的单个突变体的数量。
根据本发明的结果还提供了与相关多肽的结构和序列有关的重要信息,这是以靶向方式产生具有所需修饰特性的其他多肽所必需的。特别地,可以定义所谓的“热点”,即潜在地适合于通过引入靶向突变来修饰特性的序列区段。
也可以推导出有关氨基酸序列位置的信息,在该区域中可以发生可能对活性几乎没有影响的突变,并且可以将其指定为潜在的“沉默突变”。
e.表达本发明多肽的构建体
在本文语境中,以下定义适用:
“基因的表达”涵盖“异源表达”和“过表达”,并且涉及基因的转录和mRNA向蛋白质的翻译。过表达是指在转基因细胞或生物中,以mRNA、多肽和/或酶活性水平测量的基因产物的产生超过了相似遗传背景的非转化细胞或生物中的产生水平。
如本文所用,“表达载体”是指这样一种核酸分子,其使用分子生物学方法和重组DNA技术工程化以将外来或外源DNA递送到宿主细胞中。表达载体典型地包括正确转录核苷酸序列所需的序列。编码区通常编码目的蛋白,但是也可以编码RNA,例如反义RNA、siRNA等。
如本文所用,“表达载体”包括任何线性的或环状的重组载体,包括但不限于病毒载体、噬菌体和质粒。技术人员根据表达系统能够选择适合的载体。在一个实施方案中,表达载体包括本文实施方案的核酸,其可操作地连接到至少一个“调控序列”,其控制转录、翻译、起始和终止,例如转录启动子、操纵子或增强子,或mRNA核糖体结合位点,并且可选地包括至少一个选择标记。当调控序列功能性地涉及本文实施方案的核酸时,核苷酸序列是“可操作地连接的”。
如本文所用,“表达系统”涵盖在给定表达宿主的体内或体外表达一种,或共表达两种或更多种多肽所需的核酸分子的任何组合。各自的编码序列可以位于单个核酸分子或载体上,例如包含多个克隆位点的载体,或位于多顺反子核酸上,或者可以分布在两个或更多个物理上不同的载体上。作为一个特定的例子,可以提及一种操纵子,其包含启动子序列,一个或多个操纵子序列以及一个或多个结构基因,每个基因编码本文所述的酶。
如本文所用,术语“进行扩增(amplifying)”和“扩增(amplification)”是指使用任何合适的扩增方法用于产生或检测天然表达的核酸的重组体,如下文详细描述的。例如,本发明提供用于扩增(例如,通过聚合酶链反应,PCR)天然表达的(例如,基因组DNA或mRNA)或本发明在体内、离体或体外的重组的核酸(例如cDNA)的方法和试剂(例如,特异性简并寡核苷酸引物对,寡聚dT引物)。
“调控序列”是指这样一种核酸序列,其确定本文实施方案的核酸序列的表达水平、并且能够调控可操作地连接到该调控序列的核酸序列的转录速率。调控序列包含启动子、增强子、转录因子、启动子元件等。
根据本发明,“启动子”、“具有启动子活性的核酸”或“启动子序列”应理解为是指这样一种核酸,当与要转录的核酸功能性连接时,其调节所述核酸的转录。“启动子”尤其是指一种核酸序列,其通过提供RNA聚合酶用的结合位点以及适合转录所需的其它因子,包括但不限于转录因子结合位点、抑制子和活化子蛋白结合位点,来控制编码序列的表达。术语启动子的含义还包括术语“启动子调控序列”。启动子调控序列可以包括可能影响转录、RNA加工或相关编码核酸序列的稳定性的上游和下游元件。启动子包括天然来源的和合成的序列。编码核酸序列通常位于启动子相对于以转录起始位点为起始的转录方向的下游。
在本文语境中,“功能性”或“可操作地”连接被理解为例如指具有调控序列的核酸之一的顺序排列。例如,具有启动子活性的序列,和待转录的核酸序列以及可选的其他调控元件(例如确保核酸转录的核酸序列)和例如终止子,该顺序排列的方式为使得每个调控元件都能在核酸序列转录后执行其功能。这不一定需要化学意义上的直接连接。遗传控制序列,例如增强子序列,甚至可以从更远的位置甚至从其他DNA分子上对目标序列发挥作用。优选的排列是这样的,其中待转录的核酸序列位于启动子序列的下游(即3'端),从而使两个序列共价连接在一起。启动子序列和待重组表达的核酸序列之间的距离可以小于200个碱基对,或小于100个碱基对或小于50个碱基对。
除启动子和终止子外,还可以提及以下作为其他调控元件的例子:靶向序列,增强子,聚腺苷酸化信号,可选择标记,扩增信号,复制起点等。合适的调节序列描述于例如Goeddel,Gene Expression Technology:Methods in Enzymology 185,Academic Press,San Diego,CA(1990)。
术语“组成型启动子”是指不受调控的启动子,其允许其可操作地连接的核酸序列的持续转录。
如本文所用,术语“可操作地连接”是指处于功能性关系的多核苷酸元件的连接。当核酸与另一核酸序列处于功能性关系时,那么该核酸是“可操作地连接”的。例如,如果启动子或者转录调控序列能够影响编码序列的转录,那么该启动子或者转录调控序列是可操作地连接到该编码序列的。可操作地连接意味着被连接的DNA序列通常是邻接的。与启动子序列有关的核苷酸序列相对于要被转化的植物可以是同源或异源来源的。所述序列还可以是完全或部分合成的。不管来源如何,与启动子序列有关的核酸序列将根据在结合到本文实施方案的多肽后所连接的启动子性质而表达或沉默。相关核酸在所有时间或替代地在特定时间在整个生物体中或在特定组织、细胞或细胞室中可以编码需要表达或抑制的蛋白。此种核苷酸序列特别地编码将所需表型性状赋予给由其改变或转化的宿主细胞或生物体的蛋白质。更特别地,相关的核苷酸序列导致在细胞或生物体中产生如本文定义的一种或多种目的产物。特别地,核苷酸序列编码具有如本文定义的酶活性的多肽。
本文如上所述的核苷酸序列可以是“表达盒”的一部分。术语“表达盒”和“表达构建体”同义使用。(优选的重组)表达构建体包含这样的核苷酸序列,其编码根据本发明的多肽并且在调节核酸序列的遗传控制之下。
在根据本发明应用的方法中,表达盒可以是“表达载体”,特别是重组表达载体的一部分。
根据本发明,“表达单位”应理解为是指具有表达活性的核酸,其包含如本文所定义的启动子,并且在与待表达的核酸或基因功能性连接后调节表达,即所述核酸或所述基因的转录和翻译。因此在这方面也被称为“调节核酸序列”。除启动子外,还可以存在其他调节元件,例如增强子。
根据本发明,“表达盒”或“表达构建体”应理解为在功能上与要表达的核酸或要表达的基因连接的表达单元。因此,与表达单元相反,表达盒不仅包含调节转录和翻译的核酸序列,而且还包含由于转录和翻译而作为蛋白质表达的核酸序列。
在本发明的语境中,术语“表达”或“过表达”描述了微生物中一种或多种由相应DNA编码的多肽的细胞内活性的产生或增加。为此,例如可以将基因导入到生物体中,用另一个基因替代现有基因,增加基因的拷贝数,使用强启动子或使用编码具有高活性的相应多肽的基因。可选地,这些措施可以组合。
优选地,根据本发明的此类构建体包含各自编码序列5'上游的启动子和3'下游的终止子序列,以及可选地其他常见的调控元件,在每种情况下均与编码序列可操作地连接。
根据本发明的核酸构建体特别地包含编码多肽的序列,该多肽例如衍生自如本文所述的氨基酸相关的SEQ ID NO或其反向互补序列,或其衍生物和同源物,并且已经与一个或多个调节信号可操作地或功能性连接,用于有利地控制例如增加基因表达。
除了这些调控序列之外,这些序列的天然调控可能仍存在于实际的结构基因之前,并且可选地可能已经进行了遗传修饰,因此天然调控已被关闭,基因的表达得到了增强。然而,核酸构建体也可以具有更简单的构建,即,在编码序列之前没有插入额外的调节信号,并且具有调节作用的天然启动子尚未去除。相反,天然调节序列被突变,使得不再发生调节并且基因表达增加。
优选的核酸构建体有利地还包含与启动子功能性连接的一个或多个已经提及的“增强子”序列,该序列使得增强核酸序列的表达成为可能。还可以在DNA序列的3'末端插入其他有利的序列,例如其他调控元件或终止子。根据本发明的核酸的一个或多个拷贝可以存在于构建体中。在该构建体中,还可以可选地存在其他标记物,例如与营养缺陷性或抗生素抗性互补的基因,以便选择该构建体。
合适的调控序列的例子存在于启动子中,例如cos、tac、trp、tet、trp-tet、lpp、lac、lpp-lac、lacIq、T7、T5、T3、gal、trc、ara、rhaP(rhaP
为了在宿主生物体中表达,将核酸构建体有利地插入到载体,例如质粒或噬菌体中,这使得基因在宿主中的最佳表达成为可能。除了质粒和噬菌体,载体还应理解为是本领域技术人员已知的所有其他载体,即例如病毒,例如SV40、CMV、杆状病毒和腺病毒、转座子、IS元件、噬粒、粘粒和线性或环状DNA或人工染色体。这些载体能够在宿主生物体中自主复制或通过染色体复制。这些载体是本发明的进一步发展。二元或cpo整合载体也是适用的。
合适的质粒是例如在大肠杆菌pLG338、pACYC184、pBR322、pUC18、pUC19、pKC30、pRep4、pHS1、pKK223-3、pDHE19.2、pHS2、pPLc236、pMBL24、pLG200、pUR290、pIN-III
在载体的进一步开发中,包含本发明的核酸构建体或本发明的核酸的载体也可以有利地以线性DNA的形式引入到微生物中并通过异源或同源重组整合到宿主生物体的基因组中。该线性DNA可以由线性化的载体例如质粒组成,或者仅由本发明的核酸构建体或核酸组成。
为了在生物体中异源基因的最佳表达,有利的是修饰核酸序列以匹配生物体中使用的特定“密码子使用”。“密码子使用”可以通过对所讨论的生物体的其他已知基因的计算机评估来容易地确定。
根据本发明的表达盒通过将合适的启动子融合到合适的编码核苷酸序列和终止子或聚腺苷酸化信号来产生。为此目的使用常规的重组和克隆技术,例如描述于T.Maniatis,E.F.Fritsch and J.Sambrook,Molecular Cloning:A Laboratory Manual,Cold Spring Harbor Laboratory,Cold Spring Harbor,NY(1989)和T.J.Silhavy,M.L.Berman and L.W.Enquist,Experiments with Gene Fusions,Cold Spring HarborLaboratory,Cold Spring Harbor,NY(1984)和Ausubel,F.M.et al.,Current Protocolsin Molecular Biology,Greene Publishing Assoc.and Wiley Interscience(1987)。
为了在合适的宿主生物体中表达,将重组核酸构建体或基因构建体有利地插入到宿主特异性载体中,这使得基因在宿主中的最佳表达成为可能。载体是技术人员众所周知的,并且可以在例如"cloning vectors"(Pouwels P.H.et al.,Ed.,Elsevier,Amsterdam-New York-Oxford,1985)中找到。
本文实施方案的替代实施方案提供了一种“改变宿主细胞中的基因表达”的方法。例如,在某些语境下(例如,暴露于一定温度或培养条件下),在宿主细胞或宿主生物体中可以增强或过表达或诱导本文实施方案的多核苷酸。
本文提供的多核苷酸的表达的改变还会产生异位表达,其是在改变的以及在对照或野生型生物体中的一种不同的表达模式。表达的改变是由本文一个实施方案的多肽与外源性或内源性调节剂的相互作用而发生的或者是由于多肽的化学修饰导致的。该术语还指本文实施方案的多核苷酸的改变的表达模式,其被改变至低于检测水平或者完全被抑制活性。
在一个实施方案中,本文还提供了编码本文提供的多肽或变体多肽的分离的、重组的或合成的多核苷酸。
在一个实施方案中,多种编码多肽的核酸序列在单一宿主中共表达,特别是在不同启动子的控制下。在另一个实施方案中,多种编码多肽的核酸序列可以存在于单个转化载体上,或者可以使用分离的载体并选择包含两个嵌合基因的转化体同时进行共转化。类似地,一种或多种多肽编码基因可以与其他嵌合基因一起在单一植物、细胞、微生物或生物体中表达。
f.适用于本发明的宿主
取决于语境,术语“宿主”可以指野生型宿主或经遗传改变的重组宿主或两者。
原则上,所有的原核或真核生物都可以被认为是根据本发明的核酸或核酸构建体的宿主或重组宿主生物。
使用根据本发明的载体,可以生产重组宿主,其例如可以用至少一种根据本发明的载体转化,并可以用于生产根据本发明的多肽。有利地,将如上所述的根据本发明的重组构建体引入到合适的宿主系统中并表达。优选地,使用本领域技术人员已知的普通克隆和转染方法,例如共沉淀、原生质体融合、电穿孔、逆转录病毒转染等,以在各自的表达系统中表达所述核酸。合适的系统描述于Current Protocols in Molecular Biology,F.Ausubelet al.,Ed.,Wiley Interscience,New York 1997,或Sambrook et al.MolecularCloning:A Laboratory Manual.2nd edition,Cold Spring Harbor Laboratory,ColdSpring Harbor Laboratory Press,Cold Spring Harbor,NY,1989。
有利地,诸如细菌、真菌或酵母的微生物被用作宿主生物。有利地,使用革兰氏阳性或革兰氏阴性细菌,优选肠杆菌科(Enterobacteriaceae),假单胞菌科(Pseudomonadaceae),根瘤菌科(Rhizobiaceae),链霉菌科(Streptomycetaceae),链球菌科(Streptococcaceae)或诺卡氏菌科(Nocardiaceae)的细菌,特别优选埃希氏菌属(Escherichia),假单胞菌属(Pseudomonas),链霉菌属(Streptomyces),乳球菌属(Lactococcus),诺卡氏菌(Nocardia),伯克霍尔德氏菌属(Burkholderia),沙门氏菌属(Salmonella),农杆菌属(Agrobacterium),艰难梭菌(Clostridium)或红球菌属(Rhodococcus)的细菌。大肠杆菌(Escherichia coli)属和种是非常特别优选的。此外,在α-变形菌(alpha-Proteobacteria)、β-变形菌(beta-Proteobacteria)或γ-变形菌(gamma-Proteobacteria)组中发现了其他有利的细菌。有利地,诸如酵母属(Saccharomyces)或毕赤酵母(Pichia)家族的酵母也是合适的宿主。
或者,整个植物或植物细胞可以用作天然或重组宿主。作为非限制性例子,可以提及以下植物或自其衍生的细胞:烟草属(Nicotiana),特别是本氏烟草(Nicotianabenthamiana)和普通烟草(Nicotiana tabacum)(tobacco);以及拟南芥属(Arabidopsis),特别是阿拉伯芥(Arabidopsis thaliana)。
取决于宿主生物,根据本发明的方法中使用的生物以本领域技术人员已知的方式生长或培养。培养可以分批、半分批或连续进行。营养物可以在发酵开始时给予,也可以稍后,半连续或连续地提供。这也在下面更详细地描述。
g.根据本发明的多肽的重组生产
本发明进一步涉及重组生产根据本发明的多肽或其功能性生物学活性片段的方法,其中培养产生多肽的微生物,可选地通过施加至少一种诱导基因表达的诱导剂来诱导多肽的表达,并从培养物中分离这些多肽。如果需要,多肽也可以这种方式以工业规模生产。
根据本发明产生的微生物可以分批法或补料分批法或重复补料分批法连续或不连续培养。已知培养方法的概述可在Chmiel的教科书(Bioprozesstechnik 1.Einführungin die Bioverfahrenstechnik[Bioprocess technology 1.Introduction tobioprocess technology](Gustav Fischer Verlag,Stuttgart,1991))或在Storhas的教科书(Bioreaktoren und periphere Einrichtungen[Bioreactors and peripheralequipment](Vieweg Verlag,Braunschweig/Wiesbaden,1994))中找到。
所使用的培养基必须适当地满足各个菌株的要求。在美国细菌学学会(AmericanSociety for Bacteriology(Washington D.C.,USA,1981))的手册“Manual of Methodsfor General Bacteriology”中给出了各种微生物的培养基的描述。
可以根据本发明使用的这些培养基通常包含一种或多种碳源、氮源、无机盐、维生素和/或微量元素。
优选的碳源是糖,例如单糖、二糖或多糖。很好的碳源是例如葡萄糖,果糖,甘露糖,半乳糖,核糖,山梨糖,核酮糖,乳糖,麦芽糖,蔗糖,棉子糖,淀粉或纤维素。糖也可以通过复杂的化合物(例如糖蜜)或糖精制的其他副产品添加到培养基中。添加不同碳源的混合物也是有利的。其他可能的碳源是油和脂,例如大豆油,葵花籽油,花生油和椰子油,脂肪酸例如棕榈酸,硬脂酸或亚油酸,醇例如甘油,甲醇或乙醇,和有机酸,例如乙酸或乳酸。
氮源通常是有机或无机氮化合物或包含这些化合物的材料。氮源的例子包括氨气或铵盐,例如硫酸铵,氯化铵,磷酸铵,碳酸铵或硝酸铵,硝酸盐,尿素,氨基酸或复合氮源,例如玉米浆,大豆粉,大豆蛋白,酵母提取物,肉提取物等。氮源可以单独使用或混合使用。
可以存在于培养基中的无机盐化合物包括钙,镁,钠,钴,钼,钾,锰,锌,铜和铁的氯化物、磷或硫酸盐。
无机含硫化合物,例如硫酸盐,亚硫酸盐,连二亚硫酸盐,四硫酸盐,硫代硫酸盐,硫化物,以及有机硫化合物,例如硫醇(mercaptans)和巯类(thiols),可用作硫源。
磷酸、磷酸二氢钾或磷酸氢二钾或相应的含钠盐可用作磷源。
可以将螯合剂添加到培养基中,以将金属离子保持在溶液中。特别合适的螯合剂包括二羟基苯酚,例如儿茶酚或原儿茶酸酯,或有机酸,例如柠檬酸。
根据本发明使用的发酵培养基通常还包含其他生长因子,例如维生素或生长促进剂,其包括例如生物素,核黄素,硫胺素,叶酸,烟酸,泛酸和吡哆醇(pyridoxine)。生长因子和盐通常源自复杂培养基的成分,例如酵母提取物,糖蜜,玉米浆等。此外,可以将合适的前体添加到培养基中。化合物在培养基中的确切组成在很大程度上取决于相应的实验,并针对每种具体情况分别确定。有关培养基优化的信息可以在教科书"AppliedMicrobiol.Physiology,A Practical Approach"(Ed.P.M.Rhodes,P.F.Stanbury,IRLPress(1997)p.53-73,ISBN 0 19 963577 3)中找到。生长培养基也可以从商业供应商获得,例如Standard 1(Merck)或BHI(脑心浸液,DIFCO)等。
通过加热(在1.5bar和121℃下20分钟)或通过无菌过滤对培养基的所有成分进行灭菌。这些成分可以一起消毒,也可以根据需要单独消毒。培养基的所有成分都可以在培养开始时给予,也可以连续或分批添加。
培养物的温度通常在15℃至45℃之间,优选25℃至40℃,并且在实验过程中可以改变或保持恒定。介质的pH应在5至8.5的范围内,优选为7.0左右。生长期间的pH值可以通过添加碱性化合物(例如氢氧化钠,氢氧化钾,氨或氨水)或酸性化合物(例如磷酸或硫酸)来控制。消泡剂例如脂肪酸聚乙二醇酯可用于控制发泡。为了维持质粒的稳定性,可以向培养基中添加合适的选择性物质例如抗生素。为了维持有氧条件,将氧气或含氧气体混合物(例如环境空气)供入培养物中。培养物的温度通常在20℃至45℃的范围内。继续培养直至形成最大量的所期望产物。通常会在10到160个小时内达到此目标。
然后将发酵液进一步处理。根据需要,可以通过分离技术,例如离心、过滤、倾析或这些方法的组合,将生物质完全或部分地从发酵液中除去,或者可以完全留在其中。
如果多肽没有在培养基中分泌,那么细胞也可以被裂解,并且可以通过用于分离蛋白质的已知方法从裂解物中获得产物。可以可选地通过高频超声,高压例如在高压细胞裂解机(French press)中,通过渗透,通过去污剂、裂解酶或有机溶剂的作用,通过均化器或通过上述几种方法的组合来破坏细胞。
可以通过已知的色谱技术,例如分子筛色谱(凝胶过滤),例如Q-琼脂糖色谱,离子交换色谱和疏水色谱,以及其他常规技术,例如超滤、结晶、盐析、渗析和天然凝胶电泳来纯化多肽。合适的方法描述于例如Cooper,T.G.,Biochemische Arbeitsmethoden[Biochemical processes],Verlag Walter de Gruyter,Berlin,New York,或Scopes,R.,Protein Purification,Springer Verlag,New York,Heidelberg,Berlin。
为了分离重组蛋白,使用载体系统或寡核苷酸可能是有利的,所述载体系统或寡核苷酸通过限定的核苷酸序列延长cDNA,并因此编码改变的多肽或融合蛋白,其例如用于更容易的纯化。这种类型的合适修饰例如是充当锚的所谓“标签”,例如可以被识别为抗体抗原的被称为六-组氨酸锚或表位的修饰(例如,描述于Harlow,E.and Lane,D.,1988,Antibodies:A Laboratory Manual.Cold Spring Harbor(N.Y.)Press)。这些锚可以用于将蛋白质连接至固体载体,例如聚合物基质,其可以例如用作色谱柱中的填料,或者可以用于微量滴定板或其他载体上。
同时,这些锚也可用于识别蛋白质。为了识别蛋白质,还可以使用通常的标记物,例如荧光染料,酶标记物(与底物反应后形成可检测的反应产物),或放射性标记物,单独使用或与锚结合使用以衍生化蛋白质。
h.多肽的固定化
根据本发明的酶或多肽可以在本文描述的方法中以游离形式或固定化而使用。固定化酶是固定在惰性载体上的酶。合适的载体材料和固定在其上的酶从EP-A-1149849,EP-A-1069183和DE-OS100193773以及从其中引用的参考文献中已知。在这方面,参考这些文件的全部公开内容。合适的载体材料包括例如粘土,粘土矿物,例如高岭石,硅藻土,珍珠岩,二氧化硅,氧化铝,碳酸钠,碳酸钙,纤维素粉末,阴离子交换剂材料,合成聚合物,例如聚苯乙烯,丙烯酸树脂,酚醛树脂,聚氨酯和聚烯烃,例如聚乙烯和聚丙烯。为了制备负载的酶,通常以细分的颗粒形式,优选多孔形式使用载体材料。载体材料的粒径通常不大于5mm,特别是不大于2mm(粒径分布曲线)。类似地,当使用脱氢酶作为全细胞催化剂时,可以选择游离形式或固定形式。载体材料例如为海藻酸钙和角叉菜胶。酶和细胞也可以直接与戊二醛交联(与CLEAs交联)。相应的和其他固定化技术描述于例如J.Lalonde and A.Margolin"Immobilization of Enzymes"in K.Drauz and H.Waldmann,Enzyme Catalysis inOrganic Synthesis 2002,Vol.III,991-1032,Wiley-VCH,Weinheim中。Rehm et al.(Ed.)Biotechnology,2nd Edn,Vol 3,Chapter 17,VCH,Weinheim给出了用于进行根据本发明的方法的生物转化和生物反应器的进一步信息。
i.本发明生物催化生产方法的反应条件
本发明的反应可以在体内或体外条件下进行。
存在于本发明的方法或上文定义的多步方法的单个步骤中的至少一种多肽/酶可以天然存在于活细胞中,或于收获的细胞(即在体内条件下)中,死细胞中,透化细胞中,粗细胞提取物中,纯化提取物中,或以基本纯净或完全纯净的形式(即在体外条件下),重组产生一种或多种酶。所述至少一种酶可以以溶液形式存在或以固定在载体上的酶形式存在。一种或几种酶可以同时以可溶性和/或固定化形式存在。
根据本发明的方法可以在本领域技术人员已知的普通反应器中进行,并且可以在不同的规模范围内进行,例如从实验室规模(几毫升到几十升反应体积)到工业规模(几升到数千立方米反应体积)。如果多肽以通过无生命的、可选地透化的细胞包封的形式,以或多或少纯化的细胞提取物的形式或以纯化的形式使用,则可以使用化学反应器。化学反应器通常允许控制至少一种酶的量,至少一种底物的量,pH,温度和反应介质的循环。当活细胞中存在至少一种多肽/酶时,该过程将是发酵。在这种情况下,生物催化生产将在生物反应器(发酵罐)中进行,其中对于活细胞合适的生存条件必需的参数(例如,具有营养的培养基,温度,通气,有氧或无氧或其他气体,抗生素等)可以控制。本领域技术人员熟悉化学反应器或生物反应器,例如使用将化学或生物技术方法从实验室规模扩大到工业规模或优化工艺参数的程序,这些方法在文献中也有广泛描述(有关生物技术方法,请参见例如Crueger und Crueger,Biotechnologie–Lehrbuch der angewandten Mikrobiologie,2.Ed.,R.Oldenbourg Verlag,München,Wien,1984)。
包含至少一种酶的细胞可以通过物理或机械方式例如超声或射频脉冲,高压细胞裂解机(French press)或化学方式例如在培养基中存在的低渗介质、裂解酶和去污剂或这些方法的组合来渗透。洗涤剂的例子是洋地黄毒苷,正十二烷基麦芽糖苷,辛基糖苷,
代替活细胞,也可以将含有所需生物催化剂的非活细胞的生物质应用于本发明的生物转化反应。
如果固定了至少一种酶,则将其如上所述连接至惰性载体。
转化反应可以分批、半分批或连续进行。反应物(和可选的营养物)可以在反应开始时提供,或者可以随后半连续或连续地提供。
根据特定的反应类型,本发明的反应可以在水性、水性-有机或非水性反应介质中进行。
水性或水性-有机介质可包含合适的缓冲液,以将pH值调整为5至11,例如6至10。
在水性-有机介质中,可以使用与水可混溶、部分混溶或不混溶的有机溶剂。合适的有机溶剂的非限制性例子在下面列出。进一步的例子是一元或多元,芳族或脂族醇,特别是多元脂族醇,如甘油。
非水介质可以包含基本上不含水,即,将包含少于约1重量%或0.5重量%的水。
生物催化方法也可以在有机非水介质中进行。作为合适的有机溶剂,可以提及具有例如5至8个碳原子的脂族烃,例如戊烷,环戊烷,己烷,环己烷,庚烷,辛烷或环辛烷;芳族烃,例如苯,甲苯,二甲苯,氯苯或二氯苯,脂族无环和醚,例如二乙醚,甲基叔丁基醚,乙基叔丁基醚,二丙基醚,二异丙醚,二丁基醚;或它们的混合物。
反应物/底物的浓度可以适应于最佳反应条件,这可以取决于所应用的特定酶。例如,初始底物浓度可以为0.1至0.5M,例如10至100mM。
反应温度可以适应于最佳反应条件,这可以取决于所应用的特定酶。例如,该反应可以在0至70℃的温度下进行,例如20至50或25至40℃。反应温度的例子是约30℃,约35℃,约37℃,约40℃,约45℃,约50℃,约55℃和约60℃。
该工艺可以继续进行直到在底物和随后的产物之间达到平衡为止,但是可以更早地停止。通常的工艺时间为1分钟至25小时,特别是10分钟至6小时,例如为1小时至4小时,特别是1.5小时至3.5小时。这些参数是合适的工艺条件的非限制性例子。
如果宿主是转基因植物,则可以提供最佳的生长条件,例如最佳的光照、水和营养条件。
k.产品分离
本发明的方法可以进一步包括回收终产物或中间产物的步骤,所述终产物或中间产物可选地为立体异构体或对映异构体的基本纯净的形式。术语“回收”包括从培养基或反应介质中提取、收获、分离或纯化化合物。化合物的回收可以根据本领域已知的任何常规分离或纯化方法进行,包括但不限于用常规树脂(例如,阴离子或阳离子交换树脂,非离子吸附树脂等)处理,用常规吸附剂(例如,活性炭,硅酸,硅胶,纤维素,氧化铝等)处理,pH值的改变,溶剂萃取(例如,使用常规溶剂,例如醇,乙酸乙酯,己烷等),蒸馏,渗析,过滤,浓缩,结晶,重结晶,pH调节,冻干等。
经分离产物的身份和纯度可以通过已知技术确定,例如高效液相色谱(HPLC),气相色谱(GC),光谱学(例如IR,UV,NMR),着色方法,TLC,NIRS,酶或微生物测定(参见例如:Patek et al.(1994)Appl.Environ.Microbiol.60:133-140;Malakhova et al.(1996)Biotekhnologiya 11 27-32;und Schmidt et al.(1998)Bioprocess Engineer.19:67-70.Ullmann's Encyclopedia of Industrial Chemistry(1996)Bd.A27,VCH:Weinheim,S.89-90,S.521-540,S.540-547,S.559-566,575-581und S.581-587;Michal,G(1999)Biochemical Pathways:An Atlas of Biochemistry and Molecular Biology,JohnWiley and Sons;Fallon,A.et al.(1987)Applications of HPLC in Biochemistry in:Laboratory Techniques in Biochemistry and Molecular Biology,Bd.17.)。
可以将本文所述的任何方法生产的环状萜烯化合物转化成衍生物,例如但不限于烃,酯,酰胺,糖苷,醚,环氧化物,醛,酮,醇,二醇,缩醛或缩酮。萜烯化合物衍生物可以通过化学方法获得,例如但不限于氧化,还原,烷基化,酰化和/或重排。或者,萜烯化合物衍生物可以通过使用生化方法通过使萜烯化合物与酶接触而获得,所述酶例如但不限于氧化还原酶,单加氧酶,双加氧酶,转移酶。可以使用分离的酶,来自裂解细胞的酶在体外进行生化转化,也可以使用全细胞在体内进行生化转化。
l.萜烯醇的发酵产生
本发明还涉及用于发酵产生萜烯醇的方法。
根据本发明使用的发酵可以例如在搅拌的发酵罐、鼓泡塔和回路反应器中进行。有关可能的方法类型的全面概述,包括搅拌器类型和几何设计,请参见“Chmiel:Bioprozesstechnik:Einfuhrung in die Bioverfahrenstechnik,Band 1”。在本发明的方法中,可用的典型变型是本领域技术人员已知的或例如在“Chmiel,Hammes and Bailey:Biochemical Engineering”中解释的以下变型,例如分批、补料分批,重复补料分批进行或连续发酵,有或没有回收生物质。取决于生产应变,可以进行空气,氧气,二氧化碳,氢气,氮气或适当的气体混合物的喷射,以实现良好的收率(YP/S)。
要使用的培养基必须以适当的方式满足特定菌株的要求。在美国细菌学学会(American Society for Bacteriology(Washington D.C.,USA,1981))的手册“Manual ofMethods for General Bacteriology”中给出了各种微生物的培养基的描述。
可以根据本发明使用的这些培养基通常包含一种或多种碳源、氮源、无机盐、维生素和/或微量元素。
优选的碳源是糖,例如单糖、二糖或多糖。非常好的碳源是例如葡萄糖,果糖,甘露糖,半乳糖,核糖,山梨糖,核酮糖,乳糖,麦芽糖,蔗糖,棉子糖,淀粉或纤维素。糖也可以通过复杂的化合物(例如糖蜜)或糖精制的其他副产物添加到培养基中。添加各种碳源的混合物也是有利的。碳的其他可能来源是油和脂,例如大豆油,葵花籽油,花生油和椰子油,脂肪酸例如棕榈酸,硬脂酸或亚油酸,醇例如甘油,甲醇或乙醇,和有机酸,例如乙酸或乳酸。
氮源通常是有机或无机氮化合物或含有这些化合物的材料。氮源的例子包括氨气或铵盐,例如硫酸铵,氯化铵,磷酸铵,碳酸铵或硝酸铵,硝酸盐,尿素,氨基酸或复合氮源,例如玉米浆,大豆粉,大豆蛋白,酵母提取物,肉提取物等。氮源可以单独使用或混合使用。
可以存在于培养基中的无机盐化合物包括钙,镁,钠,钴,钼,钾,锰,锌,铜和铁的氯化物,磷酸盐或硫酸盐。
无机含硫化合物,例如硫酸盐,亚硫酸盐,连二亚硫酸盐,四硫酸盐,硫代硫酸盐,硫化物,以及有机硫化合物,例如硫醇(mercaptans)和巯类(thiols),可用作硫源。
磷酸、磷酸二氢钾或磷酸氢二钾或相应的含钠盐可用作磷源。
可以将螯合剂添加到培养基中,以将金属离子保持在溶液中。特别合适的螯合剂包括二羟基苯酚,例如儿茶酚或原儿茶酸酯,或有机酸,例如柠檬酸。
根据本发明使用的发酵培养基还可包含其他生长因子,例如维生素或生长促进剂,其包括例如生物素,核黄素,硫胺素,叶酸,烟酸,泛酸和吡哆醇。生长因子和盐通常来自培养基的复杂成分,例如酵母提取物,糖蜜,玉米浆等。另外,可以将合适的前体添加到培养基中。化合物在培养基中的精确组成在很大程度上取决于特定的实验,必须针对每种特定情况分别确定。有关培养基优化的信息可以在教科书"Applied Microbiol.Physiology,APractical Approach"(1997)中找到。生长培养基也可以从商业供应商那里获得,例如Standard 1(Merck)或BHI(脑心浸液,DIFCO)等。。
通过加热(在1.5bar和121℃下20分钟)或通过无菌过滤对培养基的所有成分进行灭菌。这些成分可以一起消毒,也可以根据需要单独消毒。培养基的所有成分都可以在生长开始时给予,或者可以选择连续添加或分批添加。
培养物的温度通常在15℃至45℃之间,优选25℃至40℃,并且可以在实验期间保持恒定或可以变化。介质的pH值应在5至8.5的范围内,优选7.0左右。生长期间的pH值可以通过添加碱性化合物(例如氢氧化钠,氢氧化钾,氨或氨水)或酸性化合物(例如磷酸或硫酸)来控制。消泡剂例如脂肪酸聚乙二醇酯可用于控制发泡。为了维持质粒的稳定性,可以向培养基中添加具有选择性作用的合适物质例如抗生素。为了维持有氧条件,将氧气或含氧气体混合物(例如环境空气)供入培养物中。培养物的温度通常为20℃至45℃。继续培养直至形成最大量的所期望产物。通常会在1到160个小时内达到此目标。
本发明的方法可以进一步包括回收所述萜烯醇的步骤。
术语“回收”包括从培养基中提取、收获、分离或纯化化合物。化合物的回收可以根据本领域已知的任何常规分离或纯化方法进行,包括但不限于用常规树脂(例如,阴离子或阳离子交换树脂,非离子吸附树脂等)处理,用常规吸附剂(例如,活性炭,硅酸,硅胶,纤维素,氧化铝等)处理,pH值的改变,溶剂萃取(例如,使用常规溶剂,例如醇,乙酸乙酯,己烷等),蒸馏,渗析,过滤,浓缩,结晶,重结晶,pH调节,冻干等。
在预期的分离之前,可以除去发酵液的生物质。去除生物质的方法是本领域技术人员已知的,例如过滤、沉降和浮选。因此,可以例如通过离心机、分离器、倾析器、过滤器或在浮选设备中去除生物质。为了最大程度地回收有价值的产品,通常建议洗涤生物质,例如以渗滤的形式。方法的选择取决于发酵液中生物质的含量和生物质的性质,以及生物质与有价值产品的相互作用。
在一个实施方案中,可以将发酵液灭菌或巴氏灭菌。在另一个实施方案中,将发酵液浓缩。根据需要,该浓缩可以分批或连续进行。应该选择压力和温度范围,使得首先不会发生产品损坏,其次需要最小化设备和能源的使用。多级蒸发的压力和温度水平的熟练选择尤其可以节省能源。
以下实施例仅是说明性的,并不意味着限制本文所述的实施方案和实施方案的范围。
在考虑了本文提供的公开内容之后,对于本领域技术人员而言将立即变得显而易见的多种可能的变型方案也落入本发明的范围内。
现在将通过以下实施例更详细地描述本发明。
材料:
除非另有说明,否则本文使用的所有化学和生物化学材料以及微生物或细胞均为可商购的产品。
除非另有说明,否则重组蛋白是通过标准方法克隆和表达的,所述方法例如描述于Sambrook,J.,Fritsch,E.F.and Maniatis,T.,Molecular cloning:A LaboratoryManual,2
通用方法:
用于确定柯巴基二磷酸磷酸酶活性的标准测定法
用两种质粒转化大肠杆菌细胞(DP1205株),
-携带编码酶的基因的质粒,该酶是柯巴基二磷酸(CPP)生物合成所必需的酶,例如pACYC-CrtE-SmCPS2质粒
-携带编码具有萜烯基磷酸磷酸酶活性的蛋白质的基因的质粒,例如pJ401-TalVeTPP或pJ401-AspWeTPP质粒。
如下所述培养细胞,并通过GC-MS分析柯巴醇的产生。
用于确定8-羟基-柯巴基二磷酸磷酸酶活性的标准测定法
用两种质粒转化大肠杆菌细胞(DP1205株),
-携带编码酶的基因的质粒,该酶是8-羟基-戊基二磷酸酯(LPP)生物合成所必需的酶,例如pACYC-CrtE-SsLPS质粒
-携带编码具有萜烯基磷酸磷酸酶活性的蛋白质的基因的质粒,例如pJ401-TalVeTPP或pJ401-AspWeTPP质粒。
如下所述培养细胞,并通过GC-MS分析赖百当烯二醇的产生。
用于确定柯巴醇脱氢酶活性的标准测定法
用两种质粒转化大肠杆菌细胞(DP1205株),
-携带编码柯巴醇生物合成所必需的酶的基因的质粒,例如pJ401-CPOL-2质粒,
-携带编码醇脱氢酶的基因的质粒,例如使用pJ423作为背景质粒。
如下所述培养细胞,并通过GC-MS分析柯巴醛的产生。
用于确定赖百当烯二醇脱氢酶活性的标准测定法
用两种质粒转化大肠杆菌细胞(DP1205株),
-带有编码赖百当烯二醇生物合成所必需的酶的基因的质粒,例如pJ401-LOH-2质粒,
-携带编码醇脱氢酶的基因的质粒,例如使用pJ423作为背景质粒。
如下所述培养细胞,并通过GC-MS分析产物的产生。
气相色谱质谱法(GC-MS)
使用连接到Agilent 5975质量检测器的Agilent 6890系列GC系统通过GC-MS分析萜烯含量。GC配备了0.25mm内径30m长HP-5MS毛细管柱(Agilent)。载气为氦气,流速为1mL/min。入口温度设定为250℃。烤箱的初始温度为100℃,持续1分钟,然后以10℃/min的梯度升至300℃。产品的鉴定是基于质谱和保留指数与真实标准品和专有质谱数据库的比较。根据内标估算浓度。
具有编码甲羟戊酸途径酶的基因的染色体整合的重组细菌菌株的制备
通过对编码甲羟戊酸途径酶的重组基因进行染色体整合,对大肠杆菌菌株进行工程改造,以产生萜烯前体法呢基焦磷酸(FPP)。另请参阅图15中所示的构建方案和重组事件。
设计了一个上游(upper)途径操纵子(从乙酰辅酶A到甲羟戊酸的操纵子1),由来自大肠杆菌的编码乙酰乙酰辅酶A硫解酶的atoB基因,以及来自金黄色葡萄球菌的分别编码HMG-CoA合酶和HMG-CoA还原酶的mvaA和mvaS基因构成。
作为下游(lower)甲羟戊酸途径操纵子(从甲羟戊酸到法呢基焦磷酸的操纵子2),选择了来自革兰氏阴性细菌肺炎链球菌的天然操纵子,其编码甲羟戊酸激酶(mvaK1),磷酸甲羟戊酸激酶(mvaK2),磷酸甲羟戊酸脱羧酶(mvaD)和异戊烯基二磷酸异构酶(fni)。
将密码子优化的酿酒酵母FPP合酶编码基因(ERG20)引入到上游途径操纵子的3'末端,以将异戊烯基二磷酸(IPP)和二甲基烯丙基二磷酸(DMAPP)转化为FPP。
通过DNA2.0合成上述操纵子,并将其整合到大肠杆菌BL21(DE3)菌株的araA基因中。使用CRISPR/Cas9基因组工程系统,在两个单独的重组步骤中引入了异源途径。待整合的第一个操纵子(下游途径;操纵子2)带有壮观霉素(Spec)标记,其用于筛选对Spec抗性的候选整合子。设计第二个操纵子以取代先前整合的操纵子的Spec标记,并在第二次重组事件之后相应地筛选Spec候选整合子(参见图15)。设计靶向araA基因的指导RNA表达载体,并通过DNA 2.0进行合成。使用PCR通过设计PCR引物来验证操纵子整合,以扩增跨araA基因整合靶标和跨整合子重组连接点。然后将产生正确PCR结果的一个克隆完全测序,并存档为菌株DP1205。
细菌细胞的培养和萜烯产生的分析
用一种或两种携带萜烯生物合成基因的表达质粒转化大肠杆菌细胞,并在LB-琼脂糖板上用适当的抗生素(卡那霉素(50μg/ml)和/或氯霉素(34μg/ml))培养经转化的细胞。使用单菌落接种5mL补充了相同抗生素,4g/l葡萄糖和10%(v/v)十二烷的液体LB培养基。第二天用0.2mL过夜培养物接种2mL补充了相同抗生素和10%(v/v)十二烷的TB培养基。将培养物在37℃下温育直至光密度达到3。通过加入1mM IPTG诱导重组蛋白的表达,将培养物在20℃下温育72小时。
然后将培养物用叔丁基甲基醚(MTBE)萃取,并将内标(α-长叶蒎烯(Aldrich))添加到有机相中。如上所述,通过GC-MS分析有机相中的萜烯含量。
TalVeTPP和AspWeTPP蛋白分别由细疣篮状菌(Talaromyces verruculosus)和温特曲霉(Aspergillus wentii)基因组中的两个预测基因编码。TalVeTPP编码基因位于具有NCBI登录号LHCL01000010.1的细疣篮状菌(Talaromyces verruculosus)基因组支架序列的150095..151030区域中。据报道,所编码的蛋白是假定的蛋白,没有功能特征(NCBI登录号KUL89334.1)。AspWeTPP编码基因位于温特曲霉(Aspergillus wentii)DTO 134E9未放置的基因组支架ASPWEscaffold_5(NCBI登录号KV878213.1)的2487776..2483627区域中。所编码的蛋白的NCBI登录号为OJJ34585.1,也被报道为推定的蛋白,没有功能特征。
TalVeTPP和AspWeTPP编码基因位于基因组中,可能与次级代谢产物生物合成相关的基因相邻,例如编码氧化酶、羟化酶、脱氢酶的基因,特别是与单官能的柯巴基二磷酸合酶或双官能的柯巴基二磷酸合酶具有高度同源性的基因,后者报道于Mitsuhashi et al,Chembiochem.2017 Nov 2;18(21):2104-2109。通过搜索蛋白质家族结构域签名的存在来对TalVeTPP和AspWeTPP氨基酸序列进行功能分析(例如,使用位于www.ebi.ac.uk/interpro/的Interpro序列分析工具或Pfam数据库搜索工具http://pfam.xfam.org/search#tabview=tab0或https://www.ebi.ac.uk/Tools/pfa/pfamscan/)显示,这两种蛋白质预计含有蛋白质酪氨酸磷酸酶签名。描述了来自酪氨酸磷酸酶家族的酶从各种磷酸化分子,特别是从蛋白质中去除磷酸基团。但是,从未证明该蛋白质家族的酶能作用于诸如柯巴基二磷酸的化合物。但是,考虑到编码TalVeTPP和AspWeTP的基因的基因组定位,我们假设TalVeTPP和AspWeTPP可以催化柯巴基二磷酸或其他类异戊二烯二磷酸化合物的二磷酸基团的裂解(图1.)。
对TalVeTPP和AspWeTPP编码cDNA(分别为SEQ ID NO:3和7)进行密码子优化(分别为SEQ ID NO:1和5),并分别克隆到表达质粒pJ401(ATUM,Newark,California)中,以提供质粒pJ401-TalVeTPP和pJ401-AspWeTPP。
构建了另一种表达质粒,其携带编码香叶基香叶基焦磷酸合酶(GGPS)的基因和编码柯巴基焦磷酸合酶(CPS)的基因。对于CPS基因,编码来自丹参(Salvia miltiorrhiza)(NCBI登录号ABV57835.1)的CPS的cDNA经过密码子优化,可在大肠杆菌中最佳表达。另外,移除前58个密码子,并添加ATG起始密码子。体外合成了编码截短的丹参(Salviamiltiorrhiza)CPS(SmCPS2)(SEQ ID NO:33)的经优化cDNA,并首先克隆到侧接NdeI和KpnI限制酶识别位点(ATUM,Newark,California)的pJ208质粒中。对于GGPS,使用了来自成团泛菌(Pantoea agglomerans)(NCBI登录号M38424.1)的CrtE基因编码的GGPP合酶(NCBI登录号AAA24819.1)。通过密码子优化(SEQ ID NO:35)并在3'和5'末端(ATUM,Newark,California)添加NcoI和BamHI限制性酶识别位点,并在pACYCDuet
用两种质粒pACYC-CrtE-SmCPS2质粒和pJ401-TalVeTPP或pJ401-AspWeTPP转化大肠杆菌细胞(如上制备的DP1205株)。如方法部分所述,培养细胞并分析萜烯化合物的产生。图2显示了重组大肠杆菌细胞产生的柯巴醇的典型GC-MS。仅表达甲羟戊酸途径酶和SmCPS2的细胞由于CPP被内源性碱性磷酸酶水解而产生少量的柯巴醇(6.7mg/l,图3)。转化为另外表达TalVeTPP或AspWeTPP的大肠杆菌细胞产生明显大量的柯巴醇:对于TalVeTPP和AspWeTPP分别为462mg/l和298mg/l(图2和图3)。该实验表明,TalVeTPP和AspWeTPP可以有效地水解(+)-CPP以产生(+)-柯巴醇。柯巴醇以高纯度(>95%)产生。在GC-MS分析(图2)中观察到的较少量乙酸柯巴基酯归因于细胞内源性乙酰转移酶活性。
使用TalVeTPP和AspVeTPP序列在公共数据库中搜索同源序列。选择了八种具有Pfam蛋白质酪氨酸磷酸酶蛋白家族PF13350签名的新序列:HelGriTPP1,一种假定蛋白灰色螺状菌(Helicocarpus griseus)(SEQ ID NO:10)(GenBank:PGG95910.1);UmbPiTPP1,一种来自泡突石耳菌(Umbilicaria pustulata)的酪氨酸磷酸酶(SEQ ID NO:13)(GenBank:SLM34787.1);TAlVeTPP2,一种来自细疣篮状菌(Talaromyces verruculosus)的假定蛋白(SEQ ID NO:16)(GenBank:KUL92314.1);HydPiTPP1,一种来自松网褶菌(Hydnomeruliuspinastri)的假定蛋白(SEQ ID NO:19)(GenBank:KIJ69780.1);TalCeTPP1,一种来自纤维素分解篮状菌(Talaromyces cellulolyticus)的假定蛋白(SEQ ID NO:22)(GenBank:GAM42000.1);TalMaTPP1,一种来自马尔尼菲篮状菌(Talaromyces marneffei)的假定蛋白(SEQ ID NO:25)(NCBI XP_002152917.1);TalAstroTPP1,一种来自踝节篮状菌(Talaromyces atroroseus)的假定蛋白(SEQ ID NO:28)(NCBI XP_020117849.1);和PeSubTPP1,PeSubTPP1,一种来自红青霉菌(Penicillium subrubescens)的假定蛋白(SEQID NO:31)(GenBank:OKP14340.1)。对蛋白质家族特征的搜索显示,第八种氨基酸序列是Pfam蛋白质酪氨酸磷酸酶蛋白质家族PF13350的成员。
10种氨基酸序列的序列比较显示序列同一性在24%至93%之间(表1)。
表1.所选推定的萜烯磷酸酶的成对序列比较。列出了每个成对比较的序列同一性百分比。
对编码HelGriTPP1(SEQ ID NO:11),UmbPiTPP1(SEQ ID NO:14),TalVeTPP2(SEQID NO:17),HydPiTPP1(SEQ ID NO:20),TalCeTPP1(SEQ ID NO:23),TalMaTPP1(SEQ IDNO:26),TalAstroTPP1(SEQ ID NO:29)和PeSubTPP1(SEQ ID NO:32)的cDNA序列进行密码子优化(针对大肠杆菌表达并分别克隆到pJ401表达质粒(ATUM,Newark,California)中。
用pACYC-CrtE-SmCPS2质粒和一种pJ401质粒转化DP1205大肠杆菌细胞,其中该pJ401质粒携带编码HelGriTPP1(SEQ ID NO:9),UmbPiTPP1(SEQ ID NO:12),TalVeTPP2(SEQ ID NO:15),HydPiTPP1(SEQ ID NO:18),TalCeTPP1(SEQ ID NO:21),TalMaTPP1(SEQID NO:24),TalAstroTPP1(SEQ ID NO:27)和PeSubTPP1(SEQ ID NO:30)的经优化cDNA。培养细胞,并在方法部分所述的条件下分析柯巴醇的产生。用pACYC-CrtE-SaLPS质粒和空pJ401质粒转化的细胞用作对照菌株。所有表达重组TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1蛋白质的菌株都累积了32至240mg/l范围内的量的柯巴醇,证实了使用所有这些重组酶都使CPP酶促转化为柯巴醇(图4)。
此实施例显示TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1和PeSubTPP1可以用于将CPP酶促转化为柯巴醇,并可以用于在工程化细胞中产生柯巴醇。
构建了表达质粒,该表达质粒携带编码香叶基香叶基焦磷酸合酶(GGPS)的基因和编码赖百当烯二醇焦磷酸合酶(LPS)的基因。对于GGPS,使用实施例1中描述的来自成团泛菌(P.agglomerans)的CrtE基因。对于LPS基因,使用编码来自快乐鼠尾草(Salviasclarea)的SsLPS的cDNA(WO2009095366,GenBank:AET21246.1)。如WO2009095366中所述优化SsLPS编码cDNA序列(SEQ ID NO:37),并将其克隆在pACYC-Crte质粒的NdeI和KpnI位点之间,从而提供携带GGP合酶基因和LPP合酶基因的质粒pACYC-CrtE-SaLPS。用pACYC-CrtE-SsLPS转化的大肠杆菌细胞(如DP1205株)积累LPP作为二萜前体化合物(图5)。
用pACYC-CrtE-SsLPS质粒和一种pJ401质粒转化DP1205大肠杆菌细胞(如上制备),该pJ401质粒携带编码TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1的经优化的cDNA(见上面的实施例1和2)。培养细胞,并在方法部分描述的条件下分析赖百当烯二醇的产生。与用空pJ401质粒和pACYC-CrtE-SsLPS转化的对照细胞相比,所有经转化以产生重组TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1蛋白质的细胞均产生明显增加量的赖百当烯二醇(增加至5至25倍)(图6)。在培养期结束时,细胞培养物中的赖百当烯二醇浓度在50至272g/l之间。
图7显示了典型的大肠杆菌产生赖百当烯二醇细胞的GC-MS分析。总离子色谱图表明,在这些条件下产生的赖百当烯二醇具有至少98%的纯度。
还评估了重组蛋白TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1和PeSubTPP1在直链底物,如法呢基焦磷酸(FPP)和香叶基香叶基焦磷酸(GGPP)上的酶活性。在类似于实施例1和2的条件下以及在方法部分中进行测定,不同之处在于pACYCDuet
用pACYC-CrtE或pACYCDuet
在前面的实施例中观察到的酶活性与四种不同底物的比较显示,TalVeTPP,AspWeTPP,HelGriTPP1,UmbPiTPP1,TalVeTPP2,HydPiTPP1,TalCeTPP1,TalMaTPP1,TalAstroTPP1或PeSubTPP1具有不同的底物选择性(图10)。因此,该方法允许基于其底物选择性来选择具有磷酸酶活性的酶。例如,与其他列出的酶相比,HelGriTPP1,HydPiTPP1或AspWeTPP显示出对CPP和LPP的活性较高,而对FPP和GGP的活性较低。因此,这些酶可用于最有效地产生在途径中间体上具有有限的副活性的柯巴醇或赖百当烯二醇。UmbPiTPP1,TalMaTPP1和TalAstroTPP1在FPP和GGPP上也显示出有限的副活性,但是,它们产生较低量的赖百当烯二醇和柯巴醇。
构建了一个操纵子,其中含有3个编码TalVeTPP的cDNA;TaTps1-del59和GGPP合酶。TaTps1-del59是来自小麦(Triticum aestivum)的N末端截短的CPP合酶(NCBI登录号BAH56559.1)。对编码TaTps1-del59的cDNA进行密码子优化(SEQ ID NO:39)。对于GGPP合酶,使用了来自成团泛菌(Pantoea agglomerans)的CrtE基因的密码子优化形式(NCBI登录号M38424.1)(SEQ ID NO:35)。将操纵子克隆到pJ401表达质粒(ATUM,Newark,California)中,以提供构建体pJ401-CPOL-2。
用与上面的CPOL-2相似的结构构建了另一个操纵子,不同之处在于编码TaTps1-del59的基因被编码SaLPS的经优化基因(SEQ ID NO:37)所替代。将该操纵子克隆到质粒pJ401(ATUM,Newark,California)中,以提供构建体pJ401-LOH-2。
如上所述制备的DP1205大肠杆菌细胞用质粒pJ401-CPOL-2或pJ401-LOH-2转化。如上所述培养细胞,并如方法部分所述分析二萜的产生。平行地,将用空的PJ401质粒和用pACYC-CrtE-SsLPS或pACYC-CrtE-SmCPS质粒转化的细胞用作对照。
用质粒CPOL-2转化的细胞产生的柯巴醇和法尼醇的平均浓度对于柯巴醇和法尼醇分别为200mg/l和300mg/l。用质粒LOH-2转化的细胞产生的赖百当烯二醇和法尼醇的平均浓度对于柯巴醇和法尼醇分别为1260mg/l和830mg/l(图11)。使用这两种构建体产生的大量法尼醇是由于FPP库向GGPP的转化不完全以及TalVeTPP除CPP之外对FPP的酶促活性所致(见图10)。例如,使用HelGriTPP1(以及图10中显示的其他具有更高特异性)的相应实验将产生更少的法呢醇。
以下醇脱氢酶(ADH)可用于氧化由前面实施例中所述的磷酸酶产生的萜烯化合物:
-来自假单胞菌属(Pseudomonas sp.)19-rlim菌株的CymB(SEQ ID NO:42)(GenBank登录号AEO27362.1);
-由位于温特曲霉(Aspergillus wentii)DTO 134E9未放置的基因组支架ASPWEscaffold_5(NCBI登录号KV878213.1)的2487333..2488627区域中的基因编码的AspWeADH1(SEQ ID NO:44)(GenBank登录号OJJ34588.1);
-来自铜绿假单胞菌(Pseudomonas aeruginosa)的PsAeroADH1(SEQ ID NO:46)(GenBank登录号WP_079868259.1);
-来自解甲苯固氮弯曲菌(Azoarcus toluclasticus)的AzTolADH1(SEQ ID NO:48)(GenBank登录号WP_018990713.1);
-来自芳香固氮弧菌(Aromatoleum aromaticum)的AroAroADH1(SEQ ID NO:50)(GenBank登录号KM105875.2)。
-来自萜烯索氏菌(Thauera terpenica)的ThTerpADH1(SEQ ID NO:52)(Genbank登录号WP_021250577.1)。
-来自解芳烃卡斯特罗尼氏菌(Castellaniella defragrans)的CdGeoA(SEQ IDNO:54)(NCBI登录号WP_043683915.1)。
-来自缬草(Valeriana officinalis)的VoADH1(SEQ ID NO:56)(GenBan登录号AVX32614.1)。
合成编码上述每种ADH的密码子优化的cDNA(分别见SEQ ID NO:41、43、45、47、49、51、53和55)并克隆到pJ423表达质粒(ATUM,Newark,California)中。
如上制备的DP1205大肠杆菌细胞用质粒pJ401-CPOL-2和这些pJ423-ADH质粒之一转化。如前所述培养细胞,并如方法部分所述分析二萜的产生。平行地,将用pJ401-CPOL-2质粒和空pJ423质粒转化的细胞用作对照(图12)。在所有细胞中观察到了柯巴醇的形成,这表明包括蛋白质酪氨酸磷酸酶和选自以上列出的ADH中的ADH的柯巴醇生物合成途径的酶的组合可用于有效地产生柯巴醛。期望对于AspWeADH1和VoADH1,细胞中柯巴醇向柯巴醛的转化率至少为90%。由于由ADHs产生的反式-柯巴醛的非酶促异构化,观察到了柯巴醛的顺式和反式异构体的混合物。使用相同的ADH,也观察到了法呢醇向法呢醛的转化(图13)。
在用pJ401-LOH-2和pJ423-ADH质粒之一共转化的大肠杆菌细胞中,观察到了赖百当烯二醇的两种氧化产物的形成(图14)。NMR分析证实这两种化合物是8,13-环氧-赖百当-15-醛的两种异构体((13R)和(13S)),如图17的方案所示。这两种化合物是由于由赖百当烯二醇氧化制得的α,β-不饱和醛8-羟基-赖百当-13-烯-15-醛的不稳定性所致。假定的醛脱水和重排为所述异构体的机理在以下方案中显示。
构建一个操纵子,其包含两个cDNA,它们编码为:
-来自温特曲霉(Aspergillus wentii)的AspWeTPP(SEQ ID NO:6),
-PvCPS,一种蛋白质,其具有来自细疣篮状菌(Talaromyces verruculosus)的异戊二烯基转移酶和柯巴基二磷酸合酶活性(SED ID NO:59)(GenBank登录号BBF88128.1)。PvCPS催化从IPP和DMAPP产生柯巴基PP。
编码AspWeTPP和PvCPS的cDNA经密码子优化(SEQ ID NO:8和60)。设计含有两个cDNA和位于每个cDNA的上游的RBS序列(AAGGAGGTAAAAAA)(SEQ ID NO:61)的操纵子。合成该操纵子并将其克隆到pJ401表达质粒(ATUM,Newark,California)中,以提供质粒pJ401-CPOL-4。
用质粒pJ401-CPOL-4转化DP1205大肠杆菌细胞。如前所述培养经转化的细胞,并如方法部分所述分析二萜的产生。在这些条件下,用质粒pJ401-CPOL-4转化的细胞产生的柯巴醇为主要产物,其浓度明显高于(最高1mg/l)用质粒pJ401-CPOL-2转化的细胞。该实验表明,与多种单功能蛋白相比,使用具有异戊二烯基转移酶活性和CPP合酶活性的多功能蛋白可以获得更高浓度的柯巴醇。
为了产生柯巴醇和柯巴醛,编码GGPP合酶CrtE(SEQ ID NO:61)(来自成团泛菌(Pantoea agglomerans),NCBI登录号M38424.1),柯巴基焦磷酸合酶SmCPS2(SEQ ID NO:63)(来自丹参(Salvia miltiorrhiza),NCBI登录号ABV57835.1),柯巴基焦磷酸磷酸酶TalVeTPP(SEQ ID NO:65)和不同的醇脱氢酶的基因(经优化用于酵母中表达的cDNA)以升高水平的内源性法呢基二磷酸(FPP)在工程化的酿酒酵母细胞中表达。
评价了四种醇脱氢酶。
-AzTolADH1(SEQ ID NO:48)(酵母优化的cDNA SEQ ID NO:66)
-PsAeroADH1(SEQ ID NO:46),(酵母优化的cDNA SEQ ID NO:67)
-来自一种黑丝孢网菌(Hyphozyma roseonigra)的SCH23-ADH1(SEQ ID NO:69)(酵母优化的cDNA SEQ ID NO:68)
-来自浅白隐球菌(Cryptococcus albidus)的SCH24-ADH1a(SEQ ID NO:71)(酵母优化的cDNA SEQ ID NO:70)
为了增加酿酒酵母细胞中内源性法呢基二磷酸(FPP)池的水平,涉及甲羟戊酸途径的所有酵母内源基因的额外副本,从编码乙酰辅酶A C-乙酰转移酶的ERG10到编码FPP合成酶的ERG20,与Paddon et al.,Nature,2013,496:528-532中所述的相似,在半乳糖诱导型启动子的控制下,整合到酿酒酵母菌株CEN.PK2-1C(Euroscarf,Frankfurt,Germany)的基因组中。简而言之,将三个盒分别整合在LEU2、TRP1和URA3基因座中。第一个盒包含在GAL10/GAL1双向启动子控制下的ERG20基因和一个截短的HMG1(tHMG1,如Donald et al.,Proc Natl Acad Sci USA,1997,109:E111-8所述),和同样在GAL10/GAL1启动子控制下的ERG19和ERG13基因,该盒的侧翼为两个100个核苷酸区域,分别对应于LEU2的上游和下游部分。第二个盒中,基因IDI1和tHMG1在GAL10/GAL1启动子的控制下,而基因ERG13在GAL7启动子区域的控制下,该盒的侧翼为两个100个核苷酸区域,分别对应于TRP1的上游和下游部分。第三个盒具有ERG10、ERG12、tHMG1和ERG8基因,均在GAL10/GAL1启动子的控制下,该盒的侧翼为两个100个核苷酸的区域,分别对应于URA3的上游和下游部分。三个盒中的所有基因都包含其自身终止子区域的200个核苷酸。而且,在ERG9启动子区域上游,整合了如Griggs and Johnston,Proc Natl Acad Sci USA,1991,88:8597-8601中所描述的,在其自身启动子的突变形式的控制下的GAL4的额外拷贝。另外,通过启动子交换修饰了ERG9的表达。使用含有带有其自身的启动子和终止子的HIS3基因的盒删除GAL7、GAL10和GAL1基因。将所得菌株与菌株CEN.PK2-1D(Euroscarf,Frankfurt,Germany)交配,获得称为YST045的二倍体菌株,其根据Solis-Escalante et al.,FEMS Yeast Res,2015,15:2诱导芽孢形成。孢子分离是通过将asci重悬于200μL、0.5M山梨糖醇和2μL的zymolyase(1000U mL
为了表达编码醇脱氢酶的不同基因,在菌株YST075中进行了基因组整合。每个整合盒由四个片段形成。
1)一片段,其含有对应于BUD9基因上游部分的261bp和序列5'-GCACTTGCTACACTGTCAGGATAGCTTCCGTCACATGGTGGCGATCACCGTACATCTGAG-3'(SEQ ID NO:72),该片段是通过PCR以来自菌株YST075的基因组DNA为模板获得的;
2)一片段,其含有序列5'-GCACTTGCTACACTGTCAGGATAGCTTCCGTCACATGGTGGCGATCACCGTACATCTGAG-3'(SEQ ID NO:72),GAL1基因的启动子区域,编码用于在酿酒酵母中表达的密码子优化的醇脱氢酶的基因之一,PGK1基因的终止子区域,和序列5'-AGGTGCAGTTCGCGTGCAATTATAACGTCGTGGCAACTGTTATCAGTCGTACCGCGCCAT-3'(SEQ ID NO:73),该片段是通过DNA合成获得的(ATUM,Menlo Park,CA 94025),
3)一片段,其含有序列5'-AGGTGCAGTTCGCGTGCAATTATAACGTCGTGGCAACTGTTATCAGTCGTACCGCGCCAT-3'(SEQ ID NO:73),具有自己的启动子和终止子区域的TRP1基因以及序列5'-TGGTCAGCAACAACGCCGAAGAATCACTCTCGTGTTGAGAATTGCACGCCTTGACCACGA-3'(SEQ IDNO:74),该片段是通过PCR以pESC-TRP1(Agilent Technologies,California,USA)为模板获得的;和
4)一片段,其含有序列5'-TGGTCAGCAACAACGCCGAAGAATCACTCTCGTGTTGAGAATTGCACGCCTTGACCACGA-3'(SEQ ID NO:74)和与BUD9基因相对应的344bp的片段,该片段是通过PCR以来自菌株YST075的基因组DNA为模板获得的。
用每种评估的醇脱氢酶的基因组整合所需的四个片段来转化YST075。按照Gietzand Woods,Methods Enzymol.,2002,350:87–96中所述,用乙酸锂方案进行酵母转化。将转化混合物铺板在含有6.7g/L无氨基酸的酵母氮碱(BD Difco,New Jersey,USA),1.6g/L不含亮氨酸的滴注补充物(Sigma Aldrich,Missouri,USA),20g/L葡萄糖和20g/L琼脂的SmLeu培养基上。将板在30℃下温育3至4天。分离出包含正确整合的单个菌落,并命名为YST149(带有SCH23-ADH1),YST150(带有SCH24-ADH1a),YST151(带有AzTolADH1)和YST152(带有PsAeroADH1)。
为了在YST149,YST150,YST151和YST152中表达CrtE,SmCPS2和TalVeTPP,使用酵母内源同源重组体内构建质粒,如Kuijpers et al.,Microb Cell Fact.,2013,12:47中所述。该质粒由用于酿酒酵母共转化的六个DNA片段组成。这些片段是:
a)LEU2酵母标记,通过使用引物5'AGGTGCAGTTCGCGTGCAATTATAACGTCGTGGCAACTGTTATCAGTCGTACCGCGCCATTCGACTACGTCGTAAGGCC-3'(SEQ ID NO:75)和5'TCGTGGTCAAGGCGTGCAATTCTCAACACGAGAGTGATTCTTCGGCGTTGTTGCTGACCATCGACGGTCGAGGAGAACTT-3'(SEQ IDNO:76)通过PCR用质粒PESC-LEU(Agilent Technologies,California,USA)作为模板构建;
b)AmpR大肠杆菌标记,通过使用引物5'-TGGTCAGCAACAACGCCGAAGAATCACTCTCGTGTTGAGAATTGCACGCCTTGACCACGACACGTGTAGAGGGTTTTGGTCATGAG-3'(SEQ ID NO:77)和5'-AACGCGTACCCTAAGTACGGCACCACAGTGACTATGCAGTCCGCACTTTGCCAATGCCAAAAATGTGCGCGGAACCCCTA-3'(SEQ ID NO:78)通过PCR用质粒pESC-URA作为模板构建;
c)酵母复制起点,通过使用引物5'-TTGGCATTGGCAAAGTGCGGACTGCATAGTCACTGTGGTGCCGTACTTAGGGTACGCGTTCCTGAACGAAGCATCTGTGCTTCA-3'(SEQ ID NO:79)和5'-CCGAGATGCCAAAGGATAGGTGCTATGTTGATGACTACGACACAGAACTGCGGGTGACATAATGATAGCATTGAAGGATGAGACT-3’(SEQ ID NO:80)通过PCR用pESC-URA作为模板获得;
d)大肠杆菌复制起点,通过使用引物5'-ATGTCACCCGCAGTTCTGTGTGTCGTAGTCATCAACATAGCACCTATCCTTTGGCATCTCGGTGAGCAAAAGGCCAGCAAAAGG-3'(SEQ ID NO:81)和5'-CTCAGATGTACGGTGATCGCCACCATGTGACGGAAGCTATCCTGACAGTGTAGCAAGTGCTGAGCGTCAGACCCCGTAGAA-3’(SEQ ID NO:82)通过PCR用质粒pESC-URA作为模板获得;
e)一片段,由片段“d”的最后60个核苷酸,酵母基因PGK1的终止密码子的下游200个核苷酸,为在酿酒酵母中表达而进行了密码子优化的GGPP合酶编码序列CrtE(SEQ IDNO:62),GAL10/GAL1的双向酵母启动子,为在啤酒酵母中表达而进行了密码子优化的TalVeTPP的编码序列(SEQ ID NO:65),酵母基因CYC1的终止密码子的下游200个核苷酸,和序列5'-ATTCCTAGTGACGGCCTTGGGAACTCGATACACGATGTTCAGTAGACCGCTCACACATGG-3'(SEQ IDNO:83)组成,该片段是通过DNA合成获得的(ATUM,Menlo Park,CA 94025),
f)一片段,由片段“e”的最后60个核苷酸,酵母基因CYC1的终止密码子的下游200个核苷酸,为在酿酒酵母中表达而进行了密码子优化的SmCPS2合酶编码序列(SEQ ID NO:63),GAL10/GAL1的双向酵母启动子,和对应于片段“a”开始的60个核苷酸组成,该片段是通过DNA合成获得的(ATUM,Menlo Park,CA 94025)。
用体内质粒组装所需的片段转化所有菌株。按照Gietz and Woods,MethodsEnzymol.,2002,350:87–96中所述,用乙酸锂方案进行酵母转化。将转化混合物铺板在含有6.7g/L无氨基酸的酵母氮碱(BD Difco,New Jersey,USA),1.6g/L不含亮氨酸的滴注补充物(Sigma Aldrich,Missouri,USA),20g/L葡萄糖和20g/L琼脂的SmLeu培养基上。将板在30℃下温育3至4天。如Westfall et al.,Proc Natl Acad Sci USA,2012,109:E111-118中所述,使用单个菌落在含有2mL培养基的玻璃管中产生柯巴醇和柯巴醛,并用十二烷作为有机覆盖物。
在这些培养条件下,由含有柯巴醇生物合成质粒的菌株YST152产生的柯巴醇的最高平均浓度为153.51mg/L。带有柯巴醇生物合成质粒的菌株YST149产生的柯巴醇的最高平均浓度为98.47mg/L。在含有柯巴醇生物合成质粒的菌株YST149,YST150,YST151和YST152中,柯巴醇转化为柯巴醛的平均百分数分别为61.6%,39.9%,30.1%和22.1%。使用内标通过GC-MS分析(图18)鉴定并定量了柯巴醇和柯巴醛的产生。
本发明中应用的序列:
NA=核酸
AA=氨基酸。
TalVeTPP优化的cDNA仅ORF–SEQ ID NO:1
ATGAGCAATGACACGACGACCACCGCGAGCGCCGGTACTGCAACTTCTAGCCGTTTTCTGAGCGTCGGCGGCGTTGTGAATTTTCGCGAGCTGGGTGGCTATCCATGCGACAGCGTGCCGCCGGCTCCGGCAAGCAACGGTTCGCCTGATAATGCGTCCGAGGCAACGCTGTGGGTTGGTCACTCCAGCATTCGTCCGGGTTTCCTGTTCCGCAGCGCGCAGCCGAGCCAGATTACGCCGGCGGGTATCGAAACGCTGATCCGCCAACTGGGCATCCAGACCATTTTTGATTTCCGTAGCCGTACCGAGATCGAACTGGTGGCGACCCGTTACCCGGACTCTCTGTTGGAAATTCCGGGCACCACGCGCTATTCCGTCCCGGTTTTCTCCGAGGGTGACTATTCTCCGGCGAGCCTGGTGAAGCGCTATGGTGTTAGCAGCGATACCGCCACGGACAGCACCTCTAGCAAGAGCGCGAAGCCGACCGGCTTCGTTCATGCATACGAAGCCATTGCGCGCAGCGCCGCTGAGAACGGTAGCTTCCGTAAAATTACCGACCACATCATCCAGCATCCTGATCGTCCAATTTTGTTCCACTGTACCCTGGGTAAAGACCGTACGGGTGTCTTTGCGGCGCTGTTGCTGAGCCTGTGTGGTGTGCCGGACGAAACCATCGTCGAAGATTACGCGATGACCACCGAAGGCTTTGGTGCATGGCGTGAGCACCTGATCCAACGTCTGCTGCAACGTAAAGACGCTGCAACCCGTGAAGATGCCGAGAGCATCATTGCGTCGCCGCCGGAGACTATGAAAGCATTTCTGGAAGATGTTGTGGCAGCGAAATTTGGTGGCGCGCGTAACTACTTCATTCAACATTGCGGCTTCACTGAAGCTGAAGTCGATAAGCTGAGCCACACCCTGGCGATCACGAACTAA
TalVeTPP氨基酸序列–SEQ ID NO:2
MSNDTTTTASAGTATSSRFLSVGGVVNFRELGGYPCDSVPPAPASNGSPDNASEATLWVGHSSIRPGFLFRSAQPSQITPAGIETLIRQLGIQTIFDFRSRTEIELVATRYPDSLLEIPGTTRYSVPVFSEGDYSPASLVKRYGVSSDTATDSTSSKSAKPTGFVHAYEAIARSAAENGSFRKITDHIIQHPDRPILFHCTLGKDRTGVFAALLLSLCGVPDETIVEDYAMTTEGFGAWREHLIQRLLQRKDAATREDAESIIASPPETMKAFLEDVVAAKFGGARNYFIQHCGFTEAEVDKLSHTLAITN
TalVeTPP野生型cDNA–SEQ ID NO:3
ATGTCTAATGACACCACTACCACGGCTTCTGCCGGAACAGCAACTTCTTCGCGGTTTCTTTCCGTGGGGGGAGTTGTGAACTTCCGTGAACTGGGCGGTTACCCATGTGATTCTGTCCCTCCTGCTCCTGCCTCAAACGGCTCACCGGACAATGCATCTGAAGCGACCCTTTGGGTTGGCCACTCGTCCATTCGGCCTGGATTTCTGTTTCGATCGGCACAGCCGTCTCAGATTACCCCGGCCGGTATTGAGACATTGATCCGCCAGCTTGGCATCCAGACAATTTTTGACTTTCGTTCAAGGACGGAAATTGAGCTTGTTGCCACTCGCTATCCTGATTCGCTACTTGAGATACCTGGCACGACTCGCTATTCCGTGCCCGTCTTCTCGGAAGGCGACTATTCCCCAGCGTCATTAGTCAAGAGGTACGGAGTGTCCTCCGATACTGCAACCGATTCCACTTCCTCCAAAAGTGCTAAGCCTACAGGATTCGTCCACGCATATGAGGCTATCGCACGCAGTGCAGCAGAAAACGGCAGTTTTCGTAAGATAACGGACCACATAATACAACATCCGGACCGGCCTATTCTGTTTCACTGTACACTGGGGAAAGACCGAACCGGTGTGTTTGCAGCATTGTTATTGAGTCTTTGCGGGGTACCAGACGAGACGATAGTTGAAGACTATGCTATGACTACCGAGGGATTTGGAGCCTGGCGGGAACATCTAATTCAACGCTTGCTACAAAGGAAGGATGCAGCTACGCGCGAGGATGCAGAATCCATTATTGCCAGCCCCCCGGAGACTATGAAGGCTTTTCTAGAAGATGTGGTAGCAGCCAAGTTCGGGGGTGCTCGAAATTACTTTATCCAGCACTGTGGATTTACGGAAGCTGAGGTTGATAAGTTAAGCCATACACTGGCCATTACGAATTGA
TalVeTPP优化的cDNA包括非编码序列–SEQ ID NO:4
GGTACCAAGGAGGTAAAAAATGAGCAATGACACGACGACCACCGCGAGCGCCGGTACTGCAACTTCTAGCCGTTTTCTGAGCGTCGGCGGCGTTGTGAATTTTCGCGAGCTGGGTGGCTATCCATGCGACAGCGTGCCGCCGGCTCCGGCAAGCAACGGTTCGCCTGATAATGCGTCCGAGGCAACGCTGTGGGTTGGTCACTCCAGCATTCGTCCGGGTTTCCTGTTCCGCAGCGCGCAGCCGAGCCAGATTACGCCGGCGGGTATCGAAACGCTGATCCGCCAACTGGGCATCCAGACCATTTTTGATTTCCGTAGCCGTACCGAGATCGAACTGGTGGCGACCCGTTACCCGGACTCTCTGTTGGAAATTCCGGGCACCACGCGCTATTCCGTCCCGGTTTTCTCCGAGGGTGACTATTCTCCGGCGAGCCTGGTGAAGCGCTATGGTGTTAGCAGCGATACCGCCACGGACAGCACCTCTAGCAAGAGCGCGAAGCCGACCGGCTTCGTTCATGCATACGAAGCCATTGCGCGCAGCGCCGCTGAGAACGGTAGCTTCCGTAAAATTACCGACCACATCATCCAGCATCCTGATCGTCCAATTTTGTTCCACTGTACCCTGGGTAAAGACCGTACGGGTGTCTTTGCGGCGCTGTTGCTGAGCCTGTGTGGTGTGCCGGACGAAACCATCGTCGAAGATTACGCGATGACCACCGAAGGCTTTGGTGCATGGCGTGAGCACCTGATCCAACGTCTGCTGCAACGTAAAGACGCTGCAACCCGTGAAGATGCCGAGAGCATCATTGCGTCGCCGCCGGAGACTATGAAAGCATTTCTGGAAGATGTTGTGGCAGCGAAATTTGGTGGCGCGCGTAACTACTTCATTCAACATTGCGGCTTCACTGAAGCTGAAGTCGATAAGCTGAGCCACACCCTGGCGATCACGAACTAACTCGAG
AspWeTPP优化的cDNA–SEQ ID NO:5
ATGGCGTCTGTCCCTGCTCCACCGTTTGTTCATGTTGAAGGTATGTCTAATTTTCGTAGCATCGGTGGCTACCCGCTGGAGACTGCCTCCACGAATAACCATCGCTCGACCCGTCAAGGCTTCGCGTTTCGTAGCGCGGACCCGACGTATGTGACGCAGAAAGGCCTGGAAACCATTCTGTCCCTGGATATTACCCGCGCATTTGACTTGCGTAGCTTGGAAGAAGCAAAGGCACAACGTGCGAAGTTGCAGGCCGCGAGCGGTTGTCTGGATTGCAGCATTAGCCAACACATGATCCACCAACCGACCCCGCTGTTCCCGGATGGTGACTGGTCCCCGGAAGCGGCGGGTGAGCGCTACTTGCAGTACGCACAAGCTGAGGGTGATGGTATCAGCGGTTATGTCGAAGTTTATGGTAATATGCTGGAAGAGGGCTGGATGGCGATCCGTGAGATTCTGCTGCACGTCCGTGACCGCCCGACCGAAGCATTCCTGTGCCACTGTTCCGCCGGTAAAGATCGTACGGGTATCGTGATTGCTGTTCTGCTCAAAGTCGCGGGTTGCAGCGACGACCTGGTGTGTCGTGAGTACGAACTGACCGAGATTGGCCTGGCGCGCCGTAGAGAGTTCATCGTTCAGCATCTGCTGAAGAAACCGGAAATGAACGGCAGCCGTGAGCTGGCGGAGCGCGTCGCAGGCGCCCGTTACGAGAACATGAAAGAAACCCTGGAAATGGTGCAGACCCGTTACCGCGGCATGCGCGGCTATTGCAAAGAAATCTGCGGTCTGACCGACGAAGATCTGAGCATTATCCAGGGTAACCTGACGAGCCCGGAGAGCCCGATTTTCTAA
AspWeTPP氨基酸序列–SEQ ID NO:6
MASVPAPPFVHVEGMSNFRSIGGYPLETASTNNHRSTRQGFAFRSADPTYVTQKGLETILSLDITRAFDLRSLEEAKAQRAKLQAASGCLDCSISQHMIHQPTPLFPDGDWSPEAAGERYLQYAQAEGDGISGYVEVYGNMLEEGWMAIREILLHVRDRPTEAFLCHCSAGKDRTGIVIAVLLKVAGCSDDLVCREYELTEIGLARRREFIVQHLLKKPEMNGSRELAERVAGARYENMKETLEMVQTRYRGMRGYCKEICGLTDEDLSIIQGNLTSPESPIF
AspWeTPP野生型cDNA–SEQ ID NO:7
ATGGCATCTGTACCAGCTCCCCCATTTGTCCACGTCGAAGGAATGAGCAATTTCCGATCGATAGGAGGATATCCCCTTGAGACAGCATCGACAAACAATCACCGCTCCACGAGGCAAGGATTCGCATTTCGCAGTGCCGATCCAACCTACGTCACCCAGAAAGGCCTGGAAACCATCCTTTCGCTCGACATCACTCGAGCCTTTGACCTCCGCTCACTGGAAGAAGCAAAGGCACAGCGCGCAAAACTCCAGGCCGCCTCAGGATGTCTCGACTGCAGCATCAGCCAGCACATGATCCACCAGCCCACACCCCTATTTCCAGATGGGGACTGGAGTCCAGAGGCCGCAGGGGAGCGGTATCTGCAGTACGCCCAGGCTGAGGGAGATGGGATATCGGGCTACGTGGAGGTCTACGGAAACATGCTCGAGGAAGGTTGGATGGCGATTCGCGAGATTCTGCTTCATGTCCGGGACCGGCCTACAGAGGCGTTTCTATGCCATTGTAGTGCAGGGAAAGATCGTACGGGGATTGTCATTGCGGTTTTGTTGAAGGTTGCAGGGTGCTCGGATGATCTTGTGTGCAGAGAGTATGAGTTGACCGAGATCGGGTTGGCTCGACGGAGGGAGTTTATCGTGCAGCATCTGCTTAAGAAGCCGGAAATGAATGGATCGAGGGAACTGGCCGAAAGAGTGGCGGGGGCCAGGTATGAGAATATGAAGGAAACGCTGGAGATGGTGCAAACTAGATATAGAGGGATGAGGGGCTATTGCAAGGAGATTTGCGGCTTGACCGACGAAGATCTATCTATTATCCAGGGGAACTTGACTAGTCCGGAGAGTCCTATCTTCTAA
AspWeTPP优化的cDNA包括非编码端–SEQ ID NO:8
GGTACCAAGGAGGTAAAAAATGGCGTCTGTCCCTGCTCCACCGTTTGTTCATGTTGAAGGTATGTCTAATTTTCGTAGCATCGGTGGCTACCCGCTGGAGACTGCCTCCACGAATAACCATCGCTCGACCCGTCAAGGCTTCGCGTTTCGTAGCGCGGACCCGACGTATGTGACGCAGAAAGGCCTGGAAACCATTCTGTCCCTGGATATTACCCGCGCATTTGACTTGCGTAGCTTGGAAGAAGCAAAGGCACAACGTGCGAAGTTGCAGGCCGCGAGCGGTTGTCTGGATTGCAGCATTAGCCAACACATGATCCACCAACCGACCCCGCTGTTCCCGGATGGTGACTGGTCCCCGGAAGCGGCGGGTGAGCGCTACTTGCAGTACGCACAAGCTGAGGGTGATGGTATCAGCGGTTATGTCGAAGTTTATGGTAATATGCTGGAAGAGGGCTGGATGGCGATCCGTGAGATTCTGCTGCACGTCCGTGACCGCCCGACCGAAGCATTCCTGTGCCACTGTTCCGCCGGTAAAGATCGTACGGGTATCGTGATTGCTGTTCTGCTCAAAGTCGCGGGTTGCAGCGACGACCTGGTGTGTCGTGAGTACGAACTGACCGAGATTGGCCTGGCGCGCCGTAGAGAGTTCATCGTTCAGCATCTGCTGAAGAAACCGGAAATGAACGGCAGCCGTGAGCTGGCGGAGCGCGTCGCAGGCGCCCGTTACGAGAACATGAAAGAAACCCTGGAAATGGTGCAGACCCGTTACCGCGGCATGCGCGGCTATTGCAAAGAAATCTGCGGTCTGACCGACGAAGATCTGAGCATTATCCAGGGTAACCTGACGAGCCCGGAGAGCCCGATTTTCTAACTCGAG
HelGriTPP1优化的cDNA–SEQ ID NO:9
ATGGCATCCCCACCAGGTCATCCGTTCGTTCAAGTTGAAGGCGTTAATAATTTTCGCTCTGTGGGTGGCTATCCGATTACGCCTAGCAGCGATGCGCGCTTCACGCGTGACAACTTTATCTACCGTAGCGCTGATCCGTGTTACATTACTCCGGAAGGCCGTAGCAAGATTCGCAGCCTGGGTATCACCACCGTGTTCGATCTGCGTAGCCAGCCGGAGGTTGACAAGCAACTGGCGAAAGACCCGAGCAGCGGTGTGCCGATTGCGGATGGTGTCATTCGTCGCTTCACCCCGGTTTTTAGCCGCGAGGATTGGGGTCCGGAAGCATCCGCGGTTCGTCACAACCTGTATGCAGACGCGTCCGGTGCTAGCGGTTACGTCGATGTGTACGCGGATATCCTGGAAAACGGTGGCGCAGCGTTCCGTGAGATCCTGCTGCACGTGCGTGACCGTCCGGGTGACGCTCTGTTGTGCCACTGCTCCGCAGGCAAAGACCGTACCGGCGTTGCGATTGCGATCCTGCTCAAACTGGCCGGTTGCGAAGATGAGTGCATTTCGAAAGAGTATGAACTGACCGAGGTCGGTCTGGCCAGCCGTAAAGAATTTATTATCGAGTACCTGATTAAGCAACCTGAGCTGGAAGGCGACCGTGCGAAAGCCGAGAAAATTGCTGGCGCGAAATACGAAAACATGTTGGGTACGCTGCAGATGATGGAACAGAAATATGGTGGCGTTGAGGGCTACGTGAAGGCCTACTGTAAGTTGACGGATAAAGACATCGCAACCATCCGTCGCAATCTGGTCAGCGGTGACAAGATGATTGCGTAA
HelGriTPP1氨基酸序列–SEQ ID NO:10
MASPPGHPFVQVEGVNNFRSVGGYPITPSSDARFTRDNFIYRSADPCYITPEGRSKIRSLGITTVFDLRSQPEVDKQLAKDPSSGVPIADGVIRRFTPVFSREDWGPEASAVRHNLYADASGASGYVDVYADILENGGAAFREILLHVRDRPGDALLCHCSAGKDRTGVAIAILLKLAGCEDECISKEYELTEVGLASRKEFIIEYLIKQPELEGDRAKAEKIAGAKYENMLGTLQMMEQKYGGVEGYVKAYCKLTDKDIATIRRNLVSGDKMIA
HelGriTPP1野生型cDNA–SEQ ID NO:11
ATGGCATCACCCCCAGGGCACCCTTTCGTGCAAGTTGAAGGCGTCAACAACTTCCGCTCTGTAGGAGGATATCCCATCACCCCATCCTCCGACGCACGCTTCACACGAGATAACTTCATCTATCGCAGCGCCGACCCGTGTTACATCACGCCCGAAGGACGCTCCAAAATCCGCTCACTCGGAATCACGACTGTTTTTGATCTGCGCTCCCAGCCAGAGGTTGACAAGCAGCTTGCCAAAGACCCTTCCTCAGGGGTTCCAATCGCCGACGGCGTCATTAGACGTTTTACGCCGGTATTTTCCCGAGAGGATTGGGGTCCGGAAGCTTCCGCCGTCCGCCATAATCTGTATGCTGATGCCTCTGGGGCTTCTGGGTACGTCGATGTGTATGCCGACATTCTGGAGAATGGAGGGGCGGCATTCCGCGAGATCTTGTTGCACGTAAGAGACCGGCCTGGTGATGCGCTGCTATGTCATTGTAGTGCCGGAAAAGATCGTACCGGCGTGGCGATAGCGATACTGCTCAAGCTTGCGGGGTGCGAGGATGAATGTATCTCAAAGGAGTACGAGCTGACCGAGGTTGGTCTAGCCTCAAGAAAGGAGTTCATTATAGAGTACCTCATCAAGCAGCCGGAACTAGAGGGGGATAGAGCAAAAGCTGAAAAAATTGCGGGAGCCAAATATGAGAACATGTTAGGGACCTTGCAAATGATGGAACAGAAATACGGGGGTGTTGAGGGGTACGTGAAAGCGTATTGCAAGTTGACGGATAAAGATATTGCTACGATACGCAGGAATCTCGTCTCAGGTGACAAAATGATTGCCTAG
UmbPiTPP1优化的cDNA–SEQ ID NO:12
ATGTCCCTGCTGCCTAGCCCACCGTTTGTTCCAGTTGAAGGTATTCACAATTTTCGCGATCTGGGCGGCTATCCGGTTAGCACCAGCCCGAGCAAGACCATTCGTCGCAATATCATCTTTCGTTGTGCCGAACCGTCGAAAATCACCCCGAACGGCATTCAAACGCTGCAGAGCCTGGGTGTGGCGACGTTCTTTGACCTCCGTAGCGGTCCGGAAATCGAGAAAATGAAAGCGCATGCACCGGTCGTTGAGATCAAGGGTATTGAGCGTGTTTTCGTGCCGGTGTTCGCGGATGGTGATTATAGCCCGGAACAAATTGCGCTGCGTTACAAAGACTATGCGTCCTCTGGCACTGGTGGCTTCACCCGTGCGTACCACGACATTCTGCGTTCTGCCCCTCCGAGCTATCGTCGTATCCTGCTGCACCTGGCAGAGAAGCCGAACCAGCCGTGCGTGATCCACTGTACCGCTGGCAAAGACCGCACGGGTGTTCTGGCAGCGCTGATTCTGGAACTGGCGGGTGTCGATCAAGACACCATCGCGCATGAGTACGCCCTGACCGAGCTGGGCCTGAAGGCATGGCGTCCGACGGTTGTCGAGCACTTACTGCAGAATCCGGCGCTGGAAGGCAATCGCGAGGGTGCATTGAATATGGTCAGCGCTCGTGCGGAGAACATGCTGGCCGCCTTGGAAATGATTCGCGAGATCTACGGTGGTGCTGAGGCGTACGTGAAAGAAAAGTGCGGTCTGAGCGACGAAGATATTGCACGCATTCGCCAGAACATTTTGCATACGCCGAGCCCGTAA
UmbPiTPP1氨基酸序列–SEQ ID NO:13
MSLLPSPPFVPVEGIHNFRDLGGYPVSTSPSKTIRRNIIFRCAEPSKITPNGIQTLQSLGVATFFDLRSGPEIEKMKAHAPVVEIKGIERVFVPVFADGDYSPEQIALRYKDYASSGTGGFTRAYHDILRSAPPSYRRILLHLAEKPNQPCVIHCTAGKDRTGVLAALILELAGVDQDTIAHEYALTELGLKAWRPTVVEHLLQNPALEGNREGALNMVSARAENMLAALEMIREIYGGAEAYVKEKCGLSDEDIARIRQNILHTPSP
UmbPiTPP1野生型cDNA–SEQ ID NO:14
ATGTCTCTGCTACCGTCACCTCCCTTCGTACCCGTTGAGGGTATCCACAACTTCCGGGACCTAGGCGGCTACCCCGTCTCGACTTCCCCTTCCAAGACCATACGTCGCAACATCATCTTTCGCTGCGCCGAACCCTCGAAAATCACTCCCAATGGCATCCAGACGCTCCAATCTTTGGGCGTCGCTACGTTCTTCGACCTCCGCTCCGGCCCGGAAATCGAGAAGATGAAAGCACATGCACCTGTCGTCGAGATTAAGGGCATCGAGCGTGTGTTCGTTCCCGTCTTCGCCGACGGGGATTACTCGCCCGAACAAATCGCTCTGCGATACAAAGACTACGCTTCCAGCGGAACGGGGGGTTTTACCAGGGCGTACCATGATATCCTCCGAAGTGCCCCTCCGAGCTATCGGCGCATACTATTACATCTGGCGGAGAAGCCCAACCAGCCATGCGTCATTCATTGCACGGCCGGGAAAGATAGGACGGGCGTATTGGCGGCGTTGATACTCGAGTTGGCCGGGGTTGATCAGGATACAATTGCGCACGAGTACGCATTGACGGAACTGGGGTTGAAGGCCTGGCGTCCCACTGTGGTGGAGCACCTCTTGCAGAATCCAGCGTTGGAGGGAAATCGGGAAGGGGCATTGAACATGGTCAGCGCGAGGGCAGAGAACATGCTGGCAGCCTTGGAGATGATCCGGGAGATCTATGGCGGCGCCGAAGCATATGTGAAGGAGAAGTGTGGCCTCAGCGACGAAGACATTGCGCGGATACGGCAGAATATTCTACACACGCCATCTCCGTGA
TalVeTPP2优化的cDNA–SEQ ID NO:15
ATGTCTGTCACCGAACATGTTGTCGAAGCTAGCACCCCGTCCACTCTGCCGCCACCGTTCATTCACGTGGACGGTGTTCCGAACTTCCGTGACATTGGTGGCTATCCGATTACCGATCTGCTGAGCACCCGTCGCAATTTCGTTTATCGCTCCGCAGTTCCTACCCGCATCACCCCAACGGGCCTGCAGACGCTGACCCAAGATCTGCAGATTACGACGGTCTACGACTTACGTTCGAATGCTGAGCTGCGTAAAGATCCTATCGCGAGCAGCCCGTTGGACACCCACGACAGCGTGACTGTCCTGCATACCCCGGTTTTCCCGGAGCGCGATTCTAGCCCGGAACAGCTGGCAAAGCGTTTTGCCAACTATATGAGCGCGAACGGTTCCGAGGGTTTCGTTGCGGCGTACGCAGAGATTCTGCGTGATGGTGTGGATGCCTACCGCAAGGTTTTTGAACACGTGCGTGACCGTCCGCGTGATGCGTTTCTGGTGCACTGCACCGGTGGCAAAGACCGTACGGGTGTGTTGGTTGCGCTGATGCTGTTGGTGGCAGGCGTCAAAGACCGTGACGTTATTGCCGATGAGTACAGCCTGACGGAAAAGGGTTTTGCGGCTGTCATCAAAGCCGATGCTGCGGAAAAGATCATCAAAGACATGGGTGTTGACGGTGCCAATCGTGCGGGCATCGAGCGTCTGTTGAGCGCACGCAAAGAAAACATGAGCGCGACCCTGGAGTACATTGAGAAGCAATTTGGTGGCGCAGAGGGCTATCTGCGCGACCAACTGGGTTTCGGCGACGAAGATGTGGAACAGATCCGTAAGAGCCTGGTCGTTGAGGATAAAGGCCTGTTCTAA
TalVeTPP2氨基酸序列–SEQ ID NO:16
MSVTEHVVEASTPSTLPPPFIHVDGVPNFRDIGGYPITDLLSTRRNFVYRSAVPTRITPTGLQTLTQDLQITTVYDLRSNAELRKDPIASSPLDTHDSVTVLHTPVFPERDSSPEQLAKRFANYMSANGSEGFVAAYAEILRDGVDAYRKVFEHVRDRPRDAFLVHCTGGKDRTGVLVALMLLVAGVKDRDVIADEYSLTEKGFAAVIKADAAEKIIKDMGVDGANRAGIERLLSARKENMSATLEYIEKQFGGAEGYLRDQLGFGDEDVEQIRKSLVVEDKGLF
TalVeTPP2野生型cDNA–SEQ ID NO:17
ATGAGCGTCACAGAACATGTAGTCGAAGCCTCGACACCATCAACCCTTCCACCACCCTTCATCCATGTCGACGGCGTCCCCAACTTCCGCGACATCGGCGGCTACCCCATCACAGACTTACTGTCAACACGACGAAACTTCGTGTATCGCTCCGCAGTCCCAACACGCATCACTCCCACAGGTCTACAGACACTCACCCAAGACCTCCAAATCACAACAGTCTACGACCTACGCTCCAACGCTGAACTGCGCAAGGATCCCATTGCCTCCAGCCCTCTAGACACCCATGACTCTGTAACGGTGCTACACACCCCCGTCTTTCCCGAACGGGACTCAAGTCCCGAACAACTCGCAAAGAGGTTTGCGAATTACATGTCCGCCAACGGCTCGGAAGGGTTTGTAGCCGCCTACGCCGAGATTTTGCGTGATGGCGTTGATGCATACCGCAAGGTGTTTGAGCATGTCCGTGATCGGCCCCGGGATGCGTTTTTGGTGCATTGTACTGGTGGGAAGGATAGAACGGGTGTCCTTGTAGCGCTCATGTTACTTGTTGCGGGTGTCAAGGATAGAGATGTGATTGCCGACGAGTACTCGTTGACGGAGAAGGGGTTTGCTGCTGTTATTAAGGCGGATGCGGCGGAGAAGATTATAAAGGATATGGGAGTGGATGGGGCGAATAGGGCGGGCATTGAGAGATTGCTGTCGGCGAGGAAGGAGAATATGAGTGCTACGTTGGAGTATATCGAGAAACAGTTTGGTGGGGCGGAGGGTTATTTGAGGGATCAGTTAGGGTTTGGTGATGAGGATGTTGAGCAGATTAGGAAGAGTCTTGTCGTGGAGGATAAGGGTTTATTTTAG
HydPiTPP1优化的cDNA–SEQ ID NO:18
ATGACTGCAACCGACAATGGCTTAGAACCGCTGGACCCTGCATACGTTGCTGATGTGTTGAGCCGTCCGCCGTTTGTCCAGATCTCCGGCGTGTGTAACGTCAGAGATCTGGGCAGCTATCCGACCGCTACCCCGAATGTGATTACCAAGCCTGGTTATGCATACCGTGGTGCCGAAGTTTCCAATATCACCGAAGAGGGCAGCCAACAAATGAAAGCACTGGGTATTACCACGATCTTTGATCTGCGTTCTGACCCAGAGATGCAGAAGTACAGCACGCCGATTCCGCATATCGAGGGTGTCCTGATTCTGCGTACCCCGGTGTTCGCCACCGAGGACTATAGCCCGGAGTCGATGGCGAAGCGTTTTGAGCTGTACGCGTCTGGTACGACCGAAGCATTCATGAAGCTGTATAGCCAGATTCTGGACCACGGCGGCAAAGCGTTCGGTACTATTCTGCGTCATGTTCGTGACCGCCCGAACAGCGTTTTTCTGTTTCACTGCACGGCCGGTAAAGATCGCACGGGCATTATTGCGGCCATCCTGTTCAAATTGGCGGGTGTGGATGATCACTTGATCTGTCAGGACTACAGCCTGACGCGCATCGGTCGTGAGCCAGACCGTGAAAAAGTTCTGCGCCGTCTGCTGAATGAACCGCTGTTCGCGGCGAATACCGAGCTTGCGCTGCGCATGTTGACGAGCCGCTACGAAACCATGCAAGCGACCCTGGGTCTGTTGAGCGACAAATATGGCGGTGTGGAAGCATACGTCAAGAACTTCTGCGGTCTGACCGATAACGACATCAGCGTTATCCGTACCAACCTGGTTGTGCCGACGAAAGCGCGTATGTAA
HydPiTPP1氨基酸序列–SEQ ID NO:19
MTATDNGLEPLDPAYVADVLSRPPFVQISGVCNVRDLGSYPTATPNVITKPGYAYRGAEVSNITEEGSQQMKALGITTIFDLRSDPEMQKYSTPIPHIEGVLILRTPVFATEDYSPESMAKRFELYASGTTEAFMKLYSQILDHGGKAFGTILRHVRDRPNSVFLFHCTAGKDRTGIIAAILFKLAGVDDHLICQDYSLTRIGREPDREKVLRRLLNEPLFAANTELALRMLTSRYETMQATLGLLSDKYGGVEAYVKNFCGLTDNDISVIRTNLVVPTKARM
HydPiTPP1野生型cDNA–SEQ ID NO:20
ATGACCGCAACAGACAACGGACTAGAACCCTTAGACCCTGCATATGTCGCAGATGTGCTCTCAAGACCACCATTCGTACAAATATCTGGTGTTTGCAACGTCCGTGATCTAGGATCCTACCCTACCGCCACTCCCAATGTCATAACAAAGCCGGGATATGCATACCGGGGCGCAGAGGTCTCTAACATTACCGAAGAAGGTAGCCAGCAAATGAAGGCGCTAGGCATAACGACTATATTTGATCTTAGATCGGATCCAGAGATGCAGAAATACAGCACTCCAATACCCCACATTGAAGGCGTACTGATATTGCGCACGCCTGTCTTCGCGACCGAGGATTATAGTCCGGAAAGTATGGCCAAGAGATTTGAGCTATACGCAAGTGGTACTACTGAAGCATTTATGAAACTATACTCTCAAATACTAGACCATGGAGGCAAAGCCTTCGGAACAATTCTCCGGCACGTTCGGGACAGGCCAAATTCTGTCTTTCTTTTCCATTGCACTGCGGGGAAAGACCGGACCGGCATCATTGCTGCAATTCTGTTCAAGCTCGCCGGCGTAGACGACCATCTCATATGTCAAGATTACTCCCTCACACGAATAGGTCGCGAGCCTGATCGTGAAAAGGTCCTCCGGCGACTCTTGAATGAACCTCTATTTGCCGCCAACACGGAACTTGCACTACGAATGCTCACGTCTCGATATGAAACTATGCAAGCAACGTTGGGGCTTCTTAGCGATAAGTATGGCGGGGTGGAGGCGTATGTGAAGAATTTCTGTGGGCTCACGGATAATGATATATCGGTCATACGAACAAATCTCGTTGTACCTACAAAGGCGCGGATGTAG
TalCeTPP1优化的cDNA–SEQ ID NO:21
ATGAGCAACGACACGACCAGCACCGCATCCGCAGGCACCGCAACTTCTTCGCGCTTTCTGAGCGTCGGTGGCGTGGTTAACTTCCGTGAGTTGGGTGGCTACCCGTGCGACAGCGTTCCTCCTGCACCAGCAAGCAATGGTAGCCCGGACAATGCGAGCGAAGCGATTCTGTGGGTTGGTCACAGCAGCATTCGTCCGCGCTTCTTGTTTCGTAGCGCACAGCCGTCCCAGATCACCCCGGCCGGTATTGAAACGCTGATTCGCCAACTCGGTATTCAAGCGATCTTTGACTTTCGTTCCCGTACCGAGATCCAACTGGTGGCAACCCGCTACCCAGATAGCCTGCTGGAAATTCCGGGCACGACTCGTTACTCTGTTCCGGTCTTTACCGAGGGCGACTACAGCCCGGCTTCTCTGGTTAAGCGTTATGGTGTCTCTAGCGACACGGCAACGGATAGCACCAGCTCAAAGTGCGCGAAACCGACCGGCTTTGTGCATGCTTATGAAGCGATTGCTCGTTCTGCCGCGGAGAACGGTAGCTTCCGCAAGATCACCGACCACATTATCCAACATCCGGATCGCCCGATCCTGTTTCACTGCACGCTGGGCAAAGACCGTACCGGTGTTTTCGCAGCGCTGCTGCTGAGCTTGTGTGGTGTCCCGAATGACACCATCGTGGAAGATTATGCGATGACGACCGAAGGCTTCGGTGTGTGGCGTGAGCACTTGATTCAGCGTCTGCTGCAGCGCAAAGATGCGGCTACGCGTGAAGATGCCGAGTTCATTATCGCGAGCCATCCGGAGAGCATGAAAGCGTTCCTGGAAGATGTCGTTGCGACCAAATTCGGTGACGCCCGCAACTACTTTATCCAGCACTGTGGTCTGACCGAAGCCGAAGTGGATAAGCTGATCCGTACGCTGGTGATCGCGAATTAA
TalCeTPP1氨基酸序列–SEQ ID NO:22
MSNDTTSTASAGTATSSRFLSVGGVVNFRELGGYPCDSVPPAPASNGSPDNASEAILWVGHSSIRPRFLFRSAQPSQITPAGIETLIRQLGIQAIFDFRSRTEIQLVATRYPDSLLEIPGTTRYSVPVFTEGDYSPASLVKRYGVSSDTATDSTSSKCAKPTGFVHAYEAIARSAAENGSFRKITDHIIQHPDRPILFHCTLGKDRTGVFAALLLSLCGVPNDTIVEDYAMTTEGFGVWREHLIQRLLQRKDAATREDAEFIIASHPESMKAFLEDVVATKFGDARNYFIQHCGLTEAEVDKLIRTLVIAN
TalCeTPP1野生型cDNA–SEQ ID NO:23
ATGTCTAATGACACCACTAGCACGGCTTCTGCCGGAACAGCAACTTCTTCGCGGTTTCTTTCTGTGGGCGGAGTTGTGAATTTCCGTGAACTGGGCGGTTATCCATGTGATTCTGTCCCTCCTGCTCCTGCCTCAAACGGCTCACCGGACAACGCATCTGAAGCGATCCTTTGGGTTGGCCACTCGTCCATTCGGCCTAGGTTTCTCTTTCGATCGGCACAGCCGTCTCAGATTACCCCGGCCGGTATTGAGACATTGATCCGCCAGCTTGGCATCCAGGCAATTTTTGACTTTCGTTCACGGACGGAAATTCAGCTTGTCGCCACTCGCTATCCTGATTCGCTACTCGAGATACCTGGTACGACTCGCTATTCCGTGCCCGTCTTCACGGAGGGCGACTATTCCCCGGCGTCATTAGTCAAGAGGTACGGAGTGTCCTCCGATACTGCAACTGATTCCACTTCCTCCAAATGTGCCAAGCCTACAGGATTCGTCCACGCATATGAGGCTATCGCACGCAGCGCAGCAGAAAACGGCAGTTTTCGTAAAATAACGGACCACATAATACAACATCCGGACCGGCCTATCCTGTTTCACTGTACATTGGGAAAAGACCGAACCGGTGTATTTGCAGCATTGTTATTGAGTCTTTGCGGGGTACCAAACGACACGATAGTTGAAGACTATGCTATGACTACCGAGGGATTTGGGGTCTGGCGAGAACATCTAATTCAACGCCTGTTACAAAGAAAGGATGCAGCTACGCGTGAGGATGCAGAATTCATTATTGCCAGCCACCCGGAGAGTATGAAGGCTTTTCTAGAAGATGTGGTAGCAACCAAGTTCGGGGATGCTCGAAATTACTTTATCCAGCACTGTGGATTGACGGAAGCGGAGGTTGATAAGCTAATTCGGACACTGGTCATTGCGAATTGA
TalMaTPP1优化的cDNA–SEQ ID NO:24
ATGTGGAATTTGCACTATTATATTCCGGGCTCTGCACCAGTTAATTTGAACGACATGCCGAACGATACGGCGACGACGGCTTCCGCAGGCACTAGCGCCACGAGCCGCTTCCTCTGTGTCAGCGGTGTTGCGAACTTCCGTGAACTGGGTGGCTATCCGTGCGACACCGTTCCTCCAGCACCGGCGAGCAATGGTAGCCCGCATAATGCATCCGAGGCCACGCTGCAAGGTTCCCACTCTAGCATTCGTCCGGGCTTCATCTTCCGTAGCGCGCAACCGAGCCAGATCAATCCGGCAGGCATCGCGACGCTGGCGCATGAACTGTCTATTCAAGTCATCTTCGACTTCCGTTCGCAGACCGAGATCCAGCTGGTCACCACCCACTACCCGGATAGCCTGTTGGAGATCCCGTGTACCACCCGTTACAGCGTGCCGGTGTTTAACGAGGGTGACTATAGCCCGGCTTCGCTGGTCAAGAAATACGGTGTGAGCCCGGACCCAGTGACGCATTCCGCTAGCAGCACCAGCGCGAATCCTGCCGGCTTTGTGCCGGCCTACGAAGCAATCGCTCGTAGCGCAGCCGAAAACGGTAGCTTTCGCAAAATCACCGAGCACATTATTCAGCACCCGGATCAGCCGATTTTGTTTCATTGCACCCTGGGTAAAGATCGCACGGGTGTGTTTGCGGCCCTGCTGCTGAGCCTGTGCGGTGTTTCCACCGAAAAGATCGTGGAAGATTACGCGATGACCACCGAGGGTTTCGGTGCTTGGCGTGAGCACCTGATTAAGCGCCTGCTGCAGCGTAAAGATGCGGCAACCCGCCAAGACGCTGAGTTCATCATTGCCAGCCACCCGGAAACCATGAAATCTTTTCTGGACGACGTTGTTCGTGCGAAGTTTGGCTCCGCGCGTAACTATTTCGTGCAACAGTGCGGTCTGACTGAGTACGAAGTTGATAAGCTGATTCATACGCTGGTCATTATCAAGTAA
TalMaTPP1氨基酸序列–SEQ ID NO:25
MWNLHYYIPGSAPVNLNDMPNDTATTASAGTSATSRFLCVSGVANFRELGGYPCDTVPPAPASNGSPHNASEATLQGSHSSIRPGFIFRSAQPSQINPAGIATLAHELSIQVIFDFRSQTEIQLVTTHYPDSLLEIPCTTRYSVPVFNEGDYSPASLVKKYGVSPDPVTHSASSTSANPAGFVPAYEAIARSAAENGSFRKITEHIIQHPDQPILFHCTLGKDRTGVFAALLLSLCGVSTEKIVEDYAMTTEGFGAWREHLIKRLLQRKDAATRQDAEFIIASHPETMKSFLDDVVRAKFGSARNYFVQQCGLTEYEVDKLIHTLVIIK
TalMaTPP1野生型cDNA–SEQ ID NO:26
ATGTGGAACCTACACTACTATATTCCTGGATCAGCACCAGTCAACTTGAACGACATGCCTAATGACACCGCTACCACGGCTTCTGCCGGAACATCAGCAACTTCACGGTTTCTTTGCGTGAGCGGAGTGGCGAATTTCCGTGAACTGGGCGGTTACCCATGCGATACTGTCCCTCCTGCTCCTGCGTCAAACGGTTCACCGCACAATGCATCTGAAGCGACCCTCCAGGGTAGTCATTCGTCTATTCGGCCTGGATTTATCTTTCGATCGGCTCAGCCGTCGCAGATTAACCCGGCTGGTATTGCCACATTAGCACACGAGCTTAGCATCCAGGTGATTTTTGACTTTCGTTCGCAAACCGAAATTCAGCTTGTCACTACTCATTATCCTGATTCGCTACTTGAGATACCTTGCACGACTCGCTATTCCGTGCCGGTCTTCAATGAGGGCGACTATTCCCCAGCGTCGTTAGTCAAGAAGTACGGGGTATCCCCCGATCCTGTAACACATTCCGCTTCCTCCACGAGTGCCAATCCTGCAGGATTTGTCCCCGCGTATGAAGCCATCGCACGAAGCGCAGCAGAAAACGGCAGTTTCCGTAAAATAACAGAGCACATAATACAGCATCCGGACCAGCCGATCCTGTTTCATTGTACTCTGGGAAAGGACCGGACCGGAGTTTTTGCAGCATTGCTATTGAGCCTTTGCGGTGTTTCGACTGAGAAGATAGTTGAAGACTATGCTATGACTACCGAGGGTTTCGGAGCCTGGCGGGAACATCTAATTAAACGCCTGCTGCAAAGGAAAGATGCAGCAACACGCCAGGATGCGGAATTCATTATCGCCAGCCACCCGGAGACTATGAAGTCTTTCCTAGACGATGTCGTGCGAGCTAAGTTCGGAAGTGCTCGAAATTACTTTGTCCAGCAGTGTGGATTGACAGAATATGAGGTTGATAAGTTAATCCATACACTCGTGATTATAAAATGA
TalAstroTPP1优化的cDNA–SEQ ID NO:27
ATGTCCACCAATGCAGATCCGACCACGTTTTCCGATAAGTCCCCGTTCATCAATGTCAGCGGCGTGGTGAATTTTCGTGACCTGGGCGGCTACAGCTGCTTGACCCCGTTGACGCCAGTCAGCAACGGCAGCCCGGTAATTGCGTCGAAGGGTAGCCCTTCTAGCTATATCCGTCCAGGTTTCCTGTTTCGCTCTGCTCAGCCGAGCCAGATTACCGAAACCGGTATCGAGGTCCTGACCCACAAGCTGAATATCGGTGCGATTTTTGACTTCCGTTCCCAAACCGAGATCCAACTGGTTGCGACGCGTTACCCGGACAGCCTGCTGGAAATTCCGTTTACCTCTCGTTATGCAGTCCCGGTTTTCGAGCATTGTGATTTCAGCCCGGTTAGCTTGAGCAAGAAATATGGTGCGCCGAGCAACGCACCGCCTACCGAAGCGGAGCACGGTAGCTTTGTGCAGGCGTACGAAGATATTGCCCGTAGCGCAGCAGAGAACGGCAGCTTCCGCAGCATCACGGACCACATTTTGCGCTACCCGGATATGCCGATCCTGTTCCACTGCACCGTGGGCAAAGACCGCACCGGCGTTTTTGCGGCGCTGCTGCTGAAACTGTGTGGTGTGAGCGACGAAGTTGTGATTCAGGACTATGCCCTGACTACGCAAGGTCTGGGTGCCTGGAGAGAGCATCTGATCCAACGCCTGCTGCAGCGTAATGACGTCGCGACGCGTGAAGATGCAGAGTTTATCCTGGCTAGCCGTCCGGAGACTATGAAATCGTTCCTGGCCGATGTTGTGGAAACCAAGTTCGGTGGCGCTCGCAACTACTTCACGCTGCTGTGCGGTCTGACCGAAGATGATGTTAACAACCTGATTAGCCTGGTTGTCATTCATAACACGAATTAA
TalAstroTPP1氨基酸序列–SEQ ID NO:28
MSTNADPTTFSDKSPFINVSGVVNFRDLGGYSCLTPLTPVSNGSPVIASKGSPSSYIRPGFLFRSAQPSQITETGIEVLTHKLNIGAIFDFRSQTEIQLVATRYPDSLLEIPFTSRYAVPVFEHCDFSPVSLSKKYGAPSNAPPTEAEHGSFVQAYEDIARSAAENGSFRSITDHILRYPDMPILFHCTVGKDRTGVFAALLLKLCGVSDEVVIQDYALTTQGLGAWREHLIQRLLQRNDVATREDAEFILASRPETMKSFLADVVETKFGGARNYFTLLCGLTEDDVNNLISLVVIHNTN
TalAstroTPP1野生型cDNA–SEQ ID NO:29
ATGTCTACCAACGCTGACCCTACTACTTTTTCCGATAAATCACCGTTTATTAACGTAAGCGGCGTTGTCAATTTTCGTGATCTGGGCGGTTACTCATGTCTCACTCCTCTCACCCCTGTCTCAAATGGTTCACCGGTGATAGCGTCAAAGGGATCCCCCTCATCATACATTCGCCCCGGCTTCTTGTTCCGTTCAGCACAGCCTTCACAAATTACCGAGACTGGTATCGAAGTTCTGACGCACAAGCTTAATATCGGAGCTATATTTGACTTTCGGTCACAGACAGAAATCCAGCTTGTTGCGACTCGATATCCAGATTCCCTGCTCGAAATACCATTTACTAGCCGATACGCTGTTCCAGTGTTCGAACATTGCGACTTTTCTCCGGTCTCGCTGTCTAAGAAGTATGGGGCTCCGTCAAACGCTCCTCCTACAGAAGCCGAGCACGGTAGCTTCGTCCAGGCTTATGAAGATATCGCCCGCAGTGCAGCGGAAAATGGAAGTTTTCGCAGCATAACAGATCATATTCTGCGATATCCCGACATGCCAATTCTTTTTCATTGTACGGTTGGCAAAGACAGAACTGGTGTGTTTGCAGCATTGTTGTTGAAGCTGTGTGGAGTGTCTGATGAAGTAGTTATTCAAGACTACGCACTCACTACTCAAGGCCTAGGTGCATGGCGCGAACACCTGATTCAGCGCCTGCTGCAAAGGAATGATGTTGCTACCCGTGAGGATGCCGAGTTCATACTCGCTAGCCGACCAGAGACTATGAAGTCATTCTTGGCAGATGTGGTGGAAACCAAATTTGGAGGAGCTCGCAACTATTTTACTCTGCTGTGCGGATTGACCGAGGACGATGTCAATAACTTGATCTCCCTTGTAGTTATTCATAATACAAATTAG
PeSubTPP1优化的cDNA–SEQ ID NO:30
ATGCAACCTTTTATTAGCGTCGATGGTGTGGTGAATTTTCGTGATATTGGTGGTTATGTTTGCCGTAATCCGGCCGGTTTGTCGAGCCTGCCGAGCAACGTTGACGAAACCCCGGAAAAGCAATGGTGTATCCGCCCAGGCTTCGTTTTCCGTGCAGCGCAACCGTCCCAAATTACGCCGGCTGGTATCGAGATTCTTAAGAAAACGCTGGCGATCCAAGCGATTTTCGATTTTCGTAGCGAGTCCGAGATCCAACTGGTGAGCAAGCGTTACCCGGACAGCCTGCTGGACATCCCGGGCACTACGCGTCATGCTGTTCCGGTGTTTCAGGAGGGTGATTACAGCCCGATCTCGTTGGCCAAACGTTACGGTGTGACCGCGGACGAGAGCACCAACGATCAGTCCTTCCGTCCGGGTTTTGTCAAAGCGTATGAAGCCATCGCACGCAACGCAGCACAGGCTGGTAGCTTCCGCGCCATTATCCAGCATATCCTGCAGGACTCCGCTGGCCCAGTTTTGTTTCACTGCACCGTAGGCAAAGATCGCACGGGTGTTTTCTCTGCACTGATTCTGAAGCTGTGCGGTGTGGCCGACGAAGATATTGTGGCAGACTATGCGCTGACCACTCAGGGCCTGGGTGTCTGGCGTGAGCACCTGATCCAGCGCCTGTTGCAGCGTGGTGAAGCGACCACCAAAGAACAAGCGGAAGCGATCATCTCTAGCGACCCGCGCGACATGAAAGCGTTCCTGAGCAACGTCGTTGAGGGCGAGTTTGGTGGCGCACGCAACTACTTCGTGAATCTGTGTGGCCTGCCTGAAGGCGAGGTTGACCGTGTCATTACCAAACTGGTCGTCCCGAAAACCACCAAGTAA
PeSubTPP1氨基酸序列–SEQ ID NO:31
MQPFISVDGVVNFRDIGGYVCRNPAGLSSLPSNVDETPEKQWCIRPGFVFRAAQPSQITPAGIEILKKTLAIQAIFDFRSESEIQLVSKRYPDSLLDIPGTTRHAVPVFQEGDYSPISLAKRYGVTADESTNDQSFRPGFVKAYEAIARNAAQAGSFRAIIQHILQDSAGPVLFHCTVGKDRTGVFSALILKLCGVADEDIVADYALTTQGLGVWREHLIQRLLQRGEATTKEQAEAIISSDPRDMKAFLSNVVEGEFGGARNYFVNLCGLPEGEVDRVITKLVVPKTTK
PeSubTPP1野生型cDNA–SEQ ID NO:32
ATGCAGCCATTCATCTCGGTGGATGGAGTCGTCAACTTCCGCGATATCGGAGGCTATGTATGCCGGAATCCCGCTGGTTTATCCTCCTTGCCCTCGAATGTCGACGAAACCCCAGAGAAACAGTGGTGCATTCGGCCAGGATTCGTCTTCCGCGCGGCACAGCCATCCCAAATCACCCCTGCAGGGATTGAGATCCTGAAAAAGACCCTTGCTATCCAAGCCATCTTTGACTTTCGGTCAGAGAGTGAGATTCAGCTTGTGTCTAAGCGCTATCCAGACTCCCTCCTCGATATTCCCGGGACAACTCGCCATGCAGTACCGGTCTTCCAAGAAGGTGATTACTCTCCCATCTCACTGGCAAAACGGTATGGAGTCACCGCGGACGAATCCACGAATGATCAGTCCTTTAGACCGGGATTCGTCAAGGCCTACGAGGCCATTGCGCGCAACGCGGCTCAAGCGGGCAGCTTCCGTGCAATCATACAGCACATTCTGCAGGATTCGGCCGGCCCGGTACTTTTCCACTGCACGGTGGGCAAGGACCGGACAGGGGTCTTTTCGGCTTTGATCCTCAAGCTGTGCGGGGTGGCCGATGAGGACATTGTCGCTGATTATGCACTCACCACGCAAGGCTTAGGTGTGTGGCGGGAGCATTTGATTCAACGGCTCTTGCAGAGAGGGGAGGCCACAACCAAGGAACAAGCCGAAGCCATAATCAGCAGTGACCCGAGAGACATGAAGGCGTTTTTGAGCAATGTAGTGGAAGGGGAATTTGGAGGTGCTCGGAACTACTTCGTCAACCTCTGCGGACTACCGGAAGGCGAAGTCGATCGGGTTATCACCAAGCTTGTGGTACCAAAGACTACTAAATAG
密码子优化的cDNA序列编码SmCPS–SEQ ID NO:33
ATGGCAACTGTTGATGCACCACAAGTTCACGATCATGACGGCACCACTGTTCACCAAGGCCACGATGCAGTCAAGAATATCGAGGACCCGATCGAGTACATTCGCACGCTGTTGCGCACCACGGGCGACGGTCGTATTTCCGTGAGCCCGTATGATACCGCATGGGTCGCGATGATCAAAGACGTTGAGGGCCGTGATGGTCCGCAGTTTCCGTCTAGCTTGGAATGGATCGTGCAAAATCAGTTGGAAGATGGTTCGTGGGGTGACCAGAAACTGTTTTGTGTGTATGATCGCTTGGTTAATACGATCGCGTGTGTGGTTGCTTTGCGTTCTTGGAACGTGCACGCGCACAAAGTGAAGCGTGGTGTGACCTATATTAAGGAAAACGTTGATAAGCTGATGGAGGGTAACGAGGAGCACATGACTTGCGGCTTCGAAGTCGTTTTCCCGGCACTGCTGCAGAAAGCCAAAAGCCTGGGTATTGAGGATTTGCCTTACGATTCGCCGGCGGTCCAAGAAGTGTATCACGTCCGCGAACAAAAGCTGAAGCGCATCCCGTTGGAAATTATGCACAAAATTCCGACCAGCCTGCTGTTTAGCCTGGAAGGTCTGGAGAATCTCGACTGGGACAAACTGCTGAAACTCCAGAGCGCTGACGGCTCTTTTCTGACGAGCCCGAGCAGCACGGCGTTCGCATTTATGCAGACGAAAGACGAAAAATGCTATCAATTTATTAAGAATACGATTGACACCTTCAATGGTGGCGCGCCGCATACCTATCCGGTGGATGTTTTTGGTCGTTTATGGGCGATTGATCGTCTGCAGAGACTGGGTATTAGCCGTTTCTTTGAGCCGGAAATTGCCGATTGCCTGTCTCATATTCACAAATTTTGGACCGACAAGGGTGTTTTCTCTGGTCGCGAGAGCGAATTTTGCGACATCGACGACACCAGCATGGGCATGCGCCTGATGCGCATGCACGGTTATGACGTCGATCCAAATGTCCTGCGCAATTTCAAACAAAAGGACGGCAAGTTCAGCTGCTACGGCGGCCAGATGATCGAGTCTCCGAGCCCGATCTATAATCTGTATCGTGCGAGCCAGTTGCGCTTCCCGGGTGAAGAAATCCTGGAAGATGCCAAACGCTTTGCTTACGACTTCTTGAAAGAGAAACTGGCGAACAACCAGATTCTGGACAAGTGGGTTATTTCGAAACACTTGCCGGACGAGATCAAACTGGGCTTAGAAATGCCGTGGTTGGCAACCCTGCCGCGCGTGGAGGCGAAGTACTACATCCAGTACTACGCGGGCAGCGGTGATGTTTGGATCGGCAAAACGTTGTACCGCATGCCTGAGATCTCGAACGACACCTATCACGACCTGGCTAAGACCGATTTTAAACGTTGTCAGGCCAAACACCAATTCGAGTGGCTGTACATGCAAGAGTGGTATGAAAGCTGCGGCATCGAAGAGTTTGGTATCAGCCGTAAAGACCTCCTGCTGAGCTATTTTCTGGCGACGGCGAGCATCTTCGAGTTGGAGCGCACCAACGAACGTATTGCGTGGGCAAAATCTCAGATTATCGCAAAAATGATCACGAGCTTCTTTAACAAAGAAACCACGAGCGAGGAAGATAAGCGCGCCCTGCTGAATGAGCTGGGCAACATCAATGGTCTGAATGATACGAACGGTGCAGGCCGCGAGGGTGGTGCTGGTAGCATCGCGCTGGCGACCCTGACCCAATTTCTGGAAGGTTTCGACCGTTATACCCGCCATCAACTCAAAAACGCCTGGAGCGTGTGGCTGACTCAGTTACAGCATGGCGAGGCAGATGATGCTGAGCTGCTGACCAATACGCTCAACATCTGCGCGGGCCATATCGCGTTCCGTGAGGAAATTCTGGCCCATAACGAGTACAAGGCCTTGAGCAACCTGACCAGCAAAATCTGCCGCCAACTGAGCTTTATTCAAAGCGAAAAGGAAATGGGCGTCGAGGGCGAGATTGCGGCAAAGAGCAGCATCAAGAATAAAGAACTGGAAGAAGATATGCAGATGCTGGTCAAACTGGTCCTGGAAAAGTACGGTGGTATCGACCGTAACATCAAAAAAGCGTTTCTGGCTGTCGCGAAAACCTATTACTATCGTGCATATCATGCTGCGGACACCATCGACACCCACATGTTTAAGGTTCTGTTTGAGCCGGTTGCATAA
SmCPS,一种来自丹参(Salvia miltiorrhiza)的CPP合酶,氨基酸序列–SEQ IDNO:34
MATVDAPQVHDHDGTTVHQGHDAVKNIEDPIEYIRTLLRTTGDGRISVSPYDTAWVAMIKDVEGRDGPQFPSSLEWIVQNQLEDGSWGDQKLFCVYDRLVNTIACVVALRSWNVHAHKVKRGVTYIKENVDKLMEGNEEHMTCGFEVVFPALLQKAKSLGIEDLPYDSPAVQEVYHVREQKLKRIPLEIMHKIPTSLLFSLEGLENLDWDKLLKLQSADGSFLTSPSSTAFAFMQTKDEKCYQFIKNTIDTFNGGAPHTYPVDVFGRLWAIDRLQRLGISRFFEPEIADCLSHIHKFWTDKGVFSGRESEFCDIDDTSMGMRLMRMHGYDVDPNVLRNFKQKDGKFSCYGGQMIESPSPIYNLYRASQLRFPGEEILEDAKRFAYDFLKEKLANNQILDKWVISKHLPDEIKLGLEMPWLATLPRVEAKYYIQYYAGSGDVWIGKTLYRMPEISNDTYHDLAKTDFKRCQAKHQFEWLYMQEWYESCGIEEFGISRKDLLLSYFLATASIFELERTNERIAWAKSQIIAKMITSFFNKETTSEEDKRALLNELGNINGLNDTNGAGREGGAGSIALATLTQFLEGFDRYTRHQLKNAWSVWLTQLQHGEADDAELLTNTLNICAGHIAFREEILAHNEYKALSNLTSKICRQLSFIQSEKEMGVEGEIAAKSSIKNKELEEDMQMLVKLVLEKYGGIDRNIKKAFLAVAKTYYYRAYHAADTIDTHMFKVLFEPVA
密码子优化的cDNA编码来自成团泛菌(Pantoea agglomerans)的GGPP合酶–SEQID NO:35
ATGGTTTCTGGTTCGAAAGCAGGAGTATCACCTCATAGGGAAATCGAAGTCATGAGACAGTCCATTGATGACCACTTAGCAGGATTGTTGCCAGAAACAGATTCCCAGGATATCGTTAGCCTTGCTATGAGAGAAGGTGTTATGGCACCTGGTAAACGTATCAGACCTTTGCTGATGTTACTTGCTGCAAGAGACCTGAGATATCAGGGTTCTATGCCTACACTACTGGATCTAGCTTGTGCTGTTGAACTGACACATACTGCTTCCTTGATGCTGGATGACATGCCTTGTATGGACAATGCGGAACTTAGAAGAGGTCAACCAACAACCCACAAGAAATTCGGAGAATCTGTTGCCATTTTGGCTTCTGTAGGTCTGTTGTCGAAAGCATTTGGCTTGATTGCTGCAACTGGTGATCTTCCAGGTGAAAGGAGAGCACAAGCTGTAAACGAGCTATCTACTGCAGTTGGTGTTCAAGGTCTAGTCTTAGGACAGTTCAGAGATTTGAATGACGCAGCTTTGGACAGAACTCCTGATGCTATCCTGTCTACGAACCATCTGAAGACTGGCATCTTGTTCTCAGCTATGTTGCAAATCGTAGCCATTGCTTCTGCTTCTTCACCATCTACTAGGGAAACGTTACACGCATTCGCATTGGACTTTGGTCAAGCCTTTCAACTGCTAGACGATTTGAGGGATGATCATCCAGAGACAGGTAAAGACCGTAACAAAGACGCTGGTAAAAGCACTCTAGTCAACAGATTGGGTGCTGATGCAGCTAGACAGAAACTGAGAGAGCACATTGACTCTGCTGACAAACACCTGACATTTGCATGTCCACAAGGAGGTGCTATAAGGCAGTTTATGCACCTATGGTTTGGACACCATCTTGCTGATTGGTCTCCAGTGATGAAGATCGCCTAA
来自成团泛菌(Pantoea agglomerans)的GGPP合酶,氨基酸序列–SEQ ID NO:36
MVSGSKAGVSPHREIEVMRQSIDDHLAGLLPETDSQDIVSLAMREGVMAPGKRIRPLLMLLAARDLRYQGSMPTLLDLACAVELTHTASLMLDDMPCMDNAELRRGQPTTHKKFGESVAILASVGLLSKAFGLIAATGDLPGERRAQAVNELSTAVGVQGLVLGQFRDLNDAALDRTPDAILSTNHLKTGILFSAMLQIVAIASASSPSTRETLHAFALDFGQAFQLLDDLRDDHPETGKDRNKDAGKSTLVNRLGADAARQKLREHIDSADKHLTFACPQGGAIRQFMHLWFGHHLADWSPVMKIA
优化的cDNA编码SsLPS–SEQ ID NO:37
ATGGCATCCCAAGCGTCCGAGAAAGATATTAGCCTGGTTCAAACCCCGCATAAGGTCGAGGTCAACGAAAAGATCGAAGAGAGCATCGAGTACGTCCAAAATCTGCTGATGACGAGCGGTGACGGTCGTATCTCCGTGTCTCCGTACGATACCGCGGTCATCGCTCTGATTAAAGATCTGAAGGGTCGCGACGCACCGCAGTTCCCGAGCTGTCTGGAGTGGATTGCGCACCACCAGTTAGCGGATGGTAGCTGGGGCGACGAGTTCTTTTGTATCTATGACCGCATTTTGAATACCCTGGCGTGCGTCGTCGCACTGAAATCTTGGAATCTGCACAGCGACATTATTGAAAAAGGCGTGACCTACATTAAGGAAAACGTCCATAAGCTGAAAGGCGCGAATGTTGAGCATAGAACCGCCGGTTTTGAGCTGGTTGTTCCGACCTTCATGCAGATGGCGACTGACCTGGGTATTCAGGATCTGCCGTACGATCATCCTCTTATCAAAGAAATCGCTGATACGAAGCAACAGCGCCTGAAAGAAATTCCGAAAGATTTGGTTTATCAGATGCCGACCAATCTGCTGTATAGCCTGGAAGGCCTGGGCGATTTAGAGTGGGAGCGTTTGCTGAAGCTGCAGTCTGGTAATGGTAGCTTCCTGACGAGCCCAAGCAGCACGGCGGCAGTTCTGATGCATACCAAAGACGAGAAGTGTTTGAAATACATTGAGAATGCGCTGAAGAACTGCGACGGTGGCGCTCCTCATACGTATCCGGTTGACATCTTTAGCCGCTTGTGGGCGATCGACCGTTTGCAACGTCTGGGCATTAGCCGTTTCTTCCAACACGAGATCAAATACTTTCTGGACCACATCGAGTCAGTCTGGGAAGAAACCGGCGTGTTTAGCGGTCGTTACACGAAGTTTAGCGACATCGATGACACGAGCATGGGTGTCCGCCTGCTGAAAATGCACGGTTACGACGTAGACCCAAACGTGTTGAAACACTTTAAGCAGCAAGACGGCAAATTCAGCTGCTACATCGGCCAGAGCGTCGAGAGCGCGAGCCCGATGTATAATCTGTACCGTGCCGCCCAGCTGCGTTTCCCGGGTGAAGAAGTGCTTGAAGAAGCAACTAAATTCGCGTTTAACTTCCTGCAAGAGATGCTGGTGAAGGATCGCTTGCAAGAGCGTTGGGTTATTAGCGATCACCTGTTTGACGAGATTAAGCTCGGTCTGAAGATGCCGTGGTATGCTACCCTGCCGCGTGTTGAGGCCGCTTATTACCTGGATCACTATGCGGGTAGCGGTGATGTGTGGATTGGTAAGTCTTTTTACCGCATGCCGGAGATTAGCAATGACACCTACAAAGAATTGGCCATCCTGGACTTTAACCGTTGTCAGACTCAGCATCAGCTGGAGTGGATTCACATGCAAGAGTGGTATGACCGCTGCTCTCTGTCCGAGTTTGGTATTAGCAAGCGTGAGCTGCTGCGTAGCTACTTCCTGGCTGCCGCAACCATTTTCGAACCGGAACGCACCCAAGAGCGTCTGCTCTGGGCAAAGACCCGCATCCTGAGCAAGATGATTACCAGCTTCGTCAACATCTCCGGTACGACCCTGAGCCTGGATTACAACTTCAACGGTTTGGATGAGATCATTTCCAGCGCGAATGAAGATCAGGGTCTGGCGGGTACGCTGTTGGCCACGTTCCATCAACTGCTGGATGGTTTCGACATTTACACCCTGCACCAACTGAAACACGTCTGGTCGCAATGGTTTATGAAAGTTCAGCAAGGCGAGGGCTCCGGCGGCGAAGATGCGGTCCTGCTGGCAAATACTCTGAATATCTGCGCGGGTCTGAATGAAGATGTGCTGTCGAACAACGAGTATACCGCGCTGAGCACGCTGACGAACAAGATCTGCAACCGTCTGGCCCAGATCCAGGACAACAAGATTCTGCAAGTGGTGGACGGCAGCATCAAAGACAAAGAACTGGAACAGGATATGCAGGCATTGGTTAAACTGGTGCTGCAGGAAAACGGTGGCGCAGTGGACCGTAACATCCGTCACACGTTTCTGAGCGTTAGCAAGACCTTCTACTATGACGCGTATCACGACGATGAAACCACCGATCTGCATATCTTTAAAGTCCTGTTCCGTCCGGTTGTTTAA
SsLPS氨基酸序列–SEQ ID NO:38
MASQASEKDISLVQTPHKVEVNEKIEESIEYVQNLLMTSGDGRISVSPYDTAVIALIKDLKGRDAPQFPSCLEWIAHHQLADGSWGDEFFCIYDRILNTLACVVALKSWNLHSDIIEKGVTYIKENVHKLKGANVEHRTAGFELVVPTFMQMATDLGIQDLPYDHPLIKEIADTKQQRLKEIPKDLVYQMPTNLLYSLEGLGDLEWERLLKLQSGNGSFLTSPSSTAAVLMHTKDEKCLKYIENALKNCDGGAPHTYPVDIFSRLWAIDRLQRLGISRFFQHEIKYFLDHIESVWEETGVFSGRYTKFSDIDDTSMGVRLLKMHGYDVDPNVLKHFKQQDGKFSCYIGQSVESASPMYNLYRAAQLRFPGEEVLEEATKFAFNFLQEMLVKDRLQERWVISDHLFDEIKLGLKMPWYATLPRVEAAYYLDHYAGSGDVWIGKSFYRMPEISNDTYKELAILDFNRCQTQHQLEWIHMQEWYDRCSLSEFGISKRELLRSYFLAAATIFEPERTQERLLWAKTRILSKMITSFVNISGTTLSLDYNFNGLDEIISSANEDQGLAGTLLATFHQLLDGFDIYTLHQLKHVWSQWFMKVQQGEGSGGEDAVLLANTLNICAGLNEDVLSNNEYTALSTLTNKICNRLAQIQDNKILQVVDGSIKDKELEQDMQALVKLVLQENGGAVDRNIRHTFLSVSKTFYYDAYHDDETTDLHIFKVLFRPVV
优化的cDNA编码TaTps1-del59–SEQ ID NO:39
ATGTATCGCCAAAGAACTGATGAGCCAAGCGAAACCCGCCAGATGATCGATGATATTCGCACCGCTTTGGCTAGCCTGGGTGACGATGAAACCAGCATGAGCGTGAGCGCATACGACACCGCCCTGGTTGCCCTGGTGAAGAACCTGGACGGTGGCGATGGCCCGCAGTTCCCGAGCTGCATTGACTGGATTGTTCAGAACCAGCTGCCGGACGGTAGCTGGGGCGACCCGGCTTTCTTTATGGTTCAGGACCGTATGATCAGCACCCTGGCCTGTGTCGTGGCCGTGAAATCCTGGAATATCGATCGTGACAACTTGTGCGATCGTGGTGTCCTGTTTATCAAAGAAAACATGTCGCGTCTGGTTGAAGAAGAACAAGATTGGATGCCATGTGGCTTCGAGATTAACTTTCCTGCACTGTTGGAGAAAGCTAAAGACCTGGACTTGGACATTCCGTACGATCATCCTGTGCTGGAAGAGATTTACGCGAAGCGTAATCTGAAACTGCTGAAGATTCCGTTAGATGTCCTCCATGCGATCCCGACGACGCTGTTGTTTTCCGTTGAGGGTATGGTCGATCTGCCGCTGGATTGGGAGAAACTGCTGCGTCTGCGTTGCCCGGACGGTTCTTTTCATTCTAGCCCGGCGGCGACGGCAGCGGCGCTGAGCCACACGGGTGACAAAGAGTGTCACGCCTTCCTGGACCGCCTGATTCAAAAGTTCGAGGGTGGCGTCCCGTGCTCCCACAGCATGGACACCTTCGAGCAACTGTGGGTTGTTGACCGTTTGATGCGTCTGGGTATCAGCCGTCATTTTACGAGCGAGATCCAGCAGTGCTTGGAGTTCATCTATCGTCGTTGGACCCAGAAAGGTCTGGCGCACAATATGCACTGCCCGATCCCGGACATTGATGACACTGCGATGGGTTTTCGTCTGTTGAGACAGCACGGTTACGACGTGACCCCGTCGGTTTTCAAGCATTTCGAGAAAGACGGCAAGTTCGTATGCTTCCCGATGGAAACCAACCATGCGAGCGTGACGCCGATGCACAATACCTACCGTGCGAGCCAGTTCATGTTCCCGGGTGATGACGACGTGCTGGCCCGTGCCGGCCGCTACTGTCGCGCATTCTTGCAAGAGCGTCAGAGCTCTAACAAGTTGTACGATAAGTGGATTATCACGAAAGATCTGCCGGGTGAGGTTGGCTACACGCTGAACTTTCCGTGGAAAAGCTCCCTGCCGCGTATTGAAACTCGTATGTATCTGGATCAGTACGGTGGCAATAACGATGTCTGGATTGCAAAGGTCCTGTATCGCATGAACCTGGTTAGCAATGACCTGTACCTGAAAATGGCGAAAGCCGACTTTACCGAGTATCAACGTCTGTCTCGCATTGAGTGGAACGGCCTGCGCAAATGGTATTTTCGCAATCATCTGCAGCGTTACGGTGCGACCCCGAAGTCCGCGCTGAAAGCGTATTTCCTGGCGTCGGCAAACATCTTTGAGCCTGGCCGCGCAGCCGAGCGCCTGGCATGGGCACGTATGGCCGTGCTGGCTGAAGCTGTAACGACTCATTTCCGTCACATTGGCGGCCCGTGCTACAGCACCGAGAATCTGGAAGAACTGATCGACCTTGTTAGCTTCGACGACGTGAGCGGCGGCTTGCGTGAGGCGTGGAAGCAATGGCTGATGGCGTGGACCGCAAAAGAATCACACGGCAGCGTGGACGGTGACACGGCACTGCTGTTTGTCCGCACGATTGAGATTTGCAGCGGCCGCATCGTTTCCAGCGAGCAGAAACTGAATCTGTGGGATTACAGCCAGTTAGAGCAATTGACCAGCAGCATCTGTCATAAACTGGCCACCATCGGTCTGAGCCAGAACGAAGCTAGCATGGAAAATACCGAAGATCTGCACCAACAAGTCGATTTGGAAATGCAAGAACTGTCATGGCGTGTTCACCAGGGTTGTCACGGTATTAATCGCGAAACCCGTCAAACCTTCCTGAATGTTGTTAAGTCTTTTTATTACTCCGCACACTGCAGCCCGGAAACCGTGGACAGCCATATTGCAAAAGTGATCTTTCAAGACGTTATCTGA
TaTps1-del59,来自小麦(Triticum aestivum)的截短的柯巴基二磷酸合酶–SEQID NO:40
MYRQRTDEPSETRQMIDDIRTALASLGDDETSMSVSAYDTALVALVKNLDGGDGPQFPSCIDWIVQNQLPDGSWGDPAFFMVQDRMISTLACVVAVKSWNIDRDNLCDRGVLFIKENMSRLVEEEQDWMPCGFEINFPALLEKAKDLDLDIPYDHPVLEEIYAKRNLKLLKIPLDVLHAIPTTLLFSVEGMVDLPLDWEKLLRLRCPDGSFHSSPAATAAALSHTGDKECHAFLDRLIQKFEGGVPCSHSMDTFEQLWVVDRLMRLGISRHFTSEIQQCLEFIYRRWTQKGLAHNMHCPIPDIDDTAMGFRLLRQHGYDVTPSVFKHFEKDGKFVCFPMETNHASVTPMHNTYRASQFMFPGDDDVLARAGRYCRAFLQERQSSNKLYDKWIITKDLPGEVGYTLNFPWKSSLPRIETRMYLDQYGGNNDVWIAKVLYRMNLVSNDLYLKMAKADFTEYQRLSRIEWNGLRKWYFRNHLQRYGATPKSALKAYFLASANIFEPGRAAERLAWARMAVLAEAVTTHFRHIGGPCYSTENLEELIDLVSFDDVSGGLREAWKQWLMAWTAKESHGSVDGDTALLFVRTIEICSGRIVSSEQKLNLWDYSQLEQLTSSICHKLATIGLSQNEASMENTEDLHQQVDLEMQELSWRVHQGCHGINRETRQTFLNVVKSFYYSAHCSPETVDSHIAKVIFQDVI
CymB,优化的cDNA–SEQ ID NO:41
ATGACTATCAATTCTATTCAACCGATTCAAGCAAAAGCCGCTGTGCTGCGTGCCGTAGGCTCCCCGTTTAACATTGAGCCGATTCGTATCAGCCCGCCGAAGGGTGATGAAGTTCTGGTCCGTATTGTGGGTGTGGGTGTCTGCCATACCGACGTCGTTTGCCGTGACAGCTTCCCGGTTCCGCTGCCAATCATCCTGGGTCACGAAGGCTCGGGTGTGATTGAAGCGATCGGTGATCAAGTTACGAGCCTGAAGCCAGGTGACCACGTCGTTCTGAGCTTCAATAGCTGCGGCCACTGTTATAACTGCGGTCATGCGGAGCCGGCAAGCTGCCTGCAGATGTTACCGTTGAACTTTGGTGGCGCGGAGCGTGCGGCGGACGGCACCATCCAAGACGACAAGGGTGAAGCCGTCCGCGGTATGTTCTTTGGCCAGTCCAGCTTTGGCACGTACGCAATCGCACGTGCGGTGAATGCTGTCAAAGTTGACGACGATCTGCCGCTGCCTCTGTTGGGCCCGCTGGGCTGTGGTATCCAGACCGGTGCGGGTGCAGCGATGAACAGCCTGTCTCTGCAGAGCGGTCAGAGCTTCATCGTTTTCGGTGGCGGCGCGGTCGGTCTGAGCGCTGTTATGGCAGCTAAAGCGCTGGGCGTGAGCCCGCTGATCGTTGTGGAGCCGAACGAAAGCCGCCGCGCCCTGGCCCTGGAACTGGGTGCATCCCACGTGTTTGATCCGTTCAACACCGAAGATCTGGTTGCCAGCATTCGCGAAGTCGTGCCTGCGGGTGCGAACCATGCACTGGACACGACCGGTCTGCCGAAAGTGATCGCGAGCGCGATTGATTGTATTATGAGCGGTGGCAAACTGGGTTTGCTGGGTATGGCGAGCCCGGAAGCGAATGTGCCGGCTACCCTGTTGGATTTGCTGAGCAAAAATGTCACGCTGAAGCCGATCACCGAGGGCGATGCGAACCCACAAGAGTTCATCCCGCGTATGCTGGCACTCTACCGTGAGGGTAAGTTCCCGTTTGAGAAACTGATCACGACCTTTCCGTTTGAGCACATTAATGAAGCAATGGAAGCCACTGAGTCCGGTAAGGCCATTAAACCGGTTCTGACGCTGTAA
CymB,氨基酸序列–SEQ ID NO:42
MTINSIQPIQAKAAVLRAVGSPFNIEPIRISPPKGDEVLVRIVGVGVCHTDVVCRDSFPVPLPIILGHEGSGVIEAIGDQVTSLKPGDHVVLSFNSCGHCYNCGHAEPASCLQMLPLNFGGAERAADGTIQDDKGEAVRGMFFGQSSFGTYAIARAVNAVKVDDDLPLPLLGPLGCGIQTGAGAAMNSLSLQSGQSFIVFGGGAVGLSAVMAAKALGVSPLIVVEPNESRRALALELGASHVFDPFNTEDLVASIREVVPAGANHALDTTGLPKVIASAIDCIMSGGKLGLLGMASPEANVPATLLDLLSKNVTLKPITEGDANPQEFIPRMLALYREGKFPFEKLITTFPFEHINEAMEATESGKAIKPVLTL
AspWeADH1,优化的cDNA–SEQ ID NO:43
ATGGGTAGCATTACTGAAGATATCCCAACCATGCGCGCTGCTACTGTTGTTGAGTACAATAAGCCGCTTCAAATCCTGAATATCCCTATTCCGACCCCGTCCCAGGATCAGATTCTGGTCAAGGTCACCGCATGCAGCCTGTGCAACAGCGACCTGGCGGGCTGGCTGGGTGTTGTTGGTGCGGTTGCGCCGTATTGTCCGGGCCATGAACCGGTGGGTGTAATTGAGAGCGTCGGTAGCGCCGTTCGCGGTTTCAAGAAAGGCGACCGTGCCGGTTTCATGCCGAGCTCCTTTACGTGTAAAGACTGCAATGAATGTCAAACCGGTAATCATCGTTTTTGTAATAAGAAAACCAGCGTGGGTTTCCAGGGTCCGTATGGCGGCTTCAGCCAATATGCCGTTGCTGACCCGTTGAGCACGGTTAAGATCCCGGACGCGCTGTCTGATGAAGTCACGGCGCCGCTGTTGTGCGCGGGTGTGACGGCGTATGGCGCACTGCGCAAGGTCCCGCCAGGCGTGCAGAGCGTGAACGTTATCGGTTGCGGTGGCGTTGGCCACCTGGTGATCCAATATGCGAAGGCTCTGGGTTACTACGTGCGTGGCTTTGACGTTAACGACAAGAAACTGGGCCTGGCAGCGCGTAGCGGTGCGGATGAAACCTTTTACAGCACCGATGCCACCCATGCGGACCAGGCATCTGCAACGATCGTCGCGACCGGCGCGGTTGCAGCGTACAAAGCCGCATTCGCAGTCACCGCCAACCACGGTCGTATCATTGCGATCGGTGTCCCGAAGGGTGAGATTCCGGTGTCGCTGCTGGACATGGTCAAACGTGATCTGAGCTTAGTGGCGACGAACCAAGGCTCCAAAGAAGAATTGGAAGAGGCTCTGGAAATTGCAGTGCAACACCAGATCGCACCGGAGTACGAAATTCGCCAGCTGGACCAGCTGAACGATGGCTTTCAAGAGATGATGAAAGGTGAGAGCCACGGTCGTCTGGTGTACCGTCTGTGGTAA
AspWeADH1,氨基酸序列–SEQ ID NO:44
MGSITEDIPTMRAATVVEYNKPLQILNIPIPTPSQDQILVKVTACSLCNSDLAGWLGVVGAVAPYCPGHEPVGVIESVGSAVRGFKKGDRAGFMPSSFTCKDCNECQTGNHRFCNKKTSVGFQGPYGGFSQYAVADPLSTVKIPDALSDEVTAPLLCAGVTAYGALRKVPPGVQSVNVIGCGGVGHLVIQYAKALGYYVRGFDVNDKKLGLAARSGADETFYSTDATHADQASATIVATGAVAAYKAAFAVTANHGRIIAIGVPKGEIPVSLLDMVKRDLSLVATNQGSKEELEEALEIAVQHQIAPEYEIRQLDQLNDGFQEMMKGESHGRLVYRLW
PsAerADH1,优化的cDNA–SEQ ID NO:45
ATGAACTCGATCCAACCTACTCAAGCAAAAGCAGCAGTCTTGCGCGCAGTCGGCGGCCCGTTCTCTATTGAGCCGATCCGCATCAGCCCACCGAAGGGTGACGAAGTGCTGGTTCGTATCGTTGGTGTGGGTGTCTGCCACACCGACGTCGTCTGTCGTGATAGCTTTCCGGTGCCGTTGCCGATCATTCTGGGTCACGAGGGCTCCGGTGTGATTGAAGCTGTGGGTGACCAAGTGACCGGTCTGAAACCGGGTGACCACGTTGTGCTGTCCTTCAATAGCTGCGGCCATTGCTACAACTGTGGTCATGACGAGCCTGCGTCTTGTCTGCAGATGCTGCCGTTGAATTTCGGTGGCGCGGAGCGTGCGGCGGACGGCACCATCGAAGATGACCAGGGCGCAGCTGTTCGTGGCCTGTTCTTCGGCCAAAGCTCCTTTGGTAGCTACGCGATTGCACGTGCGGTTAACACTGTCAAAGTTGATGACGATCTGCCGTTGGCGCTGCTGGGTCCGCTGGGTTGCGGTATTCAGACCGGCGCGGGTGCAGCCATGAATAGCCTGGGTTTACAGGGTGGCCAGAGCTTCATTGTGTTTGGCGGCGGCGCCGTCGGTCTGAGCGCGGTCATGGCCGCCAAGGCCCTGGGTGTTAGCCCGCTGATTGTTGTGGAGCCGAACGAAGCTCGCCGTGCGCTGGCACTGGAATTGGGTGCGAGCCACGCGTTTGACCCATTTAACACCGAAGATCTGGTCGCGAGCATTCGCGAAGTCGTTCCGGCTGGCGCAAACCACGCGCTGGACACGACGGGTCTGCCGAAAGTTATTGCCAACGCGATCGATTGCATCATGAGCGGCGGCAAACTGGGTCTGCTCGGTATGGCGAATCCGGAAGCGAATGTGCCGGCGACCCTGCTGGATCTGCTGAGCAAAAATGTGACGCTGAAGCCGATCACCGAGGGTGACGCAAACCCACAAGAATTTATTCCGCGTATGCTGGCTCTGTATCGTGAGGGTAAGTTTCCGTTCGATAAGCTGATCACCACGTTCCCGTTCGAGCATATCAACGAAGCAATGGAAGCTACCGAGAGCGGTAAGGCCATTAAACCGGTTCTGACCCTGTAA
PsAerADH1,氨基酸序列–SEQ ID NO:46
MNSIQPTQAKAAVLRAVGGPFSIEPIRISPPKGDEVLVRIVGVGVCHTDVVCRDSFPVPLPIILGHEGSGVIEAVGDQVTGLKPGDHVVLSFNSCGHCYNCGHDEPASCLQMLPLNFGGAERAADGTIEDDQGAAVRGLFFGQSSFGSYAIARAVNTVKVDDDLPLALLGPLGCGIQTGAGAAMNSLGLQGGQSFIVFGGGAVGLSAVMAAKALGVSPLIVVEPNEARRALALELGASHAFDPFNTEDLVASIREVVPAGANHALDTTGLPKVIANAIDCIMSGGKLGLLGMANPEANVPATLLDLLSKNVTLKPITEGDANPQEFIPRMLALYREGKFPFDKLITTFPFEHINEAMEATESGKAIKPVLTL
AzTolADH1,优化的cDNA–SEQ ID NO:47
ATGGGTTCTATTCAAGATTCTCTGTTCATCCGTGCACGCGCCGCTGTTCTGCGTACTGTCGGTGGCCCGCTGGAAATTGAAAACGTCCGCATTAGCCCTCCGAAGGGTGACGAAGTGCTCGTGCGTATGGTTGGTGTTGGTGTGTGCCATACCGACGTTGTGTGTCGCGATGGCTTCCCGGTTCCGCTGCCGATTGTGCTGGGTCACGAGGGCAGCGGTATTGTCGAGGCAGTGGGCGAGCGTGTGACCAAGGTTAAACCGGGTCAGCGTGTCGTTTTATCCTTCAATAGCTGTGGTCATTGCGCGTCCTGCTGCGAGGACCACCCGGCCACCTGTCACCAGATGCTGCCACTGAACTTTGGTGCGGCGCAGCGCGTGGATGGTGGCACCGTTATCGACGCGAGCGGCGAGGCAGTGCAGAGCCTGTTTTTTGGTCAAAGCTCTTTCGGTACGTATGCATTGGCGCGTGAAGTCAATACCGTACCGGTGCCGGATGCAGTTCCGTTGGAAATCCTGGGCCCGTTGGGTTGCGGCATCCAGACGGGTGCGGGTGCGGCTATCAACAGCCTGGCGCTGAAACCTGGTCAATCGCTGGCAATCTTCGGTGGCGGCAGCGTCGGTCTGTCCGCCCTGCTGGGCGCGCTGGCCGTGGGCGCGGGCCCGGTCGTTGTCATTGAGCCGAACGAACGTCGTCGTGCGTTGGCGCTGGACCTGGGTGCGAGCCATGCATTTGATCCGTTCAACACTGAAGATTTGGTTGCGAGCATCAAAGCCGCTACGGGTGGCGGCGTTACCCACAGCCTGGACAGCACGGGTCTGCCGCCGGTCATCGCGAATGCAATCAACTGTACCTTGCCGGGCGGCACGGTCGGTCTGCTGGGCGTCCCGAGCCCAGAGGCTGCCGTTCCGGTGACGCTGCTGGATCTGCTGGTTAAATCAGTTACCCTGCGTCCGATTACCGAGGGTGACGCCAATCCGCAAGAATTTATTCCGCGTATGGTCCAGCTGTACCGCGACGGTAAATTTCCGTTTGATAAGCTGATTACGACCTACCGCTTCGACGACATCAATCAAGCGTTCAAGGCAACCGAAACCGGTGAAGCGATTAAGCCAGTGCTGGTGTTTTAA
AzTolADH1,氨基酸序列–SEQ ID NO:48
MGSIQDSLFIRARAAVLRTVGGPLEIENVRISPPKGDEVLVRMVGVGVCHTDVVCRDGFPVPLPIVLGHEGSGIVEAVGERVTKVKPGQRVVLSFNSCGHCASCCEDHPATCHQMLPLNFGAAQRVDGGTVIDASGEAVQSLFFGQSSFGTYALAREVNTVPVPDAVPLEILGPLGCGIQTGAGAAINSLALKPGQSLAIFGGGSVGLSALLGALAVGAGPVVVIEPNERRRALALDLGASHAFDPFNTEDLVASIKAATGGGVTHSLDSTGLPPVIANAINCTLPGGTVGLLGVPSPEAAVPVTLLDLLVKSVTLRPITEGDANPQEFIPRMVQLYRDGKFPFDKLITTYRFDDINQAFKATETGEAIKPVLVF
AroAroADH1,优化的cDNA–SEQ ID NO:49
ATGGGCTCAATTCAAGATTCTCTGTTCATCCCGGCTAGAGCGGCAGTGTTGCGTGCGGTCGGTGGCCCACTGGAAATCGAAGATGTTCGTATCAGCCCGCCTAAGGGCGACGAAGTTCTGGTCCGTATGGTTGGCGTGGGCGTTTGCCACACCGACGTTGTGTGCCGCGATGGTTTCCCGGTCCCGCTGCCGATTGTCTTGGGTCACGAGGGTGCGGGTATCGTGGAAGCTGTGGGTGAGCGTGTGACCAAGGTCAAACCTGGCCAGCGTGTGGTGCTGAGCTTCAACAGCTGCGGTCACTGCAGCTCCTGTGGTGAGGATCACCCGGCGACGTGTCATCAGATGCTGCCGCTGAATTTTGGTGCAGCGCAACGTGTTGACGGTGGCTGTGTCACCGATGCGAGCGGTGAAGCTGTACATAGCCTGTTTTTCGGTCAGAGCTCTTTTTGCACCTTTGCACTGGCGCGCGAAGTGAACACCGTTCCTGTCGGTGACGGCGTTCCGCTGGAAATTCTGGGTCCGCTGGGTTGTGGTATTCAAACCGGTGCAGGCGCAGCGATCAACAGCCTGGCCATTAAACCGGGTCAGAGCCTGGCGATTTTCGGTGGCGGCAGCGTTGGTCTGTCCGCCCTGCTGGGCGCACTGGCCGTGGGCGCGGGTCCGGTTGTTGTGGTGGAGCCGAATGATCGTCGTCGTGCACTGGCCCTGGACCTGGGTGCGTCGCATGTGTTTGACCCGTTCAATACCGAAGATCTGGTTGCGAGCATTAAAGCCGCGACGGGTGGCGGCGTTACTCACAGCCTGGACAGCACTGGCTTGCCGCCGGTGATCGCAAAGGCCATTGATTGTACGTTGCCGGGTGGCACCGTCGGTTTACTGGGTGTTCCGGCTCCGGACGCCGCAGTGCCGGTCACGCTGCTGGACTTGCTGGTGAAGTCCGTTACCCTGCGCCCGATCACCGAGGGTGACGCAAACCCGCAAGAATTTATTCCACGCATGGTTCAGCTCTACCGTGATGGTAAGTTCCCATTTGATAAACTGATCACCACGTATCGTTTTGAGAACATCAATGACGCGTTCAAAGCGACGGAAACGGGTGAAGCGATCAAACCGGTCCTGGTTTTCTAA
AroAroADH1,氨基酸序列–SEQ ID NO:50
MGSIQDSLFIPARAAVLRAVGGPLEIEDVRISPPKGDEVLVRMVGVGVCHTDVVCRDGFPVPLPIVLGHEGAGIVEAVGERVTKVKPGQRVVLSFNSCGHCSSCGEDHPATCHQMLPLNFGAAQRVDGGCVTDASGEAVHSLFFGQSSFCTFALAREVNTVPVGDGVPLEILGPLGCGIQTGAGAAINSLAIKPGQSLAIFGGGSVGLSALLGALAVGAGPVVVVEPNDRRRALALDLGASHVFDPFNTEDLVASIKAATGGGVTHSLDSTGLPPVIAKAIDCTLPGGTVGLLGVPAPDAAVPVTLLDLLVKSVTLRPITEGDANPQEFIPRMVQLYRDGKFPFDKLITTYRFENINDAFKATETGEAIKPVLVF
ThTerpADH1,优化的cDNA–SEQ ID NO:51
ATGTGTAGCAATCATGATTTCACCGCAGCCCGTGCAGCAGTCTTACGTAAAGTTGGTGGCCCGTTGGAAATCGAAGATGTCCGTATTTCTGCCCCGAAAGGCGACGAAGTCCTGGTGCGTATGGTTGGCGTGGGTGTGTGTCATACCGACCTCGTCTGCCGTGATGCGTTCCCGGTGCCGCTGCCTATTGTTCTGGGTCACGAGGGTGCAGGCATCGTTGAAGCCGTGGGTGAGGGCGTGCGCTCCCTGGAGCCGGGTGACCGTGTTGTGCTGAGCTTCAATAGCTGCGGCCGCTGTGGCAACTGCGGTAGCGGTCACCCGAGCAACTGCCTGCAAATGCTGCCGCTGAATTTTGGTGGCGCGCAACGCGTTGACGGTGGCCGCATGTTGGACGCGGCGGGTAACGCTGTCCAGGGTCTGTTTTTTGGTCAATCTAGCTTCGGCACGTATGCGATCGCGCGTGAGATTAACGCCGTGAAAGTCGCCGAAGATCTGCCGCTGGAAATCCTGGGTCCGCTGGGTTGCGGTATTCAGACCGGTGCGGGTGCGGCGATTAACAGCCTGGGTATTGGTCCGGGTCAGTCCTTGGCTGTGTTCGGTGGCGGCGGCGTGGGTCTTAGCGCGTTGCTGGGCGCTCGTGCTGTGGGTGCCGCCCAAGTTGTTGTTGTTGAGCCGAACGCCGCACGTCGCGCGCTGGCGCTGGAACTGGGTGCGAGCCATGCATTCGACCCGTTTGCGGGTGACGACCTGGTCGCGGCGATCCGCGCAGCGACGGGTGGCGGCGCAACCCACGCGCTGGATACGACCGGCCTGCCGTCGGTGATTGGCAATGCAATCGATTGTACTTTGCCGGGTGGCACGGTTGGTATGGTCGGCATGCCAGCGCCTGACGCTGCGGTCCCGGCGACCCTGCTGGATTTGCTGACTAAGAGCGTCACGCTGCGTCCGATCACCGAGGGTGACGCAGATCCGCAGGCCTTCATCCCACAGATGCTGCGCTTTTACCGTGAGGGTAAGTTCCCGTTTGACCGTCTGATTACCCGTTACCGTTTTGATCAGATCAATGAAGCTCTGCACGCAACCGAAAAGGGTGGCGCGATTAAACCGGTTCTGGTGTTCTAA
ThTerpADH1,氨基酸序列–SEQ ID NO:52
MCSNHDFTAARAAVLRKVGGPLEIEDVRISAPKGDEVLVRMVGVGVCHTDLVCRDAFPVPLPIVLGHEGAGIVEAVGEGVRSLEPGDRVVLSFNSCGRCGNCGSGHPSNCLQMLPLNFGGAQRVDGGRMLDAAGNAVQGLFFGQSSFGTYAIAREINAVKVAEDLPLEILGPLGCGIQTGAGAAINSLGIGPGQSLAVFGGGGVGLSALLGARAVGAAQVVVVEPNAARRALALELGASHAFDPFAGDDLVAAIRAATGGGATHALDTTGLPSVIGNAIDCTLPGGTVGMVGMPAPDAAVPATLLDLLTKSVTLRPITEGDADPQAFIPQMLRFYREGKFPFDRLITRYRFDQINEALHATEKGGAIKPVLVF
CdGeoA优化的cDNA–SEQ ID NO:53
ATGAACGATACGCAGGATTTTATTAGCGCCCAAGCCGCAGTGTTACGTCAGGTCGGTGGCCCGCTGGCCGTTGAGCCTGTTCGTATCAGCATGCCGAAGGGTGACGAAGTCCTGATTCGTATCGCGGGTGTTGGTGTGTGCCACACCGACTTGGTGTGCCGTGATGGCTTCCCGGTGCCGCTGCCAATTGTGCTGGGTCACGAGGGTAGCGGTACTGTCGAAGCCGTCGGTGAACAAGTCCGTACCCTGAAACCGGGCGATCGCGTCGTGCTGAGCTTTAACAGCTGCGGTCATTGCGGTAACTGTCACGACGGTCACCCGAGCAATTGCCTGCAGATGCTGCCGCTGAACTTCGGTGGCGCGCAACGCGTGGACGGTGGCCAAGTTTTGGACGGTGCGGGTCATCCGGTTCAGTCCATGTTTTTCGGCCAGTCCAGCTTTGGCACCCACGCAGTAGCGCGCGAGATCAACGCAGTCAAGGTCGGCGATGATCTGCCACTGGAACTGCTGGGTCCGTTGGGTTGTGGCATTCAAACCGGTGCGGGTGCAGCTATCAATTCTCTGGGCATTGGTCCGGGTCAGTCTCTGGCTATCTTCGGCGGCGGCGGCGTGGGTCTGAGCGCACTGCTGGGCGCCCGTGCGGTGGGTGCCGACCGTGTTGTTGTCATTGAGCCGAATGCAGCGCGCCGTGCGCTGGCATTGGAACTGGGTGCCAGCCACGCACTGGACCCGCATGCCGAGGGCGACCTTGTTGCGGCGATTAAAGCTGCGACGGGTGGCGGCGCTACGCATAGCTTGGATACGACCGGCCTGCCGCCAGTCATTGGCTCCGCGATCGCGTGTACTCTGCCGGGTGGCACCGTTGGTATGGTTGGTCTGCCGGCGCCGGACGCACCGGTCCCTGCGACGCTGTTGGATCTGCTGAGCAAATCGGTTACCCTGCGTCCGATTACCGAGGGTGACGCTGACCCGCAACGCTTCATCCCGCGTATGCTGGATTTCCATCGTGCGGGCAAGTTTCCGTTCGACCGCCTGATCACCCGTTACCGCTTTGATCAGATCAATGAAGCGCTGCACGCGACCGAGAAAGGTGAAGCAATCAAACCGGTTCTGGTGTTTTAA
CdGeoA,氨基酸序列–SEQ ID NO:54
MNDTQDFISAQAAVLRQVGGPLAVEPVRISMPKGDEVLIRIAGVGVCHTDLVCRDGFPVPLPIVLGHEGSGTVEAVGEQVRTLKPGDRVVLSFNSCGHCGNCHDGHPSNCLQMLPLNFGGAQRVDGGQVLDGAGHPVQSMFFGQSSFGTHAVAREINAVKVGDDLPLELLGPLGCGIQTGAGAAINSLGIGPGQSLAIFGGGGVGLSALLGARAVGADRVVVIEPNAARRALALELGASHALDPHAEGDLVAAIKAATGGGATHSLDTTGLPPVIGSAIACTLPGGTVGMVGLPAPDAPVPATLLDLLSKSVTLRPITEGDADPQRFIPRMLDFHRAGKFPFDRLITRYRFDQINEALHATEKGEAIKPVLVF
VoADH1,优化的cDNA–SEQ ID NO:55
ATGACTAAATCCAGCGGTGAAGTGATTTCTTGTAAGGCAGCAGTGATCTATAAGAGCGGTGAGCCTGCTAAAGTTGAAGAAATTCGTGTTGATCCGCCTAAGAGCAGCGAAGTTCGTATTAAGATGCTGTACGCCTCCTTGTGTCACACGGACATTCTGTGTTGCAACGGCCTGCCGGTGCCGCTGTTTCCGCGCATTCCGGGTCACGAGGGCGTGGGTGTTGTGGAGAGCGCGGGTGAAGATGTGAAAGATGTTAAAGAGGGCGACATCGTTATGCCACTGTACCTGGGCGAGTGTGGTGAGTGCCTCAATTGCAGCAGCGGTAAGACGAATCTGTGCCACAAGTACCCACTGGACTTCTCTGGTGTGCTGCCGAGCGACGGTACGAGCCGCATGTCAGTAGCAAAATCCGGTGAGAAAATTTTCCATCACTTCAGCTGTAGCACCTGGTCCGAATATGTTGTCATCGAGAGCTCGTATGTCGTCAAAGTTGATAGCCGTCTGCCGCTGCCGCATGCGTCCTTTCTGGCATGCGGCTTCACCACGGGTTACGGCGCGGCGTGGAAAGAGGCTGACATTCCGAAGGGCAGCACCGTCGCGGTGCTGGGCCTGGGTGCGGTCGGTCTGGGTGTGGTTGCTGGTGCGCGTTCTCAGGGTGCGAGCCGCATTATTGGCGTGGACATCAACGACAAGAAAAAAGCAAAAGCCGAGATCTTTGGTGTTACTGAGTTTCTGAATCCGAAGCAACTGGGTAAAAGCGCGAGCGAAAGCATCAAAGACGTCACCGGCGGCCTGGGCGTTGACTACTGTTTCGAGTGCACCGGTGTCCCGGCCCTGTTGAACGAAGCCGTGGATGCGAGCAAGATCGGCTTGGGTACGATCGTCATGATTGGTGCGGGTATGGAAACCAGCGGTGTTATTAACTATATCCCGCTGCTGTGCGGCCGTAAACTGATCGGTAGCATTTACGGTGGCGTTCGCATCCGTAGCGACTTACCGCTGATCATTGAGAAATGCATCAACAAAGAAATTCCGCTGAACGAACTGCAGACCCACGAAGTGAGCTTGGAAGGCATTAATGATGCATTCGGCATGCTGAAGCAACCGGACTGCGTTAAGATCGTCATCAAGTTCGAGCAGAAATAA
VoADH1,氨基酸序列–SEQ ID NO:56
MTKSSGEVISCKAAVIYKSGEPAKVEEIRVDPPKSSEVRIKMLYASLCHTDILCCNGLPVPLFPRIPGHEGVGVVESAGEDVKDVKEGDIVMPLYLGECGECLNCSSGKTNLCHKYPLDFSGVLPSDGTSRMSVAKSGEKIFHHFSCSTWSEYVVIESSYVVKVDSRLPLPHASFLACGFTTGYGAAWKEADIPKGSTVAVLGLGAVGLGVVAGARSQGASRIIGVDINDKKKAKAEIFGVTEFLNPKQLGKSASESIKDVTGGLGVDYCFECTGVPALLNEAVDASKIGLGTIVMIGAGMETSGVINYIPLLCGRKLIGSIYGGVRIRSDLPLIIEKCINKEIPLNELQTHEVSLEGINDAFGMLKQPDCVKIVIKFEQK
活性位点签名基序-SEQ ID NO:57
HCxxGxxR
其中
每个x彼此独立地代表任何天然氨基酸残基。
活性位点签名基序-SEQ ID NO:58
HC(T/S)xGKDRTG
其中
x代表任何天然氨基酸残基。
PvCPS,具有异戊二烯基转移酶和柯巴基二磷酸合酶的多功能蛋白质,密码子优化的cDNA-SEQ ID NO:59
ATGAGCCCTATGGATTTGCAAGAAAGCGCCGCAGCCCTGGTCCGTCAATTGGGTGAACGCGTTGAGGATCGCCGCGGTTTTGGTTTCATGAGCCCGGCCATTTATGACACGGCCTGGGTTAGCATGATTAGCAAGACCATCGACGACCAAAAAACTTGGCTGTTTGCGGAGTGCTTCCAGTACATTCTGTCTCACCAACTGGAAGATGGTGGCTGGGCGATGTACGCATCCGAAATCGATGCCATCTTGAATACTTCCGCGTCACTGCTGTCCCTGAAACGCCACCTGTCCAACCCTTACCAGATCACCAGCATCACTCAGGAAGATCTGAGCGCTCGCATCAACCGCGCTCAAAACGCCCTGCAGAAATTGCTGAACGAGTGGAACGTTGACTCCACGCTGCACGTCGGTTTCGAGATTCTGGTTCCGGCGCTGCTGCGCTATCTGGAAGATGAAGGCATCGCGTTTGCGTTCTCGGGTCGTGAGCGTTTGTTAGAGATTGAGAAACAAAAACTGTCCAAGTTTAAAGCGCAGTATTTGTACTTACCGATTAAGGTCACCGCACTGCATAGCCTGGAAGCCTTCATCGGCGCTATTGAGTTCGACAAAGTCAGCCATCACAAAGTATCCGGTGCTTTCATGGCGTCGCCGTCTAGCACCGCAGCATACATGATGCATGCGACGCAATGGGATGACGAATGTGAGGATTACTTGCGTCACGTGATCGCGCATGCGTCAGGTAAGGGTTCTGGCGGCGTGCCGAGCGCCTTTCCGAGCACCATCTTCGAGAGCGTTTGGCCGCTGTCTACTCTGCTGAAAGTTGGCTATGATCTGAATAGCGCTCCGTTCATCGAGAAAATTCGTAGCTACTTGCACGATGCCTATATCGCAGAGAAAGGTATTCTCGGTTTCACCCCGTTCGTTGGCGCTGACGCGGACGACACCGCTACCACGATTCTGGTGTTGAATCTGCTGAACCAACCGGTGAGCGTGGACGCGATGTTGAAAGAATTTGAAGAGGAACATCACTTCAAGACCTACAGCCAAGAGCGTAATCCGAGCTTTTCCGCAAACTGTAATGTTCTGCTGGCGCTGCTGTACAGCCAGGAACCGAGCCTGTACAGCGCGCAAATCGAAAAAGCGATCCGTTTTCTGTATAAGCAATTCACCGACTCTGAGATGGATGTGCGCGATAAATGGAACCTGTCCCCGTATTATAGCTGGATGCTGATGACCCAGGCCATCACCCGTCTGACGACCCTGCAAAAGACCAGCAAGCTGAGCACGCTGCGTGATGACAGCATTAGCAAGGGCCTGATTTCTCTGCTGTTCCGCATTGCATCCACCGTGGTTAAAGATCAAAAACCGGGTGGCAGCTGGGGCACGCGTGCGAGCAAAGAAGAAACGGCATACGCCGTGCTGATTCTGACCTACGCGTTTTATCTGGACGAGGTGACCGAGTCTCTGCGCCACGATATCAAAATTGCAATCGAGAATGGTTGCTCGTTCCTGAGCGAGCGCACCATGCAAAGCGACAGCGAGTGGCTGTGGGTCGAAAAGGTTACCTACAAGAGCGAAGTGCTGAGCGAAGCATACATCCTGGCAGCTCTGAAACGTGCGGCAGACTTGCCGGATGAGAACGCTGAGGCAGCCCCAGTGATCAACGGTATCTCTACCAATGGCTTTGAGCACACCGACCGCATTAATGGTAAACTCAAGGTCAATGGTACGAATGGCACCAACGGTTCCCACGAAACGAACGGTATCAATGGCACCCATGAGATTGAGCAAATTAATGGTGTCAACGGCACGAATGGCCATAGCGACGTGCCACATGACACGAATGGTTGGGTCGAGGAACCGACGGCGATTAATGAAACGAACGGTCACTACGTTAACGGCACCAACCATGAGACTCCGCTGACCAATGGTATTAGCAATGGTGACTCCGTGAGCGTTCACACCGACCATAGCGACAGCTACTATCAGCGTAGCGACTGGACCGCGGATGAAGAACAGATCCTGCTGGGTCCATTCGATTACCTGGAATCCCTGCCTGGTAAAAATATGCGCAGCCAGCTGATCCAGTCTTTCAATACGTGGCTGAAGGTCCCGACCGAGAGCTTGGACGTGATTATTAAGGTCATTAGCATGCTGCACACTGCTAGCCTGCTGATCGACGATATTCAGGACCAAAGCATCCTGCGTCGTGGTCAGCCTGTGGCGCACTCGATCTTCGGCACCGCGCAAGCGATGAACTCTGGTAACTATGTTTACTTCCTGGCATTGCGTGAAGTTCAGAAATTGCAAAACCCGAAGGCTATCAGCATTTATGTGGACAGCTTGATCGATCTTCATCGCGGCCAGGGCATGGAACTGTTCTGGCGTGATTCTCTGATGTGCCCGACTGAAGAACAGTATCTGGACATGGTGGCGAACAAGACCGGTGGCCTGTTTTGTCTGGCGATTCAGCTGATGCAGGCAGAAGCGACCATTCAGGTTGATTTTATTCCGCTGGTGCGTCTGCTGGGTATCATTTTCCAGATTTGCGACGACTACCTGAACTTGAAAAGCACTGCGTATACCGACAACAAAGGTCTGTGTGAAGATCTTACCGAGGGTAAATTCTCCTTCCCGATCATTCACAGCATCCGTAGCAATCCGGGCAATCGTCAGCTGATCAATATTCTGAAGCAAAAACCGCGCGAAGATGACATCAAGCGTTACGCACTGTCCTATATGGAGAGCACGAATAGCTTCGAGTACACCCGTGGCGTCGTCCGTAAATTGAAAACCGAAGCAATTGACACGATTCAAGGTCTGGAGAAGCATGGCCTGGAAGAAAACATTGGTATTCGTAAGATTCTGGCGCGTATGAGCCTGGAACTGTAA
PvCPS,具有异戊二烯基转移酶和柯巴基二磷酸合酶的多功能蛋白质,氨基酸序列-SEQ ID NO:60
MSPMDLQESAAALVRQLGERVEDRRGFGFMSPAIYDTAWVSMISKTIDDQKTWLFAECFQYILSHQLEDGGWAMYASEIDAILNTSASLLSLKRHLSNPYQITSITQEDLSARINRAQNALQKLLNEWNVDSTLHVGFEILVPALLRYLEDEGIAFAFSGRERLLEIEKQKLSKFKAQYLYLPIKVTALHSLEAFIGAIEFDKVSHHKVSGAFMASPSSTAAYMMHATQWDDECEDYLRHVIAHASGKGSGGVPSAFPSTIFESVWPLSTLLKVGYDLNSAPFIEKIRSYLHDAYIAEKGILGFTPFVGADADDTATTILVLNLLNQPVSVDAMLKEFEEEHHFKTYSQERNPSFSANCNVLLALLYSQEPSLYSAQIEKAIRFLYKQFTDSEMDVRDKWNLSPYYSWMLMTQAITRLTTLQKTSKLSTLRDDSISKGLISLLFRIASTVVKDQKPGGSWGTRASKEETAYAVLILTYAFYLDEVTESLRHDIKIAIENGCSFLSERTMQSDSEWLWVEKVTYKSEVLSEAYILAALKRAADLPDENAEAAPVINGISTNGFEHTDRINGKLKVNGTNGTNGSHETNGINGTHEIEQINGVNGTNGHSDVPHDTNGWVEEPTAINETNGHYVNGTNHETPLTNGISNGDSVSVHTDHSDSYYQRSDWTADEEQILLGPFDYLESLPGKNMRSQLIQSFNTWLKVPTESLDVIIKVISMLHTASLLIDDIQDQSILRRGQPVAHSIFGTAQAMNSGNYVYFLALREVQKLQNPKAISIYVDSLIDLHRGQGMELFWRDSLMCPTEEQYLDMVANKTGGLFCLAIQLMQAEATIQVDFIPLVRLLGIIFQICDDYLNLKSTAYTDNKGLCEDLTEGKFSFPIIHSIRSNPGNRQLINILKQKPREDDIKRYALSYMESTNSFEYTRGVVRKLKTEAIDTIQGLEKHGLEENIGIRKILARMSLEL
核糖体结合位点–SEQ ID NO:61
AAGGAGGTAAAAAA
CrtE,来自成团泛菌(Pantoea agglomerans)的GGPP合酶,为在酿酒酵母中表达而进行了密码子优化-SEQ ID NO:62
ATGGTTTCTGGTTCTAAGGCTGGTGTTTCTCCACACAGAGAAATCGAAGTTATGAGACAATCTATCGACGACCACTTGGCTGGTTTGTTGCCAGAAACTGACTCTCAAGACATCGTTTCTTTGGCTATGAGAGAAGGTGTTATGGCTCCAGGTAAGAGAATCAGACCATTGTTGATGTTGTTGGCTGCTAGAGACTTGAGATACCAAGGTTCTATGCCAACTTTGTTGGACTTGGCTTGTGCTGTTGAATTGACTCACACTGCTTCTTTGATGTTGGACGACATGCCATGTATGGACAACGCTGAATTGAGAAGAGGTCAACCAACTACTCACAAGAAGTTCGGTGAATCTGTTGCTATCTTGGCTTCTGTTGGTTTGTTGTCTAAGGCTTTCGGTTTGATCGCTGCTACTGGTGACTTGCCAGGTGAAAGAAGAGCTCAAGCTGTTAACGAATTGTCTACTGCTGTTGGTGTTCAAGGTTTGGTTTTGGGTCAATTCAGAGACTTGAACGACGCTGCTTTGGACAGAACTCCAGACGCTATCTTGTCTACTAACCACTTGAAGACTGGTATCTTGTTCTCTGCTATGTTGCAAATCGTTGCTATCGCTTCTGCTTCTTCTCCATCTACTAGAGAAACTTTGCACGCTTTCGCTTTGGACTTCGGTCAAGCTTTCCAATTGTTGGACGACTTGAGAGACGACCACCCAGAAACTGGTAAGGACAGAAACAAGGACGCTGGTAAGTCTACTTTGGTTAACAGATTGGGTGCTGACGCTGCTAGACAAAAGTTGAGAGAACACATCGACTCTGCTGACAAGCACTTGACTTTCGCTTGTCCACAAGGTGGTGCTATCAGACAATTCATGCACTTGTGGTTCGGTCACCACTTGGCTGACTGGTCTCCAGTTATGAAGATCGCTTAA
SmCPS2,来自丹参(Salvia miltiorrhiza)的柯巴基焦磷酸合酶,为在酿酒酵母中表达而进行了密码子优化-SEQ ID NO:63
ATGGCTACTGTTGACGCTCCACAAGTTCACGACCACGACGGTACTACTGTTCACCAAGGTCACGACGCTGTTAAGAACATCGAAGACCCAATCGAATACATCAGAACTTTGTTGAGAACTACTGGTGACGGTAGAATCTCTGTTTCTCCATACGACACTGCTTGGGTTGCTATGATCAAGGACGTTGAAGGTAGAGACGGTCCACAATTCCCATCTTCTTTGGAATGGATCGTTCAAAACCAATTGGAAGACGGTTCTTGGGGTGACCAAAAGTTGTTCTGTGTTTACGACAGATTGGTTAACACTATCGCTTGTGTTGTTGCTTTGAGATCTTGGAACGTTCACGCTCACAAGGTTAAGAGAGGTGTTACTTACATCAAGGAAAACGTTGACAAGTTGATGGAAGGTAACGAAGAACACATGACTTGTGGTTTCGAAGTTGTTTTCCCAGCTTTGTTGCAAAAGGCTAAGTCTTTGGGTATCGAAGACTTGCCATACGACTCTCCAGCTGTTCAAGAAGTTTACCACGTTAGAGAACAAAAGTTGAAGAGAATCCCATTGGAAATCATGCACAAGATCCCAACTTCTTTGTTGTTCTCTTTGGAAGGTTTGGAAAACTTGGACTGGGACAAGTTGTTGAAGTTGCAATCTGCTGACGGTTCTTTCTTGACTTCTCCATCTTCTACTGCTTTCGCTTTCATGCAAACTAAGGACGAAAAGTGTTACCAATTCATCAAGAACACTATCGACACTTTCAACGGTGGTGCTCCACACACTTACCCAGTTGACGTTTTCGGTAGATTGTGGGCTATCGACAGATTGCAAAGATTGGGTATCTCTAGATTCTTCGAACCAGAAATCGCTGACTGTTTGTCTCACATCCACAAGTTCTGGACTGACAAGGGTGTTTTCTCTGGTAGAGAATCTGAATTCTGTGACATCGACGACACTTCTATGGGTATGAGATTGATGAGAATGCACGGTTACGACGTTGACCCAAACGTTTTGAGAAACTTCAAGCAAAAGGACGGTAAGTTCTCTTGTTACGGTGGTCAAATGATCGAATCTCCATCTCCAATCTACAACTTGTACAGAGCTTCTCAATTGAGATTCCCAGGTGAAGAAATCTTGGAAGACGCTAAGAGATTCGCTTACGACTTCTTGAAGGAAAAGTTGGCTAACAACCAAATCTTGGACAAGTGGGTTATCTCTAAGCACTTGCCAGACGAAATCAAGTTGGGTTTGGAAATGCCATGGTTGGCTACTTTGCCAAGAGTTGAAGCTAAGTACTACATCCAATACTACGCTGGTTCTGGTGACGTTTGGATCGGTAAGACTTTGTACAGAATGCCAGAAATCTCTAACGACACTTACCACGACTTGGCTAAGACTGACTTCAAGAGATGTCAAGCTAAGCACCAATTCGAATGGTTGTACATGCAAGAATGGTACGAATCTTGTGGTATCGAAGAATTCGGTATCTCTAGAAAGGACTTGTTGTTGTCTTACTTCTTGGCTACTGCTTCTATCTTCGAATTGGAAAGAACTAACGAAAGAATCGCTTGGGCTAAGTCTCAAATCATCGCTAAGATGATCACTTCTTTCTTCAACAAGGAAACTACTTCTGAAGAAGACAAGAGAGCTTTGTTGAACGAATTGGGTAACATCAACGGTTTGAACGACACTAACGGTGCTGGTAGAGAAGGTGGTGCTGGTTCTATCGCTTTGGCTACTTTGACTCAATTCTTGGAAGGTTTCGACAGATACACTAGACACCAATTGAAGAACGCTTGGTCTGTTTGGTTGACTCAATTGCAACACGGTGAAGCTGACGACGCTGAATTGTTGACTAACACTTTGAACATCTGTGCTGGTCACATCGCTTTCAGAGAAGAAATCTTGGCTCACAACGAATACAAGGCTTTGTCTAACTTGACTTCTAAGATCTGTAGACAATTGTCTTTCATCCAATCTGAAAAGGAAATGGGTGTTGAAGGTGAAATCGCTGCTAAGTCTTCTATCAAGAACAAGGAATTGGAAGAAGACATGCAAATGTTGGTTAAGTTGGTTTTGGAAAAGTACGGTGGTATCGACAGAAACATCAAGAAGGCTTTCTTGGCTGTTGCTAAGACTTACTACTACAGAGCTTACCACGCTGCTGACACTATCGACACTCACATGTTCAAGGTTTTGTTCGAACCAGTTGCTTAA
SmCPS2,来自丹参(Salvia miltiorrhiza)的柯巴基焦磷酸合酶,氨基酸序列-SEQID NO:64
MATVDAPQVHDHDGTTVHQGHDAVKNIEDPIEYIRTLLRTTGDGRISVSPYDTAWVAMIKDVEGRDGPQFPSSLEWIVQNQLEDGSWGDQKLFCVYDRLVNTIACVVALRSWNVHAHKVKRGVTYIKENVDKLMEGNEEHMTCGFEVVFPALLQKAKSLGIEDLPYDSPAVQEVYHVREQKLKRIPLEIMHKIPTSLLFSLEGLENLDWDKLLKLQSADGSFLTSPSSTAFAFMQTKDEKCYQFIKNTIDTFNGGAPHTYPVDVFGRLWAIDRLQRLGISRFFEPEIADCLSHIHKFWTDKGVFSGRESEFCDIDDTSMGMRLMRMHGYDVDPNVLRNFKQKDGKFSCYGGQMIESPSPIYNLYRASQLRFPGEEILEDAKRFAYDFLKEKLANNQILDKWVISKHLPDEIKLGLEMPWLATLPRVEAKYYIQYYAGSGDVWIGKTLYRMPEISNDTYHDLAKTDFKRCQAKHQFEWLYMQEWYESCGIEEFGISRKDLLLSYFLATASIFELERTNERIAWAKSQIIAKMITSFFNKETTSEEDKRALLNELGNINGLNDTNGAGREGGAGSIALATLTQFLEGFDRYTRHQLKNAWSVWLTQLQHGEADDAELLTNTLNICAGHIAFREEILAHNEYKALSNLTSKICRQLSFIQSEKEMGVEGEIAAKSSIKNKELEEDMQMLVKLVLEKYGGIDRNIKKAFLAVAKTYYYRAYHAADTIDTHMFKVLFEPVA*
TalVeTPP,柯巴基焦磷酸磷酸酶,为在酿酒酵母中表达而进行了密码子优化-SEQID NO:65
ATGTCTAACGACACTACTACTACTGCTTCTGCTGGTACTGCTACTTCTTCTAGATTCTTGTCTGTTGGTGGTGTTGTTAACTTCAGAGAATTGGGTGGTTACCCATGTGACTCTGTTCCACCAGCTCCAGCTTCTAACGGTTCTCCAGACAACGCTTCTGAAGCTACTTTGTGGGTTGGTCACTCTTCTATCAGACCAGGTTTCTTGTTCAGATCTGCTCAACCATCTCAAATCACTCCAGCTGGTATCGAAACTTTGATCAGACAATTGGGTATCCAAACTATCTTCGACTTCAGATCTAGAACTGAAATCGAATTGGTTGCTACTAGATACCCAGACTCTTTGTTGGAAATCCCAGGTACTACTAGATACTCTGTTCCAGTTTTCTCTGAAGGTGACTACTCTCCAGCTTCTTTGGTTAAGAGATACGGTGTTTCTTCTGACACTGCTACTGACTCTACTTCTTCTAAGTCTGCTAAGCCAACTGGTTTCGTTCACGCTTACGAAGCTATCGCTAGATCTGCTGCTGAAAACGGTTCTTTCAGAAAGATCACTGACCACATCATCCAACACCCAGACAGACCAATCTTGTTCCACTGTACTTTGGGTAAGGACAGAACTGGTGTTTTCGCTGCTTTGTTGTTGTCTTTGTGTGGTGTTCCAGACGAAACTATCGTTGAAGACTACGCTATGACTACTGAAGGTTTCGGTGCTTGGAGAGAACACTTGATCCAAAGATTGTTGCAAAGAAAGGACGCTGCTACTAGAGAAGACGCTGAATCTATCATCGCTTCTCCACCAGAAACTATGAAGGCTTTCTTGGAAGACGTTGTTGCTGCTAAGTTCGGTGGTGCTAGAAACTACTTCATCCAACACTGTGGTTTCACTGAAGCTGAAGTTGACAAGTTGTCTCACACTTTGGCTATCACTAACTAA
AzTolADH1,来自解甲苯固氮弯曲菌(Azoarcus toluclasticus)的醇脱氢酶,为在酿酒酵母中表达而进行了密码子优化-SEQ ID NO:66
ATGGGTTCTATCCAAGACTCTTTGTTCATCAGAGCTAGAGCTGCTGTTTTGAGAACTGTTGGTGGTCCATTGGAAATCGAAAACGTTAGAATCTCTCCACCAAAGGGTGACGAAGTTTTGGTTAGAATGGTTGGTGTTGGTGTTTGTCACACTGACGTTGTTTGTAGAGACGGTTTCCCAGTTCCATTGCCAATCGTTTTGGGTCACGAAGGTTCTGGTATCGTTGAAGCTGTTGGTGAAAGAGTTACTAAGGTTAAGCCAGGTCAAAGAGTTGTTTTGTCTTTCAACTCTTGTGGTCACTGTGCTTCTTGTTGTGAAGACCACCCAGCTACTTGTCACCAAATGTTGCCATTGAACTTCGGTGCTGCTCAAAGAGTTGACGGTGGTACTGTTATCGACGCTTCTGGTGAAGCTGTTCAATCTTTGTTCTTCGGTCAATCTTCTTTCGGTACTTACGCTTTGGCTAGAGAAGTTAACACTGTTCCAGTTCCAGACGCTGTTCCATTGGAAATCTTGGGTCCATTGGGTTGTGGTATCCAAACTGGTGCTGGTGCTGCTATCAACTCTTTGGCTTTGAAGCCAGGTCAATCTTTGGCTATCTTCGGTGGTGGTTCTGTTGGTTTGTCTGCTTTGTTGGGTGCTTTGGCTGTTGGTGCTGGTCCAGTTGTTGTTATCGAACCAAACGAAAGAAGAAGAGCTTTGGCTTTGGACTTGGGTGCTTCTCACGCTTTCGACCCATTCAACACTGAAGACTTGGTTGCTTCTATCAAGGCTGCTACTGGTGGTGGTGTTACTCACTCTTTGGACTCTACTGGTTTGCCACCAGTTATCGCTAACGCTATCAACTGTACTTTGCCAGGTGGTACTGTTGGTTTGTTGGGTGTTCCATCTCCAGAAGCTGCTGTTCCAGTTACTTTGTTGGACTTGTTGGTTAAGTCTGTTACTTTGAGACCAATCACTGAAGGTGACGCTAACCCACAAGAATTCATCCCAAGAATGGTTCAATTGTACAGAGACGGTAAGTTCCCATTCGACAAGTTGATCACTACTTACAGATTCGACGACATCAACCAAGCTTTCAAGGCTACTGAAACTGGTGAAGCTATCAAGCCAGTTTTGGTTTTCTAA
PsAeroADH1,来自铜绿假单胞菌(Pseudomonas aeruginosa)的醇脱氢酶,为在酿酒酵母中表达而进行了密码子优化-SEQ ID NO:67
ATGAACTCTATCCAACCAACTCAAGCTAAGGCTGCTGTTTTGAGAGCTGTTGGTGGTCCATTCTCTATCGAACCAATCAGAATCTCTCCACCAAAGGGTGACGAAGTTTTGGTTAGAATCGTTGGTGTTGGTGTTTGTCACACTGACGTTGTTTGTAGAGACTCTTTCCCAGTTCCATTGCCAATCATCTTGGGTCACGAAGGTTCTGGTGTTATCGAAGCTGTTGGTGACCAAGTTACTGGTTTGAAGCCAGGTGACCACGTTGTTTTGTCTTTCAACTCTTGTGGTCACTGTTACAACTGTGGTCACGACGAACCAGCTTCTTGTTTGCAAATGTTGCCATTGAACTTCGGTGGTGCTGAAAGAGCTGCTGACGGTACTATCGAAGACGACCAAGGTGCTGCTGTTAGAGGTTTGTTCTTCGGTCAATCTTCTTTCGGTTCTTACGCTATCGCTAGAGCTGTTAACACTGTTAAGGTTGACGACGACTTGCCATTGGCTTTGTTGGGTCCATTGGGTTGTGGTATCCAAACTGGTGCTGGTGCTGCTATGAACTCTTTGGGTTTGCAAGGTGGTCAATCTTTCATCGTTTTCGGTGGTGGTGCTGTTGGTTTGTCTGCTGTTATGGCTGCTAAGGCTTTGGGTGTTTCTCCATTGATCGTTGTTGAACCAAACGAAGCTAGAAGAGCTTTGGCTTTGGAATTGGGTGCTTCTCACGCTTTCGACCCATTCAACACTGAAGACTTGGTTGCTTCTATCAGAGAAGTTGTTCCAGCTGGTGCTAACCACGCTTTGGACACTACTGGTTTGCCAAAGGTTATCGCTAACGCTATCGACTGTATCATGTCTGGTGGTAAGTTGGGTTTGTTGGGTATGGCTAACCCAGAAGCTAACGTTCCAGCTACTTTGTTGGACTTGTTGTCTAAGAACGTTACTTTGAAGCCAATCACTGAAGGTGACGCTAACCCACAAGAATTCATCCCAAGAATGTTGGCTTTGTACAGAGAAGGTAAGTTCCCATTCGACAAGTTGATCACTACTTTCCCATTCGAACACATCAACGAAGCTATGGAAGCTACTGAATCTGGTAAGGCTATCAAGCCAGTTTTGACTTTGTAA
SCH23-ADH1,来自黑丝孢网菌(Hyphozyma roseonigra)的醇脱氢酶,为在酿酒酵母中表达而进行了密码子优化-SEQ ID NO:68
ATGCAATTCTCTATCGGTGACGTTTTGGCTATCGTTGACAAGACTATCTTGAACCCATTGGTTGTTTCTGCTGGTTTGTTGTCTTTGCACTTCTTGACTAACGACAAGTACGCTATCACTGCTAACGACGGTTTGTTCCCATACCAAATCTCTACTCCAGACTCTCACAGAAAGGCTTTGTTCGCTTTGGGTTTCGGTTTGTTGTTGAGAGCTAACAGATACATGTCTAGAAAGGCTTTGAACAACAACACTGCTGCTCAATTCGACTGGAACAGAGAAATCATCGTTGTTACTGGTGGTTCTGGTGGTATCGGTGCTCAAGCTGCTCAAAAGTTGGCTGAAAGAGGTTCTAAGGTTATCGTTATCGACGTTTTGCCATTGACTTTCGACAAGCCAAAGAACTTGTACCACTACAAGTGTGACTTGACTAACTACAAGGAATTGCAAGAAGTTGCTGCTAAGATCGAAAGAGAAGTTGGTACTCCAACTTGTGTTGTTGCTAACGCTGGTATCTGTAGAGGTAAGAACATCTTCGACGCTACTGAAAGAGACGTTCAATTGACTTTCGGTGTTAACAACTTGGGTTTGTTGTGGACTGCTAAGACTTTCTTGCCATCTATGGCTAAGGCTAACCACGGTCACTTCTTGATCATCGCTTCTCAAACTGGTCACTTGGCTACTGCTGGTGTTGTTGACTACGCTGCTACTAAGGCTGCTGCTATCGCTATCTACGAAGGTTTGCAAACTGAAATGAAGCACTTCTACAAGGCTCCAGCTGTTAGAGTTTCTTGTATCTCTCCATCTGCTGTTAAGACTAAGATGTTCGCTGGTATCAAGACTGGTGGTAACTTCTTCATGCCAATGTTGACTCCAGACGACTTGGGTGACTTGATCGCTAAGACTTTGTGGGACGGTGTTGCTGTTAACATCTTGTCTCCAGCTGCTGCTTACATCTCTCCACCAACTAGAGCTTTGCCAGACTGGATGAGAGTTGGTATGCAAGACGCTGGTGCTGAAATCATGACTGAATTGACTCCACACAAGCCATTGGAATAA
SCH23-ADH1,来自黑丝孢网菌(Hyphozyma roseonigra)的醇脱氢酶,氨基酸序列-SEQ ID NO:69
MQFSIGDVLAIVDKTILNPLVVSAGLLSLHFLTNDKYAITANDGLFPYQISTPDSHRKALFALGFGLLLRANRYMSRKALNNNTAAQFDWNREIIVVTGGSGGIGAQAAQKLAERGSKVIVIDVLPLTFDKPKNLYHYKCDLTNYKELQEVAAKIEREVGTPTCVVANAGICRGKNIFDATERDVQLTFGVNNLGLLWTAKTFLPSMAKANHGHFLIIASQTGHLATAGVVDYAATKAAAIAIYEGLQTEMKHFYKAPAVRVSCISPSAVKTKMFAGIKTGGNFFMPMLTPDDLGDLIAKTLWDGVAVNILSPAAAYISPPTRALPDWMRVGMQDAGAEIMTELTPHKPLE
SCH24-ADH1a,来自浅白隐球菌(Cryptococcus albidus)的醇脱氢酶,为在酿酒酵母中表达而进行了密码子优化-SEQ ID NO:70
ATGCCAACTCCAATCTTCGGTGCTAGAGAAGGTTTCACTATCGACTCTGTTTTGTCTATCTTGGACGCTACTGTTTTGAACCCATGGTTCACTGGTGTTTGTTTGATCGCTGTTTGTGCTAGAGACAGAACTATCACTTACCCAGACTGGCCAGCTGCTTTGGACCAAGTTTTGCCATTCTTGTCTCAAATGTGGAGAGAAACTGTTAGACCAACTTTCGGTGACAGAAACGTTTTGCACTTGTTGACTACTGTTTGTGTTGGTTTGGCTATCAGAACTAACAGAAGAATGTCTAGAGGTGCTAGAAACAACTGGGTTTGGGACACTTCTTACGACTGGAAGAAGGAAATCGTTGTTGTTACTGGTGGTGCTGCTGGTTTCGGTGCTGACATCGTTCAACAATTGGACACTAGAGGTATCCAAGTTGTTGTTTTGGACGTTGGTTCTTTGACTTACAGACCATCTTCTAGAGTTCACTACTACAAGTGTGACGTTTCTAACCCACAAGACGTTGCTTCTGTTGCTAAGGCTATCGTTTCTAACGTTGGTCACCCAACTATCTTGGTTAACAACGCTGGTGTTTTCAGAGGTGCTACTATCTTGTCTACTACTCCAAGAGACTTGGACATGACTTACGACATCAACGTTAAGGCTCACTACCACTTGACTAAGGCTTTCTTGCCAAACATGATCTCTAAGAACCACGGTCACATCGTTACTGTTTCTTCTGCTACTGCTTACGCTCAAGCTTGTTCTGGTGTTTCTTACTGTTCTTCTAAGGCTGCTATCTTGTCTTTCCACGAAGGTTTGTCTGAAGAAATCTTGTGGATCTACAAGGCTCCAAAGGTTAGAACTTCTGTTATCTGTCCAGGTCACGTTAACACTGCTATGTTCACTGGTATCGGTGCTGCTGCTCCATCTTTCATGGCTCCAGCTTTGCACCCATCTACTGTTGCTGAAACTATCGTTGACGTTTTGTTGTCTTGTGAATCTCAACACGTTTTGATGCCAGCTGCTATGCACATGTCTGTTGCTGGTAGAGCTTTGCCAACTTGGTTCTTCAGAGGTTTGTTGGCTTCTGGTAAGGACACTATGGGTTCTGTTGTTAGAAGATAA
SCH24-ADH1a,来自浅白隐球菌(Cryptococcus albidus)的醇脱氢酶,氨基酸序列-SEQ ID NO:71
MPTPIFGAREGFTIDSVLSILDATVLNPWFTGVCLIAVCARDRTITYPDWPAALDQVLPFLSQMWRETVRPTFGDRNVLHLLTTVCVGLAIRTNRRMSRGARNNWVWDTSYDWKKEIVVVTGGAAGFGADIVQQLDTRGIQVVVLDVGSLTYRPSSRVHYYKCDVSNPQDVASVAKAIVSNVGHPTILVNNAGVFRGATILSTTPRDLDMTYDINVKAHYHLTKAFLPNMISKNHGHIVTVSSATAYAQACSGVSYCSSKAAILSFHEGLSEEILWIYKAPKVRTSVICPGHVNTAMFTGIGAAAPSFMAPALHPSTVAETIVDVLLSCESQHVLMPAAMHMSVAGRALPTWFFRGLLASGKDTMGSVVRR*
用于同源重组的序列1-SEQ ID NO:72
GCACTTGCTACACTGTCAGGATAGCTTCCGTCACATGGTGGCGATCACCGTACATCTGAG
用于同源重组的序列2-SEQ ID NO:73
AGGTGCAGTTCGCGTGCAATTATAACGTCGTGGCAACTGTTATCAGTCGTACCGCGCCAT
用于同源重组的序列3-SEQ ID NO:74
TGGTCAGCAACAACGCCGAAGAATCACTCTCGTGTTGAGAATTGCACGCCTTGACCACGA
用于LEU2酵母标记的引物1-SEQ ID NO:75
AGGTGCAGTTCGCGTGCAATTATAACGTCGTGGCAACTGTTATCAGTCGTACCGCGCCATTCGACTACGTCGTAAGGCC
用于LEU2酵母标记的引物2-SEQ ID NO:76
TCGTGGTCAAGGCGTGCAATTCTCAACACGAGAGTGATTCTTCGGCGTTGTTGCTGACCATCGACGGTCGAGGAGAACTT
用于AmpR细菌标记的引物1--SEQ ID NO:77
TGGTCAGCAACAACGCCGAAGAATCACTCTCGTGTTGAGAATTGCACGCCTTGACCACGACACGTTAAGGGATTTTGGTCATGAG
用于AmpR细菌标记的引物2-SEQ ID NO:78
AACGCGTACCCTAAGTACGGCACCACAGTGACTATGCAGTCCGCACTTTGCCAATGCCAAAAATGTGCGCGGAACCCCTA
用于酵母复制起点的引物1-SEQ ID NO:79
TTGGCATTGGCAAAGTGCGGACTGCATAGTCACTGTGGTGCCGTACTTAGGGTACGCGTTCCTGAACGAAGCATCTGTGCTTCA
用于酵母复制起点的引物2-SEQ ID NO:80
CCGAGATGCCAAAGGATAGGTGCTATGTTGATGACTACGACACAGAACTGCGGGTGACATAATGATAGCATTGAAGGATGAGACT
用于大肠杆菌复制起点的引物1-SEQ ID NO:81
ATGTCACCCGCAGTTCTGTGTCGTAGTCATCAACATAGCACCTATCCTTTGGCATCTCGGTGAGCAAAAGGCCAGCAAAAGG
用于大肠杆菌复制起点的引物2-SEQ ID NO:82
CTCAGATGTACGGTGATCGCCACCATGTGACGGAAGCTATCCTGACAGTGTAGCAAGTGCTGAGCGTCAGACCCCGTAGAA
用于同源重组的序列4-SEQ ID NO:83
ATTCCTAGTGACGGCCTTGGGAACTCGATACACGATGTTCAGTAGACCGCTCACACATGG。
序列表
<110> 弗门尼舍有限公司
<120> 生物催化产生萜烯化合物的方法
<130> 10940/WO
<160> 83
<170> PatentIn version 3.5
<210> 1
<211> 936
<212> DNA
<213> 细疣篮状菌(Talaromyces verruculosus)
<220>
<221> CDS
<222> (1)..(936)
<400> 1
atg agc aat gac acg acg acc acc gcg agc gcc ggt act gca act tct 48
Met Ser Asn Asp Thr Thr Thr Thr Ala Ser Ala Gly Thr Ala Thr Ser
1 5 10 15
agc cgt ttt ctg agc gtc ggc ggc gtt gtg aat ttt cgc gag ctg ggt 96
Ser Arg Phe Leu Ser Val Gly Gly Val Val Asn Phe Arg Glu Leu Gly
20 25 30
ggc tat cca tgc gac agc gtg ccg ccg gct ccg gca agc aac ggt tcg 144
Gly Tyr Pro Cys Asp Ser Val Pro Pro Ala Pro Ala Ser Asn Gly Ser
35 40 45
cct gat aat gcg tcc gag gca acg ctg tgg gtt ggt cac tcc agc att 192
Pro Asp Asn Ala Ser Glu Ala Thr Leu Trp Val Gly His Ser Ser Ile
50 55 60
cgt ccg ggt ttc ctg ttc cgc agc gcg cag ccg agc cag att acg ccg 240
Arg Pro Gly Phe Leu Phe Arg Ser Ala Gln Pro Ser Gln Ile Thr Pro
65 70 75 80
gcg ggt atc gaa acg ctg atc cgc caa ctg ggc atc cag acc att ttt 288
Ala Gly Ile Glu Thr Leu Ile Arg Gln Leu Gly Ile Gln Thr Ile Phe
85 90 95
gat ttc cgt agc cgt acc gag atc gaa ctg gtg gcg acc cgt tac ccg 336
Asp Phe Arg Ser Arg Thr Glu Ile Glu Leu Val Ala Thr Arg Tyr Pro
100 105 110
gac tct ctg ttg gaa att ccg ggc acc acg cgc tat tcc gtc ccg gtt 384
Asp Ser Leu Leu Glu Ile Pro Gly Thr Thr Arg Tyr Ser Val Pro Val
115 120 125
ttc tcc gag ggt gac tat tct ccg gcg agc ctg gtg aag cgc tat ggt 432
Phe Ser Glu Gly Asp Tyr Ser Pro Ala Ser Leu Val Lys Arg Tyr Gly
130 135 140
gtt agc agc gat acc gcc acg gac agc acc tct agc aag agc gcg aag 480
Val Ser Ser Asp Thr Ala Thr Asp Ser Thr Ser Ser Lys Ser Ala Lys
145 150 155 160
ccg acc ggc ttc gtt cat gca tac gaa gcc att gcg cgc agc gcc gct 528
Pro Thr Gly Phe Val His Ala Tyr Glu Ala Ile Ala Arg Ser Ala Ala
165 170 175
gag aac ggt agc ttc cgt aaa att acc gac cac atc atc cag cat cct 576
Glu Asn Gly Ser Phe Arg Lys Ile Thr Asp His Ile Ile Gln His Pro
180 185 190
gat cgt cca att ttg ttc cac tgt acc ctg ggt aaa gac cgt acg ggt 624
Asp Arg Pro Ile Leu Phe His Cys Thr Leu Gly Lys Asp Arg Thr Gly
195 200 205
gtc ttt gcg gcg ctg ttg ctg agc ctg tgt ggt gtg ccg gac gaa acc 672
Val Phe Ala Ala Leu Leu Leu Ser Leu Cys Gly Val Pro Asp Glu Thr
210 215 220
atc gtc gaa gat tac gcg atg acc acc gaa ggc ttt ggt gca tgg cgt 720
Ile Val Glu Asp Tyr Ala Met Thr Thr Glu Gly Phe Gly Ala Trp Arg
225 230 235 240
gag cac ctg atc caa cgt ctg ctg caa cgt aaa gac gct gca acc cgt 768
Glu His Leu Ile Gln Arg Leu Leu Gln Arg Lys Asp Ala Ala Thr Arg
245 250 255
gaa gat gcc gag agc atc att gcg tcg ccg ccg gag act atg aaa gca 816
Glu Asp Ala Glu Ser Ile Ile Ala Ser Pro Pro Glu Thr Met Lys Ala
260 265 270
ttt ctg gaa gat gtt gtg gca gcg aaa ttt ggt ggc gcg cgt aac tac 864
Phe Leu Glu Asp Val Val Ala Ala Lys Phe Gly Gly Ala Arg Asn Tyr
275 280 285
ttc att caa cat tgc ggc ttc act gaa gct gaa gtc gat aag ctg agc 912
Phe Ile Gln His Cys Gly Phe Thr Glu Ala Glu Val Asp Lys Leu Ser
290 295 300
cac acc ctg gcg atc acg aac taa 936
His Thr Leu Ala Ile Thr Asn
305 310
<210> 2
<211> 311
<212> PRT
<213> 细疣篮状菌(Talaromyces verruculosus)
<400> 2
Met Ser Asn Asp Thr Thr Thr Thr Ala Ser Ala Gly Thr Ala Thr Ser
1 5 10 15
Ser Arg Phe Leu Ser Val Gly Gly Val Val Asn Phe Arg Glu Leu Gly
20 25 30
Gly Tyr Pro Cys Asp Ser Val Pro Pro Ala Pro Ala Ser Asn Gly Ser
35 40 45
Pro Asp Asn Ala Ser Glu Ala Thr Leu Trp Val Gly His Ser Ser Ile
50 55 60
Arg Pro Gly Phe Leu Phe Arg Ser Ala Gln Pro Ser Gln Ile Thr Pro
65 70 75 80
Ala Gly Ile Glu Thr Leu Ile Arg Gln Leu Gly Ile Gln Thr Ile Phe
85 90 95
Asp Phe Arg Ser Arg Thr Glu Ile Glu Leu Val Ala Thr Arg Tyr Pro
100 105 110
Asp Ser Leu Leu Glu Ile Pro Gly Thr Thr Arg Tyr Ser Val Pro Val
115 120 125
Phe Ser Glu Gly Asp Tyr Ser Pro Ala Ser Leu Val Lys Arg Tyr Gly
130 135 140
Val Ser Ser Asp Thr Ala Thr Asp Ser Thr Ser Ser Lys Ser Ala Lys
145 150 155 160
Pro Thr Gly Phe Val His Ala Tyr Glu Ala Ile Ala Arg Ser Ala Ala
165 170 175
Glu Asn Gly Ser Phe Arg Lys Ile Thr Asp His Ile Ile Gln His Pro
180 185 190
Asp Arg Pro Ile Leu Phe His Cys Thr Leu Gly Lys Asp Arg Thr Gly
195 200 205
Val Phe Ala Ala Leu Leu Leu Ser Leu Cys Gly Val Pro Asp Glu Thr
210 215 220
Ile Val Glu Asp Tyr Ala Met Thr Thr Glu Gly Phe Gly Ala Trp Arg
225 230 235 240
Glu His Leu Ile Gln Arg Leu Leu Gln Arg Lys Asp Ala Ala Thr Arg
245 250 255
Glu Asp Ala Glu Ser Ile Ile Ala Ser Pro Pro Glu Thr Met Lys Ala
260 265 270
Phe Leu Glu Asp Val Val Ala Ala Lys Phe Gly Gly Ala Arg Asn Tyr
275 280 285
Phe Ile Gln His Cys Gly Phe Thr Glu Ala Glu Val Asp Lys Leu Ser
290 295 300
His Thr Leu Ala Ile Thr Asn
305 310
<210> 3
<211> 936
<212> DNA
<213> 细疣篮状菌(Talaromyces verruculosus)
<400> 3
atgtctaatg acaccactac cacggcttct gccggaacag caacttcttc gcggtttctt 60
tccgtggggg gagttgtgaa cttccgtgaa ctgggcggtt acccatgtga ttctgtccct 120
cctgctcctg cctcaaacgg ctcaccggac aatgcatctg aagcgaccct ttgggttggc 180
cactcgtcca ttcggcctgg atttctgttt cgatcggcac agccgtctca gattaccccg 240
gccggtattg agacattgat ccgccagctt ggcatccaga caatttttga ctttcgttca 300
aggacggaaa ttgagcttgt tgccactcgc tatcctgatt cgctacttga gatacctggc 360
acgactcgct attccgtgcc cgtcttctcg gaaggcgact attccccagc gtcattagtc 420
aagaggtacg gagtgtcctc cgatactgca accgattcca cttcctccaa aagtgctaag 480
cctacaggat tcgtccacgc atatgaggct atcgcacgca gtgcagcaga aaacggcagt 540
tttcgtaaga taacggacca cataatacaa catccggacc ggcctattct gtttcactgt 600
acactgggga aagaccgaac cggtgtgttt gcagcattgt tattgagtct ttgcggggta 660
ccagacgaga cgatagttga agactatgct atgactaccg agggatttgg agcctggcgg 720
gaacatctaa ttcaacgctt gctacaaagg aaggatgcag ctacgcgcga ggatgcagaa 780
tccattattg ccagcccccc ggagactatg aaggcttttc tagaagatgt ggtagcagcc 840
aagttcgggg gtgctcgaaa ttactttatc cagcactgtg gatttacgga agctgaggtt 900
gataagttaa gccatacact ggccattacg aattga 936
<210> 4
<211> 961
<212> DNA
<213> 细疣篮状菌(Talaromyces verruculosus)
<400> 4
ggtaccaagg aggtaaaaaa tgagcaatga cacgacgacc accgcgagcg ccggtactgc 60
aacttctagc cgttttctga gcgtcggcgg cgttgtgaat tttcgcgagc tgggtggcta 120
tccatgcgac agcgtgccgc cggctccggc aagcaacggt tcgcctgata atgcgtccga 180
ggcaacgctg tgggttggtc actccagcat tcgtccgggt ttcctgttcc gcagcgcgca 240
gccgagccag attacgccgg cgggtatcga aacgctgatc cgccaactgg gcatccagac 300
catttttgat ttccgtagcc gtaccgagat cgaactggtg gcgacccgtt acccggactc 360
tctgttggaa attccgggca ccacgcgcta ttccgtcccg gttttctccg agggtgacta 420
ttctccggcg agcctggtga agcgctatgg tgttagcagc gataccgcca cggacagcac 480
ctctagcaag agcgcgaagc cgaccggctt cgttcatgca tacgaagcca ttgcgcgcag 540
cgccgctgag aacggtagct tccgtaaaat taccgaccac atcatccagc atcctgatcg 600
tccaattttg ttccactgta ccctgggtaa agaccgtacg ggtgtctttg cggcgctgtt 660
gctgagcctg tgtggtgtgc cggacgaaac catcgtcgaa gattacgcga tgaccaccga 720
aggctttggt gcatggcgtg agcacctgat ccaacgtctg ctgcaacgta aagacgctgc 780
aacccgtgaa gatgccgaga gcatcattgc gtcgccgccg gagactatga aagcatttct 840
ggaagatgtt gtggcagcga aatttggtgg cgcgcgtaac tacttcattc aacattgcgg 900
cttcactgaa gctgaagtcg ataagctgag ccacaccctg gcgatcacga actaactcga 960
g 961
<210> 5
<211> 852
<212> DNA
<213> 温特曲霉(Aspergillus wentii)
<220>
<221> CDS
<222> (1)..(852)
<400> 5
atg gcg tct gtc cct gct cca ccg ttt gtt cat gtt gaa ggt atg tct 48
Met Ala Ser Val Pro Ala Pro Pro Phe Val His Val Glu Gly Met Ser
1 5 10 15
aat ttt cgt agc atc ggt ggc tac ccg ctg gag act gcc tcc acg aat 96
Asn Phe Arg Ser Ile Gly Gly Tyr Pro Leu Glu Thr Ala Ser Thr Asn
20 25 30
aac cat cgc tcg acc cgt caa ggc ttc gcg ttt cgt agc gcg gac ccg 144
Asn His Arg Ser Thr Arg Gln Gly Phe Ala Phe Arg Ser Ala Asp Pro
35 40 45
acg tat gtg acg cag aaa ggc ctg gaa acc att ctg tcc ctg gat att 192
Thr Tyr Val Thr Gln Lys Gly Leu Glu Thr Ile Leu Ser Leu Asp Ile
50 55 60
acc cgc gca ttt gac ttg cgt agc ttg gaa gaa gca aag gca caa cgt 240
Thr Arg Ala Phe Asp Leu Arg Ser Leu Glu Glu Ala Lys Ala Gln Arg
65 70 75 80
gcg aag ttg cag gcc gcg agc ggt tgt ctg gat tgc agc att agc caa 288
Ala Lys Leu Gln Ala Ala Ser Gly Cys Leu Asp Cys Ser Ile Ser Gln
85 90 95
cac atg atc cac caa ccg acc ccg ctg ttc ccg gat ggt gac tgg tcc 336
His Met Ile His Gln Pro Thr Pro Leu Phe Pro Asp Gly Asp Trp Ser
100 105 110
ccg gaa gcg gcg ggt gag cgc tac ttg cag tac gca caa gct gag ggt 384
Pro Glu Ala Ala Gly Glu Arg Tyr Leu Gln Tyr Ala Gln Ala Glu Gly
115 120 125
gat ggt atc agc ggt tat gtc gaa gtt tat ggt aat atg ctg gaa gag 432
Asp Gly Ile Ser Gly Tyr Val Glu Val Tyr Gly Asn Met Leu Glu Glu
130 135 140
ggc tgg atg gcg atc cgt gag att ctg ctg cac gtc cgt gac cgc ccg 480
Gly Trp Met Ala Ile Arg Glu Ile Leu Leu His Val Arg Asp Arg Pro
145 150 155 160
acc gaa gca ttc ctg tgc cac tgt tcc gcc ggt aaa gat cgt acg ggt 528
Thr Glu Ala Phe Leu Cys His Cys Ser Ala Gly Lys Asp Arg Thr Gly
165 170 175
atc gtg att gct gtt ctg ctc aaa gtc gcg ggt tgc agc gac gac ctg 576
Ile Val Ile Ala Val Leu Leu Lys Val Ala Gly Cys Ser Asp Asp Leu
180 185 190
gtg tgt cgt gag tac gaa ctg acc gag att ggc ctg gcg cgc cgt aga 624
Val Cys Arg Glu Tyr Glu Leu Thr Glu Ile Gly Leu Ala Arg Arg Arg
195 200 205
gag ttc atc gtt cag cat ctg ctg aag aaa ccg gaa atg aac ggc agc 672
Glu Phe Ile Val Gln His Leu Leu Lys Lys Pro Glu Met Asn Gly Ser
210 215 220
cgt gag ctg gcg gag cgc gtc gca ggc gcc cgt tac gag aac atg aaa 720
Arg Glu Leu Ala Glu Arg Val Ala Gly Ala Arg Tyr Glu Asn Met Lys
225 230 235 240
gaa acc ctg gaa atg gtg cag acc cgt tac cgc ggc atg cgc ggc tat 768
Glu Thr Leu Glu Met Val Gln Thr Arg Tyr Arg Gly Met Arg Gly Tyr
245 250 255
tgc aaa gaa atc tgc ggt ctg acc gac gaa gat ctg agc att atc cag 816
Cys Lys Glu Ile Cys Gly Leu Thr Asp Glu Asp Leu Ser Ile Ile Gln
260 265 270
ggt aac ctg acg agc ccg gag agc ccg att ttc taa 852
Gly Asn Leu Thr Ser Pro Glu Ser Pro Ile Phe
275 280
<210> 6
<211> 283
<212> PRT
<213> 温特曲霉(Aspergillus wentii)
<400> 6
Met Ala Ser Val Pro Ala Pro Pro Phe Val His Val Glu Gly Met Ser
1 5 10 15
Asn Phe Arg Ser Ile Gly Gly Tyr Pro Leu Glu Thr Ala Ser Thr Asn
20 25 30
Asn His Arg Ser Thr Arg Gln Gly Phe Ala Phe Arg Ser Ala Asp Pro
35 40 45
Thr Tyr Val Thr Gln Lys Gly Leu Glu Thr Ile Leu Ser Leu Asp Ile
50 55 60
Thr Arg Ala Phe Asp Leu Arg Ser Leu Glu Glu Ala Lys Ala Gln Arg
65 70 75 80
Ala Lys Leu Gln Ala Ala Ser Gly Cys Leu Asp Cys Ser Ile Ser Gln
85 90 95
His Met Ile His Gln Pro Thr Pro Leu Phe Pro Asp Gly Asp Trp Ser
100 105 110
Pro Glu Ala Ala Gly Glu Arg Tyr Leu Gln Tyr Ala Gln Ala Glu Gly
115 120 125
Asp Gly Ile Ser Gly Tyr Val Glu Val Tyr Gly Asn Met Leu Glu Glu
130 135 140
Gly Trp Met Ala Ile Arg Glu Ile Leu Leu His Val Arg Asp Arg Pro
145 150 155 160
Thr Glu Ala Phe Leu Cys His Cys Ser Ala Gly Lys Asp Arg Thr Gly
165 170 175
Ile Val Ile Ala Val Leu Leu Lys Val Ala Gly Cys Ser Asp Asp Leu
180 185 190
Val Cys Arg Glu Tyr Glu Leu Thr Glu Ile Gly Leu Ala Arg Arg Arg
195 200 205
Glu Phe Ile Val Gln His Leu Leu Lys Lys Pro Glu Met Asn Gly Ser
210 215 220
Arg Glu Leu Ala Glu Arg Val Ala Gly Ala Arg Tyr Glu Asn Met Lys
225 230 235 240
Glu Thr Leu Glu Met Val Gln Thr Arg Tyr Arg Gly Met Arg Gly Tyr
245 250 255
Cys Lys Glu Ile Cys Gly Leu Thr Asp Glu Asp Leu Ser Ile Ile Gln
260 265 270
Gly Asn Leu Thr Ser Pro Glu Ser Pro Ile Phe
275 280
<210> 7
<211> 852
<212> DNA
<213> 温特曲霉(Aspergillus wentii)
<400> 7
atggcatctg taccagctcc cccatttgtc cacgtcgaag gaatgagcaa tttccgatcg 60
ataggaggat atccccttga gacagcatcg acaaacaatc accgctccac gaggcaagga 120
ttcgcatttc gcagtgccga tccaacctac gtcacccaga aaggcctgga aaccatcctt 180
tcgctcgaca tcactcgagc ctttgacctc cgctcactgg aagaagcaaa ggcacagcgc 240
gcaaaactcc aggccgcctc aggatgtctc gactgcagca tcagccagca catgatccac 300
cagcccacac ccctatttcc agatggggac tggagtccag aggccgcagg ggagcggtat 360
ctgcagtacg cccaggctga gggagatggg atatcgggct acgtggaggt ctacggaaac 420
atgctcgagg aaggttggat ggcgattcgc gagattctgc ttcatgtccg ggaccggcct 480
acagaggcgt ttctatgcca ttgtagtgca gggaaagatc gtacggggat tgtcattgcg 540
gttttgttga aggttgcagg gtgctcggat gatcttgtgt gcagagagta tgagttgacc 600
gagatcgggt tggctcgacg gagggagttt atcgtgcagc atctgcttaa gaagccggaa 660
atgaatggat cgagggaact ggccgaaaga gtggcggggg ccaggtatga gaatatgaag 720
gaaacgctgg agatggtgca aactagatat agagggatga ggggctattg caaggagatt 780
tgcggcttga ccgacgaaga tctatctatt atccagggga acttgactag tccggagagt 840
cctatcttct aa 852
<210> 8
<211> 877
<212> DNA
<213> 温特曲霉(Aspergillus wentii)
<400> 8
ggtaccaagg aggtaaaaaa tggcgtctgt ccctgctcca ccgtttgttc atgttgaagg 60
tatgtctaat tttcgtagca tcggtggcta cccgctggag actgcctcca cgaataacca 120
tcgctcgacc cgtcaaggct tcgcgtttcg tagcgcggac ccgacgtatg tgacgcagaa 180
aggcctggaa accattctgt ccctggatat tacccgcgca tttgacttgc gtagcttgga 240
agaagcaaag gcacaacgtg cgaagttgca ggccgcgagc ggttgtctgg attgcagcat 300
tagccaacac atgatccacc aaccgacccc gctgttcccg gatggtgact ggtccccgga 360
agcggcgggt gagcgctact tgcagtacgc acaagctgag ggtgatggta tcagcggtta 420
tgtcgaagtt tatggtaata tgctggaaga gggctggatg gcgatccgtg agattctgct 480
gcacgtccgt gaccgcccga ccgaagcatt cctgtgccac tgttccgccg gtaaagatcg 540
tacgggtatc gtgattgctg ttctgctcaa agtcgcgggt tgcagcgacg acctggtgtg 600
tcgtgagtac gaactgaccg agattggcct ggcgcgccgt agagagttca tcgttcagca 660
tctgctgaag aaaccggaaa tgaacggcag ccgtgagctg gcggagcgcg tcgcaggcgc 720
ccgttacgag aacatgaaag aaaccctgga aatggtgcag acccgttacc gcggcatgcg 780
cggctattgc aaagaaatct gcggtctgac cgacgaagat ctgagcatta tccagggtaa 840
cctgacgagc ccggagagcc cgattttcta actcgag 877
<210> 9
<211> 828
<212> DNA
<213> 灰色螺状菌(Helicocarpus griseus)
<220>
<221> CDS
<222> (1)..(828)
<400> 9
atg gca tcc cca cca ggt cat ccg ttc gtt caa gtt gaa ggc gtt aat 48
Met Ala Ser Pro Pro Gly His Pro Phe Val Gln Val Glu Gly Val Asn
1 5 10 15
aat ttt cgc tct gtg ggt ggc tat ccg att acg cct agc agc gat gcg 96
Asn Phe Arg Ser Val Gly Gly Tyr Pro Ile Thr Pro Ser Ser Asp Ala
20 25 30
cgc ttc acg cgt gac aac ttt atc tac cgt agc gct gat ccg tgt tac 144
Arg Phe Thr Arg Asp Asn Phe Ile Tyr Arg Ser Ala Asp Pro Cys Tyr
35 40 45
att act ccg gaa ggc cgt agc aag att cgc agc ctg ggt atc acc acc 192
Ile Thr Pro Glu Gly Arg Ser Lys Ile Arg Ser Leu Gly Ile Thr Thr
50 55 60
gtg ttc gat ctg cgt agc cag ccg gag gtt gac aag caa ctg gcg aaa 240
Val Phe Asp Leu Arg Ser Gln Pro Glu Val Asp Lys Gln Leu Ala Lys
65 70 75 80
gac ccg agc agc ggt gtg ccg att gcg gat ggt gtc att cgt cgc ttc 288
Asp Pro Ser Ser Gly Val Pro Ile Ala Asp Gly Val Ile Arg Arg Phe
85 90 95
acc ccg gtt ttt agc cgc gag gat tgg ggt ccg gaa gca tcc gcg gtt 336
Thr Pro Val Phe Ser Arg Glu Asp Trp Gly Pro Glu Ala Ser Ala Val
100 105 110
cgt cac aac ctg tat gca gac gcg tcc ggt gct agc ggt tac gtc gat 384
Arg His Asn Leu Tyr Ala Asp Ala Ser Gly Ala Ser Gly Tyr Val Asp
115 120 125
gtg tac gcg gat atc ctg gaa aac ggt ggc gca gcg ttc cgt gag atc 432
Val Tyr Ala Asp Ile Leu Glu Asn Gly Gly Ala Ala Phe Arg Glu Ile
130 135 140
ctg ctg cac gtg cgt gac cgt ccg ggt gac gct ctg ttg tgc cac tgc 480
Leu Leu His Val Arg Asp Arg Pro Gly Asp Ala Leu Leu Cys His Cys
145 150 155 160
tcc gca ggc aaa gac cgt acc ggc gtt gcg att gcg atc ctg ctc aaa 528
Ser Ala Gly Lys Asp Arg Thr Gly Val Ala Ile Ala Ile Leu Leu Lys
165 170 175
ctg gcc ggt tgc gaa gat gag tgc att tcg aaa gag tat gaa ctg acc 576
Leu Ala Gly Cys Glu Asp Glu Cys Ile Ser Lys Glu Tyr Glu Leu Thr
180 185 190
gag gtc ggt ctg gcc agc cgt aaa gaa ttt att atc gag tac ctg att 624
Glu Val Gly Leu Ala Ser Arg Lys Glu Phe Ile Ile Glu Tyr Leu Ile
195 200 205
aag caa cct gag ctg gaa ggc gac cgt gcg aaa gcc gag aaa att gct 672
Lys Gln Pro Glu Leu Glu Gly Asp Arg Ala Lys Ala Glu Lys Ile Ala
210 215 220
ggc gcg aaa tac gaa aac atg ttg ggt acg ctg cag atg atg gaa cag 720
Gly Ala Lys Tyr Glu Asn Met Leu Gly Thr Leu Gln Met Met Glu Gln
225 230 235 240
aaa tat ggt ggc gtt gag ggc tac gtg aag gcc tac tgt aag ttg acg 768
Lys Tyr Gly Gly Val Glu Gly Tyr Val Lys Ala Tyr Cys Lys Leu Thr
245 250 255
gat aaa gac atc gca acc atc cgt cgc aat ctg gtc agc ggt gac aag 816
Asp Lys Asp Ile Ala Thr Ile Arg Arg Asn Leu Val Ser Gly Asp Lys
260 265 270
atg att gcg taa 828
Met Ile Ala
275
<210> 10
<211> 275
<212> PRT
<213> 灰色螺状菌(Helicocarpus griseus)
<400> 10
Met Ala Ser Pro Pro Gly His Pro Phe Val Gln Val Glu Gly Val Asn
1 5 10 15
Asn Phe Arg Ser Val Gly Gly Tyr Pro Ile Thr Pro Ser Ser Asp Ala
20 25 30
Arg Phe Thr Arg Asp Asn Phe Ile Tyr Arg Ser Ala Asp Pro Cys Tyr
35 40 45
Ile Thr Pro Glu Gly Arg Ser Lys Ile Arg Ser Leu Gly Ile Thr Thr
50 55 60
Val Phe Asp Leu Arg Ser Gln Pro Glu Val Asp Lys Gln Leu Ala Lys
65 70 75 80
Asp Pro Ser Ser Gly Val Pro Ile Ala Asp Gly Val Ile Arg Arg Phe
85 90 95
Thr Pro Val Phe Ser Arg Glu Asp Trp Gly Pro Glu Ala Ser Ala Val
100 105 110
Arg His Asn Leu Tyr Ala Asp Ala Ser Gly Ala Ser Gly Tyr Val Asp
115 120 125
Val Tyr Ala Asp Ile Leu Glu Asn Gly Gly Ala Ala Phe Arg Glu Ile
130 135 140
Leu Leu His Val Arg Asp Arg Pro Gly Asp Ala Leu Leu Cys His Cys
145 150 155 160
Ser Ala Gly Lys Asp Arg Thr Gly Val Ala Ile Ala Ile Leu Leu Lys
165 170 175
Leu Ala Gly Cys Glu Asp Glu Cys Ile Ser Lys Glu Tyr Glu Leu Thr
180 185 190
Glu Val Gly Leu Ala Ser Arg Lys Glu Phe Ile Ile Glu Tyr Leu Ile
195 200 205
Lys Gln Pro Glu Leu Glu Gly Asp Arg Ala Lys Ala Glu Lys Ile Ala
210 215 220
Gly Ala Lys Tyr Glu Asn Met Leu Gly Thr Leu Gln Met Met Glu Gln
225 230 235 240
Lys Tyr Gly Gly Val Glu Gly Tyr Val Lys Ala Tyr Cys Lys Leu Thr
245 250 255
Asp Lys Asp Ile Ala Thr Ile Arg Arg Asn Leu Val Ser Gly Asp Lys
260 265 270
Met Ile Ala
275
<210> 11
<211> 828
<212> DNA
<213> 灰色螺状菌(Helicocarpus griseus)
<400> 11
atggcatcac ccccagggca ccctttcgtg caagttgaag gcgtcaacaa cttccgctct 60
gtaggaggat atcccatcac cccatcctcc gacgcacgct tcacacgaga taacttcatc 120
tatcgcagcg ccgacccgtg ttacatcacg cccgaaggac gctccaaaat ccgctcactc 180
ggaatcacga ctgtttttga tctgcgctcc cagccagagg ttgacaagca gcttgccaaa 240
gacccttcct caggggttcc aatcgccgac ggcgtcatta gacgttttac gccggtattt 300
tcccgagagg attggggtcc ggaagcttcc gccgtccgcc ataatctgta tgctgatgcc 360
tctggggctt ctgggtacgt cgatgtgtat gccgacattc tggagaatgg aggggcggca 420
ttccgcgaga tcttgttgca cgtaagagac cggcctggtg atgcgctgct atgtcattgt 480
agtgccggaa aagatcgtac cggcgtggcg atagcgatac tgctcaagct tgcggggtgc 540
gaggatgaat gtatctcaaa ggagtacgag ctgaccgagg ttggtctagc ctcaagaaag 600
gagttcatta tagagtacct catcaagcag ccggaactag agggggatag agcaaaagct 660
gaaaaaattg cgggagccaa atatgagaac atgttaggga ccttgcaaat gatggaacag 720
aaatacgggg gtgttgaggg gtacgtgaaa gcgtattgca agttgacgga taaagatatt 780
gctacgatac gcaggaatct cgtctcaggt gacaaaatga ttgcctag 828
<210> 12
<211> 807
<212> DNA
<213> 泡突石耳菌(Umbilicaria pustulata)
<220>
<221> CDS
<222> (1)..(807)
<400> 12
atg tcc ctg ctg cct agc cca ccg ttt gtt cca gtt gaa ggt att cac 48
Met Ser Leu Leu Pro Ser Pro Pro Phe Val Pro Val Glu Gly Ile His
1 5 10 15
aat ttt cgc gat ctg ggc ggc tat ccg gtt agc acc agc ccg agc aag 96
Asn Phe Arg Asp Leu Gly Gly Tyr Pro Val Ser Thr Ser Pro Ser Lys
20 25 30
acc att cgt cgc aat atc atc ttt cgt tgt gcc gaa ccg tcg aaa atc 144
Thr Ile Arg Arg Asn Ile Ile Phe Arg Cys Ala Glu Pro Ser Lys Ile
35 40 45
acc ccg aac ggc att caa acg ctg cag agc ctg ggt gtg gcg acg ttc 192
Thr Pro Asn Gly Ile Gln Thr Leu Gln Ser Leu Gly Val Ala Thr Phe
50 55 60
ttt gac ctc cgt agc ggt ccg gaa atc gag aaa atg aaa gcg cat gca 240
Phe Asp Leu Arg Ser Gly Pro Glu Ile Glu Lys Met Lys Ala His Ala
65 70 75 80
ccg gtc gtt gag atc aag ggt att gag cgt gtt ttc gtg ccg gtg ttc 288
Pro Val Val Glu Ile Lys Gly Ile Glu Arg Val Phe Val Pro Val Phe
85 90 95
gcg gat ggt gat tat agc ccg gaa caa att gcg ctg cgt tac aaa gac 336
Ala Asp Gly Asp Tyr Ser Pro Glu Gln Ile Ala Leu Arg Tyr Lys Asp
100 105 110
tat gcg tcc tct ggc act ggt ggc ttc acc cgt gcg tac cac gac att 384
Tyr Ala Ser Ser Gly Thr Gly Gly Phe Thr Arg Ala Tyr His Asp Ile
115 120 125
ctg cgt tct gcc cct ccg agc tat cgt cgt atc ctg ctg cac ctg gca 432
Leu Arg Ser Ala Pro Pro Ser Tyr Arg Arg Ile Leu Leu His Leu Ala
130 135 140
gag aag ccg aac cag ccg tgc gtg atc cac tgt acc gct ggc aaa gac 480
Glu Lys Pro Asn Gln Pro Cys Val Ile His Cys Thr Ala Gly Lys Asp
145 150 155 160
cgc acg ggt gtt ctg gca gcg ctg att ctg gaa ctg gcg ggt gtc gat 528
Arg Thr Gly Val Leu Ala Ala Leu Ile Leu Glu Leu Ala Gly Val Asp
165 170 175
caa gac acc atc gcg cat gag tac gcc ctg acc gag ctg ggc ctg aag 576
Gln Asp Thr Ile Ala His Glu Tyr Ala Leu Thr Glu Leu Gly Leu Lys
180 185 190
gca tgg cgt ccg acg gtt gtc gag cac tta ctg cag aat ccg gcg ctg 624
Ala Trp Arg Pro Thr Val Val Glu His Leu Leu Gln Asn Pro Ala Leu
195 200 205
gaa ggc aat cgc gag ggt gca ttg aat atg gtc agc gct cgt gcg gag 672
Glu Gly Asn Arg Glu Gly Ala Leu Asn Met Val Ser Ala Arg Ala Glu
210 215 220
aac atg ctg gcc gcc ttg gaa atg att cgc gag atc tac ggt ggt gct 720
Asn Met Leu Ala Ala Leu Glu Met Ile Arg Glu Ile Tyr Gly Gly Ala
225 230 235 240
gag gcg tac gtg aaa gaa aag tgc ggt ctg agc gac gaa gat att gca 768
Glu Ala Tyr Val Lys Glu Lys Cys Gly Leu Ser Asp Glu Asp Ile Ala
245 250 255
cgc att cgc cag aac att ttg cat acg ccg agc ccg taa 807
Arg Ile Arg Gln Asn Ile Leu His Thr Pro Ser Pro
260 265
<210> 13
<211> 268
<212> PRT
<213> 泡突石耳菌(Umbilicaria pustulata)
<400> 13
Met Ser Leu Leu Pro Ser Pro Pro Phe Val Pro Val Glu Gly Ile His
1 5 10 15
Asn Phe Arg Asp Leu Gly Gly Tyr Pro Val Ser Thr Ser Pro Ser Lys
20 25 30
Thr Ile Arg Arg Asn Ile Ile Phe Arg Cys Ala Glu Pro Ser Lys Ile
35 40 45
Thr Pro Asn Gly Ile Gln Thr Leu Gln Ser Leu Gly Val Ala Thr Phe
50 55 60
Phe Asp Leu Arg Ser Gly Pro Glu Ile Glu Lys Met Lys Ala His Ala
65 70 75 80
Pro Val Val Glu Ile Lys Gly Ile Glu Arg Val Phe Val Pro Val Phe
85 90 95
Ala Asp Gly Asp Tyr Ser Pro Glu Gln Ile Ala Leu Arg Tyr Lys Asp
100 105 110
Tyr Ala Ser Ser Gly Thr Gly Gly Phe Thr Arg Ala Tyr His Asp Ile
115 120 125
Leu Arg Ser Ala Pro Pro Ser Tyr Arg Arg Ile Leu Leu His Leu Ala
130 135 140
Glu Lys Pro Asn Gln Pro Cys Val Ile His Cys Thr Ala Gly Lys Asp
145 150 155 160
Arg Thr Gly Val Leu Ala Ala Leu Ile Leu Glu Leu Ala Gly Val Asp
165 170 175
Gln Asp Thr Ile Ala His Glu Tyr Ala Leu Thr Glu Leu Gly Leu Lys
180 185 190
Ala Trp Arg Pro Thr Val Val Glu His Leu Leu Gln Asn Pro Ala Leu
195 200 205
Glu Gly Asn Arg Glu Gly Ala Leu Asn Met Val Ser Ala Arg Ala Glu
210 215 220
Asn Met Leu Ala Ala Leu Glu Met Ile Arg Glu Ile Tyr Gly Gly Ala
225 230 235 240
Glu Ala Tyr Val Lys Glu Lys Cys Gly Leu Ser Asp Glu Asp Ile Ala
245 250 255
Arg Ile Arg Gln Asn Ile Leu His Thr Pro Ser Pro
260 265
<210> 14
<211> 807
<212> DNA
<213> 泡突石耳菌(Umbilicaria pustulata)
<400> 14
atgtctctgc taccgtcacc tcccttcgta cccgttgagg gtatccacaa cttccgggac 60
ctaggcggct accccgtctc gacttcccct tccaagacca tacgtcgcaa catcatcttt 120
cgctgcgccg aaccctcgaa aatcactccc aatggcatcc agacgctcca atctttgggc 180
gtcgctacgt tcttcgacct ccgctccggc ccggaaatcg agaagatgaa agcacatgca 240
cctgtcgtcg agattaaggg catcgagcgt gtgttcgttc ccgtcttcgc cgacggggat 300
tactcgcccg aacaaatcgc tctgcgatac aaagactacg cttccagcgg aacggggggt 360
tttaccaggg cgtaccatga tatcctccga agtgcccctc cgagctatcg gcgcatacta 420
ttacatctgg cggagaagcc caaccagcca tgcgtcattc attgcacggc cgggaaagat 480
aggacgggcg tattggcggc gttgatactc gagttggccg gggttgatca ggatacaatt 540
gcgcacgagt acgcattgac ggaactgggg ttgaaggcct ggcgtcccac tgtggtggag 600
cacctcttgc agaatccagc gttggaggga aatcgggaag gggcattgaa catggtcagc 660
gcgagggcag agaacatgct ggcagccttg gagatgatcc gggagatcta tggcggcgcc 720
gaagcatatg tgaaggagaa gtgtggcctc agcgacgaag acattgcgcg gatacggcag 780
aatattctac acacgccatc tccgtga 807
<210> 15
<211> 858
<212> DNA
<213> 细疣篮状菌(Talaromyces verruculosus)
<220>
<221> CDS
<222> (1)..(858)
<400> 15
atg tct gtc acc gaa cat gtt gtc gaa gct agc acc ccg tcc act ctg 48
Met Ser Val Thr Glu His Val Val Glu Ala Ser Thr Pro Ser Thr Leu
1 5 10 15
ccg cca ccg ttc att cac gtg gac ggt gtt ccg aac ttc cgt gac att 96
Pro Pro Pro Phe Ile His Val Asp Gly Val Pro Asn Phe Arg Asp Ile
20 25 30
ggt ggc tat ccg att acc gat ctg ctg agc acc cgt cgc aat ttc gtt 144
Gly Gly Tyr Pro Ile Thr Asp Leu Leu Ser Thr Arg Arg Asn Phe Val
35 40 45
tat cgc tcc gca gtt cct acc cgc atc acc cca acg ggc ctg cag acg 192
Tyr Arg Ser Ala Val Pro Thr Arg Ile Thr Pro Thr Gly Leu Gln Thr
50 55 60
ctg acc caa gat ctg cag att acg acg gtc tac gac tta cgt tcg aat 240
Leu Thr Gln Asp Leu Gln Ile Thr Thr Val Tyr Asp Leu Arg Ser Asn
65 70 75 80
gct gag ctg cgt aaa gat cct atc gcg agc agc ccg ttg gac acc cac 288
Ala Glu Leu Arg Lys Asp Pro Ile Ala Ser Ser Pro Leu Asp Thr His
85 90 95
gac agc gtg act gtc ctg cat acc ccg gtt ttc ccg gag cgc gat tct 336
Asp Ser Val Thr Val Leu His Thr Pro Val Phe Pro Glu Arg Asp Ser
100 105 110
agc ccg gaa cag ctg gca aag cgt ttt gcc aac tat atg agc gcg aac 384
Ser Pro Glu Gln Leu Ala Lys Arg Phe Ala Asn Tyr Met Ser Ala Asn
115 120 125
ggt tcc gag ggt ttc gtt gcg gcg tac gca gag att ctg cgt gat ggt 432
Gly Ser Glu Gly Phe Val Ala Ala Tyr Ala Glu Ile Leu Arg Asp Gly
130 135 140
gtg gat gcc tac cgc aag gtt ttt gaa cac gtg cgt gac cgt ccg cgt 480
Val Asp Ala Tyr Arg Lys Val Phe Glu His Val Arg Asp Arg Pro Arg
145 150 155 160
gat gcg ttt ctg gtg cac tgc acc ggt ggc aaa gac cgt acg ggt gtg 528
Asp Ala Phe Leu Val His Cys Thr Gly Gly Lys Asp Arg Thr Gly Val
165 170 175
ttg gtt gcg ctg atg ctg ttg gtg gca ggc gtc aaa gac cgt gac gtt 576
Leu Val Ala Leu Met Leu Leu Val Ala Gly Val Lys Asp Arg Asp Val
180 185 190
att gcc gat gag tac agc ctg acg gaa aag ggt ttt gcg gct gtc atc 624
Ile Ala Asp Glu Tyr Ser Leu Thr Glu Lys Gly Phe Ala Ala Val Ile
195 200 205
aaa gcc gat gct gcg gaa aag atc atc aaa gac atg ggt gtt gac ggt 672
Lys Ala Asp Ala Ala Glu Lys Ile Ile Lys Asp Met Gly Val Asp Gly
210 215 220
gcc aat cgt gcg ggc atc gag cgt ctg ttg agc gca cgc aaa gaa aac 720
Ala Asn Arg Ala Gly Ile Glu Arg Leu Leu Ser Ala Arg Lys Glu Asn
225 230 235 240
atg agc gcg acc ctg gag tac att gag aag caa ttt ggt ggc gca gag 768
Met Ser Ala Thr Leu Glu Tyr Ile Glu Lys Gln Phe Gly Gly Ala Glu
245 250 255
ggc tat ctg cgc gac caa ctg ggt ttc ggc gac gaa gat gtg gaa cag 816
Gly Tyr Leu Arg Asp Gln Leu Gly Phe Gly Asp Glu Asp Val Glu Gln
260 265 270
atc cgt aag agc ctg gtc gtt gag gat aaa ggc ctg ttc taa 858
Ile Arg Lys Ser Leu Val Val Glu Asp Lys Gly Leu Phe
275 280 285
<210> 16
<211> 285
<212> PRT
<213> 细疣篮状菌(Talaromyces verruculosus)
<400> 16
Met Ser Val Thr Glu His Val Val Glu Ala Ser Thr Pro Ser Thr Leu
1 5 10 15
Pro Pro Pro Phe Ile His Val Asp Gly Val Pro Asn Phe Arg Asp Ile
20 25 30
Gly Gly Tyr Pro Ile Thr Asp Leu Leu Ser Thr Arg Arg Asn Phe Val
35 40 45
Tyr Arg Ser Ala Val Pro Thr Arg Ile Thr Pro Thr Gly Leu Gln Thr
50 55 60
Leu Thr Gln Asp Leu Gln Ile Thr Thr Val Tyr Asp Leu Arg Ser Asn
65 70 75 80
Ala Glu Leu Arg Lys Asp Pro Ile Ala Ser Ser Pro Leu Asp Thr His
85 90 95
Asp Ser Val Thr Val Leu His Thr Pro Val Phe Pro Glu Arg Asp Ser
100 105 110
Ser Pro Glu Gln Leu Ala Lys Arg Phe Ala Asn Tyr Met Ser Ala Asn
115 120 125
Gly Ser Glu Gly Phe Val Ala Ala Tyr Ala Glu Ile Leu Arg Asp Gly
130 135 140
Val Asp Ala Tyr Arg Lys Val Phe Glu His Val Arg Asp Arg Pro Arg
145 150 155 160
Asp Ala Phe Leu Val His Cys Thr Gly Gly Lys Asp Arg Thr Gly Val
165 170 175
Leu Val Ala Leu Met Leu Leu Val Ala Gly Val Lys Asp Arg Asp Val
180 185 190
Ile Ala Asp Glu Tyr Ser Leu Thr Glu Lys Gly Phe Ala Ala Val Ile
195 200 205
Lys Ala Asp Ala Ala Glu Lys Ile Ile Lys Asp Met Gly Val Asp Gly
210 215 220
Ala Asn Arg Ala Gly Ile Glu Arg Leu Leu Ser Ala Arg Lys Glu Asn
225 230 235 240
Met Ser Ala Thr Leu Glu Tyr Ile Glu Lys Gln Phe Gly Gly Ala Glu
245 250 255
Gly Tyr Leu Arg Asp Gln Leu Gly Phe Gly Asp Glu Asp Val Glu Gln
260 265 270
Ile Arg Lys Ser Leu Val Val Glu Asp Lys Gly Leu Phe
275 280 285
<210> 17
<211> 858
<212> DNA
<213> 细疣篮状菌(Talaromyces verruculosus)
<400> 17
atgagcgtca cagaacatgt agtcgaagcc tcgacaccat caacccttcc accacccttc 60
atccatgtcg acggcgtccc caacttccgc gacatcggcg gctaccccat cacagactta 120
ctgtcaacac gacgaaactt cgtgtatcgc tccgcagtcc caacacgcat cactcccaca 180
ggtctacaga cactcaccca agacctccaa atcacaacag tctacgacct acgctccaac 240
gctgaactgc gcaaggatcc cattgcctcc agccctctag acacccatga ctctgtaacg 300
gtgctacaca cccccgtctt tcccgaacgg gactcaagtc ccgaacaact cgcaaagagg 360
tttgcgaatt acatgtccgc caacggctcg gaagggtttg tagccgccta cgccgagatt 420
ttgcgtgatg gcgttgatgc ataccgcaag gtgtttgagc atgtccgtga tcggccccgg 480
gatgcgtttt tggtgcattg tactggtggg aaggatagaa cgggtgtcct tgtagcgctc 540
atgttacttg ttgcgggtgt caaggataga gatgtgattg ccgacgagta ctcgttgacg 600
gagaaggggt ttgctgctgt tattaaggcg gatgcggcgg agaagattat aaaggatatg 660
ggagtggatg gggcgaatag ggcgggcatt gagagattgc tgtcggcgag gaaggagaat 720
atgagtgcta cgttggagta tatcgagaaa cagtttggtg gggcggaggg ttatttgagg 780
gatcagttag ggtttggtga tgaggatgtt gagcagatta ggaagagtct tgtcgtggag 840
gataagggtt tattttag 858
<210> 18
<211> 852
<212> DNA
<213> 松网褶菌(Hydnomerulius pinastri)
<220>
<221> CDS
<222> (1)..(852)
<400> 18
atg act gca acc gac aat ggc tta gaa ccg ctg gac cct gca tac gtt 48
Met Thr Ala Thr Asp Asn Gly Leu Glu Pro Leu Asp Pro Ala Tyr Val
1 5 10 15
gct gat gtg ttg agc cgt ccg ccg ttt gtc cag atc tcc ggc gtg tgt 96
Ala Asp Val Leu Ser Arg Pro Pro Phe Val Gln Ile Ser Gly Val Cys
20 25 30
aac gtc aga gat ctg ggc agc tat ccg acc gct acc ccg aat gtg att 144
Asn Val Arg Asp Leu Gly Ser Tyr Pro Thr Ala Thr Pro Asn Val Ile
35 40 45
acc aag cct ggt tat gca tac cgt ggt gcc gaa gtt tcc aat atc acc 192
Thr Lys Pro Gly Tyr Ala Tyr Arg Gly Ala Glu Val Ser Asn Ile Thr
50 55 60
gaa gag ggc agc caa caa atg aaa gca ctg ggt att acc acg atc ttt 240
Glu Glu Gly Ser Gln Gln Met Lys Ala Leu Gly Ile Thr Thr Ile Phe
65 70 75 80
gat ctg cgt tct gac cca gag atg cag aag tac agc acg ccg att ccg 288
Asp Leu Arg Ser Asp Pro Glu Met Gln Lys Tyr Ser Thr Pro Ile Pro
85 90 95
cat atc gag ggt gtc ctg att ctg cgt acc ccg gtg ttc gcc acc gag 336
His Ile Glu Gly Val Leu Ile Leu Arg Thr Pro Val Phe Ala Thr Glu
100 105 110
gac tat agc ccg gag tcg atg gcg aag cgt ttt gag ctg tac gcg tct 384
Asp Tyr Ser Pro Glu Ser Met Ala Lys Arg Phe Glu Leu Tyr Ala Ser
115 120 125
ggt acg acc gaa gca ttc atg aag ctg tat agc cag att ctg gac cac 432
Gly Thr Thr Glu Ala Phe Met Lys Leu Tyr Ser Gln Ile Leu Asp His
130 135 140
ggc ggc aaa gcg ttc ggt act att ctg cgt cat gtt cgt gac cgc ccg 480
Gly Gly Lys Ala Phe Gly Thr Ile Leu Arg His Val Arg Asp Arg Pro
145 150 155 160
aac agc gtt ttt ctg ttt cac tgc acg gcc ggt aaa gat cgc acg ggc 528
Asn Ser Val Phe Leu Phe His Cys Thr Ala Gly Lys Asp Arg Thr Gly
165 170 175
att att gcg gcc atc ctg ttc aaa ttg gcg ggt gtg gat gat cac ttg 576
Ile Ile Ala Ala Ile Leu Phe Lys Leu Ala Gly Val Asp Asp His Leu
180 185 190
atc tgt cag gac tac agc ctg acg cgc atc ggt cgt gag cca gac cgt 624
Ile Cys Gln Asp Tyr Ser Leu Thr Arg Ile Gly Arg Glu Pro Asp Arg
195 200 205
gaa aaa gtt ctg cgc cgt ctg ctg aat gaa ccg ctg ttc gcg gcg aat 672
Glu Lys Val Leu Arg Arg Leu Leu Asn Glu Pro Leu Phe Ala Ala Asn
210 215 220
acc gag ctt gcg ctg cgc atg ttg acg agc cgc tac gaa acc atg caa 720
Thr Glu Leu Ala Leu Arg Met Leu Thr Ser Arg Tyr Glu Thr Met Gln
225 230 235 240
gcg acc ctg ggt ctg ttg agc gac aaa tat ggc ggt gtg gaa gca tac 768
Ala Thr Leu Gly Leu Leu Ser Asp Lys Tyr Gly Gly Val Glu Ala Tyr
245 250 255
gtc aag aac ttc tgc ggt ctg acc gat aac gac atc agc gtt atc cgt 816
Val Lys Asn Phe Cys Gly Leu Thr Asp Asn Asp Ile Ser Val Ile Arg
260 265 270
acc aac ctg gtt gtg ccg acg aaa gcg cgt atg taa 852
Thr Asn Leu Val Val Pro Thr Lys Ala Arg Met
275 280
<210> 19
<211> 283
<212> PRT
<213> 松网褶菌(Hydnomerulius pinastri)
<400> 19
Met Thr Ala Thr Asp Asn Gly Leu Glu Pro Leu Asp Pro Ala Tyr Val
1 5 10 15
Ala Asp Val Leu Ser Arg Pro Pro Phe Val Gln Ile Ser Gly Val Cys
20 25 30
Asn Val Arg Asp Leu Gly Ser Tyr Pro Thr Ala Thr Pro Asn Val Ile
35 40 45
Thr Lys Pro Gly Tyr Ala Tyr Arg Gly Ala Glu Val Ser Asn Ile Thr
50 55 60
Glu Glu Gly Ser Gln Gln Met Lys Ala Leu Gly Ile Thr Thr Ile Phe
65 70 75 80
Asp Leu Arg Ser Asp Pro Glu Met Gln Lys Tyr Ser Thr Pro Ile Pro
85 90 95
His Ile Glu Gly Val Leu Ile Leu Arg Thr Pro Val Phe Ala Thr Glu
100 105 110
Asp Tyr Ser Pro Glu Ser Met Ala Lys Arg Phe Glu Leu Tyr Ala Ser
115 120 125
Gly Thr Thr Glu Ala Phe Met Lys Leu Tyr Ser Gln Ile Leu Asp His
130 135 140
Gly Gly Lys Ala Phe Gly Thr Ile Leu Arg His Val Arg Asp Arg Pro
145 150 155 160
Asn Ser Val Phe Leu Phe His Cys Thr Ala Gly Lys Asp Arg Thr Gly
165 170 175
Ile Ile Ala Ala Ile Leu Phe Lys Leu Ala Gly Val Asp Asp His Leu
180 185 190
Ile Cys Gln Asp Tyr Ser Leu Thr Arg Ile Gly Arg Glu Pro Asp Arg
195 200 205
Glu Lys Val Leu Arg Arg Leu Leu Asn Glu Pro Leu Phe Ala Ala Asn
210 215 220
Thr Glu Leu Ala Leu Arg Met Leu Thr Ser Arg Tyr Glu Thr Met Gln
225 230 235 240
Ala Thr Leu Gly Leu Leu Ser Asp Lys Tyr Gly Gly Val Glu Ala Tyr
245 250 255
Val Lys Asn Phe Cys Gly Leu Thr Asp Asn Asp Ile Ser Val Ile Arg
260 265 270
Thr Asn Leu Val Val Pro Thr Lys Ala Arg Met
275 280
<210> 20
<211> 852
<212> DNA
<213> 松网褶菌(Hydnomerulius pinastri)
<400> 20
atgaccgcaa cagacaacgg actagaaccc ttagaccctg catatgtcgc agatgtgctc 60
tcaagaccac cattcgtaca aatatctggt gtttgcaacg tccgtgatct aggatcctac 120
cctaccgcca ctcccaatgt cataacaaag ccgggatatg cataccgggg cgcagaggtc 180
tctaacatta ccgaagaagg tagccagcaa atgaaggcgc taggcataac gactatattt 240
gatcttagat cggatccaga gatgcagaaa tacagcactc caatacccca cattgaaggc 300
gtactgatat tgcgcacgcc tgtcttcgcg accgaggatt atagtccgga aagtatggcc 360
aagagatttg agctatacgc aagtggtact actgaagcat ttatgaaact atactctcaa 420
atactagacc atggaggcaa agccttcgga acaattctcc ggcacgttcg ggacaggcca 480
aattctgtct ttcttttcca ttgcactgcg gggaaagacc ggaccggcat cattgctgca 540
attctgttca agctcgccgg cgtagacgac catctcatat gtcaagatta ctccctcaca 600
cgaataggtc gcgagcctga tcgtgaaaag gtcctccggc gactcttgaa tgaacctcta 660
tttgccgcca acacggaact tgcactacga atgctcacgt ctcgatatga aactatgcaa 720
gcaacgttgg ggcttcttag cgataagtat ggcggggtgg aggcgtatgt gaagaatttc 780
tgtgggctca cggataatga tatatcggtc atacgaacaa atctcgttgt acctacaaag 840
gcgcggatgt ag 852
<210> 21
<211> 936
<212> DNA
<213> 纤维素分解篮状菌(Talaromyces cellulolyticus)
<220>
<221> CDS
<222> (1)..(936)
<400> 21
atg agc aac gac acg acc agc acc gca tcc gca ggc acc gca act tct 48
Met Ser Asn Asp Thr Thr Ser Thr Ala Ser Ala Gly Thr Ala Thr Ser
1 5 10 15
tcg cgc ttt ctg agc gtc ggt ggc gtg gtt aac ttc cgt gag ttg ggt 96
Ser Arg Phe Leu Ser Val Gly Gly Val Val Asn Phe Arg Glu Leu Gly
20 25 30
ggc tac ccg tgc gac agc gtt cct cct gca cca gca agc aat ggt agc 144
Gly Tyr Pro Cys Asp Ser Val Pro Pro Ala Pro Ala Ser Asn Gly Ser
35 40 45
ccg gac aat gcg agc gaa gcg att ctg tgg gtt ggt cac agc agc att 192
Pro Asp Asn Ala Ser Glu Ala Ile Leu Trp Val Gly His Ser Ser Ile
50 55 60
cgt ccg cgc ttc ttg ttt cgt agc gca cag ccg tcc cag atc acc ccg 240
Arg Pro Arg Phe Leu Phe Arg Ser Ala Gln Pro Ser Gln Ile Thr Pro
65 70 75 80
gcc ggt att gaa acg ctg att cgc caa ctc ggt att caa gcg atc ttt 288
Ala Gly Ile Glu Thr Leu Ile Arg Gln Leu Gly Ile Gln Ala Ile Phe
85 90 95
gac ttt cgt tcc cgt acc gag atc caa ctg gtg gca acc cgc tac cca 336
Asp Phe Arg Ser Arg Thr Glu Ile Gln Leu Val Ala Thr Arg Tyr Pro
100 105 110
gat agc ctg ctg gaa att ccg ggc acg act cgt tac tct gtt ccg gtc 384
Asp Ser Leu Leu Glu Ile Pro Gly Thr Thr Arg Tyr Ser Val Pro Val
115 120 125
ttt acc gag ggc gac tac agc ccg gct tct ctg gtt aag cgt tat ggt 432
Phe Thr Glu Gly Asp Tyr Ser Pro Ala Ser Leu Val Lys Arg Tyr Gly
130 135 140
gtc tct agc gac acg gca acg gat agc acc agc tca aag tgc gcg aaa 480
Val Ser Ser Asp Thr Ala Thr Asp Ser Thr Ser Ser Lys Cys Ala Lys
145 150 155 160
ccg acc ggc ttt gtg cat gct tat gaa gcg att gct cgt tct gcc gcg 528
Pro Thr Gly Phe Val His Ala Tyr Glu Ala Ile Ala Arg Ser Ala Ala
165 170 175
gag aac ggt agc ttc cgc aag atc acc gac cac att atc caa cat ccg 576
Glu Asn Gly Ser Phe Arg Lys Ile Thr Asp His Ile Ile Gln His Pro
180 185 190
gat cgc ccg atc ctg ttt cac tgc acg ctg ggc aaa gac cgt acc ggt 624
Asp Arg Pro Ile Leu Phe His Cys Thr Leu Gly Lys Asp Arg Thr Gly
195 200 205
gtt ttc gca gcg ctg ctg ctg agc ttg tgt ggt gtc ccg aat gac acc 672
Val Phe Ala Ala Leu Leu Leu Ser Leu Cys Gly Val Pro Asn Asp Thr
210 215 220
atc gtg gaa gat tat gcg atg acg acc gaa ggc ttc ggt gtg tgg cgt 720
Ile Val Glu Asp Tyr Ala Met Thr Thr Glu Gly Phe Gly Val Trp Arg
225 230 235 240
gag cac ttg att cag cgt ctg ctg cag cgc aaa gat gcg gct acg cgt 768
Glu His Leu Ile Gln Arg Leu Leu Gln Arg Lys Asp Ala Ala Thr Arg
245 250 255
gaa gat gcc gag ttc att atc gcg agc cat ccg gag agc atg aaa gcg 816
Glu Asp Ala Glu Phe Ile Ile Ala Ser His Pro Glu Ser Met Lys Ala
260 265 270
ttc ctg gaa gat gtc gtt gcg acc aaa ttc ggt gac gcc cgc aac tac 864
Phe Leu Glu Asp Val Val Ala Thr Lys Phe Gly Asp Ala Arg Asn Tyr
275 280 285
ttt atc cag cac tgt ggt ctg acc gaa gcc gaa gtg gat aag ctg atc 912
Phe Ile Gln His Cys Gly Leu Thr Glu Ala Glu Val Asp Lys Leu Ile
290 295 300
cgt acg ctg gtg atc gcg aat taa 936
Arg Thr Leu Val Ile Ala Asn
305 310
<210> 22
<211> 311
<212> PRT
<213> 纤维素分解篮状菌(Talaromyces cellulolyticus)
<400> 22
Met Ser Asn Asp Thr Thr Ser Thr Ala Ser Ala Gly Thr Ala Thr Ser
1 5 10 15
Ser Arg Phe Leu Ser Val Gly Gly Val Val Asn Phe Arg Glu Leu Gly
20 25 30
Gly Tyr Pro Cys Asp Ser Val Pro Pro Ala Pro Ala Ser Asn Gly Ser
35 40 45
Pro Asp Asn Ala Ser Glu Ala Ile Leu Trp Val Gly His Ser Ser Ile
50 55 60
Arg Pro Arg Phe Leu Phe Arg Ser Ala Gln Pro Ser Gln Ile Thr Pro
65 70 75 80
Ala Gly Ile Glu Thr Leu Ile Arg Gln Leu Gly Ile Gln Ala Ile Phe
85 90 95
Asp Phe Arg Ser Arg Thr Glu Ile Gln Leu Val Ala Thr Arg Tyr Pro
100 105 110
Asp Ser Leu Leu Glu Ile Pro Gly Thr Thr Arg Tyr Ser Val Pro Val
115 120 125
Phe Thr Glu Gly Asp Tyr Ser Pro Ala Ser Leu Val Lys Arg Tyr Gly
130 135 140
Val Ser Ser Asp Thr Ala Thr Asp Ser Thr Ser Ser Lys Cys Ala Lys
145 150 155 160
Pro Thr Gly Phe Val His Ala Tyr Glu Ala Ile Ala Arg Ser Ala Ala
165 170 175
Glu Asn Gly Ser Phe Arg Lys Ile Thr Asp His Ile Ile Gln His Pro
180 185 190
Asp Arg Pro Ile Leu Phe His Cys Thr Leu Gly Lys Asp Arg Thr Gly
195 200 205
Val Phe Ala Ala Leu Leu Leu Ser Leu Cys Gly Val Pro Asn Asp Thr
210 215 220
Ile Val Glu Asp Tyr Ala Met Thr Thr Glu Gly Phe Gly Val Trp Arg
225 230 235 240
Glu His Leu Ile Gln Arg Leu Leu Gln Arg Lys Asp Ala Ala Thr Arg
245 250 255
Glu Asp Ala Glu Phe Ile Ile Ala Ser His Pro Glu Ser Met Lys Ala
260 265 270
Phe Leu Glu Asp Val Val Ala Thr Lys Phe Gly Asp Ala Arg Asn Tyr
275 280 285
Phe Ile Gln His Cys Gly Leu Thr Glu Ala Glu Val Asp Lys Leu Ile
290 295 300
Arg Thr Leu Val Ile Ala Asn
305 310
<210> 23
<211> 936
<212> DNA
<213> 纤维素分解篮状菌(Talaromyces cellulolyticus)
<400> 23
atgtctaatg acaccactag cacggcttct gccggaacag caacttcttc gcggtttctt 60
tctgtgggcg gagttgtgaa tttccgtgaa ctgggcggtt atccatgtga ttctgtccct 120
cctgctcctg cctcaaacgg ctcaccggac aacgcatctg aagcgatcct ttgggttggc 180
cactcgtcca ttcggcctag gtttctcttt cgatcggcac agccgtctca gattaccccg 240
gccggtattg agacattgat ccgccagctt ggcatccagg caatttttga ctttcgttca 300
cggacggaaa ttcagcttgt cgccactcgc tatcctgatt cgctactcga gatacctggt 360
acgactcgct attccgtgcc cgtcttcacg gagggcgact attccccggc gtcattagtc 420
aagaggtacg gagtgtcctc cgatactgca actgattcca cttcctccaa atgtgccaag 480
cctacaggat tcgtccacgc atatgaggct atcgcacgca gcgcagcaga aaacggcagt 540
tttcgtaaaa taacggacca cataatacaa catccggacc ggcctatcct gtttcactgt 600
acattgggaa aagaccgaac cggtgtattt gcagcattgt tattgagtct ttgcggggta 660
ccaaacgaca cgatagttga agactatgct atgactaccg agggatttgg ggtctggcga 720
gaacatctaa ttcaacgcct gttacaaaga aaggatgcag ctacgcgtga ggatgcagaa 780
ttcattattg ccagccaccc ggagagtatg aaggcttttc tagaagatgt ggtagcaacc 840
aagttcgggg atgctcgaaa ttactttatc cagcactgtg gattgacgga agcggaggtt 900
gataagctaa ttcggacact ggtcattgcg aattga 936
<210> 24
<211> 990
<212> DNA
<213> 马尔尼菲篮状菌(Talaromyces marneffei)
<220>
<221> CDS
<222> (1)..(990)
<400> 24
atg tgg aat ttg cac tat tat att ccg ggc tct gca cca gtt aat ttg 48
Met Trp Asn Leu His Tyr Tyr Ile Pro Gly Ser Ala Pro Val Asn Leu
1 5 10 15
aac gac atg ccg aac gat acg gcg acg acg gct tcc gca ggc act agc 96
Asn Asp Met Pro Asn Asp Thr Ala Thr Thr Ala Ser Ala Gly Thr Ser
20 25 30
gcc acg agc cgc ttc ctc tgt gtc agc ggt gtt gcg aac ttc cgt gaa 144
Ala Thr Ser Arg Phe Leu Cys Val Ser Gly Val Ala Asn Phe Arg Glu
35 40 45
ctg ggt ggc tat ccg tgc gac acc gtt cct cca gca ccg gcg agc aat 192
Leu Gly Gly Tyr Pro Cys Asp Thr Val Pro Pro Ala Pro Ala Ser Asn
50 55 60
ggt agc ccg cat aat gca tcc gag gcc acg ctg caa ggt tcc cac tct 240
Gly Ser Pro His Asn Ala Ser Glu Ala Thr Leu Gln Gly Ser His Ser
65 70 75 80
agc att cgt ccg ggc ttc atc ttc cgt agc gcg caa ccg agc cag atc 288
Ser Ile Arg Pro Gly Phe Ile Phe Arg Ser Ala Gln Pro Ser Gln Ile
85 90 95
aat ccg gca ggc atc gcg acg ctg gcg cat gaa ctg tct att caa gtc 336
Asn Pro Ala Gly Ile Ala Thr Leu Ala His Glu Leu Ser Ile Gln Val
100 105 110
atc ttc gac ttc cgt tcg cag acc gag atc cag ctg gtc acc acc cac 384
Ile Phe Asp Phe Arg Ser Gln Thr Glu Ile Gln Leu Val Thr Thr His
115 120 125
tac ccg gat agc ctg ttg gag atc ccg tgt acc acc cgt tac agc gtg 432
Tyr Pro Asp Ser Leu Leu Glu Ile Pro Cys Thr Thr Arg Tyr Ser Val
130 135 140
ccg gtg ttt aac gag ggt gac tat agc ccg gct tcg ctg gtc aag aaa 480
Pro Val Phe Asn Glu Gly Asp Tyr Ser Pro Ala Ser Leu Val Lys Lys
145 150 155 160
tac ggt gtg agc ccg gac cca gtg acg cat tcc gct agc agc acc agc 528
Tyr Gly Val Ser Pro Asp Pro Val Thr His Ser Ala Ser Ser Thr Ser
165 170 175
gcg aat cct gcc ggc ttt gtg ccg gcc tac gaa gca atc gct cgt agc 576
Ala Asn Pro Ala Gly Phe Val Pro Ala Tyr Glu Ala Ile Ala Arg Ser
180 185 190
gca gcc gaa aac ggt agc ttt cgc aaa atc acc gag cac att att cag 624
Ala Ala Glu Asn Gly Ser Phe Arg Lys Ile Thr Glu His Ile Ile Gln
195 200 205
cac ccg gat cag ccg att ttg ttt cat tgc acc ctg ggt aaa gat cgc 672
His Pro Asp Gln Pro Ile Leu Phe His Cys Thr Leu Gly Lys Asp Arg
210 215 220
acg ggt gtg ttt gcg gcc ctg ctg ctg agc ctg tgc ggt gtt tcc acc 720
Thr Gly Val Phe Ala Ala Leu Leu Leu Ser Leu Cys Gly Val Ser Thr
225 230 235 240
gaa aag atc gtg gaa gat tac gcg atg acc acc gag ggt ttc ggt gct 768
Glu Lys Ile Val Glu Asp Tyr Ala Met Thr Thr Glu Gly Phe Gly Ala
245 250 255
tgg cgt gag cac ctg att aag cgc ctg ctg cag cgt aaa gat gcg gca 816
Trp Arg Glu His Leu Ile Lys Arg Leu Leu Gln Arg Lys Asp Ala Ala
260 265 270
acc cgc caa gac gct gag ttc atc att gcc agc cac ccg gaa acc atg 864
Thr Arg Gln Asp Ala Glu Phe Ile Ile Ala Ser His Pro Glu Thr Met
275 280 285
aaa tct ttt ctg gac gac gtt gtt cgt gcg aag ttt ggc tcc gcg cgt 912
Lys Ser Phe Leu Asp Asp Val Val Arg Ala Lys Phe Gly Ser Ala Arg
290 295 300
aac tat ttc gtg caa cag tgc ggt ctg act gag tac gaa gtt gat aag 960
Asn Tyr Phe Val Gln Gln Cys Gly Leu Thr Glu Tyr Glu Val Asp Lys
305 310 315 320
ctg att cat acg ctg gtc att atc aag taa 990
Leu Ile His Thr Leu Val Ile Ile Lys
325
<210> 25
<211> 329
<212> PRT
<213> 马尔尼菲篮状菌(Talaromyces marneffei)
<400> 25
Met Trp Asn Leu His Tyr Tyr Ile Pro Gly Ser Ala Pro Val Asn Leu
1 5 10 15
Asn Asp Met Pro Asn Asp Thr Ala Thr Thr Ala Ser Ala Gly Thr Ser
20 25 30
Ala Thr Ser Arg Phe Leu Cys Val Ser Gly Val Ala Asn Phe Arg Glu
35 40 45
Leu Gly Gly Tyr Pro Cys Asp Thr Val Pro Pro Ala Pro Ala Ser Asn
50 55 60
Gly Ser Pro His Asn Ala Ser Glu Ala Thr Leu Gln Gly Ser His Ser
65 70 75 80
Ser Ile Arg Pro Gly Phe Ile Phe Arg Ser Ala Gln Pro Ser Gln Ile
85 90 95
Asn Pro Ala Gly Ile Ala Thr Leu Ala His Glu Leu Ser Ile Gln Val
100 105 110
Ile Phe Asp Phe Arg Ser Gln Thr Glu Ile Gln Leu Val Thr Thr His
115 120 125
Tyr Pro Asp Ser Leu Leu Glu Ile Pro Cys Thr Thr Arg Tyr Ser Val
130 135 140
Pro Val Phe Asn Glu Gly Asp Tyr Ser Pro Ala Ser Leu Val Lys Lys
145 150 155 160
Tyr Gly Val Ser Pro Asp Pro Val Thr His Ser Ala Ser Ser Thr Ser
165 170 175
Ala Asn Pro Ala Gly Phe Val Pro Ala Tyr Glu Ala Ile Ala Arg Ser
180 185 190
Ala Ala Glu Asn Gly Ser Phe Arg Lys Ile Thr Glu His Ile Ile Gln
195 200 205
His Pro Asp Gln Pro Ile Leu Phe His Cys Thr Leu Gly Lys Asp Arg
210 215 220
Thr Gly Val Phe Ala Ala Leu Leu Leu Ser Leu Cys Gly Val Ser Thr
225 230 235 240
Glu Lys Ile Val Glu Asp Tyr Ala Met Thr Thr Glu Gly Phe Gly Ala
245 250 255
Trp Arg Glu His Leu Ile Lys Arg Leu Leu Gln Arg Lys Asp Ala Ala
260 265 270
Thr Arg Gln Asp Ala Glu Phe Ile Ile Ala Ser His Pro Glu Thr Met
275 280 285
Lys Ser Phe Leu Asp Asp Val Val Arg Ala Lys Phe Gly Ser Ala Arg
290 295 300
Asn Tyr Phe Val Gln Gln Cys Gly Leu Thr Glu Tyr Glu Val Asp Lys
305 310 315 320
Leu Ile His Thr Leu Val Ile Ile Lys
325
<210> 26
<211> 990
<212> DNA
<213> 马尔尼菲篮状菌(Talaromyces marneffei)
<400> 26
atgtggaacc tacactacta tattcctgga tcagcaccag tcaacttgaa cgacatgcct 60
aatgacaccg ctaccacggc ttctgccgga acatcagcaa cttcacggtt tctttgcgtg 120
agcggagtgg cgaatttccg tgaactgggc ggttacccat gcgatactgt ccctcctgct 180
cctgcgtcaa acggttcacc gcacaatgca tctgaagcga ccctccaggg tagtcattcg 240
tctattcggc ctggatttat ctttcgatcg gctcagccgt cgcagattaa cccggctggt 300
attgccacat tagcacacga gcttagcatc caggtgattt ttgactttcg ttcgcaaacc 360
gaaattcagc ttgtcactac tcattatcct gattcgctac ttgagatacc ttgcacgact 420
cgctattccg tgccggtctt caatgagggc gactattccc cagcgtcgtt agtcaagaag 480
tacggggtat cccccgatcc tgtaacacat tccgcttcct ccacgagtgc caatcctgca 540
ggatttgtcc ccgcgtatga agccatcgca cgaagcgcag cagaaaacgg cagtttccgt 600
aaaataacag agcacataat acagcatccg gaccagccga tcctgtttca ttgtactctg 660
ggaaaggacc ggaccggagt ttttgcagca ttgctattga gcctttgcgg tgtttcgact 720
gagaagatag ttgaagacta tgctatgact accgagggtt tcggagcctg gcgggaacat 780
ctaattaaac gcctgctgca aaggaaagat gcagcaacac gccaggatgc ggaattcatt 840
atcgccagcc acccggagac tatgaagtct ttcctagacg atgtcgtgcg agctaagttc 900
ggaagtgctc gaaattactt tgtccagcag tgtggattga cagaatatga ggttgataag 960
ttaatccata cactcgtgat tataaaatga 990
<210> 27
<211> 906
<212> DNA
<213> 踝节篮状菌(Talaromyces atroroseus)
<220>
<221> CDS
<222> (1)..(906)
<400> 27
atg tcc acc aat gca gat ccg acc acg ttt tcc gat aag tcc ccg ttc 48
Met Ser Thr Asn Ala Asp Pro Thr Thr Phe Ser Asp Lys Ser Pro Phe
1 5 10 15
atc aat gtc agc ggc gtg gtg aat ttt cgt gac ctg ggc ggc tac agc 96
Ile Asn Val Ser Gly Val Val Asn Phe Arg Asp Leu Gly Gly Tyr Ser
20 25 30
tgc ttg acc ccg ttg acg cca gtc agc aac ggc agc ccg gta att gcg 144
Cys Leu Thr Pro Leu Thr Pro Val Ser Asn Gly Ser Pro Val Ile Ala
35 40 45
tcg aag ggt agc cct tct agc tat atc cgt cca ggt ttc ctg ttt cgc 192
Ser Lys Gly Ser Pro Ser Ser Tyr Ile Arg Pro Gly Phe Leu Phe Arg
50 55 60
tct gct cag ccg agc cag att acc gaa acc ggt atc gag gtc ctg acc 240
Ser Ala Gln Pro Ser Gln Ile Thr Glu Thr Gly Ile Glu Val Leu Thr
65 70 75 80
cac aag ctg aat atc ggt gcg att ttt gac ttc cgt tcc caa acc gag 288
His Lys Leu Asn Ile Gly Ala Ile Phe Asp Phe Arg Ser Gln Thr Glu
85 90 95
atc caa ctg gtt gcg acg cgt tac ccg gac agc ctg ctg gaa att ccg 336
Ile Gln Leu Val Ala Thr Arg Tyr Pro Asp Ser Leu Leu Glu Ile Pro
100 105 110
ttt acc tct cgt tat gca gtc ccg gtt ttc gag cat tgt gat ttc agc 384
Phe Thr Ser Arg Tyr Ala Val Pro Val Phe Glu His Cys Asp Phe Ser
115 120 125
ccg gtt agc ttg agc aag aaa tat ggt gcg ccg agc aac gca ccg cct 432
Pro Val Ser Leu Ser Lys Lys Tyr Gly Ala Pro Ser Asn Ala Pro Pro
130 135 140
acc gaa gcg gag cac ggt agc ttt gtg cag gcg tac gaa gat att gcc 480
Thr Glu Ala Glu His Gly Ser Phe Val Gln Ala Tyr Glu Asp Ile Ala
145 150 155 160
cgt agc gca gca gag aac ggc agc ttc cgc agc atc acg gac cac att 528
Arg Ser Ala Ala Glu Asn Gly Ser Phe Arg Ser Ile Thr Asp His Ile
165 170 175
ttg cgc tac ccg gat atg ccg atc ctg ttc cac tgc acc gtg ggc aaa 576
Leu Arg Tyr Pro Asp Met Pro Ile Leu Phe His Cys Thr Val Gly Lys
180 185 190
gac cgc acc ggc gtt ttt gcg gcg ctg ctg ctg aaa ctg tgt ggt gtg 624
Asp Arg Thr Gly Val Phe Ala Ala Leu Leu Leu Lys Leu Cys Gly Val
195 200 205
agc gac gaa gtt gtg att cag gac tat gcc ctg act acg caa ggt ctg 672
Ser Asp Glu Val Val Ile Gln Asp Tyr Ala Leu Thr Thr Gln Gly Leu
210 215 220
ggt gcc tgg aga gag cat ctg atc caa cgc ctg ctg cag cgt aat gac 720
Gly Ala Trp Arg Glu His Leu Ile Gln Arg Leu Leu Gln Arg Asn Asp
225 230 235 240
gtc gcg acg cgt gaa gat gca gag ttt atc ctg gct agc cgt ccg gag 768
Val Ala Thr Arg Glu Asp Ala Glu Phe Ile Leu Ala Ser Arg Pro Glu
245 250 255
act atg aaa tcg ttc ctg gcc gat gtt gtg gaa acc aag ttc ggt ggc 816
Thr Met Lys Ser Phe Leu Ala Asp Val Val Glu Thr Lys Phe Gly Gly
260 265 270
gct cgc aac tac ttc acg ctg ctg tgc ggt ctg acc gaa gat gat gtt 864
Ala Arg Asn Tyr Phe Thr Leu Leu Cys Gly Leu Thr Glu Asp Asp Val
275 280 285
aac aac ctg att agc ctg gtt gtc att cat aac acg aat taa 906
Asn Asn Leu Ile Ser Leu Val Val Ile His Asn Thr Asn
290 295 300
<210> 28
<211> 301
<212> PRT
<213> 踝节篮状菌(Talaromyces atroroseus)
<400> 28
Met Ser Thr Asn Ala Asp Pro Thr Thr Phe Ser Asp Lys Ser Pro Phe
1 5 10 15
Ile Asn Val Ser Gly Val Val Asn Phe Arg Asp Leu Gly Gly Tyr Ser
20 25 30
Cys Leu Thr Pro Leu Thr Pro Val Ser Asn Gly Ser Pro Val Ile Ala
35 40 45
Ser Lys Gly Ser Pro Ser Ser Tyr Ile Arg Pro Gly Phe Leu Phe Arg
50 55 60
Ser Ala Gln Pro Ser Gln Ile Thr Glu Thr Gly Ile Glu Val Leu Thr
65 70 75 80
His Lys Leu Asn Ile Gly Ala Ile Phe Asp Phe Arg Ser Gln Thr Glu
85 90 95
Ile Gln Leu Val Ala Thr Arg Tyr Pro Asp Ser Leu Leu Glu Ile Pro
100 105 110
Phe Thr Ser Arg Tyr Ala Val Pro Val Phe Glu His Cys Asp Phe Ser
115 120 125
Pro Val Ser Leu Ser Lys Lys Tyr Gly Ala Pro Ser Asn Ala Pro Pro
130 135 140
Thr Glu Ala Glu His Gly Ser Phe Val Gln Ala Tyr Glu Asp Ile Ala
145 150 155 160
Arg Ser Ala Ala Glu Asn Gly Ser Phe Arg Ser Ile Thr Asp His Ile
165 170 175
Leu Arg Tyr Pro Asp Met Pro Ile Leu Phe His Cys Thr Val Gly Lys
180 185 190
Asp Arg Thr Gly Val Phe Ala Ala Leu Leu Leu Lys Leu Cys Gly Val
195 200 205
Ser Asp Glu Val Val Ile Gln Asp Tyr Ala Leu Thr Thr Gln Gly Leu
210 215 220
Gly Ala Trp Arg Glu His Leu Ile Gln Arg Leu Leu Gln Arg Asn Asp
225 230 235 240
Val Ala Thr Arg Glu Asp Ala Glu Phe Ile Leu Ala Ser Arg Pro Glu
245 250 255
Thr Met Lys Ser Phe Leu Ala Asp Val Val Glu Thr Lys Phe Gly Gly
260 265 270
Ala Arg Asn Tyr Phe Thr Leu Leu Cys Gly Leu Thr Glu Asp Asp Val
275 280 285
Asn Asn Leu Ile Ser Leu Val Val Ile His Asn Thr Asn
290 295 300
<210> 29
<211> 906
<212> DNA
<213> 踝节篮状菌(Talaromyces atroroseus)
<400> 29
atgtctacca acgctgaccc tactactttt tccgataaat caccgtttat taacgtaagc 60
ggcgttgtca attttcgtga tctgggcggt tactcatgtc tcactcctct cacccctgtc 120
tcaaatggtt caccggtgat agcgtcaaag ggatccccct catcatacat tcgccccggc 180
ttcttgttcc gttcagcaca gccttcacaa attaccgaga ctggtatcga agttctgacg 240
cacaagctta atatcggagc tatatttgac tttcggtcac agacagaaat ccagcttgtt 300
gcgactcgat atccagattc cctgctcgaa ataccattta ctagccgata cgctgttcca 360
gtgttcgaac attgcgactt ttctccggtc tcgctgtcta agaagtatgg ggctccgtca 420
aacgctcctc ctacagaagc cgagcacggt agcttcgtcc aggcttatga agatatcgcc 480
cgcagtgcag cggaaaatgg aagttttcgc agcataacag atcatattct gcgatatccc 540
gacatgccaa ttctttttca ttgtacggtt ggcaaagaca gaactggtgt gtttgcagca 600
ttgttgttga agctgtgtgg agtgtctgat gaagtagtta ttcaagacta cgcactcact 660
actcaaggcc taggtgcatg gcgcgaacac ctgattcagc gcctgctgca aaggaatgat 720
gttgctaccc gtgaggatgc cgagttcata ctcgctagcc gaccagagac tatgaagtca 780
ttcttggcag atgtggtgga aaccaaattt ggaggagctc gcaactattt tactctgctg 840
tgcggattga ccgaggacga tgtcaataac ttgatctccc ttgtagttat tcataataca 900
aattag 906
<210> 30
<211> 873
<212> DNA
<213> 红青霉菌(Penicillium subrubescens)
<220>
<221> CDS
<222> (1)..(873)
<400> 30
atg caa cct ttt att agc gtc gat ggt gtg gtg aat ttt cgt gat att 48
Met Gln Pro Phe Ile Ser Val Asp Gly Val Val Asn Phe Arg Asp Ile
1 5 10 15
ggt ggt tat gtt tgc cgt aat ccg gcc ggt ttg tcg agc ctg ccg agc 96
Gly Gly Tyr Val Cys Arg Asn Pro Ala Gly Leu Ser Ser Leu Pro Ser
20 25 30
aac gtt gac gaa acc ccg gaa aag caa tgg tgt atc cgc cca ggc ttc 144
Asn Val Asp Glu Thr Pro Glu Lys Gln Trp Cys Ile Arg Pro Gly Phe
35 40 45
gtt ttc cgt gca gcg caa ccg tcc caa att acg ccg gct ggt atc gag 192
Val Phe Arg Ala Ala Gln Pro Ser Gln Ile Thr Pro Ala Gly Ile Glu
50 55 60
att ctt aag aaa acg ctg gcg atc caa gcg att ttc gat ttt cgt agc 240
Ile Leu Lys Lys Thr Leu Ala Ile Gln Ala Ile Phe Asp Phe Arg Ser
65 70 75 80
gag tcc gag atc caa ctg gtg agc aag cgt tac ccg gac agc ctg ctg 288
Glu Ser Glu Ile Gln Leu Val Ser Lys Arg Tyr Pro Asp Ser Leu Leu
85 90 95
gac atc ccg ggc act acg cgt cat gct gtt ccg gtg ttt cag gag ggt 336
Asp Ile Pro Gly Thr Thr Arg His Ala Val Pro Val Phe Gln Glu Gly
100 105 110
gat tac agc ccg atc tcg ttg gcc aaa cgt tac ggt gtg acc gcg gac 384
Asp Tyr Ser Pro Ile Ser Leu Ala Lys Arg Tyr Gly Val Thr Ala Asp
115 120 125
gag agc acc aac gat cag tcc ttc cgt ccg ggt ttt gtc aaa gcg tat 432
Glu Ser Thr Asn Asp Gln Ser Phe Arg Pro Gly Phe Val Lys Ala Tyr
130 135 140
gaa gcc atc gca cgc aac gca gca cag gct ggt agc ttc cgc gcc att 480
Glu Ala Ile Ala Arg Asn Ala Ala Gln Ala Gly Ser Phe Arg Ala Ile
145 150 155 160
atc cag cat atc ctg cag gac tcc gct ggc cca gtt ttg ttt cac tgc 528
Ile Gln His Ile Leu Gln Asp Ser Ala Gly Pro Val Leu Phe His Cys
165 170 175
acc gta ggc aaa gat cgc acg ggt gtt ttc tct gca ctg att ctg aag 576
Thr Val Gly Lys Asp Arg Thr Gly Val Phe Ser Ala Leu Ile Leu Lys
180 185 190
ctg tgc ggt gtg gcc gac gaa gat att gtg gca gac tat gcg ctg acc 624
Leu Cys Gly Val Ala Asp Glu Asp Ile Val Ala Asp Tyr Ala Leu Thr
195 200 205
act cag ggc ctg ggt gtc tgg cgt gag cac ctg atc cag cgc ctg ttg 672
Thr Gln Gly Leu Gly Val Trp Arg Glu His Leu Ile Gln Arg Leu Leu
210 215 220
cag cgt ggt gaa gcg acc acc aaa gaa caa gcg gaa gcg atc atc tct 720
Gln Arg Gly Glu Ala Thr Thr Lys Glu Gln Ala Glu Ala Ile Ile Ser
225 230 235 240
agc gac ccg cgc gac atg aaa gcg ttc ctg agc aac gtc gtt gag ggc 768
Ser Asp Pro Arg Asp Met Lys Ala Phe Leu Ser Asn Val Val Glu Gly
245 250 255
gag ttt ggt ggc gca cgc aac tac ttc gtg aat ctg tgt ggc ctg cct 816
Glu Phe Gly Gly Ala Arg Asn Tyr Phe Val Asn Leu Cys Gly Leu Pro
260 265 270
gaa ggc gag gtt gac cgt gtc att acc aaa ctg gtc gtc ccg aaa acc 864
Glu Gly Glu Val Asp Arg Val Ile Thr Lys Leu Val Val Pro Lys Thr
275 280 285
acc aag taa 873
Thr Lys
290
<210> 31
<211> 290
<212> PRT
<213> 红青霉菌(Penicillium subrubescens)
<400> 31
Met Gln Pro Phe Ile Ser Val Asp Gly Val Val Asn Phe Arg Asp Ile
1 5 10 15
Gly Gly Tyr Val Cys Arg Asn Pro Ala Gly Leu Ser Ser Leu Pro Ser
20 25 30
Asn Val Asp Glu Thr Pro Glu Lys Gln Trp Cys Ile Arg Pro Gly Phe
35 40 45
Val Phe Arg Ala Ala Gln Pro Ser Gln Ile Thr Pro Ala Gly Ile Glu
50 55 60
Ile Leu Lys Lys Thr Leu Ala Ile Gln Ala Ile Phe Asp Phe Arg Ser
65 70 75 80
Glu Ser Glu Ile Gln Leu Val Ser Lys Arg Tyr Pro Asp Ser Leu Leu
85 90 95
Asp Ile Pro Gly Thr Thr Arg His Ala Val Pro Val Phe Gln Glu Gly
100 105 110
Asp Tyr Ser Pro Ile Ser Leu Ala Lys Arg Tyr Gly Val Thr Ala Asp
115 120 125
Glu Ser Thr Asn Asp Gln Ser Phe Arg Pro Gly Phe Val Lys Ala Tyr
130 135 140
Glu Ala Ile Ala Arg Asn Ala Ala Gln Ala Gly Ser Phe Arg Ala Ile
145 150 155 160
Ile Gln His Ile Leu Gln Asp Ser Ala Gly Pro Val Leu Phe His Cys
165 170 175
Thr Val Gly Lys Asp Arg Thr Gly Val Phe Ser Ala Leu Ile Leu Lys
180 185 190
Leu Cys Gly Val Ala Asp Glu Asp Ile Val Ala Asp Tyr Ala Leu Thr
195 200 205
Thr Gln Gly Leu Gly Val Trp Arg Glu His Leu Ile Gln Arg Leu Leu
210 215 220
Gln Arg Gly Glu Ala Thr Thr Lys Glu Gln Ala Glu Ala Ile Ile Ser
225 230 235 240
Ser Asp Pro Arg Asp Met Lys Ala Phe Leu Ser Asn Val Val Glu Gly
245 250 255
Glu Phe Gly Gly Ala Arg Asn Tyr Phe Val Asn Leu Cys Gly Leu Pro
260 265 270
Glu Gly Glu Val Asp Arg Val Ile Thr Lys Leu Val Val Pro Lys Thr
275 280 285
Thr Lys
290
<210> 32
<211> 873
<212> DNA
<213> 红青霉菌(Penicillium subrubescens)
<400> 32
atgcagccat tcatctcggt ggatggagtc gtcaacttcc gcgatatcgg aggctatgta 60
tgccggaatc ccgctggttt atcctccttg ccctcgaatg tcgacgaaac cccagagaaa 120
cagtggtgca ttcggccagg attcgtcttc cgcgcggcac agccatccca aatcacccct 180
gcagggattg agatcctgaa aaagaccctt gctatccaag ccatctttga ctttcggtca 240
gagagtgaga ttcagcttgt gtctaagcgc tatccagact ccctcctcga tattcccggg 300
acaactcgcc atgcagtacc ggtcttccaa gaaggtgatt actctcccat ctcactggca 360
aaacggtatg gagtcaccgc ggacgaatcc acgaatgatc agtcctttag accgggattc 420
gtcaaggcct acgaggccat tgcgcgcaac gcggctcaag cgggcagctt ccgtgcaatc 480
atacagcaca ttctgcagga ttcggccggc ccggtacttt tccactgcac ggtgggcaag 540
gaccggacag gggtcttttc ggctttgatc ctcaagctgt gcggggtggc cgatgaggac 600
attgtcgctg attatgcact caccacgcaa ggcttaggtg tgtggcggga gcatttgatt 660
caacggctct tgcagagagg ggaggccaca accaaggaac aagccgaagc cataatcagc 720
agtgacccga gagacatgaa ggcgtttttg agcaatgtag tggaagggga atttggaggt 780
gctcggaact acttcgtcaa cctctgcgga ctaccggaag gcgaagtcga tcgggttatc 840
accaagcttg tggtaccaaa gactactaaa tag 873
<210> 33
<211> 2211
<212> DNA
<213> 丹参(Salvia miltiorrhiza)
<220>
<221> CDS
<222> (1)..(2211)
<400> 33
atg gca act gtt gat gca cca caa gtt cac gat cat gac ggc acc act 48
Met Ala Thr Val Asp Ala Pro Gln Val His Asp His Asp Gly Thr Thr
1 5 10 15
gtt cac caa ggc cac gat gca gtc aag aat atc gag gac ccg atc gag 96
Val His Gln Gly His Asp Ala Val Lys Asn Ile Glu Asp Pro Ile Glu
20 25 30
tac att cgc acg ctg ttg cgc acc acg ggc gac ggt cgt att tcc gtg 144
Tyr Ile Arg Thr Leu Leu Arg Thr Thr Gly Asp Gly Arg Ile Ser Val
35 40 45
agc ccg tat gat acc gca tgg gtc gcg atg atc aaa gac gtt gag ggc 192
Ser Pro Tyr Asp Thr Ala Trp Val Ala Met Ile Lys Asp Val Glu Gly
50 55 60
cgt gat ggt ccg cag ttt ccg tct agc ttg gaa tgg atc gtg caa aat 240
Arg Asp Gly Pro Gln Phe Pro Ser Ser Leu Glu Trp Ile Val Gln Asn
65 70 75 80
cag ttg gaa gat ggt tcg tgg ggt gac cag aaa ctg ttt tgt gtg tat 288
Gln Leu Glu Asp Gly Ser Trp Gly Asp Gln Lys Leu Phe Cys Val Tyr
85 90 95
gat cgc ttg gtt aat acg atc gcg tgt gtg gtt gct ttg cgt tct tgg 336
Asp Arg Leu Val Asn Thr Ile Ala Cys Val Val Ala Leu Arg Ser Trp
100 105 110
aac gtg cac gcg cac aaa gtg aag cgt ggt gtg acc tat att aag gaa 384
Asn Val His Ala His Lys Val Lys Arg Gly Val Thr Tyr Ile Lys Glu
115 120 125
aac gtt gat aag ctg atg gag ggt aac gag gag cac atg act tgc ggc 432
Asn Val Asp Lys Leu Met Glu Gly Asn Glu Glu His Met Thr Cys Gly
130 135 140
ttc gaa gtc gtt ttc ccg gca ctg ctg cag aaa gcc aaa agc ctg ggt 480
Phe Glu Val Val Phe Pro Ala Leu Leu Gln Lys Ala Lys Ser Leu Gly
145 150 155 160
att gag gat ttg cct tac gat tcg ccg gcg gtc caa gaa gtg tat cac 528
Ile Glu Asp Leu Pro Tyr Asp Ser Pro Ala Val Gln Glu Val Tyr His
165 170 175
gtc cgc gaa caa aag ctg aag cgc atc ccg ttg gaa att atg cac aaa 576
Val Arg Glu Gln Lys Leu Lys Arg Ile Pro Leu Glu Ile Met His Lys
180 185 190
att ccg acc agc ctg ctg ttt agc ctg gaa ggt ctg gag aat ctc gac 624
Ile Pro Thr Ser Leu Leu Phe Ser Leu Glu Gly Leu Glu Asn Leu Asp
195 200 205
tgg gac aaa ctg ctg aaa ctc cag agc gct gac ggc tct ttt ctg acg 672
Trp Asp Lys Leu Leu Lys Leu Gln Ser Ala Asp Gly Ser Phe Leu Thr
210 215 220
agc ccg agc agc acg gcg ttc gca ttt atg cag acg aaa gac gaa aaa 720
Ser Pro Ser Ser Thr Ala Phe Ala Phe Met Gln Thr Lys Asp Glu Lys
225 230 235 240
tgc tat caa ttt att aag aat acg att gac acc ttc aat ggt ggc gcg 768
Cys Tyr Gln Phe Ile Lys Asn Thr Ile Asp Thr Phe Asn Gly Gly Ala
245 250 255
ccg cat acc tat ccg gtg gat gtt ttt ggt cgt tta tgg gcg att gat 816
Pro His Thr Tyr Pro Val Asp Val Phe Gly Arg Leu Trp Ala Ile Asp
260 265 270
cgt ctg cag aga ctg ggt att agc cgt ttc ttt gag ccg gaa att gcc 864
Arg Leu Gln Arg Leu Gly Ile Ser Arg Phe Phe Glu Pro Glu Ile Ala
275 280 285
gat tgc ctg tct cat att cac aaa ttt tgg acc gac aag ggt gtt ttc 912
Asp Cys Leu Ser His Ile His Lys Phe Trp Thr Asp Lys Gly Val Phe
290 295 300
tct ggt cgc gag agc gaa ttt tgc gac atc gac gac acc agc atg ggc 960
Ser Gly Arg Glu Ser Glu Phe Cys Asp Ile Asp Asp Thr Ser Met Gly
305 310 315 320
atg cgc ctg atg cgc atg cac ggt tat gac gtc gat cca aat gtc ctg 1008
Met Arg Leu Met Arg Met His Gly Tyr Asp Val Asp Pro Asn Val Leu
325 330 335
cgc aat ttc aaa caa aag gac ggc aag ttc agc tgc tac ggc ggc cag 1056
Arg Asn Phe Lys Gln Lys Asp Gly Lys Phe Ser Cys Tyr Gly Gly Gln
340 345 350
atg atc gag tct ccg agc ccg atc tat aat ctg tat cgt gcg agc cag 1104
Met Ile Glu Ser Pro Ser Pro Ile Tyr Asn Leu Tyr Arg Ala Ser Gln
355 360 365
ttg cgc ttc ccg ggt gaa gaa atc ctg gaa gat gcc aaa cgc ttt gct 1152
Leu Arg Phe Pro Gly Glu Glu Ile Leu Glu Asp Ala Lys Arg Phe Ala
370 375 380
tac gac ttc ttg aaa gag aaa ctg gcg aac aac cag att ctg gac aag 1200
Tyr Asp Phe Leu Lys Glu Lys Leu Ala Asn Asn Gln Ile Leu Asp Lys
385 390 395 400
tgg gtt att tcg aaa cac ttg ccg gac gag atc aaa ctg ggc tta gaa 1248
Trp Val Ile Ser Lys His Leu Pro Asp Glu Ile Lys Leu Gly Leu Glu
405 410 415
atg ccg tgg ttg gca acc ctg ccg cgc gtg gag gcg aag tac tac atc 1296
Met Pro Trp Leu Ala Thr Leu Pro Arg Val Glu Ala Lys Tyr Tyr Ile
420 425 430
cag tac tac gcg ggc agc ggt gat gtt tgg atc ggc aaa acg ttg tac 1344
Gln Tyr Tyr Ala Gly Ser Gly Asp Val Trp Ile Gly Lys Thr Leu Tyr
435 440 445
cgc atg cct gag atc tcg aac gac acc tat cac gac ctg gct aag acc 1392
Arg Met Pro Glu Ile Ser Asn Asp Thr Tyr His Asp Leu Ala Lys Thr
450 455 460
gat ttt aaa cgt tgt cag gcc aaa cac caa ttc gag tgg ctg tac atg 1440
Asp Phe Lys Arg Cys Gln Ala Lys His Gln Phe Glu Trp Leu Tyr Met
465 470 475 480
caa gag tgg tat gaa agc tgc ggc atc gaa gag ttt ggt atc agc cgt 1488
Gln Glu Trp Tyr Glu Ser Cys Gly Ile Glu Glu Phe Gly Ile Ser Arg
485 490 495
aaa gac ctc ctg ctg agc tat ttt ctg gcg acg gcg agc atc ttc gag 1536
Lys Asp Leu Leu Leu Ser Tyr Phe Leu Ala Thr Ala Ser Ile Phe Glu
500 505 510
ttg gag cgc acc aac gaa cgt att gcg tgg gca aaa tct cag att atc 1584
Leu Glu Arg Thr Asn Glu Arg Ile Ala Trp Ala Lys Ser Gln Ile Ile
515 520 525
gca aaa atg atc acg agc ttc ttt aac aaa gaa acc acg agc gag gaa 1632
Ala Lys Met Ile Thr Ser Phe Phe Asn Lys Glu Thr Thr Ser Glu Glu
530 535 540
gat aag cgc gcc ctg ctg aat gag ctg ggc aac atc aat ggt ctg aat 1680
Asp Lys Arg Ala Leu Leu Asn Glu Leu Gly Asn Ile Asn Gly Leu Asn
545 550 555 560
gat acg aac ggt gca ggc cgc gag ggt ggt gct ggt agc atc gcg ctg 1728
Asp Thr Asn Gly Ala Gly Arg Glu Gly Gly Ala Gly Ser Ile Ala Leu
565 570 575
gcg acc ctg acc caa ttt ctg gaa ggt ttc gac cgt tat acc cgc cat 1776
Ala Thr Leu Thr Gln Phe Leu Glu Gly Phe Asp Arg Tyr Thr Arg His
580 585 590
caa ctc aaa aac gcc tgg agc gtg tgg ctg act cag tta cag cat ggc 1824
Gln Leu Lys Asn Ala Trp Ser Val Trp Leu Thr Gln Leu Gln His Gly
595 600 605
gag gca gat gat gct gag ctg ctg acc aat acg ctc aac atc tgc gcg 1872
Glu Ala Asp Asp Ala Glu Leu Leu Thr Asn Thr Leu Asn Ile Cys Ala
610 615 620
ggc cat atc gcg ttc cgt gag gaa att ctg gcc cat aac gag tac aag 1920
Gly His Ile Ala Phe Arg Glu Glu Ile Leu Ala His Asn Glu Tyr Lys
625 630 635 640
gcc ttg agc aac ctg acc agc aaa atc tgc cgc caa ctg agc ttt att 1968
Ala Leu Ser Asn Leu Thr Ser Lys Ile Cys Arg Gln Leu Ser Phe Ile
645 650 655
caa agc gaa aag gaa atg ggc gtc gag ggc gag att gcg gca aag agc 2016
Gln Ser Glu Lys Glu Met Gly Val Glu Gly Glu Ile Ala Ala Lys Ser
660 665 670
agc atc aag aat aaa gaa ctg gaa gaa gat atg cag atg ctg gtc aaa 2064
Ser Ile Lys Asn Lys Glu Leu Glu Glu Asp Met Gln Met Leu Val Lys
675 680 685
ctg gtc ctg gaa aag tac ggt ggt atc gac cgt aac atc aaa aaa gcg 2112
Leu Val Leu Glu Lys Tyr Gly Gly Ile Asp Arg Asn Ile Lys Lys Ala
690 695 700
ttt ctg gct gtc gcg aaa acc tat tac tat cgt gca tat cat gct gcg 2160
Phe Leu Ala Val Ala Lys Thr Tyr Tyr Tyr Arg Ala Tyr His Ala Ala
705 710 715 720
gac acc atc gac acc cac atg ttt aag gtt ctg ttt gag ccg gtt gca 2208
Asp Thr Ile Asp Thr His Met Phe Lys Val Leu Phe Glu Pro Val Ala
725 730 735
taa 2211
<210> 34
<211> 736
<212> PRT
<213> 丹参(Salvia miltiorrhiza)
<400> 34
Met Ala Thr Val Asp Ala Pro Gln Val His Asp His Asp Gly Thr Thr
1 5 10 15
Val His Gln Gly His Asp Ala Val Lys Asn Ile Glu Asp Pro Ile Glu
20 25 30
Tyr Ile Arg Thr Leu Leu Arg Thr Thr Gly Asp Gly Arg Ile Ser Val
35 40 45
Ser Pro Tyr Asp Thr Ala Trp Val Ala Met Ile Lys Asp Val Glu Gly
50 55 60
Arg Asp Gly Pro Gln Phe Pro Ser Ser Leu Glu Trp Ile Val Gln Asn
65 70 75 80
Gln Leu Glu Asp Gly Ser Trp Gly Asp Gln Lys Leu Phe Cys Val Tyr
85 90 95
Asp Arg Leu Val Asn Thr Ile Ala Cys Val Val Ala Leu Arg Ser Trp
100 105 110
Asn Val His Ala His Lys Val Lys Arg Gly Val Thr Tyr Ile Lys Glu
115 120 125
Asn Val Asp Lys Leu Met Glu Gly Asn Glu Glu His Met Thr Cys Gly
130 135 140
Phe Glu Val Val Phe Pro Ala Leu Leu Gln Lys Ala Lys Ser Leu Gly
145 150 155 160
Ile Glu Asp Leu Pro Tyr Asp Ser Pro Ala Val Gln Glu Val Tyr His
165 170 175
Val Arg Glu Gln Lys Leu Lys Arg Ile Pro Leu Glu Ile Met His Lys
180 185 190
Ile Pro Thr Ser Leu Leu Phe Ser Leu Glu Gly Leu Glu Asn Leu Asp
195 200 205
Trp Asp Lys Leu Leu Lys Leu Gln Ser Ala Asp Gly Ser Phe Leu Thr
210 215 220
Ser Pro Ser Ser Thr Ala Phe Ala Phe Met Gln Thr Lys Asp Glu Lys
225 230 235 240
Cys Tyr Gln Phe Ile Lys Asn Thr Ile Asp Thr Phe Asn Gly Gly Ala
245 250 255
Pro His Thr Tyr Pro Val Asp Val Phe Gly Arg Leu Trp Ala Ile Asp
260 265 270
Arg Leu Gln Arg Leu Gly Ile Ser Arg Phe Phe Glu Pro Glu Ile Ala
275 280 285
Asp Cys Leu Ser His Ile His Lys Phe Trp Thr Asp Lys Gly Val Phe
290 295 300
Ser Gly Arg Glu Ser Glu Phe Cys Asp Ile Asp Asp Thr Ser Met Gly
305 310 315 320
Met Arg Leu Met Arg Met His Gly Tyr Asp Val Asp Pro Asn Val Leu
325 330 335
Arg Asn Phe Lys Gln Lys Asp Gly Lys Phe Ser Cys Tyr Gly Gly Gln
340 345 350
Met Ile Glu Ser Pro Ser Pro Ile Tyr Asn Leu Tyr Arg Ala Ser Gln
355 360 365
Leu Arg Phe Pro Gly Glu Glu Ile Leu Glu Asp Ala Lys Arg Phe Ala
370 375 380
Tyr Asp Phe Leu Lys Glu Lys Leu Ala Asn Asn Gln Ile Leu Asp Lys
385 390 395 400
Trp Val Ile Ser Lys His Leu Pro Asp Glu Ile Lys Leu Gly Leu Glu
405 410 415
Met Pro Trp Leu Ala Thr Leu Pro Arg Val Glu Ala Lys Tyr Tyr Ile
420 425 430
Gln Tyr Tyr Ala Gly Ser Gly Asp Val Trp Ile Gly Lys Thr Leu Tyr
435 440 445
Arg Met Pro Glu Ile Ser Asn Asp Thr Tyr His Asp Leu Ala Lys Thr
450 455 460
Asp Phe Lys Arg Cys Gln Ala Lys His Gln Phe Glu Trp Leu Tyr Met
465 470 475 480
Gln Glu Trp Tyr Glu Ser Cys Gly Ile Glu Glu Phe Gly Ile Ser Arg
485 490 495
Lys Asp Leu Leu Leu Ser Tyr Phe Leu Ala Thr Ala Ser Ile Phe Glu
500 505 510
Leu Glu Arg Thr Asn Glu Arg Ile Ala Trp Ala Lys Ser Gln Ile Ile
515 520 525
Ala Lys Met Ile Thr Ser Phe Phe Asn Lys Glu Thr Thr Ser Glu Glu
530 535 540
Asp Lys Arg Ala Leu Leu Asn Glu Leu Gly Asn Ile Asn Gly Leu Asn
545 550 555 560
Asp Thr Asn Gly Ala Gly Arg Glu Gly Gly Ala Gly Ser Ile Ala Leu
565 570 575
Ala Thr Leu Thr Gln Phe Leu Glu Gly Phe Asp Arg Tyr Thr Arg His
580 585 590
Gln Leu Lys Asn Ala Trp Ser Val Trp Leu Thr Gln Leu Gln His Gly
595 600 605
Glu Ala Asp Asp Ala Glu Leu Leu Thr Asn Thr Leu Asn Ile Cys Ala
610 615 620
Gly His Ile Ala Phe Arg Glu Glu Ile Leu Ala His Asn Glu Tyr Lys
625 630 635 640
Ala Leu Ser Asn Leu Thr Ser Lys Ile Cys Arg Gln Leu Ser Phe Ile
645 650 655
Gln Ser Glu Lys Glu Met Gly Val Glu Gly Glu Ile Ala Ala Lys Ser
660 665 670
Ser Ile Lys Asn Lys Glu Leu Glu Glu Asp Met Gln Met Leu Val Lys
675 680 685
Leu Val Leu Glu Lys Tyr Gly Gly Ile Asp Arg Asn Ile Lys Lys Ala
690 695 700
Phe Leu Ala Val Ala Lys Thr Tyr Tyr Tyr Arg Ala Tyr His Ala Ala
705 710 715 720
Asp Thr Ile Asp Thr His Met Phe Lys Val Leu Phe Glu Pro Val Ala
725 730 735
<210> 35
<211> 924
<212> DNA
<213> 成团泛菌(Pantoea agglomerans)
<220>
<221> CDS
<222> (1)..(924)
<400> 35
atg gtt tct ggt tcg aaa gca gga gta tca cct cat agg gaa atc gaa 48
Met Val Ser Gly Ser Lys Ala Gly Val Ser Pro His Arg Glu Ile Glu
1 5 10 15
gtc atg aga cag tcc att gat gac cac tta gca gga ttg ttg cca gaa 96
Val Met Arg Gln Ser Ile Asp Asp His Leu Ala Gly Leu Leu Pro Glu
20 25 30
aca gat tcc cag gat atc gtt agc ctt gct atg aga gaa ggt gtt atg 144
Thr Asp Ser Gln Asp Ile Val Ser Leu Ala Met Arg Glu Gly Val Met
35 40 45
gca cct ggt aaa cgt atc aga cct ttg ctg atg tta ctt gct gca aga 192
Ala Pro Gly Lys Arg Ile Arg Pro Leu Leu Met Leu Leu Ala Ala Arg
50 55 60
gac ctg aga tat cag ggt tct atg cct aca cta ctg gat cta gct tgt 240
Asp Leu Arg Tyr Gln Gly Ser Met Pro Thr Leu Leu Asp Leu Ala Cys
65 70 75 80
gct gtt gaa ctg aca cat act gct tcc ttg atg ctg gat gac atg cct 288
Ala Val Glu Leu Thr His Thr Ala Ser Leu Met Leu Asp Asp Met Pro
85 90 95
tgt atg gac aat gcg gaa ctt aga aga ggt caa cca aca acc cac aag 336
Cys Met Asp Asn Ala Glu Leu Arg Arg Gly Gln Pro Thr Thr His Lys
100 105 110
aaa ttc gga gaa tct gtt gcc att ttg gct tct gta ggt ctg ttg tcg 384
Lys Phe Gly Glu Ser Val Ala Ile Leu Ala Ser Val Gly Leu Leu Ser
115 120 125
aaa gca ttt ggc ttg att gct gca act ggt gat ctt cca ggt gaa agg 432
Lys Ala Phe Gly Leu Ile Ala Ala Thr Gly Asp Leu Pro Gly Glu Arg
130 135 140
aga gca caa gct gta aac gag cta tct act gca gtt ggt gtt caa ggt 480
Arg Ala Gln Ala Val Asn Glu Leu Ser Thr Ala Val Gly Val Gln Gly
145 150 155 160
cta gtc tta gga cag ttc aga gat ttg aat gac gca gct ttg gac aga 528
Leu Val Leu Gly Gln Phe Arg Asp Leu Asn Asp Ala Ala Leu Asp Arg
165 170 175
act cct gat gct atc ctg tct acg aac cat ctg aag act ggc atc ttg 576
Thr Pro Asp Ala Ile Leu Ser Thr Asn His Leu Lys Thr Gly Ile Leu
180 185 190
ttc tca gct atg ttg caa atc gta gcc att gct tct gct tct tca cca 624
Phe Ser Ala Met Leu Gln Ile Val Ala Ile Ala Ser Ala Ser Ser Pro
195 200 205
tct act agg gaa acg tta cac gca ttc gca ttg gac ttt ggt caa gcc 672
Ser Thr Arg Glu Thr Leu His Ala Phe Ala Leu Asp Phe Gly Gln Ala
210 215 220
ttt caa ctg cta gac gat ttg agg gat gat cat cca gag aca ggt aaa 720
Phe Gln Leu Leu Asp Asp Leu Arg Asp Asp His Pro Glu Thr Gly Lys
225 230 235 240
gac cgt aac aaa gac gct ggt aaa agc act cta gtc aac aga ttg ggt 768
Asp Arg Asn Lys Asp Ala Gly Lys Ser Thr Leu Val Asn Arg Leu Gly
245 250 255
gct gat gca gct aga cag aaa ctg aga gag cac att gac tct gct gac 816
Ala Asp Ala Ala Arg Gln Lys Leu Arg Glu His Ile Asp Ser Ala Asp
260 265 270
aaa cac ctg aca ttt gca tgt cca caa gga ggt gct ata agg cag ttt 864
Lys His Leu Thr Phe Ala Cys Pro Gln Gly Gly Ala Ile Arg Gln Phe
275 280 285
atg cac cta tgg ttt gga cac cat ctt gct gat tgg tct cca gtg atg 912
Met His Leu Trp Phe Gly His His Leu Ala Asp Trp Ser Pro Val Met
290 295 300
aag atc gcc taa 924
Lys Ile Ala
305
<210> 36
<211> 307
<212> PRT
<213> 成团泛菌(Pantoea agglomerans)
<400> 36
Met Val Ser Gly Ser Lys Ala Gly Val Ser Pro His Arg Glu Ile Glu
1 5 10 15
Val Met Arg Gln Ser Ile Asp Asp His Leu Ala Gly Leu Leu Pro Glu
20 25 30
Thr Asp Ser Gln Asp Ile Val Ser Leu Ala Met Arg Glu Gly Val Met
35 40 45
Ala Pro Gly Lys Arg Ile Arg Pro Leu Leu Met Leu Leu Ala Ala Arg
50 55 60
Asp Leu Arg Tyr Gln Gly Ser Met Pro Thr Leu Leu Asp Leu Ala Cys
65 70 75 80
Ala Val Glu Leu Thr His Thr Ala Ser Leu Met Leu Asp Asp Met Pro
85 90 95
Cys Met Asp Asn Ala Glu Leu Arg Arg Gly Gln Pro Thr Thr His Lys
100 105 110
Lys Phe Gly Glu Ser Val Ala Ile Leu Ala Ser Val Gly Leu Leu Ser
115 120 125
Lys Ala Phe Gly Leu Ile Ala Ala Thr Gly Asp Leu Pro Gly Glu Arg
130 135 140
Arg Ala Gln Ala Val Asn Glu Leu Ser Thr Ala Val Gly Val Gln Gly
145 150 155 160
Leu Val Leu Gly Gln Phe Arg Asp Leu Asn Asp Ala Ala Leu Asp Arg
165 170 175
Thr Pro Asp Ala Ile Leu Ser Thr Asn His Leu Lys Thr Gly Ile Leu
180 185 190
Phe Ser Ala Met Leu Gln Ile Val Ala Ile Ala Ser Ala Ser Ser Pro
195 200 205
Ser Thr Arg Glu Thr Leu His Ala Phe Ala Leu Asp Phe Gly Gln Ala
210 215 220
Phe Gln Leu Leu Asp Asp Leu Arg Asp Asp His Pro Glu Thr Gly Lys
225 230 235 240
Asp Arg Asn Lys Asp Ala Gly Lys Ser Thr Leu Val Asn Arg Leu Gly
245 250 255
Ala Asp Ala Ala Arg Gln Lys Leu Arg Glu His Ile Asp Ser Ala Asp
260 265 270
Lys His Leu Thr Phe Ala Cys Pro Gln Gly Gly Ala Ile Arg Gln Phe
275 280 285
Met His Leu Trp Phe Gly His His Leu Ala Asp Trp Ser Pro Val Met
290 295 300
Lys Ile Ala
305
<210> 37
<211> 2172
<212> DNA
<213> 快乐鼠尾草(Salvia sclarea)
<220>
<221> CDS
<222> (1)..(2172)
<400> 37
atg gca tcc caa gcg tcc gag aaa gat att agc ctg gtt caa acc ccg 48
Met Ala Ser Gln Ala Ser Glu Lys Asp Ile Ser Leu Val Gln Thr Pro
1 5 10 15
cat aag gtc gag gtc aac gaa aag atc gaa gag agc atc gag tac gtc 96
His Lys Val Glu Val Asn Glu Lys Ile Glu Glu Ser Ile Glu Tyr Val
20 25 30
caa aat ctg ctg atg acg agc ggt gac ggt cgt atc tcc gtg tct ccg 144
Gln Asn Leu Leu Met Thr Ser Gly Asp Gly Arg Ile Ser Val Ser Pro
35 40 45
tac gat acc gcg gtc atc gct ctg att aaa gat ctg aag ggt cgc gac 192
Tyr Asp Thr Ala Val Ile Ala Leu Ile Lys Asp Leu Lys Gly Arg Asp
50 55 60
gca ccg cag ttc ccg agc tgt ctg gag tgg att gcg cac cac cag tta 240
Ala Pro Gln Phe Pro Ser Cys Leu Glu Trp Ile Ala His His Gln Leu
65 70 75 80
gcg gat ggt agc tgg ggc gac gag ttc ttt tgt atc tat gac cgc att 288
Ala Asp Gly Ser Trp Gly Asp Glu Phe Phe Cys Ile Tyr Asp Arg Ile
85 90 95
ttg aat acc ctg gcg tgc gtc gtc gca ctg aaa tct tgg aat ctg cac 336
Leu Asn Thr Leu Ala Cys Val Val Ala Leu Lys Ser Trp Asn Leu His
100 105 110
agc gac att att gaa aaa ggc gtg acc tac att aag gaa aac gtc cat 384
Ser Asp Ile Ile Glu Lys Gly Val Thr Tyr Ile Lys Glu Asn Val His
115 120 125
aag ctg aaa ggc gcg aat gtt gag cat aga acc gcc ggt ttt gag ctg 432
Lys Leu Lys Gly Ala Asn Val Glu His Arg Thr Ala Gly Phe Glu Leu
130 135 140
gtt gtt ccg acc ttc atg cag atg gcg act gac ctg ggt att cag gat 480
Val Val Pro Thr Phe Met Gln Met Ala Thr Asp Leu Gly Ile Gln Asp
145 150 155 160
ctg ccg tac gat cat cct ctt atc aaa gaa atc gct gat acg aag caa 528
Leu Pro Tyr Asp His Pro Leu Ile Lys Glu Ile Ala Asp Thr Lys Gln
165 170 175
cag cgc ctg aaa gaa att ccg aaa gat ttg gtt tat cag atg ccg acc 576
Gln Arg Leu Lys Glu Ile Pro Lys Asp Leu Val Tyr Gln Met Pro Thr
180 185 190
aat ctg ctg tat agc ctg gaa ggc ctg ggc gat tta gag tgg gag cgt 624
Asn Leu Leu Tyr Ser Leu Glu Gly Leu Gly Asp Leu Glu Trp Glu Arg
195 200 205
ttg ctg aag ctg cag tct ggt aat ggt agc ttc ctg acg agc cca agc 672
Leu Leu Lys Leu Gln Ser Gly Asn Gly Ser Phe Leu Thr Ser Pro Ser
210 215 220
agc acg gcg gca gtt ctg atg cat acc aaa gac gag aag tgt ttg aaa 720
Ser Thr Ala Ala Val Leu Met His Thr Lys Asp Glu Lys Cys Leu Lys
225 230 235 240
tac att gag aat gcg ctg aag aac tgc gac ggt ggc gct cct cat acg 768
Tyr Ile Glu Asn Ala Leu Lys Asn Cys Asp Gly Gly Ala Pro His Thr
245 250 255
tat ccg gtt gac atc ttt agc cgc ttg tgg gcg atc gac cgt ttg caa 816
Tyr Pro Val Asp Ile Phe Ser Arg Leu Trp Ala Ile Asp Arg Leu Gln
260 265 270
cgt ctg ggc att agc cgt ttc ttc caa cac gag atc aaa tac ttt ctg 864
Arg Leu Gly Ile Ser Arg Phe Phe Gln His Glu Ile Lys Tyr Phe Leu
275 280 285
gac cac atc gag tca gtc tgg gaa gaa acc ggc gtg ttt agc ggt cgt 912
Asp His Ile Glu Ser Val Trp Glu Glu Thr Gly Val Phe Ser Gly Arg
290 295 300
tac acg aag ttt agc gac atc gat gac acg agc atg ggt gtc cgc ctg 960
Tyr Thr Lys Phe Ser Asp Ile Asp Asp Thr Ser Met Gly Val Arg Leu
305 310 315 320
ctg aaa atg cac ggt tac gac gta gac cca aac gtg ttg aaa cac ttt 1008
Leu Lys Met His Gly Tyr Asp Val Asp Pro Asn Val Leu Lys His Phe
325 330 335
aag cag caa gac ggc aaa ttc agc tgc tac atc ggc cag agc gtc gag 1056
Lys Gln Gln Asp Gly Lys Phe Ser Cys Tyr Ile Gly Gln Ser Val Glu
340 345 350
agc gcg agc ccg atg tat aat ctg tac cgt gcc gcc cag ctg cgt ttc 1104
Ser Ala Ser Pro Met Tyr Asn Leu Tyr Arg Ala Ala Gln Leu Arg Phe
355 360 365
ccg ggt gaa gaa gtg ctt gaa gaa gca act aaa ttc gcg ttt aac ttc 1152
Pro Gly Glu Glu Val Leu Glu Glu Ala Thr Lys Phe Ala Phe Asn Phe
370 375 380
ctg caa gag atg ctg gtg aag gat cgc ttg caa gag cgt tgg gtt att 1200
Leu Gln Glu Met Leu Val Lys Asp Arg Leu Gln Glu Arg Trp Val Ile
385 390 395 400
agc gat cac ctg ttt gac gag att aag ctc ggt ctg aag atg ccg tgg 1248
Ser Asp His Leu Phe Asp Glu Ile Lys Leu Gly Leu Lys Met Pro Trp
405 410 415
tat gct acc ctg ccg cgt gtt gag gcc gct tat tac ctg gat cac tat 1296
Tyr Ala Thr Leu Pro Arg Val Glu Ala Ala Tyr Tyr Leu Asp His Tyr
420 425 430
gcg ggt agc ggt gat gtg tgg att ggt aag tct ttt tac cgc atg ccg 1344
Ala Gly Ser Gly Asp Val Trp Ile Gly Lys Ser Phe Tyr Arg Met Pro
435 440 445
gag att agc aat gac acc tac aaa gaa ttg gcc atc ctg gac ttt aac 1392
Glu Ile Ser Asn Asp Thr Tyr Lys Glu Leu Ala Ile Leu Asp Phe Asn
450 455 460
cgt tgt cag act cag cat cag ctg gag tgg att cac atg caa gag tgg 1440
Arg Cys Gln Thr Gln His Gln Leu Glu Trp Ile His Met Gln Glu Trp
465 470 475 480
tat gac cgc tgc tct ctg tcc gag ttt ggt att agc aag cgt gag ctg 1488
Tyr Asp Arg Cys Ser Leu Ser Glu Phe Gly Ile Ser Lys Arg Glu Leu
485 490 495
ctg cgt agc tac ttc ctg gct gcc gca acc att ttc gaa ccg gaa cgc 1536
Leu Arg Ser Tyr Phe Leu Ala Ala Ala Thr Ile Phe Glu Pro Glu Arg
500 505 510
acc caa gag cgt ctg ctc tgg gca aag acc cgc atc ctg agc aag atg 1584
Thr Gln Glu Arg Leu Leu Trp Ala Lys Thr Arg Ile Leu Ser Lys Met
515 520 525
att acc agc ttc gtc aac atc tcc ggt acg acc ctg agc ctg gat tac 1632
Ile Thr Ser Phe Val Asn Ile Ser Gly Thr Thr Leu Ser Leu Asp Tyr
530 535 540
aac ttc aac ggt ttg gat gag atc att tcc agc gcg aat gaa gat cag 1680
Asn Phe Asn Gly Leu Asp Glu Ile Ile Ser Ser Ala Asn Glu Asp Gln
545 550 555 560
ggt ctg gcg ggt acg ctg ttg gcc acg ttc cat caa ctg ctg gat ggt 1728
Gly Leu Ala Gly Thr Leu Leu Ala Thr Phe His Gln Leu Leu Asp Gly
565 570 575
ttc gac att tac acc ctg cac caa ctg aaa cac gtc tgg tcg caa tgg 1776
Phe Asp Ile Tyr Thr Leu His Gln Leu Lys His Val Trp Ser Gln Trp
580 585 590
ttt atg aaa gtt cag caa ggc gag ggc tcc ggc ggc gaa gat gcg gtc 1824
Phe Met Lys Val Gln Gln Gly Glu Gly Ser Gly Gly Glu Asp Ala Val
595 600 605
ctg ctg gca aat act ctg aat atc tgc gcg ggt ctg aat gaa gat gtg 1872
Leu Leu Ala Asn Thr Leu Asn Ile Cys Ala Gly Leu Asn Glu Asp Val
610 615 620
ctg tcg aac aac gag tat acc gcg ctg agc acg ctg acg aac aag atc 1920
Leu Ser Asn Asn Glu Tyr Thr Ala Leu Ser Thr Leu Thr Asn Lys Ile
625 630 635 640
tgc aac cgt ctg gcc cag atc cag gac aac aag att ctg caa gtg gtg 1968
Cys Asn Arg Leu Ala Gln Ile Gln Asp Asn Lys Ile Leu Gln Val Val
645 650 655
gac ggc agc atc aaa gac aaa gaa ctg gaa cag gat atg cag gca ttg 2016
Asp Gly Ser Ile Lys Asp Lys Glu Leu Glu Gln Asp Met Gln Ala Leu
660 665 670
gtt aaa ctg gtg ctg cag gaa aac ggt ggc gca gtg gac cgt aac atc 2064
Val Lys Leu Val Leu Gln Glu Asn Gly Gly Ala Val Asp Arg Asn Ile
675 680 685
cgt cac acg ttt ctg agc gtt agc aag acc ttc tac tat gac gcg tat 2112
Arg His Thr Phe Leu Ser Val Ser Lys Thr Phe Tyr Tyr Asp Ala Tyr
690 695 700
cac gac gat gaa acc acc gat ctg cat atc ttt aaa gtc ctg ttc cgt 2160
His Asp Asp Glu Thr Thr Asp Leu His Ile Phe Lys Val Leu Phe Arg
705 710 715 720
ccg gtt gtt taa 2172
Pro Val Val
<210> 38
<211> 723
<212> PRT
<213> 快乐鼠尾草(Salvia sclarea)
<400> 38
Met Ala Ser Gln Ala Ser Glu Lys Asp Ile Ser Leu Val Gln Thr Pro
1 5 10 15
His Lys Val Glu Val Asn Glu Lys Ile Glu Glu Ser Ile Glu Tyr Val
20 25 30
Gln Asn Leu Leu Met Thr Ser Gly Asp Gly Arg Ile Ser Val Ser Pro
35 40 45
Tyr Asp Thr Ala Val Ile Ala Leu Ile Lys Asp Leu Lys Gly Arg Asp
50 55 60
Ala Pro Gln Phe Pro Ser Cys Leu Glu Trp Ile Ala His His Gln Leu
65 70 75 80
Ala Asp Gly Ser Trp Gly Asp Glu Phe Phe Cys Ile Tyr Asp Arg Ile
85 90 95
Leu Asn Thr Leu Ala Cys Val Val Ala Leu Lys Ser Trp Asn Leu His
100 105 110
Ser Asp Ile Ile Glu Lys Gly Val Thr Tyr Ile Lys Glu Asn Val His
115 120 125
Lys Leu Lys Gly Ala Asn Val Glu His Arg Thr Ala Gly Phe Glu Leu
130 135 140
Val Val Pro Thr Phe Met Gln Met Ala Thr Asp Leu Gly Ile Gln Asp
145 150 155 160
Leu Pro Tyr Asp His Pro Leu Ile Lys Glu Ile Ala Asp Thr Lys Gln
165 170 175
Gln Arg Leu Lys Glu Ile Pro Lys Asp Leu Val Tyr Gln Met Pro Thr
180 185 190
Asn Leu Leu Tyr Ser Leu Glu Gly Leu Gly Asp Leu Glu Trp Glu Arg
195 200 205
Leu Leu Lys Leu Gln Ser Gly Asn Gly Ser Phe Leu Thr Ser Pro Ser
210 215 220
Ser Thr Ala Ala Val Leu Met His Thr Lys Asp Glu Lys Cys Leu Lys
225 230 235 240
Tyr Ile Glu Asn Ala Leu Lys Asn Cys Asp Gly Gly Ala Pro His Thr
245 250 255
Tyr Pro Val Asp Ile Phe Ser Arg Leu Trp Ala Ile Asp Arg Leu Gln
260 265 270
Arg Leu Gly Ile Ser Arg Phe Phe Gln His Glu Ile Lys Tyr Phe Leu
275 280 285
Asp His Ile Glu Ser Val Trp Glu Glu Thr Gly Val Phe Ser Gly Arg
290 295 300
Tyr Thr Lys Phe Ser Asp Ile Asp Asp Thr Ser Met Gly Val Arg Leu
305 310 315 320
Leu Lys Met His Gly Tyr Asp Val Asp Pro Asn Val Leu Lys His Phe
325 330 335
Lys Gln Gln Asp Gly Lys Phe Ser Cys Tyr Ile Gly Gln Ser Val Glu
340 345 350
Ser Ala Ser Pro Met Tyr Asn Leu Tyr Arg Ala Ala Gln Leu Arg Phe
355 360 365
Pro Gly Glu Glu Val Leu Glu Glu Ala Thr Lys Phe Ala Phe Asn Phe
370 375 380
Leu Gln Glu Met Leu Val Lys Asp Arg Leu Gln Glu Arg Trp Val Ile
385 390 395 400
Ser Asp His Leu Phe Asp Glu Ile Lys Leu Gly Leu Lys Met Pro Trp
405 410 415
Tyr Ala Thr Leu Pro Arg Val Glu Ala Ala Tyr Tyr Leu Asp His Tyr
420 425 430
Ala Gly Ser Gly Asp Val Trp Ile Gly Lys Ser Phe Tyr Arg Met Pro
435 440 445
Glu Ile Ser Asn Asp Thr Tyr Lys Glu Leu Ala Ile Leu Asp Phe Asn
450 455 460
Arg Cys Gln Thr Gln His Gln Leu Glu Trp Ile His Met Gln Glu Trp
465 470 475 480
Tyr Asp Arg Cys Ser Leu Ser Glu Phe Gly Ile Ser Lys Arg Glu Leu
485 490 495
Leu Arg Ser Tyr Phe Leu Ala Ala Ala Thr Ile Phe Glu Pro Glu Arg
500 505 510
Thr Gln Glu Arg Leu Leu Trp Ala Lys Thr Arg Ile Leu Ser Lys Met
515 520 525
Ile Thr Ser Phe Val Asn Ile Ser Gly Thr Thr Leu Ser Leu Asp Tyr
530 535 540
Asn Phe Asn Gly Leu Asp Glu Ile Ile Ser Ser Ala Asn Glu Asp Gln
545 550 555 560
Gly Leu Ala Gly Thr Leu Leu Ala Thr Phe His Gln Leu Leu Asp Gly
565 570 575
Phe Asp Ile Tyr Thr Leu His Gln Leu Lys His Val Trp Ser Gln Trp
580 585 590
Phe Met Lys Val Gln Gln Gly Glu Gly Ser Gly Gly Glu Asp Ala Val
595 600 605
Leu Leu Ala Asn Thr Leu Asn Ile Cys Ala Gly Leu Asn Glu Asp Val
610 615 620
Leu Ser Asn Asn Glu Tyr Thr Ala Leu Ser Thr Leu Thr Asn Lys Ile
625 630 635 640
Cys Asn Arg Leu Ala Gln Ile Gln Asp Asn Lys Ile Leu Gln Val Val
645 650 655
Asp Gly Ser Ile Lys Asp Lys Glu Leu Glu Gln Asp Met Gln Ala Leu
660 665 670
Val Lys Leu Val Leu Gln Glu Asn Gly Gly Ala Val Asp Arg Asn Ile
675 680 685
Arg His Thr Phe Leu Ser Val Ser Lys Thr Phe Tyr Tyr Asp Ala Tyr
690 695 700
His Asp Asp Glu Thr Thr Asp Leu His Ile Phe Lys Val Leu Phe Arg
705 710 715 720
Pro Val Val
<210> 39
<211> 2100
<212> DNA
<213> 小麦(Triticum aestivum)
<220>
<221> CDS
<222> (1)..(2100)
<400> 39
atg tat cgc caa aga act gat gag cca agc gaa acc cgc cag atg atc 48
Met Tyr Arg Gln Arg Thr Asp Glu Pro Ser Glu Thr Arg Gln Met Ile
1 5 10 15
gat gat att cgc acc gct ttg gct agc ctg ggt gac gat gaa acc agc 96
Asp Asp Ile Arg Thr Ala Leu Ala Ser Leu Gly Asp Asp Glu Thr Ser
20 25 30
atg agc gtg agc gca tac gac acc gcc ctg gtt gcc ctg gtg aag aac 144
Met Ser Val Ser Ala Tyr Asp Thr Ala Leu Val Ala Leu Val Lys Asn
35 40 45
ctg gac ggt ggc gat ggc ccg cag ttc ccg agc tgc att gac tgg att 192
Leu Asp Gly Gly Asp Gly Pro Gln Phe Pro Ser Cys Ile Asp Trp Ile
50 55 60
gtt cag aac cag ctg ccg gac ggt agc tgg ggc gac ccg gct ttc ttt 240
Val Gln Asn Gln Leu Pro Asp Gly Ser Trp Gly Asp Pro Ala Phe Phe
65 70 75 80
atg gtt cag gac cgt atg atc agc acc ctg gcc tgt gtc gtg gcc gtg 288
Met Val Gln Asp Arg Met Ile Ser Thr Leu Ala Cys Val Val Ala Val
85 90 95
aaa tcc tgg aat atc gat cgt gac aac ttg tgc gat cgt ggt gtc ctg 336
Lys Ser Trp Asn Ile Asp Arg Asp Asn Leu Cys Asp Arg Gly Val Leu
100 105 110
ttt atc aaa gaa aac atg tcg cgt ctg gtt gaa gaa gaa caa gat tgg 384
Phe Ile Lys Glu Asn Met Ser Arg Leu Val Glu Glu Glu Gln Asp Trp
115 120 125
atg cca tgt ggc ttc gag att aac ttt cct gca ctg ttg gag aaa gct 432
Met Pro Cys Gly Phe Glu Ile Asn Phe Pro Ala Leu Leu Glu Lys Ala
130 135 140
aaa gac ctg gac ttg gac att ccg tac gat cat cct gtg ctg gaa gag 480
Lys Asp Leu Asp Leu Asp Ile Pro Tyr Asp His Pro Val Leu Glu Glu
145 150 155 160
att tac gcg aag cgt aat ctg aaa ctg ctg aag att ccg tta gat gtc 528
Ile Tyr Ala Lys Arg Asn Leu Lys Leu Leu Lys Ile Pro Leu Asp Val
165 170 175
ctc cat gcg atc ccg acg acg ctg ttg ttt tcc gtt gag ggt atg gtc 576
Leu His Ala Ile Pro Thr Thr Leu Leu Phe Ser Val Glu Gly Met Val
180 185 190
gat ctg ccg ctg gat tgg gag aaa ctg ctg cgt ctg cgt tgc ccg gac 624
Asp Leu Pro Leu Asp Trp Glu Lys Leu Leu Arg Leu Arg Cys Pro Asp
195 200 205
ggt tct ttt cat tct agc ccg gcg gcg acg gca gcg gcg ctg agc cac 672
Gly Ser Phe His Ser Ser Pro Ala Ala Thr Ala Ala Ala Leu Ser His
210 215 220
acg ggt gac aaa gag tgt cac gcc ttc ctg gac cgc ctg att caa aag 720
Thr Gly Asp Lys Glu Cys His Ala Phe Leu Asp Arg Leu Ile Gln Lys
225 230 235 240
ttc gag ggt ggc gtc ccg tgc tcc cac agc atg gac acc ttc gag caa 768
Phe Glu Gly Gly Val Pro Cys Ser His Ser Met Asp Thr Phe Glu Gln
245 250 255
ctg tgg gtt gtt gac cgt ttg atg cgt ctg ggt atc agc cgt cat ttt 816
Leu Trp Val Val Asp Arg Leu Met Arg Leu Gly Ile Ser Arg His Phe
260 265 270
acg agc gag atc cag cag tgc ttg gag ttc atc tat cgt cgt tgg acc 864
Thr Ser Glu Ile Gln Gln Cys Leu Glu Phe Ile Tyr Arg Arg Trp Thr
275 280 285
cag aaa ggt ctg gcg cac aat atg cac tgc ccg atc ccg gac att gat 912
Gln Lys Gly Leu Ala His Asn Met His Cys Pro Ile Pro Asp Ile Asp
290 295 300
gac act gcg atg ggt ttt cgt ctg ttg aga cag cac ggt tac gac gtg 960
Asp Thr Ala Met Gly Phe Arg Leu Leu Arg Gln His Gly Tyr Asp Val
305 310 315 320
acc ccg tcg gtt ttc aag cat ttc gag aaa gac ggc aag ttc gta tgc 1008
Thr Pro Ser Val Phe Lys His Phe Glu Lys Asp Gly Lys Phe Val Cys
325 330 335
ttc ccg atg gaa acc aac cat gcg agc gtg acg ccg atg cac aat acc 1056
Phe Pro Met Glu Thr Asn His Ala Ser Val Thr Pro Met His Asn Thr
340 345 350
tac cgt gcg agc cag ttc atg ttc ccg ggt gat gac gac gtg ctg gcc 1104
Tyr Arg Ala Ser Gln Phe Met Phe Pro Gly Asp Asp Asp Val Leu Ala
355 360 365
cgt gcc ggc cgc tac tgt cgc gca ttc ttg caa gag cgt cag agc tct 1152
Arg Ala Gly Arg Tyr Cys Arg Ala Phe Leu Gln Glu Arg Gln Ser Ser
370 375 380
aac aag ttg tac gat aag tgg att atc acg aaa gat ctg ccg ggt gag 1200
Asn Lys Leu Tyr Asp Lys Trp Ile Ile Thr Lys Asp Leu Pro Gly Glu
385 390 395 400
gtt ggc tac acg ctg aac ttt ccg tgg aaa agc tcc ctg ccg cgt att 1248
Val Gly Tyr Thr Leu Asn Phe Pro Trp Lys Ser Ser Leu Pro Arg Ile
405 410 415
gaa act cgt atg tat ctg gat cag tac ggt ggc aat aac gat gtc tgg 1296
Glu Thr Arg Met Tyr Leu Asp Gln Tyr Gly Gly Asn Asn Asp Val Trp
420 425 430
att gca aag gtc ctg tat cgc atg aac ctg gtt agc aat gac ctg tac 1344
Ile Ala Lys Val Leu Tyr Arg Met Asn Leu Val Ser Asn Asp Leu Tyr
435 440 445
ctg aaa atg gcg aaa gcc gac ttt acc gag tat caa cgt ctg tct cgc 1392
Leu Lys Met Ala Lys Ala Asp Phe Thr Glu Tyr Gln Arg Leu Ser Arg
450 455 460
att gag tgg aac ggc ctg cgc aaa tgg tat ttt cgc aat cat ctg cag 1440
Ile Glu Trp Asn Gly Leu Arg Lys Trp Tyr Phe Arg Asn His Leu Gln
465 470 475 480
cgt tac ggt gcg acc ccg aag tcc gcg ctg aaa gcg tat ttc ctg gcg 1488
Arg Tyr Gly Ala Thr Pro Lys Ser Ala Leu Lys Ala Tyr Phe Leu Ala
485 490 495
tcg gca aac atc ttt gag cct ggc cgc gca gcc gag cgc ctg gca tgg 1536
Ser Ala Asn Ile Phe Glu Pro Gly Arg Ala Ala Glu Arg Leu Ala Trp
500 505 510
gca cgt atg gcc gtg ctg gct gaa gct gta acg act cat ttc cgt cac 1584
Ala Arg Met Ala Val Leu Ala Glu Ala Val Thr Thr His Phe Arg His
515 520 525
att ggc ggc ccg tgc tac agc acc gag aat ctg gaa gaa ctg atc gac 1632
Ile Gly Gly Pro Cys Tyr Ser Thr Glu Asn Leu Glu Glu Leu Ile Asp
530 535 540
ctt gtt agc ttc gac gac gtg agc ggc ggc ttg cgt gag gcg tgg aag 1680
Leu Val Ser Phe Asp Asp Val Ser Gly Gly Leu Arg Glu Ala Trp Lys
545 550 555 560
caa tgg ctg atg gcg tgg acc gca aaa gaa tca cac ggc agc gtg gac 1728
Gln Trp Leu Met Ala Trp Thr Ala Lys Glu Ser His Gly Ser Val Asp
565 570 575
ggt gac acg gca ctg ctg ttt gtc cgc acg att gag att tgc agc ggc 1776
Gly Asp Thr Ala Leu Leu Phe Val Arg Thr Ile Glu Ile Cys Ser Gly
580 585 590
cgc atc gtt tcc agc gag cag aaa ctg aat ctg tgg gat tac agc cag 1824
Arg Ile Val Ser Ser Glu Gln Lys Leu Asn Leu Trp Asp Tyr Ser Gln
595 600 605
tta gag caa ttg acc agc agc atc tgt cat aaa ctg gcc acc atc ggt 1872
Leu Glu Gln Leu Thr Ser Ser Ile Cys His Lys Leu Ala Thr Ile Gly
610 615 620
ctg agc cag aac gaa gct agc atg gaa aat acc gaa gat ctg cac caa 1920
Leu Ser Gln Asn Glu Ala Ser Met Glu Asn Thr Glu Asp Leu His Gln
625 630 635 640
caa gtc gat ttg gaa atg caa gaa ctg tca tgg cgt gtt cac cag ggt 1968
Gln Val Asp Leu Glu Met Gln Glu Leu Ser Trp Arg Val His Gln Gly
645 650 655
tgt cac ggt att aat cgc gaa acc cgt caa acc ttc ctg aat gtt gtt 2016
Cys His Gly Ile Asn Arg Glu Thr Arg Gln Thr Phe Leu Asn Val Val
660 665 670
aag tct ttt tat tac tcc gca cac tgc agc ccg gaa acc gtg gac agc 2064
Lys Ser Phe Tyr Tyr Ser Ala His Cys Ser Pro Glu Thr Val Asp Ser
675 680 685
cat att gca aaa gtg atc ttt caa gac gtt atc tga 2100
His Ile Ala Lys Val Ile Phe Gln Asp Val Ile
690 695
<210> 40
<211> 699
<212> PRT
<213> 小麦(Triticum aestivum)
<400> 40
Met Tyr Arg Gln Arg Thr Asp Glu Pro Ser Glu Thr Arg Gln Met Ile
1 5 10 15
Asp Asp Ile Arg Thr Ala Leu Ala Ser Leu Gly Asp Asp Glu Thr Ser
20 25 30
Met Ser Val Ser Ala Tyr Asp Thr Ala Leu Val Ala Leu Val Lys Asn
35 40 45
Leu Asp Gly Gly Asp Gly Pro Gln Phe Pro Ser Cys Ile Asp Trp Ile
50 55 60
Val Gln Asn Gln Leu Pro Asp Gly Ser Trp Gly Asp Pro Ala Phe Phe
65 70 75 80
Met Val Gln Asp Arg Met Ile Ser Thr Leu Ala Cys Val Val Ala Val
85 90 95
Lys Ser Trp Asn Ile Asp Arg Asp Asn Leu Cys Asp Arg Gly Val Leu
100 105 110
Phe Ile Lys Glu Asn Met Ser Arg Leu Val Glu Glu Glu Gln Asp Trp
115 120 125
Met Pro Cys Gly Phe Glu Ile Asn Phe Pro Ala Leu Leu Glu Lys Ala
130 135 140
Lys Asp Leu Asp Leu Asp Ile Pro Tyr Asp His Pro Val Leu Glu Glu
145 150 155 160
Ile Tyr Ala Lys Arg Asn Leu Lys Leu Leu Lys Ile Pro Leu Asp Val
165 170 175
Leu His Ala Ile Pro Thr Thr Leu Leu Phe Ser Val Glu Gly Met Val
180 185 190
Asp Leu Pro Leu Asp Trp Glu Lys Leu Leu Arg Leu Arg Cys Pro Asp
195 200 205
Gly Ser Phe His Ser Ser Pro Ala Ala Thr Ala Ala Ala Leu Ser His
210 215 220
Thr Gly Asp Lys Glu Cys His Ala Phe Leu Asp Arg Leu Ile Gln Lys
225 230 235 240
Phe Glu Gly Gly Val Pro Cys Ser His Ser Met Asp Thr Phe Glu Gln
245 250 255
Leu Trp Val Val Asp Arg Leu Met Arg Leu Gly Ile Ser Arg His Phe
260 265 270
Thr Ser Glu Ile Gln Gln Cys Leu Glu Phe Ile Tyr Arg Arg Trp Thr
275 280 285
Gln Lys Gly Leu Ala His Asn Met His Cys Pro Ile Pro Asp Ile Asp
290 295 300
Asp Thr Ala Met Gly Phe Arg Leu Leu Arg Gln His Gly Tyr Asp Val
305 310 315 320
Thr Pro Ser Val Phe Lys His Phe Glu Lys Asp Gly Lys Phe Val Cys
325 330 335
Phe Pro Met Glu Thr Asn His Ala Ser Val Thr Pro Met His Asn Thr
340 345 350
Tyr Arg Ala Ser Gln Phe Met Phe Pro Gly Asp Asp Asp Val Leu Ala
355 360 365
Arg Ala Gly Arg Tyr Cys Arg Ala Phe Leu Gln Glu Arg Gln Ser Ser
370 375 380
Asn Lys Leu Tyr Asp Lys Trp Ile Ile Thr Lys Asp Leu Pro Gly Glu
385 390 395 400
Val Gly Tyr Thr Leu Asn Phe Pro Trp Lys Ser Ser Leu Pro Arg Ile
405 410 415
Glu Thr Arg Met Tyr Leu Asp Gln Tyr Gly Gly Asn Asn Asp Val Trp
420 425 430
Ile Ala Lys Val Leu Tyr Arg Met Asn Leu Val Ser Asn Asp Leu Tyr
435 440 445
Leu Lys Met Ala Lys Ala Asp Phe Thr Glu Tyr Gln Arg Leu Ser Arg
450 455 460
Ile Glu Trp Asn Gly Leu Arg Lys Trp Tyr Phe Arg Asn His Leu Gln
465 470 475 480
Arg Tyr Gly Ala Thr Pro Lys Ser Ala Leu Lys Ala Tyr Phe Leu Ala
485 490 495
Ser Ala Asn Ile Phe Glu Pro Gly Arg Ala Ala Glu Arg Leu Ala Trp
500 505 510
Ala Arg Met Ala Val Leu Ala Glu Ala Val Thr Thr His Phe Arg His
515 520 525
Ile Gly Gly Pro Cys Tyr Ser Thr Glu Asn Leu Glu Glu Leu Ile Asp
530 535 540
Leu Val Ser Phe Asp Asp Val Ser Gly Gly Leu Arg Glu Ala Trp Lys
545 550 555 560
Gln Trp Leu Met Ala Trp Thr Ala Lys Glu Ser His Gly Ser Val Asp
565 570 575
Gly Asp Thr Ala Leu Leu Phe Val Arg Thr Ile Glu Ile Cys Ser Gly
580 585 590
Arg Ile Val Ser Ser Glu Gln Lys Leu Asn Leu Trp Asp Tyr Ser Gln
595 600 605
Leu Glu Gln Leu Thr Ser Ser Ile Cys His Lys Leu Ala Thr Ile Gly
610 615 620
Leu Ser Gln Asn Glu Ala Ser Met Glu Asn Thr Glu Asp Leu His Gln
625 630 635 640
Gln Val Asp Leu Glu Met Gln Glu Leu Ser Trp Arg Val His Gln Gly
645 650 655
Cys His Gly Ile Asn Arg Glu Thr Arg Gln Thr Phe Leu Asn Val Val
660 665 670
Lys Ser Phe Tyr Tyr Ser Ala His Cys Ser Pro Glu Thr Val Asp Ser
675 680 685
His Ile Ala Lys Val Ile Phe Gln Asp Val Ile
690 695
<210> 41
<211> 1125
<212> DNA
<213> 假单胞菌属(Pseudomonas sp.) 19-rlim
<220>
<221> CDS
<222> (1)..(1125)
<400> 41
atg act atc aat tct att caa ccg att caa gca aaa gcc gct gtg ctg 48
Met Thr Ile Asn Ser Ile Gln Pro Ile Gln Ala Lys Ala Ala Val Leu
1 5 10 15
cgt gcc gta ggc tcc ccg ttt aac att gag ccg att cgt atc agc ccg 96
Arg Ala Val Gly Ser Pro Phe Asn Ile Glu Pro Ile Arg Ile Ser Pro
20 25 30
ccg aag ggt gat gaa gtt ctg gtc cgt att gtg ggt gtg ggt gtc tgc 144
Pro Lys Gly Asp Glu Val Leu Val Arg Ile Val Gly Val Gly Val Cys
35 40 45
cat acc gac gtc gtt tgc cgt gac agc ttc ccg gtt ccg ctg cca atc 192
His Thr Asp Val Val Cys Arg Asp Ser Phe Pro Val Pro Leu Pro Ile
50 55 60
atc ctg ggt cac gaa ggc tcg ggt gtg att gaa gcg atc ggt gat caa 240
Ile Leu Gly His Glu Gly Ser Gly Val Ile Glu Ala Ile Gly Asp Gln
65 70 75 80
gtt acg agc ctg aag cca ggt gac cac gtc gtt ctg agc ttc aat agc 288
Val Thr Ser Leu Lys Pro Gly Asp His Val Val Leu Ser Phe Asn Ser
85 90 95
tgc ggc cac tgt tat aac tgc ggt cat gcg gag ccg gca agc tgc ctg 336
Cys Gly His Cys Tyr Asn Cys Gly His Ala Glu Pro Ala Ser Cys Leu
100 105 110
cag atg tta ccg ttg aac ttt ggt ggc gcg gag cgt gcg gcg gac ggc 384
Gln Met Leu Pro Leu Asn Phe Gly Gly Ala Glu Arg Ala Ala Asp Gly
115 120 125
acc atc caa gac gac aag ggt gaa gcc gtc cgc ggt atg ttc ttt ggc 432
Thr Ile Gln Asp Asp Lys Gly Glu Ala Val Arg Gly Met Phe Phe Gly
130 135 140
cag tcc agc ttt ggc acg tac gca atc gca cgt gcg gtg aat gct gtc 480
Gln Ser Ser Phe Gly Thr Tyr Ala Ile Ala Arg Ala Val Asn Ala Val
145 150 155 160
aaa gtt gac gac gat ctg ccg ctg cct ctg ttg ggc ccg ctg ggc tgt 528
Lys Val Asp Asp Asp Leu Pro Leu Pro Leu Leu Gly Pro Leu Gly Cys
165 170 175
ggt atc cag acc ggt gcg ggt gca gcg atg aac agc ctg tct ctg cag 576
Gly Ile Gln Thr Gly Ala Gly Ala Ala Met Asn Ser Leu Ser Leu Gln
180 185 190
agc ggt cag agc ttc atc gtt ttc ggt ggc ggc gcg gtc ggt ctg agc 624
Ser Gly Gln Ser Phe Ile Val Phe Gly Gly Gly Ala Val Gly Leu Ser
195 200 205
gct gtt atg gca gct aaa gcg ctg ggc gtg agc ccg ctg atc gtt gtg 672
Ala Val Met Ala Ala Lys Ala Leu Gly Val Ser Pro Leu Ile Val Val
210 215 220
gag ccg aac gaa agc cgc cgc gcc ctg gcc ctg gaa ctg ggt gca tcc 720
Glu Pro Asn Glu Ser Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser
225 230 235 240
cac gtg ttt gat ccg ttc aac acc gaa gat ctg gtt gcc agc att cgc 768
His Val Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile Arg
245 250 255
gaa gtc gtg cct gcg ggt gcg aac cat gca ctg gac acg acc ggt ctg 816
Glu Val Val Pro Ala Gly Ala Asn His Ala Leu Asp Thr Thr Gly Leu
260 265 270
ccg aaa gtg atc gcg agc gcg att gat tgt att atg agc ggt ggc aaa 864
Pro Lys Val Ile Ala Ser Ala Ile Asp Cys Ile Met Ser Gly Gly Lys
275 280 285
ctg ggt ttg ctg ggt atg gcg agc ccg gaa gcg aat gtg ccg gct acc 912
Leu Gly Leu Leu Gly Met Ala Ser Pro Glu Ala Asn Val Pro Ala Thr
290 295 300
ctg ttg gat ttg ctg agc aaa aat gtc acg ctg aag ccg atc acc gag 960
Leu Leu Asp Leu Leu Ser Lys Asn Val Thr Leu Lys Pro Ile Thr Glu
305 310 315 320
ggc gat gcg aac cca caa gag ttc atc ccg cgt atg ctg gca ctc tac 1008
Gly Asp Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Leu Ala Leu Tyr
325 330 335
cgt gag ggt aag ttc ccg ttt gag aaa ctg atc acg acc ttt ccg ttt 1056
Arg Glu Gly Lys Phe Pro Phe Glu Lys Leu Ile Thr Thr Phe Pro Phe
340 345 350
gag cac att aat gaa gca atg gaa gcc act gag tcc ggt aag gcc att 1104
Glu His Ile Asn Glu Ala Met Glu Ala Thr Glu Ser Gly Lys Ala Ile
355 360 365
aaa ccg gtt ctg acg ctg taa 1125
Lys Pro Val Leu Thr Leu
370
<210> 42
<211> 374
<212> PRT
<213> 假单胞菌属(Pseudomonas sp.) 19-rlim
<400> 42
Met Thr Ile Asn Ser Ile Gln Pro Ile Gln Ala Lys Ala Ala Val Leu
1 5 10 15
Arg Ala Val Gly Ser Pro Phe Asn Ile Glu Pro Ile Arg Ile Ser Pro
20 25 30
Pro Lys Gly Asp Glu Val Leu Val Arg Ile Val Gly Val Gly Val Cys
35 40 45
His Thr Asp Val Val Cys Arg Asp Ser Phe Pro Val Pro Leu Pro Ile
50 55 60
Ile Leu Gly His Glu Gly Ser Gly Val Ile Glu Ala Ile Gly Asp Gln
65 70 75 80
Val Thr Ser Leu Lys Pro Gly Asp His Val Val Leu Ser Phe Asn Ser
85 90 95
Cys Gly His Cys Tyr Asn Cys Gly His Ala Glu Pro Ala Ser Cys Leu
100 105 110
Gln Met Leu Pro Leu Asn Phe Gly Gly Ala Glu Arg Ala Ala Asp Gly
115 120 125
Thr Ile Gln Asp Asp Lys Gly Glu Ala Val Arg Gly Met Phe Phe Gly
130 135 140
Gln Ser Ser Phe Gly Thr Tyr Ala Ile Ala Arg Ala Val Asn Ala Val
145 150 155 160
Lys Val Asp Asp Asp Leu Pro Leu Pro Leu Leu Gly Pro Leu Gly Cys
165 170 175
Gly Ile Gln Thr Gly Ala Gly Ala Ala Met Asn Ser Leu Ser Leu Gln
180 185 190
Ser Gly Gln Ser Phe Ile Val Phe Gly Gly Gly Ala Val Gly Leu Ser
195 200 205
Ala Val Met Ala Ala Lys Ala Leu Gly Val Ser Pro Leu Ile Val Val
210 215 220
Glu Pro Asn Glu Ser Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser
225 230 235 240
His Val Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile Arg
245 250 255
Glu Val Val Pro Ala Gly Ala Asn His Ala Leu Asp Thr Thr Gly Leu
260 265 270
Pro Lys Val Ile Ala Ser Ala Ile Asp Cys Ile Met Ser Gly Gly Lys
275 280 285
Leu Gly Leu Leu Gly Met Ala Ser Pro Glu Ala Asn Val Pro Ala Thr
290 295 300
Leu Leu Asp Leu Leu Ser Lys Asn Val Thr Leu Lys Pro Ile Thr Glu
305 310 315 320
Gly Asp Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Leu Ala Leu Tyr
325 330 335
Arg Glu Gly Lys Phe Pro Phe Glu Lys Leu Ile Thr Thr Phe Pro Phe
340 345 350
Glu His Ile Asn Glu Ala Met Glu Ala Thr Glu Ser Gly Lys Ala Ile
355 360 365
Lys Pro Val Leu Thr Leu
370
<210> 43
<211> 1017
<212> DNA
<213> 温特曲霉(Aspergillus wentii) DTO 134E9
<220>
<221> CDS
<222> (1)..(1017)
<400> 43
atg ggt agc att act gaa gat atc cca acc atg cgc gct gct act gtt 48
Met Gly Ser Ile Thr Glu Asp Ile Pro Thr Met Arg Ala Ala Thr Val
1 5 10 15
gtt gag tac aat aag ccg ctt caa atc ctg aat atc cct att ccg acc 96
Val Glu Tyr Asn Lys Pro Leu Gln Ile Leu Asn Ile Pro Ile Pro Thr
20 25 30
ccg tcc cag gat cag att ctg gtc aag gtc acc gca tgc agc ctg tgc 144
Pro Ser Gln Asp Gln Ile Leu Val Lys Val Thr Ala Cys Ser Leu Cys
35 40 45
aac agc gac ctg gcg ggc tgg ctg ggt gtt gtt ggt gcg gtt gcg ccg 192
Asn Ser Asp Leu Ala Gly Trp Leu Gly Val Val Gly Ala Val Ala Pro
50 55 60
tat tgt ccg ggc cat gaa ccg gtg ggt gta att gag agc gtc ggt agc 240
Tyr Cys Pro Gly His Glu Pro Val Gly Val Ile Glu Ser Val Gly Ser
65 70 75 80
gcc gtt cgc ggt ttc aag aaa ggc gac cgt gcc ggt ttc atg ccg agc 288
Ala Val Arg Gly Phe Lys Lys Gly Asp Arg Ala Gly Phe Met Pro Ser
85 90 95
tcc ttt acg tgt aaa gac tgc aat gaa tgt caa acc ggt aat cat cgt 336
Ser Phe Thr Cys Lys Asp Cys Asn Glu Cys Gln Thr Gly Asn His Arg
100 105 110
ttt tgt aat aag aaa acc agc gtg ggt ttc cag ggt ccg tat ggc ggc 384
Phe Cys Asn Lys Lys Thr Ser Val Gly Phe Gln Gly Pro Tyr Gly Gly
115 120 125
ttc agc caa tat gcc gtt gct gac ccg ttg agc acg gtt aag atc ccg 432
Phe Ser Gln Tyr Ala Val Ala Asp Pro Leu Ser Thr Val Lys Ile Pro
130 135 140
gac gcg ctg tct gat gaa gtc acg gcg ccg ctg ttg tgc gcg ggt gtg 480
Asp Ala Leu Ser Asp Glu Val Thr Ala Pro Leu Leu Cys Ala Gly Val
145 150 155 160
acg gcg tat ggc gca ctg cgc aag gtc ccg cca ggc gtg cag agc gtg 528
Thr Ala Tyr Gly Ala Leu Arg Lys Val Pro Pro Gly Val Gln Ser Val
165 170 175
aac gtt atc ggt tgc ggt ggc gtt ggc cac ctg gtg atc caa tat gcg 576
Asn Val Ile Gly Cys Gly Gly Val Gly His Leu Val Ile Gln Tyr Ala
180 185 190
aag gct ctg ggt tac tac gtg cgt ggc ttt gac gtt aac gac aag aaa 624
Lys Ala Leu Gly Tyr Tyr Val Arg Gly Phe Asp Val Asn Asp Lys Lys
195 200 205
ctg ggc ctg gca gcg cgt agc ggt gcg gat gaa acc ttt tac agc acc 672
Leu Gly Leu Ala Ala Arg Ser Gly Ala Asp Glu Thr Phe Tyr Ser Thr
210 215 220
gat gcc acc cat gcg gac cag gca tct gca acg atc gtc gcg acc ggc 720
Asp Ala Thr His Ala Asp Gln Ala Ser Ala Thr Ile Val Ala Thr Gly
225 230 235 240
gcg gtt gca gcg tac aaa gcc gca ttc gca gtc acc gcc aac cac ggt 768
Ala Val Ala Ala Tyr Lys Ala Ala Phe Ala Val Thr Ala Asn His Gly
245 250 255
cgt atc att gcg atc ggt gtc ccg aag ggt gag att ccg gtg tcg ctg 816
Arg Ile Ile Ala Ile Gly Val Pro Lys Gly Glu Ile Pro Val Ser Leu
260 265 270
ctg gac atg gtc aaa cgt gat ctg agc tta gtg gcg acg aac caa ggc 864
Leu Asp Met Val Lys Arg Asp Leu Ser Leu Val Ala Thr Asn Gln Gly
275 280 285
tcc aaa gaa gaa ttg gaa gag gct ctg gaa att gca gtg caa cac cag 912
Ser Lys Glu Glu Leu Glu Glu Ala Leu Glu Ile Ala Val Gln His Gln
290 295 300
atc gca ccg gag tac gaa att cgc cag ctg gac cag ctg aac gat ggc 960
Ile Ala Pro Glu Tyr Glu Ile Arg Gln Leu Asp Gln Leu Asn Asp Gly
305 310 315 320
ttt caa gag atg atg aaa ggt gag agc cac ggt cgt ctg gtg tac cgt 1008
Phe Gln Glu Met Met Lys Gly Glu Ser His Gly Arg Leu Val Tyr Arg
325 330 335
ctg tgg taa 1017
Leu Trp
<210> 44
<211> 338
<212> PRT
<213> 温特曲霉(Aspergillus wentii) DTO 134E9
<400> 44
Met Gly Ser Ile Thr Glu Asp Ile Pro Thr Met Arg Ala Ala Thr Val
1 5 10 15
Val Glu Tyr Asn Lys Pro Leu Gln Ile Leu Asn Ile Pro Ile Pro Thr
20 25 30
Pro Ser Gln Asp Gln Ile Leu Val Lys Val Thr Ala Cys Ser Leu Cys
35 40 45
Asn Ser Asp Leu Ala Gly Trp Leu Gly Val Val Gly Ala Val Ala Pro
50 55 60
Tyr Cys Pro Gly His Glu Pro Val Gly Val Ile Glu Ser Val Gly Ser
65 70 75 80
Ala Val Arg Gly Phe Lys Lys Gly Asp Arg Ala Gly Phe Met Pro Ser
85 90 95
Ser Phe Thr Cys Lys Asp Cys Asn Glu Cys Gln Thr Gly Asn His Arg
100 105 110
Phe Cys Asn Lys Lys Thr Ser Val Gly Phe Gln Gly Pro Tyr Gly Gly
115 120 125
Phe Ser Gln Tyr Ala Val Ala Asp Pro Leu Ser Thr Val Lys Ile Pro
130 135 140
Asp Ala Leu Ser Asp Glu Val Thr Ala Pro Leu Leu Cys Ala Gly Val
145 150 155 160
Thr Ala Tyr Gly Ala Leu Arg Lys Val Pro Pro Gly Val Gln Ser Val
165 170 175
Asn Val Ile Gly Cys Gly Gly Val Gly His Leu Val Ile Gln Tyr Ala
180 185 190
Lys Ala Leu Gly Tyr Tyr Val Arg Gly Phe Asp Val Asn Asp Lys Lys
195 200 205
Leu Gly Leu Ala Ala Arg Ser Gly Ala Asp Glu Thr Phe Tyr Ser Thr
210 215 220
Asp Ala Thr His Ala Asp Gln Ala Ser Ala Thr Ile Val Ala Thr Gly
225 230 235 240
Ala Val Ala Ala Tyr Lys Ala Ala Phe Ala Val Thr Ala Asn His Gly
245 250 255
Arg Ile Ile Ala Ile Gly Val Pro Lys Gly Glu Ile Pro Val Ser Leu
260 265 270
Leu Asp Met Val Lys Arg Asp Leu Ser Leu Val Ala Thr Asn Gln Gly
275 280 285
Ser Lys Glu Glu Leu Glu Glu Ala Leu Glu Ile Ala Val Gln His Gln
290 295 300
Ile Ala Pro Glu Tyr Glu Ile Arg Gln Leu Asp Gln Leu Asn Asp Gly
305 310 315 320
Phe Gln Glu Met Met Lys Gly Glu Ser His Gly Arg Leu Val Tyr Arg
325 330 335
Leu Trp
<210> 45
<211> 1119
<212> DNA
<213> 铜绿假单胞菌(Pseudomonas aeruginosa)
<220>
<221> CDS
<222> (1)..(1119)
<400> 45
atg aac tcg atc caa cct act caa gca aaa gca gca gtc ttg cgc gca 48
Met Asn Ser Ile Gln Pro Thr Gln Ala Lys Ala Ala Val Leu Arg Ala
1 5 10 15
gtc ggc ggc ccg ttc tct att gag ccg atc cgc atc agc cca ccg aag 96
Val Gly Gly Pro Phe Ser Ile Glu Pro Ile Arg Ile Ser Pro Pro Lys
20 25 30
ggt gac gaa gtg ctg gtt cgt atc gtt ggt gtg ggt gtc tgc cac acc 144
Gly Asp Glu Val Leu Val Arg Ile Val Gly Val Gly Val Cys His Thr
35 40 45
gac gtc gtc tgt cgt gat agc ttt ccg gtg ccg ttg ccg atc att ctg 192
Asp Val Val Cys Arg Asp Ser Phe Pro Val Pro Leu Pro Ile Ile Leu
50 55 60
ggt cac gag ggc tcc ggt gtg att gaa gct gtg ggt gac caa gtg acc 240
Gly His Glu Gly Ser Gly Val Ile Glu Ala Val Gly Asp Gln Val Thr
65 70 75 80
ggt ctg aaa ccg ggt gac cac gtt gtg ctg tcc ttc aat agc tgc ggc 288
Gly Leu Lys Pro Gly Asp His Val Val Leu Ser Phe Asn Ser Cys Gly
85 90 95
cat tgc tac aac tgt ggt cat gac gag cct gcg tct tgt ctg cag atg 336
His Cys Tyr Asn Cys Gly His Asp Glu Pro Ala Ser Cys Leu Gln Met
100 105 110
ctg ccg ttg aat ttc ggt ggc gcg gag cgt gcg gcg gac ggc acc atc 384
Leu Pro Leu Asn Phe Gly Gly Ala Glu Arg Ala Ala Asp Gly Thr Ile
115 120 125
gaa gat gac cag ggc gca gct gtt cgt ggc ctg ttc ttc ggc caa agc 432
Glu Asp Asp Gln Gly Ala Ala Val Arg Gly Leu Phe Phe Gly Gln Ser
130 135 140
tcc ttt ggt agc tac gcg att gca cgt gcg gtt aac act gtc aaa gtt 480
Ser Phe Gly Ser Tyr Ala Ile Ala Arg Ala Val Asn Thr Val Lys Val
145 150 155 160
gat gac gat ctg ccg ttg gcg ctg ctg ggt ccg ctg ggt tgc ggt att 528
Asp Asp Asp Leu Pro Leu Ala Leu Leu Gly Pro Leu Gly Cys Gly Ile
165 170 175
cag acc ggc gcg ggt gca gcc atg aat agc ctg ggt tta cag ggt ggc 576
Gln Thr Gly Ala Gly Ala Ala Met Asn Ser Leu Gly Leu Gln Gly Gly
180 185 190
cag agc ttc att gtg ttt ggc ggc ggc gcc gtc ggt ctg agc gcg gtc 624
Gln Ser Phe Ile Val Phe Gly Gly Gly Ala Val Gly Leu Ser Ala Val
195 200 205
atg gcc gcc aag gcc ctg ggt gtt agc ccg ctg att gtt gtg gag ccg 672
Met Ala Ala Lys Ala Leu Gly Val Ser Pro Leu Ile Val Val Glu Pro
210 215 220
aac gaa gct cgc cgt gcg ctg gca ctg gaa ttg ggt gcg agc cac gcg 720
Asn Glu Ala Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser His Ala
225 230 235 240
ttt gac cca ttt aac acc gaa gat ctg gtc gcg agc att cgc gaa gtc 768
Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile Arg Glu Val
245 250 255
gtt ccg gct ggc gca aac cac gcg ctg gac acg acg ggt ctg ccg aaa 816
Val Pro Ala Gly Ala Asn His Ala Leu Asp Thr Thr Gly Leu Pro Lys
260 265 270
gtt att gcc aac gcg atc gat tgc atc atg agc ggc ggc aaa ctg ggt 864
Val Ile Ala Asn Ala Ile Asp Cys Ile Met Ser Gly Gly Lys Leu Gly
275 280 285
ctg ctc ggt atg gcg aat ccg gaa gcg aat gtg ccg gcg acc ctg ctg 912
Leu Leu Gly Met Ala Asn Pro Glu Ala Asn Val Pro Ala Thr Leu Leu
290 295 300
gat ctg ctg agc aaa aat gtg acg ctg aag ccg atc acc gag ggt gac 960
Asp Leu Leu Ser Lys Asn Val Thr Leu Lys Pro Ile Thr Glu Gly Asp
305 310 315 320
gca aac cca caa gaa ttt att ccg cgt atg ctg gct ctg tat cgt gag 1008
Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Leu Ala Leu Tyr Arg Glu
325 330 335
ggt aag ttt ccg ttc gat aag ctg atc acc acg ttc ccg ttc gag cat 1056
Gly Lys Phe Pro Phe Asp Lys Leu Ile Thr Thr Phe Pro Phe Glu His
340 345 350
atc aac gaa gca atg gaa gct acc gag agc ggt aag gcc att aaa ccg 1104
Ile Asn Glu Ala Met Glu Ala Thr Glu Ser Gly Lys Ala Ile Lys Pro
355 360 365
gtt ctg acc ctg taa 1119
Val Leu Thr Leu
370
<210> 46
<211> 372
<212> PRT
<213> 铜绿假单胞菌(Pseudomonas aeruginosa)
<400> 46
Met Asn Ser Ile Gln Pro Thr Gln Ala Lys Ala Ala Val Leu Arg Ala
1 5 10 15
Val Gly Gly Pro Phe Ser Ile Glu Pro Ile Arg Ile Ser Pro Pro Lys
20 25 30
Gly Asp Glu Val Leu Val Arg Ile Val Gly Val Gly Val Cys His Thr
35 40 45
Asp Val Val Cys Arg Asp Ser Phe Pro Val Pro Leu Pro Ile Ile Leu
50 55 60
Gly His Glu Gly Ser Gly Val Ile Glu Ala Val Gly Asp Gln Val Thr
65 70 75 80
Gly Leu Lys Pro Gly Asp His Val Val Leu Ser Phe Asn Ser Cys Gly
85 90 95
His Cys Tyr Asn Cys Gly His Asp Glu Pro Ala Ser Cys Leu Gln Met
100 105 110
Leu Pro Leu Asn Phe Gly Gly Ala Glu Arg Ala Ala Asp Gly Thr Ile
115 120 125
Glu Asp Asp Gln Gly Ala Ala Val Arg Gly Leu Phe Phe Gly Gln Ser
130 135 140
Ser Phe Gly Ser Tyr Ala Ile Ala Arg Ala Val Asn Thr Val Lys Val
145 150 155 160
Asp Asp Asp Leu Pro Leu Ala Leu Leu Gly Pro Leu Gly Cys Gly Ile
165 170 175
Gln Thr Gly Ala Gly Ala Ala Met Asn Ser Leu Gly Leu Gln Gly Gly
180 185 190
Gln Ser Phe Ile Val Phe Gly Gly Gly Ala Val Gly Leu Ser Ala Val
195 200 205
Met Ala Ala Lys Ala Leu Gly Val Ser Pro Leu Ile Val Val Glu Pro
210 215 220
Asn Glu Ala Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser His Ala
225 230 235 240
Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile Arg Glu Val
245 250 255
Val Pro Ala Gly Ala Asn His Ala Leu Asp Thr Thr Gly Leu Pro Lys
260 265 270
Val Ile Ala Asn Ala Ile Asp Cys Ile Met Ser Gly Gly Lys Leu Gly
275 280 285
Leu Leu Gly Met Ala Asn Pro Glu Ala Asn Val Pro Ala Thr Leu Leu
290 295 300
Asp Leu Leu Ser Lys Asn Val Thr Leu Lys Pro Ile Thr Glu Gly Asp
305 310 315 320
Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Leu Ala Leu Tyr Arg Glu
325 330 335
Gly Lys Phe Pro Phe Asp Lys Leu Ile Thr Thr Phe Pro Phe Glu His
340 345 350
Ile Asn Glu Ala Met Glu Ala Thr Glu Ser Gly Lys Ala Ile Lys Pro
355 360 365
Val Leu Thr Leu
370
<210> 47
<211> 1128
<212> DNA
<213> 解甲苯固氮弯曲菌(Azoarcus toluclasticus)
<220>
<221> CDS
<222> (1)..(1128)
<400> 47
atg ggt tct att caa gat tct ctg ttc atc cgt gca cgc gcc gct gtt 48
Met Gly Ser Ile Gln Asp Ser Leu Phe Ile Arg Ala Arg Ala Ala Val
1 5 10 15
ctg cgt act gtc ggt ggc ccg ctg gaa att gaa aac gtc cgc att agc 96
Leu Arg Thr Val Gly Gly Pro Leu Glu Ile Glu Asn Val Arg Ile Ser
20 25 30
cct ccg aag ggt gac gaa gtg ctc gtg cgt atg gtt ggt gtt ggt gtg 144
Pro Pro Lys Gly Asp Glu Val Leu Val Arg Met Val Gly Val Gly Val
35 40 45
tgc cat acc gac gtt gtg tgt cgc gat ggc ttc ccg gtt ccg ctg ccg 192
Cys His Thr Asp Val Val Cys Arg Asp Gly Phe Pro Val Pro Leu Pro
50 55 60
att gtg ctg ggt cac gag ggc agc ggt att gtc gag gca gtg ggc gag 240
Ile Val Leu Gly His Glu Gly Ser Gly Ile Val Glu Ala Val Gly Glu
65 70 75 80
cgt gtg acc aag gtt aaa ccg ggt cag cgt gtc gtt tta tcc ttc aat 288
Arg Val Thr Lys Val Lys Pro Gly Gln Arg Val Val Leu Ser Phe Asn
85 90 95
agc tgt ggt cat tgc gcg tcc tgc tgc gag gac cac ccg gcc acc tgt 336
Ser Cys Gly His Cys Ala Ser Cys Cys Glu Asp His Pro Ala Thr Cys
100 105 110
cac cag atg ctg cca ctg aac ttt ggt gcg gcg cag cgc gtg gat ggt 384
His Gln Met Leu Pro Leu Asn Phe Gly Ala Ala Gln Arg Val Asp Gly
115 120 125
ggc acc gtt atc gac gcg agc ggc gag gca gtg cag agc ctg ttt ttt 432
Gly Thr Val Ile Asp Ala Ser Gly Glu Ala Val Gln Ser Leu Phe Phe
130 135 140
ggt caa agc tct ttc ggt acg tat gca ttg gcg cgt gaa gtc aat acc 480
Gly Gln Ser Ser Phe Gly Thr Tyr Ala Leu Ala Arg Glu Val Asn Thr
145 150 155 160
gta ccg gtg ccg gat gca gtt ccg ttg gaa atc ctg ggc ccg ttg ggt 528
Val Pro Val Pro Asp Ala Val Pro Leu Glu Ile Leu Gly Pro Leu Gly
165 170 175
tgc ggc atc cag acg ggt gcg ggt gcg gct atc aac agc ctg gcg ctg 576
Cys Gly Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Ala Leu
180 185 190
aaa cct ggt caa tcg ctg gca atc ttc ggt ggc ggc agc gtc ggt ctg 624
Lys Pro Gly Gln Ser Leu Ala Ile Phe Gly Gly Gly Ser Val Gly Leu
195 200 205
tcc gcc ctg ctg ggc gcg ctg gcc gtg ggc gcg ggc ccg gtc gtt gtc 672
Ser Ala Leu Leu Gly Ala Leu Ala Val Gly Ala Gly Pro Val Val Val
210 215 220
att gag ccg aac gaa cgt cgt cgt gcg ttg gcg ctg gac ctg ggt gcg 720
Ile Glu Pro Asn Glu Arg Arg Arg Ala Leu Ala Leu Asp Leu Gly Ala
225 230 235 240
agc cat gca ttt gat ccg ttc aac act gaa gat ttg gtt gcg agc atc 768
Ser His Ala Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile
245 250 255
aaa gcc gct acg ggt ggc ggc gtt acc cac agc ctg gac agc acg ggt 816
Lys Ala Ala Thr Gly Gly Gly Val Thr His Ser Leu Asp Ser Thr Gly
260 265 270
ctg ccg ccg gtc atc gcg aat gca atc aac tgt acc ttg ccg ggc ggc 864
Leu Pro Pro Val Ile Ala Asn Ala Ile Asn Cys Thr Leu Pro Gly Gly
275 280 285
acg gtc ggt ctg ctg ggc gtc ccg agc cca gag gct gcc gtt ccg gtg 912
Thr Val Gly Leu Leu Gly Val Pro Ser Pro Glu Ala Ala Val Pro Val
290 295 300
acg ctg ctg gat ctg ctg gtt aaa tca gtt acc ctg cgt ccg att acc 960
Thr Leu Leu Asp Leu Leu Val Lys Ser Val Thr Leu Arg Pro Ile Thr
305 310 315 320
gag ggt gac gcc aat ccg caa gaa ttt att ccg cgt atg gtc cag ctg 1008
Glu Gly Asp Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Val Gln Leu
325 330 335
tac cgc gac ggt aaa ttt ccg ttt gat aag ctg att acg acc tac cgc 1056
Tyr Arg Asp Gly Lys Phe Pro Phe Asp Lys Leu Ile Thr Thr Tyr Arg
340 345 350
ttc gac gac atc aat caa gcg ttc aag gca acc gaa acc ggt gaa gcg 1104
Phe Asp Asp Ile Asn Gln Ala Phe Lys Ala Thr Glu Thr Gly Glu Ala
355 360 365
att aag cca gtg ctg gtg ttt taa 1128
Ile Lys Pro Val Leu Val Phe
370 375
<210> 48
<211> 375
<212> PRT
<213> 解甲苯固氮弯曲菌(Azoarcus toluclasticus)
<400> 48
Met Gly Ser Ile Gln Asp Ser Leu Phe Ile Arg Ala Arg Ala Ala Val
1 5 10 15
Leu Arg Thr Val Gly Gly Pro Leu Glu Ile Glu Asn Val Arg Ile Ser
20 25 30
Pro Pro Lys Gly Asp Glu Val Leu Val Arg Met Val Gly Val Gly Val
35 40 45
Cys His Thr Asp Val Val Cys Arg Asp Gly Phe Pro Val Pro Leu Pro
50 55 60
Ile Val Leu Gly His Glu Gly Ser Gly Ile Val Glu Ala Val Gly Glu
65 70 75 80
Arg Val Thr Lys Val Lys Pro Gly Gln Arg Val Val Leu Ser Phe Asn
85 90 95
Ser Cys Gly His Cys Ala Ser Cys Cys Glu Asp His Pro Ala Thr Cys
100 105 110
His Gln Met Leu Pro Leu Asn Phe Gly Ala Ala Gln Arg Val Asp Gly
115 120 125
Gly Thr Val Ile Asp Ala Ser Gly Glu Ala Val Gln Ser Leu Phe Phe
130 135 140
Gly Gln Ser Ser Phe Gly Thr Tyr Ala Leu Ala Arg Glu Val Asn Thr
145 150 155 160
Val Pro Val Pro Asp Ala Val Pro Leu Glu Ile Leu Gly Pro Leu Gly
165 170 175
Cys Gly Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Ala Leu
180 185 190
Lys Pro Gly Gln Ser Leu Ala Ile Phe Gly Gly Gly Ser Val Gly Leu
195 200 205
Ser Ala Leu Leu Gly Ala Leu Ala Val Gly Ala Gly Pro Val Val Val
210 215 220
Ile Glu Pro Asn Glu Arg Arg Arg Ala Leu Ala Leu Asp Leu Gly Ala
225 230 235 240
Ser His Ala Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile
245 250 255
Lys Ala Ala Thr Gly Gly Gly Val Thr His Ser Leu Asp Ser Thr Gly
260 265 270
Leu Pro Pro Val Ile Ala Asn Ala Ile Asn Cys Thr Leu Pro Gly Gly
275 280 285
Thr Val Gly Leu Leu Gly Val Pro Ser Pro Glu Ala Ala Val Pro Val
290 295 300
Thr Leu Leu Asp Leu Leu Val Lys Ser Val Thr Leu Arg Pro Ile Thr
305 310 315 320
Glu Gly Asp Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Val Gln Leu
325 330 335
Tyr Arg Asp Gly Lys Phe Pro Phe Asp Lys Leu Ile Thr Thr Tyr Arg
340 345 350
Phe Asp Asp Ile Asn Gln Ala Phe Lys Ala Thr Glu Thr Gly Glu Ala
355 360 365
Ile Lys Pro Val Leu Val Phe
370 375
<210> 49
<211> 1128
<212> DNA
<213> 芳香固氮弧菌(Aromatoleum aromaticum)
<220>
<221> CDS
<222> (1)..(1128)
<400> 49
atg ggc tca att caa gat tct ctg ttc atc ccg gct aga gcg gca gtg 48
Met Gly Ser Ile Gln Asp Ser Leu Phe Ile Pro Ala Arg Ala Ala Val
1 5 10 15
ttg cgt gcg gtc ggt ggc cca ctg gaa atc gaa gat gtt cgt atc agc 96
Leu Arg Ala Val Gly Gly Pro Leu Glu Ile Glu Asp Val Arg Ile Ser
20 25 30
ccg cct aag ggc gac gaa gtt ctg gtc cgt atg gtt ggc gtg ggc gtt 144
Pro Pro Lys Gly Asp Glu Val Leu Val Arg Met Val Gly Val Gly Val
35 40 45
tgc cac acc gac gtt gtg tgc cgc gat ggt ttc ccg gtc ccg ctg ccg 192
Cys His Thr Asp Val Val Cys Arg Asp Gly Phe Pro Val Pro Leu Pro
50 55 60
att gtc ttg ggt cac gag ggt gcg ggt atc gtg gaa gct gtg ggt gag 240
Ile Val Leu Gly His Glu Gly Ala Gly Ile Val Glu Ala Val Gly Glu
65 70 75 80
cgt gtg acc aag gtc aaa cct ggc cag cgt gtg gtg ctg agc ttc aac 288
Arg Val Thr Lys Val Lys Pro Gly Gln Arg Val Val Leu Ser Phe Asn
85 90 95
agc tgc ggt cac tgc agc tcc tgt ggt gag gat cac ccg gcg acg tgt 336
Ser Cys Gly His Cys Ser Ser Cys Gly Glu Asp His Pro Ala Thr Cys
100 105 110
cat cag atg ctg ccg ctg aat ttt ggt gca gcg caa cgt gtt gac ggt 384
His Gln Met Leu Pro Leu Asn Phe Gly Ala Ala Gln Arg Val Asp Gly
115 120 125
ggc tgt gtc acc gat gcg agc ggt gaa gct gta cat agc ctg ttt ttc 432
Gly Cys Val Thr Asp Ala Ser Gly Glu Ala Val His Ser Leu Phe Phe
130 135 140
ggt cag agc tct ttt tgc acc ttt gca ctg gcg cgc gaa gtg aac acc 480
Gly Gln Ser Ser Phe Cys Thr Phe Ala Leu Ala Arg Glu Val Asn Thr
145 150 155 160
gtt cct gtc ggt gac ggc gtt ccg ctg gaa att ctg ggt ccg ctg ggt 528
Val Pro Val Gly Asp Gly Val Pro Leu Glu Ile Leu Gly Pro Leu Gly
165 170 175
tgt ggt att caa acc ggt gca ggc gca gcg atc aac agc ctg gcc att 576
Cys Gly Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Ala Ile
180 185 190
aaa ccg ggt cag agc ctg gcg att ttc ggt ggc ggc agc gtt ggt ctg 624
Lys Pro Gly Gln Ser Leu Ala Ile Phe Gly Gly Gly Ser Val Gly Leu
195 200 205
tcc gcc ctg ctg ggc gca ctg gcc gtg ggc gcg ggt ccg gtt gtt gtg 672
Ser Ala Leu Leu Gly Ala Leu Ala Val Gly Ala Gly Pro Val Val Val
210 215 220
gtg gag ccg aat gat cgt cgt cgt gca ctg gcc ctg gac ctg ggt gcg 720
Val Glu Pro Asn Asp Arg Arg Arg Ala Leu Ala Leu Asp Leu Gly Ala
225 230 235 240
tcg cat gtg ttt gac ccg ttc aat acc gaa gat ctg gtt gcg agc att 768
Ser His Val Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile
245 250 255
aaa gcc gcg acg ggt ggc ggc gtt act cac agc ctg gac agc act ggc 816
Lys Ala Ala Thr Gly Gly Gly Val Thr His Ser Leu Asp Ser Thr Gly
260 265 270
ttg ccg ccg gtg atc gca aag gcc att gat tgt acg ttg ccg ggt ggc 864
Leu Pro Pro Val Ile Ala Lys Ala Ile Asp Cys Thr Leu Pro Gly Gly
275 280 285
acc gtc ggt tta ctg ggt gtt ccg gct ccg gac gcc gca gtg ccg gtc 912
Thr Val Gly Leu Leu Gly Val Pro Ala Pro Asp Ala Ala Val Pro Val
290 295 300
acg ctg ctg gac ttg ctg gtg aag tcc gtt acc ctg cgc ccg atc acc 960
Thr Leu Leu Asp Leu Leu Val Lys Ser Val Thr Leu Arg Pro Ile Thr
305 310 315 320
gag ggt gac gca aac ccg caa gaa ttt att cca cgc atg gtt cag ctc 1008
Glu Gly Asp Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Val Gln Leu
325 330 335
tac cgt gat ggt aag ttc cca ttt gat aaa ctg atc acc acg tat cgt 1056
Tyr Arg Asp Gly Lys Phe Pro Phe Asp Lys Leu Ile Thr Thr Tyr Arg
340 345 350
ttt gag aac atc aat gac gcg ttc aaa gcg acg gaa acg ggt gaa gcg 1104
Phe Glu Asn Ile Asn Asp Ala Phe Lys Ala Thr Glu Thr Gly Glu Ala
355 360 365
atc aaa ccg gtc ctg gtt ttc taa 1128
Ile Lys Pro Val Leu Val Phe
370 375
<210> 50
<211> 375
<212> PRT
<213> 芳香固氮弧菌(Aromatoleum aromaticum)
<400> 50
Met Gly Ser Ile Gln Asp Ser Leu Phe Ile Pro Ala Arg Ala Ala Val
1 5 10 15
Leu Arg Ala Val Gly Gly Pro Leu Glu Ile Glu Asp Val Arg Ile Ser
20 25 30
Pro Pro Lys Gly Asp Glu Val Leu Val Arg Met Val Gly Val Gly Val
35 40 45
Cys His Thr Asp Val Val Cys Arg Asp Gly Phe Pro Val Pro Leu Pro
50 55 60
Ile Val Leu Gly His Glu Gly Ala Gly Ile Val Glu Ala Val Gly Glu
65 70 75 80
Arg Val Thr Lys Val Lys Pro Gly Gln Arg Val Val Leu Ser Phe Asn
85 90 95
Ser Cys Gly His Cys Ser Ser Cys Gly Glu Asp His Pro Ala Thr Cys
100 105 110
His Gln Met Leu Pro Leu Asn Phe Gly Ala Ala Gln Arg Val Asp Gly
115 120 125
Gly Cys Val Thr Asp Ala Ser Gly Glu Ala Val His Ser Leu Phe Phe
130 135 140
Gly Gln Ser Ser Phe Cys Thr Phe Ala Leu Ala Arg Glu Val Asn Thr
145 150 155 160
Val Pro Val Gly Asp Gly Val Pro Leu Glu Ile Leu Gly Pro Leu Gly
165 170 175
Cys Gly Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Ala Ile
180 185 190
Lys Pro Gly Gln Ser Leu Ala Ile Phe Gly Gly Gly Ser Val Gly Leu
195 200 205
Ser Ala Leu Leu Gly Ala Leu Ala Val Gly Ala Gly Pro Val Val Val
210 215 220
Val Glu Pro Asn Asp Arg Arg Arg Ala Leu Ala Leu Asp Leu Gly Ala
225 230 235 240
Ser His Val Phe Asp Pro Phe Asn Thr Glu Asp Leu Val Ala Ser Ile
245 250 255
Lys Ala Ala Thr Gly Gly Gly Val Thr His Ser Leu Asp Ser Thr Gly
260 265 270
Leu Pro Pro Val Ile Ala Lys Ala Ile Asp Cys Thr Leu Pro Gly Gly
275 280 285
Thr Val Gly Leu Leu Gly Val Pro Ala Pro Asp Ala Ala Val Pro Val
290 295 300
Thr Leu Leu Asp Leu Leu Val Lys Ser Val Thr Leu Arg Pro Ile Thr
305 310 315 320
Glu Gly Asp Ala Asn Pro Gln Glu Phe Ile Pro Arg Met Val Gln Leu
325 330 335
Tyr Arg Asp Gly Lys Phe Pro Phe Asp Lys Leu Ile Thr Thr Tyr Arg
340 345 350
Phe Glu Asn Ile Asn Asp Ala Phe Lys Ala Thr Glu Thr Gly Glu Ala
355 360 365
Ile Lys Pro Val Leu Val Phe
370 375
<210> 51
<211> 1122
<212> DNA
<213> 萜烯索氏菌(Thauera terpenica)
<220>
<221> CDS
<222> (1)..(1122)
<400> 51
atg tgt agc aat cat gat ttc acc gca gcc cgt gca gca gtc tta cgt 48
Met Cys Ser Asn His Asp Phe Thr Ala Ala Arg Ala Ala Val Leu Arg
1 5 10 15
aaa gtt ggt ggc ccg ttg gaa atc gaa gat gtc cgt att tct gcc ccg 96
Lys Val Gly Gly Pro Leu Glu Ile Glu Asp Val Arg Ile Ser Ala Pro
20 25 30
aaa ggc gac gaa gtc ctg gtg cgt atg gtt ggc gtg ggt gtg tgt cat 144
Lys Gly Asp Glu Val Leu Val Arg Met Val Gly Val Gly Val Cys His
35 40 45
acc gac ctc gtc tgc cgt gat gcg ttc ccg gtg ccg ctg cct att gtt 192
Thr Asp Leu Val Cys Arg Asp Ala Phe Pro Val Pro Leu Pro Ile Val
50 55 60
ctg ggt cac gag ggt gca ggc atc gtt gaa gcc gtg ggt gag ggc gtg 240
Leu Gly His Glu Gly Ala Gly Ile Val Glu Ala Val Gly Glu Gly Val
65 70 75 80
cgc tcc ctg gag ccg ggt gac cgt gtt gtg ctg agc ttc aat agc tgc 288
Arg Ser Leu Glu Pro Gly Asp Arg Val Val Leu Ser Phe Asn Ser Cys
85 90 95
ggc cgc tgt ggc aac tgc ggt agc ggt cac ccg agc aac tgc ctg caa 336
Gly Arg Cys Gly Asn Cys Gly Ser Gly His Pro Ser Asn Cys Leu Gln
100 105 110
atg ctg ccg ctg aat ttt ggt ggc gcg caa cgc gtt gac ggt ggc cgc 384
Met Leu Pro Leu Asn Phe Gly Gly Ala Gln Arg Val Asp Gly Gly Arg
115 120 125
atg ttg gac gcg gcg ggt aac gct gtc cag ggt ctg ttt ttt ggt caa 432
Met Leu Asp Ala Ala Gly Asn Ala Val Gln Gly Leu Phe Phe Gly Gln
130 135 140
tct agc ttc ggc acg tat gcg atc gcg cgt gag att aac gcc gtg aaa 480
Ser Ser Phe Gly Thr Tyr Ala Ile Ala Arg Glu Ile Asn Ala Val Lys
145 150 155 160
gtc gcc gaa gat ctg ccg ctg gaa atc ctg ggt ccg ctg ggt tgc ggt 528
Val Ala Glu Asp Leu Pro Leu Glu Ile Leu Gly Pro Leu Gly Cys Gly
165 170 175
att cag acc ggt gcg ggt gcg gcg att aac agc ctg ggt att ggt ccg 576
Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Gly Ile Gly Pro
180 185 190
ggt cag tcc ttg gct gtg ttc ggt ggc ggc ggc gtg ggt ctt agc gcg 624
Gly Gln Ser Leu Ala Val Phe Gly Gly Gly Gly Val Gly Leu Ser Ala
195 200 205
ttg ctg ggc gct cgt gct gtg ggt gcc gcc caa gtt gtt gtt gtt gag 672
Leu Leu Gly Ala Arg Ala Val Gly Ala Ala Gln Val Val Val Val Glu
210 215 220
ccg aac gcc gca cgt cgc gcg ctg gcg ctg gaa ctg ggt gcg agc cat 720
Pro Asn Ala Ala Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser His
225 230 235 240
gca ttc gac ccg ttt gcg ggt gac gac ctg gtc gcg gcg atc cgc gca 768
Ala Phe Asp Pro Phe Ala Gly Asp Asp Leu Val Ala Ala Ile Arg Ala
245 250 255
gcg acg ggt ggc ggc gca acc cac gcg ctg gat acg acc ggc ctg ccg 816
Ala Thr Gly Gly Gly Ala Thr His Ala Leu Asp Thr Thr Gly Leu Pro
260 265 270
tcg gtg att ggc aat gca atc gat tgt act ttg ccg ggt ggc acg gtt 864
Ser Val Ile Gly Asn Ala Ile Asp Cys Thr Leu Pro Gly Gly Thr Val
275 280 285
ggt atg gtc ggc atg cca gcg cct gac gct gcg gtc ccg gcg acc ctg 912
Gly Met Val Gly Met Pro Ala Pro Asp Ala Ala Val Pro Ala Thr Leu
290 295 300
ctg gat ttg ctg act aag agc gtc acg ctg cgt ccg atc acc gag ggt 960
Leu Asp Leu Leu Thr Lys Ser Val Thr Leu Arg Pro Ile Thr Glu Gly
305 310 315 320
gac gca gat ccg cag gcc ttc atc cca cag atg ctg cgc ttt tac cgt 1008
Asp Ala Asp Pro Gln Ala Phe Ile Pro Gln Met Leu Arg Phe Tyr Arg
325 330 335
gag ggt aag ttc ccg ttt gac cgt ctg att acc cgt tac cgt ttt gat 1056
Glu Gly Lys Phe Pro Phe Asp Arg Leu Ile Thr Arg Tyr Arg Phe Asp
340 345 350
cag atc aat gaa gct ctg cac gca acc gaa aag ggt ggc gcg att aaa 1104
Gln Ile Asn Glu Ala Leu His Ala Thr Glu Lys Gly Gly Ala Ile Lys
355 360 365
ccg gtt ctg gtg ttc taa 1122
Pro Val Leu Val Phe
370
<210> 52
<211> 373
<212> PRT
<213> 萜烯索氏菌(Thauera terpenica)
<400> 52
Met Cys Ser Asn His Asp Phe Thr Ala Ala Arg Ala Ala Val Leu Arg
1 5 10 15
Lys Val Gly Gly Pro Leu Glu Ile Glu Asp Val Arg Ile Ser Ala Pro
20 25 30
Lys Gly Asp Glu Val Leu Val Arg Met Val Gly Val Gly Val Cys His
35 40 45
Thr Asp Leu Val Cys Arg Asp Ala Phe Pro Val Pro Leu Pro Ile Val
50 55 60
Leu Gly His Glu Gly Ala Gly Ile Val Glu Ala Val Gly Glu Gly Val
65 70 75 80
Arg Ser Leu Glu Pro Gly Asp Arg Val Val Leu Ser Phe Asn Ser Cys
85 90 95
Gly Arg Cys Gly Asn Cys Gly Ser Gly His Pro Ser Asn Cys Leu Gln
100 105 110
Met Leu Pro Leu Asn Phe Gly Gly Ala Gln Arg Val Asp Gly Gly Arg
115 120 125
Met Leu Asp Ala Ala Gly Asn Ala Val Gln Gly Leu Phe Phe Gly Gln
130 135 140
Ser Ser Phe Gly Thr Tyr Ala Ile Ala Arg Glu Ile Asn Ala Val Lys
145 150 155 160
Val Ala Glu Asp Leu Pro Leu Glu Ile Leu Gly Pro Leu Gly Cys Gly
165 170 175
Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Gly Ile Gly Pro
180 185 190
Gly Gln Ser Leu Ala Val Phe Gly Gly Gly Gly Val Gly Leu Ser Ala
195 200 205
Leu Leu Gly Ala Arg Ala Val Gly Ala Ala Gln Val Val Val Val Glu
210 215 220
Pro Asn Ala Ala Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser His
225 230 235 240
Ala Phe Asp Pro Phe Ala Gly Asp Asp Leu Val Ala Ala Ile Arg Ala
245 250 255
Ala Thr Gly Gly Gly Ala Thr His Ala Leu Asp Thr Thr Gly Leu Pro
260 265 270
Ser Val Ile Gly Asn Ala Ile Asp Cys Thr Leu Pro Gly Gly Thr Val
275 280 285
Gly Met Val Gly Met Pro Ala Pro Asp Ala Ala Val Pro Ala Thr Leu
290 295 300
Leu Asp Leu Leu Thr Lys Ser Val Thr Leu Arg Pro Ile Thr Glu Gly
305 310 315 320
Asp Ala Asp Pro Gln Ala Phe Ile Pro Gln Met Leu Arg Phe Tyr Arg
325 330 335
Glu Gly Lys Phe Pro Phe Asp Arg Leu Ile Thr Arg Tyr Arg Phe Asp
340 345 350
Gln Ile Asn Glu Ala Leu His Ala Thr Glu Lys Gly Gly Ala Ile Lys
355 360 365
Pro Val Leu Val Phe
370
<210> 53
<211> 1122
<212> DNA
<213> 解芳烃卡斯特罗尼氏菌(Castellaniella defragrans)
<220>
<221> CDS
<222> (1)..(1122)
<400> 53
atg aac gat acg cag gat ttt att agc gcc caa gcc gca gtg tta cgt 48
Met Asn Asp Thr Gln Asp Phe Ile Ser Ala Gln Ala Ala Val Leu Arg
1 5 10 15
cag gtc ggt ggc ccg ctg gcc gtt gag cct gtt cgt atc agc atg ccg 96
Gln Val Gly Gly Pro Leu Ala Val Glu Pro Val Arg Ile Ser Met Pro
20 25 30
aag ggt gac gaa gtc ctg att cgt atc gcg ggt gtt ggt gtg tgc cac 144
Lys Gly Asp Glu Val Leu Ile Arg Ile Ala Gly Val Gly Val Cys His
35 40 45
acc gac ttg gtg tgc cgt gat ggc ttc ccg gtg ccg ctg cca att gtg 192
Thr Asp Leu Val Cys Arg Asp Gly Phe Pro Val Pro Leu Pro Ile Val
50 55 60
ctg ggt cac gag ggt agc ggt act gtc gaa gcc gtc ggt gaa caa gtc 240
Leu Gly His Glu Gly Ser Gly Thr Val Glu Ala Val Gly Glu Gln Val
65 70 75 80
cgt acc ctg aaa ccg ggc gat cgc gtc gtg ctg agc ttt aac agc tgc 288
Arg Thr Leu Lys Pro Gly Asp Arg Val Val Leu Ser Phe Asn Ser Cys
85 90 95
ggt cat tgc ggt aac tgt cac gac ggt cac ccg agc aat tgc ctg cag 336
Gly His Cys Gly Asn Cys His Asp Gly His Pro Ser Asn Cys Leu Gln
100 105 110
atg ctg ccg ctg aac ttc ggt ggc gcg caa cgc gtg gac ggt ggc caa 384
Met Leu Pro Leu Asn Phe Gly Gly Ala Gln Arg Val Asp Gly Gly Gln
115 120 125
gtt ttg gac ggt gcg ggt cat ccg gtt cag tcc atg ttt ttc ggc cag 432
Val Leu Asp Gly Ala Gly His Pro Val Gln Ser Met Phe Phe Gly Gln
130 135 140
tcc agc ttt ggc acc cac gca gta gcg cgc gag atc aac gca gtc aag 480
Ser Ser Phe Gly Thr His Ala Val Ala Arg Glu Ile Asn Ala Val Lys
145 150 155 160
gtc ggc gat gat ctg cca ctg gaa ctg ctg ggt ccg ttg ggt tgt ggc 528
Val Gly Asp Asp Leu Pro Leu Glu Leu Leu Gly Pro Leu Gly Cys Gly
165 170 175
att caa acc ggt gcg ggt gca gct atc aat tct ctg ggc att ggt ccg 576
Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Gly Ile Gly Pro
180 185 190
ggt cag tct ctg gct atc ttc ggc ggc ggc ggc gtg ggt ctg agc gca 624
Gly Gln Ser Leu Ala Ile Phe Gly Gly Gly Gly Val Gly Leu Ser Ala
195 200 205
ctg ctg ggc gcc cgt gcg gtg ggt gcc gac cgt gtt gtt gtc att gag 672
Leu Leu Gly Ala Arg Ala Val Gly Ala Asp Arg Val Val Val Ile Glu
210 215 220
ccg aat gca gcg cgc cgt gcg ctg gca ttg gaa ctg ggt gcc agc cac 720
Pro Asn Ala Ala Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser His
225 230 235 240
gca ctg gac ccg cat gcc gag ggc gac ctt gtt gcg gcg att aaa gct 768
Ala Leu Asp Pro His Ala Glu Gly Asp Leu Val Ala Ala Ile Lys Ala
245 250 255
gcg acg ggt ggc ggc gct acg cat agc ttg gat acg acc ggc ctg ccg 816
Ala Thr Gly Gly Gly Ala Thr His Ser Leu Asp Thr Thr Gly Leu Pro
260 265 270
cca gtc att ggc tcc gcg atc gcg tgt act ctg ccg ggt ggc acc gtt 864
Pro Val Ile Gly Ser Ala Ile Ala Cys Thr Leu Pro Gly Gly Thr Val
275 280 285
ggt atg gtt ggt ctg ccg gcg ccg gac gca ccg gtc cct gcg acg ctg 912
Gly Met Val Gly Leu Pro Ala Pro Asp Ala Pro Val Pro Ala Thr Leu
290 295 300
ttg gat ctg ctg agc aaa tcg gtt acc ctg cgt ccg att acc gag ggt 960
Leu Asp Leu Leu Ser Lys Ser Val Thr Leu Arg Pro Ile Thr Glu Gly
305 310 315 320
gac gct gac ccg caa cgc ttc atc ccg cgt atg ctg gat ttc cat cgt 1008
Asp Ala Asp Pro Gln Arg Phe Ile Pro Arg Met Leu Asp Phe His Arg
325 330 335
gcg ggc aag ttt ccg ttc gac cgc ctg atc acc cgt tac cgc ttt gat 1056
Ala Gly Lys Phe Pro Phe Asp Arg Leu Ile Thr Arg Tyr Arg Phe Asp
340 345 350
cag atc aat gaa gcg ctg cac gcg acc gag aaa ggt gaa gca atc aaa 1104
Gln Ile Asn Glu Ala Leu His Ala Thr Glu Lys Gly Glu Ala Ile Lys
355 360 365
ccg gtt ctg gtg ttt taa 1122
Pro Val Leu Val Phe
370
<210> 54
<211> 373
<212> PRT
<213> 解芳烃卡斯特罗尼氏菌(Castellaniella defragrans)
<400> 54
Met Asn Asp Thr Gln Asp Phe Ile Ser Ala Gln Ala Ala Val Leu Arg
1 5 10 15
Gln Val Gly Gly Pro Leu Ala Val Glu Pro Val Arg Ile Ser Met Pro
20 25 30
Lys Gly Asp Glu Val Leu Ile Arg Ile Ala Gly Val Gly Val Cys His
35 40 45
Thr Asp Leu Val Cys Arg Asp Gly Phe Pro Val Pro Leu Pro Ile Val
50 55 60
Leu Gly His Glu Gly Ser Gly Thr Val Glu Ala Val Gly Glu Gln Val
65 70 75 80
Arg Thr Leu Lys Pro Gly Asp Arg Val Val Leu Ser Phe Asn Ser Cys
85 90 95
Gly His Cys Gly Asn Cys His Asp Gly His Pro Ser Asn Cys Leu Gln
100 105 110
Met Leu Pro Leu Asn Phe Gly Gly Ala Gln Arg Val Asp Gly Gly Gln
115 120 125
Val Leu Asp Gly Ala Gly His Pro Val Gln Ser Met Phe Phe Gly Gln
130 135 140
Ser Ser Phe Gly Thr His Ala Val Ala Arg Glu Ile Asn Ala Val Lys
145 150 155 160
Val Gly Asp Asp Leu Pro Leu Glu Leu Leu Gly Pro Leu Gly Cys Gly
165 170 175
Ile Gln Thr Gly Ala Gly Ala Ala Ile Asn Ser Leu Gly Ile Gly Pro
180 185 190
Gly Gln Ser Leu Ala Ile Phe Gly Gly Gly Gly Val Gly Leu Ser Ala
195 200 205
Leu Leu Gly Ala Arg Ala Val Gly Ala Asp Arg Val Val Val Ile Glu
210 215 220
Pro Asn Ala Ala Arg Arg Ala Leu Ala Leu Glu Leu Gly Ala Ser His
225 230 235 240
Ala Leu Asp Pro His Ala Glu Gly Asp Leu Val Ala Ala Ile Lys Ala
245 250 255
Ala Thr Gly Gly Gly Ala Thr His Ser Leu Asp Thr Thr Gly Leu Pro
260 265 270
Pro Val Ile Gly Ser Ala Ile Ala Cys Thr Leu Pro Gly Gly Thr Val
275 280 285
Gly Met Val Gly Leu Pro Ala Pro Asp Ala Pro Val Pro Ala Thr Leu
290 295 300
Leu Asp Leu Leu Ser Lys Ser Val Thr Leu Arg Pro Ile Thr Glu Gly
305 310 315 320
Asp Ala Asp Pro Gln Arg Phe Ile Pro Arg Met Leu Asp Phe His Arg
325 330 335
Ala Gly Lys Phe Pro Phe Asp Arg Leu Ile Thr Arg Tyr Arg Phe Asp
340 345 350
Gln Ile Asn Glu Ala Leu His Ala Thr Glu Lys Gly Glu Ala Ile Lys
355 360 365
Pro Val Leu Val Phe
370
<210> 55
<211> 1146
<212> DNA
<213> 缬草(Valeriana officinalis)
<220>
<221> CDS
<222> (1)..(1146)
<400> 55
atg act aaa tcc agc ggt gaa gtg att tct tgt aag gca gca gtg atc 48
Met Thr Lys Ser Ser Gly Glu Val Ile Ser Cys Lys Ala Ala Val Ile
1 5 10 15
tat aag agc ggt gag cct gct aaa gtt gaa gaa att cgt gtt gat ccg 96
Tyr Lys Ser Gly Glu Pro Ala Lys Val Glu Glu Ile Arg Val Asp Pro
20 25 30
cct aag agc agc gaa gtt cgt att aag atg ctg tac gcc tcc ttg tgt 144
Pro Lys Ser Ser Glu Val Arg Ile Lys Met Leu Tyr Ala Ser Leu Cys
35 40 45
cac acg gac att ctg tgt tgc aac ggc ctg ccg gtg ccg ctg ttt ccg 192
His Thr Asp Ile Leu Cys Cys Asn Gly Leu Pro Val Pro Leu Phe Pro
50 55 60
cgc att ccg ggt cac gag ggc gtg ggt gtt gtg gag agc gcg ggt gaa 240
Arg Ile Pro Gly His Glu Gly Val Gly Val Val Glu Ser Ala Gly Glu
65 70 75 80
gat gtg aaa gat gtt aaa gag ggc gac atc gtt atg cca ctg tac ctg 288
Asp Val Lys Asp Val Lys Glu Gly Asp Ile Val Met Pro Leu Tyr Leu
85 90 95
ggc gag tgt ggt gag tgc ctc aat tgc agc agc ggt aag acg aat ctg 336
Gly Glu Cys Gly Glu Cys Leu Asn Cys Ser Ser Gly Lys Thr Asn Leu
100 105 110
tgc cac aag tac cca ctg gac ttc tct ggt gtg ctg ccg agc gac ggt 384
Cys His Lys Tyr Pro Leu Asp Phe Ser Gly Val Leu Pro Ser Asp Gly
115 120 125
acg agc cgc atg tca gta gca aaa tcc ggt gag aaa att ttc cat cac 432
Thr Ser Arg Met Ser Val Ala Lys Ser Gly Glu Lys Ile Phe His His
130 135 140
ttc agc tgt agc acc tgg tcc gaa tat gtt gtc atc gag agc tcg tat 480
Phe Ser Cys Ser Thr Trp Ser Glu Tyr Val Val Ile Glu Ser Ser Tyr
145 150 155 160
gtc gtc aaa gtt gat agc cgt ctg ccg ctg ccg cat gcg tcc ttt ctg 528
Val Val Lys Val Asp Ser Arg Leu Pro Leu Pro His Ala Ser Phe Leu
165 170 175
gca tgc ggc ttc acc acg ggt tac ggc gcg gcg tgg aaa gag gct gac 576
Ala Cys Gly Phe Thr Thr Gly Tyr Gly Ala Ala Trp Lys Glu Ala Asp
180 185 190
att ccg aag ggc agc acc gtc gcg gtg ctg ggc ctg ggt gcg gtc ggt 624
Ile Pro Lys Gly Ser Thr Val Ala Val Leu Gly Leu Gly Ala Val Gly
195 200 205
ctg ggt gtg gtt gct ggt gcg cgt tct cag ggt gcg agc cgc att att 672
Leu Gly Val Val Ala Gly Ala Arg Ser Gln Gly Ala Ser Arg Ile Ile
210 215 220
ggc gtg gac atc aac gac aag aaa aaa gca aaa gcc gag atc ttt ggt 720
Gly Val Asp Ile Asn Asp Lys Lys Lys Ala Lys Ala Glu Ile Phe Gly
225 230 235 240
gtt act gag ttt ctg aat ccg aag caa ctg ggt aaa agc gcg agc gaa 768
Val Thr Glu Phe Leu Asn Pro Lys Gln Leu Gly Lys Ser Ala Ser Glu
245 250 255
agc atc aaa gac gtc acc ggc ggc ctg ggc gtt gac tac tgt ttc gag 816
Ser Ile Lys Asp Val Thr Gly Gly Leu Gly Val Asp Tyr Cys Phe Glu
260 265 270
tgc acc ggt gtc ccg gcc ctg ttg aac gaa gcc gtg gat gcg agc aag 864
Cys Thr Gly Val Pro Ala Leu Leu Asn Glu Ala Val Asp Ala Ser Lys
275 280 285
atc ggc ttg ggt acg atc gtc atg att ggt gcg ggt atg gaa acc agc 912
Ile Gly Leu Gly Thr Ile Val Met Ile Gly Ala Gly Met Glu Thr Ser
290 295 300
ggt gtt att aac tat atc ccg ctg ctg tgc ggc cgt aaa ctg atc ggt 960
Gly Val Ile Asn Tyr Ile Pro Leu Leu Cys Gly Arg Lys Leu Ile Gly
305 310 315 320
agc att tac ggt ggc gtt cgc atc cgt agc gac tta ccg ctg atc att 1008
Ser Ile Tyr Gly Gly Val Arg Ile Arg Ser Asp Leu Pro Leu Ile Ile
325 330 335
gag aaa tgc atc aac aaa gaa att ccg ctg aac gaa ctg cag acc cac 1056
Glu Lys Cys Ile Asn Lys Glu Ile Pro Leu Asn Glu Leu Gln Thr His
340 345 350
gaa gtg agc ttg gaa ggc att aat gat gca ttc ggc atg ctg aag caa 1104
Glu Val Ser Leu Glu Gly Ile Asn Asp Ala Phe Gly Met Leu Lys Gln
355 360 365
ccg gac tgc gtt aag atc gtc atc aag ttc gag cag aaa taa 1146
Pro Asp Cys Val Lys Ile Val Ile Lys Phe Glu Gln Lys
370 375 380
<210> 56
<211> 381
<212> PRT
<213> 缬草(Valeriana officinalis)
<400> 56
Met Thr Lys Ser Ser Gly Glu Val Ile Ser Cys Lys Ala Ala Val Ile
1 5 10 15
Tyr Lys Ser Gly Glu Pro Ala Lys Val Glu Glu Ile Arg Val Asp Pro
20 25 30
Pro Lys Ser Ser Glu Val Arg Ile Lys Met Leu Tyr Ala Ser Leu Cys
35 40 45
His Thr Asp Ile Leu Cys Cys Asn Gly Leu Pro Val Pro Leu Phe Pro
50 55 60
Arg Ile Pro Gly His Glu Gly Val Gly Val Val Glu Ser Ala Gly Glu
65 70 75 80
Asp Val Lys Asp Val Lys Glu Gly Asp Ile Val Met Pro Leu Tyr Leu
85 90 95
Gly Glu Cys Gly Glu Cys Leu Asn Cys Ser Ser Gly Lys Thr Asn Leu
100 105 110
Cys His Lys Tyr Pro Leu Asp Phe Ser Gly Val Leu Pro Ser Asp Gly
115 120 125
Thr Ser Arg Met Ser Val Ala Lys Ser Gly Glu Lys Ile Phe His His
130 135 140
Phe Ser Cys Ser Thr Trp Ser Glu Tyr Val Val Ile Glu Ser Ser Tyr
145 150 155 160
Val Val Lys Val Asp Ser Arg Leu Pro Leu Pro His Ala Ser Phe Leu
165 170 175
Ala Cys Gly Phe Thr Thr Gly Tyr Gly Ala Ala Trp Lys Glu Ala Asp
180 185 190
Ile Pro Lys Gly Ser Thr Val Ala Val Leu Gly Leu Gly Ala Val Gly
195 200 205
Leu Gly Val Val Ala Gly Ala Arg Ser Gln Gly Ala Ser Arg Ile Ile
210 215 220
Gly Val Asp Ile Asn Asp Lys Lys Lys Ala Lys Ala Glu Ile Phe Gly
225 230 235 240
Val Thr Glu Phe Leu Asn Pro Lys Gln Leu Gly Lys Ser Ala Ser Glu
245 250 255
Ser Ile Lys Asp Val Thr Gly Gly Leu Gly Val Asp Tyr Cys Phe Glu
260 265 270
Cys Thr Gly Val Pro Ala Leu Leu Asn Glu Ala Val Asp Ala Ser Lys
275 280 285
Ile Gly Leu Gly Thr Ile Val Met Ile Gly Ala Gly Met Glu Thr Ser
290 295 300
Gly Val Ile Asn Tyr Ile Pro Leu Leu Cys Gly Arg Lys Leu Ile Gly
305 310 315 320
Ser Ile Tyr Gly Gly Val Arg Ile Arg Ser Asp Leu Pro Leu Ile Ile
325 330 335
Glu Lys Cys Ile Asn Lys Glu Ile Pro Leu Asn Glu Leu Gln Thr His
340 345 350
Glu Val Ser Leu Glu Gly Ile Asn Asp Ala Phe Gly Met Leu Lys Gln
355 360 365
Pro Asp Cys Val Lys Ile Val Ile Lys Phe Glu Gln Lys
370 375 380
<210> 57
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 活性位点签名基序
<220>
<221> MISC_FEATURE
<222> (3)..(4)
<223> Xaa彼此独立地代表任何天然氨基酸残基
<220>
<221> MISC_FEATURE
<222> (6)..(7)
<223> Xaa彼此独立地代表任何天然氨基酸残基
<400> 57
His Cys Xaa Xaa Gly Xaa Xaa Arg
1 5
<210> 58
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 活性位点签名基序
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> Xaa代表T或S
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Xaa代表任何天然氨基酸残基
<400> 58
His Cys Xaa Xaa Gly Lys Asp Arg Thr Gly
1 5 10
<210> 59
<211> 2892
<212> DNA
<213> 细疣篮状菌(Talaromyces ferruculosus)
<220>
<221> CDS
<222> (1)..(2892)
<400> 59
atg agc cct atg gat ttg caa gaa agc gcc gca gcc ctg gtc cgt caa 48
Met Ser Pro Met Asp Leu Gln Glu Ser Ala Ala Ala Leu Val Arg Gln
1 5 10 15
ttg ggt gaa cgc gtt gag gat cgc cgc ggt ttt ggt ttc atg agc ccg 96
Leu Gly Glu Arg Val Glu Asp Arg Arg Gly Phe Gly Phe Met Ser Pro
20 25 30
gcc att tat gac acg gcc tgg gtt agc atg att agc aag acc atc gac 144
Ala Ile Tyr Asp Thr Ala Trp Val Ser Met Ile Ser Lys Thr Ile Asp
35 40 45
gac caa aaa act tgg ctg ttt gcg gag tgc ttc cag tac att ctg tct 192
Asp Gln Lys Thr Trp Leu Phe Ala Glu Cys Phe Gln Tyr Ile Leu Ser
50 55 60
cac caa ctg gaa gat ggt ggc tgg gcg atg tac gca tcc gaa atc gat 240
His Gln Leu Glu Asp Gly Gly Trp Ala Met Tyr Ala Ser Glu Ile Asp
65 70 75 80
gcc atc ttg aat act tcc gcg tca ctg ctg tcc ctg aaa cgc cac ctg 288
Ala Ile Leu Asn Thr Ser Ala Ser Leu Leu Ser Leu Lys Arg His Leu
85 90 95
tcc aac cct tac cag atc acc agc atc act cag gaa gat ctg agc gct 336
Ser Asn Pro Tyr Gln Ile Thr Ser Ile Thr Gln Glu Asp Leu Ser Ala
100 105 110
cgc atc aac cgc gct caa aac gcc ctg cag aaa ttg ctg aac gag tgg 384
Arg Ile Asn Arg Ala Gln Asn Ala Leu Gln Lys Leu Leu Asn Glu Trp
115 120 125
aac gtt gac tcc acg ctg cac gtc ggt ttc gag att ctg gtt ccg gcg 432
Asn Val Asp Ser Thr Leu His Val Gly Phe Glu Ile Leu Val Pro Ala
130 135 140
ctg ctg cgc tat ctg gaa gat gaa ggc atc gcg ttt gcg ttc tcg ggt 480
Leu Leu Arg Tyr Leu Glu Asp Glu Gly Ile Ala Phe Ala Phe Ser Gly
145 150 155 160
cgt gag cgt ttg tta gag att gag aaa caa aaa ctg tcc aag ttt aaa 528
Arg Glu Arg Leu Leu Glu Ile Glu Lys Gln Lys Leu Ser Lys Phe Lys
165 170 175
gcg cag tat ttg tac tta ccg att aag gtc acc gca ctg cat agc ctg 576
Ala Gln Tyr Leu Tyr Leu Pro Ile Lys Val Thr Ala Leu His Ser Leu
180 185 190
gaa gcc ttc atc ggc gct att gag ttc gac aaa gtc agc cat cac aaa 624
Glu Ala Phe Ile Gly Ala Ile Glu Phe Asp Lys Val Ser His His Lys
195 200 205
gta tcc ggt gct ttc atg gcg tcg ccg tct agc acc gca gca tac atg 672
Val Ser Gly Ala Phe Met Ala Ser Pro Ser Ser Thr Ala Ala Tyr Met
210 215 220
atg cat gcg acg caa tgg gat gac gaa tgt gag gat tac ttg cgt cac 720
Met His Ala Thr Gln Trp Asp Asp Glu Cys Glu Asp Tyr Leu Arg His
225 230 235 240
gtg atc gcg cat gcg tca ggt aag ggt tct ggc ggc gtg ccg agc gcc 768
Val Ile Ala His Ala Ser Gly Lys Gly Ser Gly Gly Val Pro Ser Ala
245 250 255
ttt ccg agc acc atc ttc gag agc gtt tgg ccg ctg tct act ctg ctg 816
Phe Pro Ser Thr Ile Phe Glu Ser Val Trp Pro Leu Ser Thr Leu Leu
260 265 270
aaa gtt ggc tat gat ctg aat agc gct ccg ttc atc gag aaa att cgt 864
Lys Val Gly Tyr Asp Leu Asn Ser Ala Pro Phe Ile Glu Lys Ile Arg
275 280 285
agc tac ttg cac gat gcc tat atc gca gag aaa ggt att ctc ggt ttc 912
Ser Tyr Leu His Asp Ala Tyr Ile Ala Glu Lys Gly Ile Leu Gly Phe
290 295 300
acc ccg ttc gtt ggc gct gac gcg gac gac acc gct acc acg att ctg 960
Thr Pro Phe Val Gly Ala Asp Ala Asp Asp Thr Ala Thr Thr Ile Leu
305 310 315 320
gtg ttg aat ctg ctg aac caa ccg gtg agc gtg gac gcg atg ttg aaa 1008
Val Leu Asn Leu Leu Asn Gln Pro Val Ser Val Asp Ala Met Leu Lys
325 330 335
gaa ttt gaa gag gaa cat cac ttc aag acc tac agc caa gag cgt aat 1056
Glu Phe Glu Glu Glu His His Phe Lys Thr Tyr Ser Gln Glu Arg Asn
340 345 350
ccg agc ttt tcc gca aac tgt aat gtt ctg ctg gcg ctg ctg tac agc 1104
Pro Ser Phe Ser Ala Asn Cys Asn Val Leu Leu Ala Leu Leu Tyr Ser
355 360 365
cag gaa ccg agc ctg tac agc gcg caa atc gaa aaa gcg atc cgt ttt 1152
Gln Glu Pro Ser Leu Tyr Ser Ala Gln Ile Glu Lys Ala Ile Arg Phe
370 375 380
ctg tat aag caa ttc acc gac tct gag atg gat gtg cgc gat aaa tgg 1200
Leu Tyr Lys Gln Phe Thr Asp Ser Glu Met Asp Val Arg Asp Lys Trp
385 390 395 400
aac ctg tcc ccg tat tat agc tgg atg ctg atg acc cag gcc atc acc 1248
Asn Leu Ser Pro Tyr Tyr Ser Trp Met Leu Met Thr Gln Ala Ile Thr
405 410 415
cgt ctg acg acc ctg caa aag acc agc aag ctg agc acg ctg cgt gat 1296
Arg Leu Thr Thr Leu Gln Lys Thr Ser Lys Leu Ser Thr Leu Arg Asp
420 425 430
gac agc att agc aag ggc ctg att tct ctg ctg ttc cgc att gca tcc 1344
Asp Ser Ile Ser Lys Gly Leu Ile Ser Leu Leu Phe Arg Ile Ala Ser
435 440 445
acc gtg gtt aaa gat caa aaa ccg ggt ggc agc tgg ggc acg cgt gcg 1392
Thr Val Val Lys Asp Gln Lys Pro Gly Gly Ser Trp Gly Thr Arg Ala
450 455 460
agc aaa gaa gaa acg gca tac gcc gtg ctg att ctg acc tac gcg ttt 1440
Ser Lys Glu Glu Thr Ala Tyr Ala Val Leu Ile Leu Thr Tyr Ala Phe
465 470 475 480
tat ctg gac gag gtg acc gag tct ctg cgc cac gat atc aaa att gca 1488
Tyr Leu Asp Glu Val Thr Glu Ser Leu Arg His Asp Ile Lys Ile Ala
485 490 495
atc gag aat ggt tgc tcg ttc ctg agc gag cgc acc atg caa agc gac 1536
Ile Glu Asn Gly Cys Ser Phe Leu Ser Glu Arg Thr Met Gln Ser Asp
500 505 510
agc gag tgg ctg tgg gtc gaa aag gtt acc tac aag agc gaa gtg ctg 1584
Ser Glu Trp Leu Trp Val Glu Lys Val Thr Tyr Lys Ser Glu Val Leu
515 520 525
agc gaa gca tac atc ctg gca gct ctg aaa cgt gcg gca gac ttg ccg 1632
Ser Glu Ala Tyr Ile Leu Ala Ala Leu Lys Arg Ala Ala Asp Leu Pro
530 535 540
gat gag aac gct gag gca gcc cca gtg atc aac ggt atc tct acc aat 1680
Asp Glu Asn Ala Glu Ala Ala Pro Val Ile Asn Gly Ile Ser Thr Asn
545 550 555 560
ggc ttt gag cac acc gac cgc att aat ggt aaa ctc aag gtc aat ggt 1728
Gly Phe Glu His Thr Asp Arg Ile Asn Gly Lys Leu Lys Val Asn Gly
565 570 575
acg aat ggc acc aac ggt tcc cac gaa acg aac ggt atc aat ggc acc 1776
Thr Asn Gly Thr Asn Gly Ser His Glu Thr Asn Gly Ile Asn Gly Thr
580 585 590
cat gag att gag caa att aat ggt gtc aac ggc acg aat ggc cat agc 1824
His Glu Ile Glu Gln Ile Asn Gly Val Asn Gly Thr Asn Gly His Ser
595 600 605
gac gtg cca cat gac acg aat ggt tgg gtc gag gaa ccg acg gcg att 1872
Asp Val Pro His Asp Thr Asn Gly Trp Val Glu Glu Pro Thr Ala Ile
610 615 620
aat gaa acg aac ggt cac tac gtt aac ggc acc aac cat gag act ccg 1920
Asn Glu Thr Asn Gly His Tyr Val Asn Gly Thr Asn His Glu Thr Pro
625 630 635 640
ctg acc aat ggt att agc aat ggt gac tcc gtg agc gtt cac acc gac 1968
Leu Thr Asn Gly Ile Ser Asn Gly Asp Ser Val Ser Val His Thr Asp
645 650 655
cat agc gac agc tac tat cag cgt agc gac tgg acc gcg gat gaa gaa 2016
His Ser Asp Ser Tyr Tyr Gln Arg Ser Asp Trp Thr Ala Asp Glu Glu
660 665 670
cag atc ctg ctg ggt cca ttc gat tac ctg gaa tcc ctg cct ggt aaa 2064
Gln Ile Leu Leu Gly Pro Phe Asp Tyr Leu Glu Ser Leu Pro Gly Lys
675 680 685
aat atg cgc agc cag ctg atc cag tct ttc aat acg tgg ctg aag gtc 2112
Asn Met Arg Ser Gln Leu Ile Gln Ser Phe Asn Thr Trp Leu Lys Val
690 695 700
ccg acc gag agc ttg gac gtg att att aag gtc att agc atg ctg cac 2160
Pro Thr Glu Ser Leu Asp Val Ile Ile Lys Val Ile Ser Met Leu His
705 710 715 720
act gct agc ctg ctg atc gac gat att cag gac caa agc atc ctg cgt 2208
Thr Ala Ser Leu Leu Ile Asp Asp Ile Gln Asp Gln Ser Ile Leu Arg
725 730 735
cgt ggt cag cct gtg gcg cac tcg atc ttc ggc acc gcg caa gcg atg 2256
Arg Gly Gln Pro Val Ala His Ser Ile Phe Gly Thr Ala Gln Ala Met
740 745 750
aac tct ggt aac tat gtt tac ttc ctg gca ttg cgt gaa gtt cag aaa 2304
Asn Ser Gly Asn Tyr Val Tyr Phe Leu Ala Leu Arg Glu Val Gln Lys
755 760 765
ttg caa aac ccg aag gct atc agc att tat gtg gac agc ttg atc gat 2352
Leu Gln Asn Pro Lys Ala Ile Ser Ile Tyr Val Asp Ser Leu Ile Asp
770 775 780
ctt cat cgc ggc cag ggc atg gaa ctg ttc tgg cgt gat tct ctg atg 2400
Leu His Arg Gly Gln Gly Met Glu Leu Phe Trp Arg Asp Ser Leu Met
785 790 795 800
tgc ccg act gaa gaa cag tat ctg gac atg gtg gcg aac aag acc ggt 2448
Cys Pro Thr Glu Glu Gln Tyr Leu Asp Met Val Ala Asn Lys Thr Gly
805 810 815
ggc ctg ttt tgt ctg gcg att cag ctg atg cag gca gaa gcg acc att 2496
Gly Leu Phe Cys Leu Ala Ile Gln Leu Met Gln Ala Glu Ala Thr Ile
820 825 830
cag gtt gat ttt att ccg ctg gtg cgt ctg ctg ggt atc att ttc cag 2544
Gln Val Asp Phe Ile Pro Leu Val Arg Leu Leu Gly Ile Ile Phe Gln
835 840 845
att tgc gac gac tac ctg aac ttg aaa agc act gcg tat acc gac aac 2592
Ile Cys Asp Asp Tyr Leu Asn Leu Lys Ser Thr Ala Tyr Thr Asp Asn
850 855 860
aaa ggt ctg tgt gaa gat ctt acc gag ggt aaa ttc tcc ttc ccg atc 2640
Lys Gly Leu Cys Glu Asp Leu Thr Glu Gly Lys Phe Ser Phe Pro Ile
865 870 875 880
att cac agc atc cgt agc aat ccg ggc aat cgt cag ctg atc aat att 2688
Ile His Ser Ile Arg Ser Asn Pro Gly Asn Arg Gln Leu Ile Asn Ile
885 890 895
ctg aag caa aaa ccg cgc gaa gat gac atc aag cgt tac gca ctg tcc 2736
Leu Lys Gln Lys Pro Arg Glu Asp Asp Ile Lys Arg Tyr Ala Leu Ser
900 905 910
tat atg gag agc acg aat agc ttc gag tac acc cgt ggc gtc gtc cgt 2784
Tyr Met Glu Ser Thr Asn Ser Phe Glu Tyr Thr Arg Gly Val Val Arg
915 920 925
aaa ttg aaa acc gaa gca att gac acg att caa ggt ctg gag aag cat 2832
Lys Leu Lys Thr Glu Ala Ile Asp Thr Ile Gln Gly Leu Glu Lys His
930 935 940
ggc ctg gaa gaa aac att ggt att cgt aag att ctg gcg cgt atg agc 2880
Gly Leu Glu Glu Asn Ile Gly Ile Arg Lys Ile Leu Ala Arg Met Ser
945 950 955 960
ctg gaa ctg taa 2892
Leu Glu Leu
<210> 60
<211> 963
<212> PRT
<213> 细疣篮状菌(Talaromyces ferruculosus)
<400> 60
Met Ser Pro Met Asp Leu Gln Glu Ser Ala Ala Ala Leu Val Arg Gln
1 5 10 15
Leu Gly Glu Arg Val Glu Asp Arg Arg Gly Phe Gly Phe Met Ser Pro
20 25 30
Ala Ile Tyr Asp Thr Ala Trp Val Ser Met Ile Ser Lys Thr Ile Asp
35 40 45
Asp Gln Lys Thr Trp Leu Phe Ala Glu Cys Phe Gln Tyr Ile Leu Ser
50 55 60
His Gln Leu Glu Asp Gly Gly Trp Ala Met Tyr Ala Ser Glu Ile Asp
65 70 75 80
Ala Ile Leu Asn Thr Ser Ala Ser Leu Leu Ser Leu Lys Arg His Leu
85 90 95
Ser Asn Pro Tyr Gln Ile Thr Ser Ile Thr Gln Glu Asp Leu Ser Ala
100 105 110
Arg Ile Asn Arg Ala Gln Asn Ala Leu Gln Lys Leu Leu Asn Glu Trp
115 120 125
Asn Val Asp Ser Thr Leu His Val Gly Phe Glu Ile Leu Val Pro Ala
130 135 140
Leu Leu Arg Tyr Leu Glu Asp Glu Gly Ile Ala Phe Ala Phe Ser Gly
145 150 155 160
Arg Glu Arg Leu Leu Glu Ile Glu Lys Gln Lys Leu Ser Lys Phe Lys
165 170 175
Ala Gln Tyr Leu Tyr Leu Pro Ile Lys Val Thr Ala Leu His Ser Leu
180 185 190
Glu Ala Phe Ile Gly Ala Ile Glu Phe Asp Lys Val Ser His His Lys
195 200 205
Val Ser Gly Ala Phe Met Ala Ser Pro Ser Ser Thr Ala Ala Tyr Met
210 215 220
Met His Ala Thr Gln Trp Asp Asp Glu Cys Glu Asp Tyr Leu Arg His
225 230 235 240
Val Ile Ala His Ala Ser Gly Lys Gly Ser Gly Gly Val Pro Ser Ala
245 250 255
Phe Pro Ser Thr Ile Phe Glu Ser Val Trp Pro Leu Ser Thr Leu Leu
260 265 270
Lys Val Gly Tyr Asp Leu Asn Ser Ala Pro Phe Ile Glu Lys Ile Arg
275 280 285
Ser Tyr Leu His Asp Ala Tyr Ile Ala Glu Lys Gly Ile Leu Gly Phe
290 295 300
Thr Pro Phe Val Gly Ala Asp Ala Asp Asp Thr Ala Thr Thr Ile Leu
305 310 315 320
Val Leu Asn Leu Leu Asn Gln Pro Val Ser Val Asp Ala Met Leu Lys
325 330 335
Glu Phe Glu Glu Glu His His Phe Lys Thr Tyr Ser Gln Glu Arg Asn
340 345 350
Pro Ser Phe Ser Ala Asn Cys Asn Val Leu Leu Ala Leu Leu Tyr Ser
355 360 365
Gln Glu Pro Ser Leu Tyr Ser Ala Gln Ile Glu Lys Ala Ile Arg Phe
370 375 380
Leu Tyr Lys Gln Phe Thr Asp Ser Glu Met Asp Val Arg Asp Lys Trp
385 390 395 400
Asn Leu Ser Pro Tyr Tyr Ser Trp Met Leu Met Thr Gln Ala Ile Thr
405 410 415
Arg Leu Thr Thr Leu Gln Lys Thr Ser Lys Leu Ser Thr Leu Arg Asp
420 425 430
Asp Ser Ile Ser Lys Gly Leu Ile Ser Leu Leu Phe Arg Ile Ala Ser
435 440 445
Thr Val Val Lys Asp Gln Lys Pro Gly Gly Ser Trp Gly Thr Arg Ala
450 455 460
Ser Lys Glu Glu Thr Ala Tyr Ala Val Leu Ile Leu Thr Tyr Ala Phe
465 470 475 480
Tyr Leu Asp Glu Val Thr Glu Ser Leu Arg His Asp Ile Lys Ile Ala
485 490 495
Ile Glu Asn Gly Cys Ser Phe Leu Ser Glu Arg Thr Met Gln Ser Asp
500 505 510
Ser Glu Trp Leu Trp Val Glu Lys Val Thr Tyr Lys Ser Glu Val Leu
515 520 525
Ser Glu Ala Tyr Ile Leu Ala Ala Leu Lys Arg Ala Ala Asp Leu Pro
530 535 540
Asp Glu Asn Ala Glu Ala Ala Pro Val Ile Asn Gly Ile Ser Thr Asn
545 550 555 560
Gly Phe Glu His Thr Asp Arg Ile Asn Gly Lys Leu Lys Val Asn Gly
565 570 575
Thr Asn Gly Thr Asn Gly Ser His Glu Thr Asn Gly Ile Asn Gly Thr
580 585 590
His Glu Ile Glu Gln Ile Asn Gly Val Asn Gly Thr Asn Gly His Ser
595 600 605
Asp Val Pro His Asp Thr Asn Gly Trp Val Glu Glu Pro Thr Ala Ile
610 615 620
Asn Glu Thr Asn Gly His Tyr Val Asn Gly Thr Asn His Glu Thr Pro
625 630 635 640
Leu Thr Asn Gly Ile Ser Asn Gly Asp Ser Val Ser Val His Thr Asp
645 650 655
His Ser Asp Ser Tyr Tyr Gln Arg Ser Asp Trp Thr Ala Asp Glu Glu
660 665 670
Gln Ile Leu Leu Gly Pro Phe Asp Tyr Leu Glu Ser Leu Pro Gly Lys
675 680 685
Asn Met Arg Ser Gln Leu Ile Gln Ser Phe Asn Thr Trp Leu Lys Val
690 695 700
Pro Thr Glu Ser Leu Asp Val Ile Ile Lys Val Ile Ser Met Leu His
705 710 715 720
Thr Ala Ser Leu Leu Ile Asp Asp Ile Gln Asp Gln Ser Ile Leu Arg
725 730 735
Arg Gly Gln Pro Val Ala His Ser Ile Phe Gly Thr Ala Gln Ala Met
740 745 750
Asn Ser Gly Asn Tyr Val Tyr Phe Leu Ala Leu Arg Glu Val Gln Lys
755 760 765
Leu Gln Asn Pro Lys Ala Ile Ser Ile Tyr Val Asp Ser Leu Ile Asp
770 775 780
Leu His Arg Gly Gln Gly Met Glu Leu Phe Trp Arg Asp Ser Leu Met
785 790 795 800
Cys Pro Thr Glu Glu Gln Tyr Leu Asp Met Val Ala Asn Lys Thr Gly
805 810 815
Gly Leu Phe Cys Leu Ala Ile Gln Leu Met Gln Ala Glu Ala Thr Ile
820 825 830
Gln Val Asp Phe Ile Pro Leu Val Arg Leu Leu Gly Ile Ile Phe Gln
835 840 845
Ile Cys Asp Asp Tyr Leu Asn Leu Lys Ser Thr Ala Tyr Thr Asp Asn
850 855 860
Lys Gly Leu Cys Glu Asp Leu Thr Glu Gly Lys Phe Ser Phe Pro Ile
865 870 875 880
Ile His Ser Ile Arg Ser Asn Pro Gly Asn Arg Gln Leu Ile Asn Ile
885 890 895
Leu Lys Gln Lys Pro Arg Glu Asp Asp Ile Lys Arg Tyr Ala Leu Ser
900 905 910
Tyr Met Glu Ser Thr Asn Ser Phe Glu Tyr Thr Arg Gly Val Val Arg
915 920 925
Lys Leu Lys Thr Glu Ala Ile Asp Thr Ile Gln Gly Leu Glu Lys His
930 935 940
Gly Leu Glu Glu Asn Ile Gly Ile Arg Lys Ile Leu Ala Arg Met Ser
945 950 955 960
Leu Glu Leu
<210> 61
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> 核糖体结合位点
<400> 61
aaggaggtaa aaaa 14
<210> 62
<211> 924
<212> DNA
<213> 成团泛菌(Pantoea agglomerans)
<400> 62
atggtttctg gttctaaggc tggtgtttct ccacacagag aaatcgaagt tatgagacaa 60
tctatcgacg accacttggc tggtttgttg ccagaaactg actctcaaga catcgtttct 120
ttggctatga gagaaggtgt tatggctcca ggtaagagaa tcagaccatt gttgatgttg 180
ttggctgcta gagacttgag ataccaaggt tctatgccaa ctttgttgga cttggcttgt 240
gctgttgaat tgactcacac tgcttctttg atgttggacg acatgccatg tatggacaac 300
gctgaattga gaagaggtca accaactact cacaagaagt tcggtgaatc tgttgctatc 360
ttggcttctg ttggtttgtt gtctaaggct ttcggtttga tcgctgctac tggtgacttg 420
ccaggtgaaa gaagagctca agctgttaac gaattgtcta ctgctgttgg tgttcaaggt 480
ttggttttgg gtcaattcag agacttgaac gacgctgctt tggacagaac tccagacgct 540
atcttgtcta ctaaccactt gaagactggt atcttgttct ctgctatgtt gcaaatcgtt 600
gctatcgctt ctgcttcttc tccatctact agagaaactt tgcacgcttt cgctttggac 660
ttcggtcaag ctttccaatt gttggacgac ttgagagacg accacccaga aactggtaag 720
gacagaaaca aggacgctgg taagtctact ttggttaaca gattgggtgc tgacgctgct 780
agacaaaagt tgagagaaca catcgactct gctgacaagc acttgacttt cgcttgtcca 840
caaggtggtg ctatcagaca attcatgcac ttgtggttcg gtcaccactt ggctgactgg 900
tctccagtta tgaagatcgc ttaa 924
<210> 63
<211> 2211
<212> DNA
<213> 丹参(Salvia miltiorrhiza)
<220>
<221> CDS
<222> (1)..(2211)
<400> 63
atg gct act gtt gac gct cca caa gtt cac gac cac gac ggt act act 48
Met Ala Thr Val Asp Ala Pro Gln Val His Asp His Asp Gly Thr Thr
1 5 10 15
gtt cac caa ggt cac gac gct gtt aag aac atc gaa gac cca atc gaa 96
Val His Gln Gly His Asp Ala Val Lys Asn Ile Glu Asp Pro Ile Glu
20 25 30
tac atc aga act ttg ttg aga act act ggt gac ggt aga atc tct gtt 144
Tyr Ile Arg Thr Leu Leu Arg Thr Thr Gly Asp Gly Arg Ile Ser Val
35 40 45
tct cca tac gac act gct tgg gtt gct atg atc aag gac gtt gaa ggt 192
Ser Pro Tyr Asp Thr Ala Trp Val Ala Met Ile Lys Asp Val Glu Gly
50 55 60
aga gac ggt cca caa ttc cca tct tct ttg gaa tgg atc gtt caa aac 240
Arg Asp Gly Pro Gln Phe Pro Ser Ser Leu Glu Trp Ile Val Gln Asn
65 70 75 80
caa ttg gaa gac ggt tct tgg ggt gac caa aag ttg ttc tgt gtt tac 288
Gln Leu Glu Asp Gly Ser Trp Gly Asp Gln Lys Leu Phe Cys Val Tyr
85 90 95
gac aga ttg gtt aac act atc gct tgt gtt gtt gct ttg aga tct tgg 336
Asp Arg Leu Val Asn Thr Ile Ala Cys Val Val Ala Leu Arg Ser Trp
100 105 110
aac gtt cac gct cac aag gtt aag aga ggt gtt act tac atc aag gaa 384
Asn Val His Ala His Lys Val Lys Arg Gly Val Thr Tyr Ile Lys Glu
115 120 125
aac gtt gac aag ttg atg gaa ggt aac gaa gaa cac atg act tgt ggt 432
Asn Val Asp Lys Leu Met Glu Gly Asn Glu Glu His Met Thr Cys Gly
130 135 140
ttc gaa gtt gtt ttc cca gct ttg ttg caa aag gct aag tct ttg ggt 480
Phe Glu Val Val Phe Pro Ala Leu Leu Gln Lys Ala Lys Ser Leu Gly
145 150 155 160
atc gaa gac ttg cca tac gac tct cca gct gtt caa gaa gtt tac cac 528
Ile Glu Asp Leu Pro Tyr Asp Ser Pro Ala Val Gln Glu Val Tyr His
165 170 175
gtt aga gaa caa aag ttg aag aga atc cca ttg gaa atc atg cac aag 576
Val Arg Glu Gln Lys Leu Lys Arg Ile Pro Leu Glu Ile Met His Lys
180 185 190
atc cca act tct ttg ttg ttc tct ttg gaa ggt ttg gaa aac ttg gac 624
Ile Pro Thr Ser Leu Leu Phe Ser Leu Glu Gly Leu Glu Asn Leu Asp
195 200 205
tgg gac aag ttg ttg aag ttg caa tct gct gac ggt tct ttc ttg act 672
Trp Asp Lys Leu Leu Lys Leu Gln Ser Ala Asp Gly Ser Phe Leu Thr
210 215 220
tct cca tct tct act gct ttc gct ttc atg caa act aag gac gaa aag 720
Ser Pro Ser Ser Thr Ala Phe Ala Phe Met Gln Thr Lys Asp Glu Lys
225 230 235 240
tgt tac caa ttc atc aag aac act atc gac act ttc aac ggt ggt gct 768
Cys Tyr Gln Phe Ile Lys Asn Thr Ile Asp Thr Phe Asn Gly Gly Ala
245 250 255
cca cac act tac cca gtt gac gtt ttc ggt aga ttg tgg gct atc gac 816
Pro His Thr Tyr Pro Val Asp Val Phe Gly Arg Leu Trp Ala Ile Asp
260 265 270
aga ttg caa aga ttg ggt atc tct aga ttc ttc gaa cca gaa atc gct 864
Arg Leu Gln Arg Leu Gly Ile Ser Arg Phe Phe Glu Pro Glu Ile Ala
275 280 285
gac tgt ttg tct cac atc cac aag ttc tgg act gac aag ggt gtt ttc 912
Asp Cys Leu Ser His Ile His Lys Phe Trp Thr Asp Lys Gly Val Phe
290 295 300
tct ggt aga gaa tct gaa ttc tgt gac atc gac gac act tct atg ggt 960
Ser Gly Arg Glu Ser Glu Phe Cys Asp Ile Asp Asp Thr Ser Met Gly
305 310 315 320
atg aga ttg atg aga atg cac ggt tac gac gtt gac cca aac gtt ttg 1008
Met Arg Leu Met Arg Met His Gly Tyr Asp Val Asp Pro Asn Val Leu
325 330 335
aga aac ttc aag caa aag gac ggt aag ttc tct tgt tac ggt ggt caa 1056
Arg Asn Phe Lys Gln Lys Asp Gly Lys Phe Ser Cys Tyr Gly Gly Gln
340 345 350
atg atc gaa tct cca tct cca atc tac aac ttg tac aga gct tct caa 1104
Met Ile Glu Ser Pro Ser Pro Ile Tyr Asn Leu Tyr Arg Ala Ser Gln
355 360 365
ttg aga ttc cca ggt gaa gaa atc ttg gaa gac gct aag aga ttc gct 1152
Leu Arg Phe Pro Gly Glu Glu Ile Leu Glu Asp Ala Lys Arg Phe Ala
370 375 380
tac gac ttc ttg aag gaa aag ttg gct aac aac caa atc ttg gac aag 1200
Tyr Asp Phe Leu Lys Glu Lys Leu Ala Asn Asn Gln Ile Leu Asp Lys
385 390 395 400
tgg gtt atc tct aag cac ttg cca gac gaa atc aag ttg ggt ttg gaa 1248
Trp Val Ile Ser Lys His Leu Pro Asp Glu Ile Lys Leu Gly Leu Glu
405 410 415
atg cca tgg ttg gct act ttg cca aga gtt gaa gct aag tac tac atc 1296
Met Pro Trp Leu Ala Thr Leu Pro Arg Val Glu Ala Lys Tyr Tyr Ile
420 425 430
caa tac tac gct ggt tct ggt gac gtt tgg atc ggt aag act ttg tac 1344
Gln Tyr Tyr Ala Gly Ser Gly Asp Val Trp Ile Gly Lys Thr Leu Tyr
435 440 445
aga atg cca gaa atc tct aac gac act tac cac gac ttg gct aag act 1392
Arg Met Pro Glu Ile Ser Asn Asp Thr Tyr His Asp Leu Ala Lys Thr
450 455 460
gac ttc aag aga tgt caa gct aag cac caa ttc gaa tgg ttg tac atg 1440
Asp Phe Lys Arg Cys Gln Ala Lys His Gln Phe Glu Trp Leu Tyr Met
465 470 475 480
caa gaa tgg tac gaa tct tgt ggt atc gaa gaa ttc ggt atc tct aga 1488
Gln Glu Trp Tyr Glu Ser Cys Gly Ile Glu Glu Phe Gly Ile Ser Arg
485 490 495
aag gac ttg ttg ttg tct tac ttc ttg gct act gct tct atc ttc gaa 1536
Lys Asp Leu Leu Leu Ser Tyr Phe Leu Ala Thr Ala Ser Ile Phe Glu
500 505 510
ttg gaa aga act aac gaa aga atc gct tgg gct aag tct caa atc atc 1584
Leu Glu Arg Thr Asn Glu Arg Ile Ala Trp Ala Lys Ser Gln Ile Ile
515 520 525
gct aag atg atc act tct ttc ttc aac aag gaa act act tct gaa gaa 1632
Ala Lys Met Ile Thr Ser Phe Phe Asn Lys Glu Thr Thr Ser Glu Glu
530 535 540
gac aag aga gct ttg ttg aac gaa ttg ggt aac atc aac ggt ttg aac 1680
Asp Lys Arg Ala Leu Leu Asn Glu Leu Gly Asn Ile Asn Gly Leu Asn
545 550 555 560
gac act aac ggt gct ggt aga gaa ggt ggt gct ggt tct atc gct ttg 1728
Asp Thr Asn Gly Ala Gly Arg Glu Gly Gly Ala Gly Ser Ile Ala Leu
565 570 575
gct act ttg act caa ttc ttg gaa ggt ttc gac aga tac act aga cac 1776
Ala Thr Leu Thr Gln Phe Leu Glu Gly Phe Asp Arg Tyr Thr Arg His
580 585 590
caa ttg aag aac gct tgg tct gtt tgg ttg act caa ttg caa cac ggt 1824
Gln Leu Lys Asn Ala Trp Ser Val Trp Leu Thr Gln Leu Gln His Gly
595 600 605
gaa gct gac gac gct gaa ttg ttg act aac act ttg aac atc tgt gct 1872
Glu Ala Asp Asp Ala Glu Leu Leu Thr Asn Thr Leu Asn Ile Cys Ala
610 615 620
ggt cac atc gct ttc aga gaa gaa atc ttg gct cac aac gaa tac aag 1920
Gly His Ile Ala Phe Arg Glu Glu Ile Leu Ala His Asn Glu Tyr Lys
625 630 635 640
gct ttg tct aac ttg act tct aag atc tgt aga caa ttg tct ttc atc 1968
Ala Leu Ser Asn Leu Thr Ser Lys Ile Cys Arg Gln Leu Ser Phe Ile
645 650 655
caa tct gaa aag gaa atg ggt gtt gaa ggt gaa atc gct gct aag tct 2016
Gln Ser Glu Lys Glu Met Gly Val Glu Gly Glu Ile Ala Ala Lys Ser
660 665 670
tct atc aag aac aag gaa ttg gaa gaa gac atg caa atg ttg gtt aag 2064
Ser Ile Lys Asn Lys Glu Leu Glu Glu Asp Met Gln Met Leu Val Lys
675 680 685
ttg gtt ttg gaa aag tac ggt ggt atc gac aga aac atc aag aag gct 2112
Leu Val Leu Glu Lys Tyr Gly Gly Ile Asp Arg Asn Ile Lys Lys Ala
690 695 700
ttc ttg gct gtt gct aag act tac tac tac aga gct tac cac gct gct 2160
Phe Leu Ala Val Ala Lys Thr Tyr Tyr Tyr Arg Ala Tyr His Ala Ala
705 710 715 720
gac act atc gac act cac atg ttc aag gtt ttg ttc gaa cca gtt gct 2208
Asp Thr Ile Asp Thr His Met Phe Lys Val Leu Phe Glu Pro Val Ala
725 730 735
taa 2211
<210> 64
<211> 736
<212> PRT
<213> 丹参(Salvia miltiorrhiza)
<400> 64
Met Ala Thr Val Asp Ala Pro Gln Val His Asp His Asp Gly Thr Thr
1 5 10 15
Val His Gln Gly His Asp Ala Val Lys Asn Ile Glu Asp Pro Ile Glu
20 25 30
Tyr Ile Arg Thr Leu Leu Arg Thr Thr Gly Asp Gly Arg Ile Ser Val
35 40 45
Ser Pro Tyr Asp Thr Ala Trp Val Ala Met Ile Lys Asp Val Glu Gly
50 55 60
Arg Asp Gly Pro Gln Phe Pro Ser Ser Leu Glu Trp Ile Val Gln Asn
65 70 75 80
Gln Leu Glu Asp Gly Ser Trp Gly Asp Gln Lys Leu Phe Cys Val Tyr
85 90 95
Asp Arg Leu Val Asn Thr Ile Ala Cys Val Val Ala Leu Arg Ser Trp
100 105 110
Asn Val His Ala His Lys Val Lys Arg Gly Val Thr Tyr Ile Lys Glu
115 120 125
Asn Val Asp Lys Leu Met Glu Gly Asn Glu Glu His Met Thr Cys Gly
130 135 140
Phe Glu Val Val Phe Pro Ala Leu Leu Gln Lys Ala Lys Ser Leu Gly
145 150 155 160
Ile Glu Asp Leu Pro Tyr Asp Ser Pro Ala Val Gln Glu Val Tyr His
165 170 175
Val Arg Glu Gln Lys Leu Lys Arg Ile Pro Leu Glu Ile Met His Lys
180 185 190
Ile Pro Thr Ser Leu Leu Phe Ser Leu Glu Gly Leu Glu Asn Leu Asp
195 200 205
Trp Asp Lys Leu Leu Lys Leu Gln Ser Ala Asp Gly Ser Phe Leu Thr
210 215 220
Ser Pro Ser Ser Thr Ala Phe Ala Phe Met Gln Thr Lys Asp Glu Lys
225 230 235 240
Cys Tyr Gln Phe Ile Lys Asn Thr Ile Asp Thr Phe Asn Gly Gly Ala
245 250 255
Pro His Thr Tyr Pro Val Asp Val Phe Gly Arg Leu Trp Ala Ile Asp
260 265 270
Arg Leu Gln Arg Leu Gly Ile Ser Arg Phe Phe Glu Pro Glu Ile Ala
275 280 285
Asp Cys Leu Ser His Ile His Lys Phe Trp Thr Asp Lys Gly Val Phe
290 295 300
Ser Gly Arg Glu Ser Glu Phe Cys Asp Ile Asp Asp Thr Ser Met Gly
305 310 315 320
Met Arg Leu Met Arg Met His Gly Tyr Asp Val Asp Pro Asn Val Leu
325 330 335
Arg Asn Phe Lys Gln Lys Asp Gly Lys Phe Ser Cys Tyr Gly Gly Gln
340 345 350
Met Ile Glu Ser Pro Ser Pro Ile Tyr Asn Leu Tyr Arg Ala Ser Gln
355 360 365
Leu Arg Phe Pro Gly Glu Glu Ile Leu Glu Asp Ala Lys Arg Phe Ala
370 375 380
Tyr Asp Phe Leu Lys Glu Lys Leu Ala Asn Asn Gln Ile Leu Asp Lys
385 390 395 400
Trp Val Ile Ser Lys His Leu Pro Asp Glu Ile Lys Leu Gly Leu Glu
405 410 415
Met Pro Trp Leu Ala Thr Leu Pro Arg Val Glu Ala Lys Tyr Tyr Ile
420 425 430
Gln Tyr Tyr Ala Gly Ser Gly Asp Val Trp Ile Gly Lys Thr Leu Tyr
435 440 445
Arg Met Pro Glu Ile Ser Asn Asp Thr Tyr His Asp Leu Ala Lys Thr
450 455 460
Asp Phe Lys Arg Cys Gln Ala Lys His Gln Phe Glu Trp Leu Tyr Met
465 470 475 480
Gln Glu Trp Tyr Glu Ser Cys Gly Ile Glu Glu Phe Gly Ile Ser Arg
485 490 495
Lys Asp Leu Leu Leu Ser Tyr Phe Leu Ala Thr Ala Ser Ile Phe Glu
500 505 510
Leu Glu Arg Thr Asn Glu Arg Ile Ala Trp Ala Lys Ser Gln Ile Ile
515 520 525
Ala Lys Met Ile Thr Ser Phe Phe Asn Lys Glu Thr Thr Ser Glu Glu
530 535 540
Asp Lys Arg Ala Leu Leu Asn Glu Leu Gly Asn Ile Asn Gly Leu Asn
545 550 555 560
Asp Thr Asn Gly Ala Gly Arg Glu Gly Gly Ala Gly Ser Ile Ala Leu
565 570 575
Ala Thr Leu Thr Gln Phe Leu Glu Gly Phe Asp Arg Tyr Thr Arg His
580 585 590
Gln Leu Lys Asn Ala Trp Ser Val Trp Leu Thr Gln Leu Gln His Gly
595 600 605
Glu Ala Asp Asp Ala Glu Leu Leu Thr Asn Thr Leu Asn Ile Cys Ala
610 615 620
Gly His Ile Ala Phe Arg Glu Glu Ile Leu Ala His Asn Glu Tyr Lys
625 630 635 640
Ala Leu Ser Asn Leu Thr Ser Lys Ile Cys Arg Gln Leu Ser Phe Ile
645 650 655
Gln Ser Glu Lys Glu Met Gly Val Glu Gly Glu Ile Ala Ala Lys Ser
660 665 670
Ser Ile Lys Asn Lys Glu Leu Glu Glu Asp Met Gln Met Leu Val Lys
675 680 685
Leu Val Leu Glu Lys Tyr Gly Gly Ile Asp Arg Asn Ile Lys Lys Ala
690 695 700
Phe Leu Ala Val Ala Lys Thr Tyr Tyr Tyr Arg Ala Tyr His Ala Ala
705 710 715 720
Asp Thr Ile Asp Thr His Met Phe Lys Val Leu Phe Glu Pro Val Ala
725 730 735
<210> 65
<211> 936
<212> DNA
<213> 细疣篮状菌(Talaromyces verruculosus)
<400> 65
atgtctaacg acactactac tactgcttct gctggtactg ctacttcttc tagattcttg 60
tctgttggtg gtgttgttaa cttcagagaa ttgggtggtt acccatgtga ctctgttcca 120
ccagctccag cttctaacgg ttctccagac aacgcttctg aagctacttt gtgggttggt 180
cactcttcta tcagaccagg tttcttgttc agatctgctc aaccatctca aatcactcca 240
gctggtatcg aaactttgat cagacaattg ggtatccaaa ctatcttcga cttcagatct 300
agaactgaaa tcgaattggt tgctactaga tacccagact ctttgttgga aatcccaggt 360
actactagat actctgttcc agttttctct gaaggtgact actctccagc ttctttggtt 420
aagagatacg gtgtttcttc tgacactgct actgactcta cttcttctaa gtctgctaag 480
ccaactggtt tcgttcacgc ttacgaagct atcgctagat ctgctgctga aaacggttct 540
ttcagaaaga tcactgacca catcatccaa cacccagaca gaccaatctt gttccactgt 600
actttgggta aggacagaac tggtgttttc gctgctttgt tgttgtcttt gtgtggtgtt 660
ccagacgaaa ctatcgttga agactacgct atgactactg aaggtttcgg tgcttggaga 720
gaacacttga tccaaagatt gttgcaaaga aaggacgctg ctactagaga agacgctgaa 780
tctatcatcg cttctccacc agaaactatg aaggctttct tggaagacgt tgttgctgct 840
aagttcggtg gtgctagaaa ctacttcatc caacactgtg gtttcactga agctgaagtt 900
gacaagttgt ctcacacttt ggctatcact aactaa 936
<210> 66
<211> 1128
<212> DNA
<213> 解甲苯固氮弯曲菌(Azoarcus toluclasticus)
<400> 66
atgggttcta tccaagactc tttgttcatc agagctagag ctgctgtttt gagaactgtt 60
ggtggtccat tggaaatcga aaacgttaga atctctccac caaagggtga cgaagttttg 120
gttagaatgg ttggtgttgg tgtttgtcac actgacgttg tttgtagaga cggtttccca 180
gttccattgc caatcgtttt gggtcacgaa ggttctggta tcgttgaagc tgttggtgaa 240
agagttacta aggttaagcc aggtcaaaga gttgttttgt ctttcaactc ttgtggtcac 300
tgtgcttctt gttgtgaaga ccacccagct acttgtcacc aaatgttgcc attgaacttc 360
ggtgctgctc aaagagttga cggtggtact gttatcgacg cttctggtga agctgttcaa 420
tctttgttct tcggtcaatc ttctttcggt acttacgctt tggctagaga agttaacact 480
gttccagttc cagacgctgt tccattggaa atcttgggtc cattgggttg tggtatccaa 540
actggtgctg gtgctgctat caactctttg gctttgaagc caggtcaatc tttggctatc 600
ttcggtggtg gttctgttgg tttgtctgct ttgttgggtg ctttggctgt tggtgctggt 660
ccagttgttg ttatcgaacc aaacgaaaga agaagagctt tggctttgga cttgggtgct 720
tctcacgctt tcgacccatt caacactgaa gacttggttg cttctatcaa ggctgctact 780
ggtggtggtg ttactcactc tttggactct actggtttgc caccagttat cgctaacgct 840
atcaactgta ctttgccagg tggtactgtt ggtttgttgg gtgttccatc tccagaagct 900
gctgttccag ttactttgtt ggacttgttg gttaagtctg ttactttgag accaatcact 960
gaaggtgacg ctaacccaca agaattcatc ccaagaatgg ttcaattgta cagagacggt 1020
aagttcccat tcgacaagtt gatcactact tacagattcg acgacatcaa ccaagctttc 1080
aaggctactg aaactggtga agctatcaag ccagttttgg ttttctaa 1128
<210> 67
<211> 1119
<212> DNA
<213> 铜绿假单胞菌(Pseudomonas aeruginosa)
<400> 67
atgaactcta tccaaccaac tcaagctaag gctgctgttt tgagagctgt tggtggtcca 60
ttctctatcg aaccaatcag aatctctcca ccaaagggtg acgaagtttt ggttagaatc 120
gttggtgttg gtgtttgtca cactgacgtt gtttgtagag actctttccc agttccattg 180
ccaatcatct tgggtcacga aggttctggt gttatcgaag ctgttggtga ccaagttact 240
ggtttgaagc caggtgacca cgttgttttg tctttcaact cttgtggtca ctgttacaac 300
tgtggtcacg acgaaccagc ttcttgtttg caaatgttgc cattgaactt cggtggtgct 360
gaaagagctg ctgacggtac tatcgaagac gaccaaggtg ctgctgttag aggtttgttc 420
ttcggtcaat cttctttcgg ttcttacgct atcgctagag ctgttaacac tgttaaggtt 480
gacgacgact tgccattggc tttgttgggt ccattgggtt gtggtatcca aactggtgct 540
ggtgctgcta tgaactcttt gggtttgcaa ggtggtcaat ctttcatcgt tttcggtggt 600
ggtgctgttg gtttgtctgc tgttatggct gctaaggctt tgggtgtttc tccattgatc 660
gttgttgaac caaacgaagc tagaagagct ttggctttgg aattgggtgc ttctcacgct 720
ttcgacccat tcaacactga agacttggtt gcttctatca gagaagttgt tccagctggt 780
gctaaccacg ctttggacac tactggtttg ccaaaggtta tcgctaacgc tatcgactgt 840
atcatgtctg gtggtaagtt gggtttgttg ggtatggcta acccagaagc taacgttcca 900
gctactttgt tggacttgtt gtctaagaac gttactttga agccaatcac tgaaggtgac 960
gctaacccac aagaattcat cccaagaatg ttggctttgt acagagaagg taagttccca 1020
ttcgacaagt tgatcactac tttcccattc gaacacatca acgaagctat ggaagctact 1080
gaatctggta aggctatcaa gccagttttg actttgtaa 1119
<210> 68
<211> 1056
<212> DNA
<213> 黑丝孢网菌(Hyphozyma roseonigra)
<220>
<221> CDS
<222> (1)..(1056)
<400> 68
atg caa ttc tct atc ggt gac gtt ttg gct atc gtt gac aag act atc 48
Met Gln Phe Ser Ile Gly Asp Val Leu Ala Ile Val Asp Lys Thr Ile
1 5 10 15
ttg aac cca ttg gtt gtt tct gct ggt ttg ttg tct ttg cac ttc ttg 96
Leu Asn Pro Leu Val Val Ser Ala Gly Leu Leu Ser Leu His Phe Leu
20 25 30
act aac gac aag tac gct atc act gct aac gac ggt ttg ttc cca tac 144
Thr Asn Asp Lys Tyr Ala Ile Thr Ala Asn Asp Gly Leu Phe Pro Tyr
35 40 45
caa atc tct act cca gac tct cac aga aag gct ttg ttc gct ttg ggt 192
Gln Ile Ser Thr Pro Asp Ser His Arg Lys Ala Leu Phe Ala Leu Gly
50 55 60
ttc ggt ttg ttg ttg aga gct aac aga tac atg tct aga aag gct ttg 240
Phe Gly Leu Leu Leu Arg Ala Asn Arg Tyr Met Ser Arg Lys Ala Leu
65 70 75 80
aac aac aac act gct gct caa ttc gac tgg aac aga gaa atc atc gtt 288
Asn Asn Asn Thr Ala Ala Gln Phe Asp Trp Asn Arg Glu Ile Ile Val
85 90 95
gtt act ggt ggt tct ggt ggt atc ggt gct caa gct gct caa aag ttg 336
Val Thr Gly Gly Ser Gly Gly Ile Gly Ala Gln Ala Ala Gln Lys Leu
100 105 110
gct gaa aga ggt tct aag gtt atc gtt atc gac gtt ttg cca ttg act 384
Ala Glu Arg Gly Ser Lys Val Ile Val Ile Asp Val Leu Pro Leu Thr
115 120 125
ttc gac aag cca aag aac ttg tac cac tac aag tgt gac ttg act aac 432
Phe Asp Lys Pro Lys Asn Leu Tyr His Tyr Lys Cys Asp Leu Thr Asn
130 135 140
tac aag gaa ttg caa gaa gtt gct gct aag atc gaa aga gaa gtt ggt 480
Tyr Lys Glu Leu Gln Glu Val Ala Ala Lys Ile Glu Arg Glu Val Gly
145 150 155 160
act cca act tgt gtt gtt gct aac gct ggt atc tgt aga ggt aag aac 528
Thr Pro Thr Cys Val Val Ala Asn Ala Gly Ile Cys Arg Gly Lys Asn
165 170 175
atc ttc gac gct act gaa aga gac gtt caa ttg act ttc ggt gtt aac 576
Ile Phe Asp Ala Thr Glu Arg Asp Val Gln Leu Thr Phe Gly Val Asn
180 185 190
aac ttg ggt ttg ttg tgg act gct aag act ttc ttg cca tct atg gct 624
Asn Leu Gly Leu Leu Trp Thr Ala Lys Thr Phe Leu Pro Ser Met Ala
195 200 205
aag gct aac cac ggt cac ttc ttg atc atc gct tct caa act ggt cac 672
Lys Ala Asn His Gly His Phe Leu Ile Ile Ala Ser Gln Thr Gly His
210 215 220
ttg gct act gct ggt gtt gtt gac tac gct gct act aag gct gct gct 720
Leu Ala Thr Ala Gly Val Val Asp Tyr Ala Ala Thr Lys Ala Ala Ala
225 230 235 240
atc gct atc tac gaa ggt ttg caa act gaa atg aag cac ttc tac aag 768
Ile Ala Ile Tyr Glu Gly Leu Gln Thr Glu Met Lys His Phe Tyr Lys
245 250 255
gct cca gct gtt aga gtt tct tgt atc tct cca tct gct gtt aag act 816
Ala Pro Ala Val Arg Val Ser Cys Ile Ser Pro Ser Ala Val Lys Thr
260 265 270
aag atg ttc gct ggt atc aag act ggt ggt aac ttc ttc atg cca atg 864
Lys Met Phe Ala Gly Ile Lys Thr Gly Gly Asn Phe Phe Met Pro Met
275 280 285
ttg act cca gac gac ttg ggt gac ttg atc gct aag act ttg tgg gac 912
Leu Thr Pro Asp Asp Leu Gly Asp Leu Ile Ala Lys Thr Leu Trp Asp
290 295 300
ggt gtt gct gtt aac atc ttg tct cca gct gct gct tac atc tct cca 960
Gly Val Ala Val Asn Ile Leu Ser Pro Ala Ala Ala Tyr Ile Ser Pro
305 310 315 320
cca act aga gct ttg cca gac tgg atg aga gtt ggt atg caa gac gct 1008
Pro Thr Arg Ala Leu Pro Asp Trp Met Arg Val Gly Met Gln Asp Ala
325 330 335
ggt gct gaa atc atg act gaa ttg act cca cac aag cca ttg gaa taa 1056
Gly Ala Glu Ile Met Thr Glu Leu Thr Pro His Lys Pro Leu Glu
340 345 350
<210> 69
<211> 351
<212> PRT
<213> 黑丝孢网菌(Hyphozyma roseonigra)
<400> 69
Met Gln Phe Ser Ile Gly Asp Val Leu Ala Ile Val Asp Lys Thr Ile
1 5 10 15
Leu Asn Pro Leu Val Val Ser Ala Gly Leu Leu Ser Leu His Phe Leu
20 25 30
Thr Asn Asp Lys Tyr Ala Ile Thr Ala Asn Asp Gly Leu Phe Pro Tyr
35 40 45
Gln Ile Ser Thr Pro Asp Ser His Arg Lys Ala Leu Phe Ala Leu Gly
50 55 60
Phe Gly Leu Leu Leu Arg Ala Asn Arg Tyr Met Ser Arg Lys Ala Leu
65 70 75 80
Asn Asn Asn Thr Ala Ala Gln Phe Asp Trp Asn Arg Glu Ile Ile Val
85 90 95
Val Thr Gly Gly Ser Gly Gly Ile Gly Ala Gln Ala Ala Gln Lys Leu
100 105 110
Ala Glu Arg Gly Ser Lys Val Ile Val Ile Asp Val Leu Pro Leu Thr
115 120 125
Phe Asp Lys Pro Lys Asn Leu Tyr His Tyr Lys Cys Asp Leu Thr Asn
130 135 140
Tyr Lys Glu Leu Gln Glu Val Ala Ala Lys Ile Glu Arg Glu Val Gly
145 150 155 160
Thr Pro Thr Cys Val Val Ala Asn Ala Gly Ile Cys Arg Gly Lys Asn
165 170 175
Ile Phe Asp Ala Thr Glu Arg Asp Val Gln Leu Thr Phe Gly Val Asn
180 185 190
Asn Leu Gly Leu Leu Trp Thr Ala Lys Thr Phe Leu Pro Ser Met Ala
195 200 205
Lys Ala Asn His Gly His Phe Leu Ile Ile Ala Ser Gln Thr Gly His
210 215 220
Leu Ala Thr Ala Gly Val Val Asp Tyr Ala Ala Thr Lys Ala Ala Ala
225 230 235 240
Ile Ala Ile Tyr Glu Gly Leu Gln Thr Glu Met Lys His Phe Tyr Lys
245 250 255
Ala Pro Ala Val Arg Val Ser Cys Ile Ser Pro Ser Ala Val Lys Thr
260 265 270
Lys Met Phe Ala Gly Ile Lys Thr Gly Gly Asn Phe Phe Met Pro Met
275 280 285
Leu Thr Pro Asp Asp Leu Gly Asp Leu Ile Ala Lys Thr Leu Trp Asp
290 295 300
Gly Val Ala Val Asn Ile Leu Ser Pro Ala Ala Ala Tyr Ile Ser Pro
305 310 315 320
Pro Thr Arg Ala Leu Pro Asp Trp Met Arg Val Gly Met Gln Asp Ala
325 330 335
Gly Ala Glu Ile Met Thr Glu Leu Thr Pro His Lys Pro Leu Glu
340 345 350
<210> 70
<211> 1116
<212> DNA
<213> 浅白隐球菌(Cryptococcus albus)
<220>
<221> CDS
<222> (1)..(1116)
<400> 70
atg cca act cca atc ttc ggt gct aga gaa ggt ttc act atc gac tct 48
Met Pro Thr Pro Ile Phe Gly Ala Arg Glu Gly Phe Thr Ile Asp Ser
1 5 10 15
gtt ttg tct atc ttg gac gct act gtt ttg aac cca tgg ttc act ggt 96
Val Leu Ser Ile Leu Asp Ala Thr Val Leu Asn Pro Trp Phe Thr Gly
20 25 30
gtt tgt ttg atc gct gtt tgt gct aga gac aga act atc act tac cca 144
Val Cys Leu Ile Ala Val Cys Ala Arg Asp Arg Thr Ile Thr Tyr Pro
35 40 45
gac tgg cca gct gct ttg gac caa gtt ttg cca ttc ttg tct caa atg 192
Asp Trp Pro Ala Ala Leu Asp Gln Val Leu Pro Phe Leu Ser Gln Met
50 55 60
tgg aga gaa act gtt aga cca act ttc ggt gac aga aac gtt ttg cac 240
Trp Arg Glu Thr Val Arg Pro Thr Phe Gly Asp Arg Asn Val Leu His
65 70 75 80
ttg ttg act act gtt tgt gtt ggt ttg gct atc aga act aac aga aga 288
Leu Leu Thr Thr Val Cys Val Gly Leu Ala Ile Arg Thr Asn Arg Arg
85 90 95
atg tct aga ggt gct aga aac aac tgg gtt tgg gac act tct tac gac 336
Met Ser Arg Gly Ala Arg Asn Asn Trp Val Trp Asp Thr Ser Tyr Asp
100 105 110
tgg aag aag gaa atc gtt gtt gtt act ggt ggt gct gct ggt ttc ggt 384
Trp Lys Lys Glu Ile Val Val Val Thr Gly Gly Ala Ala Gly Phe Gly
115 120 125
gct gac atc gtt caa caa ttg gac act aga ggt atc caa gtt gtt gtt 432
Ala Asp Ile Val Gln Gln Leu Asp Thr Arg Gly Ile Gln Val Val Val
130 135 140
ttg gac gtt ggt tct ttg act tac aga cca tct tct aga gtt cac tac 480
Leu Asp Val Gly Ser Leu Thr Tyr Arg Pro Ser Ser Arg Val His Tyr
145 150 155 160
tac aag tgt gac gtt tct aac cca caa gac gtt gct tct gtt gct aag 528
Tyr Lys Cys Asp Val Ser Asn Pro Gln Asp Val Ala Ser Val Ala Lys
165 170 175
gct atc gtt tct aac gtt ggt cac cca act atc ttg gtt aac aac gct 576
Ala Ile Val Ser Asn Val Gly His Pro Thr Ile Leu Val Asn Asn Ala
180 185 190
ggt gtt ttc aga ggt gct act atc ttg tct act act cca aga gac ttg 624
Gly Val Phe Arg Gly Ala Thr Ile Leu Ser Thr Thr Pro Arg Asp Leu
195 200 205
gac atg act tac gac atc aac gtt aag gct cac tac cac ttg act aag 672
Asp Met Thr Tyr Asp Ile Asn Val Lys Ala His Tyr His Leu Thr Lys
210 215 220
gct ttc ttg cca aac atg atc tct aag aac cac ggt cac atc gtt act 720
Ala Phe Leu Pro Asn Met Ile Ser Lys Asn His Gly His Ile Val Thr
225 230 235 240
gtt tct tct gct act gct tac gct caa gct tgt tct ggt gtt tct tac 768
Val Ser Ser Ala Thr Ala Tyr Ala Gln Ala Cys Ser Gly Val Ser Tyr
245 250 255
tgt tct tct aag gct gct atc ttg tct ttc cac gaa ggt ttg tct gaa 816
Cys Ser Ser Lys Ala Ala Ile Leu Ser Phe His Glu Gly Leu Ser Glu
260 265 270
gaa atc ttg tgg atc tac aag gct cca aag gtt aga act tct gtt atc 864
Glu Ile Leu Trp Ile Tyr Lys Ala Pro Lys Val Arg Thr Ser Val Ile
275 280 285
tgt cca ggt cac gtt aac act gct atg ttc act ggt atc ggt gct gct 912
Cys Pro Gly His Val Asn Thr Ala Met Phe Thr Gly Ile Gly Ala Ala
290 295 300
gct cca tct ttc atg gct cca gct ttg cac cca tct act gtt gct gaa 960
Ala Pro Ser Phe Met Ala Pro Ala Leu His Pro Ser Thr Val Ala Glu
305 310 315 320
act atc gtt gac gtt ttg ttg tct tgt gaa tct caa cac gtt ttg atg 1008
Thr Ile Val Asp Val Leu Leu Ser Cys Glu Ser Gln His Val Leu Met
325 330 335
cca gct gct atg cac atg tct gtt gct ggt aga gct ttg cca act tgg 1056
Pro Ala Ala Met His Met Ser Val Ala Gly Arg Ala Leu Pro Thr Trp
340 345 350
ttc ttc aga ggt ttg ttg gct tct ggt aag gac act atg ggt tct gtt 1104
Phe Phe Arg Gly Leu Leu Ala Ser Gly Lys Asp Thr Met Gly Ser Val
355 360 365
gtt aga aga taa 1116
Val Arg Arg
370
<210> 71
<211> 371
<212> PRT
<213> 浅白隐球菌(Cryptococcus albus)
<400> 71
Met Pro Thr Pro Ile Phe Gly Ala Arg Glu Gly Phe Thr Ile Asp Ser
1 5 10 15
Val Leu Ser Ile Leu Asp Ala Thr Val Leu Asn Pro Trp Phe Thr Gly
20 25 30
Val Cys Leu Ile Ala Val Cys Ala Arg Asp Arg Thr Ile Thr Tyr Pro
35 40 45
Asp Trp Pro Ala Ala Leu Asp Gln Val Leu Pro Phe Leu Ser Gln Met
50 55 60
Trp Arg Glu Thr Val Arg Pro Thr Phe Gly Asp Arg Asn Val Leu His
65 70 75 80
Leu Leu Thr Thr Val Cys Val Gly Leu Ala Ile Arg Thr Asn Arg Arg
85 90 95
Met Ser Arg Gly Ala Arg Asn Asn Trp Val Trp Asp Thr Ser Tyr Asp
100 105 110
Trp Lys Lys Glu Ile Val Val Val Thr Gly Gly Ala Ala Gly Phe Gly
115 120 125
Ala Asp Ile Val Gln Gln Leu Asp Thr Arg Gly Ile Gln Val Val Val
130 135 140
Leu Asp Val Gly Ser Leu Thr Tyr Arg Pro Ser Ser Arg Val His Tyr
145 150 155 160
Tyr Lys Cys Asp Val Ser Asn Pro Gln Asp Val Ala Ser Val Ala Lys
165 170 175
Ala Ile Val Ser Asn Val Gly His Pro Thr Ile Leu Val Asn Asn Ala
180 185 190
Gly Val Phe Arg Gly Ala Thr Ile Leu Ser Thr Thr Pro Arg Asp Leu
195 200 205
Asp Met Thr Tyr Asp Ile Asn Val Lys Ala His Tyr His Leu Thr Lys
210 215 220
Ala Phe Leu Pro Asn Met Ile Ser Lys Asn His Gly His Ile Val Thr
225 230 235 240
Val Ser Ser Ala Thr Ala Tyr Ala Gln Ala Cys Ser Gly Val Ser Tyr
245 250 255
Cys Ser Ser Lys Ala Ala Ile Leu Ser Phe His Glu Gly Leu Ser Glu
260 265 270
Glu Ile Leu Trp Ile Tyr Lys Ala Pro Lys Val Arg Thr Ser Val Ile
275 280 285
Cys Pro Gly His Val Asn Thr Ala Met Phe Thr Gly Ile Gly Ala Ala
290 295 300
Ala Pro Ser Phe Met Ala Pro Ala Leu His Pro Ser Thr Val Ala Glu
305 310 315 320
Thr Ile Val Asp Val Leu Leu Ser Cys Glu Ser Gln His Val Leu Met
325 330 335
Pro Ala Ala Met His Met Ser Val Ala Gly Arg Ala Leu Pro Thr Trp
340 345 350
Phe Phe Arg Gly Leu Leu Ala Ser Gly Lys Asp Thr Met Gly Ser Val
355 360 365
Val Arg Arg
370
<210> 72
<211> 60
<212> DNA
<213> 人工序列
<220>
<223> 用于同源重组的序列
<400> 72
gcacttgcta cactgtcagg atagcttccg tcacatggtg gcgatcaccg tacatctgag 60
<210> 73
<211> 60
<212> DNA
<213> 人工序列
<220>
<223> 用于同源重组的序列
<400> 73
aggtgcagtt cgcgtgcaat tataacgtcg tggcaactgt tatcagtcgt accgcgccat 60
<210> 74
<211> 60
<212> DNA
<213> 人工序列
<220>
<223> 用于同源重组的序列
<400> 74
tggtcagcaa caacgccgaa gaatcactct cgtgttgaga attgcacgcc ttgaccacga 60
<210> 75
<211> 79
<212> DNA
<213> 人工序列
<220>
<223> 用于LEU2酵母标记的引物
<400> 75
aggtgcagtt cgcgtgcaat tataacgtcg tggcaactgt tatcagtcgt accgcgccat 60
tcgactacgt cgtaaggcc 79
<210> 76
<211> 80
<212> DNA
<213> 人工序列
<220>
<223> 用于LEU2酵母标记的引物
<400> 76
tcgtggtcaa ggcgtgcaat tctcaacacg agagtgattc ttcggcgttg ttgctgacca 60
tcgacggtcg aggagaactt 80
<210> 77
<211> 85
<212> DNA
<213> 人工序列
<220>
<223> 用于AmpR细菌标记的引物
<400> 77
tggtcagcaa caacgccgaa gaatcactct cgtgttgaga attgcacgcc ttgaccacga 60
cacgttaagg gattttggtc atgag 85
<210> 78
<211> 80
<212> DNA
<213> 人工序列
<220>
<223> 用于AmpR细菌标记的引物
<400> 78
aacgcgtacc ctaagtacgg caccacagtg actatgcagt ccgcactttg ccaatgccaa 60
aaatgtgcgc ggaaccccta 80
<210> 79
<211> 84
<212> DNA
<213> 人工序列
<220>
<223> 用于酵母复制起点的引物
<400> 79
ttggcattgg caaagtgcgg actgcatagt cactgtggtg ccgtacttag ggtacgcgtt 60
cctgaacgaa gcatctgtgc ttca 84
<210> 80
<211> 85
<212> DNA
<213> 人工序列
<220>
<223> 用于酵母复制起点的引物
<400> 80
ccgagatgcc aaaggatagg tgctatgttg atgactacga cacagaactg cgggtgacat 60
aatgatagca ttgaaggatg agact 85
<210> 81
<211> 82
<212> DNA
<213> 人工序列
<220>
<223> 用于大肠杆菌复制起点的引物
<400> 81
atgtcacccg cagttctgtg tcgtagtcat caacatagca cctatccttt ggcatctcgg 60
tgagcaaaag gccagcaaaa gg 82
<210> 82
<211> 81
<212> DNA
<213> 人工序列
<220>
<223> 用于大肠杆菌复制起点的引物
<400> 82
ctcagatgta cggtgatcgc caccatgtga cggaagctat cctgacagtg tagcaagtgc 60
tgagcgtcag accccgtaga a 81
<210> 83
<211> 60
<212> DNA
<213> 人工序列
<220>
<223> 用于同源重组的序列
<400> 83
attcctagtg acggccttgg gaactcgata cacgatgttc agtagaccgc tcacacatgg 60
- 生物催化产生萜烯化合物的方法
- 马尾松α-蒎烯合成酶在制备萜烯类化合物及包含萜烯类化合物的产品中的应用