一种利用咳嗽声检测肺部疾病的方法和装置
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及人工智能辅助诊断领域,尤其是一种利用咳嗽声检测肺部疾病的方法和装置。
背景技术
随着工业技术的不断发展,通过深度学习进行音频分类的技术不断成熟,人们更加关注相关技术在实际中的应用,利用体音检测疾病成为了目前的研究热点。感染肺部疾病之后,咳嗽是主要的症状之一,研究人员发现不同肺部疾病患者的咳嗽声具有不同的潜在特性,因此利用咳嗽声来检测肺部疾病是一种可以实现的快速检测手段。
目前常用的方法主要有以下两种。一是利用在帧级别或者段级别提取咳嗽音频相关的统计特征后利用机器学习算法进行分类。特征通常包括均方根能量、过零率、频谱质心以及它们的均值、方差等参数,之后通过逻辑回归、支持向量机等机器学习算法进行分类。二是提取基于短时傅里叶变换的时频特征输入到深度神经网络进行分类,常用的神经网络包括卷积神经网络、长短时记忆神经网络、Transformer等。在所有这些研究中卷积神经网络取得了较好的分类性能,但也存在一定的局限性。
发明内容
有鉴于此,本发明的主要目的在于提供一种利用咳嗽声检测肺部疾病的方法和装置,能提高分类网络对于差异性特征和位置信息的提取能力,很好地利用咳嗽音频中全部单个咳嗽音片段的差异性特征进行分类,进而提高检测结果的准确度。
为达到上述目的,一方面,本申请提供了一种利用咳嗽声检测肺部疾病的方法,包括:
去除原始咳嗽音频中非咳嗽音片段,得到咳嗽音频,以及该咳嗽音频中各单个咳嗽片段的起始和结束时间;
依据各单个咳嗽片段的起始和结束时间,分别生成各单个咳嗽片段对应的对数梅尔普矩阵,并分别计算各单个咳嗽片段对应的位置编码矩阵;
依据各单个咳嗽片段对应的对数梅尔普矩阵和位置编码矩阵,得到所述咳嗽音频的特征矩阵;
将咳嗽音频的特征矩阵归一化后乘比例因子,将得到的乘积与咳嗽音频的特征矩阵相加,并将得到的和输入分类网络分类。
在一个可能的实现中,所述生成单个咳嗽片段对应的对数梅尔普矩阵为:
以该单个咳嗽片段的结束时间和起始时间的差值为该单个咳嗽片段的长度,以该单个咳嗽片段的起始时间为起始点,对该单个咳嗽片段进行分帧加窗,并对得到的每一帧做短时傅里叶变换后求模平方得到功率谱;
将功率谱乘以特征维数得到梅尔频谱矩阵,对梅尔频谱矩阵取对数得到对数梅尔普矩阵。
在另一个可能的实现中,所述计算单个咳嗽片段对应的位置编码矩阵为:分别计算该单个咳嗽片段对应的对数梅尔谱矩阵中各特征的位置编码,公式如下:
其中,pos表示特征的帧序号;2i表示特征维数的序号,i取值从0到d/2-1;d表示特征维数;PE(pos,2i)即表示对数梅尔谱矩阵中第pos帧、第2i维特征的位置编码。
在另一个可能的实现中,所述得到所述咳嗽音频的特征矩阵为:分别将各单个咳嗽片段对应的对数梅尔普矩阵和其对应的位置编码矩阵相加,输出各单个咳嗽片段的特征矩阵;将各单个咳嗽片段的特征矩阵在时间维度上拼接,得到所述咳嗽音频的特征矩阵。
在另一个可能的实现中,所述得到所述咳嗽音频的特征矩阵为:将各单个咳嗽片段对应的对数梅尔普矩阵在时间维度上拼接,将各单个咳嗽片段对应的位置编码矩阵在时间维度上拼接;将拼接后得到的两矩阵相加,得到所述咳嗽音频的特征矩阵。
另一方面,本申请还提供了一种利用咳嗽声检测肺部疾病的装置,包括:咳嗽音检测单元、音频信号处理单元、拼接单元、归一化单元和分类网络单元;其中,
咳嗽音检测单元,用于去除原始咳嗽音频中非咳嗽音片段,得到咳嗽音频,以及该咳嗽音频中各单个咳嗽片段的起始和结束时间;
音频信号处理单元,用于依据各单个咳嗽片段的起始和结束时间,分别生成各单个咳嗽片段对应的对数梅尔普矩阵;并用于分别计算各单个咳嗽片段对应的位置编码矩阵;
拼接单元,用于依据各单个咳嗽片段对应的对数梅尔普矩阵和位置编码矩阵,得到所述咳嗽音频的特征矩阵;
归一化单元,用于将咳嗽音频的特征矩阵归一化后乘比例因子,将乘积与咳嗽音频的特征矩阵相加,并将得到的和输入分类网络单元;
分类网络单元,用于将所述得到的和分类。
在一个可能的实现中,所述生成单个咳嗽片段对应的对数梅尔普矩阵,所述音频信号处理单元,具体用于以该单个咳嗽片段的结束时间和起始时间的差值为该单个咳嗽片段的长度,以该单个咳嗽片段的起始时间为起始点,对该单个咳嗽片段进行分帧加窗,并对得到的每一帧做短时傅里叶变换后求模平方得到功率谱;并用于将功率谱乘以特征维数得到梅尔频谱矩阵,对梅尔频谱矩阵取对数得到对数梅尔普矩阵。
在另一个可能的实现中,所述计算单个咳嗽片段对应的位置编码矩阵,所述音频信号处理单元,具体用于分别计算该单个咳嗽片段对应的对数梅尔谱矩阵中各特征的位置编码,公式如下:
其中,pos表示特征的帧序号;2i表示特征维数的序号,i取值从0到d/2-1;d表示特征维数;PE(pos,2i)即表示对数梅尔谱矩阵中第pos帧、第2i维特征的位置编码。
在另一个可能的实现中,所述得到所述咳嗽音频的特征矩阵,所述拼接单元,具体用于分别将各单个咳嗽片段对应的对数梅尔普矩阵和其对应的位置编码矩阵相加,输出各单个咳嗽片段的特征矩阵;并用于将各单个咳嗽片段的特征矩阵在时间维度上拼接,得到所述咳嗽音频的特征矩阵。
在另一个可能的实现中,所述得到所述咳嗽音频的特征矩阵,所述拼接单元,将各单个咳嗽片段对应的对数梅尔普矩阵在时间维度上拼接,将各单个咳嗽片段对应的位置编码矩阵在时间维度上拼接;将拼接后得到的两矩阵相加,得到所述咳嗽音频的特征矩阵。
基于上述,本发明提供的一种利用咳嗽声检测肺部疾病的方法和装置,具有以下优点和特点:
1、对单个咳嗽片段进行位置编码,得到的位置编码矩阵具有一定的时移不变性,从而实现时域时移的自适应,提升模型的抗干扰能力;
2、对单个咳嗽片段的位置编码,使得分类网络具有学习咳嗽音频各单个咳嗽片段时域上相近位置信息的能力,并使得相同频域窗下的特征依然具有相同的位置编码,进而使分类网络对于频域上的差异性特征有更强的区分能力。
附图说明
图1为包含了五个单个咳嗽片段的咳嗽音频的对数梅尔普;
图2为未添加位置编码对图1所示咳嗽音频分类得到的热力图;
图3为添加了对整段咳嗽音频进行位置编码对图1所示咳嗽音频分类得到的热力图;
图4为本发明对图1所示咳嗽音频分类得到的热力图;
图5为包含了两个单个咳嗽片段的咳嗽音频的对数梅尔普;
图6A为未添加位置编码对图5所示咳嗽音频分类得到的热力图;
图6B为未添加位置编码对发生时移的图5所示咳嗽音频分类得到的热力图;
图7A为添加了对整段咳嗽音频进行位置编码对图5所示咳嗽音频分类得到的热力图;
图7B为添加了对整段咳嗽音频进行位置编码后对发生时移的图5所示咳嗽音频分类得到的热力图;
图8A为本发明对图5所示咳嗽音频分类得到的热力图;
图8B为本发明对发生时移的图5所示咳嗽音频分类得到的热力图;
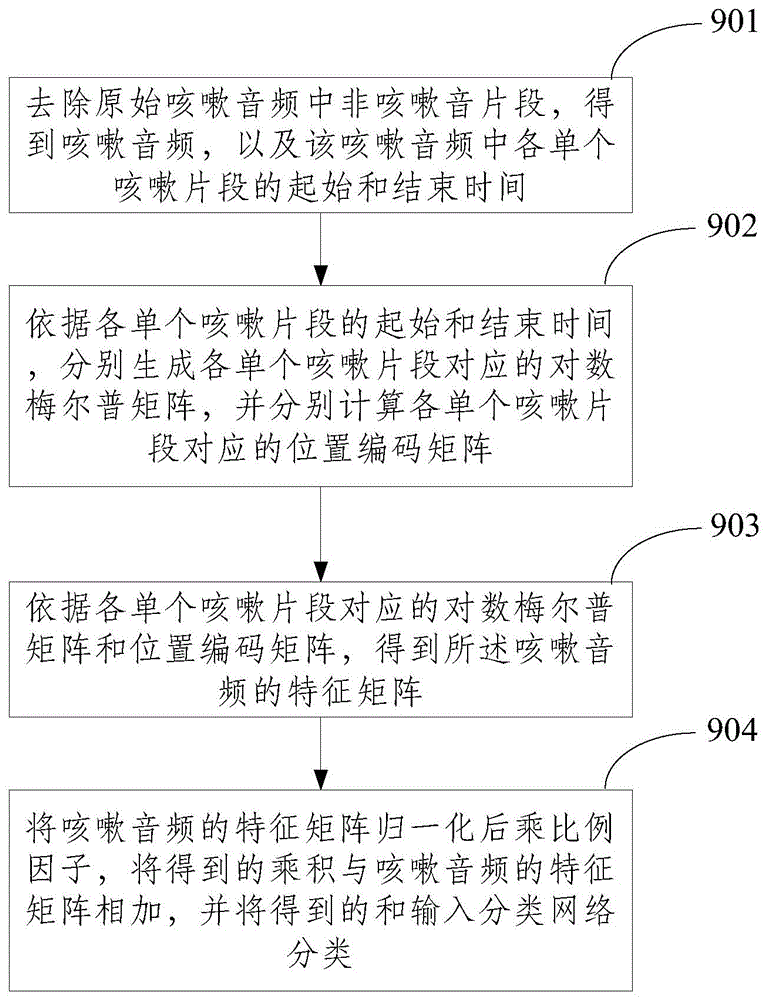
图9为本发明实施例一种利用咳嗽声检测肺部疾病的方法的流程示意图;
图10为本发明对包含两个单个咳嗽片段的咳嗽音频分类的流程示意图。
具体实施方式
采集自不同人群的咳嗽音频的时频特征存在一定的差异性,利用差异性进行分类来检测肺部疾病时,网络对于差异性特征和位置信息的捕捉都会影响分类的结果。尽管卷积神经网络中的局部滤波器和边界延拓方法使得其具有一定的位置信息的学习能力,但在数据量较小的情况下,对位置信息的捕捉并不精确。为解决此问题,现有的方案中加入了对整段咳嗽音频的位置编码,但并未能很好地解决数据量较小的情况下对位置信息的捕捉并不精确的问题,以致网络可能忽略某些单个咳嗽音片段的差异性特征,不能很好地利用咳嗽音频中全部单个咳嗽音片段的差异性特征进行分类,影响网络分类的准确性,进而使得对肺部疾病检测结果的准确度不高,且还使得在原始咳嗽音频上较小的变换可能就会使模型预测结果出现较大的偏差。
本发明提供一种利用咳嗽声检测肺部疾病的方法,分别对咳嗽音频中各单个咳嗽片段进行位置编码,并将各单个咳嗽片段的位置编码与时频特征共同输入分类网络进行分类,以提高分类网络对于差异性特征和位置信息的提取能力,进而提高分类网络对于咳嗽音频的利用率,提升分类的准确度。同时,对单个咳嗽片段进行位置编码,得到的位置编码矩阵具有一定的时移不变性,即使得单个咳嗽片段的时频特征与位置编码矩阵的对应关系并不随着咳嗽音频的时移而变动,从而实现时域时移的自适应,提升模型的抗干扰能力。
这里,所述单个咳嗽片段指承载人耳可分辨的一声咳嗽的一段音频信号。
上述现有肺部疾病检测和采用本发明对图1所示咳嗽音频进行分类的实验效果对比如图2~4所示。通过Grad-cam方法进行可视化,可以通过热力图来观察咳嗽音频所含各单个咳嗽片段对于分类结果的贡献程度,颜色越深表示贡献程度越大。其中,
图1是一段包含五个单个咳嗽片段的咳嗽音频的对数梅尔普。尽管各单个咳嗽片段含有的差异性特征并不一致,贡献程度也不一致,但是在分类时应该尽可能将各单个咳嗽片段都利用到,以得到更加准确的分类结果。
图2展示了未添加位置编码时五个单个咳嗽片段分别对分类的贡献,第四个咳嗽的热力值明显低于其他四个咳嗽,这说明在对此条咳嗽音频进行分类时,第四个单个咳嗽片段基本没有被利用到,进而可能导致检测结果存在一定的误差。
对整段咳嗽音频进行位置编码得到图3所示热力图,第四个咳嗽的特征得到了利用,但第一第二个咳嗽的贡献程度明显减弱,尤其第二个单个咳嗽音片段几乎没对分类有贡献。
而采用本发明对五个咳嗽片段分别进行位置编码之后得到图4所示的热力图,可以观察到明显的每个咳嗽片段均对分类有贡献,表明了采用本发明对单个咳嗽片段进行位置编码,各单个咳嗽片段都利用到了,进而能够得到更加准确的分类结果。
现有肺部疾病检测和采用本发明在图5所示的咳嗽音频发生时移时的实验效果对比如6A~8B所示。同样的通过Grad-cam方法进行可视化,通过热力图来观察咳嗽音频所含各单个咳嗽片段对于分类结果的贡献程度,颜色越深表示贡献程度越大。其中,
图5是一段包含两个单个咳嗽片段C1、C2的咳嗽音频的对数梅尔普。一个鲁棒的模型,期望咳嗽音频的微小变换不会使模型预测结果出现较大的偏差。
图6A展示了未添加位置编码两个单个咳嗽片段分别对分类的贡献,6B展示了未添加位置编码在发生时移后两个单个咳嗽片段分别对分类的贡献,对比可见,6A、6B两图中C1、C2两个单个咳嗽片段的热力图分布发生了很大的变化,即咳嗽音频的变换使模型检测结果出现较大的偏差。
图7A、7B为添加了对整段咳嗽音频进行位置编码得到的热力图,对比可见,图7A、7B中C1、C2两个单个咳嗽片段的热力图分布依然有较大变化,即咳嗽音频的变换使模型检测结果出现较大的偏差。
图8A、8B为采用本发明得到的热力图,两图中C1、C2两个单个咳嗽片段的热力图分布大致规律一致,这表明采用本发明的对单个咳嗽片段进行位置编码,增强了抗干扰能力,可以得出较为一致的检测结果。
具体的,本发明实施例一种利用咳嗽声检测肺部疾病的方法的流程如图9所示,包括步骤901~904,
步骤901:去除原始咳嗽音频中非咳嗽音片段,得到咳嗽音频,以及该咳嗽音频中各单个咳嗽片段的起始和结束时间。
步骤902:依据各单个咳嗽片段的起始和结束时间,分别生成各单个咳嗽片段对应的对数梅尔普矩阵,并分别计算各单个咳嗽片段对应的位置编码矩阵;
步骤903:依据各单个咳嗽片段对应的对数梅尔普矩阵和位置编码矩阵,得到所述咳嗽音频的特征矩阵;
步骤904:将咳嗽音频的特征矩阵归一化后乘比例因子,将得到的乘积与咳嗽音频的特征矩阵相加,并将得到的和输入分类网络分类,以辨别咳嗽音频来自某类肺部疾病患者或健康人。
这里,可以通过下述方法实现步骤901:
步骤9011,对原始咳嗽音频进行分帧;
步骤9012,对每一帧音频提取13维梅尔频率倒谱系数(MFCC)及其一阶、二阶差分特征构成39维特征向量;
步骤9013,将所有帧的特征向量输入由两层单向长短时记忆网络(Long Short-Term Memory)和一个全连接层构成的神经网络模型当中,该长短时记忆网络的隐含层节点个数为128,全连接层输入为128维,输出为2维,并通过logsoftmax得到每一帧是咳嗽音和非咳嗽音的概率,由此得到每一帧是否是咳嗽音,logsoftmax计算方式如下:
其中,x
步骤9014,通过一个平滑窗进行平滑得到连续的咳嗽帧和非咳嗽帧,将连续的咳嗽帧取出构成每个咳嗽,起止时间点也在此过程中同时计算得到。
在一个可能的实现中,步骤902中生成单个咳嗽片段对应的对数梅尔普矩阵具体如下:
以该单个咳嗽片段的结束时间和起始时间的差值为该单个咳嗽片段的长度,以该单个咳嗽片段的起始时间为起始点,对该单个咳嗽片段进行分帧加窗,并对得到的每一帧做短时傅里叶变换后求模平方得到功率谱;
将功率谱乘以特征维数得到梅尔频谱矩阵,对梅尔频谱矩阵取对数得到对数梅尔普矩阵。
步骤902中计算单个咳嗽片段对应的位置编码矩阵为:分别计算该单个咳嗽片段对应的对数梅尔谱矩阵中各特征的位置编码,公式如下:
/>
其中,pos表示特征的帧序号;2i表示特征维数的序号,i取值从0到d/2-1;d表示特征维数;PE(pos,2i)即表示对数梅尔谱矩阵中第pos帧、第2i维特征的位置编码。
这里,分帧操作的帧长取值范围一般为25-64ms,帧移的取值范围一般为90-32ms。所述特征维数的取值范围一般为32-256。
单个咳嗽片段内部的相邻近的帧其特征有一定的时序关联,由此,在时间域上任意的间隔k后的位置编码,都可以由当前时刻的位置编码按照下式进行表示,
PE
PE
这样,本发明提供的对单个咳嗽片段的位置编码,使得分类网络具有学习咳嗽音频各单个咳嗽片段时域上相近位置信息的能力。
且本发明提供的对单个咳嗽片段的位置编码,即使发生时移,相同频域窗下的特征依然具有相同的位置编码,使得分类网络对于频域上的差异性特征有更强的区分能力。
在一个可能的实现中,步骤903中得到所述咳嗽音频的特征矩阵为:分别将各单个咳嗽片段对应的对数梅尔普矩阵和其对应的位置编码矩阵相加,输出各单个咳嗽片段的特征矩阵;将各单个咳嗽片段的特征矩阵在时间维度上拼接,得到所述咳嗽音频的特征矩阵。
在另一个可能的实现中,步骤903中得到所述咳嗽音频的特征矩阵为:将各单个咳嗽片段对应的对数梅尔普矩阵在时间维度上拼接,将各单个咳嗽片段对应的位置编码矩阵在时间维度上拼接;将拼接后得到的两矩阵相加,得到所述咳嗽音频的特征矩阵。
在另一个可能的实现中,步骤904中将咳嗽音频的特征矩阵归一化,是由于原始咳嗽音频录制设备的多样性,我们利用实例归一化来减弱设备差异造成的影响。由于设备差异主要体现在频域,我们在每个频率窗内计算均值和方差。
其中,x∈R
考虑到利用实例归一化是对每一个样本做归一化,可能损失对于分类有帮助的信息,我们引入跳跃连接来将归一化特征乘比例因子λ后与原始特征相加输入到后续分类网络。计算方式如下所示,
其中,ε为防止分母为0的小值。
这里,如图10所示,以一条包含两个单个咳嗽片段的咳嗽音频为例,通过公式更直观的展现本发明,提高分类网络对于差异性特征和位置信息的提取能力,进而提高分类网络对于咳嗽音频的利用率,提升分类的准确度,以及实现时域时移的自适应,提升模型的抗干扰能力的优势。
假设经步骤901处理后,得到的两个单个咳嗽片段的起始时间点分别为s1、s2,结束时间点分别为e1、e2。
经步骤902,按照帧长window_length和帧移hop_length分别对两个单个咳嗽片段进行分帧,则两个单个咳嗽片段的帧数F1和F2分别为:
生成对数梅尔谱矩阵时采用频率窗的个数为d,即特征维度为d,则两个单个咳嗽片段对应的对数梅尔谱矩阵M1和M2大小分别为F1*d和F2*d。
计算每个单个咳嗽片段各自的位置编码,计算公式如下:
其中,pos=1,2,……,F表示帧序号,i=0,1,……(d/2-1),2i、2i+1表示特征维数的序号;
由此生成的两个单个咳嗽片段分别对应的位置编码矩阵PE1和PE2大小分别为F1*d和F2*d。
经步骤903,将各单个咳嗽片段对应的对数梅尔谱矩阵和位置编码矩阵分别相加得到输出out1和out2为:
out1=M1+PE1
out2=M2+PE2
将out1和out2在时间维度上拼接构成的(F1+F2)*d大小的特征矩阵为:out(e1-s1)+out(e2-s2)=M(e1-s1)+PE(e1-s1)+M(e2-s2)+PE(e2-s2)。
步骤904将咳嗽音频的特征矩阵out(e1-s1)+out(e2-s2)归一化后乘比例因子,将得到的乘积与咳嗽音频的特征矩阵相加,并将得到的和输入分类网络分类。即将两个单个咳嗽片段的时频特征M(e1-s1)+M(e2-s2)与位置编码PE(e1-s1)+PE(e2-s2)共同输入分类网络,提高了分类网络对于咳嗽音频差异性特征和位置信息的提取能力。
且通过以上计算方式,如果原始咳嗽音频发生了时移,PE(e1-s1)和PE(e2-s2)与时移之前保持一致,即每个单个咳嗽片段对应的位置编码矩阵不会因为原始咳嗽音频的时移而改变,因而out(e1-s1)和out(e2-s2)并不发生改变,进而保障了对肺部疾病的检测结果不会出现较大偏差。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。