一种不同数据源的心电数据融合方法及装置
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及心电数据分类标注处理技术领域,尤其涉及一种不同数据源的心电数据融合方法、装置及计算机存储介质。
背景技术
在实际心电数据采集过程中,我们采集的心电数据可能有多个来源,例如来自医院A、医院B或医院C。同一家医院的心电数据也有来自不同科室,比如住院部、心电图室、胸痛中心、体检中心、急诊中心等,也有可能来自基层医院,或120急救过程中。这些不同来源的心电数据中,既有静态12导联的,也有动态12导联的。这些数据往往在采样频率、信号质量、诊断结论书写方式和习惯上都存在一定的差别。以室性逸搏心律为例,有些年长的心电图医师会仍然沿用之前的习惯,将其标注为“室性逸搏心律”,而年轻的医师则可能将其标注为“室性自主心律”。目前,我们在处理因医生的个人分析水平不同和医院的知识传承所导致的“相似”心电图初始标签不一致的问题时,主要有两种处理方法:
1、首先去除心电数据中的初始标签,然后随机的分配给两名经验丰富的心电图医师,让他们独立地进行标注。如果两者标注结果不一致,则交给标注分歧仲裁人员进行后续处理;
2、先搭建一个心电图分类算法,可以是传统算法,也可以是神经网络算法,然后对心电数据进行预测。最后,比较模型输出的预测标签与初始标签,如果相同,则保留初始标签;否则,将相应心电数据交给医师进行二次标定。
第一种方法,在数据量较大时,标注所需的人力和财力成本很大。第二种方法,用于训练模型的数据是多源的,且是以初始标签为导向进行模型优化,而初始标签往往存在较大噪声,即可能因不同医院诊断标注的不统一、医师个人水平或某些心电图本身难判读等原因引起的标注错误,因此最终训练出的模型泛化能力有限,从而导致经模型筛选的需要医生进行二次标定的心电数据量较大。
发明内容
有鉴于此,有必要提供一种不同数据源的心电数据融合方法、装置及计算机存储介质,用以解决涉及多个数据源心电数据时,因噪声标签导致训练出的模型泛化能力差,从而使得需要二次标定的数据量大的问题。
本发明提供了一种不同数据源的心电数据融合方法,包括以下步骤:
从不同数据源中采集已经标注好初始标签的心电数据,建立心电数据集;
对所述心电数据集中心电数据进行预处理;
通过无监督的深度聚类对预处理后的心电数据集进行聚类,得到多个聚类簇;
分别统计每一聚类簇的心电数据初始标签中各类标签的概率;
基于概率统计结果对各聚类簇中心电数据进行融合,得到融合后的心电数据集。
进一步的,从不同数据源中采集已经标注好初始标签的心电数据,建立心电数据集,具体为:
从不同数据源中采集不同类别的心电数据,不同数据源中挑选出的同一类别的心电数据的数量在同一设定范围内,得到所述心电数据集。
进一步的,对所述心电数据集中心电数据进行预处理,具体为:
将所述心电数据转换为空间向量数据,用于提取心电数据的空间特征;
提取所述心电数据中第二导联数据,用于提取心电数据的时域特征;
获取所述心电数据的频谱图,用于提取心电数据的频域特征。
进一步的,通过无监督的深度聚类对预处理后的心电数据集进行聚类,得到多个聚类簇,具体为:
选取不同的神经网络结构,分别用于提取心电数据的空间特征、时域特征以及频域特征;
基于不同的神经网络结构搭建心电图网络;
采用所述心电数据集中心电数据对所述心电图网络进行训练,得到分类模型;
基于所述心电图网络提取的心电数据特征对心电数据集进行聚类;
基于聚类结果为心电数据标注伪标签;
将伪标签与分类模型输出的预测标签进行对比,计算损失值;
基于所述损失值对所述分类模型进行反向传播训练;
判断是否达到终止条件,如果是,则停止训练,输出聚类结果得到多个聚类簇,否则采用所述心电数据集中下一个心电数据对所述心电图网络进行训练。
进一步的,选取不同的神经网络结构,分别用于提取心电数据的空间特征、时域特征以及频域特征,具体为:
选用CNN网络,用于提取心电数据的空间特征;
选用LSTM网络,用于提取心电数据的时域特征;
选用CNN网络,用于提取心电数据的频域特征。
进一步的,基于不同的神经网络结构搭建心电图网络,具体为:
依次设置第一CNN网络、LSTM网络、第二CNN网络、全连接层,得到所述心电图网络。
进一步的,统计每一聚类簇的心电数据初始标签中各类标签的概率,具体为:
判断心电数据的初始标签是否为单标签,如果是,则保持单标签不变,否则将初始标签拆分为多个单标签;
统计所述单标签中各类标签出现的次数;
根据统计次数计算各类标签出现的概率。
进一步的,基于概率统计结果对各聚类簇中心电数据进行融合,得到融合后的心电数据集,具体为:
将标签出现的概率大于上限值的心电数据划分为高质量标签数据;
将标签出现的概率小于下限值的心电数据划分为噪声标签数据,并对噪声标签数据进行重新标定;
将标签出现的概率在上限值与下限值之间的心电数据划分为临床标签数据;
结合高质量标签数据、重新标定后的噪声标签数据以及临床标签数据,得到融合后的心电数据集。
本发明还提供一种不同数据源的心电数据融合装置,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现所述不同数据源的心电数据融合方法。
本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现所述不同数据源的心电数据融合方法。
有益效果:本发明提出了一个基于深度聚类和统计方法的两阶段多源数据融合方法。第一阶段,对不同来源的心电数据进行预处理后,通过无监督的深度聚类训练模型,得到聚类结果;第二阶段,根据初始标签统计出聚类得到的每一聚类簇的可能标签,最后根据统计结果筛选出标签错误可能性较大的数据,给医生二次标定。本发明在训练模型时,因为没有使用含噪声标签的初始标签作为训练依据,仅利用心电数据本身的特征,避免了噪声标签对训练模型的负面影响。
附图说明
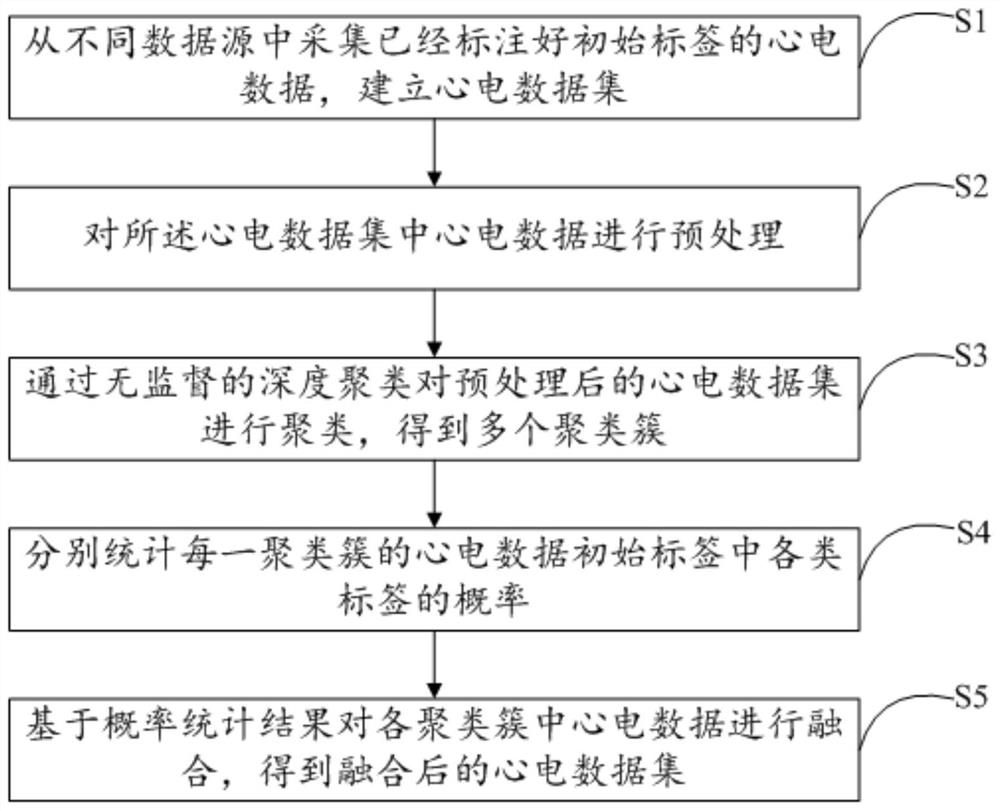
图1为本发明提供的不同数据源的心电数据融合方法第一实施例的方法流程图;
图2为本发明中同一条心电数据不同导联的叠加图;
图3为本发明中心电数据转换得到的空间向量数据的Z轴数据示意图;
图4a为本发明中神经网络卷积的8邻域示意图;
图4b为本发明中十字卷积的示意图;
图5为本发明中心电图网络的结构示意图;
图6为本发明中心电图网络的训练过程示意图。
具体实施方式
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
实施例1
如图1所示,本发明的实施例1提供了不同数据源的心电数据融合方法,包括以下步骤:
S1、从不同数据源中采集已经标注好初始标签的心电数据,建立心电数据集;
S2、对所述心电数据集中心电数据进行预处理;
S3、通过无监督的深度聚类对预处理后的心电数据集进行聚类,得到多个聚类簇;
S4、分别统计每一聚类簇的心电数据初始标签中各类标签的概率;
S5、基于概率统计结果对各聚类簇中心电数据进行融合,得到融合后的心电数据集。
本实施例提出了一个基于深度聚类和统计方法的两阶段多源数据融合方法。第一阶段在对不同来源的心电数据进行预处理后,先通过无监督的深度聚类训练模型,得到聚类结果,然后根据初始标签统计出聚类得到的每一聚类簇的可能标签,最后根据统计结果筛选出标签错误可能性较大的数据,给医生二次标定。本实施例在训练模型时,因为没有使用含噪声标签的初始标签作为训练依据,仅利用心电数据本身的特征,避免了噪声标签对训练模型的负面影响;而在第二阶段利用统计的方式确定每一类具体的标注,这在一定程度上消除了标签中的随机噪声。
优选的,从不同数据源中采集已经标注好初始标签的心电数据,建立心电数据集,具体为:
从不同数据源中采集不同类别的心电数据,不同数据源中挑选出的同一类别的心电数据的数量在同一设定范围内,得到所述心电数据集。
本实施例中有M个不同数据源的心电数据,这里我们先确定要进行处理的心电图类别,比如窦性心律、窦性心动过缓/过速/不齐、房性早搏/心动过速、房扑、房颤、交界性逸搏、室性逸搏、加速性逸搏心率、室性早搏/心动过速、室上性心动过速、左束支阻滞、室内阻滞、右束支阻滞等。然后分别从每个不同的数据源中挑选出大致相同数量的各类心电数据,组成用于分析的初始心电数据集,并记录相应的初始标签。建立心电数据集后,对该心电数据集进行数据预处理操作。
优选的,对所述心电数据集中心电数据进行预处理,具体为:
将所述心电数据转换为空间向量数据,用于提取心电数据的空间特征;
提取所述心电数据中第二导联数据,用于提取心电数据的时域特征;
获取所述心电数据的频谱图,用于提取心电数据的频域特征。
为了便于后续模型训练过程中对心电数据特征的提取,先对心电数据进行预处理。具体如图6所示,本实施例在数据预处理阶段,将原始的包含多个导联(I导联、II导联、···、V6导联)的心电数据转换为了三类数据:1、更能体现空间特征的空间向量数据,空间向量数据建立在正交坐标系下,包含X、Y、Z三轴数据;2、保留了大部分时域信息的II导联数据,II导联即第二导联;3、涵盖了丰富频域信息的II导联、V5导联数据的频谱图。
将所述心电数据转换为空间向量数据,具体为:
X=-0.172*V1-0.074*V2+0.122*V3+0.231*V4+0.239*V5+0.194*V6+0.156*I-0.010*II;
Y=0.057*V1-0.019*V2-0.106*V3-0.022*V4+0.041*V5+0.048*V6-0.227*I+0.887*II;
Z=-0.229*V1-0.310*V2-0.246*V3-0.063*V4+0.055*V5+0.108*V6+0.022*I+0.102*II;
其中,X、Y、Z为空间向量数据的三个维度,V1、V2、V3、V4、V5、V6、I、II分别代表心电数据的V1导联、V2导联、V3导联、V4导联、V5导联、V6导联、I导联、II导联的电压值。
图2为同一条心电数据,不同导联(I、II、V1、V2、V3、V4、V5、V6)的叠加图。从图2中可以直观的看到:对于同一条心电数据的不同导联,某些导联是具有较高相关性的;对于同一导联,不同的时间数据表现出了时间序列相关性。有大量研究仅使用MIT-BIH数据集中的II导联数据,就能较好的完成心电图节律的诊断,故这里我们选用II导联来提取节律特征,即时域特征。
由于行业内作频谱心电图分析时,一般只选用II导联和V5导联,故这里我们也沿用该习惯,用这两个导联的数据来提取频域特征。获取所述心电数据的频谱图,具体为:
将所述心电数据等距离分隔为多个片段,一般取1-5秒为一个片段;
对各片段进行快速傅里叶变换,得到各片段的频谱图;
对同一导联的各片段的频谱图进行归一化处理:
其中,G
快速傅里叶变换选用的窗函数为Hamming窗:
其中,w(n)为窗函数值,n为片段中数据值,N为导联的片段总数量;
将同一导联各个片断的频谱图进行拼接,得到各导联的频谱图;
将各导联的频谱图设置为相同维度。
由于心电数据的能量主要集中在0-25Hz范围的低频部分,所以,我们只选用了前25%的频谱系数以降低输入数据的维度。将各导联的片段频谱图直接拼接,就得到了整条导联的频谱图。本实施例中,为了计算的方便,每个导联的频谱图设置为相同维度:125*200。
数据预处理完后,我们开始搭建心电图模型进行聚类训练。
优选的,通过无监督的深度聚类对预处理后的心电数据集进行聚类,得到多个聚类簇,具体为:
选取不同的神经网络结构,分别用于提取心电数据的空间特征、时域特征以及频域特征;
基于不同的神经网络结构搭建心电图网络;
采用所述心电数据集中心电数据对所述心电图网络进行训练,得到分类模型;
基于所述心电图网络提取的心电数据特征对心电数据集进行聚类;
基于聚类结果为心电数据标注伪标签;
将伪标签与分类模型输出的预测标签进行对比,计算损失值;
基于所述损失值对所述分类模型进行反向传播训练;
判断是否达到终止条件,如果是,则停止训练,输出聚类结果得到多个聚类簇,否则采用所述心电数据集中下一个心电数据对所述心电图网络进行训练。
不同类型的分类器对同一数据有着不同的特征表达能力,因此本实施例分别从时域、频域、空间信息三个角度搭建了三个神经网络,三个神经网络分别对心电数据不同的特征进行提取。同时,将深度聚类引入到了心电数据分类任务中,有效避免了多源数据中高噪声标签所带来的负面影响。具体的,如图6所示,心电数据经预处理后,首先输入由三个不同的神经网络搭建的心电图网络,本实施例中心电图网络为由第一CNN网络、LSTM网络以及第二CNN网络搭建的ResNet心电图网络,第一CNN网络具体选用FCN网络;对经过三个神经网络训练后得到的特征进行合并;然后通过两个全连接层(即图6中FC层)进行特征融合,并将融合后的特征送给聚类网络进行聚类,这里的聚类方式可以是k均值聚类,k等于心电数据类别数,也可以是层次聚类或密度聚类等;将聚类得到结果作为心电数据的伪标签,与分类模型给出的预测标签进行计算,得到损失值(即图6中Loss值);然后按照梯度下降进行反向传播,对分类模型进行修正;当分类模型训练到损失值小于设定值或达到指定的训练次数后,提取出聚类结果,用作下一步分析。
优选的,选取不同的神经网络结构,分别用于提取心电数据的空间特征、时域特征以及频域特征,具体为:
选用CNN网络,用于提取心电数据的空间特征;
选用LSTM网络,用于提取心电数据的时域特征;
选用CNN网络,用于提取心电数据的频域特征。
CNN网络适合提取空间特征,LSTM网络能有效提取时域特征。故我们使用了三个不同的网络来分别提取心电数据的空间特征、时域特征、频域特征。
1、对于空间向量数据,主要使用CNN系网络进行空间特征提取,比如DCN,FCN,ResNet,AlexNet,VGG等,记作第一CNN网络,本实施例中第一CNN网络选用FCN网络。
2、对于II导联数据,主要使用LSTM网络来提取时域特征,记作LSTM网络。
3、对于频谱特征的提取,我们也使用CNN网络,记作第二CNN网络。
优选的,基于不同的神经网络结构搭建心电图网络,具体为:
依次设置第一CNN网络、LSTM网络、第二CNN网络、全连接层,得到所述心电图网络。
心电数据转换后的空间向量数据依然可以看成是序列时间数据,具体如图3所示,图3为一心电数据转换成空间向量数据后的Z轴图例。因此针对第一CNN网络,本实施例采用了更适合此类数据的十字卷积方式。神经网络中的卷积,指的是一个8邻域的结构。如图4a所示。而十字卷积方式,即在进行卷积计算时始终保持四个对角的值为0即可,如图4b所示。将网络A中用于计算卷积的8邻域结构换成了十字架形状的4邻域结构,有效减少了信息的干扰。
对于第二CNN网络,因为用于训练网络的频谱数据,本身已经作了类似于图片的处理,故这里的卷积依然使用传统的神经网络卷积,即8邻域的结构。
基于三种不同的神经网络,本实施例搭建了一个34层的ResNet心电图网络,该网络的结构图如图5所示。从图5中可知,心电数据首先进入输入层;然后进入第一CNN网络,第一CNN网络包含三层卷积层、批归一化层、ReLU层;然后进入LSTM网络,LSTM网络包括三层卷积层、批归一化层、ReLU层、Dropout层、三层卷积层以及最大池化层;然后进入第二CNN网络,第二CNN网络包括批归一化层、ReLU层、三层卷积层、批归一化层、ReLU层、Dropout层、三层批归一化层以及最大池化层;最后进入全连接层,全连接层包括批归一化层、ReLU层、Dense层,经输出层输出。
优选的,统计每一聚类簇的心电数据初始标签中各类标签的概率,具体为:
判断心电数据的初始标签是否为单标签,如果是,则保持单标签不变,否则将初始标签拆分为多个单标签;
统计所述单标签中各类标签出现的次数;
根据统计次数计算各类标签出现的概率。
分别对聚类后得到的每一聚类簇进行分析,方法如下:
1、统计聚类簇内心电数据的初始标签的唯一的单标签,如果有多标签,需要将多标签拆开成单一的单标签,单标签指单一种类的标签。并统计该各类单标签出现的次数,本实施例的统计结果如下表所示:
表1、单标签出现次数统计结果
2、按照单标签出现的次数,从大到小排序。并计算对应的出现概率:
其中,p
本实施例统计的各类单标签的出现概率如下表所示:
表2、单标签出现概率统计结果
优选的,基于概率统计结果对各聚类簇中心电数据进行融合,得到融合后的心电数据集,具体为:
将标签出现的概率大于上限值的心电数据划分为高质量标签数据;
将标签出现的概率小于下限值的心电数据划分为噪声标签数据,并对噪声标签数据进行重新标定;
将标签出现的概率在上限值与下限值之间的心电数据划分为临床标签数据;
结合高质量标签数据、重新标定后的噪声标签数据以及临床标签数据,得到融合后的心电数据集。
具体的,融合步骤如下:
1、挑选出初始标签中仅包含概率排名为后30%单标签的心电数据,因为这些心电数据的单标签在该类中出现的概率本身就比较低,如果一条心电数据中包含的都是这些概率低的单标签,我们可以认为该条心电数据可能就是标签噪声数据。将这些心电数据交给医生作二次标定,然后存入数据库,备注为专家标签数据。
2、挑选出初始标签中仅包含排名前40%的单标签的心电数据。可以认为这些心电数据的初始标签有很大可能性是正确的。将这些心电数据存储到数据库中,备注为高质量临床标签数据。
3、其余的心电数据,存入数据库中,备注为临床标签数据。
通过本方法,筛选出的需要进行二次标定(标签有很大可能性是错误)的心电数据在9%左右,二次标定数据的概率较小。
实施例2
本发明的实施例2提供了不同数据源的心电数据融合装置,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现实施例1提供的不同数据源的心电数据融合方法。
本发明实施例提供的不同数据源的心电数据融合装置,用于实现不同数据源的心电数据融合方法,因此,不同数据源的心电数据融合方法所具备的技术效果,不同数据源的心电数据融合装置同样具备,在此不再赘述。
实施例3
本发明的实施例3提供了计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现实施例1提供的不同数据源的心电数据融合方法。
本发明实施例提供的计算机存储介质,用于实现不同数据源的心电数据融合方法,因此,不同数据源的心电数据融合方法所具备的技术效果,计算机存储介质同样具备,在此不再赘述。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 一种不同数据源的心电数据融合方法及装置
- 一种基于不同数据源的用户分析方法和装置及计算设备