基于CSG-BASE Net的大场景三维点云数据建模方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及大场景三维点云数据建模,具体涉及一种基于CSG-BASE Net的大场景三维点云数据建模方法。
背景技术
由于三维形状是物体的基本属性之一,提供更加丰富和准确的信息,所以三维形状的表示是三维建模中的主要工作,点云是被广泛采用的三维数据原始输入格式,点云直接记录了物体表面的具体形态和细节,更准确地表达物体的形状和结构。而其他三维数据表示格式如体素网格和多边形网格等则可能因为采样率等问题导致物体表面细节的丢失。语义建模主要的内容是将带有语义信息的点云进行三维模型的转换,用于在特定场景下的模型生成。
近年来,诸多学者针对三维模型的生成大多数都采用点云的格式进行形状解析,其中,Su提出了一种通过组装体素基元学习三维形状抽象的方法。该方法将三维形状划分为一系列体素,并通过组装这些体素来表示整个形状。与传统方法中的三角面片表示相比,体素更好地处理形状的复杂性和不规则性。基于此,Paschalidou提出了一种基于超椭球体(Superellipsoid(Superquadrics为超正方体))的方法来实现3D形状分割。传统的3D形状分割方法通常使用基于立方体(Cubes)的模型来表示物体,但这种模型有很大的局限性,很难处理非常规形状的物体。相比之下,超椭球体更好地适应各种形状的物体,并且使用较少的参数来描述形状。但是该方法仍存在一些问题:超椭球体模型的复杂度相对于立方体模型更高,因此该方法需要更多的计算资源来进行模型训练和推理。如果某些特殊形状的物体可能需要更复杂的模型来表示,超椭球体模型可能不够准确。构造立体几何法(CSGConstructive Solid Geometry)也是一个建模过程和一个三维形状的表示,CSG由于其直观和强大的概念,广泛应用于和OpenSCAD等工业软件。Goldfeather提出了一种归一化的端到端的CSG表示方法,该方法使用树归一化技术将复杂的CSG-Tree转换为更简单的等价形式,这有助于减少树的大小和复杂性。其次,该算法提出了一种几何修剪技术,它能够在渲染过程中剪去与场景不相交的部分,从而减少渲染时间和内存使用量。虽然该技术实现近实时渲染,但是其算法复杂性较高,需要进行多次树规范化和几何修剪操作。这使得该技术难以应用于实时场景,特别是大场景的情况下会出现局限性。为了解决复杂度问题,Sharma设计了一种专门的神经网络架构CSG-Net,用于处理实体几何的建模任务,该架构的效率和准确性较高。CSG-Net使用了大量的实体几何数据来训练模型,能够处理大型的数据集,提高了模型的普适性和泛化能力。但由于生成的基元不够精细化,重建的模型不够准确。
发明内容
为了克服现有技术的不足,本发明在CSG-Net方法基础上,提出了一种基于CSG-BASE Net的大场景三维点云数据建模方法,首先聚类点云数据,从大规模点云数据中学习有用的先验知识,构建拉普拉斯矩阵,计算特征值,得到特征向量;找到质量最高的聚类结果,即基元;再通过MLP层对潜在特征进行增强,将基元数据转换为向量并映射到高维向量空间中,进行占用率计算后,生成精细化凹凸基元;随之将基元生成3D形状输入到CSG-Base构建来完成三维点云数据的建模。
本发明提供如下的技术方案:
一种基于CSG-BASE Net的大场景三维点云数据建模方法,所述方法包括以下步骤:
步骤一:聚类点云数据,过程如下:
步骤1.1)点云数据
点云数据由一组密集的三维坐标构成,每个坐标点包含点云在三维空间中的坐标信息(X,Y,Z)以及反映点云数据纹理特征的外表信息F,将包含M个点的点云数据集记作P={p
步骤1.2)定义基元
基元用来表示形状,首先通过聚类点云数据生成基元。n表示超点数量,即点云的数量,m表示超边数量,即点云与点云之间关系的连线数量,WHG∈R
步骤1.3)聚类点云
通过超图聚类中的超图粗化阶段来聚类点云,在粗化的过程中,超图被缩小为一个小的图进行操作;
步骤1.4)生成基元;
步骤二:构建CSG-Base Net,过程如下:
步骤2.1)定义几何模型
几何模型采用四种基本体来表示,分别为立方体、球体、圆柱体和锥体作为标准基元,使用以上基元作为图元集;
步骤2.2)占有率计算
为了计算不同形状在模型组合中的占用率,先生成基元的占有函数,占有函数用来判断空间中的每个点是否在物体表面,首先输入基元传递到MLP层的第一个全连接层,在这一层中,每个神经元将潜在特征与自身的权重进行加权求和,并将结果与偏置项相加得到一个加权和,然后经过激活函数的非线性变换,经过非线性变换后的结果被传递到下一层的每个神经元,直到到达MLP层的最后一层;在最后一层,MLP层的输出是基元映射到高维向量空间中的特征表示,然后再计算基元的带符号距离场(SDF,Signed Distance Field),其中MLP是一种具有输入层、隐藏层以及输出层结构的前向传播神经网络,激活函数的作用是提供网络的非线性建模能力,SDF是三维网格的一种突出的隐式表示,即空间中每个点距离表面的距离,通过将离形状表面一定距离内的空间标记为负数、形状表面的空间标记为零、形状外的空间标记为正数的方式描述一个三维几何模型,对于基元中的一个点x,其距离场函数SDF(x)定义为:
SDF(x)=min{dist(x,S)}
其中dist(x,S)是点x到几何形状S的最短距离,并且是正数、零或负数;
接收步骤1.4)中得到的基元xi计算占有率,当SDF(x)<0时,表示点x在几何形状S的内部,表示为SDF
O(x)=-η×SDF(x)
其中,标量η是表示转换为占有率的超参数,sigmoid函数将输入的实数映射到一个介于0和1之间的输出值;
步骤2.3)精细化凹凸基元的生成
通过组装不同的基元来生成多种不同的形状,生成的形状更具紧凑性,使用二次预测基元的形式来生成复杂的剩余形状,接收步骤2.2)中的进行占有率计算后的基元,并输出两个矩阵P
|a|x
其中x
P
其中
对于凹基元,曲面包围的查询点的SDF值为负,即这些点位于基元内部,对于凸基元,由曲面包围的查询点的SDF值是正的,即该空间在基元内部;
步骤2.4)构建CSG-Base
CSG-Base是3D形状的三层树表示结构,基于CSG-Tree实现具有存储操作信息的节点的分层表示,其中,CSG-Tree是一种用于几何建模的数据结构,通过布尔操作来组合和操作几何对象,允许快速计算出复杂几何形状的体积和表面积;
连接头解码器是将基元之间的联系转换为连接的过程,这些连接表示基元数据中的几何关系。通过连接头解码,构建基元之间的拓扑结构,并将基元表示为一个可解释的3D形状。拓扑结构是指基元之间的一种关系结构图;
CSG-Base利用二进制矩阵来表示不同原始基元位置之间的布尔运算,使用三个专用单层感知器将编码特征解码为连接矩阵W
CSG-Base右侧是只有一个节点的并集层(Union),中间为交集层(Intersect),左侧为补集层(complement),CSG-Base补集层的节点与基元一一对应,存储了是否对相应的基元执行补码运算,交集层上的节点记录选择在底层中生成的形状进行相交操作,并集层上的节点记录选择交集层中生成的形状进行并集操作,因此,对于CSG-Base中的每一层,引入连接头解码器生成的连接矩阵W来编码其节点的信息;
定义一个1×K矩阵W
步骤2.5)构造建模结果
输入步骤2.2)基元占用率和步骤2.4)连接矩阵W,计算整个形状的占用率,得到建模结果,初始左侧层输出F
其中W
对于补集层中的每个节点,其形状是来自步骤2.3)的基元,函数S
S
其中,W
对于并集层中的每个节点,其形状是来自补集层的节点,由函数T(x)定义:
T(x)=max
其中,W
然后将并集层的输出的结果相加得到重建结果;
步骤三:损失函数
以自监督的方式端到端地训练CSG-Base Net,CSG-Base Net学习预测具有基元及其连接的CSG-Base,自监督任务是在无标注的数据上通过设计监督任务训练模型。
进一步,所述步骤1.3)的过程如下:
步骤(1.3.1)定义粗化阶段所需的符号,c表示超点的权重集合、w表示超边的权重集合、G=(V,E,c,w)表示原始超图、iterTime表示迭代次数、coarse_limit表示粗化阈值、max_weight表示超点权重阈值、G'=(V',E',c',w')表示粗化后的图,V'表示粗化后未被合并的超点,E'表示粗化后的超边,c'表示粗化后超点的权重集合,w'表示粗化超边后的权重集合,进行步骤(1.3.2);
步骤(1.3.2)将所有超点加入到未访问超点集合UV中,进行步骤(1.3.3);
步骤(1.3.3)初始化空集合C用于记录所有被粗化的超点,进行步骤(1.3.4);
步骤(1.3.4)定义变量I用于存储迭代次数,并将其初始化为0,进行步骤(1.3.4.1-1.3.4.4),对集合UV中的超点进行粗化,进行步骤(1.3.5);
步骤(1.3.4.1)定义集合UVT,用于存储对本次迭代需要粗化的超点合集,将集合UV中的超点拷贝进集合UVT中,进行步骤(1.3.4.2);
步骤(1.3.4.2)进行步骤(1.3.4.2.1-1.3.4.2.12),对UVT中超点进行粗化,直到迭代次数到达len(UVT),进行步骤(1.3.4.3);
其中,len()表示获取集合的大小,len(UVT)表示集合UVT的大小;
步骤(1.3.4.2.1)随机取集合UVT中一个超点,命名为rv,进行步骤(1.3.4.2.2);
步骤(1.3.4.2.2)判断该超点rv是否属于集合UVT,是则进行步骤(1.3.4.2.3),否则直接进入下一轮循环;
步骤(1.3.4.2.3)定义一个超点cv,并将超点rv拷贝给cv,定义score用于存储评分,并初始化评分为0,进行步骤(1.2.4.2.4);
步骤(1.3.4.2.4)遍历与超点rv邻接的其他超点,并将该超点拷贝给iv,进行步骤(1.3.4.2.4.1-1.3.4.2.4.3),找到要与rv合并的超点iv,进行步骤(1.3.4.2.5);
其中,与超点rv邻接的其他超点即与该超点在同一边中的超点;
步骤(1.3.4.2.4.1)计算rv的权重与iv的权重之和;
步骤(1.3.4.2.4.2)判断该权重和是否大于超点权重阈值max_weight,否则进行步骤(1.3.4.2.4.3),是则直接进入下一次循环;
步骤(1.3.4.2.4.3)判断iv是不是属于集合UVT中的超点,是则直接进入下一次循环,否则直接结束循环;
步骤(1.3.4.2.5)根据评分函数计算rv与iv的评分函数,定义变量cur_score,将评分存储在cur_score中,进行步骤(1.3.4.2.6);
其中,评分函数为score(rv,iv)=a·con(rv,iv)+b·hNcut(rv,iv),a、b的值为经验值,依据实验效果调参后所得,其中,
步骤(1.3.4.2.6)判断cur_score是否大于score,是则将超点iv拷贝到cv中、将cur_score的值赋值给score,进行步骤(1.3.4.2.7);
步骤(1.3.4.2.7)将rv与cv合并,本发明使用双向链表的形式,将有合并关系的超点进行连接,然后进行步骤(1.3.4.2.8);
其中,双向链表是链表的一种,直接相连的两个节点之间有指向对方的指针;
步骤(1.3.4.2.8)将被合并超点cv的权重增加到rv,进行步骤(1.3.4.2.9);
步骤(1.3.4.2.9)在当前迭代轮次使用的UVT中移除rv与cv,,进行步骤(1.3.4.2.10);
步骤(1.3.4.2.10)在UV中移除cv,进行步骤(1.3.4.2.11);
步骤(1.3.4.2.11)将超点cv添加到集合C中,进行步骤(1.3.4.2.12);
步骤(1.3.4.2.12)如果被粗化的超点数到达粗化阈值coarse_limit,则退出迭代,执行步骤(1.3.4.3),否则直接进入下一轮迭代;
步骤(1.3.4.3)对I自增1,即I=I+1,进行步骤(1.3.4.4);
步骤(1.3.4.4)判断迭代次数I是否小于iterTime、被粗化的超点数是否到达粗化阈值coarse_limit,任一条件不符合,则停止粗化,停止迭代,执行步骤(1.3.5);
步骤(1.3.5)将粗化后的粗化后的超点、超边、超点的权重集合和超边的权重集合分别拷贝到V'、E'、c'、w'中,得到粗化结果,即超图G'=(V',E',c',w')。
再进一步,所述步骤1.4)中,生成基元的过程如下:
步骤(1.4.1)进行步骤(1.4.1.1-1.4.1.6),构建拉普拉斯矩阵,进行步骤(1.4.2);
其中,拉普拉斯矩阵是图的矩阵表示,主要应用在图论中;
步骤(1.4.1.1)定义VO和EO分别为存储超图中所有超点与对应索引位置和超图中所有超边与对应索引位置的数组,将超图中所有超点与对应索引位置存储在VO中;将超图中所有超边与对应索引位置存储在EO中;
步骤(1.4.1.2)根据点云数据构成的超边集,生成构建相似矩阵S,进行步骤(1.4.1.3);
其中,相似度矩阵是一项重要的统计学技术,用于组织一组数据点之间的彼此相似性,相似性即超边的权重;
步骤(1.4.1.3)根据相似矩阵构建超点度矩阵VD以及超边度矩阵ED,进行步骤(1.4.1.4);
其中,超点度矩阵VD是由超点度构成的对角线矩阵,对角线上的元素为超点的度dv(v
其中,超边度矩阵ED是由超边度构成的对角线矩阵,对角线上的元素为超边的度de(e
步骤(1.4.1.4)根据相似矩阵,进行步骤(1.4.1.4.1-1.4.1.4.4)构建关联矩阵H,进行步骤(1.4.1.5);
其中,关联矩阵是一个n×m的矩阵,第d行表示第d个超点所属的所有超边,第f列表示第f条超边包含的所有超点,矩阵的第d行第f列表示为
步骤(1.4.1.4.1)建立一个n×m的全为0的矩阵H,进行步骤(1.4.1.4.2);
步骤(1.4.1.4.2)遍历EO中所有超边,进行步骤(1.4.1.4.3);
步骤(1.4.1.4.3)遍历超边中所有超点,进行步骤(1.4.1.4.4);
步骤(1.4.1.4.4)在矩阵H中将该超边和超点对应索引位置的0置为1;
步骤(1.4.1.5)根据步骤(1.4.1.2)中的超边构建方式得到的超图信息进行步骤(1.4.1.5.1-1.4.1.5.3),构建权重矩阵W,进行步骤(1.4.1.6);
其中,权重矩阵W是超边权重的对角矩阵,对角线上的元素为超边的权重;
步骤(1.4.1.5.1)建立一个m×m的全为0的矩阵W进行步骤(1.4.1.5.2);
步骤(1.4.1.5.2)遍历EO中所有超边,进行步骤(3.2.1.5.3);
步骤(1.4.1.5.3)将超边的权重按照EO中的索引位置作为权重矩阵中的值替换矩阵W中的0;
步骤(1.4.1.6)根据关联矩阵、权重矩阵、超边度矩阵以及超点度矩阵构建拉普拉斯矩阵L;
其中,拉普拉斯矩阵的计算公式为L=E*-ED
步骤(1.4.2)对拉普拉斯矩阵进行归一化处理得到NL,进行步骤(1.4.3);
其中,矩阵的归一化指将矩阵的数据以列为单元,映射到区间(0,1)之间,即,将每一列数据减去该列的最小值并除以该列的最大值;
步骤(1.4.3)求解拉普拉斯矩阵NL,计算特征值,得到特征向量,进行步骤(1.4.4);
步骤(1.4.4)将特征向量按列构建成矩阵NE,并归一化处理,进行步骤(1.4.5);
步骤(1.4.5)定义bestC用于存储最佳聚类结果,定义BestE用于存储最佳聚类结果的评分,初始化BestE为0,定义T_num用于存储重复聚类次数,初始化T_num为0,定义retryTime为聚类操作重复次数,进行步骤(1.4.6);
步骤(1.4.6)执行步骤(1.4.6.1-1.4.6.5),对NE进行聚类,评估聚类的效果,循环retryTime次,找到解质量最高的聚类,执行步骤(1.4.7);
步骤(1.4.6.1)对T_num自增1,即,T_num=T_num+1,进行步骤(1.4.6.2);
步骤(1.4.6.2)对矩阵NE使用K-Means方法进行聚类,将得到的向量聚类结果作为对应超点的聚类结果,进行步骤(1.4.6.3);
其中K-Means方法将数据集分为K个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”;
步骤(1.4.6.3)根据评分函数,评估聚类的效果,进行步骤(1.4.6.4);
其中评分函数的公式为
步骤(1.4.6.4)如果本次聚类的评分高于BestE,进行步骤(1.4.6.4.1-1.4.6.4.2),用本次聚类结果替换原聚类结果,否则进行步骤(1.4.6.5);
步骤(1.4.6.4.1)将本次据聚类结果替换到bestC中,进行步骤(1.4.6.4.2);
步骤(1.4.6.4.2)将本次据聚类结果的评分赋值给BestE;
步骤(1.4.6.5)判断T_num是否大于或等于retryTime,是则退出循环,否则进入下一次循环;
步骤(1.4.7)结束循环,得到聚类结果bestC,即基元xi。这些基元被用来表示点云中的特征,提供了对点云数据更高级别的语义理解。
所述步骤三中,从形状边界框中采样测试点x
在实验中观察到远离基元表面的测试点时梯度为0出现梯度消失现象,通过一种基元丢失的方法解决该问题,将每个基元表面拉到它最近的测试点,防止梯度消失,将这一损失定义为:
其中
最后,总损失定义为上述两项的联合损失:
L
其中,λ为超参数。
本发明的有益效果主要表现在:
(1)本发明提出了一种基于CSG-BASE Net的大场景三维点云数据建模方法,首先聚类点云数据,从大规模点云数据中学习有用的先验知识,生成基元。
(2)本发明使用了大量的实体几何数据来训练模型,能够处理大型的数据集,提高了模型的普适性和泛化能力。
附图说明
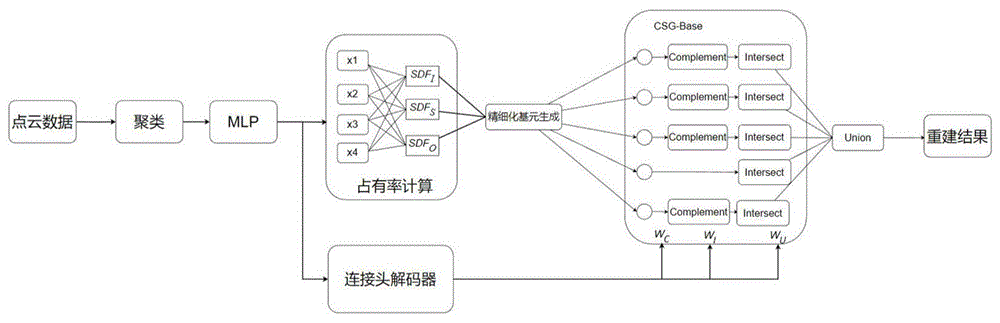
图1是CSG-Base Net结构图。
图2是验证CSG-Base Net网络有效性的点云数据集重建实验结果。
具体实施方式
下面结合附图对本发明做进一步说明。
参照图1和图2,一种基于CSG-BASE Net的大场景三维点云数据建模方法,包括以下步骤:
步骤一:聚类点云数据
步骤1.1)点云数据
点云数据由一组密集的三维坐标构成,每个坐标点包含点云在三维空间中的坐标信息(x,y,z)以及反映点云数据纹理特征的外表信息F。将包含M个点的点云数据集记作P={p
步骤1.2)定义基元
基元(例如特征、变量等)用来表示形状,本发明首先通过聚类点云数据生成基元。n表示超点数量,即点云的数量,m表示超边数量,即点云与点云之间关系的连线数量。WHG∈R
步骤1.3)聚类点云
本发明通过超图聚类中的超图粗化阶段来聚类点云,在粗化的过程中,超图被缩小为一个较小的图进行操作。
步骤(1.3.1)定义粗化阶段所需的符号,c表示超点的权重集合、w表示超边的权重集合、G=(V,E,c,w)表示原始超图、iterTime表示迭代次数、coarse_limit表示粗化阈值、max_weight表示超点权重阈值、G'=(V',E',c',w')表示粗化后的图,V'表示粗化后未被合并的超点,E'表示粗化后的超边,c'表示粗化后超点的权重集合,w'表示粗化超边后的权重集合,进行步骤(1.3.2);
步骤(1.3.2)将所有超点加入到未访问超点集合UV中,进行步骤(1.3.3);
步骤(1.3.3)初始化空集合C用于记录所有被粗化的超点,进行步骤(1.3.4);
步骤(1.3.4)定义变量I用于存储迭代次数,并将其初始化为0,进行步骤(1.3.4.1-1.3.4.4),对集合UV中的超点进行粗化,进行步骤(1.3.5);
步骤(1.3.4.1)定义集合UVT,用于存储对本次迭代需要粗化的超点合集,将集合UV中的超点拷贝进集合UVT中,进行步骤(1.3.4.2);
步骤(1.3.4.2)进行步骤(1.3.4.2.1-1.3.4.2.12),对UVT中超点进行粗化,直到迭代次数到达len(UVT),进行步骤(1.3.4.3);
其中,len()表示获取集合的大小,len(UVT)表示集合UVT的大小;
步骤(1.3.4.2.1)随机取集合UVT中一个超点,命名为rv,进行步骤(1.3.4.2.2);
步骤(1.3.4.2.2)判断该超点rv是否属于集合UVT,是则进行步骤(1.3.4.2.3),否则直接进入下一轮循环;
步骤(1.3.4.2.3)定义一个超点cv,并将超点rv拷贝给cv,定义score用于存储评分,并初始化评分为0,进行步骤(1.2.4.2.4);
步骤(1.3.4.2.4)遍历与超点rv邻接的其他超点,并将该超点拷贝给iv,进行步骤(1.3.4.2.4.1-1.3.4.2.4.3),找到要与rv合并的超点iv,进行步骤(1.3.4.2.5);
其中,与超点rv邻接的其他超点即与该超点在同一边中的超点;
步骤(1.3.4.2.4.1)计算rv的权重与iv的权重之和;
步骤(1.3.4.2.4.2)判断该权重和是否大于超点权重阈值max_weight,否则进行步骤(1.3.4.2.4.3),是则直接进入下一次循环;
步骤(1.3.4.2.4.3)判断iv是不是属于集合UVT中的超点,是则直接进入下一次循环,否则直接结束循环;
步骤(1.3.4.2.5)根据评分函数计算rv与iv的评分函数,定义变量cur_score,将评分存储在cur_score中,进行步骤(1.3.4.2.6);
其中,评分函数为score(rv,iv)=a·con(rv,iv)+b·hNcut(rv,iv),a、b的值为经验值,依据实验效果调参后所得,其中,
步骤(1.3.4.2.6)判断cur_score是否大于score,是则将超点iv拷贝到cv中、将cur_score的值赋值给score,进行步骤(1.3.4.2.7);
步骤(1.3.4.2.7)将rv与cv合并,本发明使用双向链表的形式,将有合并关系的超点进行连接,然后进行步骤(1.3.4.2.8);
其中,双向链表是链表的一种,直接相连的两个节点之间有指向对方的指针;
步骤(1.3.4.2.8)将被合并超点cv的权重增加到rv,进行步骤(1.3.4.2.9);
步骤(1.3.4.2.9)在当前迭代轮次使用的UVT中移除rv与cv,,进行步骤(1.3.4.2.10);
步骤(1.3.4.2.10)在UV中移除cv,进行步骤(1.3.4.2.11);
步骤(1.3.4.2.11)将超点cv添加到集合C中,进行步骤(1.3.4.2.12);
步骤(1.3.4.2.12)如果被粗化的超点数到达粗化阈值coarse_limit,则退出迭代,执行步骤(1.3.4.3),否则直接进入下一轮迭代;
步骤(1.3.4.3)对I自增1,即I=I+1,进行步骤(1.3.4.4);
步骤(1.3.4.4)判断迭代次数I是否小于iterTime、被粗化的超点数是否到达粗化阈值coarse_limit,任一条件不符合,则停止粗化,停止迭代,执行步骤(1.3.5);
步骤(1.3.5)将粗化后的粗化后的超点、超边、超点的权重集合和超边的权重集合分别拷贝到V'、E'、c'、w'中,得到粗化结果,即超图G'=(V',E',c',w')。
步骤1.4)生成基元
步骤(1.4.1)进行步骤(1.4.1.1-1.4.1.6),构建拉普拉斯矩阵,进行步骤(1.4.2);
其中,拉普拉斯矩阵是图的矩阵表示,主要应用在图论中;
步骤(1.4.1.1)定义VO和EO分别为存储超图中所有超点与对应索引位置和超图中所有超边与对应索引位置的数组,将超图中所有超点与对应索引位置存储在VO中;将超图中所有超边与对应索引位置存储在EO中;
步骤(1.4.1.2)根据点云数据构成的超边集,生成构建相似矩阵S,进行步骤(1.4.1.3);
其中,相似度矩阵是一项重要的统计学技术,用于组织一组数据点之间的彼此相似性,相似性即超边的权重;
步骤(1.4.1.3)根据相似矩阵构建超点度矩阵VD以及超边度矩阵ED,进行步骤(1.4.1.4);
其中,超点度矩阵VD是由超点度构成的对角线矩阵,对角线上的元素为超点的度dv(v
其中,超边度矩阵ED是由超边度构成的对角线矩阵,对角线上的元素为超边的度de(e
步骤(1.4.1.4)根据相似矩阵,进行步骤(1.4.1.4.1-1.4.1.4.4)构建关联矩阵H,进行步骤(1.4.1.5);
其中,关联矩阵是一个n×m的矩阵,第d行表示第d个超点所属的所有超边,第f列表示第f条超边包含的所有超点,矩阵的第d行第f列表示为
步骤(1.4.1.4.1)建立一个n×m的全为0的矩阵H,进行步骤(1.4.1.4.2);
步骤(1.4.1.4.2)遍历EO中所有超边,进行步骤(1.4.1.4.3);
步骤(1.4.1.4.3)遍历超边中所有超点,进行步骤(1.4.1.4.4);
步骤(1.4.1.4.4)在矩阵H中将该超边和超点对应索引位置的0置为1;
步骤(1.4.1.5)根据步骤(1.4.1.2)中的超边构建方式得到的超图信息进行步骤(1.4.1.5.1-1.4.1.5.3),构建权重矩阵W,进行步骤(1.4.1.6);
其中,权重矩阵W是超边权重的对角矩阵,对角线上的元素为超边的权重;
步骤(1.4.1.5.1)建立一个m×m的全为0的矩阵W进行步骤(1.4.1.5.2);
步骤(1.4.1.5.2)遍历EO中所有超边,进行步骤(3.2.1.5.3);
步骤(1.4.1.5.3)将超边的权重按照EO中的索引位置作为权重矩阵中的值替换矩阵W中的0;
步骤(1.4.1.6)根据关联矩阵、权重矩阵、超边度矩阵以及超点度矩阵构建拉普拉斯矩阵L;
其中,拉普拉斯矩阵的计算公式为L=E*-ED
步骤(1.4.2)对拉普拉斯矩阵进行归一化处理得到NL,进行步骤(1.4.3);
其中,矩阵的归一化指将矩阵的数据以列为单元,映射到区间(0,1)之间,即,将每一列数据减去该列的最小值并除以该列的最大值;
步骤(1.4.3)求解拉普拉斯矩阵NL,计算特征值,得到特征向量,进行步骤(1.4.4);
其中特征值,特征向量的定义为:矩阵乘法对应了一个变换,是把任意一个向量变成另一个方向或长度都大多不同的新向量,如果矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值;
步骤(1.4.4)将特征向量按列构建成矩阵NE,并归一化处理,进行步骤(1.4.5);
步骤(1.4.5)定义bestC用于存储最佳聚类结果,定义BestE用于存储最佳聚类结果的评分,初始化BestE为0,定义T_num用于存储重复聚类次数,初始化T_num为0,定义retryTime为聚类操作重复次数,进行步骤(1.4.6);
步骤(1.4.6)执行步骤(1.4.6.1-1.4.6.5),对NE进行聚类,评估聚类的效果,循环retryTime次,找到解质量最高的聚类,执行步骤(1.4.7);
步骤(1.4.6.1)对T_num自增1,即,T_num=T_num+1,进行步骤(1.4.6.2);
步骤(1.4.6.2)对矩阵NE使用K-Means方法进行聚类,将得到的向量聚类结果作为对应超点的聚类结果,进行步骤(1.4.6.3);
其中K-Means方法将数据集分为K个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”;
步骤(1.4.6.3)根据评分函数,评估聚类的效果,进行步骤(1.4.6.4);
其中评分函数的公式为
步骤(1.4.6.4)如果本次聚类的评分高于BestE,进行步骤(1.4.6.4.1-1.4.6.4.2),用本次聚类结果替换原聚类结果,否则进行步骤(1.4.6.5);
步骤(1.4.6.4.1)将本次据聚类结果替换到bestC中,进行步骤(1.4.6.4.2);
步骤(1.4.6.4.2)将本次据聚类结果的评分赋值给BestE;
步骤(1.4.6.5)判断T_num是否大于或等于retryTime,是则退出循环,否则进入下一次循环;
步骤(1.4.7)结束循环,得到聚类结果bestC,即基元xi。这些基元被用来表示点云中的特征,提供了对点云数据更高级别的语义理解。
步骤二:构建CSG-Base Net,过程如下:
步骤2.1)定义几何模型
几何模型采用四种基本体来表示,分别为立方体、球体、圆柱体和锥体作为标准基元,使用以上基元作为图元集;
步骤2.2)占有率计算
为了计算不同形状在模型组合中的占用率,先生成基元的占有函数,占有函数用来判断空间中的每个点是否在物体表面,首先输入基元传递到MLP层的第一个全连接层。在这一层中,每个神经元将潜在特征与自身的权重进行加权求和,并将结果与偏置项相加得到一个加权和,然后经过激活函数的非线性变换,这个非线性变换的目的是引入非线性关系,从而增强特征的表达能力,经过非线性变换后的结果被传递到下一层的每个神经元,直到到达MLP层的最后一层,在最后一层,MLP层的输出是基元映射到高维向量空间中的特征表示,然后计算基元的带符号距离场(SDF,Signed Distance Field)。SDF是三维网格的一种突出的隐式表示,即空间中每个点距离表面的距离,通过将离形状表面一定距离内的空间标记为负数、形状表面的空间标记为零、形状外的空间标记为正数的方式描述一个三维几何模型,对于基元中的一个点x,其距离场函数SDF(x)定义为:
SDF(x)=min{dist(x,S)}
其中dist(x,S)是点x到几何形状S的最短距离,并且是正数、零或负数;
接收步骤1.4)中得到的基元xi计算占有率,当SDF(x)<0时,表示点x在几何形状S的内部,表示为SDF
O(x)=-η×SDF(x)
其中,标量η是表示转换为占有率的超参数,sigmoid函数将输入的实数映射到一个介于0和1之间的输出值,通常用于二分类问题中;
步骤2.3)精细化凹凸基元的生成
通过组装不同的基元来生成多种不同的形状,生成的形状更具紧凑性,与预测基元的方法相比,本发明使用二次预测基元的形式来生成复杂的剩余形状。接收步骤2.2)中的进行占有率计算后的基元,并输出两个矩阵P
|a|x
其中x
P
其中
对于凹基元,曲面包围的查询点的SDF值为负,即这些点位于基元内部,对于凸基元,由曲面包围的查询点的SDF值是正的,即该空间在基元内部;
步骤2.4)构建CSG-Base
CSG-Base是3D形状的三层树表示结构,基于CSG-Tree实现具有存储操作信息的节点的分层表示,CSG-Tree是一种用于几何建模的数据结构,通过布尔操作来组合和操作几何对象,允许快速计算出复杂几何形状的体积和表面积;
连接头解码器是将基元之间的联系转换为连接的过程,这些连接可以表示基元数据中的几何关系,例如点之间的距离或者表面法线之间的夹角,通过连接头解码,可以构建基元之间的拓扑结构,并将基元表示为一个可解释的3D形状。拓扑结构是指基元之间的一种关系结构图;
CSG-Base利用二进制矩阵来表示不同原始基元位置之间的布尔运算,使用三个专用单层感知器将编码特征解码为连接矩阵W
CSG-Base右侧是只有一个节点的并集层(Union),中间为交集层(Intersect),左侧为补集层(complement),CSG-Base补集层的节点与基元一一对应,存储了是否对相应的基元执行补码运算,交集层上的节点记录选择在底层中生成的哪些形状进行相交操作。并集层的节点记录选择交集层中生成的哪些形状进行并集操作,因此,对于CSG-Base中的每一层,引入连接头解码器生成的连接矩阵W来编码其节点的信息;
定义一个1×K矩阵W
步骤2.5)构造建模结果
输入步骤2.2)基元占用率和步骤2.4)连接矩阵W,计算整个形状的占用率,得到建模结果,初始左侧层输出F
其中W
对于补集层中的每个节点,其形状是来自步骤2.3)的基元,函数S
S
其中,W
对于并集层中的每个节点,其形状是来自补集层的节点,由函数T(x)定义:
T(x)=max
其中,W
然后将并集层的输出的结果相加得到重建结果;
步骤三:损失函数
以自监督的方式端到端地训练CSG-Base Net,CSG-Base Net学习预测具有基元及其连接的CSG-Base,自监督任务是在无标注的数据上通过设计监督任务训练模型,从形状边界框中采样测试点x
在实验中观察到远离基元表面的测试点时梯度为0出现梯度消失现象,通过一种基元丢失的方法解决该问题,将每个基元表面拉到它最近的测试点,防止梯度消失,将这一损失定义为:
其中
最后,总损失可定义为上述两项的联合损失:
L
其中,λ为超参数。
如图1所示,首先通过步骤1.3)聚类点云数据后,得到粗化结果,即超图G'=(V',E',c',w')。然后输入到步骤1.4)得到聚类结果bestC,即基元xi。将基元xi输入到MLP,使得基元数据转换为向量并映射到高维向量空间中。接收步骤1.4)中高维度的基元特征基元xi计算占有率。将基元划分为x1,x2,x3,x4。当SDF(x)<0时,表示点x在几何形状S的内部,表示为SDF
参考图2,在ShapeNet数据集对CSG-Base Net进行性能测试,步骤如下:
步骤一:定义对比方法
SR:提出了一种基于学习的解决方案,该方案超越了传统的三维长方体表示,利用超二次曲面作为原子元素;
UCSG-Net:提出了一个模型,在没有任何监督的情况下提取一个CSG解析树-UCSG-NET。模型预测基元的参数,并通过可微指标函数对其SDF表示进行二元化;
步骤二:定义评价指标
指标1:CD(L2 Chamfer Distance)是用来评估两个点云之间距离的一种度量方法,这种度量方法通常用于点云配准、3D形状匹配和3D物体识别等领域,CD定义为:
其中,|A|和|B|分别表示点云S1和S2中点的数量,||x0-y0||^2表示点x0和点y0之间的欧氏距离的平方,对于点云S1中的每个点,计算它与点云S2中所有点之间的欧氏距离,并取其中最小值,这个最小值代表了点云S1中的点与点云S2之间的最短距离,将所有点的最小距离求和,除以点云S1中点的数量|A|,得到从点云S1到点云S2的距离度量,对于点云S2中的每个点,同样计算它与点云S1中所有点之间的欧氏距离,取其中最小值。将所有点的最小距离求和,除以点云S2中点的数量,得到从点云S2到点云S1的距离度量,将两个距离度量相加,得到点云S1和点云S2之间的CD,CD越小,表示点云S1和点云S2之间越相似,因此,CD可以用来评估两组点云之间的相似程度。
指标2:V-IoU是计算两个三维物体之间重叠部分的相似度的一种方法,它通过计算两个物体的交集体积与并集体积之间的比率来衡量它们的相似度,对于两个三维物体A和B,它们的体积IoU计算公式如下:
V-IoU(A,B)=V(A∩B)/V(A∪B)
其中,V表示体积,∩表示交集,∪表示并集,如果V-IoU的值为1,则表示两个物体完全重合,值为0则表示它们没有重叠部分;
指标3:Surface F1 Score(S-F1)是一种用于衡量三维物体表面重建精度的指标,它是根据F1 Score的概念而来,F1 Score的计算方式是二分类问题中精确率和召回率的调和平均数,Surface F1 Score则是在三维重建中使用;
具体来说,Surface F1 Score通过计算两个表面的交集与并集来衡量重建结果与真实表面之间的匹配程度,设P和G分别表示重建表面和真实表面的点集,那么Surface F1Score定义为:
F1(P,G)=2*|P∩G|/|(|P|+|G|)
其中,∩表示点集交集,|P|和|G|分别表示点集P和G的大小。Surface F1 Score的值越高表示重建结果与真实表面之间的匹配程度越好;
步骤三:
步骤3.1)ShapeNet数据集介绍
Shapenet是一个大规模的三维模型数据集,它为研究三维形状理解提供了丰富的数据集,Shapenet包括了广泛的3D CAD模型,其中包含数百个对象类别,覆盖了从飞机和汽车到家具、动物和植物的所有领域,Shapenet数据集被广泛用于计算机图形学、机器学习、计算机视觉、人机交互等研究领域;
步骤3.2)实验结果评估
图2给出了不同类型数据集下CD、V-IoU、Surface F1结果的比较,可以得出CSG-Base Net在每个评价指标中多数实现了优秀的结果,其中CD最优数量为6,V-IoU最优数量为10,Surface F1 Socore最优数量为6,从不同指标的实验结果上来看,CSG-Base Net的重建质量整体最佳。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 一种小型道路坑洞修补施工装置
- 一种市政道路施工的新型维护设备
- 一种桥面道路施工用防尘布铺盖设备
- 一种道路施工用节能型定向隔离噪音的环保设备
- 一种用于道路地标线施工的地面清洁设备
- 一种道路修补压平的道路施工设备及施工方法
- 一种道路修补压平的道路施工设备