一种语音信号处理方法、装置、存储介质及终端设备
文献发布时间:2023-06-19 09:26:02
技术领域
本发明涉及语音技术领域,尤其涉及一种语音信号处理方法、装置、存储介质及终端设备。
背景技术
在语音信号处理技术的快速发展和社交平台的流行推广下,语音变声成为语音信号处理领域中一个重要的研究方向,其可应用在保密通信,娱乐通信等多个领域,具有良好前景。
现有技术中,通过以下四种方法来进行语音变声,第一种是通过改变音调实现语音变声,可通过改变声源的频率,频率越高,音调也越高,频率越低,音调也越低;也可通过改变播放频率,如将放音机的放音速度加快或放慢,使播放音乐的音调提高或降低,然而该方法音调虽提高了,但是放音时间也变短了。
第二种是通过改变基频实现语音变声,基频是发浊音时声带振动的频率,基频的高低与说话人的性别直接相关,一般来说男声的基频比较低,女声的基频比较高。此外,年龄对于基频的高低也有一定影响,老年人的基频比年青人的基频低,年青人的基频要比儿童的基频低。所以通过改变基频,就能改变语音的效果,达到变声效果。
第三种是通过改变共振峰实现语音变声,共振峰是指声门波在声道里的共鸣频率。共振峰与声道的长度有很大的相关性,声道越长共振峰的频率越高,反之亦然。相对来说,男子的声道比女子的声道要长一些,所以男声的共振峰频率比女声的共振峰频率相对也要高一些。因此通过改变共振峰,能够影响人对说话人的判断。对于修改共振峰的频率,大部分方法都是基于参数合成的算法,这些方法普遍存在的问题是运算量比较大,需要人工干预,合成的语音的自然度比较差。
第四种是通过调节EQ均衡器实现语音变声,在听MP3格式的音乐文件时经常会使用EQ均衡器对数字声音的音效进行调节,EQ均衡器变音改变音效的原理是通过将数字声音信号分为多个频段,分别对所述多个频段不同频率的信号进行调节和增益,只能祈祷补偿扬声器和声场的缺陷,补偿和修饰各种声源及其它辅助作用,但是类似于花栗鼠、腹语、鬼音等特殊音效,现有通过调节EQ均衡器的变音方法就无法实现。
然而上述四种方法都是从语音频率的角度进行语音变声,通过提升高音或降低低音的方式进行语音变声,容易被逆变回来,从而暴露说话人身份,不能起到隐私保护的效果。
发明内容
本发明实施例所要解决的技术问题在于,提供一种语音信号处理方法、装置、存储介质及终端设备,难以从变声后的语音信号中识别出用户身份,加强用户的隐私保护。
为了解决上述技术问题,本发明实施例提供了一种语音信号处理方法,包括:
获取语音片段中的N个语音特征;其中,N>0;
对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征;
将N个第一语音特征划分为K个语音特征块;其中,语音特征块包含若干个第一语音特征,N≥K>0;
分别对每一个语音特征块中的第一语音特征进行调整处理,获得N个第二语音特征;其中,所述调整处理为从第k个语音特征块中截取部分第一语音特征,或者根据第k个语音特征块中的第一语音特征填充新的语音特征;其中,K≥k>0;
将N个第二语音特征输入至预设的声码器中,合成变声后的语音信号。
进一步地,任一语音特征包括基音频率、共振峰频谱包络、非周期激励信号;则,所述获取语音片段中的N个语音特征,具体包括:
按照预设的帧长度对所述语音片段进行分帧,获得N个帧信号;
基于DIO算法提取每一个帧信号中的基音频率,获得N个基音频率;
基于CheapTrick算法提取每一个帧信号中的共振峰频谱包络,获得N个共振峰频谱包络;
基于PLATINUM算法提取每一个帧信号中的非周期激励信号,获得N个非周期激励信号。
进一步地,每一个第一语音特征包括第一基音频率、第一共振峰频谱包络、第一非周期激励信号,则,所述对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征,具体包括:
对每一个基音频率进行平滑处理、非线性处理和调频处理,得到N个第一基音频率;
对每一个共振峰频谱包络进行移动处理和平滑处理,得到N个第一共振峰频谱包络;
对每一个非周期激励信号进行平滑处理和非线性处理,得到N个第一非周期激励信号。
进一步地,所述对每一个基音频率进行平滑处理、非线性处理和调频处理,得到N个第一基音频率,具体包括:
将每一个基音频率与该基音频率相邻的基音频率进行均值计算,得到N个平滑处理后的基音频率;
基于三角函数算法或指数函数算法,对每一个平滑处理后的基音频率进行非线性处理,获得N个非线性处理后的基音频率;
以预设的频率范围为参考,将每一个非线性处理后的基音频率映射到所述频率范围内,得到N个第一基音频率。
进一步地,所述对每一个共振峰频谱包络进行移动处理和平滑处理,得到N个第一共振峰频谱包络,具体包括:
将每一个共振峰频谱包络循环移动N个单位,获得N个移动处理后的共振峰频谱包络;
对每一个移动处理后的共振峰频谱包络与该移动处理后的共振峰频谱包络相邻的移动处理后的共振峰频谱包络进行均值计算,得到N个第一共振峰频谱包络。
进一步地,所述对每一个非周期激励信号进行平滑处理和非线性处理,得到N个第一非周期激励信号,具体包括:
将每一个非周期激励信号与该非周期激励信号相邻的非周期激励信号进行均值计算,得到N个平滑处理后的非周期激励信号;
基于三角函数算法或指数函数算法,对每一个平滑处理后的非周期激励信号进行非线性处理,获得N个第一非周期激励信号。
相应地,本发明还提供了一种语音信号处理装置,包括:
语音特征提取模块,用于获取语音片段中的N个语音特征;其中,N>0;
变换处理模块,用于对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征;
分块模块,用于将N个第一语音特征划分为K个语音特征块;其中,语音特征块包含若干个第一语音特征,N≥K>0;
调整处理模块,用于分别对每一个语音特征块中的第一语音特征进行调整处理,获得N个第二语音特征;其中,所述调整处理为从第k个语音特征块中截取部分第一语音特征,或者根据第k个语音特征块中的第一语音特征填充新的语音特征;其中,K≥k>0;
合成模块,用于将N个第二语音特征输入至预设的声码器中,合成变声后的语音信号。
进一步地,所述语音特征提取模块,包括:
分帧单元,用于按照预设的帧长度对所述语音片段进行分帧,获得N个帧信号;
基音频率提取单元,用于基于DIO算法提取每一个帧信号中的基音频率,获得N个基音频率;
共振峰频谱包络提取单元,用于基于CheapTrick算法提取每一个帧信号中的共振峰频谱包络,获得N个共振峰频谱包络;
非周期激励信号提取单元,用于基于PLATINUM算法提取每一个帧信号中的非周期激励信号,获得N个非周期激励信号。
相应地,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行上述任一项所述的语音信号处理方法。
相应地,本发明还提供了一种终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现上述任一项所述的语音信号处理方法。
实施本发明实施例,具有如下有益效果:
本发明实施例提供了一种语音信号处理方法、装置、存储介质及终端设备,该方法包括:获取语音片段中的N个语音特征;对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征;将N个第一语音特征划分为K个语音特征块;其中,语音特征块包含若干个第一语音特征,N≥K>0;分别对每一个语音特征块中的第一语音特征进行调整处理,获得N个第二语音特征;其中,所述调整处理为从第k个语音特征块中截取部分第一语音特征,或者根据第k个语音特征块中的第一语音特征填充新的语音特征;其中,K≥k>0;将N个第二语音特征输入至预设的声码器中,合成变声后的语音信号;相比于现有的语音处理方法,本发明先将N个第一语音特征划分为K个语音特征块,然后对各个语音特征块中的第一语音特征进行调整处理,例如,假设有两个语音特征块,只保留第一个语音特征块中的部分第一语音特征,并根据第二个语音特征块中的第一语音特征,往第二个语音特征块中添加新的语音特征,只需保证调整处理后的第二语音特征与调整处理前的第一语音特征的数目相同即可,通过上述方法改变了用户的说话节奏,避免识别出用户身份,且本发明的调整处理无单一规律,无法根据变声后的语音信号逆变回来,进一步加强用户的隐私保护。
附图说明
图1是本发明提供的一种语音信号处理方法的一个优选实施例的流程图;
图2是本发明提供的一种语音信号处理装置的一个优选实施例的结构框图;
图3是本发明提供的一种终端设备的一个优选实施例的结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本技术领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
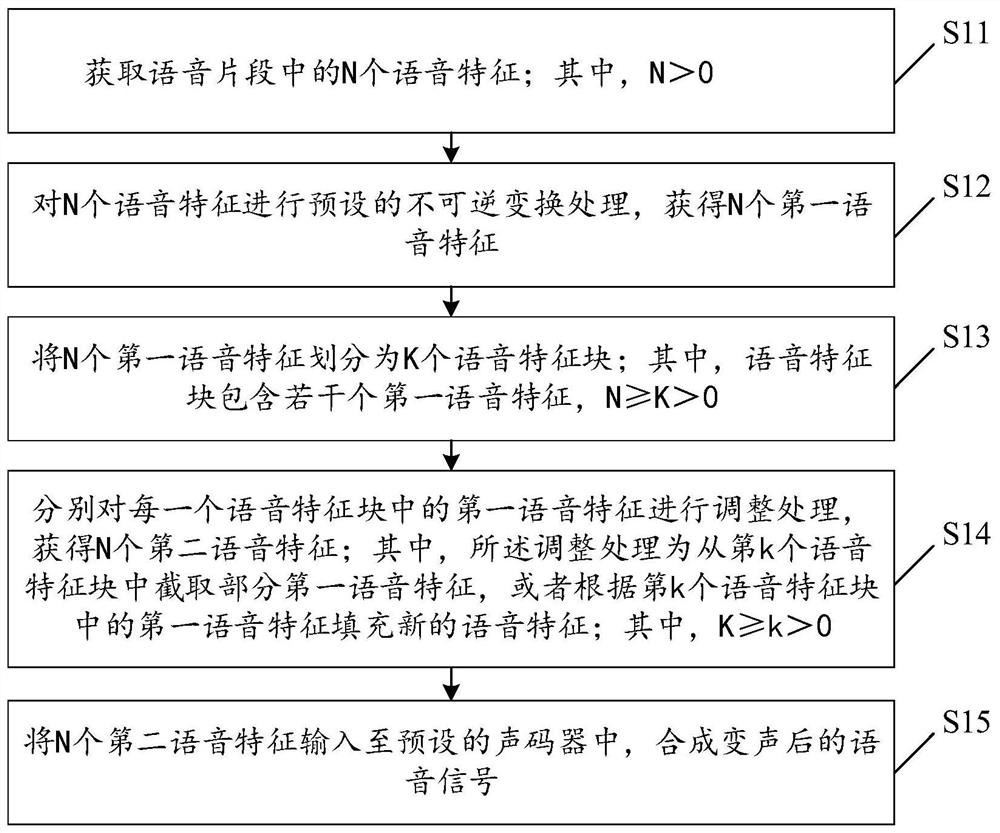
本发明实施例提供了一种语音信号处理方法,参见图1所示,是本发明提供的一种语音信号处理方法的一个优选实施例的流程图,所述方法包括步骤S11至步骤S15:
步骤S11、获取语音片段中的N个语音特征;其中,N>0;
步骤S12、对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征;
步骤S13、将N个第一语音特征划分为K个语音特征块;其中,语音特征块包含若干个第一语音特征,N≥K>0;
步骤S14、分别对每一个语音特征块中的第一语音特征进行调整处理,获得N个第二语音特征;其中,所述调整处理为从第k个语音特征块中截取部分第一语音特征,或者根据第k个语音特征块中的第一语音特征填充新的语音特征;其中,K≥k>0;
步骤S15、将N个第二语音特征输入至预设的声码器中,合成变声后的语音信号。
具体地,假设语音片段中有40个帧信号,每一个帧信号对应一个语音特征,共有40个语音特征;对40个语音特征进行不可逆变换处理,获得40个第一语音特征;将40个第一语音特征划分为4个语音特征块;每一个语音特征块包含10个第一语音特征,分别对每一个语音特征块中的第一语音特征进行调整处理,获得40个第二语音特征;例如,第一个语音特征包只截取5个第一语音特征,第二个语音特征包增添2个新的语音特征,第三个语音特征包只截取8个第一语音特征,第四个语音特征包增添5个新的语音特征,总数上还是等于40个;调整处理相当于在时间维度上,对每一个语音特征块对应的时长进行伸长或缩短处理,假设每一个帧信号的时长为1秒,语音片段的总时长为40秒,那么在未经过调整处理前,每一个语音特征块的时长均为10秒,经过调整调整后,第一个语音特征块对应的时长为5秒,第二个语音特征块对应的时长为12秒,第三个语音特征块对应的时长为8秒,第四个语音特征块对应的时长为15秒,由于调整处理相当于在时间维度上对每一个语音特征块对应的时长进行伸长或缩短处理,导致经过调整处理后的语音特征块对应的语速发生变化,例如第一语音特征块经过调整处理的语速相当于调整处理前的语速的2倍,第二语音特征块经过调整处理后的语速相当于调整处理前的语速的0.833倍,第三语音特征块经过调整处理后的语速相当于调整处理前的语速的1.25倍,第四语音特征块经过调整处理后的语速相当于调整处理前的语速的0.667倍(语速倍数的计算方法:倍数值=原时长/新时长);可见,本发明通过不可逆变换处理,改变了用户的说话节奏,使得变声后的语音信号和原来的语音信号在说话节奏上有很大的差异,从而避免识别出用户身份,且本发明的调整处理无单一规律,存在随机因素,无法通过同一参数将变声后的语音信号逆变回来,进一步加强用户的隐私保护。其中,新的语音特征的添加方法可以但不局限于通过插值法进行添加;每一个特征块所包含的第一语音特征的数目可以是不相同的,这里不作具体的限定。
在又一个优选实施例中,任一语音特征包括基音频率、共振峰频谱包络、非周期激励信号;则,所述步骤S11,具体包括:
按照预设的帧长度对所述语音片段进行分帧,获得N个帧信号;
基于DIO算法提取每一个帧信号中的基音频率,获得N个基音频率F0;
基于CheapTrick算法提取每一个帧信号中的共振峰频谱包络,获得N个共振峰频谱包络SP;
基于PLATINUM算法提取每一个帧信号中的非周期激励信号,获得N个非周期激励信号AP。
具体地,WORLD声码器中包含三个模块,分别为DIO模块、CheapTrick模块、PLATINUM模块,DIO模块包括DIO算法,该算法又称为基于声带振动周期提取的快速可靠F0估计方法(Fast and Reliable F0 Estimation Method Based on the PeriodExtraction of Vocal Fold Vibration of Singing Voice and Speech),DIO算法是用来估计基音频率;CheapTrick模块包括CheapTrick算法,主要根据波形和基音频率来计算共振峰频谱包络SP;PLATINUM模块包括PLATINUM算法,主要根据波形、基音频率及共振峰频谱包络来计算非周期激励信号AP。
在又一个优选实施例中,所述基于DIO算法提取每一个帧信号中的基音频率,获得N个基音频率,具体包括:
分别通过X个不同频带的低通滤波器对每一个帧信号进行滤波,获得X个候选基音频率及其对应的周期;其中,X>0;
根据X个候选基音频率在不同周期间的零交点、峰值以及下降间隔,计算得到每一个候选基音频率的置信度;
选取置信度最高的候选基音频率作为该帧信号的基音频率。
在又一个优选实施例中,所述基于CheapTrick算法提取每一个帧信号中的共振峰频谱包络,获得N个共振峰频谱包络,具体包括:
根据每一个帧信号的波形和每一个帧信号的基音频率进行频谱包络分析,得到对应的每一个帧信号的共振峰频谱包络。
具体地,对任意一个帧信号添加汉明窗口,然后对窗口之后的信号计算其功率;使用矩形窗函数对功率谱进行平滑化;计算功率谱的倒谱,并做倒谱提升,得到每一个帧信号的共振峰频谱包络。
在又一个优选实施例中,所述基于PLATINUM算法提取每一个帧信号中的非周期激励信号,获得N个非周期激励信号,具体包括:
根据每一个帧信号的波形、每一个帧信号的基音频率以及每一个帧信号的共振峰频谱包络,得到对应每一个帧信号的非周期激励信号。
具体地,对任意一个帧信号,对该帧信号的波形添加宽度为2倍基频周期的窗函数,并计算得到其频谱,将频谱除以最小相谱得到Xp,对Xp进行逆傅立叶变换,即可得到每一个帧信号的非周期激励信号AP。
在又一个优选实施例中,每一个第一语音特征包括第一基音频率、第一共振峰频谱包络、第一非周期激励信号,则,所述步骤S12,具体包括:
对每一个基音频率进行平滑处理、非线性处理和调频处理,得到N个第一基音频率;
对每一个共振峰频谱包络进行移动处理和平滑处理,得到N个第一共振峰频谱包络;
对每一个非周期激励信号进行平滑处理和非线性处理,得到N个第一非周期激励信号。
在又一个优选实施例中,所述对每一个基音频率进行平滑处理、非线性处理和调频处理,得到N个第一基音频率,具体包括:
将每一个基音频率与该基音频率相邻的基音频率进行均值计算,得到N个平滑处理后的基音频率;
基于三角函数算法或指数函数算法,对每一个平滑处理后的基音频率进行非线性处理,获得N个非线性处理后的基音频率;
以预设的频率范围为参考,将每一个非线性处理后的基音频率映射到所述频率范围内,得到N个第一基音频率。
具体地,将每一个基音频率与该基音频率相邻的随机个第一基音频率进行均值计算(可以与水平方向左右两侧的第一基音频率进行均值计算,也可以是与水平方向右侧的第一基音频率进行均值计算,这里不作具体限定),得到N个平滑处理后的基音频率,通过平滑处理,能够确保变声后的语音信号与原语音信号有不可修复的差异,提高用户的隐私保护;基于三角函数算法或指数函数算法,对每一个平滑处理后的基音频率进行非线性处理,获得N个非线性处理后的基音频率;进一步确保变声后的语音信号与原语音信号有不可修复的差异,提高用户的隐私保护;以预设的频率范围为参考,将每一个非线性处理后的基音频率映射到所述频率范围内,使得变声后的语音信号在高音上趋同,无论原声是男声还是女声,输出的都是预定的音效,加大变声后的语音信号的复原难度。这里的频率范围可根据实际情况自行设定,这里不作具体的限定。可见,本发明对第一基音频率进行平滑处理、非线性处理和调频处理,改变了原有的声音特征,加大复原难度,提高用户的隐私保护。
在又一个优选实施例中,所述对每一个共振峰频谱包络进行移动处理和平滑处理,得到N个第一共振峰频谱包络,具体包括:
将每一个共振峰频谱包络循环移动N个单位,获得N个移动处理后的共振峰频谱包络;
对每一个移动处理后的共振峰频谱包络与该移动处理后的共振峰频谱包络相邻的移动处理后的共振峰频谱包络进行均值计算,得到N个第一共振峰频谱包络。
具体地,每一个振峰频谱包络循环移动N个单位(可以是整体前移或后移,这里不作具体限定),使得语音音调发生了改变,增加复原难度,提高用户的隐私保护;接着对每一个移动处理后的共振峰频谱包络与该移动处理后的共振峰频谱包络相邻的移动处理后的共振峰频谱包络进行均值计算,其原理和效果与基音频率的平滑处理一样,这里不再赘述。
在又一个优选实施例中,所述对每一个非周期激励信号进行平滑处理和非线性处理,得到N个第一非周期激励信号,具体包括:
将每一个非周期激励信号与该非周期激励信号相邻的非周期激励信号进行均值计算,得到N个平滑处理后的非周期激励信号;
基于三角函数算法或指数函数算法,对每一个平滑处理后的非周期激励信号进行非线性处理,获得N个第一非周期激励信号。
具体地,将每一个非周期激励信号与该非周期激励信号相邻的非周期激励信号进行均值计算,得到N个平滑处理后的非周期激励信号;基于三角函数算法或指数函数算法,对每一个平滑处理后的非周期激励信号进行非线性处理,获得N个第一非周期激励信号,增大变声后的语音信号的复原难度,提高用户的隐私保护。
本发明实施例还提供一种语音信号处理装置,能够实现上述任一实施例所述的语音信号处理方法的所有流程,装置中的各个模块、单元的作用以及实现的技术效果分别与上述实施例所述的语音信号处理方法的作用以及实现的技术相关对应相同,这里不再赘述。
参见图2所示,是本发明提供的一种语音信号处理装置的一个优选实施例的结构框图,装置包括:
语音特征提取模块11,用于获取语音片段中的N个语音特征;其中,N>0;
变换处理模块12,用于对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征;
分块模块13,用于将N个第一语音特征划分为K个语音特征块;其中,语音特征块包含若干个第一语音特征,N≥K>0;
调整处理模块14,用于分别对每一个语音特征块中的第一语音特征进行调整处理,获得N个第二语音特征;其中,所述调整处理为从第k个语音特征块中截取部分第一语音特征,或者根据第k个语音特征块中的第一语音特征填充新的语音特征;其中,K≥k>0;
合成模块15,用于将N个第二语音特征输入至预设的声码器中,合成变声后的语音信号。
优选地,所述语音特征提取模块11,包括:
分帧单元,用于按照预设的帧长度对所述语音片段进行分帧,获得N个帧信号;
基音频率提取单元,用于基于DIO算法提取每一个帧信号中的基音频率,获得N个基音频率;
共振峰频谱包络提取单元,用于基于CheapTrick算法提取每一个帧信号中的共振峰频谱包络,获得N个共振峰频谱包络;
非周期激励信号提取单元,用于基于PLATINUM算法提取每一个帧信号中的非周期激励信号,获得N个非周期激励信号。
优选地,变换处理模块12具体包括:
基音频率处理单元,用于对每一个基音频率进行平滑处理、非线性处理和调频处理,得到N个第一基音频率;
共振峰频谱包络处理单元,用于对每一个共振峰频谱包络进行移动处理和平滑处理,得到N个第一共振峰频谱包络;
非周期激励信号处理单元,用于对每一个非周期激励信号进行平滑处理和非线性处理,得到N个第一非周期激励信号。
优选地,基音频率处理单元具体用于:
将每一个基音频率与该基音频率相邻的基音频率进行均值计算,得到N个平滑处理后的基音频率;
基于三角函数算法或指数函数算法,对每一个平滑处理后的基音频率进行非线性处理,获得N个非线性处理后的基音频率;
以预设的频率范围为参考,将每一个非线性处理后的基音频率映射到所述频率范围内,得到N个第一基音频率。
优选地,共振峰频谱包络处理单元具体用于:
将每一个共振峰频谱包络循环移动N个单位,获得N个移动处理后的共振峰频谱包络;
对每一个移动处理后的共振峰频谱包络与该移动处理后的共振峰频谱包络相邻的移动处理后的共振峰频谱包络进行均值计算,得到N个第一共振峰频谱包络。
优选地,非周期激励信号处理单元,具体用于:
将每一个非周期激励信号与该非周期激励信号相邻的非周期激励信号进行均值计算,得到N个平滑处理后的非周期激励信号;
基于三角函数算法或指数函数算法,对每一个平滑处理后的非周期激励信号进行非线性处理,获得N个第一非周期激励信号。
本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行上述任一项所述的语音信号处理方法。
本发明实施例还提供了一种终端设备,参见图3所示,是本发明提供的一种终端设备的一个优选实施例的结构框图,所示终端设备包括处理器10、存储器20以及存储在所述存储器20中且被配置为由所述处理器10执行的计算机程序,所述处理器10在执行所述计算机程序时实现上述任一实施例所述的语音信号处理方法。
优选地,所述计算机程序可以被分割成一个或多个模块/单元(如计算机程序1、计算机程序2、······),所述一个或者多个模块/单元被存储在所述存储器20中,并由所述处理器10执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述终端设备中的执行过程。
所述处理器10可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,通用处理器可以是微处理器,或者所述处理器10也可以是任何常规的处理器,所述处理器10是所述终端设备的控制中心,利用各种接口和线路连接所述终端设备的各个部分。
所述存储器20主要包括程序存储区和数据存储区,其中,程序存储区可存储操作系统、至少一个功能所需的应用程序等,数据存储区可存储相关数据等。此外,所述存储器20可以是高速随机存取存储器,还可以是非易失性存储器,例如插接式硬盘,智能存储卡(Smart Media Card,SMC)、安全数字(Secure Digital,SD)卡和闪存卡(Flash Card)等,或所述存储器20也可以是其他易失性固态存储器件。
需要说明的是,上述终端设备可包括,但不仅限于,处理器、存储器,本领域技术人员可以理解,图3结构框图仅仅是上述终端设备的示例,并不构成对终端设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件。
综上,本发明的语音信号处理方法、装置、存储介质及终端设备相比于现有的语音处理方法,具有如下有益效果:
(1)本发明将N个第一语音特征划分为K个语音特征块,然后对语音特征块中的第一语音特征进行调整处理改变了用户的说话节奏,使得变声后的语音信号和原来的语音信号在说话节奏上有很大的差异,从而避免识别出用户身份,且本发明的调整处理无单一规律,无法根据通过同一参数将变声后的语音信号逆变回来,进一步加强用户的隐私保护。
(2)对每一个基音频率进行平滑处理、非线性处理和调频处理;对每一个共振峰频谱包络进行移动处理和平滑处理;对每一个非周期激励信号进行平滑处理和非线性处理;增大变声后的语音信号的复原难度,提高用户的隐私保护。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。