一种基于粒群优化的声学模型拓扑结构选择方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于语音识别和粒群优化算法的学科交叉领域,具体地说是一种通过粒群优化算法寻找和优化语音识别系统的声学模型拓扑结构的方法。
背景技术
创建以隐马尔可夫模型为声学模型的语音识别系统时,需要为系统中的各声学模型选择状态数量以及各状态包含的高斯核数量,即选择各声学模型的拓扑结构。声学模型拓扑结构的好坏对语音识别系统的识别率具有重大影响。
目前语音识别界为声学模型选择拓扑结构的最普遍的做法是:首先,凭借经验选择各声学模型的状态数量;之后,同步、逐渐增加各模型各状态的高斯核数量,得到各状态的高斯核数量均为1的、均为2的、均为3的、……等多个语音识别系统;最后,从诸多语音识别系统中选择识别率最高的一个,被选定系统的各声学模型的拓扑结构被认为是最优的。例如,建立大词汇量语音识别系统时,统一将各音素声学模型的状态数量设置为3,并通过逐渐增加系统各状态的高斯核数量,逐步搜索使系统识别率达到最高的各状态高斯核数量。
该方法存在如下缺点:
1.手工搜索
逐一手工搜索最优的高斯核数量,工作效率低下,若能实现最佳拓扑结构的基于数据驱动的自动搜索,不仅可以提高效率,而且还将具备很多其它优势;
2.片面优化
依次而不是同时优化声学模型的状态数量和各状态的高斯核数量的做法约束声学模型的刻画能力,进而影响语音识别系统的识别率;
3.高斯核的均匀分配
该策略无法根据各状态的实际需要分配高斯核数量,容易造成高斯核数量的“过分配”和“欠分配”,影响声学模型的建模精度。
发明内容
1.发明目的
为了克服现有技术的手工搜索、片面优化和均匀分配高斯核等缺陷,本发明提出一种将语音识别系统的声学模型拓扑结构集合当作粒群优化算法中的粒子位置,通过粒群优化算法的迭代过程逐渐使粒子位置 (声学模型拓扑结构的集合)得到优化,最终在搜索到的最好的粒子位置中找到系统各声学模型优化的拓扑结构的声学模型拓扑结构优化方法。该方法的优点是:(1)使用粒群优化算法进行声学模型最优拓扑结构的自动搜索;(2)粒群优化算法的搜索结果中,如果出现某状态包含的高斯核数量为零的情形,则直接删除该状态,从而做到了同时优化声学模型的状态数量以及各状态的高斯核数量,克服了现有技术的先考虑模型状态数量再优化各状态高斯核数量的片面优化的缺点;(3)粒群优化算法的搜索过程中和搜索结果中,各状态的高斯核数量可以取指定范围内的任意整数值,且各状态的高斯核数量的取值相互独立,因而避免了现有技术的高斯核均匀分配的缺点。
2.技术方案
本发明提出的语音识别声学模型拓扑结构优化方法,总体上采用粒群优化算法的框架结构,我们做改进的地方是“调整各粒子的位置”。该方法的具体步骤为:
粒群优化是一种通过模拟自然界中鸟群或鱼群的集体觅食行为、在预定义的解空间中进行全局并行和随机搜索、寻找问题最优解的智能优化算法。该算法中,粒子代表鸟或鱼的个体,粒群代表粒子的总体。每个粒子在搜索空间中的位置代表问题的一个潜在的解,需要用问题相关编码方案进行编码。此外,每个粒子还有自己的飞行速度。在初始化阶段,算法为每个粒子随机设置位置和速度向量。之后,在每次的迭代中,结合粒子的自身经验和粒群的集体经验调整每个粒子的飞行速度,并据此刷新它们在搜索空间中的位置。该算法在达到一定的迭代次数后终止,最终返回整个粒群搜索到的最好的位置作为问题的最优解。
下面从编码方案、初始化策略、适应度计算、最佳拓扑结构(粒子位置)及其适应度的记录、循环条件、惯性权重设置、粒子速度的更新与调整、粒子位置的更新与调整以及其它问题的解决方案等方面详细说明我们的利用粒群优化算法优化语音识别系统声学模型拓扑结构的方法。
(1)编码方案
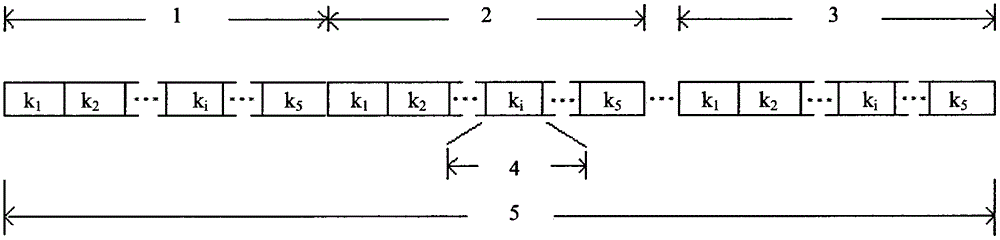
粒群由若干个粒子构成,每个粒子的位置代表语音识别系统的所有声学模型拓扑结构的一个集合,粒子位置的编码方案如说明书附图所示,具体描述如下:
每个粒子位置由5×n个整数构成,其中,n代表语音识别系统中待优化拓扑结构的声学模型的个数, 5代表各声学模型的状态数量的最大可能取值。换句话说,每个粒子位置被等分为n个部分,每个部分中的5个整数对应一个声学模型的拓扑结构。
就对应于一个声学模型的拓扑结构的整数序列而言,第i个整数k
与粒子位置相对应,粒子速度被设置为维数为5×n的实向量。
(2)初始化策略
初始化粒群中的每个粒子的位置时,理论上讲,每个粒子位置中的每个整数的取值可由闭区间[0, MaxKerNum]上的均匀分布随机产生,即从该闭区间随机选取一个整数。但是,为了更快速地找到识别率更高的语音识别系统的声学模型拓扑结构,可以为粒群设置较高的搜索起点,即,在进化开始前的粒群中设置一个或多个这样的粒子位置,它代表一个已知的识别率较高的语音识别系统的各声学模型的拓扑结构。
将每个粒子的初始速度设置为维数为5×n的零向量。
(3)适应度计算
粒子位置的适应度被定义为采纳该粒子位置所代表的各声学模型拓扑结构的语音识别系统的识别率 (词正确率或词准确率)。换句话说,以语音识别系统的识别率的高低作为评价其声学模型拓扑结构好坏的标准。适应度的具体计算过程是:从粒子位置中抽取各声学模型的拓扑结构,以此为前提使用训练语料估计语音识别系统的模型参数,最后使用测试语料获得该语音识别系统的识别率(粒子位置的适应度)。
(4)最佳拓扑结构(粒子位置)及其适应度的记录
完成每个粒子的位置向量和速度向量的初始化并结束所有粒子位置的适应度计算之后,将每个粒子的位置向量及其适应度作为到目前为止该粒子找到的最佳拓扑结构(粒子位置)和适应度记录下来,同时,将其中的适应度最高的粒子位置和相应的适应度值作为到目前为止整个粒群找到的最佳拓扑结构(粒子位置)和适应度记录下来。
在后续的迭代搜索过程中,每次完成所有粒子位置的适应度计算之后,都要判断每个粒子是否搜索到了适应度更高的拓扑结构(粒子位置),如果是,记录适应度更高的粒子位置及其适应度值;同时,判断整个粒群是否搜索到了适应度更高的拓扑结构(粒子位置),如果是,记录适应度更高的粒子位置及其适应度值。
(5)循环条件
声学模型最优拓扑结构的搜索经过一定数量的迭代后终止,例如,迭代300次。
(6)惯性权重设置
我们将惯性权重w的初始值设置为相对较大的wstart,并随着迭代的推进,让它线性递减到较小的 wend。w的线性递减公式为
其中,i与I分别是当前迭代次数和预定义的总迭代次数。
对w的值做上述设置是因为,较大的惯性权重有益于算法进行广泛搜索,从而有助于找到全局最优解,较小的惯性权重则有利于算法的收敛。
(7)粒子速度的更新与调整
每次迭代中,根据粒子的自身经验和粒群的整体经验,更新每个粒子的速度向量。
如果更新后的速度向量的任何分量超出了我们的指定范围,调整它使它回到指定的范围中。
(8)粒子位置的更新与调整
每次迭代中,在每个粒子的原位置向量上加上它的新的速度向量,从而得到它新的位置向量。
鉴于粒子位置必须为整型向量,在得到每个粒子的实向量表示的新位置后,对每个粒子位置的每个分量四舍五入取整。对于取整后的每个分量,如果它的值落在区间[0,MaxKerNum]的左边,则将其设置为 0,如果落在右边,则设置为Max_Kernel_Num。
(9)其它问题的解决方案
初始化粒子位置或四舍五入调整粒子位置之后,如果出现粒子位置中的与某个声学模型相对应的所有整数全部为零的情形,将这些整数中的任意一个设置为1,其余保持不变。
由于时间开销比较大,本方法在执行过程中有可能会遇到被意外中断(如断电)的情况。为提高其鲁棒性和实用性,我们在该方法中增加了每迭代几次就对上下文进行一次保存的措施。这样,当执行过程中遇到被意外中断的情形时,下次可以读取最近保存过的上下文参数,从断点处继续执行。
3.有益效果
本发明提出的声学模型拓扑结构优化方法的有益效果是,有效提高语音识别系统的识别率。由于克服了传统方法的诸多缺点,与传统方法相比,本方法能够搜索到更优的拓扑结构,从而能够建立起识别率更高的语音识别系统。
下表给出的是我们的对比实验的结果数据,包括使用传统方法搜索声学模型最优拓扑结构后建立的相应语音识别系统的识别率以及使用本方法搜索声学模型最优拓扑结构后建立的相应语音识别系统的识别率。由于每次搜索到的不一定是相同的优化的拓扑结构,本方法的实验进行了多次。从表中数据容易看出,具有本方法搜索到的最优声学模型拓扑结构的语音识别系统,其识别率均高于具有传统方法搜索到的最优声学模型拓扑结构的语音识别系统的识别率。
附图说明
说明书附图1为本方法的粒子位置编码方案示意图。
图中,1.模型1的拓扑结构,2.模型2的拓扑结构,3.模型n的拓扑结构,4.高斯核数量,5.粒子位置。
有关说明书附图所展示的粒子位置编码方案的详细描述,请参阅“发明内容”的“2.技术方案(1) 编码方案”部分。
具体实施方式
由于时间开销比较大,本方法的最大实际用处并不在于从零起点开始搜索优化的声学模型拓扑结构并建立相应的全新的语音识别系统,而在于在传统方法的基础上进一步优化语音识别系统的声学模型拓扑结构,从而进一步提升语音识别系统的识别率。
具体实施步骤如下:
1.基于传统方法的声学模型拓扑结构优化
利用HTK(HMM ToolKit)工具建立各声学模型状态数量为3(短停模型除外,短停模型的状态数量设置为1)、各状态高斯核数量为1的语音识别系统;之后,逐渐、同步增加各状态的高斯核数量,得到各状态的高斯核数量均为1的、均为2的、均为3的、……等多个语音识别系统;最后,从诸多语音识别系统中选择识别率最高的一个,记录其识别率和各声学模型的拓扑结构。
2.初始化粒子位置与速度
完成上述的准备工作之后,开始执行本发明提出的声学模型拓扑结构优化方法。我们在MATLAB环境下具体实现该方法。
在该方法的迭代过程开始之前,对粒群位置进行高起点初始化,即,使粒群中的每个粒子位置都代表第1步中记录的传统方法搜索到的系统声学模型最优拓扑结构。
将每个粒子的速度初始化为零向量。
3.计算适应度
针对每个粒子位置,提取其中的声学模型拓扑结构信息,建立相应的语音识别系统,获得语音识别系统的词正确率(也可选择词准确率)作为粒子位置的适应度。
关于建立与粒子位置相对应的语音识别系统,特别说明几点:
(1)按常规做法,首先建立各状态的高斯核数量均为1的单高斯语音识别系统,之后逐渐增加各状态的高斯核数量;
(2)建立单高斯语音识别系统时,自动生成最初的模型定义文件(hmmdefs文件),具体做法是:事先为每个可能的模型状态数量准备好原型文件(prototype文件),需要模型定义文件时,从粒子位置中提取各声学模型的状态数量,将与各数量对应的原型文件的内容拷贝到一起,获得最初的模型定义文件;
(3)建立的语音识别系统几乎都是高斯核非均匀分配的,在单高斯系统的基础上逐渐增加各状态的高斯核数量最终得到这样的系统时,每次增加的高斯核数量应当大一些,以免造成对系统的“过训练”。
4.初始化最佳拓扑结构(粒子位置)和惯性权重
将每个粒子的位置向量及其适应度作为该粒子已找到的最佳拓扑结构(粒子位置)和相应适应度记录下来,同时,将其中的适应度最高的粒子位置及其适应度值作为整个粒群已找到的最佳拓扑结构(粒子位置)和相应适应度记录下来。
设置惯性权重w的初始值wstart(如0.9)和终止值wend(如0.4),并将w初始化为wstart。
5.迭代优化粒子位置(系统声学模型拓扑结构)
循环执行以下步骤一定次数(如100次)
(1)更新和调整粒子速度
根据粒子的当前位置、粒子的自身经验(即粒子本身已找到的最佳粒子位置)和粒群的整体经验(即粒群整体已找到的最佳粒子位置),更新每个粒子的速度向量。如果更新后的速度向量的任何分量超出了指定区间[-V
(2)更新和调整粒子位置
在每个粒子的原位置向量上加上它的新的速度向量,得到它新的位置向量。
对每个粒子位置的每个分量四舍五入取整。如果取整后的分量值落在区间[0,Max_Kernel_Num] 的左边,则将其设置为0,如果落在右边,则设置为Max_Kernel_Num。Max_Kernel_Num为各声学模型各状态的高斯核数量的最大可能取值。
(3)更新惯性权重
根据当前的迭代次数i,并依据在“发明内容”部分中阐述的惯性权重递减公式更新惯性权重w的值。
(4)计算适应度
计算新产生的每个粒子位置的适应度值,具体做法与“具体实施方式”第3步“计算适应度”中的完全相同。
(5)记录最佳拓扑结构(粒子位置)及其适应度
判断每个粒子是否搜索到了适应度更高的拓扑结构(粒子位置),如果是,记录适应度更高的粒子位置及其适应度值;同时,判断整个粒群是否搜索到了适应度更高的拓扑结构(粒子位置),如果是,记录适应度更高的粒子位置及其适应度值。
6.获得优化结果
从记录中获得系统声学模型的最优拓扑结构(从适应度最高的粒子位置中抽取)以及采用该拓扑结构的语音识别系统的识别率(适应度最高的粒子位置的适应度值)。如果需要获得采用该最优拓扑结构的语音识别系统本身,则需要单独创建。
最后查看本方法在传统方法的基础上通过进一步优化语音识别系统的声学模型拓扑结构为语音识别系统带来了识别率的多少提升。
以上具体实施方式,发明人已利用HTK3.4工具和MATLAB R2017a环境具体实现。