基于ETL引擎的前后端分离执行方法
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及一种数据仓库技术,尤其涉及一种基于ETL引擎的前后端分离执行方法。
背景技术
信息是现代企业的重要资源,是企业运用科学管理、决策分析的基础。目前,大多数企业花费大量的资金和时间来构建联机事务处理OLTP的业务系统和办公自动化系统,用来记录事务处理的各种相关数据。
据统计,数据量每2~3年时间就会成倍增长,这些数据蕴含着巨大的商业价值,而企业所关注的通常只占总数据量的2%~4%左右。因此,企业仍然没有最大化地利用已存在的数据资源,以至于浪费了更多的时间和资金,也失去制定关键商业决策的最佳契机。因此,企业如何通过各种技术手段,并把数据转换为信息、知识,已经成了提高其核心竞争力的主要瓶颈。而ETL则是主要的一个技术手段。
ETL分别是“Extract”、“Transform”、“Load”三个单词的首字母缩写,也就是“抽取”、“转换”、“装载”。
“抽取”:将数据从各种原始的业务系统中读取出来,这是所有工作的前提。
“转换”:按照预先设计好的规则将抽取得数据进行转换,使本来异构的数据格式能统一起来。
“装载”:将转换完的数据按计划增量或全部导入到数据仓库中。
ETL是BI/DW(商务智能/数据仓库)的核心和灵魂,按照统一的规则集成并提高数据的价值。ETL负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。但是ETL为桌面应用程序,采用CS架构。相比传统的WEB应用程序,现有技术存在如下缺点:
1)、安装使用不便。传统的ETL工具要安装,并且只能本地电脑启动,在网络隔离环境下无法投入生产。
2)、UI层无法做成网页版:传统ETL工具的工作流都是图形化拖拽式设计,ETL工作流定义和参数本身非常复杂,导致要实现图形化拖拽非常困难,而网页版的图形化也无法满足全部拖拽式定义工作流的需求。
2)、传统ETL工具是单机版:同时只能单人操作。传统的ETL的UI展示粗糙繁杂,易用性极差。
3)、传统的垂直架构,紧耦合,很难扩展。传统ETL工具的工作流设计器和执行都整合在一起,代码臃肿扩展非常困难。
4)、支持多人团队协作困难:由于ETL的CS架构设计,导致操作时必须要控制不能两个用户同时操作设计同一个ETL工作流,所以在源码中用全局锁控制,一个用户操作一个转换或者作业时会锁住相关的逻辑表,其他用户再在本地访问同一个资源库时,又会对再次去锁表,发生锁等待或者死锁让同时操作多个用户都无法正常使用。
发明内容
本发明所要解决的技术问题是提供一种基于ETL引擎的前后端分离执行方法,不但安装使用方便,而且易于实现网页版拖拽式开发,扩展性和应用性更强。
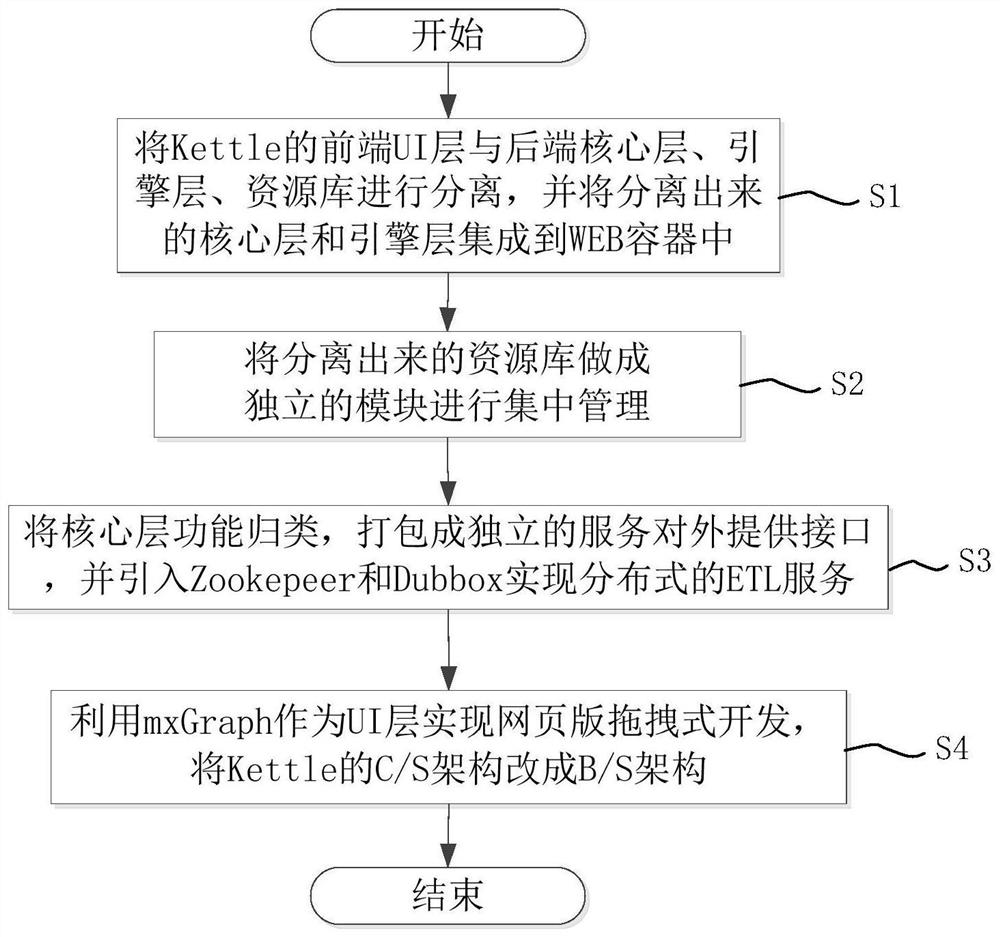
本发明为解决上述技术问题而采用的技术方案是提供一种基于ETL引擎的前后端分离执行方法,包括如下步骤:S1)将Kettle的前端UI层与后端核心层、引擎层、资源库进行分离,并将分离出来的核心层和引擎层集成到WEB容器中;S2)将分离出来的资源库做成独立的模块进行集中管理;S3)将核心层功能归类,打包成独立的服务对外提供接口,并引入Zookepeer和Dubbox实现分布式的ETL服务;S4)利用mxGraph作为UI层实现网页版拖拽式开发,将Kettle的C/S架构改成B/S架构。
进一步地,所述步骤S1抽取的Kettle的核心层包括通用工厂、通用工具、程序生命周期监听、异常处理、日志工厂管理、连接协议、插件工厂、数据源管理功能;抽取的Kettle的引擎层包括插件注册管理、执行日志管理、Job执行引擎和转换执行引擎。
进一步地,所述步骤S1先将核心层和引擎层的核心jar通过maven的依赖管理导入到springboot2框架中,使得springboot2微服务能直接使用核心层和引擎层的核心jar功能,所述步骤S3将核心功能归类及抽象,包括集群管理、Job管理、转换管理、数据源管理和目录管理,并分别写入到Service层作为服务,再将服务发布到Zookeeper注册中心,通过Dubbo的RCP协议实现分布式服务;同时引入分布式服务的接口类和Dubbo的消费者的配置文件,用来调用ETL的核心层和引擎层功能。
进一步地,所述步骤S2中分离出来的资源库分为文件资源库和数据库资源库,所述文件资源库将ETL所有节点保存为一个XML文件,所述XML文件中保存有Job参数、转换参数、连接参数、日志参数、基本参数、集群参数、共享参数和执行参数,不同参数以不同的标签进行区分;所述数据库资源库采用关系型数据库,并将各种参数拆分存储到不同的表中。
进一步地,所述步骤S4中的前端UI层采用vue和mxGraph的组合来实现,ETL流程里多个图形节点用直线相连接组成一条流水线工作,每个图形节点代表一个数据处理节点,不同节点实现不同的数据处理逻辑。
进一步地,所述步骤S2中的前端UI层还在基础功能上扩展实现资源库目录管理,目录授权,ETL执行实时监控、日志监控和历史日志管理功能,同时UI层配置好服务接口,用于调用执行引擎层提供的ETL读取/新增/更新/删除/执行/暂停/终止/监控/历史操作及获取ETL数据。
进一步地,所述前端UI层与后端核心层、引擎层、资源库的交互过程如下:a)前端UI层工作流设计器配置完成后将ETL工作流定义信息生成XML;b)前端UI层将XML通过Dubbo接口传送给后端引擎层;c)后端引擎层调用核心层的api接口检验XML正确性,并保存到独立资源库,返回保存状态给UI层;d)UI层通过Dubbo接口发起ETL执行任务;e)后端引擎层接收到指令启动ETL工作;f)UI层监控ETL工作过程和状态。
进一步地,还包括在Web应用基础上通过增加状态标记替代全局锁的代码来控制访问,支持相同资源的并发访问,并利用checkin和checkout机制检测相同资源是否存在使用冲突。
本发明对比现有技术有如下的有益效果:本发明提供的基于ETL引擎的前后端分离执行方法,将kettle前端UI和后端引擎分离,并引入新的UI层将kettle的C/S架构改成B/S架构,Web应用一处部署后,其他机器输入访问地址便可访问使用;同时通过Zookepeer和Dubbox实现分布式高可用,支持多人团队协助,可以同时管理多个项目的ETL数据,提高工作效率。
附图说明
图1为基于ETL的数据的主要转换示意图;
图2为本发明基于ETL引擎的前后端分离执行流程示意图;
图3为本发明使用的Kettle前后端分离后的关系图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
Kettle是ETL工具典型代表中的一员,采用纯Java编写(基于JAVA的OSGI架构),可以在windows、Linux、Unix上跨平台部署运行,数据抽取高效稳定。实现的主要转换如图1所示。
Kettle的主要功能特点如下:
1.支持多种数据源
Kettle本身支持各种数据源,包括数据库、文件系统、Excel、Xml、LDAP、SOAP/WebServcie、CSV文件和RSS等各种数据源。支持的数据库包括DB2、Oracle、Mysql、MS SQLServer、Sybase等各种主流数据库。Kettle提供了对以上各种数据源访问的封装,开发人员只需拖动相应的组件到控制台即可。数据库连接支持集群和数据库分区访问。
数据库连接的方式支持JDBC、ODBC和JNDI方式,本身提供了数据连接池功能,能够大大提高数据库的访问效率。
2.核心组件丰富
Kettle组件主要分为Job核心组件和转换核心组件两大类,综合起来主要的组件如下:
3.支持多任务并发,支持大数据量的抽取转换处理,执行效率高
Kettle支持多任务并发,可以在界面内配置并发数,并可以针对每个组件配置并发数。
4.成熟的异常处理流程
Kettle提供了丰富的异常处理功能,能满足各种异常处理需求。自带了大量的异常处理组件,满足各种异常情况下的处理。
5.可与Java应用很好结合
Kettle本身使用Java开发,可以与Java应用无缝结合,在应用中调用Kettle脚本。同时,Kettle提供了一组Java接口,可以通过应用控制Kettle的执行过程,并对Kettle的执行信息和结果信息进行监控。
由上可见,通过Kettle能够将数据从数据源向目标数据仓库转化的整个过程稳定高效。本发明选用Kettle作为ETL工具,引擎的前后端分离执行方法,如图2所示,包括如下步骤:
S1)将Kettle的前端UI层与后端核心层、引擎层、资源库进行分离,并将分离出来的核心层和引擎层集成到WEB容器中;
S2)将分离出来的资源库做成独立的模块进行集中管理;
S3)将核心层功能归类,打包成独立的服务对外提供接口,并引入Zookepeer和Dubbox实现分布式的ETL服务;
S4)利用mxGraph作为UI层实现网页版拖拽式开发,将Kettle的C/S架构改成B/S架构。
本发明通过将ETL的架构模型拆分,将UI层与核心层、引擎层、资源库进行分离,将原本的CS架构的UI层舍弃。将核心层和引擎层集成到WEB容器中(本发明用的是tomcat),按功能进行切分,结合高可用和分布式的技术思想,打包成独立的服务对外提供接口。将数据源层做成独立的模块进行集中管理。UI层则利用mxGraph实现网页版拖拽式开发。通过前后端分离,解藕,模块的细化切分,并结合高可用和分布式的特性,扩展性和应用行更强。采用B/S架构的web应用一处部署后,其他机器输入访问地址便可访问使用。UI层用开源的图形化工具完善实现拖拽式开发。由于改造成B/S架构后,多人团队协作就很容易实现,通过增加状态标记来替代全局锁的代码,来控制访问,利用checkin和checkout检测机制多人同时操作时即可有效避免对相同资源使用的冲突,又不会因为锁而导致雪崩的现象。
下面给出本发明对ETL的架构模型进行拆分整合的具体过程:
一、后端核心层和引擎层
抽取核心层和数据源层,集成到后台服务容器中(本平台集成到springboot2微服务框架),进行功能和模块的细化,切分后再打包,封装成独立的服务发布,对上层UI充当生产者的角色。核心层core包括通用工厂、通用工具、程序生命周期监听、异常处理、日志工厂管理、连接协议、插件工厂、数据源管理等功能。引擎层engine包括插件注册管理、执行日志管理、Job执行引擎、转换执行引擎等。
先将core和engine的核心jar通过maven的依赖管理导入到springboot2框架中,此时springboot2微服务能直接使用core和engine的核心jar功能。
将核心功能归类及抽象,包括集群管理、Job管理、转换管理、数据源管理、目录管理等分别写入到Service层作为服务。然后引入zookeeper+dubbo技术,将服务发布到zookeeper注册中心,通过dubbo的RCP协议实现分布式服务。使用了zookeeper+dubbo技术,能很方便扩展集群服务,能加入负载均衡、服务降级、故障转移的功能保证高并发高可用。
使用上,任何需要调用ETL核心层和引擎层功能的项目中,只需要引入分布式服务的接口类,引入dubbo的消费者的配置文件,就能直接调用ETL的核心层和引擎层功能。
通过对engine的core心层的底层封装和对外服务化,为B/S架构、分布式部署提供了可能。
1)Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等,本技术方案中充当dubbo的注册中心,。
2)Dubbo
Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角色。关于注册中心、协议支持、服务监控等内容。
实现分布式服务接口,相比传统的接口,分布式使得服务分工更细,彼此之间更加独立,接口与接口之间互不影响,一个接口停用或者更新不影响其他接口的调用,贯彻搞内聚低耦合的思想,并达到高可用的效果。前后端分离后的关系如图3所示。ConfigServer:为注册中心,Server(后端)中集成了ETL的核心层和引擎层,将核心功能的API封装成服务通过发布到注册中心,Client为自定义UI的项目,会更具业务所需,向注册中心订阅自己需要的服务,获取接口URL,然后根据URL向Server端调取服务。
二、独立资源库
ETL工作流的定义信息需要统一独立管理,本发明将资源库分为两大类。
1、是文件资源库,以XML形式保存为文件,Job参数、转换参数、连接参数、日志参数、基本参数、集群参数、共享参数、执行参数等都集成到一个文件中以不同的标签区分,例如转换
2、是数据库资源库,以关系型数据库为存储,将ETL定义里的转换
本发明将结合两种资源库的优点,以文件方式保存到Hadoop文件系统实现统一存储且高可用,并可开发统一服务接口对接ETL文件的读取/新增/更新/删除操作,统一对外提供服务。
独立的资源库为实现配置资源共享、分布式、团队协作等方面提供了很好的支持与实现。
三、前端UI层ETL工作流设计器
ETL工作流设计器的UI层用vue+mxGraph来替代实现。UI层将ETL设计器与执行器分离,使UI层能保用先进的图形技术,更容易扩展功能,UI层实现了ETL设计功能,实现图形化任意位置拖拽,ETL流程里多个图形节点可以用直线相连接组成一条流水线工作,每个图形节点代表一个数据处理节点,不同节点能实现不同的数据处理逻辑,例如数据采集、数据加载、数据加密,数据连接,数据拆分、数据转换等,可以设置节点的成功与失败的不同处理方向实现ETL处理分流作用。UI还在在基础功能上扩展实现了资源库目录管理,目录授权,ETL执行实时监控、日志监控、历史日志管理等功能,同时UI层只要配置好服务接口,就可以调用执行引擎层提供的ETL读取/新增/更新/删除/执行/暂停/终止/监控/历史等操作及获取ETL数据,实现了快速开发,快速响应需求的能力。
mxGraph是一个JS绘图组件适用于需要在网页中设计/编辑Workflow/BPM流程图、图表、网络图和普通图形的Web应用程序。mxgraph下载包中包括用javascript写的前端程序,也包括多个和后端程序(java/C#等等)集成的例子。
vue+mxGraph对UI层的实现,将原有客户端的用户体验完美的移植到了浏览器上。
四、ETL整体流程
1)前端UI层工作流设计器配置完成后会将ETL工作流定义信息生成XML。
2)前端UI层将XML通过dubbo接口传送给后端引擎层。
3)后端引擎层调用核心层的api检验XML正确性,并保存到独立资源库,返回保存状态给UI层。
4)UI层通过dubbo接口发起ETL执行任务。
5)后端引擎层接收到指令启动ETL工作。
6)UI层监控ETL工作过程和状态。
五、基于用户的目录权限管控
1)角色菜单权限管理:对于B/S架构系统,很容易实现基于企业或团队的角色、用户管理。利用角色、用户对菜单权限的分配,对ETL各资源进行授权访问。
2)用户目录权限分配:针对资源库的目录,通过用户对目录进行授权,未授权的资源目录其他成员不可见。提高团队成员之间资源配置的独立性,防止数据冲突。
3)数据源权限分配:角色权限分配控制用户能否新建、修改、删除数据源,再对新建的数据源授权给团队成员。
通过对系统进行角色权限的分配,可以很方便地进行团队协作和团队管理。
综上所述,本发明提供的基于ETL引擎的前后端分离执行方法,具有如下优点:
1)Kettle前端UI和后端引擎分离,kettle的功能从一个一体式的ETL工具变成了分布式服务,可以热拔插的组件式。增强了kettle的高可用性,可移植性。
2)通过Zookepeer和Dubbox实现分布式高可用的ETL服务,现有技术中,kettle没有提供高可用的服务接口。本发明用Dubbox提供分布式接口,使得服务分工更细,彼此之间更加独立,接口与接口之间互不影响,一个接口停用或者更新不影响其他接口的调用,贯彻搞内聚低耦合的思想,并达到高可用的效果。
3)将kettle的C/S架构改成B/S架构,现有技术中,kettle在网络隔离环境下无法连接,无法投入生产。本方案,改造成B/S架构,不存在网络隔离环境的问题。
4)支持多人团队协助,现有技术中,kettle只能安装在本地电脑上,只能单人操作,不符合生产环境使用条件。本方案,在Web应用基础上通过增加状态标记来替代全局锁的代码,来控制访问,利用checkin和checkout检测机制,多人同时操作时即可有效避免对相同资源使用的冲突,又不会因为锁而导致雪崩的现象,达到多人同时操作。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 基于ETL引擎的前后端分离执行方法
- 一种基于引擎模式前后端分离的快速开发平台及其使用方法