基于游客评论数据聚类的景点主题自动分类方法及系统
文献发布时间:2024-01-17 01:27:33
技术领域
本发明涉及主题自动分类技术领域,特别涉及一种基于游客评论数据聚类的景点主题自动分类方法及系统。
背景技术
随着经济的发展,人们生活水平的提高,越来越多人选择外出旅游,旅游业也逐步繁荣。旅游景区的持续发展需要进行景点的主题分类,突出景区的灵魂与主线。鲜明的主题是旅游景区设计的旗帜和形象,是景区内涵的具体化,也是旅游景区策划的核心。因此,集聚吸引力,实现区域旅游经济的快速发展,“主题”起主导作用。
目前景点的主题分类是人工进行的。人工分类易受主观影响,导致分类结果有偏差;并且需要专家经验知识支撑,以及人工参与,人力资源消耗量大。
收集游客对旅游景点的评价的数据,基于游客评论数据聚类的景点主题自动分类方法的优点:
1)全自动,无需人工分类,提高了分类的速度;
2)客观,避免人工分类的主观臆断。
数据预处理是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为决策提供分析的依据。VSM(Vector Space Model)指向量空间模型,通过将文本都表示为特征词-权重向量形式,将非结构化的文本转化为结构化的计算机可以识别和处理的信息。TF-IDF(TermFrequency and Inverted Document Frequency)指词频-逆文档频率,将文本的特征项赋予权重。
文本挖掘以文本型信息源作为分析的对象,利用定量计算的方法,从中寻找信息结构、模型、模式等各种隐含的新颖知识,主要目标是获得文本的主要内容特征,如该方法涉及的旅游主题。K-Means++算法是在K-Means算法基础上改进的文本聚类算法,通过优化初始中心点的选择步骤,改善聚类效果。使用K-Means++算法,可计算文本之间的相似度,进而将文本划分为不同的簇。簇间的文本特征相异,簇内的文本特征相似。最后分析各簇特征项,确定景点主题分类。
发明内容
本发明的目的在于克服现有技术的不足,提供一种基于游客评论数据聚类的景点主题自动分类方法及系统,能够减少风景道沿线旅游主题人工分类的时间、提高主题分类的效率及准确率。
为了实现上述目的,本发明的技术方案是,一种基于游客评论数据聚类的景点主题自动分类方法,包括:
一方面,一种基于游客评论数据聚类的景点主题自动分类方法,包括:
S101,获取游客对景点的有效评论数据集A:{a
S102,基于所述有效评论数据集A:{a
S103,计算各特征项的权重,获得游客对景点的有效评论数据特征项的权重向量;
S104,基于特征项的权重向量,采用聚类算法,将有效评论数据划分为不同的簇;
S105,根据所述簇,分析各簇特征项,确定该类景点的主题词,完成景点主题的自动分类。
优选的,有效评论数据集A:{a
根据jieba分词,利用一个中文词库,确定汉字之间的关联概率,概率大的组成词组,形成分词结果,把游客对景点的有效评论数据a
根据停用词典,去除无意义词语保留名词,得到游客对景点的有效评论数据集A:{a
优选的,所述获取游客对景点的有效评论数据集A:{a
设有效评论数据集A:{a
根据定义
如果特征项t
其中,TF
根据公式TFIDF
获得游客对景点的有效评论数据集A:{a
其中,
优选的,所述聚类算法包括Kmeans++聚类算法;所述将有效评论数据集A:{a
S401,有效评论数据集A中的第m条有效评论数据a
S402,从w
S403,设已有的聚类中心数量为e,e=1,2,...,f,...,k,计算每个w
S404,计算每个w
S405,计算出每个w
S406,以每个个体的累计概率作为区间值,用轮盘法选出下一个聚类中心,方法包括随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的下一个聚类中心;
重复上述过程S403~S406,直到找到k个聚类中心,形成聚类中心集合Y:{Y
根据公式
根据重新计算每个子集的中心点,多次迭代,直至簇内平方和最小中心点不再改变,确定最终形成的簇C={C
优选的,所述的基于游客评论数据聚类的景点主题自动分类方法,还包括:
若有新的评论数据,将新的评论数据加入游客对景点的有效评论数据集中,重新进行上述步骤S101~S105,完成景点主题的自动分类。
另一方面,一种基于游客评论数据聚类的景点主题自动分类系统,包括:
有效评论数据集获取模块,用于获取游客对景点的有效评论数据集A:{a
文本特征项提取模块,用于基于所述有效评论数据集A:{a
特征词-权重向量计算模块,用于计算各特征项的权重,获得游客对景点的有效评论数据特征项的权重向量;
簇划分模块,用于基于特征项的权重向量,采用聚类算法,将有效评论数据划分为不同的簇;
主题词提取模块,用于根据所述簇,分析各簇特征项,确定该类景点的主题词,完成景点主题的自动分类。
上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
本发明一种基于游客评论数据聚类的景点主题自动分类方法及系统,能够减少风景道沿线旅游主题人工分类的时间、提高主题分类的效率及准确率。
以下结合附图及实施例对本发明作进一步详细说明,但本发明的一种基于游客评论数据聚类的景点主题自动分类方法及系统不局限于实施例。
附图说明
图1为本发明一种基于游客评论数据聚类的景点主题自动分类方法的流程图一;
图2为本发明K-Means++的簇划分方法的流程图;
图3为本发明一种基于游客评论数据聚类的景点主题自动分类方法的流程图二;
图4为本发明一种基于游客评论数据聚类的景点主题自动分类系统的结构框图。
具体实施方式
以下将结合本发明附图,对本发明实施例中的技术方案进行详细描述和讨论。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
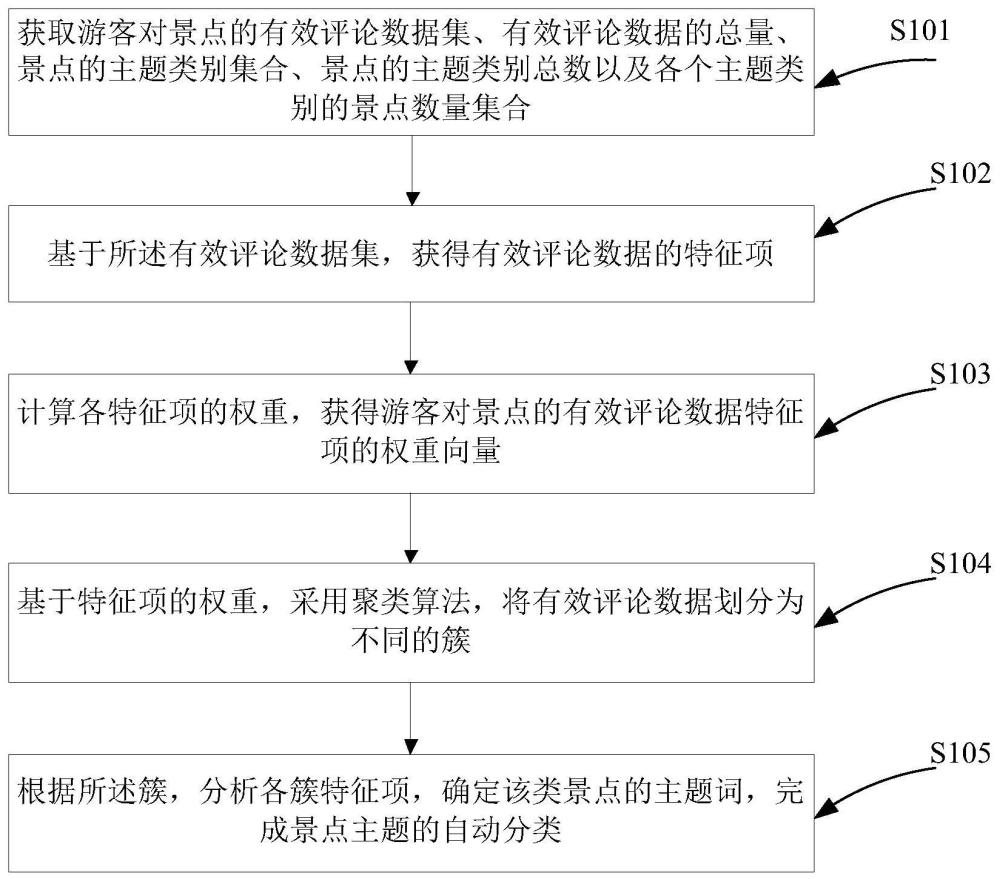
参见图1所示,本发明一种基于游客评论数据聚类的景点主题自动分类方法,其特征在于,包括:
S101,获取游客对景点的有效评论数据集、有效评论数据的总量、景点的主题类别集合、景点的主题类别总数以及各个主题类别的景点数量集合。
具体的,获取游客对景点的有效评论数据集A:{a
S102,基于所述有效评论数据集,获得有效评论数据的特征项。
具体的,根据jieba分词,利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果;将游客对景点的每条有效评论数据a
基于停用词典(包括哈工大停用词词库、四川大学机器学习智能实验室停用词库、百度停用词表与研究数据多次分词后出现的无意义词语),去除无意义词语,如“的”“了”等,保留名词得到游客对景点的有效评论数据集合A的特征项集合D:{D
S103,计算各特征项的权重,获得游客对景点的有效评论数据特征项的权重向量。
根据所述特征项,确定特征项的权重向量。
设有效评论数据集A:{a
据TF-IDF(Term Frequency and Inverted Document Frequency)词频-逆文档频率,将评论数据的特征项赋予权重;
其中,TF
其中,IDF
如果特征项t
TFIDF
基于VSM(Vector Space Model)指向量空间模型,将游客对景点的有效评论数据都表示为特征词-权重向量形式,将非结构化的评论数据转化为结构化的计算机可以识别和处理的信息。
获得游客对景点的有效评论数据集A:{a
其中,
S104,基于特征项的权重,采用聚类算法,将有效评论数据划分为不同的簇。
具体的,参见图2所示,本实施例根据K-Means++算法,将有效评论数据集A:{a
1)选择初始聚类中心
有效评论数据集A中的第m条有效评论数据a
从w
计算每个w
计算每个w
计算出每个w
以每个个体的累计概率作为区间值,用轮盘法选出下一个聚类中心,方法包括随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的下一个聚类中心;
重复上述过程,直到找到k个聚类中心,形成聚类中心集合Y:{Y
2)根据公式
将剩余的数据样本分入距离最近的中心点C
3)根据重新计算每个子集的中心点,多次迭代,直至簇内平方和最小中心点不再改变,确定最终形成的簇C={C
S105,根据所述簇,分析各簇特征项,确定该类景点的主题词,完成景点主题的自动分类。
参见图3所示,所述方法还包括:
若有新的评论数据,将新的评论数据加入游客对景点的有效评论数据集中,重新进行上述步骤,完成景点主题的自动分类。
评价方法和指标如下。
各簇的分类性能评价:
TP:真正例数量FP:假正例数量FN:假负例数量TN:真负例数量。
准确率(Accuracy):分类正确的样本个数占所有样本个数的比例,如下
平均准确率(Average per-class accuracy):每个类别下的准确率的算术平均,如下
精确率(Precision):分类正确的正样本个数占分类器所有的正样本个数的比例,如下
召回率(Recall):分类正确的正样本个数占正样本个数的比例,如下
漏检率(Mistake):每个类别w下的漏检率,如下
误检率(Omiting):每个类别w下的误检率,如下
F
参见图4所示,另一方面,本发明公开了一种基于游客评论数据聚类的景点主题自动分类系统,包括:
有效评论数据集获取模块401,用于获取游客对景点的有效评论数据集A:{a
文本特征项提取模块402,用于基于所述有效评论数据集A:{a
特征词-权重向量计算模块403,用于计算各特征项的权重,获得游客对景点的有效评论数据特征项的权重向量;
簇划分模块404,用于基于特征项的权重向量,采用聚类算法,将有效评论数据划分为不同的簇;
主题词提取模块405,用于根据所述簇,分析各簇特征项,确定该类景点的主题词,完成景点主题的自动分类。
以上仅为本发明实例中一个较佳的实施方案。但是,本发明并不限于上述实施方案,凡按本发明所做的任何均等变化和修饰,所产生的功能作用未超出本方案的范围时,均属于本发明的保护范围。
- 一种基于文本聚类的视频弹幕与评论主题融合的方法
- 基于维基百科的评论主题词聚类方法