缓存结构、工作量证明运算芯片电路及其数据调用方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明涉及集成电路技术领域,特别是指一种缓存结构、工作量证明运算芯片电路及其数据调用方法。
背景技术
工作量证明(Proof of Work,简称POW)是以太币等主流加密数字币采用的一种共识机制,其基本特征是需要进行大量的哈希运算,在特定难度值条件下找到符合条件的哈希值。但是,以ETHASH算法为核心的加密数字币在工作量证明过程中需要一个大于1GB的数据集,并需要对该数据集进行频繁访问。
传统方法是在计算芯片外使用独立的外存来存储该数据集,但是受限于带宽,该方法的性能较低。为了提升带宽,如图1所示,现有的结构一般采用计算单元与路由单元连接,路由单元再通过交叉开关与仲裁单元连接,仲裁单元再分别与存储单元连接。基于图1示出的结构,计算单元下发计算请求的原理如下:
如图1所示,由于一个计算单元连接一个路由单元,因此,每个计算单元发出的计算请求传递至与其相连接的路由单元,再由该路由单元通过交叉开关传递至各仲裁单元,直到该计算单元发出的计算请求通过某仲裁单元仲裁后,得以发送至相应的存储单元执行该请求,该计算单元才可以向其所连接的路由单元发出下一个计算请求。
图1所示结构及上述计算请求的发送机制,导致当多个计算单元发出的访问地址相同时,只有一个计算单元的请求被仲裁单元接收,导致访问效率较低。
发明内容
有鉴于此,本发明的主要目的在于提供一种缓存结构、工作量证明运算芯片电路及其数据调用方法,以能提高工作量证明运算芯片数据的访问效率。
本发明提供的一种缓存结构,包括:
多个第一缓存区、至少一个请求筛选单元和多个第二缓存区;
所述第一缓存区用于缓存接收到的计算请求;
所述请求筛选单元用于筛选出所述计算请求中请求访问的地址不同的计算请求;
所述第二缓存区用于缓存经所述请求筛选单元筛选出的计算请求。
由上,通过设置第一缓存区,可以缓存来自同一计算单元的多个计算请求,将该多个计算请求再通过请求筛选单元以获得请求访问的地址不同的多个计算请求,并将筛选出的多个计算请求缓存至第二缓存区,该结构可以同时缓存来自同一计算单元的访问路径不冲突的多个计算请求,提高了数据访问效率。
作为第一方面的一种实现方式,所述第一缓存区具体用于:以先入先存的规则对接收到的计算请求进行缓存。
作为第一方面的一种实现方式,所述第二缓存区具体用于:根据先入先存的规则对经所述请求筛选单元筛选出的计算请求进行缓存。
由上,通过先入先存的规则,可以有序的将相应计算请求缓存至第一缓存区和第二缓存区。
一种包括上述缓存结构的工作量证明运算芯片电路,其特征在于,所述电路包括:依次连接的计算单元、缓存结构、路由单元、仲裁单元和存储单元;
所述计算单元用于根据接收到的计算任务向所述缓存结构发送计算请求;
所述路由单元用于确定经所述缓存结构筛选出的计算请求的访问路径,并将所述计算请求的访问路径发送至仲裁单元;
所述仲裁单元用于对接收到的计算请求的访问路径进行仲裁,若所述计算请求的访问路径满足仲裁条件,则通过所述访问路径,将所述计算请求发送至相应存储单元调用相关数据;
所述存储单元用于存储所述工作量证明运算芯片的数据集。
作为第二方面的一种实现方式,所述计算单元、缓存结构、路由单元、仲裁单元和存储单元分别为多个,其中:
各计算单元、各缓存结构和各路由单元一一对应连接;
各仲裁单元和各存储单元一一对应连接;
各路由单元与各仲裁单元为全连接。
作为第二方面的一种实现方式,所述路由单元和所述仲裁单元通过交叉开关连接。
由上,在工作量证明运算芯片电路中添加缓存结构,可以提高整个交叉开关的效率,提高芯片数据的访问性能。
一所述工作量证明运算芯片电路的数据调用方法,包括:
根据计算任务发出计算请求;
筛选出所述计算请求中请求访问的路径不同的计算请求;
根据预先设置的路由表确定各个所述请求访问的路径不同的计算请求的访问路径,并对确定出的计算请求的访问路径进行仲裁;
分别调用通过仲裁的计算请求所需的数据。
综上,本发明可以解决下述问题:提高数据的访问效率。
附图说明
图1为现有技术中工作量证明运算芯片的结构示意图;
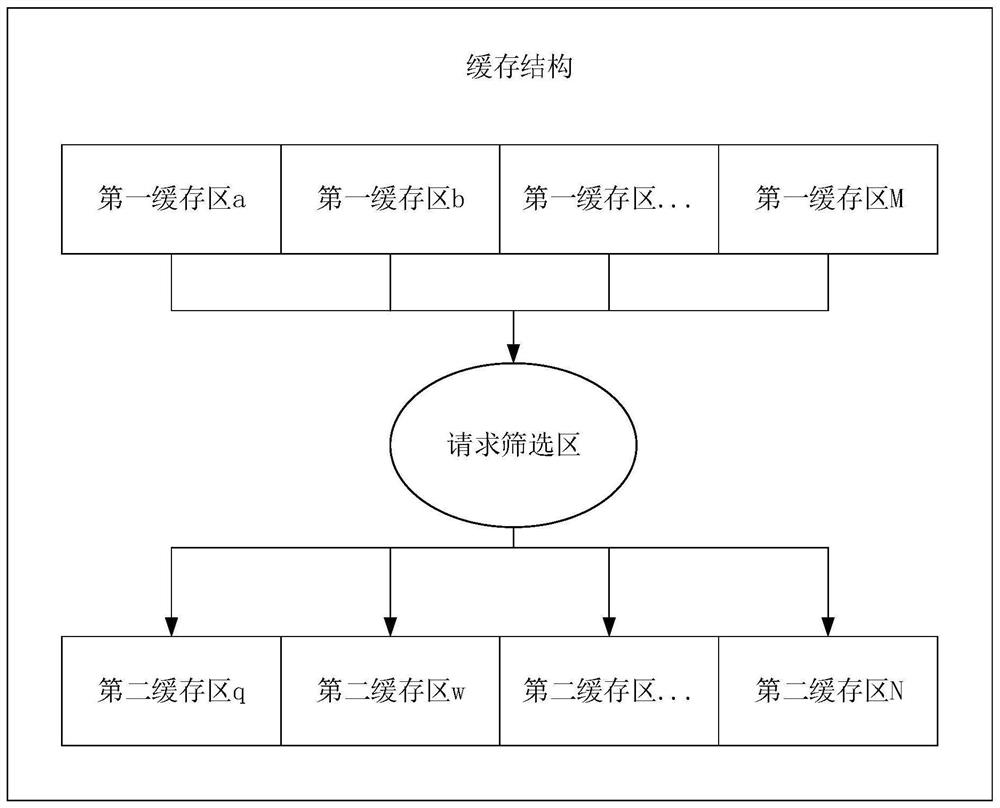
图2为本申请实施例提供的一种缓存结构的结构示意图;
图3为本申请实施例提供的工作量证明运算芯片电路图。
具体实施方式
为了便于理解本申请,下面将参照相关附图对本申请进行更全面的描述。附图中给出了本申请的首选实施例。但是,本申请可以以许多不同的形式来实现,并不局限于本文所描述的实施例。相反地,提供这些实施例的目的是使本申请的公开内容更加透彻全面。
在以下的描述中,所涉及的术语“第一\第二\第三等”或模块A、模块B、模块C等,仅用于区别类似的对象,不代表针对对象的特定排序,可以理解地,在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本申请实施例能够以除了在这里图示或描述的以外的顺序实施。
在以下的描述中,所涉及的表示步骤的标号,如S100、S200……等,并不表示一定会按此步骤执行,在允许的情况下可以互换前后步骤的顺序,或同时执行。
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中使用的属于只是为了描述具体的实施例的目的,不是旨在限制本申请。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
如图2所示,本申请的其中一个实施例提供一种缓存结构,该缓存结构包括:多个第一缓存区、至少一个请求筛选单元和多个第二缓存区。请求筛选单元的输入端与各个第一缓存区的输出端连接,请求筛选单元的输出端与各个第二缓存区的输入端连接。
第一缓存区用于缓存接收到的计算请求,并将所述计算请求发送至所述请求筛选单元。其中,第一缓存区缓存接收到的计算请求时可以根据预设的规则进行缓存,例如,该预设规则为根据接收计算请求的先后顺序,将计算请求按缓存地址从小到大的顺序依次进行缓存。例如:图2中第一缓存区a的缓存地址为0,第一缓存区b的缓存地址为1,以此类推,第一缓存区M的缓存地址为x,那么,当缓存结构接收到计算请求时,将接收到的第一个计算请求缓存在缓存地址为0的第一缓存区a中,将接收到的第二个计算请求缓存在缓存地址为1的第一缓存区b中,以此类推,直至缓存完所有计算请求或者直至第一缓存区全部内存被占用。
请求筛选单元用于从各第一缓存区中筛选出各计算请求中请求访问的地址不同的计算请求,并将筛选出的计算请求发送至所述第二缓存区。例如:请求筛选单元中接收到的第一个计算请求所要访问的地址为1,请求筛选单元中接收到的第二个计算请求所要访问的地址与第一个计算请求所要访问的地址相同,计算请求区中接收到第三个计算请求所要访问的地址为2,此时,筛选出计算请求中请求访问的地址不同的计算请求,即第一个计算请求和第三个计算请求,并同时将第一个计算请求和第三个计算请求发送至第二缓存区。相应的,对应第一个计算请求和第三个计算请求的两个第一缓存区会释放相应的存储资源。其中,对于请求访问的地址相同的计算请求筛选时,如前所述的先后顺序机制,使用先进先出的策略进行筛选,即上述例子中访问的地址均为1的第一、第二个计算请求中,第一个计算请求时间上先被存入第一缓存区,因此筛选时优先被选中,同样的对于后续的计算请求一样采用该策略进行筛选。
第二缓存区用于缓存经所述请求筛选单元筛选出的计算请求。该缓存方式与第一缓存区缓存计算请求的方式相同,故不再进行赘述。
在本实施例中,第一缓存区、请求筛选单元和第二缓存区的数量可以各自进行调整,以达到使用工况中资源和效率的平衡。即:当使用工况要求的效率较高时,此时可以设置较多的第一缓存区、请求筛选单元和第二缓存区,当使用工况要求的效率不高且受成本限制时,此时可以设置较少的第一缓存区、请求筛选单元和第二缓存区。
如图3所示,本申请的另一实施例提供一种包括上述缓存结构的工作量证明运算芯片电路,该电路包括:依次连接的计算单元、缓存结构、路由单元、仲裁单元和存储单元。
计算单元用于根据接收到的计算任务向缓存结构发送计算请求。该计算请求的数量此处不做限制。
缓存结构用于缓存并筛选计算单元发送的计算请求,具体缓存规则与筛选规则与上一实施例相同,故此处不再对其进行赘述。
路由单元用于确定经缓存结构筛选出的计算请求的访问路径,并将该计算请求的访问路径发送至仲裁单元;
仲裁单元用于对接收到的计算请求的访问路径进行仲裁,若该计算请求的访问路径满足仲裁条件,则通过该访问路径,将该计算请求发送至相应存储单元调用相关数据。
存储单元用于存储工作量证明运算芯片的数据集。
此处以图3中第一计算单元发出三个计算请求为例,来说明本实施例中的工作量证明运算芯片电路的具体工作过程:
第一步,第一计算单元根据计算任务发出第一计算请求、第二计算请求以及第三计算请求至与其相连的第一缓存结构;
第二步,第一缓存结构中的第一缓存区按照预设规则分别缓存第一计算请求、第二计算请求和第三计算请求;第一缓存结构中的请求筛选单元对第一计算请求、第二计算请求和第三计算请求的请求访问地址进行筛选,若第一个计算请求所要访问的地址为1、第二计算请求所要访问的地址也为1、第三计算请求所要访问的地址为2,则请求筛选单元同时将第一计算请求和第三计算请求发送至第一缓存结构中的第二缓存区,其缓存规则同样为上一实施例中的预设规则;
第三步,第一缓存结构中的第二缓存区将第一计算请求和第三计算请求发送至与第一缓存结构相连的第一路由单元,第一路由单元确定这两个计算请求的访问路径,并将这两个计算请求的访问路径通过交叉开关分别发送至图3所示的第一仲裁单元-第k仲裁单元中分别进行仲裁,假如第一计算请求的访问路径通过某仲裁单元的仲裁,则再由该仲裁单元将第一计算请求发送至其相连的存储单元中以调用相关数据。
由上可以看出,由于本实施例中工作量证明运算芯片增加了缓存结构,使每个路由单元可以同时发出多个计算请求,提高了整个芯片的工作效率。
结合图2和图3,下面提供一种本申请的实现方式:
首先,计算单元发出计算请求(该计算请求数量不做限制),该计算请求首先被缓存到缓存结构中的第一缓存区中空闲的缓存地址处,如果缓存结构的第一缓存区中缓存地址为0处为空,则第一个计算请求被缓存至第一缓存区中缓存地址为0处,如果缓存地址为0处中已经存在计算请求,则第一个计算请求被缓存至第一缓存区中缓存地址为1处,以此类推。计算单元可以持续发送计算请求直至缓存结构的第一缓存区满。
其次,缓存结构中的请求筛选单元从缓存结构中的第一缓存区的所有计算请求中选择出所有地址不冲突的计算请求填入缓存结构中第二缓存区,填充方式与上述填充方式相同。
然后,缓存结构中第二缓存区的计算请求会同时通过路由单元参与第一仲裁单元-第k仲裁单元的仲裁,如果计算请求没有满足仲裁条件,则没有计算请求通过第一仲裁单元-第k仲裁单元发送至存储单元,如果有一个计算请求满足仲裁条件,则有一个计算请求通过第一仲裁单元-第k仲裁单元中的一个发送至存储单元,如果有多个计算请求满足仲裁条件,则有多个计算请求通过仲裁单元第一仲裁单元-第k仲裁单元发送至存储单元。
下面,验证本申请所提供的缓存结构的效率:
例如,计算单元的数量为32,存储单元的数量为32。若使用图1所示的芯片电路结构,则当计算单元发出计算请求至路由单元时,路由单元将该计算请求发送至仲裁单元进行仲裁,如果该计算请求未通过仲裁,则该计算请求会占用路由单元的位置导致计算单元无法继续发出新的计算请求,直至该计算请求通过仲裁单元的仲裁,计算单元才能发出下一个计算请求。如果计算单元发出的计算请求的地址是完全随机或者接近随机,则该结构的效率为:
当使用本申请提供的缓存结构时,计算单元发出一个计算请求后,该计算请求首先被缓存至缓存结构中,此时计算单元可以继续发送计算请求,直到缓存结构的第一缓存区被缓存满。同时,缓存结构的一个或多个请求可以同时经过路由单元发送至仲裁单元进行仲裁。在该结构下,同样的,计算单元的数量为32,存储单元的数量为32:
若缓存结构中第一缓存区的数量为4,第二缓存区的数量为4,则该结构的效率可以达到78%。
若缓存结构中第一缓存区的数量为4,第二缓存区的数量为8,则该结构的效率可以达到90%。
若缓存结构中第一缓存区的数量为8,第二缓存区的数量为12,则该结构的效率可以达到94%。
若缓存结构中第一缓存区的数量为12,第二缓存区的数量为12,则该结构的效率可以达到95%。
在实际应用中,计算单元、存储单元、缓存结构中的第一缓存区的数量、第二缓存区的数量均可以根据实际需求进行设置。
由上,本申请提供的缓存结构对提升访问效率有显著效果。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 缓存结构、工作量证明运算芯片电路及其数据调用方法
- 缓存结构、工作量证明运算芯片电路及其数据调用方法