一种多基因SNP位点介导的抗精神病药物血药浓度的预测模型及其构建方法和应用
文献发布时间:2024-04-18 19:52:40
技术领域
本发明属于生物医学和检测分析技术领域,具体涉及一种多基因SNP位点介导的抗精神病药物血药浓度的预测模型及其构建方法和应用。
背景技术
公开该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不必然被视为承认或以任何形式暗示该信息构成已经成为本领域一般技术人员所公知的现有技术。
一般而言,抗精神病药物疗效预测模型制定用药方案后,临床医生往往给予患者较低的初始剂量,然后观察患者用药后的疗效与不良反应来调整剂量,若已增加至有效剂量后仍然无效,则考虑更换作用机制不同的药物或考虑联合用药方案继续治疗。这种在治疗过程中根据疗效和不良反应进行剂量调整或用药方案调整的方式,可能导致患者需要经历一段较长时间才能达到有效治疗,也可能由于血药浓度过高导致不良反应的发生,耽误患者治疗的同时无疑也增加了患者及其家庭的心理及经济负担。因而,识别影响抗精神病药物药代动力学的因素,在患者入院治疗初期为临床医生提供量化的个性化给药辅助工具具有重要的临床治疗意义。
已有大量研究表明,抗精神病药物体内代谢过程存在显著的个体差异,如BIGO等人研究发现不同个体对奥氮平的清除速率可相差4~10倍。抗精神病药物血药浓度影响因素是多方面的。年龄、性别、体重、吸烟、肝功能、肾功能及合并用药等非遗传因素对抗精神病药物血药浓度均有显著影响。药物细胞色素P450酶超家族是抗精神病药物的主要代谢酶,已有多项研究报道CYP2D6、CYP1A2等基因上的基因多态性位点与抗精神病药物血药浓度有关。此外,ABCB1基因编码的膜相关转运蛋白主要在肾、肝和血脑屏障中表达,参与药物的吸收、分布和消除,多项研究表明ABCB1基因多态性与奥氮平、氯氮平等抗精神病药物血药浓度有关。目前,临床实践中多根据细胞色素P450代谢酶的代谢分型进行用药剂量指导,无法提供量化的血药浓度估计,尚缺乏能够利用影响血药浓度的遗传与非遗传因素进行个性化用药指导的量化工具。群体药代学(Population pharmacokinetics,PPK)将经典药物动力学的隔室模型与统计学原理相结合,研究患者群体在给予临床相应剂量的某种药物后,体内药物运行的总体规律以及个体间药物浓度差异的来源,是可以较精确定量个性化给药的方法之一。已有多项研究构建了奥氮平、利培酮等抗精神病药物的群体药代学模型,但上述模型仅纳入了有限的非遗传因素,尚无综合考虑遗传与非遗传因素的群体药代学模型或血药浓度预测模型。
发明内容
针对上述现有技术的不足,本发明提供一种基于抗精神病药物血药浓度的群体药代学模型及其构建方法和应用。本发明筛选了影响常用抗精神病药物的血药浓度的遗传与非遗传因素,并探究了相关因素对抗精神病药物体内代谢过程的影响,基于非线性混合效应模型整合遗传与非遗传因素构建了利培酮、喹硫平、氯氮平及奥氮平等抗精神病药物的群体药代学模型;同时,本发明还采用Super Learner预测算法构建了抗精神病药物稳态谷浓度的预测模型,为临床医生确定精神分裂症患者给药剂量提供量化的科学参考。基于上述研究成果,从而完成本发明。
本发明是通过如下技术方案实现的:
本发明的第一个方面,提供一种抗精神病药物群体药代学模型的构建方法,所述构建方法包括:采集受试者的临床信息及血液样本,获取相应数据信息;采用非线性混合效应模型进行分析,具体采用一房室一级吸收和消除的药动学模型作为基础结构模型,获取血药浓度模拟数据获得相应模型药代动力学参数;随机效应模型为加法模型,并引入协变量,进行模型拟合,考察不同因素对药动力学参数影响,构建抗精神病药物群体药代学模型;
其中,抗精神病药物包括但不限于利培酮、奥氮平、氯氮平及喹硫平。
所述协变量包括遗传和非遗传因素,可采用线性模型进行定量筛选和评估。
当所述药物为利培酮时,所述协变量包括但不限于体重、吸烟、饮酒习惯、联用连花清瘟颗粒和水飞蓟宾葡甲胺片、肾小球滤过功能减退及CYP2D6酶活性评分;
最终模型Ka、V及CL的群体典型值分别为:Ka=6.113h
当所述药物为奥氮平时,所述协变量包括但不限于谷草转氨酶、肾小球滤过功能减退、联用丙戊酸钠、奥卡西平及SNP位点rs7916649、rs12768009。
最终模型Ka、V及CL的群体典型值分别为:Ka=0.144h
当所述药物为氯氮平时,所述协变量包括但不限于年龄、性别、联用普奈洛尔及SNP位点rs1135840和rs1135822。
最终模型中Ka、V及CL的群体典型值分别为:Ka=0.558h
当所述药物为喹硫平时,所述协变量包括但不限于年龄、性别、联用阿托伐他汀钙片、内生肌酐清除率及rs2242480。
最终模型Ka、V及CL的群体典型值分别为:Ka=0.163h
需要说明的是,建立群体药动学模型的关键是所选指标能够准确量化并正确反映其与疾病治疗之间的关系,而且通常具有明显量效关系的指标才能建立良好的群体药动学模型,并不是随意选取一个与疾病相关的病理或生理情况以及药效相关的指标都可以作为协变量。本发明以临床大样本为数据基础,通过科学分析,从众多的指标中选择合理的指标对总体药效进行综合性量化评价,科学设计了能定量评价药物参与的药物动力学系统,并经过群体药动学模型验证指标体系的科学准确性,能够有效反映整体药效空间随时间的动力学变化。
本发明的第二个方面,提供上述构建方法获得的抗精神病药物群体药代学模型在如下任意一种或多种中的应用:
(a)制备精确预测抗精神病药物给药剂量的产品;
(b)制备抗精神病药物个性化给药的产品。
(c)用于抗精神病药物药代动力学等相关基础研究。
其中,所述(c)中,所述抗精神病药物药代动力学包括抗精神病药物血药浓度预测。
本发明的第三个方面,提供一种抗精神病药物血药浓度预测评估系统,所述系统至少包括:
获取单元,其被配置为:获取受试者相关数据信息;
数据处理单元,其被配置为:根据获取单元所获得的数据信息并基于内置的预测评估模型,预测所述受试者的抗精神病药物的血药浓度;所述预测评估模型是通过将预先采集的患者的相关数据信息采用统计算法进行模型训练后获得。
输出单元,其被配置为:根据所述数据处理单元信息,输出受试者的抗精神病药物的血药浓度预测值。
其中,所述受试者相关数据包括但不限于受试者一般情况、疾病特征、抗精神病药物用药情况及抗精神病药物疗效相关SNP位点;
所述抗精神病药物包括但不限于利培酮、氯氮平、奥氮平及喹硫平。
所述抗精神病药物为利培酮时,所述预测评估模型构建过程中,所述相关数据信息包括但不限于服药剂量、体重、BMI、年龄、内生肌酐清除率、rs17327442、CYP2D6酶活性评分、丙戊酸钠、普奈洛尔、rs7787082、苯海索、rs3789243、rs4244285、rs11528090、rs7779562、地奥心血康软胶囊、rs762551、rs3743484、rs2235047、吸烟、rs1135840、rs28371699、rs1058164、性别、回拉西坦胶囊、饮酒、rs1081003、rs1065852、rs58440431、rs2004511、rs16947、rs75276289、rs1080996、水飞蓟宾葡甲胺片、rs116917064、阿司匹林肠溶片。
所述预测模型其是采用超强学习集成算法构建9-羟基利培酮血药浓度预测模型。
所述抗精神病药物为奥氮平时,所述预测评估模型构建过程中,所述相关数据信息包括但不限于服药剂量、用药频次、年龄、碱性磷酸酶、体重、谷丙转氨酶、谷草转氨酶、丙戊酸钠、CYP2D6酶活性评分、rs1065852、rs762551、rs3743484、阿立哌唑、rs11528090、rs35280822、rs16947、rs79331140、rs1080996、rs7787082、普奈洛尔、rs7779562、rs75276289、rs4646437、rs6583954、rs3758580、rs4244285、吸烟、饮酒、性别、rs12768009、rs7916649、rs2470890、rs17884832、rs5030865、rs17879992、rs17885098、rs28371725、肾小球滤过功能减退、酚酞片、舒必利、齐拉西酮、地榆生白片。
所述预测模型其是采用超强学习集成算法构建奥氮平血药浓度预测模型。
所述抗精神病药物为氯氮平时,所述预测评估模型构建过程中,所述相关数据信息包括但不限于服药剂量、肌酐、年龄、谷草转氨酶、肌酐清除率、体重、普奈洛尔、利培酮、rs1080996、rs75276289、rs16947、rs11528090、rs762551、性别、用药频次、rs12535512、回拉西坦胶囊、rs1135840、rs1128503、rs12720464、rs3789243、CYP2D6酶活性评分、阿司匹林肠溶片、rs3842、rs6979885、阿托伐他汀钙片、rs4728709、吸烟。
所述预测模型其是采用超强学习集成算法构建氯氮平血药浓度预测模型。
所述抗精神病药物为喹硫平时,所述预测评估模型构建过程中,所述相关数据信息包括但不限于服药剂量、年龄、BMI、碱性磷酸酶、谷草转氨酶、肌酐、谷丙转氨酶、体重、丙戊酸钠、CYP2D6酶活性评分、rs12535512、rs2246709、rs12768009、rs2242480、rs1081003、头孢呋辛酯、氨磺必利、rs58440431、rs2004511、地奥心血康软胶囊、性别、马来酸依那普利片、阿托伐他汀钙片、rs2470890、吸烟、肝功异常、rs1135822、奥卡西平、丁螺环酮、阿立哌唑及稳心颗粒。
所述预测模型其是采用超强学习集成算法构建喹硫平血药浓度预测模型。
本发明第四个方面,提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现如本发明第三方面所述系统的功能。
本发明第五个方面,提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如本发明第四方面所述系统的功能。
以上一个或多个技术方案的有益技术效果:
上述技术方案筛选了影响常用抗精神病药物的血药浓度的遗传与非遗传因素,并探究了相关因素对抗精神病药物体内代谢过程的影响,基于非线性混合效应模型整合遗传与非遗传因素构建了利培酮、喹硫平、氯氮平及奥氮平等抗精神病药物的群体药代学模型;同时,本发明还采用超强学习集成算法构建了抗精神病药物稳态谷浓度的预测模型,为临床医生确定精神分裂症患者给药剂量提供量化的科学参考,因此具有良好的实际应用之价值。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
图1为本发明实施例中利培酮血药浓度取样时间点示意图。
图2为本发明实施例中利培酮最终模型的拟合优度图。
图3为本发明实施例中利培酮最终模型的残差图。
图4为本发明实施例中利培酮用药方案为2mg(bid)时最终模型群体药代学曲线示意图(从上至下分别为预测血药浓度值的2.5%、50%和97.5%分位数;灰色圆圈为实际观测值)。
图5为本发明实施例中利培酮不同数量候选变量时RMSE比较。
图6为本发明实施例中利培酮基于随机森林的预测变量重要性评分。
图7为本发明实施例中基于Super Learner的9-羟基利培酮血压浓度预测模型预测值与实际观测值散点图。
图8为本发明实施例中奥氮平最终模型的拟合优度图。
图9为本发明实施例中奥氮平最终模型的残差图。
图10为本发明实施例中奥氮平用药方案为5mg(bid)时最终模型群体药代学曲线示意图(从上至下分别为预测血药浓度值的2.5%、50%和97.5%分位数;灰色圆圈为实际观测值)。
图11为本发明实施例中奥氮平不同数量候选变量时基于随机森林预测模型的RMSE。
图12为本发明实施例中奥氮平基于随机森林的预测变量重要性评分。
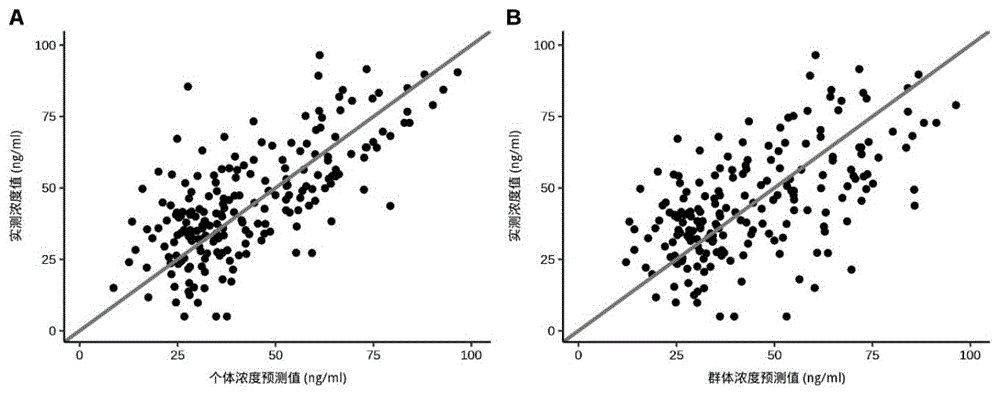
图13为本发明实施例中基于Super Learner的奥氮平血药浓度预测模型预测值与实际观测值散点图(A:训练集十折交叉;B:验证集)。
图14为本发明实施例中奥氮平最终模型的拟合优度图。
图15为本发明实施例中奥氮平最终模型的残差图分。
图16为本发明实施例中氯氮平用药方案为75mg(bid)时最终模型群体药代学曲线示意图(从上至下分别为预测血药浓度值的2.5%、50%和97.5%分位数;灰色圆圈为实际观测值)。
图17为本发明实施例中氯氮平不同数量候选变量时RMSE比较。
图18为本发明实施例中氯氮平基于随机森林的预测变量重要性评分。
图19为本发明实施例中基于Super Learner的氯氮平血药浓度预测模型预测值与实际观测值散点图(A:训练集十折交叉;B:验证集)。
图20为本发明实施例中喹硫平最终模型的拟合优度图。
图21为本发明实施例中喹硫平最终模型的残差图。
图22为本发明实施例中喹硫平用药方案为300mg(bid)时最终模型群体药代学曲线示意图(从上至下分别为预测血药浓度值的2.5%、50%和97.5%分位数;灰色圆圈为实际观测值)。
图23为本发明实施例中喹硫平不同数量候选变量时RMSE比较。
图24为本发明实施例中喹硫平基于随机森林的预测变量重要性评分。
图25为本发明实施例中基于Super Learner的喹硫平血药浓度预测模型预测值与实际观测值散点图(A:训练集十折交叉;B:验证集)。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。应理解,本发明的保护范围不局限于下述特定的具体实施方案;还应当理解,本发明实施例中使用的术语是为了描述特定的具体实施方案,而不是为了限制本发明的保护范围。下列具体实施方式中如果未注明具体条件的实验方法,通常按照本领域技术内的生物学的常规方法和条件,这种技术和条件在文献中有完整解释。
以下通过实施例对本发明做进一步解释说明,但不构成对本发明的限制。应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。另外,实施例中未详细说明的生物医学方法均为本领域常规的方法,具体操作可参看生物医学指南或产品说明书。
实施例
一、材料与方法
1.1研究对象
本研究获得了山东大学公共卫生学院伦理委员会批准。课题组在山东省临沂市平邑县心理医院纳入了2021年至2022年住院治疗的精神分裂症患者,具体纳入排除标准如下:
纳入标准:(1)《疾病和有关健康问题的国际统计分类(第10次修订本)》(ICD-10)精神分裂症临床诊断标准;(2)年龄18-65岁;(3)住院期间按医嘱规律服用利培酮、喹硫平、奥氮平或氯氮平等抗精神病药物;(4)可接受常规血药浓度监测;
排除标准:(1)患有慢性肠炎、腹泻或其他胃肠道疾病;(2)患有其他重要疾病,如严重的心脑血管疾病、癌症等;(3)无法获得完整病例资料;(4)依从性极差,无法长时间规律服药;(5)需要长期注射药物以维持治疗依从性;(6)近期因治疗耐药而定期接受氯氮平治疗(因其他原因服用氯氮平治疗的患者除外)。
1.2资料收集
本研究从平邑县心理医院收集的精神分裂症患者基本信息包括:(1)一般人口学特征:年龄、性别、身高、体重、受教育程度、婚姻状况;(2)共患病:糖尿病、高血压、冠心病和脑卒中等疾病;(3)吸烟、饮酒等生活习惯;(4)精神分裂症特征:首次发病日期、病程特点(急性、亚急性、缓慢起病)、精神疾病家族史、住院次数、住院天数等;
本研究从山东省精神卫生中心电子病历系统中住院医嘱部分获取精神分裂症患者住院期间的药物治疗情况,治疗药物包括利培酮、奥氮平、喹硫平、氯氮平、氨磺必利、阿立哌唑、齐拉西酮等抗精神病药物;碳酸锂、丙戊酸钠、丙戊酸镁等心境稳定剂;西酞普兰、米氮平、度洛西汀等抗抑郁药物;丁螺环酮、劳拉西泮等抗焦虑药物。收集的治疗信息包括:药物名称、给药起始日期与结束日期、给药频次、给药剂量等。
本研究从平邑县心理医院实验室信息系统(Lis)中获取了精神障碍患者住院治疗过程中的实验室检查数据,包括肝功能指标:谷草转氨酶(AST)、谷丙转氨酶(AST)、碱性磷酸酶(ALP);肾功能指标:肌酐(Cr)、尿素氮/肌酐比值(BUN/Cr);血常规指标:白细胞数;中性粒细胞数,血红蛋白数,血小板数。
1.3血样采集
1.3.2血药浓度血样采集
1.3.2.1常规血药浓度监测血样采集
每个病例采集抗凝紫管静脉血2毫升,一般在早晨6:30采集血样。原则上要求采血时,目标药物已经达到稳态,即固定剂量连续用药5-6个半衰期后。各药物半衰期及治疗参考浓度范围见表1。
表1四种抗精病药物半衰期及治疗浓度参考范围
1.3.2.2群体药代学血样采集
本研究以利培酮为例说明群体药代学血样采集取样时间确定过程。参照相关文献,设定利培酮群体药代学房室模型为一室模型一级吸收,群体药代学参数初始值设置为:Cl=4.6L/h,k
为了与临床实践实际相适应,增加研究方案的可操作性,我们将血样浓度取样与其他相关检测取样结合起来,设定了以下两种取样方案:在血药浓度达到稳态后(一般认为连续给药相同剂量6天后利培酮及9-羟基利培酮可达血药浓度稳态),在上午6:30、9:30点,即前一天晚上20:00服药后10.5h、13.5h取样;在上10:30服药后,于中午11:30取样一次。考虑到同一天多次取样可能会导致患者配合度降低,在患者每天服药剂量和服药时间不变的前提下,血样抽取可不在同一天完成,如患者达到血药浓度稳态后,第一天上午6:30抽取第一个血样,在之后某天上午9:30抽取第二个血样,几天后中午11:30再抽取第三个血样。取样点示意图见图1。
表2抗精神病药物血药浓度取样时间点
1.4血药浓度测定
采用高效液相色谱法(HPLC)进行抗精神病药物血药浓度测定。“FLC全自动二维液相色谱系统”及与之配套的高效液相色谱仪、移动相、色谱柱、去蛋白剂等均由湖南德米特仪器有限公司提供。
1.5候选SNP位点选择及SNP位点分型
根据遗传药理学和基因组药理学数据库(PharmGKB)中列出的抗精神病药物代谢相关基因及SNP位点为依据,结合药理学研究文献,确定了CYP2D6、CPY3A4、CYP1A2、CYP3A5及CYP2C19等代谢酶基因和ABCB1转运蛋白基因作为候选基因,选择基因内的SNP位点作为候选SNP位点。其中,PharmGKB或单核苷酸多态性数据库(SNPedia)中已有文献报道的药物代谢相关SNP位点全部入选;而候选基因其他位点,若处于连锁不平衡(linkagedisequilibrium,LD)区域(r
1.6数据整理与分析
1.6.1数据整理
由于原始数据来自于多个信息系统,为便于统计分析,我们将研究对象基本信息、住院医嘱数据、抗精神斌药物血药浓度监测数据及基因分型数据以住院号为唯一标识码进行合并。利培酮、奥氮平、喹硫平及氯氮平等抗精神病药物及其他合并用药剂量定义为:目标抗精神病药物血药浓度检测时医嘱处方中要求的剂量,药物剂量单位都转化为mg/d,并记录抗精神病药物用药频次。其他变量编码见表3。本研究对缺失率5%以内的缺失变量采用多重插补方法进行了填补。
表3变量编码表
目前,在临床实践中,临床医生多根据CYP2D6基因的代谢分型进行用药指导,为便于临床应用,本研究参照CPIC和崔一民教授提出的基于CYP2D6基因的代谢分型方法[a1a,与精神类药物相关的CYP2D6基因在中国人群中的代谢型分型方法],对本研究中研究对象进行了代谢分型。该方法根据rs3892097、rs5030865、rs28371706、rs28371717、rs769258、rs28371725、rs1135822、rs72549348、rs267608297、rs267608289、rs1065852、rs16947、rs1135840、rs28371699及rs28371701等SNP位点的基因分型结果,将SNP位点等位基因标记为:a)正常功能等位基因CYP2D6*1、*2、*33、*35、*35、*39;b)功能降低的等位基因CYP2D6*9、*10、*14、
*17、*29、*41、*49、*54、*59;c)非功能等位基因CYP2D6*3、*4、*5、*6、*8、*11、*51、*59;d)未知功能的等位基因CYP2D6*22、*28、*30、*65。确定四种功能等位基因突变个数后,带入以下公式计算酶活性得分(Activity score,AS):AS=a+d+0.5*b(其中,*10系数为0.25)。
1.6.2数据描述
本研究从两方面进行了统计描述:(1)从整体上描述研究对象的一般人口学特征、生活习惯、共患病及精神疾病患病情况;(2)抗精神病药物用药剂量及血药浓度分布情况。若连续型变量符合正态分布,则采用均值±标准差表示;若不符合正态分布,连续性变量采用中位数(P25-P75四分位数)表示;分类变量采用频数和构成比表示。
1.6.3血药浓度影响因素分析
由于研究对象在住院过程中多次进行血药浓度监测,本研究数据为重复多次测量的纵向数据,因而本研究采用广义估计方程(Generalized estimating equations,GEE)模型筛选影响抗精神病药物血药浓度的非遗传因素和SNP位点。将抗精神病药物用药剂量、距前一次服药间隔时间及候选变量同时纳入GEE模型,分析候选变量对抗精神病药物血药浓度的影响。
1.6.4群体药代学分析
为进一步分析抗精神病药物血药浓度影响因素对抗精神病药物代谢的影响,本研究采用了非线性混合效应模型进行了群体药代学分析。群体药代学模型构建基本流程如下:
非线性混合效应模型可用以下通式表示:
其中,Y
(1)确定药动学结构模型:
药动学结构模型描述了药动学群体的平均效应,给药途径和药物体内过程的差异决定了药动学模型的多样性,所有模型均可通过一组公式及参数描述。
以单次服药为例,一房室一级吸收与消除的药动学结构模型可以用以下形式表示:
在时间点t
D[i,j]=D[i,j-1]exp(-k
在时间点t
d[i,j]表示第i个研究对象在时刻t
药动学结构模型可根据药物的特征及数据特点灵活选择,本研究结合相关文献报道,利培酮、奥氮平、喹硫平及氯氮平的药动学结构模型均设定为一房室一级吸收和消除的药动学模型。
(2)固定效应模型:固定效应模型用于定量地考察固定效应(如年龄、性别、SNP位点等)对药动学参数的影响,模型结构包括线性、乘法、饱和、指示变量模型。目前常用的主要是线性和乘法模型。
1)线性模型:用公式表示如下:
式中
2)乘法模型:如研究对象体重范围很大,而且药物清除率与体重相关,用以下公式表示:
将公式两边取对数,可得到对数尺度的线性模型。式中
(3)随机效应模型:随机效应模型包括个体间变异及残差变异。前者描述群体中个体间药动学参数的差异;而后者则描述了观测值无法解释的变异。一般假设药动学参数为正态或对数正态分布,按照加法、比例、乘方模型选择目标函数值最小的模型。药动学参数的个体间变异以随机变量η表示,其均值为0,而方差为ω
1)加法模型:用公式表示如下:
其中CL
2)比例模型:用公式表示如下:
/>
(3)协变量筛选:考察年龄、性别、体重、合并用药等非遗传因素及遗传因素对药动学参数的影响。目前,协变量筛选主要采用假设检验法和向前递增或向后递减法。假设检验的基本原理如下:
非线性混合效应模型可信度可以采用最大似然法(maximum likelihoodapproach,ML)估算。模型中一系列观测值的最大似然可以用下式表示:
最大似然性可以用-2log(L)的最小值表示。θ为所建立模型的药动学参数,y
最大似然性检验即等价于OFV改变的显著性检验,采用常规统计的显著性检验方法。首先建立不含任何固定效应因素的最简模型,然后在最简模型中,逐一加入候选协变量建立增量模型。最简模型与增量模型参数差异可以用两者似然性比值表示(L
最终群体药代学模型的拟合优度通过RMSE及R2进行评价,并通过绘制诊断图进行评估,包括个体预测值对观测值(IPRED vs DV,趋势线越接近y=x,说明最终模型的个体预测能力越强)、群体预测值对观测值(PRED vs DV,趋势线越接近y=x,说明最终模型的群体预测能力越强)、权重残差对群体预测值(CWRESvsPRED,考察条件残差对预测值有无偏倚,权重残差越接近0,则说明模型群体预测能力越强)、权重残差对时间散点图(CWRESvsTIME,考察条件权重残差对血样采集时间有无偏倚)。个体预测值是指由模型的PK个体参数计算出的拟合结果。数据点应在截距为0,斜率为1的直线两侧随机均匀分布。趋势线越接近对角线说明拟合的精密程度越高。权重残差对群体预测值和权重残差对时间散点图可以评价曲线拟合总体的优劣,即加权残差介于-6至6,表明模型拟合效果较好。同时,本研究采用Bootstrap法对群体药代学模型稳定性进行验证,通过对模型进行500次的bootstrap验证,考察群体药代学参数分布及模型稳定性。
二、试验结果
2.1利培酮研究对象情况及群体药代学研究
2.1.1研究对象基本情况
本研究共纳入了239例精神分裂症患者作为研究对象,研究对象一般情况和实验室检测指标分布情况见表4。研究对象平均年龄44.3±12.0岁;男性132人,女性107人,分别占比55.2%和44.8%;身高和体重均值分别为163.6±8.7cm和68.2±13.7kg,BMI均值为25.4±4.3kg/m2;研究对象中吸烟者68人,饮酒者44人,分别占比28.5%和18.4%;糖尿病、高血压患病率分别为7.9%和6.3%。肝功能与肾功能检测指标均值均在正常参考值范围内,但有49人肾小球滤过功能减退,40人肝功能异常,分别占比20.5%和16.7%。
本研究只纳入了服药频次为每日两次的精神分裂症患者,每次服药剂量均值为2.4±0.6mg。在血药浓度稳态状态下,本研究共收集了1115例次的利培酮血药浓度,服药1.5h、5.0h、9.5h、12.5h后,研究对象的血药浓度均值分别为70.22±28.54,53.23±14.68,51.01±24.33和44.89±18.43ng/ml。按照60ng/ml的利培酮治疗浓度参考范围上限,分别有244例次服药9.5h后血药浓度和11例次服药12.5h后血药浓度超出治疗浓度参考范围上限,分别占该时间点血药浓度检测例次的26.5%和23.4%。
表4研究对象一般情况和实验室检测指标
*
2.1.2利培酮群体药代学研究
为确定精神分裂症患者群体的各种药动学参数均值与标准差及离散程度,并研究各种不同因素对利培酮代谢的影响,本研究进行了利培酮群体药代学分析。结合文献报道和本研究数据特点,最终确定基础结构模型为一房室一级吸收与消除的药动学结构模型,随机效应模型为加法模型,并采用线性模型定量地考察固定效应(如年龄、性别、SNP位点等)对药动学参数的影响。基于单因素非线性混合效应模型筛选的与群体药代学参数相关的遗传与非遗传因素见表5。结果显示,随着年龄及体重增长,表观分布容积逐渐增加,两者对表观分布容积的影响均具有统计学意义(P<0.05)。对一级消除速率影响的有统计学意义(P<0.05)的遗传因素包括:rs28371699(CYP2D6)、rs1135840(CYP2D6)、rs1058164(CYP2D6)、rs75276289(CYP2D6)、rs16947(CYP2D6)及rs72547513(CYP1A2);非遗传因素包括:吸烟、饮酒、肾小球滤过功能减退、体重、连花清瘟颗粒、水飞蓟宾葡甲胺片等。此外,CYP2D6酶活性得分与一级消除速率正相关,随着CYP2D6酶活性得分升高,一级消除速率随之增加(P<0.05)。
表5与群体药代学参数相关的遗传与非遗传因素
a
采用向前递增和向后剔除方法筛选群体药代学模型的协变量,并结合相关专业知识确定了最终群体药代学模型,9-羟基利培酮最终模型的参数估计值见表6。在最终群体药代学模型中,体重对表观分布容积有显著影响(P<0.05);吸烟、饮酒习惯、联用连花清瘟颗粒和水飞蓟宾葡甲胺片、肾小球滤过功能减退及CYP2D6酶活性评分对一级消除速率有显著影响(P<0.05)。最终模型Ka、V及CL的群体典型值分别为:Ka=6.113h
表6 9-羟基利培酮最终模型参数估计与验证结
a
9羟基利培酮最终模型的拟合优度图见图2,99-羟基利培酮个体预测与群体预测的RMSE和R
2.1.3利培酮常规监测血药浓度预测
2.1.3.1基于递归特征消除算法的变量筛选
我们采用基于随机森林的递归特征消除算法筛选预测变量用于机器学习建模。基于随机森林利用不同数量候选变量建模时的十折交叉验证RMSE见图5。由图5可知,纳入变量重要性排序前36位的预测变量时,随机森林算法十折交叉验证的RMSE最小,则基于随机森林的递归特征消除算法筛选的预测变量包括服药剂量、体重、BMI、年龄、内生肌酐清除率、rs17327442、CYP2D6酶活性评分、丙戊酸钠、普奈洛尔、rs7787082、苯海索、rs3789243、rs4244285、rs11528090、rs7779562、地奥心血康软胶囊、rs762551、rs3743484、rs2235047、吸烟、rs1135840、rs28371699、rs1058164、性别、回拉西坦胶囊、饮酒、rs1081003、rs1065852、rs58440431、rs2004511、rs16947、rs75276289、rs1080996、水飞蓟宾葡甲胺片、rs116917064、阿司匹林肠溶片。上述预测变量将被用于基于随机森林、贝叶斯累加回归树等机器学习方法的预测模型构建。
2.1.3.2模型拟合与评价
本研究分别拟合了基于梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的预测模型,同时以NNLS为损失函数,利用十折交叉验证确定了使上述模型组合交叉验证风险最小的一组权重向量,上述模型的权重分别为0.000、0.156、0.347、0.243和0.254,从而构建了基于Super Learner的9-羟基利培酮血药浓度预测模型,该模型适用于预测稳态状态下精神分裂症患者在早晨6:30时9-羟基利培酮血药浓度(用药时间分别为上午10点与晚上21点)。Super Learner中各单独算法权重及参数设置见表7。
表7各单独算法在Super Learner中权重及参数设置
注:表7中未列出的各算法参数均设定为R包默认值。
本研究中,我们随机抽取300人次常规血药浓度监测记录作为验证集,其余部分作为训练集,基于Super Learner的9-基利培酮血药浓度预测模型评价。在训练集中,SuperLearner、梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的RMSE分别为12.91ng/ml、14.25ng/ml、14.48ng/ml、12.69ng/ml、16.22ng/ml和11.31ng/ml。在验证集中,上述算法的RMSE分别为16.23ng/ml、15.67ng/ml、16.98ng/ml、16.15ng/ml、16.98ng/ml、17.31ng/ml。Super Learner在训练集和验证集中的R
表8基于Super Learner的9-基利培酮血药浓度预测模型评价
2.2奥氮平研究对象基本情况及群体药代学研究
2.2.1研究对象基本情况
该部分研究共纳入了131例接受奥氮平治疗的精神分裂症患者作为研究对象,研究对象一般情况和实验室检测指标分布情况见表9。研究对象平均年龄45.6±14.2岁;男性84人,女性47人,分别占比64.1%和35.9%;身高和体重均值分别为163.4±9.2cm和67.4±14.8kg,BMI均值为25.2±4.6kg/m2;研究对象中吸烟者47人,饮酒者30人,分别占比35.9%和22.9%;糖尿病、高血压患病率分别为5.3%和9.9%。肝功能与肾功能检测指标均值均在正常参考值范围内,但有25人肾小球滤过功能减退,22人肝功能异常,分别占比19.1%和16.8%。奥氮平服药频次为每日两次的患者73人,每晚一次的患者58人,分别占比55.7%和44.3%。每次服药剂量均值为6.8±2.4mg。
在血药浓度稳态状态下,本研究共收集了467人次的奥氮平血药浓度。服药频次为每日两次的患者服药1.5h、5.0h、9.5h、12.5h后,血药浓度均值分别为61.54±18.32,71.72±22.99,49.38±18.93和46.41±20.12ng/ml;服药频次为每晚一次的患者服药9.5h后,血药浓度均值为34.61±15.39。按照80g/ml的奥氮平治疗浓度参考范围上限,有22例次服药9.5h后血药浓度超出治疗浓度参考范围上限,占该时间点血药浓度检测例次的5.41%。
表9研究对象一般情况和实验室检测指标
*
2.2.2奥氮平群体药代学研究
为确定精神分裂症患者群体的各种药动学参数均值与标准差及离散程度,并研究各种不同因素对氯氮平代谢的影响,本研究进行了奥氮平群体药代学分析。结合文献报道和本研究数据特点,最终确定基础结构模型为一房室一级吸收与消除的药动学结构模型,随机效应模型为加法模型,并采用线性模型定量地考察固定效应(如年龄、性别、SNP位点等)对药动学参数的影响。基于单因素非线性混合效应模型筛选的与群体药代学参数相关的遗传与非遗传因素见表10。结果显示,男性、谷草转氨酶及合并丙戊酸钠、奥卡西平及碳酸锂用药与较高的奥氮平体内消除速率有关(P<0.05);而肾小球滤过功能减退与奥氮平体内消除速率降低有关(P<0.05)。rs4244285(CYP2C19)、rs12768009(CYP2C19)、rs7916649(CYP2C19)、rs3758580(CYP2C19)、rs3743484(CYP1A2)及rs11528090(CYP2C19)等SNP位点对一级消除速率影响的有统计学意义(P<0.05)。
表10与奥氮平群体药代学参数相关的遗传与非遗传因素
a
采用向前递增和向后剔除方法筛选群体药代学模型的协变量,并结合相关专业知识确定了最终群体药代学模型,奥氮平最终群体药代学模型参数估计见表11。在最终群体药代学模型中,纳入一级消除速率固定效应模型中的包括谷草转氨酶、肾小球滤过功能减退、联用丙戊酸钠、奥卡西平及rs7916649、rs12768009。最终模型Ka、V及CL的群体典型值分别为:Ka=0.144h
表11奥氮平最终群体药代学模型参数估计与验证结果
a
b
奥氮平最终群体药代学模型的拟合优度图见图8。结果显示,个体浓度预测值、群体浓度预测值与实测浓度值拟合度良好,RMSE和R
2.2.3奥氮平常规监测血药浓度预测
2.2.3.1基于递归特征消除算法的变量筛选
我们采用基于随机森林的递归特征消除算法筛选预测变量用于机器学习建模。基于随机森林利用不同数量候选变量建模时的十折交叉验证RMSE见图11。由图11可知,纳入变量重要性排序前42位的预测变量时,随机森林算法十折交叉验证的RMSE最小,随机森林变量重要性见图12。基于随机森林的递归特征消除算法筛选的预测变量包括服药剂量、用药频次、年龄、碱性磷酸酶、体重、谷丙转氨酶、谷草转氨酶、丙戊酸钠、CYP2D6酶活性评分、rs1065852、rs762551、rs3743484、阿立哌唑、rs11528090、rs35280822、rs16947、rs79331140、rs1080996、rs7787082、普奈洛尔、rs7779562、rs75276289、rs4646437、rs6583954、rs3758580、rs4244285、吸烟、饮酒、性别、rs12768009、rs7916649、rs2470890、rs17884832、rs5030865、rs17879992、rs17885098、rs28371725、肾小球滤过功能减退、酚酞片、舒必利、齐拉西酮、地榆生白片。上述预测变量将被用于基于随机森林、贝叶斯累加回归树等机器学习方法的预测模型构建。
2.2.3.2模型拟合与评价
本研究分别拟合了基于梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的预测模型,同时以NNLS为损失函数,利用十折交叉验证确定了使上述模型组合交叉验证风险最小的一组权重向量,上述模型的权重分别为0.424、0.454、0.000、0.028和0.094,从而构建了基于Super Learner的氯氮平血药浓度预测模型,该模型适用于预测稳态状态下精神分裂症患者在早晨6:30时奥氮平血药浓度(用药时间分别为上午10点和/或晚上21点)。Super Learner中各单独算法权重及参数设置见表12。
表12各单独算法在Super Learner中权重及参数设置
注:表12中未列出的各算法参数均设定为R包默认值。
本研究中,我们随机抽取100人次常规血药浓度监测记录作为验证集,剩余部分作为训练集,基于Super Learner的奥氮平血药浓度预测模型模型评价见表13。在训练集中,Super Learner、梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的RMSE分别为9.18ng/ml、9.36ng/ml、10.12ng/ml、9.03ng/ml、11.51ng/ml和7.31ng/ml。在验证集中,上述算法的RMSE分别为13.90ng/ml、13.74ng/ml、14.96ng/ml、13.74ng/ml、15.07ng/ml和14.17ng/ml。Super Learner在训练集和验证集中的R
表13基于Super Learner的奥氮平血药浓度预测模型模型评价
2.3氯氮平研究对象基本情况及群体药代学研究
2.3.1研究对象基本情况
该部分研究共纳入了136例接受氯氮平治疗的精神分裂症患者作为研究对象,研究对象一般情况和实验室检测指标分布情况见表14。研究对象平均年龄44.8±9.9岁;男性70人,女性63人,分别占比51.5%和48.5%;身高和体重均值分别为163.7±8.8cm和70.6±14.5kg,BMI均值为26.3±4.7kg/m
本研究纳入了氯氮平服药频次为每日两次或每日一次的精神分裂症患者,每次服药剂量均值为75.9±35.5mg。在血药浓度稳态状态下,本研究共收集了665人次的氯氮平血药浓度,服药1.5h、5.0h、9.5h、12.5h后,研究对象的血药浓度均值分别为588.2±235.5,460.2±227.5,337.4±233.8和249.1±198.9ng/ml。按照600ng/ml的氯氮平治疗浓度参考范围上限,分别有7例次服药1.5h后血药浓度和66例次服药9.5h后血药浓度超出治疗浓度参考范围上限,分别占该时间点血药浓度检测例次的53.8%和10.69%。
表14研究对象一般情况和实验室检测指标
*
2.3.2氯氮平群体药代学研究
为确定精神分裂症患者群体的各种药动学参数均值与标准差及离散程度,并研究各种不同因素对氯氮平代谢的影响,本研究进行了喹硫平群体药代学分析。结合文献报道和本研究数据特点,最终确定基础结构模型为一房室一级吸收与消除的药动学结构模型,随机效应模型为加法模型,并采用线性模型定量地考察固定效应(如年龄、性别、SNP位点等)对药动学参数的影响。基于单因素非线性混合效应模型筛选的与群体药代学参数相关的遗传与非遗传因素见表15。结果显示,男性表观分布容积显著大于女性(P>0.05);而随着年龄增加,表观分布容积逐渐降低(P<0.05)。对一级消除速率影响的有统计学意义(P<0.05)的遗传因素包括:rs1135840(CYP2D6)、rs1065164(CYP2D6)、rs28371699(CYP2D6)及rs1135822(CYP2D6);非遗传因素包括:年龄、性别、吸烟、谷草转氨酶水平及合并普奈洛尔用药等。此外,CYP2D6酶活性得分与一级消除速率正相关,随着CYP2D6酶活性得分升高,一级消除速率随之增加(P<0.05)。
表15与氯氮平群体药代学参数相关的遗传与非遗传因素
V:表观分布容积(L);CL:一阶消除速率常数(L/H);
采用向前递增和向后剔除方法筛选群体药代学模型的协变量,并结合相关专业知识确定了最终群体药代学模型,氯氮平最终群体药代学模型参数估计见表16。在最终群体药代学模型中,性别对表观分布容积有显著影响(P<0.05);年龄、性别、联用普奈洛尔及SNP位点rs1135840和rs1135822对一级消除速率有显著影响(P<0.05)。最终模型的参数估计值见表18。结果表明,最终模型Ka、V及CL的群体典型值分别为:Ka=0.558h
表16氯氮平最终模型参数估计与验证结果
a
b
最终模型的拟合优度图见图14。结果显示,个体浓度预测值、群体浓度预测值与实测浓度值拟合度较好,RMSE和R
2.3.3氯氮平常规监测血药浓度预测
2.3.3.1基于递归特征消除算法的变量筛选
我们采用基于随机森林的递归特征消除算法筛选预测变量用于机器学习建模。基于随机森林利用不同数量候选变量建模时的十折交叉验证RMSE见图17。由图17可知,纳入变量重要性排序前28位的预测变量时,随机森林算法十折交叉验证的RMSE最小,则基于随机森林的递归特征消除算法筛选的预测变量包括服药剂量、肌酐、年龄、谷草转氨酶、肌酐清除率、体重、普奈洛尔、利培酮、rs1080996、rs75276289、rs16947、rs11528090、rs762551、性别、用药频次、rs12535512、回拉西坦胶囊、rs1135840、rs1128503、rs12720464、rs3789243、CYP2D6酶活性评分、阿司匹林肠溶片、rs3842、rs6979885、阿托伐他汀钙片、rs4728709、吸烟。上述预测变量将被用于基于随机森林、贝叶斯累加回归树等机器学习方法的预测模型构建。
2.3.3.2模型拟合与评价
本研究分别拟合了基于梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的预测模型,同时以NNLS为损失函数,利用十折交叉验证确定了使上述模型组合交叉验证风险最小的一组权重向量,上述模型的权重分别为0.271、0.342、0.213、0.155和0.019,从而构建了基于Super Learner的氯氮平血药浓度预测模型,该模型适用于预测稳态状态下精神分裂症患者在早晨6:30时氯氮平血药浓度(用药时间分别为上午10点和/或晚上21点)。Super Learner中各单独算法权重及参数设置见表17。
表17各单独算法在Super Learner中权重及参数设置
注:表19中未列出的各算法参数均设定为R包默认值。
本研究中,我们随机抽取150人次常规血药浓度监测记录作为验证集,剩余部分作为训练集,基于Super Learner的奥氮平血药浓度预测模型模型评价见表18。在训练集中,Super Learner、梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的RMSE分别为68.88ng/ml、69.26ng/ml、72.76ng/ml、64.41ng/ml、80.73ng/ml和55.89ng/ml。在验证集中,上述算法的RMSE分别为88.51ng/ml、92.08ng/ml、90.45ng/ml、90.68ng/ml、88.98ng/ml和96.31ng/ml。Super Learner在训练集和验证集中的R
表18基于Super Learner的奥氮平血药浓度预测模型模型评价
2.4喹硫平研究对象基本情况及群体药代学研究
2.4.1研究对象基本情况
该部分研究共纳入了177例接受喹硫平治疗的精神分裂症患者作为研究对象,研究对象一般情况和实验室检测指标分布情况见表19。研究对象平均年龄46.3±12.6岁;男性104人,女性73人,分别占比58.8%和41.2%;身高和体重均值分别为163.3±8.6cm和71.5±16.5kg,BMI均值为26.7±5.5kg/m2;研究对象中吸烟者44人,饮酒者35人,分别占比24.9%和19.8%;糖尿病、高血压患病率分别为11.3%和13.6%。肝功能与肾功能检测指标均值均在正常参考值范围内,但有38人肾小球滤过功能减退,21人肝功能异常,分别占比21.5%和11.9%。
本研究只纳入了喹硫平服药频次为每日两次的精神分裂症患者,每次服药剂量均值为242.9±88.3mg。在血药浓度稳态状态下,本研究共收集了551例次的喹硫平血药浓度,服药1.5h、5.0h、9.5h、12.5h后,研究对象的血药浓度均值分别为334.5±218.2,286.3±141.2,209.1±144.5和141.9±125.5ng/ml。按照500ng/ml的喹硫平治疗浓度参考范围上限,分别有9例次服药1.5h后血药浓度和18例次服药9.5h后血药浓度超出治疗浓度参考范围上限,分别占该时间点血药浓度检测例次的25.7%和3.9%。
表19研究对象一般情况和实验室检测指标
*
2.4.2喹硫平群体药代学研究
为确定精神分裂症患者群体的各种药动学参数均值与标准差及离散程度,并研究各种不同因素对氯氮平代谢的影响,本研究进行了喹硫平群体药代学分析。结合文献报道和本研究数据特点,最终确定基础结构模型为一房室一级吸收与消除的药动学结构模型,随机效应模型为加法模型,并采用线性模型定量地考察固定效应(如年龄、性别、SNP位点等)对药动学参数的影响。基于单因素非线性混合效应模型筛选的与群体药代学参数相关的遗传与非遗传因素见表20。结果显示,结果显示,随着体重增加,表观分布容积逐渐增加,体重对表观分布容积的影响均具有统计学意义(P<0.05)。对一级消除速率影响的有统计学意义(P<0.05)的遗传因素包括:rs5030865(CYP2D6)、rs2069526(CYP1A2)、rs2242480(CYP3A4)、rs2235047(ABCB1);非遗传因素包括:年龄、性别、内生肌酐清除率、碱性磷酸酶、谷草转氨酶、回拉西坦胶囊、阿立哌唑、阿托伐他汀钙片及血肌酐水平等。
表20与喹硫平群体药代学参数相关的遗传与非遗传因素
a
采用向前递增和向后剔除方法筛选群体药代学模型的协变量,并结合相关专业知识确定了最终群体药代学模型,喹硫平最终群体药代学模型参数估计见表21。在最终群体药代学模型中,年龄、性别、联用阿托伐他汀钙片、内生肌酐清除率及rs2242480对一级消除速率有显著影响(P<0.05)。最终模型Ka、V及CL的群体典型值分别为:Ka=0.163h
表21喹硫平最终群体药代学模型参数估计
a
b
最终模型的拟合优度图见图20。结果显示,个体浓度预测值、群体浓度预测值与实测浓度值拟合度较好,RMSE和R2分别为63.11ng/ml、0.857和136.13ng/ml、0.316。血药浓度观测值均匀分布在趋势线(y=x)两侧且同对角线基本重合。最终模型的残差图见图21。结果表明,条件加权残差均匀分布在y=0的两侧,且与时间和群体预测值无明显相关性,说明模型拟合效果较好。喹硫平用药方案为300mg(bid)时最终模型群体药代学曲线示意图见图22。
2.4.3喹硫平常规监测血药浓度预测
2.4.3.1基于递归特征消除算法的变量筛选
我们采用基于随机森林的递归特征消除算法筛选预测变量用于机器学习建模。基于随机森林利用不同数量候选变量建模时的十折交叉验证RMSE见图23。由图可知,纳入变量重要性排序前31位的预测变量时,随机森林算法十折交叉验证的RMSE最小,基于随机森林的预测变量重要性评分见图24。基于随机森林的递归特征消除算法筛选的预测变量包括服药剂量、年龄、BMI、碱性磷酸酶、谷草转氨酶、肌酐、谷丙转氨酶、体重、丙戊酸钠、CYP2D6酶活性评分、rs12535512、rs2246709、rs12768009、rs2242480、rs1081003、头孢呋辛酯、氨磺必利、rs58440431、rs2004511、地奥心血康软胶囊、性别、马来酸依那普利片、阿托伐他汀钙片、rs2470890、吸烟、肝功异常、rs1135822、奥卡西平、丁螺环酮、阿立哌唑及稳心颗粒。上述预测变量将被用于基于随机森林、贝叶斯累加回归树等机器学习方法的预测模型构建。
2.4.3.2模型拟合与评价
本研究分别拟合了基于梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的预测模型,同时以NNLS为损失函数,利用十折交叉验证确定了使上述模型组合交叉验证风险最小的一组权重向量,上述模型的权重分别为0.000、0.083、0.674、0.243和0.000,从而构建了基于Super Learner的9-羟基利培酮血药浓度预测模型,该模型适用于预测稳态状态下精神分裂症患者在早晨6:30时9-羟基利培酮血药浓度(用药时间分别为上午10点与晚上21点)。Super Learner中各单独算法权重及参数设置见表22。
表22单独算法在Super Learner中权重及参数设置
注:表22未列出的各算法参数均设定为R包默认值。
本研究中,我们随机抽取100人次常规血药浓度监测记录作为验证集,剩余部分作为训练集,基于Super Learner的喹硫平血药浓度预测模型模型评价见表23。在训练集中,Super Learner、梯度提升树、支持向量机、随机森林、贝叶斯累加回归树及xgboost算法的RMSE分别为68.43ng/ml、67.61ng/ml、75.28ng/ml、63.27ng/ml、88.60ng/ml和48.66ng/ml。在验证集中,上述算法的RMSE分别为85.27ng/ml、81.09ng/ml、84.18ng/ml、86.90ng/ml、89.35ng/ml和90.23ng/ml。Super Learner在训练集和验证集中的R
表23 Super Learner的喹硫平血药浓度预测模型模型评价
应注意的是,以上实例仅用于说明本发明的技术方案而非对其进行限制。尽管参照所给出的实例对本发明进行了详细说明,但是本领域的普通技术人员可根据需要对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
- 一种基于SNP位点的儿童个性化用药分析的检测方法及其应用
- 一种ALDH2的SNP位点的快速扩增检测试剂盒及检测方法
- 一种基于perl语言的种群特异SNP位点的自动化分析方法
- 一种面向真实世界的多SNP位点介导的抗精神病药物疗效预测与精准决策系统
- 一种基于单核苷酸多态性的肺血栓栓塞症风险预测模型的构建方法、SNP位点组合及应用