面向张量计算单元卷积算子优化实现方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及的是一种人工智能领域的技术,具体是一种面向NVIDIA GPU的张量计算单元(Tensor Core)卷积算子优化实现方法。
背景技术
深度学习编译器技术被提出以提升深度学习算子的研发效率,其中TVM编译优化技术能够有效的解决融合算子的自动代码生成问题。然而TVM生成的算子性能,极度依赖于算子调度策略的开发以及调度空间的设计。实际深度学习的业务场景要求TVM生成的算子性能和手工优化一样发挥硬件的极致性能。
现有的通用矩阵乘(GEMM)运算加速技术应用领域较为狭窄,或无法进行卷积算子的计算或无法运行融合算子,现有的改进GEMM处理技术则基于汇编指令集的操作编程难度较大,也不具备跨平台的通用性。
发明内容
本发明针对现有技术存在的上述不足,提出一种面向张量计算单元卷积算子优化实现方法,通过领域领域特定语言(DSL)编写卷积算子的计算与面向张量计算单元的调度,然后通过自动调优技术生成卷积计算代码,本发明能够提升半精度计算中卷积算子自动代码生成的性能,为神经网络推理计算中融合算子的自动代码生成的性能提供保证。
本发明是通过以下技术方案实现的:
本发明涉及一种面向张量计算单元卷积算子优化实现方法,通过深度学习编译器的DSL表示卷积算子,经对卷积计算进行坐标变换得到隐式通用矩阵乘法的计算表示;然后对卷积算子进行调度优化得到调度模板后,经搜索得到最优搜索参数并通过深度学习编译器的后端生成CUDA C代码,再将生成的CUDA C代码集成入神经网络,实现卷积神经网络在NVIDIA GPU平台上的推理速度提升。
所述的对卷积算子进行面向Tensor Core的调度优化,得到调度模板,具体包括:
步骤1)对输入数据、权重数据以及输出结果分别进行局部存储器(sharedmemory)和张量寄存器(wmma fragment)的缓存。
步骤2)利用半精度浮点类型存储空间小的特点,对缓存读写步骤进行双缓冲调度优化。
步骤3)利用半精度浮点类型读写带宽高的优势,对缓存读写步骤进行向量化调度优化。
步骤4)对计算维度进行切分,即将GEMM_M维度切分为bm,tm,om,im四个维度;将GEMM_N维度切分为bn,tn,on,in四个维度;根据切分参数im、in将GEMM_K切分为ok,ik两个维度。
步骤5)进行GPU的线程块绑定和线程绑定,即分别将切分出的维度bm绑定至blockIdx.y、tm绑定至threadIdx.y、bn绑定至blockIdx.x、in绑定至threadIdx.x。
步骤6)将未绑定的计算维度,映射为wmma::mma_sync表示的GEMM计算;经绑定后实现每个线程块将计算om*on个GEMM,计算的结果尺寸为im*in。
所述的切分,其参数为可搜索的参数模板,通过深度学习编译器中的自动搜索方式得到最优的切分参数。
为了参数搜索的高效性,本发明针对计算尺寸和硬件架构的特点,对切分参数im、in的搜索空间与搜索方法进行了特殊的设计,具体包括:
①当GEMM_M为32的倍数时,设置im的搜索空间为[8,16,32]并转到步骤④;否则转到步骤②。
②当GEMM_M为16的倍数时,设置im的搜索空间为[8,16]并转到步骤④;否则转到步骤③。
③设置im的搜索空间为[8]。
④对im进行参数搜索和调优。
⑤根据im的搜索结果,确定in的值:当im的的搜索空间为8、16或32时,in对应为32、16或8。
本发明涉及一种实现上述方法的系统,包括:算子表示单元、调度优化单元、参数搜索单元、代码生成单元以及推理优化单元,其中:算子表示单元根据用户给定的计算语义适用深度学习编译器的DSL表达出计算逻辑;调度优化单元根据算子的计算逻辑以及硬件平台的架构特点对算子进行调度优化处理,得到算子的调度优化模版;参数搜索单元根据调度优化参数模版信息,进行启发式搜索,得到最优的切分参数;代码生成单元根据最优的切分参数,生成高效的CUDA C代码;推理优化单元将生成的CUDA C代码与NVIDIA GPU平台上的神经网络进行编译连接,实现卷积神经网络的推理加速。
技术效果
本发明利用Implicit GEMM算法的坐标变换对卷积算子进行调度优化,同时针对计算尺寸和硬件平台的架构特点进行特定的参数搜索方法的设计。
与现有技术相比,本发明显著提升了卷积算子在NVIDIA GPU平台上的计算性能和推理速度。
附图说明
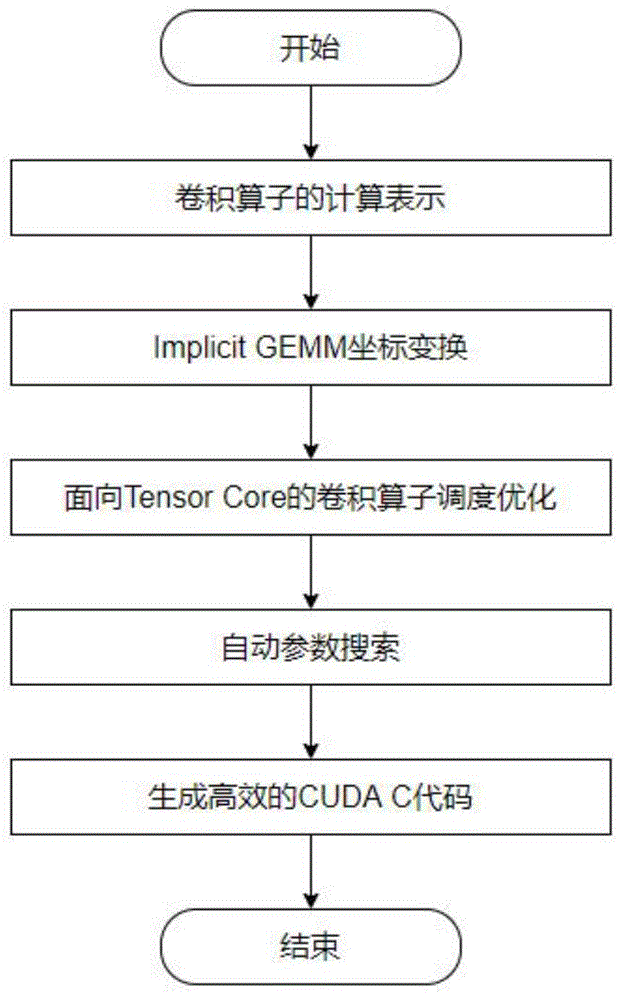
图1为本发明流程示意图;
图2为面向张量计算单元的卷积算子调度流程示意图;
图3为面向张量计算单元的划分参数自动搜索流程示意图;
图4为原始TVM卷积调度结果示意图;
图5为本方法卷积调度结果示意图。
具体实施方式
如图1所示,为本实施例涉及一种面向张量计算单元的卷积算子优化实现方法,使用TVM的DSL编写卷积算子的计算表示,并对其基于Implicit GEMM算法进行坐标变换后;通过如图2所示的调度方法对卷积计算进行面向Tensor Core的调度优化。经过调度优化后,卷积算子的计算图表示如图5所示,再使用如图3所示的自动调优过程对im、in进行参数搜索与确定,最后依据搜索结果使用TVM后端生成高效的CUDA C代码。
所述的调度优化使用TVM的cache_read、cache_write、double_buffer、vectorize、split、tensorize等调度原语进行编写。
在调度优化流程中,本实施例将分块参数设置为可搜索参数。
所述的自动调优过程采用AutoTVM算法实现,通过启发式搜索以及基于XGBoost的代价模型在搜索空间内搜索出性能最好的参数。
经过具体实际实验,在GPU型号为NVIDIA RTX 2070的平台上进行测试。其中GPU计算采用的CUDA框架版本为11.0,所使用的TVM版本为0.8。与图4所示的原始TVM卷积算子调度优化相比,本实施例在代码生成阶段综合考虑了Implicit GEMM的坐标变换方法、张量计算单元的使用、存储器体系结构、以及半精度浮点类型的特性,并根据所选GPU架构的特点设计了特定的参数搜索空间,从而提升了卷积算子自动生成的性能。
在本次实施例的基础上通过ResNet50、MobileNetv1、MobileNetv2、SqueezeNet等卷积神经网络验证了本发明的正确性,同时本发明相较于社区开源TVM的实现在不同的网络推理速度上都有不同程度的提升。
本发明实现的卷积算子相较于开源深度学习编译器TVM的卷积算子性能对比如下表:
使用本发明实施的卷积神经网络推理速度相较于开源深度学习编译器的推理速度对比如下表:
与现有技术相比,本发明得到的卷积算子的计算性能相比开源深度学习编译器TVM取得最大为15.4的加速比;卷积神经网络的推理性能相比TVM取得最大为1.70的加速比。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。