基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法
文献发布时间:2023-06-19 11:21:00
技术领域
本发明涉及潮流机故障识别领域,具体涉及一种基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法。
背景技术
随着全球人口的增多以及工业化进程的加快,能源危机成为了各国不得不面对的一大问题,于是大量的研究工作聚焦在了可再生能源的开发利用上。潮流能是一种蕴藏在海水周期性涨落过程中的能源,由于这种过程是月球、太阳等的引力作用引起的,所以潮流能是一种很有前景的可再生能源,潮流机则是一种将潮流能转换为电能的机械设备。由于长期运行在复杂的海洋环境下,潮流机的叶片上会滋生肉眼可见的附着物,这些附着物会以附加转矩的形式影响发电质量和效率。因此,设计一种强鲁棒的叶片附着物识别方法对于保障潮流发电系统的平稳运行是至关重要的。
目前,潮流机叶片附着物的识别方法有两大类:第一类是基于图像分类网络的方法,能够实现对多种附着物分布类别的诊断识别,但缺少对附着物区域的可视化显示;第二类是基于语义分割网络的方法,能够实现对附着物的定位识别,即可视化显示,但仍存在以下三点问题:(1)大量未标注的图像数据没有被充分利用起来;(2)对高速旋转的潮流机图像进行识别的准确率有待提高;(3)识别不确定度的估计过程耗时过长,而不确定度越高即表示置信度越低。
发明内容
为解决上述提到的基于语义分割网络的潮流机叶片附着物识别方法存在的问题,本发明提供一种基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法,其能实现对标注数据和未标注数据的准确识别。
本发明提供的一种基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法,包括以下步骤:
步骤1:获取潮流机在中高速、高速旋转工况下的图像数据,然后使用语义标注工具labelme对中高速图像进行人工标注:背景、叶片、附着物区域分别被标注为像素标签0、1、2,然后转换为one-hot编码格式[1,0,0]、[0,1,0]、 [0,0,1],编码中1所对应的索引即为像素标签0、1、2;由于高速图像存在较大的运动模糊,人工标注困难,所以不对高速图像进行标注;由此,便完成了中高速标注图像数据集以及高速未标注图像数据集的创建。
步骤2:采用连续旋转图像增强技术对中高速标注图像数据进行扩充,每次扩充都是对上一次得到的扩充图像和标签进行连续旋转操作,以降低人工标注的工作量;其中,连续性体现在每次都以上次的结果为基准进行连续旋转增强,并且图像与标签需要进行同步的旋转操作,这样便能构造出丰富的标注数据。
步骤3:对于标注数据,分别设置随机的连续旋转角度来扩充出有标签的训练集、验证集和测试集,数据比例可按照实际需求进行设置;对于未标注数据,则通过随机采样的方式来创建无标签的训练集、验证集和测试集,数据比例可按照实际需求进行设置。
步骤4:在TensorFlow深度学习开源框架下搭建半监督条件生成对抗网络,该网络由生成器和判别器组成;其中,生成器采用的是编码器—解码器结构的语义分割网络,主要负责从潮流机图像中分割出背景、叶片和附着物区域;判别器采用的是条件全卷积网络,主要负责对生成器的分割结果进行质量评价。
步骤5:为了加快网络的训练速度,需先将标注数据和未标注数据归一化到[-1,1]范围内,然后输入到半监督条件生成对抗网络中进行训练,训练过程包含两个阶段:第一个阶段仅输入标注数据,采用有监督条件对抗策略对网络进行优化;当训练稳定后,进入第二个阶段,即同时输入标注数据和未标注数据,采用半监督策略对网络继续进行优化。
步骤6:当训练次数达到设定的最大迭代次数后,开始进入测试阶段,即将有标签和无标签的测试集数据输入到训练好的半监督条件生成对抗网络中,并由生成器输出潮流机叶片附着物的定位识别图,由判别器输出相应的识别置信度图。
作为本发明进一步的改进:步骤4,具体地,生成器采用的是具有编码器—解码器结构的VGG16-SegUnet语义分割网络,该网络利用最大池化索引保留技术和特征级联技术输出了较好的分割图;判别器采用了条件全卷积网络,网络的输入不仅包含生成器的输出,还包含了输入图像,两者通过特征级联的形式实现对判别器的条件建模,判别器能够迫使生成器输出更精确的潮流机叶片附着物识别图;该网络使用4个步长为2的3×3全卷积代替了最大池化以减少降维过程中空间特征的丢失,然后通过双线性插值上采样将降维特征图拉伸到输入尺寸,最后使用sigmoid激活函数输出数值范围在(0,1)的置信度图。判别器给予生成器输出的潮流机叶片附着物识别图较低的置信度,而给予语义标签图较高的置信度。
由于中高速潮流机图像较为模糊,边缘轮廓不清晰,所以附着物识别精度不高。该处理便是为了解决上述问题,输出更加精确的潮流机叶片附着物识别图。
作为本发明进一步的改进:步骤4,所述最大池化索引保留技术,即在训练的过程中存储每次最大池化操作的最大值位置索引;所述特征级联技术,即通过跳跃连接的形式来融合编码器和解码器的特征。
作为本发明进一步的改进:步骤5,具体地,第一个阶段仅输入标注的潮流机中高速图像数据,采用有监督条件对抗策略对生成器和判别器进行优化,并且首先对判别器进行优化,其损失函数定义如下:
其中,判别器的损失函数L
然后对生成器进行优化,其损失函数定义如下:
其中,生成器损失函数L
当训练稳定后,进入第二个阶段,即同时输入标注的潮流机中高速图像数据和未标注的潮流机高速图像数据,采用半监督策略对网络继续进行优化,具体地,对标注数据仍使用L
其中,半监督损失函数L
生成器和判别器的损失函数可以通过任意一种基于训练误差反向传播的梯度下降算法进行优化;综上,整个训练过程的损失函数定义如下:
其中,L
首先,本发明内容的发明点有:
步骤2、步骤4和步骤5。其中步骤2采用图像旋转生成的方式来模拟潮流机叶片的真实旋转工况,步骤4在编码器-解码器语义分割网络的基础上引入了条件全卷积网络,通过对抗学习的方式迫使分割网络注重对边缘、轮廓等细节信息的捕获,从而实现更为准确的附着物识别,步骤5充分利用潮流机叶片旋转的周期相似性,即:中高速和高速旋转叶片图像具有大量类似的特征信息,由此提出了半监督训练策略。
其次,核心的公式创新是:
创新之处在于:1.先利用带标注的潮流机中高速图像数据训练网络,然后使用训练好的网络去预测未标注的潮流机高速图像数据的概率识别图,再基于该图计算出伪one-hot语义标签;2.提出了一种基于均值计算的阈值选择方法Dis(I
最后,与现有技术相比,本发明提供一种基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法有如下几点技术效果:
1、本发明采用连续旋转图像增强技术实现了对潮流机运行过程更为逼真的模拟,生成了丰富的标注数据。
2、本发明采用的半监督条件生成对抗网络包含了生成器和判别器。其中,生成器使用具有编码器—解码器结构的VGG16-SegUnet语义分割网络,输出较为粗糙的初始识别图;判别器使用条件全卷积网络输出识别置信度图。
3、本发明在语义分割网络的基础上,通过引入有监督条件对抗机制,实现了对初始识别图的轮廓精炼,进一步提升了识别精度。传统的语义分割网络常在预测未知数据方面表现较差,而本发明设计的一种半监督训练策略利用在中高速图像上训练好的网络预测大量未标注的高速旋转图像数据,通过优化半监督交叉熵损失函数来提升对高速旋转图像的识别准确率。
4、相较于通过多次蒙特卡洛采样来实现不确定度的估计,本发明使用仅含4个卷积层和一个上采样层的判别器输出置信度图,极大降低了估计过程的时间成本。
附图说明
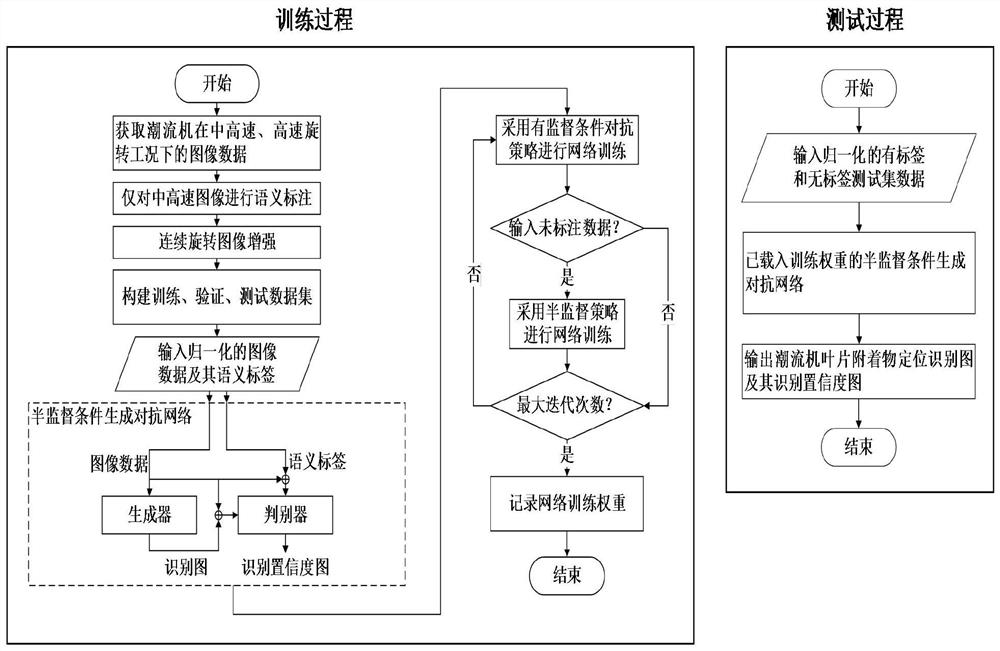
图1为本发明中基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法的算法流程示意图。
图2展示了在中高速、高速旋转工况下采集到的潮流机图像数据。
图3为本发明中所提出的半监督条件生成对抗网络的架构示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
如图1所示,本发明提供一种基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法包括以下步骤:
步骤1:获取潮流机在中高速、高速旋转工况下的图像数据,如图2所示;然后使用语义标注工具labelme对中高速图像进行人工标注:背景、叶片、附着物区域分别被标注为像素标签0、1、2,然后转换为one-hot编码格式 [1,0,0]、[0,1,0]、[0,0,1],编码中1所对应的索引即为像素标签0、1、2;由于高速图像存在较大的运动模糊,人工标注困难,所以不对高速图像进行标注;由此,便完成了中高速标注图像数据集以及高速未标注图像数据集的创建。
步骤2:采用连续旋转图像增强技术对中高速标注图像数据进行扩充,以降低人工标注的工作量;其中,连续性体现在每次都以上次的结果为基准进行连续旋转增强,并且图像与标签需要进行同步的旋转操作,这样便能构造出丰富的标注数据。连续旋转图像增强的过程就是:对中高速标注图像数据进行扩充,每次扩充都是对上一次得到的扩充图像和标签进行连续旋转操作。
步骤3:对于标注数据,分别设置随机的连续旋转角度来扩充出有标签的训练集、验证集和测试集,数据比例可按照实际需求进行设置;对于未标注数据,则通过随机采样的方式来创建无标签的训练集、验证集和测试集,数据比例可按照实际需求进行设置。
步骤4:在TensorFlow深度学习开源框架下搭建半监督条件生成对抗网络,如图3所示;该网络由生成器和判别器组成;其中,生成器采用的是编码器—解码器结构的语义分割网络,主要负责从潮流机图像中分割出背景、叶片和附着物区域;判别器采用的是条件全卷积网络,主要负责对生成器的分割结果进行质量评价。
具体地,生成器采用的是具有编码器—解码器结构的VGG16-SegUnet语义分割网络,该网络利用最大池化索引保留技术和特征级联技术输出了较好的分割图;判别器采用了条件全卷积网络,网络的输入不仅包含生成器的输出,还包含了输入图像,两者通过特征级联的形式实现对判别器的条件建模,判别器能够迫使生成器输出更精确的潮流机叶片附着物识别图。另外该网络使用4个步长为2的3×3全卷积代替了最大池化以减少降维过程中空间特征的丢失,然后通过双线性插值上采样将降维特征图拉伸到输入尺寸,最后使用sigmoid激活函数输出数值范围在(0,1)的置信度图。判别器给予生成器输出的潮流机叶片附着物识别图较低的置信度,而给予语义标签图较高的置信度。生成器本质上是用来生成数据的,判别器本质上是用来监督生成器的生成过程的,目的在于迫使生成器生成越来越逼真的数据。当将生成器和判别器用于语义分割领域时即附着物识别,所表现的功能就如上表述。
步骤5:为了加快网络的训练速度,需先将标注数据和未标注数据归一化到[-1,1]范围内,然后输入到半监督条件生成对抗网络中进行训练,训练过程包含两个阶段:第一个阶段仅输入标注数据,采用有监督条件对抗策略对网络进行优化;当训练稳定后,进入第二个阶段,即同时输入标注数据和未标注数据,采用半监督策略对网络继续进行优化。
具体地,第一个阶段仅输入标注的潮流机中高速图像数据,采用有监督条件对抗策略对生成器和判别器进行优化,并且首先对判别器进行优化,其损失函数定义如下:
其中,判别器的损失函数L
然后对生成器进行优化,其损失函数定义如下:
其中,生成器损失函数L
当训练稳定后,进入第二个阶段,即同时输入标注的潮流机中高速图像数据和未标注的潮流机高速图像数据,采用半监督策略对网络继续进行优化,具体地,对标注数据仍使用L
其中,半监督损失函数L
生成器和判别器的损失函数可以通过任意一种基于训练误差反向传播的梯度下降算法进行优化;综上,整个训练过程的损失函数定义如下:
其中,L
步骤6:当训练次数达到设定的最大迭代次数后,开始进入测试阶段,即将有标签和无标签的测试集数据输入到训练好的半监督条件生成对抗网络中,并由生成器输出潮流机叶片附着物的定位识别图,由判别器输出相应的识别置信度图。
相比于其他经典语义分割网络,半监督条件生成对抗网络除了提升了对潮流机有标签图像中附着物的识别精度外,还实现了对无标签图像中附着物的准确识别。
- 基于连续旋转图像增强和条件生成对抗网络的潮流机叶片附着物识别方法
- 基于VGG16-SegUnet和dropout的海流机叶片附着物识别方法