基于时序的多维度指标异常检测方法及装置
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及时间序列数据挖掘领域和机器学习领域,尤其涉及一种基于时序的多维度指标异常检测方法及装置。
背景技术
随着物联网(IoT)网络和许多其他连接的数据源的快速增长,时间序列数据有了巨大的增长。与传统的时间序列数据相比,它的数量很大,而且通常有很长的季节性周期。管理和利用这些时间序列数据的基本问题之一是将季节性与趋势分解出来。一个好的季节与趋势分解可以揭示时间序列的基本见解,并在进一步的分析中发挥作用[Hochenbaum J,Vallis O S,Kejariwal A.Automatic Anomaly Detection in the Cloud ViaStatistical Learning:,10.48550/arXiv.1704.07706[P].2017.]。例如,在异常检测中,局部异常可能是闲置期间的一个尖峰。如果没有季节性趋势分解,它就会被遗漏,因为它的值仍然比繁忙时期的基线异常值低很多。此外,不同类型的异常现象在分解后对应于不同组件的不同模式。
所以时序的异常检测[Zeyan Li,Junjie Chen,Rui Jiao,Nengwen Zhao,ZhijunWang,Shuwei Zhang,Yanjun Wu,Long Jiang,Leiqin Yan,Zikai Wang,Zhekang Chen,Wenchi Zhang,Xiaohui Nie,Kaixin Sui,Dan Pei:Practical Root Cause Localizationfor Microservice Systems via Trace Analysis.IWQoS2021:1-10]在时序数据监控领域,面临着很多技术挑战:比如说周期是非常复杂的,可能是无周期的、单周期的或者多周期的。同时即便是单周期,它里面会有很多的这种周期的偏移幅度的变化等等。这种周期的趋势它也会包含一些周期,趋势的缓变、突变现象,在实际数据中大量噪声是一种常见的情况。另外运维平台也会收集一些预先定义的指标,通过历史数据与最新收集的数据进行对比,如果与历史数据产生了明显的偏离则有可能出现异常,但是如果物理资源充足的情况下仅仅通过以上预先定义的指标是无法检测到异常的。并且,这种智能运维本身对实时处理要求很高,要求算法的计算复杂度必须要低,能够进行及时的服务响应,并且由于指标没有基线,所以减少异常检测的误判率也是所面临的挑战。
目前基于日志的在线异常检测通常基于无监督[Nandi A,Mandal A,Atreja S,etal.Anomaly Detection Using Program Control Flow Graph Mining From ExecutionLogs[C]//the22nd ACM SIGKDDInternational Conference.ACM,2016.]的机器学习算法,该算法用于处理应用服务产生的日志,以检测某些服务中是否发生了一些异常情况。特别是,无监督学习算法被用来学习应用服务在无故障运行中的日志行为的基线模型。然后,基线模型被用于在线检测服务新记录的事件是否与基线模型不同,从而表明该服务遭受了某些异常情况。但是由于日志系统体量很大,需要耗费大量的资源但是不能得到较高的准确率,而且也无法保证历史日志可以作为基线使用,所以此方法局限性很大。
基于Trace的异常检测既有无监督[Liu P,Xu H,Ouyang Q,et al.UnsupervisedDetection of Microservice Trace Anomalies through Service-Level Deep BayesianNetworks[C]//2020IEEE 31st International Symposium on Software ReliabilityEngineering(ISSRE).IEEE,2020.]、也有有监督的机器学习[Nedelkoski S,Cardoso J,Kao O.Anomaly Detection and Classification using Distributed Tracing and DeepLearning[C]//2019 19th IEEE/ACM International Symposium on Cluster,Cloud andGrid Computing(CCGRID).ACM,2019.]、还有Trace数据比对[Wang T,Zhang W,Xu J,etal.Workflow-Aware Automatic Fault Diagnosis for Microservice-BasedApplications With Statistics[J].IEEE Transactions on Network and ServiceManagement,2020,PP(99):1-1.]。在所有这些情况下,共同的假设是,应用程序在训练运行中产生的Trace数据与它在运行时产生的Trace数据是一致的,因此提供了一个基线来比较新产生的Trace数据。这与刚才讨论的基于日志的异常检测技术的假设几乎相同,因此带来了同样的局限性:如果应用程序的运行条件与训练运行中的条件不同,同时也未考虑时序问题,异常检测的准确性可能会下降。
基于监控信息的异常检测最常见的技术是利用无监督[Gulenko A,Schmidt F,Acker A,et al.Detecting Anomalous Behavior of Black-Box Services Modeled withDistance-Based Online Clustering[C]//2018:912-915.]或有监督[Du Q,Xie T,HeY.Anomaly Detection and Diagnosis for Container-Based Microservices withPerformance Monitoring[C]//International Conference on Algorithms andArchitectures for Parallel Processing.Springer,Cham,2018.]的机器学习算法来处理监测的KPI,训练一个基线模型,并通过比较新监测的KPI和这种基线来检测任何应用服务是否发生了异常。这样的方法可以在应用层面和服务层面确定功能和性能异常,但前提是应用在训练阶段和运行时的运行条件是一样的。当应用程序的运行时间条件发生变化时,例如由于终端用户请求的高峰期产生了更高的负载,或者由于部署了新的服务来取代过时的服务,这样的假设导致所颁布的异常检测的准确性可能会下降。
综上,目前没有一种在资源充足的环境下,利用监控指标与时序相结合的算法。
发明内容
针对现有技术中存在的技术问题,本发明提供一种基于时序的多维度指标异常检测方法及装置,该方法在容器微服务环境下,微服务存在冗余备份和负载均衡策略,将磁盘IO、数据库读写等指标进行非参数估计后加入到STMV(服务调用的指标向量)中重新训练模型,同时将时间序列分解的方法将上述模型得到的异常Trace进行二次检测得到最终的异常Trace(微服务调用链)。本发明可以在物理资源充足的情况下对现有研究的STMV二次重构,并且基于时序的多维度进行异常检测,对此前方法进行优化且提高准确率。
本发明的技术方案,包括:
一种基于时序的多维度指标异常检测方法,包括:
获取目标微服务备份的所有节点,并通过监控该些节点的物理资源数据,构造每一节点对应的时间序列和每一微服务调用链对应的PCA摘要;
基于所述PCA摘要形成改良后的STMV后,基于所述改良后的STMV进行分类,以得到每一微服务调用链的第一异常检测结果;
根据异常检测准确率要求,提取对应的时间序列;
将所述对应的时间序列分解为趋势序列、随机成分序列和季节性序列后,进行异常值的统计检验,以生成异常值集合;
基于所述异常值集合对所述第一异常检测结果中的异常微服务调用链进行检测,得到微服务调用链的最终检测结果。
进一步地,所述物理资源数据包括:CPU占用率、内存使用率和硬盘使用率。
进一步地,所述基于所述改良后的STMV进行分类,以得到每一微服务调用链的第一异常检测结果,包括:
对VAE模型进行无监督学习的训练,以得到训练后的VAE模型;
基于所述训练后的VAE模型对所述改良后的STMV进行分类,以得到每一微服务调用链的第一异常检测结果。
进一步地,所述根据异常检测准确率要求,提取对应的时间序列,包括:
在异常检测准确率要求大于一准确率阈值的情况下,提取所有节点对应的时间序列;
在异常检测准确率要求不大于该准确率阈值的情况下,提取所述第一异常检测结果中正常微服务调用链所涵盖节点对应的时间序列。
进一步地,所述将所述对应的时间序列分解为趋势序列、随机成分序列和季节性序列,包括:
对所述对应的时间序列进行周期提取,得到该对应的时间序列包含的所有周期长度;
对每一周期长度进行周期分解,以得到趋势序列、随机成分序列和季节性序列。
进一步地,对所述对应的时间序列进行周期提取,得到该对应的时间序列包含的所有周期长度,包括:
预处理所述对应的时间序列,所述预处理的过程包括:使用线性差值法对所述对应的时间序列中的缺失值进行填充,和使用HP滤波对时间序列中的趋势项进行提取并剔除;
针对预处理后的时间序列,使用最大重复离散小波转换分离出不同层次的周期性;
基于分解出的周期成分和该周期成分对应的小波方差,对所有周期成分进行强弱排序;
依据所有周期成分由强到弱的顺序,输出不同层次的周期性;
针对每一层次的周期性,基于费歇尔检验生成每个层次的周期长度候选项后,利用ACF对该周期长度候选项进行验证优化,以该层次的周期性所包含的所有周期长度;
综合所有层次的周期性所包含的所有周期长度,得到该对应的时间序列包含的所有周期长度。
进一步地,所述对每一周期长度进行周期分解,以得到趋势序列、随机成分序列和季节性序列,包括:
基于具有稀疏正则化的最小绝对偏差损失,得到该周期长度中所包含的趋势序列;
结合所述趋势序列,应用非局部季节性滤波来提取季节性序列;
将该周期长度中非趋势序列以及非季节性序列的部分设定为随机成分序列。
进一步地,所述进行异常值的统计检验,以生成异常值集合,包括:
对于所述趋势序列,计算该趋势序列的均值和标准差,将该趋势序列中的每个数据点与该趋势序列的均值比较,以得到第一差值,并通过所述第一差值与该趋势序列的标准差的比较,判断该趋势序列中的数据点是否为异常值;
对于随机成分序列,将该随机成分序列作为残差序列,计算该残差序列的均值和标准差,将随机成分序列中的每个数据点与均值比较,以得到第二差值,并通过所述第二差值与该残差序列的标准差的比较,判断该随机成分序列中的数据点是否为异常值;
对于季节性序列,将该季节性序列中的数据点放入一个箱子里,根据该箱子中的数据点计算出上下四分位数和中位数,进而绘制出箱线图,并根据所述箱线图的四分位距来判断该季节性序列中的数据点是否为异常值。
一种基于时序的多维度指标异常检测装置,包括:
数据采集模块,用于获取目标微服务备份的所有节点,并通过监控该些节点的物理资源数据,构造每一节点对应的时间序列和每一微服务调用链对应的PCA摘要;
向量构建模块,用于基于所述PCA摘要形成改良后的STMV后,基于所述改良后的STMV进行分类,以得到每一微服务调用链的第一异常检测结果;
时序异常检测模块,用于根据异常检测准确率要求,提取对应的时间序列;将所述对应的时间序列分解为趋势序列、随机成分序列和季节性序列后,进行异常值的统计检验,以生成异常值集合;基于所述异常值集合对所述第一异常检测结果中的异常微服务调用链进行检测,得到微服务调用链的最终检测结果。
一种计算机设备,其特征在于,所述计算机设备包括:处理器以及存储有计算机程序指令的存储器;所述处理器执行所述计算机程序指令时实现上述任一项所述的基于时序的多维度指标异常检测方法。
与现有技术方案相比,本发明最少具有以下优势:
1.本发明可以检测出在物理资源充足的情况下,除响应时间以外环境的异常。
2.本发明考虑时序,可以更精准的判断出是否因为某个活动大促而导致异常误报或者漏报。
附图说明
图1物理资源充足内存变化图。
图2物理资源充足情况下磁盘io的变化图。
图3过去2分钟内每秒增量的时间序列。
图4考虑时序的CPU变化图。
图5时序检测流程图。
图6时间序列构造。
图7周期分解图。
具体实施方式
本发明将时序异常检测与系统机器级指标结合在一起,基于[施园.面向微服务的异常根因算法研究与实现[D].北京:中国科学院大学,2023]的异常检测基础上,进行对机器指标纬度的扩建,并将时序异常检测结合进来进行微服务系统的异常检测。检测过程主要分为三个模块:数据采集与向量构建、时序异常检测。
1、数据采集与向量构建
1)数据采集
此前的研究只采集了物理机CPU、Memory的指标并进行计算,在微服务多备份的情况下,如果某一个服务出现异常,Kubernetes会根据计算后迅速启用其它备份的微服务,此时只根据微服务的响应时间是无法观测出来的,则可以通过机器指标来判断是否出现异常情况,即如果切换了微服务后,物理机的CPU、Memory会出现异常抖动或者持续负载过高,则可以判断出异常情况。但是此方案未考虑在物理资源充足的情况下,CPU和Memory变化是微小的,无法检测出机器已经异常,如图1物理资源充足内存变化图所示,此图模拟为物理资源充足的情况下(RAM共450GB,已使用50GB)内存负载过高情况的情况,在此情况下,正常状态的内存使用大约在10GB左右,所以50GB已经是持续异常,但是无法检测出此异常,CPU亦是如此,所以本发明提出将磁盘io的变化率考虑进来,如图2物理资源充足情况下磁盘io的变化图所示,此时磁盘io的变化率完全可以体现出来存在异常情况;另外大部分多服务平台下所使用的数据库采用MongoDB,但是现有的研究未考虑数据库异常会导致最终微服务异常的情况,所以本发明将利用prometheus监控MongoDB数据,采集rate(mongodb_mongod_wiredtiger_transactions_checkpoint_milliseconds_total[5m])指标,表示在过去2分钟内每秒增量的时间序列,此指标用于监控和分析时间序列数据的变化趋势,通过计算每秒增量,可以了解在给定时间范围内该指标的平均变化速率,以帮助评估系统的性能、资源使用情况或其他关注的指标。如图3示。目前的研究也没有考虑时序变化对异常检测带来的影响,如图4CPU变化所示,此时情况可以模拟为电商平台有大促活动、火车票节假日购票时的CPU变化,当持续CPU负载过高时,此情况应该是正常情况,以往的判断会将其识别为异常,如果将此数据作为数据集中的训练集后,通过VAE模型,准确率不够高,误报率和漏报率过高。
2)向量构建
现有研究的STMV只有响应时间与服务所利用的CPU、Memory,并未考虑磁盘io与数据库每秒增量的这些指标,但是所以本发明重新绑定成新的STMV形成向量。又考虑到如今在互联网发达时代,微服务系统中的每个微服务存在多个备份,他们会分布在不同的node上,基于此前的研究对STMV的处理方法,对纬度扩展后,进行主成分分析法进行构造,本发明以每个微服务存在四个备份其中每个备份可能分布在同个节点也可能分布在不同节点上,构造每个微服务的PCA摘要,其中PCA序列就是每个备份所在节点下CPU、Memory、Disk、MongoDB构成的序列摘要,如表1微服务PCA摘要所示。
表1微服务PCA摘要
将上述PCA摘要加入到STMV,形成改良后的STMV,此表的微服务备份为2个,如表2所示,此表已经覆盖异常时的各种场景。
表2:真实的STMV示例
2、时序异常检测
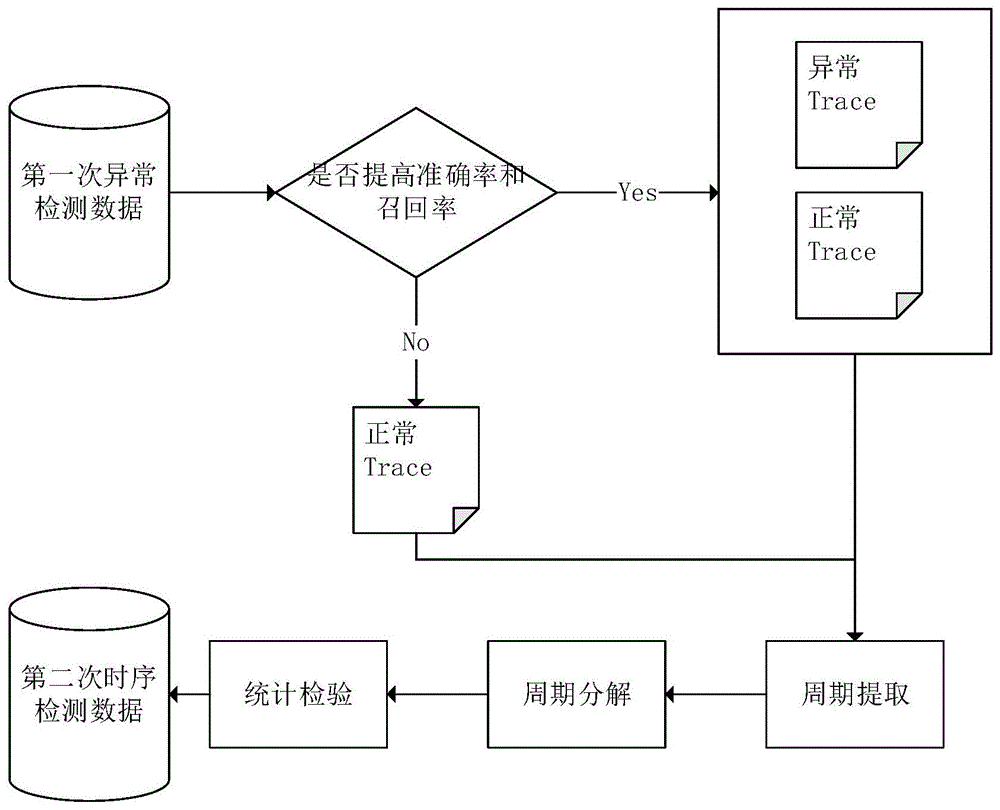
本模块采用时序异常检测,根据本发明改良后的STMV向量利用VAE模型进行无监督学习后得到的第一轮异常检测数据。其中可以根据需求来判断是否需要对第一轮异常检测数据的正常、异常数据进行全部二次检测。如果需要较高的准确率和召回率,那么则需要对正确、异常数据全部进行二次时序检测,如果只需要较高的召回率那么只需要对所有正确的数据进行二次时序检测,如图5所示。
1)数据收集
本发明通过Prometheus监控每个node的物理资源数据,该物理资源数据包括CPU占用率、内存使用率、硬盘使用率,每分钟采集一次后存入MySQL数据库,记录当前时间序列的各个指标值,得到Trace的开始时间后,查询这个微服务备份在哪些不同的节点上,抽取当前时间至前120分钟的时间作为时间序列,分别对这些不同时间点进行时序检测,如果最后一个时间点为异常时间点,那么此个微服务则为异常,查询顺序如图6所示。
2)周期提取
首先是时间序列预处理阶段,使用线性差值法对缺失值进行填充以应对大段数据缺失。使用HP滤波对时间序列中的趋势项进行提取并剔除。然后进行多重周期的分解,首先使用最大重复离散小波转换(Maximal overlap discrete wavelet transform,MODWT)分离出不同层次的周期性。基于分解出的周期成分和它们对应的小波方差,对这些周期成分进行强弱排序,优先输出更显著的周期。最后进行单周期检测,完成多重周期的分解后,首先是利用基于Huber-Periodogram的Fisher’s Test生成每个层次的周期长度候选项,然后利用ACF对这些候选项进行验证优化,最终得到序列的所有周期长度供周期分解使用。
3)周期分解
本部分是将时间序列按照上述提取出来的周期后,将复杂的时间序列分解为趋势(trend)、季节性(seasonality)和其他部分(remainder)。趋势是时间序列中长期的、持续性的变化趋势。通过将时间序列分解为趋势部分,可以提取出长期变化的趋势信息。时序异常往往表现为与趋势明显不符的突然变化或异常波动。季节性是时间序列中周期性的重复模式,如每年、每月或每周的季节性波动。通过将时间序列分解为季节性部分,可以提取出周期性变化的季节性信息。如果时间序列中的观测值在某个特定季节上出现异常或偏离季节性模式,那么这可能是一个异常的指示。其他部分是指除了趋势和季节性之外的残差部分,即时间序列中不能被趋势和季节性解释的部分。这部分通常包含了随机波动、噪声或无法被模型捕捉的非周期性变化。
通过使用具有稀疏正则化的最小绝对偏差损失来解决回归问题,从而稳健地提取趋势分量。基于提取的趋势,本发明应用非局部季节性滤波来提取季节性成分。重复这个过程,直到获得准确的分解。并可用于进一步分析。图7就是周期分解后得到的例子。
4)统计检验
本模块分别对周期分解出的趋势序列、随机成分序列、季节性序列进行统计检验。对于趋势序列,使用均值和标准差来检测异常值。计算出均值和标准差,然后将每个数据点与均值比较,如果其绝对值大于3倍的标准差,则认为该数据点为异常值。对于随机成分序列,使用残差的均值和标准差来检测异常值。将分解得到的随机成分序列作为残差序列,然后计算其均值和标准差,将每个数据点与均值比较,如果其绝对值大于3倍的标准差,则认为该数据点为异常值。对于季节性序列,使用箱线图来检测异常值。将每个季节中的数据点放入一个箱子里,然后根据箱子中的数据点计算出上下四分位数和中位数,进而绘制出箱线图。使用IQR(四分位距)来判断箱子中的数据点是否为异常值,如果数据点的值小于Q1-1.5IQR或大于Q3+1.5IQR,则认为该数据点为异常值。
5)异常检测
将上述统计检验的异常值全部加入到异常值集合中,代表这条Trace前120分钟内所有异常点,如果最后一个时间点是异常,那么这条Trace则时序异常。
为了证明本发明的方法可行性,将本发明提出的想法与以前的方法进行了比较,搭建了一个开源测试平台TrainTicket,这个平台包含了四十一个微服务,其中在本发明的测试中,每个微服务存在3个备份,对于数据的采集,使用开源链路追踪系统Jaeger去提取每个Trace信息,通过ElasticSearch将数据收集出来,利用Fluentbit作为缓冲机制,将数据发送给Kibana后展示出来,同时利用Prometheus监控系统来采集每个机器指标信息,使用ChaosMesh混沌测试平台模拟真实故障场景进行测试。
在本发明的实验中,收集历史数据与实时数据,分两个方面测试其有效性。第一个实验是检测系统对物理资源充足情况下的异常检测,第二个实验是考虑时序变化的情况下的异常检测,对比多个模型,结果如表3所示。
表3本方法和其它方法比较结果
可以看到,在针对物理资源充足的微服务系统负载异常和时序异常的检测上具有明显提升。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 基于多指标时序预测的微服务系统异常检测方法及装置
- 基于多指标时序预测的微服务系统异常检测方法及装置