噪声降低控制方法、烹饪器具和可读存储介质
文献发布时间:2023-06-19 09:24:30
技术领域
本发明属于语音识别技术领域,具体而言,涉及一种噪声降低控制方法、一种烹饪器具和一种计算机可读存储介质。
背景技术
语音识别广泛应用于各种烹饪器具中。在壁挂微波炉等产品在运行过程中会产生噪音,其中的语音识别模块在噪音的影响下无法识别出用户是否发出了语音控制指令。
发明内容
本发明旨在解决现有技术或相关技术中存在的技术问题之一。
为此,本发明的第一方面提出了一种噪声降低控制方法。
本发明的第二方面提出了一种烹饪器具。
本发明的第三方面提出了一种计算机可读存储介质。
有鉴于此,根据本发明的第一方面提出了一种噪声降低控制方法,用于烹饪器具,烹饪器具包括音频获取装置,包括:通过音频获取装置获取烹饪器具运行过程中的第一音频信号集合;通过第一音频信号集合训练声学模型,以得到目标声学模型;采集第二音频信号,通过目标声学模型滤除第二音频信号中的第一音频信号。
本发明提出的噪声降低控制方法用于烹饪器具,烹饪器具包括语音识别装置。烹饪器具能够通过音频获取装置采集音频,再通过语音识别装置识别用户发出的语音指令,并根据语音指令对烹饪器具进行控制,省去了用户对控制面板进行控制操作。当烹饪器具运行时,烹饪器具的音频获取装置采集到的音频信号中不仅有用户的语音信息还包括其他噪声,当音频信号中的噪声音量过大时,则无法触发语音识别功能。本发明提供的噪声降低控制方法为,烹饪器具在运行时,通过音频获取装置获取第一音频信号集合,其中,第一音频信号集合中包括噪声信号。将第一音频信号集合作为训练集输入至声学模型中进行训练模型,从而得到目标声学模型。再通过音频获取装置采集第二音频信号,第二音频信号中至少含有第一音频信号,通过利目标声学模型对第二音频信号进行过滤,由于目标声学模型是通过第一音频信号训练得到的,故目标声学模型能够有效地将第二音频信号中的第一音频信号过滤掉。实现了能够将接收到的音频信号中的噪声信号过滤掉,从而达到了对接收到的音频进行降噪的作用,进而提高了烹饪器具中语音识别功能的触发率,避免用户在烹饪器具运行的过程中无法成功唤出语音识别功能。
可以理解的是,第一音频信号可选为烹饪器具运行产生的噪声信号,第二音频信号可选为混有噪声信号的人声指令。
通过噪声信号训练出的目标声学模型能够有效快速的识别出音频信号中的噪声信号,并通过设置相应的音频处理的方法步骤,能够将识别出的噪声信号进行滤除,仅保留音频信号中的非噪声信号。再通过语音识别模块对非噪声信号进行识别,判断其中是否存在语音指令,如果存在语音指令则执行,否则忽略该信号。保证了烹饪器具中语音识别模块对接收到的音频信号的触发率。避免用户多次重复同一语音指令,提高了用户的使用体验。
另外,根据本发明提供的上述技术方案中的噪声降低控制方法,还可以具有如下附加技术特征:
在一种可能的设计中,烹饪器具包括风机,风机的运行模式的数量为至少两个,获取烹饪器具运行过程中的第一音频信号集合的步骤,具体包括:控制风机分别在至少两个运行模式下运行,采集至少两个运行模式中每个运行模式下的风机运行过程中发出的第一音频信号;根据在至少两个运行模式下采集到的第一音频信号确定第一音频信号集合。
在该设计中,烹饪器具中包括风机,风机在运行的过程中会带动空气流动,产生大量噪声。在烹饪器具的实际运行中,根据烹饪器具运行模式的不同,通常将风机也设置不同的运行模式。风机在不同运行模式下,风机的转速不同,导致控制流动的速度不同,则导致风机产生的噪声的声学特性也不相同。控制风机在不同的运行模式下运行,并分别采集不同运行模式下风机运行产生的第一音频号,将在风机不同运行模式下采集到的第一音频信号以数据集的形式存储,从而得到第一音频信号集合。
考虑到风机在不同运行模式下产生的音频的声学特性不同,并且在烹饪器具的实际应用过程中风机也会以不同运行模式运行,因此在获取用于训练声学模型的数据集时,需要采集风机的不同运行模式下的音频确定训练声学模型用的数据集合,即第一音频信号集合,从而保证了根据该数据集合训练出的目标声学模型能够有效滤除风机运行产生的第一音频信号,提高了烹饪器具对音频信号进行降噪处理的效果。
在一种可能的设计中,通过第一音频信号集合训练声学模型,以得到目标声学模型的步骤,具体包括:提取第一音频信号集合中的每个第一音频信号的声纹特征;将声纹特征输入至声学模型中,以得到声学子模型,并确定声学子模型与运行模式的对应关系;根据声学子模型和对应关系确定目标声学模型。
在该设计中,将第一音频信号集合作为数据集对声学模型进行训练时,需要将第一音频信号集合中的每个第一音频信号逐个输入至声学模型中。即利用风机在同一运行模式下采集到的第一音频信号训练一个声学子模型,并将该声学子模型与风机的运行模式的对应关系进行存储,保证根据风机的不同运行模式能够快速找到对应的声学子模型,以及能够根据声学子模型找到该模型对应的运行模式。并将声学子模型配置到目标声学模型中,实现了当声学模型接收到需要滤除第一音频信号的指令时,能够快速找到待处理的音频信号对应的声学子模型。能够对风机不同运行模式下运行时接收的音频信号,采用对应的声学子模型进行过滤处理,保证了能够准确且快速地滤除第一音频信号。
可以理解的是,在训练声学子模型过程中,提取第一音频信号的声纹特征,利用声纹特征对目标声学模型进行训练,从而得到相应的声学子模型。风机产生的噪声的声纹特征与人声的音频信号的声纹特征差别较大,通过声纹特征训练得到的声学模型,能够准确地将人声和风机产生的噪声分离,进一步提高了对第一音频信号滤除的效率。
在一种可能的设计中,通过目标声学模型滤除第二音频信号中的第一音频信号的步骤,具体包括:确定采集第二音频信号时风机的实际运行模式;根据实际运行模式和对应关系,确定实际运行模式际对应的声学子模型,通过对应的声学子模型滤除第二音频信号中的第一音频信号。
在该设计中,在对第二音频信号滤除第一音频信号的过程中,需要确定在音频获取装置采集到第二音频信号时,风机所处的实际运行模式。根据确定得到的实际运行模式和运行模式与声学子模型的对应关系,能够找到与第二音频信号相匹配的声学子模型,并通过声学子模型对第二音频信号中的第一音频信号进行滤除。实现了根据对风机不同运行模式下采集到的第二音频信号选用与运行模式对应的声学子模型进行处理,提高了滤除第一音频信号的准确性。
在一种可能的设计中,确定第二音频信号对应的风机的实际运行模式的步骤,具体包括:获取风机的运行参数,根据运行参数确定风机的实际运行模式;和/或确定每个运行模式下发出的第一音频信号的音量值,根据第一音频信号的音量值确定设定音量值范围;确定第二音频信号的音量值,根据第二音频信号的音量值和设定音量值范围确定风机的实际运行模式。
在该设计中,可以选择不同判断方式,来确定第二音频信号对应的风机的实际运行模式。能够通过烹饪器具的处理器直接获取风机的运行参数,例如根据风机运行时采集到的运行电流、运行电压和功率等运行参数判断出风机的实际运行模式,或者直接根据串口通信协议获取风机的实际运行模式。还可以根据采集到的第二音频信号的音量值和设定音量值范围的数值关系确定风机的实际运行模式。通过不同的方式均能够准确地判断出风机的实际运行模式,根据判断的实际运行模式选择声学子模型能够提高判断的准确性。
在一个具体实施例中,烹饪器具中风机在运行过程中,能够对风机的运行参数进行采集,具体采集风机的运行电流、运行电压和运行功率,并根据上述运行参数判断风机所处于的运行模式。
在另一个具体实施例中,烹饪器具中的各个模块之间存在通信串口,即烹饪器具风机以设定运行模式运行,处理器能够通过串口通信协议获取风机的实际运行模式。通过串口通信协议获取风机的实际运行模式不需要对各种参数进行多余的计算处理步骤,简化了确定风机实际运行模式的流程步骤。
在再一个具体实施例中,烹饪器具通过音频获取装置获取第二音频信号的音量值。并调用运行模式与设定音量值范围的对应关系,根据第二页音频信号的音量值确定风机的运行模式。
可以理解的是,风机的转速不同,则采集到的风机运行过程中的第一音频信号的音量值大小不同,则带有第一音频信号的第二音频信号的音量值大小不同。因此根据第二音频信号的音量值大小能够准确地对风机所处的运行模式进行准确判断。
值得说明的是,上述三种实施例可选以任意组合的形式来对风机的运行模式进行判断,即通过一种判断方式进行初步判断,再结合另一个方式进行进一步判断,从而提高对风机运行模式判断的准确性。
在一种可能的设计中,采集第二音频信号的步骤之前,还包括:获取模型测试信号;将模型测试信号输入至目标声学模型中,校验目标声学模型。
在该设计中,在采集待检测的第二音频信号之前,需要判断得到的目标声学模型进行校验,具体采用将模型测试信号直接输入至目标声学模型中,判断目标声学模型是否将模型测试信号处理成为预设的音频信号,如果经过目标声学模型处理后得到的信号为预设的音频信号,则判断目标声学模型是准确的,如果经过目标声学模型处理得到的信号与预设音频信号不同,则判断目标声学模型不够准确,需要重新训练。避免由于训练得到的目标声学模型不准确导致的无法利用目标声学模型对第二音频信号进行过滤处理。
可以理解的是,模型测试信号可选为通过已知声纹特征的至少两个音频信号合成得到,根据目标声学信号对模型测试信号处理后得到的目标音频信号与合成模型测试信号用的音频信号进行比对,即能够确定目标声学模型是否准确。
在一种可能的设计中,获取模型测试信号的步骤,具体包括:采集距离音频获取装置设定距离范围内的音源发出的目标音频信号;将目标音频与第一音频信号叠加,以确定模型测试信号,其中,设定距离范围为大于等于0.5米,小于等于3.5米。
在该设计中,获取模型测试信号的步骤为采集设定位置的音源发出的音频信号,并将其与第一音频信号进行叠加,使模型测试信号中带有两种已知的音频信号。其中,设定距离范围的为0.5米至3.5米。通过将模型测试信号输入至目标声学模型中进行过滤第一音频信号,由于目标音频信号为已知的音频信号,故经过目标音频模型处理后最终得到的音频与目标音频信号进行比对,能够准确判断目标声学模型的准确性。烹饪器具的语音识别模块通常会对处于0.5米至3.5米范围内的音源发出的音频信号进行采集并识别,将设定距离范围设置为与烹饪器具的语音识别模块的识别范围相同,提高了对目标声学模型检测的准确性。
在一种可能的设计中,校验目标声学模型的步骤具体包括:获取目标声学模型输出的第三音频信号,确定第三音频信号与目标音频信号的相似度;相似度大于等于设定相似度,确定目标声学模型通过检验;或相似度小于设定相似度,确定目标声学模型未通过检验,返回执行通过音频获取装置获取烹饪器具运行过程中的第一音频信号集合的步骤。
在该设计中,对目标声学模型进行校验需要获取目标声学模型输出的第三音频信号,并处理得到第三音频信号与目标音频信号的相似度,并对相似度与设定相速度进行比较,如果相似度大于等于设定相似度,则判定目标声学模型能够准确地将第二音频信号中的第一音频信号滤除,即目标声学模型通过检验。如果相似度小于设定相似度,则判定目标声学模型不能够准确地将第二音频信号中的第一音频信号滤除,即目标声学膜性能未能通过检验。在目标声学模型未通过检验时,需要返回执行获取第一音频集合的步骤,并根据重新获取的第一音频集合训练目标声学模型。实现了在对第二音频信号进行降噪处理之前,对目标声学模型进行检测,并在检验不通过时重新训练目标声学模型,从而保证通过目标声学模型对第二音频信号进行过滤处理的准确性,进一步提高了降噪的精度。
在一种可能的设计中,控制风机分别在至少两个运行模式下运行的步骤之前,还包括:通过音频获取装置获取第四音频信号;确定第四音频信号的音量值小于设定音量值。
在该设计中,在控制风机在多个不同的运行模式下运行之前,需要判断环境是否足够安静。通过音频获取装置获取风机运行之前的环境声,即第四音频信号,并对第四音频信号进行分析处理,确定第四音频信号的音量值,将第四音频信号的音量值与设定音量值进行数值上的比较,根据比较结果判断环境是否足够安静。如果第四音频信号的音量值大于设定音量值,则可以认为环境存在较大噪声,则不再继续控制风机运行并采集第一音频信号的步骤。如果第四音频信号的音量值大于设定音量值,则可以认为环境存在的噪声较小,不会影响到采集第一音频信号,则继续控制风机运行并采集第一音频信号的步骤。通过判断环境音量的大小能够保证采集到的第一音频信号均是烹饪器具在运行过程中产生的噪音,避免环境噪音对训练得到的目标训练模型产生不利影像,提高了目标声学模型对第一音频信号的过滤效果。
根据本发明的第二方面提出了一种烹饪器具,包括:壳体,壳体内部设置有烹饪腔;加热装置,设置于烹饪腔内;排烟通道,设置于壳体内;风机,设置于排烟通道内,风机能够使外部空气流入排烟通道内;音频获取装置,设置于壳体上;存储器,存储器中存储有计算机程序;处理器,处理器与音频获取装置、加热装置和风机相连,处理器执行存储在存储器中的计算机程序以实现如上述任一可能设计中的噪声降低控制方法。
本发明提供的烹饪器具包括壳体、设置在壳体内的烹饪腔、加热装置、排烟通道和风机。加热装置设置在烹饪腔内,加热装置运行时能够对烹饪腔内进行加热,起到了对烹饪腔内食材加热烹饪的效果。排烟通道也设置在壳体内,风机设置在排烟通道中,排烟通道的一端设置在室内,排烟通道的另一端设置在室外,风机运行的过程中,能够将室内的空气经过排烟通道输送至室外,由于烹饪器具通常设置在厨房内,通过风机的运行实现了能够对厨房内的油烟排出的效果。
烹饪器具还包括存储器和处理器,处理器与加热装置和风机相连,处理器能够控制风机和加热装置的运行,实现对烹饪器具进行加热烹饪以及排出油烟功能的控制。存储器中存储有计算机程序,处理器能够运行存储在存储器中的计算机程序。处理运行存储在存储器中计算机程序能够实现如上述任一可能设计中的噪声降低控制方法,因而具有上述任一可能设计中的噪声降低控制方法的全部有益技术效果,在此不再做过多赘述。
可以理解的是,烹饪器具还包括语音识别装置和音频采集装置。音频采集装置能够音频,语音识别装置能够对音频采集装置采集到的音频信号中人声进行识别,并确定用户发出的控制指令,处理器能够根据控制指令对风机的运行模式进行调整,以及控制加热装置的运行功率。
在一种可能的设计中,烹饪器具为壁挂式微波炉、壁挂式微蒸烤一体机、壁挂式蒸箱、壁挂式烤箱、壁挂式蒸烤一体机。
根据本发明的第三方面提出了一种计算机可读存储介质,计算机可读存储介质上存储有烹饪器具的控制程序,烹饪器具的控制程序被处理器执行时实现如如上述任一可能设计中的噪声降低控制方法,因而具有上述任一可能设计中的噪声降低控制方法的全部有益技术效果,在此不再做过多赘述。
本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1示出了本发明的第一个实施例中的噪声降低控制方法的流程示意图;
图2示出了本发明的第二个实施例中的噪声降低控制方法的流程示意图之一;
图3示出了本发明的第二个实施例中的噪声降低控制方法的流程示意图之二;
图4示出了本发明的第二个实施例中的噪声降低控制方法的流程示意图之三;
图5示出了本发明的第三个实施例中的噪声降低控制方法的流程示意图之一;
图6示出了本发明的第三个实施例中的噪声降低控制方法的流程示意图之二;
图7示出了本发明的第三个实施例中的噪声降低控制方法的流程示意图之三;
图8示出了本发明的第四个实施例中的噪声降低控制方法的流程示意图;
图9示出了本发明的第五个实施例中的噪声降低控制方法的流程示意图;
图10示出了本发明的第六个实施例中的烹饪器具的示意框图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
下面参照图1至图10描述根据本发明一些实施例的一种噪声降低控制方法、一种烹饪器具和一种计算机可读存储介质。
实施例一:
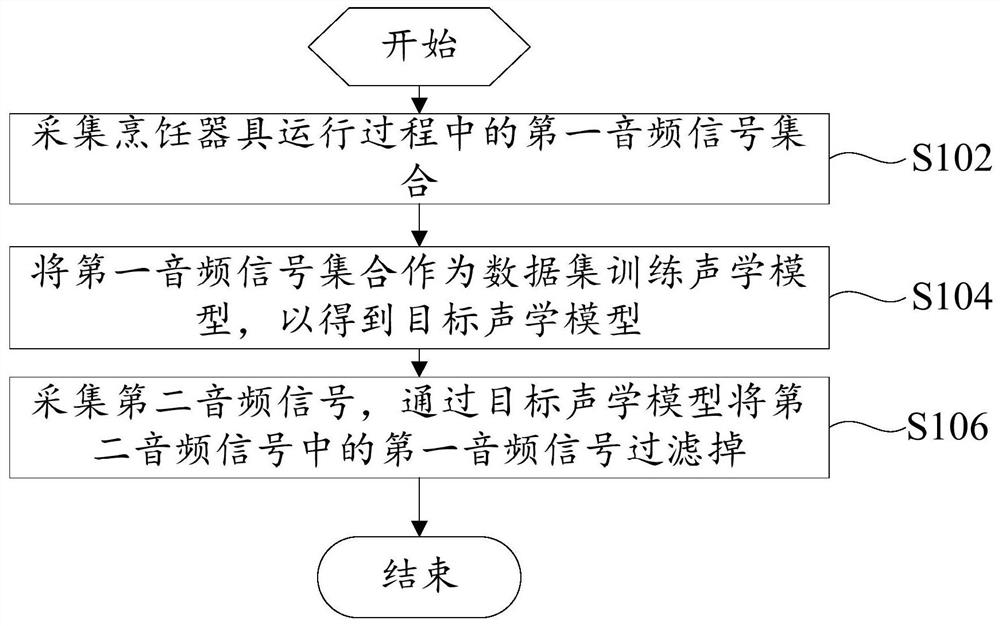
如图1所示,本发明的一个实施例中提供了一种噪声降低控制方法,用于烹饪器具,烹饪器具包括音频获取装置,噪声降低控制方法包括:
步骤S102,采集烹饪器具运行过程中的第一音频信号集合;
步骤S104,将第一音频信号集合作为数据集训练声学模型,以得到目标声学模型;
步骤S106,采集第二音频信号,通过目标声学模型将第二音频信号中的第一音频信号过滤掉。
在该实施例中,噪声降低控制方法用于烹饪器具,烹饪器具包括语音识别装置。烹饪器具能够通过音频获取装置采集音频,再通过语音识别装置识别用户发出的语音指令,并根据语音指令对烹饪器具进行控制,省去了用户对控制面板进行控制操作。当烹饪器具运行时,烹饪器具的音频获取装置采集到的音频信号中不仅有用户的语音信息还包括其他噪声,当音频信号中的噪声音量过大时,则无法触发语音识别功能。本发明提供的噪声降低控制方法为,烹饪器具在运行时,通过音频获取装置获取第一音频信号集合,其中,第一音频信号集合中包括噪声信号。将第一音频信号集合作为训练集输入至声学模型中进行训练模型,从而得到目标声学模型。再通过音频获取装置采集第二音频信号,第二音频信号中至少含有第一音频信号,通过利目标声学模型对第二音频信号进行过滤,由于目标声学模型是通过第一音频信号训练得到的,故目标声学模型能够有效地将第二音频信号中的第一音频信号过滤掉。实现了能够将接收到的音频信号中的噪声信号过滤掉,从而达到了对接收到的音频进行降噪的作用,进而提高了烹饪器具中语音识别功能的触发率,避免用户在烹饪器具运行的过程中无法成功唤出语音识别功能。
可以理解的是,第一音频信号可选为烹饪器具运行产生的噪声信号,第二音频信号可选为混有噪声信号的人声指令。
通过噪声信号训练出的目标声学模型能够有效快速的识别出音频信号中的噪声信号,并通过设置相应的音频处理的方法步骤,能够将识别出的噪声信号进行滤除,仅保留音频信号中的非噪声信号。再通过语音识别模块对非噪声信号进行识别,判断其中是否存在语音指令,如果存在语音指令则执行,否则忽略该信号。保证了烹饪器具中语音识别模块对接收到的音频信号的触发率。避免用户多次重复同一语音指令,提高了用户的使用体验。
可以理解的是,第一音频信号为在语音识别过程中的噪声信号,第一音频信号的音源为烹饪器具中的部件,例如风机、搅拌电机、微波模块等。
实施例二:
如图2所示,本发明的一个实施例中提供了一种噪声降低控制方法,用于烹饪器具,烹饪器具包括音频获取装置和风机,风机在运行过程中会产生噪声,噪声降低控制方法包括:
步骤S202,控制风机在多个不同的运行模式下运行;
步骤S204,采集每个运行模式下的风机发出的第一音频信号;
步骤S206,根据不同模式下采集的第一音频信号确定第一音频信号集合;
步骤S208,将第一音频信号集合作为数据集训练声学模型,以得到目标声学模型;
步骤S210,采集第二音频信号,通过目标声学模型将第二音频信号中的第一音频信号过滤掉。
在该实施例中,烹饪器具包括音频获取装置和风机。烹饪器具能够通过音频获取装置采集音频,再通过语音识别装置识别用户发出的语音指令,并根据语音指令对烹饪器具进行控制。风机在运行的过程中会带动空气流动,产生大量噪声。在烹饪器具的实际运行中,根据烹饪器具运行模式的不同,通常将风机也设置不同的运行模式。风机在不同运行模式下,风机的转速不同,导致控制流动的速度不同,则导致风机产生的噪声的声学特性也不相同。控制风机在不同的运行模式下运行,并分别采集不同运行模式下风机运行产生的第一音频号,将在风机不同运行模式下采集到的第一音频信号以数据集的形式存储,从而得到第一音频信号集合。将第一音频信号集合作为训练集输入至声学模型中进行训练模型,从而得到目标声学模型。再通过音频获取装置采集第二音频信号,第二音频信号中至少含有第一音频信号,通过利目标声学模型对第二音频信号进行过滤,由于目标声学模型是通过第一音频信号训练得到的,故目标声学模型能够有效地将第二音频信号中的第一音频信号过滤掉。实现了能够将接收到的音频信号中的噪声信号过滤掉,从而达到了对接收到的音频进行降噪的作用,进而提高了烹饪器具中语音识别功能的触发率,避免用户在烹饪器具运行的过程中无法成功唤出语音识别功能。
考虑到风机在不同运行模式下产生的音频的声学特性不同,并且在烹饪器具的实际应用过程中风机也会以不同运行模式运行,因此在获取用于训练声学模型的数据集时,需要采集风机的不同运行模式下的音频确定训练声学模型用的数据集合,即第一音频信号集合,从而保证了根据该数据集合训练出的目标声学模型能够有效滤除风机运行产生的第一音频信号,提高了烹饪器具对音频信号进行降噪处理的效果。
如图3所示,将第一音频信号集合作为数据集训练声学模型,最终得到目标声学模型的步骤包括:
步骤S302,对第一音频信号集合中的每个第一音频信号进行提取声纹特征;
步骤S304,将提取得到的声纹特征输入至声学模型,得到声学子模型;
步骤S306,获取声学子模型与运行模式的对应关系;
步骤S308,根据声学子模型和对应关系确定目标声学模型。
在该实施例中,将第一音频信号集合作为数据集对声学模型进行训练时,需要将第一音频信号集合中的每个第一音频信号逐个输入至声学模型中。即利用风机在同一运行模式下采集到的第一音频信号训练一个声学子模型,并将该声学子模型与风机的运行模式的对应关系进行存储,保证根据风机的不同运行模式能够快速找到对应的声学子模型,以及能够根据声学子模型找到该模型对应的运行模式。并将声学子模型配置到目标声学模型中,实现了当声学模型接收到需要滤除第一音频信号的指令时,能够快速找到待处理的音频信号对应的声学子模型。能够对风机不同运行模式下运行时接收的音频信号,采用对应的声学子模型进行过滤处理,保证了能够准确且快速地滤除第一音频信号。
可以理解的是,在训练声学子模型过程中,提取第一音频信号的声纹特征,利用声纹特征对目标声学模型进行训练,从而得到相应的声学子模型。风机产生的噪声的声纹特征与人声的音频信号的声纹特征差别较大,通过声纹特征训练得到的声学模型,能够准确地将人声和风机产生的噪声分离,进一步提高了对第一音频信号滤除的效率。
如图4所示,在上述实施例中,通过目标声学模型将第二音频信号中的第一音频信号进行过滤的步骤,具体包括:
步骤S402,采集第二音频信号时,获取并记录风机的实际运行模式;
步骤S404,根据实际运行模式,以及风机的运行模式和声学子模型的对应关系确定声学子模型,将第二音频信号输入声学子模型中对第一音频信号进行过滤。
在该实施例中,在对第二音频信号滤除第一音频信号的过程中,需要确定在音频获取装置采集到第二音频信号时,风机所处的实际运行模式。根据确定得到的实际运行模式和运行模式与声学子模型的对应关系,能够找到与第二音频信号相匹配的声学子模型,并通过声学子模型对第二音频信号中的第一音频信号进行滤除。实现了根据对风机不同运行模式下采集到的第二音频信号选用与运行模式对应的声学子模型进行处理,提高了滤除第一音频信号的准确性。
其中,获取并记录风机的实际运行模式的方式包括多种,在风机运行过程中采集风机的运行参数,根据运行参数和对应的运行参数范围内进行比较,确定风机的实际运行模式;和/或采集每个运行模式下发出的第一音频信号,并确定采集到的第一音频信号的音量值,根据第一音频信号的音量值确定设定音量值范围,根据第二音频信号的音量值和设定音量值范围的数值关系对风机的实际运行模式进行确定。具体实施例如下。
在一个具体实施例中,烹饪器具中风机在运行过程中,能够对风机的运行参数进行采集,具体采集风机的运行电流、运行电压和运行功率,并根据上述运行参数判断风机所处于的运行模式。
在另一个具体实施例中,烹饪器具中的各个模块之间存在通信串口,即烹饪器具风机以设定运行模式运行,处理器能够通过串口通信协议获取风机的实际运行模式。通过串口通信协议获取风机的实际运行模式不需要对各种参数进行多余的计算处理步骤,简化了确定风机实际运行模式的流程步骤。
在再一个具体实施例中,烹饪器具通过音频获取装置获取第二音频信号的音量值。并调用运行模式与设定音量值范围的对应关系,根据第二页音频信号的音量值确定风机的运行模式。
可以理解的是,风机的转速不同,则采集到的风机运行过程中的第一音频信号的音量值大小不同,则带有第一音频信号的第二音频信号的音量值大小不同。因此根据第二音频信号的音量值大小能够准确地对风机所处的运行模式进行准确判断。
值得说明的是,上述三种实施例可选以任意组合的形式来对风机的运行模式进行判断,即通过一种判断方式进行初步判断,再结合另一个方式进行进一步判断,从而提高对风机运行模式判断的准确性。
可以选择不同判断方式,来确定第二音频信号对应的风机的实际运行模式。能够通过烹饪器具的处理器直接获取风机的运行参数,例如根据风机运行时采集到的运行电流、运行电压和功率等运行参数判断出风机的实际运行模式,或者直接根据串口通信协议获取风机的实际运行模式。还可以根据采集到的第二音频信号的音量值和设定音量值范围的数值关系确定风机的实际运行模式。通过不同的方式均能够准确地判断出风机的实际运行模式,根据判断的实际运行模式选择声学子模型能够提高判断的准确性。
实施例三:
如图5所示,本发明的一个实施例中提供了一种噪声降低控制方法,用于烹饪器具,烹饪器具包括音频获取装置和风机,风机在运行过程中会产生噪声,噪声降低控制方法包括:
步骤S502,控制风机在多个不同的运行模式下运行;
步骤S504,采集每个运行模式下的风机发出的第一音频信号;
步骤S506,根据不同模式下采集的第一音频信号确定第一音频信号集合;
步骤S508,将第一音频信号集合作为数据集训练声学模型,以得到目标声学模型;
步骤S510,调用模型测试信号,输入模型测试信号至目标声学模型中;
步骤S512,判断目标声学模型是否符合检测标准,判断结果为是则执行步骤S514,判断结果为否则返回执行步骤S502;
步骤S514,采集第二音频信号,通过目标声学模型将第二音频信号中的第一音频信号过滤掉。
在该实施例中,烹饪器具包括音频获取装置和风机。烹饪器具能够通过音频获取装置采集音频,再通过语音识别装置识别用户发出的语音指令,并根据语音指令对烹饪器具进行控制。风机在运行的过程中会带动空气流动,产生大量噪声。在烹饪器具的实际运行中,根据烹饪器具运行模式的不同,通常将风机也设置不同的运行模式。风机在不同运行模式下,风机的转速不同,导致控制流动的速度不同,则导致风机产生的噪声的声学特性也不相同。控制风机在不同的运行模式下运行,并分别采集不同运行模式下风机运行产生的第一音频号,将在风机不同运行模式下采集到的第一音频信号以数据集的形式存储,从而得到第一音频信号集合。将第一音频信号集合作为训练集输入至声学模型中进行训练模型,从而得到目标声学模型。再通过音频获取装置采集第二音频信号,第二音频信号中至少含有第一音频信号,通过利目标声学模型对第二音频信号进行过滤,由于目标声学模型是通过第一音频信号训练得到的,故目标声学模型能够有效地将第二音频信号中的第一音频信号过滤掉。实现了能够将接收到的音频信号中的噪声信号过滤掉,从而达到了对接收到的音频进行降噪的作用,进而提高了烹饪器具中语音识别功能的触发率,避免用户在烹饪器具运行的过程中无法成功唤出语音识别功能。
在采集待检测的第二音频信号之前,还需要判断得到的目标声学模型进行校验,具体采用将模型测试信号直接输入至目标声学模型中,判断目标声学模型是否将模型测试信号处理成为预设的音频信号,如果经过目标声学模型处理后得到的信号为预设的音频信号,则判断目标声学模型是准确的,如果经过目标声学模型处理得到的信号与预设音频信号不同,则判断目标声学模型不够准确,需要重新训练。避免由于训练得到的目标声学模型不准确导致的无法利用目标声学模型对第二音频信号进行过滤处理。
可以理解的是,模型测试信号可选为通过已知声纹特征的至少两个音频信号合成得到,根据目标声学信号对模型测试信号处理后得到的目标音频信号与合成模型测试信号用的音频信号进行比对,即能够确定目标声学模型是否准确。
如图6所示,在上述实施例中,调用的模型测试信号需要预先采集并存储在本地存储区,具体采集模型测试信号的步骤,包括:
步骤S602,通过音频获取装置采集设定距离范围内的音源发出的目标音频信号;
步骤S604,叠加第一音频信号和目标音频信号得到模型测试信号。
其中,设定距离范围为大于等于0.5米,小于等于3.5米。
在该实施例中,获取模型测试信号的步骤为采集设定位置的音源发出的音频信号,并将其与第一音频信号进行叠加,使模型测试信号中带有两种已知的音频信号。其中,设定距离范围的为0.5米至3.5米。通过将模型测试信号输入至目标声学模型中进行过滤第一音频信号,由于目标音频信号为已知的音频信号,故经过目标音频模型处理后最终得到的音频与目标音频信号进行比对,能够准确判断目标声学模型的准确性。烹饪器具的语音识别模块通常会对处于0.5米至3.5米范围内的音源发出的音频信号进行采集并识别,将设定距离范围设置为与烹饪器具的语音识别模块的识别范围相同,提高了对目标声学模型检测的准确性。
如图7所示,在上述任一实施例中,判断目标声学模型是否符合检测标准的步骤,具体包括:
步骤S702,接收目标声学模型输出的第三音频信号,并确定目标音频信号与第三音频信号之间的相似度;
步骤S704,判断相似度是否大于等于设定相似度,判断结果为是则执行步骤S706,判断结果为否则执行步骤S708;
步骤S706,确定目标声学模型符合检测标准。
步骤S708,确定目标声学模型不符合检测标准。
在该实施例中,对目标声学模型进行校验需要获取目标声学模型输出的第三音频信号,并处理得到第三音频信号与目标音频信号的相似度,并对相似度与设定相速度进行比较,如果相似度大于等于设定相似度,则判定目标声学模型能够准确地将第二音频信号中的第一音频信号滤除,即目标声学模型通过检验。如果相似度小于设定相似度,则判定目标声学模型不能够准确地将第二音频信号中的第一音频信号滤除,即目标声学膜性能未能通过检验。在目标声学模型未通过检验时,需要返回执行获取第一音频集合的步骤,并根据重新获取的第一音频集合训练目标声学模型。实现了在对第二音频信号进行降噪处理之前,对目标声学模型进行检测,并在检验不通过时重新训练目标声学模型,从而保证通过目标声学模型对第二音频信号进行过滤处理的准确性,进一步提高了降噪的精度。
实施例四:
如图8所示,本发明的一个实施例中提供了一种噪声降低控制方法,用于烹饪器具,烹饪器具包括音频获取装置和风机,风机在运行过程中会产生噪声,噪声降低控制方法包括:
步骤S802,采集第四音频信号;
步骤S804,判断第四音频信号的音量值是否小于设定音量值,判断结果为是则执行步骤S806,判断结果为否则返回执行步骤S802;
步骤S806,控制风机在多个不同的运行模式下运行;
步骤S808,采集每个运行模式下的风机发出的第一音频信号;
步骤S810,根据不同模式下采集的第一音频信号确定第一音频信号集合;
步骤S812,将第一音频信号集合作为数据集训练声学模型,以得到目标声学模型;
步骤S814,采集第二音频信号,通过目标声学模型将第二音频信号中的第一音频信号过滤掉。
在该实施例中,在控制风机在多个不同的运行模式下运行之前,需要判断环境是否足够安静。通过音频获取装置获取风机运行之前的环境声,即第四音频信号,并对第四音频信号进行分析处理,确定第四音频信号的音量值,将第四音频信号的音量值与设定音量值进行数值上的比较,根据比较结果判断环境是否足够安静。如果第四音频信号的音量值大于设定音量值,则可以认为环境存在较大噪声,则不再继续控制风机运行并采集第一音频信号的步骤。如果第四音频信号的音量值大于设定音量值,则可以认为环境存在的噪声较小,不会影响到采集第一音频信号,则继续控制风机运行并采集第一音频信号的步骤。通过判断环境音量的大小能够保证采集到的第一音频信号均是烹饪器具在运行过程中产生的噪音,避免环境噪音对训练得到的目标训练模型产生不利影像,提高了目标声学模型对第一音频信号的过滤效果。
在烹饪器具的实际运行中,根据烹饪器具运行模式的不同,通常将风机也设置不同的运行模式。风机在不同运行模式下,风机的转速不同,导致控制流动的速度不同,则导致风机产生的噪声的声学特性也不相同。控制风机在不同的运行模式下运行,并分别采集不同运行模式下风机运行产生的第一音频号,将在风机不同运行模式下采集到的第一音频信号以数据集的形式存储,从而得到第一音频信号集合。将第一音频信号集合作为训练集输入至声学模型中进行训练模型,从而得到目标声学模型。再通过音频获取装置采集第二音频信号,第二音频信号中至少含有第一音频信号,通过利目标声学模型对第二音频信号进行过滤,由于目标声学模型是通过第一音频信号训练得到的,故目标声学模型能够有效地将第二音频信号中的第一音频信号过滤掉。实现了能够将接收到的音频信号中的噪声信号过滤掉,从而达到了对接收到的音频进行降噪的作用,进而提高了烹饪器具中语音识别功能的触发率,避免用户在烹饪器具运行的过程中无法成功唤出语音识别功能。
实施例五:
如图9所示,本发明的一个具体实施例中提供了一种噪声降低控制方法,用于烹饪器具,烹饪器具包括音频获取装置和风机,风机在运行过程中会产生噪声,噪声降低控制方法包括:
步骤S902,在消音室安静环境下,采集风机各个运行模式下的第一音频信号,以及不同距离下,叠加有目标音频信号的第一音频信号;
步骤S904,通过分析采集到的第一音频信号,在工作站进行仿真,创建目标声学模型,分别建立风机各个档位下声学子模型;
步骤S906,根据叠加有目标音频信号的第一音频信号对目标声学模型进行校验;
步骤S908,在烹饪器具实际运行过程中,当风机的运行模式发生变化时,通过通信协议确定风机实时的运行模式;
步骤S910,利用目标声学模型对采集到的第二音频信号中的第一音频信号进行过滤。
在该实施例中,将风机设置在固定的档位,使用多通道高速音频采集器,同时采集机器上不同结构位置的噪声信号,确定受噪声影响较小的麦克风安装位置。确定麦克风安装位置后,在消音室安静环境下,采集风机在不同档位下的纯噪声信号,以及叠加了1米至3米的人声信号。使用采集到的信号,进行软件仿真,建立噪声数据库及噪声比对程序,并将噪声数据存储至语音模块中。语音模块通过串口通讯协议实时得知风机所处的档位,结合实时采集到的声音信号,判断风机所处的工作模式,调用相应的降噪程序及噪声数据,提高语音识别用户体验。
噪声降低控制方法用于烹饪器具,烹饪器具包括语音识别装置。烹饪器具能够通过音频获取装置采集音频,再通过语音识别装置识别用户发出的语音指令,并根据语音指令对烹饪器具进行控制,省去了用户对控制面板进行控制操作。当烹饪器具运行时,烹饪器具的音频获取装置采集到的音频信号中不仅有用户的语音信息还包括其他噪声,当音频信号中的噪声音量过大时,则无法触发语音识别功能。本发明提供的噪声降低控制方法为,烹饪器具在运行时,通过音频获取装置获取第一音频信号集合,其中,第一音频信号集合中包括噪声信号。将第一音频信号集合作为训练集输入至声学模型中进行训练模型,从而得到目标声学模型。再通过音频获取装置采集第二音频信号,第二音频信号中至少含有第一音频信号,通过利目标声学模型对第二音频信号进行过滤,由于目标声学模型是通过第一音频信号训练得到的,故目标声学模型能够有效地将第二音频信号中的第一音频信号过滤掉。实现了能够将接收到的音频信号中的噪声信号过滤掉,从而达到了对接收到的音频进行降噪的作用,进而提高了烹饪器具中语音识别功能的触发率。
实施例六:
如图10所示,本发明的一个实施例中提供了一种烹饪器具1000,包括:壳体,壳体内部设置有烹饪腔;加热装置1010,设置于烹饪腔内;排烟通道,设置于壳体内;风机1006,设置于排烟通道内,风机1006能够使外部空气流入排烟通道内;音频获取装置1008,设置于壳体上;存储器1002,存储器1002中存储有计算机程序;处理器1004,处理器1004与音频获取装置1008、加热装置1010和风机1006相连,处理器1004执行存储在存储器1002中的计算机程序以实现如上述任一实施例中的噪声降低控制方法。
本发明提供的烹饪器具1000包括壳体、设置在壳体内的烹饪腔、加热装置1010、排烟通道和风机1006。加热装置1010设置在烹饪腔内,加热装置1010运行时能够对烹饪腔内进行加热,起到了对烹饪腔内食材加热烹饪的效果。排烟通道也设置在壳体内,风机1006设置在排烟通道中,排烟通道的一端设置在室内,排烟通道的另一端设置在室外,风机1006运行的过程中,能够将室内的空气经过排烟通道输送至室外,由于烹饪器具1000通常设置在厨房内,通过风机1006的运行实现了能够对厨房内的油烟排出的效果。
烹饪器具1000还包括存储器1002和处理器1004,处理器1004与加热装置1010和风机1006相连,处理器1004能够控制风机1006和加热装置1010的运行,实现对烹饪器具1000进行加热烹饪以及排出油烟功能的控制。存储器1002中存储有计算机程序,处理器1004能够运行存储在存储器1002中的计算机程序。处理运行存储在存储器1002中计算机程序能够实现如上述任一实施例中的噪声降低控制方法,因而具有上述任一实施例中的噪声降低控制方法的全部有益技术效果,在此不再做过多赘述。
可以理解的是,烹饪器具1000还包括语音识别装置和音频采集装置。音频采集装置能够音频,语音识别装置能够对音频采集装置采集到的音频信号中人声进行识别,并确定用户发出的控制指令,处理器1004能够根据控制指令对风机1006的运行模式进行调整,以及控制加热装置1010的运行功率。
在上述任一实施例中,烹饪器具1000为壁挂式(OTR)微波炉、壁挂式微蒸烤一体机、壁挂式蒸箱、壁挂式烤箱、壁挂式蒸烤一体机。
OTR微波炉(壁挂式微波炉)使用场景,整个微波炉嵌入在墙体中,底部有一个抽风机,用于将厨房内的油烟抽出。
实施例七:
本发明一个实施例中提供了一种本发明的一个实施例中提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如上述任一实施例中的噪声降低控制方法,因而具有上述任一实施例中的噪声降低控制方法的全部有益技术效果。
其中,计算机可读存储介质,如只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等。
需要明确的是,本发明并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本发明的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本发明的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
还需要说明的是,本发明中提及的示例性实施例,基于一系列的步骤或者装置描述一些方法或系统。但是,本发明不局限于上述步骤的顺序,也就是说,可以按照实施例中提及的顺序执行步骤,也可以不同于实施例中的顺序,或者若干步骤同时执行。
在本发明中,术语“多个”则指两个或两个以上,除非另有明确的限定。术语“安装”、“相连”、“连接”、“固定”等术语均应做广义理解,例如,“连接”可以是固定连接,也可以是可拆卸连接,或一体地连接;“相连”可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。