卷积神经网络运算装置及其运算的方法
文献发布时间:2023-06-19 12:14:58
技术领域
本公开是有关于一种卷积神经网络运算装置及运用此运算装置执行卷积神经网络运算的方法。
背景技术
CNN模型的运算,几乎以卷积运算的运算量和传输数据量来决定运算的时间。近年发展的趋势在追求精准以外,亦要降低卷积运算的运算量与数据传输量。CNN运算同时具备高平行度与高相依性这两种矛盾但是又实际上共存的特性,如何在硬件中加速上述的CNN模型运算量,乃是本领域的重要课题。
CNN运算有六个维度,包括输入的长、宽、与通道,以及卷积权重核心参数(亦即“卷积核”)的长、宽、与通道。高“平行度”发生在输入的通道方向的数据和卷积核的通道方向的数据的乘法运算,此乘法运算需要大量的平行化的乘法与加法阵列来进行处理。而高“相依性”则发生在输入的长与宽的方向的数据,和卷积核的长与宽的方向的数据的乘法运算;此乘法运算则需要设计特殊的数据输入顺序,以运用平行的乘法与加法阵列来进行处理。
然而,重要的各种CNN模型各有其特色,使得高效率的操作难以达成。第一种情况是,当需处理通道维度不同的运算时,会造成运算装置设计效能不佳。例如,Resnet和MobileNet这两种模型,Resnet具备很深(64~2048)的通道数量,但是MobileNet同时具备很深(例如64~512)的通道数量和很浅(例如1)的通道数量,且MobileNet浅通道运算方法(depth-wise)与传统卷积运算不同。传统卷积运算输入与输出的深度维度无相关,而depth-wise卷积运算输入与输出的深度维度须相同。这两种CNN模型使用的卷积核的尺寸具有3x3和1x1两种型态。
对于浅的通道数量而言,在公知设计架构中,会使用3x3=9个乘法器作为单位阵列,来加速长宽为3x3的卷积核的处理。这样的架构适合浅的通道数量的运算处理,但是遇到深的通道数量和1x1的卷积核时,则会有使用率不佳的问题。对于深的通道数量而言,在公知设计架构中,是使用32~64个乘法器来处理深的通道数量的乘法和累加计算。但是这样的架构于浅的通道数量的相关运算中,使用率将会不佳。
另一种情况是卷积核的长与宽的维度不同,而造成运算装置设计效能不佳。以上述的Resnet、MobileNet这两个模型来对比Inception模型,Resnet、MobileNet的卷积核长宽具有1x1和3x3两种类型,但是Inception模型则有多种不同卷积核长宽,包含1x7、7x1、1x3、3x1等。
对于包含1x7、7x1、1x3、3x1等卷积核类型来说,公知设计架构是使用3x3=9个乘法器作为单位阵列,来加速长宽为3x3的卷积核的运算处理。这样的架构适合于3x3的卷积核,但是遇到1x7、7x1、1x3、3x1等的卷积核时,则有使用率不佳的问题。
因此,如何规划CNN运算硬件运算装置架构,能于深与浅不同的通道数量、长与宽不同的卷积核的卷积运算中,均能得到良好的硬件使用效率,是重要的议题。
发明内容
根据本公开的第一方面,提出一种卷积神经网络运算装置,包括双向运算模组与数据调度器。双向运算模组包括多个双向输出运算器、多个行输出累加器、及多个列输出累加器。双向输出运算器各具有行输出端口与列输出端口。这些行输出累加器是耦接到这些行输出端口。这些列输出累加器是耦接到对应的这些列输出端口。数据调度器用以提供输入数据的多个数据数值和多个卷积核的多个卷积数值至这些双向输出运算器。其中,在第一运算模式时,这些双向输出运算器通过这些列输出端口输出运算结果至对应的这些列输出累加器。在第二运算模式时,这些双向输出运算器通过这些行输出端口输出运算结果至这些行输出累加器。
根据本公开的另一方面,提出一种执行卷积神经网络运算的方法,包括下列步骤。提供双向运算模组,双向运算模组包括多个双向输出运算器、多个行输出累加器、及多个列输出累加器。这些双向输出运算器各具有行输出端口与列输出端口。这些行输出累加器是耦接到这些行输出端口。这些列输出累加器是耦接到对应的这些列输出端口。通过数据调度器提供输入数据的多个数据数值和多个卷积核的多个卷积数值至这些双向输出运算器。在第一运算模式时,这些双向输出运算器通过这些列输出端口输出运算结果至对应的这些列输出累加器。在第二运算模式时,这些双向输出运算器通过这些行输出端口输出运算结果至这些行输出累加器。
为了对本公开的上述及其他方面有更佳的了解,下文特举实施例,并配合附图详细说明如下:
附图说明
图1示出一种卷积神经网络运算装置处理深与浅维度卷积时的示意图。
图2A示出本公开实施例的卷积神经网络运算装置方块图。
图2B示出图2A的卷积神经网络运算装置的详细实施方式的示例的方块图。
图3示出图2A中运算装置的双向运算模组的方块图。
图4示出图2A中运算装置的单向运算模组的方块图。
图5A~5B示出图2A中本公开实施例执行卷积运算的详细流程图。
图6A~6C示出本公开实施例执行浅维度卷积运算的示意图。
图7A~7E图示出本公开实施例执行深维度卷积运算的示意图。
图8A示出本公开另一实施例的卷积神经网络运算装置方块图。
图8B示出图8A的卷积神经网络运算装置的详细实施方式的示例的方块图。
图9A示出本公开又一实施例的卷积神经网络运算装置方块图。
图9B示出图9A的卷积神经网络运算装置的详细实施方式的示例的方块图。
具体实施方式
以表一所示的MobileNet CNN模型运算为例,此模型包含下列顺序排列的不同深度卷积运算,此模型特色之一是深维度卷积运算和浅维度卷积运算是交错进行的。如表一所示,第1、3、5、7、9、11和13层等奇数层卷积运算的深度KC分别是32、64、128、128、256、256和512层,而第2、4、6、8、10、12层等偶数层卷积运算的深度都是1层(depth-wise,DW),且运算方法与传统卷积运算不同,传统卷积运算输入与输出的深度维度无相关,而depth-wise卷积运算输入与输出的深度维度须相同。
表一MobileNet模型卷积运算层级
请参照图1,其示出一种公知卷积神经网络运算装置的架构示意方块图,包括数据调度器101与运算模组阵列103。运算模组阵列103具有多个单向运算模组105,每个单向运算模组105是包含多个单向输出乘法器。兹以运算模组阵列103具有8个单向运算模组105,每个单向运算模组105是包含8个单向输出乘法器P1为例做说明,则运算模组阵列103总共包含64个乘法器P1(1)~P1(64)。当进行公知卷积运算,例如MobileNet第三层时,数据调度器会给予每一列的乘法器,相同的8个输入数据IM数值,依照深度维度排列,即P1(1)=P1(9)=…=P1(57),P1(2)=P1(10)…=P1(58),…,P1(8)=P1(16)=…P1(64);同时,数据调度器会给予每一列的乘法器,不同的8个卷积核KR、每个卷积核有8个数值,依照深度维度排列,所以共有64个数值。以上行为即是共用输入数据IM,计算8个不同卷积核KR的结果。另一方面,当进行MobileNet第二层深度为1的浅维度(depth-wise)卷积运算时,因为对于输入数据深度维度数据须分离,且输入数据不可共用,即P1(1)≠P1(9)≠…≠P1(57),不同在公知卷积运算对于输入数据深度维度数据须加和,故使用公知的数据调度器时和卷积神经网络运算装置的架构时,在第一个时钟周期中,每一个单向运算模组105的8个乘法器中,只有P1(1)一个乘法器能被分配到卷积运算工作,另外63个乘法器保持闲置。在第二个时钟周期中,仍然只有P1(1)乘法器会被分配到卷积运算工作,另外63个乘法器保持闲置。以此类推,显示此种卷积神经网络运算装置在进行具有大量的浅维度(depth-wise)卷积运算的CNN模型运算时(例如:MobileNet模型),其运算装置的乘法器硬件使用效率会大幅降低,如此会显著地增加完成浅维度CNN运算所需时间。
考量避免闲置硬件与增加运算效率的问题,本公开的实施例提出一种卷积神经网络(Convolutional Neural Network)运算装置。卷积神经网络运算装置包括双向运算模组(Operation Module)与数据调度器(Data Scheduler)。双向运算模组包括多个双向输出运算器、多个行输出累加器、及多个列输出累加器。这些双向输出运算器各具有行输出端口与列输出端口。这些行输出累加器是耦接到这些行输出端口。这些列输出累加器是耦接到对应的这些列输出端口。数据调度器用以提供输入数据(例如是输入图像(Image))的多个数据数值(例如是多个图像数值)和多个卷积核(Kernel)的多个卷积数值至这些双向输出运算器。其中,在第一运算模式时,数据调度器给予该第一种运算模式所需的数据顺序,使这些双向输出运算器通过这些列输出端口输出运算结果至对应的这些列输出累加器,处理浅维度(depth-wise)卷积运算。在第二运算模式时,数据调度器给予该第二种运算模式所需的数据顺序,使这些双向输出运算器通过这些行输出端口输出运算结果至对应的这些行输出累加器,处理深维度卷积运算。
依照本公开的实施例,更提出一种执行卷积神经网络运算的方法,包括下列步骤。第一步骤,从卷积运算维度参数决定使用第一运算模式或第二运算模式;第二步骤,分别将上述卷积运算维度参数给予数据调度器;第三步骤,由数据调度器传输数据给双向运算模组中的双向输出运算器。在第一运算模式时,这些双向输出运算器通过这些列输出端口输出运算结果至对应的这些列输出累加器。在第二运算模式时,这些双向输出运算器通过这些行输出端口输出运算结果至这些行输出累加器。
上述的这些双向输出运算器例如包括MR个双向输出乘法器P2(1)~P2(MR)。这些列输出累加器包括MR个列输出累加器ACC(1)~ACC(MR)。当卷积神经网络运算装置设定在第一运算模式时,MR个双向输出乘法器中的第i个双向输出乘法器P2(i)在第一时钟周期内输出第一子卷积运算结果,在第二时钟周期内输出第二子卷积运算结果。第i个列输出累加器ACC(i)加和第一子卷积运算结果和第二子卷积运算结果。兹进一步详细说明如下。
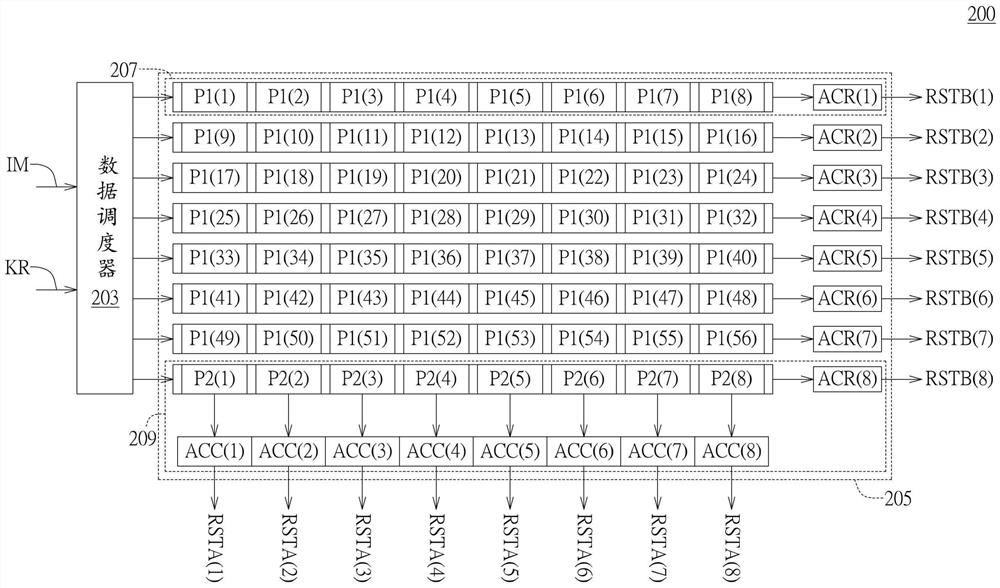
请参照图2A,是示出本公开实施例的卷积神经网络运算装置的方块图。此卷积神经网络运算装置可依据多个卷积核KR,对输入数据IM执行卷积神经网络运算。卷积神经网络运算装置200包括数据调度器203与运算模组阵列205。运算模组阵列205具有MC个运算模组,MC为正整数,代表每列的乘法器数目(Multiplier Per Column)。MC个运算模组至少包含双向运算模组209(Bidirectional Operation Module)。每个双向运算模组209是包含MR个双向输出乘法器(Bidirectional Multiplier),每个单向运算模组207(UnidirectionalOperation Module)是包含MR个单向输出乘法器(Unidirectional Multiplier),MR为正整数,MR代表每行的乘法器数目(Multiplier Per Row)。如图2A所示,在本实施例中,是以MC=8,MR=8为例做说明,然本实施例不限于此。运算模组阵列205具有8个运算模组,例如第1个至第7个运算模组均为单向运算模组207,第8个运算模组则为双向运算模组209。在本实施例中,是以一个运算模组为双向运算模组209为例做说明,然本实施例不限于此。第1个单向运算模组207包含8个单向输出乘法器P1(1)~P1(8),第2个单向运算模组207包含8个单向输出乘法器P1(9)~P1(16),以此类推,第7个单向运算模组207包含8个单向输出乘法器P1(49)~P1(56),第8行的双向运算模组209包含8个双向输出乘法器P2(1)~P2(8)。
当数据调度器203接收输入数据IM和多个卷积核KR后,可依据不同运算模式,将输入数据IM的多个数据数值和这些卷积核KR的多个卷积数值,输出分配给8个运算模组以进行卷积运算。如图2A所示,当运算装置设定在第一运算模式时,可从列输出累加器ACC(1)~ACC(8)得到第一卷积结果RSTA(1)~RSTA(8)。当运算装置设定在第二运算模式时,可自行输出累加器ACR(1)~ACR(8)得到第二卷积结果RSTB(1)~RSTB(8)。其中,同一列的输出乘法器所接收的输入数据IM的数据数值例如为相同。
请参照图2B,是示出图2A的卷积神经网络运算装置的详细实施方式的示例的方块图。数据调度器203是可由多种方式实施。例如,数据调度器203可包括数据维度判断与控制单元202、第一维度数据流控制数据调度单元(例如是浅维度数据流控制数据调度单元204)、第二维度数据流控制数据调度单元(例如是深维度数据流控制数据调度单元206)、多工器208及数据馈入单元210。浅维度数据流控制数据调度单元204是受控于数据维度判断与控制单元202,并在第一运算模式(例如是浅维度运算模式)下根据输入数据的多个数据数值和多个卷积核的多个卷积数值输出对应的第一数据数值数据流与第一卷积数值数据流。深维度数据流控制数据调度单元206是受控于数据维度判断与控制单元202,并在第二运算模式(例如是深维度运算模式)下根据输入数据IM的多个数据数值和多个卷积核的多个卷积数值输出对应的第二数据数值数据流与第二卷积数值数据流。多工器208是与浅维度数据流控制数据调度单元204与深维度数据流控制数据调度单元206耦接,用以在第一运算模式下输出第一数据数值数据流与第一卷积数值数据流,并在第二运算模式下输出第二数据数值数据流与第二卷积数值数据流。而数据馈入单元210则是与多工器208耦接,用以在第一运算模式下输出第一数据数值数据流与第一卷积数值数据流至多个双向输出乘法器P2(例如是双向输出乘法器P2(1)~P2(8)),并在第二运算模式下输出第二数据数值数据流与第二卷积数值数据流至多个双向输出乘法器P2(例如是双向输出乘法器P2(1)~P2(8))。数据调度器203还可包括数据馈入单元212。数据馈入单元212则在第二运算模式(例如是深维度运算模式)下根据输入数据的多个数据数值和多个卷积核的多个卷积数值,输出适用于7行的单向输出乘法器P1的数据数值数据流与卷积数值数据流至7行的单向输出乘法器P1。
请参照图3,是示出图2A中运算装置中的第8个运算模组,亦即双向运算模组209的示例的详细方块图。双向运算模组209包含MR个双向输出乘法器P2(1)~P2(MR)、行输出累加器ACR(m)、和MR个列输出累加器ACC(1)~ACC(MR),m为介于1~MC的正整数。在本实施例中是以MR=8,m=8为例来做说明,然本实施例不限于此。在本实施例中,双向运算模组209有行输出累加器ACR(8)、8个列输出累加器ACC(1)~ACC(8)和8个双向输出乘法器P2(1)~P2(8)。8个双向输出乘法器P2(1)~P2(8)各别具有行输出端口25与列输出端口27。
如图3所示,行输出累加器ACR(8)耦接至8个双向输出乘法器P2(1)~P2(8)的8个行输出端口25。当进行卷积运算时,行输出累加器ACR(8)可先加和第一时钟周期内的8个双向输出乘法器P2(1)~P2(8)的乘法运算所得到的8个子乘积,并将此总和作为原始第二卷积结果RSTB(8)。之后,再把下一个时钟周期的8个双向输出乘法器P2(1)~P2(8)的乘法运算所得到的8个子乘积进行加和,并将此加和后的总和与原始第二卷积结果RSTB(8)相加,以得到更新后的第二卷积结果RSTB(8)。之后的多个时钟周期内是重复上述的将8个子乘积加和,并将此总和与更新后的第二卷积结果RSTB(8)相加,以得到再次更新后的第二卷积结果RSTB(8)。8个列输出累加器ACC(1)~ACC(8)各别耦接到对应的8个双向输出乘法器P2(1)~P2(8)的8个列输出端口27其中之一。以第1个列输出累加器ACC(1)为例来做说明,列输出累加器ACC(1)是耦接到双向输出乘法器P2(1)的列输出端口27。当进行卷积运算时,列输出累加器ACC(1)先把第一时钟周期内对应的1个双向输出乘法器P2(1)运算所得到的子乘积作为原始第一卷积结果RSTA(1),再把稍后各个时钟周期的双向输出乘法器P2(1)的子乘积与此原始第一卷积结果RSTA(1)逐次相加,最后得到更新后的第一卷积结果RSTA(1)。
请参照图4,是示出图2A中运算装置中的第1~7个运算模组其中的1个单向运算模组207的示例的方块图。每个单向运算模组207包含MR个单向输出乘法器P1(1)~P1(MR)、多个行输出累加器ACR(m),m为介于1~MC的正整数。在本实施例中,是以MR=8,MC=8,m=1为例来做说明,然本实施例不限于此。本实施例是以每个单向运算模组207具8个单向输出乘法器P1(1)~P1(8)为例做说明。8个单向输出乘法器P1(1)~P1(8)中的每一个各别具有行输出端口25。如图4所示,在第1个单向运算模组207中,行输出累加器ACR(1)耦接至8个单向输出乘法器P1(1)~P1(8)的8个行输出端口25。当进行卷积运算时,行输出累加器ACR(1)先加和第一时钟周期内的8个单向输出乘法器P1(1)~P1(8)运算所得到8个子乘积,并将此总和作为原始第二卷积结果RSTB(1)。之后,再把各个时钟周期的8个单向输出乘法器P1(1)~P1(8)运算所得到8个子乘积的总和与此原始第二卷积结果RSTB(1)逐次相加,最后得到更新后的第二卷积结果RSTB(1)。
请参照图5A~5B,是示出本实施例的执行卷积神经网络运算的方法的示例的详细流程图,此流程相关参数包含:(a)输入数据IM的高度、宽度和深度是分别为输入数据高度H、输入数据宽度W与输入数据深度IC;(b)这些卷积核KR的高度、宽度和深度是分别为卷积核高度KH、卷积核宽度KW、和卷积核深度KC;以及(c)这些卷积运算结果的高度、宽度和深度分别为卷积输出高度OH、卷积输出宽度OW和卷积输出深度OC。MR为正整数,代表每行的乘法器数目,MC为正整数,代表每列的乘法器数目。
在图5B中,在流程步骤522中,首先判断是否进入第一运算模式。例如,是以卷积核深度KC是否大于等于特定值来判断。此特定值例如为每行的乘法器数目MR。当卷积核深度KC小于此特定值时,卷积神经网络运算装置200被设定在第一运算模式,第一运算模式例如为浅维度运算模式,此时执行流程步骤502~520。当判定卷积核的深度KC大于等于此特定值时,卷积神经网络运算装置200被设定在第二运算模式,第二运算模式例如为深维度运算模式,此时执行流程步骤524~548。
在步骤502中,令循环参数X1=0。接着,执行步骤504,令循环参数X2=0。之后,执行步骤506,令循环参数X3=0。接着,执行步骤508,列输出累加器ACC(i)将目前的时钟周期内对应的1个双向输出乘法器P2(i)乘积和原始第一卷积结果RSTA(i)相加,以得到更新后的第一卷积结果RSTA(i),i为1至MR范围间的正整数。
接着,执行步骤510,将循环参数X3之值加1。之后,执行步骤512,判断循环参数X3是否等于卷积核高度KH x卷积核宽度KW。若是,则执行步骤514;若否,则回到步骤508。在步骤514中,将循环参数X2的值加1。之后,执行步骤516,判断循环参数X2是否等于卷积输出宽度OWx卷积输出高度OH。若是,则进入步骤518;若否,则回到步骤506。在步骤518中,将循环参数X1之值加1。接着,进步步骤520,判断循环参数X1是否等于卷积输出深度OC/每行的乘法器数目MR。若是,则结束本流程;若否,则回到步骤504。
在步骤524中,令循环参数Y1=0。接着,执行步骤526,令循环参数Y2=0。之后,执行步骤528,令循环参数Y3=0。接着,执行步骤530,令循环参数Y4=0。之后,进入步骤532,行输出累加器ACR(m)将目前的时钟周期内的MR个乘法器的乘积和原始第二卷积结果RSTB(m)相加,以得到更新后的第二卷积结果RSTB(m),m为介于1至MC范围间的正整数。接着,执行步骤534,将循环参数Y4之值加1。之后,进入步骤536,判断循环参数Y4是否等于输入数据深度IC/每行的乘法器数目MR。若是,则进入步骤538;若否,则回到步骤532。在步骤538,将循环参数Y3之值加1。之后,执行步骤540,判断循环参数Y3是否等于卷积核宽度KW x卷积核高度KH。若是,则进入步骤542;若否,则回到步骤530。在步骤542中,将循环参数Y2之值加1。接着进入步骤544,判断循环参数Y2是否等于卷积输出宽度OW x卷积输出高度OH。若是,则进入步骤546;若否,则回到步骤528。在步骤546,将循环参数Y1之值加1。接着,进入步骤548,判断循环参数Y1是否等于卷积输出深度OC/每列的乘法器数目MC。若是,则结束本流程;若否,则回到步骤526。
在实施例中,对应于浅维度运算模式,流程步骤502~520共具有三层次的循环,由内而外分别为与循环参数X3相关的包含步骤508-512的第一循环、与循环参数X2相关的包含步骤506-516的第二循环、以及与循环参数X1相关的包含步骤504-520的第三循环。这三层次循环共同重复执行步骤508。在步骤508中,列输出累加器ACC(i)将目前的时钟周期内对应的1个双向输出乘法器P2(i)乘积和原始第一卷积结果RSTA(i)相加,以得到更新后的第一卷积结果RSTA(i),i为1至MR范围间的正整数。亦即第一卷积结果RSTA(i)等于列输出累加器ACC(i)先把第一时钟周期内对应1个双向输出乘法器P2(i)运算所得到的子乘积作为原始第一卷积结果RSTA(i),再把稍后各个时钟周期的双向输出乘法器P2(i)的子乘积与此原始第一卷积结果RSTA(i)逐次相加,最后得到更新后的第一卷积结果RSTA(i)。
跳出这三层次循环的判断准则分别为:(1)步骤512,当循环参数X3=卷积核高度KH x卷积核宽度KW时,亦即重复执行第一循环KH x KW次后,跳出第一循环;(2)步骤516,当循环参数X2=卷积输出宽度OWx卷积输出高度OH时,亦即重复执行第二循环OWxOH次后,跳出第二循环;以及(3)步骤520,当循环参数X1=卷积输出深度OC/每行的乘法器数目MR时,亦即重复执行第三循环OC/MR次后,跳出第三循环。
在实施例中,对应于深维度运算模式,流程步骤524~548共具有四层次循环,由内而外分别为与循环参数Y4相关的包含步骤532-536的第四循环、与循环参数Y3相关的包含步骤530-540的第五循环、与循环参数Y2相关的包含步骤528-544的第六循环、和与循环参数Y1相关的包含步骤526-548的第七循环。这四层次循环共同重复执行步骤532。在步骤532中,行输出累加器ACR(m)将目前的时钟周期内的MR个乘法器的乘积和原始第二卷积结果RSTB(m)相加,以得到更新后的第二卷积结果RSTB(m),m为介于1至MC范围间的正整数。亦即第二卷积结果是等于行输出累加器ACR(m)先加和第一时钟周期内位于对应第m运算模组中的MR个乘法器运算所得到MR个子乘积,将将此总和作为原始第二卷积结果RSTB(m),再把之后各个时钟周期的MR个乘法器运算所得到MR个子乘积的总和与此原始第二卷积结果RSTB(m)逐次相加,最后得到更新后的第二卷积结果RSTB(m)。
跳出这四层次循环的判断准则分别为:(1)步骤536,当循环参数Y4=输入数据深度IC/每行的乘法器数目MR时,亦即重复执行第四循环IC/MR次后,跳出第四循环;(2)步骤540,当循环参数Y3=卷积核宽度KW x卷积核高度KH时,亦即重复执行第五循环KW x KH次后,跳出第五循环;(3)步骤544,当循环参数Y2=卷积输出宽度OW x卷积输出高度OH时,亦即重复执行第六循环OW x OH次后,跳出第六循环;以及(4)步骤548,当循环参数Y1=卷积输出深度OC/每列的乘法器数目MC时,亦即重复执行第一循环OC/MC次后,跳出第七循环。
请参照第6A~6B图,其示出本公开实施例执行浅维度卷积运算的示意图。图6A是示出本实施例卷积神经网络运算装置200执行第一运算模式,亦即浅维度卷积时的示例的示意图。图6A是显示了在单层深度(depth-wise,DW)卷积神经网络运算中,相关运算数据的三维尺寸和数量。输入数据IM的高度、宽度和深度表示为输入数据宽度W x输入数据高度Hx输入数据深度IC,本例是以WxHxIC例如等于5x6x4为例做说明。四个卷积核K(1)~K(4)的宽度、高度和深度分别表示为卷积核宽度KW x卷积核高度KH x卷积核深度KC,本例是以KWxKHxKC例如等于3x3x1为例做说明。输出卷积结果的高度、宽度和深度表示为卷积输出宽度OW x卷积输出高度OH x卷积输出深度OC,本例是以OWxOHxOC例如等于4x5x4为例做说明。因为单层深度DW卷积神经网络运算的卷积核深度KC=1,小于每行的乘法器数目MR=8,因此卷积神经网络运算装置200被设定在第一运算模式,亦即浅维度运算模式,并执行流程步骤502~520来进行卷积运算。
请参照图6B,当卷积神经网络运算装置200设定在第一运算模式,亦即浅维度运算模式时,数据调度器203是将各个卷积核所需要进行的相关卷积运算的卷积数值分配给第8行双向运算模组209中的其中一个双向输出乘法器P2(i)来进行卷积运算,i为1至MR范围间的正整数,并由列输出端口27输出给对应的列输出累加器ACC(i)进行累加。因为在图6A中所示的例子中,卷积运算只会使用到4个卷积核,故浅维度运算模式所会使用到的运算模组阵列205的部分电路是如图6B所示的粗方框部分,包含前4个双向输出乘法器P2(1)~P2(4)与前4个列输出累加器ACC(1)~ACC(4)。而运算模组阵列205第1行至第7行的单向运算模组207因为不会被使用到,可以选择性地进入省电模式,以节省电能消耗。
对应图5A的流程图的第一循环,在X3=0的第一次循环中,亦即在第一时钟周期内,数据调度器203在各个卷积核KR的高度KH和宽度KW所定义的平面上选取第一位置的第一卷积数值,并在输入数据IM的高度H和宽度W所定义的平面上选取对应第一位置的第一数据数值,数据调度器203将第一卷积数值与第一数据数值输出至1个双向输出乘法器P2(i),执行步骤508以得到第一子卷积运算结果,i为1至MR范围间的正整数。
图6A~6B是本实施例中数据调度器203将第一卷积数值与第一数据数值输出至1个双向输出乘法器P2(i)的示例,然本实施例并不限于限。在X3=0的第一次循环中,亦即在第一时钟周期内,数据调度器203执行:(a)输入数据IM的数据数值A1与第一个卷积核K(1)的卷积数值E1分配到第8行的第1个双向输出乘法器P2(1)中进行卷积运算;(b)输入数据IM的数据数值B1与第二个卷积核K(2)的卷积数值F1分配到第8行的第2个双向输出乘法器P2(2)中进行卷积运算;(c)输入数据IM的数据数值C1与第三个卷积核K(3)的卷积数值G1分配到第8行的第3个双向输出乘法器P2(3)中进行卷积运算;以及(d)输入数据IM的数据数值D1与第四个卷积核K(4)的卷积数值H1分配到第8行的第4个双向输出乘法器P2(4)中进行卷积运算。当第一时钟周期结束时,前4个列输出累加器ACC(1)~ACC(4)各别累加对应的4个双向输出乘法器P2(1)~P2(4)其中之一在第一时钟周期内输出第一子卷积运算结果。举例来说,第1个列输出累加器ACC(1)总和初始值为0,第1个双向输出乘法器P2(1)在第一时钟周期内输出第一子卷积运算结果,第1个列输出累加器ACC(1)将总和初始值加上第一子卷积运算结果。如此当第一时钟周期结束时,第1个列输出累加器ACC(1)所暂存的原始第一卷积结果RSTA(1)等于此第一子卷积运算结果。以此类推。第4个列输出累加器ACC(4)总和初始值为0,第4个双向输出乘法器P2(4)在第一时钟周期内输出另一子卷积运算结果,第4个列输出累加器ACC(4)将总和初始值加上此另一子卷积运算结果。如此当第一时钟周期结束时,第4个列输出累加器ACC(4)所暂存的原始第一卷积结果RSTA(4)等于此另一子卷积运算结果。
在X3=1时,图5A流程第一循环执行第二次时,亦即在第二时钟周期内,数据调度器203在卷积核的高度KH和宽度KW所定义的平面上选取第二位置的第二卷积数值,并在输入数据IM的高度H和宽度W所定义的平面上选取对应第二位置的第二数据数值,数据调度器203将第二卷积数值与第二数据数值输出至第i个双向输出乘法器P2(i)以得到第二子卷积运算结果,第二位置不同于第一位置。其中,第二位置是为第一位置平移q个步距单位后的位置,q为正整数。例如平移1个步距单位或2个步距单位之后的位置,本发明不限于此。
如图6A~6B所示,在X3=1的第二次循环中,亦即在第二时钟周期内,数据调度器203执行:(a)将输入数据IM的数据数值A2与第一个卷积核K(1)的卷积数值E2分配到第8行的第1个双向输出乘法器P2(1)中进行卷积运算;(b)输入数据IM的数据数值B2与第二个卷积核K(2)的卷积数值F2分配到第8行的第2个双向输出乘法器P2(2)中进行卷积运算;(c)输入数据IM的数据数值C2与第三个卷积核K(3)的卷积数值G2分配到第8行的第3个双向输出乘法器P2(3)中进行卷积运算;(d)输入数据IM的数据数值D2与第四个卷积核K(4)的卷积数值H2分配到第8行的第4个双向输出乘法器P2(4)中进行卷积运算。当第二时钟周期结束时,前4个列输出累加器ACC(1)~ACC(4)各别累加对应的4个双向输出乘法器P2(1)~P2(4)其中之一在第二时钟周期内输出的第二子卷积运算结果。例如,当第一时钟周期结束时,第1个列输出累加器ACC(1)所暂存的原始第一卷积结果RSTA(1)等在第一子卷积运算结果,而第1个双向输出乘法器P2(1)在第二时钟周期内输出第二子卷积运算结果,第1个列输出累加器ACC(1)将原始第一卷积结果RSTA(1)加上第二子卷积运算结果。如此当第二时钟周期结束时,第1个列输出累加器ACC(1)是储存更新后的第一卷积结果RSTA(1),此更新后的第一卷积结果RSTA(1)等于加和第一子卷积运算结果和第二子卷积运算结果所得到的总和。以此类推,当第一时钟周期结束时,第4个列输出累加器ACC(4)所暂存的原始第一卷积结果RSTA(4)等于另一子卷积运算结果,而第4个双向输出乘法器P2(4)在第二时钟周期内输出再一子卷积运算结果,第4个列输出累加器ACC(4)将原始第一卷积结果RSTA(4)加上再一子卷积运算结果。如此当第二时钟周期结束时,第4个列输出累加器ACC(4)是储存更新后的第一卷积结果RSTA(4),此更新后的第一卷积结果RSTA(4)等于加和原始第一卷积结果RSTA(4)和又一子卷积运算结果所得到的总和。
如图6A所示,4个卷积核K(1)~K(4)的宽度和高度分别为宽KWx高KH=3x3,故各个卷积核各有9个卷积数值;如此经过9个时钟周期运算后,(a)第1个列输出累加器ACC(1)储存第一个卷积核K(1)的9个卷积数值E1~E9与对应位置的数据数值A1~A9的9次子卷积运算结果的总和,列输出累加器ACC(1)此时可以输出卷积输出点Z1的卷积运算结果;(b)第2个列输出累加器ACC(2)储存第二个卷积核K(2)的9个卷积数值F1~F9与对应位置的数据数值A1~A9的9次子卷积运算结果的总和,列输出累加器ACC(2)此时可以输出卷积输出点Z2的卷积运算结果;(c)第3个列输出累加器ACC(3)储存第三个卷积核K(3)的9个卷积数值G1~G9与对应位置的数据数值A1~A9的9次子卷积运算结果的总和,列输出累加器ACC(3)此时可以输出卷积输出点Z3的卷积运算结果;(d)第4个列输出累加器ACC(4)储存第四个卷积核K(4)的9个卷积数值H1~H9与对应位置的数据数值A1~A9的9次子卷积运算结果的总和,列输出累加器ACC(4)此时可以输出卷积输出点Z4的卷积运算结果。如此第一循环已经执行卷积核宽度KW x卷积核高度KH次,满足流程步骤512的X3=卷积核宽度KW x卷积核高度KH,而跳出第一循环。
第二循环是针对不同位置的卷积输出结果进行卷积运算,例如:图6A中,卷积输出结果的卷积输出宽度OW和卷积输出高度OH为4x5,亦即共有20个卷积输出点。如图6A所示,第二循环执行第一次时,是由输入数据IM的第一数据数值立体方块cube1与第一卷积核K(1)进行卷积运算,得到第1个卷积输出点Z1,此第一数据数值立体方块cube1包含数据数值A1~A9。如图6C所示,第二循环执行第二次时,是由输入数据IM的第二数据数值立体方块cube2与第一卷积核K(1)进行卷积运算后,得到第5个卷积输出点Z5,此第二数据数值立体方块cube2包含数据数值A2~A3、A5~A6、A8~A9、A10~A12。于每次第二循环中,数据调度器203把此3x3数据数值立体方块向右或向下移动一个步距单位,选取输入数据IM上不同位置的3x3数据数值立体方块来与第一卷积核K(1)进行卷积运算,而得到1个卷积输出点。当第二循环执行卷积输出宽度OWx卷积输出高度OH次,亦即重复执4x5=20次后,数据调度器203已经选取20个不同位置的3x3数据数值立体方块,完成20个卷积输出点,满足流程步骤516的X2=卷积输出宽度OWx卷积输出高度OH的条件,而跳出第二循环。
第三循环是选择不同卷积核进行卷积运算。在图7A中,卷积输出深度OC=4,每行的乘法器数目MR=8,故卷积输出深度OC/每行的乘法器数目MR小于等于1,亦即第三循环执行1次即可。如此第一循环重复执行9次,第二循环重复执行4x5=20次,第三循环执行1次,总共需要9x20x1=180个循环,亦即本实施例卷积神经网络运算装置200运算经过180个时钟周期后,可完成图6A的浅维度卷积运算。
请参照图7A,是示出本实施例卷积神经网络运算装置200执行第二运算模式,亦即深维度卷积的示意图。如图7A所示,传统深维度卷积神经网络运算中,相关运算数据的三维尺寸和数量。其中输入数据IM的高度、宽度和深度表示为输入数据宽度W x输入数据高度Hx输入数据深度IC,例如为5x6x128。256个卷积核的高度、宽度和深度表示为卷积核宽度KWx卷积核高度KH x卷积核深度KC,例如为3x3x128。256个卷积核包括第一卷积核K(1)、第二卷积核K(2)…第256卷积核K(256)。第一卷积核K(1)具有卷积核深度方向KC(1),第二卷积核K(2)具有卷积核深度方向KC(2)。输出卷积结果的高度、宽度和深度表示为卷积输出宽度OW x卷积输出高度OH x卷积输出深度OC,例如为4x5x256。因为卷积核深度KC=128,大于每行的乘法器数目MR=8,故卷积神经网络运算装置200被设定在第二运算模式,亦即深维度运算模式,执行图5B流程步骤524~548来进行卷积运算。
请参照图7B,当卷积神经网络运算装置200设定在第二运算模式,亦即深维度运算模式时,深维度运算模式所会使用到的运算模组阵列205电路是图7B所示的粗方框部分,所有8个运算模组中的64个乘法器(包括56个单向输出乘法器P1(1)~P1(56)与8个双向输出乘法器P2(1)~P2(8))与行输出累加器ACR(1)~ACR(8)都会参与卷积运算工作。并由64个乘法器(包括56个单向输出乘法器P1(1)~P1(56)与8个双向输出乘法器P2(1)~P2(8))各自的行输出端口25输出给对应的行输出累加器ACR(1)~ACR(8)其中之一。行输出累加器ACR(m)先加和第一时钟周期内8个乘法器乘积而得到原始第二卷积结果RSTB(8),m为1至MC范围间的正整数。行输出累加器ACR(m)之后再加和第二时钟周期内8个乘法器乘积与原始第二卷积结果RSTB(m),而得到更新后的第二卷积结果RSTB(m)。
以下是以第1个双向运算模组207为例说明,然本实施例不限于限。当卷积神经网络运算装置200设定在第二运算模式时,8个单向输出乘法器P1(1)~P1(8)是通过各自的行输出端口25输出运算结果。例如,第1个单向输出乘法器P1(1)在第一时钟周期内输出第1子卷积运算结果O1(1),在第二时钟周期内输出第2子卷积运算结果O1(2)。第2个双向输出乘法器P1(2)在第一时钟周期内输出第3子卷积运算结果O1(3),在第二时钟周期内输出第4子卷积运算结果O1(4)。以此类推,第8个双向输出乘法器P1(8)在第一时钟周期内输出第207子卷积运算结果O1(15),在第二时钟周期内输出第16子卷积运算结果O1(16)。当第一时钟周期结束时,行输出累加器ACR(1)先加和第1子卷积运算结果O1(1)、第3子卷积运算结果O1(3)...与第15子卷积运算结果O1(15)等8个子卷积运算结果,而得到原始第二卷积结果RSTB(1)。当第二时钟周期结束时,行输出累加器ACR(1)再加和第2子卷积运算结果O1(2)、第4子卷积运算结果O1(4)...与第16子卷积运算结果O1(16)等8个子卷积运算结果以及此原始第二卷积结果RSTB(1)而得到更新后的第二卷积结果RSTB(1)。
兹将第1个单向运算模组207的详细操作进一步说明如下。如图7A~7B所示,对应图5B流程的第四循环,在Y4=0的第一次运算中,亦即在第一时钟周期内,数据调度器203执行:(a)沿着第一卷积核K(1)的深度方向KC(1)上选取第1位置,并取得第1位置的第1卷积数值E1,并沿着输入数据IM的深度IC的方向上选取对应第1位置的第1数据数值A1,数据调度器203将第1卷积数值E1与第1数据数值A1传递给第1个单向输出乘法器P1(1)以得到第1子卷积运算结果O1(1);(b)沿着第一卷积核K(1)的深度方向KC(1)上选取第2位置,并取得第2位置的第2卷积数值E2,并沿着输入数据IM的深度IC的方向上选取对应第2位置的第2数据数值A2,数据调度器203将第2卷积数值E2与第2数据数值A2传递给第2个单向输出乘法器P1(2)以得到第3子卷积运算结果O1(3);(c)以此类推,沿着第一卷积核K(1)的深度方向KC(1)上选取第8位置,并取得第8位置的第8卷积数值E8,并沿着输入数据IM的深度IC的方向上选取对应第8位置的第8数据数值A8,数据调度器203将第8卷积数值E8与第8数据数值A8传递给第8个单向输出乘法器P1(8)以得到第15子卷积运算结果O1(15)。如此在第一时钟周期内,数据调度器203沿着第一卷积核K(1)的深度方向KC(1)上共选取8个位置而取得8个卷积数值E1~E8,同时取得输入数据IM对应位置的8个数据数值A1~A8,而分别交由8个单向输出乘法器P1(1)~P1(8)进行卷积运算而得到8个子卷积运算结果O1(1)、O1(3)...O1(15),并通过各自的行输出端口25输出给行输出累加器ACR(1)。当第一时钟周期结束时,行输出累加器ACR(1)加和8个子卷积运算结果O1(1)、O1(3)...O1(15)而得到原始第二卷积结果RSTB(1)。
在Y4=1时,图5B流程第四循环执行第二次运算时,亦即在第二时钟周期内,数据调度器203执行:(a)沿着第一卷积核K(1)的深度方向KC(1)上选取第9位置,并取得第9位置的第9卷积数值E9,并沿着输入数据IM的深度IC的方向上选取对应第9位置的第9数据数值A9,数据调度器203将第9卷积数值E9与第9数据数值A9传递给第1个单向输出乘法器P1(1)以得到第2子卷积运算结果O1(2);(b)沿着第一卷积核K(1)的深度方向KC(1)上选取第10位置,并取得第10位置的第10卷积数值E10,并沿着输入数据IM的深度IC的方向上选取对应第10位置的第10数据数值A10,数据调度器203将第10卷积数值E10与第10数据数值A10传递给第2个单向输出乘法器P1(2)以得到第4子卷积运算结果O1(4);(c)以此类推,沿着第一卷积核K(1)的深度方向KC(1)上选取第16位置,并取得第16位置的第16卷积数值E16,并沿着输入数据IM的深度IC的方向上选取对应第16位置的第16数据数值A16,数据调度器203将第16卷积数值E16与第16数据数值A16传递给第8个单向输出乘法器P1(8)以得到第16子卷积运算结果O1(16)。在第二时钟周期内,数据调度器203沿着第一卷积核K(1)的深度方向KC(1)上共选取8个位置而取得8个卷积数值E9~E16,同时取得输入数据IM对应位置的8个数据数值A9~A16,而分别交由8个单向输出乘法器P1(1)~P1(8)进行卷积运算而得到第2时钟周期的8个子卷积运算结果O1(2)、O1(4)...O1(16),并通过各自的行输出端口25输出给行输出累加器ACR(1)。当第二时钟周期结束时,行输出累加器ACR(1)加和8个子卷积运算结果O1(2)、O1(4)...O1(16)和第一时钟周期得到的原始第二卷积结果RSTB(1),而得到更新后的第二卷积结果RSTB(1)。
请参照图7A~7B,运算模组阵列205中的其他运算模组阵列(第2个~第7个的单向运算模组207、第8个的双向运算模组17)也进行和上述第1个单向运算模组207相同的运算,只是对应到不同的卷积核。例如第2个单向运算模组207运算可以是:在第一时钟周期内,数据调度器203执行(a)沿着第二卷积核K(2)的深度方向KC(2)上选取第1位置,并取得第1位置的第1卷积数值F1,并沿着输入数据IM的深度IC的方向上选取对应第1位置的第1数据数值A1,数据调度器203将第1卷积数值F1与第1数据数值A1传递给第9个单向输出乘法器P1(9)以得到第1子卷积运算结果O2(1);(b)沿着第二卷积核K(2)的深度方向KC(2)上选取第2位置,并取得第2位置的第2卷积数值F2,并沿着输入数据IM的深度IC的方向上选取对应第2位置的第2数据数值A2,数据调度器203将第2卷积数值F2与第2数据数值A2传递给第10个单向输出乘法器P1(10)以得到第3子卷积运算结果O2(3);(c)以此类推,沿着第二卷积核K(2)的深度方向KC(2)上选取第8位置,并取得第8位置的第8卷积数值F8,并沿着输入数据IM的深度IC的方向上选取对应第8位置的第8数据数值A8,数据调度器203将第8卷积数值E8与第8数据数值A8传递给第16个单向输出乘法器P1(16)以得到第15子卷积运算结果O2(15)。如此在第一时钟周期内,数据调度器203沿着第二卷积核K(2)的深度方向KC(2)上共选取8个位置而取得8个卷积数值F1~F8,同时取得输入数据IM对应位置的8个数据数值A1~A8,而分别交由8个单向输出乘法器P1(9)~P1(16)进行卷积运算而得到8个子卷积运算结果O2(1)、O2(3)...O2(15),并通过各自的行输出端口25输出给行输出累加器ACR(2)。当第一时钟周期结束时,行输出累加器ACR(2)加和8个子卷积运算结果O2(1)、O2(3)...O2(15)而得到原始第二卷积结果RSTB(2)。
在Y4=1时,图5B流程第四循环执行第二次时,亦即在第二时钟周期内,数据调度器203执行:(a)沿着第二卷积核K(2)的深度方向KC(2)上选取第9位置,并取得第9位置的第9卷积数值F9,并沿着输入数据IM的深度IC的方向上选取对应第9位置的第9数据数值A9,数据调度器203将第9卷积数值E9与第9数据数值A9传递给第9个单向输出乘法器P1(9)以得到第2子卷积运算结果O2(2);(b)沿着第二卷积核K(2)的深度方向KC(2)上选取第10位置,并取得第10位置的第10卷积数值F10,并沿着输入数据IM的深度IC的方向上选取对应第10位置的第10数据数值A10,数据调度器203将第10卷积数值E10与第10数据数值A10传递给第10个单向输出乘法器P1(10)以得到第4子卷积运算结果O2(4);(c)以此类推,沿着第二卷积核K(2)的深度方向KC(2)上选取第16位置,并取得第16位置的第16卷积数值F16,并沿着输入数据IM的深度IC的方向上选取对应第16位置的第16数据数值A16,数据调度器203将第16卷积数值F16与第16数据数值A16传递给第16个单向输出乘法器P1(16)以得到第16子卷积运算结果O2(16)。在第二时钟周期内,数据调度器203沿着第二卷积核K(2)的深度方向KC(2)上共选取8个位置而取得8个卷积数值F9~F16,同时取得输入数据IM对应位置的8个数据数值A9~A16,而分别交由8个单向输出乘法器P1(9)~P1(16)进行卷积运算而得到第2时钟周期的8个子卷积运算结果O2(2)、O2(4)...O2(16),并通过各自的行输出端口25输出给行输出累加器ACR(2)。当第二时钟周期结束时,行输出累加器ACR(2)加和8个子卷积运算结果O2(2)、O2(4)...O2(16)和第一时钟周期得到的原始第二卷积结果RSTB(2),而得到更新后的第二卷积结果RSTB(2)。
请参照图7A,此256个卷积核K(1)~K(256)的卷积核深度KC为128,而每次第四循环最多能进行每行乘法器数目MR个卷积运算。在本实施例中,每次第四循环最多能进行8个卷积运算。当第四循环执行输入数据深度IC/每行乘法器数目MR(=128/8)次后,亦即第四循环执行16次后,(a)第1个行输出累加器ACR(1)储存第一个卷积核K(1)的128个卷积数值E1~E128与对应位置的数据数值A1~A128的128次子卷积运算结果的总和,行输出累加器ACR(1)此时可以得到输出累加器ACR(1)的暂存值。(b)第2个行输出累加器ACR(2)储存第二个卷积核K(2)的128个卷积数值F1~F128与对应位置的数据数值A1~A128的128次子卷积运算结果的总和,行输出累加器ACR(2)此时可以得到输出累加器ACR(2)的暂存值;(c)以此类推,第8个行输出累加器ACR(8)储存第八个卷积核K(8)于KC(8)深度方向上的128个卷积数值与对应位置的数据数值A1~A128的128次子卷积运算结果的总和,行输出累加器ACR(8)此时可以得到输出累加器ACR(2)的暂存值。此时第四循环已经重复执行16次,满足Y4=输入数据深度IC/每行乘法器数目MR=128/8=16,满足流程步骤536而跳出第四循环。
第五循环是要完成各个卷积核高度KH和宽度KW所定义的平面上所有的卷积运算。如图7A所示,第五循环执行第一次时,是输入数据IM的第三数据数值立体方块cube3与第一卷积核K(1)的第四卷积数值立体方块cube4进行卷积运算,此第一数据数值立体方块cube1包含数据数值A1~A128,此第四卷积数值立体方块cube4包含卷积数值E1~E128,行输出累加器ACR(m)得到一输出累加器ACR(m)的暂存值。如第7C图所示,第五循环执行第二次时,数据调度器203把上述两个1x128立体方块cube3与cube4均向右移动一个步距单位得到立体方块cube5与cube6(亦可为平移2个步距单位或3个步距单位,本公开并不限于此),由输入数据IM的第五数据数值立体方块cube5与第一卷积核K(1)的第六卷积数值立体方块cube6进行卷积运算,此第五数据数值立体方块cube5包含数据数值A129~A256,此第六卷积数值立体方块cube6包含卷积数值E129~E256,行输出累加器ACR(m)将第五循环执行第二次所得卷积运算结果和输出累加器ACR(m)的暂存值相加而得到更新后的输出累加器ACR(m)的暂存值。以此类推,在每次第五循环中,数据调度器203把此两个1x128立体方块向右或向下移动一个步距单位,选取输入数据IM上不同位置的1x128数据数值立体方块与第一卷积核K(1)上不同位置的1x128卷积数值立体方块进行卷积运算,行输出累加器ACR(m)将第五循环各次执行所得卷积运算结果和输出累加器ACR(m)的暂存值相加而得到更新后的输出累加器ACR(m)的暂存值。各个卷积核的宽高分别例如为宽KWx高KH=3x3,当循环参数Y3=卷积核宽度KWx卷积核高度KH=9时,亦即第五循环重复执行9次后,数据调度器203已经选取卷积核K(1)的9个不同位置的1x128立体方块,完成和输入数据IM的卷积运算,行输出累加器ACR(m)将更新后的输出累加器ACR(m)的暂存值作为1个卷积输出点Z1输出,并跳出第五循环。
第六循环是针对不同位置的卷积输出结果进行卷积运算,如图7D所示,第六循环执行第一次时,是输入数据IM的第七数据数值立体方块cube7与第一卷积核K(1)进行卷积运算,得到1个卷积输出点Z1,此第七数据数值立体方块cube7包含3x3x128个数据数值。如第7E图所示,第六循环执行第二次时,数据调度器203把此输入数据IM的3x3x128立体方块向右移动一个步距单位,是由输入数据IM的第八数据数值立体方块cube8与第一卷积核K(1)进行卷积运算,得到1个卷积输出点Z257。如此在每次第六循环中,数据调度器203把此3x3x128立体方块向右或向下移动一个步距单位,选取输入数据IM上不同位置的3x3x128数据数值立体方块来与第一卷积核K(1)进行卷积运算。如图7A所示,本实施例的卷积输出结果的卷积输出宽度OW为4,而卷积输出高度OH为5,因此第六循环需执行20次(=卷积输出宽度OWx卷积输出高度OH),亦即数据调度器203已经选取20个不同位置的3x3x128数据数值立体方块,行输出累加器ACR(m)输出完成20个卷积输出点后,满足流程步骤544而跳出第六循环。
第七循环是针对不同卷积核进行卷积运算;在图7A中,卷积输出深度OC为256,而第七循环每次最多可同时处理8个卷积核(=每列乘法器数目MC)。如此当循环参数Y1=卷积输出深度OC/每列乘法器数目MC时,亦即第七循环重复执行256/8=32次后,跳出第七循环。
如此第四循环需重复执行128/8=16次,第五循环需重复执行3x3=9次,第六循环需重复执行4x5=20次,第七循环需重复执行256/8=32次,总共需要执行16x9x20x32=92160次个循环,亦即本实施例卷积神经网络运算装置200运算经过92160个时钟周期可完成图7A的深维度卷积运算。
请参照图8A,是示出本公开卷积神经网络运算装置200的另一实施例,同样地,可依据多个卷积核KR,对输入数据IM执行卷积神经网络运算。卷积神经网络运算装置200包括数据调度器801与运算模组阵列803。运算模组阵列803具有MC个运算模组,MC为正整数代表每列的乘法器数目。在此MC个运算模组中包含两个双向运算模组17。每个双向运算模组17是包含MR个双向输出乘法器,每个单向运算模组207是包含MR个单向输出乘法器,MR为正整数,代表每行的乘法器数目。
如图8A所示,在另一实施例中,是以MC=8,MR=8为例来做说明,但另一实施例不以此为限。运算模组阵列803具有8个运算模组,其中前6个运算模组均为单向运算模组207,而第7-8个运算模组是为双向运算模组17。每个单向运算模组207包含8个单向输出乘法器,故前6个单向运算模组207共包含48个单向输出乘法器P1(1)~P1(48)。每个双向运算模组17包含8个双向输出乘法器,故第7-8个双向运算模组17共包含16个双向输出乘法器P2(1)~P2(16)。
当运算装置设定在浅维度运算模式时,类似图6A~6B所示实施例的数据分配方式,是将各个卷积核所需要进行的相关卷积运算分配给第7行~第8行双向运算模组17中的其中一个双向输出乘法器P2(i)来进行卷积运算,i为1至MR范围间的正整数,并由双向输出乘法器P2(i)的列输出端口27输出给对应的列输出累加器ACC(i)进行累加,可自列输出累加器ACC(i)得到第一卷积结果RSTA(i)。运算模组阵列803之前6行的单向运算模组207因为不会被使用到,可以选择性地进入省电模式,以节省电能消耗。
当运算装置设定于深维度运算模式时,类似图7A~7B所示实施例的数据分配方式,运算模组阵列803中所有8个运算模组中的64个乘法器(包括48个单向输出乘法器P1(1)~P1(48)与16个双向输出乘法器P2(1)~P2(16))都会被分配到部分卷积运算工作,并由64个乘法器(包括48个单向输出乘法器P1(1)~P1(48)与16个双向输出乘法器P2(1)~P2(16))各自的行输出端口25输出给对应的行输出累加器ACR(m),m为1至MC范围间的正整数。行输出累加器ACR(m)先加和第一时钟周期内所耦接的8个乘法器运算所得到8个子乘积的总和作为原始第二卷积结果RSTB(i),再把稍后各个时钟周期的8个乘法器运算所得到8个子乘积的总和与此原始第二卷积结果RSTB(i)相加,最后得到更新后的第二卷积结果RSTB(i)。
请参照图8B,是示出图8A的卷积神经网络运算装置的详细实施方式的示例的方块图。数据调度器801是可由多种方式实施。例如,数据调度器801可包括数据维度判断与控制单元802、第一维度数据流控制数据调度单元(例如是浅维度数据流控制数据调度单元804)、第二维度数据流控制数据调度单元(例如是深维度数据流控制数据调度单元806)、多工器808、数据馈入单元810。数据调度器801的操作类似在图2B之数据调度器203的操作,不同之处在于数据调度器801中的各单元是以2行的双向输出乘法器P2(例如是双向输出乘法器P2(1)~P2(16))来决定所要输出的数据流。亦即,浅维度数据流控制数据调度单元804在第一运算模式(例如是浅维度运算模式)下,根据输入数据的多个数据数值和多个卷积核的多个卷积数值,输出适用于2行的双向输出乘法器P2的第一数据数值数据流与第一卷积数值数据流,并通过多工器808与数据馈入单元810输出至多个双向输出乘法器P2(例如是双向输出乘法器P2(1)~P2(16))。数据馈入单元812则在第二运算模式(例如是深维度运算模式)下根据输入数据的多个数据数值和多个卷积核的多个卷积数值,输出适用于6行的单向输出乘法器P1的数据数值数据流与卷积数值数据流至6行的单向输出乘法器P1。
请参照图9A,是示出本公开卷积神经网络运算装置200的又一实施例,图示相同标号部分电路元件同实施例不再赘述。运算模组阵列903具有MC个运算模组,且MC个运算模组全部都为双向运算模组17,MC为正整数,代表每列的乘法器数目。每个双向运算模组17是包含MR个双向输出乘法器,MR为正整数,代表每列的乘法器数目。如图9A所示,在又一实施例中,是以MC=8,MR=8为例来做说明,但另一实施例不以此为限。运算模组阵列903具有8个运算模组,所有8个运算模组是为双向运算模组17。每个双向运算模组17包含8个双向输出乘法器,故8个双向运算模组17共包含64个双向输出乘法器P2(1)~P2(64)。
当运算装置设定于浅维度运算模式时,类似图6A~6B所示的实施例的数据分配方式,是将各个卷积核所需要进行的相关卷积运算分配给所有8行双向运算模组17中的其中一个双向输出乘法器P2(i)来进行卷积运算,i为1至MR范围间的正整数,并由双向输出乘法器P2(i)的列输出端口27输出给对应的列输出累加器ACC(i)进行累加,可自列输出累加器ACC(i)得到第一卷积结果RSTA(i)。运算模组阵列205所有的双向运算模组17都会参与处理到部分卷积运算。
当运算装置设定于深维度运算模式时,类似图7A~7B所示的实施例的数据分配方式,运算模组阵列903中所有8个运算模组中的64个乘法器都会参与处理到部分卷积运算,并由64个乘法器各自的行输出端口25输出给对应的行输出累加器ACR(m),m为1至MC范围间的正整数。行输出累加器ACR(m)先加和第一时钟周期内所耦接的8个乘法器运算所得到8个子乘积的总和作为原始第二卷积结果RSTB(i),再把稍后各个时钟周期的8个乘法器运算所得到8个子乘积的总和与此原始第二卷积结果RSTB(i)相加,最后得到更新后的第二卷积结果RSTB(i)。
请参照图9B,是示出图9A的卷积神经网络运算装置的详细实施方式的示例的方块图。数据调度器901是可由多种方式实施。例如,数据调度器901可包括数据维度判断与控制单元902、第一维度数据流控制数据调度单元(例如是浅维度数据流控制数据调度单元904)、第二维度数据流控制数据调度单元(例如是深维度数据流控制数据调度单元906)、多工器908、数据馈入单元910。数据调度器901的操作类似在图2B的数据调度器203的操作,不同之处在于数据调度器901中的各单元是以8行的双向输出乘法器P2(例如是双向输出乘法器P2(1)~P2(64))来决定所要输出的数据流。亦即,浅维度数据流控制数据调度单元904在第一运算模式(例如是浅维度运算模式)下,根据输入数据的多个数据数值和多个卷积核的多个卷积数值,输出适用于8行的双向输出乘法器P2的第一数据数值数据流与第一卷积数值数据流,并通过多工器908与数据馈入单元910输出至多个双向输出乘法器P2(例如是双向输出乘法器P2(1)~P2(64))。
本公开卷积神经网络运算装置,在运算模组阵列中使用双向运算模组,在双向运算模组中采用单输入双输出方向的乘法器,并且搭配数据调度器在深维度运算和浅维度运算两种模式下不同的数据流分配,使卷积神经网络运算装置能有效兼顾深、浅维度的卷积运算。本公开的实施例可保持原本深维度卷积运算时乘法器高使用效率,且同时可以达成浅维度卷积运算时的可选择性地让未参与运算的单向行乘法器和行输出累加器进入省电模式以节省电能,并大幅提高乘法器的使用效率。例如,以图1所示的8X8公知架构运算单层深度(depth-wise,DW)卷积神经网络运算时,仅有1/64的乘法器使用率,而使用图9A的架构则可达到64/64的乘法器使用率。
综上所述,虽然本公开已以实施例公开如上,然其并非用以限定本公开。本公开所属技术领域中具有通常知识者,在不脱离本公开的精神和范围内,当可作各种的更动与润饰。因此,本公开的保护范围当视后附的权利要求书所界定者为准。
【符号说明】
200:卷积神经网络运算装置
IM:输入数据
KR、K(1)~K(4):卷积核
RSTA(1)~RSTA(8):第一卷积结果
RSTB(1)~RSTB(8):第二卷积结果
101、203、801、901:数据调度器
103、205、803、903:运算模组阵列
207、105:单向运算模组
P1(1)~P1(56):单向输出乘法器
17:双向运算模组
P2(1)~P2(64):双向输出乘法器
25:行输出端口
27:列输出端口
ACR(1)~ACR(8):行输出累加器
ACC(1)~ACC(8):列输出累加器
502~548:流程步骤
Cube1~Cube8:立体方块
202、802、902:数据维度判断与控制单元
204、804、904:浅维度数据流控制数据调度单元
206、806、906:深维度数据流控制数据调度单元
208、808、908:多工器
210、212、810、812、910:数据馈入单元
- 运算装置、运算装置的椭圆标量乘法方法、椭圆标量乘法程序、运算装置的剩余运算方法、剩余运算程序、运算装置的零判定方法以及零判定程序
- 运算装置、运算装置的椭圆标量乘法方法以及运算装置的剩余运算方法