一种基于数据库的文档管理方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及大数据领域,特别涉及一种基于数据库的文档管理方法。
背景技术
随着用户注册数量的不断增大,用户的文档数据也随着几何级的增长。所有的用户文档数据都存贮在一张表中,这张表的大小也会不断加大,虽然数据库单表支持上亿条数据的查询,但是实时查询效率还是会有所下降,最终影响整个用户文档数据查询的性能,成为系统性能的瓶颈所在。在系统高并发量的时候可能会影响业务流程的正常执行,造成损失。
发明内容
为了克服现有技术的不足,本发明提供一种基于数据库的文档管理方法。
本发明解决其技术问题所采用的技术方案是:
一种基于数据库的文档管理方法,包括以下步骤:
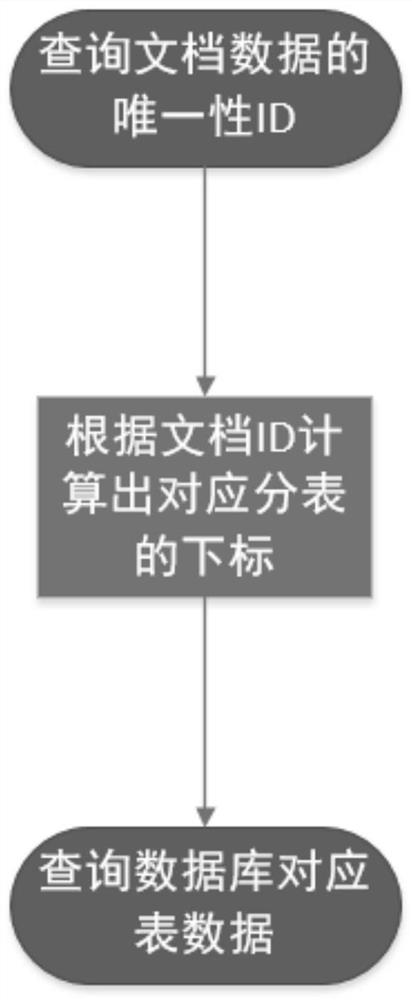
S1、取出需要查询的文档数据的唯一性ID;
S2、根据唯一性ID计算出该条文档数据存在的分表;
S3、根据计算出的分表下标值i查询对应的表,得到文档数据信息。
进一步地,所述S2包括:
S2.1、设整个文档数据容量为X(X<60000)条,规划为每张表的数据量不超过一千万条,则首先需要计算出存贮X条数据所需要的表的张数Y,Y为大于X的最小的2^n数;
S2.2、根据hash算法计算出当前查询的唯一性ID的hash值设为hash(ID);
S2.3、将hash(ID)的高16位与低16位进行数据中和,计算出这条数据的hash值的实际值为hashCode(ID):
hashCode(ID)=hash(ID)^(hash(ID)>>>16);
S2.4、将hashCode(ID)与Y进行取模运算即可以得到这条数据所在表的下标值i:
i=hashCode(ID)%Y=hashCode(ID)&(Y-1)。
进一步地,所述将hash(ID)的高16位与低16位进行数据中和包括:将高16位与低16位进行异或运算以使最终得到的hashCode(ID)值范围更大。
进一步地,运用Java开发语言进行编程,采用Oracle数据库存贮文档数据。
本发明的有益效果是:本发明一种基于数据库的文档管理方法本发明是基于数据库的分表查询,结合对应的分表算法,将这个大表的数据均匀的拆分到多张表中,这样在查询时能够提升查询效率,通过空间换取时间,提升系统的并发量。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明一种基于数据库的文档管理方法的结构流程图。
具体实施方式
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,专利中涉及到的所有联接/连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少联接辅件,来组成更优的联接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。
参考图1,本发明解决其技术问题所采用的技术方案是:
一种基于数据库的文档管理方法,包括以下步骤:
S1、取出需要查询的文档数据的唯一性ID;
S2、根据唯一性ID计算出该条文档数据存在的分表:
S2.1、设整个文档数据容量为X(X<60000)条,规划为每张表的数据量不超过一千万条,则首先需要计算出存贮X条数据所需要的表的张数Y,Y为大于X的最小的2^n数;
S2.2、根据hash算法计算出当前查询的唯一性ID的hash值设为hash(ID);
S2.3、将hash(ID)的高16位与低16位进行数据中和,计算出这条数据的hash值的实际值为hashCode(ID):
hashCode(ID)=hash(ID)^(hash(ID)>>>16);
S2.4、将hashCode(ID)与Y进行取模运算即可以得到这条数据所在表的下标值i:
i=hashCode(ID)%Y=hashCode(ID)&(Y-1)。
S3、根据计算出的分表下标值i查询对应的表,得到文档数据信息。
进一步地,所述将hash(ID)的高16位与低16位进行数据中和包括:将高16位与低16位进行异或运算以使最终得到的hashCode(ID)值范围更大。
进一步地,运用Java开发语言进行编程,采用Oracle数据库存贮文档数据。
如下为一个具体实施例举例:
根据唯一性ID计算出该条文档数据存在的分表
1、整个文档数据预估的容量为X(X<60000)千万条数据,规划为每张表的数据量不超过一千万条,则首先需要计算出存贮X亿条数据所需要的表的张数Y。
Y为大于X的最小的2^n数,取2^n是为了便于后面进行取模运算。
比如:X为100,则Y为2^8=128。
2、首先根据hash算法计算出当前查询的唯一性ID的hash值为hash(ID),然后再将hash(ID)与Y进行取模运算即可以得到这条数据所在表的下标值i。
一个数对2^n进行取模运算,可以简化为二进制中的与运算,提升计算效率。
i=hash(ID)%Y=hash(ID)&(Y-1)
根据该公式可以得到,hash(ID)&(Y-1)即可以确定文档数据保存的是哪一张表。
3、根据hash算法的原则,要尽可能的避免hash冲突。而目前表的总数为Y张,而Y的最大值为2^16,这就导致hash值在与Y进行与运算时,高16位始终不会参与运算,加大了hash冲突的概率。因此需要将高16位与低16位进行数据进行中和,这样计算出这条数据的hash值实际为hashCode(ID):
hashCode(ID)=hash(ID)^(hash(ID)>>>16)
然后在根据步骤2计算出最终所在的标的下标为:
i=hashCode(ID)&(Y-1)
将高16位与低16位进行异或运算,使最终得到的hash值范围更大,最终落到所有分表的数据也更加散列。
本发明的有益效果是:本发明一种基于数据库的文档管理方法本发明是基于数据库的分表查询,结合对应的分表算法,将这个大表的数据均匀的拆分到多张表中,这样在查询时能够提升查询效率,通过空间换取时间,提升系统的并发量。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 一种基于数据库的文档管理方法
- 一种基于数据更新的文档管理方法及文档管理系统