一种基于显式和隐式混合编码的动态场景重建方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及动态场景重建技术领域,更具体的说是涉及一种基于显式和隐式混合编码的动态场景重建方法。
背景技术
使用一组2D图像重建和渲染3D场景的问题一直是计算机视觉和图形学领域的一个挑战。这项任务在虚拟现实、互动游戏和电影制作等各种应用中具有重要意义。最近,神经辐射场(NeRF)通过使用可微分体绘制技术,使静态场景重建任务的性能取得了显著的进步。NeRF仅需要将3D位置(X,Y,Z)和2D观察方向(θ,φ)作为输入,采用单个多层感知器(MLP)来拟合静态场景,即可得到3D点的颜色和密度,使其能够从多个2D图像准确地重建3D结构,并从以前未见过的视点生成逼真的图像。然而,由于现实世界是动态的,并且在复杂场景中经常涉及运动,因此将NeRF重建静态场景的功能扩展到动态场景是亟待解决的问题。但是,由于NeRF完全依赖于MLP这种隐式表示,为了获取采样点的颜色和密度,在每轮迭代中采样点都要经过数百万次的查询,使得动态场景的重建方法更加复杂。例如,D-NeRF利用形变网络和规范网络来建模和拟合动态场景,但需要注意的是,这个过程要20多个小时才能收敛。与时间处理相关的高计算成本对这些技术在现实生活场景中的广泛应用提出了挑战。
最近的几种静态场景重建方法通过使用显式和隐式混合表示的方法,证明了比NeRF这种纯隐式MLP场景表达具有更快的速度,仅需要十几分钟就可使模型收敛,这种速度的提高是利用体素网格的三线性插值来填充体素内的3D空间来实现的。但是,这种方法大多数是为静态场景重建而设计的,现有的方法不能直接应用于动态场景重建。主要原因是直接将静态场景的3D空间(x,y,z)表示扩展到具有时间维度的4D空间(x,y,z,t)会带来巨大的存储成本,该成本随着时间帧的数量呈线性增加,造成单一场景训练参数需要几十GB来存储,这是不切实际的。为了改善这个问题,一些动态NeRF方法利用形变网络来学习点的映射关系,并将形变后的采样点输入到规范空间中。变形网络将三维点从观察空间(t≠0)映射到规范空间(t=0),有效地将动态场景重建问题转化为熟悉的静态场景。这种方法节省了大量存储空间,但是这些方法过度依赖于准确的位移估计模块,并且位移的累积误差估计会对规范网络的学习产生负面影响。另一方面,现有的体素表达通常采用单一分辨率体素网格来重建场景,然而,高分辨率体素网格不足以模拟大幅度运动,而低分辨率体素网格则无法捕获小小幅度运动中的细节。最终导致无法兼顾不同程度的运动,使得渲染结果变低。
发明内容
有鉴于此,本发明提供了一种基于显式和隐式混合编码的动态场景重建方法,以解决背景技术中的问题。
为了实现上述目的,本发明提供如下技术方案:
一种基于显式和隐式混合编码的动态场景重建方法,具体步骤包括如下:
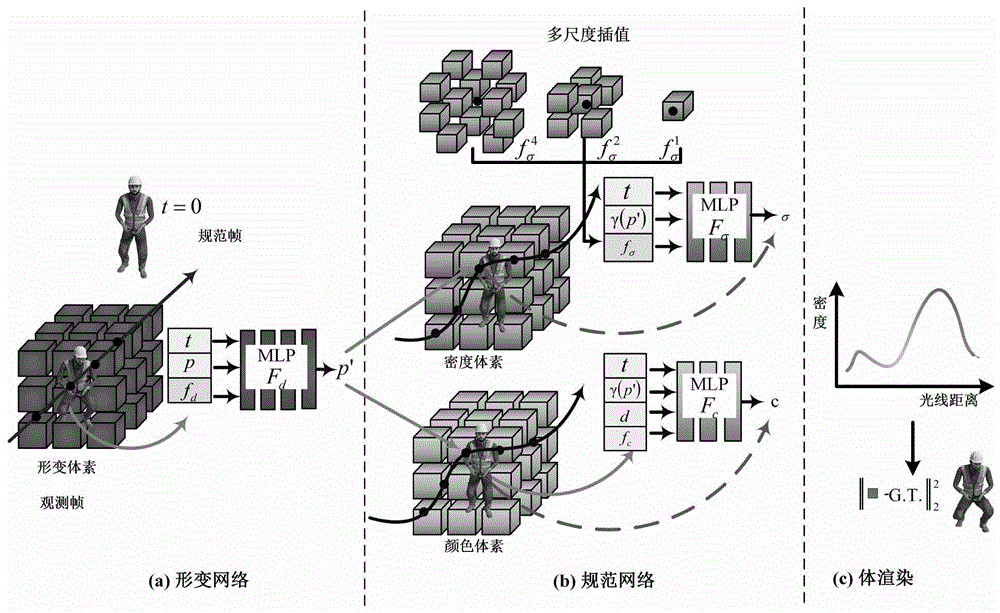
构建动态场景重建模型,包括依次连接的形变网络、规范网络和体渲染场;形变网络利用显式体素网格来存储3D动态特征,同时采用轻量级MLP来解码所述3D动态特征,输出位移估计;所述规范网络修正所述形变网络中位移估计的误差,将时间信息编码融入到密度和颜色的估计中;所述体渲染场利用规范网络预测的颜色和密度来计算像素点的颜色值;
构建批处理数据,并将批处理数据送入构建好的动态场景重建模型中进行训练,通过渲染得到的图像与真实图像的像素值做损失,利用损失函数值来优化网络参数直到收敛,得到最优动态场景重建模型;
输入待测数据到所述最优动态场景重建模型,获得渲染后的图像。
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,所述形变网络包括依次设置形变体素网格和形变多层感知器;给定体素网格分辨率
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,所述规范网络包括密度模块和颜色模块;
在所述密度模块中依次设置密度体素网格G
在所述颜色模块中依次设置颜色体素网格G
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,所述体渲染场,计算每条光线的颜色,设p(h)=o+hd是从相机光心的中心o发射到投影像素的相机射线上的一点,其中射线方向d即投影像素点到光心的单位向量,经过密度模块和颜色模块后得到一条光线上n个采样点的密度σ和颜色c,则该光线的估计颜色为
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,构建批处理数据具体步骤如下:每轮从训练集图像中随机选取N_rays个像素点,以相机光心为原点o,沿着投影像素方向d发出一条射线,获得批处理所用的N_rays条光线,同时记录每条光线所属相片的时间N_rays_t,以光线的近端near和远端far为区间,在光线上采样N_sample个采样点p(x,y,z),至此获得批处理数据为(N_rays,N_sample,p)和(N_rays,N_sample,N_rays_t)。
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,将批处理数据送入构建好的动态场景重建模型中进行训练具体步骤如下:
查询采样点p位于形变体素网格中的位置,根据所处体素的顶点进行三线性插值,得到p点的N
查询采样点p'位于颜色体素网格中的位置,变形网络通过迭代过程学习t时刻点的位移,逐渐向正确的结果收敛,在规范网络的密度和颜色估计网络中加入了对时间信息编码γ(N_ray_t),获得采样点的颜色c;
查询采样点p'位于密度体素网格中的位置,采用多尺度三线性插值来获得密度特征向量f
获得一条光线上N_sample个采样点的颜色c
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,还包括:分段式训练方法;过滤掉对目标计算目标像素颜色没有贡献的采样点,具体步骤如下:粗阶段训练和细阶段训练;
粗阶段训练,采用第一网络参数,并且在估计颜色和密度时,由体素网格直接插值得到,快速恢复场景的粗略几何形状;
粗阶段结束后通过查询当前所有网格顶点的密度信息,在掩码推理时,光线权重U(h,t)σ(p′(h,t))小于α
优选的,在上述的一种基于显式和隐式混合编码的动态场景重建方法中,还包括测试步骤:
给定测试图像序列,相机位姿为,帧的时间序列构成测试集,图像分辨率为H×W,其中N为正整数,表示测试集中一个场景所包含的RGB图像数量;
将测试集图像序列、相机位姿和时间序列送入训练好的模型中,依次从每个相机位姿逐像素点的发出光线进行采样,采样点依次获得对应颜色和密度,最终利用体渲染模块获得渲染后的图像,图像序列作为真实值来评估测试结果。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于显式和隐式混合编码的动态场景重建方法,并通过多尺度插值和时间感知来高质量重建动态场景。动态场景重建模型为三个模块,分别是形变网络、规范网络和体渲染场,用以避免学习高维映射的复杂关系并降低存储成本。在形变网络中,采用可优化的显式体素网格来存储3D动态特征,同时采用轻量级MLP来解码这些形变特征,通过此设置大大的减少了MLP这种全局性的重建负担,将重建任务分配给每一个小体素,从而显著的加速了训练过程以及收敛速度。在规范网络中,为了纠正形变网络中位移估计的误差,将时间信息编码融入到密度和颜色的估计中,增强规范网络的鲁棒性和对运动的感知力。此外,在密度场中放弃了简单的三线性插值,而是设计了多尺度插值,从多种距离的体素中获取特征信息,这种方法可以在捕获较大幅度的运动时,很好的兼顾小幅度运动中的复杂细节。体渲染场则利用规范网络预测的颜色和密度来计算像素点的颜色值,用于与真值做损失来优化网络。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明的框架图。
图2为本发明的多尺度插值的示意图;
图3为本发明的不同场景下的测试结果;
图4为本发明的在细节处效果示意图;
图5为本发明在HyperNeRF真实场景数据集上的结果。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出的一种基于显式和隐式混合编码的动态场景重建方法,其总体实现框图如图1所示,其包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:数据的加载,给定单目相机捕获的动态场景的图像序列
步骤1_2:构建动态场景重建模型,其中包括形变网络,规范网络,体渲染场。
对于形变网络,依次设置形变体素网格G
对于规范网络,其中包含密度模块和颜色模块。在密度模块中依次设置密度体素网格G
在颜色模块中依次设置颜色体素网格G
对于体渲染场,负责计算每条光线的颜色,设p(h)=o+hd是从相机光心的中心o发射到投影像素的相机射线上的一点,其中射线方向d即投影像素点到光心的单位向量,经过密度模块和颜色模块后我们可以得到一条光线上n个采样点的密度σ和颜色c,则该光线的估计颜色为
步骤1_3:构建批处理数据,每轮我们从训练集图像中随机选取N_rays个像素点,以相机光心为原点o,沿着投影像素方向d发出一条射线,获得批处理所用的N_rays条光线,同时记录每条光线所属相片的时间N_rays_t,以光线的近端near和远端far为区间,在光线上采样N_sample个采样点p(x,y,z),至此我们获得批处理数据为(N_rays,N_sample,p)和(N_rays,N_sample,N_rays_t)。
步骤1_4:将批处理数据送入构建好的动态场景重建模型中进行训练。为了缓解动态场景显式重建消耗内存大的问题,首先设定t=0时刻为规范空间,则t≠0时刻为观察空间,利用形变网络来查询t≠0时刻的点p移动到t=0时刻该点对应的位置p'所需要位移的距离Δp(Δx,Δy,Δz)。
具体来说,查询采样点p位于形变体素网格中的位置,根据所处体素的8个顶点进行三线性插值,得到p点的N
关于p'点的颜色和密度,为了获得更好的渲染结果将其分开重建。对于颜色c,首先查询采样点p'位于颜色体素网格中的位置,找到所处体素的8个顶点,进行三线性插值得到p'点的N
对于密度σ,首先查询采样点p'位于密度体素网格中的位置。然而,这里并没有像之前一样采用简单的三线性插值来获得密度特征向量f
至此获得了一条光线上N_sample个采样点的颜色c
步骤1_5:重复执行步骤1_3和步骤1_4共20k次,得到训练后的动态场景重建模型。为了加快训练过程,采用了一种分段式训练方法来过滤掉对目标计算目标像素颜色没有贡献的采样点,避免构建没有明确考虑目标对象的区域,这些区域对学习过程没有贡献,可以安全地排除在外。因此,通过两阶段训练的方法来解决这个问题:粗训练和细训练。首先进行粗阶段训练,我们采用较低的网格分辨率迭代5k次,形变网格G
除了重建损失外,我们还会获得总编差正则化L
所述的测试阶段过程的具体步骤为:
步骤2_1:给定测试图像序列
步骤2_2:将测试集图像序列、相机位姿和时间序列送入训练好的模型中,依次从每个相机位姿逐像素点的发出光线进行采样,采样点依次经过步骤1_4获得对应颜色和密度,最终利用体渲染模块获得渲染后的图像,图像序列作为真实值来评估测试结果。
为了进一步验证本发明方法的可行性和有效性,进行实验。
使用基于pytorch的深度学习库搭建动态场景重建模型。采用NeRF的blender类型数据集,使用其中的测试集来分析本发明方法合成的新视角图像质量如何。这里,利用评估图像质量的3个常用客观参量作为评价指标,即峰值信噪比(Peak Signal to NoiseRatio,PSNR)、结构相似性指数(structural similarity index,SSIM)、学习感知图像块相似度(Learned Perceptual Image Patch Similarity,LPIPS)来评价生成新视角图像的质量。
利用本发明方法对NeRF数据集中的测试集图像进行合成,得到每幅生成图像与真实图像的评估结果,反映本发明方法的生成质量峰值信噪比PSNR、结构相似性指数SSIM、学习感知图像块相似度LPIPS如表1所列。从表1所列的数据可知,按本发明方法得到的新视角图像结果是较好的,并且耗时短,速度快。表明利用本发明方法重建三维场景来合成新视角图像是可行性且有效的。
表1利用本发明方法在测试集上的评测结果
如图4所示,(a)(b)是真实值,(f)是本发明的结果示意图,其余的为其他先进方法的结果;(c)D-NeRF:Neural Radiance Fields for Dynamic Scenes;(d)NDVG NeuralDeformable Voxel Grid for Fast Optimization ofDynamic View Synthesis(e)Hexplane HexPlane:A Fast Representation for Dynamic Scenes。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 基于隐式光流场的动态场景实时三维重建方法与装置
- 基于隐式场的十亿像素场景人群三维重建方法和装置