基于多模态的声音驱动动漫视频生成方法、装置及系统
文献发布时间:2023-06-19 11:14:36
技术领域
本发明书一个或多个实施例涉及计算机技术领域,尤其涉及一种基于多模态的声音驱动动漫视频生成方法、装置及系统、芯片和计算机可读存储介质。
背景技术
本部分旨在为权利要求书中陈述的本发明的实施方式提供背景或上下文。此处的描述可包括可以探究的概念,但不一定是之前已经想到或者已经探究的概念。因此,除非在此指出,否则在本部分中描述的内容对于本申请的说明书和权利要求书而言不是现有技术,并且并不因为包括在本部分中就承认是现有技术。
随着计算机技术的快速发展,动画制作也得到了广泛的应用,目前,普通存在生成的动画人物无法根据语音制作相对应的口型,动画播放出来之后经常会出现口型与语音不对应的问题,甚至动画人物的口型十分夸张,从而导致动画不够自然,不够真实,生成的动画质量比较差。
现有的解决办法,主要有四部分构成:第一部分接受语音音频和语音音频对应的语音文本;第二部分获取所述语音音频的每个音频帧中的候选音素概率和所述语音文本对应的音素序列;第三部分根据所述语音音频的每个音频帧中的候选音素概率和所述音素序列生成所述语音音频对应的音素集合列表;第四部分根据所述音素集合列表在预设的动画人物素材库中查找并播放对应的动画人物口型。
但该方法存在如下问题:
(1)在第一部分中除了需要语音音频信息还需要语音对应文本信息;
(2)在第四部分模中需要根据音素集合提前制作大量的人物素材库即动画人物口型;
(3)该技术只能生成不同口型动画人物,无法生成脸部其他表情和身体动作。
有鉴于此,亟需一种新的数据处理技术,适用于基于一段语音音频,无需制作大量人物素材库,即可不但生成与之匹配的播音/说话动漫视频、而且可生成脸部整体动作,并匹配生成身体动作。
发明内容
本说明书一个或多个实施例描述了一种基于多模态的声音驱动动漫视频生成方法、装置及系统,其通过语音作为系统输入,无需制作大量人物素材库,即可生成自然流畅的动漫视频,解决了现有技术中存在的需大量人物素材库及无法生成脸部其他表情和身体动作等问题。
本说明书一个或多个实施例提供的技术方案如下:
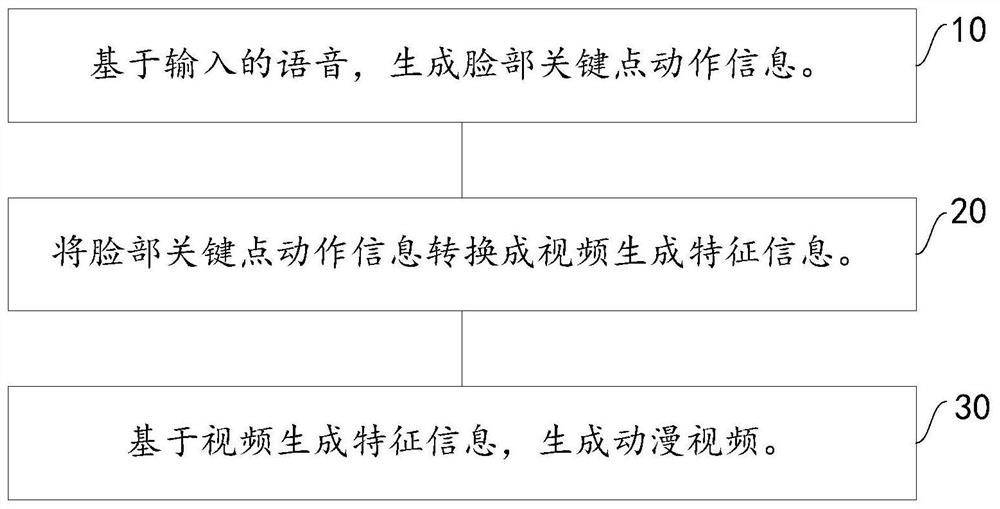
第一方面,本发明提供了基于多模态的声音驱动动漫生成方法,包括:
基于输入的语音,生成脸部关键点动作信息;
将脸部关键点动作信息转换成视频生成特征信息;
基于视频生成特征信息,生成动漫视频。
在一个可能的实现方式中,所述基于输入的语音,生成脸部关键点动作,具体为:
将输入的语音转换为长短时特征;
利用语音长短时特征生成脸部关键点动作信息。
在一个可能的实现方式中,所述将输入的语音转换为长短时特征,具体为:
对输入的语音提取长时韵律及短时信息;
基于提取的所述长时韵律及短时信息,将输入的语音转换为长短时特征。
在一个可能的实现方式中,将所述语音情绪分析转换为对应的情感参数,通过所述情感参数控制人体姿势动作。
在一个可能的实现方式中,所述将脸部关键点动作信息转换成视频生成特征信息,具体为:
通过脸部关键点动作信息转换为脸部各部分参数以及对应的情感参数。
在一个可能的实现方式中,所述基于视频生成特征信息,生成动漫视频,具体为:
基于视频生成特征信息生成视频帧序列,通过将视频帧序列和输入的语音结合生成动漫视频。
第二方面,本发明提供了基于多模态的声音驱动动漫生成装置,包括脸部关键点动作信息生成模块、参数转换模块和视频生成模块;其中,
所述脸部关键点动作信息生成模块,用于基于输入的语音,生成脸部关键点动作信息;
所述参数转换模块,用于将脸部关键点动作信息转换成视频生成特征信息;
所述视频生成模块,用于基于视频生成特征信息,生成动漫视频。
在一个可能的实现方式中,所述脸部生成关键点动作信息模块包括第一转换单元和生成单元;其中,
所述第一转换单元,用于将输入的语音转换为长短时特征;
所述生成单元,用于利用语音长短时特征生成脸部关键点动作信息。
在一个可能的实现方式中,所述第一转换单元包括提取单元和第二转换单元;其中,
所述提取单元,用于对输入的语音提取长时韵律及短时信息;
所述第二转换单元,用于基于提取的所述长时韵律及短时信息,将输入的语音转换为长短时特征。
第三方面,本发明提供了基于多模态的声音驱动动漫生成系统,该系统包括至少一个处理器和存储器;
所述存储器,用于存储一个或多个程序指令;
所述处理器,用于运行一个或多个程序指令,用以执行如第一方面中一个或多个所述的方法。
第四方面,本发明提供了一种芯片,所述芯片与系统中的存储器耦合,使得所述芯片在运行时调用所述存储器中存储的程序指令,实现如第一方面中一个或多个所述的方法。
第五方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质包括一个或多个程序指令,所述一个或多个程序指令可被如第三方面所述的系统执行,以实现如第一方面中一个或多个所述的方法。
本发明实施例提供的方法充分利用音频信息,获取目标面部关键点信息,生成清晰流畅动漫视频;因为其通过视频生成视频参数控制动漫生成而不是通过大量素材库,大大减少了人力的投入;通过视频生成情绪参数控制人体姿态,保证了动漫生成的流畅性和准确性。
附图说明
图1为本发明实施例提供的基于多模态的声音驱动动漫生成方法流程示意图;
图2为基于输入的语音,生成脸部关键点动作的流程示意图;
图3为本发明实施例提供的将输入的语音转换为长短时特征流程示意图;
图4为本发明实施例提供的基于多模态的声音驱动动漫生成装置结构示意图;图5为脸部生成关键点动作信息模块结构示意图;
图6为第一转换单元的结构示意图;
图7为本发明实施例提供的基于多模态的声音驱动动漫生成系统结构示意图。
具体实施方式
下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为便于描述,附图中仅示出了与有关发明相关的部分。
应当理解,尽管在本申请一个或多个实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请一个或多个实施例范围的情况下,第一也可以被称为第二,类似地,第二也可以被称为第一。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
首先,对本发明一个或多个实施例涉及的名词术语进行解释。
ASR,Automatic Speech Recognition的简称,自动语音识别技术。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
本发明实现一种声音驱动动漫视频生成,其通过语音作为系统输入,生成自然流畅的动漫视频。具体的:
图1示出一个实施例的基于多模态的声音驱动动漫生成方法流程图,如图1所示,所述方法包括以下步骤:
步骤10,基于输入的语音,生成脸部关键点动作信息。
具体的,如图2所示,该步骤主要包括2个步骤:
步骤101,将输入的语音转换为长短时特征。
该过程由ASR模型处理的,比如黑盒。具体的,如图3所示,该步骤包括以下步骤:
步骤1011,对输入的语音提取长时韵律及短时信息。
步骤1012,基于提取的所述长时韵律及短时信息,将输入的语音转换为长短时特征。
步骤102,利用语音长短时特征生成脸部关键点动作信息。
利用语音长短时特征合成关键点序列,生成脸部关键点动作信息。
其中,脸部关键点包含脸部68个关键点,比如嘴、双眼和鼻子等,后面根据嘴部关键点判断人的情绪,比如分析判断此人的情绪是笑或哭等。
本发明充分利用音频信息,获取目标面部关键点信息,方便了后续生成清晰流畅动漫视频。
步骤20,将脸部关键点动作信息转换成视频生成特征信息。
通过脸部关键点动作信息转换为脸部各部分参数以及对应的情感参数,并通过所述情感参数控制人体姿势动作。比如通过嘴部关键点,双眼关键点及鼻子关键点转换成人脸头部旋转参数、眼睛参数、口型参数以及对应的情感参数。比如:
根据脸部关键点信息,计算头部的上下左右旋转角度;
根据嘴部关键点信息,角度和距离判断人的情绪;
根据眼睛关键点信息,判断人是否眨眼。
即我们可根据嘴部关键点判断人的情绪,比如是笑还是在哭,还是其他表情。比如,通过该关键点判断这个人在笑,就匹配一个笑的人的动作。匹配的过程是进行人体姿态选择,在判断人的情绪后,根据该情绪在个人体姿态库中选择对应的情绪即可。通过视频生成情绪参数控制人体姿态,保证了动漫生成的流畅性和准确性
步骤30,基于视频生成特征信息,生成动漫视频。
具体的,基于视频生成特征信息生成视频帧序列,通过将视频帧序列和输入的语音结合生成动漫视频。即以视频特征作为系统输入,通过视频生成特征输入到渲染引擎后生成视频帧序列,最后通过将视频帧序列和音频结合生成动漫视频。通过视频生成视频参数来控制动漫生成而不是通过大量素材库,大大减少人力的投入。
与上述实施例方法对应的,本发明还提供了基于多模态的声音驱动动漫生成装置,如图4所示,该结构包括脸部关键点动作信息生成模块41、参数转换模块42和视频生成模块43;其中,
所述脸部关键点动作信息生成模块41,用于基于输入的语音,生成脸部关键点动作信息;
所述参数转换模块42,用于将脸部关键点动作信息转换成视频生成特征信息;
所述视频生成模块43,用于基于视频生成特征信息,生成动漫视频。
在一个示例中,图5为脸部生成关键点动作信息模块结构示意图,如图5所示,该模块41包括第一转换单元411和生成单元412;其中,
所述第一转换单元411,用于将输入的语音转换为长短时特征;
所述生成单元412,用于利用语音长短时特征生成脸部关键点动作信息。
在一个示例中,图6为第一转换单元的结构示意图,如图6所示,该单元包括提取单元4111和第二转换单元4112;其中,
所述提取单元4111,用于对输入的语音提取长时韵律及短时信息;
所述第二转换单元4112,用于基于提取的所述长时韵律及短时信息,将输入的语音转换为长短时特征。
本发明实施例提供的装置中各部件所执行的功能均已在上述方法中做了详细介绍,因此这里不做过多赘述。
与上述实施例相对应的,本发明实施例、还提供了基于多模态的声音驱动动漫生成系统,具体如图7所示,该系统包括至少一个处理器71和存储器72;
存储器71,用于存储一个或多个程序指令;
处理器72,用于运行一个或多个程序指令,执行如上述实施例所介绍的基于多模态的声音驱动动漫生成方法中的任一方法步骤。
与上述实施例相对应的,本发明实施例还提供了一种芯片,该芯片与上述系统中的存储器耦合,使得所述芯片在运行时调用所述存储器中存储的程序指令,实现如上述实施例所介绍的基于多模态的声音驱动动漫生成方法。
与上述实施例相对应的,本发明实施例还提供了一种计算机存储介质,该计算机存储介质中包括一个或多个程序,其中,一个或多个程序指令用于被基于多模态的声音驱动动漫生成系统执行如上介绍的基于多模态的声音驱动动漫生成方法。
本申请提供的方案,充分利用音频信息,获取目标面部关键点信息,生成清晰流畅动漫视频;因为其通过视频生成视频参数控制动漫生成而不是通过大量素材库,大大减少了人力的投入;通过视频生成情绪参数控制人体姿态,保证了动漫生成的流畅性和准确性。
专业人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(RAM)、内存、只读存储器(ROM)、电可编程ROM、电可擦除可编程ROM、寄存器、硬盘、可移动磁盘、CD-ROM、或技术领域内所公知的任意其它形式的存储介质中。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于多模态的声音驱动动漫视频生成方法、装置及系统
- 一种基于声音和视觉的多模态视频场景分割方法