用于处理多声道音频信号的装置和方法
文献发布时间:2024-04-18 19:53:33
技术领域
本公开涉及处理多声道音频信号的领域。更具体地,本公开涉及处理来自多声道音频信号的较低声道布局(例如,收听者前方的三维(3D)音频声道布局)的音频信号的领域。本公开涉及根据音频场景类型对多声道音频信号执行下混合处理或上混合处理的领域。此外,本公开涉及根据高度声道的音频信号的能量值对多声道音频信号执行下混合处理或上混合处理的领域。
背景技术
音频信号通常是二维(2D)音频信号,比如2声道音频信号、5.1声道音频信号、7.1声道音频信号和9.1声道音频信号。
然而,由于音频信息在高度方向上的不确定性,可能需要从2D音频信号生成三维(3D)音频信号(n声道音频信号或多声道音频信号,其中n是大于2的整数)以提供声音的空间3D效果。
在针对3D音频信号的传统声道布局中,声道被全向地布置在收听者周围。然而,随着机顶盒(OTT)服务的扩展、电视(TV)分辨率的增加、以及比如平板电脑等电子设备屏幕的扩大,观众对想要体验沉浸式声音(比如家庭环境中的影院内容)的需求日益增长。因此,需要处理3D音频声道布局(收听者前方的3D音频声道布局)的音频信号,其中考虑到对象(声源)在屏幕上的声像(sound image)表现,声道被布置在收听者前方。
此外,在传统的3D音频信号处理系统的情况下,已经对3D音频信号的每个独立声道的独立音频信号进行了编码/解码。具体地,为了在重建3D音频信号之后重建二维(2D)音频信号(比如传统的立体声音频信号),需要对重建的3D音频信号进行下混合。
发明内容
技术问题
本公开的实施例提供了对多声道音频信号的处理以支持收听者前方的三维(3D)音频声道布局。
问题的解决方案
根据本公开的一个方面,一种处理音频的方法包括:识别音频信号的音频场景类型,该音频信号包括至少一帧;以帧为单位确定下混合相关信息,该下混合相关信息对应于音频场景类型;通过使用下混合相关信息来对音频信号进行下混合;以及发送下混合音频信号和下混合相关信息。
音频场景类型的识别可以包括:从音频信号获得中心声道音频信号;从所获得的中心声道音频信号中识别对话类型;从音频信号获得前声道音频信号和侧声道音频信号;基于前声道音频信号和侧声道音频信号识别声音效果类型;以及基于所识别的对话类型和所识别的声音效果类型中的至少一个来识别音频场景类型。
对话类型的识别可以包括:通过使用用于识别对话类型的第一神经网络来识别对话类型;当通过使用第一神经网络识别出的对话类型的概率值大于第一对话类型的预定第一概率值时,将对话类型识别为第一对话类型;以及当通过使用第一神经网络识别出的对话类型的概率值小于或等于预定的第一概率值时,将对话类型识别为默认对话类型。
声音效果类型的识别可以包括:通过使用用于识别声音效果类型的第二神经网络来识别声音效果类型;当通过使用第二神经网络识别出的声音效果类型的概率值大于第一声音效果类型的预定第二概率值时,将声音效果类型识别为第一声音效果类型;以及当通过使用第二神经网络识别出的声音效果类型的概率值小于或等于预定的第二概率值时,将声音效果类型识别为默认声音效果类型。
基于所识别的对话类型或所识别的声音效果类型中的至少一个来识别音频场景类型可以包括:当所识别的对话类型是第一对话类型时,将音频场景类型识别为第一对话类型;当所识别的声音效果类型是第一声音效果类型时,将音频场景类型识别为第一声音效果类型;以及当所识别的对话类型是默认类型并且所识别的声音效果类型是默认类型时,将音频场景类型识别为默认类型。
发送的下混合相关信息可以包括指示多个音频场景类型之一的索引信息。
该方法还可以包括:检测声源对象;以及基于关于检测到的声源对象的信息,识别用于从环绕声道混合到高度声道的附加权重参数,其中,下混合相关信息还包括附加权重参数。
该方法还可以包括:从音频信号中识别高度声道音频信号的能量值;从音频信号中识别环绕声道音频信号的能量值;以及基于所识别的高度声道音频信号的能量值和所识别的环绕声道音频信号的能量值,识别用于从环绕声道混合到高度声道的附加权重参数,其中,下混合相关信息还包括附加权重参数。
附加权重参数的识别可以包括:当高度声道音频信号的能量值大于预定的第一值并且高度声道音频信号的能量值与环绕声道音频信号的能量值的比率大于预定的第二值时,将附加权重参数识别为第一值;以及当高度声道音频信号的能量值小于或等于预定的第一值或者该比率小于或等于预定的第二值时,将附加权重参数识别为第二值。
附加权重参数的识别可以包括:基于音频信号的音频内容内的权重目标比率来识别音频信号的至少一个时间段的权重级别;以及识别对应于该权重级别的附加权重参数,并且其中,音频信号的第一时间段与音频信号的第二时间段之间的边界段的权重具有第一时间段中除边界段之外的剩余段的权重与第二时间段中除边界段之外的剩余段的权重之间的值。
下混合可以包括:识别对应于音频场景类型的下混合简档;根据下混合简档获得用于从至少一个第一声道的第一音频信号混合到第二声道的第二音频信号的下混合权重参数;以及基于所获得的下混合权重参数来对音频信号进行下混合,并且该下混合权重参数可以对应于先前确定的音频场景类型。
声源对象的检测可以包括:基于音频信号的声道之间的相关性和延迟来识别声源对象的移动和声源对象的方向;以及通过使用基于高斯混合模型的对象估计概率模型从音频信号中识别声源对象的类型和声源对象的特性,其中,关于检测到的声源对象的信息包括关于声源对象的移动、声源对象的方向、声源对象的类型、或声源对象的特性中的至少一个的信息,并且其中,识别附加权重参数包括基于声源对象的移动、声源对象的方向、声源对象的类型、或声源对象的特性中的至少一个来识别用于从环绕声道混合到高度声道的附加权重参数。
根据本公开的一个方面,一种处理音频的方法包括:从比特流中获得下混合音频信号;从比特流获得下混合相关信息,其中,该下混合相关信息通过使用音频场景类型以帧为单位生成;通过使用下混合相关信息对下混合音频信号进行解混合;以及基于解混合的音频信号重建包括至少一帧的音频信号。
音频场景类型可以基于对话类型或声音效果类型中的至少一个来识别。
音频信号可以包括上混合声道组音频信号,其中,上混合声道组音频信号包括至少一个上混合声道的上混合声道音频信号,并且其中,上混合声道音频信号包括通过从至少一个第一声道的第一音频信号解混合而获得的第二音频信号。
下混合相关信息还可以包括关于用于从高度声道解混合到环绕声道的附加权重参数的信息,音频信号的重建可以包括通过使用下混合权重参数和关于附加权重参数的信息来重建音频信号。
根据本公开的一个方面,一种用于处理音频的装置包括被配置为执行一个或多个指令的至少一个处理器,其中,该至少一个处理器还被配置为识别音频信号的音频场景类型,该音频信号包括至少一帧;以帧为单位确定下混合相关信息,该下混合相关信息对应于音频场景类型;通过使用下混合相关信息来对音频信号进行下混合;以及发送下混合音频信号和下混合相关信息。
根据本公开的一个方面,一种用于处理音频的装置包括被配置为执行一个或多个指令的至少一个处理器,其中,该至少一个处理器还被配置为从比特流中获得下混合音频信号;从比特流获得下混合相关信息,其中,下混合相关信息通过使用音频场景类型以帧为单位被生成;通过使用下混合相关信息对下混合音频信号进行解混合;以及基于解混合的音频信号重建包括至少一帧的音频信号。
一种根据实施例的处理音频的方法包括:识别包括至少一帧的音频信号的音频场景类型,确定下混合相关信息以对应于音频场景类型;通过使用下混合相关信息对包括至少一帧的音频信号进行下混合;基于前一帧的音频场景类型和当前帧的音频场景类型,生成指示前一帧的音频场景类型是否与当前帧的音频场景类型相同的标志信息;以及发送下混合音频信号、标志信息、或下混合相关信息中的至少一个。
该发送可以包括:当前一帧的音频场景类型与当前帧的音频场景类型相同时,发送指示前一帧的音频场景类型和当前帧的音频场景类型相同的标志信息以及前一帧的下混合相关信息,其中,可以不发送当前帧的下混合相关信息。
该发送可以包括:当前一帧的音频场景类型与当前帧的音频场景类型相同时,发送下混合音频信号和前一帧的下混合相关信息,其中,可以不发送指示前一帧的音频场景类型和当前帧的音频场景类型彼此相同的标志信息以及当前帧的下混合相关信息。
根据本公开的实施例,一种用于处理音频的方法包括:从比特流获得下混合音频信号,从比特流获得指示前一帧的音频场景类型和当前帧的音频场景类型是否彼此相同的标志信息,基于标志信息获得当前帧的下混合相关信息,其中,当前帧的下混合相关信息是通过使用其音频场景类型而生成的信息,通过使用当前帧的下混合相关信息对下混合音频信号进行解混合,以及基于解混合的音频信号重建包括至少一帧的音频信号。
当前帧的下混合相关信息的获取可以包括:当标志信息指示前一帧的音频场景类型与当前帧的音频场景类型相同时,基于前一帧的下混合相关信息获取当前帧的下混合相关信息。
一种计算机可读记录介质,其上可以记录有用于实施本公开的上述方面的方法的程序。
本公开的有益效果
利用根据本公开的实施例的用于处理多声道音频信号的方法和装置,在支持向后兼容传统的立体声(2声道)音频信号的同时,对收听者前方的三维(3D)音频声道布局的音频信号和全向围绕收听者的3D音频声道布局的音频信号两者均可以进行编码。
然而,根据本公开的实施例的处理多声道音频信号的装置和方法所实现的效果不限于上述的那些效果,并且本公开所属领域的普通技术人员将从以下描述中清楚地理解未提及的其他效果。
附图说明
本公开的某些实施例的上述和其他方面、特征和优点将从以下结合附图的描述中变得更加明显,其中:
图1A是用于描述根据实施例的可缩放声道布局结构的视图。
图1B是用于描述详细的可缩放音频声道布局结构的示例的视图。
图2A是根据实施例的音频编码装置的框图。
图2B是根据实施例的音频编码装置的框图。
图2C是根据实施例的多声道音频信号处理器的结构的框图。
图2D是用于描述音频信号分类器的详细操作的示例的视图。
图3A是根据实施例的多声道音频解码装置的结构的框图。
图3B是根据实施例的多声道音频解码装置的结构的框图。
图3C是根据实施例的多声道音频信号重建器的结构的框图。
图3D是根据实施例的上混合声道组音频生成器的结构的框图。
图4A是根据实施例的音频编码装置的框图。
图4B是根据实施例的误差消除相关信息生成器的结构的框图。
图5A是根据实施例的音频解码装置的结构的框图。
图5B是根据实施例的多声道音频信号重建器的结构的框图。
图6A是用于描述根据实施例的音频编码装置在每个声道组中的音频流的传输顺序和规则的视图。
图6B和图6C示出了根据实施例的用于逐步下混合的机制的示例。
图7A是根据实施例的音频编码装置的框图。
图7B是根据实施例的音频编码装置的框图。
图8是根据实施例的音频编码装置的框图。
图9A是根据实施例的多声道音频解码装置的结构的框图。
图9B是根据实施例的音频解码装置的框图。
图10是根据实施例的音频解码装置的框图。
图11是用于详细描述根据实施例的通过音频编码装置识别音频场景内容的类型的过程的视图。
图12是用于描述根据实施例的用于识别对话类型的第一深度神经网络(DNN)的视图。
图13是用于描述根据实施例的用于识别声音效果的类型的第二DNN的视图。
图14是用于详细描述根据实施例的通过音频编码装置识别用于从环绕声道混合到高度声道的附加解混合参数权重的过程的视图。
图15是用于详细描述根据实施例的通过音频编码装置识别用于从环绕声道混合到高度声道的附加解混合参数权重的过程的视图。
图16是根据实施例的音频处理方法的流程图。
图17A是根据实施例的音频处理方法的流程图。
图17B是根据实施例的音频处理方法的流程图。
图17C是根据实施例的音频处理方法的流程图。
图17D是根据实施例的音频处理方法的流程图。
图18A是根据实施例的音频处理方法的流程图。
图18B是根据实施例的音频处理方法的流程图。
图18C是根据实施例的音频处理方法的流程图。
图18D是根据实施例的音频处理方法的流程图。
具体实施方式
在整个公开中,表述“a、b或c中的至少一个”表示仅a、仅b、仅c、a和b两者、a和c两者、b和c两者、a、b和c全部或其变体。
本公开可以具有对其的各种修改和本公开的各种实施例,因此本公开的特定实施例将在附图中图示并在具体实施方式中详细描述。然而,应该理解,这并不旨在将本公开限制于本公开的特定实施例,并且应该理解为包括落入本公开的精神和范围内的所有变化、等同方案和替代方案。
在描述本公开的实施例时,当确定相关技术的详细描述会不必要地模糊主题时,将省略其详细描述。此外,在描述本公开的实施例的过程中使用的数字(例如,第一、第二等)仅仅是用于区分一个组件与另一个组件的标识符号。
此外,在本文中,当提到组件“连接”或“耦接”到另一个组件时,它可以直接连接或直接耦接到另一个组件,但是除非另有说明,否则应该理解,该组件也可以经由其间的又一个组件连接或耦接到另一个组件。
此外,对于由“…单元”、“模块”等表示的组件,两个或更多个组件可以被集成为一个组件,或者一个组件可以被分成两个或更多个针对每个具体功能的组件。下面要描述的每个组件除了该组件的主要功能之外还可以附加地执行负责其他组件的一些或全部功能中的功能,并且这些组件的一些主要功能可以专用于其他组件并由其他组件执行。
这里,“深度神经网络(DNN)”是模拟脑神经的人工神经网络模型的代表性示例,并且不限于使用特定算法的人工神经网络模型。
这里,“参数”可以是在构成神经网络的每一层的操作过程中使用的值,并且可以包括例如在将输入值应用于预定的计算公式时使用的权重(和偏差)。该参数可以以矩阵的形式表达。该参数可以是作为训练的结果设置的值,并且可以根据需要通过单独的训练数据来更新。
这里,“多声道音频信号”可以指n个声道的音频信号(其中,n是大于2的整数)。“单声道音频信号”可以是一维(1D)音频信号,“立体声声道音频信号”可以是二维(2D)音频信号,并且“多声道音频信号”可以是三维(3D)音频信号。
这里,“声道(扬声器)布局”可以表示至少一个声道的组合,并且可以指定声道(扬声器)的空间布置。这里使用的声道是通过其实际输出音频信号的声道,因此可以被称为呈现声道。
例如,声道布局可以是“X.Y.Z声道布局”。这里,X可以是环绕声道(surroundchannel)的数量,Y可以是低音炮声道(subwoofer channel)的数量,Z可以是高度声道(height channel)的数量。声道布局可以指定环绕声道/低音炮声道/高度声道的空间位置。
“声道(扬声器)布局”的示例可以包括1.0.0声道(或单声道)布局、2.0.0声道(或立体声声道)布局、5.1.0声道布局、5.1.2声道布局、5.1.4声道布局、7.1.0布局、7.1.2布局和3.1.2声道布局,但是“声道布局”不限于此,并且可以存在各种其他声道布局。
由“声道(扬声器)布局”指定的声道可以被称为各种名称,但是为了便于解释,可以统一命名。
构成“声道(扬声器)布局”的声道可以基于声道各自的空间位置来命名。
例如,1.0.0声道布局的第一环绕声道可以被命名为单声道。对于2.0.0声道布局,第一环绕声道可以被命名为L2声道,并且第二环绕声道可以被命名为R2声道。
这里,“L”表示位于收听者左侧的声道,“R”表示位于收听者右侧的声道。“2”表示环绕声道的数量为2。
对于5.1.0声道布局,第一环绕声道可以被命名为L5声道,第二环绕声道可以被命名为R5声道,第三环绕声道可以被命名为C声道,第四环绕声道可以被命名为Ls5声道,并且第五环绕声道可以被命名为Rs5声道。这里,“C”表示相对于收听者位于中心的声道。“s”指位于收听者一侧的声道。5.1.0声道布局的第一低音炮声道可以被命名为低频效果(LFE)声道。这里,LFE可以指低频效果。换句话说,LFE声道可以是用于输出低频声音效果的声道。
5.1.2声道布局和5.1.4声道布局的环绕声道可以与5.1.0声道布局的环绕声道命名相同。类似地,5.1.2声道布局和5.1.4声道布局的低音炮声道可以与5.1.0声道布局的低音炮声道命名相同。
5.1.2声道布局的第一高度声道可以被命名为Hl5声道。这里,H表示高度声道。第二高度声道可以被命名为Hr5声道。
对于5.1.4声道布局,第一高度声道可以被命名为Hfl声道,第二高度声道可以被命名为Hfr声道,第三高度声道可以被命名为Hbl声道,并且第四高度声道可以被命名为Hbr声道。这里,f表示相对于收听者的前方声道,b表示相对于收听者的后方声道。
对于7.1.0声道布局,第一环绕声道可以被命名为L声道,第二环绕声道可以被命名为R声道,第三环绕声道可以被命名为C声道,第四环绕声道可以被命名为Ls声道,第五环绕声道可以被命名为Rs声道,第六环绕声道可以被命名为Lb声道,并且第七环绕声道可以被命名为Rb声道。
7.1.2声道布局和7.1.4声道布局的各个环绕声道可以与7.1.0声道布局的环绕声道命名相同。类似地,7.1.2声道布局和7.1.4声道布局的各个低音炮声道可以与7.1.0声道布局的低音炮声道命名相同。
对于7.1.2声道布局,第一高度声道可以被命名为Hl7声道,并且第二高度声道可以被命名为Hr7声道。
对于7.1.4声道布局,第一高度声道可以被命名为Hfl声道,第二高度声道可以被命名为Hfr声道,第三高度声道可以被命名为Hbl声道,并且第四高度声道可以被命名为Hbr声道。
对于3.1.2声道布局,第一环绕声道可以被命名为L3声道,第二环绕声道可以被命名为R3声道,并且第三环绕声道可以被命名为C声道。3.1.2声道布局的第一低音炮声道可以被命名为LFE声道。对于3.1.2声道布局,第一高度声道可以被命名为Hfl3声道(或Tl声道),并且第二高度声道可以被命名为Hfr3声道(或Tr声道)。
这里,根据声道布局,一些声道可以被不同地命名,但是可以表示相同的声道。例如,Hl5声道和Hl7声道可以是相同的声道。类似地,Hr5声道和Hr7声道可以是相同的声道。
同时,声道不限于上述声道名称,并且可以使用各种其他声道名称。
例如,L2声道可以被命名为L”声道,R2声道可以被命名为R”声道,L3声道可以被命名为ML3(L’)声道,R3声道可以被命名为MR3(R’)声道,Hfl3声道可以被命名为MHL3声道,Hfr3声道可以被命名为MHR3声道,Ls5声道可以被命名为MSL5(Ls’)声道,Rs5声道可以被命名为MSR5(Rs’)声道,Hl5声道可以被命名为MHL5(Hl’)声道,Hr5声道可以被命名为MHR5(Hr’)声道,并且C声道可以被命名为MC声道。
上述布局的声道布局的声道可以如表1中命名。
[表1]
同时,“传输声道”是用于发送压缩音频信号的声道,并且“传输声道”的一部分可以与“呈现声道”相同,但是不限于此,并且“传输声道”的另一部分可以是其中混合了呈现声道的音频信号的音频信号的声道(混合声道)。换句话说,“传输声道”可以是包含“呈现声道”的音频信号的声道,但也可以是一部分与呈现声道相同而剩余部分是与呈现声道不同的混合声道的声道。
“传输声道”可以被命名为与“呈现声道”区分开。例如,当传输声道是A/B声道时,A/B声道可以包含L2/R2声道的音频信号。当传输声道是T/P/Q声道时,T/P/Q声道可以包含C/LFE/Hfl3和Hfr3声道的音频信号。当传输声道是S/U/V声道时,S/U/V声道可以包含L和R/Ls以及Rs/Hfl和Hfr声道的音频信号。
在本公开中,“3D音频信号”可以指用于检测3D空间中的声音分布和声源位置的音频信号。
在本公开中,“收听者前方的3D音频声道”可以指基于布置在收听者前方的音频声道的布局的3D音频声道。“收听者前方的3D音频声道”可以被称为“前方3D音频声道”。具体地,“收听者前方的3D音频声道”可以被称为“以屏幕为中心的3D音频声道”,因为它是基于布置在位于收听者前方的屏幕周围的音频声道的布局的3D音频声道。
在本公开中,“收听者全向3D音频声道”可以指基于围绕收听者全向布置的音频声道的布局的3D音频声道。“收听者全向3D音频声道”可以被称为“全3D音频声道”。这里,全向可以指包括前方、侧向和后方方向中的所有方向。具体地,“收听者全向3D音频声道”也可以被称为“以收听者为中心的3D音频声道”,因为它是基于围绕收听者全向布置的音频声道的布局的3D音频声道。
在本公开中,作为一种数据单元的“声道组”可以包括至少一个声道的(压缩的)音频信号。更具体地,声道组可以包括独立于另一个声道组的基本声道组或依赖于至少一个声道组的从属声道组中的至少一个。在这种情况下,从属声道组所依赖的目标声道组可以是另一个从属声道组,并且可以是与较低声道布局相关的从属声道组。或者,从属声道组所依赖的声道组可以是基本声道组。“声道组”包含声道组的一种数据,因此声道组可以被称为“编解码组”。用于从包括在基本声道组中的声道进一步扩展声道数量的从属声道组可以被称为可缩放声道组或扩展声道组。
“基本声道组”的音频信号可以包括单声道的音频信号或立体声声道的音频信号。不限于此,“基本声道组”的音频信号可以包括收听者前方的3D音频声道的音频信号。
例如,“从属声道组”的音频信号可以包括在收听者前方的3D音频声道的音频信号或收听者全向3D音频声道的音频信号中除了“基本声道组”的音频信号之外的声道的音频信号。在这种情况下,另一个声道的音频信号的一部分可以是其中混合了至少一个声道的音频信号的音频信号(即,混合声道的音频信号)。
例如,“基本声道组”的音频信号可以是单声道的音频信号或立体声声道的音频信号。基于“基本声道组”和“从属声道组”的音频信号重建的“多声道音频信号”可以是收听者前方的3D音频声道的音频信号或收听者全向3D音频声道的音频信号。
在本公开中,“上混合(up-mixing)”可以指通过解混合,输出音频信号的呈现声道的数量与输入音频信号的呈现声道的数量相比增加的操作。
在本公开中,“解混合(de-mixing)”可以指将特定声道的音频信号与其中混合了各种声道的音频信号的音频信号(即,混合声道的音频信号)分离的操作,并且可以指混合操作之一。在这种情况下,“解混合”可以被实施为使用“解混合矩阵”(或与其对应的“下混合矩阵”)的计算,并且“解混合”矩阵可以包括至少一个“解混合权重参数”(或与其对应的“下混合权重参数”)作为解混合矩阵(或与其对应的“下混合矩阵”)的系数。可替换地,“解混合”可以被实施为基于“解混合矩阵”(或与其对应的“下混合矩阵”)的一部分的算术计算,并且可以以各种方式实施而不限于此。如上所述,“解混合”可以与“上混合”相关。
“混合”可以指通过将多个声道的音频信号中的每个音频信号乘以对应的权重而获得的值相加(即,通过混合多个声道的音频信号)来生成新声道(即,混合声道)的音频信号的任何操作。
“混合”可以分为狭义上由音频编码装置执行的“混合”和由音频解码装置执行的“解混合”。
在音频编码装置中执行的“混合”可以被实施为使用“(下)混合矩阵”的计算,并且“(下)混合矩阵”可以包括至少一个“(下)混合权重参数”作为(下)混合矩阵的系数。或者,“(下)混合”可以被实施为基于“(下)混合矩阵”的一部分的算术计算,并且可以以各种方式实施而不限于此。
在本公开中,“上混合声道组”可以指包括至少一个上混合声道的组,并且“上混合声道”可以指通过针对编码/解码声道的音频信号的解混合而分离的解混合声道。狭义上的“上混合声道组”可以包括“上混合声道”。然而,广义上的“上混合声道组”还可以包括“编码/解码声道”以及“上混合声道”。这里,“编码/解码声道”可以指经编码(压缩)并包括在比特流中的音频信号的独立声道或通过从比特流解码获得的音频信号的独立声道。在这种情况下,为了获得编码/解码声道的音频信号,不需要单独的(解)混合操作。
广义上的“上混合声道组”的音频信号可以是多声道音频信号,并且输出的多声道音频信号可以是作为通过比如扬声器等设备输出的音频信号的至少一个多声道音频信号(即,至少一个上混合声道组的音频信号或上混合声道音频信号)之一。
在本公开中,“下混合”可以指通过混合,输出音频信号的呈现声道的数量与输入音频信号的呈现声道的数量相比减少的操作。
在本公开中,“用于误差消除的因子”(或误差消除因子(ERF))可以是用于消除由于有损编解码而发生的音频信号的误差的因子。
由于有损编解码而发生的音频信号的误差可以包括由量化,更具体地,由基于心理声学特性的编码(量化)引起的误差等,引起的误差。“用于误差消除的因子”可以被称为“编解码误差消除(CER)因子”或“误差消除比率”等。具体地,“误差消除因子”可以被称为“缩放因子”,因为误差消除操作基本上对应于缩放操作。
在下文中,将依次详细描述根据本公开的技术精神的本公开的实施例。
图1A是用于描述根据本公开的实施例的可缩放声道布局结构的视图。
传统的3D音频解码装置从比特流接收特定声道布局的独立声道的压缩音频信号。传统的3D音频解码装置通过使用从比特流接收的独立声道的压缩音频信号来重建收听者全向3D音频声道的音频信号。在这种情况下,只有特定声道布局的音频信号可以被重建。
或者,传统的3D音频解码装置从比特流接收特定声道布局的独立声道(第一独立声道组)的压缩音频信号。例如,特定声道布局可以是5.1声道布局,并且在这种情况下,第一独立声道组的压缩音频信号可以是五个环绕声道和一个低音炮声道的压缩音频信号。
这里,为了增加声道的数量,传统的3D音频解码装置还接收独立于第一独立声道组的其他声道(第二独立声道组)的压缩音频信号。例如,第二独立声道组的压缩音频信号可以是两个高度声道的压缩音频信号。
也就是说,传统的3D音频解码装置通过与从比特流接收的第一独立声道组的压缩音频信号分开地使用从比特流接收的第二独立声道组的压缩音频信号来重建收听者全向3D音频声道的音频信号。因此,重建了声道数量增加的音频信号。这里,收听者全向3D音频声道的音频信号可以是5.1.2声道的音频信号。
另一方面,仅支持立体声声道的音频信号的再现的传统音频解码装置不能正确地处理包括在比特流中的压缩音频信号。
支持3D音频信号的再现的传统的3D音频解码装置也首先对第一独立声道组和第二独立声道组的压缩音频信号进行解压缩(解码)以再现立体声声道的音频信号。然后,传统的3D音频解码装置对通过解压缩生成的音频信号进行上混合。然而,为了再现立体声声道的音频信号,必须执行比如上混合等操作。
因此,需要一种能够在传统音频解码装置中处理压缩音频信号的可缩放声道布局结构。此外,在根据本公开的各种实施例的支持3D音频信号的再现的音频解码装置300和500(参见图3A、图3B、图5A和图5B)中,需要一种能够根据支持再现的3D音频声道布局来处理压缩音频信号的可缩放声道布局结构。这里,可缩放声道布局结构可以指其中声道数量可以从基本声道布局自由增加的布局结构。
根据本公开的各种实施例的音频解码装置300和500可以从比特流重建可缩放声道布局结构的音频信号。利用根据本公开的实施例的可缩放声道布局结构,声道的数量可以从立体声声道布局100增加到收听者前方的3D音频声道布局110。此外,利用可缩放声道布局结构,声道的数量可以从收听者前方的3D音频声道布局110增加到全向位于收听者周围的3D音频声道布局120(或者收听者全向3D音频声道布局120)。例如,收听者前方的3D音频声道布局110可以是3.1.2声道布局。收听者全向3D音频声道布局120可以是5.1.2或7.1.2声道布局。然而,可以在本公开中实施的可缩放声道布局不限于此。
作为基本声道组,传统的立体声声道的音频信号可以被压缩。传统音频解码装置可以从比特流解压缩基本声道组的压缩音频信号,从而平滑地再现传统的立体声声道的音频信号。
另外,作为从属声道组,可以压缩多声道音频信号中除了传统的立体声声道的音频信号之外的声道的音频信号。
然而,在增加声道数量的过程中,声道组的音频信号的一部分可以是混合了特定声道布局的音频信号中的一些独立声道的信号的音频信号。
因此,在音频解码装置300和500中,基本声道组的音频信号的一部分和从属声道组的音频信号的一部分可以被解混合以生成包括在特定声道布局中的上混合声道的音频信号。
同时,可以存在一个或多个从属声道组。例如,收听者前方的3D音频声道布局110的音频信号中除了立体声声道的音频信号之外的声道的音频信号可以被压缩为第一从属声道组的音频信号。
收听者全向3D音频声道布局120的音频信号中除了从基本声道组和第一从属声道组重建的声道的音频信号之外的声道的音频信号可以被压缩为第二从属声道组的音频信号。
根据本公开的实施例的音频解码装置300和500可以支持收听者全向3D音频声道布局120的音频信号的再现。
因此,根据本公开的实施例的音频解码装置300和500可以基于基本声道组的音频信号以及第一从属声道组和第二从属声道组的音频信号来重建收听者全向3D音频声道布局120的音频信号。
传统音频信号处理装置可以忽略可以不从比特流重建的从属声道组的压缩音频信号,并且再现从比特流重建的立体声声道的音频信号。
类似地,音频解码装置300和500可以处理基本声道组和从属声道组的压缩音频信号以重建可缩放声道布局中可支持的声道布局的音频信号。音频解码装置300和500可以不从比特流重建关于不支持的较高声道布局的压缩音频信号。因此,可以从比特流重建可支持的声道布局的音频信号,同时忽略与音频解码装置300和500不支持的较高声道布局相关的压缩音频信号。
具体地,传统的音频编码和解码装置对特定声道布局的独立声道的音频信号进行压缩和解压缩。因此,对有限声道布局的音频信号的压缩和解压缩是可能的。
然而,通过根据本公开的各种实施例的支持可缩放声道布局的音频编码装置200和400(参见图2A、图2B和图4A)以及音频解码装置300和500,立体声声道的音频信号的传输和重建是可能的。利用根据本公开的各种实施例的音频编码装置200和400以及音频解码装置300和500,在收听者前方的3D声道布局的音频信号的传输和重建是可能的。此外,利用根据本公开的实施例的音频编码装置200和400以及音频解码装置300和500,可以发送和重建全向围绕收听者的3D声道布局的音频信号。
也就是说,根据本公开的各种实施例的音频编码装置200和400以及音频解码装置300和500可以根据立体声声道的布局发送和重建音频信号。此外,根据本公开的各种实施例的音频编码装置200和400以及音频解码装置300和500可以自由地将当前声道布局的音频信号转换成另一种声道布局的音频信号。通过包括在不同声道布局中的声道的音频信号之间的混合/解混合,声道布局之间的转换是可能的。根据本公开的各种实施例的音频编码装置200和400以及音频解码装置300和500可以支持各种声道布局之间的转换,从而发送和再现各种3D声道布局的音频信号。也就是说,在收听者前方的声道布局与收听者全向声道布局之间或在立体声声道布局与收听者前方的声道布局之间,不保证声道独立性,但是通过音频信号的混合/解混合,自由转换是可能的。
根据本公开的各种实施例的音频编码装置200和400以及音频解码装置300和500支持对收听者前方的声道布局的音频信号进行处理,从而发送和重建与布置在屏幕周围的扬声器相对应的音频信号,从而改善收听者的沉浸感。
将参照图2A至图5B描述根据本公开的各种实施例的音频编码装置200和400以及音频解码装置300和500的详细操作。
图1B是用于描述详细的可缩放音频声道布局结构的示例的视图。在该图中,编号的/有向的边(1)至(10)中的每一个可以表示由音频解码装置300和500执行的解混合操作。
参照图1B,为了发送立体声声道布局160的音频信号,音频编码装置200和400可以通过压缩L2/R2信号来生成基本声道组的压缩音频信号(A/B信号)。
在这种情况下,音频编码装置200和400可以通过压缩L2/R2信号来生成基本声道组的音频信号。
此外,为了发送作为收听者前方的3D音频声道之一的3.1.2声道的布局170的音频信号,音频编码装置200和400可以通过压缩C、LFE、Hfl3和Hfr3信号来生成从属声道组的压缩音频信号。音频解码装置300和500可以通过解压缩基本声道组的压缩音频信号来重建L2/R2信号。音频解码装置300和500可以通过解压缩从属声道组的压缩音频信号来重建C、LFE、Hfl3和Hfr3信号。
音频解码装置300和500可以通过对L2信号和C信号进行解混合来重建3.1.2声道布局170的L3信号(1)。音频解码装置300和500可以通过对R2信号和C信号进行解混合来重建3.1.2声道布局170的R3信号(2)。
结果,音频解码装置300和500可以输出L3、R3、C、Lfe、Hfl3和Hfr3信号作为3.1.2声道布局170的音频信号。
同时,为了发送收听者全向5.1.2声道布局180的音频信号,音频编码装置200和400可以进一步压缩L5和R5信号以生成第二从属声道组的压缩音频信号。
如上所述,音频解码装置300和500可以通过解压缩基本声道组的压缩音频信号来重建L2/R2信号,并通过解压缩第一从属声道组的压缩音频信号来重建C、LFE、Hfl3和Hfr3信号。此外,音频解码装置300和500可以通过解压缩第二从属声道组的压缩音频信号来重建L5和R5信号。此外,如上所述,音频解码装置300和500可以通过对一些解压缩的音频信号进行解混合来重建L3和R3信号。
此外,音频解码装置300和500可以通过对L3和L5信号进行解混合来重建Ls5信号(3)。音频解码装置300和500可以通过对R3和R5信号进行解混合来重建Rs5信号(4)。
音频解码装置300和500可以通过解混合Hfl3和Ls5信号来重建Hl5信号(5)。Hfl3和Hl5是高度声道中的左前声道。
音频解码装置300和500可以通过对Hfr3和Rs5信号进行解混合来重建Hr5信号(6)。Hfr3和Hr5是高度声道中的右前声道。
结果,音频解码装置300和500可以输出Hl5、Hr5、LFE、L、R、C、Ls5和Rs5信号作为5.1.2声道布局180的音频信号。
同时,为了发送7.1.4声道布局190的音频信号,音频编码装置200和400可以进一步压缩Hfl、Hfr、Ls和Rs信号作为第三从属声道组的音频信号。
如上所述,音频解码装置300和500可以解压缩基本声道组的压缩音频信号、第一从属声道组的压缩音频信号和第二从属声道组的压缩音频信号,并通过解混合(1)、(2)、(3)、(4)、(5)和(6)来重建Hl5、Hr5、LFE、L、R、C、Ls5和Rs5信号。
此外,音频解码装置300和500可以通过解压缩第三从属声道组的压缩音频信号来重建Hfl、Hfr、Ls和Rs信号。音频解码装置300和500可以通过(7)对Ls5信号和Ls信号进行解混合来重建7.1.4声道布局190的Lb信号。
音频解码装置300和500可以通过(8)对Rs5信号和Rs信号进行解混合来重建7.1.4声道布局190的Rb信号。
音频解码装置300和500可以通过(9)对Hfl信号和Hl5信号进行解混合来重建7.1.4声道布局190的Hbl信号。
音频解码装置300和500可以通过(10)对Hfr信号和Hr5信号进行解混合来重建7.1.4声道布局190的Hbr信号。
结果,音频解码装置300和500可以输出Hfl、Hfr、LFE、C、L、R、Ls、Rs、Lb、Rb、Hbl和Hbr信号作为7.1.4声道布局190的音频信号。
因此,音频解码装置300和500可以通过支持其中声道数量通过解混合操作而增加的可缩放声道布局,来重建收听者前方的3D音频声道的音频信号和收听者全向3D音频声道的音频信号以及传统的立体声声道布局的音频信号。
以上参照图1B详细描述的可缩放声道布局结构仅仅是示例,并且声道布局结构可以被可缩放地实施为包括各种声道布局。
图2A是根据本公开的实施例的音频编码装置的框图。
音频编码装置200可以包括存储器210和处理器230。音频编码装置200可以被实施为能够执行音频处理的装置,比如服务器、电视(TV)、相机、蜂窝电话、平板个人计算机(PC)、膝上型计算机等。
虽然在图2A中分开示出了存储器210和处理器230,但是存储器210和处理器230可以通过一个硬件模块(例如,芯片)来实施。
处理器230可以被实施为用于基于神经网络的音频处理的专用处理器。或者,处理器230可以通过通用处理器(比如应用处理器(AP)、中央处理单元(CPU)或图形处理单元(GPU))与软件的组合来实施。专用处理器可以包括用于实施本公开的实施例的存储器或用于使用外部存储器的存储器处理器。
处理器230可以包括多个处理器。在这种情况下,处理器230可以被实施为专用处理器的组合,或者可以通过软件和多个通用处理器(比如AP、CPU或GPU)的组合来实施。
存储器210可以存储一个或多个用于音频处理的指令。在本公开的实施例中,存储器210可以存储神经网络。当神经网络以用于人工智能的专用硬件芯片的形式或者作为现有通用处理器(例如,CPU或AP)或图形专用处理器(例如,GPU)的一部分来实施时,神经网络可以不被存储在存储器210中。神经网络可以通过外部设备(例如,服务器)实施,并且在这种情况下,音频编码装置200可以从外部设备请求和接收基于神经网络的结果信息。
处理器230可以根据存储在存储器210中的指令顺序地处理连续的帧并获得连续的经编码的(经压缩的)帧。连续的帧可以指构成音频的帧。
处理器230可以以原始音频信号作为输入来执行音频处理操作,并且输出包括压缩音频信号的比特流。在这种情况下,原始音频信号可以是多声道音频信号。压缩音频信号可以是其声道数小于或等于原始音频信号的声道数的多声道音频信号。
在这种情况下,比特流可以包括基本声道组,此外,还包括n个从属声道组(n是大于或等于1的整数)。因此,根据从属声道组的数量,可以自由地增加声道的数量。
图2B是根据本公开的实施例的音频编码装置的框图。
参照图2B,音频编码装置200可以包括多声道音频编码器250、比特流生成器280和附加信息生成器285。多声道音频编码器250可以包括多声道音频信号处理器260和压缩器270。
返回参照图2A,如上所述,音频编码装置200可以包括存储器210和处理器230,并且用于实施图2B的组件250、260、270、280和285的指令可以存储在图2A的存储器210中。处理器230可以执行存储在存储器210中的指令。
多声道音频信号处理器260可以从原始音频信号获得基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号。例如,当原始音频信号是7.1.4声道布局的音频信号时,多声道音频信号处理器260可以获得2声道(立体声声道)的音频信号作为7.1.4声道布局的音频信号中的基本声道组的音频信号。
多声道音频信号处理器260可以从3.1.2声道布局的音频信号中获得除了2声道的音频信号之外的声道的音频信号,作为第一从属声道组的音频信号,以重建作为收听者前方的3D音频声道之一的3.1.2声道布局的音频信号。在这种情况下,第一从属声道组的一些声道的音频信号可以被解混合以生成解混合声道的音频信号。
多声道音频信号处理器260可以从作为收听者前方和后方的3D音频声道之一的5.1.2声道布局的音频信号中获得除了基本声道组的音频信号和第一从属声道组的音频信号之外的声道的音频信号,作为第二从属声道组的音频信号,以重建5.1.2声道布局的音频信号。在这种情况下,第二从属声道组的一些声道的音频信号可以被解混合以生成解混合声道的音频信号。
多声道音频信号处理器260可以从作为收听者全向3D音频声道之一的7.1.4声道布局的音频信号中获得除了第一从属声道组的音频信号和第二从属声道组的音频信号之外的声道的音频信号,作为第三从属声道组的音频信号,以重建7.1.4声道布局的音频信号。同样,第三从属声道组的一些声道的音频信号可以被解混合以获得解混合声道的音频信号。
稍后将参照图2C描述多声道音频信号处理器260的详细操作。
压缩器270可以压缩基本声道组的音频信号和从属声道组的音频信号。也就是说,压缩器270可以压缩基本声道组的至少一个音频信号以获得基本声道组的至少一个压缩音频信号。这里,压缩可以指基于各种音频编解码器的压缩。例如,压缩可以包括变换和量化过程。
这里,基本声道组的音频信号可以是单声道信号或立体声信号。或者,基本声道组的音频信号可以包括通过将左立体声声道的音频信号L与C_1混合而生成的第一声道的音频信号。这里,C_1可以是在压缩之后被解压缩的收听者前方的中心声道的音频信号(例如,中心声道音频信号)。在本公开中,当使用名称(“X_Y”)来描述音频信号时,“X”可以表示声道的名称,“Y”可以表示被解码、被上混合、被应用误差消除因子(即,被缩放)、或被应用的LFE增益。例如,解码的信号可以被表示为“X_1”,并且通过对解码的信号进行上混合而生成的信号(上混合信号)可以被表示为“X_2”。或者,对解码的LFE信号应用了LFE增益的信号也可以被表示为“X_2”。向上混合信号应用了误差消除因子的信号(即,缩放信号)可以被表示为“X_3”。
基本声道组的音频信号可以包括通过将右立体声声道的音频信号R与C_1混合而生成的第二声道的音频信号。
压缩器270可以通过压缩至少一个从属声道组的至少一个音频信号来获得(例如,生成)至少一个从属声道组的至少一个压缩音频信号。
附加信息生成器285可以基于原始音频信号、基本声道组的压缩音频信号、或从属声道组的压缩音频信号中的至少一个来生成附加信息。在这种情况下,附加信息可以是与多声道音频信号相关的信息并且包括用于重建多声道音频信号的各种信息。
例如,附加信息可以包括收听者前方的3D音频声道的音频对象信号,其指示音频对象(声源)的音频信号、位置、形状、面积、或方向中的至少一个。或者,附加信息可以包括关于音频流的总数的信息,该音频流包括基本声道音频流和从属声道音频流。附加信息可以包括下混合增益信息。附加信息可以包括声道映射表信息。附加信息可以包括音量信息。附加信息可以包括LFE增益信息。附加信息可以包括动态范围控制(DRC)信息。附加信息可以包括声道布局呈现信息。附加信息还可以包括关于耦合的音频流的数量的信息、指示多声道布局的信息、关于音频信号中是否存在对话的信息和对话级别、指示是否输出LFE的信息、关于屏幕上是否存在音频对象的信息、关于连续音频声道的音频信号(或基于场景的音频信号或环绕声音频信号)的存在或不存在的信息、以及关于离散音频声道的音频信号(或基于对象的音频信号或空间多声道音频信号)的存在或不存在的信息。附加信息可以包括关于解混合的信息,该信息包括用于重建多声道音频信号的解混合矩阵的至少一个解混合权重参数。解混合和(下)混合彼此对应,使得关于解混合的信息可以对应于关于(下)混合的信息,并且关于解混合的信息可以包括关于(下)混合的信息。例如,关于解混合的信息可以包括(下)混合矩阵的至少一个(下)混合权重参数。可以基于(下)混合权重参数来获得解混合权重参数。
附加信息可以是上述多条信息的各种组合。换句话说,附加信息可以包括前述多条信息中的至少一条。
当存在对应于基本声道组的至少一个音频信号的从属声道的音频信号时,附加信息生成器285可以生成指示从属声道的音频信号存在的从属声道音频信号标识信息。
比特流生成器280可以生成包括基本声道组的压缩音频信号和从属声道组的压缩音频信号的比特流。比特流生成器280可生成进一步包括由附加信息生成器285生成的附加信息的比特流。
更具体地,比特流生成器280可以生成基本声道音频流和从属声道音频流。基本声道音频流可以包括基本声道组的压缩音频信号,从属声道音频流可以包括从属声道组的压缩音频信号。
比特流生成器280可以生成包括基本声道音频流和多个从属声道音频流的比特流。多个从属声道音频流可以包括n个从属声道音频流(其中,n是大于1的整数)。在这种情况下,基本声道音频流可以包括单声道的音频信号或立体声声道的压缩音频信号。
例如,在从基本声道音频流和第一从属声道音频流重建的第一多声道布局的声道中,环绕声道的数量可以是S
在这种情况下,S
也就是说,第二多声道布局的环绕声道的数量需要大于第一多声道布局的环绕声道的数量。替代地或附加地,第二多声道布局的低音炮声道的数量需要大于第一多声道布局的低音炮声道的数量。替代地或附加地,第二多声道布局的高度声道的数量需要大于第一多声道布局的高度声道的数量。
此外,第二多声道布局的环绕声道的数量可以不小于第一多声道布局的环绕声道的数量。同样,第二多声道布局的低音炮声道的数量可以不小于第一多声道布局的低音炮声道的数量。第二多声道布局的高度声道的数量可以不小于第一多声道布局的高度声道的数量。
此外,第二多声道布局的环绕声道的数量等于第一多声道布局的环绕声道的数量、第二多声道布局的低音炮声道的数量等于第一多声道布局的低音炮声道的数量、并且第二多声道布局的高度声道的数量等于第一多声道布局的高度声道的数量的情况不存在。也就是说,第二多声道布局的所有声道可以不与第一多声道布局的所有声道相同。
更具体地,例如,当第一多声道布局是5.1.2声道布局时,第二多声道布局可以是7.1.4声道布局。
此外,比特流生成器280可以生成包括附加信息的元数据。
结果,比特流生成器280可以生成包括基本声道音频流、从属声道音频流、和元数据的比特流。
比特流生成器280可以以声道数量可以从基本声道组自由增加的形式生成比特流。
也就是说,可以从基本声道音频流重建基本声道组的音频信号,并且可以从基本声道音频流和从属声道音频流重建其中声道数量从基本声道组增加的多声道音频信号。
同时,比特流生成器280可以生成具有多个音轨的文件流。比特流生成器280可以生成包括基本声道组的至少一个压缩音频信号的第一音轨的音频流。比特流生成器280可以生成包括从属声道音频信号标识信息的第二音轨的音频流。在这种情况下,跟随第一音轨的第二音轨可以与第一音轨相邻。
当存在对应于基本声道组的至少一个音频信号的从属声道音频信号时,比特流生成器280可以生成包括至少一个从属声道组的至少一个压缩音频信号的第二音轨的音频流。
同时,当不存在对应于基本声道组的至少一个音频信号的从属声道音频信号时,比特流生成器280可以相对于基本声道组的第一音轨的音频信号生成包括下一个基本声道组的音频信号的第二音轨的音频流。
图2C是根据本公开的实施例的多声道音频信号处理器260的结构的框图。
参照图2C,多声道音频信号处理器260可以包括声道布局识别器261、下混合声道音频生成器262、和音频信号分类器266。
声道布局识别器261可以从原始音频信号识别至少一个声道布局。在这种情况下,至少一个声道布局可以包括多个分层声道布局。声道布局识别器261可以识别原始音频信号的声道布局。声道布局识别器261可以识别低于原始音频信号的声道布局的声道布局。例如,当原始音频信号是7.1.4声道布局的音频信号时,声道布局识别器261可以识别7.1.4声道布局并识别低于7.1.4声道布局的5.1.2声道布局、3.1.2声道布局、2声道布局等。较高声道布局可以指布局中的环绕声道/低音炮声道/高度声道中的至少一个的数量大于较低声道布局的布局。根据环绕声道的数量是大还是小,可以确定较高/较低声道布局,并且对于相同数量的环绕声道,可以根据低音炮声道的数量是大还是小来确定较高/较低声道布局。对于相同数量的环绕声道和低音炮声道,可以根据高度声道的数量是大还是小来确定较高/较低声道布局。
此外,所识别的声道布局可以包括目标声道布局。目标声道布局可以指包括在最终输出比特流中的音频信号的最高声道布局。目标声道布局可以是原始音频信号的声道布局或比原始音频信号的声道布局更低的声道布局。
更具体地,从原始音频信号识别的声道布局可以从原始音频信号的声道布局来分层地确定。在这种情况下,声道布局识别器261可以识别预定的声道布局中的至少一个声道布局。例如,声道布局识别器261可以从原始音频信号的布局中识别一些预定的声道布局,7.1.4声道布局、5.1.4声道布局、5.1.2声道布局、3.1.2声道布局、和2声道布局。
声道布局识别器261可以基于所识别的声道布局,向对应于所识别的至少一个声道布局的特定下混合声道音频生成器发送控制信号。特定下混合声道音频生成器可以是第一下混合声道音频生成器263、第二下混合声道音频生成器264、…、或第N下混合声道音频生成器265中的至少一个。下混合声道音频生成器262可以基于由声道布局识别器261识别的至少一个声道布局从原始音频信号生成下混合声道音频。下混合声道音频生成器262可以通过使用包括至少一个下混合权重参数的下混合矩阵来从原始音频信号生成下混合声道音频。
例如,当原始音频信号的声道布局是预定的声道布局中按升序排列的第n个声道布局时,下混合声道音频生成器262可以从原始音频信号生成正好低于(immediatelylower than)原始音频信号的声道布局的第(n-1)个声道布局的下混合声道音频。通过重复该过程,下混合声道音频生成器262可以生成比当前声道布局更低的声道布局的下混合声道音频。
例如,下混合声道音频生成器262可以包括第一下混合声道音频生成器263、第二下混合声道音频生成器264、…、和第(n-1)下混合声道音频生成器。(n-1)可以小于或等于N。
在这种情况下,第(n-1)下混合声道音频生成器可以从原始音频信号生成第(n-1)声道布局的音频信号。另外,第(n-2)下混合声道音频生成器可以从原始音频信号生成第(n-2)声道布局的音频信号。以这种方式,第一下混合声道音频生成器263可以从原始音频信号生成第一声道布局的音频信号。第一声道布局可以是预定的声道布局的分层排序列表、集合或组中的第一个布局。在这种情况下,第一声道布局的音频信号可以是基本声道组的音频信号。
同时,下混合声道音频生成器(例如,第一下混合声道音频生成器263、第二下混合声道音频生成器264、…、和第N下混合声道音频生成器265)中的每一个可以以级联方式连接。也就是说,下混合声道音频生成器(例如,第一下混合声道音频生成器263、第二下混合声道音频生成器264、…、和第N下混合声道音频生成器265)可以被连接为使得较高下混合声道音频生成器的输出变成较低下混合声道音频生成器的输入。例如,第(n-1)声道布局的音频信号可以以原始音频信号作为输入从第(n-1)下混合声道音频生成器输出,并且第(n-1)声道布局的音频信号可以被输入到第(n-2)下混合声道音频生成器,并且第(n-2)下混合声道音频可以从第(n-2)下混合声道音频生成器生成。以这种方式,下混合声道音频生成器(例如,第一下混合声道音频生成器263、第二下混合声道音频生成器264、…、和第N下混合声道音频生成器265)可以被连接以输出每个声道布局的音频信号。
音频信号分类器266可以基于至少一个声道布局的音频信号来获得基本声道组的音频信号和从属声道组的音频信号。在这种情况下,音频信号分类器266可以通过混合器267混合包括在至少一个声道布局的音频信号中的至少一个声道的音频信号。音频信号分类器266可以将混合的音频信号分类为基本声道组的音频信号或从属声道组的音频信号中的至少一个。
图2D是用于描述音频信号分类器的详细操作的示例的视图。
参照图2D,图2C的下混合声道音频生成器262可以从7.1.4声道布局290的原始音频信号获得5.1.2声道布局291的音频信号、3.1.2声道布局292的音频信号、2声道布局293的音频信号、和单声道布局294的音频信号,这些音频信号是较低声道布局的音频信号。下混合声道音频生成器262的下混合声道音频生成器(例如,第一下混合声道音频生成器263、第二下混合声道音频生成器264、…、和第N下混合声道音频生成器265)以级联方式连接,使得可以从当前声道布局到下一个较低声道布局顺序地获得音频信号。
图2C的音频信号分类器266可以将单声道布局294的音频信号分类为基本声道组的音频信号。
音频信号分类器266可以将作为2声道布局293的音频信号的一部分的L2声道的音频信号分类为从属声道组#1 296的音频信号。同时,L2声道的音频信号和R2声道的音频信号被混合以生成单声道布局294的音频信号,使得相反,音频解码装置300和500可以对单声道布局294的音频信号和L2声道的音频信号进行解混合以重建R2声道的音频信号。因此,R2声道的音频信号可以不被分类为单独声道组的音频信号。换句话说,可能没有必要将R2声道的音频信号分类为单独声道组的音频信号。
音频信号分类器266可以将3.1.2声道布局292的音频信号中的Hfl3声道的音频信号、C声道的音频信号、LFE声道的音频信号、和Hfr3声道的音频信号分类为从属声道组#2297的音频信号。通过混合L3声道的音频信号和C声道的音频信号来生成L2声道的音频信号,使得相反,音频解码装置300和500可以通过对L2声道的音频信号和C声道的音频信号进行解混合来重建从属声道组#2 297的L3声道的音频信号。
因此,3.1.2声道布局292的音频信号中的L3声道的音频信号可以不被分类为特定声道组的音频信号。
出于同样的原因,R3声道可以不被分类为特定声道组的音频信号。
音频信号分类器266可以将作为5.1.2声道布局291的一些声道的音频信号的L声道的音频信号和R声道的音频信号作为从属声道组#3 298的音频信号进行发送,以便发送5.1.2声道布局291的音频信号。同时,Ls5、Hl5、Rs5和Hr5声道之一的音频信号可以是5.1.2声道布局291的音频信号之一,但是可以不被分类为单独从属声道组的音频信号。这是因为Ls5、Hl5、Rs5、和Hr5声道的信号可能不是收听者前方的声道音频信号,而可能是其中可能混合了7.1.4声道布局290的音频信号中的收听者前方、旁边、和后方的音频声道中的至少一个的音频信号的信号。通过从原始音频信号中压缩收听者前方的音频声道的音频信号,而不是将混合信号分类为从属声道组的音频信号并对其进行压缩,可以提高收听者前方的音频声道的音频信号的声音质量。结果,收听者可以感觉到再现的音频信号的声音质量得到改善。
然而,根据情况,可以将Ls5或Hl5而不是L分类为从属声道组#3 298的音频信号,并且可以将Rs5或Hr5而不是R分类为从属声道组#3 298的音频信号。
音频信号分类器266可以将7.1.4声道布局290的音频信号中的Ls、Hfl、Rs或Hfr声道的音频信号分类为从属声道组#4 299的音频信号。在这种情况下,Lb、Hbl、Rb和Hbr可以不被分类为从属声道组#4 299的音频信号。通过压缩靠近收听者前方的侧音频声道的音频信号,而不是将7.1.4声道布局290的音频信号中的收听者后方的音频声道的音频信号分类为声道组的音频信号并对其进行压缩,可以提高靠近收听者前方的侧音频声道的音频信号的声音质量。因此,收听者可以感觉到再现的音频信号的声音质量得到改善。然而,根据情况,可以将代替Ls的Lb、代替Hfl的Hbl、代替Rs的Rb、和代替Hfr的Hbr分类为从属声道组#4299的音频信号。
结果,图2C的下混合声道音频生成器262可以基于从原始音频信号布局识别的多个较低声道布局来生成多个较低布局的音频信号(下混合声道音频)。图2C的音频信号分类器266可以对基本声道组的音频信号和从属声道组#1、#2、#3和、#4的音频信号进行分类。根据每个声道布局,分类后的声道的音频信号可以将每个声道的音频信号中的独立声道的音频信号的一部分分类为声道组的音频信号。音频解码装置300和500可以通过解混合来重建未被音频信号分类器266分类的音频信号。同时,当相对于收听者的左声道的音频信号被分类为特定声道组的音频信号时,对应于左声道的右声道的音频信号可以被分类为对应声道组的音频信号。也就是说,耦合的声道的音频信号可以被分类为一个声道组的音频信号。
当立体声声道布局的音频信号被分类为基本声道组的音频信号时,耦合的声道的音频信号都可以被分类为一个声道组的音频信号。然而,如上面参照图2D所述,当单声道布局的音频信号被分类为基本声道组的音频信号时,例外地,立体声声道的音频信号之一可以被分类为从属声道组#1的音频信号。然而,对声道组的音频信号进行分类的方法可以是多种的,而不限于参照图2D进行的描述。也就是说,当分类后的声道组的音频信号被解混合并且没有被分类为声道组的音频信号的声道的音频信号可以从解混合的音频信号重建时,则声道组的音频信号可以以各种形式被分类。
图3A是根据本公开的实施例的多声道音频解码装置的结构的框图。
音频解码装置300可以包括存储器310和处理器330。音频解码装置300可以被实施为能够进行音频处理的装置,比如服务器、电视、相机、移动电话、计算机、数字广播终端、平板PC、膝上型计算机等。
尽管在图3A中分开图示了存储器310和处理器330,但是存储器310和处理器330可以通过一个硬件模块(例如,芯片)来实施。
处理器330可以被实施为用于基于神经网络的音频处理的专用处理器。或者,处理器330可以通过通用处理器(比如,AP、CPU、或GPU)和软件的组合来实施。专用处理器可以包括用于实施本公开的实施例的存储器或用于使用外部存储器的存储器处理器。
处理器330可以包括多个处理器。在这种情况下,处理器330可以被实施为专用处理器的组合,或者可以通过软件和多个通用处理器(比如AP、CPU或GPU)的组合来实施。
存储器310可以存储一个或多个用于音频处理的指令。根据本公开的实施例,存储器310可以存储神经网络。当神经网络以用于AI的专用硬件芯片的形式实施或者实施为现有通用处理器(例如,CPU或AP)或图形专用处理器(例如,GPU)的一部分时,神经网络可以不被存储在存储器310中。神经网络可以被实施为外部装置(例如,服务器)。在这种情况下,音频解码装置300可以从外部装置请求基于神经网络的结果信息,并且从外部装置接收基于神经网络的结果信息。
处理器330可以根据存储在存储器310中的指令顺序地处理连续的帧以获得连续的经重建的帧。连续的帧可以指构成音频的帧。
处理器330可以通过对输入比特流执行音频处理操作来输出多声道音频信号。比特流可以以可缩放的形式来实施,以增加来自基本声道组的声道数量。例如,处理器330可以从比特流获得基本声道组的压缩音频信号,并且可以通过解压缩基本声道组的压缩音频信号来重建基本声道组的音频信号(例如,立体声声道音频信号)。另外,处理器330可以通过从比特流解压缩从属声道组的压缩音频信号来重建从属声道组的音频信号。处理器330可以基于基本声道组的音频信号和从属声道组的音频信号来重建多声道音频信号。
同时,处理器330可以通过从比特流解压缩第一从属声道组的压缩音频信号来重建第一从属声道组的音频信号。处理器330可以通过解压缩第二从属声道组的压缩音频信号来重建第二从属声道组的音频信号。
处理器330可以基于基本声道组的音频信号以及第一和第二从属声道组的相应音频信号来重建数量增加的声道的多声道音频信号。类似地,处理器330可以解压缩n个从属声道组(其中,n是大于2的整数)的压缩音频信号,并且可以基于基本声道组的音频信号和n个从属声道组的相应音频信号来重建数量进一步增加的声道的多声道音频信号。
图3B是根据本公开的实施例的多声道音频解码装置的结构的框图。
参照图3B,音频解码装置300可以包括信息获取器350和多声道音频解码器360。多声道音频解码器360可以包括解压缩器370和多声道音频信号重建器380。
音频解码装置300可以包括图3A的存储器310和处理器330,并且用于实施图3B的组件350、360、370和380的指令可以存储在存储器310中。处理器330可以执行存储在存储器310中的指令。
信息获取器350可以从比特流获取基本声道组的压缩音频信号。也就是说,信息获取器350可以从比特流中分类包括基本声道组的至少一个压缩音频信号的基本声道音频流。
信息获取器350还可以从比特流获取至少一个从属声道组的至少一个压缩音频信号。也就是说,信息获取器350可以从比特流中分类包括从属声道组的至少一个压缩音频信号的至少一个从属声道音频流。
同时,比特流可以包括基本声道音频流和多个从属声道流。多个从属声道音频流可以包括第一从属声道音频流和第二从属声道音频流。
在这种情况下,将描述通过基本声道音频流和第一从属声道音频流重建的多声道第一音频信号以及通过基本声道音频流、第一从属声道音频流、和第二从属声道音频流重建的多声道第二音频信号的声道的限制。
例如,在从基本声道音频流和第一从属声道音频流重建的第一多声道布局的声道中,环绕声道的数量可以是S
也就是说,第二多声道布局的环绕声道的数量需要大于第一多声道布局的环绕声道的数量。替代地或附加地,第二多声道布局的低音炮声道的数量需要大于第一多声道布局的低音炮声道的数量。替代地或附加地,第二多声道布局的高度声道的数量需要大于第一多声道布局的高度声道的数量。
此外,第二多声道布局的环绕声道的数量可以不小于第一多声道布局的环绕声道的数量。同样,第二多声道布局的低音炮声道的数量可以不小于第一多声道布局的低音炮声道的数量。第二多声道布局的高度声道的数量可以不小于第一多声道布局的高度声道的数量。
此外,第二多声道布局的环绕声道的数量等于第一多声道布局的环绕声道的数量、并且第二多声道布局的低音炮声道的数量等于第一多声道布局的低音炮声道的数量、并且第二多声道布局的高度声道的数量等于第一多声道布局的高度声道的数量的情况不存在。也就是说,第二多声道布局的所有声道可以不与第一多声道布局的所有声道相同。
更具体地,例如,当第一多声道布局是5.1.2声道布局时,第二多声道布局可以是7.1.4声道布局。
同时,比特流可以包括具有包括第一音轨和第二音轨的多个音轨的文件流。下面将描述信息获取器350根据包括在音轨中的附加信息获取至少一个从属声道组的至少一个压缩音频信号的过程。
信息获取器350可以从第一音轨获取基本声道组的至少一个压缩音频信号。
信息获取器350可以从与第一音轨相邻的第二音轨获取从属声道音频信号标识信息。
当从属声道音频信号标识信息指示从属声道音频信号存在于第二音轨中时,信息获取器350可以从第二音轨中获取至少一个从属声道组的至少一个音频信号。
当从属声道音频信号标识信息指示从属声道音频信号不存在于第二音轨中时,信息获取器350可以从第二音轨获取基本声道组的下一个音频信号。
信息获取器350可以从比特流获取与多声道音频的重建相关的附加信息。也就是说,信息获取器350可以从比特流分类包括附加信息的元数据并且从分类后的元数据获取附加信息。
解压缩器370可以通过解压缩基本声道组的至少一个压缩音频信号来重建基本声道组的音频信号。
解压缩器370可以通过解压缩至少一个从属声道组的至少一个压缩音频信号来重建至少一个从属声道组的至少一个音频信号。
在这种情况下,解压缩器370可以包括用于解码各个声道组(n个声道组)的压缩音频信号的单独的第一至第n解压缩器。在这种情况下,第一解压缩器至第n解压缩器可以彼此并行操作。
多声道音频信号重建器380可以基于基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号来重建多声道音频信号。
例如,当基本声道组的音频信号是立体声声道的音频信号时,多声道音频信号重建器380可以基于基本声道组的音频信号和第一从属声道组的音频信号来重建收听者前方的3D音频声道的音频信号。例如,收听者前方的3D音频声道可以是3.1.2声道。
或者,多声道音频信号重建器380可以基于基本声道组的音频信号、第一从属声道组的音频信号和第二从属声道组的音频信号来重建收听者全向音频声道的音频信号。例如,收听者全向3D音频声道可以是5.1.2声道或7.1.4声道。
多声道音频信号重建器380不仅可以基于基本声道组的音频信号和从属声道组的音频信号,而且还可以基于附加信息来重建多声道音频信号。在这种情况下,附加信息可以是用于重建多声道音频信号的附加信息。多声道音频信号重建器380可以输出经重建的至少一个多声道音频信号。
根据本公开的实施例的多声道音频信号重建器380可以根据基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号来生成收听者前方的3D音频声道的第一音频信号。多声道音频信号重建器380可以基于收听者前方的3D音频声道的第一音频信号和音频对象信号来重建包括收听者前方的3D音频声道的第二音频信号的多声道音频信号。在这种情况下,音频对象信号可以指示音频对象(例如,声源)的音频信号、形状、面积、位置、或方向中的至少一个,并且可以从信息获取器350获得。
现在将参照图3C描述多声道音频信号重建器380的详细操作。
图3C是根据本公开的实施例的多声道音频信号重建器380的结构的框图。
参照图3C,多声道音频信号重建器380可以包括上混合声道组音频生成器381和渲染器386。
上混合声道组音频生成器381可以基于基本声道组的音频信号和从属声道组的音频信号来生成上混合声道组的音频信号。在这种情况下,上混合声道组的音频信号可以是多声道音频信号。在这种情况下,另外,进一步基于附加信息(例如,关于动态解混合权重参数的信息),可以生成多声道音频信号。
上混合声道组音频生成器381可以通过对基本声道组的音频信号和从属声道组的一些音频信号进行解混合来生成上混合声道的音频信号。例如,通过对基本声道组的音频信号L和R以及从属声道组的部分音频信号C进行解混合,可以生成解混合声道(或上混合声道)的音频信号L3和R3。
上混合声道组音频生成器381可以通过绕过针对从属声道组的一些音频信号的解混合操作来生成多声道音频信号的一些声道的音频信号。例如,上混合声道组音频生成器381可以通过绕过针对作为从属声道组的一些音频信号的C、LFE、Hfl3和Hfr3声道的音频信号的解混合操作,来生成多声道音频信号的C、LFE、Hfl3和Hfr3声道的音频信号。
结果,上混合声道组音频生成器381可以基于通过解混合生成的上混合声道的音频信号和其中解混合操作被绕过的从属声道组的音频信号来生成上混合声道组的音频信号。例如,上混合声道组音频生成器381可以基于作为解混合声道的音频信号的L3和R3声道的音频信号以及作为从属声道组的音频信号的C、LFE、Hfl3、和Hfr3声道的音频信号,生成作为3.1.2声道的音频信号的L3、R3、C、LFE、Hfl3、和Hfr3声道的音频信号。
稍后将参照图3D描述上混合声道组音频生成器381的详细操作。
渲染器386可以包括音量控制器388和限制器389。输入到渲染器386的多声道音频信号可以是至少一个声道布局的多声道音频信号。输入到渲染器386的多声道音频信号可以是脉冲编码调制(PCM)信号。
同时,可以基于ITU-R BS.1770来测量每个声道的音频信号的音量(响度),这可以通过接收到的关于比特流的附加信息进行信令通知。
音量控制器388可以基于通过比特流信令通知的音量信息,将每个声道的音频信号的音量控制到目标音量(例如,-24LKFS)。
同时,可以基于ITU-R BS.1770来测量真实峰值。
限制器389可以在音量控制之后限制音频信号的真实峰值电平(例如,限制到-1dBTP)。
虽然到目前为止已经描述了包括在渲染器386中的后处理组件388和389,但是可以省略至少一个组件并且可以根据情况改变每个组件的顺序而不限于此。
多声道音频信号输出器390可以接收经后处理的多声道音频信号并且可以输出至少一个多声道音频信号。例如,以经后处理的多声道音频信号作为输入,根据目标声道布局,多声道音频信号输出器390可以将多声道音频信号的每个声道的音频信号输出到对应于每个声道的音频输出设备。音频输出设备可以包括各种类型的扬声器。
图3D是根据本公开的实施例的上混合声道组音频生成器的结构的框图。
参照图3D,上混合声道组音频生成器381可以包括解混合器382。解混合器382可以包括第一解混合器383和第二解混合器384到第N解混合器385。
解混合器382可以从基本声道组的音频信号和从属声道组的音频信号中的一些声道(解码声道)的音频信号获得新声道(上混合声道或解混合声道)的音频信号。也就是说,解混合器382可以从混合了几个声道的至少一个音频信号获得一个上混合声道的音频信号。解混合器382可以输出包括上混合声道的音频信号和解码声道的音频信号的特定布局的音频信号。
例如,可以绕过解混合器382中的解混合操作,使得基本声道组的音频信号可以作为第一声道布局的音频信号被输出。
以基本声道组的音频信号和第一从属声道组的音频信号作为输入,第一解混合器383可以解混合一些声道的音频信号。在这种情况下,可以生成解混合声道(或上混合声道)的音频信号。第一解混合器383可以通过绕过针对其他声道的音频信号的混合操作来生成独立声道的音频信号。第一解混合器383可以输出第二声道布局的音频信号,该音频信号是包括上混合声道的音频信号和独立声道的音频信号的信号。
第二解混合器384可以通过对第二声道布局的音频信号和第二从属声道的音频信号中的一些声道的音频信号进行解混合来生成解混合声道(或上混合声道)的音频信号。第二解混合器384可以通过绕过针对其他声道的音频信号的混合操作来生成独立声道的音频信号。第二解混合器384可以输出第三声道布局的音频信号,该音频信号包括上混合声道的音频信号和独立声道的音频信号。
类似于第二解混合器384的操作,第n解混合器可以基于第(n-1)声道布局的音频信号和第(n-1)从属声道组的音频信号来输出第n声道布局的音频信号。n可以小于或等于N。
第N解混合器385可以基于第(N-1)声道布局的音频信号和第(N-1)从属声道组的音频信号来输出第N声道布局的音频信号。
尽管示出了较低声道布局的音频信号被直接输入到各个解混合器383、384至385,但是通过图3C的渲染器386输出的声道布局的音频信号可以替代地被输入到解混合器383、384至385中的每一个。也就是说,较低声道布局的经后处理的音频信号可以被输入到解混合器383、384至385中的每一个。
参照图3D,描述了解混合器383、384、和385可以以级联方式连接以输出每个声道布局的音频信号。
然而,在不以级联方式连接解混合器383、384、和385的情况下,可以从基本声道组的音频信号和至少一个从属声道组的音频信号输出特定布局的音频信号。
同时,通过使用用于防止削波的下混合增益,通过在音频编码装置200和400中混合几个声道的信号而生成的音频信号可以具有降低的电平。音频解码装置300和500可以基于用于通过混合而生成的信号的对应的下混合增益来将音频信号的电平与原始音频信号的电平匹配。
同时,可以对每个声道或声道组执行基于上述下混合增益的操作。音频编码装置200和400可以通过关于每个声道或每个声道组的比特流的附加信息来信令通知关于下混合增益的信息。因此,音频解码装置300和500可以从关于每个声道或每个声道组的比特流的附加信息获得关于下混合增益的信息,并且基于该下混合增益执行上述操作。
同时,解混合器382可以基于解混合矩阵的动态解混合权重参数(对应于下混合矩阵的下混合权重参数)来执行解混合操作。在这种情况下,音频编码装置200和400可以通过关于比特流的附加信息来信令通知动态解混合权重参数或与其对应的动态下混合权重参数。一些解混合权重参数可能不会被信令通知并且具有固定值。
因此,音频解码装置300和500可以从关于比特流的附加信息获得关于动态解混合权重参数的信息(或关于动态下混合权重参数的信息),并且基于所获得的关于动态解混合权重参数的信息(或关于动态下混合权重参数的信息)执行解混合操作。
图4A是根据本公开的实施例的音频编码装置的框图。
参照图4A,音频编码装置400可以包括多声道音频编码器450、比特流生成器480和误差消除相关信息生成器490。多声道音频编码器450可以包括多声道音频信号处理器460和压缩器470。
图4A的组件450、460、470、480、和490可以由图2A的存储器210和处理器230来实施。
图4A的多声道音频编码器450、多声道音频信号处理器460、压缩器470、和比特流生成器480的操作分别对应于多声道音频编码器250、多声道音频信号处理器260、压缩器270、和比特流生成器280的操作,因此其详细描述将由图2B的描述代替。
误差消除相关信息生成器490可以被包括在图2B的附加信息生成器285中,但是也可单独存在而不限于此。
误差消除相关信息生成器490可以基于第一功率值和第二功率值确定误差消除因子(例如,缩放因子)。在这种情况下,第一功率值可以是原始音频信号的一个声道的能量值或者可以是通过从原始音频信号下混合而获得的一个声道的音频信号的能量值。第二功率值可以是作为上混合声道组的音频信号之一的上混合声道的音频信号的功率值。上混合声道组的音频信号可以是通过对基本声道重建信号和从属声道重建信号进行解混合而获得的音频信号。
误差消除相关信息生成器490可以确定每个声道的误差消除因子。
误差消除相关信息生成器490可以生成包括关于所确定的误差消除因子的信息的与误差消除相关的信息(或误差消除相关信息)。比特流生成器480可以生成进一步包括误差消除相关信息的比特流。现在将参照图4B描述误差消除相关信息生成器490的详细操作。
图4B是根据本公开的实施例的误差消除相关信息生成器490的结构的框图。
参考图4B,误差消除相关信息生成器490可以包括解压缩器492、解混合器494、均方根(RMS)值确定器496和误差消除因子确定器498。
解压缩器492可以通过解压缩基本声道组的压缩音频信号来生成基本声道重建信号。此外,解压缩器492可以通过解压缩从属声道组的压缩音频信号来生成从属声道重建信号。
解混合器494可以对基本声道重建信号和从属声道重建信号进行解混合以生成上混合声道组的音频信号。更具体地,解混合器494可以通过对基本声道组和从属声道组的音频信号中的一些声道的音频信号进行解混合来生成上混合声道(或解混合声道)的音频信号。解混合器494可以绕过针对基本声道组和从属声道组的音频信号中的一些音频信号的解混合操作。
解混合器494可以获得包括上混合声道的音频信号和其解混合操作被绕过的音频信号的上混合声道组的音频信号。
RMS值确定器496可以确定上混合声道组的一个上混合声道的第一音频信号的RMS值。RMS值确定器496可以确定原始音频信号的一个声道的第二音频信号的RMS值或从原始音频信号下混合的音频信号的一个声道的第二音频信号的RMS值。在这种情况下,第一音频信号的声道和第二音频信号的声道可以指示声道布局中的相同声道。
误差消除因子确定器498可以基于第一音频信号的RMS值和第二音频信号的RMS值来确定误差消除因子。例如,可以获得通过将第一音频信号的RMS值除以第二音频信号的RMS值而生成的值作为误差消除因子的值。误差消除因子确定器498可以生成关于所确定的误差消除因子的信息。误差消除因子确定器498可以输出包括关于误差消除因子的信息的误差消除相关信息。
图5A是根据本公开的实施例的音频解码装置的结构的框图。
参照图5A,音频解码装置500可以包括信息获取器550、多声道音频解码器560、解压缩器570、多声道音频信号重建器580和误差消除相关信息获取器555。图5A的组件550、555、560、570、和580可以由图3A的存储器310和处理器330来实施。
用于实施图5A的组件550、555、560、570、和580的指令可以存储在图3A的存储器310中。处理器330可以执行存储在存储器310中的指令。
图5A的信息获取器550、解压缩器570、和多声道音频信号重建器580的操作分别包括图3B的信息获取器350、解压缩器370、和多声道音频信号重建器380的操作,因此多余的描述将由参照图3B进行的描述代替。在下文中,将提供与图3B的描述不重复的描述。
信息获取器550可以从比特流获取元数据。
误差消除相关信息获取器555可以从包括在比特流中的元数据获得误差消除相关信息。这里,包括在误差消除相关信息中的关于误差消除因子的信息可以是上混合声道组的一个上混合声道的音频信号的误差消除因子。误差消除相关信息获取器555可以包括在信息获取器550中。
多声道音频信号重建器580可以基于基本声道的至少一个音频信号和至少一个从属声道组的至少一个音频信号来生成上混合声道组的音频信号。上混合声道组的音频信号可以是多声道音频信号。多声道音频信号重建器580可以通过将误差消除因子应用于包括在上混合声道组中的一个上混合声道的音频信号来重建该一个上混合声道的音频信号。
多声道音频信号重建器580可以输出包括该一个上混合声道的重建音频信号的多声道音频信号。
图5B是根据本公开的实施例的多声道音频信号重建器的结构的框图。
多声道音频信号重建器580可以包括上混合声道组音频生成器581和渲染器583。渲染器583可以包括误差消除器584、音量控制器585、限制器586和多声道音频信号输出器587。
图5B的上混合声道组音频生成器581、误差消除器584、音量控制器585、限制器586、和多声道音频信号输出器587可以包括图3C的上混合声道组音频生成器381、音量控制器388、限制器389、和多声道音频信号输出器390的操作,因此多余的描述将由参照图3C进行的描述代替。在下文中,将描述与图3C不重复的部分。
误差消除器584可以基于多声道音频信号的上混合声道组的第一上混合声道的音频信号和第一上混合声道的误差消除因子来重建第一声道的经误差消除的音频信号。在这种情况下,误差消除因子可以是基于原始音频信号或从原始音频信号下混合的音频信号的第一声道的音频信号的RMS值以及上混合声道组的第一上混合声道的音频信号的RMS值的值。第一声道和第一上混合声道可以指示声道布局的相同声道。误差消除器584可以通过使当前上混合声道组的第一上混合声道的音频信号的RMS值为原始音频信号或从原始音频信号下混合的音频信号的第一声道的音频信号的RMS值来消除由编码引起的误差。
同时,相邻音频帧之间的误差消除因子可以不同。在这种情况下,在前一帧的结束部分和下一帧的开始部分中,音频信号可能由于不连续的误差消除因子而跳动。
因此,误差消除器584可以通过对误差消除因子执行平滑来确定在帧边界相邻部分中使用的误差消除因子。帧边界相邻部分可以指前一帧相对于边界的结束部分和下一帧相对于边界的第一部分。每个部分可以包括预定数量的样本。
这里,平滑可以指将相邻音频帧之间的不连续误差消除因子转换成帧边界部分中的连续误差消除因子的操作。
多声道音频信号输出器587可以输出包括一个声道的经误差消除的音频信号的多声道音频信号。
同时,可以省略包括在渲染器583中的后处理组件585和586中的至少一个组件,并且可以根据情况改变包括误差消除器584的后处理组件584、585、和586的顺序。
如上所述,音频解码装置200和400可以生成比特流。音频编码装置200和400可以发送所生成的比特流。
在这种情况下,比特流可以以文件流的形式生成。音频解码装置300和500可以接收该比特流。音频解码装置300和500可以基于从接收到的比特流获得的信息来重建多声道音频信号。在这种情况下,比特流可以被包括在预定的文件容器中。例如,文件容器可以是用于压缩各种多媒体数字数据的运动图片专家组(MPEG)-4媒体容器,比如MPEG-4第14部分(MP4)等。
图6A是用于描述根据本公开的实施例的由音频编码装置200和400进行的每个声道组中的音频流的传输顺序和规则的视图。
在可缩放格式中,每个声道组中的音频流的传输顺序和规则可以如下所述。
音频编码装置200和400可以首先发送耦合流,然后发送非耦合流。
音频编码装置200和400可以首先发送用于环绕声道的耦合流,然后发送用于高度声道的耦合流。
音频编码装置200和400可以首先发送用于前声道的耦合流,然后发送用于侧声道或后声道的耦合流。
对于非耦合流传输,音频编码装置200和400可以首先发送用于中心声道的流,然后发送用于LFE声道和另一个声道的流。这里,当基本声道组包括单声道信号时,可以存在另一个声道。在这种情况下,另一个声道可以是立体声声道的左声道L2或右声道R2之一。
音频编码装置200和400可以将耦合声道的音频信号压缩成一对。音频编码装置200和400可以首先发送包括被压缩成一对的音频信号的耦合流。例如,耦合声道可以指左右对称声道,比如L/R、Ls/Rs、Lb/Rb、Hfl/Hfr、Hbl/Hbr声道等。
在下文中,根据每个声道组中的流的上述传输顺序和规则,将描述情况1的比特流610中的每个声道组的流配置。
参照图6A,例如,音频编码装置200和400可以压缩作为2声道音频信号的L1和R1信号,并且经压缩的L1和R1信号可以被包括在基本声道组(BCG)的C1比特流中。
紧接着基本声道组,音频编码装置200和400可以将4声道音频信号压缩成从属声道组#1的音频信号。
音频编码装置200和400可以压缩Hfl3信号和Hfr3信号,并且经压缩的Hfl3信号和Hfr3信号可以被包括在从属声道组#1的比特流中的C2比特流中。
音频编码装置200和400可以压缩C信号,并且经压缩的C信号可以被包括在从属声道组#1的比特流中的M1比特流中。
音频编码装置200和400可以压缩LFE信号,并且经压缩的LFE信号可以被包括在从属声道组#1的比特流中的M2比特流中。
音频解码装置300和500可以基于基本声道组和从属声道组#1的压缩音频信号来重建3.1.2声道布局的音频信号。
紧接着从属声道组#1,音频编码装置200和400可以将6声道音频信号压缩成从属声道组#2的音频信号。
音频编码装置200和400可以首先压缩L信号和R信号,并且经压缩的L信号和R信号可以被包括在从属声道组#2的比特流中的C3比特流中。
紧接着C3比特流,音频编码装置200和400可以压缩Ls信号和Rs信号,并且经压缩的Ls信号和Rs信号可以被包括在从属声道组#2的比特流中的C4比特流中。
紧接着C4比特流,音频编码装置200和400可以压缩Hfl信号和Hfr信号,并且经压缩的Hfl和Hfr信号可以被包括在从属声道组#2的比特流中的C5比特流中。
音频解码装置300和500可以基于基本声道组、从属声道组#1和从属声道组#2的压缩音频信号来重建7.1.4声道布局的音频信号。
在下文中,根据每个声道组中的流的上述传输顺序和规则,将描述情况2的比特流620中的每个声道组的流配置。
音频编码装置200和400可以压缩作为2声道音频信号的L2信号和R2信号,并且经压缩的L2信号和R2信号可以被包括在基本声道组的比特流中的C1比特流中。
紧接着基本声道组,音频编码装置200和400可以将6声道音频信号压缩成从属声道组#1的音频信号。
音频编码装置200和400可以首先压缩L信号和R信号,并且经压缩的L信号和R信号可以被包括在从属声道组#1的比特流中的C2比特流中。
音频编码装置200和400可以压缩Ls信号和Rs信号,并且经压缩的Ls信号和Rs信号可以被包括在从属声道组#1的比特流中的C3比特流中。
音频编码装置200和400可以压缩C信号,并且经压缩的C信号可以被包括在从属声道组#1的比特流中的M1比特流中。
音频编码装置200和400可以压缩LFE信号,并且经压缩的LFE信号可以被包括在从属声道组#1的比特流中的M2比特流中。
音频编码装置200和400可以基于基本声道组和从属声道组#1的压缩音频信号来重建7.1.0声道布局的音频信号。
紧接着从属声道组#1,音频编码装置200和400可以将4声道音频信号压缩成从属声道组#2的音频信号。
音频编码装置200和400可以压缩Hfl信号和Hfr信号,并且经压缩的Hfl信号和Hfr信号可以被包括在从属声道组#2的比特流中的C4比特流中。
音频编码装置200和400可以压缩Hbl信号和Hbr信号,并且经压缩的Hfl信号和Hfr信号可以被包括在从属声道组#2的比特流中的C5比特流中。
音频解码装置300和500可以基于基本声道组、从属声道组#1和从属声道组#2的压缩音频信号来重建7.1.4声道布局的音频信号。
在下文中,根据每个声道组中的流的上述传输顺序和规则,将描述情况3的比特流630中的每个声道组的流配置。
音频编码装置200和400可以压缩作为2声道音频信号的L2信号和R2信号,并且经压缩的L2信号和R2信号可以被包括在基本声道组的比特流中的C1比特流中。
紧接着基本声道组,音频编码装置200和400可以将10声道音频信号压缩成从属声道组#1的音频信号。
音频编码装置200和400可以首先压缩L信号和R信号,并且经压缩的L信号和R信号可以被包括在从属声道组#1的比特流中的C2比特流中。
音频编码装置200和400可以压缩Ls信号和Rs信号,并且经压缩的Ls信号和Rs信号可以被包括在从属声道组#1的比特流中的C3比特流中。
音频编码装置200和400可以压缩Hfl信号和Hfr信号,并且经压缩的Hfl信号和Hfr信号可以被包括在从属声道组#1的比特流中的C4比特流中。
音频编码装置200和400可以压缩Hbl信号和Hbr信号,并且经压缩的Hfl信号和Hfr信号可以被包括在从属声道组#1的比特流中的C5比特流中。
音频编码装置200和400可以压缩C信号,并且经压缩的C信号可以被包括在从属声道组#1的比特流中的M1比特流中。
音频编码装置200和400可以压缩LFE信号,并且经压缩的LFE信号可以被包括在从属声道组#1的比特流中的M2比特流中。
音频编码装置200和400可以基于基本声道组和从属声道组#1的压缩音频信号来重建7.1.4声道布局的音频信号。
同时,音频解码装置300和500可以通过使用至少一个上混合单元以逐步的方式执行解混合。可以基于包括在至少一个声道组中的声道的音频信号来执行解混合。
例如,1.x至2.x上混合单元(第一上混合单元)可以从作为混合右声道的单声道的音频信号中解混合右声道的音频信号。
或者,2.x至3.x上混合单元(第二上混合单元)可以从对应于混合中心声道的L2和R2声道的音频信号中解混合中心声道的音频信号。或者,2.x至3.x上混合单元(第二上混合单元)可以从混合L3和R3声道的L2和R2声道的音频信号以及C声道的音频信号中解混合L3声道的音频信号和R3声道的音频信号。
3.x至5.x上混合单元(第三上混合单元)可以从对应于Ls5/Rs5混合声道的L3、R3、L(5)、和R(5)声道的音频信号中解混合Ls5声道和Rs5声道的音频信号。
5.x至7.x上混合单元(第四上混合单元)可以从对应于混合Lb/Rb声道的Ls5、Ls7、和Rs7声道的音频信号中解混合Lb声道的音频信号和Rb声道的音频信号。
x.x.2(FH)至x.x.2(H)上混合单元(第四上混合单元)可以从对应于混合Ls/Rs声道的Hfl3、Hfr3、L3、L5、R3、和R5声道的音频信号中解混合Hl声道和Hr声道的音频信号。
x.x.2(H)至x.x.4上混合单元(第五上混合单元)可以从对应于混合Hbl/Hbr声道的Hl、Hr、Hfl、和Hfr声道的音频信号中解混合Hbl声道和Hbr声道的音频信号。
例如,音频解码装置300和500可以通过使用第一上混合单元来执行到3.2.1声道布局的解混合。
音频解码装置300和500可以通过使用用于环绕声道的第二上混合单元和第三混合单元以及用于高度声道的第四上混合单元和第五上混合单元来执行到7.1.4声道布局的解混合。
或者,音频解码装置300和500可以通过使用第一混合单元、第二混合单元、和第三混合单元来执行到7.1.0声道布局的解混合。音频解码装置300和500可以不执行从7.1.0声道布局到7.1.4声道布局的解混合。
或者,音频解码装置300和500可以通过使用第一混合单元、第二混合单元、和第三混合单元来执行到7.1.4声道布局的解混合。音频解码装置300和500可以不对高度声道执行解混合。
在下文中,将描述用于由音频编码装置200和400生成声道组的规则。对于可缩放格式的声道布局CLi(i是从0到n的整数,并且Cli表示Si、Wi、和Hi),Si+Wi+Hi可以指声道组#i的声道数量。声道组#i的声道数量可以大于声道组#i-1的声道数量。
声道组#i可以包括尽可能多Cli的原始声道(显示声道)。原始声道可以遵循下面描述的优先级。
当H
高度前声道的优先级可以在侧声道和高度后声道的优先级之前。
侧声道的优先级可以在后声道的优先级之前。此外,左声道的优先级可以在右声道的优先级之前。
例如,当n是4,CL0是立体声声道,CL1是3.1.2声道,CL2是5.1.2声道,CL3是7.1.4声道时,可以如下所述生成声道组。
音频编码装置200和400可以生成包括A(L2)和B(R2)信号的基本声道组。音频编码装置200和400可以生成包括Q1(Hfl3)、Q2(Hfr3)、T(=C)、和P(=LFE)信号的从属声道组#1。音频编码装置200和400可以生成包括S1(=L)和S2(=R)信号的从属声道组#2。
音频编码装置200和400可以生成包括V1(Hfl)、V2(Hfr)、U1(Ls)和U2(Rs)信号的从属声道组#3。
同时,音频解码装置300和500可以通过使用下混合矩阵从解压缩的音频信号重建7.1.4声道的音频信号。在这种情况下,下混合矩阵可以包括例如如下提供的表2中的下混合权重参数。
[表2]
这里,cw表示中心权重,当基本声道组的声道布局是3.1.2声道布局时,cw可以是0,当基本声道组的声道布局是2声道布局时,cw可以是1。w可以表示环绕到高度混合权重。α、β、γ、和δ可以表示下混合权重参数并且可以是可变的。音频编码装置200和400可以生成包括比如α、β、γ、δ、和w等下混合权重参数信息的比特流,音频解码装置300和500可以从该比特流获得下混合权重参数信息。
另一方面,关于下混合矩阵(或解混合矩阵)的权重参数信息可以是索引的形式。例如,关于下混合矩阵(或解混合矩阵)的权重参数信息可以是指示多个下混合(或解混合)权重参数集中的一个下混合(或解混合)权重参数集的索引信息,并且对应于一个下混合(或解混合)权重参数集的至少一个下混合(或解混合)权重参数可以以查找表(LUT)的形式存在。例如,关于下混合(或解混合)矩阵的权重参数信息可以是指示多个下混合(或解混合)权重参数集中的一个下混合(或解混合)权重参数集的信息,并且α、β、γ、δ、或w中的至少一个可以在对应于该一个下混合(或解混合)权重参数集的LUT中预定义。因此,音频解码装置300和500可以获得对应于该一个下混合(解混合)权重参数集的α、β、γ、δ、和w。
用于从第一声道布局下混合到第二声道布局的矩阵可以包括多个矩阵。例如,该矩阵可以包括用于从第一声道布局下混合到第三声道布局的第一矩阵和用于从第三声道布局下混合到第二声道布局的第二矩阵。
更具体地,例如,用于从7.1.4声道布局的音频信号下混合到3.1.2声道布局的音频信号的矩阵可以包括用于从7.1.4声道布局的音频信号下混合到5.1.4声道布局的音频信号的第一矩阵和用于从5.1.4声道布局的音频信号下混合到3.1.2声道布局的音频信号的第二矩阵。
表3和表4示出了用于基于基于内容的下混合参数和基于环绕到高度的权重从7.1.4声道布局的音频信号下混合到3.1.2声道布局的音频信号的第一矩阵和第二矩阵。
[表3]
第一矩阵(7.1至5.1下混合矩阵)
[表4]
第二矩阵(5.1.4至3.1.2下混合矩阵)
这里,α、β、γ、或δ表示下混合参数之一,并且w表示环绕到高度权重。
对于从5.x声道到7.x声道的上混合(或解混合),可以使用解混合权重参数α和β。
对于从x.x.2(H)声道到x.x.4声道的上混合,可以使用解混合权重参数γ。
对于从3.x声道到5.x声道的上混合,可以使用解混合权重参数δ。
对于从x.x.2(FH)声道到x.x.2(H)声道的上混合,可以使用解混合权重参数w和δ。
对于从2.x声道到3.x声道的上混合,可以使用-3dB的解混合权重参数。也就是说,解混合权重参数可以是固定值并且可以不进行信令通知。
此外,对于上混合到1.x声道和2.x声道,可以使用-6dB的解混合权重参数。也就是说,解混合权重参数可以是固定值并且可以不进行信令通知。
同时,用于解混合的解混合权重参数可以是包括在多种类型之一中的参数。例如,类型1的解混合权重参数α、β、γ、和δ可以是0dB、0dB、-3dB、和-3dB。类型2的解混合权重参数α、β、γ、和δ可以是-3dB、-3dB、-3dB、和-3dB。类型3的解混合权重参数α、β、γ、和δ可以是0dB、-1.25dB、-1.25dB、和-1.25dB。类型1可以是指示音频信号是普通音频信号的情况的类型,类型2可以是指示音频信号中包括对话的情况的类型(对话类型),类型3可以是指示音频信号中存在声音效果的情况的类型(声音效果类型)。
音频编码装置200和400可以分析音频信号并且根据所分析的音频信号确定多种类型之一。音频编码装置200和400可以通过使用所确定类型的解混合权重参数针对原始音频执行下混合以产生较低声道布局的音频信号。
音频编码装置200和400可以生成包括指示多种类型之一的索引信息的比特流。音频解码装置300和500可以从比特流获得索引信息并且基于所获得的索引信息识别多种类型之一。音频解码装置300和500可以通过使用所识别类型的解混合权重参数来对解压缩的声道组的音频信号进行上混合以重建特定声道布局的音频信号。
或者,根据下混合生成的音频信号可以表示为下面提供的等式1。也就是说,可以基于使用一次多项式形式的等式的运算来执行下混合,并且可以生成每个下混合的音频信号。
[等式1]
Ls5=α×Ls7+β×Lb7
Rs5=α×Rs7+β×Rb7
L3=L5+δ×Ls5
R3=R5+δ×Rs5
L2=L3+p
R2=R3+p
Mono=p
Hl=Hfl+γ×Hbl
Hr=Hfr+γ×Hbr
Hfl3=Hl×w′×δ×Ls5
Hfr3=Hr×w′×δ×Rs5
这里,p
类似地,通过解混合生成的音频信号可以表示为等式2。也就是说,可以基于使用一次多项式形式的等式的运算以逐步的方式(每个等式的运算过程对应于一个解混合过程)执行解混合,而不限于使用解混合矩阵的运算,并且可以生成每个解混合的音频信号。
[等式2]
L3=L2-p
R3=R2-p
Hl=Hf3-w′×(L3-L5)
Hr=Hfr3-w'×(R3-R5)
w’可以是用于从H2(例如,5.1.2声道布局或7.1.2声道布局的高度声道)下混合到Hf2(3.1.2声道布局的高度声道)或者用于从Hf2(3.1.2声道布局的高度声道)解混合到H2(例如,5.1.2声道布局或7.1.2声道布局的高度声道)的值。
可以根据w来更新sum
例如,sum
[表5]
不限于此,可以通过合并多个解混合过程来执行解混合。例如,从L2和R2的2个环绕声道解混合的Ls5声道或Rs5声道的信号可以表示为等式3,其排列了等式2的第二至第五等式。
[等式3]
/>
从L2和R2的2个环绕声道解混合的Hl声道或Hr声道的信号可以表示为等式4,其排列了等式2的第二和第三等式以及第八和第九等式。
[等式4]
H=Hfl3-w×(L2-p
Hr=Hfr3-w×(R2-p
图6B和图6C示出了根据实施例的用于逐步下混合的机制的示例。用于环绕声道和高度声道的逐步下混合可以具有例如图6B和图6C所示的机制。
下混合相关信息(或解混合相关信息)可以是指示基于预设的5个下混合权重参数(或解混合权重参数)的组合的多个模式之一的索引信息。例如,如表6所示,可以预先确定对应于多个模式的下混合权重参数。
[表6]
在下文中,将参照图7A至图18D描述用于基于音频场景类型执行下混合或解混合的音频编码处理和音频解码处理。此外,将描述用于基于高度声道的音频信号(例如,高度声道音频信号)等的能量分析来执行下混合或解混合的音频编码处理和音频解码处理。
在下文中,将依次详细描述根据本公开的技术精神的本公开的实施例。
图7A是根据本公开的实施例的音频编码装置的框图。
音频编码装置700可以包括存储器710和处理器730。音频编码装置700可以被实施为能够执行音频处理的装置,比如服务器、TV、相机、蜂窝电话、平板PC、膝上型计算机等。
虽然在图7A中分开示出了存储器710和处理器730,但是存储器710和处理器730可以通过一个硬件模块(例如,芯片)来实施。
处理器730可以被实施为用于基于神经网络的音频处理的专用处理器。或者,处理器730可以通过通用处理器(比如,AP、CPU、或GPU)和软件的组合来实施。专用处理器可以包括用于实施本公开的实施例的存储器或用于使用外部存储器的存储器处理器。
处理器730可以包括多个处理器。在这种情况下,处理器330可以被实施为专用处理器的组合,或者可以通过软件和多个通用处理器(比如AP、CPU或GPU)的组合来实施。
存储器710可以存储一个或多个用于音频处理的指令。在本公开的实施例中,存储器710可以存储神经网络。当神经网络以用于人工智能的专用硬件芯片的形式或者作为现有通用处理器(例如,CPU或AP)或图形专用处理器(例如,GPU)的一部分来实施时,神经网络可以不存储在存储器710中。神经网络可以由外部设备(例如,服务器)实施,并且在这种情况下,音频编码装置700可以从外部设备请求和接收基于神经网络的结果信息。
处理器730可以根据存储在存储器710中的指令顺序地处理连续的帧并获得连续的经编码的(经压缩的)帧。连续的帧可以指构成音频的帧。
处理器730可以以原始音频信号作为输入来执行音频处理操作,并且输出包括压缩音频信号的比特流。在这种情况下,原始音频信号可以是多声道音频信号。压缩音频信号可以是其声道数小于或等于原始音频信号的声道数的多声道音频信号。在这种情况下,比特流可以包括基本声道组的压缩音频信号,此外,还包括n个从属声道组的压缩音频信号(n是大于或等于1的整数)。因此,根据从属声道组的数量,可以自由地增加声道的数量。
图7B是根据本公开的实施例的音频编码装置的框图。
参照图2B,音频编码装置700可以包括多声道音频编码器740、比特流生成器780和附加信息生成器785。多声道音频编码器740可以包括多声道音频信号处理器750和压缩器776。
返回参照图7A,如上所述,音频编码装置700可以包括存储器710和处理器730,并且用于实施图1B的组件740、750、760、765、770、775、776、780、和785的指令可以存储在图7A的存储器710中。处理器730可以执行存储在存储器710中的指令。
多声道音频信号处理器750可以从原始音频信号获得(例如,生成)基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号。
多声道音频信号处理器750可以包括音频场景类型识别器760、下混合权重参数识别器765、下混合声道音频生成器770、和音频信号分类器775。
音频场景类型识别器760可以识别原始音频信号的音频场景类型。可以针对每一帧识别音频场景类型。
音频场景类型识别器760可以对原始音频信号进行下采样并且基于下采样的原始音频信号来识别音频场景类型。
音频场景类型识别器760可以从原始音频信号获得中心声道的音频信号。音频场景类型识别器760可以从所获得的中心声道的音频信号中识别对话类型。在这种情况下,音频场景类型识别器760可以通过使用用于识别对话类型的第一神经网络来识别对话类型。更具体地,当通过使用第一神经网络识别的对话类型的概率值大于第一对话类型的预定第一概率值时,音频场景类型识别器760可以将第一对话类型识别为对话类型。
当通过使用第一神经网络识别的对话类型的概率小于或等于第一对话类型的预定第一概率值时,音频场景类型识别器760可以将默认类型(例如,默认对话类型)识别为对话类型。
音频场景类型识别器760可以基于前声道的音频信号(例如,前声道音频信号)和侧声道的音频信号(例如,侧声道音频信号)从原始音频信号中识别声音效果的类型。
音频场景类型识别器760可以通过使用用于识别声音效果类型的第二神经网络来识别声音效果的类型。更具体地,当通过使用第二神经网络识别的声音效果类型的概率值大于第一声音效果类型的预定第二概率值时,音频场景类型识别器760可以将声音效果类型识别为第一声音效果类型。
当通过使用第二神经网络识别的声音效果类型的概率值小于或等于第一声音效果类型的预定第二概率值时,音频场景类型识别器760可以将声音效果类型识别为默认类型(例如,默认声音效果类型)。
音频场景类型识别器760可以基于所识别的对话类型或所识别的声音效果类型中的至少一个来识别音频场景类型。换句话说,音频场景类型识别器760可以识别多个音频场景类型中的一个音频场景类型。下面将参照图5详细描述用于识别音频场景类型的过程。
下混合权重参数识别器765可以识别对应于音频场景类型的下混合简档。下混合权重参数识别器765可以获得用于根据下混合简档从至少一个第一声道的第一音频信号(下)混合到第二声道的第二音频信号的下混合权重参数。可以预先确定对应于特定音频场景类型的特定下混合权重参数。
下混合声道音频生成器770可以基于所获得的下混合权重参数来对原始音频信号进行下混合。下混合声道音频生成器770可以生成预定声道布局的音频信号作为下混合的结果。
音频信号分类器775可以基于预定声道布局的音频信号生成基本声道组的至少一个音频信号和从属声道组的至少一个音频信号。
压缩器776可以压缩基本声道组的音频信号和从属声道组的音频信号。也就是说,压缩器776可以压缩基本声道组的至少一个音频信号以获得基本声道组的至少一个压缩音频信号。这里,压缩可以指基于各种音频编解码器的压缩。例如,压缩可以包括变换和量化过程。
压缩器776可以通过压缩至少一个从属声道组的至少一个音频信号来获得至少一个从属声道组的至少一个压缩音频信号。
附加信息生成器785可以生成包括关于音频场景类型的信息的附加信息。
比特流生成器780可以生成包括基本声道组的压缩音频信号和从属声道组的压缩音频信号的比特流。
比特流生成器780可生成进一步包括由附加信息生成器785生成的附加信息的比特流。
更具体地,比特流生成器780可以生成基本音频流和辅助音频流。基本音频流可以包括基本声道组的压缩音频信号,辅助音频流可以包括从属声道组的压缩音频信号。
此外,比特流生成器780可以生成包括附加信息的元数据。结果,比特流生成器780可以生成包括基本音频流、辅助音频流、和元数据的比特流。
图8是根据本公开的实施例的音频编码装置的框图。
参照图8,音频编码装置800可以包括多声道音频编码器840、比特流生成器880和附加信息生成器885。
多声道音频信号处理器850可以包括下混合权重参数识别器855、附加权重参数识别器860、下混合声道音频生成器870、和音频信号分类器875。
下混合权重参数识别器855可以识别下混合权重参数。
如在参考图7B描述的下混合权重参数识别器765中,下混合权重参数识别器855可以基于音频场景类型识别下混合权重参数。然而,该示例不限于此,并且可以以各种方式来识别下混合权重参数。
附加权重参数识别器860可以从原始音频信号中识别高度声道的音频信号的能量值。附加权重参数识别器860可以从原始音频信号中识别环绕声道的音频信号的能量值。同时,附加权重参数识别器860可以根据音频场景类型确定附加权重的范围或附加权重候选(例如,第一权重和第八权重)的值。
附加权重参数识别器860可以基于所识别的高度声道的音频信号的能量值和所识别的环绕声道的能量值来识别用于从环绕声道混合到高度声道的附加权重参数。环绕声道的能量值可以是关于环绕声道的总功率的移动平均值。更具体地,环绕声道的能量值可以是基于长期时间窗口的均方根能量(RMSE)值。高度声道的能量值可以是关于高度声道的短期时间功率值。更具体地,高度声道的能量值可以是基于短期时间窗口的RMSE值。当高度声道的能量值大于预定的第一值时,或者当高度声道的能量值与环绕声道的能量值的比率大于预定的第二值时,附加权重参数识别器860可以将附加权重参数识别为第一值。例如,第一值可以是0。
当高度声道的能量值小于或等于预定的第一值时,或者当高度声道的能量值与环绕声道的能量值的比率小于或等于预定的第二值时,附加权重参数识别器860可以将附加权重参数识别为第二值。第二值可以是1,但不限于此,并且可以是大于第一值的值,比如0.5。
附加权重参数识别器860可以基于音频信号的音频内容内的权重目标比率来识别原始音频信号的至少一个时间段的权重级别。例如,当级别1的目标比率是30%,级别2的目标比率是60%,级别3的目标比率是10%时,附加权重参数识别器860可以根据目标比率识别至少一个时间段的权重级别。换句话说,附加权重参数识别器860可以在内容的早期部分的时间段的情况下识别级别0,在内容的中间部分的时间段的情况下识别级别1,并且在内容的后期部分的时间段的情况下识别级别2。在这种情况下,可以识别对应于各个级别的附加权重参数。当对应于每个级别的权重是常数时,在时间段之间的边界段中可能会出现权重不连续。
附加权重参数识别器860可以确定时间段之间的边界段中的不同权重。更具体地,对于第一时间段与第二时间段之间的边界段的权重,附加权重参数识别器860可以识别从第一时间段中排除边界段的剩余段的权重与从第二时间段中排除边界段的剩余段的权重之间的值。为了最小化边界段中的权重不连续性,附加权重参数识别器860可以将与边界段外部相邻的权重之间的值识别为该边界段的权重。例如,在早期部分(级别0)和中间部分(级别1)之间的边界段中,可以为每个子段增加级别的值(例如,增加0.1),并且可以确定对应于级别的权重(例如,基于级别的函数的输出)。在这种情况下,对应于级别0与级别1之间的级别的权重可以是级别0的权重与级别1的权重之间的值。结果,权重不连续性可以被最小化。
下混合声道音频生成器870可以基于所获得的下混合权重参数和附加权重参数,根据预定的声道布局对原始音频信号进行下混合。下混合声道音频生成器870可以生成预定声道布局的音频信号作为下混合的结果。
下混合声道音频生成器870可以基于用于从环绕声道混合到高度声道的下混合权重参数和附加权重参数来生成高度声道的音频信号。在这种情况下,用于从环绕声道混合到高度声道的最终权重参数可以被表示为通过将下混合权重参数乘以附加权重参数而获得的结果。
附加信息生成器885可以生成包括附加权重参数的附加信息。
图9A是根据本公开的实施例的多声道音频解码装置的结构的框图。
音频解码装置900可以包括存储器910和处理器930。音频解码装置900可以被实施为能够进行音频处理的设备,比如服务器、TV、相机、移动电话、平板PC、膝上型电脑等。
虽然在图9A中分开示出了存储器910和处理器930,但是存储器910和处理器930可以通过一个硬件模块(例如,芯片)来实施。
处理器930可以被实施为用于基于神经网络的音频处理的专用处理器。或者,处理器930可以通过通用处理器(比如,AP、CPU、或GPU)和软件的组合来实施。专用处理器可以包括用于实施本公开的实施例的存储器或用于使用外部存储器的存储器处理器。
处理器930可以包括多个处理器。在这种情况下,处理器330可以被实施为专用处理器的组合,或者可以通过软件和多个通用处理器(比如AP、CPU或GPU)的组合来实施。
存储器910可以存储一个或多个用于音频处理的指令。在本公开的实施例中,存储器910可以存储神经网络。当神经网络以用于人工智能的专用硬件芯片的形式或者作为现有通用处理器(例如,CPU或AP)或图形专用处理器(例如,GPU)的一部分来实施时,神经网络可以不存储在存储器910中。神经网络可以被实施为外部装置(例如,服务器)。在这种情况下,音频解码装置900可以从外部装置请求基于神经网络的结果信息,并且从外部装置接收基于神经网络的结果信息。
处理器930可以根据存储在存储器910中的指令顺序地处理连续的帧以获得连续的经重建的帧。连续的帧可以指构成音频的帧。
处理器930可以通过对输入比特流执行音频处理操作来输出多声道音频信号。比特流可以以可缩放的形式来实施,以增加来自基本声道组的声道数量。例如,处理器930可以从比特流获得基本声道组的压缩音频信号,并且可以通过解压缩基本声道组的压缩音频信号来重建基本声道组的音频信号(例如,立体声声道音频信号)。另外,处理器930可以通过从比特流解压缩从属声道组的压缩音频信号来重建从属声道组的音频信号。处理器930可以基于基本声道组的音频信号和从属声道组的音频信号来重建多声道音频信号。
同时,处理器930可以通过从比特流解压缩第一从属声道组的压缩音频信号来重建第一从属声道组的音频信号。处理器930可以通过解压缩第二从属声道组的压缩音频信号来重建第二从属声道组的音频信号。
处理器930可以基于基本声道组的音频信号以及第一和第二从属声道组的相应音频信号来重建数量增加的声道的多声道音频信号。类似地,处理器330可以解压缩n个从属声道组(其中,n是大于2的整数)的压缩音频信号,并且可以基于基本声道组的音频信号以及基本声道组和n个从属声道组的相应音频信号来重建数量进一步增加的声道的多声道音频信号。
图9B是根据本公开的实施例的音频解码装置的结构的框图。
参照图9B,音频解码装置900包括信息获取器950和多声道音频解码器960。多声道音频解码器960包括解压缩器970和多声道音频信号重建器980。
音频解码装置900可以包括图9A的存储器910和处理器930,并且用于实施图9B的组件950、960、970、980、985、990、和995中的每一个的指令可以存储在存储器910中。处理器930可以执行存储在存储器910中的指令。
信息获取器950可以从比特流获取基本音频流和至少一个辅助音频流。基本音频流可以包括基本声道组的至少一个压缩音频信号。辅助音频流可以获得至少一个从属声道组的至少一个压缩音频信号。
信息获取器950可以从比特流获取元数据。元数据可以包括附加信息。例如,元数据可以是关于原始音频信号的音频场景类型的信息。关于音频场景类型的信息可以是指示音频场景类型之一的索引信息。关于音频场景类型的信息可以针对每一帧获得,但是可以针对各种数据单元周期性地获得。或者,关于音频场景类型的信息可以在每次场景改变时非周期性地获得。
解压缩器970可以通过解压缩基本声道组的至少一个压缩音频信号来获得包括在基本音频流中的基本声道组的音频信号。解压缩器970可以从至少一个从属声道组的至少一个压缩音频信号获得包括在辅助音频流中的至少一个从属声道组的至少一个音频信号。
解混合参数识别器990可以基于关于音频场景类型的信息来识别解混合权重参数。也就是说,解混合参数识别器990可以识别对应于音频场景类型的解混合权重参数。也就是说,解混合参数识别器990可以基于关于音频场景类型的索引信息从多个音频场景类型中识别一个音频场景类型,并且识别对应于所识别的音频场景类型的解混合权重参数。可以预先确定并存储分别对应于多个音频场景类型的解混合权重参数。
上混合声道组音频生成器985可以通过对基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号进行解混合来生成上混合声道组音频信号。在这种情况下,上混合声道组音频信号可以是多声道音频信号。
多声道音频信号输出器995可以输出至少一个上混合声道组音频信号。
图10是根据本公开的实施例的音频解码装置的结构的框图。
音频解码装置1000可以包括信息获取器1050和多声道音频解码器1060。多声道音频解码器1060可以包括解压缩器1070和多声道音频信号重建器1075。
图10的信息获取器1050、解压缩器1070、和多声道音频信号输出器1095可以执行以上参照图9描述的信息获取器950、解压缩器970、和多声道音频信号输出器995的各种操作。因此,将省略与图9的操作重复的操作的描述。
信息获取器1050可以从比特流获取包括关于附加解混合权重参数的信息的附加信息。
附加解混合参数识别器1090可以基于关于附加解混合权重参数的信息来识别附加解混合权重参数。附加解混合权重参数可以是对应于用于从环绕声道混合到高度声道的权重参数的解混合权重参数。也就是说,附加解混合参数识别器1090可以识别用于从高度声道解混合到环绕声道的权重参数。然而,本公开不限于此,附加解混合参数识别器1090可以基于从比特流获得的关于音频场景类型的信息来识别附加解混合权重参数的范围或附加解混合权重参数候选的值。附加解混合参数识别器1090可以基于附加解混合权重参数的范围或附加解混合权重参数候选的值来识别附加解混合权重参数。在这种情况下,可以使用关于附加解混合权重参数的信息。
上混合声道组音频生成器1080可以根据解混合权重参数和附加解混合权重参数对音频信号执行解混合。可以对基本声道组的音频信号和从属声道组的音频信号执行解混合。例如,上混合声道组音频生成器1080可以根据从高度声道到环绕声道的解混合权重参数和附加权重参数来执行从高度声道到环绕声道的解混合。在解混合到其他声道的情况下,上混合声道组音频生成器1080可以根据解混合权重参数而不需要附加权重参数来执行解混合。
图11是用于详细描述根据本公开的实施例的由音频编码装置700识别音频场景类型的过程的视图。
参照图11,音频编码装置700可以从原始音频信号获得(步骤1100)中心声道的音频信号。
音频编码装置700可以通过使用用于识别对话类型的第一神经网络来计算至少一个对话类型的类别的概率值(步骤1110)。第一神经网络1110可以将中心声道的音频信号识别为输入。
音频编码装置700可以识别(步骤1120)第一对话类型的类别的概率值P
当第一对话类型类别的概率值P
当第一对话类型的类别的概率值P
在下文中,将描述音频编码装置700识别声音效果类型的过程。
音频编码装置700可以从原始音频信号获得(步骤1130)前声道的音频信号和侧声道的音频信号。
音频编码装置700可以通过使用用于识别声音效果类型的第二神经网络来计算至少一个声音效果类型的类别的概率值(步骤1140)。第二神经网络1140可以接收前声道的音频信号和侧声道的音频信号作为输入。声音效果可以包括在比如游戏或电影等音频内容中,并且可以是定向的或在空间中移动的声音。
音频编码装置700可以识别(步骤1150)第一声音效果类型的类别的概率值P
当第一声音效果类型的类别的概率值P
当第一声音效果类型的类别的概率值P
在这种情况下,根据优先级,可以识别一种声音效果类型,或者可以识别最高概率值的声音效果类型。当声音效果不对应于多个声音效果类型中的任何一个时,音频编码装置700可以识别默认类型。
然而,本公开不限于此,并且除了对话类型和音效类型之外,还可以识别各种音频场景类型,比如音乐类型和运动/人群类型。音乐类型可以是在音频声道之间具有平衡声音的音频场景的类型。运动/人群类型可以是表现出许多人在欢呼的气氛或具有清晰的解说声音的音频场景的类型。这里,默认类型可以是在没有识别出特定音频场景类型时所识别的类型。可以通过使用单独的神经网络来识别各种音频场景类型。可以单独训练用于识别每个音频场景类型的神经网络。
在图11中,首先识别对话类型,然后识别声音效果类型。然而,本公开不限于此,可以首先识别声音效果类型,然后,可以识别对话类型。当存在其他音频场景类型时,可以根据音频场景类型中的优先级来识别各个音频场景类型的类型。
图12是用于描述根据本公开的实施例的用于识别对话类型的第一深度神经网络(DNN)1200的视图。
第一DNN 1200可以包括至少一个卷积层、池化层和全连接层。卷积层通过使用具有预定义大小的滤波器处理输入数据来获得特征数据。卷积层的滤波器的参数可以通过下面将要描述的训练过程来优化。池化层可以是用于从特征数据的所有样本的特征值中仅选择并输出一些样本的特征值以减小输入数据的大小的层。池化层可以包括最大池化层和平均池化层。全连接层是用于对特征进行分类的层,其中一层的每个神经元都连接到下一层的每个神经元。
参照图12,对中心声道的音频信号1201执行预处理(步骤1202-1204),然后,将中心声道的预处理后的音频信号1205输入到第一DNN 1200。
首先,对中心声道的音频信号1201执行RMS归一化(步骤1202)。因为每个声源的能量不同,所以音频信号的能量值可以根据特定标准进行归一化。当样本数量为N时,中心声道的音频信号1201可以是N×1大小的一维信号。例如,中心声道的音频信号1201可以是8640×1大小的一维信号。为了减少计算量,可以对中心声道的音频信号1201进行下采样,然后,可以对其执行RMS归一化(步骤1202)。
接下来,对执行了RMS归一化的音频信号执行短时频率变换(步骤1203)。以时间为单位的一维输入信号被输出为以时间和频率为单位的二维信号。以时间和频率为单位的二维信号可以是X×Y×1大小的二维信号。例如,对其执行短时频率变换的中心声道的音频信号可以是68×127×1大小的二维信号。
通过执行短时频率变换获得的输出信号是具有实数部分和虚数部分的复数信号(a+jb)。因为难以直接使用复数,所以可以使用复数信号的绝对值(root(a
对以时间和频率为单位的二维信号执行梅尔标度(Mel-scale)(步骤1204)。梅尔标度是一种考虑人类对低频信号的变化认知敏感而对高频信号的变化相对不太敏感的特征的标度,指的是在频率轴上重新缩放数据的操作,使得人类认为认知上更敏感的信号数据得到更精确地强调。结果,输出二维信号可以是具有减少的频率轴数据的X×Y”×1大小的二维信号。例如,中心声道的经Mel缩放的音频信号可以是68×68×1大小的二维信号。
参照图12,对中心声道的音频信号1201执行预处理,然后,将预处理后的音频信号输入到第一DNN 1200。
参照图12,中心声道的预处理后的信号1205被输入到第一DNN 1200。中心声道的预处理后的音频信号1205包括按时间和频率划分的样本。也就是说,中心声道的预处理后的音频信号1205可以是二维样本数据。中心声道的预处理后的音频信号1205的每个样本在特定时间具有特定频率的特征值。
包括c个a×b大小的滤波器的第一卷积层1220处理中心声道的预处理后的音频信号1205。例如,作为第一卷积层1220的处理的结果,可以获得(68,68,c)大小的第一中间信号1206。在这种情况下,第一卷积层1220可以包括多个卷积层,并且第一层的输入和第二层的输出可以彼此连接以进行训练。第一层和第二层可以是相同的层。然而,本公开不限于此,并且第二层可以是第一层的后续层。当第二层是第一层的后续层时,第一层的激活函数可以是修正线性单位(ReLU)。
可以通过使用第一池化层1230对第一中间信号1206执行池化。例如,作为池化层1230处理的结果,可以获得(34,34,c)大小的第二中间层1207。
第二卷积层1240处理用f个d×e大小的滤波器输入的信号。作为第二卷积层1240处理的结果,可以获得(17,17,f)大小的第三中间层1208。
可以通过使用第二池化层1250对第三中间层1208执行池化。例如,作为池化层1250的处理的结果,可以获得(9,9,f)大小的第四中间层1209。
第一全连接层1260可以通过对输入特征信号进行分类来输出一维特征信号。作为第一完全连接层1260的处理的结果,可以获得(1,1,N)大小的音频特征信号1210。这里,N可以表示类别的数量。这些类别可以对应于相应的对话类型。
根据本公开的实施例的第一DNN 1200从中心声道的音频信号1201获得音频特征信号1210(例如,概率信号)。
在图12中,第一DNN 1200包括两个卷积层、两个池化层和一个全连接层。然而,这仅是示例,第一DNN 1200中包括的卷积层的数量、池化层的数量、和全连接层的数量可以进行各种修改,只要可以从中心声道的音频信号1201获得N个类别的音频特征信号1210。同样,在每个卷积层中使用的滤波器的数量和大小可以进行各种修改,并且每个层的连接和连接方法也可以进行各种修改。
图13是用于描述根据本公开的实施例的用于识别声音效果类型的第二DNN 1300的视图。
第二DNN 1300可以包括至少一个卷积层、池化层和全连接层。卷积层通过用预定义大小的滤波器处理输入数据来获得特征数据。卷积层的滤波器的参数可以通过下面将要描述的训练过程来优化。池化层是用于从特征数据的所有样本的特征值中仅选择并输出一些样本的特征值以减小输入数据的大小的层,池化层可以包括最大池化层和平均池化层。全连接层是用于对特征进行分类的层,其中一层的每个神经元都连接到下一层的每个神经元。
参考图13,对前/侧/高度声道的音频信号1301执行预处理(步骤1302-1304),然后,将预处理后的音频信号输入到第二DNN 1300。前/侧/高度声道的音频信号1301的预处理过程类似于图12的预处理过程,因此,将省略其详细描述。
参考图13,前/侧/高度声道的预处理后的音频信号1305被输入到第二DNN 1300。前/侧/高度声道的预处理后的音频信号1301包括按声道、时间和频率划分的样本。也就是说,前/侧/高度声道的预处理后的音频信号1305可以是三维样本数据。前/侧/高度声道的预处理后的音频信号1305的每个样本在特定时间具有特定频率的特征值。
第一卷积层1320包括c个a×b大小的滤波器并且处理中心声道的预处理后的音频信号1305。例如,作为第一卷积层1320的处理的结果,可以获得(68,68,c)大小的第一中间信号1306。在这种情况下,第一卷积层1320可以包括多个卷积层,并且第一层的输入和第二层的输出可以彼此连接以进行训练。第一层和第二层可以是相同的层,但不限于此,并且第二层可以是第一层的后续层。当第二层是第一层的后续层时,第一层的激活函数可以是修正线性单位(ReLU)。
可以通过使用第一池化层1330对第一中间信号1306执行池化。例如,作为池化层1330处理的结果,可以获得(34,34,c)大小的第二中间层1307。
第二卷积层1340处理用f个d×e大小的滤波器输入的信号。作为第二卷积层1340处理的结果,可以获得(17,17,f)大小的第三中间层1308。
可以通过使用第二池化层1350对第三中间层1308执行池化。例如,作为池化层1350的处理的结果,可以获得(9,9,f)大小的第四中间层1309。
第一全连接层1360可以通过对输入的特征信号进行分类来输出一维特征信号。作为第一完全连接层1360的处理的结果,可以获得(1,1,N)大小的音频特征信号1310。这里,N可以表示类别的数量。这些类别可以对应于相应的声音效果类型。
根据本公开的实施例的第二DNN 1300从前/侧/高度声道的音频信号1301获得音频特征信号1310(例如,概率信号)。
在图13中,第二DNN 1300包括两个卷积层、两个池化层和一个全连接层。然而,这仅是示例,第二DNN 1300中包括的卷积层的数量、池化层的数量、全连接层的数量可以进行各种修改,只要可以从前/侧/高度声道的音频信号1301获得N个类别的音频特征信号1310。同样,在每个卷积层中使用的滤波器的数量和大小可以进行各种修改,并且每个层之间的连接和连接方法也可以进行各种修改。
图14是用于详细描述根据本公开的实施例的通过音频编码装置800识别用于从环绕声道混合到高度声道的附加解混合参数权重的过程的视图。
参照图14,音频编码装置800可以从原始音频信号获得(步骤1400)高度声道的音频信号。音频编码装置800可以对高度声道的音频信号执行能量分析(步骤1410)。
可以通过使用用于能量分析的神经网络来执行能量分析(步骤1410)。在这种情况下,可以基于高度声道的音频信号,通过使用用于能量分析的神经网络来识别用于从环绕声道混合到高度声道的附加权重(第一权重)。
音频编码装置800可以识别(步骤1420)高度声道的音频信号的功率值E
当识别出E
当高度声道的音频信号的功率值E
在这种情况下,可以基于高度声道的音频信号和环绕声道的音频信号,通过使用用于能量分析的神经网络来识别用于从环绕声道混合到高度声道的附加权重(第一权重或第二权重)。
音频编码装置800可以从原始音频信号获得(步骤1430)环绕声道的音频信号。音频编码装置800可以对环绕声道的音频信号执行能量分析(步骤1440)。
音频编码装置800可以识别(步骤1450)高度声道的音频信号的功率值E
当高度声道的音频信号的功率值E
当高度声道的音频信号的功率值E
以上,音频编码装置800执行将高度声道的音频信号的功率值E
图15是用于详细描述根据本公开的实施例的通过音频编码装置800识别用于从环绕声道混合到高度声道的附加解混合参数权重的过程的视图。
参照图15,音频编码装置800可以从原始音频信号获得(步骤1500)高度声道的音频信号和全部声道的音频信号。
音频编码装置800可以通过对高度声道的音频信号执行能量分析(步骤1510)来获得功率值E
音频编码装置800可以识别(步骤1520)高度声道的音频信号的功率值E
当识别出高度声道的音频信号的功率值E
当识别出高度声道的音频信号的功率值E
音频编码装置800可以从原始音频信号获得(步骤1530)环绕声道的音频信号。音频编码装置800可以对环绕声道的音频信号执行能量分析(步骤1540)。
音频编码装置800可以识别(步骤1550)高度声道的音频信号的功率值E
当高度声道的音频信号的功率值E
当高度声道的音频信号的功率值E
以上,音频编码装置800执行将高度声道的音频信号的功率值E
图16是根据本公开的实施例的处理音频的方法的流程图。
在操作S1605中,音频编码装置800可以基于包括至少一帧的音频信号的声道之间的相关性和延迟来识别声源对象的移动和方向。
在操作S1610中,音频编码装置800可以通过使用基于高斯混合模型的对象估计概率模型从包括至少一帧的音频信号中识别声源对象的类型和特性。
在操作S1615中,音频编码装置800可以基于声源对象的移动、方向、类型或特性中的至少一个来识别用于从环绕声道混合到高度声道的附加权重参数。
图17A是根据本公开的实施例的处理音频的方法的流程图。
在操作S1702中,音频编码装置700可以识别原始音频信号的音频场景类型。
在操作S1704中,音频编码装置700可以基于所识别的音频场景类型根据预定的声道布局对原始音频信号进行下混合。
在操作S1706中,音频编码装置700可以从预定声道布局的音频信号获得基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号。
在操作S1708中,音频编码装置700可以通过压缩基本声道组的至少一个音频信号来生成基本声道组的至少一个压缩音频信号。
在操作S1710中,音频编码装置700可以通过压缩至少一个从属声道组的至少一个音频信号来生成至少一个从属声道组的至少一个压缩音频信号。
在操作S1712中,音频编码装置700可以生成包括基本声道组的至少一个压缩音频信号和至少一个从属声道组的至少一个压缩音频信号的比特流。音频编码装置700可以生成进一步包括关于音频场景内容的信息的比特流。
图17B是根据本公开的实施例的处理音频的方法的流程图。
在操作S1722中,音频编码装置800可以从原始音频信号中识别高度声道的能量值。
在操作S1724中,音频编码装置800可以从原始音频信号中识别环绕声道的能量值。
在操作S1726中,音频编码装置800可以基于所识别的高度声道的能量值和所识别的环绕声道的能量值来识别用于从环绕声道混合到高度声道的附加权重。
在操作S1728中,音频编码装置700可以基于附加权重根据预定的声道布局对原始音频信号进行下混合。
在操作S1730中,音频编码装置700可以从预定声道布局的音频信号获得基本声道组的至少一个音频信号和至少一个从属声道组的音频信号。
在操作S1732中,音频编码装置700可以通过压缩基本声道组的至少一个音频信号来生成基本声道组的至少一个压缩音频信号。
在操作S1734中,音频编码装置700可以通过压缩至少一个从属声道组的至少一个音频信号来生成至少一个从属声道组的压缩音频信号。
在操作S1736中,音频编码装置700可以生成包括基本声道组的至少一个压缩音频信号和至少一个从属声道组的至少一个压缩音频信号的比特流。音频编码装置700可以生成进一步包括关于所识别的附加权重的信息的比特流。更具体地,音频编码装置700可以生成进一步包括用于解混合的权重的比特流,该权重是与用于混合的附加权重相对应的附加权重。用于解混合的权重可以是用于从高度声道解混合到环绕声道的权重。
图17C是根据本公开的实施例的处理音频的方法的流程图。
在操作S1742中,音频编码装置700可以识别包括至少一帧的音频信号的音频场景类型。
在操作S1744中,音频编码装置700可以以帧为单位确定下混合相关信息以对应于音频场景类型。
在操作S1746中,音频编码装置700可以通过使用以帧为单位确定的下混合相关信息来对包括至少一帧的音频信号进行下混合。
在操作S1748中,音频编码装置700可以发送下混合音频信号和以帧为单位确定的下混合相关信息。
图17D是根据本公开的实施例的处理音频的方法的流程图。
在操作S1752中,音频编码装置700可以识别包括至少一帧的音频信号的音频场景类型。
在操作S1754中,音频编码装置700可以以帧为单位确定下混合相关信息以对应于音频场景类型。
在操作S1756中,音频编码装置700可以通过使用下混合相关信息来对包括至少一帧的音频信号进行下混合。
在操作S1758中,音频编码装置700可以基于前一帧的音频场景类型和当前帧的音频场景类型生成指示前一帧的音频场景类型是否与当前帧的音频场景类型相同的标志信息。
根据实施例,当前一帧的音频场景类型与当前帧的音频场景类型相同时,音频编码装置700可以生成指示前一帧的音频场景类型与当前帧的音频场景类型相同的标志信息。
当前一帧的音频场景类型与当前帧的音频场景类型不同时,音频编码装置700可以不生成标志信息。因为没有生成标志信息,所以可以不发送标志信息。
根据实施例,当前一帧的音频场景类型与当前帧的音频场景类型相同时,音频编码装置700可以不生成标志信息,并且因为没有生成标志信息,所以可以不发送标志信息。
当前一帧的音频场景类型不同于当前帧的音频场景类型时,音频编码装置700可以生成标志信息。
在操作S1760中,音频编码装置700可以发送下混合音频信号、标志信息、或下混合相关信息中的至少一个。
根据实施例,当前一帧的音频场景类型与当前帧的音频场景类型相同时,音频编码装置700可以发送下混合音频信号和指示前一帧的音频场景类型与当前帧的音频场景类型相同的标志信息。在这种情况下,可以不另外发送当前帧的下混合相关信息。
当前一帧的音频场景类型与当前帧的音频场景类型不同时,音频编码装置700可以发送当前帧的下混合音频信号和下混合相关信息。可以不另外发送标志信息。
通常,当前一帧的音频场景类型与当前帧的音频场景类型相同时,可以不发送当前帧的标志信息和下混合相关信息。
当前一帧的音频场景类型与当前帧的音频场景类型不同时,可以发送当前帧的标志信息和下混合相关信息。
然而,本公开不限于选择性地发送标志信息的示例,音频编码装置700可以发送标志信息,而不管前一帧的音频场景类型是否与当前帧的音频场景类型相同。
同时,当包括在比该帧更高的数据单元中的帧的音频场景类型是相同的音频场景类型时,可以为更高的数据单元生成标志信息并发送。在这种情况下,不针对每一帧发送下混合相关信息,并且可以发送关于较高数据单元的下混合相关信息。
图18A是根据本公开的实施例的处理音频的方法的流程图。
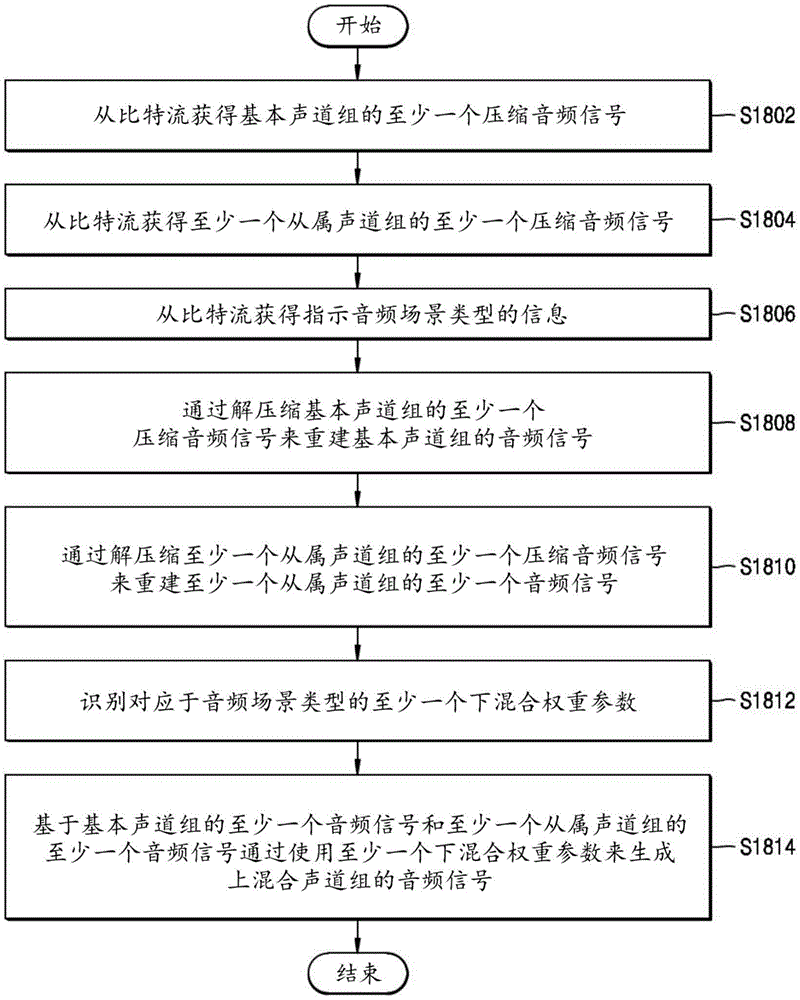
在操作S1802中,音频解码装置900可以从比特流获得基本声道组的至少一个压缩音频信号。
在操作S1804中,音频解码装置900可以从比特流获得至少一个从属声道组的至少一个压缩音频信号。
在操作S1806中,音频解码装置900可以从比特流获得指示音频场景类型的信息。
在操作S1808中,音频解码装置900可以通过解压缩基本声道组的至少一个压缩的音频信号来重建基本声道组的音频信号。
在操作S1810中,音频解码装置900可以通过解压缩至少一个从属声道组的至少一个压缩音频信号来重建至少一个从属声道组的至少一个音频信号。
在操作S1812中,音频解码装置900可以识别对应于音频场景类型的至少一个下混合权重参数。
在操作S1814中,音频解码装置900可以基于基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号通过使用至少一个下混合权重参数来生成上混合声道组的音频信号。
图18B是根据本公开的实施例的处理音频的方法的流程图。
在操作S1822中,音频解码装置1000可以从比特流获得基本声道组的至少一个压缩音频信号。
在操作S1824中,音频解码装置1000可以从比特流获得至少一个从属声道组的至少一个压缩音频信号。
在操作S1826中,音频解码装置1000可以从比特流获得关于用于从高度声道解混合到环绕声道的附加权重的信息。
在操作S1828中,音频解码装置1000可以通过解压缩基本声道组的至少一个压缩的音频信号来重建基本声道组的音频信号。
在操作S1830中,音频解码装置1000可以通过解压缩至少一个从属声道组的至少一个压缩音频信号来重建至少一个从属声道组的至少一个音频信号。
在操作S1832中,音频解码装置1000可以基于基本声道组的至少一个音频信号和至少一个从属声道组的至少一个音频信号,通过使用至少一个下混合权重参数和关于附加权重的信息来生成上混合声道组的音频信号。
图18C是根据本公开的实施例的处理音频的方法的流程图。
在操作S1842中,音频解码装置900可以从比特流获得下混合音频信号。
在操作S1844中,音频解码装置900可以从比特流获得下混合相关信息。下混合相关信息可以是通过使用音频场景类型以帧为单位生成的信息。
在操作S1846中,音频解码装置900可以通过使用以帧为单位生成的下混合相关信息来对下混合音频信号进行解混合。
在操作S1848中,音频解码装置900可以基于解混合的音频信号重建包括至少一帧的音频信号。
图18D是根据本公开的实施例的处理音频的方法的流程图。
在操作S1852中,音频解码装置900可以从比特流获得下混合音频信号。
在操作S1854中,音频解码装置900可以从比特流获得指示前一帧的音频场景类型是否与当前帧的音频场景类型相同的标志信息。根据情况,音频解码装置900可以不从比特流获得标志信息并且可以推导标志信息。
在操作S1856中,音频解码装置900可以基于标志信息获得关于当前帧的下混合相关信息。
例如,当标志信息指示前一帧的音频场景类型与当前帧的音频场景类型相同时,音频解码装置900可以基于关于前一帧的下混合相关信息获得关于当前帧的下混合相关信息。音频解码装置900可以不从比特流获得关于当前帧的下混合相关信息。
当标志信息指示前一帧的音频场景类型与当前帧的音频场景类型不相同时,音频解码装置900可以从比特流获得关于当前帧的下混合相关信息。
在操作S1858中,音频解码装置900可以通过使用关于当前帧的下混合相关信息来对下混合音频信号进行解混合。
在操作S1860中,音频解码装置900可以基于解混合的音频信号重建包括至少一帧的音频信号。
以上,音频解码装置900和1000通过使用以帧为单位生成的下混合相关信息来执行对下混合音频信号进行解混合的操作。然而,可以重建比输出声道布局中的音频信号更高的声道布局(例如,7.1.4声道布局)中的音频信号。也就是说,输出布局中的音频信号可能无法通过解混合来重建。
在这种情况下,音频解码装置900和1000可以通过使用以帧为单位生成的下混合相关信息对较高声道布局中的重建的音频信号进行下混合来重建输出声道布局中的音频信号。结果,从音频编码装置700和800接收的下混合相关信息不限于在音频解码装置900和1000的解混合操作中使用,也可以根据情况在下混合操作中使用。
然而,标志信息不限于以帧为单位发送,并且可以针对包括k个帧(k是大于1的整数)的较高音频数据单元(例如,参数采样单元)信令通知下混合相关信息。在这种情况下,关于较高音频数据单元的大小的信息和从较高音频数据单元接收的下混合相关信息可以通过比特流进行信令通知。关于较高音频数据单元的大小的信息可以是关于k的值的信息。
当从较高音频数据单元接收到下混合相关信息时,可能无法以包括在较高数据单元中的帧为单位获得该下混合相关信息。例如,下混合相关信息可以在包括在较高音频数据单元中的第一帧中获得,而可能无法在较高音频数据单元的第一帧之后的帧中获得。
同时,可以在较高音频数据单元的第一帧之后的帧中获得标志。
基于该标志,当识别出前一帧的音频场景类型与当前帧的音频场景类型不相同时,可以另外获得下混合相关信息。通过该标志更新的下混合相关信息可以在较高音频数据单元中获得该标志的帧之后的帧中使用。
同时,当前一帧的音频场景类型与当前帧的音频场景类型相同时,不获得当前帧的标志,但是可以使用先前获得的下混合相关信息。
根据本公开的实施例,可以根据音频场景类型通过适当的下混合或上混合处理来保持原始声音效果。
根据本公开的实施例,音频信号可以被动态混合,使得环绕声道的音频和高度声道的音频可以在大屏幕中良好地呈现。也就是说,当被再现的音频集中在环绕中时,环绕声道Ls和Rs的音频信号不仅可以被分配到L/R声道而且可以被分配到高度声道,从而使环绕效果最大化。或者,通过将环绕声道Ls和Rs的音频信号混合到L/R声道而不是高度声道,可以区分水平声音和垂直声音,从而可以同时以平衡的方式表达环绕效果和高度效果。
同时,本公开的上述实施例可以被写成可在计算机上执行的程序或指令,并且该程序或指令可以被存储在存储介质中。
机器可读存储介质可以以非暂时性存储介质的形式提供。其中,术语“非暂时性存储介质”仅意味着存储介质是有形设备,并且不包括信号(例如,电磁波),但是该术语不在数据被半永久性地存储在存储介质中与数据被临时存储在存储介质中进行区分。例如,“非暂时性存储介质”可以包括临时存储数据的缓冲区。
根据本公开的实施例,根据本文披露的各种实施例的方法可以被包括并提供在计算机程序产品中。计算机程序产品可以作为产品在卖方和买方之间进行交易。计算机程序产品可以以机器可读存储介质(例如,紧凑盘只读存储器(CD-ROM))的形式来分发,或者经由应用商店(例如,PlayStore
同时,与上述神经网络相关联的模型可以被实施为软件模块。当被实施为软件模块(例如,包括指令的程序模块)时,神经网络模型可以被存储在计算机可读记录介质上。
此外,神经网络模型可以以硬件芯片的形式集成,并且可以是上述装置的一部分。例如,神经网络模型可以以用于人工智能的专用硬件芯片的形式制造,或者作为传统通用处理器(例如,CPU或AP)或专用图形处理器(例如,GPU)的一部分。
此外,神经网络模型可以以可下载软件的形式提供。计算机程序产品可以包括通过制造商或电子市场以电子方式分发的软件程序形式的产品(例如,可下载的应用程序)。对于电子分发,软件程序的至少一部分可以被存储在存储介质中或者临时生成。在这种情况下,存储介质可以是制造商或电子市场的服务器,或者中继服务器的存储介质。
参考示例实施例详细描述了本公开的技术精神,但是本公开的技术精神不限于上述实施例,并且本领域普通技术人员可以在本公开的技术精神内对本公开的技术精神进行各种改变和修改,而不限于前述实施例。