多模型语音命令词的识别方法、系统、设备及储存介质
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及语音识别领域,尤其涉及一种多模型语音命令词的识别方法、系统、设备及储存介质。
背景技术
命令词识别技术使得机器对语音指令进行识别和理解的人工只能技术。命令词识别技术已经广泛用在我们的生活当中,智能家居,穿戴设备,智能车载系统等等。
传统的命令词识别技术需要语音端点检测(vad)后通过声学建模,wfst解码得到识别的内容,只能对命令词进行精准识别,命令词的前后如果有人声干扰或者说话人说的其他语音识别的性能会下降很多,虽然可以使用在建立wfst时前后加入filler来对额外的语音进行吸收,但是实际使用时会造成大量误识别的出现,同时这种解码识别需要加载包含所有命令词的模型,只能在一个CPU上运行,无法多核并行。
发明内容
本发明目的是为了克服现有技术的不足而提供一种以命令词进行建模,然后通过模型对语音命令词进行识别,最后得到语音识别的结果快速且精准,同时能在不损失识别性能的前提下增加命令词的数量的多模型语音命令词的识别方法、系统、设备及储存介质。
为达到上述目的,本发明采用的技术方案是:一种多模型语音命令词的识别方法,包括如下步骤:
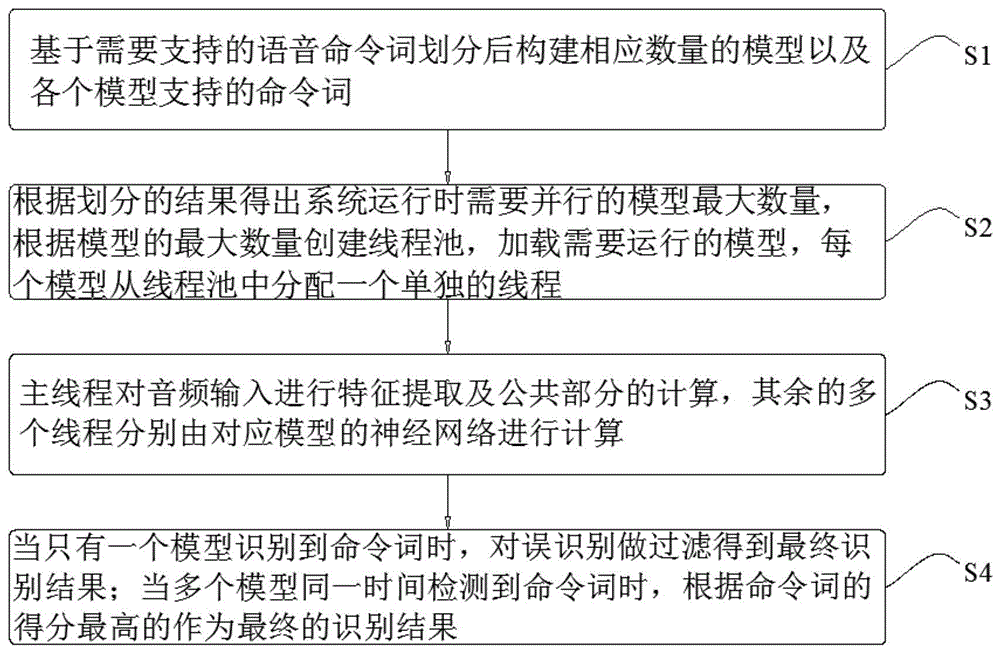
基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;
根据划分的结果得出系统运行时需要并行的模型最大数量,根据模型的最大数量创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;
主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;
当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。
进一步的,语音命令词按照功能或者类别和命令词的长度进行划分。
进一步的,每个模型的命令词个数不超过10个。
进一步的,命令词的得分的计算方式如下:
其中,N是选中命令词片段的帧数,C
进一步的,对不同的模型设置不同的长度限制,由于相近长度的命令词分在了一组,当选中的命令词片段的时长未达到设置的长度时将其认为是误识别。
进一步的,所述语音命令词包括主命令词,在每个所述主命令词下划分有依次层层分级的次级命令词;
其中,每个次级命令词构建的模型在使用场景上是主命令词或上一个次级命令词构建模型的具体功能的命令词。
一种多模型语音命令词的识别系统,包括:
分组建模模块:基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;
线程池构建模块:基于系统运行时需要并行的模型最大数量来创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;
并行解码模块:主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;
获取识别结果模块:当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。
一种处理设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述的方法。
一种可读存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行前述的方法。
由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
本发明方案的多模型语音命令词的识别方法、系统、设备及储存介质,首先不需要语音端点检测,输出层参数量更小,得到模型结果后不需要进行wfst解码只需要简单的后处理既可以得到识别的结果;能够在不损失识别性能的前提下增加命令词的数量,多线程并行计算也能带来效率的提高,同时在使用和后期维护更新时更加的灵活;另外,在后续添加或者删除命令词时只需要做局部的调整,不需要对所有的模型重新训练。
附图说明
下面结合附图对本发明技术方案作进一步说明:
图1为本发明一实施例的流程示意图;
图2为本发明一实施例中构建命令词后进行语音命令词识别的流程示意图;
图3为本发明的步骤S3中以主命令词构建的两个模型A和B并行运行的流程图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细说明。
参阅图1,本发明实施例所述的一种多模型语音命令词的识别方法,包括如下步骤:
S1基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;
S2根据划分的结果得出系统运行时需要并行的模型最大数量,根据模型的最大数量创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;
S3主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;
S4当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。
作为本发明的进一步的优选实施例,在步骤S1中,语音命令词按照功能和命令词的长度或者按照类别和命令词的长度进行划分,将命令词长度相近或者相同的划分为一组;同时,由于相近长度的命令词分在了一组,还可以对不同的模型设置不同的长度限制,当选中的命令词片段的时长未达到设置的长度时将其认为是误识别,提升了识别的精准度。
另外,为了保证模型识别的精准,所以每个模型的命令词个数不超过10个。
作为本发明的进一步的优选实施例,在步骤S2中,由于线程池的数量等于系统运行时最大的模型并行数量,这样在需要使用某一个模型时,从线程池中拿出空闲的线程进行计算,卸载时,回收模型对应的线程到线程池里去,从而尽可能的节省系统的开销。
作为本发明的进一步的优选实施例,在步骤S4中,命令词的得分的计算方式如下:
其中,N是选中命令词片段的帧数,C
通过命令词的得分来决定最终的识别效果,这样的识别准确率高。
作为本发明的进一步的优选实施例,语音命令词包括主命令词,在每个所述主命令词下划分有依次层层分级的次级命令词;其中,每个次级命令词构建的模型在使用场景上是主命令词或上一个次级命令词构建模型的具体功能的命令词。
具体来说,语音命令词可以包括多个主命令词,主命令词的下设有多个第一次级命令词,第一次级命令词下设有多个第二次级命令词,依次类推,可以有多个次级命令词;其中,第一次级命令词构建的模型在使用场景上是主命令词构建模型的具体功能的命令词,第二次级命令词构建的模型在使用场景上是第一次级命令词构建模型的具体功能的命令词。
参阅图2为本发明一实施例的具体工作流程图,本实施例中以主命令词的长度构建了两个模型A和B来进行使用,同时还具有由主命令词的下一级命令词构成的C,D,E三个模型,其中C和D在使用场景上是实现模型A的具体功能的命令词,E是实现B的具体功能的命令词;C和D也是按照长度划分的。
系统启动时,A和B两个初始模型并行运行,当识别结果是A的命令词时,切换到C和D并行;识别结果是B的命令词时切换到E,如果A和B或者C和D同时抛出识别结果会对两个结果打分选择最佳的结果,当然,图2只是举了某个特定的例子,实际使用时可以任意的去组合使用:比如初始模型的数量为三个或多个,主命令词的下一级命令词构建的模型为二个、三个或者四个。
综上所述,本发明中建模的单元是命令词,然后对每个由命令词构建的模型单独分配一个线程,最后通过模型对命令词来进行识别,当有多个模型检测到同一命令词时,通过命令词的最高得分来最为最终的识别结果。
参阅图3,其是对步骤S3的一个具体实施例的描述,其以主命令词构建的两个模型A和B并行为例进行应用,可以推广到多个模型并行。
本发明的识别方法具有如下优点:首先不需要语音端点检测,输出层参数量更小,得到模型结果后不需要进行wfst解码只需要简单的后处理既可以得到识别的结果;能够在不损失识别性能的前提下增加命令词的数量,多线程并行计算也能带来效率的提高,同时在使用和后期维护更新时更加的灵活;另外,在后续添加或者删除命令词时只需要做局部的调整,不需要对所有的模型重新训练。
本发明还公开了一种多模型语音命令词的识别系统,包括:
分组建模模块:基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;
线程池构建模块:基于系统运行时需要并行的模型最大数量来创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;
并行解码模块:主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;
获取识别结果模块:当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。
本发明另一实施例还提供一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述所述的方法。
本发明另一实施例还提供一种可读存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行前述所述的多模型语音命令词的识别方法。
以上仅是本发明的具体应用范例,对本发明的保护范围不构成任何限制。凡采用等同变换或者等效替换而形成的技术方案,均落在本发明权利保护范围之内。