一种同时识别人声和非人声的装置及方法
文献发布时间:2023-06-19 09:29:07
技术领域
本发明属于语音智能识别技术领域,具体涉及一种同时识别人声和非人声的装置及方法。
背景技术
目前基于语音交互的产品大多集中于人声的识别或者说集中于声音信号中某一种类型信号的识别,但语音识别本身绝不仅仅限于人声识别,语音本身就是多源复杂信号。随着语音识别的快速落地,也催生出更多种类需求的产品。如何同时识别人声和非人声,能够将多源信息进行有效利用,丰富产品的实用性,将成为未来语音识别发展的一种趋势。
人声语音识别主要有以下几个问题:1)语音信息量大。语音模式不仅对不同的说话人不同,对同一说话人也是不同的,例如,一个说话人在随意说话和认真说话时的语音信息是不同的。一个人的说话方式随着时间变化。2)语音的模糊性。说话者在讲话时,不同的词可能听起来是相似的。这在英语和汉语中常见。3)单个字母或词、字的语音特性受上下文的影响,以致改变了重音、音调、音量和发音速度等。4)环境噪声和干扰对语音识别有严重影响,致使识别率低。受以上因素的影响,在人声识别测试中,各使用者或评价者之间很难在识别率上达成一致。
而非人声的语音识别主要有以下问题:1)采集数据受限。非人声类型繁多且特定环境及场所采集受限,例如鼾声、地震预警声或小孩哭声等,语料数量将直接影响识别效果好坏。2)易受人声环境干扰。非人声类识别在人声为背景环境识别时,识别优劣直接受嘈杂度的影响。3)识别速度慢,人声和非人声同时识别时想要获得较为良好的效果可能需要两个及以上的模型同时进行识别,受端侧语音识别的硬件及内存限制,识别速度受限。由于上述原因,在非人声识别的测试中,如何获得良好的识别且受人声干预小是主要技术难点。
发明内容
为克服现有语料处理技术存在的缺陷,本发明公开了一种同时识别人声和非人声的装置及方法。
本发明所述同时识别人声和非人声的装置,包括声源输入单元及与其连接的特征提取单元,所述装置还包括N个识别模型和N个识别结果处理单元,每个识别模型连接有一个识别结果处理单元;所述N个识别模型由人声识别模型和非人声识别模型两种识别模型组成;N大于等于2;
所述N个识别模型的输入端均与所述特征提取单元的输出端连接,所述N个识别结果处理单元的输出端均与识别结果融合单元的输入端连接,
所述识别结果处理单元对全部识别模型的输出结果进行判断识别为人声或非人声;
所述装置还包括识别结果融合单元,所述融合单元的作用是根据人声非人声识别结果处理单元的结果触发上层应用。
具体的,所述识别模型为以下形式:
第一部分P(Y|W)表示给定文本序列W*时出现对应语音的概率,即声学模型;第二部分表示文本序列W*的概率P(W),即语言模型,argmax函数的下标w表示组成文本序列的W*的字或词。
优选的,所述识别结果处理单元的判断方式具体为:
对人声识别,计算N个识别模型输出的N帧解码结果的N帧平均概率和N帧累计概率,N帧平均概率达到人声的指定平均阈值且N帧累计概率达到人声的指定累计阈值,则输出人声识别结果;
对非人声识别,计算非人声识别模型的N帧解码结果的N帧平均概率和N帧累计概率,N帧平均概率达到非人声的指定平均阈值且N帧累计概率达到非人声的指定累计阈值,则输出非人声识别结果;
其中,N帧结果的平均值达到指定平均阈值P(mean),即符合式(4),
且N帧结果的累计值达到指定累计阈值P(acc),即符合式(5);
P(i)表示第i帧的概率。
优选的,所述人声识别模型采用以下方法训练:
准备人声语料、非人声语料、多种非目标人声及非人声的噪声语料以提取神经网络训练的特征;
其中训练的特征分为关键特征及非关键特征,将人声特征标注为对应的文本作为人声神经网络输入的关键特征;
选择任意部分非人声特征和多种非目标人声及非人声的噪声特征标注为噪声作为人声神经网络输入的非关键特征;
其中非关键特征与关键特征的数据量之比不超过1:3;
将关键特征及非关键特征作为人声声学模型训练的所有输入,进行神经网络训练输出人声识别模型。
优选的,所述非人声识别模型采用以下方法训练:
将非人声特征标注为对应的文本作为非人声神经网络输入的关键特征,选择任意部分人声特征和多种非目标人声及非人声的噪声特征标注为噪声作为非人声神经网络输入的非关键特征;
其中非关键特征与关键特征的数据量之比不超过1:3;
将关键非人声特征和非关键噪声特征作为非人声声学模型训练的所有输入,进行神经网络训练输出非人声声学模型。
本发明还公开了一种同时识别人声和非人声的方法,包括如下步骤:
对输入的声音信号进行预处理;
预处理的声音信号提取声学特征信号;
特征信号同时输入由人声识别模型和非人声识别模型两种识别模型组成的N个识别模型;
N个识别模型将识别结果分别输入N个识别结果处理单元,
识别结果处理单元对各自识别模型的输出结果进行判断识别为人声或非人声。
优选的,所述识别结果处理单元的判断方式具体为:
对人声识别,计算N个识别模型输出的N帧解码结果的N帧平均概率和N帧累计概率,N帧平均概率达到人声的指定平均阈值且N帧累计概率达到人声的指定累计阈值,则输出人声识别结果;
对非人声识别,计算非人声识别模型的N帧解码结果的N帧平均概率和N帧累计概率,N帧平均概率达到非人声的指定平均阈值且N帧累计概率达到非人声的指定累计阈值,则输出非人声识别结果;
其中,N帧结果的平均值达到指定平均阈值P(mean),即符合式(4),
且N帧结果的累计值达到指定累计阈值P(acc),即符合式(5);
P(i)表示第i帧的概率。
优选的,所述预处理包括以下处理方式:进行端点检测找到语音信号的起始点和结束点;通过预加重对语音的高频信号进行加重去除口唇辐射的影响;分帧将音频处理为具有短时平稳性的信号并对分帧后各个短段信号的中心片段进行加窗强调操作。
优选的,所述提取声学特征信号的方式为MFCC、LPC、PLP、LPCC中的任意一种。
本发明可以解决复杂声音环境下对声源中的多源复杂信号同时分别识别,即同时识别人声及非人声的技术问题,且针对非特定说话人识别效果良好;人声音频识别受目标非人声环境影响小;非人声音频通过扩展语料等方法使得整体识别效果良好,同时受人声环境影响小;在保证人声和非人声识别效果的情况下,识别响应速度快,反应灵敏。
附图说明
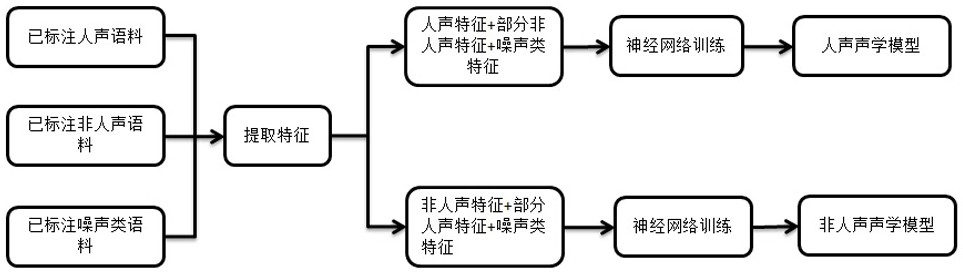
图1为本发明所述训练人声和非人声声学模型一种具体实施方式示意图;
图2为本发明所述同时识别人声和非人声装置的一种具体实施方式示意图。
具体实施方式
下面对本发明的具体实施方式作进一步的详细说明。
本发明所述同时识别人声和非人声的装置,包括声源输入单元及与其连接的特征提取单元,所述装置还包括N个识别模型和N个识别结果处理单元,每个识别模型连接有一个识别结果处理单元;所述N个识别模型由人声识别模型和非人声识别模型两种识别模型组成;N大于等于2;
所述N个识别模型的输入端均与所述特征提取单元的输出端连接,所述N个识别结果处理单元的输出端均与识别结果融合单元的输入端连接,
所述识别结果处理单元对全部识别模型的输出结果进行判断识别为人声或非人声;
所述装置还包括识别结果融合单元,所述融合单元的作用是根据人声非人声识别结果处理单元的结果触发上层应用
本发明提出的方法是对声源中的多源复杂信号同时分别识别,人声信号识别转变为相应的文本或命令,指定类型的非人声信号则转变成自定义的输出,装置主要包括人声非人声神经网络训练模块和人声非人声联合识别模块。
人声非人声神经网络训练模块主要是利用神经网络架构输入已标注的语料训练输出声学模型(AM),可对未知标注的声源输入进行发音概率的预测统计并输出统计结果,同时结合语言模型(LM)进行维特比解码,获取最优路径输出文本及对应联合概率。
典型的语音识别概率模型如公式(1)所示,
公式(1)中W*表示文本序列,Y表示输入的语音信号,P(W|Y)表示利用给定未知标注语音的情况下,获取语音对应的最大可能性的文本序列。argmax是对函数求参数(集合)的函数, argmax函数的下标w表示组成文本序列的W*的字或词。
根据贝叶斯准则可以得到公式(2),
其中公式(2)分母P(Y)表示该条音频出现的概率,在给定输入时可以将其概率视为P(Y)=1,进而得到公式(3)。
公式(3)中第一部分P(Y|W)表示给定文本序列出现对应语音的概率,即声学模型(AM);第二部分表示文本序列的概率P(W),即语言模型(LM)。在实际应用中,声学模型AM由投入大规模语料经过神经网络训练得到,语言模型LM即利用预设实际使用场景中会出现的词条进行建模,两者通过解码结合得到有效的识别结果。
为训练出识别误识别效果均衡的声学模型,需控制语料的分布,训练结构的典型过程图如图1。
准备人声语料、非人声语料、多种非目标人声及非人声的噪声语料以提取神经网络训练的特征;其中分为关键特征及非关键特征,将人声特征标注为对应的文本作为人声神经网络输入的关键特征,部分非人声特征和多种非目标人声及非人声的噪声特征标注为噪声作为人声神经网络输入的非关键特征。将关键人声特征和非关键噪声特征作为人声声学模型训练的所有输入,进行神经网络训练输出人声声学模型。将非人声特征标注为对应的文本作为非人声神经网络输入的关键特征,部分人声特征和多种非目标人声及非人声的噪声特征标注为噪声作为非人声神经网络输入的非关键特征,其中非关键特征:关键特征的数据量之比不超过1:3。将关键非人声特征和非关键噪声特征作为非人声声学模型训练的所有输入,其中非关键特征:关键特征的数据量之比不超过1:3,进行神经网络训练输出非人声声学模型。
为减少目标非人声的声音信号在人声声学模型识别过程中误识别为人声的情况,将部分非人声特征作为噪声训练;随机选择非人声特征中不包含明显人声的语料作为人声的噪声。
本发明所述同时识别人声和非人声的装置包括声源输入单元、特征提取单元、模型识别单元、识别结果处理单元、识别结果融合单元,一个具体的结构原理图如图2所示。
其中声源输入单元对实时输入的可能包括人声、非人声和噪音的多源声音复杂信号进行必要的预处理。
所述预处理一般包括以下处理: 进行端点检测找到语音信号的起始点和结束点、通过预加重对语音的高频信号进行加重去除口唇辐射的影响、分帧将音频处理为具有短时平稳性的信号并对分帧后各个短段信号的中心片段进行加窗强调操作。
特征提取单元对预处理过后的语音信号进行特征的提取,特征提取方式类型不限于MFCC(梅尔频率倒谱系数,Mel Frequency Cepstrum Coefficient)、LPC(LinearPrediction Coefficient线性预测系数)、PLP(Perceptual Linear Predict ive,感知线性预测) 、LPCC(线性预测倒谱系数,Linear Prediction Cepstrum Coefficient)等方式;
模型识别单元包括N个识别模型(N≥2),分为人声识别模型及非人声识别模型两类,例如同如图2所示的具体实施方式中,包括1个人声识别模型和n 个非人声识别模型。对应的,也包括1个人声的识别结果处理单元和n 个非人声的识别结果处理单元。
每个识别模型从特征提取单元接收输入同样的特征信号,并行分别对每帧特征进行识别,人声声学模型结合语言模型进行识别解码得到识别内容及对应概率计算,非人声声学模型可结合语言模型进行解码得到识别内容及对应概率计算,也可直接利用其声学模型的最优输出作为识别内容,同时以多帧结果的平均概率和累计概率作为判断依据,这种方式略去解码步骤,节省了运算资源。
识别结果处理单元分为N 个处理单元(N≥2),与模型识别单元一一对应连接且不同的识别结果处理单元之间相互不相关,各个处理单元对其自身连接的模型识别单元输出的每帧识别结果进行独立的处理判断。
各个识别结果处理单元对人声识别和非人声识别同时进行判断,
对人声识别,计算N个识别模型输出的N帧解码结果的N帧平均概率和N帧累计概率,N帧平均概率达到人声的指定平均阈值且N帧累计概率达到人声的指定累计阈值,则输出人声识别结果。
对非人声识别,计算非人声识别模型的N帧解码结果的N帧平均概率和N帧累计概率,N帧平均概率达到非人声的指定平均阈值且N帧累计概率达到非人声的指定累计阈值,则输出非人声识别结果。
需要说明,每个识别结果处理单元仅处理各自对应的识别模型输出的结果,例如2个人声的识别结果处理单元,一个识别英文命令词一个识别中文命令词;两个非人声的识别结果处理单元,一个识别婴儿哭声,一个识别地震预警声,各自输出识别结果,但对各个识别结果的值进行统一计算平均值和累计值。
多帧结果的平均值即N帧平均概率达到指定平均阈值P(mean),即符合式(4),
且多帧结果的累计值即N帧累计概率达到指定累计阈值P(acc),即符合式(5);
P(i)表示第i帧的概率,则输出非人声识别结果。
识别结果融合单元根据人声非人声识别结果处理单元的结果触发对应的上层应用,例如,可能存在以下几种结果:人声已识别且非人声已识别、人声已识别但非人声未识别、人声未识别但非人声已识别、人声未识别且非人声未识别。
例如在人声已识别且非人声已识别的情况下,可由识别结果融合单元触发上层应用,通过判断两种识别的优先级以及是否冲突,可以选择优先响应人声非人声识别中的一种,例如识别到人声结果为“关闭灯光”、非人声识别结果为“Earthquake-warningA”(地震预警声A),则优先响应非人声识别结果进行灯光闪烁。
为解决多源复杂声音信号中人声及非人声的识别在于终端产品上同时识别资源有限及响应速度慢的问题,本发明通过在识别模型训练的过程中,调整语料比例及通过训练参数缩小声学模型,声学模型越小,识别运算所需的资源越少,以此来实现并行运行多个识别模型的同时降低终端产品上资源使用率,并且有效地提升了识别速度。
为达到人声识别与非人声识别效果良好,利于采集语料进行多种类型语料的扩充且控制模型参数,达到了控制识别模型大小且识别效果良好;为解决人声与非人声模型在识别过程中易受复杂环境中非目标音的干扰问题,在识别结果处理过程中利用多帧语音信号的识别结果进行联合判断,设置一定门限,很大程度的降低了非目标环境音对目标声识别的干扰。
目标非人声不存在时人声测试识别效果正常,如“智能管家”“打开空调”等等;循环播放目标非人声时,目标非人声识别效果良好,如“Earthquake-warningA”“Earthquake-warningB”;循环播放目标非人声,且同时进行人声测试,人声及非人声识别效果均良好。
本发明可以解决复杂声音环境下对声源中的多源复杂信号同时分别识别,即同时识别人声及非人声的技术问题,且针对非特定说话人识别效果良好;人声音频识别受目标非人声环境影响小;非人声音频通过扩展语料等方法使得整体识别效果良好,同时受人声环境影响小;在保证人声和非人声识别效果的情况下,识别响应速度快,反应灵敏。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。