一种面向表情识别的用户体验评价建模方法及装置
文献发布时间:2023-06-19 13:46:35
技术领域
本发明属于计算机技术领域,具体涉及一种面向表情识别的用户体验评价建模方法及装置。
背景技术
随着科学技术的发展,人们在选择产品时由于可选择面较广、信息公开度高,选择的标准也越来越高,越来越多的人不再单纯的追求产品性能,产品体验感的重要程度正不断提升。目前,在各大厂家竞相开发、创新以及升级之后,产品质量已变成准入门槛,技术的鸿沟也越来越平,产品想要脱颖而出,提升用户的体验感已成为主要的产品设计思路之一。“体验经济”的发展驱动了“体验设计”的发展。
要提升用户的体验感为导向进行产品设计改进,关键在于准确获取用户体验产品时的感受。传统的体验感获取方式主要是在客户身上设置传感器设备,检测用户体验产品时的生理体征数据,如心跳、体温等,再对体征数据进行分析以判断用户的体验感,这样的方式操作复杂、耗时耗力,而用户由于需要像体检似的在身上设置检测装置,愿意配合的很少,样本量难以保证;除此,由于人在不同情绪下的体征数据可能会很相似,例如人在气愤和兴奋时,体征数据会非常接近,这种检测方式的结果不够直观细腻。
发明内容
本发明的目的在于,提供一种面向表情识别的用户体验评价建模方法,能够准确、便捷的获取用户使用产品时的体验感信息。
本发明提供的基础方案为:
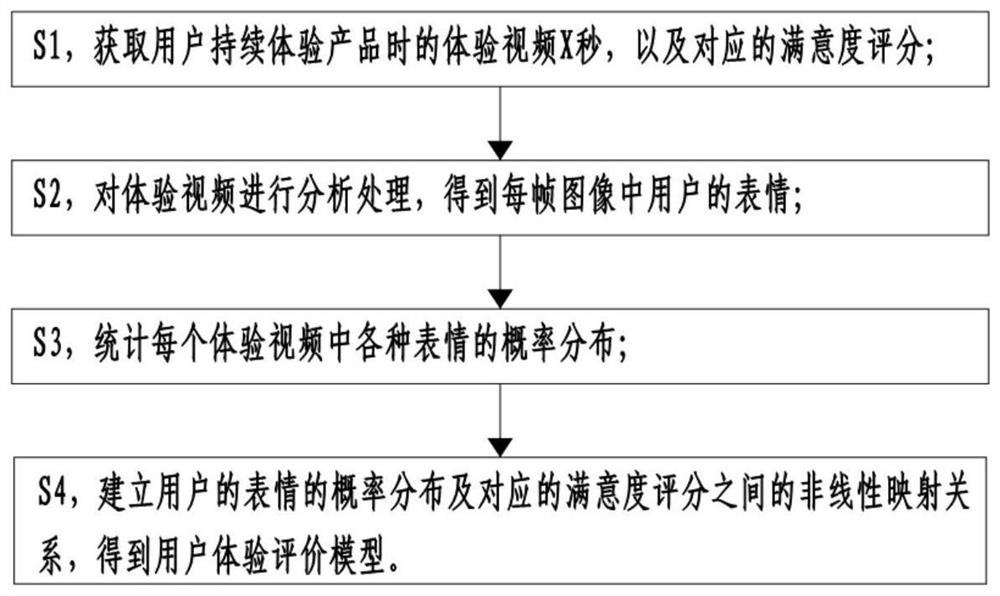
一种面向表情识别的用户体验评价建模方法,包括:
S1,获取用户体验产品时的体验视频X秒,以及对应的满意度评分;
S2,对体验视频进行分析处理,得到每帧图像中用户的表情;
S3,统计每个体验视频中各种表情的概率分布;
S4,建立用户的表情的概率分布及对应的满意度评分之间的非线性映射关系,得到以表情的概率分布为输入,对应的满意度评分为输出的用户体验评价模型。
基础方案工作原理及有益效果:
使用本方法,可先通过内测的方式获取部分用户的体验视频及满意度评分,以此建立用户体验评价模型。
具体的,在内侧阶段,用户体验产品时,拍摄一端持续时间为X秒的体验视频,并让该用户填写满意度评分后获取对应的数据。之后,将体验视频进行分析处理,得到每帧图像中的表情。
然后,对每个体验视频中的表情出现的概率分布进行统计,如高兴、厌恶、惊讶等情绪类型出现的情况。接着,建立用户表情的概率分布及对应的满意度评分之间的非线性映射关系。再然后,可以根据上述非线性映射关系,得到以表情的概率分布与满意度评分之间的应对关系。基于这个评价模型,可开发出对应的用户评价系统/装置,后续在获取到某个用户的体验视频后,可通过分析其表情的概率分布后,直接得到其对应的满意度评分。
与现有技术通过采集用户的体征数据获取用户的体验感信息相比,本申请的获取方式简单,样本获取难度低,样本量有保证。并且,由于将满意度与表情分布概率分布进行关联,而表情分布概率是一种确定且直观的统计数据,准确性与直观性均可以有效果兼顾。
再然后,当商家想要获取用户的满意度评分时,只需要获取带有用户表情的用户的体验视频即可。而用户的体验视频既可以通过用户自拍实现,也可以在体验点处进行拍摄,无论哪种都很方便快捷。并且,由于表情分析的技术已经较为成熟,其后分析得到的表情的概率分布的可信度非常高,可以保证得到的满意度评分的有效性。
综上,本申请能够准确、便捷的获取用户使用产品时的体验感信息。
进一步,S4包括:
S41,以用户的表情的概率分布为输入,对应的满意度评分为输出,构建神经网络;
S42,对神经网络进行训练,更新神经网络的权值及阈值;
S43,通过L2范数正则化优化神经网络,在神经网络预置的损失函数基础上添加L2范数惩罚项抑制过拟合,得到训练所需要的最小化函数,建立用户的表情的概率分布及对应的满意度评分之间的非线性映射关系;
S44,得到以表情的概率分布为输入,对应的满意度评分为输出的用户体验评价模型。
有益效果:通过神经网络特有的非线性适应性信息处理能力,可以得到用户的表情的概率分布及对应的满意度评分之间较为精准的基础映射关系,而在神经网络预置的损失函数基础上添加L2范数惩罚项抑制过拟合,则可以防止神经网络出现过拟合的情况,保证得到的非线性映射关系的精准性,从而保证模型的有效性和精准性。
进一步,S1中,体验视频的时长大于等于5秒。
有益效果:除了特别符合个人喜好或者特别不符合个人喜好的极端情况外,大多数用户在进行产品(如食物)体验时,都需要一定的时间来进行感受,大于等于5秒的体验视频,可以保证获取足够的表情信息。
进一步,S1中,体验视频的时长小于等于10秒。
有益效果:体验视频的时间若过长,一方面会使得用户的配合度降低,另一方面对体验视频进行分析处理时,需要花费的时间会很长,导致整体的效率较低。
进一步,S2中,所述对体验视频进行分析处理包括:将体验视频进行解析,得到完整的视频帧图像数据,再识别各视频帧中的表情。
有益效果:由于性格等原因,人在出现情绪时,其面部表情的程度和反应时间存在细微的区别,通过对视频解析得到完整的视频帧图像后,进行表情的识别和统计分析,可以保证统计分析时数据量的充足,进而保证后续建模的精准性。
进一步,S2中,识别各视频帧的表情时,根据预先定义的表情库,通过机器视觉识别从视频帧中提取统计特征后,得到各视频帧的表情。
有益效果:视频帧的像素点非常多,而每秒钟的视频又有20帧的视频帧,如果采用特征值提取处理或者表情向量提取分析的方式进行表情识别,效率会非常低,并且运算量非常大。采用机器视觉识别的方式进行统计特征提取得到表情,由于表情识别的特征提取时,特征选择的维度低、计算量小,可以在保证整体准确性的基础上,快速完成表情的识别。
进一步,S2中,表情库中的表情包括无情绪、厌恶、恐惧、高兴、伤心、惊讶、愤怒、噘嘴和鬼脸。
有益效果:与常规的表情库相比,申请人创造性的加入了噘嘴和鬼脸,因为部分用户的性格比较机灵活泼,在体验时会下意识的做出噘嘴或鬼脸的表情,但这两种表情并不一定就表示正向体验或者负向体验,而需要与其他的表情进行结合分析才能得出是正向或负向,以及正向或负向的程度。按照常规的表情库进行分析,在遇到这类用户时,非常容易出现分析的程度不准确的情况,如用户的真实体验只是比较好,但现有表情库分析出来却是非常好。使用本申请的表情库,则可以避免上述情况出现,保证用户体验评价模型的精准性,进而保证后续通过用户体验视频得到的满意度评分的精准性,为商家提供更加准确的反馈数据,让商家更加精准的了解用户体验情况。
进一步,S1中,通过调查问卷的方式获取用户对各属性的满意度评分后,通过URWA算法对每个用户各属性的评分进行集成,得到用户的满意度评分;URWA算法的公式为:
其中,S
有益效果:URWA算法为申请人自定义算法,通过这样的方式,去除了打分时的不确定性,避免了个别与大体数据差异较大的数据对最后建模结果的影响,可以去除因人而异,因体验环境而异等噪声,直接获得产品的用户体验。
进一步,S1中,体验视频为连贯的视频。
有益效果:如果体验视频是通过多段视频剪辑而成,则难以对用户体验过程表情及情绪的变化过程进行精准的捕捉,进而影响到后续得到的用户体验评价模型的准确性。
进一步,还包括S21,分析带有表情的视频帧在所有视频帧中的占比,若占比小于预设值则返回S1,若有则根据视频帧的时间序列将视频帧分为多个时段的视频帧,并按照时间顺序逐一分析各时段内带表情的视频帧的数量,若各时段内的带表情的视频帧的数量均大于预设标准值,则转到S3,否则返回S1。
有益效果:本发明得到的用户体验评价模型的核心,在于对用户体验过程中的表情的统计分析,想要用户体验评价模型有效,首先就要保证表情统计分析有效,如果体验视频中带有表情的视频帧在所有视频帧中的占比小于预设值,则说明该体验视频中不少时间点都没有拍摄到用户的表情,得到的表情概率分布也不能准确的反应真实情况,因此返回S1,重新获取体验视频。
除此,即使整体占比大于预设值,如果某时段内的带表情的视频帧的数量存在不大于预设标准值的情况,也可能会存在得到的表情概率分布也不能准确的反应真实情况。例如产品为某种入口感觉为先苦后甜的食物,用户在吃该食物时,正常情况下,表情会有一个负向表情(如厌恶)到正向表情(如高兴)的转变,并且,其中各表情的占比,可以作为用户体验食物时体验到的味道转换快慢及口感层次的参考依据,而体验到的食物味道转换快慢及味道层次又会影响到用户的满意度评分。如果某个时段中带表情的视频帧的数量不满足预设值,则该时段内的对应表情数量会较少,进而使得其各表情的占比失真,该体验视频的概率分布会在建立非线性映射关系时成为干扰数据,影响后续获取的用户评价模型的准确性。因此返回S1重新获取体验视频。
由于当不满足上述第二各条件(即某时段内的带表情的视频帧的数量存在不大于预设标准值的情况)的情况时,说明拍摄的角度可能存在问题,通常也不满足第一个条件(即体验视频中带有表情的视频帧在所有视频帧中的占比小于预设值)。而整体分析的效率快于单个时段的分析,通过这样的方式,还可以保证体验视频筛分的整体效率。
综上,通过S21,可以保证后续获取的用户评价模型的准确性,以及体验视频筛分时的整体效率。
本发明的另一目的,在于提供一种面向表情识别的用户体验评价装置,使用上述面向表情识别的用户体验评价建模方法;包括采集模块、分析模块和存储模块;
采集模块用于采集用户连续X秒的体验视频;分析模块内预存有用户体验评价模型;分析模块用于对用户体验视频进行分析处理得到每帧图像中的表情后,统计各种表情出现的概率分布;分析模块还用于根据用户评价模型,结合用户各种表情出现的概率分布,得到该用户的满意度评分;存储单元用于存储用户的满意度评分。
有益效果:使用本装置,当商家想要获取用户的满意度评分时,可通过采集模块采集带有用户表情的用户的体验视频,分析模块会自动进行后续的图像处理、统计各种表情出现的概率分布、分析满意度评分,并将满意度评分存储在存储单元内。商家只需要对存储单元内的满意度评分进行查看、了解即可。
与现有技术通过采集用户的体征数据获取用户的体验感信息相比,本申请能够方便、快速、准确的获取用户的满意度评分数据。
附图说明
图1为本发明一种面向表情识别的用户体验评价建模方法实施例一的流程图;
图2为本发明一种面向表情识别的用户体验评价装置实施例一的逻辑框图。
具体实施方式
下面通过具体实施方式进一步详细的说明:
实施例一
如图1所示,一种面向表情识别的用户体验评价建模方法,包括:
S1,获取用户持续体验产品时的体验视频X秒,以及对应的满意度评分;其中5≤X≤10。体验视频的具体内容,可以根据商家的具体需求确定,以食物为例,商家想要获取客户对某款食物产品的体验数据,可以获取客户食用产品时的连续视频X秒。获取的具体方式,则可以通过客户自拍或者线下体验店中其他拍摄方式进行,这些方式都很方便快捷。本实施例中为体验店中手机拍摄。
本实施例中,视频时长X的数值为5.5。由于除了特别符合个人喜好或者特别不符合个人喜好的极端情况外,大多数用户在进行产品(如食物)体验时,都需要一定的时间来进行感受,不小于5秒的体验视频,可以保证获取足够的表情信息。除此,体验视频的时间若过长,一方面会使得用户的配合度降低,另一方面对体验视频进行分析处理时,需要花费的时间会很长,导致整体的效率较低。5到10秒的体验视频,则可以兼顾表情信息的充足性、顾客的配合意愿度以及分析处理效率。
需要说明的是,S1中的体验视频为连贯的视频。如果体验视频是通过多段视频剪辑而成,则难以对用户体验过程表情及情绪的变化过程进行精准的捕捉,进而影响到后续得到的用户体验评价模型的准确性。
本实施例中,满意度评分一调查问卷的形式获取,调查问卷可以为纸质问卷,也可以为电子问卷,本实施例中为电子问卷,可通过扫码方式获取填写,与纸质问卷相比,电子问卷更加便于后续的统计分析。其中问卷调查的内容为对此次体验的产品的各个属性的满意度,产品属性的编码为G
表1满意度得分表
第i个体验者的第j个属性对应的满意度为a
表2体验者属性满意度示意表
获取用户满意度时,通过URWA算法对每个用户对每种属性的评分进行集成,最终得到这个用户对这个产品最后满意度评分,URWA算法的公式为:
其中,S
通过这样的方式,去除了打分时的不确定性,避免了个别与大体数据差异较大的数据对最后建模结果的影响,可以去除因人而异,因体验环境而异等噪声,直接获得产品的用户体验。
S2,对体验视频进行分析处理,得到每帧图像中用户的表情;其中,所述对体验视频进行分析处理包括:将体验视频进行解析,得到完整的视频帧图像数据,再识别各视频帧中的表情。
具体的,识别各视频帧的表情时,根据预先定义的表情库,通过机器视觉识别从视频帧中提取统计特征后,得到各视频帧的表情。由于视频帧的像素点非常多,而每秒钟的视频又有20帧的视频帧,如果采用特征值提取处理或者表情向量提取分析的方式进行表情识别,效率会非常低并且运算量非常大,而采用机器视觉识别的方式进行统计特征提取得到表情,由于表情识别的特征提取时特征选择的维度低、计算量小,可以在保证整体准确性的基础上,快速完成表情的识别。本实施例中,表情库中的表情包括无情绪、厌恶、恐惧、高兴、伤心、惊讶、愤怒、噘嘴和鬼脸,表情及代码如表3所示:
表3表情与其代码对应表
S3,统计每个体验视频中各种表情的概率分布;
具体的,如表4所示,统计每段体验视频中9种表情出现的概率,即无情绪E
表4表情概率与用户体验满意度评分记录表
S4中,建立用户的表情的概率分布及对应的满意度评分之间的非线性映射关系,得到以表情的概率分布为输入,对应的满意度评分为输出的用户体验评价模型。具体的,S4包括:
S41,以用户的表情的概率分布为输入,对应的满意度评分为输出,构建神经网络;本实施例中,构建的神经网络为BP神经网络。
具体的,神经网络的输入为由9种表情概率分布数据构成的输入矩阵X:
输出为各个人脸表情视频的用户体验满意度评分数据构成的输出矩阵T:
T=[S
在其他实施例中,如果用户体验满意度与性别/年龄相关性较大大,也可以加入用户的性别和年龄作为输入参数。此时,S3中,统计每个体验视频中各种表情的概率分布和每段视频中人物的性别与年龄;
具体的,如表5所示,统计每段体验视频中9种表情出现的概率和人物的性别与年龄,即无情绪E
表5表情概率与用户体验满意度评分记录表二
S4,建立用户的表情的概率分布及对应的满意度评分之间的非线性映射关系,得到以表情的概率分布为输入,对应的满意度评分为输出的用户体验评价模型。具体的,S4包括:
S41,以用户的表情的概率分布为输入,对应的满意度评分为输出,构建神经网络;本实施例中,构建的神经网络为BP神经网络。
具体的,神经网络的输入为由9种表情概率分布数据及人物性别和年龄数据构成的输入矩阵X:
输出为各个人脸表情视频的用户体验满意度评分数据构成的输出矩阵T:
T=[S
S42,对神经网络进行训练,更新神经网络的权值及阈值;
S43,通过L2范数正则化优化神经网络,在神经网络预置的损失函数基础上添加L2范数惩罚项抑制过拟合,得到训练所需要的最小化函数,建立用户的表情的概率分布及对应的满意度评分之间的非线性映射关系。通过L2范数正则化优化神经网络的技术中涉及的表达式,均属于本领域管用的技术表达式,在此不再赘述。本实施例中,神经网络为径向基神经网络。
S44,得到以表情的概率分布为输入,对应的满意度评分为输出的用户体验评价模型。
通过神经网络特有的非线性适应性信息处理能力,可以得到用户的表情的概率分布及对应的满意度评分之间较为精准的基础映射关系,而在神经网络预置的损失函数基础上添加L2范数惩罚项抑制过拟合,则可以防止神经网络出现过拟合的情况,保证得到的非线性映射关系的精准性,从而保证模型的有效性和精准性。
如图2所示,基于上述面向表情识别的用户体验评价建模方法,本申请还提供一种面向表情识别的用户体验评价装置,使用上述面向表情识别的用户体验评价建模方法中的用户体验评价模型开发;包括采集模块、分析模块和存储模块。其中,采集模块为摄像头,分析模块和存储模块集成在后台端,本实施例中后台端为云服务器。
采集模块用于采集用户连续X秒的体验视频;分析模块内预存有用户体验评价模型;分析模块用于对用户体验视频进行分析处理得到每帧图像中的表情后,统计各种表情出现的概率分布;分析模块还用于根据用户评价模型,结合用户各种表情出现的概率分布,得到该用户的满意度评分;存储单元用于存储用户的满意度评分。
具体实施过程如下:
人脸表情是人与人之间进行沟通的重要手段。一个人情绪和心情往往会通过面部表情体现出来。人脸表情识别是人类感情识别的基础,用户体验测试的结果与用户在参与体验时的表情反馈息息相关。
使用本方法,可先通过内测的方式获取部分用户的体验视频及满意度评分,以此建立用户体验评价模型。具体的,在内测阶段,用户体验产品时,拍摄一端持续时间为X秒的体验视频,并让该用户填写满意度评分后获取对应的数据。之后,将体验视频进行分析处理,得到每帧图像中的表情。
由于性格等原因,人在出现情绪时,其面部表情的程度和反应时间存在细微的区别,本申请中,通过对视频解析得到完整的视频帧图像后,进行表情的识别和统计分析,可以保证统计分析时数据量的充足,进而保证后续建模的精准性。
与常规的表情库相比,申请人在本申请的表情库中创造性的加入了噘嘴和鬼脸,因为部分用户的性格比较机灵活泼,在体验时会下意识的做出噘嘴或鬼脸的表情,但这两种表情并不一定就表示正向体验或者负向体验,而需要与其他的表情进行结合分析才能得出是正向或负向,以及正向或负向的程度。按照常规的表情库进行分析,在遇到这类用户时,非常容易出现分析的程度不准确的情况,如用户的真实体验只是比较好,但现有表情库分析出来却是非常好。使用本申请的表情库,则可以避免上述情况出现,保证用户体验评价模型的精准性,进而保证后续通过用户体验视频得到的满意度评分的精准性,为商家提供更加准确的反馈数据,让商家更加精准的了解用户体验情况。
再然后,对每个体验视频中的表情出现的概率分布进行统计,如高兴、厌恶、惊讶等情绪类型出现的情况。接着,建立用户表情的概率分布及对应的满意度评分之间的非线性映射关系。再然后,可以根据上述非线性映射关系,得到以表情的概率分布与满意度评分之间的应对关系。基于这个评价模型,可开发出对应的用户评价系统/装置,后续在获取到某个用户的体验视频后,可通过分析其表情的概率分布后,直接得到其对应的满意度评分。
当商家想要获取用户的满意度评分时,只需要获取带有用户表情的用户的体验视频即可。具体的,可通过采集模块采集带有用户表情的用户的体验视频,分析模块会自动进行后续的图像处理、统计各种表情出现的概率分布、分析满意度评分,并将满意度评分存储在存储单元内。商家只需要对存储单元内的满意度评分进行查看、了解即可。
与现有技术通过采集用户的体征数据获取用户的体验感信息相比,本申请的获取方式简单,样本获取难度低,样本量有保证。并且,由于将满意度与表情分布概率分布进行关联,而表情分布概率是一种确定且直观的统计数据,准确性与直观性均可以有效果兼顾。
综上,本申请能够准确、便捷的获取用户使用产品时的体验感信息。
实施例二
与实施例一不同的是,本实施例中的一种面向表情识别的用户体验评价建模方法用于食物类产品,该方法还包括S21,分析带有表情的视频帧在所有视频帧中的占比,若占比小于预设值则返回S1,若有则根据视频帧的时间序列将视频帧分为多个时段的视频帧,并按照时间顺序逐一分析各时段内带表情的视频帧的数量,若各时段内的带表情的视频帧的数量均大于预设标准值,则转到S3,否则返回S1。其中,所述占比及预设标准值,本领域技术人员均可根据拍摄体验视频的装置及体验产品的具体类型具体设置。
本发明得到的用户体验评价模型的核心,在于对用户体验过程中的表情的统计分析,想要用户体验评价模型有效,首先就要保证表情统计分析有效,如果体验视频中带有表情的视频帧在所有视频帧中的占比小于预设值,则说明该体验视频中不少时间点都没有拍摄到用户的表情,得到的表情概率分布也不能准确的反应真实情况,因此返回S1,重新获取体验视频。
除此,即使整体占比大于预设值,如果某时段内的带表情的视频帧的数量存在不大于预设标准值的情况,也可能会存在得到的表情概率分布也不能准确的反应真实情况。例如产品为某种入口感觉为先苦后甜的食物,用户在吃该食物时,正常情况下,表情会有一个负向表情(如厌恶)到正向表情(如高兴)的转变,并且,其中各表情的占比,可以作为用户体验食物时体验到的味道转换快慢及口感层次的参考依据,而体验到的食物味道转换快慢及味道层次又会影响到用户的满意度评分。如果某个时段中带表情的视频帧的数量不满足预设值,则该时段内的对应表情数量会较少,进而使得其各表情的占比失真,该体验视频的概率分布会在建立非线性映射关系时成为干扰数据,影响后续获取的用户评价模型的准确性。因此返回S1重新获取体验视频。
由于当不满足上述第二各条件(即某时段内的带表情的视频帧的数量存在不大于预设标准值的情况)的情况时,说明拍摄的角度可能存在问题,通常也不满足第一个条件(即体验视频中带有表情的视频帧在所有视频帧中的占比小于预设值)。而整体分析的效率快于单个时段的分析,通过这样的方式,还可以保证体验视频筛分的整体效率。
综上,通过S21,可以保证后续获取的用户评价模型的准确性,以及体验视频筛分时的整体效率。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 一种面向表情识别的用户体验评价建模方法及装置
- 面向用户体验的整车级音频系统抗电磁干扰测试装置及评价测试方法