基于图神经网络的双过滤证据感知虚假新闻检测方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及互联网大数据及深度学习领域,具体涉及基于图神经网络的双过滤证据感知虚假新闻检测方法。
背景技术
社交媒体促进了信息的传播和交流,改变了人们获取信息的方式。然而,由于现有技术无法验证大量的实时新闻信息的真实性,社交媒体也成为了虚假新闻扩散的温床。在信息飞速传播的今天,在政治和公共卫生等不同领域都能见到虚假新闻的身影,对网络安全和人类社会构成了巨大威胁。
虚假新闻检测任务作为一项文本分类任务,主要有两种方法,基于文本模式的虚假新闻检测和基于证据的虚假新闻检测。其中基于文本模式的虚假新闻检测仅根据新闻文本的写作风格,惯用词等文本的模式信息来验证新闻的准确性,通常存在泛化性和可解释性较差的问题。基于证据的虚假新闻检测是将任务建模为一个类似人类推理的过程,在其中提供与待检测新闻相关的外部证据,比如相关的文章、通知等信息,模型需要发现并整合给定外部证据中有用的信息,通过总结到的外部信息来判断新闻的真实性。
然而,现有基于证据的虚假新闻检测方法忽略了对新闻和证据的细粒度语义的探索。总的来说,现有的工作主要有以下不足,1)对长距离语义的研究较少。在一篇证据文档中,两个相关的重要信息可能出现在文档开头和文档结尾,这些信息之间的长距离语义相关性难以被捕获,导致虚假新闻检测的准确性不足。2)现有基于证据的虚假新闻检测方法将检索到的文本直接作为正确的证据,然而搜索引擎检索到的内容可能与新闻相关度不高,这可能会在新闻和证据交互部分引入噪声,影响模型的检测性能和检测效率。因此,如何提高虚假新闻检测的准确性和效率是亟需解决的技术问题。
发明内容
针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种基于图神经网络的双过滤证据感知虚假新闻检测方法,能够通过建模图来解决文本中信息的距离问题,改善了现有模型难以捕获长距离文本语义相关性的问题,同时通过双过滤结构尽可能的保留有效且必要的证据,改善在新闻和证据交互部分引入噪声的问题,从而提高虚假新闻检测的准确性和效率。
为了解决上述技术问题,本发明采用了如下的技术方案:
基于图神经网络的双过滤证据感知虚假新闻检测方法,包括:
S1:获取新闻、新闻作者以及与新闻相关的证据和证据发布者作为待检测信息;
S2:将待检测信息输入经过训练的虚假新闻检测模型中,输出对应新闻的真实性预测概率;
通过如下步骤训练虚假新闻检测模型:
S201:获取作为训练数据的新闻、新闻作者以及与新闻相关的证据和证据发布者;
S202:对证据进行筛选:过滤与新闻相关性低的证据,保留与新闻相关性高的证据;
S203:基于新闻和保留的证据构建对应的新闻图结构和证据图结构;
S204:对新闻图结构进行图结构语义编码,得到新闻嵌入表示;
S205:对证据图结构进行图语言结构细化:丢弃证据图结构中冗余的证据节点,根据非冗余的证据节点生成对应的证据细粒度节点嵌入;
S206:通过注意力分数将证据细粒度节点嵌入集成为文档嵌入,得到证据嵌入表示;
S207:分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接,得到文档级嵌入表示,进而通过分类器生成新闻的真实性预测概率;
S208:根据新闻的真实性预测概率和真实性标签计算任务损失来优化模型参数;
S209:重复步骤S201至S208,直至虚假新闻检测模型收敛;
S3:将对应新闻的真实性预测概率作为其虚假检测结果。
优选的,首先使用预训练语言模型BERT分别对新闻和每个证据的文本信息进行编码,然后使用[CLS]标记的最终表示作为文本信息的语义特征,得到对应的新闻嵌入矩阵
公式描述为:
ε′={e:e∈ε,cossim(H
式中:ε′表示保留的与新闻的相关性高于或等于相似度阈值的证据集合,证据集合中的证据数量为n
优选的,为新闻和证据构建图结构时,连接每一个单词的上下文信息,将所有重复出现的单词都使用同一个节点表示;同时对图结构的邻接矩阵进行拉普拉斯归一化,记为
最终,将新闻和证据初始归一化的邻接矩阵作为新闻图结构
优选的,先将门控图神经网络作为图语义编码器在新闻图结构上传播并聚合邻居信息以获取完整的上下文语义,得到对应的新闻节点嵌入;再将经过语义编码的新闻节点嵌入进行平均池化,生成对应的新闻嵌入表示;
1)门控图神经网络的处理公式描述为:
z
r
式中:c表示一个图结构中的节点集合;
2)平均池化的公式描述为:
式中:
优选的,通过基于高斯核的节点筛选器计算证据图结构中每个证据节点的冗余分数和非冗余分数,进而筛选出非冗余分数最高的k个证据节点,并将筛选出的k个证据节点的节点嵌入表示拼接在一起得到证据细粒度节点嵌入。
优选的,通过如下步骤生成证据细粒度节点嵌入:
S2051:计算证据图结构中证据节点的自身冗余分数;
公式描述为:
s
式中:s
S2052:计算证据图结构中证据节点与新闻之间的相关冗余分数;
公式描述为:
s
式中:s
S2053:将证据节点的自身冗余分数和相关冗余分数进行线性相加,得到冗余得分;
公式描述为:
s
式中:s
S2054:通过门控图神经网络根据证据节点的冗余得分计算每个证据节点结构感知的冗余分数;
公式描述为:
式中:s
S2055:通过f(·)筛选出非冗余分数最高的k个证据节点,并且将筛选出的证据节点的嵌入表示拼接在一起作为语义结构细化后的证据细粒度节点嵌入;
公式描述为:
s
[H
式中:H
优选的,首先使用新闻嵌入表示计算证据细粒度节点嵌入中每一个单词的注意力权重,进而将单词加权求和得到一个完整的嵌入表示,即证据嵌入表示;
公式描述为:
式中:
优选的,通过如下步骤生成新闻的真实性预测概率:
S2071:分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接,得到新闻文档级嵌入表示和证据文档级嵌入表示;
公式描述为:
式中:h
S2072:根据新闻文档级嵌入表示和证据文档级嵌入表示捕获新闻与多个证据之间的文档级交互信息,得到新闻与证据交互的文档级嵌入表示;
公式描述为:
式中:h
S2073:将新闻文档级嵌入表示和新闻与证据交互的文档级嵌入表示融合生成最终表示;
公式描述为:
h=[h
式中:h表示最终表示;h
S2074:通过多层感知机根据最终表示输出对应新闻的真实性预测概率;
公式描述为:
式中:
优选的,计算虚假新闻检测模型的交叉熵损失
公式描述为:
式中:
优选的,计算虚假新闻检测模型的对比损失;然后将虚假新闻检测模型的任务损失和对比损失结合得到联合损失;最终基于联合损失优化虚假新闻检测模型的模型参数;
1)对比损失的计算公式为:
式中:
2)联合损失的计算公式为:
式中:
本发明中基于图神经网络的双过滤证据感知虚假新闻检测方法与现有技术相比,具有如下有益效果:
本发明的虚假新闻检测模型在检测新闻真实性时通过对证据进行筛选,过滤了与新闻相关性低的证据并保留与新闻相关性高的证据,不仅能够改善在新闻和证据交互部分引入噪声的问题,还能够过滤无效或无意义的证据,从而保证模型的检测性能,并提高虚假新闻检测的准确性和效率。
本发明分别对新闻文本和保留下来的证据进行建模得到图结构,而图结构将文本中分散的语义信息紧密地连接在图上,即能够通过建模图来解决文本中信息的距离问题,改善了现有模型难以捕获长距离文本语义相关性的问题,同样能够提高虚假新闻检测的准确性。随后,本发明对证据图结构进行图语言结构细化,能够丢弃证据图结构中冗余的证据节点,并且根据非冗余的证据节点生成对应的证据细粒度节点嵌入,这进一步消除了证据中可能含有的广告信息或无意义的词(如的、了等高频词),减少了证据中无用的冗余信息,从而提高虚假新闻检测的准确性,并保证检测效率。
本发明通过“证据的相关性过滤”和“证据冗余节点丢弃”形成了双过滤结构,该双过滤结构的两次过滤是逐渐深入和细化的,即先过滤得到相关性高的证据,再从相关性高的证据中过滤得到非冗余的证据节点,最终能够尽可能的保留有效且必要的证据。
本发明分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接得到文档级嵌入表示,进而通过分类器生成新闻的真实性预测概率,其中新闻作者和证据发布者的信息对虚假新闻检测有重要意义,因此将新闻和证据的嵌入表示与相应的作者和发布者向量拼接可进一步丰富信息的内容,进而捕获新闻与多个证据之间的文档级交互信息,从而进一步提高虚假新闻检测的准确性。
附图说明
为了使发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
图1为基于图神经网络的双过滤证据感知虚假新闻检测方法的逻辑框图;
图2为虚假新闻检测模型的网络结构图;
图3为虚假新闻检测模型中图语义结构细化层的网络结构图;
图4为不同数据集上门控阈值T对性能的影响;
图5为不同数据集上节点丢弃率r对性能的影响;
图6为不同数据集上冗余分数融合率β对性能的影响;
图7为不同数据集上双过滤模块有效性分析;
图8为不同数据集上随着迭代过程的验证集性能变化。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件能够以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。此外,术语“水平”、“竖直”等术语并不表示要求部件绝对水平或悬垂,而是可以稍微倾斜。例如“水平”仅是指其方向相对“竖直”而言更加水平,并不是表示该结构一定要完全水平,而是可以稍微倾斜。在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
下面通过具体实施方式进一步详细的说明:
实施例:
本实施例中公开了一种基于图神经网络的双过滤证据感知虚假新闻检测方法。
如图1所示,基于图神经网络的双过滤证据感知虚假新闻检测方法,包括:
S1:获取新闻、新闻作者以及与新闻相关的证据和证据发布者作为待检测信息;
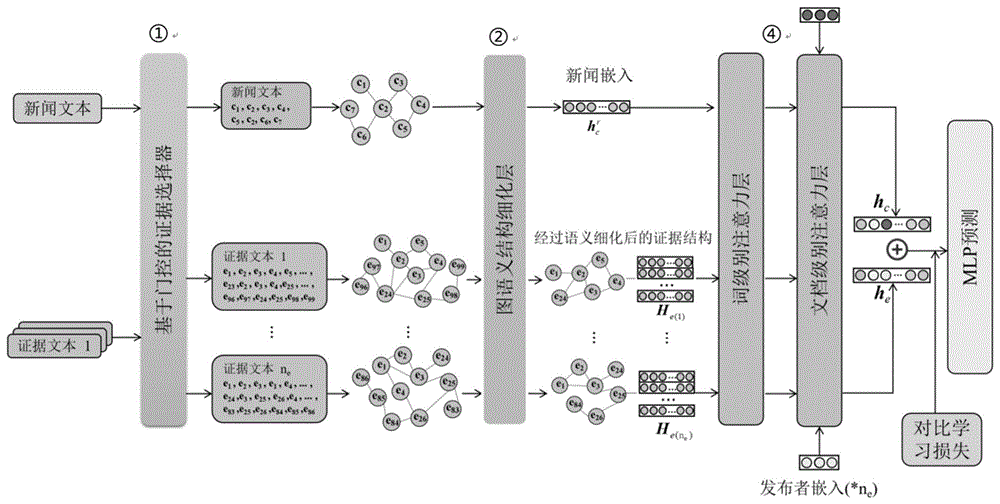
S2:将待检测信息输入经过训练的虚假新闻检测模型(Graph Neural Network-based Dual Filter Evidence-aware Fake News Detection,GDFEND)中,输出对应新闻的真实性预测概率;
如图2所示,虚假新闻检测模型(后续也称为GDFEND)的输入是一个新闻c,与新闻对应的若干个证据ε={e
通过如下步骤训练虚假新闻检测模型:
S201:获取作为训练数据的新闻、新闻作者以及与新闻相关的证据和证据发布者;
S202:通过基于门控的文档选择器对证据进行筛选:过滤与新闻相关性低的证据,保留与新闻相关性高的证据;
S203:基于新闻和保留的证据构建对应的新闻图结构和证据图结构;
S204:对新闻图结构进行图结构语义编码和平均池化,得到新闻嵌入表示;
S205:通过图语义结构细化层对证据图结构进行图语言结构细化:丢弃证据图结构中冗余的证据节点,根据非冗余的证据节点生成对应的证据细粒度节点嵌入;
S206:在词级别注意层通过注意力分数将证据细粒度节点嵌入集成为文档嵌入,得到证据嵌入表示;
S207:分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接,得到文档级嵌入表示,进而通过分类器生成新闻的真实性预测概率;
S208:根据新闻的真实性预测概率和真实性标签计算任务损失来优化模型参数;
S209:重复步骤S201至S208,直至虚假新闻检测模型收敛;
S3:将对应新闻的真实性预测概率作为其虚假检测结果。
首先,本发明的虚假新闻检测模型在检测新闻真实性时通过对证据进行筛选,过滤了与新闻相关性低的证据并保留与新闻相关性高的证据,不仅能够改善在新闻和证据交互部分引入噪声的问题,还能够过滤无效或无意义的证据,从而保证模型的检测性能,并提高虚假新闻检测的准确性和效率。其次,本发明分别对新闻文本和保留下来的证据进行建模得到图结构,而图结构将文本中分散的语义信息紧密地连接在图上,即能够通过建模图来解决文本中信息的距离问题,改善了现有模型难以捕获长距离文本语义相关性的问题,同样能够提高虚假新闻检测的准确性。随后,本发明对证据图结构进行图语言结构细化,能够丢弃证据图结构中冗余的证据节点,并且根据非冗余的证据节点生成对应的证据细粒度节点嵌入,这进一步消除了证据中可能含有的广告信息或无意义的词(如的、了等高频词),减少了证据中无用的冗余信息,从而提高虚假新闻检测的准确性,并保证检测效率。同时,本发明通过“证据的相关性过滤”和“证据冗余节点丢弃”形成了双过滤结构,该双过滤结构的两次过滤是逐渐深入和细化的,即先过滤得到相关性高的证据,再从相关性高的证据中过滤得到非冗余的证据节点,最终能够尽可能的保留有效且必要的证据。最后,本发明分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接得到文档级嵌入表示,进而通过分类器生成新闻的真实性预测概率,其中新闻作者和证据发布者的信息对虚假新闻检测有重要意义,因此将新闻和证据的嵌入表示与相应的作者和发布者向量拼接可进一步丰富信息的内容,进而捕获新闻与多个证据之间的文档级交互信息,从而进一步提高虚假新闻检测的准确性。
具体实施过程中,使用预训练语言模型BERT分别对新闻和每个证据的文本信息进行编码,然后使用[CLS]标记的最终表示作为文本信息的语义特征,得到对应的新闻嵌入矩阵
由于搜索引擎检索出的证据并非都是对新闻真实性预测有帮助的,为了从大量证据中提取与新闻高度相关的证据。本发明通过基于门控的文档选择器根据新闻嵌入矩阵和证据嵌入矩阵来过滤掉与新闻的相关性低于相似度阈值的证据,保留与新闻的相关性高于或等于相似度阈值的证据集合;
公式描述为:
ε′={e:e∈ε,cossim(H
式中:ε′表示保留的与新闻的相关性高于或等于相似度阈值的证据集合,证据集合中的证据数量为n
本发明的虚假新闻检测模型在检测新闻真实性时通过对证据进行筛选,能够过滤与新闻相关性低的证据并保留与新闻相关性高的证据,不仅能够改善在新闻和证据交互部分引入噪声的问题,还能够过滤无效的证据,从而保证模型的检测性能,并提高虚假新闻检测的准确性和效率。
具体实施过程中,为了获得长距离文本信息的语义相关性,本发明首先将原始的新闻和证据转换为图。
与之前在其他NLP任务中使用的基于图的方法相同,本发明在为新闻和每个证据构建图结构时,连接每一个单词的上下文信息。为了建模长距离语义相关性,将所有重复出现的单词都使用同一个节点表示。通过上文的图结构建,一些在文档中分散得很远的单词被拉近为图中的邻居节点,其中每个节点的初始状态是相应单词的嵌入。
为了保证数值的稳定性,对图结构的邻接矩阵进行拉普拉斯归一化,记为
最终,将新闻和证据初始归一化的邻接矩阵作为新闻图结构
本发明分别对新闻文本和保留下来的证据进行建模得到图结构,图结构将文本中分散的语义信息紧密地连接在图上,即能够通过建模图来解决文本中信息的距离问题,改善了现有模型难以捕获长距离文本语义相关性的问题,同样能够提高虚假新闻检测的准确性。
具体实施过程中,图神经网络在捕获上下文语义信息方面展现了较好的表现,为了更好的关注图中节点信息,控制信息的流动和筛选,本发明使用了门控图神经网络(gated graph neural network,GGNN)作为图语义编码器。
通过图语义编码器在新闻图结构上传播并聚合邻居信息以获取完整的上下文语义,得到对应的新闻节点嵌入;再将经过语义编码的新闻节点嵌入进行平均池化,生成对应的新闻嵌入表示;
1)门控图神经网络的处理公式描述为:
z
r
式中:c表示一个图结构中的节点集合;
本实施例中,将上述的门控图神经网络处理过程简化为
2)平均池化的公式描述为:
式中:
具体实施过程中,虚假新闻检测模型虽然过滤掉了与新闻相关性较低的证据,但是保留的证据中仍可能会存在部分噪音,比如证据中可能含有的广告信息等,这些噪音可能会导致模型减少对重要信息的关注。值得注意的是,一些无意义的词比如“的”、“了”由于在文中的词频较高,在图结构中可能会有较多的邻居,这使得它们会有较高的注意力分数,但是这些节点对检测新闻的真假并无帮助。
由于冗余信息主要涉及证据中的词(即图结构中的节点),本发明通过丢弃冗余节点来细化证据图的结构。具体的,通过基于高斯核的节点筛选器计算证据图结构中每个证据节点的冗余分数和非冗余分数,并且筛选出非冗余分数最高的k个证据节点,最终将筛选出的k个证据节点的节点嵌入表示拼接在一起得到证据细粒度节点嵌入。
结合图3所示,通过如下步骤生成证据细粒度节点嵌入:
S2051:计算证据图结构中证据节点的自身冗余分数;
在GDFEND中,证据节点自身冗余分数是通过将证据的嵌入矩阵投影为一维获得。公式描述为:
s
式中:s
S2052:计算证据图结构中证据节点与新闻之间的相关冗余分数;
为了获得节点与新闻相关的冗余分数,本发明使用了余弦相似度范围内的高斯核函数(Gaussian Kernel Function)来度量证据中每个单词与新闻中所有单词的细粒度相关性。公式描述为:
s
式中:s
S2053:将证据节点的自身冗余分数和相关冗余分数进行线性相加,得到冗余得分;
公式描述为:
s
式中:s
S2054:通过门控图神经网络根据证据节点的冗余得分计算每个证据节点结构感知的冗余分数;
为了多角度地评估节点地冗余性得分,本发明再次使用门控图神经网络(后续也称为GGNN)来计算每个证据节点结构感知的冗余分数,从而每个节点的冗余得分都是由自身信息,与新闻的相关性和图结构信息(即GGNN中获得的上下文信息)三部分综合得出。公式描述为:
式中:s
S2055:通过f(·)筛选出非冗余分数最高的k个证据节点,并且将筛选出的证据节点的嵌入表示拼接在一起作为语义结构细化后的证据细粒度节点嵌入;
公式描述为:
s
[H
式中:H
需要说明的是,GDFEND只对证据进行冗余节点的丢弃,因为新闻通常很短(少于10个单词),语义结构很较为简单,没有必要进行节点丢弃。
本发明对证据图结构进行图语言结构细化,能够丢弃证据图结构中冗余的证据节点,并且根据非冗余的证据节点生成对应的证据细粒度节点嵌入,这进一步消除了证据中可能含有的广告信息或无意义的词(如的、了等高频词),减少了证据中无用的冗余信息,从而提高虚假新闻检测的准确性,并保证检测效率。同时,本发明通过“证据的相关性过滤”和“证据冗余节点丢弃”形成了双过滤结构,该双过滤结构的两次过滤是逐渐深入和细化的,即先过滤得到相关性高的证据,再从相关性高的证据中过滤得到非冗余的证据节点,最终能够尽可能的保留有效且必要的证据。
具体实施过程中,经过了两次过滤,本发明已经获得了经过语义结构细化层的每个证据的证据图结构
为了获得新闻与证据的交互信息,本发明将证据的节点嵌入通过注意力分数集成为文档嵌入。具体的,本发明首先使用新闻嵌入表示计算证据细粒度节点嵌入中每一个单词的注意力权重,进而将单词加权求和得到一个完整的嵌入表示,即证据嵌入表示;这一步骤的目的是让模型能侧重重要性高的单词。
公式描述为:
/>
式中:
本实施例中,将证据细粒度节点嵌入的注意分数计算操作过程中简化为
具体实施过程中,通过如下步骤生成新闻的真实性预测概率:
S2071:在词级别注意层和文档级别注意层分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接,得到新闻文档级嵌入表示和证据文档级嵌入表示;
申请人发现,新闻作者和证据发布者的信息对虚假新闻检测有重要意义,本发明通过将新闻和证据的嵌入表示与相应的作者和发布者向量拼接从而丰富信息的内容。公式描述为:
式中:h
S2072:通过文档级注意层根据新闻文档级嵌入表示和证据文档级嵌入表示捕获新闻与多个证据之间的文档级交互信息,得到新闻与证据交互的文档级嵌入表示;
在获得新闻和证据的文档级嵌入表示后,本发明进一步采用与上文结构相同的文档级注意层,来捕获新闻与多个证据之间的文档级交互信息。公式描述为:
式中:h
S2073:将新闻文档级嵌入表示和新闻与证据交互的文档级嵌入表示融合生成最终表示;
公式描述为:
h=[h
式中:h表示最终表示;h
S2074:通过多层感知机(Multi-Layer perceptron,MLP)根据最终表示输出对应新闻的真实性预测概率;
公式描述为:
式中:
本发明分别将新闻嵌入表示和证据嵌入表示与新闻作者和证据发布者拼接得到文档级嵌入表示,进而通过分类器生成新闻的真实性预测概率,其中新闻作者和证据发布者的信息对虚假新闻检测有重要意义,因此将新闻和证据的嵌入表示与相应的作者和发布者向量拼接可进一步丰富信息的内容,进而能够捕获新闻与多个证据之间的文档级交互信息,从而进一步提高虚假新闻检测的准确性。
具体实施过程中,虚假新闻本质上是一个文本分类任务,本发明使用标准的交叉熵损失
公式描述为:
式中:
具体实施过程中,鉴于对比学习在分类任务中有较好表现,本发明添加了一个有监督对比学习任务来帮助提升分类效果,即将同一类聚类并分离不同类别的样本。
具体来说,通过使用新闻数据的真实性标签作为监督信号,拉近同一类别的新闻-证据的融合表示,拉远不同类别的新闻-证据的交互表示,从而更好地的优化模型对新闻的真实性判断。计算虚假新闻检测模型的对比损失;然后将虚假新闻检测模型的任务损失和对比损失结合得到联合损失;最终基于联合损失优化虚假新闻检测模型的模型参数;
1)对比损失的计算公式为:
式中:
2)联合损失的计算公式为:
式中:
本发明在任务损失的基础上引入了有监督对比学习,使得能够辅助任务通过最大化相同类型实例之间的一致性和与其他不同类型实例之间的区别来增强表示学习,从而能够进一步提高虚假新闻检测的准确性和有效性。
为了更好的说明本发明技术方案的优势,本实施例公开了如下实验。
本实验的配置为:Ubuntu 20.04.1操作系统,Intel(R)Core(TM)i9-10900K CPU@3.70GHz CPU,NVIDIA RTX 3090Ti GPU,Python 3.8.12开发环境以及PyTorch 1.7.1的学习框架。本实验中K的值为11,每个高斯核的均值均匀的分布在[-1,1],间隔为0.2,方差均为0.01。然后添加一个均值为0.99方差为0.01的高斯核,用于模拟极其相似的情况。对比学习融合度λ的取值为0.1,其余的超参数将在实验部分介绍。
1、实验数据集
为了评估GDFEND在基于证据的虚假新闻检测上的性能,本实验使用了两个广泛使用的公开数据集来验证模型。详细的数据统计见表1。
Snopes,新闻及其相应的标签(真或假)从事实核查网站收集。将每条新闻作为查询,通过搜索引擎检索证据及其发布者。
PolitiFact,新闻标签对从另一个关于美国政治的事实核查网站收集,证据与Snopes收集方式类似。除了证据发布者信息外,新闻作者也被添加到数据集中。
表1数据集统计
2、评价指标
在模型评估中,本实验采用精确率(Precision)、召回率(Recall)和F1值(F1-score)综合评估GDFEND模型在基于证据的虚假新闻检测任务中的性能。其计算方式如下
Precision=TP/(TP+FP);
Recall=TP/(TP+FN);
F1=2*(Precision*Recall)/(Precision+Recall);
其中,TP(TruePositive)表示预测类别和实际类别都为“真实”。FP(FalsePositive)表示预测类别为“真实”,而实际类别为“虚假”。FN(False Negative)表示预测类别为“虚假”,而实际类别为“真实”。
3、对比模型
为了证明本发明提出的模型GDFEND的有效性,本实验将其与几种现有的方法进行了比较,其中包括基于模式的模型和基于证据的模型:
基于模式的方法
1)LSTM(参考Sheng Q,Cao J,Zhang X,et al.Zoom out and observe:Newsenvironment perception for fake news detection)利用LSTM对输入新闻的语义进行编码,并通过平均池化获得新闻的最终表示。
2)TextCNN(参考Hochreiter S,Schmidhuber J.Long short-term memory)应用了一个一维卷积网络来嵌入新闻的语义。
3)BERT(参考Devlin J,Chang M W,Lee K,et al.Bert:Pre-training of deepbidirectional transformers for language understanding)采用BERT来学习新闻的表示。获取最后隐藏层的标记[CLS],通过一个线性层预测出结果。
基于证据的方法
1)DeClarE(参考Popat K,Mukherjee S,Yates A,et al.Declare:Debunkingfake news and false claims using evidence-aware deep learning)使用bi-lstm获得证据的语义,并通过平均池化获得新闻的表示,然后在新闻和证据中的每个词之间使用注意力机制,生成最终的新闻感知表示。
2)HAN(参考Ma J,Gao W,Joty S,et al.Sentence-level evidence embeddingfor claim verification with hierarchical attention networks)使用GRU获得语义嵌入,设计了主题一致性模块和语义隐含的模块来建立文档级注意力机制的新闻-证据交互模型。
3)EHIAN(参考Zhang D,Nan F,Wei X,et al.Supporting clustering withcontrastive learning)利用自注意力机制来学习语义,并专注于交互证据的重要部分。
4)MAC(参考Vo N,Lee K.Hierarchical multi-head attentive network forevidence-aware fake news detection)引入了一个层次注意力框架来建模词级和证据级的交互。
5)GET(参考Xu W,Wu J,Liu Q,et al.Evidence-aware fake news detectionwith graph neural networks)通过GGNN对证据图结构进行细化,然后使用词级和文档级注意力进行新闻证据交互。
4、总体实验
将本发明的模型GDFEND与8个基线模型进行了比较,包括3种基于文本模式的方法和5种基于证据的方法。实验结果如表2所示,其中“F1-Ma”和“Fi-Mi”分别表示指标F1-Macro和F1-Micro。在计算精度和召回值时,“-T”表示“真实新闻”为Positive,“-F”表示“虚假新闻为Positive”;最佳性能用黑体字突出显示;
首先,本发明的模型GDFEND在两个数据集上的大多数指标上都显著优于所有现有的方法,证明了GDFEND的有效性。值得注意的是,GDFEND在最近的三个基于序列模型的基线(EHIAN、MAC和GET)中脱颖而出,而且EHIAN、MAC和GET的表现比较接近,这表明了引入图结构对基于证据的虚假新闻检测有着积极影响。具体来说,与两个数据集上最好的基线模型GET相比,GDFEND在各项指标上的性能都获得了较大提高,这可以更好地反映模型的整体检测能力。即使考虑更精细的性能,GDFEND也在两个数据集的F1-T和F1-F的分数上取得了最好的结果。其次,与基于模式的方法(即表2中的前三种方法)相比,基于证据的方法有了很大的性能改进,这可能是由于基于证据的方法有着更好的泛化能力,其中的外部信息被用来探测新闻的真实性,避免了对新闻文本模式的过度依赖。第三,在5个基于证据的基线模型中,DeClarE和HAN的性能远不如其他三种模型,这是因为它们缺乏对不同粒度语义的探索,DeClarE只考虑单词级的语义交互,而HAN仅依赖于文档级的表示来建模新闻证据交互。
表2两个数据集上的总体实验和模型比较
5、消融实验
为了验证GDFEND的语义编码器等的组件的影响,本实验通过去除特定的组件进行消融实验,见表3:-GSE删除了图语义编码器(GGNN),使用BiLSTM作为语义编码器;-GK表示在语义结构细化层中去除高斯核函数(用于捕捉新闻与证据中每一个词的相关性),只通过节点的自身信息进行冗余分评估;-CL去除对比学习损失,仅使用分类任务的交叉熵损失进行训练;-DS不使用模型最初的基于门控的文档选择器。具体结果如表3所示,从中可以观察到,F1-Micro和F1-Macro在两个数据集上都出现了明显的下降。GDFEND-GK-CL和GDFEND-GSE-CL的性能较低,说明捕捉文本中的长距离语义相关性以及消除文本的冗余信息对检验新闻真假具有重要意义。同时GDFEND-GK和GDFEND-DS对模型也有较大的影响,二者都是一个筛选的过程,证明了本发明设计的双过滤结构的有效性,这也侧面证明了对文档和词的筛选并不会和后部分注意力机制产生冲突。此外,GDFEND在GDFEND-CL上也出现了明显的降低,这表明对比学习是有益的,它可以挖掘每个类之间潜在的关系,帮助模型识别不同类之间的重要差异,增强模型的泛化能力。
表3消融实验
6、参数敏感性实验
6.1门控阈值和节点丢弃率
门控阈值T是用来筛选出与新闻相关性高的文档,T值越高代表选出的证据与新闻相关性越高,相应的入选证据的数量也会减少,可能会导致证据信息的不足,所以需要找到一个合适的阈值来平衡。节点丢弃率r决定了过滤掉的证据中冗余信息的比例,当r=0时,该模型在语义结构细化中不删除节点,仅使用GGNN来获取图结构中的重要信息。如图4和图5所示,本发明模型的两个过滤模块中,随着门控阈值和节点丢弃率的提升(代表获取的证据信息的精度提升),模型的性能也在提升,当门控阈值T设置为0.55(Snopes数据集)或0.60(PolitiFact数据集),节点丢弃率r设置为0.3(Snopes数据集)和0.2(PolitiFact数据集)的时候取得最佳性能,过大的门控阈值和节点丢弃率会导致证据信息的丢失,从而影响模型的性能。同时,两个数据集上的F1-ma和F1-mi的波动都在1.5%以内,这也证明了模型的鲁棒性。
6.2冗余分数融合率
冗余分数融合率β在语义结构细化模块中用于控制节点自身得分和节点-新闻相关性得分。如图6所示,当β=0时,表示节点的冗余得分只通过证据节点自身信息来评估,当β=1时,模型只根据证据节点与新闻的相关性来评估节点的冗余得分。如图6所示,当β设置为0或1时,性能相对较差,它只从单个角度来确定冗余得分。当β从0变到1时,性能先提高,然后下降,这表明适度的融合二者分数是有效的。
7、过滤有效性验证
本发明提出的模型包含两个过滤模块,文档选择器和语义结构细化模块,分别用来过滤无效证据和证据中的冗余词节点。为了两种过滤的有效性,本实验使用了MAC,GET,GDFEND-DS和GDFEND本身来进行了对比实验(这四种模型都使用了多层次的注意力机制)如图7。如图7所示,MAC模型由于没有任何筛选机制,导致效果不佳,而GET和GDFEND-DS都使用了图结构学习来过滤冗余节点(GET仅通过节点自身信息,而GDFEND-DS使用了节点自身信息以及节点-新闻相关性信息),二者都取得了较好的性能。最后,包含了文档和节点双过滤模块的GDFEND取得了最佳的效果,验证了本发明提出的双过滤模块的有效性。
8、迭代过程分析
为了进一步验证模型的鲁棒性,本实验在两个数据集的验证集上都进行了迭代过程分析,结果如图8所示,在两个数据集上的AUC曲线都比较稳定平滑,但是随着epoch(迭代次数,1个epoch表示将数据集全部数据都训练一次)的增加,模型性能在后期出现了略微下降。为了解决过拟合的问题,本实验使用了Early Stop方法,当模型在验证集上的表现连续10个epoch都没有提升的时候将终止训练过程。
9、案例分析
在消融实验中可以看出如果删除GDFEND所使用的基于门控的文档选择器会导致性能有较大地下降,为了分析该模块的工作过程,本实验在此设置了一个案例分析见表4,(其中数据来源于PolitiFact数据集,翻译自英文)。根据案例可以看出,证据1虽然是由新闻检索出来的,但是它和新闻的相关性不够高,甚至叙述的并不是同一件事情,若把它作为判别新闻真假的直接证据会导致模型性能的降低。作为对比,本发明模型所保留的证据2与新闻直接相关,能帮助模型准确地判断出新闻的真假。
表4PolitiFact数据集中的案例分析
最后需要说明的是,以上实施例仅用以说明本发明的技术方案而非限制技术方案,本领域的普通技术人员应当理解,那些对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,均应涵盖在本发明的权利要求范围当中。
- 智慧大屏显示管理系统和电厂智慧大屏显示管理系统
- 一种智慧电厂视频识别监控管理系统和方法