一种从社交媒体中自动发掘不良药物反应的方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及药物信息发掘应用技术领域,具体为一种从社交媒体中自动 发掘不良药物反应的方法。
背景技术
明确不良药物反应(ADR,Adverse Drug Reaction)是药物研发的一个 重点,但上市前的临床实验往往会受到受试者人数,研究时间和制药公司以 及患者经济压力等的限制,近年来的一些研究也试图用药物的化学结构、靶 点蛋白或者药物研发周期中的治疗指征等,对药物的不良反应进行预测,然 而,某些药物的新不良反应只有在上市后,在不同的人种中或伴有不同疾病 的人群中被广泛使用后,才会被认知,又或者某些不良反应要经过一段较长 时间的积累才会显现,而这个时间跨度甚至可能超出该药物的研发周期,为 避免事故的发生,药品监管部门和制药公司都不惜付出巨大努力和代价去进 行上市后的四期临床实验以计算机为基础在现有的数据资源中发掘不良药物 反应的研究,也成为对昂贵的四期临床实验的一种有效的补充。
近年来,越来越多的研究旨在从各种数据资源中发掘药物的不良反应, 随着数据资源的不同(可以是结构化也可以是非结构化的文本),使用的挖掘 方法也不同,结构化资源主要指卫生部门(比如FDA)收集的正式的不良事件 报告,这些报告由于严格遵守不良事件报告标准,因此相对易于处理,但是, 提交报告的程序相对复杂,而且大部分患者不了解自发报告系统,因此此类 报告的数量非常有限,而非结构化的数据资源包括生物医学文献,临床记录 或病历以及线上的健康讨论等,但对这些数据资源的处理存在较大的挑战,因为有用的信息被嵌在了自然语言里,被赋予了固有的模棱两可性和嘈杂性, 其中,生物医学文献还是相对较好挖掘的,因为药物和不良反应都会以各自 正规的名字被提及,但这些信息不会实时更新甚至有时还会产生偏差,用各 种文本挖掘的方法也能从临床记录和病历提取相应的不良药物反应信息,但 考虑到病人隐私以及访问限制等问题,这样的数据来源也是十分有限的,所 以,相对而言,线上的社交媒体,特别是一些健康论坛,能为药物的使用情 况提供最为全面和及时的信息,但同时想从这些信息中发掘不良药物反应, 会遇到很多挑战,主要包括大量口语的使用,拼写和语法错误等。
现有的从社交媒体中进行文本挖掘的方法可以归纳为如下几种:基于词 汇的方法、统计学方法、基于规则的方法、高级自然语言处理(NLP)方法以 及神经网络,之前大多数方法都侧重于扩充词汇库以求在文本中找到对应不 良反应相关描述,这些基于词汇库的方法,可能由于对不良反应描述的新的 网络用语不断出现,而无法识别词汇库中未包含的非常规不良反应,此外, 它们还会因为词语拼写错误而导致近似字符串匹配不佳,于是一些研究人员 开始另辟蹊径,他们利用统计学方法或者基于规则(或模式)的方法又或者借助支持向量机(SVM)和条件随机场(CRF)等高级自然语言处理方法,寻 求从社交媒体中发掘ADR的更佳方案,这些方法虽然都可以到达合理的准确 性,但它们的构建都需要监督训练,在机器学习过程中还要用到大量数据, 这些都是需要耗费大量人力操作的,此外,研究者们还尝试过用各种结构的 神经网络来检测社交媒体中的ADR,比如,卷积神经网络,递归神经网络以及 它们的组合等,甚至注意力机制和条件随机场有时也会被加入到神经网络结 构中以提高其系统性能,另外,即使之前已经有很多研究关于如何从英文的 网上论坛中发掘未知的不良反应,但对中文论坛发掘的研究却鲜有,故而提 出一种从中文社交媒体中自动发掘不良药物反应的方法,并且来解决上述其 他方案中遇到的问题。
发明内容
(一)解决的技术问题
针对现有技术的不足,本发明提供了一种从社交媒体中自动发掘不良药 物反应的方法,具备精准高效的发掘药物已知和未知不良反应及其在特定人 群中发生频率等优点,解决了现有方法对发掘未知不良药物反应信息的不稳 定,且难以以中文文本为基础进行信息发掘的问题。
(二)技术方案
为实现上述精准、高效、稳健地发掘不良药物反应的目的,本发明提供 如下技术方案:一种从社交媒体中自动发掘不良药物反应的方法,包括以下 步骤:
1)、构建药物和不良反应词汇库,其中包括药物和不良药物反应的正规 或者专业名称,以及用它们的同音词汇或者口语化词汇进行扩充的词汇组;
2)、在中文社交媒体中,选取包含感兴趣药物的帖子,对它们进行分词 处理,再根据步骤1)中构件的词汇库,提取药物与候选不良反应组合,以及 该组合所在的文本证据;
3)、用半监督的支持向量机(SVM)模型作为分类器对步骤2)中药物与 不良反应的组合以及它们所在的文本证据进行分类,判断是否为有效组合, 以及判断有效组合所在的文本证据是正例还是反例;
4)、将步骤3)分出的正例中的候选不良药物反应进行排序和整理,用这 些候选不良反应在正例和反例中出现频率的差作为排序的依据,最后统计出 该感兴趣药物在帖子涉及的人群中,产生的各种已知或未知不良反应的频率。
(三)有益效果
与现有技术相比,本发明提供了一种从社交媒体中自动发掘不良药物反 应的方法,具备以下有益效果:
1、该从社交媒体中自动发掘不良药物反应的方法,在保证精确度的同时 更稳健,通过手动标记的文本证据作为测试集去比较不同方案的分类检测效 果,并使用召回率(Recall)、精确度(Precision)和F1分数(F1-score) 这三个常用指标作为评价的依据(其中召回率体现了分类模型对正向数据的 识别能力,精确度体现了模型对负向数据的识别能力,而F1分数是两者的综 合),该半监督标记的支持向量机(SVM)模型具有最高的F1分数(见具体实 施方式中的表4),即较其他方案而言,在保证精确度的同时更稳健。
2、该从社交媒体中自动发掘不良药物反应的方法,既可用来验证说明书 上标记的已知不良药物反应并计算它们在特定人群中的相对发生频率,还可 以用来挖掘未知的不良反应,能够使该方法使用时适用性好,例如,通过该 方法在中文社交媒体中检测到四种常见药物的前十种不良反应(见具体实施 方式中的表5),其中既有已知不良反应的报告频率信息也有未知不良反应的 报告,此外,该方案侧重于从中文线上社交媒体中提取和分析不良要药物反 应,其填补了从中文社交媒体中挖掘此类信息的空白,从而有效的补充了不 良药物反应信息发掘在广度和深度上的完善,且解决了难以以中文为基础进 行信息发掘的问题。
附图说明
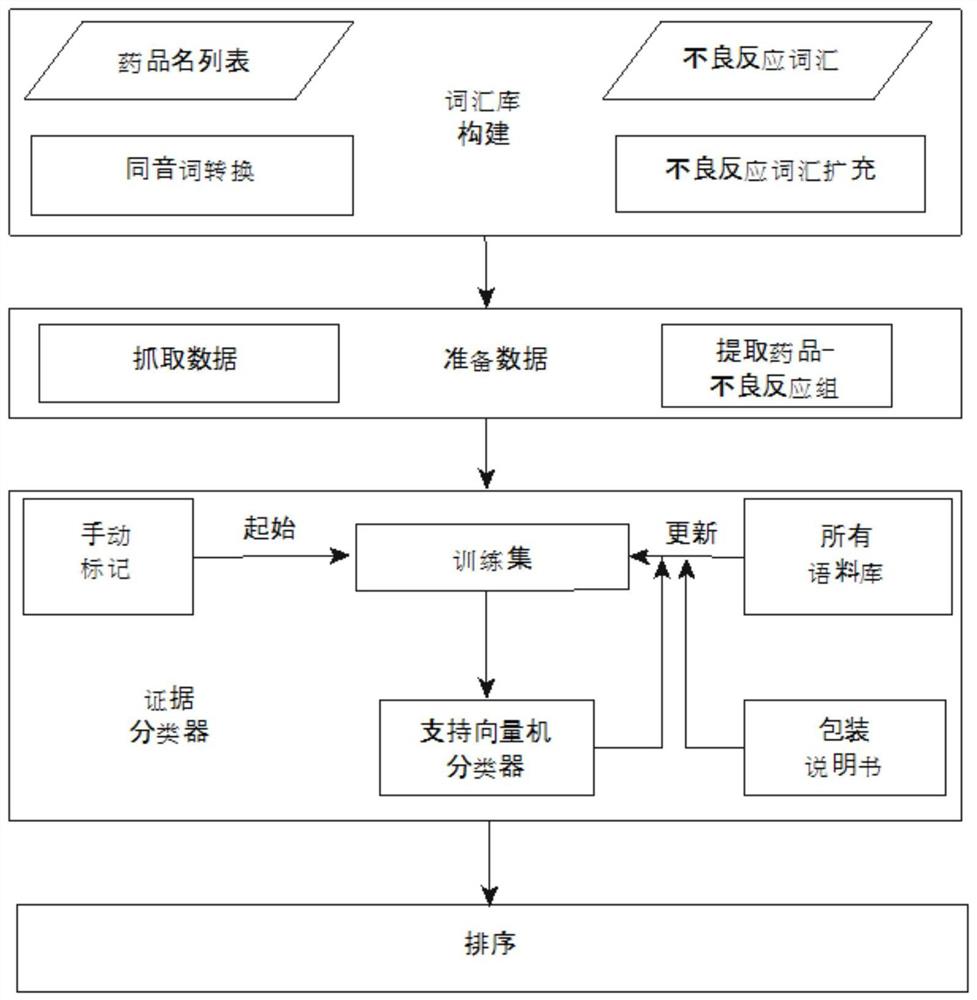
图1为本发明提出的一种从社交媒体中自动发掘不良药物反应的方法系 统框架图;
图2为本发明中扩充不良反应词汇库算法的展示图;
图3为本发明中自动标记分类过程的算法示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行 清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而 不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做 出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-3,一种从社交媒体中自动发掘不良药物反应的方法,包括以 下步骤:
1)、构建药物和基础不良药物反应词汇库,其中药物词汇库包括药物的 常规名或者注册商标名以及它们的同音或同形等口语化词汇等,而构建的基 础不良反应词汇库主要基于四个来源:
(1)、美国国家癌症研究所制定的不良事件通用术语标准(CTCAE),其 包含了用于报告不良反应事件给药品监管组织的标准不良反应词汇;
(2)、拼音输入法包含的不良反应词汇,使用其为来源主要是因为其中 包含了很多口语化的词汇;
(3)、国际医药技术需求协调委员会对人用药品制定的医学监管活动词 典(MedDRA);
(4)、2014年由叶浩等人发表在《PLoS ONE》杂志9(2)上的论文中收 录的不良反应数据库,其中收录了大约6000个不良反应的词汇;
然后要将所有收录的词汇进行分类,因为不同来源的词汇可能表达同一个或 类似的意思,需要将它们合并在同一个词汇组里,比如,“体重减少”和“体 重下降”表达的是同一个意思,理应将它们归在同一个不良反应组里,这个 组的结果就会累加(即该不良反应被提及的频率增加,也符合实际情况),然 后输出一个总的结果,最后,还要跟据MedDRA的类别,将不良反应词汇分成 具有四个级别水平的结构化词汇,最下面的一级就是从其他三个来源中收录 的不良反应词汇,上面的三个级别都是MedDRA中定义的类别,如表1所示,最左边的一列就是第四个级别的词汇(最下面一级),右边三列都是来自 MedDRA词典的上层分级词汇,为了更好的匹配线上论坛中口语化的相关词汇, 在构建基础词汇库的基础上,还要通过增加词汇变体对其进行扩充,比如, 当某个患者出现头痛的反应,他或她会说“头痛”或者“头有点痛”,后者较 前者的微小差异就在于增加了一个程度副词,这样的差异词汇也会被添加到 我们的词汇库中,其实,像这样的程度修饰副词有很多种,为了尽量减少不 良反应词汇的遗漏,我们采用了一个数据驱动的方法,通过器官名称和一个 症状中间最多可以相隔五个中文字符这样的匹配模式去挖掘此类具有程度修 饰的不良反应词汇,比如,“头XXXXX痛”这种匹配模式,图2简单展示了 扩充不良反应词汇库的算法。
表1不良药物反应词汇的分级展示
2)、构建好两个词汇库后,接下来是从网上社交媒体中提取有效候选信 息,比如从“寻医问药”和“好大夫在线”网提取,“寻医问药”成立于2004 年,到2014年止,它已经拥有超过1亿的注册用户和超过2千万的日独立访 客,是医疗和健康产业中居首位的网站,该论坛有14个类别,平均每天有64, 000多个讨论话题,每个话题都是从某个患者的提问开始,跟随其后的是多个 医生或者其他患者的回应;“好大夫在线”成立于2006年,是中国领先的互 联网医疗平台之一,拥有超过23万名实名注册的医生,提供线上医疗服务, 截止2016年,它有29个类别和超过18,000,000个讨论话题,其讨论的形 式与“寻医问药”网类似,在开始挖掘这两大网站论坛中不良药物反应之前, 先要对所有用户的帖子进行预处理,如果一个帖子中包含感兴趣的某个药品 名,那么它将被视为有效帖子,此时可使用了一种被称为ICTCLAS(2003年 发表于期刊杂志“Association for ComputationalLinguistics"第17期) 的中文分词工具,对有效帖子中的所有句子进行分词处理,然后对照构建的 不良反应词汇库,从有效帖子中找到候选词汇,然而,有时候会遇到这些情 况:当某个用户在帖子中提到某种药品名X的时候,该用户可能并没有开始 使用这种药物;同样,当一种不良反应被提到的时候,其用户可能还没有出 现这种症状又或者该症状并不是服用药物X导致的结果,所以,当找到一对 药品名和不良反应的组合时,还要根据该组合在帖子中的上下文来判断此不 良反应是不是真的由该组中对应的药物导致,如果药品名和不良反应在帖子 中的距离太远,显然是不太可靠的,所以上下文就被定义为一个或多个连续 的句子,药品名和不良反应组合之间的距离应该小于55个中文字符(包括标 点符号但不包括空格),当满足这个条件时,才确定该组合是一个有效的药品 名和不良反应组合,根据这样的处理方式,一共抓取了从2011年1月到2015 年4月发表于“寻医问药”和“好大夫在线”网站的456,753个帖子,涉及 11种类型或疾病的79种药物(如表2所示),得到了包含药品名和不良反应 有效组合的一共302,180个句子。
表2 79种药物对应11种类型或疾病的具体分类
3)、将步骤2)中提取的包含药品名和不良反应有效组合的文本证据(它 们的合集被称为语料库)进行分类,我们首先定义,包含某个有效组合的文 本为正例:当该文本中候选不良反应确是该对应药物的已知不良反应时;否 则,该文本被列为反例,比如下面这两个句子:
正例:服用
反例:吃的是
接下来就需要一种高效的分类器去自动区分语料库中的正例和反例,可以用 带监督的分类器来实现,首先需要有带标签的训练集,手动标记证据可以建 立这样的训练集,但显然做不到规模化,因为网站信息会使用大量非正式的 或口语化的语言,给证据分类其实就是要确定句子中涉及的不良反应是否由 其有效组合中对应的药物引起,尽管药物包装里的使用说明,同时包含了其 适应症和已知的不良反应,为自动标记数据提供了便利:将包含药物和已知 不良反应的文本证据视为正例,而将包含药物和适应症的文本视为反例,然 而实际情况下,患者的真实体验会比说明书里的描述复杂得多,所以这里采 用了一种半监督分类器,先根据药物说明书手动标记了1200个文本证据去训 练一个简单的支持向量机(SVM)分类器,并用它去预判语料库里收集的所有 其他句子,当分类器判定一个句子为正例,同时它所包含的症状又恰好是药 物说明里已知的不良反应时,就将这个句子加入到正例训练集中;相反,当 分类器判定一个句子为反例,而包含的症状又恰好是药物说明里已知的适应 症时,将该句子加入到反例训练集中;当分类器判定一个句子的结果与药物 说明书内容不一致时,将这样的句子去掉,如此反复,就可以在起始少量手 动标记的基础上得到一个大得多的正例/反例训练集,从步骤2)提取的文本 证据中,最后得到了一个包含12,238个文本证据的训练集,通过人工验证 该训练集,发现这种自动标记方法的准确性可以达到82%,证据分类器就是通 过如表3所列的这7种特征来对文本证据进行预判的,随着训练集的扩大, 即使采集的特征不变,分类器辨识对应药物未知不良反应的能力会得到增强。
表3证据分类器采集的特征列表
此外,选择支持向量机(SVM)作为主分类器是因为这里的特征向量具有 较高的维度(包含很多不同的词汇),整个分类过程的算法如下图所示。
以上这个算法就是利用药物包装里的说明信息和一个起始分类器M去生 成更多的训练数据,有益之处就在于通过新的训练集得到新的分类器M,它再 去标记更多的训练数据,进而又得到一个更新的分类器,这种迭代过程可以 一直持续下去直到检测不到新的训练数据为止,最后得到的训练集我们称之 为半监督训练集,并用它去训练SVM分类器进而对所有从两大社交媒体中提 取的信息进行分类。
4)通过步骤3)的分类处理,在正例中,每一种药物都会对应多个候选 的不良反应,我们自然对那些具有高可信度的更感兴趣,所以需要对所有候 选不良药物反应进行排序,一种排序方法是统计某个不良反应在正例中出现 的次数,但这种方法效果欠佳,因为大多数关于某种药物的讨论都会提到该 药物的适应症,这样适应症就会在很多文本证据中出现,虽然分类器能达到 较高的准确度,但是考虑到该适应症被提及之广,还是会有不少证据被误判 成正例即该适应症被错误识别为不良反应,结果导致该适应症在所有候选的 不良反应中排序靠前,为了解决这个问题,改用候选者在正例和反例中出现 频率的差作为排序的依据,可有效规避适应症被当作不良反应的失误。
该从社交媒体中自动发掘不良药物反应的方法,与其他方案比较,在保 证较高精确度的同时更加稳健,通过采用200个手动标记文本证据的测试集 去比较不同方案的分类检测效果,并且用召回率(Recall)、精确度 (Precision)和F1分数(F1-score)这三个常用指标作为评价的依据(其中 召回率体现了分类模型对正向数据的识别能力,精确度体现了模型对负向数 据的识别能力,而F1分数是两者的综合),该半监督的支持向量机(SVM)分类模型具有最高的F1分数(如下表所示),即较其他方案而言,能够稳定, 高效,准确地发掘文本中的不良药物反应信息。
表4不同方案之间分类效果比较
综上所述,该从社交媒体中自动发掘不良药物反应的方法,通过既可用 来验证说明书上标记的已知不良药物反应并计算它们在特定人群中的相对发 生频率,还可以用来挖掘未知的不良反应,能够使该方法使用时适用性好, 例如,通过该方法在中文社交媒体中检测到四种常见药物的前十种不良反应 (如下表所示),其中既有已知不良反应的报告频率信息也有未知不良反应 (表中带下划线的部分)的报告,此外,该方案侧重于从中文线上社交媒体 中提取和分析不良要药物反应,其填补了从中文社交媒体中挖掘此类信息的空白,从而有效的补充了不良药物反应信息发掘在广度和深度上的完善,且 解决了难以以中文为基础进行信息发掘的问题。
表5检测到的4种常见药物的前十种不良反应
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来 将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示 这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包 括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包 括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括 没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备 所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的 要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外 的相同要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而 言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行 多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限 定。
- 一种从社交媒体中自动发掘不良药物反应的方法
- 医院不良事件管理中品管圈鱼骨图自动生成装置及方法