一种针对分类问题的进化集成学习方法
文献发布时间:2023-06-19 10:48:02
技术领域
本发明属于机器学习和数据挖掘领域,具体包含了基于树形编码的基学习器搜索群体和基于二进制编码的集成学习器搜索群体。两个层次的搜索优化进程可通过进化迭代机制动态地结合起来,再通过彼此之间的信息交流实现协同优化。这种架构可促使基学习器群体不断演变,并在个体的高质量和群体的多样性间保持平衡,同时实现对集成学习器结构的全局优化。此外,这种计算架构有利于降低集成学习器构造过程对人为设计决策的依赖,转而通过数据驱动的模式实现集成学习器的自动化生成。
背景技术
随着信息技术的飞速发展,在如今的大数据时代,数据呈爆炸式增长,呈现出海量、复杂多样以及变化快等特征。如何从海量数据中高效地寻找出有价值信息背后的关联受到人们越来越多的关注。
集成学习是数据挖掘方法的一种,适合于处理复杂的高维数据。传统集成学习器的构造过程大体可分为两步:首先产生一定数量的以决策树为代表的基学习器,然后通过对基学习器进行叠加构成集成学习器。传统使用贪心算法所搜索到的基学习器结构通常是局部最优而不是全局最优,而基学习器的叠加过程只能单向递增,冗余度的增大会影响基学习器群体的多样性,同时人为的设计决策也会影响构造结果。此外,通常认为集成模型中各基学习器之间的多样性越高则集成学习的泛化性能越好,但传统集成模型构造机制中缺乏评测以及维持各基学习器之间多样性的机制。另一方面,传统集成模型通过独立或按序生成不同的基学习器,再通过相互叠加集成来达到更佳的计算效果。这种模式虽然可以提高集成模型的构造效率和泛化性能,但单个基学习器之间的交互和协作优势没有得到充分的发挥,并且会存在冗余结构。选择集成机制一定程度上有利于在不影响泛化性能的基础上降低集成模型的复杂度,但这种机制在基学习器生成时并没有参考其与其他基学习器组合形成集成学习器的组合效应。特别是依然无法对基学习器自身进行结构调整,且基学习器之间可能存在的组合效果要直到完整的集成学习器产生之后才能被利用。因此只能被动地对已存在的基学习器进行组合优化,而无法主动地寻找更为有效的基学习器组合。
发明内容
针对现有集成学习存在的问题,本文发明了一种针对分类问题的双进化架构自动集成学习方法,通过建立对基学习器群体的进化搜索和在基学习器群体进化基础之上的集成学习器群体进化两个优化过程,使集成器群体与基学习器群体的不断交互协同构造生成集成模型。
为实现上述目的,本发明的具体技术方案如下:
步骤1:初始化基学习器个体种群,可表示为
步骤1.1:生成根节点,从训练样本中随机选择一个特征并随机选择该特征的分割阈值作为当前节点的内部属性;
步骤1.2:递归的生成树结构,当树的深度大于D
步骤1.3:当树的深度等于D
步骤2:基学习器个体的搜索过程。在双进化搜索过程中我们依靠针对树形编码设计的交叉和变异机制来产生基学习器子代个体,节点交叉概率为P
步骤2.1:交叉操作。首先从决策树群体T中随机选择两个个体t
步骤2.2:变异操作。变异将对分类树进行局部调整,具体方式包括:改变节点上的数值,以及改变节点的分支结构。首先对交叉后生成的子代群体中每个个体t
步骤3:集成学习器个体的搜索过程。一个集成器个体e可用一个二进制串表示,若e(i)=1表示决策树t
步骤3.1:交叉操作:参与交叉的父辈个数k从2到群体规模N之间随机确定,公式如下:
其中,i={1,2,...,N}为个体的基因编码位数,j={1,2,...,k}为父辈个体数,e
步骤3.2:变异操作。对集成交叉产生的所有个体e
步骤4:评估机制;
步骤4.1:基学习器个体的评估。分类树的多样性是衡量树群中子树之间的差异性。公式如下:
其中f
f
其中max_depth(t
其中f
其中f
F
步骤4.2:集成器个体评估。集成器群体优化的目标是寻找最佳的分类树组合,适应度函数以准确率和最小集成规模为目标:
其中,f
步骤5:群体迭代机制;
步骤5.1:基学习器群体进行多目标选择。父代个体和搜索产生的子代个体将组成大小为2N的群体,通过多目标选择产生规模为N的下代群体。具体操作如下:
步骤5.1.1:首先根据4个目标函数计算群体中所有个体的优势等级(即支配关系),然后根据优势等级进行分层;
步骤5.1.2:针对同一层的个体,其他的多目标优化算法根据不同的密度估计方法进行排序,目的是维护群体的多样性,由于在适应度评估中已经计算了基学习器之间的多样性,这与其他密度估计方法类似,所以同一层个体根据它们的多样性进行排序;
步骤5.1.3:从优势等级为0的层开始向后续层次截断前N个个体作为下代群体,为了与集成学习器的编码对应,截断后的N个下代群体中,来自父代的个体放入原始的编码位置,来自子代的个体放入空置的编码位置。此过程中由于被选择的子代个体比被淘汰的父代个体更优秀,所以替换后并不会降低集成学习器的性能。
步骤5.2:集成学习器群体选择操作。父代个体和子代个体组成大小为2N的群体,然后依据集成器个体的准确度挑选产生规模为N的下代群体。具体操作如下:
步骤5.2.1:为了保持集成学习器之间的多样性,将每个集成器对验证集的预测标签作为集成器的特征,然后通过AP聚类算法对集成器进行聚类,因为AP 聚类不需要指定最终的聚类族个数,并且对数据的初始值不敏感,不需要进行随机选取初值步骤。
步骤5.2.2:聚类后的每个簇内都是相似度较高的集成学习器集合。故首先在每个簇中按集成学习器的准确度进行排名,然后依次从每个簇中选择前半部分集成器个体加入下代群体,最终获得个体数量为N的下代群体。
步骤6:判断当前迭代次数是否满足最大迭代次数,若不满足则转至步骤2,否则将当前基学习器群体和最优集成器组合作为集成模型,输出分类结果。
附图说明
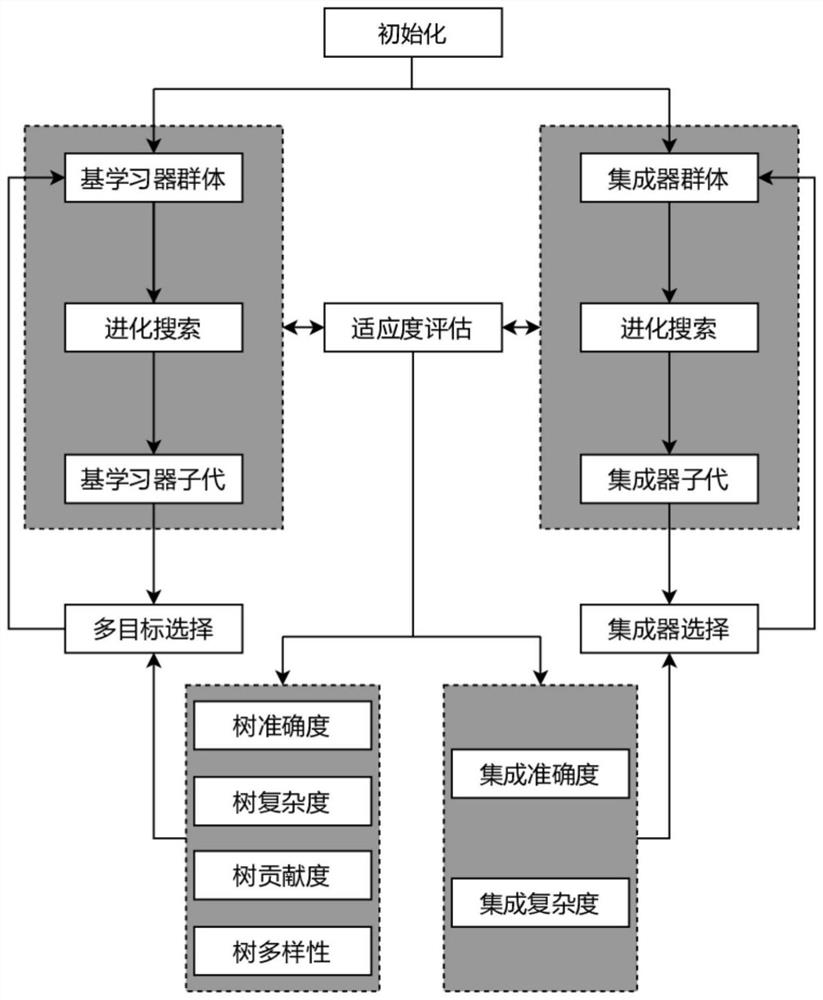
图1为本发明实施例中针对分类问题的双进化架构自动集成学习方法;
图2为本发明实施例中树形编码的基学习器结构;
图3为本发明实施例中基学习器的交叉过程;
图4为本发明实施例中基学习器的变异过程;
图5为本发明实施例中集成器的交叉过程;
图6为本发明实施例中分类结果混淆矩阵;
图7为本发明实施例中双进化架构自动集成学习方法的流程图;
具体实施方式
下面结合附图对本发明作进一步描述。以下以Bupa问题为例来说明本发明的技术方案及其实施过程,不能以此来限制本发明的保护范围。如图1所示的是一种针对分类问题的双进化架构自动集成学习方法的过程,其具体实现步骤如下:
步骤1:初始化基学习器个体种群,设定基学习器群体规模为20。从Bupa 数据集中树形编码的基学习器提取的特征和分割阈值如图2所示;
步骤2:基学习器个体的搜索过程。譬如将1号树和2号树进行部分分支的交换得到3号和4号子树,如图3所示;对3号子树的分割阈值进行变异得到5 号子树,对4号子树进行分支变异得到6号子树,如图4所示;
步骤3:集成学习器个体的搜索过程。集成器通过二进制遗传算法的交叉获得子代个体,图5为一个k=3的例子,W
e`(1)=sign(0.2*1-0.4*1+0.3*1)
=sign(0.2-0.4+0.3)
=sign(0.1)
=1
变异是对交叉的子代个体进行翻转,以上一步交叉后的e`为例,变异概率为 1/20,变异前后为:
变异前:1 0 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1
变异后:1 0 0 1 1 1 1 1 0 1 0 0 1 1 1 1 0 1 0 1
步骤4:对基学习器和集成器的性能进行评估,计算适应度值。
步骤5:群体迭代,基学习器和集成器根据适应度值进行子代选择。优化计算后可得最优集成器的编码为[0 0 1 0 0 1 0 1 1 0 0 0 0 0 1 1 0 0 1 0]。
步骤6:集成模型的分类结果,将Bupa问题的测试集作为输入值,输入步骤 5中得到的最优集成器,分类结果的混淆矩阵如图6所示,其分类准确率为 80.85%,集成规模为7。
- 一种针对分类问题的进化集成学习方法
- 一种针对航空发动机高压转子故障诊断的集成学习方法