文件数据源入库解析接入方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及数据库技术领域,尤其涉及一种文件数据源入库解析接入方法、装置、设备及存储介质。
背景技术
目前,把数据从源数据库中转移到目的数据库中进行存储或计算时,需要使用数据接入工具来进行转移。当使用多种源数据库时,就需要使用多种接入工具将多种源数据库中的数据接入至目标数据库。
传统技术中,目标数据库从不同的源数据库中接入数据时,其根据不同的数据库以及实时还是离线的情况,可以选择使用不同的接入工具来分别接入数据。例如:使用DataX和Sqoop等数据接入工具,可以离线接入Mysql、Oracle等数据库中的数据;使用Canal等数据接入工具可以接入实时增量数据等。
但是上述数据接入方法在接入数据时,数据接入面临的业务场景较多,数据来源的方式种类均未知,另外,数据接入时可能存在数据量反复变化的情况,且用户对每个接入工具的配置信息非常熟悉,其对用户专业知识要求较高,用户操作体验不佳。
专利公开号为CN109669977A的中国专利公开了一种跨数据库的数据接入方法、装置、计算机设备及存储介质,但该专利技术方案在面临的业务场景较多,数据来源的方式种类均未知,数据接入时可能存在数据量反复变化等情况时,依旧不能得到很好的解决。
因此,如何提高多数据来源和数据量反复变化的数据接入的用户操作体验,是一个亟需解决的技术问题。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
发明内容
本发明的主要目的在于提供一种文件数据源入库解析接入方法、装置、设备及存储介质,旨在解决现有技术中存在的在面临的业务场景较多,数据来源的方式种类均未知,数据接入时可能存在数据量反复变化等情况时,数据接入效率低依旧不能很好解决的技术问题。
为实现上述目的,本发明提出文件数据源入库解析接入方法,包括以下步骤:
获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库;
利用所述待接入数据文件对应的设计器,根据所述待接入数据配置接入信息和处理信息;
利用所述待接入数据文件对应的执行器,根据所述配置接入信息和处理信息对所述待接入数据文件进行数据读取、数据处理和数据写入。
可选的,获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库步骤之前,还包括:
获取待接入数据文件并识别所述数据文件类型;
调用数据类型适配器,利用所述数据类型适配器将所述待接入数据文件转换为所需数据类型。
可选的,调用数据类型适配器,利用所述数据类型适配器将所述待接入数据文件转换为所需数据类型步骤,具体包括:
利用所述数据类型适配器,将所述待接入数据文件在包括Oracle、万里开源、DB2、Mysql、达梦、HBase、Hive或人大金仓中的任意两种类型之间进行转换。
可选的,获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库步骤,具体包括:
构建用以连接交互设备的设计器,以使所述设计器接收交互设备传输的配置接入信息和处理信息;
构建用以连接处理器和存储器的执行器,以使所述执行器调用所述处理器和存储器执行数据接入。
可选的,利用所述待接入数据文件对应的设计器,根据所述待接入数据配置接入信息和处理信息步骤,具体包括:
利用交互设备提供的可视化配置界面,通过可视化配置节点的自定义拖拉拽,配置所述待接入数据文件接入过程中的数据输入、数据处理和数据输出方式;
利用交互设备提供的申请单录入界面,通过填写申请单配置来源数据源、目标数据源和来源数据与目标数据的对应关系。
可选的,利用所述待接入数据文件对应的执行器,根据所述配置接入信息和处理信息对所述待接入数据文件进行数据读取、数据处理和数据写入步骤,具体包括:
采用可视化配置界面的后端执行器,对接入数据进行分批读取和处理,将处理后的数据输出;
采用默认执行器,并通过Kafka消息队列和分布式部署对待接入数据快速接入并进行读写分离,将处理后的数据输出;
采用个性化扩展执行器,对接入数据中的定制数据按其预设逻辑进行处理,进而将数据封装并写入Kafka队列后输出。
此外,为实现上述目的,本发明还提出一种文件数据源入库解析接入装置,所述文件数据源入库解析接入装置包括:
构建模块,用于获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库;
配置模块,用于利用所述待接入数据文件对应的设计器,根据所述待接入数据配置接入信息和处理信息;
执行模块,用于利用所述待接入数据文件对应的执行器,根据所述配置接入信息和处理信息对所述待接入数据文件进行数据读取、数据处理和数据写入。
此外,为实现上述目的,本发明还提出一种文件数据源入库解析接入设备,所述文件数据源入库解析接入设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的文件数据源入库解析接入程序,所述文件数据源入库解析接入程序被所述处理器执行时实现如上述的文件数据源入库解析接入方法的步骤。
此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有文件数据源入库解析接入程序,所述文件数据源入库解析接入程序被处理器执行时实现如上述的文件数据源入库解析接入方法的步骤。
本发明中,通过获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库;一方面,利用所述待接入数据文件对应的设计器,根据所述待接入数据配置接入信息和处理信息;另一方面,利用所述待接入数据文件对应的执行器,根据所述配置接入信息和处理信息对所述待接入数据文件进行数据读取、数据处理和数据写入。本发明所提供的方法采用了设计器与执行器分离,数据获取与数据入库分离,再加上Kafka消息中间件的方式进行实现。旨在解决现有技术中存在的在面临的业务场景较多,数据来源的方式种类均未知,数据接入时可能存在数据量反复变化等情况时,数据接入效率低依旧不能很好解决的技术问题。
附图说明
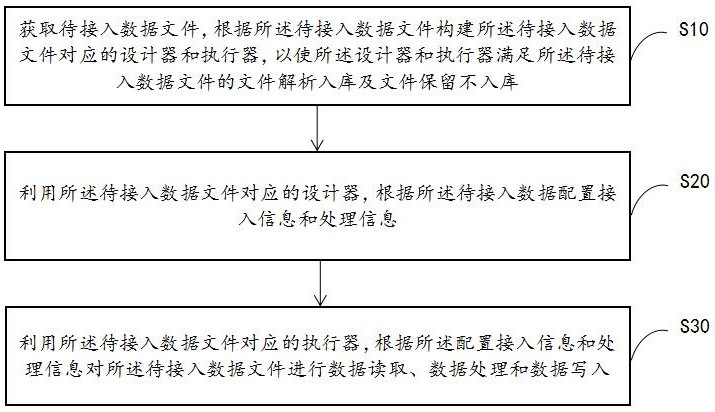
图1为本发明文件数据源入库解析接入方法第一实施例的流程示意图。
图2为本发明文件类型转换的流程示意图。
图3为本发明构建设计器和执行器的流程示意图。
图4为本发明设计器配置信息的流程示意图。
图5为本发明执行器接入数据的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明文件数据源入库解析接入方法第一实施例的流程示意图,提出本发明文件数据源入库解析接入方法第一实施例。
在本实施例中,文件数据源入库解析接入方法,包括以下步骤:
步骤S10:获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库;
步骤S20:利用所述待接入数据文件对应的设计器,根据所述待接入数据配置接入信息和处理信息;
步骤S30:利用所述待接入数据文件对应的执行器,根据所述配置接入信息和处理信息对所述待接入数据文件进行数据读取、数据处理和数据写入。
需要说明的是,参照图2,获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库步骤之前,还包括:
步骤A10:获取待接入数据文件并识别所述数据类型;
步骤A20:调用数据类型适配器,利用所述数据类型适配器将所述待接入数据文件转换为所需数据类型。
需要理解的是,调用数据类型适配器,利用所述数据类型适配器将所述待接入数据文件转换为所需数据类型步骤,具体包括:
利用所述数据类型适配器,将所述待接入数据文件在包括Oracle、万里开源、DB2、Mysql、达梦、HBase、Hive或人大金仓中的任意两种类型之间进行转换。
需要说明的是,参照图3,获取待接入数据文件,根据所述待接入数据文件构建所述待接入数据文件对应的设计器和执行器,以使所述设计器和执行器满足所述待接入数据文件的文件解析入库及文件保留不入库步骤,具体包括:
步骤S101:构建用以连接交互设备的设计器,以使所述设计器接收交互设备传输的配置接入信息和处理信息。
步骤S102:构建用以连接处理器和存储器的执行器,以使所述执行器调用所述处理器和存储器执行数据接入。
需要说明的是,参照图4,利用所述待接入数据文件对应的设计器,根据所述待接入数据配置接入信息和处理信息步骤,具体包括:
步骤S201:利用交互设备提供的可视化配置界面,通过可视化配置节点的自定义拖拉拽,配置所述待接入数据文件接入过程中的数据输入、数据处理和数据输出方式。
步骤S202:利用交互设备提供的申请单录入界面,通过填写申请单配置来源数据源、目标数据源和来源数据与目标数据的对应关系。
需要理解的是,对于可视化配置界面(Web-ETL):
WEB-ETL采用流程节点的方式设计,一条流程由多个流程节点组合而成。每个流程节点对应到不同的组件,从而实现相应的节点功能。
每一个流程环节只有一个特定功能,由多个组件连接在一起会形成一个链式的流程。每个流程环节只关注节点本身的处理过程配置,与上游节点或下游节点只有输入、输出内容的关系,因此可通过流程环节的不同组合,可以达到整个数据流程的自定义配置。通过平台提供的“输入源”“输出源”“处理”三大类节点完成复杂的清洗、转换、过滤、筛选等数据处理过程,节点可定制化扩展,每个节点只关注本身的业务所需属性以及输入、输出内容。
通过Web-ETL(可视化配置)创建的数据接入任务将通过Web-ETL的执行器进行数据接入处理。
需要理解的是,对于申请单录入界面:
接入申请单主要采用表单填写的方式,配置时选择来源数据源及数据表/文件/接口(输入源)、选择目标数据源及数据表(输出源)、配置来源数据与目标数据表的数据项对应关系、配置接入处理方式,保存后平台根据配置的内容及处理方式自动生成相应的数据接入任务。接入申请单不需要关注数据接入的中间处理过程,只需要明确输入、输出的内容以及数据项的对应关系即可完成配置。
通过接入申请单(表单)创建的数据接入任务可指定执行器进行数据接入处理。平台提供Web-ETL、默认执行器、登录验证执行器、其他自定义执行器等多种执行器。当选择“Web-ETL”时,将根据表单的配置内容,并通过Web-ETL提供的接口自动创建“Web-ETL” 流程任务。
需要说明的是,参照图5,利用所述待接入数据文件对应的执行器,根据所述配置接入信息和处理信息对所述待接入数据文件进行数据读取、数据处理和数据写入步骤,具体包括:
步骤S301:采用可视化配置界面的后端执行器,对接入数据进行分批读取和处理,将处理后的数据输出。
步骤S302:采用默认执行器,并通过Kafka消息队列和分布式部署对待接入数据快速接入并进行读写分离,将处理后的数据输出.
步骤S303:采用个性化扩展执行器,对接入数据中的定制数据按其预设逻辑进行处理,进而将数据封装并写入Kafka队列后输出。
需要理解的是,对于可视化配置界面的后端执行器:
通过Web-ETL可视化界面配置的数据接入任务,以及配置接入申请单时处理方式选择“Web-ETL”的数据接入任务将由Web-ETL后端执行器处理。数据接入按照配置的流程过程进行执行。
每条流程由Flow类进行表示,每一个流程环节(如表输入和表输出)由一个FlowLink类进行表示。每一个FlowLink类会记录该组件所需要的参数信息、所属组件(EtlComponent)和下一个组件的ID。
参数信息采用Json字符串的方式进行存储。
所属组件表示该FlowLink采用哪个组件来进行处理,不同的组件有不同的处理类来进行处理,功能主要在处理类中进行实现。如表输入组件,即实现数据库连接,并从指定数据表中读取数据;文件输入组件,即实现文件服务器连接,获取并解析文件。
下一个组件的ID用来将FlowLink串成一条完整的Flow。一条完整的流程包含一个输入源节点、N个数据转换节点(N>=0)、一个输出源节点。
输入源节点主要实现数据的读取。在数据读取时,组件类根据读取目标表的数据量分批获取数据,读取完成后将数据传递到下一组件节点,并开始读取下一批次数据,避免大批量一次性获取数据可能出现的内存溢出问题,提升数据处理性能。
数据转换节点主要实现数据的内容处理,如数据类型转换(Number->String、Date->String……)。在数据转换时,组件从上一节点的输出内容作为数据输入,通过本身的业务逻辑处理后输出给下一节点,每种类型的数据转换节点只做节点关注节点本身的业务逻辑。
输出源节点主要实现数据的入库保存。在数据存储时,组件获取上一节点的输出内容,根据节点配置的匹配关系及指定的目标数据库,将数据写入保存到数据表中。
需要理解的是,对于默认执行器:
在配置申请单时,可选择默认执行器进行数据接入。
在数据接入时,平台以任务调度服务为起点,调用设计器获取表单配置信息及对应的执行器。若执行器为默认执行器,则调用执行器并传入申请单ID。执行器执行以下步骤:
根据申请单ID获取申请单配置的参数内容。
根据申请单配置连接数据库获取接入数据。
封装处理数据,将数据写入Kafka队列中,内容包括目标库地址、目标表及数据内容。一种类型的数据库一个TOPIC。
平台自动监听Kafka队列消息,当有新数据写入队列时,将数据保存到数据库中。
需要理解的是,对于个性化扩展执行器:
在项目落地过程中会出现一些平台无法满足的定制数据接入,如多级表头的EXCEL接入、非对称加密的接口接入……由于数据接入过程中主要问题是数据来源未知,而入库操作恒定,因此平台支持“第三方服务”定制扩展,以满足定制化数据接入的需求。个性化扩展执行器实现以下内容:
以微服务的方式开发,并支持自动注册到Nacos。
提供调用接口,支持设计器调用并接收申请单相关信息。
根据申请单配置,从来源数据源中获取数据。
解析数据,并根据申请单配置对数据进行结构化处理。
将数据放入对应的Kafka队列。
在数据接入时,平台以任务调度服务为起点,调用设计器获取表单配置信息及对应的执行器。若执行器为个性化扩展执行器,则调用执行器并传入申请单ID。执行器按照本身的逻辑进行处理,最终将封装好的数据写入Kafka队列中。平台自动监听Kafka队列消息,当有新数据写入队列时,将数据保存到数据库中。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如只读存储器镜像(ReadOnlyMemoryimage,ROM)/随机存取存储器(RandomAccessMemory,RAM)、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 文件数据源入库解析接入方法
- 文件解析入库、文件生成方法及装置