模型训练方法、模型应用方法和相关装置
文献发布时间:2024-04-18 19:58:30
技术领域
本申请涉及数据处理领域,特别是涉及一种模型训练方法和相关装置。
背景技术
语音合成技术是当下热门的数据处理技术之一,其作用是模拟真实的语音发音方式,基于输入的文本信息生成对应的语音信息。其中,在使用语音合成技术时,为了使得到的语音信息更加真实、贴合实际需求,语音合成方通常会根据自身的语音合成需求调节语音信息的相关参数。
在相关技术中,语音合成技术并不支持语音信息生成过程中的参数调节,语音合成方只能够在语音信息合成后,再调节语音信息的语调、时长等参数。
由于这种参数调节方式只能够在音频信息合成后进行,是基于语音信息本身来进行调节的,因此难以参考待合成的文本信息所包含的上下文信息,导致调节后的语音信息容易出现失真问题,语音合成效果较差。
发明内容
为了解决上述技术问题,本申请提供了一种模型训练方法,使训练得到的模型可以直接基于调节参数和待合成文本合成语音信息,从而使语音信息既可以满足调节需求,又可以贴合待合成文本的文本特点,提高语音合成效果。
本申请实施例公开了如下技术方案:
第一方面,本申请实施例公开了一种模型训练方法,所述方法包括:
获取样本文本信息集合,所述样本文本信息集合包括多个样本文本信息,所述样本文本信息具有对应的样本语音信息和样本调节参数,所述样本语音信息是基于所述样本调节参数生成的;
将所述多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,根据所述目标样本文本信息生成所述目标样本文本信息对应的语音特征信息,所述语音特征信息用于标识所述目标样本文本信息在语音信息中的发音方式;
通过所述初始语音合成模型,根据所述目标样本文本信息对应的目标样本调节参数对所述语音特征信息进行调节,得到调节后的语音特征信息;
通过所述初始语音合成模型,根据所述调节后的语音特征信息生成所述目标样本文本信息对应的待定语音信息;
根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型对应的模型参数,得到语音合成模型,所述语音合成模型用于根据待合成文本信息和所述待合成文本信息对应的调节参数合成语音信息。
第二方面,本申请实施例公开了一种模型应用方法,所述方法包括:
获取语音合成对象输入的待合成文本信息和所述待合成文本信息对应的调节参数,所述调节参数用于调节所述待合成文本信息在语音信息中的发音方式;
将所述待合成文本信息和所述待合成文本信息对应的调节参数输入语音合成模型,通过所述语音合成模型,生成所述待合成文本信息对应的目标语音信息;
向所述语音合成对象发送所述目标语音信息。
第三方面,本申请实施例公开了一种模型训练装置,所述装置包括获取单元、第一生成单元、第一调节单元、第二生成单元和第二调节单元:
所述获取单元,用于获取样本文本信息集合,所述样本文本信息集合包括多个样本文本信息,所述样本文本信息具有对应的样本语音信息和样本调节参数,所述样本语音信息是基于所述样本调节参数生成的;
所述第一生成单元,用于将所述多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,根据所述目标样本文本信息生成所述目标样本文本信息对应的语音特征信息,所述语音特征信息用于标识所述目标样本文本信息在语音信息中的发音方式;
所述第一调节单元,用于通过所述初始语音合成模型,根据所述目标样本文本信息对应的目标样本调节参数对所述语音特征信息进行调节,得到调节后的语音特征信息;
所述第二生成单元,用于通过所述初始语音合成模型,根据所述调节后的语音特征信息生成所述目标样本文本信息对应的待定语音信息;
所述第二调节单元,用于根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型对应的模型参数,得到语音合成模型,所述语音合成模型用于根据待合成文本信息和所述待合成文本信息对应的调节参数合成语音信息。
在一种可能的实现方式中,所述第一生成单元具体用于:
确定所述目标样本文本信息对应的音素特征信息、语义特征信息和韵律特征信息,所述音素特征信息用于标识所述目标样本文本信息对应的音素组成,所述语义特征信息用于标识所述目标样本文本信息对应的语义,所述韵律特征信息用于标识所述目标样本文本信息对应的发音韵律;
根据所述音素特征信息、所述语义特征信息和所述韵律特征信息,生成所述目标样本文本信息对应的语音特征信息。
在一种可能的实现方式中,所述样本文本信息具有对应的样本情绪标签,所述初始语音合成模型中包括多个情绪标签分别对应的初始情绪特征信息,所述第一生成单元具体用于:
确定所述目标样本文本信息所对应目标样本情绪标签对应的目标初始情绪特征信息;
根据所述目标初始情绪特征信息和所述目标样本文本信息,生成所述目标样本文本信息对应的语音特征信息;
所述第二调节单元具体用于:
根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型对应的模型参数和所述目标初始情绪特征信息,得到语音合成模型,所述语音合成模型包括所述多个情绪标签分别对应的情绪特征信息,所述情绪特征信息是通过调节情绪标签对应的初始情绪特征信息得到的,所述语音合成模型用于根据待合成文本信息、所述待合成文本信息对应的调节参数和所述待合成文本信息对应的情绪标签合成语音信息。
在一种可能的实现方式中,所述目标样本调节参数包括第一调节参数,所述第一调节参数用于调节所述语音特征信息中包括的第一特征参数,所述第一调节单元具体用于:
通过所述初始语音合成模型,根据所述第一调节参数对所述语音特征信息中包括的第一特征参数进行调节,得到调节后的语音特征信息。
在一种可能的实现方式中,所述初始语音合成模型包括参数预测部分,所述目标样本调节参数包括第二调节参数,所述第二调节参数用于调节根据所述语音特征信息确定出的第二特征参数,所述语音特征信息中不包括所述第二特征参数,所述目标样本文本信息具有对应的样本第二特征参数;
所述装置还包括确定单元:
所述确定单元,用于通过所述参数预测部分确定所述语音特征信息对应的待定第二特征参数;
所述第一调节单元具体用于:
根据所述样本第二特征参数和所述第二调节参数确定待调节第二特征参数;
通过所述初始语音合成模型,根据所述待调节第二特征参数对所述语音特征信息进行调节,得到调节后的语音特征信息;
所述第二调节单元具体用于:
根据所述待定第二特征参数与所述样本第二特征参数之间的差异调节所述参数预测部分对应的模型参数,以及根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型中除所述参数预测部分外的模型参数,得到所述语音合成模型。
在一种可能的实现方式中,所述目标样本调节参数具有对应的情绪标签,所述第二调节单元具体用于:
确定所述情绪标签对应的第一情绪特征参数;
根据所述第一目标特征参数对所述样本第二特征参数进行归一化处理;
根据所述待定第二特征参数与归一化处理后的所述样本第二特征参数之间的差异,调节所述参数预测部分对应的模型参数,所述语音合成模型中的参数预测部分用于确定语音特征信息对应的归一化处理后的第二特征参数,并根据所述待合成文本信息所对应情绪标签对应的第二情绪特征参数和所述归一化处理后的第二特征参数,确定所述语音特征信息对应的第二特征参数。
在一种可能的实现方式中,所述第一调节参数包括拖音控制参数、重音控制参数和打断控制参数中的任意一种或多种的组合,所述拖音控制参数用于调节所述第一特征参数中的拖音参数,所述重音控制参数用于调节所述第一特征参数中的重音参数,所述打断控制参数用于调节所述第一特征参数中的打断参数。
在一种可能的实现方式中,所述第二调节参数包括时长控制参数、语调控制参数和起伏控制参数中的任意一种或多种的组合,所述时长控制参数用于调节所述第二特征参数中的时长参数,所述语调控制参数用于调节所述第二特征参数中的语调参数,所述起伏控制参数用于调节所述第二特征参数中的起伏参数。
在一种可能的实现方式中,所述第二调节单元具体用于:
根据所述待定语音信息生成第一语谱图,以及根据所述目标样本语音信息生成第二语谱图;
通过生成对抗网络判别器,确定所述第一语谱图与所述第二语谱图之间的相似参数,所述相似参数用于标识所述第一语谱图与所述第二语谱图之间的差异;
根据所述相似参数调节所述初始语音合成模型对应的模型参数得到语音合成模型,根据所述语音合成模型确定出的相似参数大于预设阈值。
第四方面,本申请实施例公开了一种模型应用装置,所述装置包括获取单元、生成单元和发送单元:
所述获取单元,用于获取语音合成对象输入的待合成文本信息和所述待合成文本信息对应的调节参数,所述调节参数用于调节所述待合成文本信息在语音信息中的发音方式;
所述生成单元,用于将所述待合成文本信息和所述待合成文本信息对应的调节参数输入语音合成模型,通过所述语音合成模型,生成所述待合成文本信息对应的目标语音信息;
所述发送单元,用于向所述语音合成对象发送所述目标语音信息。
在一种可能的实现方式中,所述生成单元具体用于:
确定所述待合成文本信息对应的音素特征信息、语义特征信息和韵律特征信息,所述音素特征信息用于标识所述待合成文本信息对应的音素组成,所述语义特征信息用于标识所述待合成文本信息对应的语义,所述韵律特征信息用于标识所述待合成文本信息对应的发音韵律;
根据所述音素特征信息、所述语义特征信息和所述韵律特征信息,生成所述待合成文本信息对应的语音特征信息,所述语音特征信息用于标识所述待合成文本信息在语音信息中的发音方式;
根据所述待合成文本信息对应的调节参数调节所述语音特征信息;
根据调节后的所述语音特征信息生成所述待合成文本信息对应的目标语音信息。
在一种可能的实现方式中,所述语音合成模型包括参数调节部分和参数预测部分,所述调节参数包括第一调节参数和第二调节参数,所述第一调节参数用于调节所述语音特征信息中包括的第一特征参数,所述第二调节参数用于调节根据所述语音特征信息确定出的第二特征参数,所述语音特征信息中不包括所述第二特征参数;
所述生成单元具体用于:
通过所述参数预测部分,根据所述语音特征信息确定所述语音特征信息对应的第二特征参数;
根据所述第二调节参数和所述第二特征参数确定待调节第二特征参数;
通过所述参数调节部分,根据所述第一调节参数调节所述语音特征信息中包括的第一特征参数,以及根据所述待调节第二特征参数调节所述语音特征信息。
在一种可能的实现方式中,所述调节参数包括情绪标签,所述生成单元具体用于:
根据所述语音特征信息,确定所述语音特征信息对应的归一化处理后的第二特征参数;
根据所述情绪标签对应的情绪特征参数和所述归一化处理后的第二特征参数,确定所述语音特征信息对应的第二特征参数。
在一种可能的实现方式中,所述调节参数包括情绪标签和情绪程度参数,所述情绪程度参数用于标识将所述待合成文本信息在语音信息中的发音方式向所述情绪标签标识的情绪进行调节的程度,所述生成单元具体用于:
确定所述情绪标签对应的情绪特征信息;
根据所述情绪特征信息、所述情绪特征参数、所述音素特征信息、所述语义特征信息和所述韵律特征信息,生成所述待合成文本信息对应的语音特征信息。
在一种可能的实现方式中,所述装置还包括展示单元:
所述展示单元,用于向所述语音合成对象展示信息输入界面,所述信息输入界面用于输入待合成文本信息和调节参数;
所述获取单元具体用于:
通过所述信息输入界面获取语音合成对象输入的待合成文本信息和所述待合成文本信息对应的调节参数。
第五方面,本申请实施例公开了一种计算机设备,所述计算机设备包括处理器以及存储器:
所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
所述处理器用于根据所述程序代码中的指令执行第一方面中任意一项所述的模型训练方法,或第二方面中任意一项所述的模型应用方法。
第六方面,本申请实施例公开了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行第一方面中任意一项所述的模型训练方法,或第二方面中任意一项所述的模型应用方法。
第七方面,本申请实施例公开了一种包括指令的计算机程序产品,当其在计算机上运行时,使得所述计算机执行第一方面中任意一项所述的模型训练方法,或第二方面中任意一项所述的模型应用方法。
由上述技术方案可以看出,在进行模型训练时,先获取用于进行模型训练的样本文本信息集合,该样本文本信息集合包括多个样本文本信息,样本文本信息具有对应的样本语音信息和样本调节参数,其中,样本语音信息是基于该样本文本信息和样本调节参数生成的,即该样本语音信息匹配该调节参数对样本文本信息在语音信息中发音方式的调节。在语音信息合成过程中,将多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,先根据该目标样本文本信息生成目标样本文本信息对应的语音特征信息,该语音特征信息用于标识目标样本文本信息在语音信息中的发音方式。从而,通过该目标样本文本信息对应的目标样本调节参数调节该语音特征信息,可以以与该目标样本文本信息对应的目标样本语音信息相同的调节方式调节该目标样本文本信息的发音方式。通过该初始语音合成模型根据调节后的语音特征信息生成该目标样本文本信息对应的待定语音信息,从而,通过待定语音信息和目标样本语音信息之间的差异,能够体现出初始语音合成模型在基于文本信息和调节参数直接合成语音信息时的准确度,进而通过基于该差异对初始语音合成模型进行参数调节得到的语音合成模型,可以实现直接基于待合成文本信息和调节参数,较为准确的合成待合成文本信息对应的语音信息,使该语音信息既符合调节参数对于发音方式调节的需求,又贴合该待合成文本信息整体的语音发音特点,从而在保障对语音信息准确调节的前提下,提高调节后的语音信息的真实性,进而提高语音合成效果。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种实际应用场景中模型训练方法的示意图;
图2为本申请实施例提供的一种模型训练方法的流程图;
图3为本申请实施例提供的一种模型训练方法的示意图;
图4为本申请实施例提供的一种模型训练方法的示意图;
图5为本申请实施例提供的一种模型训练方法的示意图;
图6为本申请实施例提供的一种模型训练方法的示意图;
图7为本申请实施例提供的一种模型应用方法的流程图;
图8为本申请实施例提供的一种模型应用方法的示意图;
图9为本申请实施例提供的一种信息输入界面的示意图;
图10为本申请实施例提供的一种实际应用场景中模型训练方法的示意图;
图11为本申请实施例提供的一种实际应用场景中模型训练方法的示意图;
图12为本申请实施例提供的一种模型训练装置的结构框图;
图13为本申请实施例提供的一种模型应用装置的结构框图;
图14为本申请实施例提供的一种终端的结构图;
图15为本申请实施例提供的一种服务器的结构图。
具体实施方式
下面结合附图,对本申请的实施例进行描述。
在通过语音合成得到待合成文本信息对应的语音信息时,为了提高语音信息的效果或满足语音合成对象的各种语音合成需求,语音合成对象通常会对语音信息进行各种调节,例如调节语音信息中发音的语调、停顿等。
在相关技术中,由于用于生成语音信息的语音合成模型不具备语音信息调节的能力,因此语音合成对象需要在语音合成模型输出语音信息后,才能对语音信息进行调节。由于相关技术中的语音信息调节是在语音合成结束后进行的,通常只能针对特定文字的发音方式进行调节,没有参考待合成文本信息整体的文本信息特点,因此难以结合文本信息中的上下文信息进行调节,使调节后的语音信息与待合成文本信息的文本特征匹配度较低,缺乏真实感,从而语音合成效果较差。
为了解决上述技术问题,本申请实施例提供了一种模型训练方法,在模型训练过程中使模型直接结合文本信息和调节参数来生成待定语音信息,然后基于待定语音信息与样本语音信息之间的差异调节模型参数,从而能够使模型学习到如何在结合调节参数合成语音信息的同时,使语音信息能够贴合文本信息对应的准确的样本语音信息,从而使训练得到的模型能够结合调节参数和文本信息准确地合成语音信息,实现语音合成和参数调节的同步进行,使参数调节可以结合文本信息的文本特征,进而提高语音信息的真实性,提高语音合成效果。
可以理解的是,该方法可以应用于处理设备上,该处理设备为能够进行模型训练的处理设备,例如可以为具有模型训练功能的终端设备或服务器。该方法可以通过终端设备或服务器独立执行,也可以应用于终端设备和服务器通信的网络场景,通过终端设备和服务器配合执行。其中,终端设备可以为计算机、手机等设备。服务器可以理解为是应用服务器,也可以为Web服务器,在实际部署时,该服务器可以为独立服务器,也可以为集群服务器。
本申请还涉及人工智能(Artificial Intelligence,AI)技术,人工智能技术是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。本申请主要涉及其中的语音处理技术、自然语音处理技术和机器学习技术。
语音技术(Speech Technology)的关键技术有自动语音识别技术(ASR)和语音合成技术(TTS)以及声纹识别技术。让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音成为未来最被看好的人机交互方式之一。
自然语言处理(Nature Language processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。
本申请对于文本信息在多个文本特征维度的提取会应用到自然语言处理技术,在模型训练、参数调节部分可以用到机器学习技术,通过语音技术可以实现整体的语音合成。
为了便于理解本申请实施例提供的技术方案,接下来,将结合一种实际应用场景,对本申请实施例提供的一种模型训练方法进行介绍。
参见图1,图1为本申请实施例提供的一种实际应用场景中模型训练方法的示意图,在该实际应用场景中,处理设备为具有模型训练功能的模型训练服务器101。
模型训练服务器101获取的样本文本信息集合中包括样本文本信息1、样本文本信息2…样本文本信息N这N个样本文本信息,每个样本文本信息都具有对应的样本语音信息和样本调节参数。将N个样本文本信息分别作为目标样本文本信息,模型训练服务器101将该目标样本文本信息和目标样本文本信息对应的目标样本调节参数输入到初始语音合成模型中,通过初始语音合成模型可以先确定该目标样本文本信息对应的语音特征信息,该语音特征信息用于标识目标样本文本信息在语音信息中的发音方式,即语音信息是根据语音特征信息中标识的发音方式生成的。
为了使初始语音合成模型能够学习到如何直接基于调节参数生成最终的语音信息,在模型训练过程中,可以通过初始语音合成模型,根据该目标样本调节参数调节语音特征信息,得到调节后的语音特征信息,然后通过初始语音合成模型,根据调节后的语音特征信息生成待定语音信息。
由于该目标样本语音信息是目标样本文本信息基于该目标样本调节参数进行调整后,所对应的准确、真实的语音信息,与目标样本文本信息的文本表达较为匹配,因此,模型训练服务器101可以根据该待定语音信息和目标样本语音信息之间的语音信息差异,调节该初始语音合成模型对应的模型参数,使初始语音合成模型输出的待定语音信息接近该目标样本语音信息,从而使初始语音合成模型能够学习到如何结合文本信息和调节参数,生成与文本信息的文本表达匹配,且贴合调节参数所标识的发音方式调节的语音信息,进而可以提高生成的语音信息的真实感,改善语音合成效果。在训练得到语音合成模型后,如图1所示,可以通过该语音合成模型,根据待合成文本信息和调节参数,直接生成该待合成文本信息对应的较为真实、准确的语音信息,无需对语音信息进行后续的调节。
接下来,将结合附图,对本申请实施例提供的一种模型训练方法进行介绍。
参见图2,图2为本申请实施例提供的一种模型训练方法的流程图,该方法包括:
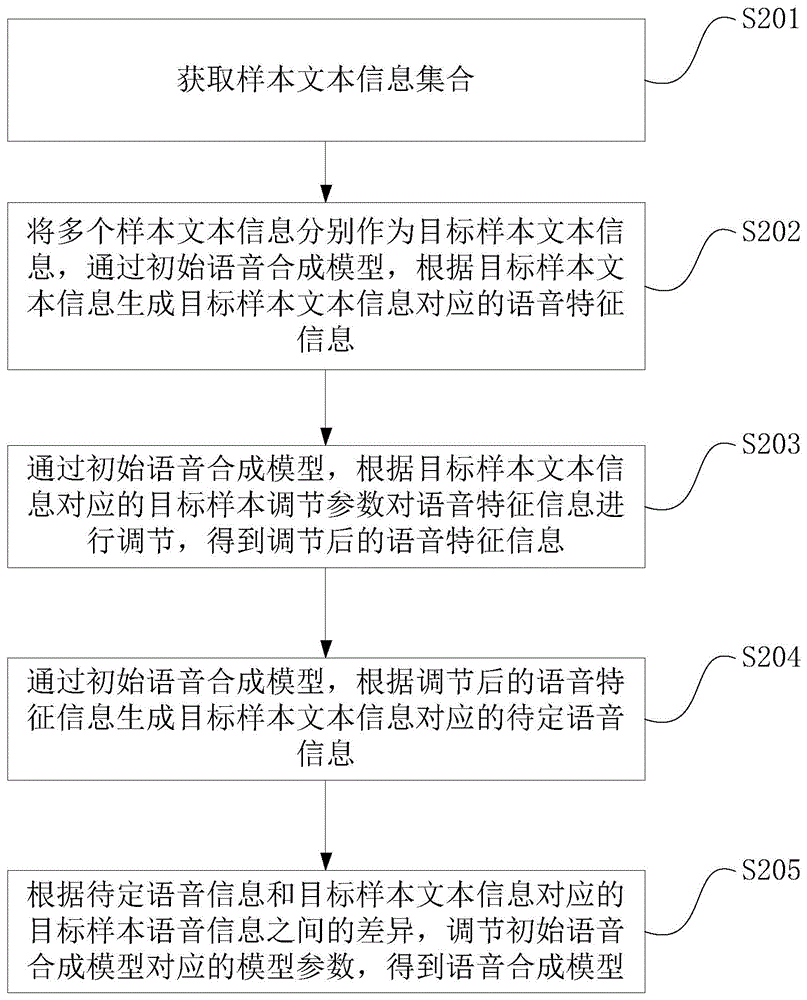
S201:获取样本文本信息集合。
首先,处理设备获取用于进行模型训练的样本文本信息集合,该样本文本信息集合包括多个样本文本信息,该样本文本信息具有对应的样本语音信息和样本调节参数,该样本语音信息是基于样本调节参数生成的。即,该样本调节参数用于标识对该样本文本信息在语音信息中的发音方式的调节方式,例如调节方向、调节力度等,该样本语音信息为满足该样本调节参数标识的调节方式的,样本文本信息所对应的真实、准确的语音信息,贴合该样本文本信息的文本表达。
S202:将多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,根据目标样本文本信息生成目标样本文本信息对应的语音特征信息。
在相关技术中,语音合成模型只基于待合成文本信息来生成语音信息,对于语音信息的调节只能在已有的语音信息的基础上进行调节。然而,语音信息只有在生成过程中才参考了待合成文本信息的文本特征和文本表达,因此相关技术中的调节方式难以贴合待合成文本信息的文本表达,导致调节后的语音信息与待合成文本信息的文本表达有较大差距,缺乏真实感。
为了解决上述技术问题,本申请中的初始语音合成模型并不是只根据样本文本信息来生成语音信息,而是基于样本文本信息和对应的样本调节参数来生成语音信息,从而将样本调节参数的调节作用体现在语音信息的生成过程中,而并不是在语音信息生成后再进行参数调节。由于语音信息的生成是基于通过样本文本信息体现出的文本特征和文本表达来生成的,因此这种语音信息调节方式可以在参数调节时贴合样本文本信息的文本表达,增强语音信息的真实感。
处理设备依次提取样本文本信息集合中的每一个样本文本信息作为目标样本文本信息,将该目标样本文本信息和目标样本文本信息对应的目标样本调节参数输入到初始语音合成模型中,即该目标样本文本信息可以为多个样本文本信息中的任意一个。首先,通过该初始语音合成模型,可以根据该目标样本文本信息生成该目标样本文本信息对应的语音特征信息,该语音特征信息用于标识目标样本文本信息在语音信息中的发音方式,例如基于该语音特征信息可以确定出目标样本文本信息中的文字在语音信息中的发音、语调、停顿、起伏等,因此基于该语音特征信息可以生成该目标样本文本信息对应的语音信息。
需要强调的是,该语音特征信息并不是模型最终输出的语音信息,语音信息是基于该语音特征信息中所标识的发音方式生成的,本申请中的语音合成模型是基于模型参数,根据该语音特征信息来生成语音信息的,这个过程即结合了文本信息所对应的文本特征和文本表达。
S203:通过初始语音合成模型,根据目标样本文本信息对应的目标样本调节参数对语音特征信息进行调节,得到调节后的语音特征信息。
上已述及,通过该语音特征信息可以标识出文本信息在语音信息中的发音方式,为了使模型学习到如何在语音信息合成的过程中通过调节参数实现对发音方式的调节,处理设备可以在生成语音信息之前,通过该初始语音合成模型,根据目标样本文本信息对应的目标样本调节参数对该语音特征信息进行调节,从而可以调节最终目标样本文本信息在语音信息中的发音方式,得到调节后的语音特征信息。
S204:通过初始语音合成模型,根据调节后的语音特征信息生成目标样本文本信息对应的待定语音信息。
通过初始语音合成模型,处理设备可以基于该调节后的语音特征信息分析目标样本文本信息在语音信息中的发音方式,从而可以根据该发音方式来生成该目标样本文本信息对应的待定语音信息,该待定语音信息为未训练完成的初始语音合成模型基于目标样本文本信息和目标样本调节参数所生成的语音信息。
可以理解的是,由于初始语音合成模型是基于调节后的语音特征信息生成的,调节后的语音特征信息是基于目标样本调节参数对语音特征信息调节得到的,因此本申请的语音合成模型中的参数调节过程是在语音信息生成的过程中进行的,模型在语音信息生成之后可以不进行参数调节。
S205:根据待定语音信息和目标样本文本信息对应的目标样本语音信息之间的差异,调节初始语音合成模型对应的模型参数,得到语音合成模型。
由于该目标样本语音信息为满足该目标样本调节参数标识的调节方式的,目标样本文本信息所对应的真实、准确的语音信息,因此通过该待定语音信息和目标样本语音信息之间的差异,一方面能够体现出待定语音信息对于目标样本文本信息的文本表达上的准确度和真实性,另一方面能够体现出初始语音合成模型在基于目标样本调节参数进行参数调节时的调节准确度。处理设备可以根据该语音信息之间的差异调节初始语音合成模型对应的模型参数,使调节后的初始语音合成模型输出的待定语音信息逐渐接近该目标样本语音信息,从而可以使初始语音合成模型学习到如何基于目标样本调节参数实现对目标样本文本信息在语音信息中发音方式的准确调节,以及能够学习到如何结合参数调节,生成与目标样本文本信息的文本特征和文本表达较为匹配的语音信息,进而使训练得到的语音合成模型具有直接结合文本信息和调节参数生成语音信息的能力,无需在语音信息生成后再进行调节,使训练得到的语音合成模型所生成的语音信息既贴合文本信息的文本表达含义,也满足调节参数所体现出的语音调节需求,提高生成的语音信息的真实性和准确度。
因此,该语音合成模型可以用于根据待合成文本信息和待合成文本信息对应的调节参数合成语音信息,待合成文本信息为任意需要进行语音合成的文本信息,该调节参数用于体现语音合成对象在进行语音信息合成时,对待合成文本信息在语音信息中的发音方式调节的需求,语音合成对象为发起语音合成的对象。
由上述技术方案可以看出,在进行模型训练时,先获取用于进行模型训练的样本文本信息集合,该样本文本信息集合包括多个样本文本信息,样本文本信息具有对应的样本语音信息和样本调节参数,其中,样本语音信息是基于该样本文本信息和样本调节参数生成的,即该样本语音信息匹配该调节参数对样本文本信息在语音信息中发音方式的调节。在语音信息合成过程中,将多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,先根据该目标样本文本信息生成目标样本文本信息对应的语音特征信息,该语音特征信息用于标识目标样本文本信息在语音信息中的发音方式。从而,通过该目标样本文本信息对应的目标样本调节参数调节该语音特征信息,可以以与该目标样本文本信息对应的目标样本语音信息相同的调节方式调节该目标样本文本信息的发音方式。通过该初始语音合成模型根据调节后的语音特征信息生成该目标样本文本信息对应的待定语音信息,从而,通过待定语音信息和目标样本语音信息之间的差异,能够体现出初始语音合成模型在基于文本信息和调节参数直接合成语音信息时的准确度,进而通过基于该差异对初始语音合成模型进行参数调节得到的语音合成模型,可以实现直接基于待合成文本信息和调节参数,较为准确的合成待合成文本信息对应的语音信息,使该语音信息既符合调节参数对于发音方式调节的需求,又贴合该待合成文本信息整体的语音发音特点,从而在保障对语音信息准确调节的前提下,提高调节后的语音信息的真实性,进而提高语音合成效果。
可以理解的是,通过文本信息所能够分析出的特征信息可以包括多种。例如,当文本信息为中文文本信息时,通过文字的拼音信息可以分析出文本信息对应的音素特征,通过文字的字词组合可以分析出该文本信息在语音信息中发音时的停顿、间隔特征等,这些维度的特征信息在一定程度上都能够影响文本信息在语音信息中的发音方式。
基于此,在一种可能的实现方式中,为了提高语音特征信息的准确度,处理设备可以结合多个维度的特征信息来确定文本信息对应的语音特征信息。在根据目标样本文本信息生成目标样本文本信息对应的语音特征信息时,处理设备可以先确定该目标样本文本信息对应的音素特征信息、语义特征信息和韵律特征信息,该音素特征信息用于标识目标样本文本信息对应的音素组成,音素是根据语音的自然属性划分出来的最小语音单位,依据音节里的发音动作来分析,一个动作构成一个音素。如汉语音节啊(ā)只有一个音素,爱(ài)有两个音素,代(dài)有三个音素等。
语义特征信息用于标识目标样本文本信息对应的语义,可以理解的是,在不同的语义下,相同的文本信息在语音信息中可能有不同的发音方式。例如,“我去”这一文本信息在表达“我去xx地方”这一动作的时候,在通俗的发音方式中,“我”字为三声,“我去”这一文本信息在表达“我去!他也太厉害了!”这一感叹时,在通俗的发音方式中“我”字为四声,同时在两种不同的表达方式中,该文本信息的发音语速也有所不同。因此,为了提高语音特征信息所标识的发音方式的准确度,处理设备可以结合目标样本文本信息的语义来确定该目标样本文本信息对应的语音特征信息,该语义特征信息例如可以通过变换器(Bidirectional Encoder Representation from Transformers,简称BERT)模型来确定。
韵律特征信息用于标识目标样本文本信息对应的发音韵律,韵律是指目标样本文本信息对应的发音韵律,例如分词、韵律短语、韵律词等信息,通过韵律信息可以使最终生成的语音信息在韵律表达上更加贴合在通过语音表达该目标样本文本信息时的真实韵律
综上所述,处理设备可以根据该音素特征信息、语义特征信息和韵律特征信息,生成所述目标样本文本信息对应的语音特征信息,从而使该语音特征信息所标识出的发音方式可以同时贴合目标样本文本信息的音素构成、文本语义和韵律特点,进而使基于该语音特征信息生成的语音信息可以具有因贴合音素构成而带来的发音准确度,因贴合文本语义和韵律特点带来的发音真实感。
如图3所示,图3为本申请实施例提供的一种模型训练方法的示意图,在初始语音合成模型中的语音特征信息确定部分包括深度学习模型编码器(Transformer encoder)、变换器编码器(BERT encoder)和嵌入层(Embedded),在将目标样本文本信息和目标样本调节参数输入到初始语音合成模型后,初始语音合成模型可以先确定该目标样本文本信息对应的音素级特征(Phoneme level features)、字符级特征(Character level features)和单词和短语级特征(Word&phrase level features),该音素级特征可以为目标样本文本信息的音素构成,该字符级特征可以为目标样本文本信息所包括的字符,单词和短语级特征可以为目标样本文本信息中包括的单词和短语,通过单词和短语可以分析出在通过语音方式表达该目标样本文本信息时的发音韵律。
通过深度学习编码器可以生成该音素级特征对应的音素特征信息,通过变换器编码器可以生成该字符集特征对应的语义特征信息,通过嵌入层可以生成该单词和短语级特征对应的韵律特征信息。将这三部分特征信息融合可以得到语音特征信息,然后基于目标样本调节参数和语音特征信息可以得到调节后的语音特征信息,基于调节后的语音特征信息生成待定语音信息。
可以理解的是,在通过语音进行交流时,若交流者的情绪不同,在通过语音方式表达信息时的发音方式也会有所不同。例如,交流者在“生气”情绪下发出的语音信息通常比在“平淡”情绪下发出的语音信息的语速更快、语调更高。基于此,为了进一步提高合成的语音信息的真实性和多样性,满足多样化的语音合成需求,在一种可能的实现方式中,处理设备还可以结合情绪信息来对初始语音合成模型进行模型训练。
首先,可以为样本文本信息添加对应的样本情绪标签,样本文本信息集合中的样本文本信息具有对应的样本情绪标签,该样本情绪标签用于标识样本文本信息对应的情绪偏向,即在通过样本语音信息表达该样本文本信息时所能够体现出的情绪。该样本情绪标签可以为人工分析得出的,也可以为通过多种自动化文本情绪分析方式得到的,例如通过情绪识别模型对样本文本信息进行识别得出的。此外,在人工录制该样本文本信息对应的样本语音信息时,样本语音信息的录制者也可以基于特定的情绪进行语音信息录制,并基于该情绪来确定样本文本信息的样本情绪标签。
该初始语音合成模型中可以包括多个情绪标签分别对应的初始情绪特征信息,该初始情绪特征信息在通过模型训练过程的参数调节后可以变为多个情绪标签分别对应的情绪特征信息,该情绪特征信息用于将语音特征信息所标识的发音方式向所对应的情绪进行调整,使基于调整后的语音特征信息在发音方式上能够体现出该情绪。例如,通过“生气”这一情绪标签所对应的情绪特征信息对语音特征信息进行调节后,可以使最终生成的语音信息的语调变高、语速变快,来体现“生气”的情绪等。
在根据目标样本文本信息生成目标样本文本信息对应的语音特征信息时,处理设备可以确定该目标样本文本信息所对应目标样本情绪标签对应的目标初始情绪特征信息,然后根据该目标初始情绪特征信息和目标样本文本信息,生成该目标样本文本信息对应的语音特征信息,从而使该语音特征信息所标识的发音方式能够体现出该目标样本情绪标签对应的情绪,如图4所示。
为了使情绪特征信息能够准确的体现出所对应情绪在发音方式上的特点,在根据待定语音信息和目标样本文本信息对应的目标样本语音信息之间的差异,调节初始语音合成模型对应的模型参数,得到语音合成模型时,处理设备可以根据该待定语音信息和目标样本文本信息对应的目标样本语音信息之间的差异,调节初始语音合成模型对应的模型参数和目标初始情绪特征信息,得到语音合成模型。由于该目标样本情绪标签所标识的情绪为该目标样本语音信息所表达出的准确的情绪,因此通过目标样本语音信息和待定语音信息之间的差异,能够体现出初始语音合成模型在根据目标初始情绪特征信息生成语音特征信息时,对语音特征信息所标识的发音方式向该目标样本情绪标签所对应的情绪方向进行调节的准确度,从而通过这种训练方式可以使训练得到的语音合成模型中具有各个情绪所对应的准确的情绪特征信息,该情绪特征信息可以用于生成能够真实体现各种情绪下的发音方式的语音特征信息,以及可以使语音合成模型学习到如何基于情绪特征信息准确的生成语音特征信息。
从而,该语音合成模型可以包括通过调节多个情绪标签分别对应的初始情绪特征信息,得到的多个情绪标签分别对应的情绪特征信息,该语音合成模型可以用于根据待合成文本信息、待合成文本信息对应的调节参数和待合成文本信息对应的情绪标签合成语音信息,使该语音信息在贴合待合成文本信息的文本表达的前提下,满足该调节参数对发音方式的调节,同时使语音信息能够体现出该情绪标签对应的情绪,丰富语音信息的真实感。
可以理解的是,在对语音特征信息进行参数调节时,语音特征信息对应的部分特征参数是直接存在于语音特征信息中的,模型可以直接通过调节参数对这部分特征参数进行调节。例如,打断参数用于控制语音信息中的停顿,这种特征参数可以直接通过在语音特征信息中增加信息间隔来实现;重音参数用于控制语音信息中的轻重音,这种特征参数可以直接通过调节语音特征信息中特定文本对应的音量大小来实现,拖音参数用于控制语音信息中是否出现拖音(即某一文本信息对应的尾音拖长),这种特征参数可以直接通过调节语音特征信息中特定文本的尾音对应的信息量来实现。
部分特征参数不是直接存在于语音特征信息中的,需要通过对语音特征信息进行整体分析来实现,例如语音信息的语调、时长和起伏特征等,因此对于这部分特征参数的调节就需要模型先具有对调节前的语音信息的特征参数具有准确分析的能力。接下来,将介绍如何针对两类不同的特征参数来训练模型参数调节的能力。
在一种可能的实现方式中,该目标样本调节参数包括第一调节参数,该第一调节参数用于调节语音特征信息中包括的第一特征参数,即该第一特征参数可以直接从语音特征信息中获取到。在通过初始语音合成模型,根据目标样本文本信息对应的目标样本调节参数对语音特征信息进行调节,得到调节后的语音特征信息时,处理设备可以通过该初始语音合成模型,根据第一调节参数对该语音特征信息中包括的第一特征参数进行调节,得到调节后的语音特征信息。
其中,第一调节参数可以包括拖音控制参数、重音控制参数和打断控制参数中的任意一种或多种的组合。拖音控制参数用于调节第一特征参数中的拖音参数,重音控制参数用于调节第一特征参数中的重音参数,打断控制参数用于调节所述第一特征参数中的打断参数,拖音参数、重音参数和打断参数的作用在上述内容中有所介绍。如图5所示,在结合多种维度的特征信息生成语音特征信息后,初始语音合成模型可以根据目标样本调节参数中的第一调节参数(包括重音控制参数、拖音控制参数和打断控制参数)来得到调节后的语音特征信息。
在一种可能的实现方式中,该目标样本调节参数包括第二调节参数,该第二调节参数用于调节根据所述语音特征信息确定出的第二特征参数,该语音特征信息中不包括所述第二特征参数,即模型无法直接基于第二调节参数对语音特征信息中的第二特征参数进行调节。因此,处理设备需要先训练模型具有准确分析语音特征信息对应的第二特征参数的能力。
在本申请实施例中,该初始语音合成模型包括参数预测部分,参数预测部分用于确定语音特征信息对应的第二特征参数。该目标样本文本信息具有对应的样本第二特征参数,该样本第二特征参数为基于目标样本文本信息所生成的语音特征信息对应的准确的第二特征参数。
处理设备可以通过该参数预测部分确定语音特征信息对应的待定第二特征参数,该待定第二特征参数即为模型所分析出的语音特征信息对应的第二特征参数。在通过初始语音合成模型,根据目标样本文本信息对应的目标样本调节参数对语音特征信息进行调节,得到调节后的语音特征信息时,由于需要保障模型具有准确的参数调节能力,因此在训练模型参数调节的准确度时,处理设备可以将参数预测和参数调节分开进行训练,以避免两者的准确度互相影响,例如避免由于预测出的第二特征参数本身不准确,导致虽然参数调节能力已经较为准确,但仍然使生成的语音信息与样本语音信息之间差异较大,导致模型训练效率低的问题。
处理设备可以先根据该样本第二特征参数和第二调节参数确定待调节第二特征参数,由于样本第二特征参数和第二调节参数都是目标样本文本信息对应的准确参数,因此该待调节第二特征参数为对应目标样本语音信息的准确特征参数。处理设备可以通过该初始语音合成模型,根据待调节第二特征参数对所述语音特征信息进行调节,得到调节后的语音特征信息,使调节后的语音特征信息满足该待调节第二特征参数。
在根据待定语音信息和目标样本文本信息对应的目标样本语音信息之间的差异,调节初始语音合成模型对应的模型参数,得到语音合成模型时,由于待定第二特征参数为模型确定出的第二特征参数,样本第二特征参数为目标样本文本信息对应的准确的第二特征参数,因此通过该待定第二特征参数与样本第二特征参数之间的差异能够体现出参数预测模型对于第二特征参数分析的准确度,从而,处理设备可以根据该待定第二特征参数与样本第二特征参数之间的差异调节参数预测部分对应的模型参数。
以及,处理设备可以根据该待定语音信息和目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型中除该参数预测部分外的模型参数,得到该语音合成模型。由于该待定语音信息是通过基于准确的待调节第二特征参数生成的,因此该差异能够有针对性的体现出模型在语音特征信息生成、参数调节和基于语音特征信息生成语音信息上的准确性,从而可以有针对性的对初始语音合成模型进行训练。
其中,第二调节参数可以包括时长控制参数、语调控制参数和起伏控制参数中的任意一种或多种的组合,时长控制参数用于调节第二特征参数中的时长参数,语调控制参数用于调节第二特征参数中的语调参数,起伏控制参数用于调节第二特征参数中的起伏参数。时长参数用于控制文本信息在语音信息中的发音时长,语调参数用于控制文本信息在语音信息中的发音语调,起伏参数用于控制文本信息在语音信息中的发音起伏。如图6所示,第二调节参数包括语调控制参数、起伏控制参数和时长控制参数,样本第二特征参数包括样本语调参数、样本起伏参数和样本时长参数,初始语音合成模型中的参数预测部分包括时长适配器(Duration adapter)、语调适配器(Pitch adapter)和起伏适配器(Rangeadapter),分别用于确定语音特征信息对应的待定时长参数、待定语调参数和待定起伏参数。基于样本第二特征参数和第二调节参数可以确定出待调节语调参数、待调节起伏参数和待调节时长参数,与上文中所述的第一调节参数一同生成调节后的语音特征信息。该第二调节参数也可以为不调节,同样可以实现对参数预测部分的训练,以及通过样本第二特征参数对语音特征信息进行调节也可以实现模型对于参数调节能力的训练。
在参数预测过程中,参数的数值越复杂、变化幅度越大,则预测的难度通常越高,基于此,在一种可能的实现方式中,为了降低模型中参数预测部分的训练难度,处理设备可以对第二特征参数进行归一化处理,以降低参数的变化幅度,从而降低参数的预测难度。
上已述及,在不同的情绪下,语音信息的发音方式会有所不同,同理,对应同一情绪的语音信息在发音方式上通常较为接近,因此在对第二特征参数进行归一化处理时,处理设备可以分析同一情绪的语音特征信息所具有的第二特征参数的共性,从而得到归一化处理的基准。
处理设备可以根据上述多种情绪标签确定方式,确定各个样本文本信息对应的情绪标签,同时,处理设备可以获取同一情绪标签对应的多个文本信息,通过对这些文本信息对应的准确的语音特征信息的分析,确定该情绪标签对应的情绪特征参数,该情绪特征参数用于作为对对应该情绪标签的文本信息对应的语音特征信息的第二特征参数进行归一化的基准。例如,该情绪特征参数可以为该情绪标签下的语音特征信息所对应的第二特征参数的均值和方差。
在该实现方式中,目标样本调节参数具有对应的情绪标签,在根据待定第二特征参数与样本第二特征参数之间的差异调节参数预测部分对应的模型参数时,处理设备可以先确定该情绪标签对应的第一情绪特征参数,然后根据该第一目标特征参数对样本第二特征参数进行归一化处理。
处理设备可以根据待定第二特征参数与归一化处理后的样本第二特征参数之间的差异,调节参数预测部分对应的模型参数,从而使该参数预测部分能够确定出语音特征信息所对应的准确的归一化处理后的第二特征参数。可以理解的是,由于归一化处理后的第二特征参数并不是最终需要调节的第二特征参数,为了对语音特征信息进行准确的参数调节,在进行参数调节之前需要对归一化处理后的第二特征参数进行逆归一化处理,以得到准确的第二特征参数。
即,语音合成模型中的参数预测部分可以用于确定语音特征信息对应的归一化处理后的第二特征参数,并根据该待合成文本信息所对应情绪标签对应的第二情绪特征参数和归一化处理后的第二特征参数,确定该语音特征信息对应的第二特征参数。
例如,由于不同情绪对应的语调(Pitch)参数通常差异较大,处理设备可以预先确定各个情绪对应的语调参数的均值和方差,例如μ
在一种可能的实现方式中,为了进一步提高语音合成的准确度,在分析待定语音信息与目标样本语音信息之间的差异时,处理设备可以结合生成对抗网络(GenerativeAdversarial Nets,GAN)模型来分析,GAN模型在信息分析上具有更高的精细度。
在根据待定语音信息和目标样本文本信息对应的目标样本语音信息之间的差异,调节初始语音合成模型对应的模型参数,得到语音合成模型时,处理设备可以根据该待定语音信息生成第一语谱图,以及根据目标样本语音信息生成第二语谱图,该第一语谱图为待定语音信息基于时序进行展开的频谱图,能够准确、细致的体现出待定语音信息在时域上的信息特点;该第二语谱图为目标样本语音信息基于时序进行展开的频谱图,能够准确、细致的体现出目标样本语音信息在时域上的信息特点。
处理设备可以通过生成对抗网络判别器(GAN discriminator),确定该第一语谱图与第二语谱图之间的相似参数,该相似参数用于标识第一语谱图与所述第二语谱图之间的差异,相似参数越大则表明第一语谱图与第二语谱图之间越相似,即待定语音信息与目标样本语音信息之间的差异越小。处理设备可以根据该相似参数调节初始语音合成模型对应的模型参数得到语音合成模型,根据该语音合成模型确定出的相似参数大于预设阈值,即满足根据语音合成模型确定出的语音信息足够接近样本语音信息。
其中,生成对抗网络判别器可以通过训练生成对抗网络模型得到,在训练过程中,处理设备可以通过生成对抗网络生成器(GAN generator)在语音信息语谱图中添加噪声干扰,让生成对抗网络判别器分析干扰后的语谱图和干扰前的语谱图之间的差异,从而让训练得到的生成对抗网络判别器具有准确识别语谱图之间差异的能力。
基于通过上述模型训练方法训练得到的语音合成模型,接下来,将详细介绍该模型的应用过程。
首先,本申请实施例提供了一种模型应用方法,参见图7,图7为本申请实施例提供的一种模型应用方法的流程图,该方法包括:
S701:获取语音合成对象输入的待合成文本信息和待合成文本信息对应的调节参数。
其中,语音合成对象是需要进行语音合成的对象,通常情况下为调节参数和待合成文本信息的提供方。该调节参数用于调节待合成文本信息在语音信息中的发音方式。该调节参数可以包括上述第一调节参数和第二调节参数,其中,由于情绪标签可以用于将语音信息中的发音方式向对应的情绪进行调节,因此情绪标签也可以视为一种调节参数。
S702:将待合成文本信息和待合成文本信息对应的调节参数输入语音合成模型,通过语音合成模型,生成待合成文本信息对应的目标语音信息。
通过上述模型训练方法得到的语音合成模型,处理设备可以直接基于该待合成文本信息和调节参数生成对应的目标语音信息,该目标语音信息为贴合待合成文本信息的文本表达,且符合该调节参数对于发音方式调节的语音信息,从而该目标语音信息具有较高的真实性和准确度。由于该语音合成模型可以在生成目标语音信息时就融入调节参数对于发音方式的调节,因此无需针对目标语音信息进行后续的调节工作,提高了语音信息的调节效率。
S703:向语音合成对象发送目标语音信息。
处理设备在目标语音信息生成完毕后,可以将该目标语音信息发送给语音合成对象,以便语音合成对象应用该目标语音信息。
在一种可能的实现方式中,在生成待合成文本信息对应的目标语音信息时,处理设备可以通过该语音合成模型,确定该待合成文本信息对应的音素特征信息、语义特征信息和韵律特征信息,该音素特征信息用于标识待合成文本信息对应的音素组成,语义特征信息用于标识待合成文本信息对应的语义,韵律特征信息用于标识待合成文本信息对应的发音韵律。
处理设备可以根据该音素特征信息、语义特征信息和韵律特征信息,结合多维度的文本特征生成该待合成文本信息对应的语音特征信息,该语音特征信息用于标识待合成文本信息在语音信息中的发音方式。然后,通过该语音合成模型,处理设备可以根据该待合成文本信息对应的调节参数调节语音特征信息,最后根据调节后的语音特征信息生成待合成文本信息对应的目标语音信息。由此可见,该模型应用方式再次强调了本申请中的语音信息是在调节参数起到发音方式调节作用后生成的。
在一种可能的实现方式中,该语音合成模型包括参数调节部分和参数预测部分,该调节参数包括第一调节参数和第二调节参数,第一调节参数用于调节语音特征信息中包括的第一特征参数,该第二调节参数用于调节根据语音特征信息确定出的第二特征参数,该语音特征信息中不包括第二特征参数。即,本申请中的语音合成模型既可以对语音特征信息中直接具有的特征参数进行调节,也可以对需要通过对语音特征信息进行分析来确定的特征参数进行调节。
在根据待合成文本信息对应的调节参数调节语音特征信息时,处理设备可以通过参数预测部分,根据该语音特征信息确定语音特征信息对应的第二特征参数,然后根据第二调节参数和第二特征参数确定待调节第二特征参数。处理设备可以通过该参数调节部分,根据第一调节参数调节该语音特征信息中包括的第一特征参数,以及根据该待调节第二特征参数调节该语音特征信息,从而得到调节后的语音特征信息,该调节后的语音特征信息同时满足第一调节参数在第一特征参数维度上的调节,以及第二调节参数在第二特征参数维度上的调节。
在一种可能的实现方式中,为了丰富对语音信息调节的方式和维度,处理设备还可以通过该语音合成模型向语音合成对象提供情绪维度的参数调节。处理设备可以向语音合成对象提供情绪标签输入功能,以便语音合成对象输入情绪标签作为调节参数之一,该情绪标签用于标识语音合成对象所期望的通过合成的语音信息所表达出的情绪。
该调节参数可以包括情绪标签,在根据语音特征信息确定语音特征信息对应的第二特征参数时,处理设备可以根据该语音特征信息,确定语音特征信息对应的归一化处理后的第二特征参数,其中,该归一化处理后的第二特征参数是对应于该情绪标签所标识情绪的特征参数,处理设备可以根据该情绪标签对应的情绪特征参数和归一化处理后的第二特征参数,确定该语音特征信息对应的第二特征参数,该情绪特征参数用于对该情绪标签下对应的归一化处理后的第二特征参数进行逆归一化处理,是基于对对应该情绪标签的多个语音特征信息在第二特征参数上的共性分析得到的,例如可以为对于该情绪标签的语音特征信息的第二特征参数的均值和方差。
在结合情绪维度的调节参数进行参数调节时,处理设备不仅可以向语音合成对象提供情绪调节的方向选择,还可以提供情绪调节的程度选择。该调节参数可以包括情绪标签和情绪程度参数,该情绪程度参数用于标识将待合成文本信息在语音信息中的发音方式向该情绪标签标识的情绪进行调节的程度。例如,当情绪标签为“愤怒”时,通过不同的情绪程度参数,可以使最终生成的语音信息体现出“略有愤怒”、“一般愤怒”、“十分愤怒”等不同程度的“愤怒”情绪,从而提高对情绪维度的调节自由度,丰富语音调节效果。
在根据音素特征信息、语义特征信息和韵律特征信息,生成待合成文本信息对应的语音特征信息时,上已述及,情绪标签对应的情绪特征信息用于将语音特征信息所标识的发音方式向所对应的情绪进行调整,因此通过调节该情绪特征信息,即可实现将发音方式向对应的情绪进行调整的程度。
处理设备可以先通过语音合成模型,确定该情绪标签对应的情绪特征信息,然后根据该情绪特征信息、情绪特征参数、音素特征信息、语义特征信息和韵律特征信息,共同生成待合成文本信息对应的语音特征信息,使该语音特征信息在充分匹配该待合成文本信息的文本表达的基础上,满足语音合成对象对于情绪调节方向和程度的需求,提供使语音合成对象更加满意的语音信息。例如,例如,将“这是一个例子”作为待合成文本信息,调节参数包括指定情绪标签为“愤怒”,情绪程度参数为0.5,把该待合成文本信息中的“例”字对应的语调提高50%。语音合成模型会分析该待合成文本信息得到拼音序列,作为音素级特征;对应的汉字作为字符级特征;韵律结果“这是/一个/例子”、韵律词边界“/”作为单词和短语级特征,得到该待合成文本信息对应的音素特征信息、语义特征信息和韵律特征信息。以及,根据情绪标签“愤怒”得到对应的情绪特征信息,该情绪特征信息例如可以为一个向量信息,将该向量信息乘以情绪程度参数0.5,作为用于生成语音特征信息的情绪特征;在通过语调适配器预测出来的“例”字的语调参数乘以150%,作为待调节语调参数来调节语音特征信息。
参见图8,图8为本申请实施例提供的一种模型应用方法的示意图,将待合成文本信息和调节参数输入到语音合成模型后,通过待合成文本信息分别对应的音素级特征、字符级特征、单词和短语级特征可以分别得到音素特征信息、语义特征信息和韵律特征信息,结合这三个维度的文本特征信息,以及情绪标签对应的情绪特征信息和情绪程度参数,可以确定出待合成文本信息对应的语音特征信息,语音合成模型的参数预测部分包括时长适配器、语调适配器和起伏适配器,分别用于确定语音特征信息对应的时长参数、语调参数和起伏参数,调节参数中的第二调节参数包括时长控制参数、语调控制参数和起伏控制参数,根据时长控制参数和调节参数可以确定出待调节时长参数,根据语调控制参数和语调参数可以确定出待调节语调参数,根据起伏控制参数和起伏参数可以确定出待调节起伏参数。结合这三个待调节第二特征参数,以及第一调节参数所包括的重音控制参数、拖音控制参数和打断控制参数,可以对语音特征信息进行调节,得到调节后的语音特征信息,最终基于调节后的语音特征信息生成待合成文本信息对应的语音信息。
为了便于语音合成对象输入用于语音合成的信息,在一种可能的实现方式中,处理设备可以向该语音合成对象展示信息输入界面,该信息输入界面用于输入待合成文本信息和调节参数。处理设备可以通过该信息输入界面获取语音合成对象输入的待合成文本信息和待合成文本信息对应的调节参数。
如图9所示,图9为本申请实施例提供的一种信息输入界面的示意图,在该信息输入界面中,语音合成对象可以选择合成语音信息的音色(包括音色A在内的多种音色选择),选择情绪标签,输入情绪程度参数、时长控制参数(以语速为时长控制参数,通过调节语速实现不同的语音信息时长)、语调控制参数(包括语调升降和语调范围)、打断控制参数(以语音信息的停顿为实际效果)和起伏控制参数(以语气强弱为实际效果)。在语音信息合成完毕后,语音合成对象可以通过该界面收听语音信息,并且看到语音信息展示,在展示中可以看到“这是一个测试”这一待合成文本信息的各个字符对应的语调参数、时长参数和韵律情况。
为了便于理解本申请实施例提供的技术方案,接下来,将结合一种实际应用场景,对本申请实施例提供的模型训练方法进行介绍。
参见图10,图10为本申请实施例提供的一种实际应用场景中模型训练方法的示意图。
该实际应用场景可以涉及多个领域,例如在游戏领域中,通过该方式训练得到的语音合成模型可以生成游戏中非玩家角色(non-player character,简称NPC)的语音信息,从而使游戏中的非玩家角色向玩家提供的语音信息更加自然、真实,带给玩家更加优质的游戏体验。同时,由于本申请中的模型支持结合多样化的参数调节和文本特征来生成语音信息,因此游戏开发者可以高效的生成多样化的优质语音信息,丰富游戏内容,提高游戏开发效率。
或者,在人机交互领域,对象在日常生活中使用的各种具有语音交互功能的设备都可以通过该语音合成模型来实时生成语音信息,用于与对象进行语音交互。其中,基于不同对象的语音交互需求,语音交互设备可以在语音合成模型中设置不同的音色、语调、语速、情绪等调节参数,以尽可能满足对象的多样化语音交互需求。
除了上述领域外,通过该模型训练方法训练得到的语音合成模型还可以应用在车载技术领域、智能教育领域等需要真实、自然且多样化语音信息的多种领域,此处不作限定。
为了提高样本信息的准确度,在生成样本文本信息和样本语音信息之前,可以先对人设进行定义,人设是指人物设定,然后根据人设进行情绪分类,并且对同一种情绪进行程度分级,匹配不同场景下的情绪表达;接下来根据人设以及情绪进行文本信息的设计,针对该人设不同情绪状态设计对应的文本信息;录制过程中,提前定义好录音的场景、人物状态等,选择符合人设的录音对象,让录音对象进入角色,再开始录音,从而得到贴合情绪的样本文本信息,以及该样本文本信息所对应的真实、准确的样本语音信息作为样本信息。
在数据预处理中,处理设备可以为样本文本信息添加对应的样本情绪标签和调节参数,基于这些信息进行模型训练,产出语音合成(Text to speech,简称TTS)模型。通过该语音合成模型和语音合成对象基于信息输入界面输入的待合成文本信息和调节参数,可以合成对应的语音信息。
模型训练的过程如图11所示,样本文本信息样本中的音素级特征、字符级特征、单词和短语级特征分别作为深度学习模型编码器、变换器编码器和嵌入层的输入,其中音素级特征会作为深度学习模型编码器输入,字符级特征作为变换器编码器的输入,单词和短语级特征,例如:分词,韵律短语,韵律词的信息作为嵌入层的输入。模型会根据样本文本信息对应的样本情绪标签选择对应的情绪特征向量(style embedding),该情绪特征向量即为情绪特征信息,再用这个向量乘以对应的情绪程度参数,比如:情绪程度参数是1.5,那就是情绪特征向量*1.5作为情绪维度的特征,从而达到对应的情绪的合成,这部分动作是在初始语音合成模型中用于进行情绪维度调节的隐层实现的,该隐层可以在模型应用过程中用于基于情绪特征信息和情绪程度参数生成语音特征信息。第二特征参数的调节也是类似的方法,在应用过程中是在预测出来的值上进行调整,在训练过程中用样本第二特征参数乘以对应的第二调节参数,达到语音合成效果控制。
初始语音合成模型可以根据第一调节参数生成对应的参数向量,该参数向量用于调节语音特征信息中的第一特征参数,例如,基于重音控制参数可以生成重音参数向量(Emphasis embedding)、基于拖音控制参数可以生成拖音参数向量(Stretch embedding)、基于打断控制参数可以生成打断参数向量(Interrupt embedding)。通过这些参数向量和待调节第二特征参数中的待调节语调参数、待调节起伏参数和待调节时长参数可以对语音特征信息进行调节,得到调节后的语音特征信息。
通过自我注意上采样(Self—Attention upsampling)可以对调节后的语音特征信息进行上采样,得到该样本文本信息所对应的待定语音信息,其中,自我注意上采样可以使语音信息中各个字符所对应的语音信息之间的连接更为自然。通过自回归解码器(Autoregressive decoder)可以得到待定语音信息对应的语谱图(Melspectrogram),初始语音合成模型可以通过生成对抗网络判别器分析该语谱图和样本语音信息对应的语谱图(Ground-truth Melspectrogram)之间的相似参数,从而确定两个语谱图是否匹配,进而分析出待定语音信息与样本语音信息之间的差异,该差异可以用于调节自回归解码器、自我注意上采样、调节语音特征信息和生成语音特征信息相关的模型参数,以及可以用于调节情绪特征向量;待定第二特征参数和样本第二特征参数之间的差异可以调节各种用于确定第二特征参数的适配器。
最终,训练得到的语音合成模型既可以输出语音信息对应的语谱图,也可以直接输出语音信息,提供多样化的结果输出方式以供语音合成对象选择。
基于上述实施例提供的一种模型训练方法,本申请实施例还提供了一种模型训练装置,参见图12,图12为本申请实施例提供的一种模型训练装置1200的结构框图,该装置1200包括获取单元1201、第一生成单元1202、第一调节单元1203、第二生成单元1204和第二调节单元1205:
所述获取单元1201,用于获取样本文本信息集合,所述样本文本信息集合包括多个样本文本信息,所述样本文本信息具有对应的样本语音信息和样本调节参数,所述样本语音信息是基于所述样本调节参数生成的;
所述第一生成单元1202,用于将所述多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,根据所述目标样本文本信息生成所述目标样本文本信息对应的语音特征信息,所述语音特征信息用于标识所述目标样本文本信息在语音信息中的发音方式;
所述第一调节单元1203,用于通过所述初始语音合成模型,根据所述目标样本文本信息对应的目标样本调节参数对所述语音特征信息进行调节,得到调节后的语音特征信息;
所述第二生成单元1204,用于通过所述初始语音合成模型,根据所述调节后的语音特征信息生成所述目标样本文本信息对应的待定语音信息;
所述第二调节单元1205,用于根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型对应的模型参数,得到语音合成模型,所述语音合成模型用于根据待合成文本信息和所述待合成文本信息对应的调节参数合成语音信息。
在一种可能的实现方式中,所述第一生成单元1202具体用于:
确定所述目标样本文本信息对应的音素特征信息、语义特征信息和韵律特征信息,所述音素特征信息用于标识所述目标样本文本信息对应的音素组成,所述语义特征信息用于标识所述目标样本文本信息对应的语义,所述韵律特征信息用于标识所述目标样本文本信息对应的发音韵律;
根据所述音素特征信息、所述语义特征信息和所述韵律特征信息,生成所述目标样本文本信息对应的语音特征信息。
在一种可能的实现方式中,所述样本文本信息具有对应的样本情绪标签,所述初始语音合成模型中包括多个情绪标签分别对应的初始情绪特征信息,所述第一生成单元1202具体用于:
确定所述目标样本文本信息所对应目标样本情绪标签对应的目标初始情绪特征信息;
根据所述目标初始情绪特征信息和所述目标样本文本信息,生成所述目标样本文本信息对应的语音特征信息;
所述第二调节单元1205具体用于:
根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型对应的模型参数和所述目标初始情绪特征信息,得到语音合成模型,所述语音合成模型包括所述多个情绪标签分别对应的情绪特征信息,所述情绪特征信息是通过调节情绪标签对应的初始情绪特征信息得到的,所述语音合成模型用于根据待合成文本信息、所述待合成文本信息对应的调节参数和所述待合成文本信息对应的情绪标签合成语音信息。
在一种可能的实现方式中,所述目标样本调节参数包括第一调节参数,所述第一调节参数用于调节所述语音特征信息中包括的第一特征参数,所述第一调节单元1203具体用于:
通过所述初始语音合成模型,根据所述第一调节参数对所述语音特征信息中包括的第一特征参数进行调节,得到调节后的语音特征信息。
在一种可能的实现方式中,所述初始语音合成模型包括参数预测部分,所述目标样本调节参数包括第二调节参数,所述第二调节参数用于调节根据所述语音特征信息确定出的第二特征参数,所述语音特征信息中不包括所述第二特征参数,所述目标样本文本信息具有对应的样本第二特征参数;
所述装置还包括确定单元:
所述确定单元,用于通过所述参数预测部分确定所述语音特征信息对应的待定第二特征参数;
所述第一调节单元1203具体用于:
根据所述样本第二特征参数和所述第二调节参数确定待调节第二特征参数;
通过所述初始语音合成模型,根据所述待调节第二特征参数对所述语音特征信息进行调节,得到调节后的语音特征信息;
所述第二调节单元1205具体用于:
根据所述待定第二特征参数与所述样本第二特征参数之间的差异调节所述参数预测部分对应的模型参数,以及根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型中除所述参数预测部分外的模型参数,得到所述语音合成模型。
在一种可能的实现方式中,所述目标样本调节参数具有对应的情绪标签,所述第二调节单元1205具体用于:
确定所述情绪标签对应的第一情绪特征参数;
根据所述第一目标特征参数对所述样本第二特征参数进行归一化处理;
根据所述待定第二特征参数与归一化处理后的所述样本第二特征参数之间的差异,调节所述参数预测部分对应的模型参数,所述语音合成模型中的参数预测部分用于确定语音特征信息对应的归一化处理后的第二特征参数,并根据所述待合成文本信息所对应情绪标签对应的第二情绪特征参数和所述归一化处理后的第二特征参数,确定所述语音特征信息对应的第二特征参数。
在一种可能的实现方式中,所述第一调节参数包括拖音控制参数、重音控制参数和打断控制参数中的任意一种或多种的组合,所述拖音控制参数用于调节所述第一特征参数中的拖音参数,所述重音控制参数用于调节所述第一特征参数中的重音参数,所述打断控制参数用于调节所述第一特征参数中的打断参数。
在一种可能的实现方式中,所述第二调节参数包括时长控制参数、语调控制参数和起伏控制参数中的任意一种或多种的组合,所述时长控制参数用于调节所述第二特征参数中的时长参数,所述语调控制参数用于调节所述第二特征参数中的语调参数,所述起伏控制参数用于调节所述第二特征参数中的起伏参数。
在一种可能的实现方式中,所述第二调节单元1205具体用于:
根据所述待定语音信息生成第一语谱图,以及根据所述目标样本语音信息生成第二语谱图;
通过生成对抗网络判别器,确定所述第一语谱图与所述第二语谱图之间的相似参数,所述相似参数用于标识所述第一语谱图与所述第二语谱图之间的差异;
根据所述相似参数调节所述初始语音合成模型对应的模型参数得到语音合成模型,根据所述语音合成模型确定出的相似参数大于预设阈值。
基于上述实施例提供的一种模型应用方法,本申请实施例还提供了一种模型应用装置,参见图13,图13为本申请实施例提供的一种模型应用装置1300的结构框图,所述装置包括获取单元1301、生成单元1302和发送单元1303:
所述获取单元1301,用于获取语音合成对象输入的待合成文本信息和所述待合成文本信息对应的调节参数,所述调节参数用于调节所述待合成文本信息在语音信息中的发音方式;
所述生成单元1302,用于将所述待合成文本信息和所述待合成文本信息对应的调节参数输入语音合成模型,通过所述语音合成模型,生成所述待合成文本信息对应的目标语音信息;
所述发送单元1303,用于向所述语音合成对象发送所述目标语音信息。
在一种可能的实现方式中,所述生成单元1302具体用于:
确定所述待合成文本信息对应的音素特征信息、语义特征信息和韵律特征信息,所述音素特征信息用于标识所述待合成文本信息对应的音素组成,所述语义特征信息用于标识所述待合成文本信息对应的语义,所述韵律特征信息用于标识所述待合成文本信息对应的发音韵律;
根据所述音素特征信息、所述语义特征信息和所述韵律特征信息,生成所述待合成文本信息对应的语音特征信息,所述语音特征信息用于标识所述待合成文本信息在语音信息中的发音方式;
根据所述待合成文本信息对应的调节参数调节所述语音特征信息;
根据调节后的所述语音特征信息生成所述待合成文本信息对应的目标语音信息。
在一种可能的实现方式中,所述语音合成模型包括参数调节部分和参数预测部分,所述调节参数包括第一调节参数和第二调节参数,所述第一调节参数用于调节所述语音特征信息中包括的第一特征参数,所述第二调节参数用于调节根据所述语音特征信息确定出的第二特征参数,所述语音特征信息中不包括所述第二特征参数;
所述生成单元1302具体用于:
通过所述参数预测部分,根据所述语音特征信息确定所述语音特征信息对应的第二特征参数;
根据所述第二调节参数和所述第二特征参数确定待调节第二特征参数;
通过所述参数调节部分,根据所述第一调节参数调节所述语音特征信息中包括的第一特征参数,以及根据所述待调节第二特征参数调节所述语音特征信息。
在一种可能的实现方式中,所述调节参数包括情绪标签,所述生成单元1302具体用于:
根据所述语音特征信息,确定所述语音特征信息对应的归一化处理后的第二特征参数;
根据所述情绪标签对应的情绪特征参数和所述归一化处理后的第二特征参数,确定所述语音特征信息对应的第二特征参数。
在一种可能的实现方式中,所述调节参数包括情绪标签和情绪程度参数,所述情绪程度参数用于标识将所述待合成文本信息在语音信息中的发音方式向所述情绪标签标识的情绪进行调节的程度,所述生成单元具体用于:
确定所述情绪标签对应的情绪特征信息;
根据所述情绪特征信息、所述情绪特征参数、所述音素特征信息、所述语义特征信息和所述韵律特征信息,生成所述待合成文本信息对应的语音特征信息。
在一种可能的实现方式中,所述装置还包括展示单元:
所述展示单元,用于向所述语音合成对象展示信息输入界面,所述信息输入界面用于输入待合成文本信息和调节参数;
所述获取单元1301具体用于:
通过所述信息输入界面获取语音合成对象输入的待合成文本信息和所述待合成文本信息对应的调节参数。
本申请实施例还提供了一种计算机设备,下面结合附图对该设备进行介绍。请参见图14所示,本申请实施例提供了一种设备,该设备还可以是终端设备,该终端设备可以为包括手机、平板电脑、个人数字助理(Personal Digital Assistant,简称PDA)、销售终端(Point of Sales,简称POS)、车载电脑等任意智能终端,以终端设备为手机为例:
图14示出的是与本申请实施例提供的终端设备相关的手机的部分结构的框图。参考图14,手机包括:射频(Radio Frequency,简称RF)电路710、存储器720、输入单元730、显示单元740、传感器750、音频电路760、无线保真(Wireless Fidelity,简称WiFi)模块770、处理器780、以及电源790等部件。本领域技术人员可以理解,图14中示出的手机结构并不构成对手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图14对手机的各个构成部件进行具体的介绍:
RF电路710可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器780处理;另外,将设计上行的数据发送给基站。通常,RF电路710包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器(Low NoiseAmplifier,简称LNA)、双工器等。此外,RF电路710还可以通过无线通信与网络和其他设备通信。上述无线通信可以使用任一通信标准或协议,包括但不限于全球移动通讯系统(Global System of Mobile communication,简称GSM)、通用分组无线服务(GeneralPacket Radio Service,简称GPRS)、码分多址(Code Division Multiple Access,简称CDMA)、宽带码分多址(Wideband Code Division Multiple Access,简称WCDMA)、长期演进(Long Term Evolution,简称LTE)、电子邮件、短消息服务(Short Messaging Service,简称SMS)等。
存储器720可用于存储软件程序以及模块,处理器780通过运行存储在存储器720的软件程序以及模块,从而执行手机的各种功能应用以及数据处理。存储器720可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器720可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
输入单元730可用于接收输入的数字或字符信息,以及产生与手机的用户设置以及功能控制有关的键信号输入。具体地,输入单元730可包括触控面板731以及其他输入设备732。触控面板731,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板731上或在触控面板731附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板731可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器780,并能接收处理器780发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板731。除了触控面板731,输入单元730还可以包括其他输入设备732。具体地,其他输入设备732可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
显示单元740可用于显示由用户输入的信息或提供给用户的信息以及手机的各种菜单。显示单元740可包括显示面板741,可选的,可以采用液晶显示器(Liquid CrystalDisplay,简称LCD)、有机发光二极管(Organic Light-Emitting Diode,简称OLED)等形式来配置显示面板741。进一步的,触控面板731可覆盖显示面板741,当触控面板731检测到在其上或附近的触摸操作后,传送给处理器780以确定触摸事件的类型,随后处理器780根据触摸事件的类型在显示面板741上提供相应的视觉输出。虽然在图14中,触控面板731与显示面板741是作为两个独立的部件来实现手机的输入和输入功能,但是在某些实施例中,可以将触控面板731与显示面板741集成而实现手机的输入和输出功能。
手机还可包括至少一种传感器750,比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示面板741的亮度,接近传感器可在手机移动到耳边时,关闭显示面板741和/或背光。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于手机还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
音频电路760、扬声器761,传声器762可提供用户与手机之间的音频接口。音频电路760可将接收到的音频数据转换后的电信号,传输到扬声器761,由扬声器761转换为声音信号输出;另一方面,传声器762将收集的声音信号转换为电信号,由音频电路760接收后转换为音频数据,再将音频数据输出处理器780处理后,经RF电路710以发送给比如另一手机,或者将音频数据输出至存储器720以便进一步处理。
WiFi属于短距离无线传输技术,手机通过WiFi模块770可以帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图14示出了WiFi模块770,但是可以理解的是,其并不属于手机的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。
处理器780是手机的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器720内的软件程序和/或模块,以及调用存储在存储器720内的数据,执行手机的各种功能和处理数据,从而对手机进行整体检测。可选的,处理器780可包括一个或多个处理单元;优选的,处理器780可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器780中。
手机还包括给各个部件供电的电源790(比如电池),优选的,电源可以通过电源管理系统与处理器780逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。
尽管未示出,手机还可以包括摄像头、蓝牙模块等,在此不再赘述。
在本实施例中,该终端设备所包括的处理器780还具有以下功能:
获取样本文本信息集合,所述样本文本信息集合包括多个样本文本信息,所述样本文本信息具有对应的样本语音信息和样本调节参数,所述样本语音信息是基于所述样本调节参数生成的;
将所述多个样本文本信息分别作为目标样本文本信息,通过初始语音合成模型,根据所述目标样本文本信息生成所述目标样本文本信息对应的语音特征信息,所述语音特征信息用于标识所述目标样本文本信息在语音信息中的发音方式;
通过所述初始语音合成模型,根据所述目标样本文本信息对应的目标样本调节参数对所述语音特征信息进行调节,得到调节后的语音特征信息;
通过所述初始语音合成模型,根据所述调节后的语音特征信息生成所述目标样本文本信息对应的待定语音信息;
根据所述待定语音信息和所述目标样本文本信息对应的目标样本语音信息之间的差异,调节所述初始语音合成模型对应的模型参数,得到语音合成模型,所述语音合成模型用于根据待合成文本信息和所述待合成文本信息对应的调节参数合成语音信息。
或具有以下功能:
获取语音合成对象输入的待合成文本信息和所述待合成文本信息对应的调节参数,所述调节参数用于调节所述待合成文本信息在语音信息中的发音方式;
将所述待合成文本信息和所述待合成文本信息对应的调节参数输入语音合成模型,通过所述语音合成模型,生成所述待合成文本信息对应的目标语音信息;
向所述语音合成对象发送所述目标语音信息。
本申请实施例还提供一种服务器,请参见图15所示,图15为本申请实施例提供的服务器800的结构图,服务器800可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(Central Processing Units,简称CPU)822(例如,一个或一个以上处理器)和存储器832,一个或一个以上存储应用程序842或数据844的存储介质830(例如一个或一个以上海量存储设备)。其中,存储器832和存储介质830可以是短暂存储或持久存储。存储在存储介质830的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器822可以设置为与存储介质830通信,在服务器800上执行存储介质830中的一系列指令操作。
服务器800还可以包括一个或一个以上电源826,一个或一个以上有线或无线网络接口850,一个或一个以上输入输出接口858,和/或,一个或一个以上操作系统841,例如Windows Server
上述实施例中由服务器所执行的步骤可以基于图15所示的服务器结构。
本申请实施例还提供一种计算机可读存储介质,用于存储计算机程序,该计算机程序用于执行前述各个实施例所述的模型训练方法或模型应用方法中的任意一种实施方式。
本申请实施例还提供了一种包括指令的计算机程序产品,当其在计算机上运行时,使得所述计算机执行上述实施例中任意一项所述的模型训练方法或模型应用方法。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质可以是下述介质中的至少一种:只读存储器(英文:read-only memory,缩写:ROM)、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备及系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的设备及系统实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上所述,仅为本申请的一种具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。