零扩展52比特整数融合乘法加法和减法指令
文献发布时间:2024-04-18 20:01:23
技术领域
本公开总体涉及零扩展52比特整数融合乘法加法和减法指令。
背景技术
隐私保护机器学习(privacy-preserving machine learning,PPML)是一个即将到来的趋势,它使得能够在保持数据隐私的同时从数据中学习。PPML技术包括使用安全执行技术、联合学习、安全多方计算以及同态加密(homomorphic encryption,HE)。HE是一种加密形式,它使得能够对加密的数据进行计算。然而,HE方案在计算上是昂贵的。因此,减少HE的计算费用的技术有益于PPML和其他隐私保护分析技术,这些技术使得能够对私密数据执行计算,而不将底层数据暴露给计算设备。
发明内容
根据本公开的第一实施例,提供了一种处理器,包括:第一电路,用于将指令解码成经解码的指令,所述指令指示出第一源操作对象、第二源操作对象以及目的地操作对象;以及第二电路,包括用于执行所述经解码的指令的处理资源,其中,响应于所述经解码的指令,所述处理资源被配置为:对所述第一源操作对象和所述第二源操作对象的相应64比特数据元素中的52比特数据值执行按元素乘法,以生成一组中间结果,所述中间结果存储由对所述52比特数据值执行的按元素乘法产生的104比特中间乘积;对于具有第一操作码的经解码的指令,将所述104比特中间乘积的高52比特零扩展到64比特值;对于具有第二操作码的经解码的指令,将所述104比特中间乘积的低52比特零扩展到64比特值;以及将所述64比特值紧缩成紧缩数据类型,并且将所述紧缩数据类型存储在由所述目的地操作对象指定的位置。
根据本公开的第二实施例,提供了一种处理器,包括:第一电路,用于将指令解码成经解码的指令,所述指令指示出第一源操作对象、第二源操作对象、第三源操作对象以及目的地操作对象;以及第二电路,包括用于执行所述经解码的指令的处理资源,其中,响应于所述经解码的指令,所述处理资源被配置为:对所述第二源操作对象和所述第三源操作对象的相应64比特数据元素中的52比特数据值执行按元素乘法,以生成一组中间结果,所述中间结果存储由对所述52比特数据值执行的按元素乘法产生的104比特中间乘积;对于具有第一操作码的经解码的指令:将所述104比特中间乘积的高52比特零扩展到第一64比特数据值;对所述第一64比特数据值和所述第一源操作对象的64比特数据元素内的第二64比特数据值执行算术操作;对所述第二64比特数据值的低52比特进行零扩展以生成第三64比特数据值;以及将所述第三64比特数据值紧缩成紧缩数据类型并且将所述紧缩数据类型存储在指定的目的地位置。
根据本公开的第三实施例,提供了一种方法,包括:取得指令并且将该指令解码成经解码的指令,所述指令具有多个源操作对象和一个或多个目的地操作对象;执行所述经解码的指令,其中,执行所述经解码的指令包括:对所述多个源操作对象中的两个源操作对象的相应64比特数据元素中的52比特数据值执行按元素乘法,以生成一组中间结果,所述中间结果存储由对所述52比特数据值的乘法产生的104比特中间乘积;对于具有第一操作码的经解码的指令,对所述104比特中间乘积的高52比特进行零扩展以生成64比特结果值;对于具有第二操作码的经解码的指令,对所述104比特中间乘积的低52比特进行零扩展以生成所述64比特结果值;以及将所述64比特结果值紧缩成紧缩数据类型,并且将所述紧缩数据类型存储在由目的地操作对象指定的位置。
根据本公开的第四实施例,提供了一种系统,包括:网络接口;存储器设备,被配置为存储指令,所述指令提供同态加密加速库,所述指令包括用于加速同态加密操作的基元;一个或多个处理器,与所述存储器设备和所述网络接口耦合,所述一个或多个处理器执行存储在所述存储器设备中的指令,所述指令使得所述一个或多个处理器被配置为:经由所述网络接口接收一组加密数据,其中,该组加密数据是经由同态加密方案来加密的;以及经由所述同态加密加速库提供的基元对该组加密数据执行算术操作,所述算术操作包括对多组52比特数据值执行的数据并行乘法-减法操作,其中,所述数据并行乘法-减法操作是通过由所述一个或多个处理器执行的单个指令来执行的。
附图说明
在附图中以示例而非限制方式图示了本发明,附图中相似的标记表示类似的要素,并且其中:
图1图示了可以用于经由HE执行PPML的系统;
图2图示了同态评估器,它被配置为执行硬件加速的同态加密操作;
图3图示了一组用于执行52比特乘法、乘法-加法和乘法-减法操作的整数指令,这些操作可以用于加速数论变换操作;
图4图示了根据一实施例的执行向量紧缩52比特乘法指令的电路;
图5A-图5B图示了根据一实施例的执行向量紧缩52比特乘法-加法或乘法-减法指令的电路;
图6图示了根据本文描述的实施例的执行52比特向量紧缩乘法指令的方法;
图7图示了根据本文描述的实施例的执行52比特向量紧缩乘法-加法或乘法-减法指令的方法;
图8是根据一实施例的处理系统的框图;
图9A-图9B图示了由本文描述的实施例提供的计算系统和图形处理器;
图10A-图10B图示了处理器和关联的处理器体系结构的示例性有序管线和示例性寄存器重命名、无序发出/执行管线;
图11图示了根据本文描述的实施例的执行单元电路;
图12是根据一些实施例的寄存器体系结构的框图;
图13图示了根据一实施例的指令格式的实施例;
图14图示了指令格式的寻址字段的实施例;
图15图示了指令格式的第一前缀的实施例;
图16A-图16D图示了根据一些实施例的第一前缀的R、X和B字段的使用;
图17A-图17B图示了根据实施例的第二前缀;
图18图示了根据实施例的第三前缀;
图19图示了根据一实施例的与使用软件指令转换器来将源指令集中的二进制指令转换成目标指令集中的二进制指令进行对比的框图;
图20A-图20D图示了IP核开发和可以从不同的IP核组装成的关联封装组合件;以及
图21图示了根据本文描述的各种实施例的可以使用一个或多个IP核制造的示例性集成电路和关联的处理器。
具体实施方式
出于说明目的,记载了许多具体细节以便提供对下面描述的各种实施例的透彻理解。然而,本领域技术人员将会清楚,没有这些具体细节中的一些也可以实现实施例。在其他情况中,以框图形式示出了公知的结构和设备以避免模糊底层原理,并且提供对实施例的更透彻理解。本文描述的技术和教导可以被应用于包括各种类型的电路或半导体器件的设备、系统或装置,包括通用处理设备或者图形处理设备。本文提及“一个实施例”或“一实施例”指的是与该实施例相联系或关联描述的特定特征、结构或特性可以被包括在至少一个这种实施例中。然而,在说明书中各种地方出现短语“在一个实施例中”不一定都指的是同一实施例。
在接下来的说明书和/或权利要求中,可以使用术语“耦合”和“连接”以及其衍生词。这些术语并不意图是彼此的同义词。“耦合”用于表示两个或更多个元素,它们可能与或不与彼此发生直接实体或电气接触、与或不与彼此合作或者交互。“连接”用于表示与彼此耦合的两个或更多个元素之间的通信的建立。
有限域
国家标准与技术研究所(National Institute of Standards and Technology,NIST)后量子密码术标准化进程有几个入围者,它们利用NTT进行高效实现,包括提出的四个加密方案中的三个(Crystals-Kyber、NTRU、Saber)。具体地,NTT被用来加快多项式环上的多项式乘法速度。多项式乘法是这些密码术工作负载中的一个大瓶颈。例如,多项式乘法可以消耗Saber加密方案的多达60%的运行时间。
NTT计算的核心是模数整数算术,尤其是模数加法和乘法。NTT已经得到了很好的研究,从浮点等价物——快速傅里叶变换(Fast Fourier Transform,FFT)——中继承了丰富的理论,并且得到了高度优化,但仍然是一个瓶颈。因此,即使是增量的性能改善也是有价值的。
本文描述的是一组新的指令,用于优化正向和逆向的NTT操作。这些指令执行52比特整数的紧缩(packed)乘法,并且还可以对高位或低位的52比特乘积执行额外的加法、减法或者存储操作。与现有的并行整数融合乘法-加法指令相比,这些指令使得NTT和逆向NTT操作的显著性能改善成为可能。
图1图示了可以用于经由HE执行PPML的系统100。系统100包括同态评估器110,它包括为HE提供硬件加速的处理系统。系统100使得私密数据102A-102N能够被处理,而不向同态评估器110暴露底层数据。私密数据102A-102N代表任何受保护不被广泛散播的数据,例如个人、个人可识别、金融、敏感或者受监管的信息。私密数据102A-102N可以是与单个客户端设备相关联的私密数据的多个元素,或者可以代表由多个客户端设备提供的私密数据的同一元素的不同实例。
与私密数据102A-102N相关联的(一个或多个)客户端设备可以准备(例如,格式化)数据,然后将数据加密为加密的私密数据104A-104N。然后,加密的私密数据104A-104N可以被提供给同态评估器110,以便以保护隐私的方式进行处理。同态评估器110使用HE计算来对加密数据执行推理、分析和其他数学操作。由同态评估器110执行的HE操作产生加密的结果112,该结果与对未加密的数据执行等同数学操作时会产生的结果一致。然后,加密的结果112可以被提供给数据消费者114以进行解密和消费。为了实现对私密数据102A-102N的加密和对加密结果112的解密,数据消费者114可以生成公共和私密同态密钥对。公钥使得私密数据的加密(例如,由拥有私密数据102A-102N的一个或多个客户端)成为可能。私钥使得数据消费者114能够解密由同态评估器110基于加密数据生成的分析结果。
由同态评估器110执行的HE操作的性能和效率可以经由使用处理资源(例如,中央处理单元(central processing unit,CPU)、图形处理单元(graphics processing unit,GPU)、计算加速器、现场可编程门阵列(Field Programmable Gate Array,FPGA),等等)来改善,这些资源提供对指令集体系结构(instruction set architecture,ISA)的支持,该体系结构包括加速常规执行的HE操作的性能和/或效率的指令。例如,可以通过提供指令来改善HE操作的性能和效率,这些指令使得能够使用减少数目的指令来执行常见操作。本文描述的实施例提供了处理资源,这些资源包括对加速HE操作的指令的支持。
图2图示了系统200,其包括同态评估器110,该同态评估器被配置为执行硬件加速的同态加密操作。在一个实施例中,同态评估器110包括数据存储装置210、一个或多个CPU220、以及一个或多个GPU 230。同态评估器110可以使用由一个或多个CPU 220和/或一个或多个GPU 230提供的指令来执行HE操作。数据存储装置210可以包括用于促进程序执行的系统存储器,它可以是易失性或非易失性存储器,以及非易失性存储存储器,以促进持久性数据存储。各种存储器类型和设备可以具有不同的物理地址空间,同时共享虚拟存储器地址空间。数据存储装置210还可以包含(一个或多个)GPU 230中的本地存储器,该存储器也可以被包括在(一个或多个)CPU 220和(一个或多个)GPU 230之间共享的统一虚拟地址空间中。
数据存储装置210可以包括安全数据存储装置212的区域,该区域用于存储加密的私密数据104A-104N。虽然加密的私密数据104A-104N是加密的,但可以使用额外的加密密钥来进一步加密安全数据存储装置212,例如,特定于同态评估器110、与同态评估器110相关联的服务提供商的密钥,和/或特定于由加密私密数据104A-104N管理的客户端的密钥。数据存储装置210还可以包括同态加密库(HE库214)。示例性HE库214包括但不限于SEAL、PALISADE和HElib库,它们使得能够对加密数据执行同态加密操作。HE库214还可以包括HEXL(同态加密加速)库,它包括可以用于加速SEAL、PALISADE和HElib库的性能的功能。HEXL库提供了对伽罗瓦域的整数算术的高效实现,这些算术在一般的加密、尤其是同态加密中是普遍的和经常执行的操作。
虽然描述了具体的示例性库,但本文描述的实施例提供了可由本文描述的处理资源可执行的任何特定软件使用的指令,而不是特定于任何特定软件的指令。例如,HE库214以及任何其他程序代码可以使用本文提供的指令来加速数论变换操作(NTT操作215)、按元素模数乘法操作216以及多项式模数加法操作217。经由(一个或多个)CPU 220内的硬件逻辑225和/或(一个或多个)GPU内的硬件逻辑235来执行加速,其中(一个或多个)CPU 220的硬件逻辑225和(一个或多个)GPU 230的硬件逻辑235是经由包括可配置硬件逻辑和/或固定功能硬件逻辑的电路在各个处理器中实现的。
与NTT操作215相关联的NTT相当于有限(伽罗瓦)域中的快速傅里叶变换(FFT),从而所有的加法和乘法都是相对于模数q执行的。如上所述,在这个域中两个多项式的相乘f(x)*g(x)通常被计算为InvNTT(FwdNTT(f)⊙FwdNTT(g)),,其中⊙表示按元素向量-向量模数乘法。基于NTT的公式将多项式-多项式模数乘法的运行时间从O(N
正向NTT可以使用表格1中所示的库利-图基基数-2(Cooley-Tukey radix-2)变换来实现,其中按照标准排序
表格1—库利-图基基数-2 NTT
库利-图基基数-2 NTT的第9-14行中的“蝶形”操作是关键指令,第10-13行构成了大部分的计算。加法和乘法操作是模数加法和模数乘法,它们是有限域Z
表格2—哈维NTT蝶形
在库利-图基NTT中使用哈维蝶(Harvey butterfly)产生
表格3中示出了Gentleman-Sande逆向NTT过程形式的示例性逆向NTT操作。
表格3—Gentleman-Sande基数-2逆向NTT
第10-13行的蝶形操作代表了大部分的计算,其中加法和乘法是在有限域Z
表格4—哈维逆向NTT蝶形
表格4中示出的用于逆向NTT的哈维蝶形传递了模数化简以实现改善的性能。与正变换一样,当使用哈维蝶形时,如果希望,最后通过NTT计算应当将输出化简到[0,q)。
由于上述的NTT操作被用于HE计算中,改善上述操作的性能可以改善HE实现方式的性能。
紧缩52比特整数算术
加密过程可以利用52比特整数操作来对已被分割成多个52比特的分支的大整数值执行算术。使用52比特算术为大整数的分支提供了额外的溢出比特,并且允许对每个分支的算术被并行地而不是顺序地执行。vpmadd52huq和vpmadd52luq指令由Intel
图3图示了一组用于执行52比特乘法、乘法-加法和乘法-减法操作的整数指令,这些操作可用于加速NTT操作。这组指令也被示出在下面的表格5中。
表格5—向量紧缩52比特整数操作
图3和表格5的指令执行52比特整数操作,在输出到目的地之前,零扩展到64比特。本文描述的实施例提供的指令包括52比特乘法指令300、310(vpm52huq、vpm52luq),52比特乘法-加法指令320、330(vpmadd52huq52z、vpmadd52huq52),以及52比特乘法-减法指令340、350(vpmsub52huq52z、vpmsub52huq52)。在一个实施例中,指令的格式包括识别该指令的操作码302,以及目的地操作对象304(dst)、第一源操作对象306(src1)、以及第二源操作对象308(src2)。52比特乘法-加法指令320、330和52比特乘法-减法指令340、350还包括第三源操作对象309(src3)。在一个实施例中,指令可以被指定为原位操作,其中目的地操作对象304是基于第一源操作对象306来确定的。操作对象可以被存储在128比特(xmm)寄存器、256比特(ymm)寄存器、或者512比特(zmm)寄存器中。操作对象也可以被从存储128比特、256比特或512比特紧缩数据的存储器地址读取或者向其写入,其中每个输入元素是存储在64比特数据元素中的52比特整数值。虽然示出了使用128比特、256比特和512比特寄存器或紧缩存储器位置的指令,但实施例不限于这些特定的宽度。
在表格6中示出了52比特乘法指令300(vpm52huq)的示例。
表格6—向量紧缩52比特整数乘法指令(高52)
52比特乘法指令300(vpm52huq)省略了由现有vpmadd52huq指令执行的加法操作。52比特乘法指令300使得处理器的功能单元执行表格7中所示的操作。
表格7—向量紧缩52比特整数乘法操作(高52)
vpm52huq指令使得处理器的功能单元将src1和src2的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,该指令使得功能单元将结果的高52比特存储在目的地中。
在表格8中示出了52比特乘法指令310(vpm52luq)的示例。
表格8—向量紧缩52比特整数乘法指令(低52)
vpm52luq指令省略了由vpmadd52luq指令执行的加法操作,并且使得处理器的功能单元执行表格9中所示的操作。
表格9—向量紧缩52比特整数乘法操作(低52)
vpm52luq指令使得处理器的功能单元将src1和src2的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,该指令使得功能单元将结果的低52比特存储在目的地中。
在表格10中示出了52比特乘法-加法指令320的示例。
表格10—向量紧缩52比特整数乘法-加法指令
vpmadd52huq52z指令使得处理器的功能单元执行表格11中所示的操作。
表格11—向量紧缩52比特整数乘法-加法操作
vpmadd52huq52z指令使得处理器的功能单元将src2和src3输入的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,该功能单元将来自中间结果的高52比特无符号整数与src1输入中的相应无符号64比特整数相加,丢弃可能的溢出比特。然后,该功能单元将结果的低52比特存储在目的地中,并且将0存储在目的地的高12比特中。
在表格12中示出了52比特乘法-加法指令330的示例。
表格12—替代向量紧缩52比特整数乘法-加法指令
vpmadd52huq52指令与vpmadd52huq52z的不同之处在于它清除src1中的加数(summand)的高12比特,而不是目的地。vpmadd52huq52指令使得处理器的功能单元执行表格13中所示的操作。
表格13—替代向量紧缩52比特整数乘法-加法操作
vpmadd52huq52指令使得处理器的功能单元将src2和src3输入的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,该功能单元将来自中间结果的高52比特无符号整数与src1输入中的相应无符号52比特整数相加,并且将结果(包括溢出比特)存储在目的地中。
在表格14中示出了52比特乘法-减法指令340的示例。
表格14—向量紧缩52比特整数乘法-减法指令
vpmsub52huq52z指令使得处理器的功能单元执行表格15中所示的操作。
表格15—向量紧缩52比特整数乘法-减法操作
vpmsub52huq52z指令使得处理器的功能单元将src2和src3输入的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,该功能单元用来自中间结果的高52比特无符号整数减去src1中的相应无符号64比特整数,并且将结果的低52比特存储在目的地中,丢弃由于下溢而产生的可能的额外比特。然后,该功能单元在目的地的高12比特中存储0。
在表格16中示出了52比特乘法-减法指令350的示例。
表格16—替代向量紧缩52比特整数乘法-减法指令
vpmsub52huq52指令与vpmsub52huq52z的不同之处在于它清除了src1中的减数的高12比特,而不是目的地,而与vpmadd52huq52的不同之处在于它执行减法而不是加法。vpmsub52huq52指令使得处理器的功能单元执行表格17中所示的操作。
表格17—替代向量紧缩52比特整数乘法-减法操作
vpmadd52huq52指令使得处理器的功能单元将src2和src3输入的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,功能单元用来自中间结果的高52比特无符号整数减去src1中的相应无符号52比特整数,丢弃由于下溢而产生的可能的额外比特,并且将中间结果的低52比特存储在目的地中。
如上所述,乘法后可选地跟随着加法或减法的指令可以体现为几种形式,包括128比特、256比特和512比特形式,其中每个操作对象包括两个、四个或八个64比特数据元素,这些数据元素存储52比特数据值。在其他实施例中,提供了指令,其中一个、两个或三个输入操作对象是单个64比特整数,这在所有数据元素存储相同值的情况下是有用的,当操作对象存储模值时可能就是这种情况。此外,一个实施例提供了一组对有符号整数进行操作的指令,这在使用[-q/2,q/2)范围表示Z
表格18—掩蔽向量紧缩52比特整数乘法-加法掩码指令
示例性掩蔽指令使得处理器的功能单元将src2和src3输入的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。然后,该功能单元将来自中间结果的高52比特无符号整数与src1输入中的相应无符号64比特整数相加。在索引i处的64比特整数发生溢出的情况下,该功能单元将在目标掩码中设置i比特。然后,该功能单元将结果的低52比特存储在目的地中,并且将0存储在目的地的高12比特中。对于下溢,可以以类似的方式来修改指令340和指令350。
图4图示了根据一实施例的执行向量紧缩52比特乘法指令的电路400。电路400可配置为执行52比特乘法指令300(vpm52huq)和执行上述的52比特乘法指令310(vpm52luq)。以框图形式图示出的电路400包括一组乘法器411A-411D,这些乘法器被配置为将第一源操作对象306(src1)和第二源操作对象308(src2)的每个64比特元素中的紧缩无符号52比特整数相乘,以形成104比特中间结果。电路400被图示为对四元素紧缩数据输入执行256比特操作。被处理的数据元素的数目可以取决于操作的宽度而变化。例如,对64比特数据元素的512比特操作将对八元素紧缩数据输入进行操作。
然后,电路可以将中间结果的高52比特或者低52比特存储到由目的地操作对象304指定的目的地。在一个实施例中,52比特数据元素是在第一源操作对象306和第二源操作对象308的零扩展64比特数据元素内提供的,乘法器411A-411D被配置为执行64比特x64比特乘法,以生成128比特值,该值包括52比特乘法的104比特中间乘积。乘法器411A-411D可配置为输出64比特结果,该结果包括基于存储在乘法器411A-411D输出的128比特值中的104比特中间结果的高52比特([103:52])的64比特零扩展值。乘法器411A-411D也可配置为输出结果64比特结果,该结果包括基于存储在乘法器输出的128比特值中的104比特中间结果的较低52比特([51:0])的64比特零扩展值。由每个乘法器411A-411D输出的64比特值被存储到由目的地操作对象304指定的目的地。
在一个实施例中,乘法器411A-411D被配置为执行直接52比特x52比特乘法,以生成104比特中间乘积。在这样的实施例中,乘法器411A-411D可以驻留在可配置为执行双精度浮点操作的浮点单元中,因为双精度浮点格式包括52比特尾数,并且在双精度浮点乘法期间执行52比特x52比特乘法操作。
图5A-图5B图示了根据一实施例的执行向量紧缩52比特乘法-加法或乘法-减法指令的电路500、550。在图5A中以框图形式图示出的电路500包括一组乘法器511A-511D和加法器/减法器电路512A-512D。电路500可配置为执行上述52比特乘法-加法指令320(vpmadd52huq52z)、52比特乘法-加法指令330(vpmadd52huq52)、52比特乘法-减法指令340(vpmsub52huq52z)、以及52比特乘法-减法指令350(vpmsub52huq52)。
在一个实施例中,在第一源操作对象306(src1)、第二源操作对象308(src2)和第三源操作对象309(src3)的64比特数据元素内提供输入数据值。对于每个乘法-加法或者乘法-减法指令,乘法器511A-511D被配置为对来自第二源操作对象308和第三源操作对象309的相应数据元素执行64比特×64比特乘法操作,以生成128比特值,该值包括52比特乘法的104比特中间结果。然后,乘法器511A-511D可以将128比特中间结果输出到加法器/减法器电路512A-512D,它们可以取决于指令的操作码来执行不同的操作。
在一个实施例中,乘法器511A-511D被配置为执行直接52比特x52比特乘法,以生成104比特中间乘积。在这样的实施例中,乘法器511A-511D可以驻留在可配置为执行双精度浮点操作的浮点单元中,因为双精度浮点格式包括52比特尾数,并且在双精度浮点乘法期间执行52比特x52比特乘法操作。对于vpmadd52huq52z指令,加法器/减法器电路512A-512D将104比特中间结果的零扩展高52比特与从第一源操作对象306接收的64比特值相加,以生成64比特中间结果,对64比特中间结果的低52比特进行零扩展以生成输出结果,然后将输出结果输出到由目的地操作对象304指定的目的地。由加法器/减法器电路512A-512D执行的加法操作丢弃可能的溢出比特。在一个实施例中,如果溢出比特被丢弃,则在对于函数的掩码启用版本而输出的掩码505中设置比特。
对于vpmadd52huq52指令,第一源操作对象306中的加数的高12比特被清除,而不是在目的地中。加法器/减法器电路512A-512D将104比特中间结果的高52比特与从第一源操作对象306接收的52比特值相加,以生成53比特中间结果,每个中间结果包括52比特中间值和溢出比特。然后,53比特中间值被零扩展到64比特并且被存储到由目的地操作对象304指定的目的地。由于输出是基于零扩展的53比特值的,因此在一些实施例中可以排除掩码/溢出变体。
对于vpmsub52huq52z指令,加法器/减法器电路512A-512D从104比特中间结果的零扩展高52比特中减去从第一源操作对象306接收的64比特值以生成64比特中间结果,对64比特中间结果的低52比特进行零扩展以生成输出结果,然后将输出结果输出到由目的地操作对象304指定的目的地。由加法器/减法器电路512A-512D执行的减法操作丢弃由于下溢(例如,回绕)而产生的可能的额外比特。在一个实施例中,如果对于给定的执行通路或通道发生了下溢,则在对于函数的掩码启用版本而输出的掩码505中设置相应的比特。
对于vpmsub52huq52指令,第一源操作对象306中的减数的高12比特被清除,而不是在目的地中。加法器/减法器电路512A-512D从104比特中间结果的高52比特中减去从第一源操作对象306接收的52比特值,以生成52比特中间结果。然后,52比特中间值被零扩展到64比特并且被存储到由目的地操作对象304指定的目的地。由加法器/减法器电路512A-512D执行的减法操作丢弃由于下溢(例如,回绕)而产生的可能的额外比特。在一个实施例中,如果对于给定的执行通路或通道发生了下溢,则在对于函数的掩码启用版本而输出的掩码505中设置相应的比特。
图5B中以方框形式图示的电路550与电路500相似,不同之处在于提供单个52比特值作为第一源操作对象506。在图示的实施例中,52比特值是乘法-加法操作的加数或者乘法-减法操作的减数。52比特第一源操作对象506值可以被广播到向量紧缩并行操作的所有通路或通道。在各种替代实施例中,第二源操作对象308或者第三源操作对象309可以是被广播到电路的所有通路或通道的单个数据元素值。
上述电路400、500和550的多个实例可以在CPU或GPU的算术逻辑单元(arithmeticlogic unit,ALU)内找到,这取决于所支持的物理SIMD通路的数目。此外,该电路可以被用于支持单指令多线程(single instruction multiple thread,SIMT)执行模型的GPU的SIMD后端中。
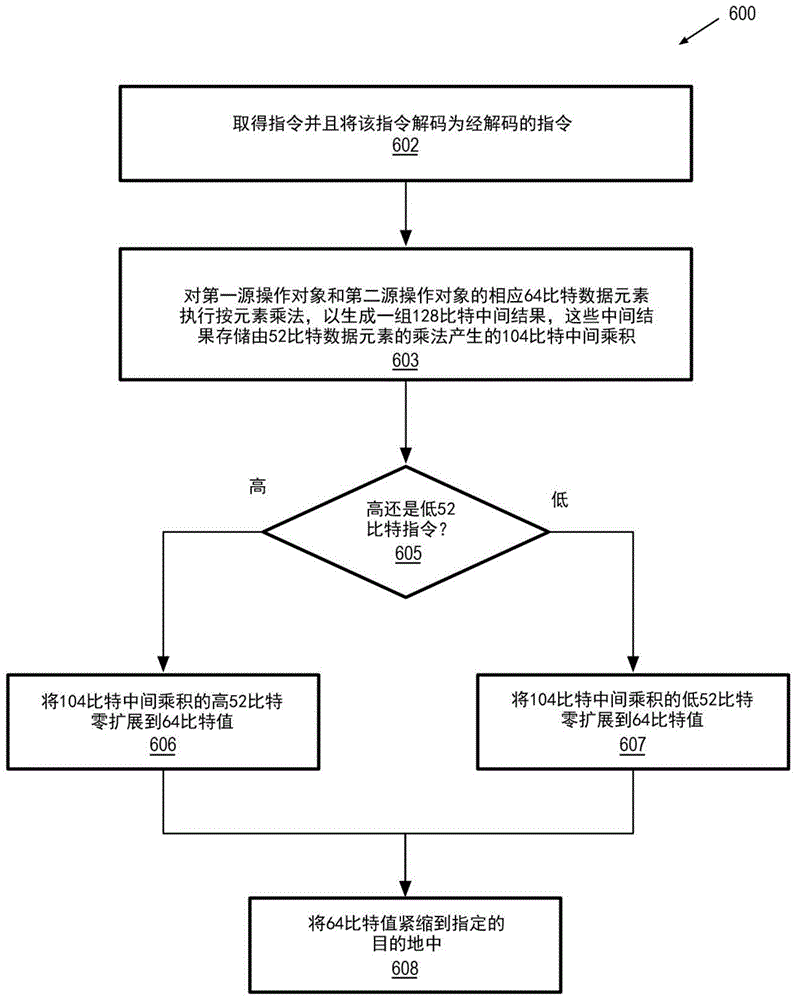
图6图示了根据本文所描述的实施例的执行52比特向量紧缩乘法指令的方法600。方法600可以由处理器的功能单元执行,该处理器可以包括通用处理器(general-purposeprocessor,CPU)、图形处理器(graphics processor,GPU)、或者被配置为加速图形和计算操作的通用图形处理器(general-purpose graphics processor,GPGPU)。
根据方法600,处理器可以取得指令,并且将该指令解码为经解码的指令,如块602处所示。该指令可以是例如图3的指令300或指令310,并且包括第一和第二源操作对象,这些操作对象可以包括64比特数据元素,这些数据元素在存储器位置中被紧缩成128比特、256比特或者512比特向量或紧缩数据类型。处理器可以在功能单元中配置乘法器,以对第一源操作对象和第二源操作对象的相应64比特数据元素执行按元素乘法,以生成一组128比特中间结果,这些中间结果存储由52比特数据元素的乘法产生的104比特中间乘积,如块603处所示。或者,一组52比特x52比特乘法操作可以由浮点硬件执行,以生成104比特中间结果。
方法600还包括让处理器确定指令是对104比特中间乘积的高52比特还是低52比特进行操作,如块605处所示。为了执行指令300(vpm52huq),处理器被配置为对104比特中间乘积的高52比特进行操作。处理器可以对104比特中间乘积的高52比特进行零扩展,以产生64比特值,如块606处所示。为了执行指令310(vpm52luq),处理器被配置为对104比特中间乘积的低52比特进行操作。处理器可以对104比特中间乘积的低52比特进行零扩展,以产生64比特值,如块607处所示。对于这两条指令,处理器然后将由乘法器输出的64比特值紧缩到指定的目的地中,如块608处所示。该目的地可以是例如128比特、256比特或512比特向量寄存器。可以在多个执行通道上同时执行乘法操作,其中通道的数目是基于指令的执行大小或指令宽度来确定的(例如,对于128比特、256比特或512比特操作对象,有两个、四个或八个通道)。
图7图示了根据本文描述的实施例的执行52比特向量紧缩乘法-加法或乘法-减法指令的方法700。方法700可以由处理器的功能单元执行,该处理器可以包括通用处理器(CPU)、图形处理器(GPU)或者被配置为加速图形和计算操作的通用图形处理器(GPGPU)。
根据方法700,处理器可以取得指令,并且将该指令解码为经解码的指令,如块702处所示。该指令可以是例如图3的指令320、指令330、指令340或指令350,并且包括第一、第二和第三源操作对象,这些操作对象可以包括64比特数据元素,这些数据元素在存储器位置中被紧缩成128比特、256比特或者512比特向量或紧缩数据类型。操作对象中的一个或多个也可以是单个64比特数据元素,它被广播到所有的执行通路或通道。处理器可以在功能单元中配置乘法器,以对第二源操作对象和第三源操作对象的相应64比特数据元素执行按元素乘法,以生成一组128比特中间结果,这些中间结果存储由52比特数据元素的乘法产生的104比特中间乘积,如块703处所示。或者,一组52比特x52比特乘法操作可以由浮点硬件执行,以生成104比特中间结果。
方法700还包括让处理器确定指令的执行是否包括对中间乘积进行零扩展,如块705处所示。指令320(vpmadd52huq52z)和指令340(vpmsub52huq52z)使得中间乘积在执行加法或减法操作之前被零扩展。指令330(vpmadd52huq52)和指令350(vpmsub52huq52)不对中间乘积进行零扩展。对于vpmadd52huq52z和vpmsub52huq52z,处理器可以配置功能单元来将104比特中间乘积的高52比特零扩展到64比特值,如块706处所示。然后,功能单元可以使用第一源操作对象的64比特数据元素来向64比特值进行加法或者从其中进行减法,以生成64比特中间值,如块708处所示。然后,功能单元可以将64比特中间值的低52比特零扩展到64比特值,如块710处所示。对于vpmadd52huq52和vpmsub52huq52,处理器可以配置功能单元来使用第一源操作对象的64比特数据元素的低52比特向104比特中间乘积的高52比特进行加法或者从其中进行减法,以生成52比特(vpmsub52huq52)或者53比特(vpmadd52huq52)中间值,如块707处所示。然后,功能单元可以将低52比特或者53比特中间值零扩展到64比特值,如块709处所示。对于每个指令,为了返回结果值,功能单元可以将64比特值紧缩到指定的目的地中,如块712处所示。该目的地可以是例如128比特、256比特或512比特向量寄存器。可以在多个执行通道上同时执行乘法操作,其中通道的数目是基于指令的执行大小或指令宽度来确定的(例如,对于128比特、256比特或512比特操作对象,有两个、四个或八个通道)。对于vpmadd52huq52,在输出中包括溢出。对于vpmadd52huq52z、vpmsub52huq52和vpmsub52huq52z,识别每个通道溢出的溢出标志或比特掩码也可以作为输出被提供。
本文描述的指令可以用于减少一些HE操作中使用的指令数目,如表格19和表格20中所示的示例性正向NTT蝶形操作和表格22和表格23中所示的示例性逆向NTT蝶形操作所示。
表格19—正向NTT蝶形
/>
表格20—具有新的52比特指令的正向NTT蝶形
表格19和表格20中所示的正向NTT蝶形例程是使用内在指令实现的,这些内在指令直接映射到关联的汇编指令。对于表格19中所示的例程,第06-08行的指令将紧缩无符号52比特整数相乘,并且将来自中间结果的高或低52比特无符号整数与额外的相应无符号64比特整数输入值相加。第06行和第07行提供零值输入,因为先前没有提供52比特紧缩向量乘法指令。在第08行上向指令提供了负的模数值,因为先前没有提供52比特紧缩向量乘法-减法指令。在第12行和第13行上执行额外的操作,以丢弃紧缩64比特数据元素的高12比特。
表格19的正向NTT蝶形例程的效率可以通过使用本文描述的指令而得到显著改善,其中内在指令与本文根据表格21描述的指令相对应。
表格21—内在指令对应关系
使用本文描述的52比特乘法和乘法-加法或者乘法-减法指令,在示例实现方式中用于执行正向NTT操作的汇编指令的数目可以从十一条指令减少到八条指令,并且产生显著的性能改善。对于加数有零输入的52比特乘法-加法指令可以用52比特乘法指令来替换。不再需要明确地丢弃高12比特的操作。还启用了一种实现方式,其利用乘法-减法操作进行模数算术,而不是使用负模的乘法-加法操作。也可以为逆向NTT蝶形例程实现类似的改善。
表格22—逆向NTT蝶形
表格23—具有新的52比特指令的逆向NTT蝶形
使用本文描述的52比特乘法和乘法-加法或者乘法-减法指令,在示例实现方式中用于执行逆向NTT操作的汇编指令的数目可以从十一条指令减少到八条指令,并且产生显著的性能改善。表格22的第08行至第12行上的指令可以用表格23的第07行至第12行上所示出的一个或多个化简指令实现方式来替换,其中可以包括用负模输入执行52比特乘法-加法操作的实现方式或者52比特乘法-减法实现方式。
上述实施例提供了一种处理器,其包括第一电路,用于将指令解码为经解码的指令,该指令指示出第一源操作对象和第二源操作对象。该处理器还包括第二电路,该第二电路包括用于执行经解码的指令的处理资源。响应于经解码的指令,处理资源可以对第一源操作对象和第二源操作对象的相应64比特数据元素执行按元素乘法,以生成一组128比特中间结果,这些中间结果存储由52比特数据元素的乘法产生的104比特中间乘积。然后,处理资源可以对于具有第一操作码的经解码的指令,将104比特中间乘积的高52比特零扩展到64比特值,并且对于具有第二操作码的经解码的指令,将104比特中间乘积的低52比特零扩展到64比特值。然后,第二电路可以将64比特值紧缩成紧缩数据类型,并且将紧缩数据类型存储在指定的目的地位置。
一个实施例提供了一种处理器,其包括第一电路,用于将指令解码为经解码的指令,该指令指示出第一源操作对象、第二源操作对象、第三源操作对象和目的地操作对象,以及第二电路,该第二电路包括用于执行经解码的指令的处理资源。响应于经解码的指令,处理资源被配置为对第二源操作对象和第三源操作对象的相应64比特数据元素中的52比特数据值执行按元素乘法,以生成一组中间结果,这些中间结果存储由对52比特数据值执行的按元素乘法产生的104比特中间乘积,并且,对于具有第一操作码的经解码的指令,将104比特中间乘积的高52比特零扩展到第一64比特数据值,对第一64比特数据值和第一源操作对象的64比特数据元素内的第二64比特数据值执行算术操作,对第二64比特数据值的低52比特进行零扩展以生成第三64比特数据值,并且将第三64比特数据值紧缩成紧缩数据类型并且将紧缩数据类型存储在指定的目的地位置。
在另一个实例中,算术操作是减法操作,并且第一操作码与52比特乘法-减法指令相关联。算术操作也可以是加法操作,其中第一操作码与52比特乘法-加法指令相关联。第二电路可以进一步被配置为,对于具有第二操作码的经解码的指令,对104比特中间乘积的高52比特和第一源操作对象的64比特数据元素的低52比特执行算术操作,以生成中间值。中间值可以是52比特或53比特中间值。然后,第二电路可以对中间值进行零扩展以生成第四64比特数据值,并且将第四64比特数据值紧缩成紧缩数据类型,并且将紧缩数据类型存储在指定的目的地位置。在中间值是53比特中间值的情况下,53比特中间值包括52比特中间值和溢出比特,算术操作是加法操作,并且第二操作码与52比特乘法-加法指令相关联。在中间值是52比特中间值的情况下,第二电路可以响应于确定中间值超过52比特而在掩码中设置比特,并且算术操作可以是减法操作,其中第二操作码与52比特乘法-减法指令相关联,或者算术操作是加法操作,其中第二操作码与52比特乘法-加法指令相关联。该处理器可以是通用处理单元(例如,CPU)或者通用图形处理单元(GPGPU)。
另一个实施例提供了一种方法,该方法包括取得指令并且将该指令解码为经解码的指令,该指令具有多个源操作对象和一个或多个目的地操作对象。该方法还包括执行经解码的指令,其中执行经解码的指令包括对多个源操作对象中的两个的相应64比特数据元素中的52比特数据值执行按元素乘法,以生成一组中间结果,该中间结果存储由52比特数据值的乘法产生的104比特中间乘积,对于具有第一操作码的经解码的指令,对104比特中间乘积的高52比特进行零扩展以生成64比特结果值,对于具有第二操作码的经解码的指令,对104比特中间乘积的低52比特进行零扩展以生成64比特结果值,并且将64比特结果值紧缩成紧缩数据类型,并且将紧缩数据类型存储在由目的地操作对象指定的位置。
执行经解码的指令还可以包括,对于具有第三操作码的经解码的指令,对104比特中间乘积的高52比特进行零扩展以生成第一64比特中间值,使用多个源操作对象中的额外源操作对象的64比特数据元素来对第一64比特中间值进行加法或减法以生成第二64比特中间值,并且在将64比特结果值紧缩成紧缩数据类型之前将64比特中间值的低52比特零扩展到64比特结果值。执行经解码的指令还可以包括,对于具有第四操作码的经解码的指令,对104比特中间乘积的高52比特值和多个源操作对象中的额外源操作对象的64比特数据元素的低52比特进行加法或减法,以生成52比特或者53比特的中间值,并且在将64比特结果值紧缩成紧缩数据类型之前对中间值进行零扩展以生成64比特结果值。
一个实施例提供了一种数据处理系统,其包括网络接口、存储指令的存储器设备、以及与网络接口和存储器设备耦合的一个或多个处理器。该一个或多个处理器包括通用处理器(例如,CPU)和/或通用图形处理器(GPGPU)。提供同态加密加速库的指令包括用于加速同态加密操作的基元。该一个或多个处理器,响应于指令的执行,被配置为经由网络接口接收一组加密数据,其中该组加密数据是经由同态加密方案来加密的,并且经由同态加密加速库提供的基元对该组加密数据执行算术操作。
也可以基于上述细节和下面提供的体系结构细节来提供其他处理器、设备和/或系统。
CPU和GPU系统体系结构
图8是根据一实施例的处理系统800的框图。处理系统800可以被用于单处理器桌面系统、多处理器工作站系统、或者具有大量处理器802或处理器核心807的服务器系统中。在一个实施例中,处理系统800是包含在片上系统(system-on-a-chip,SoC)集成电路内的处理平台,用于移动、手持或嵌入式设备,例如在具有与局域网或广域网的有线或无线连通性的物联网(Internet-of-things,IoT)设备内。
在一个实施例中,处理系统800可以包括以下所列项、与以下所列项耦合或者被集成在以下所列项内:基于服务器的游戏平台;游戏控制台,包括游戏和媒体控制台;移动游戏控制台、手持游戏控制台、或者在线游戏控制台。在一些实施例中,处理系统800是移动电话、智能电话、平板计算设备或者移动互联网连接设备的一部分,例如内部存储容量较低的膝上型电脑。处理系统800还可以包括以下所列项、与以下所列项耦合或者被集成在以下所列项内:可穿戴设备,例如智能手表可穿戴设备;智能眼镜或服装,其被用增强现实(augmented reality,AR)或虚拟现实(virtual reality,VR)特征来增强,以提供视觉、音频或触觉输出,来补充现实世界的视觉、音频或触觉体验,或者以其他方式提供文本、音频、图形、视频、全息图像或视频,或者触觉反馈;其他增强现实(AR)设备;或者其他虚拟现实(VR)设备。在一些实施例中,处理系统800包括电视机或机顶盒设备或者是其一部分。在一个实施例中,处理系统800可以包括自动驾驶载具、与其耦合或者被集成在其内,其中自动驾驶载具例如是公共汽车、拖拉机拖车、汽车、马达或电力循环、飞机或滑翔机(或者它们的任意组合)。自动驾驶载具可以使用处理系统800来处理在载具周围感测到的环境。
在一些实施例中,一个或多个处理器802各自包括一个或多个处理器核心807,以处理指令,这些指令在被执行时,执行系统或用户软件的操作。在一些实施例中,一个或多个处理器核心807中的至少一者被配置为处理特定的指令集809。在一些实施例中,指令集809可以促进复杂指令集计算(Complex Instruction Set Computing,CISC),精简指令集计算(Reduced Instruction Set Computing,RISC),或者经由超长指令字(Very LongInstruction Word,VLIW)的计算。一个或多个处理器核心807可以处理不同的指令集809,其中可以包括促进对其他指令集的仿真的指令。处理器核心807也可以包括其他处理设备,例如数字信号处理器(Digital Signal Processor,DSP)。
在一些实施例中,处理器802包括缓存存储器804。取决于体系结构,处理器802可以具有单个内部缓存或者多个级别的内部缓存。在一些实施例中,在处理器802的各种组件之间共享缓存存储器。在一些实施例中,处理器802还使用外部缓存(例如,第3级(L3)缓存或者最后一级缓存(Last Level Cache,LLC))(未示出),可以使用已知的缓存一致性技术在处理器核心807之间共享这些外部缓存。在处理器802中还可以包括寄存器堆806,并且寄存器堆806可以包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器、以及指令指针寄存器)。一些寄存器可以是通用的寄存器,而其他寄存器可以是特定于处理器802的设计的。
在一些实施例中,一个或多个处理器802与一个或多个接口总线810耦合,以在处理器802和处理系统800中的其他组件之间传输通信信号,例如地址、数据、或者控制信号。在一个实施例中,接口总线810可以是处理器总线,例如直接媒体接口(Direct MediaInterface,DMI)总线的一个版本。然而,处理器总线不限于DMI总线,而是可以包括一个或多个外围组件互连总线(例如,PCI,PCI快速)、存储器总线、或者其他类型的接口总线。在一个实施例中,(一个或多个)处理器802包括集成存储器控制器816和平台控制器中枢830。存储器控制器816促进存储器设备与处理系统800的其他组件之间的通信,而平台控制器中枢(platform controller hub,PCH)830经由本地I/O总线提供到I/O设备的连接。
存储器设备820可以是动态随机存取存储器(dynamic random-access memory,DRAM)设备、静态随机存取存储器(static random-access memory,SRAM)设备、闪存设备、相变存储器设备、或者具有适当的性能来用作进程存储器的某种其他存储器设备。在一个实施例中,存储器设备820可以充当处理系统800的系统存储器,以存储数据822和指令821来在一个或多个处理器802执行应用或进程时使用。存储器控制器816还与可选的外部图形处理器818耦合,该外部图形处理器可以与处理器802中的一个或多个图形处理器808通信以执行图形和媒体操作。在一些实施例中,图形、媒体和/或计算操作可以由加速器812协助,该加速器是协处理器,该协处理器可以被配置为执行一组专门的图形、媒体或计算操作。例如,在一个实施例中,加速器812是矩阵乘法加速器,用于优化机器学习或计算操作。在一个实施例中,加速器812是光线追踪加速器,其可以用于与图形处理器808协同地执行光线追踪操作。在一个实施例中,外部加速器819可以取代加速器812被使用或者与之协同被使用。
在一些实施例中,显示设备811可以连接到(一个或多个)处理器802。显示设备811可以是像在移动电子设备或膝上型电脑设备中那样的内部显示设备或者经由显示接口(例如,DisplayPort等等)附接的外部显示设备中的一个或多个。在一个实施例中,显示设备811可以是头戴式显示器(head mounted display,HMD),例如立体显示设备,来用于虚拟现实(virtual reality,VR)应用或增强现实(augmented reality,AR)应用中。
在一些实施例中,平台控制器中枢830使得外设能够经由高速I/O总线连接到存储器设备820和处理器802。I/O外设包括但不限于音频控制器846、网络控制器834、固件接口828、无线收发器826、触摸传感器825、数据存储设备824(例如,非易失性存储器、易失性存储器、硬盘驱动器、闪存、NAND、3D NAND、3D XPoint,等等)。数据存储设备824可以经由存储接口(例如,SATA)或者经由外围总线(例如,外围组件互连总线(例如,PCI、PCI快速))连接。触摸传感器825可以包括触摸屏传感器、压力传感器、或者指纹传感器。无线收发器826可以是Wi-Fi收发器、蓝牙收发器、或者移动网络收发器,例如3G、4G、5G或者长期演进(Long-Term Evolution,LTE)收发器。固件接口828使得能够与系统固件进行通信,并且可以是例如统一可扩展固件接口(unified extensible firmware interface,UEFI)。网络控制器834可以实现与有线网络的网络连接。在一些实施例中,高性能网络控制器(未示出)与接口总线810耦合。音频控制器846在一个实施例中是多通道高清晰度音频控制器。在一个实施例中,处理系统800包括可选的传统I/O控制器840,用于将传统(例如,个人系统2(PersonalSystem 2,PS/2))设备耦合到系统。平台控制器中枢830也可以连接到一个或多个通用串行总线(Universal Serial Bus,USB)控制器842连接输入设备,例如键盘和鼠标843组合、相机844、或者其他USB输入设备。
将会明白,所示出的处理系统800是示例性的,而不是限制性的,因为也可以使用不同配置的其他类型的数据处理系统。例如,存储器控制器816和平台控制器中枢830的实例可以被集成到分立的外部图形处理器中,例如外部图形处理器818。在一个实施例中,平台控制器中枢830和/或存储器控制器816可以在一个或多个处理器802的外部。例如,处理系统800可以包括外部存储器控制器816和平台控制器中枢830,其可以被配置为与(一个或多个)处理器802通信的系统芯片组内的存储器控制器中枢和外围控制器中枢。
例如,可以使用电路板(“托架”(sled)),其上放置诸如CPU、存储器和其他组件之类的组件,并且其设计是针对提高热性能的。在一些示例中,处理组件,例如处理器,位于托架的顶侧,而近端存储器,例如DIMM,位于托架的底侧。由于这种设计提供了增强的气流,组件可以在比典型系统更高的频率和功率水平下操作,从而提高性能。此外,托架被配置为与机架中的电力和数据通信电缆盲配对,从而增强了其被迅速移除、升级、重安装和/或更换的能力。类似地,位于托架上的个体组件,例如处理器、加速器、存储器和数据存储驱动器,由于它们彼此之间的间距增大,被配置为易于升级。在说明性实施例中,这些组件还包括硬件鉴证(attestation)特征,以证明其真实性。
数据中心可以利用单个网络体系结构(“结构”(fabric)),其支持多个其他网络体系结构,包括以太网和Omni-Path。托架可以经由光纤耦合到交换机,这比典型的双绞线电缆提供了更高的带宽和更低的延时。由于高带宽、低延时的互连和网络体系结构,数据中心在使用中可以汇集资源,例如存储器、加速器(例如,GPU、图形加速器、FPGA、ASIC、神经网络和/或人工智能加速器,等等),以及在物理上解聚集的数据存储驱动器,并且根据需要将其提供给计算资源(例如,处理器),使得计算资源能够好像资源在本地那样访问汇集的资源。
电力供应源或电源可以向处理系统800或者本文描述的任何组件或系统提供电压和/或电流。在一个示例中,电力供应源包括AC到DC(交流电到直流电)适配器,以插入到壁式插座中。这种AC电力可以是可再生能量(例如,太阳能)电源。在一个示例中,电源包括DC电源,例如外部AC到DC转换器。在一个示例中,电源或电力供应源包括无线充电硬件,以经由接近充电场来充电。在一个示例中,电源可以包括内部电池、交流供应源、基于运动的电力供应源、太阳能电力供应源、或者燃料电池源。
图9A-图9B图示了由本文描述的实施例提供的计算系统和图形处理器。图9A-图9B的具有与本文的任何其他附图中的元素相同的标号(或名称)的那些元素可以按与本文别处所描述的相似的任何方式操作或工作,但不限于此。
图9A是具有一个或多个处理器核心902A-902N、一个或多个集成存储器控制器914以及集成图形处理器908的处理器900的实施例的框图。处理器900包括至少一个核心902A并且还可以包括额外的核心,多达并包括额外核心902N,如虚线框所表示。处理器核心902A-902N中的每一者包括一个或多个内部缓存单元904A-904N。在一些实施例中,每个处理器核心还能够访问一个或多个共享缓存单元906。内部缓存单元904A-904N和共享缓存单元906代表处理器900内的缓存存储器层次体系。该缓存存储器层次体系可以包括每个处理器核心内的至少一级指令和数据缓存以及一个或多个级别的共享中间级缓存,例如第2级(L2)、第3级(L3)、第4级(L4)或者其他级别的缓存,其中外部存储器之前的最高级别缓存被分类为LLC。在一些实施例中,缓存一致性逻辑维持各种缓存单元906和904A-904N之间的一致性。
在一些实施例中,处理器900还可以包括一组一个或多个总线控制器单元916和一系统代理核心910。一个或多个总线控制器单元916管理一组外围总线,例如一个或多个PCI或PCI快速总线。系统代理核心910为各种处理器组件提供管理功能。在一些实施例中,系统代理核心910包括一个或多个集成存储器控制器914,以管理对各种外部存储器设备(未示出)的访问。
在一些实施例中,处理器核心902A-902N中的一个或多个包括对同时多线程的支持。在这样的实施例中,系统代理核心910包括用于在多线程处理期间协调和操作核心902A-902N的组件。系统代理核心910还可以包括功率控制单元(power control unit,PCU),其包括调节处理器核心902A-902N和图形处理器908的功率状态的逻辑和组件。
在一些实施例中,处理器900还包括图形处理器908,以执行图形处理操作。在一些实施例中,图形处理器908与一组共享缓存单元906以及系统代理核心910(包括一个或多个集成存储器控制器914)相耦合。在一些实施例中,系统代理核心910还包括显示控制器911,以驱动图形处理器输出到一个或多个耦合的显示器。在一些实施例中,显示控制器911也可以是经由至少一个互连与图形处理器相耦合的单独模块,或者可以被集成在图形处理器908内。
在一些实施例中,使用基于环的互连912来耦合处理器900的内部组件。然而,也可以使用替代的互连单元,例如点到点互连、交换式互连或者其他技术,包括本领域公知的技术。在一些实施例中,图形处理器908经由I/O链路913与基于环的互连912耦合。
示例性I/O链路913代表多个种类的I/O互连中的至少一种,包括封装上I/O互连,它促进了各种处理器组件和存储器模块918之间的通信,例如eDRAM模块或者高带宽存储器(high-bandwidth memory,HBM)存储器模块。在一个实施例中,存储器模块918可以是eDRAM模块,并且处理器核心902A-902N中的每一者和图形处理器908可以使用存储器模块918作为共享LLLC。在一个实施例中,存储器模块918是HBM存储器模块,该HBM存储器模块可以被用作主存储器模块或者被用作分层级或混合存储器系统的一部分,该存储器系统还包括双数据速率同步DRAM,例如DDR5 SDRAM,和/或持久性存储器(persistent memory,PMem)。处理器900可以包括I/O链路913和存储器模块918的多个实例。
在一些实施例中,处理器核心902A-902N是执行相同指令集体系结构的同构核心。在另一实施例中,处理器核心902A-902N就指令集体系结构(instruction setarchitecture,ISA)而言是异构的,其中处理器核心902A-902N中的一个或多个执行第一指令集,而其他核心中的至少一个执行第一指令集的子集或者不同的指令集。在一个实施例中,处理器核心902A-902N就微体系结构而言是异构的,其中具有相对更高功率消耗的一个或多个核心与具有更低功率消耗的一个或多个功率核心相耦合。在一个实施例中,处理器核心902A-902N就计算能力而言是异构的。此外,处理器900可以被实现在一个或多个芯片上,或者被实现为SoC(片上系统)集成电路,该SoC集成电路除了其他组件以外还具有图示的组件。
图9B是根据本文描述的一些实施例的图形处理器核心块919的硬件逻辑的框图。图形处理器核心块919是图形处理器的一个分区的示范。如本文所述的图形处理器可以包括基于目标功率和性能包络的多个图形核心块。每个图形处理器核心块919可以包括与多个执行核心921A-921F耦合的功能块930,这些执行核心包括固定功能逻辑和通用可编程逻辑的模块。图形处理器核心块919还包括可被所有执行核心921A-921F访问的共享/缓存存储器936、光栅化器逻辑937、以及额外的固定功能逻辑938。
在一些实施例中,功能块930包括可由图形处理器核心块919中的所有执行核心共享的几何/固定功能管线931。在各种实施例中,几何/固定功能管线931包括3D几何管线、视频前端单元、线程产生器以及全局线程调遣器,以及统一返回缓冲区管理器,它管理统一返回缓冲区。在一个实施例中,功能块930还包括图形SoC接口932、图形微控制器933、以及媒体管线934。图形SoC接口932提供图形处理器核心块919与图形处理器或计算加速器SoC内的其他核心块之间的接口。图形微控制器933是可编程的子处理器,它可配置为管理图形处理器核心块919的各种功能,包括线程调遣、调度和先占。媒体管线934包括逻辑来促进包括图像和视频数据在内的多媒体数据的解码、编码、预处理和/或后处理。媒体管线934经由对执行核心921-921F内的计算或采样逻辑的请求来实现媒体操作。一个或多个像素后端935也可以被包括在功能块930内。像素后端935包括存储像素颜色值的缓存存储器,并且可以执行混合操作和渲染的像素数据的无损颜色压缩。
在一个实施例中,SoC接口932使得图形处理器核心块919能够与SoC内的通用应用处理器核心(例如,CPU)和/或其他组件或者经由外围接口与SoC耦合的系统主机CPU进行通信。SoC接口932还使得能够与片外存储器层次体系元素进行通信,例如共享的最后一级缓存存储器、系统RAM和/或嵌入式片上或封装上DRAM。SoC接口932还可以使得能够与SoC内的固定功能设备进行通信,例如相机成像管线,并且使得能够使用和/或实现全局存储器原子,该全局存储器原子可以在SoC内的图形处理器核心块919和CPU之间共享。SoC接口932还可以实现对于图形处理器核心块919的功率管理控制,并且使得能够实现图形处理器核心块919的时钟域与SoC内其他时钟域之间的接口。在一个实施例中,SoC接口932使得能够从命令流器和全局线程调遣器接收命令缓冲区,这些命令缓冲区被配置为向图形处理器内的一个或多个图形核心中的每一者提供命令和指令。当要执行媒体操作时,命令和指令可以被调遣到媒体管线934,当要执行图形处理操作时,命令和指令可以被调遣到几何和固定功能管线931。当要执行计算操作时,计算调遣逻辑可以将命令调遣到执行核心921A-921F,绕过几何和媒体管线。
图形微控制器933可以被配置为为图形处理器核心块919执行各种调度和管理任务。在一个实施例中,图形微控制器933可以在执行核心921A-921F内的执行单元(execution unit,EU)阵列922A-922F、924A-924F内的各种图形并行引擎上执行图形和/或计算工作负载调度。在这个调度模型中,在包括图形处理器核心块919的SoC的CPU核心上执行的主机软件可以提交工作负载给多个图形处理器门铃之一,这调用了适当的图形引擎上的调度操作。调度操作包括确定接下来要运行哪个工作负载,将工作负载提交给命令流器,先占在引擎上运行的现有工作负载,监视工作负载的进度,并且在工作负载完成时通知主机软件。在一个实施例中,图形微控制器933还可以促进图形处理器核心块919的低功率或空闲状态,为图形处理器核心块919提供在低功率状态转换中保存和恢复图形处理器核心块919内的寄存器的能力,而不依赖于操作系统和/或系统上的图形驱动软件。
图形处理器核心块919可以具有多于或少于图示的执行核心921A-921F,最多为N个模块化执行核心。对于每一组N个执行核心,图形处理器核心块919还可以包括共享/缓存存储器936(它可以被配置为共享存储器或者缓存存储器),光栅化器逻辑937,以及额外的固定功能逻辑938,以加速各种图形和计算处理操作。
在执行核心921A-921F中的每一者内有一组执行资源,这些执行资源可以用于响应于图形管线、媒体管线或者着色器程序的请求而执行图形、媒体和计算操作。图形执行核心921A-921F包括多个向量引擎922A-922F、924A-924F,矩阵加速单元923A-923F、925A-925D,缓存/共享本地存储器(shared local memory,SLM),采样器926A-926F,以及光线追踪单元927A-927F。
向量引擎922A-922F、924A-924F是通用图形处理单元,能够执行浮点和整数/定点逻辑操作,为图形、媒体或计算操作服务,包括图形、媒体或计算/GPGPU程序。向量引擎922A-922F、924A-924F可以使用SIMD、SIMT或者SIMT+SIMD执行模式以可变向量宽度操作。矩阵加速单元923A-923F、925A-925D包括矩阵-矩阵和矩阵-向量加速逻辑,该逻辑改善矩阵操作的性能,尤其是用于机器学习的低精度和混合精度(例如,INT8、FP16)矩阵操作。在一个实施例中,矩阵加速单元923A-923F、925A-925D中的每一者包括处理元素的一个或多个脉动阵列,它们可以对矩阵元素执行并发的矩阵乘法或者点积操作。
采样器925A-925F可以将媒体或纹理数据读入到存储器中,并且可以基于配置的采样器状态和正在读取的纹理/媒体格式对数据进行不同的采样。在向量引擎922A-922F、924A-924F或者矩阵加速单元923A-923F、925A-925D上执行的线程可以利用每个执行核心内的缓存/SLM 928A-928F。缓存/SLM 928A-928F可以被配置为缓存存储器或者被配置为在各个执行核心921A-921F中的每一者本地的共享存储器的池。执行核心921A-921F内的光线追踪单元927A-927F包括光线遍历/交叉电路,用于使用限界体积层次体系(boundingvolume hierarchy,BVH)执行光线追踪,并且识别光线与BVH体积内所包围的基元之间的交叉。在一个实施例中,光线追踪单元927A-927F包括用于执行深度测试和剔除的电路(例如,使用深度缓冲器或者类似的布置)。在一个实现方式中,光线追踪单元927A-927F与图像去噪协同地执行遍历和交叉操作,其中至少一部分可以使用关联的矩阵加速单元923A-923F、925A-925D来执行。
图10A的框图图示出了本文描述的处理器的示例性有序管线和示例性寄存器重命名、无序发出/执行管线。图10B的框图图示出了处理器核心的体系结构,它可以被配置为有序体系结构核心或者寄存器重命名、无序发出/执行体系结构核心。考虑到有序方面是无序方面的子集,将描述无序方面。
如图10A所示,处理器管线1000包括取得阶段1002、可选的长度解码阶段1004、解码阶段1006、可选的分配阶段1008、可选的重命名阶段1010、调度(也称为调遣或发出)阶段1012、可选的寄存器读取/存储器读取阶段1014、执行阶段1016、写回/存储器写入阶段1018、可选的异常处置阶段1022、以及可选的提交阶段1024。在这些处理器管线阶段的每一者中可以执行一个或多个操作。例如,在取得阶段1002期间,从指令存储器取得一个或多个指令,在解码阶段1006期间,可以对取得的一个或多个指令进行解码,可以生成使用转发寄存器端口的地址(例如,加载存储单元(load store unit,LSU)地址),并且可以执行分支转发(例如,立即数偏移或者链接寄存器(link register,LR))。在一个实施例中,解码阶段1006和寄存器读取/存储器读取阶段1014可以被组合到一个管线阶段中。在一个实施例中,在执行阶段1016期间,可以执行解码的指令,可以执行到高级微控制器总线(AdvancedMicrocontroller Bus,AHB)接口的LSU地址/数据管线化,可以执行乘法和加法操作,可以执行具有分支结果的算术操作,等等。
如图10B所示,处理器核心1090可以包括与执行引擎电路1050耦合的前端单元电路1030,两者都与存储器单元电路1070耦合。处理器核心1090可以是如图9A中的处理器核心902A-902N之一。处理器核心1090可以是精简指令集计算(reduced instruction setcomputing,RISC)核心、复杂指令集计算(complex instruction set computing,CISC)核心、超长指令字(very long instruction word,VLIW)核心、或者混合或替代性核心类型。作为另外一个选项,处理器核心1090可以是专用核心,例如网络或通信核心、压缩引擎、协处理器核心、通用计算图形处理单元(general purpose computing graphics processingunit,GPGPU)核心、图形核心,等等。
前端单元电路1030可以包括分支预测单元电路1032,其耦合到指令缓存单元电路1034,该指令缓存单元电路耦合到指令转译后备缓冲器(translation lookaside buffer,TLB)1036,该指令TLB耦合到指令取得单元电路1038,该指令取得单元电路耦合到解码单元电路1040。在一个实施例中,指令缓存单元电路1034被包括在存储器单元电路1070中,而不是前端单元电路1030。解码单元电路1040(或解码器)可以对指令解码,并且生成一个或多个微操作、微代码入口点、微指令、其他指令或者其他控制信号作为输出,这些微操作、微代码入口点、微指令、其他指令或者其他控制信号是从原始指令解码来的,或者以其他方式反映原始指令,或者是从原始指令得出的。解码单元电路1040还可以包括地址生成单元电路(AGU,未示出)。在一个实施例中,AGU使用转发的寄存器端口来生成LSU地址,并且可以进一步执行分支转发(例如,立即数偏移分支转发,LR寄存器分支转发,等等)。可以利用各种不同的机制来实现解码单元电路1040。适当机制的示例包括但不限于查找表、硬件实现方式、可编程逻辑阵列(programmable logic array,PLA)、微代码只读存储器(read onlymemory,ROM),等等。在一个实施例中,处理器核心1090包括微代码ROM(未示出)或其他介质,其为某些宏指令存储微代码(例如,在解码单元电路1040中或者以其他方式在前端单元电路1030内)。在一个实施例中,解码单元电路1040包括微操作(micro-op)或操作缓存(未示出),以保持/缓存在解码或处理器管线1000的其他阶段期间生成的经解码的操作、微标记或微操作。解码单元电路1040可以耦合到执行引擎电路1050中的重命名/分配器单元电路1052。
执行引擎电路1050包括重命名/分配器单元电路1052,其耦合到引退单元电路1054和一组一个或多个调度器电路1056。调度器电路1056代表任何数目的不同调度器,包括预留站、中央指令窗口,等等。在一些实施例中,调度器电路1056可以包括算术逻辑单元(arithmetic logic unit,ALU)调度器/调度电路、ALU队列、算术生成单元(arithmeticgeneration unit,AGU)调度器/调度电路、AGU队列,等等。调度器电路1056耦合到物理寄存器堆电路1058。物理寄存器堆电路1058中的每一者表示一个或多个物理寄存器堆,这些物理寄存器堆中的不同物理寄存器堆存储一个或多个不同的数据类型,例如标量整数、标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针),等等。在一个实施例中,物理寄存器堆电路1058包括向量寄存器单元电路、写入掩码寄存器单元电路、以及标量寄存器单元电路。这些寄存器单元可以提供体系结构式向量寄存器、向量掩码寄存器、通用寄存器,等等。物理寄存器堆电路1058与引退单元电路1054(也称为退役队列或引退队列)重叠,以说明可用来实现寄存器重命名和无序执行的各种方式(例如,利用(一个或多个)重排序缓冲器(reorder buffer,ROB)和(一个或多个)引退寄存器堆;利用(一个或多个)未来堆、(一个或多个)历史缓冲器、以及(一个或多个)引退寄存器堆;利用寄存器图谱和寄存器的池;等等)。引退单元电路1054和(一个或多个)物理寄存器堆电路1058耦合到(一个或多个)执行集群1060。(一个或多个)执行集群1060包括一组一个或多个执行单元电路1062和一组一个或多个存储器访问电路1064。执行单元电路1062可以对各种类型的数据(例如,标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点)执行各种算术、逻辑、浮点或其他类型的操作(例如,移位、加法、减法、乘法)。虽然一些实施例可以包括专用于特定功能或功能集合的若干个执行单元或执行单元电路,但其他实施例可以只包括一个执行单元电路或者全部执行所有功能的多个执行单元/执行单元电路。调度器电路1056、物理寄存器堆电路1058、以及(一个或多个)执行集群1060被示为可能是多个,因为某些实施例为某些类型的数据/操作创建单独的管线(例如,标量整数管线、标量浮点/紧缩整数/紧缩浮点/向量整数/向量浮点管线和/或存储器访问管线,它们各自具有其自己的调度器电路、物理寄存器堆单元电路和/或执行集群—并且在单独的存储器访问管线的情况下,实现了某些实施例,其中只有此管线的执行集群具有存储器访问单元电路1064)。还应当理解,在使用分开的管线的情况下,这些管线中的一个或多个可以是无序发出/执行,而其余的是有序的。
在一些实施例中,执行引擎电路1050可以执行到高级微控制器总线(AHB)接口(未示出)的加载存储单元(LSU)地址/数据管线化,以及地址阶段和写回、数据阶段加载、存储、以及分支。
存储器访问电路1064的集合耦合到存储器单元电路1070,该存储器单元电路包括数据TLB单元电路1072,该数据TLB单元电路耦合到数据缓存电路1074,该数据缓存电路耦合到第2级(L2)缓存电路1076。在一个示例性实施例中,存储器访问电路1064可以包括加载单元电路、存储地址单元电路、以及存储数据单元电路,它们中的每一者耦合到存储器单元电路1070中的数据TLB电路1072。指令缓存电路1034进一步耦合到存储器单元电路1070中的第2级(L2)缓存电路1076。在一个实施例中,指令缓存电路1034和数据缓存电路1074在L2缓存电路1076、第3级(L3)缓存单元电路(未示出)和/或主存储器中被组合成单个指令和数据缓存(未示出)。L2缓存电路1076耦合到一个或多个其他级别的缓存并且最终耦合到主存储器。
处理器核心1090可以支持一个或多个指令集(例如,x86指令集(带有已随着较新版本添加的一些扩展);MIPS指令集;ARM指令集(带有可选的额外扩展,例如NEON)),包括本文描述的(一个或多个)指令。在一个实施例中,处理器核心1090包括逻辑来支持紧缩数据指令集扩展(例如,AVX1、AVX2、AVX512),从而允许了被许多多媒体应用或者高性能计算应用(包括同态加密应用)使用的操作被利用紧缩或向量数据类型来执行。
图10B的处理器核心1090可以实现图10A的处理器管线1000,如下:1)指令取得电路1038执行取得和长度解码阶段1002和1004;2)指令解码单元电路1040执行解码阶段1006;3)重命名/分配器单元电路1052执行分配阶段1008和重命名阶段1010;4)调度器单元电路1056执行调度阶段1012;5)(一个或多个)物理寄存器堆电路1058和存储器单元电路1070执行寄存器读取/存储器读取阶段1014;执行集群1060执行执行阶段1016;6)存储器单元电路1070和(一个或多个)物理寄存器堆电路1058执行写回/存储器写入阶段1018;7)在异常处置阶段1022中可涉及各种单元(单元电路);并且8)引退单元电路1054和(一个或多个)物理寄存器堆电路1058执行提交阶段1024。
图11图示了根据本文描述的实施例的执行单元电路,例如图10B的执行单元电路1062。如图所示,执行单元电路1062可以包括一个或多个ALU电路1101、向量/SIMD单元电路1103、加载/存储单元电路1105、分支/跳转单元电路1107、和/或FPU电路1109。在执行单元电路1062可配置为执行GPGPU并行计算操作的情况下,执行单元电路还可以包括SIMT电路1111和/或矩阵加速电路1112。ALU电路1101执行整数算术和/或布尔操作。向量/SIMD单元电路1103对紧缩数据(例如,SIMD/向量寄存器)执行向量/SIMD操作。加载/存储单元电路1105执行加载和存储指令,以将数据从存储器加载到寄存器中,或者从寄存器存储到存储器。加载/存储单元电路1105也可以生成地址。分支/跳转单元电路1107取决于指令而引起到某个存储器地址的分支或跳转。FPU电路1109执行浮点算术。在一些实施例中,SIMT电路1111使得执行单元电路1062能够使用一个或多个ALU电路1101和/或向量/SIMD单元电路1103执行SIMT GPGPU计算程序。在一些实施例中,执行单元电路1062包括矩阵加速电路1112,其中包括图9B的矩阵加速单元923A-923F、925A-925D中的一个或多个的硬件逻辑。执行单元电路1062的宽度取决于实施例而有所不同,并且可以在从16比特到4096比特的范围中。在一些实施例中,两个或更多个更小的执行单元被从逻辑上组合以形成更大的执行单元(例如,两个128比特执行单元被从逻辑上组合以形成256比特执行单元)。
图12是根据一些实施例的寄存器体系结构1200的框图。如图所示,存在向量寄存器1210,其宽度从128比特到1024比特不等。在一些实施例中,向量寄存器1210在物理上是512比特的,并且取决于映射,只有一些低位比特被使用。例如,在一些实施例中,向量寄存器1210是512比特的ZMM寄存器:低位256比特被用于YMM寄存器,并且低位128比特被用于XMM寄存器。因此,存在寄存器的覆盖。在一些实施例中,向量长度字段在最大长度和一个或多个其他更短的长度之间做出选择,其中每个这种更短长度是前一长度的一半长度。标量操作是在ZMM/YMM/XMM寄存器中的最低阶数据元素位置上执行的操作;更高阶数据元素位置或者被保持与其在该指令之前相同,或者被归零,这取决于实施例。
在一些实施例中,寄存器体系结构1200包括写入掩码/谓词寄存器1215。例如,在一些实施例中,有8个写入掩码/谓词寄存器(有时称为k0至k7),其中每一者是16比特、32比特、64比特或128比特大小的。写入掩码/谓词寄存器1215可以允许合并(例如,允许目的地中的任何元素集合在任何操作的执行期间免受更新)和/或归零(例如,归零向量掩码允许了目的地中的任何元素集合在任何操作的执行期间被归零)。在一些实施例中,给定的写入掩码/谓词寄存器1215中的每个数据元素位置对应于目的地的一个数据元素位置。在其他实施例中,写入掩码/谓词寄存器1215是可缩放的,并且由针对给定向量元素的设定数目个使能比特组成(例如,给每个64比特向量元素8个使能比特)。
寄存器体系结构1200包括多个通用寄存器1225。这些寄存器可以是16比特、32比特、64比特等等,并能够被用于标量操作。在一些实施例中,这些寄存器被用名称RAX、RBX、RCX、RDX、RBP、RSI、RDI、RSP以及R8至R15来引用。
在一些实施例中,寄存器体系结构1200包括标量浮点寄存器1245,它被用于使用x87指令集扩展对32/64/80比特浮点数据进行标量浮点操作,或者作为MMX寄存器以对64比特紧缩整数数据执行操作,以及为在MMX和XMM寄存器之间执行的一些操作保存操作对象。
一个或多个标志寄存器1240(例如,EFLAGS,RFLAGS,等等)存储状态和控制信息,用于算术、比较和系统操作。例如,一个或多个标志寄存器1240可以存储条件代码信息,例如进位、奇偶性、辅助进位、零、符号、以及溢出。在一些实施例中,一个或多个标志寄存器1240被称为程序状态和控制寄存器。
段寄存器1220包含用于存取存储器的段点。在一些实施例中,这些寄存器由名称CS、DS、SS、ES、FS和GS来称呼。
机器特定寄存器(machine-specific register,MSR)1235控制和报告处理器性能。大多数MSR 1235处置与系统有关的功能,并且是应用程序不可访问的。机器检查寄存器1260由用于对硬件错误进行检测和报告的控制、状态和错误报告MSR组成。
一个或多个指令指针寄存器1230存储指令指针值。(一个或多个)控制寄存器1255(例如,CR0-CR4)确定处理器的操作模式和当前在执行的任务的特性。调试寄存器1250控制并允许监视处理器或核心的调试操作。
存储器管理寄存器1265指定用于保护模式存储器管理中的数据结构的位置。这些寄存器可以包括GDTR、IDRT、任务寄存器、以及LDTR寄存器。
替代性实施例使用更宽或更窄的寄存器,并且也可以使用更多、更少或者不同的寄存器堆和寄存器。
示例性指令格式
本文描述的(一个或多个)指令可以按不同的格式实现。此外,下文详述了示例性系统、体系结构和管线。可以在这种系统、体系结构和管线上执行(一个或多个)指令的实施例,但不限于详述的那些。
图13图示了根据一实施例的指令格式的实施例。如图所示,指令可以包括多个成分,这些成分包括但不限于用于以下所列项的一个或多个字段:一个或多个前缀1301、操作码1303、寻址信息1305(例如,寄存器标识符、存储器寻址信息,等等)、位移值1307、和/或立即数1309。注意,一些指令利用了该格式的一些或所有字段,而其他指令可能只使用操作码1303的字段。在一些实施例中,图示的顺序是这些字段要被编码的顺序,然而,应当明白,在其他实施例中,这些字段可以被以不同的顺序来编码、被组合,等等。
(一个或多个)前缀字段1301当被使用时会修改指令。在一些实施例中,一个或多个前缀被用于重复字符串指令(例如,0xF0、0xF2、0xF3,等等),以提供片段覆盖(例如,0x2E、0x36、0x3E、0x26、0x64、0x65、0x2E、0x3E,等等),以执行总线锁定操作,和/或改变操作对象(例如,0x66)和地址大小(例如,0x67)。某些指令要求强制性的前缀(例如,0x66、0xF2、0xF3,等等)。这些前缀中的某些可以被认为是“传统”前缀。其他前缀(本文详述了其一个或多个示例)指示出和/或提供了进一步的能力,例如指定特定的寄存器等等。这些其他前缀通常跟随在“传统”前缀之后。
操作码字段1303被用于至少部分地定义在指令的解码时要执行的操作。在一些实施例中,在操作码字段1303中编码的主操作码的长度为1、2或3个字节。在其他实施例中,主操作码可以是不同的长度。额外的3比特操作码字段有时被编码在另一个字段中。
寻址字段1305被用于寻址指令的一个或多个操作对象,例如存储器中的位置或者一个或多个寄存器。
图14图示了寻址字段1305的实施例。在这个图示中,示出了可选的Mod R/M字节1402和可选的缩放、索引、基址(Scale,Index,Base,SIB)字节1404。Mod R/M字节1402和SIB字节1404被用于编码一指令的多达两个操作对象,每个操作对象是直接寄存器或有效存储器地址。注意,这些字段中的每一者是可选的,即,不是所有的指令都包括这些字段中的一个或多个。MOD R/M字节1402包括MOD字段1442、寄存器字段1444、和R/M字段1446。
MOD字段1442的内容区分存储器访问和非存储器访问模式。在一些实施例中,当MOD字段1442的值为b11时,就利用了寄存器直接寻址模式,否则就使用寄存器间接寻址。
寄存器字段1444可以编码目的地寄存器操作对象或者源寄存器操作对象,或者也可以编码操作码扩展而不被用于编码任何指令操作对象。寄存器索引字段1444的内容直接指定或者通过地址生成指定源或目的地操作对象的位置(在寄存器中或者在存储器中)。在一些实施例中,寄存器字段1444被补充以来自前缀(例如,前缀1301)的额外比特,以允许更大的寻址。
R/M字段1446可以用来编码引用了存储器地址的指令操作对象,或者可以用来编码目的地寄存器操作对象或源寄存器操作对象。注意R/M字段1446在一些实施例中可以被与MOD字段1442相组合以规定寻址模式。
SIB字节1404包括缩放字段1452、索引字段1454、以及基址字段1456,以用于地址的生成。缩放字段1452指示缩放因子。索引字段1454指定要使用的索引寄存器。在一些实施例中,索引字段1454被补充以来自前缀(例如,前缀1301)的额外比特,以允许更大的寻址。基址字段1456指定了要使用的基址寄存器。在一些实施例中,基址字段1456被补充以来自前缀(例如,前缀1301)的额外比特,以允许更大的寻址。在实践中,缩放字段1452的内容允许缩放索引字段1454的内容以进行存储器地址生成(例如,对于使用2
一些寻址形式利用位移值来生成存储器地址。例如,可以根据2
在一些实施例中,立即数字段1309为指令指定立即数。立即数可以被编码为1字节值、2字节值、4字节值,等等。
图15图示了第一前缀1301(A)的实施例。在一些实施例中,第一前缀1301(A)是REX前缀的实施例。使用这个前缀的指令可以指定通用寄存器、64比特紧缩数据寄存器(例如,单指令多数据(single instruction,multiple data,SIMD)寄存器或向量寄存器)、和/或控制寄存器和调试寄存器(例如,CR8-CR15和DR8-DR15)。
使用第一前缀1301(A)的指令可以使用3比特字段指定最多三个寄存器,这取决于格式:1)使用Mod R/M字节1402的reg字段1444和R/M字段1446;2)使用Mod R/M字节1402与SIB字节1404,包括使用reg字段1444和基址字段1456和索引字段1454;或者3)使用操作码的寄存器字段。
在第一前缀1301(A)中,比特位置7:4被设置为0100。比特位置3(W)可以被用于确定操作对象大小,但不能单独确定操作对象宽度。因此,当W=0时,操作对象大小由代码段描述符(code segment descriptor,CS.D)决定,而当W=1时,操作对象大小为64比特。
注意,添加另一个比特则允许了寻址16(2
在第一前缀1301(A)中,比特位置2(R)可以是MOD R/M reg字段1444的扩展,并且当该字段编码通用寄存器、64比特紧缩数据寄存器(例如,SSE寄存器)或者控制或调试寄存器时,可被用来修改Mod R/M reg字段1444。当Mod R/M字节1402指定其他寄存器或定义扩展操作码时,R被忽略。
比特位置1(X)X比特可以修改SIB字节索引字段1454。
比特位置B(B)B可以修改Mod R/M R/M字段1446或SIB字节基址字段1456中的基址;或者它可以修改用于访问通用寄存器(例如,通用寄存器1225)的操作码寄存器字段。
图16A-图16D图示了根据一些实施例的第一前缀1301(A)的R、X和B字段的使用。图16A图示了当SIB字节1404不被用于存储器寻址时,来自第一前缀1301(A)的R和B被用来扩展MOD R/M字节1402的reg字段1444和R/M字段1446。图16B图示了当不使用SIB字节1404时,来自第一前缀1301(A)的R和B被用来扩展MOD R/M字节1402的reg字段1444和R/M字段1446(寄存器-寄存器寻址)。图16C图示了当SIB字节1404被用于存储器寻址时,来自第一前缀1301(A)的R、X和B被用于扩展MOD R/M字节1402的reg字段1444以及索引字段1454和基址字段1456。图16D图示了当寄存器被编码在操作码1303中时,来自第一前缀1301(A)的B被用来扩展MOD R/M字节1402的reg字段1444。
图17A-图17B图示了根据实施例的第二前缀1301(B)。在一些实施例中,第二前缀1301(B)是VEX前缀的实施例。第二前缀1301(B)编码允许指令具有多于两个操作对象,并且允许SIMD向量寄存器(例如,向量寄存器1210)长于64比特(例如,128比特和256比特)。第二前缀1301(B)的使用提供了三操作对象(或更多)的语法。例如,先前的两操作对象指令执行诸如A=A+B之类的操作,这覆写了源操作对象。对第二前缀1301(B)的使用使得操作对象能够执行非破坏性操作,比如A=B+C。
在一些实施例中,第二前缀1301(B)有两种形式——两字节形式和三字节形式。两字节的第二前缀1301(B)被主要用于128比特、标量和一些256比特指令;而三字节的第二前缀1301(B)提供了3字节操作码指令和第一前缀1301(A)的紧凑替换。
图17A图示了第二前缀1301(B)的两字节形式的实施例。在一个示例中,格式字段1701(字节0 1703)包含值C5H。在一个示例中,字节11705在比特[7]中包括“R”值。这个值是第一前缀1301(A)的相同值的补码。比特[2]被用来规定向量的长度(L)(其中0的值是标量或者128比特向量,而1的值是256比特向量)。比特[1:0]提供等同于一些传统前缀的操作码扩展性(例如,00=无前缀,01=66H,10=F3H,并且11=F2H)。被示为vvvv的比特[6:3]可以被用于:1)编码第一源寄存器操作对象,该操作对象以反转(反码)形式指定,对于具有2个或更多个源操作对象的指令有效;2)编码目的地寄存器操作对象,该操作对象以反码形式指定,用于某些向量移位;或者3)不编码任何操作对象,该字段被保留并且应当包含某个值,例如1111b。
使用这个前缀的指令可以使用Mod R/M R/M字段1446来编码引用存储器地址的指令操作对象,或者编码目的地寄存器操作对象或源寄存器操作对象。
使用这个前缀的指令可以使用Mod R/M reg字段1444来编码目的地寄存器操作对象或者源寄存器操作对象,被作为操作码扩展来对待,而不被用于编码任何指令操作对象。
对于支持四个操作对象的指令语法,vvvv,Mod R/M R/M字段1446和Mod R/M reg字段1444编码了四个操作对象中的三个。然后立即数1309的比特[7:4]被用来编码第三源寄存器操作对象。
图17B图示了第二前缀1301(B)的三字节形式的实施例。在一个示例中,格式字段1711(字节0 1713)包含值C4H。字节1 1715在比特[7:5]中包括“R”、“X”和“B”,它们是第一前缀1301(A)的这些值的补码。字节1 1715的比特[4:0](示为mmmmm)包括根据需要来对一个或多个隐含的前导操作码字节进行编码的内容。例如,00001意味着0FH前导操作码,00010意味着0F38H前导操作码,00011意味着前导0F3AH操作码,等等。
字节2 1717的比特[7]与第一前缀1301(A)的W被类似地使用,包括帮助确定可提升的操作对象大小。比特[2]被用来规定向量的长度(L)(其中0的值是标量或者128比特向量,而1的值是256比特向量)。比特[1:0]提供等同于一些传统前缀的操作码扩展性(例如,00=无前缀,01=66H,10=F3H,并且11=F2H)。被示为vvvv的比特[6:3]可以被用于:1)编码第一源寄存器操作对象,该操作对象以反转(反码)形式指定,对于具有2个或更多个源操作对象的指令有效;2)编码目的地寄存器操作对象,该操作对象以反码形式指定,用于某些向量移位;或者3)不编码任何操作对象,该字段被保留并且应当包含某个值,例如1111b。
使用这个前缀的指令可以使用Mod R/M R/M字段1446来编码引用存储器地址的指令操作对象,或者编码目的地寄存器操作对象或源寄存器操作对象。
使用这个前缀的指令可以使用Mod R/M reg字段1444来编码目的地寄存器操作对象或者源寄存器操作对象,被作为操作码扩展来对待,而不被用于编码任何指令操作对象。
对于支持四个操作对象的指令语法,vvvv,Mod R/M R/M字段1446和Mod R/M reg字段1444编码了四个操作对象中的三个。然后立即数1309的比特[7:4]被用来编码第三源寄存器操作对象。
图18图示了第三前缀1301(C)的实施例。在一些实施例中,第一前缀1301(A)是EVEX前缀的实施例。第三前缀1301(C)是四字节前缀。
第三前缀1301(C)能够在64比特模式中编码32个向量寄存器(例如,128比特、256比特和512比特寄存器)。在一些实施例中,利用写入掩码/操作掩码(参见先前图中对于寄存器的论述,例如图12)或预测的指令利用这个前缀。操作掩码寄存器允许了条件处理或选择控制。操作掩码指令——其源/目的地操作对象是操作掩码寄存器并且将操作掩码寄存器的内容视为单个值——是使用第二前缀1301(B)而被编码的。
第三前缀1301(C)可以编码特定于指令类别的功能(例如,具有“加载+操作”语义的紧缩指令可以支持嵌入式广播功能,具有舍入语义的浮点指令可以支持静态舍入功能,具有非舍入算术语义的浮点指令可以支持“抑制所有异常”功能,等等)。
第三前缀1301(C)的第一字节是格式字段1811,其值在一个示例中为0x62,这是一个唯一的值,其识别向量友好指令格式。随后的字节被称为有效载荷字节1815、1817、1819,并且共同形成P[23:0]的24比特值,以(本文中详述的)一个或多个字段的形式提供特定的能力。
在一些实施例中,有效载荷字节1819的P[1:0]与低位的两个mmmmm比特相同。在一些实施例中,P[3:2]被保留。比特P[4](R’)在与P[7]和Mod R/M reg字段1444相组合时允许了对高16个向量寄存器集合的访问。当不需要SIB类型寻址时,P[6]也可以提供对高16个向量寄存器的访问。P[7:5]由R、X和B构成,它们是向量寄存器、通用寄存器、存储器寻址的操作对象指定符修饰符比特,并且当与Mod R/M寄存器字段1444和Mod R/M R/M字段1446相组合时,允许了对低8个寄存器之外的下一组8个寄存器的访问。P[9:8]提供等同于一些传统前缀的操作码外延性(例如,00=无前缀,01=0x66,10=0xF3,并且11=0xF2)。P[10]在一些实施例中是固定值1。被示为vvvv的P[14:11]可以被用于:1)编码第一源寄存器操作对象,该操作对象以反转(反码)形式指定,对于具有2个或更多个源操作对象的指令有效;2)编码目的地寄存器操作对象,该操作对象以反码形式指定,用于某些向量移位;或者3)不编码任何操作对象,该字段被保留并且应当包含某个值,例如1111b。
P[15]类似于第一前缀1301(A)和第二前缀1301(B)的W,并且可以作为操作码扩展比特或操作对象大小提升。
P[18:16]指定操作掩码(写入掩码)寄存器(例如,写入掩码/谓词寄存器1215)中的寄存器的索引。在本发明的一个实施例中,特定值aaa=000具有特殊行为,暗示着没有操作掩码被用于特定指令(这可按多种方式来实现,包括使用硬连线到全一的操作掩码或者绕过掩蔽硬件的硬件)。当合并时,向量掩码允许目的地中的任何元素集合在(由基本操作和增强操作指定的)任何操作的执行期间被保护免于更新;在其他的一个实施例中,保留目的地的相应的掩码比特具有0的每个元素的旧值。与之不同,当归零向量掩码允许了目的地中的任何元素集合在(由基本操作和增强操作指定的)任何操作的执行期间被归零时;在一个实施例中,目的地的元素在相应的掩码比特具有0值时被设置到0。这个功能的子集是控制被执行的操作的向量长度(即,被修改的元素的跨度,从第一个到最后一个)的能力;然而,被修改的元素不一定要连续。因此,操作掩码字段允许了部分向量操作,包括加载、存储、算术、逻辑,等等。虽然描述了其中操作掩码字段的内容选择若干个操作掩码寄存器中包含要使用的操作掩码的那一个(从而操作掩码字段的内容间接识别要执行的该掩蔽)的本发明实施例,但替代性实施例作为替代或附加允许掩码写入字段的内容直接指定要执行的掩蔽。
P[19]可以与P[14:11]相组合,来以非破坏性源语法来编码第二源向量寄存器,该语法可以利用P[19]来访问高16个向量寄存器。P[20]编码多种功能,这些功能在不同类别的指令中有所不同,并且可以影响向量长度/舍入控制指定符字段(P[22:21])的含义。P[23]指示出对合并-写入掩蔽的支持(例如,当被设置为0时)或者对归零和合并-写入掩蔽的支持(例如,当被设置为1时)。
在下面的表格中详述了在使用第三前缀1301(C)的指令中对寄存器的编码的示例性实施例。
表格16—64比特模式中的32寄存器支持
表格17—在32比特模式中编码寄存器指定符
表格18—操作掩码寄存器指定符编码
程序代码可以被应用到输入指令以执行本文描述的功能并且生成输出信息。输出信息可以按已知的方式被应用到一个或多个输出设备。对于本申请而言,处理系统包括任何具有处理器的系统,例如数字信号处理器(digital signal processor,DSP)、微控制器、专用集成电路(application specific integrated circuit,ASIC)、或者微处理器。
可以用高级别过程式或面向对象的编程语言来实现程序代码以与处理系统进行通信。如果希望,程序代码也可以用汇编或机器语言来实现,因为本文描述的机制在范围上不限于任何特定的编程语言。此外,该语言可以是经编译或者解释的语言。
本文公开的机制可以用硬件、软件、固件或者这些实现途径的组合来实现。本发明的实施例可以被实现为在包括以下项的可编程系统上执行的计算机程序或程序代码:至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备、以及至少一个输出设备。
ISA仿真和二进制转译
在一些情况下,指令转换器可以被用于将指令从源指令集转换到目标指令集。例如,指令转换器可以将指令转译(例如,利用静态二进制转译、包括动态编译的动态二进制转译)、变形、仿真或者以其他方式转换到要被核心处理的一个或多个其他指令。可以用软件、硬件、固件或者其组合来实现指令转换器。指令转换器可以在处理器上、在处理器外、或者一部分在处理器上而一部分在处理器外。
图19图示了根据一实施例的与使用软件指令转换器来将源指令集中的二进制指令转换成目标指令集中的二进制指令进行对比的框图。在图示的实施例中,指令转换器是软件指令转换器,虽然可替代地,可以用软件、固件、硬件或者其各种组合来实现指令转换器。图19示出了高级别语言1902的程序可被利用第一ISA编译器1904来编译以生成第一ISA二进制代码1906,第一ISA二进制代码1906可以由具有至少一个第一指令集核心的处理器1916原生执行。具有至少一个第一ISA指令集核心的处理器1916表示任何这样的处理器:这种处理器可以通过兼容地执行或以其他方式处理(1)第一ISA指令集核心的指令集的实质部分或者(2)目标为在具有至少一个第一ISA指令集核心的英特尔处理器上运行的应用或其他软件的目标代码版本,来执行与具有至少一个第一ISA指令集核心的英特尔
IP核实现方式
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性代码实现,该代表性代码表示和/或定义诸如处理器之类的集成电路内的逻辑。例如,机器可读介质可以包括表示处理器内的各种逻辑的指令。当被机器读取时,指令可以使得该机器制作逻辑来执行本文描述的技术。这种被称为“IP核”的表现形式是针对集成电路的逻辑的可重复使用单元,这些单元可作为描述该集成电路的结构的硬件模型被存储在有形机器可读介质上。该硬件模型可以被提供给各种客户或制造设施,它们在制造集成电路的制作机器上加载该硬件模型。可以制造集成电路,使得该电路执行与本文描述的任何实施例关联描述的操作。
图20A-图20D图示了IP核开发和可以从不同的IP核组装成的关联封装组合件。
图20A的框图图示出了IP核开发系统2000,该系统可以用于制造集成电路来执行根据实施例的操作。IP核开发系统2000可以用于生成模块化的、可重复使用的设计,这些设计可以被包含到更大的设计中或者被用于构造整个集成电路(例如,SOC集成电路)。设计设施2030可以以高级别编程语言(例如,C/C++)生成IP核设计的软件仿真2010。软件仿真2010可以用于使用仿真模型2012来设计、测试和验证IP核的行为。仿真模型2012可以包括功能、行为和/或定时仿真。然后可以从仿真模型2012创建或合成寄存器传送级(registertransfer level,RTL)设计2015。RTL设计2015是对硬件寄存器之间的数字信号的流动进行建模的集成电路的行为的抽象,其包括利用经建模的数字信号执行的关联逻辑。除了RTL设计2015以外,也可以创建、设计或者合成在逻辑级或晶体管级的更低级别设计。因此,初始设计和仿真的具体细节可变化。
RTL设计2015或等同物还可以被设计设施合成为硬件模型2020,该硬件模型可以采取硬件描述语言(hardware description language,HDL)或者物理设计数据的某种其他表现形式。HDL可以被进一步仿真或测试来验证IP核设计。IP核设计可以被存储来利用非易失性存储器2040(例如,硬盘、闪速存储器、或者任何其他非易失性存储介质)输送到第3方制作设施2065。或者,IP核设计可以通过有线连接2050或无线连接2660(例如,经由互联网)被传输。制作设施2065随后可制作至少部分地基于该IP核设计的集成电路。制作的集成电路可以被配置为根据本文描述的至少一个实施例来执行操作。
图20B图示了根据本文描述的一些实施例的集成电路封装组合件2070的截面侧视图。集成电路封装组合件2070说明了如本文所述的一个或多个处理器或加速器设备的实现方式。封装组合件2070包括连接到衬底2080的多个硬件逻辑单元2072、2074。逻辑2072、2074可以至少部分地以可配置逻辑或固定功能逻辑硬件来实现,并且可以包括本文描述的任何(一个或多个)处理器核心、(一个或多个)图形处理器或者其他加速器设备的一个或多个部分。每个逻辑单元2072、2074可以在半导体管芯内实现,并且经由互连结构2073与衬底2080耦合。互连结构2073可以被配置为在逻辑2072、2074和衬底2080之间路由电信号,并且可以包括互连,例如但不限于凸块或支柱。在一些实施例中,互连结构2073可以被配置为路由电信号,例如,与逻辑2072、2074的操作相关联的输入/输出(I/O)信号和/或电力或接地信号。在一些实施例中,衬底2080是基于环氧树脂的层压衬底。在其他实施例中,衬底2080可以包括其他适当类型的衬底。封装组合件2070可以经由封装互连2083连接到其他电气器件。封装互连2083可以耦合到衬底2080的表面,以将电信号路由到其他电气器件,例如主板、其他芯片组或者多芯片模块。
在一些实施例中,逻辑单元2072、2074与桥接器2082电耦合,该桥接器被配置为在逻辑2072、2074之间路由电信号。桥接器2082可以是一种为电信号提供路线的密集互连结构。桥接器2082可以包括由玻璃或者适当的半导体材料构成的桥接器衬底。电气路由特征可以在桥接器衬底上形成,以提供逻辑2072、2074之间的芯片到芯片连接。
虽然图示了两个逻辑单元2072、2074和桥接器2082,但本文描述的实施例可以包括一个或多个管芯上的更多或更少的逻辑单元。一个或多个管芯可以由零个或多个桥接器连接,因为当逻辑被包括在单个管芯上时,桥接器2082可以被排除。或者,多个管芯或者逻辑单元可以由一个或多个桥接器连接。此外,多个逻辑单元、管芯和桥接器可以按其他可能的配置来连接,包括三维配置。
图20C图示了封装组合件2090,它包括连接到衬底2080的多个硬件逻辑小芯片(chiplet)单元。如本文所述的图形处理单元、并行处理器和/或计算加速器可以由单独制造的不同硅小芯片构成。在这种情况下,小芯片是至少部分封装的集成电路,它包括不同的逻辑单元,这些逻辑单元可以与其他小芯片组装成更大的封装件。具有不同IP核逻辑的不同小芯片组可以被组装成单个器件。此外,可以使用有源插入件技术将小芯片集成到基础管芯或基础小芯片中。本文描述的概念使得GPU内的不同形式的IP之间的互连和通信成为可能。可以使用不同的工艺技术来制造IP核,并且在制造期间构成IP核,这就避免了将多个IP——尤其是在具有几种风格的IP的大型SoC上——会聚到同一制造工艺的复杂性。使得能够使用多种工艺技术会改善上市时间,并且为创建多个产品SKU提供了一种具有成本效益的方式。此外,解聚集的IP更适合于被独立地进行功率门控,在给定工作负载上不使用的组件可以被断电,减少整体功率消耗。
在各种实施例中,封装组合件2090可以包括由结构2085和/或一个或多个桥接器2087互连的组件和小芯片。封装组合件2090内的小芯片可以具有2.5D布置,使用芯片在晶圆上在衬底上(Chip-on-Wafer-on-Substrate)堆叠,其中多个管芯并排堆叠在硅插入件2089上,该硅插入件将小芯片与衬底2080耦合。衬底2080包括与封装互连2083的电气连接。在一个实施例中,硅插入件2089是无源插入件,它包括硅通孔(through-silicon vias,TSV),以将封装组合件2090内的小芯片与衬底2080电耦合。在一个实施例中,硅插入件2089是有源插入件,除了TSV之外它还包括嵌入式逻辑。在这样的实施例中,使用3D面对面管芯堆叠在硅插入件2089的顶部布置封装组合件2090内的小芯片。硅插入件2089,当是有源插入件时,除了互连结构2085和硅桥接器2087以外,还可以包括用于I/O的硬件逻辑2091、缓存存储器2092、以及其他硬件逻辑2093。结构2085使得各种逻辑小芯片2072、2074和硅插入件2089内的逻辑2091、2093之间的通信成为可能。结构2085可以是NoC(片上网络)互连或者另一种形式的分组交换结构,它在封装组合件的组件之间交换数据分组。对于复杂的组合件,结构2085可以是专用小芯片,其使得封装组合件2090的各种硬件逻辑之间的通信成为可能。
硅插入件2089内的桥接结构2087可以用于促进例如逻辑或I/O小芯片2074和存储器小芯片2075之间的点到点互连。在一些实现方式中,桥接结构2087也可以被嵌入在衬底2080内。硬件逻辑小芯片可以包括专用硬件逻辑小芯片2072、逻辑或I/O小芯片2074、和/或存储器小芯片2075。硬件逻辑小芯片2072和逻辑或I/O小芯片2074可以至少部分地以可配置逻辑或固定功能逻辑硬件来实现,并且可以包括本文描述的任何(一个或多个)处理器核心、(一个或多个)图形处理器、并行处理器或者其他加速器设备的一个或多个部分。存储器小芯片2075可以是DRAM(例如,GDDR、HBM)存储器或者缓存(SRAM)存储器。硅插入件2089(或者衬底2080)内的缓存存储器2092可以充当封装组合件2090的全局缓存、分布式全局缓存的一部分、或者充当结构2085的专用缓存。
每个小芯片可以被制造为单独的半导体管芯,并且与基础管芯耦合,该基础管芯被嵌入在衬底2080内或者与衬底2080耦合。与衬底2080的耦合可以经由互连结构2073执行。互连结构2073可以被配置为在衬底2080内的各种小芯片和逻辑之间路由电信号。互连结构2073可以包括互连,例如但不限于凸块或支柱。在一些实施例中,互连结构2073可以被配置为路由电信号,例如,与逻辑、I/O和存储器小芯片的操作相关联的输入/输出(I/O)信号和/或电力或接地信号。在一个实施例中,额外的互连结构将硅插入件2089与衬底2080耦合。
在一些实施例中,衬底2080是基于环氧树脂的层压衬底。在其他实施例中,衬底2080可以包括其他适当类型的衬底。封装组合件2090可以经由封装互连2083连接到其他电气器件。封装互连2083可以耦合到衬底2080的表面,以将电信号路由到其他电气器件,例如主板、其他芯片组或者多芯片模块。
在一些实施例中,逻辑或I/O小芯片2074和存储器小芯片2075可以经由桥接器2087电耦合,该桥接器被配置为在逻辑或I/O小芯片2074和存储器小芯片2075之间路由电信号。桥接器2087可以是一种为电信号提供路线的密集互连结构。桥接器2087可以包括由玻璃或者适当的半导体材料构成的桥接器衬底。电气路由特征可以在桥接器衬底上形成,以提供逻辑或I/O小芯片2074和存储器小芯片2075之间的芯片到芯片连接。桥接器2087也可以被称为硅桥接器或者互连桥接器。例如,在一些实施例中,桥接器2087是嵌入式多管芯互连桥接器(Embedded Multi-die Interconnect Bridge,EMIB)。在一些实施例中,桥接器2087可能就简单地是从一个小芯片到另一个小芯片的直接连接。
图20D图示了根据一实施例的包括可互换小芯片2095的封装组合件2094。可互换小芯片2095可以被组装到一个或多个基础小芯片2096、2098上的标准化插槽中。基础小芯片2096、2098可以经由桥式互连2097耦合,该桥式互连可以类似于本文描述的其他桥式互连,并且可以是例如EMIB。存储器小芯片也可以经由桥式互连与逻辑或I/O小芯片相连接。I/O和逻辑小芯片可以经由互连结构进行通信。基础小芯片可以各自支持标准化格式的一个或多个插槽,用于逻辑或I/O或者存储器/缓存中的一个。
在一个实施例中,SRAM和电力输送电路可以被制造到一个或多个基础小芯片2096、2098中,相对于堆叠在基础小芯片之上的可互换小芯片2095,基础小芯片可以使用不同的工艺技术来制造。例如,基础小芯片2096、2098可以使用较大的工艺技术来制造,而可互换小芯片可以使用较小的工艺技术来制造。一个或多个可互换小芯片2095可以是存储器(例如,DRAM)小芯片。基于使用封装组合件2094的产品的功率和/或性能目标,可以为封装组合件2094选择不同的存储器密度。此外,可以基于产品的功率和/或性能目标,在组装时选择具有不同数目的功能单元类型的逻辑小芯片。此外,包含不同类型的IP逻辑核心的小芯片可以被插入到可互换小芯片插槽中,使得能够实现混合处理器设计,这些设计可以混合和匹配不同技术IP块。
图21图示了根据本文描述的各种实施例的可以使用一个或多个IP核制造的示例性集成电路和关联的处理器。除了图示的内容以外,还可以包括其他逻辑和电路,包括额外的图形处理器/核心、外围接口控制器、或者通用处理器核心。如图21所示,集成电路2100可以包括一个或多个应用处理器2105(例如,CPU),至少一个图形处理器2110,并且还可以包括图像处理器2115和/或视频处理器2120,其中任何一者可以是来自相同或多个不同的设计设施的模块化IP核。集成电路2100包括外围或总线逻辑,其中包括USB控制器2125、UART控制器2130、SPI/SDIO控制器2135、以及I
本文提及“一个实施例”、“一实施例”、“一示例实施例”等等表明描述的实施例可以包括特定的特征、结构或特性,但可能不一定每个实施例都包括该特定特征、结构或特性。此外,这种短语不一定指的是同一实施例。另外,当联系一实施例来描述特定的特征、结构或特性时,认为联系其他实施例(无论是否明确描述)来实现这种特征、结构或特性,是在本领域技术人员的知识范围内的。
在上文描述的各种实施例中,除非另有特别注明,否则诸如短语“A、B或C中的至少一者”之类的析取语言旨在被理解为意指A、B或C,或者其任意组合(例如,A、B和/或C)。因此,析取语言并不旨在也不应当被理解为暗示给定的实施例要求至少一个A、至少一个B或者至少一个C各自都存在。
因此,说明书和附图应当被认为是示例性的,而不是限制性的。本领域技术人员将会明白,可以按各种形式来实现本文描述的实施例的宽广技术。因此,虽然已联系其示例描述了实施例,但实施例的真实范围不应当限于此,因为本领域技术人员在研习了附图、说明书和所附权利要求后,将清楚其他修改。
- 一种四杆钻孔破碎水泥块装置
- 一种多功能受潮结块水泥破碎装置
- 一种用于含油污泥预处理的铰刀破碎工艺、控制方法和装置
- 一种水泥制备破碎处理装置
- 一种水泥生产用的废旧水泥块破碎装置及其破碎方法