一种采用标准化流的双向计算机辅助发音训练方法及设备
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于计算机辅助语音处理领域,尤其针对计算机辅助发音的反馈及校正,具体涉及一种采用标准化流的双向计算机辅助发音训练方法及设备。
背景技术
第二语言(L2)学习者可能由于语言迁移(在第二语言学习中,学习者在使用第二语言时,借助于第一语言(L1)的发音、词义、结构规则或习惯来表达思想)、错误的字母到声音转换等情况而产生错误的发音。
计算机辅助发音训练(CAPT)是一项重要的技术,它能够通过计算机检测错误发音并且提供反馈,为L2学习者提供有效的教育服务。CAPT能够通过计算机检测错误发音并且提供反馈,为L2学习者提供有效的教育服务。但是到目前为止,大多数现有的CAPT方法基本只专注于检测错误发音的位置,而不能给予学习者正确发音的指导,使他们无法学习正确的发音。然而,关于CAPT中基于语音的教学的讨论很少。尽管错误发音检测很重要,但仅仅知道错误位置对于语言学习是不够的,没有正确发音的指导,学习者只会盲目尝试。
发明内容
为解决现有技术存在的上述技术问题,本发明提供一种采用标准化流的双向计算机辅助发音训练方法及设备,在检测错误发音的同时也能够生成正确的发音。本发明提出的新颖的双向CAPT方法,即BiCAPT(Bidirectional CAPT,即双向CAPT方法),在检测错误发音的同时能够生成正确的发音,并且通过校正原始发音而不是完整的文本到语音(TTS)生成得到最终的语音。这样做既可以使L2学习者在语言学习的过程中有效地找到自己的错误读音并对其进行校正,又可以保留原始的说话风格。
本发明采用的技术方案是:
一种采用标准化流的双向计算机辅助发音训练方法,其特征在于,包括以下步骤:
S1:输入频谱通过标准化流生成输入的隐变量;
S2:检测模型检测出错误发音;
S3:通过时间检测得到持续时间;
S4:错误发音的音素通过校正模型生成一个新的隐变量序列;
S5:通过融合器将两个隐变量融合生成校正后的隐变量;
S6:通过标准化流转换回校正频谱。
进一步的,所述步骤S1的具体过程为:输入频谱通过标准化流,以说话人向量为条件,生成输入的隐变量;说话人向量使模型能更好地适应说话人的变化;通过使用仿射操作确保标准化流的双射性;
标准化流通过使用可逆变换充当频谱特征空间X和语言隐变量空间Z之间的双射器;标准化流在频谱x和隐变量z之间应用了一系列可逆变换函数f:
/>
同样频谱x可通过以下公式获得:
以上的转换以说话人向量s作为条件,通过使用仿射操作来保证双射性;对于文本到语音的生成,所有语音生成模型都设置为具有相同超参数的Glow-TTS(基于标准化流的并行化语音生成模型)主干;该模型将目标音素编码为z,并使用等式(2)将z转换为x,因此,z中包含语言特征。
进一步的,所述步骤S2的具体过程为:使用基于识别的方法进行检测,检测模型识别输入语音的发音音素,然后将识别的音素与目标文本对齐,不匹配的被标记为错误的发音。
进一步的,语音识别用Transformer(利用注意力机制来提高模型训练速度的模型)结构进行,使用隐变量作为Transformer编码器的输入;每个Transformer编码器层,设置注意力维度d
进一步的,所述步骤S3中是通过对齐图A搜索单调对齐路径获得每个音素的持续时间。
进一步的,所述步骤S4的具体过程为:使用正确发音的话语来训练模型以根据目标音素生成相应的隐变量;校正模型采用Glow-TTS作为主干,使用检测模型的交叉注意力图进行对齐。
进一步的,所述步骤S5的具体过程为:在融合器中,将步骤S1与步骤S4中生成的两个隐变量对齐进行融合,将步骤S1中隐变量检测出来错误的位置用步骤S4中相应的部分进行替换,再附加上持续时间,最终生成校正后的隐变量。
进一步的,所述方法使用数据集Librispeech(包含文本和语音的有声读物数据集)作为训练数据集,使用来自数据集L2-Arctic的3599条人工注释话语作为测试集,评估错误检测以及语音生成方面的性能。
一种设备,其特征在于,所述设备包括Adam(Adaptive Moment Estimation,自适应矩估计)优化器和热身学习调度器,所述的Adam优化器和热身学习调度器应用于如权利要求1-8中任意一项所述的方法在实验使用的所有检测模型和校正模型中。
进一步的,还包括Parallel-WaveGAN(无蒸馏的对抗生成网络,快速且占用空间小的波形生成方法)声码器,所述Parallel-WaveGAN声码器用于在语音生成性能的评估中将所有生成的语音转换为频谱,再进行重建。
与现有技术相比,本发明的有益效果体现在:
本发明的BiCAPT可以在检测错误发音的同时生成正确的发音,给予L2学习者更加有效的帮助,这点是在目前绝大部分的CAPT方法的基础上做了非常大的改进和提升;同时BiCAPT在具有较少模型参数的情况下能够实现较好的检测结果;通过实验可以证明,BiCAPT可以达到较好的F1分数(用来衡量模型精确度和召回率的一种指标),但与其他模型相比,BiCAPT使用的模型参数更少。BiCAPT还可以在不同的CAPT要求下生成自然语音;通过广泛的实验证明了本发明是一种很有前途的CAPT方法。
附图说明
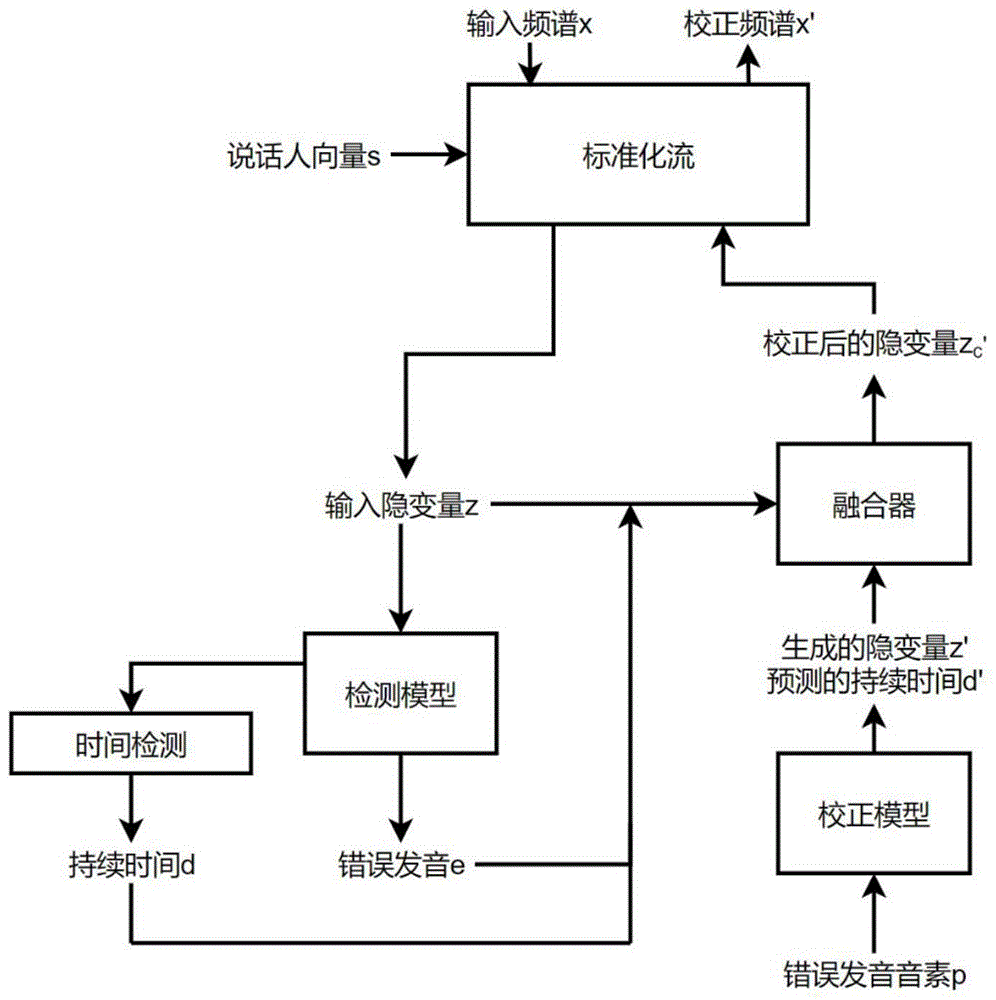
图1是本发明用于错误发音检测与校正的流程图。
具体实施方式
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面将参考附图并结合示例性实施例来详细说明本发明。
参考图1,本发明的一种采用标准化流的双向计算机辅助发音训练方法,包括以下步骤:
S1:输入频谱通过标准化流生成输入的隐变量;
S2:检测模型检测出错误发音;
S3:通过时间检测得到持续时间;
S4:错误发音的音素通过校正模型生成一个新的隐变量序列;
S5:通过融合器将两个隐变量融合生成校正后的隐变量;
S6:通过标准化流转换回校正频谱。
在一种实施例中,所述步骤S1的具体过程为:输入频谱通过标准化流,以说话人向量为条件,生成输入的隐变量;说话人向量使模型能更好地适应说话人的变化;通过使用仿射操作确保标准化流的双射性;
标准化流通过使用可逆变换充当频谱特征空间X和语言隐变量空间Z之间的双射器;标准化流在频谱x和隐变量z之间应用了一系列可逆变换函数f:
同样频谱x可通过以下公式获得:
以上的转换以说话人向量s作为条件,通过使用仿射操作来保证双射性;对于文本到语音的生成,所有语音生成模型都设置为具有相同超参数的Glow-TTS主干;该模型将目标音素编码为z,并使用等式(2)将z转换为x,因此,z中包含语言特征。
在一种实施例中,所述步骤S2的具体过程为:使用基于识别的方法进行检测,检测模型识别输入语音的发音音素,然后将识别的音素与目标文本对齐,不匹配的被标记为错误的发音。
在一种实施例中,语音识别用Transformer结构进行,使用隐变量作为Transformer编码器的输入;每个Transformer编码器层,设置注意力维度d
在一种实施例中,所述步骤S3中是通过对齐图A搜索单调对齐路径获得每个音素的持续时间。
在一种实施例中,所述步骤S4的具体过程为:使用正确发音的话语来训练模型以根据目标音素生成相应的隐变量;校正模型采用Glow-TTS作为主干,使用检测模型的交叉注意力图进行对齐。
在一种实施例中,所述步骤S5的具体过程为:在融合器中,将步骤S1与步骤S4中生成的两个隐变量对齐进行融合,将步骤S1中隐变量检测出来错误的位置用步骤S4中相应的部分进行替换,再附加上持续时间,最终生成校正后的隐变量。
在一种实施例中,所述方法使用数据集Librispeech作为训练数据集,使用来自数据集L2-Arctic的3599条人工注释话语作为测试集,评估错误检测以及语音生成方面的性能。
本发明的一种设备,所述设备包括Adam优化器和热身学习调度器,所述的Adam优化器和热身学习调度器应用于上述所述的方法在实验使用的所有模型中。
在一种实施例中,还包括Parallel-WaveGAN声码器,所述Parallel-WaveGAN声码器用于在语音生成性能的评估中将所有生成的语音转换为频谱,再进行重建。
图1是根据本发明的实施方式的用于错误发音检测与校正的流程图。输入的频谱x通过标准化流并附加上说话人向量s,生成输入的隐变量z,检测模型找出该隐变量中的错误发音e并通过时间检测得到持续时间d。错误发音的音素p通过校正模型生成一个新的隐变量序列z’并附加上预测的持续时间d’,再通过融合器与z融合生成校正后的隐变量z
标准化流通过使用可逆变换充当频谱特征空间X和语言隐变量空间Z之间的双射器。标准化流在频谱x和隐变量z之间应用了一系列可逆变换函数f:
同样频谱x可通过以下公式获得:
以上的转换以说话人向量s作为条件,通过使用仿射操作来保证双射性。对于文本到语音的生成,该模型将目标音素编码为z,并使用等式(2)将z转换为x。因此,z中包含语言特征。对于语音到错误的检测,输入频谱x通过使用公式(1)转换为z。检测模型强制z带有语言特征,以便模型可以区分音素。因此,生成和检测训练共享z是适用的。
错误检测模型:
本发明使用基于识别的方法进行发音错误检测。检测模型识别输入语音的发音音素,然后将识别的音素与目标文本对齐,不匹配的被标记为错误的发音。例如,学生试图学习单词“apple”(它的音素是“AE PAH L”),但将其误读为“AE PAO L”。该模型识别出发音的“AO”与目标“AH”不同,因此将“AH”判断为错误。我们采用Transformer结构进行识别,使用隐变量z作为Transformer编码器的输入。标准化流可以视为将频谱x转换为高级语言z的前端特征提取器。说话人向量s有助于模型能更好地适应说话人话语的变化。与传统的基于Transformer的模型相比,更少的编码器足以进行识别。
校正模型:
本发明使用正确发音的话语来训练模型以根据目标音素生成相应的隐变量,采用Glow-TTS作为主干,主要区别在于本发明没有应用原始的单调对齐搜索(MAS)来对齐音素级特征和频谱级的隐变量。相反,我们使用检测模型的交叉注意力图进行对齐。
为了评估本发明在错误检测以及语音生成方面的性能,已经使用了数据集Librispeech作为训练数据集,并使用来自数据集L2-Arctic的3599条人工注释话语进行测试。将24kHz原始波形转换为80维的对数梅尔谱(nFFT=2048,nwin=1200,nhop=300)进行实验,将Adam优化器与热身学习调度器应用在实验使用的所有模型中,从输入语音中提取X-vector作为说话者向量,将所有语音生成模型都设置为具有相同超参数的Glow-TTS主干。
检测性能的评估。使用F1分数作为主要的检测性能指标。为了证明共享潜在值是有效的,将BiCAPT与使用单独的Transformer模型的级联检测校正方法进行了比较。对于每个Transformer编码器(或解码器)层,设置注意力维度d
表1示出了未带卷积模块与带有卷积模块测试结果。通过将带有语言特征的隐变量共享于检测模型中,BiCAPT得到了较好的F1分数,并且只使用了两个编码器层。表1中Conv表示卷积模块,GW表示高斯加权。
表1未带卷积模块与带有卷积模块测试结果对比
语音生成性能的评估。需要注意的是,可以通过改变校正条件来切换校正粒度以满足不同的CAPT要求。为了证明粒度的影响,使用两组不同的错误标签e来进行基于校正方法的评估。一个是来自检测模型的预测,另一个是来自数据集L2Arctic的注释。由于检测模型仅在标准数据集Librispeech上进行训练,因此L2Arctic中某些正确的发音将被归类为误报。换句话说,更多的音素将被判断为发音错误,然后进行纠正。对于来自L2Arctic的注释,某些错误发音会被忽略并主观标记为正确。下面将从内容和风格方面评估性能。对于内容,生成的语音应该是与目标文本相匹配的标准发音。为了评估这种性能,使用在标准数据集上训练的单词级自动语音识别系统来测试单词错误率(WER),使用平均意见分数(MOS)来评估主观表现,使用说话人编码器余弦相似度(SECS)来计算生成语音和原始输入语音之间的说话人向量的相似度,使用梅尔倒谱失真(MCD)来评估两种语音的频谱之间的兼容性。为了公平比较,将所有生成的语音都被转换为频谱,再使用相同的Parallel-WaveGAN声码器进行重建。
表2示出了各个训练方法测试结果。原始输入、Google TTS和主干Glow-TTS的指标列在第一组中以供参考。第2组和第3组用于比较基于光谱的校正和本发明提出的方法。通常,在WER和其他指标之间存在权衡。如果更多的发音被修改为生成的发音,WER会降低,但原始信息也会丢失,从而导致其他性能下降。反之亦然,在更细的粒度下生成保留了更多的原始语音,因此MOS,SECS和MCD得到改善。对于第2组,直接修改错误发音音素的对应谱会产生不一致的现象。相比之下,本发明提出的方法修改了内部的隐变量。隐变量通过标准化流进一步转换以生成更自然的频谱。在相同粒度下,与基于频谱的模型相比,BiCAPT实现了更好的MOS和WER。表2中Anno表示使用来自L2Arctic的注释标签作为错误标签e,Det表示使用检测结果作为错误标签e。
表2各个训练方法测试结果对比
本发明将判别错误发音的检测和用于生成语音的TTS模型结合起来用于CAPT。具体来说就是检测并纠正错误的发音再给予学习者有关错误发音的反馈。本发明应用校正而不是完整的TTS生成,可以更好地保留原始说话风格。此外,为了充分利用CAPT的内部语言特征,本发明采用标准化流来建立频谱和隐变量之间的映射。由于映射是双向的,因此判别任务和生成任务可以共享隐变量,使结构更加紧凑。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。