肢体骨架和头手部件轮廓融合的手势识别方法
文献发布时间:2023-06-19 09:26:02
技术领域
本发明中设计肢体骨架和头手部件轮廓融合的手势识别方法,属于电子信息领域,是一种基于计算机视觉、可应用于人机交互的人体手势识别方法。
背景技术
手势是人与人之间非语言交流的最重要方式。由于手势具有自然、形式多样等特征,其识别是人机交互研究的一个重要领域。依据手势识别设备是否与身体接触,其识别方法可分为接触式手势识别和基于视觉的手势识别。其中,接触式手势识别使用的设备(如数据手套)复杂、价格高,需用户熟悉相应设备后才能进行手势识别,限制了手势的自然表达,不利于自然交互。基于视觉的手势识别无需高昂的设备,且具有操作方便、自然等优点,更符合自然人机交互的大趋势,有广泛的应用前景。基于计算机视觉的方法易于实现,但其识别准确率易受背景、光照或人体手势运动变化等因素影响。近年来深度学习算法在图像识别、自然语言处理等领域应用取得优异效果,为人体手势识别提供了新的实现方法。
针对基于计算机视觉的人体手势识别中存在的问题,本发明引入基于深度学习的卷积姿势机(Convolutional Pose Machines,CPM)、单发多框检测器(Single ShotMultiBox Detector,SSD)以及长短时记忆(Long Short Time Memory,LSTM)进行人体手势识别。
发明内容
本发明针对基于计算机视觉的人体手势识别方法易受光照、背景和手势动态变化影响等问题,结合CPM、SSD、LSTM构造人体动态手势识别机(Gesture Recognizer based onSpatial Context and Temporal Feature Fusion,GRSCTFF)提取人体手势的时空特征,实现人体手势的快速准确识别;
本发明的发明内容具体如下:
(1)在分析人体手势空间上下文特征的基础上,建立基于人体骨架和部件轮廓特征的动态手势模型;
在采用手势交互时,动态手势的形态主要由人体骨架形态与手、头部轮廓构成,其本质是基于骨架关节点与各骨架段的相对位置(如骨架的长度、角度)以及手和头部外部形态的组合。其中,人体骨架由骨架的关键节点互相链接构成。本发明中“人体骨架关键节点”指代人体骨架链接结构所包含关键节点,而“部件”特指具有形状轮廓特征的手、头和脚。借鉴3维人体模型思想,建立融合人体骨架、手和头等部件轮廓特征的通用手势模型。
(2)采用卷积姿势机和单发多框检测器技术构造深度神经网络进行人体手势骨架和部件轮廓特征提取,并将其组合为人体空间上下文特征;
手势空间上下文信息由手势骨架构型及手势部件轮廓构成。手势骨架构型中包括人体骨架的相对长度特征以及相对于重力加速度方向的角度特征,为了提取手势骨架构型特征,需要建立人体骨架关键节点提取网络,本发明借鉴CPM思想,裁剪了CPM深度,构造了包含3个阶段的人体骨架关键节点提取网络KEN:
设Z为图像中人体骨架所有位置坐标(i,j)的集合;在图像中人体骨架每个关键节点的位置用Y
Y
基于公式(1)可计算出人体骨架中的每个关键节点的位置,建立初步的人体骨架形态。
图1所示为手势骨架特征的提取过程。φ
其中,11表示本发明人体骨架模型中总共包含11段人体肢体骨架,v
此外,由于重力加速度的方向始终垂直于地面,为了描述人体骨架中每个骨架段相对于地面的方向,本发明引入了骨架与重力加速度的夹角。并使用φ
本发明采用骨架与重力加速度方向的三角函数值来描述骨架的角度特征。公式(3)中,d表示一个单位矢量,方向与重力方向相同。
手势部件轮廓中包括人体的头部、手部的类别特征,为了获取部件轮廓的类别,本发明借鉴SSD思想,采用参数量更少的MobileNet替换SSD中的特征提取网络VGGNet,进而构建手势部件轮廓特征提取网络GPEN:
GPEN在多尺度的卷积特征图上对部件轮廓特征进行检测与分类。其中,对每一尺度卷积特征图上的每个单元,GPEN都有不同尺度和长宽比的锚定框对框内的手势部件进行预测,生成预测框的位置以及不同手势部件轮廓的类别置信度。设S为GPEN从图像中识别出的部件轮廓特征值(L,C)的集合,其中L表示部件轮廓预测框的位置信息,由预测框中心点的坐标、预测框宽度和高度构成;C表示将预测框中包含的对象轮廓预测为不同部件轮廓类别的置信度集合。例如,c
对于每个部件轮廓p(s
1)取G中置信度值c
2)识别同一部件轮廓的重叠度阈值为J
3)当对排序后的部件集合G完成以上操作后,将l
重复上述3步,直至集合G为空,最终得到左手部件轮廓特征S
G=φ
(3)引入长短时记忆网络提取动态人体手势中骨架、左右手和头部轮廓的时序特征,融合人体空间上下文特征,进而分类识别手势,完成GRSCTFF的搭建;
在动态手势识别中,手势类型不仅与当前手势特征有关,还与之前的手势特征有关。f
classification=f
公式(6)说明为了准确识别当前动态手势类别,需要一种结构来保存此前手势的空间上下文特征。因此,本发明引入LSTM网络将动态手势中的空间特征与时间顺序相关联并最终完成动态手势分类。
本发明的创造性主要体现在:
(1)本发明提出了使用人体骨架姿态特征结合手势部件轮廓特征描述人体手势。假设仅使用人体骨架姿态特征表征人体手势,当人体处于被遮挡的状态时容易导致手势类别被误判;假设仅使用部件轮廓表征人体手势,则会过于依赖人体部位的表观特征如颜色、纹理、边缘信息等,有一定的局限性。如发明内容中公式(5)所示,本发明技术难点在于通过人体骨骼特征拼接手势部件轮廓特征表征人体整体模型,其中人体骨骼特征由公式(3)计算得到,创造性地提出了使用相对于人体头部至颈部的规格化相对长度和肢体相对于重力加速度方向的相对角度作为人体骨骼特征;另外手势部件轮廓特征由公式(4)得到,本发明使用轮廓检测网络识别出的手势部件类别表征人体局部信息,使得人体模型结构更加完整。
(2)本发明剪裁CPM网络构造人体骨架关键节点识别网络KEN,使其具有足够的实时性,在实际测试中可以达到每秒15帧的识别速度,同时具有较高的识别精度,该网络模型的优势在于不依赖特定的人体空间约束,打破了传统的人体手势识别网络依赖于人体部位的表观特征的局限性;另一方面,本发明提出的手势部件轮廓特征提取网络GPEN,根据数据集中的人体部件轮廓改进锚定框的尺寸,使其应对手部、头部等较小轮廓时具有足够的检测能力,当人体部分肢体骨架被遮挡时手势部件轮廓网络提取的特征可以很好地对人体进行补充描述,同时具有网络模型参数少,检测速度快的优点;最后采用LSTM网络提取人体动态手势的时序特征,构建了人体动态手势进行过程中的时序关联,解决了独立的人体手势导致动态连续手势被误判的问题。
(3)本发明设计并实现了人体动态手势识别机GRSCTFF,使其可以在多种复杂场景下较为准确的识别人体动态手势的类别,解决了基于计算机视觉的人体手势识别方法易受光照、背景和手势动态变化影响等问题;GRSCTFF网络模型具有参数量较少,运算速度快,识别精度高的特点。
附图说明
图1为手势骨架特征提取过程;
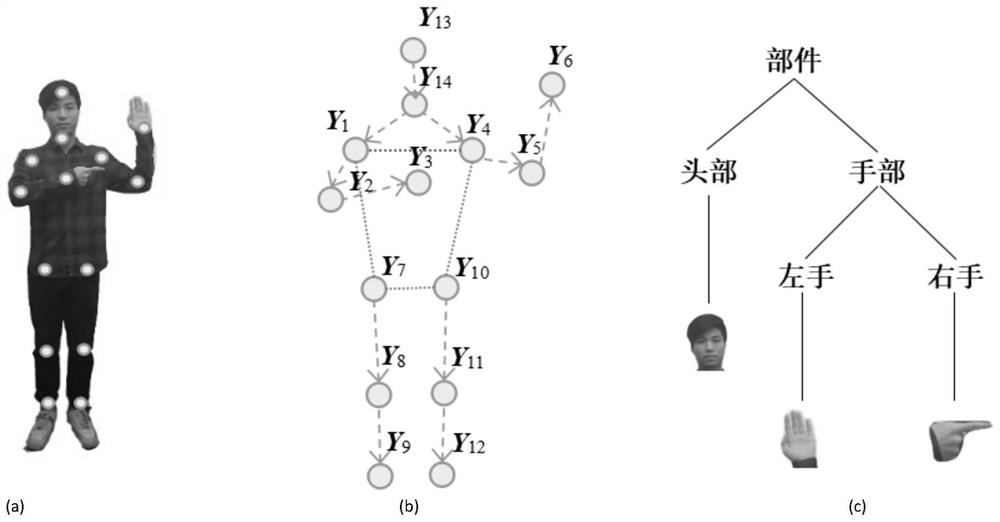
图2(a)为人体手势;
图2(b)为人体手势对应骨架关键节点与骨架矢量;
图2(c)为人体手势对应手势部件轮廓;
图3为KEN网络架构;
图4为GPEN网络架构;
图5为深度可分离卷积的卷积过程;
图6为特征尺寸比例散点图
图7为LSTM网络架构。
具体实施方式
本发明采用了如下的技术方案及实现步骤:
(1)在分析人体手势空间上下文特征的基础上,建立基于人体骨架和部件轮廓特征的动态手势模型;
图2(a)所示为通用人体手势模型。为了识别该手势,需要识别人体骨架(b)、以及其头部和左右手的轮廓特征(c)。
人体的骨架可抽象为14个关键节点及其连线,如图2(a)所示。图2(b)中这些关键节点的坐标集合为Y,Y
v为其中的一条关键节点连接(即v∈V),其起始关键节点和终止关键节点分别为Y
(2)空间上下文特征提取模块的设计实现,其具体方式为采用卷积姿势机和单发多框检测器技术构造深度神经网络进行人体手势骨架和部件轮廓特征提取,并将其组合为人体空间上下文特征。
空间上下文特征提取模块主要包括两个部分,其中一个部分为人体骨架关键节点识别网络KEN的设计与实现,另外一个部分为手势部件轮廓特征提取网络GPEN的设计与实现,如下所示:
1)人体骨架关键节点识别网络KEN的设计与实现:
传统CPM在监测人体活动时输出15个热点图。其中,14个热点图对应人体相应的关键节点,另外1个为背景热点图。本发明借鉴CPM思想,在输出端补充了人体骨架关键节点间的关联关系。同时,为了支持手势实时识别,裁剪了CPM深度,构造了包含3个阶段的人体关键节点提取网络KEN,图3为其网络架构。
图3中,C代表卷积层,K表示卷积核尺寸,OC表示输出通道数,t表示阶段。KEN采用VGG-19网络的前10层作为图像特征提取网络对输入图像进行处理,从第1层到第10层卷积层的卷积核大小分别为:3×3×64、3×3×64、3×3×128、3×3×128、3×3×512、3×3×512、3×3×256、3×3×256、3×3×256、3×3×256,另外在第2层、第4层、第6层的卷积层后接一个最大值池化,所有最大值池化的卷积核大小为2×2且步长为2,最后经过上述处理得到图像的特征x
KEN包含了3个代价函数,它们分别计算上述3个阶段输出的关节点置信度集合b
公式中,
本发明采用AI Challenger公开的人体关键节点数据集作为训练样本来训练KEN网络。在人体骨架特征提取网络KEN的训练中,batch值为15;梯度下降采用了Adam优化器,其学习率为0.0008,每20000步的指数衰减率为0.8。
2)手势部件轮廓特征提取网络GPEN的设计与实现:
由于数据集中的标注数据相对较少,直接使用SSD网络进行训练易导致过拟合现象。为了缓解过拟合现象的发生,减少网络模型的参数量,本发明采用参数量更少的MobileNet替换SSD中的特征提取网络VGGNet,进而构建手势部件轮廓特征提取网络GPEN。图4为GPEN的网络结构。
图4中,GPEN的第0层卷积层(Conv0)使用传统卷积核,其大小为3×3×32;GPEN中图像特征提取网络部分,即第1层卷积层至第13层卷积层(Conv1-Conv13)基于深度可分离卷积的堆叠技术构建,每组深度可分离卷积包含一个单深度卷积核与一个单点卷积核,则Conv1-Conv13的单深度卷积核大小按顺序分别为3×3×32、3×3×64、3×3×128、3×3×128、3×3×256、3×3×256、3×3×512、3×3×512、3×3×512、3×3×512、3×3×512、3×3×512、3×3×1024,Conv1-Conv13的单点卷积核大小按顺序分别为1×1×32×64、1×1×64×128、1×1×128×128、1×1×128×256、1×1×256×256、1×1×256×512、1×1×512×512、1×1×512×512、1×1×512×512、1×1×512×512、1×1×512×512、1×1×512×1024、1×1×1024×1024。其后Conv14_1至Conv17_2共8层卷积层的卷积核大小按先后顺序分别为1×1×1024×256、3×3×256×512、1×1×512×128、3×3×128×256、1×1×256×128、3×3×128×256、1×1×256×64、3×3×64×128。
Conv1-Conv13中的深度可分离卷积将通道相关性和空间相关性分离,并用深度可分离卷积核代替传统卷积核,因此大大减少了网络的参数量,其完整卷积过程如图5所示。其中,M为图像输入通道数,OC为输出通道数,K表示卷积核尺寸,则K×K表示卷积核大小,D
由于卷积网络提取图像特征时OC较大,项值
GPEN网络训练的损失函数由分类损失和定位损失构成,如公式(10)所示。
其中,L
GPEN在进行网络训练前需依据人体手势中手和头部轮廓特征优化SSD锚定框。本发明所采用的公开交警手势数据集已标注视频样本的左右手和头部轮廓尺度比例的散点图如图6所示。图6中,横坐标表示部件轮廓标注框宽度占整幅图像宽度的比例;纵坐标表示部件轮廓标注框高度占整幅图像高度的比例。由图6可以发现,部件轮廓标注框高度与原图像高度比小于0.25、部件轮廓标注框宽度与原图像宽度比小于0.20,部件轮廓标注框归一化尺度介于0.05至0.25之间。为了训练GPEN,本发明将锚定框的归一化尺度取值介于0.05至0.3之间。GPEN与原SSD网络都含有6层包含了锚定框的特征层,每个特征层上的锚定框归一化尺度如下表所示:
本发明的GPEN网络训练部分,由于网络模型设计时将手势部件轮廓特征提取网络的图像特征提取器从VGGNet改换为MobileNet,故直接将Google公司提供的MobileNet预训练模型加载至GPEN。改换预训练模型后的GPEN以人体手势视频帧数据集作为样本进行训练,batch值为24。在训练过程中,通过随机梯度下降以及反向传播机制不断减小损失函数值,从而使锚定框的位置逼近真实框位置,同时提高分类置信度。累计训练120000步后,网络收敛、系统准确率不再变化,将模型保存下来用以识别并提取人体手势部件轮廓特征,结合KEN网络计算出的人体手势中骨架的相对长度和角度特征数据,得到空间上下文特征。
(3)时序特征特征提取网络及动态手势分类。
依据KEN输出的关键节点及节点间的关联关系,可以分别计算出人体骨架中各骨架段的相对长度及其与重力加速度间的夹角,同时结合GPEN输出的左右手和头部轮廓类别可以生成τ时刻的人体手势空间上下文特征F
获取到人体手势空间上下文特征F
本发明采用Xavier对LSTM网络中的神经元进行初始化设置,并采用截断反向传播算法训练LSTM网络。训练中,人体手势视频数据集被随机切分成长度为90秒的小片视频,128个小片视频组装起来构成一个batch。LSTM的学习率是0.0004,梯度下降算法采用了Adam优化器。累计训练50000步后停止LSTM网络训练。
GRSCTFF动态手势识别机搭建完成后采用公开数据集进行训练。人体骨架关键节点网络KEN采用AI Challenger公开的人体关键节点数据集作为训练样本,手势部件轮廓特征提取网络GPEN采用公开交警手势数据集的训练集进行训练。
最后GRSCTFF采用公开交警手势数据集的测试集进行实验验证,通过编辑距离计算人体手势识别的准确率,即模型预测识别的手势信息转成真实标注手势信息所需的最少编辑次数,编辑距离距离按照公式(11)计算。其中,Accuracy代表准确率,H为视频中姿势总数,I是视频中插入姿势的总数,D是系统中删除姿势的总数,P是系统中替换姿势的总数。
实验证明GRSCTFF可以快速准确的识别人体手势,系统的准确率达到94.12%,并对光线、背景和人体手势位置变化具有较强的抗干扰能力。