使用加权策略投影的多目标强化学习
文献发布时间:2024-04-18 19:58:30
背景技术
本说明书涉及使用神经网络控制代理。
神经网络是机器学习模型,其采用一个或多个非线性单元层来预测接收到的输入的输出。一些神经网络除了包括输出层之外还包括一个或多个隐藏层。每个隐藏层的输出均用作网络中的下一层(即,下一隐藏层或输出层)的输入。网络的每一层均根据相应参数集的当前值而从接收到的输入生成输出。
发明内容
本说明书描述了一种系统和方法,其被实现为一个或多个位置中的一个或多个计算机上的计算机程序,所述计算机程序学习控制代理执行任务,同时平衡权衡。
在一个方面,描述了一种训练行动选择策略神经网络的计算机实现的方法,该行动选择策略神经网络定义行动选择策略,该行动选择策略用于选择将由代理执行的行动以控制代理执行环境中的任务,该任务具有多个相关联的目标。一般而言,一个目标是最大化针对任务相关目标的来自环境的回报,即针对任务相关目标的累积的时间折扣奖励。另一目标可以是保持接近先前行为策略,诸如教师的行动选择策略。在一些实施方式中,先前行为策略是由先前行为数据集定义,并且系统离线学习。在一些实施方式中,另一目标可以是基于例如勘察而最大化辅助奖励,或最大化针对第二不同任务相关目标的来自环境的回报。所述技术提供了用于明确定义这些不同目标之间的权衡的机制。
在实施方式中,该方法包括获得定义行动选择策略的更新版本的数据以响应于环境的状态的观察值而选择代理的行动。可以基于奖励例如使用强化学习技术来获得行动选择策略的更新版本。在一些实施方式中,行动选择策略的更新版本是基于习得Q值的策略的非参数更新。
在实施方式中,该方法还获得定义第二行动选择策略的数据以响应于环境的状态的观察值而选择代理的行动。第二行动选择策略可以是教师或专家的行动选择策略,或例如旨在最大化所选行动的熵的行动选择策略,或例如旨在最大化针对第二不同任务相关目标的来自环境的回报的行动选择策略。
在实施方式中,该方法根据行动选择策略的更新版本与行动选择策略之间的差异的估计度量来确定第一策略投影值。在实施方式中,该方法还根据第二行动选择策略与行动选择策略之间的差异的估计度量来确定第二策略投影值。第二行动选择策略可以是例如根据定义第二行动选择策略的数据的第二行动选择策略的版本,或通过对该数据的采样(例如,加权采样)获得的版本。
该方法从第一策略投影值与第二策略投影值的加权组合确定组合目标值。该方法通过调整行动选择策略神经网络的参数以优化组合目标值(例如,通过反向传播组合目标值的梯度)来训练行动选择策略神经网络。
该方法可以推广到两个以上的行动选择策略。因此,该方法的一些实施方式具有三个或更多个行动选择策略,每个行动选择策略均用于确定相应的策略投影值。然后,可以使用加权组合来组合所有的策略投影值以确定组合目标值。
还描述了一种代理,其包括经训练的行动选择策略神经网络,该经训练的行动选择策略神经网络被配置为选择将由代理执行的行动以控制代理执行环境中的任务。在实施方式中,行动选择策略神经网络已经如本文所述被训练。代理可被配置为实现如本文所述的训练方法,例如使得代理被配置为在初始训练之后继续学习。例如,代理可包括训练引擎以及如本文所述的一个或多个Q值网络,以如本文所述训练代理。
本文所述的系统和方法提供了一种新的强化学习方法,其可以比先前的技术更好地运行。例如,所述技术可以实现更好的结果,诸如学习以更好地执行任务,例如具有更高的成功几率,或具有更少的能量或磨损,或更加准确。它们可以比一些先前的方法更快地学习,使用更少的计算资源和能量;并且训练可以涉及更少地使用代理,具有更少的中断或磨损。
该系统的一些实施方式使代理能够离线学习,即仅仅根据训练数据的数据集而无需与环境进一步互动。本文所述的离线学习技术的优点在于,尽管它们可以由这种数据集中的示例行为引导,但是它们可以将其行动延伸到该行为之外。所述技术还允许权重的明确选择放在这个示例行为上。
该系统的一些实施方式还有利于代理的行为的微调。例如,代理可以由教师系统所定义的先前行为策略引导,而且还可以建立在该基础上,通过在环境中进行行动来学习对先前行为策略进行改进。
在实施方式中,额外的奖励(例如,调整学习)被视作与最大化针对一个或多个明确任务相关目标的来自环境的回报的目标不同的目标。
所述系统和方法的一些实施方式提供了其中涉及权衡的学习任务的解决方案。例如,它们可以找到关于凹面帕累托前沿(concave Pareto front)的目标之间的权衡。这可以有助于找到竞争目标之间的更好的平衡,例如任务奖励与成本的更好的整体组合;并且还可以有助于识别满足特定约束条件的解决方案。
强化学习目标常常需要相互权衡。所述技术允许根据不同目标的权重来为强化学习过程指定直观的平衡,并且允许调整这些权重以改变权衡。进一步,所述技术并不要求为不同的目标完全满足特定约束条件。
所述技术的另一优点在于,定义目标之间的权衡的权重是尺度不变的:它们不是根据奖励等级来定义的,奖励等级通常可以在不同的奖励之间并且随着时间显著变化;它们也不是根据特定Q值的等级来定义的。因此,权重的选择与目标的改进脱离。
所述技术的又一优点在于,可以随着时间调整权重。例如,当目标中的一者将保持接近先前行为策略的情况下,强化学习系统最初可能希望保持接近该先前行为策略以从教师获得最大益处,但是之后可能希望分开以使系统能够改进超过教师策略。
在下面的附图以及描述中阐述了本说明书的主题的一个或多个实施例的细节。根据描述、附图以及权利要求书,该主题的其它特点、方面和优点将变得显而易见。
附图说明
图1示出了用于训练行动选择策略神经网络的系统的示例。
图2是用于训练行动选择策略神经网络的示例过程的流程图。
图3A-3C示出了系统的示例在训练行动选择策略神经网络中的性能。
各个附图中的相似的附图标记和名称指示相似的元件。
具体实施方式
本说明书描述了强化学习系统,其可以用于在线多目标学习,用于微调教师行动选择策略,以及用于离线强化学习,其中代理根据演示数据的数据集学习而无需与环境进一步互动。
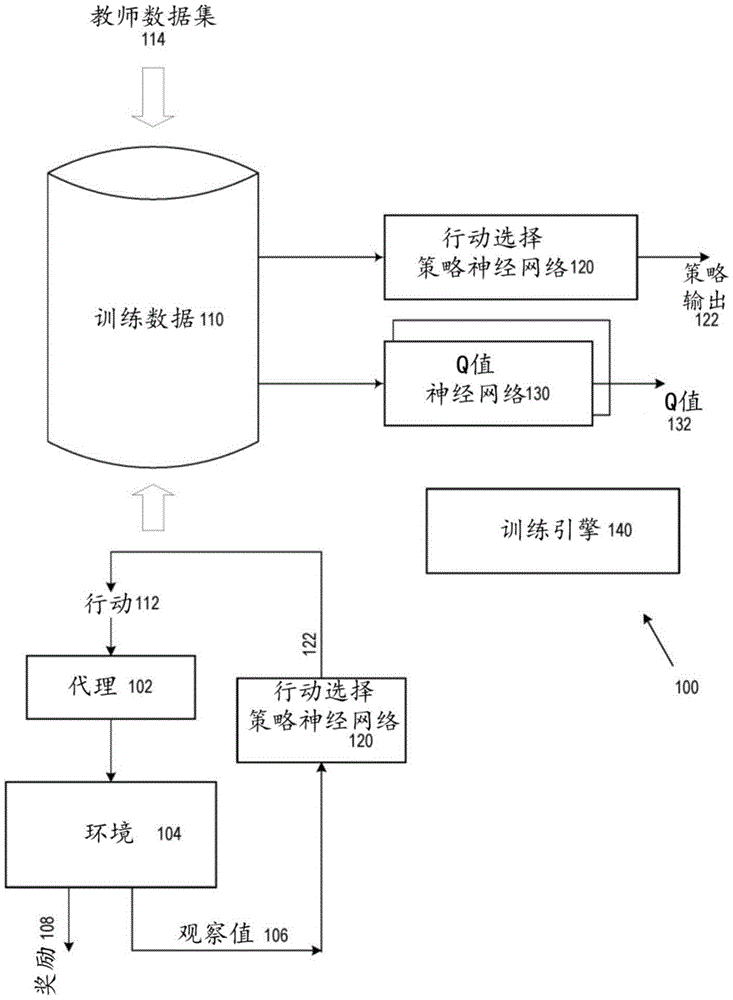
图1示出了用于训练行动选择策略神经网络120的系统100的示例,系统100可以被实现为一个或多个位置中的一个或多个计算机上的一个或多个计算机指令。行动选择策略神经网络120用于在训练期间或之后控制与环境104互动的代理102,以选择将由代理执行的行动112来执行任务。行动选择策略神经网络120是基于在所选行动之后接收到的奖励而使用表征环境104的状态的观察值106进行训练的。
系统100有许多应用,并且稍后描述一些示例应用。仅作为一个示例,环境可以是真实世界环境,并且代理可以是诸如机器人或者自主或半自主交通工具之类的机械代理。然后,可以训练行动选择策略神经网络120以响应于从感测真实世界环境的一个或多个传感器获得的观察值而选择将由机械代理执行的行动,从而控制代理执行任务,同时与真实世界环境互动。行动选择策略神经网络120通过获得环境的观察值并生成行动选择策略输出来控制代理,该行动选择策略输出用于选择行动以控制代理执行任务。
在一些实施方式中,对行动选择策略神经网络120进行离线训练,这仅仅基于观察值、行动和奖励的数据集而无需与环境104互动。数据集可能已经由人类或机器专家从任务执行的一个或多个演示中获得。在一些实施方式中,对行动选择策略神经网络120进行在线训练,这通过与环境104互动完成。在这些实施方式中,训练可以由来自教师(例如,另一机器)的模型行动选择策略(即,由来自行动选择模型的模型策略输出)引导;或者可以在没有外部引导的情况下训练行动选择策略神经网络120。
在图1中,存储训练数据110表示可能已经从教师数据集114接收到的数据或可能已经通过使用行动选择策略神经网络120选择在环境104中执行的行动而生成的数据。生成训练数据可包括:获得环境的状态的观察值106;根据行动选择策略神经网络120的当前参数集而使用行动选择策略神经网络120处理观察值,从而生成行动选择策略输出122;使用策略输出122响应于观察值而选择将由代理102执行的行动112;以及使代理执行所选行动并且作为响应,接收表征任务进展的奖励108。奖励可以表示任务的完成或完成进展。
在实施方式中,存储训练数据110定义转换集。每个转换均可包括表征在时间步长处环境的状态的观察值和在时间步长处执行的行动、在执行行动之后接收到的奖励,以及在实施方式中,表征在执行行动之后环境的后续状态的后续观察值。使用这些观察值并且基于在所选行动之后接收到的奖励来训练行动选择策略神经网络120,如稍后所述。
行动选择策略神经网络120可以具有任何合适的架构,并且可以包括例如一个或多个前馈神经网络层、一个或多个卷积神经网络层、一个或多个循环神经网络层、一个或多个注意力神经网络层或一个或多个归一化层。策略输出122可直接定义行动,例如它可包括用于定义行动的连续值(诸如转矩或速度)的值,或者它可以参数化连续或类别分布,定义行动的值可以从该连续或类别分布选择,或者它可以定义分数集,可能行动集中的每一个行动对应一个分数,以用于选择行动。仅作为一个示例,策略输出122可定义具有对角协方差矩阵的多元高斯(Gaussian)分布。
系统100被配置为评价并更新(即,改进)由行动选择策略神经网络120实现的当前行动选择策略。通常,这包括基于在所选行动之后接收到的奖励而使用强化学习技术。在特定实施方式中,这是通过使用Q学习来完成,更具体而言,通过维持一个或多个Q值神经网络130来完成,所述一个或多个Q值神经网络130被配置为根据Q值神经网络130的当前参数集来处理状态的观察值以及代理的行动以生成一个或多个相应的Q值132。Q值神经网络130可以具有任何合适的架构,并且可以包括例如一个或多个前馈神经网络层、一个或多个卷积神经网络层、一个或多个循环神经网络层、一个或多个注意力神经网络层或一个或多个归一化层。
通常,Q值是状态行动值或预期回报,以用于在由观察值表征的状态中采取行动并随后根据由行动选择策略神经网络参数的当前值定义的行动选择策略来行动。通常,回报是当代理在多个时间步长中与环境互动时接收到的奖励的累积度量,例如时间折扣奖励总和。
任务可具有一个或多个任务相关最终目标,并且每个最终目标可以由相应的Q值表示。通常,系统的实施方式允许在优化多个目标的同时训练行动选择策略神经网络120。在系统的一些实施方式中,目标中的一者是优化(例如,最大化)任务的Q值,而目标中的另一者是维持行动选择策略接近由教师数据集114或由模型行动选择策略表示的行动选择策略。在一些实施方式中,当代理试图执行任务例如以最大化奖励或最小化成本时,系统被配置为在优化任务的多个不同Q值的同时在线训练行动选择策略神经网络120,每个Q值表示不同的最终目标,诸如不同的奖励或成本(即,负奖励)。真实世界环境中的示例成本可包括惩罚,例如对于电力或能量使用,或对于机械磨损。
在实施方式中,系统100被配置为通过基于接收到的奖励使用强化学习技术来训练Q值神经网络130,以优化第一任务相关目标函数。可以类似地使用强化学习技术并基于接收到的奖励来训练第二Q值神经网络130(如果存在的话),以优化第二任务相关目标函数。可使用任何强化学习(评论家学习)技术来训练Q值神经网络130,例如使用一步或n步回报,例如追溯目标(arXiv:1606.02647)。在一些实施方式中,使用分布式Q学习,例如如Bellemare等人“A distributional perspective on reinforcement learning(强化学习的分布视角)”(arXiv:1707.06887)中所述的C51算法。通常,训练Q值神经网络包括通过反向传播任务相关目标函数的梯度(例如,基于Q值目标的时间差异)来调整Q值神经网络的参数的值。
训练引擎140控制行动选择策略神经网络120的训练,如下文进一步描述的。从广义上讲,这包括在保持接近不同目标的行动选择策略的同时改进行动选择策略神经网络120的当前行动选择策略。更具体而言,这包括:找到改进行动选择策略神经网络120的当前行动选择策略的行动选择策略,例如以优化第一任务相关目标函数;以及还使用定义第二行动选择策略的数据以响应于环境的状态的观察值而选择代理的行动。第二行动选择策略可以是模型行动选择策略,或者可以由教师数据集114表示,或者可以通过找到改进行动选择策略神经网络120的当前行动选择策略以优化第二任务相关目标函数的行动选择策略来确定。
为了训练行动选择策略神经网络120,在对这些行动选择策略的效果进行求和以得到组合目标函数J(θ)之前对它们进行显式加权,组合目标函数J(θ)取决于行动选择策略神经网络参数θ。组合目标函数用于训练行动选择策略神经网络120。将权衡明确并入组合目标函数中允许系统用于离线强化学习,因为它使得能够计算教师数据集114对组合目标函数的影响,而使用其它方法是难以处理的。它还有利于学习不同目标的行动选择策略之间的权衡。更具体而言,行动选择策略神经网络120的训练包括使用组合目标函数来将不同目标的行动选择策略投影回由行动选择策略神经网络的当前参数值定义的空间。
图2是使用系统100来训练行动选择策略神经网络的示例过程的流程图。图2的过程可以由一个或多个位置中的一个或多个计算机实现。
参考图2,训练行动选择策略神经网络120包括获得定义行动选择策略的更新(尤其是改进)版本的数据以响应于环境的状态的观察值而选择代理的行动(步骤202)。更具体而言,使用强化学习、使用观察值并且基于在所选行动之后接收到的奖励来获得行动选择策略的改进版本。这可以通过使用Q值神经网络130来评价训练数据110并随后使用Q值神经网络130确定行动选择策略的更新版本来完成。可能已经使用策略输出122选择了行动,或者行动可以来自教师数据集114。
然后,该方法根据行动选择策略的更新版本与行动选择策略神经网络120的(当前)行动选择策略之间的差异的度量来确定第一策略投影值(步骤204)。该方法还根据第二行动选择策略与行动选择策略神经网络120的(当前)行动选择策略之间的差异的度量来确定第二策略投影值(步骤206)。在实施方式中,第一策略投影值和第二策略投影值各自包括相应行动选择策略之间(即,行动选择策略的更新版本与(当前)行动选择之间、以及第二行动选择策略与(当前)行动选择策略之间)的KL散度的度量。
然后,该方法从第一策略投影值与第二策略投影值的加权组合中确定组合目标值(步骤208)。第一策略投影值与第二策略投影值的加权组合可包括分别乘以第一权重和第二权重的第一和第二策略投影值的总和。加权组合中的权重可合计为一。
尽管为了清晰起见,确定第一和第二策略投影值与确定组合目标值在图2中被显示为不同的步骤,但是在实践中,它们可以组合为单个步骤以确定组合目标值,如下文所述。
通过调整行动选择策略神经网络的参数以优化组合目标值(例如,通过将组合目标函数的梯度反向传播到行动选择策略神经网络120中)来训练行动选择策略神经网络120(步骤210)。
在实施方式中,迭代地执行该过程的步骤202-210(步骤214)。在一些实施方式中,这包括获得进一步的训练数据,该训练数据是通过使用行动选择策略神经网络来选择环境中的行动而生成(步骤212)。
获得进一步的训练数据可包括:在一个或多个时间步长中的每一者处,获得环境的状态的观察值,使用行动选择策略神经网络来处理观察值以生成策略输出122,以及使用策略输出122来响应于观察值而选择将由代理执行的行动。然后,可以使代理执行所选的行动(例如,通过控制代理执行行动),并且作为响应,接收表征任务的进展的奖励(其可以是零)。时间步长的状态、行动、奖励以及可选的下一状态转换(s,a,r,s′)可以存储在重播缓冲区中。
在离线设置中,未获得新的训练数据,但尽管如此,经训练的行动选择策略神经网络120影响Q学习以及因此获得下一迭代的行动选择策略的改进版本。例如,对于包括状态、行动、奖励、下一状态转换(s,a,r,s′)的转换数据集,训练Q值神经网络可包括使用行动选择策略神经网络从s′确定行动,以用于引导。
在该系统的一些实施方式中,该过程还可包括调整加权组合中的权重,例如以优化目标中的权衡,以优化来自环境的奖励或回报(步骤214)。这可以手动或自动完成,并稍后进一步描述。在一些实施方式中,权重合计为定义值,诸如1。在那种情况下,第一策略投影值与第二策略投影值的加权组合可以由单个权重定义。
现在描述获得定义行动选择策略的更新版本的数据的一个特定示例。定义行动选择策略神经网络120的行动选择策略以用于当环境处于状态s中时选择行动a的策略输出122可以表示为π(a|s)。然后,行动选择策略的更新版本(即,改进行动分布q(a|s))可以通过将π(a|s)乘以策略改进因子exp(Q(s,a)/η)来确定,其中Q(s,a)是针对行动a和状态s的来自Q值神经网络130的Q值,并且η是温度参数。例如,q(a|s)可以被确定为
策略改进因子用作行动概率的权重。例如,当与根据更新(改进)行动分布选择的行动配对时,它可以旨在最大化训练数据中的状态(观察值)中的Q值的平均值。通常,任何改进算子均可以用于获得q(a|s),并且所述技术并不限于特定策略改进因子exp(Q(s,a)/η)。例如,原则上,可以维持神经网络接近q(a|s)。
温度参数η控制改进策略q(a|s)相对于Q(s,a)的程度(greedy),即重点放在Q(s,a)上。温度参数可以是系统的固定超参数或习得参数,例如通过优化
如本文所述,温度参数独立于加权组合中的权重,这使改进算子与加权组合中的权重的选择解耦合。这有利于将所述技术应用于离线设置以及行为微调,并且还有利于由特定权重组合指定的目标组合的直观解释。仅作为说明性示例,在一个特定实施方式中,η≈10。
在存在多个Q值神经网络130且每个Q值神经网络均生成相应的Q值Q
如前所述,改进行动选择策略和第二行动选择策略用于确定策略投影值,策略投影值继而用于确定组合目标值,组合目标值是通过训练行动选择策略神经网络而进行优化。这将改进行动选择策略和第二行动选择策略投影到由行动选择策略神经网络的参数定义的参数化策略的空间中。
更具体而言,该投影可以表示为根据以下等式来确定组合目标函数J(θ):
其中k表示第一和第二(通常为K个)策略投影值,使得q
对于第二行动选择策略是模型行动选择策略或由教师数据集114表示的情况,下面描述用于根据该方法评价J(θ)的一些技术。
在行动选择策略神经网络120将优化第一和第二任务相关目标函数(即,用于多目标强化学习)的情况下,可以使用改进策略q
类似地,可以维持另一Q值神经网络,该另一Q值神经网络被配置为处理状态的观察值和代理的行动以生成另一Q值Q
通常,在多目标实施方式中,可以通过从重播缓冲区对状态s进行Monte Carlo采样并随后使用(当前)行动选择策略π(·|s)对每一状态的行动进行采样来确定组合目标的值
在一些实施方式中,第二行动选择策略是行动选择模型的模型行动选择策略(即,行为策略π
行为策略π
这种方法可以用于改进或“微调”另一系统(例如,另一基于神经网络的行动选择系统)的行为策略π
在一些实施方式中,可以根据第一策略投影值与第二策略投影值的加权组合将组合目标值J(θ)确定为:
其中通过权重α(例如,如果α
在一些实施方式中,例如在离线学习中,第二行动选择策略由教师数据集114表示。在这些实施方式中,不可能直接询问行为策略π
在实施方式中,定义第二行动选择策略的教师数据集114包括转换数据集,每个转换集均包括表征在时间步长处环境的状态的观察值、在时间步长处执行的行动、以及在执行行动之后接收到的奖励。转换还可以包括表征在下一时间步长处环境的状态的观察值。
如前所述,可以基于教师数据集114中表示的状态、行动和奖励使用强化学习技术(诸如Q学习)来获得定义行动选择策略的更新版本q(a|s)的数据。更具体而言,可以使用教师数据集114以及行动选择策略的更新改进版本q(a|s)来训练Q值神经网络130,该更新改进版本是通过将π(a|s)乘以前述策略改进因子exp(Q(s,a)/η)而确定的。
在实施方式中,教师数据集114包括从行为策略π
作为一个特定示例,可以根据第一策略投影值与第二策略投影值的加权组合将组合目标值J(θ)确定为:
其中变量如前所定义。确定第一项中的期望值包括在从教师数据集114采样的状态(观察值)中以及在使用行动选择策略logπ(a|s)选择的对应行动中计算平均值。确定第二项中的期望值包括在从教师数据集114采样的状态(观察值)和对应行动中计算平均值。该方法的实施方式允许系统除了利用如教师数据集114所定义的“专家”所采取的那些之外利用行动的Q值估计。
第二项可以由(指数化)优势函数A(s,a)=Q(s,a)-V(s)加权,其中V(s)是状态值函数。例如,第二项可被定义为
可选地,在上述实施方式中,J(θ)的评价可受额外的限制,例如关于q(a|s)或关于策略输出122的均值或协方差的信赖域或软KL限制。
在一些实施方式中,权重α或权重α
在一些实施方式中,行动选择策略神经网络是以投影值与由权重定义的对应目标之间的权衡为条件。第一策略投影值与第二策略投影值的加权组合可以由权重向量α定义,其中一个或多个元素对应于所述一个或多个权重。然后,行动选择策略神经网络可被配置为处理观察值和权重向量以生成策略输出122。这种以权重为条件的行动选择策略可被表示为π(a|s,α)。
类似地,所述一个或多个Q值神经网络130可被配置为处理状态的观察值、代理的行动以及权重向量α以生成所述一个或多个相应的Q值132,Q(s,a,α)。行动选择策略的更新(改进)版本可被确定为
例如通过在行动选择策略神经网络的训练期间对权重向量的值进行随机或系统采样,或通过自动调整权重向量以优化奖励(例如,通过强化学习),可以调整权重向量α以优化来自环境的奖励或回报。搜索目标之间的最佳权衡(即,最佳权重向量α)可以帮助补偿不准确的习得Q值,例如在离线设置中。
在一个示例实施方式中,可以通过基于损耗更新α来学习权重向量:
其中c是超参数,其定义保持接近行为策略π
帕累托前沿是由帕累托最优策略集定义,其中帕累托最优策略是行动选择策略,来自行动选择策略的一个最终目标的回报在没有降低来自另一最终目标的回报的情况下无法得到提高。在无约束的多目标强化学习的情况下,通常没有单个最优策略,但是有定义帕累托前沿的集。在在线多目标设置中,甚至当帕累托前沿是凹面的时,其中行动选择策略是以权重为条件的系统的实施方式可以沿着整个帕累托前沿找到最优解决方案。因此,可以同时针对多个任务相关奖励(或惩罚)优化系统,并且随后例如根据其它所需特性或为了满足一个或多个所需约束条件,可以从可能的最优解决方案范围中选择最优解决方案。
如前所述,本文所述的技术并不依赖任何特定系统或神经网络架构。然而,仅作为示例,可以在行动者-学习者配置(例如,具有多个行动者的异步配置)的上下文中实现所述技术。在这种布置中,每个行动者从学习者取得行动选择策略神经网络120的参数并在环境中行动,从而将转换存储在重播缓冲区中。学习者从重播缓冲区对成批的转换进行采样并使用这些转换来更新行动选择策略神经网络以及Q值神经网络130。在离线设置中,转换数据集通常是给定和固定的(即,没有行动者)并且学习者从该数据集对成批的转换进行采样。
可选地,为了使学习稳定,可以维持目标神经网络用于每个经训练的神经网络。目标网络用于计算梯度,例如使用诸如Adam之类的最优化算法,可选地具有权重衰减。每隔一段时间,例如每固定数量的步长,更新目标神经网络的参数以匹配在线神经网络的参数。
在实施方式中,行动选择策略神经网络120是以权衡为条件。权衡对于每个片段可以是固定的。例如,在每个片段的开始,行动者可以从分布α~ν(α)对包括一个或多个权重α的权衡进行采样,并且随后可以在该片段期间基于π(a|s,α)而行动。在下一片段的开始,行动者可以对不同的权衡进行采样并重复该过程。
在一些实施方式中,行动选择策略神经网络120和Q值神经网络130是前馈神经网络,其具有ELU(指数线性单元)激活并可选地具有层归一化。在实施方式中,来自行动选择策略神经网络的策略输出被参数化为具有对角协方差矩阵的高斯分布。
下表示出了本文所述的被实现用于离线学习的系统的示例的性能。针对来自RLUnplugged(Gulcehre等人“RL unplugged:A suite of benchmarks for offlinereinforcement learning(RL unplugged:离线强化学习的一套基准),”Advances inNeural Information Processing Systems 33-NeurIPS2020)的各种不同离线学习任务,将该系统与其它算法进行比较。该表示出了与以下比较的DiME(BC)和DiME(AWBC)以及这些的“多”版本(其包括用不同的随机种子训练十个策略)的性能:行为克隆(BC)基准(其为
图3A示出了本文所述的被实现为微调教师行动选择策略的系统的示例的性能(x轴是行动者步长×10
曲线图示出了α的不同值的效果,从曲线300中的α=0(其对应于从零开始学习),经过曲线302中的α=0.25以及曲线304中的α=0.5,到曲线306中的α=1(其对应于完全模拟先前行为策略)。包括曲线308以用于如上所述习得的α的值。可以看出,加权组合允许选择与从零开始学习或简单模拟先前行为策略相比学习较快且实现较高最终奖励的权衡。而且,与其中将权衡考虑到策略改进步骤中的方法相比,所述技术(“DiME”)学习较快且实现较高的最终奖励。
图3B示出了本文中所述的被实现用于多目标学习的系统的示例的性能。图3B涉及基于具有凹面帕累托前沿的Fonseca-Fleming函数的玩具任务。x轴和y轴示出了两个不同奖励的平均任务奖励;圆形表示DiME,而三角形表示其中将权衡考虑到策略改进步骤中的上述可替代方法。图3B示出了DiME能够沿着整个帕累托前沿找到解决方案,而可替代方法仅在函数的极端处找到解决方案。
图3C也示出了本文中所述的被实现用于多目标学习的系统的示例的性能。图3C涉及仿人跑步任务;x轴示出了平均负行动规范成本,其对应于关于-||a||
在该方法的一些实施方式中,环境是真实世界环境。代理可以是机械代理,诸如与环境互动以完成任务的机器人或者在环境中导航的自主或半自主陆地或空中或水上交通工具。在一些实施方式中,可以使用机械代理在真实世界环境的模拟中的模拟来训练行动选择神经网络,以使行动选择神经网络随后用于控制真实世界环境中的机械代理。观察值随后可涉及真实世界环境,从某种意义上说,它们是真实世界环境的模拟的观察值。行动可涉及将由在真实世界环境中行动以执行任务的机械代理执行的行动,从某种意义上说,它们是稍后将在真实世界环境中执行的行动的模拟。无论是否在模拟中部分或完全训练,在训练后,行动选择神经网络可以用于控制机械代理执行任务,同时通过从感测真实世界环境的一个或多个传感器获得观察值并使用策略输出来选择行动以控制机械代理执行任务来与真实世界环境互动。
通常,观察值可包括例如图像、物体位置数据以及传感器数据中的一个或多个,传感器数据用于在代理与环境互动时捕获观察值,例如传感器数据来自图像、距离或位置传感器或来自致动器。在机器人或其它机械代理或交通工具的情况下,观察值可类似地包括以下中的一个或多个:位置、线速度或角速度、力、扭矩或加速度、以及代理的一个或多个部件的全局或相对姿态。可以以一维、二维或三维定义观察值,并且观察值可以是绝对和/或相对的观察值。例如,在机器人的情况下,观察值可包括表征机器人的当前状态的数据,例如以下中的一个或多个:关节位置、关节速度、关节力、扭矩或加速度、以及机器人的部位(诸如臂)和/或机器人持有的物品的全局或相对姿态。观察值还可包括例如:感测的电子信号,诸如电机电流或温度信号;和/或例如来自照相机或LIDAR传感器的图像或视频数据,例如来自代理的传感器的数据或来自与环境中的代理分开定位的传感器的数据。如本文中所用,图像包括点例如来自LIDAR传感器的云图像。
行动可包括控制信号以控制机械代理(例如,机器人)的物理行为,例如机器人关节的扭矩或更高等级的控制命令;或控制自主或半自主陆地或空中或海上交通工具,例如交通工具的控制面或其它控制元件的扭矩或更高等级的控制命令。换句话说,行动可包括例如机器人的一个或多个关节或另一机械代理的部件的位置、速度、或力/扭矩/加速度数据。控制信号还可包括或替代地可包括诸如电机控制数据之类的电子控制数据,或更一般而言,用于控制环境内的一个或多个电子设备的数据,对电子设备的控制对环境的观察状态具有影响。例如,在自主或半自主陆地或空中或海上交通工具的情况下,信号可定义行动以控制交通工具的导航(例如,转向)以及移动(例如,制动和/或加速)。
在这些应用中,任务相关奖励可包括接近或实现一个或多个目标位置、一个或多个目标姿态、或者一个或多个其它目标配置的奖励,例如以奖励机器人臂到达位置或姿态和/或限制机器人臂的移动。成本可与机械代理的部件与诸如物体或墙壁或障碍物之类的实体的碰撞相关联。通常,奖励或成本可取决于前述观察值中的任一者,例如机器人或交通工具位置或姿态。例如,在机器人的情况下,奖励或成本可取决于关节取向(角度)或速度/速率(例如,用于限制移动速度)、末端执行器位置、质心位置、或身体部位群组的位置和/或取向;或者可以与致动器或末端执行器所施加的力相关联,例如取决于在与物体交互时的阈值或最大施加力;或者由机械代理的部件施加的扭矩。在另一示例中,奖励或成本可取决于例如机器人、机器人部位或交通工具的能量或电力使用、移动速度或位置。
由机器人执行的任务可以是例如任何任务,其包括捡起、移动或操纵一个或多个物体,例如以组装、处理或包装物体;和/或包括机器人移动的任务。由交通工具执行的任务可以是包括交通工具在环境中移动的任务。
上述观察值、行动、奖励和成本可应用于代理在真实世界环境的模拟中的模拟。一旦该系统在模拟中经过训练,例如一旦该系统/方法的神经网络已经过训练,则该系统/方法就可用于控制真实世界环境中的真实世界代理。即,该系统/方法所生成的控制信号可用于响应于来自真实世界环境的观察值而控制真实世界代理以执行真实世界环境中的任务。可选地,该系统/方法可继续在真实世界环境中训练。
在一些应用中,环境是网络化系统,代理是电子代理,并且行动包括配置网络化系统的设置,这些设置影响网络化系统的能量效率或性能。对应任务可包括优化网络化系统的能量效率或性能。网络化系统可以是例如电网或数据中心。例如,所述系统/方法可具有平衡电网、或优化例如可再生能源发电(例如,移动太阳能电池板或控制风力发电机叶片)或例如电池中的电能存储的任务;在对应奖励或成本的情况下,观察值可涉及电网的操作、发电或存储;并且行动可包括控制行动以控制电网的操作、发电或能量存储。
在一些应用中,代理包括静态或移动软件代理,即被配置为自主地操作和/或与其它软件代理或人一起操作以执行任务的计算机程序。例如,环境可以是电路或集成电路设计或路由环境,并且代理可被配置为执行设计或路由任务以路由电路或集成电路(例如,ASIC)的互连线路。然后,奖励和/或成本可取决于一个或多个设计或路由度量,诸如互连长度、电阻、电容、阻抗、损耗、速度或传播延迟;和/或物理线路参数,诸如宽度、厚度或几何形状,以及设计规则;或者可涉及全局性质,诸如操作速度、功耗、材料使用、冷却要求、或电磁辐射等级。观察值可以是例如组件位置和互连的观察值;行动可包括组件放置行动,例如以定义组件位置或取向和/或互连路由行动(例如,互连选择和/或放置行动)。该过程可包括输出用于制造的设计或布线信息,例如以用于制造电路或集成电路的计算机可执行指令的形式。该过程可包括根据确定的设计或布线信息来制造电路或集成电路。
在一些应用中,代理可以是电子代理,并且观察值可包括来自监测工厂、建筑物或服务设施或相关联设备的一部分的一个或多个传感器以及其它传感器的数据(诸如电流、电压、功率、温度),和/或表示设备(例如,计算机或工业控制设备)的电子和/或机械项目的功能的电子信号。代理可控制包括设备项目的真实世界环境中的行动,例如在诸如数据中心、服务器群(farm)、电网主电源或配水系统之类的设施中,或在制造工厂、建筑物或服务设施中。然后,观察值可涉及工厂、建筑物或设施的操作,例如它们可包括设备的电力或水使用或设备的操作效率的观察值,或者发电或配电控制的观察值、或者资源使用或废物生产的观察值、或者环境(例如,空气温度)的观察值。行动可包括控制工厂/建筑物/设施的设备项目上的操作条件或将操作条件强加于工厂/建筑物/设施的设备项目上的行动,和/或导致改变工厂/建筑物/设施的操作中的设置的行动,例如以调整或接通/断开工厂/建筑物/设施的组件。仅举例而言,设备可包括工业控制设备、计算机、或者加热、冷却或照明设备。奖励和/或成本可包括以下中的一个或多个:效率度量,例如资源使用;在环境中操作的环境影响的度量,例如废物输出;电或其它电力或能量消耗;加热/冷却要求;设施中的资源使用,例如水使用;或设施的温度或设施中设备项目的温度。对应任务可包括优化对应奖励或成本以最小化能量或资源使用或优化效率。
更具体而言,在一些实施方式中,环境是用于制造产品(诸如化学、生物或机械产品、或食品)的真实世界制造环境。如本文中所用,“制造”产品还包括精炼原料以创造产品,或处理原料例如以去除污染物以生成清洁的或再生的产品。制造工厂可包括多个制造单元,诸如用于化学或生物物质的容器、或用于处理固体或其它材料的机器(例如,机器人)。制造单元被配置为使得产品的中间版本或组件在产品制造期间例如经由管或机械运输在制造单元之间可移动。如本文中所用,产品的制造还包括由厨房机器人制造食品。
代理可包括电子代理,该电子代理被配置为控制制造单元或诸如机器人之类的机器,其操作以制造产品。即,代理可包括控制系统,该控制系统被配置为控制化学、生物或机械产品的制造。例如,控制系统可被配置为控制制造单元或机器中的一个或多个或者控制产品的中间版本或组件在制造单元或机器之间的移动。
作为一个示例,由代理执行的任务可包括制造产品或其中间版本或组件的任务。作为另一示例,由代理执行的任务可包括控制(例如,最小化)资源使用的任务,诸如控制电力消耗或水消耗或制造过程中使用的任何材料或消耗品的消耗的任务。
行动可包括控制行动以控制机器或制造单元的使用以处理固体或液体材料以制造产品或其中间版本或组件,或控制产品的中间版本或组件在制造环境内例如在制造单元或机器之间的移动。通常,行动可以是对环境的观察状态具有影响的任何行动,例如被配置为调整下面所述感测参数中的任一者的行动。这些可包括调整制造单元的物理或化学条件的行动、或者控制机器的机械部件或机器人的关节的移动的行动。行动可包括将操作条件强加于制造单元或机器上的行动,或者导致改变设置以调整、控制或接通或断开制造单元或机器的操作的行动。
奖励或回报可涉及任务的执行的度量。例如,在任务为制造产品的情况下,度量可包括制造的产品的数量、产品的质量、生产产品的速度、或执行制造任务的实物成本的度量,例如用于执行任务的能量、材料或其它资源的数量的度量。在任务为控制使用资源的情况下,度量可包括资源使用的任何度量。
通常,环境的状态的观察值可包括表示设备的电子和/或机械项目的运行的任何电子信号。例如,环境的状态的表示可源自感测制造环境的状态的传感器(例如,感测制造单元或机器的状态或配置的传感器、或者感测材料在制造单元或机器之间的移动的传感器)产生的观察值。作为一些示例,这些传感器可被配置为感测机械移动或力、压力、温度;诸如电流、电压、频率、阻抗之类的电气条件;一种或多种材料的数量、等级、流动/移动速率或流动/移动路径;物理或化学条件,例如物理状态、形状或配置或者化学状态(诸如pH);单元或机器的配置,诸如单元或机器的机械配置、或阀配置;用于捕获制造单元或机器或移动的图像或视频观察值的图像或视频传感器;或任何其它合适类型的传感器。在诸如机器人之类的机器的情况下,来自传感器的观察值可包括位置、线速度或角速度、力、扭矩或加速度、或者机器的一个或多个部件的姿态的观察值,例如表征机器或机器人的或由机器或机器人持有或处理的项目的当前状态的数据。观察值还可包括例如诸如电机电流或温度信号之类的感测的电子信号,或例如来自照相机或LIDAR传感器的图像或视频数据。诸如这些之类的传感器可以是环境中的代理的一部分或与环境中的代理分开定位。
在一些实施方式中,环境是服务设施的真实世界环境,其包括多个电子设备项目,诸如服务器群或数据中心(例如,电信数据中心)、或用于存储或处理数据的计算机数据中心、或任何服务设施。服务设施还可包括辅助控制设备,其控制设备项目的操作环境,例如环境控制设备,诸如温度控制(例如,冷却)设备、或空气流动控制或空气调节设备。任务可包括控制(例如,最小化)资源的使用的任务,诸如控制电力消耗或水消耗的任务。代理可包括电子代理,其被配置为控制设备项目的操作或控制辅助(例如,环境)控制设备的操作。
通常,行动可以是对环境的观察状态具有影响的任何行动,例如被配置为调整下面所述感测参数中的任一者的行动。这些可包括控制设备项目或辅助控制设备上的操作条件或将操作条件强加于设备项目或辅助控制设备上的行动,例如导致改变设置以调整、控制或接通或断开设备项目或辅助控制设备项目的操作的行动。
通常,环境的状态的观察值可包括表示设施或设施中的设备的运行的任何电子信号。例如,环境的状态的表示可源自感测设施的物理环境的状态的任何传感器得到的观察值或感测一个或多个设备项目或一个或多个辅助控制设备项目的状态的任何传感器得到的观察值。这些包括被配置为感测以下内容的传感器:诸如电流、电压、功率或能量之类的电气条件;设施的温度;在设施内或在设施的冷却系统内的流体流量、温度或压力;或物理设施配置,诸如通风口是否打开。
奖励或回报可涉及任务的执行的度量。例如,在控制(例如,最小化)资源的使用的任务(诸如控制电力或水的使用的任务)的情况下,度量可包括资源的使用的任何度量。
在一些应用中,环境可以是数据包通信网络环境,并且代理可包括在通信网络上路由数据包的路由器。任务可包括数据路由任务。行动可包括数据包路由行动,并且观察值可包括例如路由表的观察值,该路由表包括路由度量,诸如路由路径长度、带宽、负载、跳数、路径成本、延迟、最大传输单元(MTU)以及可靠性的度量。奖励或成本可以关于路由度量中的一个或多个来定义,例如以最大化或限制路由度量中的一个或多个。
在一些其它应用中,代理是软件代理,其任务是管理任务在例如移动设备上和/或数据中心中的计算资源上的分配。在这些实施方式中,观察值可包括计算资源(诸如计算和/或存储容量)或因特网可访问资源的观察值;并且行动可包括将任务分配给特定计算资源。奖励或成本可以是最大化或限制以下中的一个或多个:计算资源的使用、电力、带宽以及计算速度。
在一些其它应用中,环境可以是计算机药物设计环境,例如分子对接环境;并且代理可以是计算机系统,任务是确定药物的元素或化学结构。药物可以是小分子或生物药物。观察值可以是药物与药物靶点的模拟组合的观察值。行动可以是修改药物和药物靶点的相对位置、姿态或构象的行动(或者这可以自动地执行)和/或修改药物的化学成分和/或从候选药物库中选择候选药物的行动。一个或多个奖励或成本可以基于以下中的一个或多个来定义:药物与药物靶点之间的互动的度量,例如药物与药物靶点之间的适合或结合的度量;药物的估计效力;药物的估计选择率;药物的估计毒性;药物的估计药代动力学特征;药物的估计生物药效率;药物的估计合成容易度;以及药物的一个或多个基本化学性质。药物与药物靶点之间的相互作用的度量可取决于例如蛋白质-配体键合、范德瓦尔相互作用、静电相互作用和/或接触面区域或能量;它可包括例如对接分数(docking score)。
在一些其它应用中,环境是因特网或移动通信环境,并且代理是管理用户的个性化推荐的软件代理。任务可以是生成用户的推荐。观察值可包括用户采取的先前行动,例如表征这些的特征;行动可包括向用户推荐诸如内容项目之类的项目的行动。奖励或成本可以是最大化或限制以下中的一个或多个:用户将积极响应被推荐的(内容)项目的估计可能性、一个或多个推荐项目的适合不适合、被推荐项目的成本、以及可选地在时间跨度内用户接收到的推荐的数量。在另一示例中,推荐可以是为用户提供减少能量使用或环境影响的方式。
在一些其它应用中,环境是医疗保健环境,并且代理是用于为患者建议治疗的计算机系统。然后,观察值可包括患者的状态的观察值,例如表征患者健康的数据(例如,来自一个或多个传感器(诸如图像传感器或生物标志物传感器)的数据)、生命体征数据、实验室测试数据、和/或处理文本(例如,来自病历)。行动可包括患者的可能的治疗,例如提供药物治疗或干预。任务可以是稳定或改善患者的健康,例如稳定生命体征或充分改善患者的健康以使他们离开医疗保健环境或医疗保健环境的一部分,例如离开重症监护部分;或者任务可以是提高患者在出院后的生存可能性或减少对患者的长期损害。奖励或成本可以根据任务而相应地定义,例如奖励可指示任务的进展(例如,患者健康或预后的改善),或者成本可指示患者健康或预后的恶化。
一旦经过训练,系统就可以用于执行它被训练的任务,可选地在此使用期间训练继续。任务可以是例如上述任务中的任一者。通常,经过训练的系统可用于控制代理实现奖励或最小化成本,如上所述。仅举例而言,一旦经过训练,系统就可以用于控制机器人或交通工具执行任务,诸如操纵、组装、处理或移动一个或多个物体;或者控制设备例如以最小化能量使用;或者在医疗保健中,建议药物治疗。
可选地,在上述实施方式中的任一者中,在任何给定时间步长处的观察值可包括可能有利于表征环境的来自前一时间步长的数据,例如在前一时间步长处执行的行动、在前一时间步长处接收到的奖励、或这两者。
本说明书使用与系统和计算机程序组件有关的术语“配置”。对于一个或多个计算机的系统,被配置为执行特定操作或行动表示系统上已经安装有软件、固件、硬件或其组合,在操作中所述软件、固件、硬件或其组合使系统执行操作或行动。对于一个或多个计算机程序,被配置为执行特定操作或行动表示所述一个或多个程序包括指令,所述指令在由数据处理装置执行时使装置执行操作或行动。
本说明书中所述的主题的实施例以及功能操作可以在数字电子电路、有形体现的计算机软件或固件、计算机硬件(包括本说明书中公开的结构及其结构等效物)、或它们中的一个或多个的组合中实现。本说明书中所述的主题的实施例可以被实现为一个或多个计算机程序,即在有形非暂时性存储介质上编码以用于由数据处理装置执行或控制数据处理装置的操作的计算机程序指令的一个或多个模块。计算机存储介质可以是机器可读存储设备、机器可读存储衬底、随机或串行存取存储器设备、或它们中的一个或多个的组合。可替代地或另外,可以在人工生成的传播信号(例如,机器生成的电信号、光信号或电磁信号)上编码程序指令,该人工生成的传播信号被生成为编码信息以发送至合适的接收器装置以由数据处理装置执行。
术语“数据处理装置”是指数据处理硬件并且包括用于处理数据的所有种类的装置、设备和机器,包括例如可编程处理器、计算机或多个处理器或计算机。装置还可以是或进一步包括专用逻辑电路,例如FPGA(现场可编程门阵列)或ASIC(专用集成电路)。可选地,除了硬件,装置还可包括为计算机程序创建执行环境的代码,例如构成处理器固件、协议栈、数据库管理系统、操作系统或它们中的一个或多个的组合的代码。
可以以任何形式的编程语言(包括已编译或已解释的语言、或者陈述性或程序性语言)书写计算机程序,计算机程序也可以被称为或被描述为程序、软件、软件应用程序、应用程序、模块、软件模块、脚本或代码;并且计算机程序可以以任何形式部署,包括作为独立程序或作为模块、组件、子程序或适用于计算环境中的其它单元。程序可以但是不需要对应于文件系统中的文件。程序可以存储在保存了其它程序或数据(例如,存储在标记语言文档中的一个或多个脚本)的文件的一部分中、存储在专用于所述程序的单个文件中、或者存储在多个协调文件(例如,存储一个或多个模块、子程序或代码部分的文件)中。计算机程序可被部署为在一个计算机上或在多个计算机上执行,所述多个计算机位于一个地点或分布在多个地点并且通过数据通信网络互连。
在本说明书中,术语“数据库”广泛地用于指任何数据集:数据不需要以任何特定方式结构化、或根本不需要结构化,并且它可以存储在一个或多个位置中的存储设备上。因此,例如,索引数据库可包括多个数据集,每个数据集可被不同地组织和访问。
类似地,在本说明书中,术语“引擎”广泛地用于指被编程为执行一个或多个具体功能的基于软件的系统、子系统或过程。通常,引擎将被实现为一个或多个软件模块或组件,安装在一个或多个位置中的一个或多个计算机上。在一些情况下,一个或多个计算机将专用于特定引擎;在其它情况下,多个引擎可以安装在相同计算机上并在相同计算机上运行。
本说明书中所述的过程和逻辑流可以由一个或多个可编程计算机执行,所述一个或多个可编程计算机执行一个或多个计算机程序以通过对输入数据进行操作并生成输出来执行功能。过程和逻辑流还可以由专用逻辑电路(例如,FPGA或ASIC)执行,或者由专用逻辑电路与一个或多个编程计算机的组合执行。
适于执行计算机程序的计算机可以基于通用或专用微处理器或这两者、或者任何其它种类的中央处理单元。通常,中央处理单元从只读存储器或随机存取存储器或这两者接收指令和数据。计算机的元件是用于执行或实施指令的中央处理单元以及用于存储指令和数据的一个或多个存储器设备。中央处理单元和存储器可以辅以专用逻辑电路或并入专用逻辑电路中。通常,计算机还包括用于存储数据的一个或多个大容量存储设备(例如,磁盘、磁光盘或光盘),或者被可操作地联接以从所述一个或多个大容量存储设备接收数据或将数据发送至所述一个或多个大容量存储设备,或这两种情况都有。然而,计算机不需要具有这种设备。此外,计算机可以嵌入另一设备中,例如移动电话、个人数字助理(PDA)、移动音频或视频播放器、游戏机、全球定位系统(GPS)接收器、或便携式存储设备,例如通用串行总线(USB)闪存驱动器,仅举几例。
适于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,包括例如半导体存储器设备,例如EPROM、EEPROM、以及闪存设备;磁盘,例如内置硬盘或可移动磁盘;磁光盘;以及CD ROM和DVD-ROM磁盘。
为了提供与用户的互动,本说明书中所述的主题的实施例可以在具有用于向用户显示信息的显示设备(例如,CRT(阴极射线管)或LCD(液晶显示)显示器)以及键盘和指向设备(例如,鼠标或跟踪球)的计算机上实现,用户可以通过键盘和指向设备向计算机提供输入。也可以使用其它种类的设备来提供与用户的互动;例如,提供给用户的反馈可以是任何形式的感觉反馈,例如视觉反馈、听觉反馈、或触觉反馈;并且来自用户的输入可以以任何形式接收,包括声音、语音或触觉输入。另外,计算机可以通过将文档发送至用户所使用的设备并从该设备接收文档来与用户互动;例如,通过响应于从网页浏览器接收到的请求而将网页发送至用户设备上的网页浏览器。而且,计算机可以通过向个人设备(例如,正在运行消息应用程序的智能手机)发送文本消息或其它形式的消息并且作为回应从用户接收响应消息来与用户互动。
用于实现机器学习模型的数据处理装置还可包括例如专用硬件加速器单元,其用于处理机器学习训练或生产的通用和计算密集型部分,即推断,工作负载。
可以使用机器学习框架(例如,TensorFlow框架、Microsoft Cognitive Toolkit框架、Apache Singa框架、或Apache MXNet框架)来实现并部署机器学习模型。
本说明书中所述的主题的实施例可以在计算系统中实现,该计算系统包括后端组件(例如,作为数据服务器),或者包括中间件组件(例如,应用服务器),或者包括前端组件(例如,客户端计算机,其具有图形用户界面、网页浏览器、或用户可用来与本说明书中所述的主题的实施方式互动的应用程序),或者包括一个或多个这种后端、中间件或前端组件的任何组合。系统的组件可以通过数字数据通信的任何形式或介质(例如,通信网络)互连。通信网络的示例包括局域网(LAN)以及广域网(WAN),例如因特网。
计算系统可包括客户端和服务器。客户端和服务器通常远离彼此,并且通常通过通信网络互动。客户端与服务器的关系由于计算机程序而产生,计算机程序在相应计算机上运行并且彼此具有客户端-服务器关系。在一些实施例中,服务器将数据(例如,HTML页面)发送至用户设备,例如以用于向与该设备互动的用户显示数据并从该用户接收用户输入,该设备用作客户端。可在服务器处从该设备接收在用户设备处生成的数据(例如,用户互动的结果)。
尽管本说明书包含许多具体实施细节,但是这些不应被解释为对任何发明的范围或对可能要求保护的范围的限制,而是应该被解释为可能针对特定发明的特定实施例的特征的描述。在不同实施例的上下文中在本说明书中描述的某些特征也可以在单个实施例中组合地实现。相反,在单个实施例的上下文中描述的各种特征也可以分别地在多个实施例中或以任何合适的子组合实现。此外,尽管特征可能在上文中被描述为以某些组合起作用并且甚至最初被如此要求保护,但是来自要求保护的组合的一个或多个特征在一些情况下可以从该组合中删去,并且要求保护的组合可以指向子组合或子组合的变化形式。
类似地,尽管操作是以特定顺序在附图中描绘并且在权利要求书中列举,但是这不应被理解为为了实现令人满意的结果,要求这些操作以所示特定顺序或以先后顺序执行或者所有示出的操作均被执行。在某些情况下,多任务处理和并行处理可能是有利的。此外,上述实施例中的各种系统模块和组件的分开不应被理解为在所有实施例中需要这种分开,并且应理解,所述程序组件和系统通常可以一起集成到单个软件产品中或打包到多个软件产品中。
已经描述了主题的特定实施例。其它实施例在以下权利要求书的范围内。例如,权利要求书中列举的行动可以按不同的顺序执行并且仍然实现令人满意的结果。作为一个示例,为了实现令人满意的结果,附图中描绘的过程不一定要求所示的特定顺序或先后顺序。在一些情况下,多任务处理和并行处理可能是有利的。
- 一种基于加权平均策略的分布式雷达网络多目标定位方法
- 一种基于加权平均策略的分布式雷达网络多目标定位方法