面向MRI影像的多中心数据校正方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及计算机应用技术领域,具体涉及一种面向MRI影像的多中心数据校正方法。
背景技术
fMRI技术(Functional Magnetic Resonance Imaging,功能磁共振成像技术)自20世纪90年代早期诞生以来取得了长足的发展,现已成为临床及学术研究精神科学必不可缺的研究工具。通过测量人脑的血氧水平依赖(Blood oxygenation level dependent,Bold)信号,fMRI脑影像可以量化大脑代谢区域性和时域性变化,从而反应大脑的健康状态。其中,Resting-state fMRI技术(rs-fMRI,静息态功能磁共振成像技术)可以反映人体在安静状态下大脑的自发性活动,已经被广泛应用于研究精神分裂症、孤独症、阿尔兹海默症、重型抑郁症等神经精神疾病。
虽然越来越多的精神医学研究基于fMRI数据展开,但是由于fMRI脑影像数据获取成本较高,因此大多数中心被试数据量往往较少。例如国际最大的多中心重型抑郁症数据集Rest-meta-MDD中共包含来自25个中心2438个被试的数据,其中只有7个中心的被试数据量大于等于100例,而且数据量最少的中心只有24例数据。而Turner等人的研究表明,小样本量降低了task-based fMRI(基于任务的功能磁共振成像)研究的可复制性,并且作者提倡使用更大样本量的数据进行研究。进一步,Button等人的研究也揭露出基于小样本数据的生物医学研究中所产生的问题,作者指出,在生物医学领域,小样本数据所产生的研究结果假阳性率很高,并且可重复率以及统计效力都很低。
研究表明,不同中心的脑影像数据存在差异,这种差异严重阻碍了脑影像数据的跨中心整合分析,这也使结果的可重复性以及统计效力大大降低。多中心脑影像数据间的差异主要可以归结为以下两点:
1)中心效应(site effects),即由于各中心核磁共振设备型号、扫描参数等差异,造成的各中心功能磁共振影像数据差异。如Fortin等人在2018年发表在NeuroImage上的文章详细展示了来自两个多中心研究中的11台核磁共振扫描仪的扫描仪效应(scannereffects),文章指出扫描设备的磁场强度、生产厂商、被试的扫描姿势等等都会对脑影像的各项测量值有影响。
2)患者人群分布的差异,也是造成各中心功能磁共振影响数据差异的另一个重要原因。由于各中心的患者收录标准不同、地域差异等原因,造成了各中心就诊人群分布的差异。例如,本文收集到的Center2中心的重型抑郁症数据,患者被试主要由18岁以下的青少年组成。既往的研究发现,年龄与fMRI数据的改变息息相关。特别的,针对不同病种的精神疾病,其脑影像数据会呈现不同的模式。如Yang等人的研究表明,从fALFF(Fractionalamplitude of low-frequency fluctuation)数据上看,精神分裂症患者的组间变化主要发生在腹外侧前额叶皮质、纹状体和丘脑,而重型抑郁症患者的组间变化则主要发生在左侧运动皮质和顶叶。
发明内容
为了克服现有技术上的缺陷,本发明提出了一种面向MRI影像的多中心数据校正方法。本方法从配准后的脑影像数据开始,避免了预处理流程的不同所造成的数据差异,从根本上对数据进行校正,只需一次校正,能够作用到后续处理的所有特征数据。通过本文的基于移动样本的多中心数据校正算法,借助移动被试数据,可以从整体上减少多中心静息态核磁共振数据间的差异。
本发明采取的技术方案是:一种面向MRI影像的多中心数据校正方法,其包括如下步骤:
步骤1、数据收集,
收集各中心独立扫描的被试数据,并额外招募健康状态相同的移动被试,分别在各中心进行扫描;
步骤2、数据预处理,
收集到数据后,先对每个中心数据进行统一的预处理;
步骤3、扫描参数校正,
得到配准后的脑影像数据后,对参数进行校正,得到统一规格的多中心脑影像数据;
步骤4、基于移动样本的多中心数据校正算法对数据进行校正,
所述算法分成两步:第一步,为特征建立回归方程,利用全部被试数据估计特征的均值、方差以及生物学变量系数等,第二步,单独利用移动被试数据估计回归方程中的中心效应因子。
进一步的,步骤1中,不仅收集了各中心独立扫描的被试数据,而且为了更好的校正效果,还额外招募了一批健康状态相同的移动被试,分别在各中心进行扫描。
进一步的,步骤2中,收集到数据后,因为原始数据具有扫描噪声、扫描层错位、被试头动、大脑大小不一致等问题。因此在数据校正前,需要先对每个中心数据进行统一的预处理。预处理主要分为如下4个步骤:
(1)去除前10个时间点数据。由于被试刚进入扫描状态时需要适应扫描环境以及梯度磁场的稳定性等问题,按照惯例,需要去除前10个图像噪声较多的时间点数据,保留之后扫描较为稳定的时间点数据进行后续的分析研究;
(2)扫描层顺序调整:在核磁共振扫描时,为了避免相邻层间频谱域的部分重叠而产生串扰现象,通常采用隔层扫描的方式。因此需要对扫描层顺序进行调整,将扫描层标号从小达到依次排列;
(3)头动校正:在扫描过程中,难免会出现被试头部移动的情况。如果不做处理,则会出现影像偏移,进而影响数据质量。因此需要做头动校正,用算法将头动校正回原始角度;
(4)配准到蒙特利尔空间:由于不同被试的大脑大小、形状存在差异,会使不同被试的相同脑组织出现错位的情况。为了解决这个问题,需要将所有被试的脑图像都配准到标准蒙特利尔空间,使得相同脑结构都处于同一空间位置。
进一步的,步骤3中,得到配准后的脑影像数据后,由于不同中心设备扫描参数的差异会反映到脑影像数据上,因此本文选择了几个重要的参数进行校正,在减少一部分差异的前提下,得到统一规格的多中心脑影像数据。在扫描参数中,射频脉冲激发间隔时间TR表示一次全脑扫描所需要的时间,扫描层数Slices表示在一次全脑扫描过程中,共分成了多少层来进行扫描,而扫描时间点TP则表示进行了多少次的全脑扫描。本发明将各中心的射频脉冲激发间隔时间记作TR
更进一步的,首先,对来自中心m编号为n
以两个中心为例,本发明在对实验所使用的两个中心Center1和Center2做扫描参数校正时,具体步骤如下。Center1中心共进行了200个时间点的全脑扫描,其中射频脉冲激发间隔时间为2000毫秒即一次全脑扫描的时间为2000毫秒,而Center2中心的数据则进行了960个时间点的扫描,且一次全脑扫描时间为500毫秒。本文按上述方法对扫描参数进行校正,首先,以Center1中心的一次全脑扫描的时间为基准,将Center2中心的一次全脑扫描的时间调整为2000毫秒,但是在2000毫秒中,Center2进行了4次全脑扫描,本文对这四次全脑扫描数据取均值,并把它当做一次2000毫秒时间间隔的扫描结果,这样Center2的扫描时间点总数就变成了230。之后,以Center1的190个时间点总数为基准,取Center2前190个时间点数据。经过上面的两个步骤,本文就对两个中心的扫描时间点和射频脉冲激发间隔时间做了统一。这样做的目的是为了统一两个中心的数据规格,以方便后续的数据校正操作。。
进一步的,步骤4中,提出一种新颖的面向磁共振脑影像的多中心数据校正方法,校正过程在完成配准与参数校正后的数据上进行。假设,同一被试在不同中心扫描得到的脑影像数据应该相同。基于上述假设,利用额外招募的移动被试数据以及各中心已有的独立扫描数据来进行多中心数据校正。算法主要分成两步,第一步,为特征建立回归方程,利用全部被试数据估计特征的均值、方差以及生物学变量系数等,第二步,单独利用移动被试数据估计回归方程中的中心效应因子。
更进一步的,校正算法为每个大脑体素特征值建立回归公式,用y
中心效应因子分为两个部分,一个是加和因子,一个是乘法因子。首先,
其次,δ
在计算时,由于移动被试数量较少,不能代表数据的整体分布,单独使用移动被试数据去估计特征均值α
之后通过经验贝叶斯算法估计加和及乘法因子γ
与之前的做法不同,之前的研究者在使用ComBat校正多中心核磁影像数据时,一般只是选用各自中心独立扫描的被试数据进行回归变量估计,计算时也只是考虑了不同被试间年龄、性别等可以量化的生物学变量,而忽略了其他因素如心理健康状态、生理健康状态等,这会影响回归变量的估计结果。理想的做法是,全部使用健康状态一致并且在多中心进行扫描的移动被试数据来估计回归变量,但这样的实验成本高昂,难以实现。因此,本文的数据校正算法尝试结合已有的独立在各中心扫描的被试数据以及移动被试数据来进行回归方程的变量估计。本文对被试的每个时间点数据使用AAL90(Automated AnatomicalLabeling)模板进行过滤,只保留大脑区域体素从而去除小脑以及非脑部区域体素。这样做不仅可以减少校正时的计算量,而且因为后续一些列分析以及特征数据也只使用大脑区域体素,因此不影响结果。最后,本文将每个被试校正后的大脑区域体素与其校正前的小脑以及非脑部区体素结合,还原成Bold信号数据
与现有技术相比,本发明的有益效果是:鉴于传统的ALFF、ReHo以及FC等数据在不同的预处理流程下会呈现完全不同的结果,本发明从配准后的脑影像数据开始,避免了预处理流程的不同所造成的数据差异,从根本上对数据进行校正,只需一次校正,能够作用到后续处理的所有特征数据。通过本发明的基于移动样本的多中心数据校正算法,借助移动被试数据,不仅从整体上减少了多中心数据见的差异,而且对于移动被试的优化也取得了最优的结果。
附图说明
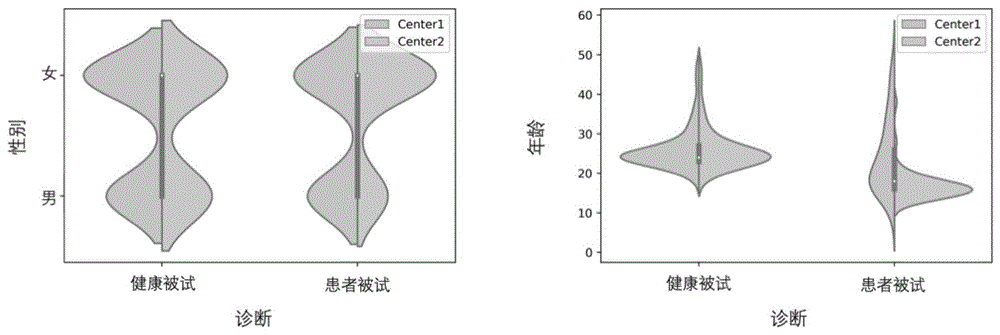
图1是本发明实施例中两个中心性别年龄数据图;
图2是本发明实施例中校正前后Bold信号数据数值分布图;
图3是本发明实施例中5校正前后ALFF和ReHo数据数值分布图;
图4是本发明实施例中校正前后数值分布Wasserstein距离比例图;
图5是本发明实施例中校正Bold信号数据散点图;
图6是本发明实施例中校正前后ALFF和ReHo数据散点图;
图7是本发明实施例中距离度量结果图;
图8是本发明实施例中校正前后t检验结果图;
图9是本发明实施例中效应量结果图。
具体实施方式
下面结合实施例,对本发明的具体实施方式作进一步详细描述。
本实施例提供一种面向MRI影像的多中心数据校正方法,首先,本方法额外招募了一批健康状态相同的移动被试,分别在多个中心进行扫描,并整合了各中心独立扫描数据以及移动被试数据,其次,本方法对多中心数据进行了预处理,将数据配准到标准蒙特利尔(Montreal Neurological Institute,MNI)空间,以对被试的大脑组织特征进行对齐,再次,本方法进行了扫描参数校正,消除了一部分数据差异,并统一了数据规格,最后,本方法采用基于移动样本的多中心数据校正算法对数据进行校正,更好地消除了由不同扫描设备、扫描参数等中心效应对数据的影响。下面对本发明的实施应用进行具体介绍:
一、数据集介绍
本方法一共收集了Center1和Center2共两个中心309个被试的静息态功能磁共振数据,其中Center1包含206例数据,其中有100例精神分裂症患者被试以及106例健康对照被试,Center2包含103例数据,其中有50例重型抑郁症症患者以及53例健康对照被试。最小的被试年龄为8岁,最大的被试年龄为51岁,收集的数据一共包括有125名男性被试以及184名女性被试。在这些被试中,有6个健康被试分别在Center1和Center2两个中心进行了扫描,并且在两中心的扫描时间间隔均小于20天。两个中心的核磁共振扫描设备分别为CEHDxT 3T和西门子Magnetom Prisma 3.0T,详细的扫描参数如表1所示。在这些参数中,Scanner表示扫描仪的品牌和型号,TR(ms)表示两次射频脉冲激发的间隔时间,TE(ms)即Echo Time表示射频脉冲激发到形成最大回波的时间,FOV(mm2)即Field-of-view表示获取MR图像的成像范围也称为视野,Slices表示扫描的层数,Thickness(mm)表示扫描层的厚度,Gap(mm)表示两层扫描的层间距,Time Points表示扫描的时间点总数。
从图1可以看出,在年龄层面,两个中心的患者被试具有很大差异,并且针对年龄的独立双样本t检验结果也呈显著性(P<0.001),而健康被试则差异不明显,同时独立双样本t检验结果也没有显示出显著性(P>0.05),在性别层面,两个中心的患者被试和健康被试差异很小,并且针对性别的独立双样本t检验结果也都没有呈现出显著性(P>0.05)。为了尽量避免引入因为患者收录标准不同所造成的人群分布差异以及病种差异,数据校正和分析只局限在各个中心的健康对照数据上进行。
表1两个中心扫描设备型号以及主要参数
二、数据预处理与特征计算
本方法选择磁共振脑影像领域常用的数据预处理软件Dpabi(版本v4.3.200401)进行数据处理。在数据校正前,先对数据进行4步预处理操作,得到配准后的Bold信号数据。并且分别计算校正前后的ALFF和ReHo特征数据。其中预处理主要分为如下4个步骤:
(1)去除前10个时间点数据。由于被试刚进入扫描状态时需要适应扫描环境以及梯度磁场的稳定性等问题,按照惯例,需要去除前10个图像噪声较多的时间点数据,保留之后扫描较为稳定的时间点数据进行后续的分析研究。
(2)扫描层顺序调整。在核磁共振扫描时,为了避免相邻层间频谱域的部分重叠而产生串扰现象,通常采用隔层扫描的方式。因此需要对扫描层顺序进行调整,将扫描层标号从小达到依次排列。
(3)头动校正。在扫描过程中,难免会出现被试头部移动的情况。如果不做处理,则会出现影像偏移,进而影响数据质量。因此需要做头动校正,用算法将头动校正回原始角度。
(4)配准到蒙特利尔空间。由于不同被试的大脑大小、形状存在差异,会使不同被试的相同脑组织出现错位的情况。为了解决这个问题,需要将所有被试的脑图像都配准到标准蒙特利尔空间,使得相同脑结构都处于同一空间位置。
三、扫描参数校正
得到配准后的脑影像数据后,由于不同中心设备扫描参数的差异会反映到脑影像数据上,因此本文选择了几个重要的参数进行校正,在减少一部分差异的前提下,得到统一规格的多中心脑影像数据。在扫描参数中,射频脉冲激发间隔时间TR表示一次全脑扫描所需要的时间,扫描层数Slices表示在一次全脑扫描过程中,共分成了多少层来进行扫描,而扫描时间点TP则表示进行了多少次的全脑扫描。本文将各中心的射频脉冲激发间隔时间记作TR
首先,对来自中心m编号为n
四、基于移动样本的多中心数据校正算法对数据进行校正
算法主要分成两步,第一步,为特征建立回归方程,利用全部被试数据估计特征的均值、方差以及生物学变量系数等,第二步,单独利用移动被试数据估计回归方程中的中心效应因子。
校正算法为每个大脑体素特征值建立回归公式,用y
中心效应因子分为两个部分,一个是加和因子,一个是乘法因子。首先,
其次,δ
在计算时,由于移动被试数量较少,不能代表数据的整体分布,单独使用移动被试数据去估计特征均值α
之后通过经验贝叶斯算法估计加和及乘法因子γ
五、对校正结果进行验证
在校正结果分析过程中,本实施例将在校正环节中使用ComBat算法的方法称为“方法一”,而在校正环节中采用基于移动样本的多中心数据校正算法的方法称为“方法二”。结果验证将从两部分进行,一部分是数据整体的校正效果验证,将分别从数值分布图、散点图、数值独立双样本t检验等方面来进行,另一部分则是从6名移动被试入手,在个体级别做校正效果验证。
(1)数据维度处理
在实验中,主要使用了标准蒙特利尔空间的Bold信号数据以及预处理后的ALFF和ReHo数据等三个模态数据进行结果展示。在进行数值分布图、数据散点图以及数据t检验分析时,由于Bold信号数据的维度过大,在不影响整体效果的前提下,采用对扫描时间点维度取均值的方式来减小维度,从而将每个被试的数据矩阵大小由61*73*61*190减小到61*73*61,以方便后续的分析处理。
(2)数值分布图
通过数值分布图可以从整体上直观的感受各中心数值分布变化情况,其中横坐标表示体素值,纵坐标表示体素值的密度。针对校正前后的Bold信号数据以及ALFF和ReHo数据,绘制了数值分布图,来观察校正前后的数值分布变化情况。另外,还分别计算了校正前后两个中心数值分布的Wasserstein距离,用来衡量两个分布的相似度,Wasserstein距离越小说明分布越相近数据差异越小,反之则数据差异越大。在计算时分别将校正前每个模态的两中心分布的Wasserstein距离当做标准,计算校正后Wasserstein距离与该标准的比值。
从图2可以清晰地看出,在Bold信号数据上,校正前两个中心的Bold信号数据数值分布具有较大差异,而在使用校正方法对数据校正后,可以发现两中心的分布峰值以及数值分布范围明显缩小。其中,在使用方法一校正后,Bold信号数据的分布的峰值差异缩小最为明显,两中心具体数值的分布范围也趋于一致。同样的,在使用方法二校正后,Bold信号数据的分布峰值的差异差异也大大缩小,数值分布范围相比原来也同样缩小。从图4也可以看出,经过校正后两中心分布的Wasserstein距离大幅下降,分布明显差异减小。这说明,从数值分布上看,校正方法一和方法二都能较好的对数据做校正。
另外,做数据校正的主要目的是为特征数据服务,接下来将对比校正前后,数据预处理得到的ALFF和ReHo两种特征数据的变化情况。从图3可以看到,在数据校正前,两种模态数据的数值分布峰值以及形态都具有较大差异,这种差异造成了多中心数据的跨中心数据融合以及模型应用的隔阂。而从校正后的结果看,方法一成功地缩小了两个中心两种模态数据间的数值分布峰值以及形态差异。同时,方法二也成功地减少了两个中心两种特征数据分布的峰值以及形态差异。从图4也可以看出,经过校正后ALFF和ReHo两种特征数据的两中心分布Wasserstein距离大幅下降,分布差异减小。
综合数值分布图的结果可以发现,校正方法一和方法二对Bold信号数据做校正后,两中心的数值分布差异显著减小,并且使用两中心校正后数据预处理得到的ALFF和ReHo数据的数值分布差异也大大减小。至于校正后的两中心数据并没有处于同一分布的问题,本实施例认为这是由健康人中的个体差异引起的,在健康人中也存在生理以及心理状态的差异问题,这种差异会反应到脑影像数据上,因此校正后数值分布并不会完全一致。
(3)数据散点图以及移动被试距离度量
通过散点图可以从整体上观察多中心数据的分布情况,而且也可以从个体的角度观察被试间的关系。本实施例选用经典的可视化降维算法Isomap,将高维的Bold信号数据以及ALFF和ReHo数据降到2维。该算法能够保证在降维后的低维空间内,样本间原有的相对距离保持不变,从而保证降维后能够还原原始高维空间数据间的关系。
同时,还对移动被试的数据点进行了放大处理,并且进行了特殊的标注,用编号Ci-j表示,其中i=1,2表示中心编号,j=1,2,3…6表示移动被试编号,从而观察校正前后,移动被试的数据点变化情况。另外,为了保证校正前后散点数据的可比较性,本实施例分别使用校正前的Bold信号数据、ALFF以及ReHo数据训练Isomap降维模型,然后将训练好的模型应用于两种校正方法校正后数据的降维过程中。并且为了更清楚的观察数据变化情况,本文对于相同模态的数据采用同一坐标尺度进行展示。
从图5可以看出,数据校正前,不同中心Bold信号数据的数据点分布形态具有非常显著的差异,不同中心间数据点距离较远,中心间分界明显。而经过方法一和方法二的校正后,两中心数据间的差异都明显减小,数据基本分布在同一区域,并且方法二校正后的散点图可以清晰的看出,两个中心的6名移动被试数据点散落在距离相近的位置。而且从图6校正前后ALFF和ReHo模态数据散点图可以看到,经过校正方法一和二校正后,两个中心中心数据点间距离显著减小,说明方法一和方法二成功减少了两中心数据间的差异。另外,6名移动被试数据点间的距离也明显减小,这在方法二的结果中更加明显。
针对图5以及图6校正前后的降维散点数据,分别计算6名移动被试Bold信号、ALFF以及ReHo数据在两个中心对应散点的欧式距离,以此来衡量每个被试数据的中心间差异大小。因为不同模态间距离的数量级差异,本文针对每个模态数据,选择以6名被试校正前数据的平均距离为标准,计算6名被试的平均距离比例。结果如7所示,从ALFF和ReHo数据看,两种方法校正后的平均距离比例都有明显下降,而且校正方法二的平均距离比例下降要更加显著,从Bold信号数据看,虽然方法一校正后缩小了两中心数据间的差异,但是6名移动被试的平均距离反而增大了,而方法二校正不仅减少了整体数据间的差异,而且6名移动被试间距离更是显著减小。这说明,校正方法二在独立扫描数据的基础上,借助移动被试数据,实现了更好的校正效果。
(4)特征值独立双样本t检验
针对大脑数据的每个体素点进行两个中心健康被试间的t检验,可以得到大脑差异体素的矩阵,从而判断校正前后,差异体素比例的变化情况。本实施例利用Dpabi软件进行Bold信号数据、ALFF以及ReHo数据的t检验,将显著性p值设置0.001,并对得到的结果进行GRF(高斯随机场)多重比较校正,获取到通过校正的t值矩阵即具有显著性差异数据的t值矩阵。最后计算校正后t值矩阵中差异体素占全脑体素的比例,以此来体现校正前后t检验结果差异的变化。
图8中校正前的结果可以发现,两个中心的Bold信号数据、ALFF以及ReHo数据的差异体素占全脑体素比例都是最高的。从校正后的结果看,采用方法一和方法二做校正后,三种模态数据的t检验差异数据值占全体数值的比例都有所下降,并且校正方法一在Bold信号数据校正后差异体素占比下降幅度最大。
(5)效应量变化
针对每种数据校正方法,利用6名移动被试数据做个体性验证。针对不同数据校正方法的每种数据模态,分别计算两个中心对应被试数据的Cohen's d效应量,用来统计每个人在两个中心数据的差异。Cohen's d效应量的具体公式如下:
其中,M
其中,N
从图9效应量计算的结果可以看出,除ALFF数据外,经过校正后的数据,6个被试的均值效应量都大幅度减小,尤其方法二对于6名被试的校正最为成功,其Cohen’s d效应量均值在两个模态上达到了最小,这也说明方法二通过借助移动被试这一校正“金标准”实现了更好的校正结果。而从ALFF数据的结构看,经过方法一和方法而校正后,效应量均值比例反而升高,本文认为这一现象是由于不同模态的计算过程中,对于数据差异的进一步放大导致的。
六、结果分析
从上面的几个指标综合来看,本实施例提出的从配准后的脑影像数据出发进行多中心数据校正的方法,能够在生成其他特征数据前进行数据的有效校正,一劳永逸,并且能够为下游特征以及各种分析任务提供可靠的支持。综合上面的一列结果看,使用本专利研发的基于移动样本的多中心数据校正算法不仅能够从整体上达到与使用ComBat校正算法相近的效果,而且对于移动被试的校正效果更加明显。这一现象也说明,健康人群中可能也存在因为生理或者心理健康状态差异造成的人群分布差异,从而使得校正并不能取得完全理想的效果。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域的普通技术人员应该了解,上述实施例不以任何形式限制本发明的保护范围,凡采用等同替换等方式所获得的技术方案,均落于本发明的保护范围内。
本发明未涉及部分均与现有技术相同或可采用现有技术加以实现。