一种声音处理方法及相关装置
文献发布时间:2023-06-19 19:28:50
技术领域
本申请涉及媒体技术领域,尤其涉及一种声音处理方法及相关装置。
背景技术
随着计算机技术的快速发展,电子游戏、增强现实(Augmented Reality,AR)应用以及虚拟现实(Virtual Reality,VR)应用等创建有虚拟环境的应用,都开始追求虚拟环境与现实世界规则的高度接近化,以给用户带来更真实的用户体验。在虚拟环境中,图像和声音是用户感知最强的两个要素。在图像渲染已经较为成熟的当下,声音的效果是否真实则成为了优化用户体验的关键。
目前,相关技术中对虚拟环境中的声音进行处理的方式是:采用专门的声音引擎存储各种类型的障碍物对应的声音参数,例如各种障碍物对应的声音反射参数以及声音阻挡参数,并且结合三维模型中所指定的障碍物的类型,综合确定声音在三维模型中的效果。
然而,这种方案需要在预置的声音引擎中存储大量的声音参数,以便于在处理不同的三维模型时能够匹配到各个三维模型中所指定的障碍物类型,从而导致声音引擎的体量较大。而且从引擎中加载声音参数也会影响声音处理的效率。
发明内容
本申请提供了一种声音处理方法,通过在三维模型的描述文件中携带该三维模型相关的声音参数,能够基于描述文件实现三维模型中的声音处理,无需加载声音引擎,提高了声音处理的效率。
本申请第一方面提供一种声音处理方法,应用于能够在虚拟环境中构建三维模型的电子设备。该方法包括:获取三维模型的描述文件,所述三维模型包括第一对象,该第一对象是指能够对声音的传播产生影响的物体,例如第一对象可以是建筑物、树木、箱子、山峰、汽车或液体等任何可能影响声音的传播方向或传播能量的物体。其中,三维模型的描述文件中包括三维模型中的各个对象的参数,基于三维模型的描述文件,能够实现三维模型的构建。
解析所述描述文件,以得到所述描述文件中的场景参数和声音参数,所述场景参数用于渲染以得到所述三维模型,所述声音参数用于执行所述三维模型中的声音处理。例如,所述场景参数包括所述第一对象的位置参数、所述第一对象的形状参数、所述第一对象的材质参数和所述第一对象的纹理参数中的一种或多种。所述声音参数则包括影响声音在三维模型中的传播路径以及声能衰减量的参数。根据所述场景参数,进行渲染以得到所述三维模型。
根据所述场景参数和所述声音参数,对所述三维模型中声源位置发出的源声音进行追踪处理,以得到目标位置的目标声音。简单来说,在声音处理阶段,基于三维模型中与声音传播有关的场景参数和声音参数,对三维模型中的源声音进行追踪,以模拟声音在三维模型中的真实传播方式,从而得到特定位置的声音效果。
本方案中,通过解析三维模型的描述文件中携带的声音参数,能够基于描述文件实现三维模型中的声音处理,无需加载声音引擎,提高了声音处理的效率。此外,基于在三维模型的描述文件中携带声音参数的方式,能够根据三维模型本身的特点,有针对性地携带只与声音在当前三维模型中传播相关的参数,避免预先在声音引擎中定义大量的声音参数,提高了声音处理的灵活性,也可以在实现三维模型的声音渲染的同时,实现三维模型渲染引擎的轻量化。
在一个可能的实现方式中,所述声音参数包括所述第一对象的声阻抗参数、所述第一对象的声音吸收能力参数、所述第一对象的漫反射系数以及所述第一对象的声音传播速度中的一种或多种。
在一个可能的实现方式中,所述第一对象的声阻抗参数用于指示不同频率的声音在所述第一对象中传输时的声阻抗;声阻抗是指声音在介质中传播时需要克服的阻力。基于声阻抗参数,电子设备可以计算声波在与对象相交时,反射的声波与折射的声波的能量分配。
所述第一对象的声音吸收能力参数用于指示所述第一对象对不同频率的声音的声能吸收能力。例如,所述声音吸收能力参数可以包括对象的每米吸声量,用于指示声音在对象中每传输一米距离时,对象所吸收的声能。
所述第一对象的漫反射系数用于指示所述第一对象对不同频率的声音的漫反射能力。漫反射能力则可以是指对象在反射声音的过程中,对象对声音进行漫反射的能力。基于漫反射系数,电子设备可以计算声波在反射过程中镜面反射和漫反射的能量分配。
所述第一对象的声音传播速度用于指示声音在所述第一对象中传输时的速度。
本方案中,通过引入对象的声音反射能力、声音折射能力和声音吸收能力等参数,能够模拟声音在虚拟环境中的真实传播路径和声能衰减量,提高处理得到的声音的真实度,即提高声音的处理精度。
在一个可能的实现方式中,所述声音参数还包括所述第一对象的法线数据,所述第一对象的法线数据用于确定第一声音射线与所述第一对象相交时的反射角以及折射角,所述第一声音射线是所述源声音传播过程中的任意射线。
应理解,源声音可以包括从源位置发出的多条声音射线,而在这多条声音射线各自的传播过程中,每条声音射线遇到三维模型中的障碍物(即三维模型中的对象)时,会发生反射、折射等现象,所以从源位置发出的多条声音射线在传播过程中又会分裂为更多的声音射线。上述声音射线可以是源声音在传播过程中的任意射线。
基于各个对象的法线数据,电子设备可以快速地求取源声音与各个对象的交点的反射角以及折射角,从而提高声音处理的效率。
在一个可能的实现方式中,还包括:解析所述描述文件,以得到所述描述文件中的全局参数;根据所述全局参数,确定是否停止对第二声音射线进行追踪处理,所述第二声音射线是所述源声音传播过程中的任意射线。简单来说,所述全局参数定义了对三维模型中的声音射线进行追踪处理的停止条件。当三维模型中的任意声音射线达到了全局参数所指示的停止条件时,则停止追踪该声音射线,以避免陷入无限追踪声音射线的循环过程。
本方案中,通过停止追踪满足预设条件的声音射线,能够提前停止追踪部分对目标位置的声音效果影响较小或者无影响的声音射线,从而降低对电子设备计算资源的消耗,提高电子设备的声音处理速度。
在一个可能的实现方式中,所述全局参数包括最小声能和/或最大递归深度;所述根据所述全局参数,确定是否停止对第二声音射线进行追踪处理包括:若所述第二声音射线的声能小于或等于所述最小声能,则停止对所述第二声音射线进行追踪处理;或者,若所述第二声音射线与所述三维模型中的一个或多个对象的相交次数大于或等于所述最大递归深度,则停止对所述第二声音射线进行追踪处理。
本方案中,通过解析三维模型的描述文件中携带的全局参数来指定声音追踪处理的停止条件,能够针对各个三维模型个性化地定义声音追踪处理的停止条件,从而能够在保证三维模型中声音处理精度的同时,提高声音处理的效率。例如,对于规模较大且包含较多对象的三维模型,可以设置该三维模型中全局参数的最小声能较大或最大递归深度较小,尽可能地减少追踪不影响最终声音效果的声音射线,降低声音处理的复杂度,提高声音处理的效率;例如,对于规模较小且包含较少对象的三维模型,可以设置该三维模型中全局参数的最小声能较小或最大递归深度较大,提高声音处理的精度。
在一个可能的实现方式中,所述根据所述场景参数和所述声音参数,对所述三维模型中声源位置发出的源声音进行追踪处理,以得到目标位置的目标声音,包括:获取所述场景参数中的目标参数,所述目标参数包括所述第一对象的位置参数和形状参数。
根据所述目标参数和所述声音参数对所述源声音进行追踪处理,以确定所述源声音的一条或多条目标传播路径以及所述源声音经过所述一条或多条目标传播路径传播后的剩余声能,所述一条或多条目标传播路径为所述源声音从所述声源位置到达所述目标位置的一条或多条路径。由于声源位置所发出的源声音是以声源位置为中心向四周传播的,而三维模型中的对象会对源声音的传播路径产生影响。因此,基于三维模型中的对象对声音的反射能力以及折射能力,能够确定源声音在三维模型中的各种传播路径。由于目标位置是唯一的,因此可以在源声音的各种传播路径中选择出从声源的位置到达目标位置的目标传播路径。其中,目标位置可以是指三维模型中收听声音的位置,例如是目标人物的位置等。
根据所述剩余声能,确定所述目标位置的目标声音。
本方案中,为三维模型中的对象引入了与声音相关的材质参数。这些与声音相关的材质参数能够影响声音的传播路径以及声能的衰减量。基于各个对象中与声音相关的材质参数,能够计算声音在三维模型中的实际传播路径以及声音在实际传播路径中所衰减的声能,从而得到声音传播至收听者位置时的声音效果。基于本方案来实现虚拟环境中的声音处理,能够模拟声音在虚拟环境中的真实传播方式,提高处理以得到的声音的真实度,即提高声音的处理精度。
在一个可能的实现方式中,所述源声音包括一条或多条声音射线,所述根据所述目标参数和所述声音参数对所述源声音进行追踪处理,以确定所述源声音的一条或多条目标传播路径,包括:分别对所述一条或多条声音射线中的每条声音射线进行追踪,以得到所述一条或多条声音射线的追踪结果;根据所述一条或多条声音射线的追踪结果确定所述一条或多条目标传播路径。
其中,在分别对所述一条或多条声音射线中的每条声音射线进行追踪的过程中,若第三声音射线与所述第一对象存在交点,则根据所述第一对象的位置参数和形状参数确定由所述第三声音射线所产生的反射射线和折射射线,并继续对所述反射射线和所述折射射线进行追踪,所述第三声音射线为所述一条或多条声音射线中的任意一条声音射线。
本方案中,通过生成声音射线并对声音射线进行追踪,能够实现模拟声音在三维模型中的真实传播路径,从而提高处理得到的声音的真实度,即提高声音的处理精度。
在一个可能的实现方式中,所述根据所述剩余声能,确定所述目标位置的目标声音,包括:获取所述剩余声能与所述源声音的初始声能的比值;根据所述比值和所述源声音的初始响度,确定所述目标位置的目标声音的响度。其中,初始声能是指所述源声音在声源位置处的声能。初始响度则是指在声源位置处收听所述源声音时,所述源声音的响度。
在一个可能的实现方式中,第一目标传播路径包括一条或多条子传播路径,每条所述子传播路径为声音射线在所述三维模型中的两个对象之间的传播路径或声音射线在所述三维模型中的一个对象内的传播路径,所述第一目标传播路径为所述一条或多条目标传播路径中的任意目标传播路径。
在一个可能的实现方式中,所述根据所述第一对象的位置参数和形状参数确定由所述第三声音射线所产生的反射射线和折射射线,包括:根据所述第三声音射线在所述交点的入射角,确定所述第三声音射线在所述交点的反射角。其中,第三声音射线在交点的反射角角度等于入射角角度。
根据所述反射角以及所述声速,确定所述第三声音射线在所述交点的折射角。在确定第三声音射线在交点的反射角和折射角的情况下,电子设备相当于确定了反射射线和折射射线的传播方向,因此电子设备则可以根据所述反射角生成反射射线,以及根据所述折射角生成折射射线。
在一个可能的实现方式中,若所述一条或多条目标传播路径包括所述第三声音射线的传播路径和所述第三声音射线所产生的射线的传播路径,则所述确定所述源声音经过所述一条或多条目标传播路径传播后的剩余声能,包括:根据所述第三声音射线在与所述第一对象相交之前的传播距离,确定所述第三声音射线在所述交点所剩余的第一声能。即根据第三声音射线在空气中的传播距离,确定第三声音射线经过空气吸收后所剩余的声能。
根据所述第一对象的声阻抗参数确定所述第三声音射线在所述交点的反射系数,所述反射系数用于确定所述反射射线的声能以及所述折射射线的声能分别与所述第一声能的比例。
根据所述反射系数和所述第一声能确定所述反射射线的声能或所述折射射线的声能;根据反射射线的声能或所述折射射线的声能确定所述剩余声能。具体地,在确定反射射线以及折射射线的声能之后,可以根据实际到达目标位置的声音射线来确定源声音经过所述目标传播路径传播后的剩余声能。
在一个可能的实现方式中,由对象反射得到的反射射线包括一条镜面反射射线和多条漫反射射线。由于漫反射的射线是均匀地射向各个方向,因此漫反射的能量也是均匀地射向各个方向,漫反射的射线数量较多且能量分布较低,难以进行追踪。
因此,电子设备可以是只对镜面反射射线进行追踪。具体地,若所述一条或多条目标传播路径包括所述反射射线中的镜面反射射线的传播路径,则根据所述第一对象的漫反射系数和所述反射射线的声能确定所述镜面反射射线的声能。其中,漫反射系数表示漫反射射线的能量与反射射线的能量之间的比例,即漫反射能量占反射能量的比例。
根据所述镜面反射射线的传播距离和所述镜面反射射线的声能,确定所述镜面反射射线在空气中传播后到达所述目标位置时的第一剩余声能,所述剩余声能包括所述第一剩余声能。
在一个可能的实现方式中,第三声音射线在与第一对象的交点产生折射射线之后,折射射线在第一对象内传播一定距离后穿出第一对象外,并继续在空气中传播,直至到达目标位置。当折射射线在第一对象内传播时,折射射线会由于第一对象的声音吸收能力而发生声能衰减。
因此,若所述一条或多条目标传播路径包括所述折射射线的传播路径,则可以根据所述折射射线在所述第一对象中的传播距离、所述第一对象的声音吸收能力参数以及所述折射射线的声能,确定所述折射射线穿出所述第一对象时的第二剩余声能。由于折射射线在穿出对象时,即折射射线从对象内射入到空气时,折射射线会再次发生折射,从而产生新的反射射线以及新的折射射线。新的折射射线的声能即为折射射线穿出所述第一对象时的第二剩余声能。
根据所述第二剩余声能和所述折射射线穿出所述第一对象后的传播距离,确定所述折射射线在空气中传播后并到达所述目标位置时的第三剩余声能,所述剩余声能包括所述第三剩余声能。
本申请第二方面提供一种声音处理装置,包括:获取单元,用于获取三维模型的描述文件;处理单元,用于解析所述描述文件,以得到所述描述文件中的场景参数和声音参数;所述处理单元,还用于根据所述场景参数,渲染以得到所述三维模型;所述处理单元,还用于根据所述场景参数和所述声音参数,对所述三维模型中声源位置发出的源声音进行追踪处理,以得到目标位置的目标声音。
在一个可能的实现方式中,所述三维模型包括第一对象,所述声音参数包括所述第一对象的声阻抗参数、所述第一对象的声音吸收能力参数、所述第一对象的漫反射系数以及所述第一对象的声音传播速度中的一种或多种。
在一个可能的实现方式中,所述第一对象的声阻抗参数用于指示不同频率的声音在所述第一对象中传输时的声阻抗;所述第一对象的声音吸收能力参数用于指示所述第一对象对不同频率的声音的声能吸收能力;所述第一对象的漫反射系数用于指示所述第一对象对不同频率的声音的漫反射能力;所述第一对象的声音传播速度用于指示声音在所述第一对象中传输时的速度。
在一个可能的实现方式中,所述声音参数还包括所述第一对象的法线数据,所述第一对象的法线数据用于确定第一声音射线与所述第一对象相交时的反射角以及折射角,所述第一声音射线是所述源声音传播过程中的任意射线。
在一个可能的实现方式中,所述处理单元,还用于:解析所述描述文件,以得到所述描述文件中的全局参数;根据所述全局参数,确定是否停止对第二声音射线进行追踪处理,所述第二声音射线是所述源声音传播过程中的任意射线。
在一个可能的实现方式中,所述全局参数包括最小声能和/或最大递归深度;所述处理单元,具体用于包括:若所述第二声音射线的声能小于或等于所述最小声能,则停止对所述第二声音射线进行追踪处理;或者,若所述第二声音射线与所述三维模型中的一个或多个对象的相交次数大于或等于所述最大递归深度,则停止对所述第二声音射线进行追踪处理。
在一个可能的实现方式中,所述场景参数包括所述第一对象的位置参数、所述第一对象的形状参数、所述第一对象的材质参数和所述第一对象的纹理参数中的一种或多种。
在一个可能的实现方式中,所述获取单元,还用于获取所述场景参数中的目标参数;所述处理单元,具体用于根据所述目标参数和所述声音参数对所述源声音进行追踪处理,以确定所述源声音的一条或多条目标传播路径以及所述源声音经过所述一条或多条目标传播路径传播后的剩余声能,所述一条或多条目标传播路径为所述源声音从所述声源位置到达所述目标位置的一条或多条路径;所述处理单元,具体用于根据所述剩余声能,确定所述目标位置的目标声音。
在一个可能的实现方式中,所述源声音包括一条或多条声音射线,所述目标参数包括所述第一对象的位置参数和形状参数,所述处理单元,具体用于:分别对所述一条或多条声音射线中的每条声音射线进行追踪,以得到所述一条或多条声音射线的追踪结果;根据所述一条或多条声音射线的追踪结果确定所述一条或多条目标传播路径;其中,在分别对所述一条或多条声音射线进行追踪的过程中,若第三声音射线与所述第一对象存在交点,则根据所述第一对象的位置参数和形状参数确定由所述第三声音射线所产生的反射射线和折射射线,并继续对所述反射射线和所述折射射线进行追踪,所述第三声音射线为所述一条或多条声音射线中的任意一条声音射线。
在一个可能的实现方式中,所述处理单元,具体用于:获取所述剩余声能与所述源声音的初始声能的比值;根据所述比值和所述源声音的初始响度,确定所述目标位置的目标声音的响度。
在一个可能的实现方式中,第一目标传播路径包括一条或多条子传播路径,每条所述子传播路径为声音射线在所述三维模型中的两个对象之间的传播路径或声音射线在所述三维模型中的一个对象内的传播路径,所述第一目标传播路径为所述一条或多条目标传播路径中的任意目标传播路径。
本申请第三方面提供一种数据结构,所述数据结构应用于三维模型的描述文件,所述数据结构包括场景(scene),场景为三维模型的入口,场景下包括至少一个节点(node),节点为三维模型中的场景的组织者,用于描述场景的构成,每个节点下包括至少一个网格(mesh),网格用于描述在场景中出现的几何物体,即对象,每个网格包括材料(material)参数和PBA(Physical based audio)参数,PBA参数为声音参数,所述声音参数用于执行所述三维模型中的声音处理。在另一种可能的实现方式中,PBA参数放在material参数之下,material参数还包括PBR(Physical based rendering)参数。
在第三方面的一个可能的实现方式中,所述声音参数包括第一对象的声阻抗参数、所述第一对象的声音吸收能力参数、所述第一对象的漫反射系数以及所述第一对象的声音传播速度中的一种或多种。
在第三方面的一个可能的实现方式中,所述第一对象的声阻抗参数用于指示不同频率的声音在所述第一对象中传输时的声阻抗;所述第一对象的声音吸收能力参数用于指示所述第一对象对不同频率的声音的声能吸收能力;所述第一对象的漫反射系数用于指示所述第一对象对不同频率的声音的漫反射能力;所述第一对象的声音传播速度用于指示声音在所述第一对象中传输时的速度。
在第三方面的一个可能的实现方式中,所述声音参数还包括所述第一对象的法线数据。上述法线数据用于确定第一声音射线与所述第一对象相交时的反射角以及折射角,所述第一声音射线是所述源声音传播过程中的任意射线。
在第三方面的一个可能的实现方式中,上述数据结构还包括全局参数,上述全局参数用于指示对声音进行追踪处理的停止条件。例如,全局参数可以包括声音射线的最小声能和/或最大递归深度。具体地,所述全局参数可以放在数据结构中的节点之下。
本申请第四方面提供了一种电子设备,可以包括处理器,处理器和存储器耦合,存储器存储有程序指令,当存储器存储的程序指令被处理器执行时实现上述第一方面所述的方法。对于处理器执行第一方面的各个可能实现方式中的步骤,具体均可以参阅第一方面,此处不再赘述。
本申请第五方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面中任一实现方式所述的方法。
本申请第六方面提供了一种电路系统,所述电路系统包括处理电路,所述处理电路配置为执行上述第一方面或第一方面中任一实现方式所述的方法。
本申请第七方面提供了一种计算机程序产品,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面中任一实现方式所述的方法。
本申请第八方面提供了一种芯片系统,该芯片系统包括处理器,用于支持服务器或门限值获取装置实现上述第一方面中所涉及的功能,例如,发送或处理上述方法中所涉及的数据和/或信息。在一种可能的设计中,所述芯片系统还包括存储器,所述存储器,用于保存服务器或通信设备必要的程序指令和数据。该芯片系统,可以由芯片构成,也可以包括芯片和其他分立器件。
附图说明
图1为本申请实施例提供的声音处理方法的应用场景示意图;
图2为本申请实施例提供的一种电子设备101的结构示意图;
图3为本申请实施例提供的一种声音处理方法300的流程示意图;
图4A为本申请实施例提供的三维模型的描述文件的一种结构示意图;
图4B为本申请实施例提供的三维模型的描述文件的实例示意图;
图5为本申请实施例提供的三维模型的描述文件的另一种结构示意图;
图6A为本申请实施例提供的三维模型的描述文件的又一种结构示意图;
图6B为本申请实施例提供的一种描述文件中的全局参数的实例示意图;
图7为本申请实施例提供的一种声音射线与对象相交的示意图;
图8为本申请实施例提供的折射射线在穿出对象时的示意图;
图9为本申请实施例提供的一种声音处理过程中的递归示意图;
图10为本申请实施例提供的一种声音处理的场景图;
图11为本申请实施例提供的一种声音处理装置的结构示意图;
图12为本申请实施例提供的执行设备的一种结构示意图;
图13为本申请实施例提供的芯片的一种结构示意图。
具体实施方式
下面结合附图,对本申请的实施例进行描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。本领域普通技术人员可知,随着技术的发展和新场景的出现,本申请实施例提供的技术方案对于类似的技术问题,同样适用。
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。
此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或模块的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或模块,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或模块。在本申请中出现的对步骤进行的命名或者编号,并不意味着必须按照命名或者编号所指示的时间/逻辑先后顺序执行方法流程中的步骤,已经命名或者编号的流程步骤可以根据要实现的技术目的变更执行次序,只要能达到相同或者相类似的技术效果即可。
为便于理解,以下先对本实施例涉及的技术术语进行介绍。
VR技术是一种可以创建和体验虚拟世界的计算机仿真系统。VR技术利用现实生活中的数据,通过计算机技术产生的电子信号,将其与各种输出设备结合使其转化为能够让人们感受到的现象。这些现象具体是通过三维模型表现的,可以是现实中真真切切的物体,也可以是人们肉眼所看不到的物质。因为这些现象不是人们直接所能看到的,而是通过计算机技术模拟出来的现实中的世界,故称为虚拟现实。
VR中的虚拟环境是指被设计为仅包括针对至少一种感觉的计算机创建的感官输入的模拟环境。VR中的虚拟环境包括用户可与之交互和/或对其进行感知的多个虚拟对象。用户可通过在计算机创建的虚拟环境内模拟个体动作,来与VR环境中的虚拟对象进行交互和/或感知VR环境中的虚拟对象。
AR技术是一种将虚拟信息与真实世界巧妙融合的技术。AR技术广泛运用了多媒体、三维建模、实时跟踪及注册、智能交互以及传感等多种技术手段,将计算机生成的文字、图像、三维模型、音乐、视频等虚拟信息模拟仿真后,应用到真实世界中,从而实现对真实世界的“增强”。AR技术将原本在现实世界的空间范围中难以进行体验的实体信息在电脑等科学技术的基础上,实施模拟仿真处理,从而将虚拟信息内容叠加在真实世界中并加以有效应用。并且,通过AR技术将虚拟信息叠加在真实世界的过程能够被人类感官所感知,从而实现超越现实的感官体验。真实世界和虚拟物体之间重叠之后,能够在同一个画面以及空间中同时存在。
AR中的虚拟环境是指至少一个虚拟对象叠加在物理环境或其表示之上的模拟环境。例如,电子系统可具有不透明显示器和至少一个成像传感器,成像传感器用于捕获物理环境的图像或视频,这些图像或视频是物理环境的表示。系统将图像或视频与虚拟对象组合,并在不透明显示器上显示该组合。用户利用电子系统经由物理环境的图像或视频间接地查看物理环境,并且观察叠加在物理环境之上的虚拟对象。
AR中的虚拟环境也可以是指物理环境的表示被计算机创建的感官信息改变的模拟环境。例如,物理环境的表示的一部分可被以图形方式改变(例如,放大),使得所改变的部分仍可代表初始捕获的图像但不是真实还原的版本。
声能是指声音的能量。声音通过声波的方式在介质中传播。介质中传播声音时所具有的总能量与介质中无声波存在时的能量之差即为声能,因此声能也可以理解为声波所具有的能量。
三维模型是物体的多边形表示,通常用计算机或者其它视频设备进行显示。显示的物体可以是现实世界的实体,也可以是虚构的物体。任何物理自然界存在的东西都可以用三维模型表示。
以上介绍了本实施例所涉及的技术术语,以下将详细介绍本申请实施例所提供的声音处理方法。
在虚拟环境中,图像和声音是用户感知最强的两个要素。在图像渲染已经成熟的当下,声音的效果是否真实则成为了优化用户体验的关键。目前,相关技术中对虚拟环境中的声音进行处理的方式是:使用几何体积来表示声源和障碍物,并基于声源到收听者的距离以及声源与收听者之间的障碍物的体积来综合确定声音的效果。
然而,该方案主要考虑的是障碍物的体积对音频的阻挡效果以及距离对声音衰减的影响,并没有充分考虑声音的实际传播方式对声音衰减的影响,导致处理以得到的声音的精度较差。
经研究发现,在现实生活中,当声音遇到介质后将会发生如反射和折射等物理变化,从而改变声音的传播路径。相应的,人们听到的声音通常是经过阻挡物反射、绕过阻挡物或从阻挡物穿过的声音的混合效果。
其中,不同材质的阻挡物对声音的反射效果、折射效果以及吸收效果是不同的。例如,表面光滑且坚硬的阻挡物(比如墙壁)对声音的反射效果较好,表面粗糙且松软的阻挡物(比如沙堆)对声音的反射效果则较差。又例如,内部疏松多孔的阻挡物(比如海绵)对声音的吸收效果较好。
阻挡物对声音的反射和折射会改变声音的传播路径,声音的传播路径决定了声音是否能够到达收听者以及到达收听者的距离。并且,阻挡物本身对声音的吸收又会降低声音的能量,从而影响声音到达收听者时的效果。
有鉴于此,在本实施例中,为三维模型中的对象引入了与声音相关的材质参数。这些与声音相关的材质参数能够影响声音的传播路径以及声能的衰减量。基于各个对象中与声音相关的材质参数,能够计算声音的实际传播路径以及声音在实际传播路径中所衰减的声能,从而以得到声音传播至收听者位置时的声音效果。基于本实施例所提供的方案来实现虚拟环境中的声音处理,能够模拟声音在虚拟环境中的真实传播方式,提高处理以得到的声音的真实度,即提高声音的处理精度。
为了便于理解,以下先介绍本申请实施例提供的声音处理方法的应用场景。
可以参阅图1,图1为本申请实施例提供的声音处理方法的应用场景示意图。如图1所示,在一个虚拟环境中,存在着声源、收听者以及障碍物。该虚拟环境例如可以为游戏场景、AR场景或者VR场景中的虚拟环境。在该虚拟环境中,声源、收听者、障碍物1和障碍物2均处于由障碍物3所构成的封闭空间中。在声音处理过程中,电子设备需要计算从声源发出的声音经过传播后到达收听者所处的位置时的实际声音效果。
具体地,电子设备可以是根据虚拟环境中各个障碍物的材质参数,确定声音的传播路径,例如声音的反射路径和折射路径。电子设备再根据声音的传播路径确定声音在传播过程中的声能衰减量,从而以得到声音到达收听者所处的位置时的实际声音效果。
示例性地,在电子设备运行电子游戏的场景下,电子设备可以在游戏中建立各种三维模型,例如竞技场模型。并且,电子设备获取到游戏中三维模型的各种对象的材质参数,例如柱子、沙包、墙壁以及大门等对象的材质参数。随着游戏的推进,在电子设备所建立的三维模型的不同位置中,可能会出现不同的声源。例如,在游戏中的用户角色参与运动竞技比赛的过程中,赛道上可能会出现哨声,看台上可能会出现观众的呐喊声。
在电子设备运行导航应用的场景下,电子设备可以在虚拟环境中建立基于真实世界中的博物馆、智慧园区、机场、高铁站或商业建筑等空间所还原的三维模型。并且,电子设备获取到虚拟环境中三维模型的各种对象的材质参数,例如玻璃橱窗、广告牌、电梯以及建筑物等对象的材质参数。在电子设备所建立的三维模型的不同位置中,可以设置有不同的声源,以介绍三维模型中不同位置的特点。例如,在电子设备所建立的三维模型为博物馆的模型时,博物馆三维模型的不同路口上可以设置有相应的声源,这些声源分别用于介绍对应的路口所通向的地点。
在不同的场景下,电子设备均可以基于三维模型中各种对象的材质参数,确定声源所发出的声音在三维模型中的传播路径以及声音在传播过程中的声能衰减量,从而以得到各个位置下的声音效果。
本申请实施例提供的方法可以应用于能够在虚拟环境中构建三维模型的电子设备。示例性地,本申请实施例中的电子设备可以是服务器、智能手机(mobile phone)、个人电脑(personal computer,PC)、笔记本电脑、平板电脑、智慧电视、移动互联网设备(mobileinternet device,MID)、可穿戴设备(如智能手表、智能眼镜或者智能头盔等),虚拟现实(virtual reality,VR)设备、增强现实(augmented reality,AR)设备、工业控制(industrial control)中的无线电子设备、无人驾驶(self driving)中的无线电子设备、远程手术(remote medical surgery)中的无线电子设备、智能电网(smart grid)中的无线电子设备、运输安全(transportation safety)中的无线电子设备、智慧城市(smart city)中的无线电子设备、智慧家庭(smart home)中的无线电子设备等。以下实施例对该电子设备的具体形式不做特殊限制。
可以参阅图2,图2为本申请实施例提供的一种电子设备101的结构示意图。如图2所示,电子设备101包括处理器103,处理器103和系统总线105耦合。处理器103可以是一个或者多个处理器,其中每个处理器都可以包括一个或多个处理器核。显示适配器(videoadapter)107,显示适配器可以驱动显示器109,显示器109和系统总线105耦合。系统总线105通过总线桥111和输入输出(I/O)总线耦合。I/O接口115和I/O总线耦合。I/O接口115和多种I/O设备进行通信,比如输入设备117(如:触摸屏等),外存储器121,(例如,硬盘、软盘、光盘或优盘),多媒体接口等)。收发器123(可以发送和/或接收无线电通信信号),摄像头155(可以捕捉静态和动态数字视频图像)和外部USB端口125。其中,可选地,和I/O接口115相连接的接口可以是USB接口。
其中,处理器103可以是任何传统处理器,包括精简指令集计算(reducedinstruction set Computing,RISC)处理器、复杂指令集计算(complex instruction setcomputing,CISC)处理器或上述的组合。可选地,处理器可以是诸如ASIC的专用装置。
电子设备101可以通过网络接口129和软件部署服务器149通信。示例性的,网络接口129是硬件网络接口,比如,网卡。网络127可以是外部网络,比如因特网,也可以是内部网络,比如以太网或者虚拟私人网络(virtual private network,VPN)。可选地,网络127还可以是无线网络,比如WiFi网络,蜂窝网络等。
硬盘驱动器接口131和系统总线105耦合。硬件驱动接口和硬盘驱动器133相连接。内存储器135和系统总线105耦合。运行在内存储器135的数据可以包括电子设备101的操作系统(OS)137、应用程序143和调度表。
处理器103可以通过系统总线105与内存储器135通信,从内存储器135中取出应用程序143中的指令和数据,从而实现程序的执行。
操作系统包括Shell 139和内核(kernel)141。Shell 139是介于使用者和操作系统的内核间的一个接口。Shell 139是操作系统最外面的一层。Shell 139管理使用者与操作系统之间的交互:等待使用者的输入,向操作系统解释使用者的输入,并且处理各种各样的操作系统的输出结果。
内核141由操作系统中用于管理存储器、文件、外设和系统资源的那些部分组成。内核141直接与硬件交互,操作系统内核通常运行进程,并提供进程间的通信,提供CPU时间片管理、中断、内存管理和IO管理等等。
示例性地,在电子设备101为智能手机的情况下,应用程序143包括即时通讯相关的程序。在一个实施例中,在需要执行应用程序143时,电子设备101可以从软件部署服务器149下载应用程序143。
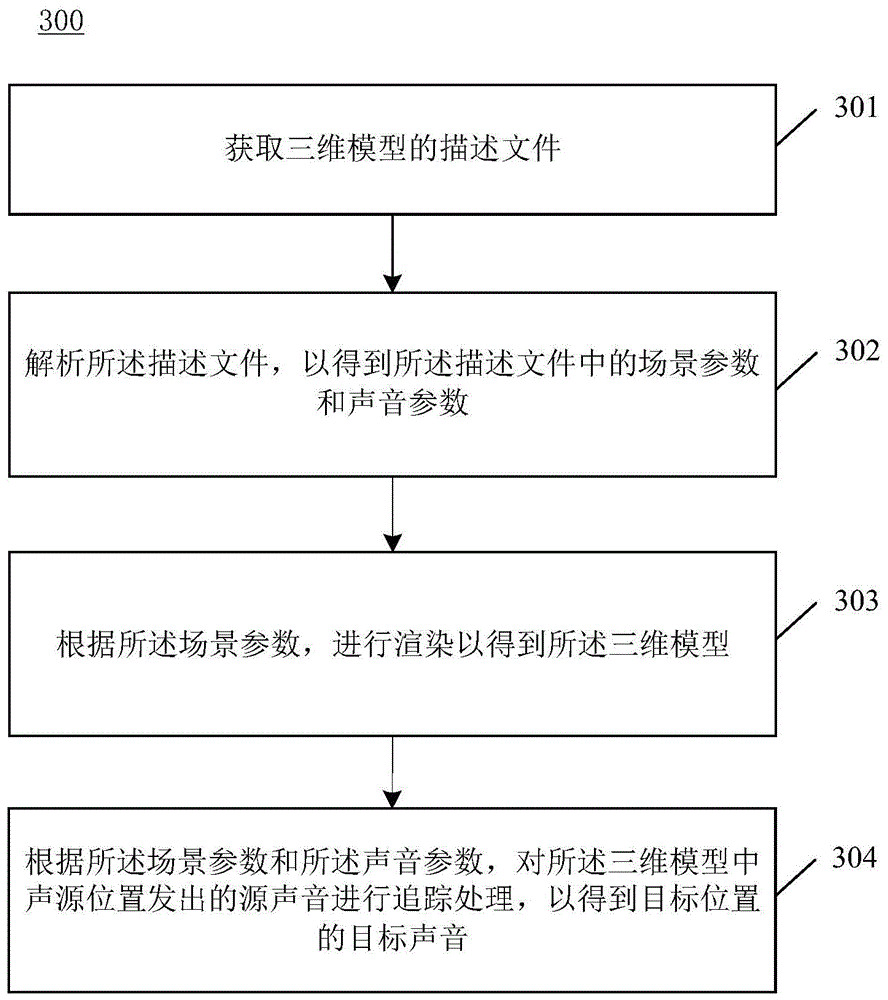
可以参阅图3,图3为本申请实施例提供的一种声音处理方法300的流程示意图。如图3所示,该声音处理方法300包括以下的步骤301-304。
步骤301,获取三维模型的描述文件。
其中,所述描述文件用于构建所述三维模型,所述描述文件中包括用于构建所述三维模型的各种要素。也就是说,所述描述文件中包括用于构建三维模型必备的对象参数。例如,所述描述文件中可以包括对象的位置、形状、表面纹理、颜色等基于物理的渲染(Physical based rendering,PBR)参数,这些PBR参数用于对三维模型进行模型渲染。
具体地,在三维模型中可以包括一个或多个对象。该一个或多个对象是指能够对声音的传播产生影响的物体。其中,三维模型中的对象对声音的传播产生影响是指对象能够改变声音的传播路径,以及降低声音的声能。示例性地,三维模型中的对象例如可以包括建筑物、树木、箱子、山峰、桥梁或汽车等物体,这些对象都能够影响三维模型中的声音传播。上述的第一对象可以为三维模型中的任意一个对象。
步骤302,解析所述描述文件,以得到所述描述文件中的场景参数和声音参数,所述场景参数用于渲染以得到所述三维模型,所述声音参数用于执行所述三维模型中的声音处理。
本实施例中,描述文件中的场景参数可以包括所述第一对象的位置参数、所述第一对象的形状参数、所述第一对象的材质参数和所述第一对象的纹理参数中的一种或多种。所述声音参数则包括影响声音在三维模型中的传播路径以及声能衰减量的参数。
可选的,描述文件中的声音参数用于表示三维模型中的对象的声音反射能力、声音折射能力和声音吸收能力。基于对象的声音反射能力和声音折射能力,电子设备可以确定传播过程中的声音在与对象相交时的反射方向、声音在反射后剩余的声能、折射方向以及声音在折射后剩余的声能。基于对象的基于声音吸收能力,电子设备可以确定声音在折射进入对象内部并穿过对象的过程中所衰减的声能。因此,基于对象的声音反射能力、声音折射能力和声音吸收能力,电子设备可以确定对象对传播过程中的声音所产生的影响。
此外,在三维模型中,声音参数也可以称为基于物理的音频(Physical basedaudio,PBA)参数。基于所述描述文件中的PBA参数,电子设备则能够实现三维模型中的声音处理,从而播放在三维模型中不同位置所收听到的声音。
步骤303,根据所述场景参数,进行渲染以得到所述三维模型。
在解析得到描述文件中的场景参数之后,基于所述描述文件中的场景参数,电子设备能够实现三维模型的渲染,从而以图像的形式在电子设备的显示设备上可视化地显示三维模型。
步骤304,根据所述场景参数和所述声音参数,对所述三维模型中声源位置发出的源声音进行追踪处理,以得到目标位置的目标声音。
在获取到三维模型中的场景参数和声音参数之后,电子设备可以基于场景参数和声音参数模拟声源所发出的源声音在三维模型中的传播路径。具体地,由于声源位置所发出的源声音是以声源位置为中心向四周传播的,而三维模型中的对象会对源声音的传播路径产生影响。因此,电子设备可以基于三维模型中的对象对声音的反射能力以及折射能力来确定源声音在三维模型中的各种传播路径。由于目标位置是唯一的,电子设备可以在源声音的各种传播路径中选择出从声源的位置到达目标位置的目标传播路径。其中,目标位置可以是指三维模型中收听声音的位置。
此外,在声音的传播过程中,声音无论是在空气中传播还是在对象中传播,都会产生声能的衰减。因此,电子设备可以根据三维模型中对象的声音吸收能力以及空气的声音吸收能力,确定源声音经过目标传播路径传播后的剩余声能。其中,源声音在声源的位置处会具有初始声能。源声音经过传播之后,声能发生衰减,源声音在到达目标位置时所剩余的声能即为所述源声音经过所述目标传播路径传播后的剩余声能。
示例性地,电子设备可以获取所述场景参数中的目标参数,所述目标参数包括所述第一对象的位置参数和形状参数。然后,电子设备根据所述目标参数和所述声音参数对所述源声音进行追踪处理,以确定所述源声音的一条或多条目标传播路径以及所述源声音经过所述一条或多条目标传播路径传播后的剩余声能,所述一条或多条目标传播路径为所述源声音从所述声源位置到达所述目标位置的一条或多条路径。
基于源声音在到达目标位置时所剩余的声能,即可确定目标位置的目标声音。在确定源声音到达目标位置后所剩余的声能的情况下,电子设备则可以基于剩余声音确定在所述目标位置收听到的目标声音的效果,从而在相应的音频设备上播放所述目标位置的目标声音。
示例性地,电子设备可以获取目标位置的剩余声能与所述源声音的初始声能的比值,并根据所述比值和所述源声音的初始响度,确定所述目标位置的响度。其中,初始声能是指所述源声音在声源位置处的声能。初始响度则是指在声源位置处收听所述源声音时,所述源声音的响度。
一般来说,响度又称为音量,是指人耳感受到的声音强弱。响度是人对声音大小的一个主观感觉量。响度的大小决定于声音接收处的波幅,就同一声源来说,波幅传播的愈远,响度愈小;当传播距离一定时,声源振幅愈大,响度愈大。
例如,假设目标位置的剩余声能为S1,源声音的初始声能为S0,源声音的初始响度为L0。那么,对于目标位置的响度L1,电子设备可以确定L1=L0*(S1/S0)。当目标位置的剩余声能为源声音的初始声能的1/2时,目标位置的响度则可以为源声音的响度的1/2。
在本实施例中,为三维模型中的对象引入了与声音相关的材质参数。这些与声音相关的材质参数能够影响声音的传播路径以及声能的衰减量。基于各个对象中与声音相关的材质参数,能够计算声音在三维模型中的实际传播路径以及声音在实际传播路径中所衰减的声能,从而以得到声音传播至收听者位置时的声音效果。基于本实施例所提供的方案来实现虚拟环境中的声音处理,能够模拟声音在虚拟环境中的真实传播方式,提高处理以得到的声音的真实度,即提高声音的处理精度。
具体来说,本实施例中提出了一种应用于三维模型中的对象的PBA材质参数。该PBA材质参数与三维模型的PBR材质类似,能够数值化地表示三维模型中的对象在声音传播方面的参数,例如声音反射、声音吸收以及声音折射方面的属性。此外,对象的PBA材质参数直接保存于三维模型的数据中,用于在不同平台实现三维虚拟环境的音频处理,提高三维模型下音频的真实感和处理效率。
在一个可能的实施例中,所述声音参数包括所述第一对象的声阻抗参数、所述第一对象的声音吸收能力参数、所述第一对象的漫反射系数以及所述第一对象的声音传播速度中的一种或多种。
其中,声阻抗参数指示了第一对象在传播声音时的声阻抗。声阻抗是指声音在介质中传播时需要克服的阻力。基于声阻抗参数,电子设备可以计算声波在与对象相交时,反射的声波与折射的声波的能量分配。对于不同频率的声音,同一个介质所对应的声阻抗也是不一样的。因此,所述声阻抗参数可以是用于指示不同频率的声音在所述第一对象中传输时的声阻抗。
声音吸收能力参数指示了第一对象对在该第一对象中传输的声音的声能吸收能力。示例性地,所述声音吸收能力参数可以包括对象的每米吸声量,用于指示声音在对象中每传输一米距离时,对象所吸收的声能。基于声音吸收能力参数,电子设备可以计算声波在对象中随传播距离增加的声能衰减量。
对于不同频率的声音,同一个介质所对应的声音吸收能力也是不一样的。因此,所述声音吸收能力参数可以用于指示所述第一对象对不同频率的声音的声能吸收能力。
漫反射系数指示了第一对象对声音的漫反射能力。一般来说,介质对声音进行反射时,会产生镜面反射和漫反射。镜面反射是指平行入射的声音射线射到反射面时,仍会平行地向一个方向反射出来。漫反射则是指平行入射的声音射线射到介质表面时,表面会把声音射线向着四面八方反射,因此入射的声音射线虽然互相平行,但反射射线实际上时向不同的方向无规则地反射,这种反射称之为漫反射。
基于此,漫反射能力则可以是指第一对象在反射声音的过程中,对象对声音进行漫反射的能力。基于漫反射系数,电子设备可以计算声波在反射过程中镜面反射和漫反射的能量分配。对于不同频率的声音,同一个介质所对应的漫反射系数也是不一样的。因此,所述目标参数中的漫反射系数可以用于指示所述第一对象对不同频率的声音的漫反射能力。
声速用于指示声音在所述第一对象中传输时的速度,也可以称为音速。
在实际应用中,描述文件中的声音参数可以包括多个对象的声音参数集合,每个对象的声音参数集合均包括声阻抗参数、声音吸收能力参数、漫反射系数以及声音传播速度中的一种或多种。
可选的,所述声音参数还包括:第一对象的法线数据。其中,所述第一对象的法线数据也可以称为法线贴图,法线数据是指在对象的凹凸表面的每个点上均作法线,并标记法线的方向。所述法线数据用于确定所述源声音与所述第一对象的交点的反射角以及折射角。基于法线数据,电子设备可以快速地求取源声音与对象的交点的反射角以及折射角,从而提高声音处理的效率。
示例性地,可以参阅表1,表1指示了三维模型中的某一个对象对应的声阻抗参数、声音吸收能力参数、漫反射系数以及声速等参数。这些参数分别指示了位于不同频率范围内的声音在该对象中传输时对应的声阻抗值、声音吸收能力值、漫反射系数以及声速值。其中,声阻抗的单位为Pa·s/m
表1
为了便于理解,以下将详细介绍三维模型的描述文件的数据结构。
可以参阅图4A和图4B,图4A为本申请实施例提供的三维模型的描述文件的一种结构示意图;图4B为本申请实施例提供的三维模型的描述文件的实例示意图。如图4A所示,在三维模型的描述文件的数据结构中,包括多个层级结构,分别为:场景(scene)、节点(node)、网格点(mesh)和材质(material)。其中,scene层级为三维模型中整个场景的入口点,scene层级下包括三维模型中整个场景的渲染相关参数以及声音参数;node层级为scene层级中的一个节点,node层级为三维模型中的场景的组织者,用于描述场景的构成;mesh层级位于node层级之下,用于描述在场景中出现的几何物体(即上述的对象);material层级位于mesh层级之下,material层级下包括了用于定义几何物体的模型外观的参数。
如图4A所示,在一个可能的实现方式中,material层级下包括了PBR参数和PBA参数。其中,PBR参数包括对象的位置、形状、表面纹理、颜色等用于渲染场景的参数;PBA参数则包括了声阻抗参数、声音吸收能力参数、漫反射系数以及声速等用于实现声音处理的参数。
如图4B所示,通过在描述文件的每个material层级下增加额外添加参数(extras)项,并在每个extras项中增加音频特征(HW_Feature_Audio)项来实现在描述文件中定义PBA参数。其中,HW_Feature_Audio项下的参数用于描述每个对象在声音处理过程中的相关参数,即上述的PBA参数。具体地,HW_Feature_Audio项下包括了每个对象自身所对应的PBA参数,即声阻抗、漫反射系数、声音吸收能力参数以及声速等参数。并且,对于声阻抗、漫反射系数以及声音吸收能力参数,分别表示了在不同频率的声音下所对应的声阻抗值、漫反射系数值、声音吸收能力值。
此外,如图4B所示,material层级下的PBR参数具体可以包括金属粗糙度、金属因子、粗糙因子、基础颜色纹理、标准纹理等参数。
对于法线数据,一般是以法线贴图的形式存在。在material层级下的PBR参数中包括有法线贴图的情况下,则可以复用material层级下的法线贴图参数;此外,也可以是在HW_Feature_Audio项下设置法线数据的描述方式。
可以参阅图5,图5为本申请实施例提供的三维模型的描述文件的另一种结构示意图。如图5所示,在另一个可能的实现方式中,PBA参数还可以是位于mesh层级之下,即mesh层级下包括了material层级和PBA参数,并且material层级下包括PBR参数。
在一种可能的实现方式中,PBA参数也可以位于node层级之下,与mesh层级并列。
可以参阅图6A,图6A为本申请实施例提供的三维模型的描述文件的又一种结构示意图。如图6A所示,三维模型的描述文件中还可以包括全局参数,该全局参数用于定义声音处理过程中停止对声音射线进行追踪的条件。其中,该全局参数可以是位于描述文件的scene层级之下。可以理解的是,在声音处理过程中,实际上是通过对声源位置所发出的一条或多条声音射线进行追踪处理来得到声音处理结果。通过全局参数来定义停止对声音射线进行追踪的条件,能够提前停止追踪部分对声音效果影响较小或者无影响的声音射线,从而降低对计算资源的消耗,提高声音处理速度。
可以参阅图6B,图6B为本申请实施例提供的一种描述文件中的全局参数的示意图。如图6B所示,描述文件的scenes层级下增加了extras项,并在extras项中增加HW_Feature_Audio项。HW_Feature_Audio项下包括声音最小声能、最大递归深度以及空气的每米吸声量等全局参数。其中,递归深度可以是指声音射线发生反射或折射,进而衍生出新的声音射线的次数;由于声音射线是在与对象相交时发生反射和折射,因此在声音处理算法中可以采用递归深度来表示声音射线与对象的相交次数。也就是说,上述的最大递归深度即可以理解为声音射线与对象的最大相交次数。因此,在HW_Feature_Audio项下,声音最小声能和最大递归深度均用于指示电子设备停止追踪声音射线的条件。当声音射线的声音小于或等于声音最小声能,或者声音射线与三维模型中的对象的相交次数大于或等于最大递归深度时,则停止对声音射线进行追踪处理。
值得注意的是,三维模型的描述文件中也可以不包括指示停止条件的全局参数,而是将全局参数写入到声音处理算法中。
为了便于理解,以下将详细介绍电子设备基于以上的目标参数确定声音的传播路径的过程。
在一个可能的实施例中,上述的步骤304(即根据所述场景参数和所述声音参数,对所述三维模型中声源位置发出的源声音进行追踪处理)具体包括以下的多个步骤。
首先,获取从所述声源发出的多条声音射线。
可以理解的是,在实际的物理世界中,同一个声源所发出的声音会向四面八方传播,即声音从声源所处的位置向三维空间中不同的方向传播。因此,本实施例中可以通过声音射线来模拟声源所发出的声音的传播方式。
具体地,电子设备可以是通过以声源所处的位置为中心点,均匀地向外发射多条不同角度的声音射线,来获取从所述声源发出的多条声音射线。每条声音射线的起点均为声源所处的位置,且每条声音射线的发射角度均不相同。此外,相邻的任意两条声音射线之间的角度差相同。也就是说,从声源所发出的多条声音射线近似于从三维球体的中心均匀地向三维球面发射的射线。
此外,对于从同一个声源发出的多条声音射线,每条声音射线的初始声能是相同的。电子设备具体可以根据声源所发出的实际声音来决定每条声音射线的初始声能。例如,在声源当前所发出的声音响度较大的情况下,电子设备所获取到的多条声音射线的初始声能也较大;在声源当前所发出的声音响度较小的情况下,电子设备所获取到的多条声音射线的初始声能也较小。
然后,分别对所述多条声音射线进行追踪,以得到所述多条声音射线的追踪结果。
在获取到从声源发出的多条声音追踪之后,电子设备则对所述多条声音射线中的每一条声音射线进行追踪,即追踪每条声音射线在三维模型中的传播路径,从而以得到每条声音的追踪结果。
具体地,在电子设备对声音射线进行追踪的过程中,声音射线在三维模型中的传播过程中通常包括以下的三种情况。
情况1,声音射线经过空气的传播,不与三维模型中的对象相交而到达目标位置。
在三维模型中,除了三维模型中的对象所处的位置,可以认为三维模型中的其他空间都充斥着空气。因此,在声音射线指向三维模型中目标位置且声源与目标位置之间不存在对象的情况下,该声音射线则会经过空气的传播而到达目标位置,且该声音射线在传播过程中不与三维模型中的对象相交。
在电子设备对声音射线的追踪过程中,电子设备可以将属于情况1中的声音射线的传播路径确定为目标传播路径。
此外,在电子设备确定某一条声音射线属于情况1的传播情况时,电子设备可以继续求取该声音射线在经过目标传播路径传播后的剩余声能,即求取该声音射线在到达目标位置后的剩余声能。具体地,电子设备可以根据声音射线在到达目标位置前在空气中的传播距离,以及空气吸收声能的能力来确定声音射线在经过目标传播路径传播后的剩余声能。
示例性地,当声音在空气中传播时,声音中的能量(即声能)会被吸收。其中,空气吸收声能的公式如以下的公式l所示。
E′=E-αh 公式1
其中,E′表示声音在空气中的传播距离为h时的所剩余的声能;E表示声音在空气中传输之前的初始声能;α表示声音在空气中每传播1米的吸声量,不同频率的声音有不同的吸声量,且α≥0;h表示声音在空气中的传播距离,单位为m。
情况2,声音射线经过空气的传播,不与三维模型中的对象相交且不到达目标位置。
在声音射线的发射方向并非是指向目标位置的方向,且声音射线的发射方向上不存在对象时,则声音射线在传播过程中不与三维模型中的对象相交且不到达目标位置。
例如,声音射线从声源所处的位置向与目标位置相反的方向发射,且该声音射线发射的方向上没有对象。又例如,声音射线发射的方向为从声源所处的位置指向天空的方向,声音射线在传播过程中不与三维模型中的任何对象相交且不到达目标位置。
在电子设备对声音射线的追踪过程中,电子设备可以将属于情况2中的声音射线的传播路径确定为非目标传播路径。
情况3,声音射线经过空气的传播后,与三维模型中的对象相交。
在声音射线指向任意方向的情况下,当声音射线所指向的方向上存在对象时,声音射线则会与三维模型中的对象相交。当声音射线与对象相交时,该对象会对声音射线产生反射以及折射,从而生成反射射线以及折射射线。其中,新生成的反射射线与折射射线会继续在三维模型中传播,且传播过程同样遵循上述的三种情况。即,新生成的反射射线或折射射线在传播过程同样可以是上述的情况1、情况2和情况3中的任意一种情况。
因此,电子设备通过追踪声音射线,发现声音射线与三维模型中的对象相交之后,电子设备生成相应的反射射线和折射射线,并且继续对新生成的反射射线和折射射线进行追踪,直至能够确认所追踪的声音射线是否到达目标位置。
可以理解的是,电子设备通过追踪从声源发出的声音射线并确认该声音射线与三维模型中的对象相交之后,电子设备继续追踪新生成的反射射线和折射射线。但是,在电子设备对新生成的反射射线和折射射线进行追踪的过程中,新生成的反射射线和折射射线可能仍会与三维模型中其他的对象相交并且进一步生成其他的反射射线和折射射线,因此电子设备可以是再继续追踪生成的声音射线,直至能够确认所追踪的声音射线是否到达目标位置。
简单来说,在电子设备追踪任意一条声音射线的过程中,如果该声音射线与对象相交而产生反射射线和折射射线时,电子设备则继续追踪新生成的反射射线和折射射线。其中,电子设备在追踪的任意一条新生成的反射射线和折射射线均属于声音射线。
其次,根据所述多条声音射线的追踪结果确定所述目标传播路径。
在电子设备获取到所述多条声音射线的追踪结果之后,相当于电子设备确定了每条声音射线的传播路径,因此电子设备可以从多条声音射线的传播路径中确定能够到达目标位置的目标传播路径。
为便于理解,以下将详细介绍声音射线在与三维模型中的对象相交时生成反射射线和折射射线的具体方式。
在一个可能的实施例中,在电子设备分别对所述多条声音射线进行追踪的过程中,若所述多条声音射线中的第三声音射线与所述三维模型中的对象存在交点,电子设备则根据所述第一对象的目标参数和声音参数确定由所述第三声音射线所产生的反射射线和折射射线,并继续对所述反射射线和所述折射射线进行追踪。其中,所述第三声音射线为从声源发出的多条声音射线中的任意一条声音射线。所述第一对象的目标参数包括所述第一对象的位置参数和形状参数。
具体地,电子设备可以根据所述第三声音射线在所述交点的入射角,确定所述第三声音射线在所述交点的反射角。其中,对于任意一条声音射线,声音射线在交点的反射角角度等于入射角角度。因此,电子设备可以基于第三声音射线在交点的入射角,确定所述第三声音射线在所述交点的反射角。
可选的,在与第三声音射线相交的对象的声音参数中具有法线数据的情况下,电子设备可以基于该对象的法线数据来确定该对象的交点处的法线方向,以得到该对象的交点处的平面方向,从而确定第三声音射线在所述交点的入射角。
通过采用对象的法线数据来计算声音射线在交点处的入射角,免却了计算交点处的平面方向的过程,提高了声音处理的效率。
在确定第三声音射线在交点的反射角之后,电子设备根据所述反射角以及对象的目标参数中的声速,确定所述第三声音射线在所述交点的折射角。在确定第三声音射线在交点的反射角和折射角的情况下,电子设备相当于确定了反射射线和折射射线的传播方向,因此电子设备则可以根据所述反射角生成反射射线,以及根据所述折射角生成折射射线。
示例性地,由于反射射线、折射射线和入射射线在同一个平面上,且折射射线的折射角的计算方式遵循斯涅耳定律,因此折射射线的折射角可以基于以下的公式2来计算以得到。
其中,θ
具体地,可以参阅图7,图7为本申请实施例提供的一种声音射线与对象相交的示意图。如图7所示,入射射线在空气中传播后与对象表面上的一点相交,并生成对应的反射射线和折射射线。其中,反射射线的反射角与入射射线的入射角相等,虚线表示对象中的交点的法线。折射射线的折射角则与空气的声速、对象的声速以及反射射线的反射角有关。
在第三声音射线所产生的反射射线或折射射线最终到达目标位置的情况下,电子设备则需要计算第三声音射线所产生的反射射线或折射射线最终到达目标位置时的剩余声能。具体地,电子设备需要计算第三声音射线在产生反射射线和折射射线时的声能分配,即所产生的反射射线和折射射线的声能,并根据反射射线或折射射线在后续传播过程中的声能衰减量确定反射射线或折射射线最终到达目标位置时的剩余声能。
示例性地,若目标传播路径包括所述第三声音射线的传播路径和所述第三声音射线所产生的射线的传播路径,则电子设备可以根据以下的多个步骤来计算第三声音射线目标传播路径的剩余声能。
首先,根据所述第三声音射线在与所述第一对象相交之前的传播距离,确定所述第三声音射线在所述交点所剩余的第一声能。
在第三声音射线与对象相交之前,所述第三声音射线在空气中传播了一定的距离,并衰减了一定的声能。因此,电子设备可以根据所述第三声音射线在与所述第一对象相交之前的传播距离以及空气的吸声能力,确定所述第三声音射线在所述交点所剩余的第一声能。
示例性地,电子设备可以根据上述的公式1来确定所述第三声音射线在所述交点所剩余的第一声能。
然后,根据所述第一对象的声阻抗参数确定所述第三声音射线在所述交点的反射系数,所述反射系数用于确定所述反射射线的声能以及所述折射射线的声能分别与所述第一声能的比例。
可以理解的是,当声音遇到三维模型中的对象时,即障碍物,声音的一部分声能被反射,另一部分声能则通过折射穿透至对象内部。假设,E
E
换句话说,当第三声音射线的声能为E
反射射线的声能与入射射线的声能之间的比例即为反射系数。反射系数的计算过程可以如公式4所示。
其中,γ
折射射线的声能与入射射线的声能之间的比例为折射系数。根据声音的折射定律,折射系数的计算方法如公式5所示。
其中,τ表示折射系数;E
因此,折射射线的声能可以基于以下的公式6来计算。
E
其中,τ表示折射系数;E
其次,根据所述反射系数和所述第一声能确定所述反射射线的声能或所述折射射线的声能。
在获取到第三声音射线在到达交点的第一声能时,基于上述的公式3和公式4,电子设备则可以确定反射射线的声能以及所述折射射线的声能。
最后,根据反射射线的声能或所述折射射线的声能确定所述剩余声能。
在确定反射射线以及折射射线的声能之后,可以根据实际到达目标位置的声音射线来确定源声音经过所述目标传播路径传播后的剩余声能。具体地,电子设备可以基于以下的两种情况分别确定源声音经过所述目标传播路径传播后的剩余声能。
情况1,目标传播路径包括所述反射射线中的镜面反射射线的传播路径,即第三声音射线产生的镜面反射射线到达目标位置。
一般来说,对于任意一条入射射线,由对象反射以得到的反射射线包括一条镜面反射射线和多条漫反射射线。其中,镜面反射射线的反射角与入射射线的入射角相同。多条漫反射射线则以交点为中心均匀地向射向四周的各个方向。在声音发生反射时,反射的能量可以分为镜面反射的能量和漫反射的能量。由于漫反射的射线是均匀地射向各个方向,因此漫反射的能量也是均匀地射向各个方向,漫反射的射线数量较多且能量分布较低,难以进行追踪。
基于此,在本实施例中,电子设备可以是只对镜面反射射线进行追踪。
可选的,电子设备可以根据所述第一对象的漫反射系数和所述反射射线的声能确定镜面反射射线的声能。其中,漫反射系数表示漫反射射线的能量与反射射线的能量之间的比例,即漫反射能量占反射能量的比例。
示例性地,电子设备可以基于公式7来确定镜面反射射线的声能。
E
其中,E
然后,电子设备根据所述镜面反射射线的传播距离和所述镜面反射射线的声能,确定所述镜面反射射线到达所述目标位置时的第一剩余声能,所述剩余声能包括所述第一剩余声能。
在产生镜面反射射线之后,镜面反射射线在空气中继续传播,最终到达目标位置。镜面反射射线在空气中传播的过程中,由于空气的吸声能力,镜面反射射线同样会衰减一部分的声能。因此,电子设备可以根据镜面反射射线从交点到目标位置的传播距离,以及空气的声音吸收能力,来确定镜面反射射线到达所述目标位置时的第一剩余声能,该第一剩余声能即为源声音到达目标位置时的剩余声能。具体地,电子设备可以是根据上述的公式1来确定镜面反射射线到达所述目标位置时的第一剩余声能。
情况2,所述目标传播路径包括所述折射射线的传播路径,即第三声音射线产生的折射射线到达目标位置。
第三声音射线在对象的交点产生折射射线之后,折射射线在对象内传播一定距离后穿出对象外,并继续在空气中传播,直至到达目标位置。当折射射线在对象内传播时,折射射线会由于对象的声音吸收能力而发生声能衰减。
因此,电子设备可以根据所述折射射线在所述第一对象中的传播距离、所述第一对象的声音吸收能力参数以及所述折射射线的声能,确定所述折射射线在对象内传播后所剩余的声能。
此外,由于折射射线在穿出对象时,即折射射线从对象内射入到空气时,折射射线会再次发生折射,从而产生新的反射射线以及新的折射射线。新的折射射线的声能即为折射射线穿出所述第一对象时的第二剩余声能。
可以参阅图8,图8为本申请实施例提供的折射射线在穿出对象时的示意图。如图8所示,折射射线在对象内传播至对象与空气的交界处时,折射射线产生反射以及折射,从而产生新的反射射线以及新的折射射线。其中,折射射线产生反射以及折射的规律与第三声音射线从空气中射至对象时产生的反射规律以及折射规律类似,具体可以参考上文的介绍,在此不再赘述。
示例性地,电子设备可以基于公式8和公式9来求取折射射线在对象内传播后所剩余的声能。
E
E
其中,E
在确定折射射线在对象内传播后所剩余的声能之后,电子设备可以基于公式10来确定新的折射射线的声能,即声音射线穿出所述第一对象时的第二剩余声能。
E
其中,τ表示折射系数;E
在产生新的折射射线之后,新的折射射线在空气中继续传播,最终到达目标位置。新的折射射线在空气中传播的过程中,由于空气的吸声能力,新的折射射线同样会衰减一部分的声能。因此,电子设备可以根据所述第二剩余声能和所述折射射线穿出所述第一对象后的传播距离,确定所述折射射线到达所述目标位置时的第三剩余声能,该第三剩余声能即为源声音到达目标位置时的剩余声能。具体地,电子设备可以是根据上述的公式1来确定镜面反射射线到达所述目标位置时的第三剩余声能。
可以理解的是,以上介绍了计算由第三声音射线所产生的反射射线和折射射线在到达目标位置时的剩余声能的过程,即从声源所发出的声音射线在与对象发生一次相交后则到达目标位置的情况。
在实际应用中,从声源所发出的声音射线可能会与三维模型中的多个对象发生多次相交后才到达目标位置,电子设备同样可以是根据以上的公式1-公式10来求取声音射线每次与对象相交时所产生的新的射线的角度和声能分配,从而计算以得到最终到达目标位置的声音射线的剩余声能。
在电子设备同时对大量声音射线进行持续追踪的情况下,需要耗费电子设备较多的计算资源,并降低电子设备的声音处理速度。因此,为了降低对电子设备计算资源的消耗,同时提高电子设备的声音处理速度,电子设备可以是提前停止追踪部分对目标位置的声音效果影响较小或者无影响的声音射线。
可选的,在对所述多条声音射线的追踪过程中,电子设备停止追踪满足预设条件的声音射线。其中,所述预设条件包括以下的三个条件中的任意一个。也就是说,当声音射线满足以下三个条件中的任意一个时,电子设备停止追踪该声音射线。
条件1,声音射线的声能小于或等于最小声能。
其中,最小声能的取值可以根据实际应用场景来确定或调整。例如,在电子设备的性能较高的情况下,最小声能的取值可以较小;在电子设备的性能较低的情况下,最小声能的取值则可以较大。
当声音射线的声能小于或等于最小声能时,可以认为该声音射线对最终的声音效果影响很小,因此可以停止追踪该声音射线。
条件2,声音射线与所述三维模型中的对象的相交次数大于或等于最大递归深度。
本实施例中,声音射线与所述三维模型中的对象的相交次数是指该声音射线与对象的相交次数以及该声音射线的上游射线与对象的相交次数之和。其中,声音射线的上游射线是指影响该声音射线的产生的射线。例如,从声源的位置所发出的声音射线1与对象相交后产生声音射线2,声音射线2与其他的对象相交后产生声音射线3,那么声音射线1和声音射线2均为声音射线3的上游射线。
示例性地,从声源发出的声音射线与对象相交后产生反射射线和折射射线,则可以认为声音射线与对象的相交次数为1;该声音射线与对象相交后所产生反射射线或折射射线与其他的对象相交后,则可以认为该反射射线或折射射线与对象的相交次数为2;同理,反射射线或折射射线与其他的对象相交后所产生的新的反射射线或新的折射射线继续与其他的对象相交后,则可以认为新的反射射线或新的折射射线与对象的相交次数为3。
其中,最大递归深度的取值同样可以根据实际应用场景来确定或调整。例如,在电子设备的性能较高的情况下,最大递归深度的取值可以较大,例如最大递归深度的取值为3;在电子设备的性能较低的情况下,最大递归深度的取值则可以较小,例如最大递归深度的取值为1。
当声音射线与所述三维模型中的对象的相交次数大于或等于最大递归深度时,可以认为该声音射线是经过了多次与对象相交后所产生的射线。由于在产生该声音射线之前,该声音射线的上游射线已经与对象发生了多次相交,声能衰减较多,因此该声音射线实际所剩余的声能较低,对最终的声音效果影响很小,因此可以停止追踪该声音射线。
对于条件1和条件2,电子设备可以通过解析描述文件,得到描述文件中的全局参数,并根据全局参数来确定是否停止对声音射线进行追踪处理。
示例性地,电子设备在解析得到描述文件中的全局参数后,根据所述全局参数,确定是否停止对第二声音射线进行追踪处理,所述第二声音射线是所述源声音传播过程中的任意射线。所述全局参数包括条件1所述的最小声能和/或条件2所述的最大递归深度。
在电子设备根据全局参数,确定是否停止对第二声音射线进行追踪处理的过程中,若所述第二声音射线的声能小于或等于所述最小声能,则停止对所述第二声音射线进行追踪处理;或者,若所述第二声音射线与所述三维模型中的一个或多个对象的相交次数大于或等于所述最大递归深度,则停止对所述第二声音射线进行追踪处理。
条件3,声音射线与所述三维模型中的对象不相交且所述声音射线不经过所述目标位置。
如果某一条声音射线与所述三维模型中的任意一个对象均不相交,并且该声音射线不经过所述目标位置,那么该声音射线最终并不会到达目标位置,即不对目标位置的声音效果产生影响。因此,电子设备可以停止追踪不会到达目标位置的声音射线。
可以理解的是,在实际应用中,电子设备除了追踪从声源的位置所发出的声音射线之外,电子设备还会追踪由对象反射以得到的反射射线以及由对象折射以得到的折射射线等声音射线。在电子设备追踪上述的任意一条声音射线的过程中,如果电子设备确认该声音射线满足上述的预设条件,则电子设备可以停止追踪该声音射线。
本实施例中,通过停止追踪满足预设条件的声音射线,能够提前停止追踪部分对目标位置的声音效果影响较小或者无影响的声音射线,从而降低对电子设备计算资源的消耗,提高电子设备的声音处理速度。
基于上述的三维模型的描述文件对三维模型中的声音进行处理的过程包括以下的步骤1-步骤6。
步骤1,系统初始化。设置系统参数,指定声音最小声能和最大递归深度,避免声音射线不断地进行反射和折射。加载三维模型的描述文件中各个对象的PBA材质。
步骤2,从声源中心点出发,朝周围各个角度均匀射出声音射线,每条声音射线具有的声能均为声源具有的声能。
步骤3,通过追踪声音射线,来求取声音射线与三维场景中对象的交点,并根据空气的每米吸收量以及声音射线在射到交点前的传输距离计算声音射线在交点处的剩余声能。
步骤4,从交点处沿反射方向和折射方向分别衍生一条反射射线和一条折射射线。进一步地,根据对象的声阻抗、声速、漫反射系数、声音吸收能力参数和法线数据计算镜面反射、漫反射和折射方向的声能分配及折射角,并将镜面反射的声能作为反射射线的声能。当折射射线离开对象时,根据对象的声音吸收能力参数计算随距离增加而产生的声能吸收,获得折射射线出射时的最终声能。
步骤5,分别对衍生出的反射射线和折射射线递归地执行步骤3-步骤4。每当声音射线发生反射或折射时,增加声音射线的递归深度。一般来说,当声音射线与三维模型中的对象相交时,声音射线会发生反射和折射。因此,在确定声音射线发生反射或折射时,可以确定声音射线与对象发生了相交,声音射线每发生反射或折射一次,则可以认为声音射线与对象发生一次相交。此外,在实际的应用中,为了便于声音处理算法的编写,以下将以递归深度来表示声音射线与三维模型中的对象的相交次数。当声音射线与三维模型中的任何物体均不相交且不经过收听者的位置,或声音射线的声能小于最小声能,或声音射线的递归深度大于最大递归深度时,停止递归过程。
步骤6,递归结束,计算声音射线在收听者位置所叠加的声能与声音射线的初始声能的比值,从而基于该比值以及声源位置的响度确定收听者位置的响度。
具体地,可以参阅图9,图9为本申请实施例提供的一种声音处理过程中的递归示意图。如图9所示,在递归过程中,首先从声源发出多条声音射线,并追踪每一条声音射线。
在声音射线的追踪过程中,判断声音射线是否到达收听者位置。
如果声音射线到达收听者位置,则继续判断声音射线的声能是否小于最小声能。若声音射线的声能小于最小声能,则停止追踪该声音射线;若声音射线的声能不小于最小声能,则加上该声音射线到达收听者位置的剩余声能,以用于后续求取收听者位置的响度。
如果声音射线不到达收听者位置,则判断声音射线是否与三维模型中的对象有交点。若声音射线与对象不存在交点,则停止追踪该声音射线;若声音射线与对象存在交点,则继续判断该声音射线在到达与对象的交点处时的声能是否小于最小声能。
假如声音射线在到达与对象的交点处时的声能小于最小声能,则停止追踪该声音射线;假如声音射线在到达与对象的交点处时的声能不小于最小声能,则生成该声音射线对应的反射射线和折射射线,并分别计算反射射线和折射射线的声能,以便于后续继续追踪反射射线和折射射线。
在生成反射射线和折射射线之后,将声音射线对应的递归深度加1,并判断当前的递归深度是否大于最大递归深度。若当前的递归深度大于最大递归深度,则停止追踪新生成的反射射线和折射射线;若当前的递归深度不大于最大递归深度,则继续按照上述的递归过程追踪新生成的反射射线和折射射线。
为便于理解,以下将结合附图以及示例详细介绍在三维模型中追踪声音射线的过程。
可以参阅图10,图10为本申请实施例提供的一种声音处理的场景图。如图10所示,以图10中的房间模型作为虚拟环境中需进行声音处理的三维模型。图10所示的房间模型中包括书房、卧室和书架,书架隔在书房和卧室之间,且书架与墙壁之间还预留有一条用于连接书房和卧室的通道。
在图10的房间模型中,书房的书桌上放置有正在播放音乐的智能手机,卧室的床上则躺有正在休息的收听者。电子设备需要计算智能手机所播放的音乐在房间内传播后,到达收听者时的声音效果。具体地,电子设备可以是以智能手机为中心,向各个方向发射声音射线,并追踪每条声音射线的传播路径。
以图10中的4条声音射线为例,声音射线1从智能手机处出发后射到书架上,并产生相应的反射射线(图中未示出)和折射射线。声音射线1所产生的折射射线在书架中继续传播,并在穿出书架时再次发生折射,从而生成新的折射射线。最终,新的折射射线经过空气的传播后到达收听者的位置。
声音射线2从智能手机处出发后射到书架上,并产生相应的反射射线(图中未示出)和折射射线。声音射线2所产生的折射射线在书架中继续传播,并在穿出书架时再次发生折射,从而生成新的折射射线。新的折射射线在空气中传播一定距离后射到房间的墙壁上,并产生相应的反射射线和折射射线(图中未示出)。经由墙壁所产生的反射射线经过空气的传播后到达收听者的位置。
声音射线3从智能手机处出发后射到房间的墙壁上,并产生相应的反射射线和折射射线(图中未示出)。经由墙壁所产生的反射射线经过空气的传播后到达收听者的位置。
声音射线4从智能手机处出发后射到窗户外,不与房间中的任何对象相交。因此,在确定声音射线4不与房间中的任何对象相交且不经过收听者位置时,可以停止追踪声音射线4。
在追踪以得到声音射线1、声音射线2和声音射线3分别衍生的射线最终到达收听者的位置的情况下,计算最终到达收听者位置的多条声音射线的剩余声能,并叠加多条声音射线的剩余声能。然后,计算多条声音射线的剩余声能的叠加值与多条声音射线的初始声能之间的比例,并根据该比例和智能手机所播放的声音的初始响度,确定收听者位置收听到的声音的响度。
在图1至图10所对应的实施例的基础上,为了更好的实施本申请实施例的上述方案,下面还提供用于实施上述方案的相关设备。
可以参阅图11,图11为本申请实施例提供的一种声音处理装置的结构示意图。如图11所示,该声音处理装置包括获取单元1101和处理单元1102;获取单元1101,用于获取三维模型的描述文件;处理单元1102,用于解析所述描述文件,以得到所述描述文件中的场景参数和声音参数;所述处理单元1102,还用于根据所述场景参数,进行渲染以得到所述三维模型;所述处理单元1102,还用于根据所述场景参数和所述声音参数,对所述三维模型中声源位置发出的源声音进行追踪处理,以得到目标位置的目标声音。
在一个可能的实现方式中,所述三维模型包括第一对象,所述声音参数包括所述第一对象的声阻抗参数、所述第一对象的声音吸收能力参数、所述第一对象的漫反射系数以及所述第一对象的声音传播速度中的一种或多种。
在一个可能的实现方式中,所述第一对象的声阻抗参数用于指示不同频率的声音在所述第一对象中传输时的声阻抗;所述第一对象的声音吸收能力参数用于指示所述第一对象对不同频率的声音的声能吸收能力;所述第一对象的漫反射系数用于指示所述第一对象对不同频率的声音的漫反射能力;所述第一对象的声音传播速度用于指示声音在所述第一对象中传输时的速度。
在一个可能的实现方式中,所述声音参数还包括所述第一对象的法线数据,所述法线数据用于确定第一声音射线与所述第一对象相交时的反射角以及折射角,所述第一声音射线是所述源声音传播过程中的任意射线。
在一个可能的实现方式中,所述处理单元1102,还用于:解析所述描述文件,以得到所述描述文件中的全局参数;根据所述全局参数,确定是否停止对第二声音射线进行追踪处理,所述第二声音射线是所述源声音传播过程中的任意射线。
在一个可能的实现方式中,所述全局参数包括最小声能和/或最大递归深度;所述处理单元1102,具体用于包括:若所述第二声音射线的声能小于或等于所述最小声能,则停止对所述第二声音射线进行追踪处理;或者,若所述第二声音射线与所述三维模型中的一个或多个对象的相交次数大于或等于所述最大递归深度,则停止对所述第二声音射线进行追踪处理。
在一个可能的实现方式中,所述场景参数包括所述第一对象的位置参数、所述第一对象的形状参数、所述第一对象的材质参数和所述第一对象的纹理参数中的一种或多种。
在一个可能的实现方式中,所述获取单元1101,还用于获取所述场景参数中的目标参数;所述处理单元1102,具体用于根据所述目标参数和所述声音参数对所述源声音进行追踪处理,以确定所述源声音的一条或多条目标传播路径以及所述源声音经过所述一条或多条目标传播路径传播后的剩余声能,所述一条或多条目标传播路径为所述源声音从所述声源位置到达所述目标位置的一条或多条路径;所述处理单元1102,具体用于根据所述剩余声能,确定所述目标位置的目标声音。
在一个可能的实现方式中,所述源声音包括一条或多条声音射线,所述目标参数包括所述第一对象的位置参数和形状参数,所述处理单元1102,具体用于:分别对所述一条或多条声音射线进行追踪,以得到所述一条或多条声音射线的追踪结果;根据所述一条或多条声音射线的追踪结果确定所述一条或多条目标传播路径;其中,在分别对所述一条或多条声音射线进行追踪的过程中,若第三声音射线与所述第一对象存在交点,则根据所述第一对象的位置参数和形状参数确定由所述第三声音射线所产生的反射射线和折射射线,并继续对所述反射射线和所述折射射线进行追踪,所述第三声音射线为所述一条或多条声音射线中的任意一条声音射线。
在一个可能的实现方式中,所述处理单元1102,具体用于:获取所述剩余声能与所述源声音的初始声能的比值;根据所述比值和所述源声音的初始响度,确定所述目标位置的响度。
在一个可能的实现方式中,第一目标传播路径包括一条或多条子传播路径,每条所述子传播路径为声音射线在所述三维模型中的两个对象之间的传播路径或声音射线在所述三维模型中的一个对象内的传播路径,所述第一目标传播路径为所述一条或多条目标传播路径中的任意目标传播路径。
接下来介绍本申请实施例提供的一种电子设备,请参阅图12,图12为本申请实施例提供的电子设备的一种结构示意图,电子设备1200具体可以表现为手机、平板、笔记本电脑、智能穿戴设备、服务器等,此处不做限定。其中,电子设备1200上可以部署有图11对应实施例中所描述的声音处理装置,用于实现图11对应实施例中声音处理的功能。具体的,电子设备1200包括:接收器1201、发射器1202、处理器1203和存储器1204(其中电子设备1200中的处理器1203的数量可以一个或多个,图12中以一个处理器为例),其中,处理器1203可以包括应用处理器12031和通信处理器12032。在本申请的一些实施例中,接收器1201、发射器1202、处理器1203和存储器1204可通过总线或其它方式连接。
存储器1204可以包括只读存储器和随机存取存储器,并向处理器1203提供指令和数据。存储器1204的一部分还可以包括非易失性随机存取存储器(non-volatile randomaccess memory,NVRAM)。存储器1204存储有处理器和操作指令、可执行模块或者数据结构,或者它们的子集,或者它们的扩展集,其中,操作指令可包括各种操作指令,用于实现各种操作。
处理器1203控制电子设备的操作。具体的应用中,电子设备的各个组件通过总线系统耦合在一起,其中总线系统除包括数据总线之外,还可以包括电源总线、控制总线和状态信号总线等。但是为了清楚说明起见,在图中将各种总线都称为总线系统。
上述本申请实施例揭示的方法可以应用于处理器1203中,或者由处理器1203实现。处理器1203可以是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器1203中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器1203可以是通用处理器、数字信号处理器(digital signal processing,DSP)、微处理器或微控制器,还可进一步包括专用集成电路(application specific integratedcircuit,ASIC)、现场可编程门阵列(field-programmable gate array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。该处理器1203可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本申请实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器1204,处理器1203读取存储器1204中的信息,结合其硬件完成上述方法的步骤。
接收器1201可用于接收输入的数字或字符信息,以及产生与电子设备的相关设置以及功能控制有关的信号输入。发射器1202可用于通过第一接口输出数字或字符信息;发射器1202还可用于通过第一接口向磁盘组发送指令,以修改磁盘组中的数据;发射器1202还可以包括显示屏等显示设备。
本申请实施例中还提供一种包括计算机程序产品,当其在计算机上运行时,使得计算机执行如前述执行设备所执行的步骤,或者,使得计算机执行如前述训练设备所执行的步骤。
本申请实施例中还提供一种计算机可读存储介质,该计算机可读存储介质中存储有用于进行信号处理的程序,当其在计算机上运行时,使得计算机执行如前述执行设备所执行的步骤,或者,使得计算机执行如前述训练设备所执行的步骤。
本申请实施例提供的执行设备或终端设备具体可以为芯片,芯片包括:处理单元和通信单元,所述处理单元例如可以是处理器,所述通信单元例如可以是输入/输出接口、管脚或电路等。该处理单元可执行存储单元存储的计算机执行指令,以使执行设备内的芯片执行上述实施例描述的编译方法。可选地,所述存储单元为所述芯片内的存储单元,如寄存器、缓存等,所述存储单元还可以是所述无线接入设备端内的位于所述芯片外部的存储单元,如只读存储器(read-only memory,ROM)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,RAM)等。
具体的,请参阅图13,图13为本申请实施例提供的芯片的一种结构示意图,所述芯片可以表现为处理器1300,NPU 1300作为协处理器挂载到主CPU(Host CPU)上,由Host CPU分配任务。NPU的核心部分为运算电路1303,通过控制器1304控制运算电路1303提取存储器中的矩阵数据并进行乘法运算。
在一些实现中,运算电路1303内部包括多个处理单元(Process Engine,PE)。在一些实现中,运算电路1303是二维脉动阵列。运算电路1303还可以是一维脉动阵列或者能够执行例如乘法和加法这样的数学运算的其它电子线路。在一些实现中,运算电路1303是通用的矩阵处理器。
举例来说,假设有输入矩阵A,权重矩阵B,输出矩阵C。运算电路从权重存储器1302中取矩阵B相应的数据,并缓存在运算电路中每一个PE上。运算电路从输入存储器1301中取矩阵A数据与矩阵B进行矩阵运算,以得到的矩阵的部分结果或最终结果,保存在累加器(accumulator)1308中。
统一存储器1306用于存放输入数据以及输出数据。权重数据直接通过存储单元访问控制器(Direct Memory Access Controller,DMAC)1305,DMAC被搬运到权重存储器1302中。输入数据也通过DMAC被搬运到统一存储器1306中。
BIU为Bus Interface Unit即,总线接口单元1313,用于AXI总线与DMAC和取指存储器(Instruction Fetch Buffer,IFB)1309的交互。
总线接口单元1313(Bus Interface Unit,简称BIU),用于取指存储器1309从外部存储器获取指令,还用于存储单元访问控制器1305从外部存储器获取输入矩阵A或者权重矩阵B的原数据。
DMAC主要用于将外部存储器DDR中的输入数据搬运到统一存储器1306或将权重数据搬运到权重存储器1302中或将输入数据数据搬运到输入存储器1301中。
向量计算单元1307包括多个运算处理单元,在需要的情况下,对运算电路1303的输出做进一步处理,如向量乘,向量加,指数运算,对数运算,大小比较等等。主要用于神经网络中非卷积/全连接层网络计算,如Batch Normalization(批归一化),像素级求和,对特征平面进行上采样等。
在一些实现中,向量计算单元1307能将经处理的输出的向量存储到统一存储器1306。例如,向量计算单元1307可以将线性函数;或,非线性函数应用到运算电路1303的输出,例如对卷积层提取的特征平面进行线性插值,再例如累加值的向量,用以生成激活值。在一些实现中,向量计算单元1307生成归一化的值、像素级求和的值,或二者均有。在一些实现中,处理过的输出的向量能够用作到运算电路1303的激活输入,例如用于在神经网络中的后续层中的使用。
控制器1304连接的取指存储器(instruction fetch buffer)1309,用于存储控制器1304使用的指令;
统一存储器1306,输入存储器1301,权重存储器1302以及取指存储器1309均为On-Chip存储器。外部存储器私有于该NPU硬件架构。
其中,上述任一处提到的处理器,可以是一个通用中央处理器,微处理器,ASIC,或一个或多个用于控制上述程序执行的集成电路。
另外需说明的是,以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本申请提供的装置实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条或多条通信总线或信号线。
通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件的方式来实现,当然也可以通过专用硬件包括专用集成电路、专用CPU、专用存储器、专用元器件等来实现。一般情况下,凡由计算机程序完成的功能都可以很容易地用相应的硬件来实现,而且,用来实现同一功能的具体硬件结构也可以是多种多样的,例如模拟电路、数字电路或专用电路等。但是,对本申请而言更多情况下软件程序实现是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以软件产品的形式体现出来,该计算机软件产品存储在可读取的存储介质中,如计算机的软盘、U盘、移动硬盘、ROM、RAM、磁碟或者光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,训练设备,或者网络设备等)执行本申请各个实施例所述的方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。
所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、训练设备或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、训练设备或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的训练设备、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘(Solid State Disk,SSD))等。