靶向IL-1R1和NLPR3的双特异性抗体
文献发布时间:2023-06-19 11:27:38
技术领域
本发明涉及NLRP3炎症小体通路的调节剂,特别是抗体及其片段以及适体分子(可形成能够特异性结合蛋白质或其他细胞靶的二级结构和三级结构的小RNA/DNA分子),它们各自对NLRP3炎症小体成员具有结合特异性。本发明进一步延伸到此类抗体和适体及其片段用于治疗和预防由NLRP3炎症小体信号传导和活化介导的炎症性疾病的用途。
背景技术
炎症小体是识别多种炎症诱导刺激物的一组蛋白质复合物,所述刺激物包括病原体相关分子模式(PAMP)和危险相关分子模式(DAMP)。已知不同的炎症小体复合物;在这些复合物中,NLRP3由于多种活化它的信号而为研究最多的炎症小体,所述信号包括LPS、细菌毒素、灰尘、诸如ATP的应激信号、结晶和颗粒材料、胆固醇晶体、氧化的LDL、淀粉样β、朊病毒蛋白纤维和原纤维α突触核蛋白、剪切应力、压力。
NLRP3(核苷酸结合寡聚结构域(NACHT))、富亮氨酸重复(LRR)结构域和含有热蛋白结构域的蛋白质3炎症小体牵涉到许多传染性疾病和多种退行性炎症型疾病,包括动脉粥样硬化、糖尿病、炎症性眼病、其他眼病诸如干眼综合征、青光眼、年龄相关性黄斑变性、抑郁症、阿尔茨海默氏病(Alzheimer’s Disease)、帕金森氏病(Parkinson’s Disease)、炎症性肠病、关节炎病状诸如类风湿性关节炎、衰老、皮肤病状和癌症。
NLRP3蛋白的主要作用是感知危险信号或异物,并将信号传递到半胱天冬酶1,进而活化促炎性细胞因子IL-1β的分泌,所述细胞因子接着引发炎症以试图保护身体。IL-1β是所有细胞因子中研究最多的细胞因子,因为它在炎症过程中起重要作用。虽然活化IL-1β对身体有用,但在许多疾病中,此炎症可能失控并成为疾病的发病机理的原因。迄今为止,大多数治疗策略都集中在开发针对IL-1β的疗法以减轻炎症,但正如我们在此所提出的,靶向此细胞因子的上游控制器(即NLRP3炎症小体)有许多优势。
活化机制尚不完全清楚,但是通过炎症小体加工IL-1β已被证明涉及两个通路。首先,由DAMP或PAMP通过Toll样受体(TLR)和/或CD36受体活化NFκB通路。这导致IL-1β和NLRP3的前体形式的转录和表达。
还认为需要第二种信号,由此由DAMP诸如ATP刺激嘌呤能受体导致细胞内钙增加和细胞肿胀,所述细胞肿胀导致钾从细胞流出、溶酶体失稳定、膜透化、线粒体损伤和随后产生活性氧类,从而导致NLRP3活化。其他工作表明,氧化的LDL胆固醇本身确实可充当NLRP3活化所需的两个信号。在所有研究中,钾外流似乎是NLRP3活化的唯一共同点。
NLRP3蛋白随后通过热蛋白结构域的同型相互作用而与ASC(凋亡相关斑点样蛋白)相互作用。然后,ASC与前体半胱天冬酶1相互作用,导致半胱天冬酶1的裂解和活化,进而将前体IL-1β裂解成其活性形式。然后将IL-1β裂解以产生具有生物活性的和分泌的形式。
当前用于炎症小体相关病症的最佳治疗方法是靶向炎症小体活性的主要产物IL-1β。在过去20年内,已经开发了许多抗IL-1β疗法。然而,抗IL-1β疗法存在若干缺点。由于这些感染的惰性和危险性质,针对条件致病性微生物以及常规细菌感染的宿主防御已成为所有抗细胞因子剂的主要关注点。抗IL-1β疗法有其他副作用,诸如恶心、中性粒细胞增多和不良过敏反应。
与IL-1β疗法相比,抗NLRP3疗法的一些优势如下:
NLRP3是nod样受体,因此减弱对疾病根本原因(即识别异物/危险物质)的识别可能比减弱反应更有利。这意味着通过疾病特异性刺激物(例如,氧化的LDL、β淀粉样蛋白或α突触核蛋白)或特定病原体活化的NLRP3通路将不会分泌IL-1β。然而,IL-1β仍可通过其他通路响应于如在极端情况(诸如大规模或机会性感染)下所需的其他非疾病相关刺激而活化,因为存在负责IL-1β活化的其他通路。
炎症小体与特殊形式的细胞死亡、焦亡性细胞坏死(pyronecrosis)(不依赖半胱天冬酶1)和细胞焦亡有关,这可能发生在炎症加剧的情况下。因此,抗NLRP3疗法也将减少此类死亡通路,已证明所述死亡通路牵涉到某些疾病诸如动脉粥样硬化的发病机理。细胞焦亡是此疾病中响应于氧化的LDL而导致斑块破裂的危险因素。
最近还表明几种先前表征的小分子抑制剂影响了NLRP3炎症小体功能。磺酰脲类药物格列本脲是此种抑制剂的实例。MCC950(如下所示)是NLRP3炎症小体的特定小分子抑制剂的另一个实例:
然而,目前可用的抑制剂存在若干问题。事实上,这些当前可用的炎症小体功能抑制剂中的许多抑制剂是临床上不成功的,是非特异性的并且重要的是半衰期非常短。
人源化抗体类型疗法的发展可能证明比NLRP3炎症小体的小分子抑制剂更具优势。
与小分子抑制剂相比,人源化抗体的一些优势如下:
·不被人免疫系统识别。
·在循环中的半衰期比非人抗体长。
·特异性比小分子抑制剂高。
·与迄今为止尚未出现小分子药物的具有挑战性的靶标相互作用。此相互作用的最佳实例是蛋白质-蛋白质相互作用,其特征在于几乎不具有带电荷袋的大且通常平坦的表面。
·嵌合和人源化mAb已为进入临床研究的主要mAb,其批准成功率(分别为18%和24%)高于包括小分子剂(5%)的新化学实体(NCE),特别是在肿瘤学领域中。
·生物制剂的商业潜力非常有前途。生物制剂在处方药和非处方药的总销售额中的份额从2004年的12%增长到2011年的19%。更有趣的是,生物制品在2004年的前100名医药产品中占销售额的17%;在2011年占34%。据估计,到2025年,全球生物制剂市场将达到近40亿美元。
·生物制剂似乎比小分子药物提供更好的总体经济回报。
·研究还表明,生物制剂的损耗率低于小分子的损耗率。据报道,进入临床前测试的生物制剂中24.4%最终进入市场,相比之下,小分子药物的成功率仅为7.1%。
·生物制剂在所有开发阶段都比小分子表现得好,其中在第2阶段的成功率为惊人的116%。
NLRP3(也称为NALP3和隐热蛋白(cryopyrin))是胞质蛋白;因此,为了靶向此蛋白质,任何疗法都必须进入细胞。人源化抗体的尺寸相当大,并且可能难以进入细胞溶质。小抗体片段的开发还提供了克服此种挑战的可能性,其中抗体片段可为Fab片段(其为抗体的抗原结合片段)或单链可变片段(其为通过肽接头连接的抗体的重链可变区和轻链可变区的融合蛋白)。如下文进一步讨论的,本发明人已设计出另外的策略来确保治疗性抗体或适体及其片段可进入细胞。
在领域中有一些报道描述了使用各种剂靶向NLRP3炎症小体或相关分子。例如,WO2013/007763A1公开了一种能够在细胞内定位并与炎症小体组成员(包括NLRP3)发生细胞溶质结合的抑制剂,以用于预防/治疗痤疮的方法中。
US20080008652A1公开了用于调节免疫反应和佐剂活性并且特别是通过调节隐热蛋白(NPRL3)信号传导来调节的方法和组合物。提及了靶向隐热蛋白调节蛋白或隐热蛋白信号通路组分的人源化抗体,并且公开了产生隐热蛋白抗体的方法。
WO2002026780A2公开了与含有PAAD结构域的多肽结合的抗体以及通过施用抗PAAD抗体来治疗包括炎症的各种病理的方法。还提及了单链抗体、嵌合抗体、双功能抗体和人源化抗体以及其抗原结合片段。
WO2011109459A2公开了一种治疗皮肤/毛发炎症性疾病的方法,其通过提供包含至少一种与哺乳动物炎症小体的一种或多种组分(诸如ASC或NLRP1)特异性结合的抗体的组合物来进行。提及了可商购获得的针对ASC和NPRL1的抗体。
EP2350315B1公开了用于早期诊断动脉粥样硬化的方法和试剂盒,所述诊断包括测量NLRP3、ASC和/或半胱天冬酶-1的表达水平。表达水平可通过涉及抗体的方法来测量,所述抗体包括人抗体、人源化抗体、重组抗体和抗体片段,所述抗体片段进而包括Fab、Fab’、F(ab)2、F(ab’)2、Fv和scFv。
WO2013119673A1公开了一种评估疑似患有CNS损伤的患者的方法,所述方法包括测量至少一种炎症小体蛋白(诸如NLRP1(NALP-1)、ASC和半胱天冬酶-1)的水平。提及了可商购获得的针对NPRL-1、ASC和半胱天冬酶-1的抗体。
WO2007077042A1公开了一种用于治疗痛风或假性痛风的方法,所述方法包括施用NALP3炎症小体抑制剂。NALP3炎症小体抑制剂被描述为在NALP3炎症小体的下游起作用,并且选自抑制IL-1活性的抗体。
WO2013138795A1公开了一种融合蛋白,所述融合蛋白包含Surf+穿透多肽和结合到细胞内靶标的抗体或抗体模拟部分(AAM部分),其中融合蛋白穿透细胞并结合到细胞内靶标以抑制靶标与细胞内另一种蛋白质之间的结合。
本发明提供了NLRP3炎症小体的新颖且有效的调节剂。此类调节剂包括靶向IL-1R1和NLRP3两者的双抗体或适体及其片段。双抗体首先通过与IL-1R1结合来进入细胞,所述IL-1R1触发快速内化并且一旦被内化,双抗体接着就靶向细胞内蛋白NLRP3,从而抑制NLRP3炎症小体的组装,进而预防IL-1β从细胞分泌,并减少炎症的发生/放大。
发明内容
因此,在本发明的第一方面,提供了一种能够结合IL-1R1和NLRP3两者的NLRP3炎症小体调节剂任选地,调节剂还能够结合NLRP3的PYD结构域。
任选地,调节剂选自包括以下的组:多克隆抗体、单克隆抗体、人源化抗体、嵌合抗体、融合蛋白或适体分子、其组合以及其各自的片段。
调节剂可为能够结合IL-1R1和NLRP3两者的双抗体。任选地,调节剂为能够结合IL-1R1和NLRP3两者的重组人源化双抗体。
任选地,调节剂为包含能够结合IL-1R1的第一抗体的结合区中的一个或多个和能够结合NLRP3的第二抗体的结合区中的一个或多个的双抗体。任选地,调节剂为包含能够结合IL-1R1的第一抗体的一个或多个互补决定区(CDR)和能够结合NLRP3的第二抗体的一个或多个CDR的双抗体。任选地,第一抗体和/或第二抗体为单克隆抗体。
任选地,调节剂选自能够结合IL-1R1和NLRP3两者的抗体片段。任选地,抗体片段选自以下中的一个或多个:Fab、Fv、Fab’、(Fab’)2、scFv、双-scFv、微抗体、Fab2和Fab3。
任选地,调节剂选自能够结合以下两者的重组人源化抗体或抗体片段:IL-1R1和NLRP3。
任选地,调节剂是针对选自IL-1R1和NLRP3两者的一种或多种抗原而产生的抗体或抗体片段。任选地,调节剂针对选自IL-1R1和NLRP3两者的全部或部分的一种或多种抗原而产生。任选地,调节剂针对选自NLRP3(其任选地缀合至载体蛋白诸如钥孔血蓝蛋白(KLH)(在下文中为NLRP3免疫原))和IL-1R1(任选地重组IL-1R1)的一种或多种抗原而产生。
任选地,IL-1R1的细胞外结构域(在下文中为IL-1R1免疫原)包含以下序列:
MKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQHKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKPLLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSDIAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKLEGGPSVFIFPPNIKDVLMISLTPKVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTIRVVSHLPIQHQDWMSGKEFKCKVNNKDLPSPIERTISKPKGLVRAPQVYTLPPPAEQLSRKDVSLTCLVVGFNPGDISVEWTSNGHTEENYKDTAPVLDSDGSYFIYSKLNMKTSKWEKTDSFSCNVRHEGLKNYYLKKTISRSPGK*(SEQ ID NO:1)。
(*或**在整个本说明书中表示终止密码子)。
任选地,NLRP3免疫原包含以下序列:
EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)。
任选地,NLRP3免疫原包含与序列EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)缀合,任选地与序列EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)的N末端缀合的载体蛋白。
在本领域中已知与肽缀合的载体蛋白有助于肽产生更强的免疫反应。任选地,载体蛋白为KLH。
任选地,载体蛋白通过接头缀合至序列EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30),任选地接头为酰肼-Ahx。
任选地,NLRP3免疫原为:
KLH-酰肼-Ahx-EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)。
如本领域中所理解的,酰肼是一类有机化合物,其特征在于具有四个取代基的氮-氮共价键,其中所述取代基中的至少一个为酰基。Ahx表示6碳线性氨基己酸接头。
任选地,可产生、任选地产生针对选自NLRP3免疫原和IL-1R1免疫原的一种或多种免疫原的调节剂,其中IL-1R1免疫原包含以下序列:
MKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQHKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKPLLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSDIAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKLEGGPSVFIFPPNIKDVLMISLTPKVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTIRVVSHLPIQHQDWMSGKEFKCKVNNKDLPSPIERTISKPKGLVRAPQVYTLPPPAEQLSRKDVSLTCLVVGFNPGDISVEWTSNGHTEENYKDTAPVLDSDGSYFIYSKLNMKTSKWEKTDSFSCNVRHEGLKNYYLKKTISRSPGK*(SEQ ID NO:1)。
(*表示终止密码子)
并且NLRP3免疫原包含以下序列:
KLH-酰肼-Ahx-EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)。
任选地,调节剂为双抗体,所述双抗体包含针对并且包含以下序列的IL-1R1免疫原可产生、任选地产生的第一抗体的结合区中的一个或多个:
MKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQHKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKPLLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSDIAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKLEGGPSVFIFPPNIKDVLMISLTPKVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTIRVVSHLPIQHQDWMSGKEFKCKVNNKDLPSPIERTISKPKGLVRAPQVYTLPPPAEQLSRKDVSLTCLVVGFNPGDISVEWTSNGHTEENYKDTAPVLDSDGSYFIYSKLNMKTSKWEKTDSFSCNVRHEGLKNYYLKKTISRSPGK*(SEQ ID NO:1),
(*表示终止密码子)
以及针对包含以下序列的NLRP3免疫原产生的第二抗体的结合区中的一个或多个:
KLH-酰肼-Ahx-EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)。
任选地,调节剂为双抗体,所述双抗体包含针对并且包含以下序列的IL-1R1免疫原可产生、任选地产生的第一抗体的一个或多个互补决定区(CDR):
MKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQHKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKPLLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSDIAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKLEGGPSVFIFPPNIKDVLMISLTPKVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTIRVVSHLPIQHQDWMSGKEFKCKVNNKDLPSPIERTISKPKGLVRAPQVYTLPPPAEQLSRKDVSLTCLVVGFNPGDISVEWTSNGHTEENYKDTAPVLDSDGSYFIYSKLNMKTSKWEKTDSFSCNVRHEGLKNYYLKKTISRSPGK*(SEQ ID NO:1),
(*表示终止密码子)
以及针对包含以下序列的NLRP3免疫原产生的第二抗体的一个或多个CDR:
KLH-酰肼-Ahx-EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)。
任选地,第一抗体和/或第二抗体为单克隆抗体。
任选地,第一抗体(针对IL-1R1)的重链的共有序列为MGWVWNLPFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLA(SEQ ID NO:7)。
任选地,第一抗体的重链CDR包含:GYPFTTAG(SEQ ID NO:60);MNTQSEVP(SEQ IDNO:61);和AKSVYFNWRYFDV(SEQ ID NO:62)。
任选地,第一抗体(针对IL-1R1)的轻链的共有序列为MRSPAQFLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPK(SEQ ID NO:12)。
任选地,第一抗体的轻链CDR包含:QSISDY(SEQ ID NO:63);YAS;和QHGHSFPLT(SEQID NO:64)。
任选地,第二抗体(针对NLRP3)的重链的共有序列为MDFGLSWVFLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAAKTTPPSVYPLA(SEQ ID NO:36)。
任选地,第二抗体的重链CDR包含:GFTFSDYY(SEQ ID NO:65);ISDGGTYT(SEQ IDNO:66);和ARGWVSTMVKLLSSFPY(SEQ ID NO:67)。
任选地,第二抗体(针对NLRP3)的轻链的共有序列为MAWISLLLSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLFPPSTEELSL(SEQ ID NO:43)。
任选地,第二抗体的轻链CDR包含:TGAVTTSNY(SEQ ID NO:68);GTN;和ALWYSNYWV(SEQ ID NO:69)。
任选地,调节剂能够同时结合到IL-1R1和NLRP3。任选地或另外地,调节剂能够依次地结合到IL-1R1和NLRP3。
任选地,本发明的双特异性抗体的轻链具有以下氨基酸序列:
MVSSAQFLGLLLLCFQGTRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRNEC**(SEQ ID NO:57)。
任选地,本发明的双特异性抗体的重链具有以下氨基酸序列:MGWTLVFLFLLSVTAGVHSQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTAPSVYPLAPVCGDTTGSSVTLGCLVKGYFPEPVTLTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVTSSTWPSQSITCNVAHPASSTKVDKKIEPRGPTIKPCPPCKCPAPNLLGGPSVFIFPPKIKDVLMISLSPIVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTLRVVSALPIQHQDWMSGKEFKCKVNNKDLPAPIERTISKPKGSVRAPQVYVLPPPEEEMTKKQVTLTCMVTDFMPEDIYVEWTNNGKTELNYKNTEPVLDSDGSYFMYSKLRVEKKNWVERNSYSCSVVHEGLHNHHTTKSFSRTPGKGSAGGSGGDSEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPK**(SEQ ID NO:59)。
“同时结合”到IL-1R1和NLRP3两者意指调节剂能够结合到IL-1R1和/或NLRP3中的每一者,无论所述IL-1R1和/或NLRP3是作为复合物形成或它们不作为复合物形成。
在第二方面,本发明提供了一种如本文所定义的调节剂,其用于治疗或预防炎症相关病症,其中已知NLRP3炎症小体在疾病发病机理中起关键作用。
双特异性抗体作为调节剂的优势在于,与单一抗体相比,它可以更低的浓度(且因此更小毒性)使用,因此降低了细胞毒性可能。具有双特异性使抗体更稳定且纯度更高。
与小分子抑制剂相比,所述双特异性抗体作为生物制品具有更长的半衰期,因此赋予主要优势。
在第三方面,本发明提供了一种用于治疗和/或预防炎症相关病症的方法,所述方法包括以下步骤:
提供治疗有效量的本发明的第一方面的调节剂,其抑制NLRP3炎症小体的活化和/或信号传导,以及向需要此种治疗的受试者施用治疗有效量的所述化合物。
在第四方面,本发明提供了本发明的第一方面的调节剂在制备用于治疗炎症相关病症的药物中的用途。
在第五方面,本发明提供了一种减少或预防或治疗受试者中的炎症相关病症的至少一种症状的方法,所述方法包括通过使用本发明的第一方面的调节剂来选择性地抑制和/或减少炎症小体通路的活化。
任选地,调节剂用于治疗或预防受试者中的炎症相关病症的至少一种症状,包括通过使用本发明的第一方面的调节剂来选择性地抑制和/或减少炎症小体通路的活化。
任选地,InflaMab可在诸如但不限于动脉粥样硬化的系统性病状中具有疾病缓解作用,由此其预防/抑制炎症,从而预防斑块积聚和/或斑块破裂,从而降低心肌梗塞的风险。
任选地,InflaMab可在诸如但不限于青光眼的眼部疾病中具有疾病缓解作用,由此其预防/抑制炎症、降低眼内压且/或预防视网膜神经节细胞和轴突的丢失,从而保护视神经并保护视力和/或预防失明。
任选地,InflaMab可在诸如但不限于阿尔茨海默氏病的神经病状中具有疾病缓解作用,由此其预防/抑制炎症、减少/抑制淀粉样斑块负荷且/或预防认知障碍。
本发明的第一方面的调节剂可在患有与炎症相关的多病变(multi-morbidity)或共病(co-morbidity)的个体中具有效用。
任选地,本发明的任一前述方面的调节剂(表示为Inflamab)是由通过二硫键复合在一起的两对轻链和两对重链组成的210千道尔顿(kDa)双特异性小鼠抗体,其中scFv结构域融合至N端。
如本文所用,“炎症相关病症”包括但不限于动脉粥样硬化、炎症性眼部病状(诸如年龄相关性黄斑变性、干眼综合症、青光眼、舍格伦综合症(Sjogren’s syndrome))、糖尿病、炎症性眼病、抑郁症、阿尔茨海默氏病、帕金森氏病、炎症性肠病、类风湿性关节炎、衰老、皮肤病状和癌症。
任选地,受试者为哺乳动物,诸如人。
术语“抗体”应解释为涵盖具有带有所需特异性的结合结构域的任何结合成员或物质。本发明的抗体可为单克隆抗体或其片段、功能等效物或同系物。所述术语包括包含免疫球蛋白结合结构域的任何多肽,无论是天然的还是全部或部分合成的。因此,包括包含与另一种多肽融合的免疫球蛋白结合结构域或等效物的嵌合分子。
完整抗体的片段可执行抗原结合的功能。此类结合片段的实例为:Fab片段,其包含VL、VH、CL和CH1抗体结构域;Fv片段,其由单个抗体的VL和VH结构域组成;F(ab’)2片段,其为包含两个连接的Fab片段的二价片段;单链Fv分子(scFv),其中VH结构域和VL结构域通过允许两个结构域缔合以形成抗原结合位点的肽接头连接;或双特异性或三特异性抗体,其可为通过基因融合构建的多价或多特异性片段。
用于本发明的抗体或多肽的片段通常意指一段氨基酸残基,其具有至少5至7个连续氨基酸、经常至少约7至9个连续氨基酸、通常至少约9至13个连续氨基酸、更优选地至少约20至30或更多个连续氨基酸并且最优选至少约30至40或更多个连续氨基酸。
术语“抗体”包括已被“人源化”的抗体。用于制备人源化抗体的方法为本领域中已知的。
适体是与特定靶分子结合的肽分子。适体为小分子与生物制品之间的领域。相对于抗体治疗剂,它们在尺寸、合成可及性和修饰方面表现出显著的优势。
如本文所述的调节剂可用于诸如ELISA的测定中,以检测来自人血液或组织样品的NLRP3。因此,在另一方面,本发明提供了一种试剂盒,其包含本发明的第一方面的一种或多种调节剂。任选地,试剂盒还包括所述试剂盒的使用说明书。任选地,试剂盒用于检测人细胞、血液或组织样品中的NLRP3。
附图说明
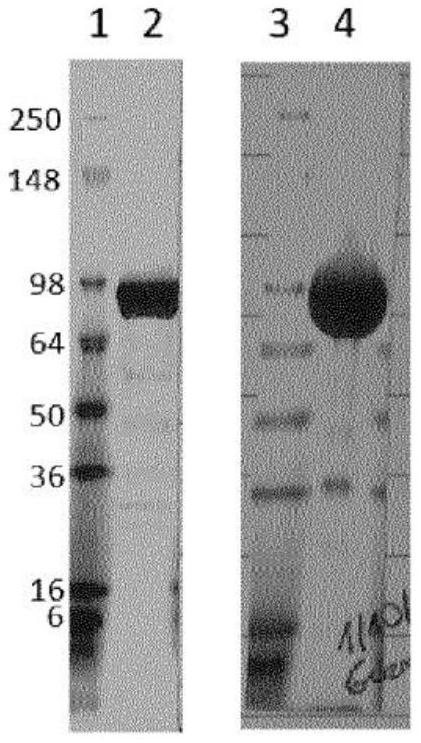
图1:IL-1R1 FC的4-20%变性、还原和非还原SDS-PAGE分析。分子量标记以千道尔顿表示。
图2:UUC IL-1R第1次出血。
图3:UUC IL-1R第2次出血。
图4:融合后筛选结果。
图5:第1次原生质体克隆24孔。
图6:LD1筛选结果。
图7:24孔板筛选结果。
图8:来自F237 5D1-1A8的最终选择的杂交瘤。
图9:来自F237 5D1-1A8最终24孔筛选的最终选择的杂交瘤。
图10:THP1细胞中的IL-1R1内化-免疫荧光成像。从用LPS和ATP处理以诱导IL-1R1表达的THP1巨噬细胞拍摄的荧光显微图像。
图11:THP1细胞中的IL-1R1内化-流式细胞术。
图12:使用Ig可变结构域引物的几种组合进行的PCR。
图13:CDR环的图形表示。参考文献:Lefranc,M.-P.等人,Dev.Comp.Immunol.,27,55-77(2003)PMID:12477501
图14:CDR环的图形表示(Lefranc,M.-P.等人,Dev.Comp.Immunol.,27,55-77(2003)PMID:12477501)。
图15:NLRP3炎症小体的结构。Bergsbaken,T.;Fink,S.L.;Cookson,B.T.(2009).“Pyroptosis:Host cell death and inflammation”.Nature Reviews Microbiology.7(2):99–109.doi:10.1038/nrmicro2070.PMC2910423 .PMID 19148178.以及Dagenais,M.;Skeldon,A.;Saleh,M.(2011).“The inflammasome:In memory of Dr.Jurg Tschopp”.Cell Death and Differentiation.19(1):5–12.doi:10.1038/cdd.2011.159.PMC3252823.PMID22075986.
http://jonlieffmd.com/blog/cellular-intelligence-blog/inflammasomes-are-large-complex-signaling-platforms
图16:使用CLUSTAL 0(1.2.4)对人和小鼠NALP(NLRP)蛋白C端结构域的共有序列进行序列比对。
图17:使用Protean 3D版本14.0.1来与显示二级结构特征的NLRP3 PDB:3QF2进行比对的肽FUS_746_001(黄色)的Novafold预测的结构
图18:免疫的小鼠表达高水平的NLRP3 mAb。
图19:UUC NLRP3第1次出血。
图20:UUC NLRP3第2次出血。
图21:融合后筛选结果。
图22:第1次原生质体克隆24孔。
图23:LD1筛选结果。
图24:24孔板筛选结果。
图25:来自F226的最终选择的杂交瘤。
图26:斑点印迹分析。
图27:蛋白质印迹分析。
图28:使用Ig可变结构域引物的几种组合进行的PCR。
图29:CDR环的图形表示(Lefranc,M.-P.等人,Dev.Comp.Immunol.,27,55-77(2003)PMID:12477501)。
图30:CDR环的图形表示(Lefranc,M.-P.等人,Dev.Comp.Immunol.,27,55-77(2003)PMID:12477501)。
图31:示出InflaMab的双特异性设计和质粒图谱的图。
图32:InflaMab的4-20%SDS-PAGE分析。分子量标记以千道尔顿表示。
图33:Inflamab预防IL-1β释放。(注意,“Ulster Ab”是“Inflamab”和“双特异性Ab”的同义词。)
图34:Inflamab预防THP1细胞中的半胱天冬酶-1活化。
图35:Inflamab的内化。
图36:InflaMab抑制IL-1β从骨髓来源的巨噬细胞(BMDM)中分泌。
图37:通过LPS攻击在体内抑制IL-1β而非TNFα。
图38:InflaMab在动脉粥样硬化的体内apoE-/-模型中减小斑块尺寸。
在特定治疗用途或方法中,本发明的调节剂(例如双特异性抗体)根据包括以下的步骤起作用:
1.将双特异性抗体靶向IL-1R1,以使抗体内化并进入细胞。
2.将抗体靶向NLRP3,以便抑制NLRP3炎症小体组装和随后IL-1β从细胞释放,从而减轻炎症。
3.将抗体靶向IL-1R1触发IL-1R1的内化,从而使可用于IL-1β结合的IL-1R1更少,导致进一步抑制炎症的增强和放大。
本发明的第一方面的此种调节剂作为整体(不仅是NLRP3蛋白质部分)对NLRP3炎症小体提供了令人惊讶的累加抑制作用,并因此将提供对炎症小体相关疾病的更有效的抑制剂。
具体实施方式
·IL-1R1 FC融合物的瞬时表达(实施例1)
·针对IL-1R1的单克隆抗体的产生(实施例2)
·IL-1R1单克隆抗体测序报告(实施例3)
·NLRP3肽合成(实施例4)
·针对NLRP3的单克隆抗体的产生(实施例5)
·NLRP3单克隆测序报告(实施例6)
·InflaMab设计(实施例7)
·InflaMab瞬时表达(实施例8)
·用于动脉粥样硬化/冠状动脉疾病的InflaMab(实施例9)
IL-1R1 Fc在HEK293细胞中瞬时表达并纯化。通过SDS PAGE评估纯化的蛋白质的尺寸和纯度,并测试内毒素水平。最后,通过ELISA评估蛋白质的活性。
将编码白介素-1受体(IL-1R1)Fc融合蛋白的哺乳动物表达载体转染到HEK293细胞中。随后使用标准色谱技术从细胞培养上清液中纯化表达的Fc融合蛋白。确定纯化产物的浓度和纯度。
HEK293细胞的瞬时转染和蛋白质的纯化
合成编码IL-1R1 Fc的氨基酸序列的DNA(参见实施例1A),并将其克隆到哺乳动物瞬时表达质粒pD2610-v1(DNA2.0)中。使用基于HEK293细胞的瞬时表达系统表达IL-1R1Fc,并通过离心和过滤使所得的含有抗体的细胞培养上清液澄清。通过蛋白A亲和色谱从细胞培养上清液中纯化出两批IL-1R1 Fc(使用AKTA色谱设备)。对纯化的蛋白质进行透析/将缓冲液交换到磷酸盐缓冲盐水溶液中。如通过十二烷基硫酸钠聚丙烯酰胺凝胶判断,重组蛋白的纯度被确定为>95%(图1)。通过测量吸光度确定蛋白质浓度(1.0mg/ml=1.37的A280)。纯化产物的详情总结于表1中。
图1示出IL-1R1 FC的4-20%变性、还原和非还原SDS-PAGE分析。分子量标记以千道尔顿表示。泳道如下:
表1:纯化总结:IL-1R1 Fc
缩写如下;ND,未确定。
MKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQHKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKPLLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSDIAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKLEGGPSVFIFPPNIKDVLMISLTPKVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTIRVVSHLPIQHQDWMSGKEFKCKVNNKDLPSPIERTISKPKGLVRAPQVYTLPPPAEQLSRKDVSLTCLVVGFNPGDISVEWTSNGHTEENYKDTAPVLDSDGSYFIYSKLNMKTSKWEKTDSFSCNVRHEGLKNYYLKKTISRSPGK*(SEQ ID NO:1)
此项目的目的是产生针对IL-1R1的单克隆抗体。对5只小鼠的群体进行免疫,并筛选阳性免疫反应。在选择合适的融合候选物后,将脾细胞与伴侣细胞融合以产生杂交瘤群体。此群体经历了一系列的有限稀释和筛选测定,以产生完全单克隆的细胞系。
细胞系命名法
产品名称“F237 5D1-1A8-2A5”是指10种选择的单克隆杂交瘤细胞系中的一种。名称由描述每个阶段的生产通路的组件组成。向选自融合后筛选和每次有限稀释的每种杂交瘤给予对应于选择杂交瘤的板编号和在该板上的孔位置的编号(即5D1-1A8-2A5)。此命名法追踪每种单独的杂交瘤的起源,从而允许在筛选过程中明确区分。
缩写
材料
试剂和培养基
一次性用品
设备
·CO
·Sunrise读板器(Tecan)
·Centurion Scientific K40R离心机
·Grant-Bio Multishaker PSU 20
方法
抗原制备
一旦免疫原(IL-1R1)得到纯化,就将这些溶液在无菌EF-PBS中稀释至200μg/ml,并且将其等分成用于进行免疫的600μl体积和用于进行增强和ELISA筛选的150μl体积。将这些等分试样标记并储存在-20℃下。
免疫
用200μl弗氏完全佐剂(Sigma)1:1乳剂和600μl本文制备的IL-1R1等分试样皮下免疫5只BalbC小鼠的群体。第1次免疫后两周,以与仅使用弗氏不完全佐剂(Sigma)代替的初始注射相同的体积和浓度,用第2次注射免疫群体。第2次免疫后一周,通过耳钳(NP、RP、LP、LRP、2LP)标记小鼠,并如本文所述筛选测试出血以得到初步结果。第2次免疫后三周,使用与第2次注射相同的方法对群体进行第3次免疫。第3次免疫后一周,筛选测试出血,并且然后选择具有RP耳标的小鼠进行融合。
测试出血ELISA
从5只BalbC小鼠的群体中取得尾部出血,并在RT(室温)下以8000rpm离心10min。收集每只小鼠的血清,在筛选的同一天将其加载到板上,并储存在-20℃下。进行两次此筛选以选择合适的小鼠进行融合。
在筛选前一天,通过添加100μl/孔的含有1μg/ml IL-1R1的50mM碳酸钠包被缓冲液(pH 9.5),对Maxi Sorp板进行包被。通过将APO-A1在同一包被缓冲液中以1μg/ml稀释来制备单独的包被溶液。将这些溶液以交替行的形式加载到板上,以便提供两个孔来加载显示阳性和阴性结果的每个样品。将此板在静态条件下在4℃下孵育过夜。
第二天早上,去除包被缓冲液,并且添加200μl/孔的封闭溶液(4.0%w/v半脱脂奶粉,1x PBS),并在RT下以150rpm搅拌2小时。将板用PBS-T(0.1%v/v Tween 20)洗涤三次。将PBS以100μl/孔加载到每个孔中,并且将1μl的每个测试出血血清加载到每个阳性孔和阴性孔中。将板在室温下以150rpm(Grant Shaker)孵育2小时。然后将这些样品移出并用PBS-T洗涤四次。添加100μl/孔、1:5000稀释的GAM-HRP(Sigma,UK),并将板在RT下在搅拌下以150rpm孵育1小时。将二级抗体移除,并且将板用PBS-T洗涤四次并在PBS中洗涤一次。添加100μl/孔的TMB底物溶液,并在37℃下孵育10分钟。每孔添加50μl 1M HCl,并立即在TecanSunrise读板器上在450nm处对板读数。
在第二次测试出血ELISA筛选后,通过表达最阳性的免疫反应选择具有RP耳标的小鼠进行融合。
增强注射
第3次免疫和最终免疫后一周,通过注射100μl不含任何佐剂的200μg/ml等分的IL-1R1向BalbC小鼠RP给予增强注射。
融合物F237
在融合前一周,将SP2细胞从液氮中分离并在补充有1%Pen/Strep、1%L-谷氨酰胺的10%FCS DMEM中传代,直到3x12 ml T75烧瓶在融合当天75%-90%汇合。在融合当天,通过敲击烧瓶使SP2细胞脱离,并在37℃下以1000rpm离心5min。将细胞重悬于20ml SFMDMEM中,再次离心,并重悬于10ml SFM DMEM中。将SP2细胞在37℃、6%CO
实施安乐死后,从显示出最强免疫反应的小鼠中无菌取出脾脏。通过用细表针穿刺脾脏的两端并冲洗10-15ml SFM DMEM来提取脾细胞。将脾细胞转移到无菌管中,并通过在37℃下以1300rpm离心5min并轻轻移除上清液来用20ml无血清DMEM洗涤两次。将脾细胞重悬于在无菌管中的10ml无血清DMEM中。
使用储存在37℃下的SP2细胞,将SP2细胞添加到脾细胞中。将此SP2/脾细胞培养物在37℃下以1300rpm离心5min。丢弃上清液后,将1ml PEG逐滴添加到SP2/脾细胞培养物中,同时在3min时间段内持续搅拌。将1ml SFM DMEM添加到融合混合物中,并搅拌4min。将10ml SFM DMEM逐滴添加到新鲜培养物中,并在37℃水浴中孵育5min。然后将细胞在37℃下以1000rpm离心5min。将沉淀物重悬于200mL HATR培养基中,并以200μl/孔铺板在10x 96孔培养板中,在筛选前将所述培养板在37℃、6%CO
融合后筛选和LD后筛选
融合后十一天,通过ELISA筛选原生质体克隆。如本文所述,使用1μg/ml的APO-A1作为特异性的阴性对照,对20x Maxi Sorp 96孔板进行包被。如本文所述,将包被溶液去除并将板封闭。通过从十个融合板、有限稀释板或24孔板的每个孔中取出160μl上清液并将其转移到含有50μl 1xPBS的新鲜96孔培养板中来制备样品。封闭2小时后,去除封闭溶液,并将板用PBS-T洗涤3次。考虑到包被抗原的特异性,通过在ELISA板上每2行从每个稀释板中添加1行,将每个稀释板中的样品以100μl/孔加载到ELISA板上。将每个ELISA的两个孔与100μl 1xPBS一起孵育,作为阴性对照。将这些样品在室温下以150rpm孵育2小时。
有限稀释
一旦杂交瘤群体在24孔板中扩增并生长良好,就进行二次筛选,以选择最具特异性和产量最高的群体进行数轮有限稀释。
通过以1个细胞/孔以200μl培养物/孔接种2-4x 96孔板中,对1-3个原生质体克隆进行两种有限稀释。通过对24孔板中的每种培养物进行计数来制备板,并将其稀释10x作为中间稀释液,然后稀释至40ml中的200个细胞。将培养物以200μl/孔铺板,并在37℃、6%CO
最终克隆选择
在第二次有限稀释后,选择10个克隆用于在24孔板中扩增。使每个克隆在37℃、6%CO
单克隆细胞系的冷冻保存
一旦在T25烧瓶中充分建立克隆(80%-90%汇合),就将每种5ml培养物在37℃下以1000rpm离心5min,并重悬于1ml新鲜的10%DMEM HATR培养基中。将每种1ml培养物转移到含有300μl 1:1比率的FCS与DMSO的冷冻小瓶中。将小瓶密封并放置在Mr.Frosty中,并将其转移到-70℃冰箱中以进行短期存储。
用于测序的细胞制备
选择由克隆F237 5D1-1A8-2A5产生的抗IL-1R1进行测序。一旦培养物在T25烧瓶中汇合,就将上清液丢弃。通过细胞刮擦到2ml新鲜培养基中来使细胞脱离,并在RT下以7,600rpm离心5min。然后将上清液丢弃,并且将沉淀物在液氮中快速冷冻,并置于-70℃直至准备好进行mRNA提取。
免疫和测试出血的筛选
向小鼠群落免疫IL-1R1免疫原(在CHO细胞内部产生),并在11周时间段内取得定期的测试出血。使用ELISA针对IL-1R1 mAb表达水平筛选测试出血,并使用pHrodo荧光测定针对内化能力筛选(Thermo Fisher Scientific,UK https://www.thermofisher.com/order/catalog/product/P35369和https://www.sigmaaldrich.com/catalog/product/sigma/m4280?lang=en®ion=GB)。
结果
测试出血1
第2次免疫后一周,从5只小鼠中的每一只取得尾部出血,并针对IL-1R和APO-A1进行筛选,以确定适用于融合的动物和所产生的多克隆抗体的相对特异性–参见图2。
测试出血2
从尾部出血中筛选血清后,选择具有RP耳标的小鼠,将其脾细胞与融合伴侣SP2培养物融合,因为它表现出最佳的免疫反应–参见图3。
融合后筛选
一旦每个板中的孔达到70%-80%汇合,就通过ELISA针对IL-1R1和APO-A1筛选板。选择产生最高反应的杂交瘤群体以在24孔板中进行扩增–参见图4。
第1次24孔板筛选
从融合后筛选中选择克隆,并将其排列在24孔板中进行扩增,之后进行二次筛选,确定适用于第一轮有限稀释的原生质体克隆–参见图5。
有限稀释1次筛选
一旦第1次有限稀释板汇合,就通过ELISA针对IL-1R1和APO-A1筛选有限稀释。从F237 2H12、F2375D1和F237 7E6中选择了十一个杂交瘤群体,它们表现出最高且最具特异性的反应–参见图6。
第2次24孔板筛选
当克隆在24孔板中汇合时,通过ELISA针对IL-1R1和APO-A1筛选每个克隆。选择F237-5D1-1A8在4x 96孔板上进行第2轮有限稀释–参见图7。
有限稀释2次筛选
一旦每个板中的孔达到70%-80%汇合,就通过ELISA针对IL-1R1和APO-A1筛选板。选择产生最高反应和最高特异性的杂交瘤群体在24孔板中进行扩增和冷冻保存–参见图8。
对THP1细胞中的IL-1R1内化进行免疫荧光成像
从用LPS和ATP处理以诱导IL-1R1表达的THP1巨噬细胞取得的荧光显微图像–参见图10。将细胞与来自几只不同小鼠的小鼠血清一起孵育,所述小鼠血清含有针对IL-1R1的测试抗体,所述抗体缀合至pHrodo
用LPS和ATP处理以诱导IL-1R1表达的THP1巨噬细胞(参见图11)。将细胞与来自几只小鼠的小鼠血清一起孵育,所述小鼠血清含有针对IL-1R1的测试单克隆抗体,所述抗体缀合至pHrodo染料(将仅在细胞内发出荧光)并用流式细胞术分析。与仅对照二级抗体处理的细胞(ii)相比,在IL-1R1抗体处理的细胞(i)中看到更多荧光。使用此数据和来自图3的数据,选择最佳小鼠进入融合杂交瘤和克隆阶段。
结论
所述项目的目的是生产一系列针对IL-1R1的抗体。一旦对小鼠进行免疫和筛选,就选择RP进行融合。由两轮有限稀释产生10个单克隆杂交瘤细胞系。由IL-1R1的最高产量和最高特异性来选择每个群体。已将这些最终细胞系冷冻,并且将对由此细胞系表达的抗体进行测序。
从杂交瘤细胞沉淀物中提取mRNA。使用常规RNA提取方案从沉淀物中提取总RNA。使用RNA STAT-60试剂使细胞沉淀物均质化。添加氯仿后,将均质物分离成水相和有机相,并在水相中分离出总RNA。使用异丙醇使RNA沉淀,之后用乙醇洗涤并将其溶解在水中。
RT-PCR
通过用寡聚(dT)引物逆转录从RNA中产生cDNA。使用可变结构域引物建立PCR反应,以扩增单克隆抗体DNA的VH和VL区,从而产生以下带–参见图12。
将VH和VL产物克隆到Invitrogen测序载体pCR2.1中,并将其转化到TOP10细胞中,并通过PCR筛选阳性转化子。挑出选择的集落,并在ABI3130xl基因分析仪上通过DNA测序进行分析,结果如下所示。
测序结果
V
VH1.1(SEQ ID NO:2)
VH1.4(SEQ ID NO:3)
VH1.3(SEQ ID NO:4)
VH2.1(SEQ ID NO:5)
VH2.5(SEQ ID NO:6)
VH2.3(SEQ ID NO:7)
VH1.2(SEQ ID NO:8)
VH2.4(SEQ ID NO:9)
共有(SEQ ID NO:7)
氨基酸阴影的关键:
V
MGWVWNLPFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKAS
可变结构域以粗体突出显示。
如通过IMGT编号系统确定的,互补决定区(CDR)加下划线(Lefranc,M.-P.等人,Nucleic Acids Research,27,209-212(1999))–参见图13。
氨基酸阴影的关键,图13中:
蓝色阴影圆圈是框架1-3中大多数抗体疏水的位点处的疏水性(非极性)残基。
黄色阴影圆圈是脯氨酸残基。
方框是CDR开头和结尾的关键残基。
框架中的红色氨基酸是结构上保守的氨基酸。
V
VK1.1(SEQ ID NO:10)
VK1.5(SEQ ID NO:11)
VK1.3(SEQ ID NO:12)
VK1.4(SEQ ID NO:13)
VK2.1(SEQ ID NO:14)
VK2.6(SEQ ID NO:15)
共有(SEQ ID NO:12)
氨基酸阴影的关键:
V
MRSPAQFLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRAS
可变结构域以粗体突出显示。
如通过IMGT编号系统确定的,互补决定区(CDR)加下划线(Lefranc,M.-P.等人,Nucleic Acids Research,27,209-212(1999))–参见图14。
氨基酸阴影的关键,图14中:
蓝色阴影圆圈是框架1-3中大多数抗体疏水的位点处的疏水性(非极性)残基。
黄色阴影圆圈是脯氨酸残基。
方框是CDR开头和结尾的关键残基。
框架中的红色氨基酸是结构上保守的氨基酸。
VH测序结果:
VH1.1 DNA序列:
ATGGAATGGAGCTGTGTCATGCTCTTTCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCCTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCACCCGTTTATCCACTGGCC(SEQ ID NO:16)
VH1.1 氨基酸序列:
MEWSCVMLFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLA(SEQ ID NO:2)
VH1.3 DNA序列:
ATGGGATGGAGCTGGGTCATGCTCTTTCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGACTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCACCCGTTTATCCCTTGGCC(SEQ ID NO:17)
VH1.3 氨基酸序列:
MGWSWVMLFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLA(SEQ ID NO:4)
VH1.4 DNA序列:
ATGGAATGCAGCTGTGTAATGCTCTTTCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCCGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCATCCGTCTTCCCCCTGGCA(SEQ ID NO:18)
VH1.4 氨基酸序列:
MECSCVMLFLMAAAQSIQAQIQLVQSGPELRKPGETVRISRKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPSVFPLA(SEQ ID NO:3)
VH2.1 DNA序列:
ATGGGTTGGGTGTGGAACTTGCTATTCCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGCTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCACCCGTCTATCCACTGGTC(SEQ ID NO:19)
VH2.1 氨基酸序列:
MGWVWNLLFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLV(SEQ ID NO:5)
VH1.2 DNA序列:
ATGGATTGGGTGTGGACCTTGCCATTCCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCATCTGTCTATCCACTGGCC(SEQ ID NO:20)
VH1.2 氨基酸序列:
MDWVWTLPFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPSVYPLA(SEQ ID NO:8)
VH2.3 DNA序列:
ATGGGTTGGGTGTGGAACTTGCCATTCCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTACCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGCACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCACCCGTCTATCCATTGGCC(SEQ ID NO:21)
VH2.3 氨基酸序列:
MGWVWNLPFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLA(SEQ ID NO:7)
VH2.4 DNA序列:
ATGGATTGGCTGTGGAACTTGCCATTCCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCAACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCACCCGTCTATCCACTGGCC(SEQ ID NO:22)
VH2.4 氨基酸序列:
MDWLWNLPFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLA(SEQ ID NO:9)
VH2.5 DNA序列:
ATGGGTTGGGTGTGGACCTTGCCATTCCTCATGGCAGCAGCTCAAAGTATCCAAGCACAGATCCAGTTGGTGCAGTCTGGACCTGAGCTGAGGAAGCCTGGAGAGACAGTCAGGATCTCCTGCAAGGCTTCTGGGTATCCCTTCACAACTGCTGGATTGCAGTGGGTACAGAAGATGTCAGGAAAGGGTTTGAAATGGATTGGCTGGATGAACACCCAGTCTGAAGTGCCAAAATATGCAGAAGAGTTCAAGGGACGGATTGCCTTCTCTTTGGAAACCGCTGCCAGTACTGCATATTTACAGATAAACAACCTCAAAACTGAGGACACGGCGACGTATTTCTGTGCGAAATCGGTCTATTTTAACTGGAGATATTTCGATGTCTGGGGTGCAGGGACCACGGTCACCGTCTCCTCAGCCAAAACGACACCCCCACCCGTCTATCCCCTGGTC(SEQ ID NO:23)
VH2.5 氨基酸序列:
MGWVWTLPFLMAAAQSIQAQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTPPPVYPLV(SEQ ID NO:6)
VL测序结果:
VK1.1 DNA序列:
ATGAGGGCCCCTGCTCAGTTTCTTGGGCTTTTGCTTCTCTGGACTTCAGCCTCCAGATGTGACATTGTGATGACTCAGTCTCCAGCCACCCTGTCTGTGACTCCAGGAGATAGAGTCTCTCTTTCCTGCAGGGCCAGCCAGAGTATTAGCGACTACTTATCCTGGTATCAACAAAGATCTCATGAGTCTCCAAGGCTTATCATCAAATATGCTTCCCAATCCATCTCTGGGATCCCCTCCAGGTTCAGTGGCAGTGGATCAGGGTCAGACTTCACTCTCAGTATCAACAGTGTGGAACCTGAAGATGTTGGAGTGTATTACTGTCAACATGGTCACAGCTTTCCGCTCACGTTCGGTTCTGGGACCAAGCTGGAGCTGAAACGGGCTGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAAAGA(SEQ ID NO:24)
VK1.1 氨基酸序列:
MRAPAQFLGLLLLWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPK(SEQ ID NO:10)
VK1.3 DNA序列:
ATGAGGTCCCCTGCTCAGTTCCTTGGGCTTTTGCTTTTCTGGACTTCAGCCTCCAGATGTGACATTGTGATGACTCAGTCTCCAGCCACCCTGTCTGTGACTCCAGGAGATAGAGTCTCTCTTTCCTGCAGGGCCAGCCAGAGTATTAGCGACTACTTATCCTGGTATCAACAAAGATCTCATGAGTCTCCAAGGCTTATCATCAAATATGCTTCCCAATCCATCTCTGGGATCCCCTCCAGGTTCAGTGGCAGTGGATCAGGGTCAGACTTCACTCTCAGTATCAACAGTGTGGAACCTGAAGATGTTGGAGTGTATTACTGTCAACATGGTCACAGCTTTCCGCTCACGTTCGGTTCTGGGACCAAGCTGGAGCTGAAACGGGCTGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAAA(SEQ ID NO:25)
VK1.3 氨基酸序列:
MRSPAQFLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPK(SEQ ID NO:12)
VK1.4 DNA序列:
ATGAGGTCCCCAGCTCAGTTTCTGGGGCTTTTGCTTTTCTGGACTTCAGCCTCCAGATGTGACATTGTGATGACTCAGTCTCCAGCCACCCTGTCTGTGACTCCAGGAGATAGAGTCTCTCTTTCCTGCAGGGCCAGCCAGAGTATTAGCGACTACTTATCCTGGTATCAACAAAGATCTCATGAGTCTCCAAGGCTTATCATCAAATATGCTTCCCAATCCATCTCTGGGATCCCCTCCAGGTTCAGTGGCAGTGGATCAGGGTCAGACTTCACTCTCAGTATCAACAGTGTGGAACCTGAAGATGTTGGAGTGTATTACTGTCAACATGGTCACAGCTTTCCGCTCACGTTCGGTTCTGGGACCAAGCTGGAGCTGAAACGGGCTGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAGAGA(SEQ ID NO:26)
VK1.4 氨基酸序列:
MRSPAQFLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPR(SEQ ID NO:13)
VK1.5 DNA序列:
ATGAGGGCCCCTGCTCAGCTCCTGGGGCTTTTGCTTTTCTGGACTTCAGCCTCCAGATGTGACATTGTGATGACTCAGTCTCCAGCCACCCTGTCTGTGACTCCAGGAGATAGAGTCTCTCTTTCCTGCAGGGCCAGCCAGAGTATTAGCGACTACTTATCCTGGTATCAACAAAGATCTCATGAGTCTCCAAGGCTTATCATCAAATATGCTTCCCAATCCATCTCTGGGATCCCCTCCAGGTTCAGTGGCAGTGGATCAGGGTCAGACTTCACTCTCAATATCAACAGTGTGGAACCTGAAGATGTTGGAGTGTATTACTGTCAACATGGTCACAGCTTTCCGCTCACGTTCGGTTCTGGGACCAAGCTGGAGCTGAAACGGGCTGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTATCCCAAAGA(SEQ ID NO:27)
VK1.5 氨基酸序列:
MRAPAQLLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLNINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPK(SEQ ID NO:11)
VK2.1 DNA序列:
ATGGTATCCTCAGCTCAGTTCCTTGGACTTTTGCTTTTCTGGACTTCAGCCTCCAGATGTGACATTGTGATGACTCAGTCTCCAGCCACCCTGTCTGTGACTCCAGGAGATAGAGTCTCTCTTTCCTGCAGGGCCAGCCAGAGTATTAGCGACTACTTATCCTGGTATCAACAAAGATCTCATGAGTCTCCAAGGCTTATCATCAAATATGCTTCCCAATCCATCTCTGGGATCCCCTCCAGGTTCAGTGGCAGTGGATCAGGGTCAGACTTCACTCTCAGTATCAACAGTGTGGAACCTGAAGATGTTGGAGTGTATTACTGTCAACATGGTCACAGCTTTCCGCTCACGTTCGGTTCTGGGACCAAGCTGGAGCTGAAACGGGCTGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAAA(SEQ ID NO:28)
VK2.1 氨基酸序列:
MVSSAQFLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPK(SEQ ID NO:14)
VK2.6 DNA序列:
ATGGTGTCCACAGCTCAGTTCCTTGGACTTTTGCTTTTCTGGACTTCAGCCTCCAGATGTGACATTGTGATGACTCAGTCTCCAGCCACCCTGTCTGTGACTCCAGGAGATAGAGTCTCTCTTTCCTGCAGGGCCAGCCAGAGTATTAGCGACTACTTATCCTGGTATCAACAAAGATCTCATGAGTCTCCAAGGCTTATCATCAAATATGCTTCCCAATCCATCTCTGGGATCCCCTCCAGGTTCAGTGGCAGTGGATCAGGGTCAGACTTCACTCTCAGTATCAACAGTGTGGAACCTGAAGATGTTGGAGTGTATTACTGTCAACATGGTCACAGCTTTCCGCTCACGTTCGGTTCTGGGACCAAGCTGGAGCTGAAACGGGCTGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAGAGA(SEQ ID NO:29)
VK2.6 氨基酸序列:
MVSTAQFLGLLLFWTSASRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPR(SEQ ID NO:15)
设计针对NLRP3的肽(抗原),所述肽将产生能够抑制NLRP3炎症小体形成的抗体反应。
NLRP-3炎症小体是在哺乳动物细胞中响应于炎症刺激而形成的异质蛋白复合物,调节和减弱其形成的能力可对一系列炎症性病症具有重要的治疗潜力。将设计衍生自NALP3蛋白序列的肽,所述序列应产生能够阻断NALP3与NLRP3炎症小体复合物中其他蛋白质组分结合的抗体。
NLRP3活化通过NLRP蛋白与ASC的自组装而发生,所述ASC是CARD、PYD和半胱天冬酶-1结构域的杂合物。NLRP3和ASC通过其各自的PYD结构域相互作用,所述结构域含有大比例的高度保守的带电荷氨基酸残基,所述残基相互作用以形成静电相互作用,从而使复合物稳定–参见图15。
图16示出了使用CLUSTAL 0(1.2.4)对人和小鼠NALP(NLRP)蛋白C端结构域的共有序列进行的序列比对。红色指示通过定点诱变识别为NLRP/ASC相互作用所必需的残基(Vajjhala等人,2012)。
肽的选择集中在1-61的序列区,所述序列区已被广泛研究并参与了与ASC的相互作用(Vajjhala等人,2012)。所述区也已通过晶体学进行了很好的建模,其中许多PDB结构可用于此结构域。选择由NLRP3的PYR结构域组成的PDB模型3QF2作为最有用的PDB结构参考。基于潜在表位的可及性和可见性以及小鼠和人序列之间的相似度来选择初始肽候选序列,同时保持与其他NLRP变体的差异。使用NovaFold将这些初始3种肽建模成3D结构。
NovaFold分析
NovaFold是使用I-TASSER算法(基于模板的穿线法(来自PDB)和从头计算法的组合)来预测蛋白质或肽的折叠的3D蛋白质建模软件。在此情况下,它被用于预测肽中二级结构特征的存在,已知所述二级结构特征通过亲本蛋白内的原位序列表现出来。这可以帮助优化对肽序列的选择,所述肽序列最能反映亲本蛋白内基于折叠和邻近度的关系,从而帮助最大化免疫原性蛋白的潜力,从而产生针对全长蛋白中相应表位的具有完全活性的抗体。
肽的建模以及比对
使用NovaFold对四个不同的序列进行建模,并评估所得的最高评分模型,并且然后将其与由PDB:3QF2表示的亲本NLRP3结构进行比对。
表2:使用Novafold 12.0建模并使用Protean 3D版本14.0.1与NLRP3结构PDB:3QF2比对的肽候选物的比对和结构特征的比较。
所述建模和比较指示,肽FUS_746_001是用作肽免疫原的优选候选物。除了表现出与亲本蛋白模型的最大比对之外,它还在二级结构的预测中表现出高度相似性,并且是可接近的表位靶标。
图17示出了使用Novafold预测的结构进行的肽FUS_746_001比对。
结论
应始终将软件的建模视为建议性的而不是确定性的并在此基础上进行解释,特别是在不知道是否在亲本分子内发现强大的二级结构特征的情况下。然而,考虑到这一点,建模表明肽FUS_746_001序列EDYPPQKGCIPLPRGQTEKADHVD(SEQ ID NO:30)将是基于与亲本蛋白的比对和预测的抗原性选择作为此项目的免疫原的最佳候选者。肽还显示出在小鼠和人序列之间仅有几个差异点,这支持在小鼠中产生抗体反应,从而可能允许这些物种之间发生交叉反应,这也是理想的特征,同时最小化与其他NLRP类型的交叉反应性。注意:建议添加N端Cys残基以与KLH交联。
参考文献
Zhang,Y.,2008.I-TASSER server for protein 3D structure prediction.BMCBioinformatics,23Jan.9(40).
Vajjhala,P.R.,Mirams,R.E.,and Hill,J.M.(2012).Multiple binding siteson the pyrin domain of ASC protein allow self-association and interactionwith NLRP3 proteinJ.Biol.Chem.287,41732-41743
NLRP3抗原合成
NLRP3肽由bioSynthesis Inc,Texas合成,使用马来酰亚胺偶联通过另外的C端半胱氨酸残基缀合到KLH。
用NLRP3免疫原免疫的小鼠的第1次出血的ELISA筛选结果-参见图18。
对5只小鼠的群体进行免疫,并筛选阳性免疫反应。在选择合适的融合候选物后,将脾细胞与伴侣细胞融合以产生杂交瘤群体。此群体经历了一系列的有限稀释和筛选测定,以产生完全单克隆的细胞系。
细胞系命名法
产品名称“F226 7A7-1E1-2D5”是指10种选择的单克隆杂交瘤细胞系中的一种。名称由描述每个阶段的生产通路的组件组成。向选自融合后筛选和每次有限稀释的每种杂交瘤给予对应于选择杂交瘤的板编号和在该板上的孔位置的编号(即7A7-1E1-2D5)。此命名法追踪每种单独的杂交瘤的起源,从而允许在筛选过程中明确区分。
缩写
材料
试剂和培养基
一次性用品
设备
·CO
·Sunrise读板器(Tecan)
·Centurion Scientific K40R离心机
·Grant-Bio Multishaker PSU 20
方法
抗原制备
一旦接收到免疫原;NLRP3肽-KLH缀合物(bioSynthesis Inc,Texas),就将这些溶液在无菌EF-PBS中稀释至400μg/ml,并且将其等分成用于进行免疫的600μl体积和用于进行增强和ELISA筛选的150μl体积。将这些等分试样标记并储存在-20℃下。
免疫
用200μl弗氏完全佐剂(Sigma)1:1乳剂和600μl本文制备的NLRP3肽-KLH缀合物等分试样皮下免疫5只BalbC小鼠的群体。第1次免疫后两周,以与仅使用弗氏不完全佐剂(Sigma)代替的初始注射相同的体积和浓度,用第2次注射免疫群体。第2次免疫后一周,通过耳钳(NP、RP、LP、LRP、2LP)标记小鼠,并如本文所述筛选测试出血以得到初步结果。第2次免疫后三周,使用与第2次注射相同的方法对群体进行第3次免疫。第3次免疫后一周,筛选测试出血,并且然后选择RP进行融合。
测试出血ELISA
从5只BalbC小鼠的群体中取得尾部出血,并在RT下以8000rpm离心10min。收集每只小鼠的血清,在筛选的同一天将其加载到板上,并储存在-20℃下。进行两次此筛选以选择合适的小鼠进行融合。
在筛选前一天,通过添加100μl/孔的含有1μg/ml游离NLRP3肽的50mM碳酸钠包被缓冲液(pH 9.5),对Maxi Sorb板进行包被。通过将APO-A1在同一包被缓冲液中以1μg/ml稀释来制备单独的包被溶液。将这些溶液以交替行的形式加载到板上,以便提供两个孔来加载显示阳性和阴性结果的每个样品。将此板在静态条件下在4℃下孵育过夜。
第二天早上,去除包被缓冲液,并且添加200μl/孔的封闭溶液(4.0%w/v半脱脂奶粉,1x PBS),并在RT下以150rpm搅拌2小时。将板用PBS-T(0.1%v/v Tween 20)洗涤三次。将PBS以100μl/孔加载到每个孔中,并且将1μl的每个测试出血血清加载到每个阳性孔和阴性孔中。将板在室温下以150rpm(Grant Shaker)孵育2小时。然后将这些样品移出并用PBS-T洗涤四次。添加100μl/孔、1:5000稀释的GAM-HRP(Sigma,UK),并将板在RT下在搅拌下以150rpm孵育1小时。将二级抗体移除,并且将板用PBS-T洗涤四次并在PBS中洗涤一次。添加100μl/孔的TMB底物溶液,并在37℃下孵育10分钟。每孔添加50μl 1M HCl,并立即在TecanSunrise读板器上在450nm处对板读数。
在第二测试出血ELISA筛选后,通过表达最阳性的免疫反应选择RP进行融合。
增强注射
第3次免疫和最终免疫后一周,通过注射100μl不含任何佐剂的200μg/ml等分的IL-1R向BalbC小鼠RP给予增强注射。
融合物F226
在融合前一周,将SP2细胞从液氮中分离并在补充有1%Pen/Strep、1%L-谷氨酰胺的10%FCS DMEM中传代,直到3x12 ml T75烧瓶在融合当天75%-90%汇合。在融合当天,通过敲击烧瓶使SP2细胞脱离,并在37℃下以1000rpm离心5min。将细胞重悬于20ml SFMDMEM中,再次离心,并重悬于10ml SFM DMEM中。将SP2细胞在37℃、6%CO
实施安乐死后,从显示出最强免疫反应的小鼠中无菌取出脾脏。通过用细表针穿刺脾脏的两端并冲洗10-15ml SFM DMEM来提取脾细胞。将脾细胞转移到无菌管中,并通过在37℃下以1300rpm离心5min并轻轻移除上清液来用20ml无血清DMEM洗涤两次。将脾细胞重悬于在无菌管中的10ml无血清DMEM中。
使用储存在37℃下的SP2细胞,将SP2细胞添加到脾细胞中。将此SP2/脾细胞培养物在37℃下以1300rpm离心5min。丢弃上清液后,将1mL PEG逐滴添加到SP2/脾细胞培养物中,同时在3min时间段内持续搅拌。将1ml SFM DMEM添加到融合混合物中,并搅拌4min。将10ml SFM DMEM逐滴添加到新鲜培养物中,并在37℃水浴中孵育5min。然后将细胞在37℃下以1000rpm离心5min。将沉淀物重悬于200mL HATR培养基中,并以200μl/孔铺板在10x 96孔培养板中,在筛选前将所述培养板在37℃、6%CO
融合后筛选和LD后筛选
融合后十一天,通过ELISA筛选原生质体克隆。如0部分所述,使用1μg/ml的APO-A1作为特异性的阴性对照,对20x Maxi Sorb 96孔板进行包被。如本文所述,将包被溶液去除并将板封闭。通过从十个融合板、有限稀释板或24孔板的每个孔中取出160μl上清液并将其转移到含有50μl 1xPBS的新鲜96孔培养板中来制备样品。封闭2小时后,去除封闭溶液,并将板用PBS-T洗涤3次。考虑到包被抗原的特异性,通过在ELISA板上每2行从每个稀释板中添加1行,将每个稀释板中的样品以100μl/孔加载到ELISA板上。将每个ELISA的两个孔与100μl 1xPBS一起孵育,作为阴性对照。将这些样品在室温下以150rpm孵育2小时。
有限稀释
一旦杂交瘤群体在24孔板中扩增并生长良好,就进行二次筛选,以选择最具特异性和产量最高的群体进行数轮有限稀释。
通过以1个细胞/孔以200μl培养物/孔接种2-4x 96孔板中,对1-3个原生质体克隆进行两种有限稀释。通过对24孔板中的每种培养物进行计数来制备板,并将其稀释10x作为中间稀释液,然后稀释至40ml中的200个细胞。将培养物以200μl/孔铺板,并在37℃、6%CO
最终克隆选择
在第二次有限稀释后,选择10个克隆用于在24孔板中扩增。使每个克隆在37℃、6%CO
单克隆细胞系的冷冻保存
一旦在T25烧瓶中充分建立克隆(80%-90%汇合),就将每种5ml培养物在37℃下以1000rpm离心5min,并重悬于1ml新鲜的10%DMEM HATR培养基中。将每种1ml培养物转移到含有300μl 1:1比率的FCS与DMSO的冷冻小瓶中。将小瓶密封并放置在Mr.Frosty中,并将其转移到-70℃冰箱中以进行短期存储。
用于测序的细胞制备
选择由克隆F226 7A7-1E1-2D5产生的抗NLRP3进行测序。一旦培养物在T25烧瓶中汇合,就将上清液丢弃。通过细胞刮擦到2ml新鲜培养基中来使细胞脱离,并在RT下以7,600rpm离心5min。然后将上清液丢弃,并且将沉淀物在液氮中快速冷冻,并置于-70℃直至准备好进行mRNA提取。
免疫和测试出血的筛选
用NLRP3肽-KLH缀合物(由bioinformatics设计并由bioSynthesis Inc,Texas合成)免疫小鼠群落,并在11周时间段内取得定期的测试出血。然后针对抗原筛选测试出血。
在鉴定阳性小鼠后,进行融合,并且然后验证来自杂交瘤克隆的上清液。然后对特异性抗体进行有限稀释和克隆,以产生针对NLRP3的稳定杂交瘤细胞系。
使用ELISA筛选针对靶蛋白NLRP3的抗体,并选择信号为背景的至少3倍的克隆。选择了来自24个克隆的抗体,并且进行进一步的内部测试以挑出最佳的6个克隆。
结果
测试出血1
第2次免疫后一周,从5只小鼠中的每一只取得尾部出血,并针对未缀合的NLRP3肽和APO-A1进行筛选,以确定适用于融合的动物和所产生的多克隆抗体的相对特异性–参见图19。
测试出血2
从尾部出血中筛选血清后,选择2RP,将其脾细胞与融合伴侣SP2培养物融合,因为它表现出最佳的免疫反应–参见图20。
融合后筛选
一旦每个板中的孔达到70%-80%汇合,就通过ELISA针对NLRP3肽和APO-A1筛选板。选择产生最高反应的杂交瘤群体以在24孔板中进行扩增–参见图21。
第1次24孔板筛选
从融合后筛选中选择克隆,并将其排列在24孔板中进行扩增,之后进行二次筛选,确定适用于第一轮有限稀释的原生质体克隆。选择3个克隆并制备有限稀释–参见图22。
有限稀释1次筛选
一旦第1次有限稀释板汇合,就通过ELISA针对NLRP3肽和APO-A1筛选有限稀释。从F226 5B7和7A7中选择了31个杂交瘤种群,它们表现出最高且最具特异性的反应。没有来自3D4的克隆是合适的–参见图23。
第2次24孔板筛选
当克隆在24孔板中汇合时,通过ELISA针对NLRP3肽和APO-A1筛选每个克隆。选择F226 5B7-1E10、5B7-1G2、7A7-1C4和7A7-1E1在每个克隆的2x 96孔板上进行第2轮有限稀释–参见图24。
有限稀释2次筛选
一旦每个板中的孔达到70%-80%汇合,就通过ELISA针对NLRP3肽和APO-A1筛选板。选择产生最高反应和最高特异性的24个杂交瘤群体在24孔板中进行扩增并冷冻保存–参见图25。
斑点印迹分析如图26所示。使用来自THP-1巨噬细胞的蛋白裂解物进行斑点印迹,以测试含有从融合杂交瘤细胞系的最佳24个克隆中收集的抗NLRP3单克隆抗体的上清液(A25=阳性对照商业抗NLRP3单克隆抗体(R&D Systems),A26=阴性对照PBS)。选择克隆6、11、15、16、18和20,并通过蛋白质印迹进一步测试。
蛋白质印迹分析如图27所示。使用来自THP-1巨噬细胞的蛋白裂解物进行蛋白质印迹,以测试含有从未处理(泳道1)和用LPS和ATP刺激(泳道2,(蛋白梯泳道3))的融合杂交瘤细胞系的最佳6个克隆中收集的抗NLRP3单克隆抗体的上清液。选择克隆18进行测序,并将其用于双特异性单克隆抗体的开发。
结论
目的是生产一系列针对NLRP3的抗体,所述抗体具有预防NLRP3炎症小体组装的功能。一旦对小鼠进行免疫和筛选,就选择2RP进行融合。由两轮有限稀释产生24个单克隆杂交瘤细胞系。通过NLRP3的最高产量和最高特异性来选择每个群体。在体外测定中,克隆F226 7A7-1E1-2D5在阻止NLRP3组装方面表现出最大的活性。已将这些最终细胞系冷冻,并且对由此7A7-1E1-2D5表达的抗体进行测序,以用于产生双特异性InflaMab的下一阶段。
在2016年2月23日从杂交瘤细胞沉淀物中提取mRNA。使用Fusion Antibodies Ltd内部RNA提取方案从沉淀物中提取总RNA(参见实施例3)。
RT-PCR
通过用寡聚(dT)引物逆转录从RNA中产生cDNA。使用可变结构域引物建立PCR反应,以扩增单克隆抗体DNA的VH和VL区,从而产生以下带(参见图28):
将VH和VL产物克隆到Invitrogen测序载体pCR2.1中,并将其转化到TOP10细胞中,并通过PCR筛选阳性转化子。挑出选择的集落,并在ABI3130xl基因分析仪上通过DNA测序进行分析,结果如下所示。
测序结果
V
VH1.1(SEQ ID NO:33)
VH3.7(SEQ ID NO:34)
VH3.4(SEQ ID NO:35)
VH3.1(SEQ ID NO:36)
VH3.5(SEQ ID NO:36)
VH3.8(SEQ ID NO:36)
共有(SEQ ID NO:36)
氨基酸阴影的关键:
V
MDFGLSWVFLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAAS
可变结构域以粗体突出显示。
如通过IMGT编号系统确定的,互补决定区(CDR)加下划线(Lefranc,M.-P.等人,Nucleic Acids Research,27,209-212(1999))–参见图29。
氨基酸阴影的关键,图29中:
蓝色阴影圆圈是框架1-3中大多数抗体疏水的位点处的疏水性(非极性)残基。
黄色阴影圆圈是脯氨酸残基。
方框是CDR开头和结尾的关键残基。
框架中的红色氨基酸是结构上保守的氨基酸。
V
VL1.1(SEQ ID NO:37)
VL1.6(SEQ ID NO:38)
VL1.2(SEQ ID NO:39)
VL1.7(SEQ ID NO:40)
VL1.4(SEQ ID NO:41)
VL1.5(SEQ ID NO:42)
共有(SEQ ID NO:43)
氨基酸阴影的关键:
V
MAWISLLLSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSS
可变结构域以粗体突出显示。
如通过IMGT编号系统确定的,互补决定区(CDR)加下划线(Lefranc,M.-P.等人,Nucleic Acids Research,27,209-212(1999))–参见图30。
氨基酸阴影的关键,图30中:
蓝色阴影圆圈是框架1-3中大多数抗体疏水的位点处的疏水性(非极性)残基。
黄色阴影圆圈是脯氨酸残基。
方框是CDR开头和结尾的关键残基。
框架中的红色氨基酸是结构上保守的氨基酸。
VH测序结果:
VH1.1 DNA序列:
ATGAACTTCGGGTTGAGCTTGGTTTTCCTTGTCCTTGTTTTAAAAGGTGCCCAGTGTGAAGTGCAGCTGGTGGAGTCTGGGGGAGGCTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTGACTATTACATGTATTGGGTTCGCCAGACTCCGGAAAAGAGGCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTACTTACACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACAACCTTTACCTGCAAATGAACAGTCTGAAG(SEQ ID NO:44)
VH1.1氨基酸序列:
MNFGLSLVFLVLVLKGAQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLK(SEQ ID NO:33)
VH3.1 DNA序列:
ATGGACTTCGGGTTGAGCTGGGTTTTCCTTGTCCTTGTTTTAAAAGGTGTCCAGTGTGAAGTGCAGCTGGTGGAGTCTGGGGGAGGCTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTGACTATTACATGTATTGGGTTCGCCAGACTCCGGAAAAGAGGCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTACTTACACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACAACCTTTACCTGCAAATGAACAGTCTGAAGTCTGAGGACACAGCCATGTATTACTGTGCAAGAGGATGGGTTTCTACTATGGTTAAACTTCTTTCCTCCTTTCCTTACTGGGGCCAAGGGACTCTGGTCACTGTCTCTGCAGCCAAAACGACACCCCCATCTGTCTATCCACTGGCC(SEQ ID NO:45)
VH3.1氨基酸序列:
MDFGLSWVFLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAAKTTPPSVYPLA(SEQ ID NO:36)
VH3.4 DNA序列:
ATGGACTTCGGGCTGAGCAGGGTTTTCCTTGTCCTTGTTTTAAAAGGTGTCCAGTGTGAAGTGCAGCTGGTGGAGTCTGGGGGAGGCTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTGACTATTACATGTATTGGGTTCGCCAGACTCCGGAAAAGAGGCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTACTTACACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACAACCTTTACCTGCAAATGAACAGTCTGAAGTCTGAGGACACAGCCATGTATTACTGTGCAAGAGGATGGGTTTCTACTATGGTTAAACTTCTTTCCTCCTTTCCTTACTGGGGCCAAGGGACTCTGGTCACTGTCTCTGCAGCCAAAACGACACCCCCATCTGTCTATCCACTGGCC(SEQ ID NO:46)
VH3.4氨基酸序列:
MDFGLSRVFLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAAKTTPPSVYPLA(SEQ ID NO:35)
VH3.5 DNA序列:
ATGGACTTCGGGCTGAGCTGGGTTTTCCTTGTCCTTGTTTTAAAAGGTGTCCAGTGTGAAGTGCAGCTGGTGGAGTCTGGGGGAGGCTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTGACTATTACATGTATTGGGTTCGCCAGACTCCGGAAAAGAGGCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTACTTACACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACAACCTTTACCTGCAAATGAACAGTCTGAAGTCTGAGGACACAGCCATGTATTACTGTGCAAGAGGATGGGTTTCTACTATGGTTAAACTTCTTTCCTCCTTTCCTTACTGGGGCCAAGGGACTCTGGTCACTGTCTCTGCAGCCAAAACGACACCCCCATCTGTCTATCCACTGGCC(SEQ ID NO:47)
VH3.5 氨基酸序列:
MDFGLSWVFLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAAKTTPPSVYPLA(SEQ ID NO:36)
VH3.7 DNA序列:
TTTTCCTTGTCCTTGTTTTAAAAGGTGTCCAGTGTGAAGTGCAGCTGGTGGAGTCTGGGGGAGGCTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTGACTATTACATGTATTGGGTTCGCCAGACTCCGGAAAAGAGGCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTACTTACACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACAACCTTTACCTGCAAATGAACAGTCTGAAGTCTGAGGACACAGCCATGTATTACTGTGCAAGAGGATGGGTTTCTACTATGGTTAAACTTCTTTCCTCCTTTCCTTACTGGGGCCAAGGGACTCTGGTCACTGTCTCTGCAGCCAAAACGACACCCCCATCTGTCTATCCACTGGCC(SEQID NO:48)
VH3.7 氨基酸序列:
FLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAAKTTPPSVYPLA(SEQ ID NO:33)
VH3.8 DNA序列:
ATGGACTTCGGGCTGAGCTGGGTTTTCCTTGTCCTTGTTTTAAAAGGTGTCCAGTGTGAAGTGCAGCTGGTGGAGTCTGGGGGAGGCTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTGACTATTACATGTATTGGGTTCGCCAGACTCCGGAAAAGAGGCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTACTTACACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACAACCTTTACCTGCAAATGAACAGTCTGAAGTCTGAGGACACAGCCATGTATTACTGTGCAAGAGGATGGGTTTCTACTATGGTTAAACTTCTTTCCTCCTTTCCTTACTGGGGCCAAGGGACTCTGGTCACTGTCTCTGCAGCCAAAACGACACCCCCATCTGTCTATCCACTGGCC(SEQ ID NO:49)
VH3.8 氨基酸序列:
MDFGLSWVFLVLVLKGVQCEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAAKTTPPSVYPLA(SEQ ID NO:36)
VL测序结果:
VL1.1 DNA序列:
ATGGCCTGGATTTCTCTTATATTCTCTCTCCTGGCTCTCAGCTCAGGGGCCATTTCCCAGGCTGTTGTGACTCAGGAATCTGCACTCACCACATCACCTGGTGAAACAGTCACACTCACTTGTCGCTCAAGTACTGGGGCTGTTACAACTAGTAACTATGCCAACTGGGTCCAAGAAAAACCAGATCATTTATTCACTGGTCTAGTAGGTGGTACCAACAACCGAGCTCCAGGTGTTCCTGCCAGATTCTCAGGCTCCCTGATTGGAGACAAGGCTGCCCTCACCATCACAGGGGCACAGACTGAGGATGAGGCAATATATTTCTGTGCTCTATGGTACAGCAATTATTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGCCAGCCCAAGTCTTCGCCATCAGTCACCCTGTTCCCACCCTCCACTGAAGAGCTAAGCTTGGG(SEQ ID NO:50)
VL1.1 氨基酸序列:
MAWISLIFSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLVGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLFPPSTEELSL(SEQ ID NO:37)
VL1.2 DNA序列:
ATGGCCTGGACTTCACTCTTACTCTCTCTCCTGGCTCTCAGCTCAGGGGCCATTTCCCAGGCTGTTGTGACTCAGGAATCTGCACTCACCACATCACCTGGTGAAACAGTCACACTCACTTGTCGCTCAAGTACTGGGGCTGTTACAACTAGTAACTATGCCAACTGGGTCCAAGAAAAACCAGATCATTTATTCACTGGTCTAATAGGTGGTACCAACAACCGAGCTCCAGGTGTTCCTGCCAGATTCTCAGGCTCCCTGATTGGAGACAAGGCTGCCCTCACCATCACAGGGGCACAGACTGAGGATGAGGCAATATATTTCTGTGCTCTATGGTACAGCAATTATTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGCCAGCCCAAGTCTTCGCCATCAGTCACCCTGTGCCCGCCCTCCTCAGAGAAGCTAAGCTTGGG(SEQ ID NO:51)
VL1.2 氨基酸序列:
MAWTSLLLSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLCPPSSEKLSL(SEQ ID NO:39)
VL1.4 DNA序列:
ATGGCCTGGATTCCTCTTTTATTCTCTCTCCTGGCTCTCAGCTCAGGGGCCATTTCCCAGGCTGTTGTGACTCAGGAATCTGCACTCACCACATCACCTGGTGAAACAGTCACACTCACTTGTCGCTCAAGTACTGGGGCTGTTACAACTAGTAACTATGCCAACTGGGTCCAAGAAAAACCAGATCATTTATTCACTGGTCTAATAGGTGGTACCAACAACCGAGCTCCAGGTGTTCCTGCCAGATTCTCAGGCTCCCTGATTGGAGACAAGGCTGCCCTCACCATCATAGGGGCACAGACTGAGGATGAGGCAATATATTTCTGTGCTCTATGGTACAGCAATTATTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGCCAGCCCAAGTCTTCGCCATCAGTCACCCTGTTCCCGCCCTCCTTAGAAAAGCTTAGCTTGGG(SEQ ID NO:52)
VL1.4 氨基酸序列:
MAWIPLLFSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTIIGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLFPPSLEKLSL(SEQ ID NO:41)
VL1.5 DNA序列:
ATGGCCTGGATTTCACTTTTACTCTCTCTCCTGGCTCTCAGCTCAGGGGCCATTTCCCAGGCTGTTGTGACTCAGGAATCTGCACTCACCACATCACCTGGTGAAACAGTCACACTCACTTGTCGCTCAAGTACTGGGGCTGTTACAACTAGTAACTATGCCAACTGGGTCCAAGAAAAACCAGATCATTTATTCACTGGTCTAATAGGTGGTACCAACAACCGAGCTCCAGGTGTTCCTGCCAGATTCTCAGGCTCCCTGATTGGAGACAAGGCTGCCCTCACCATCACAGGGGCACAGACTGAGGATGAGGCAATATATTTCTGTGCTCTATGGTACAGCAATTATTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGCCAGCCCAAGTCTTCGCCATCAGTCACCCTGTTTCCACCCTCCACAGAAGAGCTAAGCTTGGG(SEQ ID NO:53)
VL1.5 氨基酸序列:
MAWISLLLSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLFPPSTEELSL(SEQ ID NO:42)
VL1.6 DNA序列:
ATGGCCTGGATTTCACTTATCTTCTCTCTCCTGGCTCTCAGCTCAGGGGCCATTTCCCAGGCTGTTGTGACTCAGGAATCTGCACTCACCACATCACCTGGTGAAACAGTCACACTCACTTGTCGCTCAAGTACTGGGGCTGTTACAACTAGTAACTATGCCAACTGGGTCCAAGAAAAACCAGATCATTTATTCACTGGTCTAATAGGTGGTACCAGCAACCGAGCTCCAGGTGTTCCTGCCAGATTCTCAGGCTCCCTGATTGGAGACAAGGCTGCCCTCACCATCACAGGGGCACAGACTGAGGATGAGGCAATATATTTCTGTGCTCTATGGTACAGCAATTATTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGCCAGCCCAAGTCTTCGCCATCAGTCACCCTGTACCCGCCCTCTACAAAGGAGCTTAGCTTGGG(SEQ ID NO:54)
VL1.6 氨基酸序列:
MAWISLIFSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTSNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLYPPSTKELSL(SEQ ID NO:38)
VL1.7 DNA序列:
ATGGCCTGGACTTCTCTCTTATTCTCTCTCCTGGCTCTCAGCTCAGGGGCCATTTCCCAGGCTGTTGTGACTCAGGAATCTGCACTCACCACATCACCTGGTGAAACAGTCACACTCACTTGTCGCTCAAGTACTGGGGCTGTTACAACTAGTAACTATGCCAACTGGGTCCAAGAAAAACCAGATCATTTATTCACTGGTCTAATAGGTGGTACCAACAACCGAGCTCCAGGTGCTCCTGCCAGATTCTCAGGCTCCCTGATTGGAGACAAGGCTGCCCTCACCATCACAGGGGCACAGACTGAGGATGAGGCAATATATTTCTGTGCTCTATGGTACAGCAATTATTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGCCAGCCCAAGTCTTCGCCATCAGTCACCCTGTGCCCGCCCTCTACAGAAAAGCTAAGCTTGGG(SEQ ID NO:55)
VL1.7 氨基酸序列:
MAWTSLLFSLLALSSGAISQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGAPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPKSSPSVTLCPPSTEKLSL(SEQ ID NO:40)
对单克隆抗体IL-1R1和NLRP3的可变结构域序列进行测序。
使用具有IgG2a小鼠恒定结构域序列的IL-1R1抗体构建抗体。将短的接头添加到重链的C末端,并且连接具有接头(GGGGS)
将构建体克隆到ATUM载体pD2610-v5中,并通过测序进行验证。图31示出了InflaMab的双特异性设计和质粒图谱。
设计的双特异性抗体序列
轻链DNA序列:
ATGGTCAGCTCTGCTCAATTTCTCGGACTCCTTCTTCTGTGCTTTCAAGGAACACGCTGCGATATTGTGATGACCCAGTCCCCCGCCACCCTGTCCGTGACTCCGGGCGACCGGGTGTCCCTGTCGTGCCGGGCATCACAGAGCATCTCCGACTACCTGTCGTGGTACCAGCAGAGATCACACGAGAGCCCTCGCCTGATCATCAAATACGCCAGCCAGTCAATCTCCGGCATCCCCTCGCGGTTCTCCGGGTCCGGTTCCGGCTCCGACTTCACACTGTCCATTAACTCCGTGGAACCTGAGGACGTGGGAGTGTACTACTGTCAACACGGCCATTCGTTCCCGCTGACTTTCGGGTCGGGAACCAAGCTGGAATTGAAGAGGGCGGACGCGGCCCCTACCGTGTCAATTTTCCCACCGAGCTCCGAACAGCTCACCAGCGGCGGTGCCTCGGTCGTGTGCTTCCTCAACAACTTCTATCCAAAAGACATTAACGTCAAGTGGAAGATCGATGGATCGGAGAGACAGAACGGAGTGCTGAACAGCTGGACTGATCAGGACTCCAAGGATTCGACCTACTCCATGAGCTCCACTCTGACCCTGACCAAGGACGAATACGAGCGGCACAATTCCTACACTTGCGAAGCCACCCACAAGACCTCAACGTCCCCCATCGTGAAGTCCTTCAACCGCAACGAGTGTTGATAA(SEQ ID NO:56)
轻链氨基酸序列:
MVSSAQFLGLLLLCFQGTRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRNEC**(SEQ ID NO:57)
重链DNA序列:
ATGGGCTGGACCCTCGTGTTCCTGTTCCTGCTGAGCGTGACGGCGGGCGTGCACTCCCAAATCCAGCTTGTGCAGTCCGGACCCGAGCTCAGGAAGCCGGGCGAAACTGTGCGCATCAGCTGCAAGGCTTCAGGGTACCCTTTCACCACCGCCGGGCTGCAATGGGTGCAGAAGATGTCCGGGAAGGGTCTGAAGTGGATCGGATGGATGAACACCCAGTCCGAAGTGCCTAAATACGCCGAAGAATTCAAGGGCCGCATTGCGTTCAGCCTGGAGACAGCCGCCTCGACCGCGTACCTTCAGATCAACAATCTCAAGACTGAGGACACTGCCACCTACTTCTGTGCCAAGAGCGTGTACTTCAACTGGAGATACTTCGACGTGTGGGGCGCCGGAACCACCGTGACCGTGTCCAGCGCCAAGACTACCGCCCCGAGCGTGTACCCTCTGGCGCCAGTGTGCGGCGACACGACTGGCAGCTCGGTGACCTTGGGCTGCCTCGTGAAGGGTTACTTCCCCGAGCCCGTGACTCTGACTTGGAACTCGGGCTCACTGTCGTCCGGAGTGCATACCTTCCCGGCTGTGCTGCAAAGCGACCTCTATACCTTGTCATCGTCCGTGACTGTGACCTCCTCCACCTGGCCGTCCCAGAGCATCACCTGTAATGTCGCCCACCCTGCTTCATCGACTAAGGTCGACAAGAAGATCGAGCCCAGAGGACCTACCATCAAGCCCTGCCCGCCCTGCAAATGCCCGGCCCCAAACTTGCTGGGAGGGCCTTCCGTGTTCATCTTCCCTCCGAAAATCAAGGACGTGCTGATGATCTCCCTGAGCCCAATTGTCACTTGCGTGGTGGTGGATGTGTCCGAAGATGACCCAGATGTGCAGATTTCATGGTTCGTGAACAACGTCGAAGTCCATACCGCACAGACCCAGACCCACCGCGAGGATTACAACTCGACGCTGCGCGTCGTCAGCGCCCTGCCGATTCAGCACCAGGATTGGATGAGCGGAAAGGAATTCAAGTGCAAAGTCAACAACAAGGACCTTCCGGCGCCGATCGAACGGACCATCTCGAAGCCTAAGGGATCAGTGCGGGCGCCTCAGGTCTACGTGCTCCCGCCTCCGGAAGAGGAAATGACCAAGAAACAAGTCACCCTGACTTGCATGGTCACCGACTTCATGCCTGAGGACATCTATGTGGAGTGGACTAACAACGGAAAGACTGAACTGAACTACAAAAACACCGAACCAGTGCTGGACTCTGACGGCTCCTACTTCATGTACTCGAAGCTGCGGGTGGAGAAGAAAAACTGGGTGGAACGAAACTCCTACTCGTGTTCCGTGGTGCACGAGGGTCTGCACAACCACCATACCACCAAGTCCTTCTCCCGGACCCCCGGAAAGGGATCCGCCGGGGGATCCGGAGGGGACTCCGAAGTGCAACTGGTGGAGTCGGGTGGCGGACTCGTGAAGCCCGGGGGGTCATTGAAGCTTTCCTGTGCTGCCTCCGGTTTCACTTTCTCCGACTATTACATGTACTGGGTCAGACAGACCCCGGAGAAGCGGCTCGAATGGGTGGCCACCATTTCGGACGGTGGAACCTACACTTACTACCCTGACTCCGTCAAGGGCCGGTTTACTATCTCCCGCGACAACGCGAAGAACAATCTGTACCTCCAAATGAACTCCCTGAAGTCCGAGGACACCGCCATGTACTATTGCGCAAGGGGATGGGTCAGCACTATGGTCAAGCTGCTGTCATCCTTCCCTTACTGGGGACAGGGAACCCTTGTGACTGTGTCAGCCGGTGGCGGGGGGTCGGGCGGCGGCGGTTCCGGTGGAGGGGGATCCCAGGCCGTCGTGACCCAAGAGTCGGCTCTGACTACTTCACCCGGAGAAACCGTGACCCTGACATGCCGCTCCTCCACTGGCGCAGTGACCACGAGCAATTACGCCAACTGGGTGCAGGAAAAGCCCGATCACCTGTTCACTGGACTCATTGGGGGAACCAACAACCGGGCGCCGGGCGTGCCCGCTCGGTTTAGCGGCTCCCTGATTGGAGACAAGGCCGCCCTGACTATCACCGGAGCCCAGACCGAAGATGAAGCCATCTACTTTTGCGCACTCTGGTACTCTAACTACTGGGTGTTTGGCGGCGGAACCAAGCTGACTGTGCTCGGACAGCCGAAGTGATAAAA(SEQ ID NO:58)
重链氨基酸序列:
MGWTLVFLFLLSVTAGVHSQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTAPSVYPLAPVCGDTTGSSVTLGCLVKGYFPEPVTLTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVTSSTWPSQSITCNVAHPASSTKVDKKIEPRGPTIKPCPPCKCPAPNLLGGPSVFIFPPKIKDVLMISLSPIVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTLRVVSALPIQHQDWMSGKEFKCKVNNKDLPAPIERTISKPKGSVRAPQVYVLPPPEEEMTKKQVTLTCMVTDFMPEDIYVEWTNNGKTELNYKNTEPVLDSDGSYFMYSKLRVEKKNWVERNSYSCSVVHEGLHNHHTTKSFSRTPGKGSAGGSGGDSEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPK**(SEQ ID NO:59)
目的是在ExpiCHO细胞中对InflaMab载体DNA进行瞬时转染。培养后,从培养上清液中纯化表达的InflaMab,并对纯化的蛋白质进行QC分析。
InflaMab是由通过二硫键复合在一起的两对轻链和两对重链组成的210千道尔顿(kDa)双特异性小鼠抗体,其中ScFv结构域融合至N端。将编码InflaMab的哺乳动物表达载体转染到ExpiCHO细胞中。随后通过蛋白A亲和色谱法从澄清的培养上清液中纯化表达的抗体。使用NanoDrop Lite,Thermofisher测量纯化抗体的浓度,并使用SDS-PAGE评估纯度。
序列
合成编码InflaMab的氨基酸序列的DNA,并将其克隆到哺乳动物瞬时表达质粒pD2610-v5(Atum)中。
质粒InflaMab:
>InflaMab轻链(理论MW=26.7kDa)
MVSSAQFLGLLLLCFQGTRCDIVMTQSPATLSVTPGDRVSLSCRASQSISDYLSWYQQRSHESPRLIIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYYCQHGHSFPLTFGSGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRNEC(SEQ ID NO:57)
>InflaMab重链(理论MW=79.3kDa)
MGWTLVFLFLLSVTAGVHSQIQLVQSGPELRKPGETVRISCKASGYPFTTAGLQWVQKMSGKGLKWIGWMNTQSEVPKYAEEFKGRIAFSLETAASTAYLQINNLKTEDTATYFCAKSVYFNWRYFDVWGAGTTVTVSSAKTTAPSVYPLAPVCGDTTGSSVTLGCLVKGYFPEPVTLTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVTSSTWPSQSITCNVAHPASSTKVDKKIEPRGPTIKPCPPCKCPAPNLLGGPSVFIFPPKIKDVLMISLSPIVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTLRVVSALPIQHQDWMSGKEFKCKVNNKDLPAPIERTISKPKGSVRAPQVYVLPPPEEEMTKKQVTLTCMVTDFMPEDIYVEWTNNGKTELNYKNTEPVLDSDGSYFMYSKLRVEKKNWVERNSYSCSVVHEGLHNHHTTKSFSRTPGKGSAGGSGGDSEVQLVESGGGLVKPGGSLKLSCAASGFTFSDYYMYWVRQTPEKRLEWVATISDGGTYTYYPDSVKGRFTISRDNAKNNLYLQMNSLKSEDTAMYYCARGWVSTMVKLLSSFPYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNNRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNYWVFGGGTKLTVLGQPK(SEQ ID NO:59)
CHO细胞的瞬时转染
将悬浮液适应的ExpiCHO细胞(Thermo Fisher,UK)每2-3天以1.0–3.0x10
转染前二十四小时,将ExpiCHO细胞以4.0x 10
转染后二十小时,将培养物用0.6%(体积/体积)Expi CHO增强子(ThermoFisher,英国)和24%ExpiCHO进料(Thermo Fisher,英国)补充。密切监测细胞的存活力,并在第8天通过在室温下以4000rpm离心40分钟来收获培养物。
InflaMab的纯化
使用AKTA(GE Healthcare)色谱设备进行纯化。使用前,将所有AKTA设备用1MNaOH彻底消毒。离心后,将过滤的(0.22μm)细胞培养上清液施加到装有1ml HiTrap蛋白A柱(用洗涤缓冲液平衡)的AKTA系统。加载后,用20个柱体积的洗涤缓冲液洗涤柱。用10个柱体积的洗脱缓冲液逐步洗脱结合的抗体。用Tris pH 9.0缓冲液中和所有洗脱的级分。选择对应于洗脱峰的洗脱级分以过夜透析到PBS中。如通过SDS-聚丙烯酰胺中型凝胶判断,抗体的纯度>95%。
SDS-PAGE分析–参见图32
使用标准方法对纯化的抗体进行十二烷基硫酸钠聚丙烯酰胺电泳(SDS PAGE)。
分子量标记以千道尔顿表示。图32中的泳道如下:
如通过SDS-聚丙烯酰胺凝胶的分析判断,InflaMab≥95%纯。在还原条件下,抗体的重链和轻链为可见的,并分别以大约80kDa和27kDa的预期分子量观察到。在非还原条件下,观察到单个主带和几个次带。另外的带(杂质)可能是非糖基化IgG和IgG降解产物(例如,单条[部分]轻链、两条重链和一条轻链的组合、两条重链、两条重链和一条轻链)的结果。
纯化的InflaMab的评估
按照制造商的说明,使用Nanodrop Lite分光光度计和消光系数330,685M
表3:来自250ml转染的抗体InflaMab的浓度和产量。
总结:InflaMab
材料:纯化的抗体
来源:在中国仓鼠(Cricetulus griseus)卵巢细胞系(不添加仓鼠或动物成分)中产生
无害、非传染性。仅供研究使用。
Inflamab预防IL-1β释放–参见图33a和图33b。对于图33a和图33b,将THP1细胞以100,000个细胞/200μl完全培养基在96孔板中培养。使用PMA(100μg/ml,持续72小时)将THP-1细胞分化为巨噬细胞。静置24小时后,将分化的THP1细胞用LPS(1μg/ml)刺激3小时,用MCC950(1μM)或以剂量依赖形式用图33a的0.0025ng/ml至2.5ng/ml IL-1R1/NLRP3 Ab或用图33b的IL-1R1/NLRP3 Ab(1nM)或用IgG对照抗体处理30分钟,之后用ATP(5mM)处理1小时。通过ELISA测量上清液中的IL-1β释放。
Inflamab预防THP1细胞中的半胱天冬酶-1活化–参见图34。对于图34,将THP1细胞以100,000个细胞/200ul完全培养基在96孔板中培养。使用PMA(100ug/ml,持续72小时)将THP-1细胞分化为巨噬细胞。静置24小时后,将分化的THP1细胞用LPS(1ug/ml)刺激3小时,用IL-1R1/NLRP3 Ab(1ug/ml)处理30分钟,之后用ATP(5mM)处理1小时。通过用非细胞毒性荧光标记的半胱天冬酶-1抑制剂(FAM-FLICA)和DAPI(核染色)对细胞进行染色来评估半胱天冬酶-1活化。用单独的LPS(阴性对照)、LPS+ATP(阳性对照)、小鼠IgG2a(1ug/ml,Ab对照)或IL-1r/NLRP3双特异性Ab(1ug/ml,实验)处理细胞。示出了每个组的代表性共聚焦图像。绿色=活性半胱天冬酶-1并且蓝色=Dapi/核染色。
Inflamab的内化–参见图35。对于图35,将THP1细胞以100,000个细胞/200ul完全培养基在96孔板中培养。通过PMA(100ug/ml,持续72小时)诱导THP1细胞的分化。静置24小时后,将分化的THP1细胞用LPS(1ug/ml)刺激3小时,用pHrodo红标记的IL-1r/NLRP3 Ab(1ug/ml)处理30分钟,之后用ATP(5mM)处理1小时。使用仅在内化时发出荧光的pHrodo红标记的双特异性Ab追踪Ab的内化。(A)代表性共聚焦图像显示出pHrodo红标记的双特异性Ab在分化的THP1细胞中的内化。(B)代表性共聚焦图像显示出与未使Ab内化(仅绿色)的THP1细胞相比,已使双特异性Ab内化(红色、白色箭头)的THP1细胞中半胱天冬酶-1活化(绿色)显著降低。
实施例9–用于动脉粥样硬化/冠状动脉疾病的InflaMab
材料和方法
BMDM体外培养
从C57BL/6小鼠的胫骨和股骨分离出骨髓细胞。为了获得骨髓来源的树突状细胞(BMDC),在补充有8%胎牛血清(FCS)、1%青霉素/链霉素(GE Healthcare Life Sciences,Marlborough,MA,USA)、1%glutamax(Thermo Fisher Scientific,Waltham,MA,USA)和20μMβ-巯基乙醇(Sigma-Aldrich,St.Louis,MO,USA)的伊斯科夫改良杜尔贝科培养基(Iscove's modified Dulbecco's medium,IMDM)中在20ng/mL gm-CSF(Preprotech,RockyHill,NJ,USA)存在下将细胞在37℃和5%CO
炎症小体活化测定
对于体外刺激,将每孔0.1x 10
体内LPS攻击
向雌性apoE-/-小鼠饲喂含有0.25%胆固醇和15%可可脂(SDS,Sussex,UK)的西方饮食,在治疗前1周开始并贯穿所述实验。随意提供饮食和水。在饲喂饮食1周后,用PBS或InflaMab(100μg或200μg)腹膜内注射小鼠,在第10天和第14天施用。在饲喂饮食2周和治疗1周后,用LPS(50μg/kg,明尼苏达沙氏杆菌(Salmonella Minnesota)R595,ListBiological Laboratories Inc.)静脉内攻击小鼠并在0.5、1、2和4小时后收集血液。在4小时后处死小鼠并通过ELISA测量IL-1β和TNF-α的血清水平。
动脉粥样硬化
向雌性apoE-/-小鼠饲喂含有0.25%胆固醇和15%可可脂(SDS,Sussex,UK)的西方饮食,在手术前两周开始并贯穿所述实验。在饲喂饮食2周后,通过在这些小鼠中放置血管周套环来诱导颈动脉斑块形成,如先前所述(von der Thüsen等人,Circulation.2001;103(8):1164-1170)。在病变发展的4周期间,每周用PBS(对照)或InflaMab(100μg)向小鼠注射3次。贯穿所述实验,每周称量小鼠并通过尾静脉获得血液样品。使用酶比色程序(Roche/Hitachi,Mannheim,Germany)确定血清中的总胆固醇水平。将Precipath(Roche/Hitachi)用作内部标准。在开始用InflaMab治疗后2周确定小鼠的空腹葡萄糖水平,并且使用Accu-Check血糖仪(Roche Diagnostics,Almere,The Netherlands)测量所述水平。对于脂质特性分析,使用从3只小鼠合并的血清样品(n=3个样品/组),将所述样品稀释6次,并且使用AKTA-FPLC进行血浆脂蛋白分级。在每个级分中,通过用胆固醇CHOD-PAP试剂(Roche,Woerden,The Netherlands)孵育来确定总胆固醇水平。在492nm下测量吸光度。
在治疗4周后,将小鼠麻醉且原位灌注,此后收集颈动脉,将其冷冻在OCT化合物(TissueTek;Sakura Finetek,The Netherlands)并将其保存在-80℃下。在Leica CM3050S Cryostat(Leica Instruments)上在近端方向上制备横向10μm冷冻切片以用于(免疫)组织化学分析。
组织学和形态测量学
常规地用苏木精(Sigma-Aldrich,Zwijndrecht,The Netherlands)和曙红(MerckDiagnostica,Darmstadt,Germany)染色冷冻切片。在苏木精-曙红染色的颈动脉切片上进行形态测量学分析(Leica Qwin图像分析软件)。对于每个颈动脉,从套环近端的病变第一次出现到来自动脉的病变完全消失,每100μm定量病变尺寸。所分析的切片数目的范围为每只小鼠5至15个切片,由其计算平均斑块尺寸和斑块体积。将具有最大斑块尺寸的切片标注为具有最大狭窄的斑块。对于定量颈动脉中的病变含量,使用含有最大病变的四个连续横切片。为了确定脂质含量,用油红O(Sigma-Aldrich)染色切片。使用大鼠单克隆MOMA-2抗体(Serotec,Kidlington,Oxford,UK)评定病变的巨噬细胞含量。使用天狼星红染色(Sigma-Aldrich)使胶原可视化。通过用萘酚AS-D氯乙酸盐酯酶(Sigma-Aldrich)染色冷冻切片来使肥大细胞和嗜中性粒细胞可视化。在含有最大病变的两个连续横切片中手动评定肥大细胞和嗜中性粒细胞的数目。通过Leica Qwin图像分析软件使用Leica DM-RE显微镜(LeicaMicrosystems Inc.,Wetzlar,Germany)定量MOMA-2和胶原阳性区域。由盲检操作者(T.v.d.H.)进行所有形态测量学分析。
流式细胞术
在处死后,分离血液和脾并通过捣碎奇怪使其穿过70μm细胞过滤网来获得单细胞悬浮液。使用ACK裂解缓冲液(0.15M NH4Cl、1mM KHCO3、0.1mM Na2EDTA,pH 7.3)从血液和脾细胞悬浮液去除红血细胞。使用流式细胞术使用相关抗体分析免疫细胞群体(表4)。将细胞与针对所指示标记的抗体和可固定活力染料780一起孵育以进行活/死细胞测定。所有抗体均购自eBioscience和BD Biosciences。在FACSCanto II(Beckton Dickinson,MountainView,CA)上进行流式细胞术分析并且使用FlowJo软件分析所获得的数据。
表4:用于流式细胞术的抗体
结果
在此研究中,已证明InflaMab特异性且剂量依赖性地抑制IL-1β从鼠类骨髓来源的巨噬细胞中分泌。通过在这些相同细胞中未观察到TNFα分泌作用来证实特异性(参见图36)。还已证明InflaMab特异性抑制体内IL-1β分泌,如在apoe-/-小鼠中证明。通过在这些小鼠中未观察到TNFα分泌作用来证实特异性(参见图37)。
已进一步证明InflaMab在动脉粥样硬化/冠状动脉疾病中具有疾病缓解作用。已发现InflaMab在动脉粥样硬化的apoe-/-小鼠模型体内抑制斑块发展的尺寸。在此研究中,从斑块开始直到结束,每80μm制成颈动脉斑块的横切片。以μm
下表5和表6包括示出未对其表现出作用的中脉尺寸(其为中膜平滑肌层的尺寸)的列,正如预期。内腔尺寸为动脉中仍用于血液流动的面积,其在InflammAb(InflaMab)组中与对照IgG相比显著更大。这很容易理解,因为斑块在InflammAb组中更小(参见“斑块”列)。总血管面积为斑块+中脉+内腔,因此为总血管表面,其在InflammAb组与对照IgG之间为不同的。由此可以推断动脉不存在向外重塑,这是一个阳性发现结果。
表5:在用对照IgG或InflammAb(InflaMab)处理的小鼠中的最大狭窄部位的斑块尺寸的比较(μm
表6:在用对照IgG或InflammAb(InflaMab)处理的小鼠中的平均斑块尺寸(μm
对这些小鼠的心脏进行切片以用于主动脉根斑块分析,并进行组织学检查,例如巨噬细胞含量。在处死后,对血液、脾和腹腔细胞的单核细胞子集进行流式细胞术分析。进行其他测量,包括血浆胆固醇水平。测量小鼠体重和一般白细胞水平(血液学分析)并且未发现InflaMab与对照组之间的差异。
总之,这些结果提供证据来支持使用InflaMab预防/治疗动脉粥样硬化/冠状动脉疾病。实际上,这些数据表明InflaMab也可以减小斑块破裂的风险,从而预防急性冠状动脉综合征和/或心肌梗死。
NLRP3炎症小体长期牵涉到动脉粥样硬化并因此牵涉到冠状动脉疾病、斑块破裂和急性冠状动脉综合征/心肌梗死(参见以下支持文献)。炎症小体与特殊形式的细胞死亡、焦亡性细胞坏死(Bergsbaken等人2009)(不依赖半胱天冬酶1)和细胞焦亡(Willingham等人2007)有关,这可能发生在炎症加剧的情况下。因此,抗NLRP3疗法也将减少此类死亡通路,已证明所述死亡通路牵涉到某些疾病诸如动脉粥样硬化的发病机理。细胞焦亡是此疾病中响应于氧化的LDL而导致斑块破裂从而导致心脏事件的危险因素(Lin等人2013)。因此确保靶向NLRP3炎症小体以减小斑块尺寸、可能的斑块破裂和可能的心脏事件。
InflaMab抑制BMDM中的IL-1β分泌–参见图36。双特异性IL-1RI/NLRP3抗体InflaMab剂量依赖性抑制来自骨髓来源的巨噬细胞(BMDM)的IL-1β。将BMDM用LPS(50ng/ml)刺激3小时,用或不用MCC950或Inflamab处理30分钟,随后用明矾(50μg/ml)处理1小时。通过ELISA测量上清液中的IL-1β释放。
通过LPS攻击在体内抑制IL-1β而非TNFα–参见图37。在WTD时1周后,用PBS或InflaMab(100μg或200μg)腹膜内注射雌性apoE-/-小鼠,在第10天和第14天施用。在饮食2周和治疗1周后,用LPS(50μg/kg)静脉内攻击小鼠并通过ELISA测量(a)IL-1β和(b)TNF-α。
动脉粥样硬化研究:InflaMab减小动脉粥样硬化的体内apoe-/-模型中的斑块尺寸–参见图38。在雌性apoE-/-小鼠中饲喂西方饮食2周后,通过在血管周放置套环来诱导颈动脉斑块形成。用PBS或InflaMab(100μg或200μg)腹膜内注射小鼠,每周3次,持续4周。然后收集颈动脉用于冷冻切片。对于每个颈动脉,从套环近端的病变第一次出现到来自动脉的病变完全消失,每80μm定量病变尺寸。
本发明不限于本文所描述的实施方案,而可在不脱离本发明范围的情况下加以修订或修改。
序列表
<110> 阿尔斯特大学(UNIVERSITY OF ULSTER)
<120> 靶向IL-R1和NLPR3的双特异性抗体
<130> P124774PC00
<140>
<141> 2019-09-16
<150> GB1815045.8
<151> 2018-09-14
<160> 69
<170> PatentIn version 3.5
<210> 1
<211> 550
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 1
Met Lys Val Leu Leu Arg Leu Ile Cys Phe Ile Ala Leu Leu Ile Ser
1 5 10 15
Ser Leu Glu Ala Asp Lys Cys Lys Glu Arg Glu Glu Lys Ile Ile Leu
20 25 30
Val Ser Ser Ala Asn Glu Ile Asp Val Arg Pro Cys Pro Leu Asn Pro
35 40 45
Asn Glu His Lys Gly Thr Ile Thr Trp Tyr Lys Asp Asp Ser Lys Thr
50 55 60
Pro Val Ser Thr Glu Gln Ala Ser Arg Ile His Gln His Lys Glu Lys
65 70 75 80
Leu Trp Phe Val Pro Ala Lys Val Glu Asp Ser Gly His Tyr Tyr Cys
85 90 95
Val Val Arg Asn Ser Ser Tyr Cys Leu Arg Ile Lys Ile Ser Ala Lys
100 105 110
Phe Val Glu Asn Glu Pro Asn Leu Cys Tyr Asn Ala Gln Ala Ile Phe
115 120 125
Lys Gln Lys Leu Pro Val Ala Gly Asp Gly Gly Leu Val Cys Pro Tyr
130 135 140
Met Glu Phe Phe Lys Asn Glu Asn Asn Glu Leu Pro Lys Leu Gln Trp
145 150 155 160
Tyr Lys Asp Cys Lys Pro Leu Leu Leu Asp Asn Ile His Phe Ser Gly
165 170 175
Val Lys Asp Arg Leu Ile Val Met Asn Val Ala Glu Lys His Arg Gly
180 185 190
Asn Tyr Thr Cys His Ala Ser Tyr Thr Tyr Leu Gly Lys Gln Tyr Pro
195 200 205
Ile Thr Arg Val Ile Glu Phe Ile Thr Leu Glu Glu Asn Lys Pro Thr
210 215 220
Arg Pro Val Ile Val Ser Pro Ala Asn Glu Thr Met Glu Val Asp Leu
225 230 235 240
Gly Ser Gln Ile Gln Leu Ile Cys Asn Val Thr Gly Gln Leu Ser Asp
245 250 255
Ile Ala Tyr Trp Lys Trp Asn Gly Ser Val Ile Asp Glu Asp Asp Pro
260 265 270
Val Leu Gly Glu Asp Tyr Tyr Ser Val Glu Asn Pro Ala Asn Lys Arg
275 280 285
Arg Ser Thr Leu Ile Thr Val Leu Asn Ile Ser Glu Ile Glu Ser Arg
290 295 300
Phe Tyr Lys His Pro Phe Thr Cys Phe Ala Lys Asn Thr His Gly Ile
305 310 315 320
Asp Ala Ala Tyr Ile Gln Leu Ile Tyr Pro Val Thr Asn Phe Gln Lys
325 330 335
Leu Glu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Asn Ile Lys Asp
340 345 350
Val Leu Met Ile Ser Leu Thr Pro Lys Val Thr Cys Val Val Val Asp
355 360 365
Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn Asn
370 375 380
Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn
385 390 395 400
Ser Thr Ile Arg Val Val Ser His Leu Pro Ile Gln His Gln Asp Trp
405 410 415
Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro
420 425 430
Ser Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Leu Val Arg Ala
435 440 445
Pro Gln Val Tyr Thr Leu Pro Pro Pro Ala Glu Gln Leu Ser Arg Lys
450 455 460
Asp Val Ser Leu Thr Cys Leu Val Val Gly Phe Asn Pro Gly Asp Ile
465 470 475 480
Ser Val Glu Trp Thr Ser Asn Gly His Thr Glu Glu Asn Tyr Lys Asp
485 490 495
Thr Ala Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Ile Tyr Ser Lys
500 505 510
Leu Asn Met Lys Thr Ser Lys Trp Glu Lys Thr Asp Ser Phe Ser Cys
515 520 525
Asn Val Arg His Glu Gly Leu Lys Asn Tyr Tyr Leu Lys Lys Thr Ile
530 535 540
Ser Arg Ser Pro Gly Lys
545 550
<210> 2
<211> 151
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 2
Met Glu Trp Ser Cys Val Met Leu Phe Leu Met Ala Ala Ala Gln Ser
1 5 10 15
Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Pro
130 135 140
Pro Pro Val Tyr Pro Leu Ala
145 150
<210> 3
<211> 153
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 3
Val His Met Glu Cys Ser Cys Val Met Leu Phe Leu Met Ala Ala Ala
1 5 10 15
Gln Ser Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu
20 25 30
Arg Lys Pro Gly Glu Thr Val Arg Ile Ser Arg Lys Ala Ser Gly Tyr
35 40 45
Pro Phe Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys
50 55 60
Gly Leu Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys
65 70 75 80
Tyr Ala Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala
85 90 95
Ala Ser Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr
100 105 110
Ala Thr Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe
115 120 125
Asp Val Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr
130 135 140
Thr Pro Pro Ser Val Phe Pro Leu Ala
145 150
<210> 4
<211> 153
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 4
Val His Met Gly Trp Ser Trp Val Met Leu Phe Leu Met Ala Ala Ala
1 5 10 15
Gln Ser Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu
20 25 30
Arg Lys Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Pro Phe Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys
50 55 60
Gly Leu Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys
65 70 75 80
Tyr Ala Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala
85 90 95
Ala Ser Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr
100 105 110
Ala Thr Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe
115 120 125
Asp Val Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr
130 135 140
Thr Pro Pro Pro Val Tyr Pro Leu Ala
145 150
<210> 5
<211> 151
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 5
Met Gly Trp Val Trp Asn Leu Leu Phe Leu Met Ala Ala Ala Gln Ser
1 5 10 15
Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Pro
130 135 140
Pro Pro Val Tyr Pro Leu Val
145 150
<210> 6
<211> 151
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 6
Met Gly Trp Val Trp Thr Leu Pro Phe Leu Met Ala Ala Ala Gln Ser
1 5 10 15
Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Pro
130 135 140
Pro Pro Val Tyr Pro Leu Val
145 150
<210> 7
<211> 151
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 7
Met Gly Trp Val Trp Asn Leu Pro Phe Leu Met Ala Ala Ala Gln Ser
1 5 10 15
Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Pro
130 135 140
Pro Pro Val Tyr Pro Leu Ala
145 150
<210> 8
<211> 151
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 8
Met Asp Trp Val Trp Thr Leu Pro Phe Leu Met Ala Ala Ala Gln Ser
1 5 10 15
Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Pro
130 135 140
Pro Ser Val Tyr Pro Leu Ala
145 150
<210> 9
<211> 151
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 9
Met Asp Trp Leu Trp Asn Leu Pro Phe Leu Met Ala Ala Ala Gln Ser
1 5 10 15
Ile Gln Ala Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Pro
130 135 140
Pro Pro Val Tyr Pro Leu Ala
145 150
<210> 10
<211> 162
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 10
Met Arg Ala Pro Ala Gln Phe Leu Gly Leu Leu Leu Leu Trp Thr Ser
1 5 10 15
Ala Ser Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Lys
<210> 11
<211> 162
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 11
Met Arg Ala Pro Ala Gln Leu Leu Gly Leu Leu Leu Phe Trp Thr Ser
1 5 10 15
Ala Ser Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Asn Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Lys
<210> 12
<211> 162
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 12
Met Arg Ser Pro Ala Gln Phe Leu Gly Leu Leu Leu Phe Trp Thr Ser
1 5 10 15
Ala Ser Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Lys
<210> 13
<211> 162
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 13
Met Arg Ser Pro Ala Gln Phe Leu Gly Leu Leu Leu Phe Trp Thr Ser
1 5 10 15
Ala Ser Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Arg
<210> 14
<211> 162
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 14
Met Val Ser Ser Ala Gln Phe Leu Gly Leu Leu Leu Phe Trp Thr Ser
1 5 10 15
Ala Ser Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Lys
<210> 15
<211> 162
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 15
Met Val Ser Thr Ala Gln Phe Leu Gly Leu Leu Leu Phe Trp Thr Ser
1 5 10 15
Ala Ser Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Arg
<210> 16
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 16
atggaatgga gctgtgtcat gctctttctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggcct ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccacccgt ttatccactg gcc 453
<210> 17
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 17
atgggatgga gctgggtcat gctctttctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggctt ctgggtatcc cttcacaact gctggactgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccacccgt ttatcccttg gcc 453
<210> 18
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 18
atggaatgca gctgtgtaat gctctttctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
cgcaaggctt ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccatccgt cttccccctg gca 453
<210> 19
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 19
atgggttggg tgtggaactt gctattcctc atggcagcag ctcaaagtat ccaagcacag 60
atccagctgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggctt ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccacccgt ctatccactg gtc 453
<210> 20
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 20
atggattggg tgtggacctt gccattcctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggctt ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccatctgt ctatccactg gcc 453
<210> 21
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 21
atgggttggg tgtggaactt gccattcctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggctt ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtacc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagcac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccacccgt ctatccattg gcc 453
<210> 22
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 22
atggattggc tgtggaactt gccattcctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggctt ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcaacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccacccgt ctatccactg gcc 453
<210> 23
<211> 453
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 23
atgggttggg tgtggacctt gccattcctc atggcagcag ctcaaagtat ccaagcacag 60
atccagttgg tgcagtctgg acctgagctg aggaagcctg gagagacagt caggatctcc 120
tgcaaggctt ctgggtatcc cttcacaact gctggattgc agtgggtaca gaagatgtca 180
ggaaagggtt tgaaatggat tggctggatg aacacccagt ctgaagtgcc aaaatatgca 240
gaagagttca agggacggat tgccttctct ttggaaaccg ctgccagtac tgcatattta 300
cagataaaca acctcaaaac tgaggacacg gcgacgtatt tctgtgcgaa atcggtctat 360
tttaactgga gatatttcga tgtctggggt gcagggacca cggtcaccgt ctcctcagcc 420
aaaacgacac ccccacccgt ctatcccctg gtc 453
<210> 24
<211> 488
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 24
atgagggccc ctgctcagtt tcttgggctt ttgcttctct ggacttcagc ctccagatgt 60
gacattgtga tgactcagtc tccagccacc ctgtctgtga ctccaggaga tagagtctct 120
ctttcctgca gggccagcca gagtattagc gactacttat cctggtatca acaaagatct 180
catgagtctc caaggcttat catcaaatat gcttcccaat ccatctctgg gatcccctcc 240
aggttcagtg gcagtggatc agggtcagac ttcactctca gtatcaacag tgtggaacct 300
gaagatgttg gagtgtatta ctgtcaacat ggtcacagct ttccgctcac gttcggttct 360
gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 420
tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac 480
cccaaaga 488
<210> 25
<211> 486
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 25
atgaggtccc ctgctcagtt ccttgggctt ttgcttttct ggacttcagc ctccagatgt 60
gacattgtga tgactcagtc tccagccacc ctgtctgtga ctccaggaga tagagtctct 120
ctttcctgca gggccagcca gagtattagc gactacttat cctggtatca acaaagatct 180
catgagtctc caaggcttat catcaaatat gcttcccaat ccatctctgg gatcccctcc 240
aggttcagtg gcagtggatc agggtcagac ttcactctca gtatcaacag tgtggaacct 300
gaagatgttg gagtgtatta ctgtcaacat ggtcacagct ttccgctcac gttcggttct 360
gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 420
tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac 480
cccaaa 486
<210> 26
<211> 488
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 26
atgaggtccc cagctcagtt tctggggctt ttgcttttct ggacttcagc ctccagatgt 60
gacattgtga tgactcagtc tccagccacc ctgtctgtga ctccaggaga tagagtctct 120
ctttcctgca gggccagcca gagtattagc gactacttat cctggtatca acaaagatct 180
catgagtctc caaggcttat catcaaatat gcttcccaat ccatctctgg gatcccctcc 240
aggttcagtg gcagtggatc agggtcagac ttcactctca gtatcaacag tgtggaacct 300
gaagatgttg gagtgtatta ctgtcaacat ggtcacagct ttccgctcac gttcggttct 360
gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 420
tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac 480
cccagaga 488
<210> 27
<211> 488
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 27
atgagggccc ctgctcagct cctggggctt ttgcttttct ggacttcagc ctccagatgt 60
gacattgtga tgactcagtc tccagccacc ctgtctgtga ctccaggaga tagagtctct 120
ctttcctgca gggccagcca gagtattagc gactacttat cctggtatca acaaagatct 180
catgagtctc caaggcttat catcaaatat gcttcccaat ccatctctgg gatcccctcc 240
aggttcagtg gcagtggatc agggtcagac ttcactctca atatcaacag tgtggaacct 300
gaagatgttg gagtgtatta ctgtcaacat ggtcacagct ttccgctcac gttcggttct 360
gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 420
tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctat 480
cccaaaga 488
<210> 28
<211> 486
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的]
<400> 28
atggtatcct cagctcagtt ccttggactt ttgcttttct ggacttcagc ctccagatgt 60
gacattgtga tgactcagtc tccagccacc ctgtctgtga ctccaggaga tagagtctct 120
ctttcctgca gggccagcca gagtattagc gactacttat cctggtatca acaaagatct 180
catgagtctc caaggcttat catcaaatat gcttcccaat ccatctctgg gatcccctcc 240
aggttcagtg gcagtggatc agggtcagac ttcactctca gtatcaacag tgtggaacct 300
gaagatgttg gagtgtatta ctgtcaacat ggtcacagct ttccgctcac gttcggttct 360
gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 420
tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac 480
cccaaa 486
<210> 29
<211> 488
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 29
atggtgtcca cagctcagtt ccttggactt ttgcttttct ggacttcagc ctccagatgt 60
gacattgtga tgactcagtc tccagccacc ctgtctgtga ctccaggaga tagagtctct 120
ctttcctgca gggccagcca gagtattagc gactacttat cctggtatca acaaagatct 180
catgagtctc caaggcttat catcaaatat gcttcccaat ccatctctgg gatcccctcc 240
aggttcagtg gcagtggatc agggtcagac ttcactctca gtatcaacag tgtggaacct 300
gaagatgttg gagtgtatta ctgtcaacat ggtcacagct ttccgctcac gttcggttct 360
gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 420
tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac 480
cccagaga 488
<210> 30
<211> 24
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 30
Glu Asp Tyr Pro Pro Gln Lys Gly Cys Ile Pro Leu Pro Arg Gly Gln
1 5 10 15
Thr Glu Lys Ala Asp His Val Asp
20
<210> 31
<211> 19
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 31
Gln Lys Gly Cys Ile Pro Leu Pro Arg Gly Gln Thr Glu Lys Ala Asp
1 5 10 15
His Val Asp
<210> 32
<211> 15
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 32
Gln Lys Gly Cys Ile Pro Leu Pro Arg Gly Gln Thr Glu Lys Ala
1 5 10 15
<210> 33
<211> 106
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 33
Met Asn Phe Gly Leu Ser Leu Val Phe Leu Val Leu Val Leu Lys Gly
1 5 10 15
Ala Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys
20 25 30
Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Asp Tyr Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu
50 55 60
Glu Trp Val Ala Thr Ile Ser Asp Gly Gly Thr Tyr Thr Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Asn Leu Tyr Leu Gln Met Asn Ser Leu Lys
100 105
<210> 34
<211> 147
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 34
Phe Leu Val Leu Val Leu Lys Gly Val Gln Cys Glu Val Gln Leu Val
1 5 10 15
Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly Ser Leu Lys Leu Ser
20 25 30
Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr Tyr Met Tyr Trp Val
35 40 45
Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val Ala Thr Ile Ser Asp
50 55 60
Gly Gly Thr Tyr Thr Tyr Tyr Pro Asp Ser Val Lys Gly Arg Phe Thr
65 70 75 80
Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr Leu Gln Met Asn Ser
85 90 95
Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys Ala Arg Gly Trp Val
100 105 110
Ser Thr Met Val Lys Leu Leu Ser Ser Phe Pro Tyr Trp Gly Gln Gly
115 120 125
Thr Leu Val Thr Val Ser Ala Ala Lys Thr Thr Pro Pro Ser Val Tyr
130 135 140
Pro Leu Ala
145
<210> 35
<211> 155
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 35
Met Asp Phe Gly Leu Ser Arg Val Phe Leu Val Leu Val Leu Lys Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys
20 25 30
Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Asp Tyr Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu
50 55 60
Glu Trp Val Ala Thr Ile Ser Asp Gly Gly Thr Tyr Thr Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Asn Leu Tyr Leu Gln Met Asn Ser Leu Lys Ser Glu Asp Thr Ala Met
100 105 110
Tyr Tyr Cys Ala Arg Gly Trp Val Ser Thr Met Val Lys Leu Leu Ser
115 120 125
Ser Phe Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ala Ala
130 135 140
Lys Thr Thr Pro Pro Ser Val Tyr Pro Leu Ala
145 150 155
<210> 36
<211> 155
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 36
Met Asp Phe Gly Leu Ser Trp Val Phe Leu Val Leu Val Leu Lys Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys
20 25 30
Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Asp Tyr Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu
50 55 60
Glu Trp Val Ala Thr Ile Ser Asp Gly Gly Thr Tyr Thr Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Asn Leu Tyr Leu Gln Met Asn Ser Leu Lys Ser Glu Asp Thr Ala Met
100 105 110
Tyr Tyr Cys Ala Arg Gly Trp Val Ser Thr Met Val Lys Leu Leu Ser
115 120 125
Ser Phe Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ala Ala
130 135 140
Lys Thr Thr Pro Pro Ser Val Tyr Pro Leu Ala
145 150 155
<210> 37
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 37
Met Ala Trp Ile Ser Leu Ile Phe Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Val Gly Gly Thr Asn Asn Arg Ala Pro Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Thr Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Phe Pro Pro Ser Thr
130 135 140
Glu Glu Leu Ser Leu
145
<210> 38
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 38
Met Ala Trp Ile Ser Leu Ile Phe Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Ile Gly Gly Thr Ser Asn Arg Ala Pro Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Thr Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Tyr Pro Pro Ser Thr
130 135 140
Lys Glu Leu Ser Leu
145
<210> 39
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 39
Met Ala Trp Thr Ser Leu Leu Leu Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Ile Gly Gly Thr Asn Asn Arg Ala Pro Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Thr Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Cys Pro Pro Ser Ser
130 135 140
Glu Lys Leu Ser Leu
145
<210> 40
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 40
Met Ala Trp Thr Ser Leu Leu Phe Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Ile Gly Gly Thr Asn Asn Arg Ala Pro Gly Ala Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Thr Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Cys Pro Pro Ser Thr
130 135 140
Glu Lys Leu Ser Leu
145
<210> 41
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 41
Met Ala Trp Ile Pro Leu Leu Phe Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Ile Gly Gly Thr Asn Asn Arg Ala Pro Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Ile Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Phe Pro Pro Ser Leu
130 135 140
Glu Lys Leu Ser Leu
145
<210> 42
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 42
Met Ala Trp Ile Ser Leu Leu Leu Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Ile Gly Gly Thr Asn Asn Arg Ala Pro Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Thr Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Phe Pro Pro Ser Thr
130 135 140
Glu Glu Leu Ser Leu
145
<210> 43
<211> 149
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 43
Met Ala Trp Ile Ser Leu Leu Phe Ser Leu Leu Ala Leu Ser Ser Gly
1 5 10 15
Ala Ile Ser Gln Ala Val Val Thr Gln Glu Ser Ala Leu Thr Thr Ser
20 25 30
Pro Gly Glu Thr Val Thr Leu Thr Cys Arg Ser Ser Thr Gly Ala Val
35 40 45
Thr Thr Ser Asn Tyr Ala Asn Trp Val Gln Glu Lys Pro Asp His Leu
50 55 60
Phe Thr Gly Leu Ile Gly Gly Thr Asn Asn Arg Ala Pro Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Leu Ile Gly Asp Lys Ala Ala Leu Thr Ile
85 90 95
Thr Gly Ala Gln Thr Glu Asp Glu Ala Ile Tyr Phe Cys Ala Leu Trp
100 105 110
Tyr Ser Asn Tyr Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
115 120 125
Gly Gln Pro Lys Ser Ser Pro Ser Val Thr Leu Phe Pro Pro Ser Thr
130 135 140
Glu Lys Leu Ser Leu
145
<210> 44
<211> 318
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 44
atgaacttcg ggttgagctt ggttttcctt gtccttgttt taaaaggtgc ccagtgtgaa 60
gtgcagctgg tggagtctgg gggaggctta gtgaagcctg gagggtccct gaaactctcc 120
tgtgcagcct ctggattcac tttcagtgac tattacatgt attgggttcg ccagactccg 180
gaaaagaggc tggagtgggt cgcaaccatt agtgatggtg gtacttacac ctactatcca 240
gacagtgtga aggggcgatt caccatctcc agagacaatg ccaagaacaa cctttacctg 300
caaatgaaca gtctgaag 318
<210> 45
<211> 465
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 45
atggacttcg ggttgagctg ggttttcctt gtccttgttt taaaaggtgt ccagtgtgaa 60
gtgcagctgg tggagtctgg gggaggctta gtgaagcctg gagggtccct gaaactctcc 120
tgtgcagcct ctggattcac tttcagtgac tattacatgt attgggttcg ccagactccg 180
gaaaagaggc tggagtgggt cgcaaccatt agtgatggtg gtacttacac ctactatcca 240
gacagtgtga aggggcgatt caccatctcc agagacaatg ccaagaacaa cctttacctg 300
caaatgaaca gtctgaagtc tgaggacaca gccatgtatt actgtgcaag aggatgggtt 360
tctactatgg ttaaacttct ttcctccttt ccttactggg gccaagggac tctggtcact 420
gtctctgcag ccaaaacgac acccccatct gtctatccac tggcc 465
<210> 46
<211> 465
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 46
atggacttcg ggctgagcag ggttttcctt gtccttgttt taaaaggtgt ccagtgtgaa 60
gtgcagctgg tggagtctgg gggaggctta gtgaagcctg gagggtccct gaaactctcc 120
tgtgcagcct ctggattcac tttcagtgac tattacatgt attgggttcg ccagactccg 180
gaaaagaggc tggagtgggt cgcaaccatt agtgatggtg gtacttacac ctactatcca 240
gacagtgtga aggggcgatt caccatctcc agagacaatg ccaagaacaa cctttacctg 300
caaatgaaca gtctgaagtc tgaggacaca gccatgtatt actgtgcaag aggatgggtt 360
tctactatgg ttaaacttct ttcctccttt ccttactggg gccaagggac tctggtcact 420
gtctctgcag ccaaaacgac acccccatct gtctatccac tggcc 465
<210> 47
<211> 465
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 47
atggacttcg ggctgagctg ggttttcctt gtccttgttt taaaaggtgt ccagtgtgaa 60
gtgcagctgg tggagtctgg gggaggctta gtgaagcctg gagggtccct gaaactctcc 120
tgtgcagcct ctggattcac tttcagtgac tattacatgt attgggttcg ccagactccg 180
gaaaagaggc tggagtgggt cgcaaccatt agtgatggtg gtacttacac ctactatcca 240
gacagtgtga aggggcgatt caccatctcc agagacaatg ccaagaacaa cctttacctg 300
caaatgaaca gtctgaagtc tgaggacaca gccatgtatt actgtgcaag aggatgggtt 360
tctactatgg ttaaacttct ttcctccttt ccttactggg gccaagggac tctggtcact 420
gtctctgcag ccaaaacgac acccccatct gtctatccac tggcc 465
<210> 48
<211> 443
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 48
ttttccttgt ccttgtttta aaaggtgtcc agtgtgaagt gcagctggtg gagtctgggg 60
gaggcttagt gaagcctgga gggtccctga aactctcctg tgcagcctct ggattcactt 120
tcagtgacta ttacatgtat tgggttcgcc agactccgga aaagaggctg gagtgggtcg 180
caaccattag tgatggtggt acttacacct actatccaga cagtgtgaag gggcgattca 240
ccatctccag agacaatgcc aagaacaacc tttacctgca aatgaacagt ctgaagtctg 300
aggacacagc catgtattac tgtgcaagag gatgggtttc tactatggtt aaacttcttt 360
cctcctttcc ttactggggc caagggactc tggtcactgt ctctgcagcc aaaacgacac 420
ccccatctgt ctatccactg gcc 443
<210> 49
<211> 465
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 49
atggacttcg ggctgagctg ggttttcctt gtccttgttt taaaaggtgt ccagtgtgaa 60
gtgcagctgg tggagtctgg gggaggctta gtgaagcctg gagggtccct gaaactctcc 120
tgtgcagcct ctggattcac tttcagtgac tattacatgt attgggttcg ccagactccg 180
gaaaagaggc tggagtgggt cgcaaccatt agtgatggtg gtacttacac ctactatcca 240
gacagtgtga aggggcgatt caccatctcc agagacaatg ccaagaacaa cctttacctg 300
caaatgaaca gtctgaagtc tgaggacaca gccatgtatt actgtgcaag aggatgggtt 360
tctactatgg ttaaacttct ttcctccttt ccttactggg gccaagggac tctggtcact 420
gtctctgcag ccaaaacgac acccccatct gtctatccac tggcc 465
<210> 50
<211> 449
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 50
atggcctgga tttctcttat attctctctc ctggctctca gctcaggggc catttcccag 60
gctgttgtga ctcaggaatc tgcactcacc acatcacctg gtgaaacagt cacactcact 120
tgtcgctcaa gtactggggc tgttacaact agtaactatg ccaactgggt ccaagaaaaa 180
ccagatcatt tattcactgg tctagtaggt ggtaccaaca accgagctcc aggtgttcct 240
gccagattct caggctccct gattggagac aaggctgccc tcaccatcac aggggcacag 300
actgaggatg aggcaatata tttctgtgct ctatggtaca gcaattattg ggtgttcggt 360
ggaggaacca aactgactgt cctaggccag cccaagtctt cgccatcagt caccctgttc 420
ccaccctcca ctgaagagct aagcttggg 449
<210> 51
<211> 449
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 51
atggcctgga cttcactctt actctctctc ctggctctca gctcaggggc catttcccag 60
gctgttgtga ctcaggaatc tgcactcacc acatcacctg gtgaaacagt cacactcact 120
tgtcgctcaa gtactggggc tgttacaact agtaactatg ccaactgggt ccaagaaaaa 180
ccagatcatt tattcactgg tctaataggt ggtaccaaca accgagctcc aggtgttcct 240
gccagattct caggctccct gattggagac aaggctgccc tcaccatcac aggggcacag 300
actgaggatg aggcaatata tttctgtgct ctatggtaca gcaattattg ggtgttcggt 360
ggaggaacca aactgactgt cctaggccag cccaagtctt cgccatcagt caccctgtgc 420
ccgccctcct cagagaagct aagcttggg 449
<210> 52
<211> 449
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 52
atggcctgga ttcctctttt attctctctc ctggctctca gctcaggggc catttcccag 60
gctgttgtga ctcaggaatc tgcactcacc acatcacctg gtgaaacagt cacactcact 120
tgtcgctcaa gtactggggc tgttacaact agtaactatg ccaactgggt ccaagaaaaa 180
ccagatcatt tattcactgg tctaataggt ggtaccaaca accgagctcc aggtgttcct 240
gccagattct caggctccct gattggagac aaggctgccc tcaccatcat aggggcacag 300
actgaggatg aggcaatata tttctgtgct ctatggtaca gcaattattg ggtgttcggt 360
ggaggaacca aactgactgt cctaggccag cccaagtctt cgccatcagt caccctgttc 420
ccgccctcct tagaaaagct tagcttggg 449
<210> 53
<211> 449
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 53
atggcctgga tttcactttt actctctctc ctggctctca gctcaggggc catttcccag 60
gctgttgtga ctcaggaatc tgcactcacc acatcacctg gtgaaacagt cacactcact 120
tgtcgctcaa gtactggggc tgttacaact agtaactatg ccaactgggt ccaagaaaaa 180
ccagatcatt tattcactgg tctaataggt ggtaccaaca accgagctcc aggtgttcct 240
gccagattct caggctccct gattggagac aaggctgccc tcaccatcac aggggcacag 300
actgaggatg aggcaatata tttctgtgct ctatggtaca gcaattattg ggtgttcggt 360
ggaggaacca aactgactgt cctaggccag cccaagtctt cgccatcagt caccctgttt 420
ccaccctcca cagaagagct aagcttggg 449
<210> 54
<211> 449
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 54
atggcctgga tttcacttat cttctctctc ctggctctca gctcaggggc catttcccag 60
gctgttgtga ctcaggaatc tgcactcacc acatcacctg gtgaaacagt cacactcact 120
tgtcgctcaa gtactggggc tgttacaact agtaactatg ccaactgggt ccaagaaaaa 180
ccagatcatt tattcactgg tctaataggt ggtaccagca accgagctcc aggtgttcct 240
gccagattct caggctccct gattggagac aaggctgccc tcaccatcac aggggcacag 300
actgaggatg aggcaatata tttctgtgct ctatggtaca gcaattattg ggtgttcggt 360
ggaggaacca aactgactgt cctaggccag cccaagtctt cgccatcagt caccctgtac 420
ccgccctcta caaaggagct tagcttggg 449
<210> 55
<211> 449
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 55
atggcctgga cttctctctt attctctctc ctggctctca gctcaggggc catttcccag 60
gctgttgtga ctcaggaatc tgcactcacc acatcacctg gtgaaacagt cacactcact 120
tgtcgctcaa gtactggggc tgttacaact agtaactatg ccaactgggt ccaagaaaaa 180
ccagatcatt tattcactgg tctaataggt ggtaccaaca accgagctcc aggtgctcct 240
gccagattct caggctccct gattggagac aaggctgccc tcaccatcac aggggcacag 300
actgaggatg aggcaatata tttctgtgct ctatggtaca gcaattattg ggtgttcggt 360
ggaggaacca aactgactgt cctaggccag cccaagtctt cgccatcagt caccctgtgc 420
ccgccctcta cagaaaagct aagcttggg 449
<210> 56
<211> 708
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 56
atggtcagct ctgctcaatt tctcggactc cttcttctgt gctttcaagg aacacgctgc 60
gatattgtga tgacccagtc ccccgccacc ctgtccgtga ctccgggcga ccgggtgtcc 120
ctgtcgtgcc gggcatcaca gagcatctcc gactacctgt cgtggtacca gcagagatca 180
cacgagagcc ctcgcctgat catcaaatac gccagccagt caatctccgg catcccctcg 240
cggttctccg ggtccggttc cggctccgac ttcacactgt ccattaactc cgtggaacct 300
gaggacgtgg gagtgtacta ctgtcaacac ggccattcgt tcccgctgac tttcgggtcg 360
ggaaccaagc tggaattgaa gagggcggac gcggccccta ccgtgtcaat tttcccaccg 420
agctccgaac agctcaccag cggcggtgcc tcggtcgtgt gcttcctcaa caacttctat 480
ccaaaagaca ttaacgtcaa gtggaagatc gatggatcgg agagacagaa cggagtgctg 540
aacagctgga ctgatcagga ctccaaggat tcgacctact ccatgagctc cactctgacc 600
ctgaccaagg acgaatacga gcggcacaat tcctacactt gcgaagccac ccacaagacc 660
tcaacgtccc ccatcgtgaa gtccttcaac cgcaacgagt gttgataa 708
<210> 57
<211> 234
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 57
Met Val Ser Ser Ala Gln Phe Leu Gly Leu Leu Leu Leu Cys Phe Gln
1 5 10 15
Gly Thr Arg Cys Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Val Thr Pro Gly Asp Arg Val Ser Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Ile Ser Asp Tyr Leu Ser Trp Tyr Gln Gln Arg Ser His Glu Ser Pro
50 55 60
Arg Leu Ile Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser
65 70 75 80
Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn
85 90 95
Ser Val Glu Pro Glu Asp Val Gly Val Tyr Tyr Cys Gln His Gly His
100 105 110
Ser Phe Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys Arg
115 120 125
Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln
130 135 140
Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr
145 150 155 160
Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg Gln
165 170 175
Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser Thr
180 185 190
Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu Arg
195 200 205
His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser Pro
210 215 220
Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
225 230
<210> 58
<211> 2201
<212> DNA
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 58
atgggctgga ccctcgtgtt cctgttcctg ctgagcgtga cggcgggcgt gcactcccaa 60
atccagcttg tgcagtccgg acccgagctc aggaagccgg gcgaaactgt gcgcatcagc 120
tgcaaggctt cagggtaccc tttcaccacc gccgggctgc aatgggtgca gaagatgtcc 180
gggaagggtc tgaagtggat cggatggatg aacacccagt ccgaagtgcc taaatacgcc 240
gaagaattca agggccgcat tgcgttcagc ctggagacag ccgcctcgac cgcgtacctt 300
cagatcaaca atctcaagac tgaggacact gccacctact tctgtgccaa gagcgtgtac 360
ttcaactgga gatacttcga cgtgtggggc gccggaacca ccgtgaccgt gtccagcgcc 420
aagactaccg ccccgagcgt gtaccctctg gcgccagtgt gcggcgacac gactggcagc 480
tcggtgacct tgggctgcct cgtgaagggt tacttccccg agcccgtgac tctgacttgg 540
aactcgggct cactgtcgtc cggagtgcat accttcccgg ctgtgctgca aagcgacctc 600
tataccttgt catcgtccgt gactgtgacc tcctccacct ggccgtccca gagcatcacc 660
tgtaatgtcg cccaccctgc ttcatcgact aaggtcgaca agaagatcga gcccagagga 720
cctaccatca agccctgccc gccctgcaaa tgcccggccc caaacttgct gggagggcct 780
tccgtgttca tcttccctcc gaaaatcaag gacgtgctga tgatctccct gagcccaatt 840
gtcacttgcg tggtggtgga tgtgtccgaa gatgacccag atgtgcagat ttcatggttc 900
gtgaacaacg tcgaagtcca taccgcacag acccagaccc accgcgagga ttacaactcg 960
acgctgcgcg tcgtcagcgc cctgccgatt cagcaccagg attggatgag cggaaaggaa 1020
ttcaagtgca aagtcaacaa caaggacctt ccggcgccga tcgaacggac catctcgaag 1080
cctaagggat cagtgcgggc gcctcaggtc tacgtgctcc cgcctccgga agaggaaatg 1140
accaagaaac aagtcaccct gacttgcatg gtcaccgact tcatgcctga ggacatctat 1200
gtggagtgga ctaacaacgg aaagactgaa ctgaactaca aaaacaccga accagtgctg 1260
gactctgacg gctcctactt catgtactcg aagctgcggg tggagaagaa aaactgggtg 1320
gaacgaaact cctactcgtg ttccgtggtg cacgagggtc tgcacaacca ccataccacc 1380
aagtccttct cccggacccc cggaaaggga tccgccgggg gatccggagg ggactccgaa 1440
gtgcaactgg tggagtcggg tggcggactc gtgaagcccg gggggtcatt gaagctttcc 1500
tgtgctgcct ccggtttcac tttctccgac tattacatgt actgggtcag acagaccccg 1560
gagaagcggc tcgaatgggt ggccaccatt tcggacggtg gaacctacac ttactaccct 1620
gactccgtca agggccggtt tactatctcc cgcgacaacg cgaagaacaa tctgtacctc 1680
caaatgaact ccctgaagtc cgaggacacc gccatgtact attgcgcaag gggatgggtc 1740
agcactatgg tcaagctgct gtcatccttc ccttactggg gacagggaac ccttgtgact 1800
gtgtcagccg gtggcggggg gtcgggcggc ggcggttccg gtggaggggg atcccaggcc 1860
gtcgtgaccc aagagtcggc tctgactact tcacccggag aaaccgtgac cctgacatgc 1920
cgctcctcca ctggcgcagt gaccacgagc aattacgcca actgggtgca ggaaaagccc 1980
gatcacctgt tcactggact cattggggga accaacaacc gggcgccggg cgtgcccgct 2040
cggtttagcg gctccctgat tggagacaag gccgccctga ctatcaccgg agcccagacc 2100
gaagatgaag ccatctactt ttgcgcactc tggtactcta actactgggt gtttggcggc 2160
ggaaccaagc tgactgtgct cggacagccg aagtgataaa a 2201
<210> 59
<211> 731
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 59
Met Gly Trp Thr Leu Val Phe Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Arg Lys
20 25 30
Pro Gly Glu Thr Val Arg Ile Ser Cys Lys Ala Ser Gly Tyr Pro Phe
35 40 45
Thr Thr Ala Gly Leu Gln Trp Val Gln Lys Met Ser Gly Lys Gly Leu
50 55 60
Lys Trp Ile Gly Trp Met Asn Thr Gln Ser Glu Val Pro Lys Tyr Ala
65 70 75 80
Glu Glu Phe Lys Gly Arg Ile Ala Phe Ser Leu Glu Thr Ala Ala Ser
85 90 95
Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Thr Glu Asp Thr Ala Thr
100 105 110
Tyr Phe Cys Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
115 120 125
Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Ala Lys Thr Thr Ala
130 135 140
Pro Ser Val Tyr Pro Leu Ala Pro Val Cys Gly Asp Thr Thr Gly Ser
145 150 155 160
Ser Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu Pro Val
165 170 175
Thr Leu Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser Val Thr
195 200 205
Val Thr Ser Ser Thr Trp Pro Ser Gln Ser Ile Thr Cys Asn Val Ala
210 215 220
His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Glu Pro Arg Gly
225 230 235 240
Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro Asn Leu
245 250 255
Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys Asp Val
260 265 270
Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val Asp Val
275 280 285
Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn Asn Val
290 295 300
Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser
305 310 315 320
Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met
325 330 335
Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ala
340 345 350
Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg Ala Pro
355 360 365
Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys Lys Gln
370 375 380
Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp Ile Tyr
385 390 395 400
Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys Asn Thr
405 410 415
Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser Lys Leu
420 425 430
Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser Cys Ser
435 440 445
Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser Phe Ser
450 455 460
Arg Thr Pro Gly Lys Gly Ser Ala Gly Gly Ser Gly Gly Asp Ser Glu
465 470 475 480
Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly Ser
485 490 495
Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr Tyr
500 505 510
Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val Ala
515 520 525
Thr Ile Ser Asp Gly Gly Thr Tyr Thr Tyr Tyr Pro Asp Ser Val Lys
530 535 540
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr Leu
545 550 555 560
Gln Met Asn Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys Ala
565 570 575
Arg Gly Trp Val Ser Thr Met Val Lys Leu Leu Ser Ser Phe Pro Tyr
580 585 590
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ala Gly Gly Gly Gly Ser
595 600 605
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ala Val Val Thr Gln
610 615 620
Glu Ser Ala Leu Thr Thr Ser Pro Gly Glu Thr Val Thr Leu Thr Cys
625 630 635 640
Arg Ser Ser Thr Gly Ala Val Thr Thr Ser Asn Tyr Ala Asn Trp Val
645 650 655
Gln Glu Lys Pro Asp His Leu Phe Thr Gly Leu Ile Gly Gly Thr Asn
660 665 670
Asn Arg Ala Pro Gly Val Pro Ala Arg Phe Ser Gly Ser Leu Ile Gly
675 680 685
Asp Lys Ala Ala Leu Thr Ile Thr Gly Ala Gln Thr Glu Asp Glu Ala
690 695 700
Ile Tyr Phe Cys Ala Leu Trp Tyr Ser Asn Tyr Trp Val Phe Gly Gly
705 710 715 720
Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys
725 730
<210> 60
<211> 8
<212> PRT
<213> 未知的(Unknown)
<220>
<223> 合成的
<400> 60
Gly Tyr Pro Phe Thr Thr Ala Gly
1 5
<210> 61
<211> 8
<212> PRT
<213> 合成的(Synthetic)
<400> 61
Met Asn Thr Gln Ser Glu Val Pro
1 5
<210> 62
<211> 13
<212> PRT
<213> 合成的(Synthetic)
<400> 62
Ala Lys Ser Val Tyr Phe Asn Trp Arg Tyr Phe Asp Val
1 5 10
<210> 63
<211> 6
<212> PRT
<213> 合成的(Synthetic)
<400> 63
Gln Ser Ile Ser Asp Tyr
1 5
<210> 64
<211> 9
<212> PRT
<213> 合成的(Synthetic)
<400> 64
Gln His Gly His Ser Phe Pro Leu Thr
1 5
<210> 65
<211> 8
<212> PRT
<213> 合成的(Synthetic)
<400> 65
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 66
<211> 8
<212> PRT
<213> 合成的(Synthetic)
<400> 66
Ile Ser Asp Gly Gly Thr Tyr Thr
1 5
<210> 67
<211> 17
<212> PRT
<213> 合成的(Synthetic)
<400> 67
Ala Arg Gly Trp Val Ser Thr Met Val Lys Leu Leu Ser Ser Phe Pro
1 5 10 15
Tyr
<210> 68
<211> 9
<212> PRT
<213> 合成的(Synthetic)
<400> 68
Thr Gly Ala Val Thr Thr Ser Asn Tyr
1 5
<210> 69
<211> 9
<212> PRT
<213> 合成的(Synthetic)
<400> 69
Ala Leu Trp Tyr Ser Asn Tyr Trp Val
1 5
- 靶向IL-1R1和NLPR3的双特异性抗体
- 靶向IL-1R1和NLPR3的双特异性抗体