基于细粒度和增量学习的可见光图像中航天器分类方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于数据识别技术领域,更进一步涉及应用计算机进行图像识别技术领域中的一种基于细粒度和增量学习的航天器分类方法。本发明可用于对可见光图像中的航天器类型进行分类。
背景技术
航天领域针对可见光图像中航天器分类的深度学习模型少,为实现项目自动化、智能化,需要使用深度学习模型进行与航天器有关的图像分类。但是航天器图像样本分布不均匀且存在相似性,这使得传统方法表现不佳,分类准确率低,无法满足使用需求。实际工作环境输入可能包含未知或者无关的图像,传统深度学习模型对未见过的类别存在盲目自信问题,影响判断准确率。
西北工业大学在其申请的专利文献“一种航天器可见光图像分类方法”(申请号:201410453974;申请公布号:CN 106446965A)中提出了一种航天器图像分类的方法。该方法的实现方案是:第一步,对航天器图像训练样本提取尺度旋转不变特征SIFT;第二步,用该特征训练稀疏字典;第三步,对所提取的特征使用稀疏字典进行稀疏编码并采用空间金字塔匹配策略得到特征描述;第四步:使用线性支持向量机训练分类器并完成分类。该方法存在的不足之处是,由于该方法中的SIFT方法是人工设计的,对于复杂的图像和多类别分类问题无法捕捉到足够的抽象特征,而SVM在使用核函数,在处理非线性分类问题时存在限制,其模型复杂性相对较低,无法处理复杂的类别边界,多类别分类需要逐次进行,且在设计上也无法检测出训练集之外的目标而会错分成某一类,因此分类正确率较低。
广州大学在其申请的专利文献“一种基于K最近邻图的分布外检测技术”(申请号:CN202310222879.3;申请公布号:CN 116467650A)中提出了一种分布外检测的方法。该方法的实现方案是:第一步,使用神经网络对分布内训练数据进行特征提取;第二步:把分布内数据集的特征作为结点,使用这些结点初始化并重建K最近邻图;第三步:K最近邻图中搜索测试样本的K个最近邻结点,并为测试样本计算分布外检测分数;如果分布外检测分数小于阈值,则判断测试样本为分布内数据,并把代表该样本的结点加入K最近邻图,否则判断该测试样本为分布外数据。该方法有效的划分了未知类,但是,仍然存在的不足之处是,由于域值的设计,会带来未知类检出率和已知类误检率之间的矛盾。将阈值设计较大,未知类图像可能落入某已知类别的置信域,而阈值设计较小,会使某些已知种类图片无法落入对应类别的置信域而被错分,干扰后续分类,影响模型的可拓展性。
发明内容
本发明的目的在于针对上述现有技术的不足,提出一种基于细粒度和增量学习的可见光图像中航天器分类方法,用于解决使用机器学习方法分类可见光图像中航天器分类正确率较低,模型可拓展性较差的问题。
实现本发明目的的思路是:本发明通过对一个可见光图像分类网络进行三步训练,提升了模型的可见光图像中航天器的分类准确度。第一步,使用交叉熵损失训练模型直到损失函数收敛,将航天器的特征与标签完成匹配,使网络初步实现图像分类。第二步,再使用余弦损失函数对第一步训练好的网络继续训练得到第二步训练好的网络,该网络通过扩大航天器特征的类间距离,缩小类内距离,优化了相似图像的分类。第三步,使用增量学习对第二步训练好的网络进行训练得到航天器可见光分类网络,该网络通过在增量学习时使用特征匹配和阈值判断方法相结合,通过匹配特征的方式初步分类图像,缓解了阈值判断时未知类检出率和已知类误检率之间的矛盾,降低了更新样本集时的错误率,提升了模型的可拓展性,增加了可识别航天器的类别。
本发明实现的具体步骤包括如下:
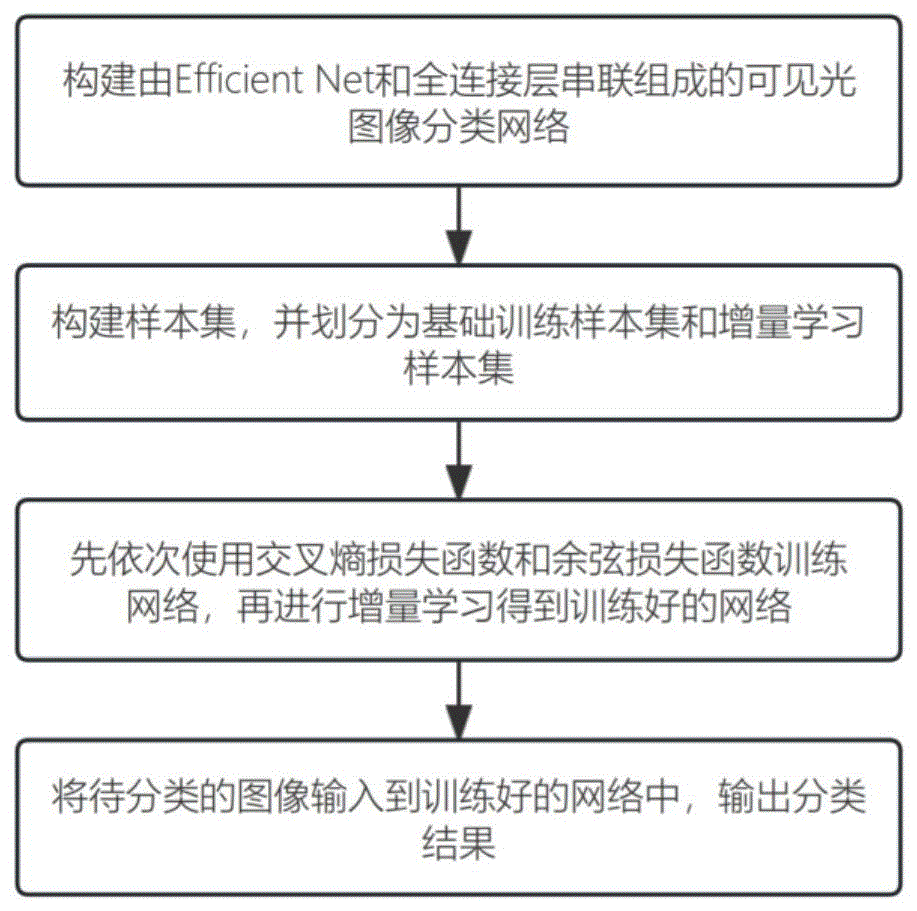
步骤1,构建一个由Efficient Net网络与全连接层串联组成的可见光图像分类网络;
步骤2,生成训练集:
步骤2.1,采集至少500张可见光图像,其中80%为含有航天器的可见光图像,其余为与航天器无关的图像;可见光图像中至少包含5类不同的航天器;将样本集图像进行归一化操作,所有归一化的图像和对应的标签组成样本集;
步骤2.2,从样本集中选取包含一个航天器类别的全部可见光图像以及除所选类别之外其他航天器类别的20%图像组成增量学习训练集;将样本集中其余图像组成基础训练样本集;
步骤3,训练可见光图像分类网络:
步骤3.1,将基础训练样本集输入到可见光图像分类网络中,利用梯度下降法迭代更新网络参数,直到网络的交叉熵损失函数收敛为止,得到第一次训练后的分类网络;
步骤3.2,将基础训练样本集输入到第一次训练后的分类网络中,利用梯度下降法迭代更新初步训练好的分类网络参数,直到该网络的余弦损失函数收敛为止,得到第二次训练后的分类网络;
步骤3.3,将增量学习训练集输入到第二次训练后的分类网络中,通过对全连接层输出的每张图像特征logits分数的Softmax运算,得到每张图像分类的置信度;将置信度低于阈值或不包含在基础训练样本集的类别中的图像,添加到基础训练样本集,得到更新后的样本集;
步骤3.4,将更新后的样本集输入到第二次训练后的分类网络中,利用梯度下降法迭代更新网络参数,直到交叉熵损失函数收敛为止,得到训练完成的可见光图像分类网络。
步骤4,对可见光图像中的航天器进行分类:
将待分类的可见光图像输入到训练好的可见光图像分类网络中,输出分类结果。
本发明与现有的技术相比具有以下优点:
第一,本发明采用交叉熵损失和余弦损失两种损失函数依次对航天器分类网络进行了训练得到第二步训练后的航天器分类网络,该网络克服了现有技术遇到的航天器可见光图像数据相似性高的难题,使得本发明提高了可见光图像中航天器分类的准确率。
第二,本发明采用增量学习的方式对第二步训练后的航天器分类网络进行训练,得到训练完成的航天器分类网络,在增量学习时使用特征匹配和阈值判断方法相结合,通过匹配特征的方式初步分类图像,缓解了阈值判断时未知类检出率和已知类误检率之间的矛盾,克服了现有技术更新样本集时错误率过高的问题,使得本发明提高了网络的可拓展性。
附图说明
图1为本发明的流程图;
图2为本发明训练可见光图像分类网络的流程图。
具体实施方式
下面结合附图和实施例,对本发明做进一步的详细描述
参照图1,对本发明实施例的实现步骤做进一步的详细描述。
步骤1,构建一个由Efficient Net网络与全连接层串联组成的可见光图像分类网络。
所述的Efficient Net网络的结构依次串联为:第一卷积层,第一批归一化层,第一激活层,移动倒残差组,第二卷积层,第二批归一化层,第二激活层,池化层,全连接层;所述移动倒残差组由七个结构相同的移动倒残差层串联组成;每个移动倒残差层的结构依次串联为:第一卷积层,第一批归一化层,第一激活层,第二卷积层,第二批归一化层,第二激活层,SE注意力层,第三卷积层,第三批归一化层,Dropout层,残差连接层串联组成;当第二卷积层的步长为1时,由残差连接层输出;当第二卷积层的步长为2时,由第三批归一化层输出;所述SE注意力层由平均池化,Swish激活层,Sigmoid激活层和1*1卷积层组成;第三卷积层的输入是SE注意力层的输入和输出的按位相乘;第一到第七倒残差层分别重复1,2,2,3,3,4,1次,所有移动倒残差层之间通过批归一化层和Swish激活层连接;所述移动倒残差组中所有移动倒残差层的第一卷积层的卷积核尺寸均为1;步长均为1;移动倒残差组中第一至第七卷积核的数量分别为16,24,40,80,112,192,320;移动倒残差组中第一到第七移动倒残差层中的第二卷积层的卷积核尺寸依次设置为3,3,5,5,3,5,3;第二卷积层的步长分别为1,2,2,2,1,2,1;卷积核的数量依次为96,144,240,480,672,1152,1920;第一到第七移动倒残差组中的第三卷积层的输入是卷积核尺寸均为1,步长均为1,移动倒残差组中第一至第七卷积核的数量分别为16,24,40,80,112,192,320;分别将Efficient Net网络的第一、第二卷积层卷积核大小设置为3*3,1*1,步长设置为2,1,卷积核的个数设置为32,1280;移动倒残差层的残差连接层中的Dropout层的随机失活比率为0.2,Efficient Net网络的全连接层的随机失活比率为0.2。
步骤2,生成训练集。
本发明的实施例是从互联网采集882张可见光图像,其中,769张为含有航天器的可见光图像,不含有航天器的可见光图像113张,即每张图像均与航天器无关。所有的可见光图像中共包含5类不同的航天器,分别为火箭,无人航天器,空间站,载人飞船以及航天飞机。从所采集的含有航天器的769张可见光图像中随机选取562张图像。将所选图像与不含有航天器的可见光图像113张组成样本集,样本集中共有675张图像。将采集到的882张可见光图像中剩余的207张图像组成测试集。
本发明的实施例是从样本集图像中选取空间站的全部可见光图像共60张以及除所选类别之外其他航天器类别的100张图像,总计160张图像组成增量学习训练集。把样本集中剩余的515张图像组成基础训练样本集。
对基础训练样本集和增量学习训练集中的每张图像采用下述步骤进行图像增强:
使用transforms.RandomHorizontalFlip以0.4的概率对图像进行水平翻转;
使用transforms.ColorJitter对图像进行颜色抖动,包括亮度、对比度和饱和度等方面的变化,每个方面的变化量上限为0.2;
使用transforms.RandomRotation使图像在30度的范围对图像进行随机旋转;
使用transforms.RandomPerspective以0.1的概率对图像进行透视变换;
使用transforms.RandomAffine对图像进行随机仿射变换;
对增强后的每张图像和测试集中每张图像采用下述步骤进行归一化处理:
使用transforms.Resize调整图像大小为224x224像素;
使用transforms.ToTensor将图像转换为PyTorch中的Tensor类型;
使用transforms.Normalize对图像进行归一化操作。
步骤3,训练可见光图像分类网络。
参照图2,对本发明可见光图像分类网络的训练过程做进一步的详细描述。
第一步,将基础训练样本集输入到可见光图像分类网络中,利用梯度下降法迭代更新网络参数,直到网络的交叉熵损失函数收敛为止,得到第一次训练后的分类网络。通过交叉熵损失函数,可以将图像特征与图像标签关联起来,该网络可以进行图像的初步分类。
所述交叉熵损失函数如下:
其中,H表示当前迭代输出的预测标签与基础训练样本集中的真实标签的损失值,∑表示求和操作,i表示基础训练样本中样本的序号,M表示基础训练样本集中样本的总数,p
第二步,将基础训练样本集输入到第一次训练后的分类网络中以2为底的对数操作。利用梯度下降法迭代更新初步训练好的分类网络参数,直到该网络的余弦损失函数收敛为止,得到第二次训练后的分类网络。通过余弦损失函数,可以将扩大图像的类间特征,缩小类内特征。这是由于余弦损失迫使同类的特征向量余弦值趋于1,因此同类图像的特征相似;不同类图像的特征向量余弦值尽量小于特征分离距离,因此不同类图像的特征不相似。
本实施例中,选取了特征分离距离为0和0.5两种情况进行仿真测试。
所述余弦损失函数如下:
其中,Loss表示当前迭代输出基础训练样本集中样本经分类网络预测的标签a与基础训练样本集中另一样本经分类网络预测的标签b两个预测标签之间的余弦损失值,cos表示余弦操作,max表示取最大值操作,margin表示特征分离距离,y表示两个样本在基础训练样本集中的真实标签是否相同,y=1表示样本所代表的真实标签不同,y=-1表示样本所代表的图像的真实标签相同。
第三步,将增量学习训练集输入到第二次训练后的分类网络中,通过对全连接层输出的每张图像特征logits分数的Softmax运算,得到每张图像分类的置信度。
第四步,将置信度低于阈值或不包含在基础训练样本集的类别中的图像,添加到基础训练样本集,得到更新后的样本集。更新后的样本集包含了样本集中所有航天器的类别,并且去除了无关图像。
所述Softmax运算是由下式实现:
其中,Z表示增量学习训练集中样本预测标签的置信度,z
所述每张图像分类的置信度指的是,对第二次训练后的分类网络输出每张增量学习训练集的图像特征logits分数,通过Softmax运算得到该图像中每个航天器标签属于每种类别的概率,在一个类别上的概率在0到1之间,且在所有航天器类别的概率上和为1。取所有类别概率中的最大值作为该航天器标签的置信度。
所述阈值是指将增量学习训练集中图像分类到基础训练样本集中类别所需要的置信度的最小值。该阈值取值较低,表明分类网络会把不那么确定类别的图像划分到基础训练样本集中的类别;该阈值取值较高,表明分类网络只会把较为确定类别的图像划分到基础训练样本集中的类别。本发明的实施例中阈值取0.5。
第五步,将更新后的样本集输入到第二次训练后的分类网络中,利用梯度下降法迭代更新网络参数,直到交叉熵损失函数收敛为止,得到训练好的可见光图像分类网络。该网络能够分类样本集中涉及到的所有航天器类别,并保证较高的准确度。
所述交叉熵损失函数如下:
其中,H表示第二次训练后的分类网络在当前迭代时输出的预测标签与更新后的样本集中真实标签的损失值,g表示更新后的样本集中样本的序号,G表示更新后的样本集中样本的总数,p
步骤4,对可见光图像中的航天器进行分类。
将测试集输入到训练好的可见光图像分类网络中,输出分类结果和置信度信息,以及图像的特征从高维空间降维可视化信息。
本发明的效果可以通过下面的仿真得到进一步证明。
1.仿真实验条件。
本发明的仿真实验的硬件平台为:处理器为AMD Ryzen 9 5900HX,处理器主频为3.301GHz,显卡为NVIDIA GeForce RTX 3080。
本发明的仿真实验的软件平台为:Windows 11系统。
本发明的仿真实验是在Python3.7的Pytorch下搭建的基于可见光图像分类网络上实现的,其开发语言为Python。主要使用的软件版本为Python 3.7.1,CUDA 11.6,Pytorch 1.13.0,Torchvision 0.14.0。
2.仿真内容与结果分析。
本发明的仿真实验是将本发明步骤2实施例中生成的测试集,分别输入到采用本发明和两个现有技术(卷积神经网络VGG16分类方法,残差神经网络Res Net分类方法)所训练好的网络中进行测试。
在仿真实验中,采用的两个现有技术是指:
Simonyan K和Zisserman A在其发表的论文“Very deep convolutionalnetworks for large-scale image recognition[J].arXivpreprint arXiv:1409.1556,2014.”中提出的深度学习图像分类网络,简称卷积神经网络VGG16。
He等人在其发表的论文“Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and patternrecognition.2016:770-778.”中提出的深度学习图像分类网络,简称残差神经网络ResNet。
本发明的仿真实验使用不同的网络对测试集中的航天器可见光图像进行分类。实验结果如表1。表中准确率AP的表达示如下
表1:可见光图像中航天器分类网络的结果对比表
以上仿真实验表明:利用本发明方法搭建的可见光图像分类网络,能够提取可见光图像中航天器的细粒度特征,通过控制margin的大小,能够提升分类准确率,解决了现有技术方案中存在的可见光图像中的航天器分类准确率不高的问题。
上述步骤得到第二次训练后的航天器可见光图像分类网络。使用增量学习训练集更新基础训练集得到更新后的样本集,完成增量训练得到训练完成的分类网络,准确率为96.5%,能保持稳定,网络可拓展性好;作为对比,仅使用阈值判断方法进行增量训练的样本准确率仅为92.5%,有较大幅度下降,网络可拓展性差。
综上所述,本发明提出的基于细粒度和增量学习的航天器分类方法可以对可见光图像中的航天器进行分类,解决了现有技术方法中存在的精度不高,可拓展性差的问题,是一种非常实用的可见光图像分类方法。
- 电动车辆的驱动防滑控制方法、介质、整车控制器及控制装置
- 滑移滑转率线性控制方法、装置及防抱死和驱动防滑控制系统
- 一种前后轴双电机驱动车辆路面防滑控制系统及方法
- 一种多轮分布式混合动力系统驱动防滑控制方法
- 驱动防滑控制方法、装置以及驱动防滑控制系统
- 驱动防滑控制方法、装置以及驱动防滑控制系统