一种组装和注释绵羊基因组的方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于生物信息技术领域,具体是指一种组装和注释绵羊基因组的方法。
背景技术
绵羊是偶蹄目洞角科绵羊属哺乳动物,体躯丰满,被毛绵密,公羊多有螺旋状大角,母羊无角或角细小,颅骨上具泪窝,鼻骨较隆起,四蹄有趾腺;嘴尖、唇薄而灵活,体重自数十千克至百余千克不等,自然寿命约15年,绵羊发源地在中亚,后逐渐向世界各地扩展,性情温驯,仿效性、合群性强,有跟随领头羊集合成群的习性,食短草,亦采食粗硬秸秆、树枝,人工饲养可喂饲料,绵羊毛为毛纺工业的主要原料,皮张可用作工业原料和装饰品,野生绵羊驯化为家畜始于约11000年以前的新石器时代,绵羊是免疫学研究、生理学实验、实验外科手术、微生物学教学实习及医疗检验中常用的实验动物,用绵羊可制备抗正常人全血清的免疫血清,绵羊红细胞是血清学补体结合试验的主要实验材料,绵羊的蓝舌病还可用于人类脑积水等相关疾病的研究。
基因组序列组装能够为绵羊的遗传选育等生物研究提供参考基因序列,而染色体水平的基因组在应用层面上具备了更高的实用价值,比较基因组学及重测序、三维基因组研究工作,都需要高质量的染色体水平基因组,虽然绵羊的基因组已被组装,但由于组装技术的限制和实际情况的复杂性,目前关于绵羊的基因组学研究中,绵羊的基因组尚未完成染色体水平的组装,这使得绵羊遗传特性研究和新品种培育领域缺乏高质量的参考基因组,首次构建了绵羊的参考基因组,提高了绵羊基因组装质量,推动了绵羊基因组学的研究进展,为绵羊遗传特性研究和新品种培育奠定基础。
发明内容
针对上述情况,为克服现有技术的缺陷,本发明提供了一种组装和注释绵羊基因组的方法,为了解决当前对主流从总DNA中分离细胞器DNA方法存在的对高拷贝的细胞器DNA测序成本增加、对拷贝数低细胞器DNA则需增加测序量才能满足其拼接覆盖度要求的问题,提供了一种用于绵羊基因组组装及注释方法,可优化基因组组装流程,直接从样品总DNA测序入手,无需单独分离细胞器DNA再测序,优化后的方案能够从总DNA拼接结果中直接一次成环地拿到细胞器基因组;本发明构建了绵羊的参考基因组,提高了绵羊基因组装质量,推动了绵羊基因组学的研究进展,为绵羊遗传特性研究和新品种培育奠定基础。
为了实现上述目的,本发明采取的技术方案如下:本发明提出了一种组装和注释绵羊基因组的方法,所述方法包括如下步骤:
(1)绵羊基因组片段采集:分别从血液和组织提取绵羊的DNA和RNA,用基因组试剂盒从绵羊血液和组织标本中提取基因组DNA,冷冻保存;将绵羊基因组DNA打断,再经加A尾、加测序接头、末端修复、PCR扩增、纯化过程最终形成整个文库;
(2)基因组序列的组装:使用SPAdes软件对cleandata质控,进行初步拼接;使用已公布的绵羊基因组数据与蛋白编码基因序列作为参考,分别进行blastn与Exonerate比对;使用PRICE和MITObim软件对收集到的零碎目标序列,进行延伸合并拼接;对迭代拼接的结果使用bowtie2软件将原始测序reads进行回帖,对匹配上的成对reads挑出用SPAdes重拼接;查看路径是否形成明显的环状图,如无重复上述步骤;
(3)基因组序列的注释:绵羊基因组序列注释分为蛋白编码基因注释、RNA注释、控制区注释三部分:①蛋白编码基因注释:使用UGENEORFsfinder工具,选择对应密码子表对序列进行ORF预测,将预测出的ORF使用blastp与nr数据库进行比对,注释其功能;②RNA注释:结合tRNAscan-SE和Mitoswebserver在线工具对22个tRNA进行注释,对无法通过在线软件预测的tRNA基因,根据tRNA基因的二级结构图谱进行手动校对;③控制区注释:控制区中串联重复序列使用TandemRepeatsFinder在线软件识别;
(4)结构注释:序列注释结束后,经Sequin编辑,生成可提交至GenBank数据库的提交文件,使用编辑好的genbank注释文件使用在线工具绘制注释图谱。
优选地,所述步骤(1)中DNA提取自绵羊血液和肝脏组织;RNA提取自绵羊组织,所述的绵羊组织是指心脏、肝脏、肺脏、脾脏、瘤胃和肌肉的混合。
优选地,所述步骤(1)中文库的初步定量使用Qubit2.0软件,经过对文库进行合适的稀释后Agilent2100检测文库中插入片段的大小,为保证文库质量,检测结果合格后,文库的有效浓度用Q-PCR方法进行准确定量。
优选地,所述步骤(2)中测序数据的质量评估采用Illumina高通量测序平台进行测序,用e表示测序错误率,用Q
优选地,所述步骤(2)中组装采用从头组装方式。
优选地,所述步骤(2)中contig筛选参数设置为蛋白相似性阈值为70%,比对阈值为evalue1e
优选地,所述步骤(2)中零碎收集到的目标序列在MITObim和PRICE中进行延伸合并以及拼接,将拼接后scaffold在bowtie2中进行回帖,然后挑出匹配的成对reads用SPAdes再次拼接。
优选地,所述步骤(2)中拼接出的基因成环状图,若不成环,则重复延伸、补洞以及重新拼接直至拼出环状基因组。
本发明取得的有益效果如下:(1)本发明提供的方法取得高质量的绵羊参考基因组,并对绵羊的基因结构和基因功能进行了全面注释,对于绵羊的遗传改良和保护至关重要,为绵羊遗传特性研究和新品种培育奠定基础;(2)本发明的组装方法获得了连续性更好的绵羊参考基因组,为后续进行大规模基因组进化和功能研究提供保障;(3)采用本发明方法鉴定到的重复序列更多,基因注释的完整性更高,注释到的基因数目更加接近于绵羊的平均基因数量。
附图说明
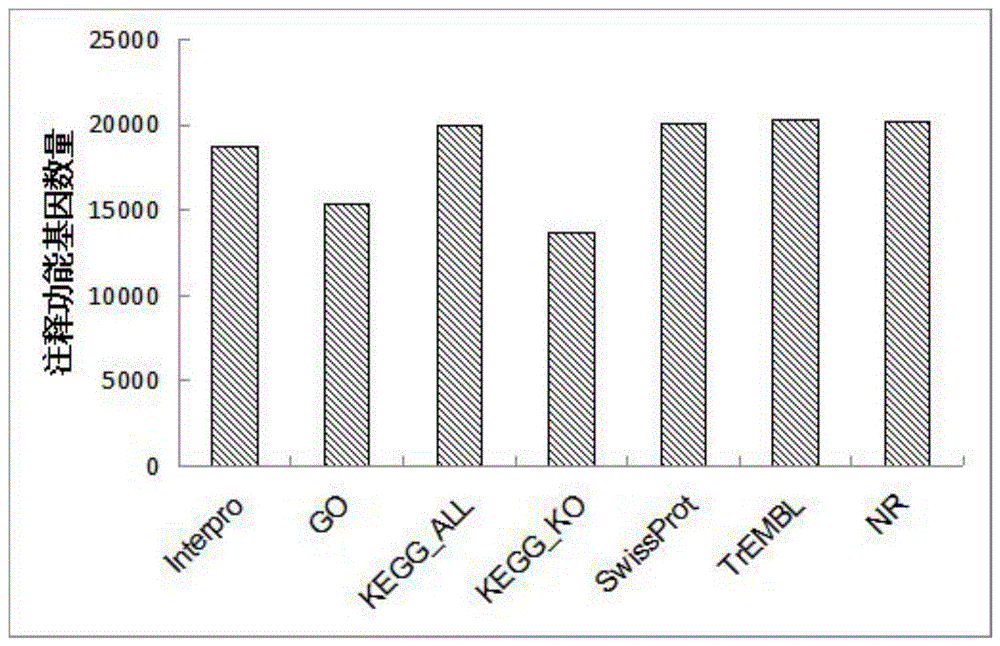
图1一种组装和注释绵羊基因组的方法的功能注释结果图。
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例;基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
除非另行定义,文中所使用的所有专业与科学用语与本领域技术人员所熟悉的意义相同。此外,任何与所记载内容相似或均等的方法及材料皆可应用于本发明中。文中所述的较佳实施方法与材料仅作示范之用,但不能限制本申请的内容。
下述实施例中的实验方法,如无特殊说明,均为常规方法;下述实施例中所用的试验材料及试验菌株,如无特殊说明,均为从商业渠道购买得到的。
实施例1
绵羊基因组片段采集的方法
DNA提取自绵羊血液和肝脏组织;RNA提取自绵羊组织
总DNA提取步骤如下:取绵羊血液和肝脏组织,冲洗后加入200μL缓冲液GTL,匀浆;加入20μL10mg/ml蛋白酶K溶液混匀,56℃放置6-8h,离心去上清;加入200μL缓冲液GL,充分混匀后70℃放置10min,离心去上清;加入预冷无水乙醇200μL,充分振荡混匀15s后,离心去除管盖内壁水珠;将得到的溶液加入组装好的CB3吸附柱中,12000rmp离心30s,弃废液;向吸附柱加入500μL缓冲液GW1,12000rmp离心30s,弃废液;向吸附柱加入500μL缓冲液GW2,12000rmp离心30s,弃废液;将吸附柱CB3放回收集管中,12000rmp离心2min,弃废液;将吸附柱置于室温数分钟彻底晾干;将吸附柱放入灭菌烘干后离心管中,向吸附膜中间部位悬空加入100μl灭菌水,室温放置2min,12000rmp离心2min,离心管中的溶液分装至4-5个PCR管中。
使用TRlzol Reagent(Invitrogen,美国)提取绵羊心脏、肝脏、肺脏、脾脏、瘤胃和肌肉组织中的总RNA并进行质检,用于转录组文库构建。
实施例2
基因组序列的组装的方法
初始拼接:采用从头组装方式,选用SPAdesv3.9.0(环状基因最优拼接软件)对序列进行拼接,使用默认参数的SPAdes软件对质控合格的cleandata进行初步拼接,提取出拼接后的scaffold;筛选contig:将提取出的scaffold与NCBI中已公布的目标物种的近源物种序列进行比对(参数设置:蛋白相似性阈值为70%,比对阈值为evalue1e-10),将匹配的scaffold进行覆盖度排序,最后删除低覆盖度的片段;延伸、补洞与重拼接:将零碎收集到的目标序列在MITObim和PRICE(迭代次数:50次)中进行延伸合并以及拼接,将拼接后scaffold在bowtie2中进行回帖,然后挑出匹配的成对reads用SPAdes再次拼接,若拼接出的基因成环状图,若不成环,则重复延伸、补洞以及重新拼接直至拼出环状基因组。
实施例3
基因组序列和结构注释的方法
使用UGENEORFsfinder工具,选择对应密码子表对序列进行ORF预测,将预测出的ORF使用blastp与nr数据库进行比对,注释其功能;结合tRNAscan-SE和Mitoswebserver在线工具对22个tRNA进行注释,对无法通过在线软件预测的tRNA基因,根据tRNA基因的二级结构图谱进行手动校对;控制区中串联重复序列使用TandemRepeatsFinder在线软件识别;序列注释结束后,经Sequin编辑,生成可提交至GenBank数据库的提交文件,使用编辑好的genbank注释文件使用在线工具绘制注释图谱。
实验例1
借助外源蛋白数据库InterPro、GO、KEGG_ALL、KEGG_KO、SwissProt、TrEMBL和NR对绵羊基因集中的蛋白进行功能注释,结果如图1所示:共注释到20568个编码蛋白质的基因,占上述7种蛋白数据库的98.23%,使用BUSCO软件进行绵羊基因组注释评估,能完整比对BUSCO的基因有3689个,占比为91.8%。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的应用并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的方式及实施例,均应属于本发明的保护范围。
- 一种基因组单倍体组装方法及装置
- 绵羊基因组2号染色体上绵羊脱毛症相关基因的分析方法
- 一种基于三代PacBio和Hi-C技术组装和注释霍巴藏绵羊基因组的方法
- 一种基于三代PacBio和Hi-C技术组装和注释湖羊基因组的方法