倦怠检测预警方法、系统及计算设备
文献发布时间:2023-06-19 19:32:07
技术领域
本发明涉及医疗设备技术领域,特别是涉及一种基于语音倦怠检测预警方法、系统及计算设备。
背景技术
职业倦怠(burnout)由Freudenberger于1974年首次提出,主要描述以人为服务对象的工作中的个体由于工作时间过长、工作量大和工作强度高引起的个体体验到的一组负性症状,如长期的情感耗竭、身体疲劳以及成就感降低等症状。
职业倦怠主要发生在人际接触频繁的服务性职业中,目前对于职业倦怠应用最广泛的理论时Maslach提出的三维理论:
1、情感耗竭,职业倦怠的个体压力维度,指个体的情感资源过度消耗、疲乏不堪、精力丧失,是由于个体在心理水平上的过度付出而导致无法在对工作或他人倾注关注与感情;
2、去人格化,是职业倦怠的人际关系维度,指个体对待服务对象消极的、负性的、冷淡的、过度疏远的甚至麻木不仁的态度,将服务对象当作一件无生命体的物体看待;
3、低个人成就,是职业倦怠的自我评价维度,表现为个体在工作中对自我及所从事工作的意义和价值评价偏低,甚至对自己所作的贡献表示怀疑,对工作的胜任感和成就感下降。
医护人员相对于其他群体更易发生职业倦怠,主要原因包括:
1、工作负担重,医护人员工作量较大且需面对不同背景、职业和性格的患者及其家属,进而加大了工作量;
2、风险高,医疗工作本身具有风险性,贯穿在门诊、急诊、住院、出院等各个环节以及诊断、治疗、康复等诊疗行为的全过程,更是造成了从而导致医护人员心理负担过重;
3、工作时间不确定,主要是由于日夜班制度以及无规律的加班抢救患者所导致,因而不可避免的对医护人员的生活规律和习惯产生影响,进而影响医护人员的生理和心理状态;
4、工作节奏失衡,患者就诊的突然性和紧迫性易于导致医护人员工作节奏的失衡,从而使得医护人员时时处于应激状态,造成身心素质下降;
5、同情心,患者病情变化导致医护人员内心感受的波动也较易引发心理健康问题。
因此医护人员职业倦怠的比例一直处于比较高的水平,随着新冠肺炎的流行该状况变得愈发严重。美国国家医学院(NAM)发布报告称,21世纪,医疗保健服务质量面临的挑战之一,是“维护医疗从业人员的健康”。并且该报告指出,35%-54%的医护存在职业倦怠。在医学生和住院医师中,这一比例达60%。而在中国,根据一项包含2.5万余医生的研究结果显示,有60%医生存在职业倦怠。
医护人员职业倦怠可能会带来严重后果。首先,对于医生本人,长期处于倦怠状态可加大患抑郁的风险,进而引发缺勤、离职甚至自杀等严重后果。此外,处于职业倦怠状态还会增大医护人员提供医疗服务过程中发生医疗安全事件和医疗事故的风险,造成对患者的身心伤害。
早期发现并及时干预是有效提升医护人员精神健康、降低职业倦怠危害的有效方式。目前针对职业倦怠的评估主要包括访谈和职业倦怠专用量表自测两种方法。而医护人员由于职业的特殊性导致在出现职业倦怠相关症状后其往往羞于寻求专业的心理帮助。而量表自测相对访谈虽然易于实施,但由于其完全由使用者自填,测量结果缺乏客观性且影响其准确度,而且量表中的问题往往容易引起处于倦怠状态下使用者心理上的不适。
鉴于上述情况,面对医护人员职业倦怠高发情况极其所带来的不良后果,尤其是在新冠肺炎流行下医护人员职业倦怠状况的加重,目前迫切需要简便、快捷、客观且智能化的辅助手段,能够及早的发现并监测医护人员的倦怠状态,对其进行预警并给出进一步的干预建议,成为亟待解决的医疗技术问题。
发明内容
(一)要解决的技术问题
本发明要解决的技术问题是:提供一种操作方便且及时有效的倦怠检测预警方法、系统及计算设备。
(二)技术方案
为解决上述问题,本发明一方面提出了一种倦怠检测预警方法,该方法包括以下步骤:
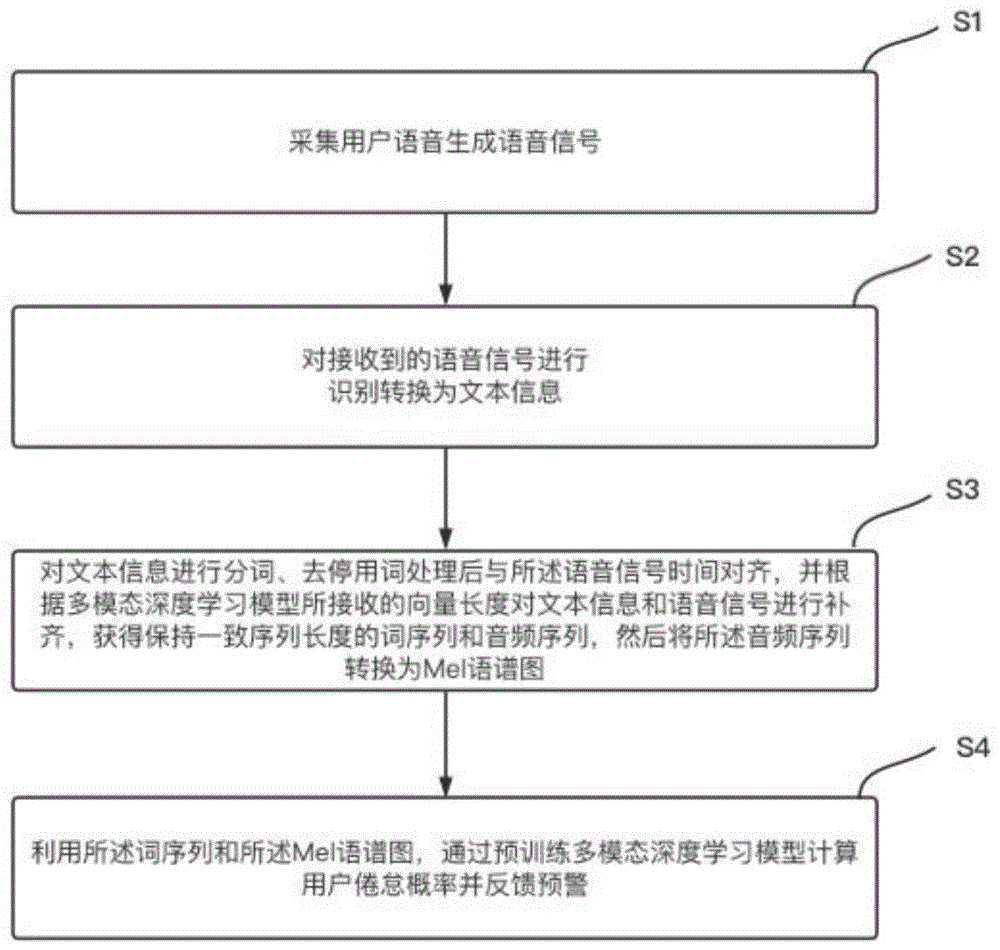
S1:采集用户语音生成语音信号;
S2:对接收到的语音信号进行识别转换为文本信息;
S3:对所述文本信息进行分词和去停用词处理,并与所述语音信号时间对齐,根据预训练多模态深度学习模型所接受向量的长度对文本信息和语音信号进行补齐,获得保持一致序列长度的词序列和音频序列,然后将所述音频序列转换为Mel语谱图;
S4:利用所述词序列和所述Mel语谱图,通过预训练多模态深度学习模型计算用户倦怠概率并反馈预警。
优选地,所述步骤S1和步骤S2之间还包括步骤S102,所述步骤S102对步骤S1生成的语音信号进行降噪并删除语音信号中的空白片段。
优选地,所述步骤S3在将所述音频序列转换为Mel语谱图时,通过预加重、分帧、加窗、短时傅里叶变换获得音频序列的频域线性谱,然后采用Mel滤波器组进一步将频域线性谱转换为Mel语谱图。
优选地,所述步骤S4在计算用户倦怠概率时,首先采用预训练的BERT模型对所述词序列进行词嵌入,获得嵌入后文本词向量,将所述嵌入后文本词向量输入到预训练的双向长短期记忆网络(Bi-LSTM),获得文本的新的表示e
优选地,所述步骤S1进一步包括如下子步骤:S11:提示用户输入账号密码登陆系统,S12:向用户提示环境要求,设备要求及回答时长要求,S13:向用户显示须回答问题,用户点击“开始回答”按钮后开始录音进行语音采集,S14:采集完成后通过回放检查录音是否正常,若正常保存录音生成语音信号,若异常删除重新录制;
所述步骤S102进一步包括如下步骤:采用Asteroid工具包中预先训练好的模型对步骤S1生成的语音信号中的用户语音进行分离,从而消除背景噪声,再采用光谱门控技术进行降噪,然后删除语音信号中的空白片段,形成新的纯净的语音信号;
所述步骤S3进一步包括如下步骤:对所述文本信息进行分词处理及去停用词,并与所述语音信号时间对齐,对齐过程中使用P2FA获得每个词的时间步长,并根据所述时间步长获取该词对应的音频序列,文本信息与音频序列对齐后,根据预训练多模态深度学习模型所接受向量的长度对文本信息和音频序列进行补齐,获得保持一致序列长度的词序列和音频序列,然后将所述音频序列转换为Mel语谱图;
所述步骤S4进一步包括如下步骤:首先采用BERT模型对所述词序列进行词嵌入,获得嵌入后文本词向量,将所述嵌入后文本词向量输入到预训练的双向长短期记忆网络(Bi-LSTM),获得文本的新的表示e
本发明另一方面提出了一种倦怠检测预警系统,该系统包括语音采集端、语音识别模块、文本音频处理模块和倦怠检测预警模块;所述语音采集端采集用户语音生成语音信号,并将语音信号传输至语音识别模块;所述语音识别模块对接收到的语音信号进行识别转换为文本信息;所述文本音频处理模块对所述文本信息进行分词和去停用词处理,并与所述语音信号时间对齐,根据预训练多模态深度学习模型所接受向量的长度对文本信息和语音信号进行补齐,获得保持一致序列长度的词序列和音频序列,然后将所述音频序列转换为Mel语谱图;所述倦怠检测预警模块利用所述词序列和所述Mel语谱图,通过预训练多模态深度学习模型计算用户倦怠概率并反馈预警。
优选地,该系统还包括语音预处理模块,所述语音预处理模块包括降噪单元和/或空白删除单元,所述降噪单元和所述空白删除单元分别对语音采集端生成的语音信号进行降噪和删除语音信号中的空白片段。
优选地,该系统文本音频处理模块还包括Mel语谱图单元,所述Mel语谱图单元将所述音频序列通过预加重、分帧、加窗、短时傅里叶变换获得音频序列的频域线性谱,然后采用Mel滤波器组进一步将频域线性谱转换为Mel语谱图。
优选地,该系统倦怠检测预警模块包括文本表示单元、音频表示单元和倦怠计算单元,所述文本表示单元采用BERT模型对所述词序列训练进行词嵌入,获得嵌入后文本词向量,将所述嵌入后文本词向量输入到预训练的双向长短期记忆网络(Bi-LSTM),获得文本的新的表示e
本发明再一方面提出了一种计算设备,该计算设备包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述倦怠检测预警方法的步骤。
(三)有益效果
本发明的上述倦怠检测预警方法、系统及计算设备,通过向用户提示问题并采集用户回答问题的语音进行分析,通过运算识别用户注意力状态确定用户的倦怠风险并向用户或管理人员预警,检测方法客观有效,能够实现较好的倦怠风险预警效果,不仅可以用于医护人员的倦怠检测预警,还可以用于交通运输、安全生产等领域,具有广阔的应用前景。
附图说明
图1为本发明实施例1的倦怠检测预警方法的流程示意图。
图2为本发明实施例2的倦怠检测预警方法的流程示意图。
图3为本发明实施例3的倦怠检测预警方法的多模态深度学习模型处理流程示意图。
图4为本发明实施例4的倦怠检测预警系统的结构示意图。
具体实施方式
下面结合附图及实施例对本发明进行详细说明如下。
图1是本发明一个实施例的倦怠检测预警方法的流程示意图。如图1所示,该方法包括以下步骤:
S1:采集用户语音生成语音信号;
S2:对接收到的语音信号进行识别转换为文本信息;
S3:对所述文本信息进行分词和去停用词处理,并与所述语音信号时间对齐,根据预训练多模态深度学习模型所接受向量的长度对文本信息和语音信号进行补齐,获得保持一致序列长度的词序列和音频序列,然后将所述音频序列转换为Mel语谱图;
S4:利用所述词序列和所述Mel语谱图,通过预训练多模态深度学习模型计算用户倦怠概率并反馈预警。
在本发明的一个实施例中,如图2所示,所述步骤S1和步骤S2之间还包括步骤S102,所述步骤S102对步骤S1生成的语音信号进行降噪并删除语音信号中的空白片段。
在本发明的一个实施例中,所述步骤S3在将所述音频序列转换为Mel语谱图时,通过预加重、分帧、加窗、短时傅里叶变换获得音频序列的频域线性谱,然后采用Mel滤波器组进一步将频域线性谱转换为Mel语谱图。
在本发明的一个实施例中,所述步骤S4在计算用户倦怠概率时,首先采用BERT模型对所述词序列进行词嵌入,获得文本词向量,将所述文本词向量输入到预训练的双向长短期记忆网络(Bi-LSTM),获得文本的新的表示e
如图3所示,本发明实施例的倦怠检测预警方法的多模态深度学习模型采用其文本表示单元对输入文本词序列进行处理,采用音频表示单元对输入的Mel语谱图进行处理,最后由倦怠计算单元对新的文本表示和音频表示进行融合并计算倦怠概率:
所述文本表示单元处理流程如下:
(1)为了用一个低维稠密向量来表示输入对象文本,将文本词序列形式输入到嵌入层,嵌入层包含3个不同的层分别进行不同的嵌入操作:
Token嵌入层:将词划分成一组有限的公共词单元;
Segment嵌入层:区别两个句子的向量表示;
Position嵌入层:将词的位置信息编码成特征向量;
经过上述操作后,文本词序列被被转换成(1,n,768)的张量,并作为输入进入到预训练的BERT模型。
(2)所述预训BERT模型由12层Transformer单元和12层多头注意力组成,将768维的词向量X=[x
(3)将BERT模型输出的Y=(y
所述音频表示单元处理流程如下:
(1)同时将所述Mel语谱图分块进行扁平化后输入到线性层,获得Mel语谱图的分块嵌入表达;
(2)将Mel语谱图的分块嵌入表达加入位置嵌入参数后输入到Transformer编码器中获得音频的新的表示e
所述倦怠计算单元处理流程如下:
(1)文本的新的表示e
(2)将根据注意力权重加权后的得到的文本向量与音频向量输入线性层后进入到输出层,其中输出层采用sigmoid函数作为激活函数,计算得出用户倦怠概率。
在本发明的一个实施例中,所述步骤S1进一步包括如下子步骤:S11:提示用户输入账号密码登陆系统,S12:向用户提示环境要求,设备要求及回答时长要求,S13:向用户显示须回答问题,用户点击“开始回答”按钮后开始录音进行语音采集,S14:采集完成后通过回放检查录音是否正常,若正常保存录音生成语音信号,若异常删除重新录制。
在子步骤S11中,用户登陆系统既可以通过直接输入账号密码直接登陆,也可以通过微信授权接口采用微信绑定账号方式登陆系统,通过用户的登陆信息或者微信授权获取的openid与数据库参数比对,查出用户是否存在,若不存在可提示用户注册,用户注册时可通过用户输入手机号进行短信验证,并限制用户的发送次数,验证通过后输入账号密码,密码可通过aes_128_cbc方式加密。
在子步骤S12中,系统向用户提示环境要求,设备要求及回答时长要求。环境要求包括低环境噪音,尽量保证不出现他人语音等。设备要求包括是否选用耳机或手机麦克风等。回答时长要求包括每道题的录制语音时长等,例如不低于20秒等。
在子步骤S14中,生成的语音信号可通过silk-v3-decoder转成WAV格式音频文件,然后再转换成JSON格式,以便于数据传输。
所述步骤S102进一步包括如下步骤:采用Asteroid工具包中预先训练好的模型对步骤S1生成的语音信号中的用户语音进行分离,从而消除背景噪声,防止可能存在的他人语音对测试结果造成影响。再采用光谱门控技术进行降噪,估计语音信号的每个频带的噪声阈值,该阈值用于计算掩模,掩模将噪声控制在频率变化阈值以下。噪声阈值根据动态方案选取,即随着时间不断更新估计噪声阈值,更具体的,该方法首先通过语音信号计算出频谱图,通过在每个频率信道上向前和向后应用IIR滤波器计算频谱图的时间平滑版本。基于该时间平滑的谱图计算出掩码。掩码用滤波器对频率和时间进行平滑,同时掩码应用于信号的谱图,并进行反转成时域语音信号。然后删除语音信号中的空白片段,形成新的纯净的语音信号;
在步骤S2中,在对接收到的语音信号进行识别转换为文本信息时,可通过百度语音识别REST API接口,输入JSON序列,其中包括WAV格式的语音文件、语音文件信息(采样率、声道)、用户信息(用户唯一标识、开发者Token)和语音信号数据,生成相应的文本信息。
所述步骤S3进一步包括如下步骤:对所述文本信息进行分词处理及去停用词,并与所述语音信号时间对齐,对齐过程中使用P2FA获得每个词的时间步长,并根据所述时间步长获取该词对应的音频序列,文本信息与音频序列对齐后,根据预训练多模态深度学习模型所接受向量的长度对文本信息和音频序列进行补齐,获得保持一致序列长度的词序列和音频序列,然后将所述音频序列转换为Mel语谱图;
在步骤S3中,对文本信息的加工包括分词处理及去停用词,随后将文本信息与所述语音信号时间对齐,对齐过程中使用P2FA获得每个词的时间步长,并根据所述时间步长获取该词对应的音频序列,文本信息与音频序列对齐后,根据预训练多模态深度学习模型所接受向量的长度对文本信息和音频序列进行补齐,获得保持一致序列长度的词序列和音频序列,然后通过预加重、分帧、加窗、短时傅里叶变换等操作得到音频序列的频域线性谱,此时语音信号从时域转换至频域,随后采用Mel滤波器组进一步将频谱转换至Mel域并生成Mel频谱图。具体流程为:首先通过预加重对低频信号进行抑制,保留语音高频部分的信息,预加重的时域表达式如下:y(n)=x(n)-a×x(n-1),其中,0.9≤a≤1。对经过预加重的语音信号进一步进行短时傅里叶变换,具体地,可将窗长设置为25ms,帧重叠设置为10ms,则对于语音波形时域信号x(m),加窗分帧后第n帧语音信号x
所述步骤S4进一步包括如下步骤:首先采用BERT模型对所述词序列进行词嵌入,获得文本词向量,将所述文本词向量输入到预训练的双向长短期记忆网络(Bi-LSTM),获得文本的新的表示e
在步骤S4中,需要采用不同的策略先对词序列和Mel语谱图进行处理,简单来说就是需要获得文本信息的词序列和Mel语谱图在潜在空间的新的表示,然后采用注意力机制对二者进行融合,并获得模型最终的输出,即用户倦怠风险。
要获得文本信息的词序列在潜在空间的新的表示,需要首先采用BERT模型对所述词序列进行词嵌入,获得文本词向量,Y=[y
在经过Bi-LSTM层后,获得文本的第i个词的表示为:
进一步的,以H表示Bi-LSTM中的所有h
要获得Mel语谱图在潜在空间的新的表示,可将该二维Mel语谱图分割成K个大小为16×16的分块,且不同分块之间保持重叠(时域和频域重叠大小均设置为6),其中分块数目K=12[(100t-16)/10]。将K个分块进行扁平化后输入到线性层,获得Mel语谱图的分块嵌入表达,同时为对不同的分块进行位置标记,加入位置嵌入参数,并将其与语谱图分块嵌入表达一同输入到预训练多模态深度学习模型中的Transformer编码器中获得音频的新的表示e
在获得文本的新的表示e
在获取相似矩阵C后,可进一步由相似矩阵C计算分别计算语音和文本的注意力地图(Attention map),其具体计算方式如下:
H
H
H
在获得注意力地图后,可进一步根据注意力地图随后利用softmax函数分别计算出音频和文本的注意力概率:
其中W
最后将根据注意力权重加权后的得到的文本向量与音频向量输入线性层后进入到输出层,
其中输出层采用sigmoid函数作为激活函数,其具体计算方式如下:
其中z表示输出层的输出值,在经过sigmoid函数变换后可计算出该受测试用户发生职业倦怠的概率,然后向用户反馈预警。
如图4所示,在本发明另一方面的倦怠检测预警系统的一个实施例中,该系统包括语音采集端、语音识别模块、文本音频处理模块和倦怠检测预警模块;所述语音采集端采集用户语音生成语音信号,并将语音信号传输至语音识别模块;所述语音识别模块对接收到的语音信号进行识别转换为文本信息;所述文本音频处理模块对所述文本信息进行分词和去停用词处理,并与所述语音信号时间对齐,根据预训练多模态深度学习模型所接受向量的长度对文本信息和语音信号进行补齐,获得保持一致序列长度的词序列和音频序列,然后将所述音频序列转换为Mel语谱图;所述倦怠检测预警模块利用所述词序列和所述Mel语谱图,通过预训练多模态深度学习模型计算用户倦怠概率并反馈预警。
在本发明另一方面的倦怠检测预警系统的一个实施例中,该系统还包括语音预处理模块,所述语音预处理模块包括降噪单元和/或空白删除单元,所述降噪单元和所述空白删除单元分别对语音采集端生成的语音信号进行降噪和删除语音信号中的空白片段。
在本发明另一方面的倦怠检测预警系统的一个实施例中,该系统文本音频处理模块还包括Mel语谱图单元,所述Mel语谱图单元将所述音频序列通过预加重、分帧、加窗、短时傅里叶变换获得音频序列的频域线性谱,然后采用Mel滤波器组进一步将频域线性谱转换为Mel语谱图。
在本发明另一方面的倦怠检测预警系统的一个实施例中,该系统倦怠检测预警模块包括文本表示单元、音频表示单元和倦怠计算单元,所述文本表示单元采用BERT模型对所述词序列训练进行词嵌入,获得嵌入后文本词向量,将所述文本词向量输入到预训练的双向长短期记忆网络(Bi-LSTM),获得文本的新的表示e
在本发明再一方面的计算设备的一个实施例中,本发明再一方面提出了一种计算设备,该计算设备包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述倦怠检测预警方法的步骤。
以上实施方式仅用于说明本发明,而并非对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。