一种执法记录仪背景声音放大方法与系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明及声音处理领域,具体为一种执法记录仪背景声音放大方法与系统。
背景技术
随着信息技术的飞速发展,执法记录仪也已经成为当今社会不可或缺的组成部分。执法记录仪是一种现代化设备,它可以提供准确可靠的记录、实时监控和管理,极大地提高了执法机关的执法效率。它的出现,使得执法机关的执法更加有力,更加安全、有效。但执法记录仪在实际使用过程中,会由于执法环境的不同,严重影响执法记录仪所收集的信息的质量,而其中声音是执法记录仪收集信息的重要信息来源,而现有技术中执法记录仪所收集的声音中由于更靠近使用者,所以声音信息中执法记录仪的使用者声音大,远离执法记录仪使用者周边的声音小,但在大部分场景中周边的声音往往也很重要,因此,提出一种执法记录仪背景声音放大系统是十分必要的。
发明内容
本发明的目的在于提供一种执法记录仪背景声音放大方法与系统,能够获得无近端声音影响且放大后的远端背景声音,以及得到无远端声音影响的近端声音,以解决现有的技术缺陷和不能达到的技术要求。
为实现上述目的,本发明提供如下技术方案:一种执法记录仪背景声音放大系统,包括:
近端频域模块:用于采集执法记录仪使用者的近端声音,得到PCM数据,在对PCM数据进行重叠切片,得到采样点,再对得到的采样点进一步处理,得到近端频域分片数据,然后近端频域模块再把近端频域分片数据发送给声音分离模块;
远端频域模块:用于采集执法记录仪周边的声音,得到PCM数据,在对PCM数据进行重叠切片,得到远端频域分片数据,然后远端频域模块把远端频域分片数据分别发送给声音分离模块、近端声音增益模块和远端声音强化模块;
声音分离模块:用于接收近端频域模块中的近端频域分片数据和远端频域模块中的远端频域分片数据,将远端频域分片数据根据远端频域分片数据中背景音的频点能量值进行能量同步处理,再把近端频域分片数据与远端频域分片数据的频点能量值相减,差值为使用者声音频域分片数据,然后声音分离模块把使用者声音频域分片数做为新的近端频域分片数据发送给近端声音增益模块。
近端声音增益模块:用于接收声音分离模块中的近端频域分片数据和远端频域模块中的远端频域分片数据,再将接受的近端频域分片数据的各个频点能量值大于预设阀值作为有效频点,在跟把近端频域分片数据的有效频点的能量值进行增益适应处理,得到增益适应后的近端频域分片数据,然后近端声音增益模块处理后的近端频域分片数据发送给远端声音强化模块与声音复原模块;
远端声音强化模块:用于接受接收近端声音增益模块发来的近端频域分片数据和远端频域模块发来的远端频域分片数据,再将远端频域分片数据的各个频点的能量值减去近端频域分片数据,得到差分频域分片数据,然后再把差分频域分片数据中的有效频点的能量值增益放大处理,得到放大后差分频域分片数据,最后远端声音强化模块把差分频域分片数据作为远端频域分片数据发送给声音复原模块;
声音复原模块:用于接收近端声音增益模块发来的近端频域分片数据和远端声音强化模块发来的的远端频域分片数据,再分别对近端频域分片数据和远端频域分片数据进行处理,得到采样点时域PCM分片数据,再进一步处理,最终得到近端PCM分片数据与远端PCM分片数据。
一种执法记录仪背景声音放大方法,包括以下步骤:
1)、近端频域模块得到近端频域分片数据;
1.1、将安装有近端频域模块的麦克风方向朝向执法记录仪使用者,使近端频域模块对近端的使用者声音进行采集,得到PCM数据;
1.2、近端频域模块对PCM数据进行进行重叠切片,得到采样点;
1.3、近端频域模块再将得到的采样点进行FFT快速傅立叶变化计算,得到近端频域分片数据;
1.4、近端频域模块将得到的近端频域分片数据发送给声音分离模块;
2)、远端频域模块得到远端频域分片数据。
2.1、将安装有远端频域模块的麦克风方向指向执法记录仪使用者的正前方,使近端频域模块对使用者周边的声音进行采集,得到PCM数据;
2.2、远端频域模块对PCM数据进行进行重叠切片,得到采样点;
2.3、远端频域模块再将得到的采样点进行FFT快速傅立叶变化计算,得到远端频域分片数据;
2.4、远端频域模块将远端频域分片数据分别发给送声音分离模块、近端声音增益模块和远端声音强化模块;
3)、声音分离模块从近端频域分片数据分离使用者的声音;
3.1、声音分离模块接收近端频域模块中的近端频域分片数据和远端频域模块中的远端频域分片数据;
3.2、声音分离模块对近端频域分片数据与远端频域分片数据进行处理,区分出有使用者声音的频道点和只有周边环境声音的频道点;
3.3、声音分离模块计算出周边环境声音的频道点的比例值;
3.4、声音分离模块利用周边环境声音的频道点的比例值将远端频域分片数据的频道点的能量值等于近端频域分片数据对应频点能量值;
3.5、声音分离模块将3.4中得到的远端频域分片数据的频点能量值和把近端频域分片数据的频点能量值进一步计算,得到使用者声音频域分片数据;
3.6、声音分离模块把使用者声音频域分片数做为新的近端频域分片数据发送近端声音增益模块;
4)、近端声音增益模块调整使用者声音的合适能力值;
4.1、近端声音增益模块接收声音分离模块发送来的近端频域分片数据和远端频域模块发送来的的远端频域分片数据;
4.2、近端声音增益模块筛选出近端频域分片数据的有效频点;
4.3、近端声音增益模块根据4.2中的有效频点计算出近端系数;
4.4、近端声音增益模块再根据4.2中的有效频点所对应远端频域分片数据的频点计算出远端系数;
4.5、近端声音增益模块通过4.3中得到的近端系数和4.4中得到的远端系数和近端系数把近端频域分片数据的有效频点的能量值进行增益适应处理,得到到增益增益适应后的近端频域分片数据;
4.6、近端声音增益模块把放大后的近端频域分片数据发送给远端声音强化模块与声音复原模块;
5)、端声音强化模块分离并增强远端中的背景声音;
5.1、端声音强化模块接收近端声音增益模块发送过来的的近端频域分片数据和远端频域模块发送过来的的远端频域分片数据;
5.2、端声音强化模块把远端频域分片数据与近端频域分片数据相减,得到差分频域分片数据;
5.3、远端声音强化模块筛选出差分频域分片数据的有效频点;
5.4、远端声音强化模块根据5.3中的有效频点计算出差分系数;
5.5、远端声音强化模块同样把近端频域分片数据取有效频点,再根据得到的有效频点计算出近端系数;
5.6、远端声音强化模块通过5.4中得到的差分系数和5.5中得到的近端系数把差分频域分片数据的有效频点的能量值进行增益放大处理,得到放大后差分频域分片数据;
5.7、远端声音强化模块把放大后的差分频域分片数据作为新的远端频域分片数据发送给声音复原模块;
6)、声音复原模块得到最终的近端PCM分片数据和远端PCM分片数据;
6.1、声音复原模块接收近端声音增益模块发送来的的近端频域分片数据和远端声音强化模块发送来的远端频域分片数据;
6.2、声音复原模块对接受到的近端频域分片数据与远端频域分片数据进行IFFT快速傅立叶逆变换处理,得到各自的采样点时域PCM分片数据;
6.3、声音复原模块对6.2中得到的采样点时域PCM分片数据进一步计算处理,最终得到近端PCM分片数据与远端PCM分片数据。
优选的,所述步骤1)中,得到采样点具体方法为:
所述近端频域模块对PCM数据进行按256个采样点进行重叠切片,相邻的两个切片重叠192个采样点。
优选的,所述步骤1)中,所述近端频域模块得到近端频域分片数据的具体过程为:
所述近端频域模块对256个采样点进行256位FFT快速傅立叶变化计算,得到近端频域分片数据;
所述近端频域分片数据包含128个频点能量值数据。
优选的,所述步骤2)中远端频域模块获得采样点和远端频域分片数据的方法与步骤1)中的方法相同。
优选的,所述步骤3.2中区分区分有使用者声音的频点和只有周边环境声音的频道点的方法为:
所述声音分离模块把近端频域分片数据与远端频域分片数据按照128个频点能量值依次相减,得到的值大于预设阀值,为该频道点有使用者的声音,否则则认为该频点只有周边环境的声音。
优选的,所述步骤3)中,所述声音分离模块得到新的近端频域分片数据的方法为:
所述声音分离模块把近端频域分片数据与远端频域分片数据的频点能量值相除,得到周边环境声音的频道点的比例值;
再对周边环境的声音的频道点的比例值取中位数,作为近端频域分片数据与远端频域分片数据的调节系数;
然后把远端频域分片数据的所有频道点都乘以调节系数,得到新的远端频域分片数据的频点能量值,所述声音分离模块把近端频域分片数据的频点能量值与新得到的远端频域分片数据的频点能量值相减,差值为使用者声音频域分片数据;
将得到的使用者声音频域分片数据作为新的近端频域分片数据。
优选的,所述步骤4)中,所述增益适应的近端频域分片数据的获取方法为:
所述近端声音增益模块把近端频域分片数据的各个频点能量值大于预设阀值作为有效频点;
再把近端频域分片数据的有效频点的能量值取平均值得到近端系数;
再将有效频点对应远端频域分片数据的频点的能量值也取平均值得到远端系数;
然后将近端频域分片数据的有效频点的能量值乘以远端系数再除以近端系数,得到增益适应后的近端频域分片数据。
优选的,所述步骤5)中,所述新的远端频域分片数据获取方法为:
所述远端声音强化模块把远端频域分片数据的各个频点的能量值减去近端频域分片数据中对应频点的能量值,得到128个差分频域分片数据;
再把差分频域分片数据的各个频点能量值大于预设阀值作为有效频点;
再将差分频域分片数据的有效频点取平均值作为差分系数;
然后把近端频域分片数据取有效频点,再计算平均值得到近端系数;
所述远端声音强化模块把差分频域分片数据的有效频点的能量值乘以近端系数再除以差分系数,得到放大后差分频域分片数据;
最后将放大后得差分频域分片数据作为远端频域分片数据使用。
优选的,所述步骤6.2中,得到各自所述采样点时域PCM分片数据的具体方法为:
所述声音复原模块对接收到的近端频域分片数据与远端频域分片数据进行IFFT快速傅立叶逆变换,分别得到256个采样点时域PCM分片数据。
优选的,所述步骤6.3中,所述近端PCM分片数据与远端PCM分片数据的获得方法具体为:
所述声音复原模块把第一块PCM分片上第193~256采样点的64个PCM数值分别加上:第二块PCM分片第129~192采样点的PCM数值、第三块PCM分片第65~128采样点的PCM数值和第四块PCM分片第1~64采样点的PCM数值;
所述声音复原模块求合后的64个PCM数值分别除以4,最终得到64个采样点PCM分片数据;
所述声音复原模块按照上述方法分别对近端频域分片数据与远端频域分片数据,最终得到近端PCM分片数据与远端PCM分片数据。
与现有技术相比,本发明的有益效果是:
1、本申请设置声音分离模块,通过声音分离模块能够将近端模块采集的使用者声音分离,再经过近端增益模块对分理处的使用者声音增益,进而通过声音复原模块得到无周边声音影响的使用者声音。
2、本申请设置远端声音强化模块,将远端中的环境声音分离出来并加以放大,使远端中的周边声音更加清楚,以获得无使用者声音影响的的周边环境声音。
3、本申请天设置近端增益模块,其既能实现对近端使用者声音进行增益,还能够提前将近端使用者的声音与远端中的使用者声音进行频点能量值同步,为远端强化模块中的声音分离做准备,实现一模块多功能。
附图说明
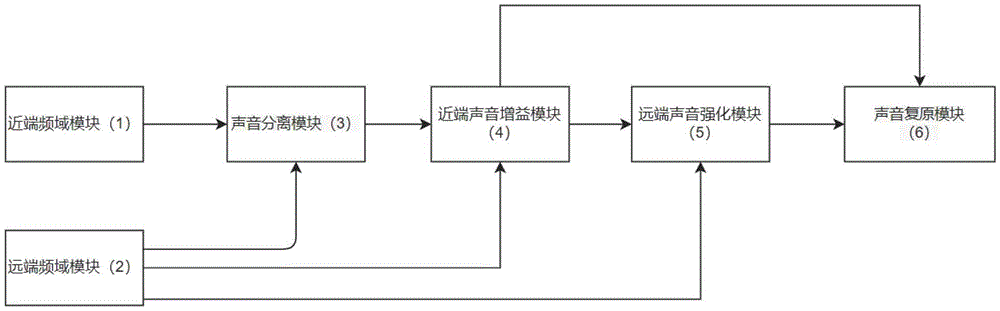
图1为本发明的整体逻辑流程图。
图中:近端频域模块1、远端频域模块2、声音分离模块3、近端声音增益模块4、远端声音强化模块5、声音复原模块6。
具体实施方式
下面将结合本发明实施例中的附图1,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明实施例
实施例1:
如图所示:一种执法记录仪背景声音放大系统,包括:
近端频域模块1:用于采集执法记录仪使用者的近端声音,得到PCM数据,在对PCM数据进行重叠切片,得到采样点,再对得到的采样点进一步处理,得到近端频域分片数据,然后近端频域模块1再把近端频域分片数据发送给声音分离模块3;
近端频域模块1所收集的近端声音包括,使用者声音和背景声音,本实施例中背景声音就是周边环境声音。
远端频域模块2:用于采集执法记录仪周边的声音,得到PCM数据,在对PCM数据进行重叠切片,得到远端频域分片数据,然后远端频域模块2把远端频域分片数据分别发送给声音分离模块3、近端声音增益模块4和远端声音强化模块5;
远端频域模块2所收集的远端声音同样包括使用者声音和背景声音,但远端模块所收集的生意声音中的能量以及两种声音的能量占比是不同与近端近端频域模块1所收集近端声音的。
声音分离模块3:用于接收近端频域模块1中的近端频域分片数据和远端频域模块2中的远端频域分片数据,将远端频域分片数据根据近端频域分片数据中背景音的频点能量值进行能量同步处理,再把近端频域分片数据与远端频域分片数据的频点能量值相减,差值为使用者声音频域分片数据,然后声音分离模块3把使用者声音频域分片数做为新的近端频域分片数据发送给近端声音增益模块4;
本申请请通过设置通过声音分离模块3,将远端中的背景声音根据近端近端声音中的背景声音能量值进行处理,使远端声音中的能量值与近端声音的能量值相同,且此时远端声音中的使用者声音根据远端声音中背景声音的同步处理,再用近端的声音能量与远端的声音能量相减,以达到消除近端声音中的背景声音的目的,以实现对近端声音中的使用者的使用者进行分离。
近端声音增益模块4:用于接收声音分离模块3中的近端频域分片数据和远端频域模块2中的远端频域分片数据,再将接受的近端频域分片数据的各个频点能量值大于预设阀值作为有效频点,在跟把近端频域分片数据的有效频点的能量值进行增益适应处理,得到增益适应后的近端频域分片数据,然后近端声音增益模块4处理后的近端频域分片数据发送给远端声音强化模块5与声音复原模块6;
本申请通过近端增益模块对声音分离模块3中处理后的仅剩使用者声音的近端声音进行增益适应处理,将仅剩使用者声音的近端声音根据远端频域模块2中的使用者声音能量进行增益处理,使仅剩使用者声音的近端声音得到放大的同时,还是的其声音能量与远端声音中的使用者声音能量相同,为将远端声音中的背景声音分离作准备,实现适应调节的目的。
远端声音强化模块5:用于接受接收近端声音增益模块4发来的近端频域分片数据和远端频域模块2发来的远端频域分片数据,再将远端频域分片数据的各个频点的能量值减去近端频域分片数据,得到差分频域分片数据,然后再把差分频域分片数据中的有效频点的能量值增益放大处理,得到放大后差分频域分片数据,最后远端声音强化模块5把差分频域分片数据作为远端频域分片数据发送给声音复原模块6;
远端声音强化模块5将远端声音能量减去已经经过增益适应处理后的近端声音能量,以得到只剩背景声音的远端声音,以达到对远端声音中背景声音的分离,再将得到的仅剩背景声音的远端声音进行放大处理。
声音复原模块6:用于接收近端声音增益模块4发来的近端频域分片数据和远端声音强化模块5发来的的远端频域分片数据,再分别对近端频域分片数据和远端频域分片数据进行处理,得到采样点时域PCM分片数据,再进一步处理,最终得到近端PCM分片数据与远端PCM分片数据。
最后通过声音复原模块6将仅剩使用者声音的近端声音以及仅剩背景声音的远端声音进行处理,得到清楚且唯一的使用者声音和背景声音,最终达到对背景声音和使用者声音清晰的分离提取的目的。
一种执法记录仪背景声音放大方法,包括以下步骤:
1)、近端频域模块1得到近端频域分片数据;
1.1、将安装有近端频域模块1的麦克风方向朝向执法记录仪使用者,使近端频域模块1对近端的使用者声音进行采集,得到PCM数据;
1.2、近端频域模块1对PCM数据进行进行重叠切片,得到采样点;
1.3、近端频域模块1再将得到的采样点进行FFT快速傅立叶变化计算,得到近端频域分片数据;
1.4、近端频域模块1将得到的近端频域分片数据发送给声音分离模块3;
2)、远端频域模块2得到远端频域分片数据。
2.1、将安装有远端频域模块2的麦克风方向指向执法记录仪使用者的正前方,使近端频域模块1对使用者周边的声音进行采集,得到PCM数据;
2.2、远端频域模块2对PCM数据进行进行重叠切片,得到采样点;
2.3、远端频域模块2再将得到的采样点进行FFT快速傅立叶变化计算,得到远端频域分片数据;
2.4、远端频域模块2将远端频域分片数据分别发给送声音分离模块3、近端声音增益模块4和远端声音强化模块5;
3)、声音分离模块3从近端频域分片数据分离使用者的声音;
3.1、声音分离模块3接收近端频域模块1中的近端频域分片数据和远端频域模块2中的远端频域分片数据;
3.2、声音分离模块3对近端频域分片数据与远端频域分片数据进行处理,区分出有使用者声音的频道点和只有周边环境声音的频道点;
3.3、声音分离模块3计算出周边环境声音的频道点的比例值;
3.4、声音分离模块3利用周边环境声音的频道点的比例值将远端频域分片数据的频道点的能量值等于近端频域分片数据对应频点能量值;
3.5、声音分离模块3将3.4中得到的远端频域分片数据的频点能量值和把近端频域分片数据的频点能量值进一步计算,得到使用者声音频域分片数据;
3.6、声音分离模块3把使用者声音频域分片数做为新的近端频域分片数据发送近端声音增益模块4;
4)、近端声音增益模块4调整使用者声音的合适能力值;
4.1、近端声音增益模块4接收声音分离模块3发送来的近端频域分片数据和远端频域模块2发送来的的远端频域分片数据;
4.2、近端声音增益模块4筛选出近端频域分片数据的有效频点;
4.3、近端声音增益模块4根据4.2中的有效频点计算出近端系数;
4.4、近端声音增益模块4再根据4.2中的有效频点所对应远端频域分片数据的频点计算出远端系数;
4.5、近端声音增益模块4通过4.3中得到的近端系数和4.4中得到的远端系数和近端系数把近端频域分片数据的有效频点的能量值进行增益适应处理,得到到增益增益适应后的近端频域分片数据;
4.6、近端声音增益模块4把放大后的近端频域分片数据发送给远端声音强化模块5与声音复原模块6;
5)、端声音强化模块分离并增强远端中的背景声音;
5.1、端声音强化模块接收近端声音增益模块4发送过来的的近端频域分片数据和远端频域模块2发送过来的的远端频域分片数据;
5.2、端声音强化模块把远端频域分片数据与近端频域分片数据相减,得到差分频域分片数据;
5.3、远端声音强化模块5筛选出差分频域分片数据的有效频点;
5.4、远端声音强化模块5根据5.3中的有效频点计算出差分系数;
5.5、远端声音强化模块5同样把近端频域分片数据取有效频点,再根据得到的有效频点计算出近端系数;
5.6、远端声音强化模块5通过5.4中得到的差分系数和5.5中得到的近端系数把差分频域分片数据的有效频点的能量值进行增益放大处理,得到放大后差分频域分片数据;
5.7、远端声音强化模块5把放大后的差分频域分片数据作为新的远端频域分片数据发送给声音复原模块6;
6)、声音复原模块6得到最终的近端PCM分片数据和远端PCM分片数据;
6.1、声音复原模块6接收近端声音增益模块4发送来的的近端频域分片数据和远端声音强化模块5发送来的远端频域分片数据;
6.2、声音复原模块6对接受到的近端频域分片数据与远端频域分片数据进行IFFT快速傅立叶逆变换处理,得到各自的采样点时域PCM分片数据;
6.3、声音复原模块6对6.2中得到的采样点时域PCM分片数据进一步计算处理,最终得到近端PCM分片数据与远端PCM分片数据。
本申请通过根据近端和远端的有效频点分别计算出近端系数和远端系数,再通过声音乘以近端系数或远端系数得到与另一种声音中的其中一类声音(使用者声音或背景音声音)相同能量值的新声音,再将得到的新声音有效频点能量值与参考目标声音的有效声音频点能量值相减,以实现对使用设声音和背景声音的分离。
所述步骤1)中,得到采样点具体方法为:
所述近端频域模块1对PCM数据进行按256个采样点进行重叠切片,相邻的两个切片重叠192个采样点。
使用重叠切片目的是让声音复原模块6避免因切片引入频谱逃逸带来杂音。
所述步骤1)中,所述近端频域模块1得到近端频域分片数据的具体过程为:
所述近端频域模块1对256个采样点进行256位FFT快速傅立叶变化计算,得到近端频域分片数据;
所述近端频域分片数据包含128个频点能量值数据。
所述步骤2)中远端频域模块2获得采样点和远端频域分片数据的方法与步骤1)中的方法相同。
所述步骤3.2中区分区分有使用者声音的频点和只有周边环境声音的频道点的方法为:
所述声音分离模块3把近端频域分片数据与远端频域分片数据按照128个频点能量值依次相减,得到的值大于预设阀值,为该频道点有使用者的声音,否则则认为该频点只有周边环境的声音。
近端频域分片数据与远端频域分片数据同时包含执法记录仪使用者的声音与执法记录仪周边的声音,其中近端频域分片数据与远端频域分片数同时包含使用者的声音与周边环境的声音,使用者的声音的能量值在近端频域分片数据要比远端频域分片数据大,周边环境的声音的能量值在近端频域分片数据与远端频域分片数据接近,但不相同;
且要说明的是,因为都设置近端频域模块1和远端频域模块2都是在执法记录仪上的,所以无论在近端声音中还是远端声音中,使用者声音的能量始终大于背景声音的能量;
所以上述频点能量值相减,是近端频域分片数据的频点能量值减去远端频域分片数据的频点能量值。
所述步骤3)中,所述声音分离模块3得到新的近端频域分片数据的方法为:
所述声音分离模块3把近端频域分片数据与远端频域分片数据的频点能量值相除,得到周边环境声音的频道点的比例值;
再对周边环境的声音的频道点的比例值取中位数,作为近端频域分片数据与远端频域分片数据的调节系数;
然后把远端频域分片数据的所有频道点都乘以调节系数,得到新的远端频域分片数据的频点能量值,所述声音分离模块3把近端频域分片数据的频点能量值与新得到的远端频域分片数据的频点能量值相减,差值为使用者声音频域分片数据;
将得到的使用者声音频域分片数据作为新的近端频域分片数据。
如此处理的目的是为了让远端频域分片数据的周边环境的声音的频道点的能量与近端频域分片数据对应频点能量值相等,即让周边环境的声音在两个分片中能量值相等,以便于方便更加准确提取使用者的声音。
所述步骤4)中,所述增益适应的近端频域分片数据的获取方法为:
所述近端声音增益模块4把近端频域分片数据的各个频点能量值大于预设阀值作为有效频点;
再把近端频域分片数据的有效频点的能量值取平均值得到近端系数;
再将有效频点对应远端频域分片数据的频点的能量值也取平均值得到远端系数;
然后将端频域分片数据的有效频点的能量值乘以远端系数再除以近端系数,得到增益适应后的近端频域分片数据。
将近端频域分片数据的有效频点的能量值乘以远端系数再除以近端系数,即可理解为先远端系数再除以近端系数计算出系数比值,再将近端频域分片数据的有效频点的能量值乘以此系数比值,因为近端声音增益模块4中的近端声音是经过声音分离模块3处理后的,是仅剩使用者声音近端近端声音,但由于此声音是通过能量相减得到的,所以剩余能量比之前能量值低,所以经过近端声音增益模块4处理,即端频域分片数据的有效频点的能量值乘以远端系数再除以近端系数,会使近端声音放大,且此过程的目的是为了近端声音中的使用者声音能量与远端声音中的使用者声音能量相同,为分离出远端声音中的背静声音做准备,以达到适应处理的目的,需要强调的是近端声音增益模块4中的阀值与声音分离模块3中的阀值不相同。
且近端声音增益模块4只对有效频点进行放大,能够使得到的声音无杂质,使使用者声音更加具有唯一性。
所述步骤5)中,所述新的远端频域分片数据获取方法为:
所述远端声音强化模块5把远端频域分片数据的各个频点的能量值减去近端频域分片数据中对应频点的能量值,得到128个差分频域分片数据;
再把差分频域分片数据的各个频点能量值大于预设阀值作为有效频点;
再将差分频域分片数据的有效频点取平均值作为差分系数;
然后把近端频域分片数据取有效频点,再计算平均值得到近端系数;
所述远端声音强化模块5把差分频域分片数据的有效频点的能量值乘以近端系数再除以差分系数,得到放大后差分频域分片数据;
最后将放大后得差分频域分片数据作为远端频域分片数据使用。
远端声音强化模块5、近端声音增益模块4和声音分离模块3中的预设阀值均不相同,此过程中通过远端频域分片数据的各个频点的能量值减去近端频域分片数据中对应频点的能量值,是为了将远端声音中的背景声音分离出来,而后续计算处理,即差分频域分片数据的有效频点的能量值乘以近端系数再除以差分系数,得到放大后差分频域分片数据,是因为将远端声音中的背景音放大;
同样远端声音强化模块5只对有效频点进行放大,能够使得到的声音无杂质,使背景声音更加具有唯一性。
所述步骤6.2中,得到各自所述采样点时域PCM分片数据的具体方法为:
所述声音复原模块6对接收到的近端频域分片数据与远端频域分片数据进行IFFT快速傅立叶逆变换,分别得到256个采样点时域PCM分片数据。
此PCM分片数据避免因切片引入频谱逃逸带来杂音。
所述步骤6.3中,所述近端PCM分片数据与远端PCM分片数据的获得方法具体为:
所述声音复原模块6把第一块PCM分片上第193~256采样点的64个PCM数值分别加上:第二块PCM分片第129~192采样点的PCM数值、第三块PCM分片第65~128采样点的PCM数值和第四块PCM分片第1~64采样点的PCM数值;
所述声音复原模块6求合后的64个PCM数值分别除以4,最终得到64个采样点PCM分片数据;
所述声音复原模块6按照上述方法分别对近端频域分片数据与远端频域分片数据,最终得到近端PCM分片数据与远端PCM分片数据。
最终得到的使用者声音和背景声音,都是分离,放大,且无杂音的,使其具有清晰性、独立性和唯一性。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也能够经适当组合,形成本领域技术人员能够理解的其他实施方式。