一种联邦语音智能电梯控制方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及计算机技术领域,尤其涉及一种联邦语音智能电梯控制方法。
背景技术
针对智能化电梯的发展需求,集成电梯语音信号采集设备的智慧电梯应运而生,智慧电梯通过用户对电梯进行语音控制,提升了电梯非接触式控制能力,减少了用户手动控制电梯按键,降低了手动选择开关门、楼层目的地等操作。智慧电梯通过用户对电梯进行语音控制,一是可以避免因接身体触电梯按键导致的细菌、病毒等附着与用户的交叉感染;二是通过语音唤醒电梯、语音控制电梯,非接触式操作电梯,解放用户乘坐电梯时双手,实现智慧电梯出行。
然而,相关技术中智慧电梯采用的传统语音检测方法中语音识别、语音控制技术均会采集用户语音数据,但用户语音信号包含用户的语言习惯、口音、响度等个人信息,具有隐私保护要求。因此,在进行电梯语音控制模型训练时,大量采集用户具有隐私属性的声音信号数据,面临用户语音数据隐私泄露风险;同时,不同用户的语音信号具有不同的语音信号特点,小样本,高噪声,方言、语气、习惯等导致用于语音识别模型训练的数据不满足传统机器学习要求的独立同分布特性。
因此,亟需一种能够实现兼顾各类用户电梯语音控制信号特点和隐私保护需求,完成语音控制电梯模型训练、语音唤醒、识别、控制功能的电梯语音检测方法。
发明内容
针对现有技术存在的不足,本发明的目的在于提供一种能够实现兼顾各类用户电梯语音控制信号特点和隐私保护需求,完成语音控制电梯模型训练、语音唤醒、识别、控制功能的电梯语音检测方法的基于联邦语音的电梯语音检测方法。
为了实现上述目的,本发明提供了一种联邦语音智能电梯控制方法,具有采用以下技术方案予以实现:
一种联邦语音智能电梯控制方法,包括以下步骤:
步骤一、构建训练数据集:利用各电梯的语音信号数据采集设备中的语音识别模块和语音唤醒模块采集语音信号数据特征和用户个性化特征,并构建用户识别记录表;
提取用户识别记录表中的语音信号数据特征和用户个性化特征,形成本地训练数据集;
步骤二、构建语音模型:基于用户识别记录表,提取模型训练所需的语音信号数据特征,和前后语音唤醒模块的C帧和语音识别模块的C帧,共计2C+1帧作为模型输入;模型输出为“开门、关门、去一楼、二楼、三楼、四楼、N楼、负一楼、负M楼”等关键词对应的独热码编码向量;
步骤三、联邦语音模型训练:利用本地数据进行本地语音识别模型的模型训练,且模型训练过程中,各电梯本地模型的输入为语音信号数据特征和用户个性化特征;
本地模型训练完成后模型参数发送至全局模型,全局模型对各电梯的模型参数进行汇总,最后将聚合参数下发至各本地模型,重复上述步骤,直至模型收敛;
训练好的全局模型下发至各电梯语音识别模块和语音唤醒模块,各电梯的本地语音唤醒模型最终模型参数为基于本地训练数据和全局模型下发的参数共同形成,用于本地的电梯语音唤醒;全局语音识别模型由各地语音识别模型参数共享训练聚合形成,用于各电梯的语音识别。
进一步的,所述步骤一中语音唤醒模块在用户体温达到33℃~39℃后,采集语音信号流,每隔500ms-800ms截取一段时长为2s-3s的语音,并存储于用户识别记录表;语音识别模块,在用户进入轿厢后,采集每隔800ms-1100ms截取一段时长为2s-4s的用户语音信号流,并存储于用户识别记录表。
进一步的,所述语音唤醒模块具备LED显示屏和红外测温装置,部署于电梯轿厢外侧入梯口,平时处于待机状态,只有当用户体温处于为33℃~39℃之间,且对其喊出指定词语之后才会进入工作状态,并对用户的话语进行监听、识别与回应。
进一步的,所述语音识别模块部署于电梯轿厢内侧,用户通过语音唤醒功能进入电梯轿厢后,轿厢内部语音识别模块开启,根据用户语言习惯、方言、口音、性别等不同语音信号特点,完成语音识别,识别出用户要进入的楼层,支持多楼层识别功能,完成电梯按键的自动触发和关门操作。
进一步的,所述步骤二中,本地语音唤醒模型和全局语音识别模型的骨干网络均为10个隐藏层的循环神经网络(RNN),激活函数采用Mish激活函数。
进一步的,所述步骤三中,语音模型的训练涉及用于为模型参数添加ε-本地差分隐私噪声的隐私保护机制设置,具体步骤如下:
(1)在语音识别模型的骨干网络RNN中,随机选择一层i(1<=i<=10),选取k各参数构建参数集合S;
(2)对于S中每个参数wi执行如下操作:
令f为[0,1]区间随机数,
当f大于ε/k时,该参数为wi*C,
否则,该参数为-wi*C;
(3)输出隐私保护的模型参数。
进一步的,所述步骤三中,语音模型的训练涉及用于平衡语音识别性能的准确率、添加本地差分隐私噪声带来噪声影响的损失函数设置,具体包括如下部分:
包括如下部分:
(1)表征识别准确率的交叉熵损失,xi,yi为训练数据和标签,
(2)具备差分隐私容忍度的噪声扩散损失,∈t服从正态分布,α
/>
∈t~N(0,1)
其中联邦学习训练过程中,整体的损失函数为L=Loss1+Loss2。
本发明与现有技术相比,具有如下技术效果:
本发明设计了基于电梯语音信号数据采集设备的语音唤醒和语音识别本地训练数据集,形成了具备噪声特征、方言特征、语气特征、能量、音高等声学和用户人数特征、体温数据等个性化特征的训练数据。在数据编码过程中,输入数据为39维MFCC音频特征,和前后语音唤醒部分的C帧和语音识别部分的C帧,共计2C+1帧,具有更加丰富的语音信号特征表达能力。
本发明联邦语音智能电梯控制方法的语音识别模型中,骨干网络为10个隐藏层的循环神经网络(RNN),利用Mish激活函数提升语音识别精度,模型输出的编码维语音关键词的独热码编码向量,具有简易、轻量化特征。
且本发明中联邦语音模型训练过程中,通过设置随机化参数,
本发明统一的语音唤醒、语音识别、语音控制电梯的功能,解决用户手动控制电梯按键带来的公共卫生安全、操作不方便等问题。语音唤醒模块具备LED显示屏和红外测温装置,部署于电梯轿厢外侧入梯口,平时处于待机状态,只有当用户体温正常(容忍阈值设置为33℃~39℃之间,可动态设置),且对其喊出指定词语之后才会进入工作状态,并对用户的话语进行监听、识别与回应。否则,一直处于工作状态,解决传统语音唤醒功能单一,识别准确率低的问题;在电梯轿厢内侧,部署语音识别模块,
由于本发明基于语音识别的智能电梯采集大量用户个性化声音数据,尤其在语音唤醒、识别、控制模型的训练过程中涉及用户语音数据的隐私保护问题,因此,在实现统一的语音唤醒、识别、控制的同时,采用基于本地差分隐私的联邦学习机制,对多个电梯在语音唤醒、语音识别等多个过程中采集的语音信号数据进行隐私保护处理。在进行模型训练时,通过本地差分隐私噪声,对用户语音信号进行隐私保护,同时完成不同电梯的本地语音模型和全局共享模型的训练,并将各电梯训练好的本地语音识别模型作为电梯轿厢外侧的语音唤醒模型,将全局共享模型部署为电梯轿厢内侧的语音识别模型,完成统一的支持隐私保护的语音唤醒、识别、控制。
附图说明
图1为本发明实施例一种联邦语音智能电梯控制方法的整体框架图;
图2为本发明实施例中语音模型的结构图;
图3为本发明实施例一种联邦语音智能电梯控制方法的基本架构图。
具体实施方式
以下结合实施例对本发明的具体内容做进一步详细解释说明。
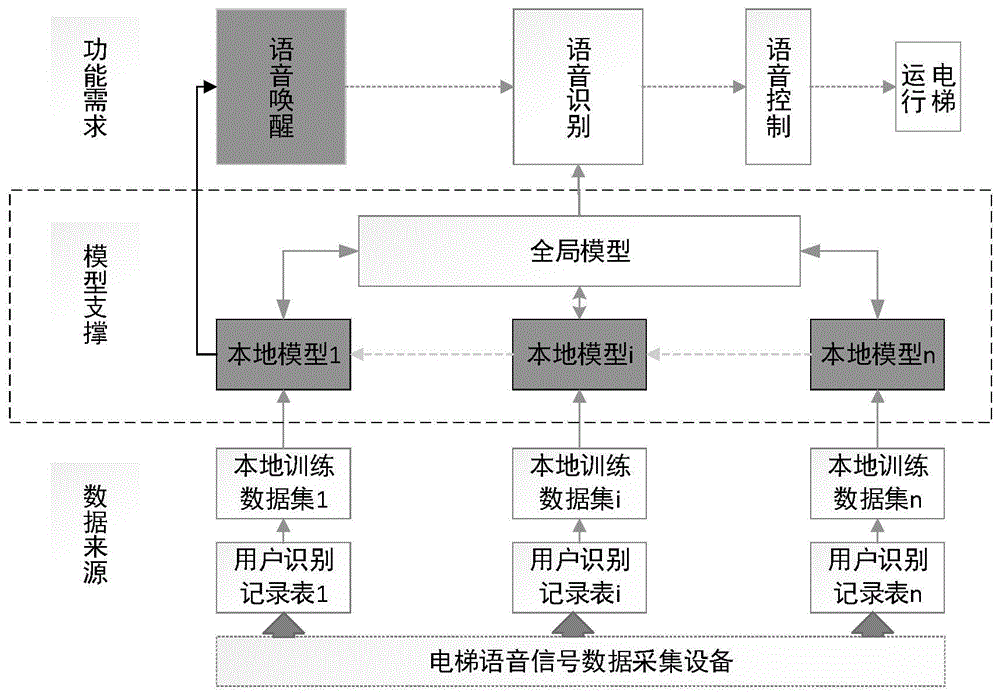
参照图1本发明一种联邦语音智能电梯控制方法的整体框架图,本发明一种联邦语音智能电梯控制方法主要包括三个层次,底层为数据来源,以电梯语音信号数据采集设备为主体,支持语音识别模块和语音唤醒模块共享的用户识别记录表,基于用户识别记录表构建各电梯的本地语音模型训练数据集。中间层为模型支撑,包括个性化的本地电梯语音模型和全局性的语音识别模型,前者基于各电梯本地采集的语音信号数据集,用于各电梯本地的语音唤醒,后者利用联邦学习模式,形成适用于各电梯全局性的语音识别模型。顶层为功能需求按照唤醒、识别、控制流程,对各电梯采集的语音信号数据、本地个性化语音识别模型、全局性语音识别模型,完成电梯的智能语音控制,保障电梯的运行。
在数据来源层面,核心目标为构建训练数据集。涉及电梯语音信号数据采集设备、用户识别记录表、电梯本地训练数据集。其中,电梯语音信号数据采集设备是部署于电梯轿厢外侧语音唤醒模块、轿厢内侧语音识别模块,用户在电梯内外实现用户语音信号的采集,并通过用户识别记录表进行电梯内外用户相关语音信号的记录,该表包括时间戳、采集位置、噪声特征、方言特征、语气特征、人数特征、体温数据、语音信号数据及标签、其他等属性字段,如表1所示。
表1:
基于各电梯不断采集形成的用户识别记录表,以定时采集的语音信号数据为核心,构建具备用户个性化特征的语音训练数据集。语音唤醒模块采集用户在进入电梯前的语音信号等数据,包括用户进入电梯前的时间戳、轿厢外噪声特征、用户的方言特征、语气特征、人数特征、体温数据、唤醒语音信号数据等;语音识别模块采集用户在轿厢中的语音信号时间戳、轿厢内噪声特征、用户的方言特征、语气特征、人数特征、语音控制电梯的信号数据等。
训练数据集构建的具体过程为,语音唤醒模块在用户体温达到规定范围内后,采集语音信号流,每隔一定间隔(例如,100ms)截取一段时长语音(例如,2s),并存储于用户识别记录表;同理,语音识别模块,在用户进入轿厢后,采集每隔一定间隔(例如,200ms)截取一段用户语音信号流(例如,2s),并存储于用户识别记录表。最后在每个电梯形成本地化的用户识别记录表,其中,为语音信号数据打标记,分为“开门、关门、去一楼、二楼、三楼、四楼、N楼、负一楼、负M楼等(N为最高楼层,M为地下最低楼层)”等关键词的语音信号。
最终形成的语音训练数据集中,每一条数据以语音信号为主体,以表1涉及的多个属性标签字段(具有时长、能量、音高等声学特征)为辅的本地化语音训练数据。
其中,语音模型的构建如下:多个电梯场景下语音模型构建包括面向语音唤醒的各电梯本地模型和用户语音识别的全局模型,每个语音识别模型的骨干网络均为10个隐藏层的循环神经网络(RNN),其输入为语音信号数据特征(MFCC)和用户个性化特征,具体为,t时刻的特征xt(为39维的MFCC特征),和前后语音唤醒部分的C帧和语音识别部分的C帧,共计2C+1帧;输出为“开门、关门、去一楼、二楼、三楼、四楼、N楼、负一楼、负M楼等(N为最高楼层,M为地下最低楼层)”等关键词对应的独热码(例如,某个关键词出现,则该位置为1,未出现则为0,形成语音输出标签)。各层的激活函数采用Mish激活函数,以提升语音识别精度,公式为y=x*tanh(ln(1+e
语音模型结构参照图2,为保护各电梯本地采集的语音信号数据的隐私,各电梯基于本地数据训练的语音模型用于语音唤醒,基于联邦学习训练的全局模型,用于语音识别。
综上所述语音识别模型构建的流程如下:
1、基于用户识别记录表,提取模型训练所需的语音信号数据特征(MFCC),和前后语音唤醒部分的C帧和语音识别部分的C帧,共计2C+1帧作为模型输入,该输入的特征点包括各电梯本地化采集的用户语音的时长、能量、音高等声学特征等;
2、各电梯的本地语音唤醒模型和全局语音识别模型的骨干网络均为10个隐藏层的循环神经网络(RNN),激活函数采用Mish激活函数;
3、模型输出为“开门、关门、去一楼、二楼、三楼、四楼、N楼、负一楼、负M楼等”等关键词对应的独热码编码向量;
4、各电梯的本地语音唤醒模型最终模型参数为基于本地训练数据和全局模型下发的参数共同形成,用于本地的电梯语音唤醒;全局语音识别模型由各地语音识别模型参数共享训练聚合形成,用户各电梯的语音识别。
并且语音模型训练中,语音识别模型的训练涉及隐私保护机制设置、训练的损失函数设置,具体如下:
1、隐私保护机制
为保证训练数据的隐私,为模型参数添加ε-本地差分隐私噪声,具体步骤如下:
(1)在语音识别模型的骨干网络RNN中,随机选择一层i(1<=i<=10),选取k各参数构建参数集合S;
(2)对于S中每个参数wi执行如下操作:
令f为[0,1]区间随机数,
当f大于ε/k时,该参数为wi*C,
否则,该参数为-wi*C;
(3)输出隐私保护的模型参数。
上述隐私保护机制满足ε-本地差分隐私,可保证在语音识别模型训练过程中,训练数据的隐私。
2、损失函数设置
根据待识别语音关键词,联邦学习模型训练过程中,损失函数包括如下部分:
(1)表征识别准确率的交叉熵损失,xi,yi为训练数据和标签:
(2)具备差分隐私容忍度的噪声扩散损失,∈t服从正态分布,α
∈t~N(0,1)
在联邦学习训练过程中,整体的损失函数L=Loss1+Loss2,进而平衡语音识别性能的准确率,以及添加本地差分隐私噪声带来的噪声影响。
参照图3,以含有三个电梯(A、B、C)的场景为例,电梯A、B和C,具有电梯语音信号数据采集设备,利用语音唤醒模块和语音识别模块构建用户识别记录表,基于此形成各电梯的用户隐私语音数据训练集;按照联邦学习模式,全局模型和电梯A、B、C本地模型以10个隐藏层的RNN为骨干网络,以交叉熵损失与噪声扩散损失加和为损失函数,本地模型参数添加ε-本地差分隐私噪声后上报至全局模型,全局模型汇总平均后下发本地模型,进行模型迭代训练。训练完成的全局模型作为各电梯轿厢内的语音识别模型,各电梯的本地模型作为个性化语音唤醒模型,实现支持隐私保护的联邦语音智能电梯控制。本实施例共分为七大步骤,基本架构参照图3。
具体讲,第一步,电梯A、B和C分别利用电梯语音信号数据采集设备,构建用户识别记录表,在电梯外侧,语音唤醒模块具备LED显示屏和红外测温装置,部署于电梯轿厢外侧入梯口,平时处于待机状态,只有当用户体温正常(容忍阈值设置为33℃~39℃之间,可动态设置),且对其喊出指定词语(例如,开门)之后才会进入工作状态,并对用户的话语进行监听、识别与回应。通过语音唤醒模块采集如下信息,如表2所示。
表2:
在电梯内,通过语音识别模块采集如表3所示。
表3:
/>
在同一电梯中,将表2连接表3,形成该电梯最终的用户识别记录表,如表4所示。
表4:
第二步,电梯A、B和C基于形成的用户识别记录表,提取语音信号数据特征和用户个性化特征,形成本地训练数据集。每隔100ms截取一段时长语音唤醒信号和语音识别信号,形成用户原始语音信号和具有时长、能量、音高等声学特征的多个属性标签字段,即本地化语音训练数据。其中,用户原始语音信号数据特征(MFCC)是训练数据的主体,具体为,t时刻的一条语音信号特征xt的构成为,39维的MFCC特征和前后语音唤醒部分的2帧、语音识别部分的2帧,共计5帧,主要的语音标签为“开门,三楼”等关键词。
第三步至第五步,电梯A、B和C的初始化本地语音模型来自全局模型的下发,本地模型和全局模型的骨干网络均为10个隐藏层的循环神经网络(RNN),其输入为语音信信号数据特征(MFCC),激活函数采用Mish激活函数。模型训练过程中,电梯A、B和C的本地模型的输入为语音信号数据特征(MFCC)和用户个性化特征,利用本地数据进行模型训练,然后,随机选择骨干网络RNN的一层,选取部分参数构建参数,添加ε-本地差分隐私噪声,模型训练的损失函数为交叉熵损失和噪声扩散损失的加和。本地模型训练完成后,模型参数发送至全局模型,全局模型对电梯A、B和C的模型参数进行汇总,最后将聚合参数下发至各本地模型,重复上述步骤,直至模型收敛。
第六步至第七步,训练好的全局模型下发至电梯A、B和C的语音识别模块,用于用户电梯控制指令的语音识别;各电梯的本地模型部署于语音唤醒模块,用于实现本地化的用户语音唤醒。最终形成兼顾用户语音数据隐私保护和语音识别性能的联邦语音智能电梯控制方法。
如此,本发明利用基于电梯语音信号数据采集设备和用户识别记录表,丰富了语音识别所需的训练数据,为后续其他语音识别任务奠定数据集成。同时,将语音唤醒、语音识别、语音控制通过统一的语音模型进行表征,利用联邦学习训练的模型具有本地适应性和全局泛化性能,解决训练数据不足问题;
并且基于ε-本地差分隐私的联邦学习训练机制,可以保护原始用户语音信号数据隐私,并兼顾模型参数的可用性;结合交叉熵损失和噪声扩散损失,可以平衡差分隐私和联邦学习分布式训练带来的语音识别性能的准确率和对噪声的鲁棒性,解决语音识别模型的鲁棒性和用户隐私保护问题。