一种基于时序情感信息建模的语音情感识别方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及语音信号处理技术领域,尤其是一种基于时序情感信息建模的语音情感识别方法及系统。
背景技术
语音情感识别的目的是使计算机能够通过人类的声音判别人类的情感状态(如快乐、惊讶、悲伤等),已成为情感计算、人机交互等领域的研究热点。国内外许多研究机构均致力于语音情感识别研究,并开始尝试应用于教育、医疗等领域。
目前语音情感识别技术的难点在于语音中包含环境噪声以及静默片段等干扰因素,导致语音信号中的情感特征分布在不同人、不同语种下差异显著,严重影响了语音情感识别方法的可推广性与泛化性。语音信号作为时序信号,其时序中具有蕴含丰富的情感信息,如何挖掘语音的时序情感信息用于情感特征的提取和情感的表征是实现鲁棒语音情感识别的关键。
发明内容
本发明所要解决的技术问题在于,提供一种基于时序情感信息建模的语音情感识别方法及系统,泛化性好、识别率更高。
为解决上述技术问题,本发明提供一种基于时序情感信息建模的语音情感识别方法,包括如下步骤:
步骤1、获取语音样本,对其进行短时离散傅里叶变换后取对数获得对数短时离散傅里叶变换谱特征x,作为网络的输入;
步骤2、将语音样本的对数短时离散傅里叶变换谱特征x输入卷积模块中进行特征降维并得到加权的语音时序情感特征x′;
步骤3、将加权时序语音情感特征输入长短期记忆网络中,对其长程依赖关系进行建模,进一步提取语音时序中的情感特征x″;
步骤4、利用Transformer编码器对语音时序中的情感特征x″进行注意力增强,提高特征的情感判别性;
步骤5、将经过注意力增强后的特征x″′经过情感分类器进行分类;
步骤6、对卷积模块、长短期记忆网络、Transformer编码器和情感分类器进行联合训练,将用于模型训练的语音对数短时离散傅里叶变换谱特征作为网络输入,通过前向传播与反向传播来更新网络参数,不断减小模型的交叉熵损失,并利用Adam优化器来优化模型,得到最优模型参数;
步骤7、将待识别的情感语音样本输入训练好的卷积模块、长短期记忆网络、Transformer编码器和情感分类器,识别出语音样本的情绪类别。
优选的,步骤1中,获取语音样本,对其进行短时离散傅里叶变换后取对数获得对数短时离散傅里叶变换谱特征x,作为网络的输入,具体包括如下步骤:
步骤11、对归一化处理后的语音样本进行预加重、分帧、加窗预处理操作;
步骤12、对预处理后的语音信号进行短时离散傅里叶变换并取对数得到短时离散傅里叶变换谱作为网络的输入。
优选的,步骤2中,将语音样本的对数短时离散傅里叶变换谱特征x输入卷积模块中进行特征降维并得到加权的语音时序情感特征x′,具体包括如下步骤:
步骤21、将对数短时离散傅里叶变换谱特征x输入到2D卷积层中进行时序编码和降维;
步骤22、将编码后的时序特征通过2D批归一化层与激活函数层用于加快模型训练速度并提高模型的非线性表达能力;
步骤23、卷积模块包括2D卷积层、2D正则化层、激活函数层、2D卷积层、2D正则层、2激活函数层,最终的输出是特征x′。
优选的,步骤5中,情感分类器包括池化层和全连接层,采用平均池化,全连接层的隐节点维度为512、情感类别数c。
相应的,一种基于时序情感信息建模的语音情感识别系统,包括:
特征提取模块,用于提取语音样本的对数短时离散傅里叶变换谱特征;
卷积模块,用于时序编码与特征降维;
长短期记忆网络模块,用于对语音信号的长程依赖关系进行建模;
Transformer编码器模块,用于对语音特征进行时序注意力增强;
情感分类器模块,用于对语音特征进行情感判别分类;
时序情感信息建模网络训练模块,用于建立由卷积网络、长短期记忆网络、Transformer编码器网络、情感分类网络合并而成的联合学习网络,对时序情感信息建模网络进行训练;
语音情感识别模块,用于将待识别的语音信号输入到训练好的时序情感信息建模网络,得到语音样本的情感类别。
优选的,特征提取模块具体包括:预加重单元,用于对语音信号进行预加重;分帧加窗单元,用于将语音信号进行分帧、加窗操作;频谱提取单元,用于对分帧加窗后的语音信号进行短时离散傅里叶变换并取对数提取对数频谱,得到对数短时离散傅里叶变换谱特征。
优选的,卷积模块具体包括:2D卷积神经网络,用于对语音的频谱特征进行降维并时域编码;2D批归一化,用于加快模型训练速度;激活函数,用于提高模型的非线性表达能力。
优选的,长短期记忆网络模块具体包括:2个级联的双向长短期记忆网络,用于对语音这一时序信号的长度依赖关系进行建模。
优选的,Transformer编码器模块具体包括:标准的Transformer编码器,用于对语音的时序上进行注意力增强,减小情感无关语段对情感识别的影响。
优选的,情感分类器模块具体包括:池化单元,用于对所述语音样本的高层特征进行情感特征空间映射;全连接层,用于对所述语音样本的情感特征进行分类预测。
本发明的有益效果为:本发明首先通过特征提取模块获取语音信号的对数短时离散傅里叶变换谱特征,鲁棒性更好,然后通过卷积模块进行时序编码并特征降维,循环神经网络模块进行长程依赖关系建模,Transformer编码器模块进行注意力增强,获取与异常噪声(如背景噪声、说话人身份、语种等)无关但与情感有关的泛化性的特征,最后利用情感分类器模块判别出语音样本的情绪类别,本发明能够有效减少情感无关帧对语音情感识别的干扰,提取情感识别精度,泛化性好、识别率更高。
附图说明
图1为本发明的方法流程示意图。
图2为本发明与其他方法在IEMOCAP和EMO-DB数据集下的实验结果对比示意图。
图3为本发明在IEMOCAP数据集下的归一化混淆矩阵。
图4为本发明在EMO-DB数据集下的归一化混淆矩阵。
具体实施方式
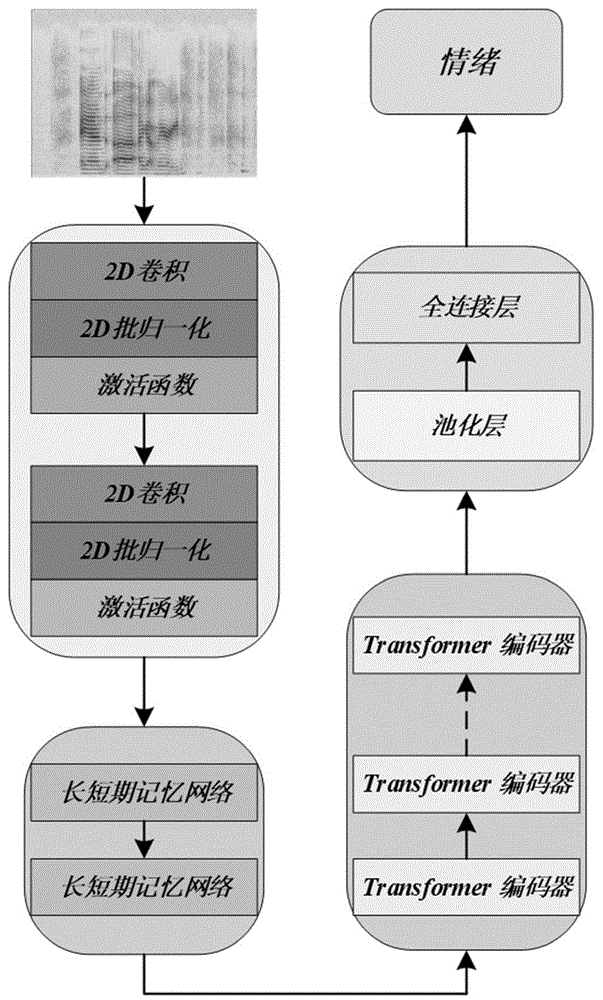
如图1所示,一种基于时序情感信息建模的语音情感识别方法,包括如下步骤:
步骤1、对语音信号进行短时离散傅里叶变换并取对数获得对数频谱特征,作为网络的输入。
该步骤具体包括:(1-1)对归一化处理后的语音信号进行预加重、分帧、加窗等预处理操作;(1-2)对预处理后的语音信号进行短时离散傅里叶变换并取对数得到短时离散傅里叶变换谱作为网络的输入。
本实施例中,预加重系数为0.97,分帧、加窗、短时离散傅里叶变换均采用Librosa开源语音信号处理库,该处理库采用Hanning窗,窗长25ms,帧间重叠率50%,fft点数512。
步骤2、将语音样本的对数短时离散傅里叶变换谱输入卷积模块中进行特征降维并得到加权的时序情感特征。
该步骤具体包括:(2-1)将对数短时离散傅里叶变换谱输入到2D卷积层中进行时序编码和降维;(2-2)将编码后的时序特征通过2D批归一化层(Batch Normalization)与激活函数层(ReLU)用于加快模型训练速度并提高模型的非线性表达能力;(2-3)卷积模块包括2D卷积层,2D正则化层,激活函数层,2D卷积层,2D正则层,2激活函数层,最终的输出是特征x′。
本实施例中卷积核大小依次为[41,1],[21,1],卷积步长均为[2,1],卷积的零填充的尺寸分别为[20,0]、[10,0],卷积的输出通道数均为64。
步骤3、将加权时序语音情感特征输入长短期记忆网络中,对其长程依赖关系进行建模,进一步提取语音时序中的情感特征。
该步骤具体包括:(3-1)将卷积模块的输出特征x′输入到双向长短期记忆网络中进行时序的长程依赖关系建模,得到特征x″(3-2)该模块有2个级联的双向长短期记忆网络构成。
本实施例中双向LSTM,隐节点数为128。
步骤4、利用Transformer编码器对语音的时序特征进行注意力增强,提高特征的情感判别性。
该步骤具体包括:(4-1)将特征x″输入到Transformer编码器中进行注意力加权,得到特征x″′;(4-2)该模块由N个级联的标准Transformer编码器构成,注意力的头数为M。
本实施例中Transformer编码器的输入特征维度为256,前馈神经网络的节点数为512,对于IEMOCAP数据集,Transformer编码器个数为1,注意力头数为8;对于EMO-DB数据集,Transformer编码器个数为2,注意力头数为8。
步骤5、将经过注意力增强后的特征x″′经过情感分类器进行分类。
该步骤具体包括:(5-1)对情感特征x″′经过情感分类器进行情感分类;(5-2)情感分类器由池化层和全连接层构成,采用平均池化,全连接层的隐节点维度为512、情感类别数c。
本实施例中,根据具体数据库的不同情感类别c的设置为:IEMOCAP的情感类别c为4,EMO-DB的情感类别c为7。
步骤6、对卷积模块、长短期记忆网络、Transformer编码器和情感分类器进行联合训练,得到最优模型参数。
本实施例中,卷积模块、长短期记忆网络、Transformer编码器和情感分类器均采用随机梯度下降方法。
步骤7、将待识别的情感语音样本输入训练好的卷积模块、长短期记忆网络、Transformer编码器和情感分类器,识别出语音样本的情绪类别。
其中,在训练好神经网络后进行测试,测试结果如下:
为验证本发明的时序情感信息建模网络的有效性与必要性,在IEMOCAP和EMO-DB数据集上进行了实验,选取准确率(Accuracy)作为评价指标,结果如图2所示,可以观察到本发明的时序情感信息建模网络在两个数据集上均取得了最好的效果。为避免由于数据集中各类情绪样本不平衡导致的识别率无法完全客观地评价模型的问题,我们对于时序情感信息建模网络在两个数据集上的结果计算了归一化混淆矩阵,如图3和图4所示。
本实施例还提供了一种基于时序情感信息建模的语音情感识别系统,包括:
特征提取模块,用于提取语音样本的对数短时离散傅里叶变换谱特征;
卷积模块,用于时序编码与特征降维;
长短期记忆网络模块,用于对语音信号的长程依赖关系进行建模;
Transformer编码器模块,用于对语音特征进行时序注意力增强;
情感分类器模块,用于对语音特征进行情感判别分类;
时序情感信息建模网络训练模块,用于建立由卷积网络、长短期记忆网络、Transformer编码器网络、情感分类网络合并而成的联合学习网络,对时序情感信息建模网络进行训练;
语音情感识别模块,用于将待识别的语音信号输入到训练好的时序情感信息建模网络,得到语音样本的情感类别。
其中,特征提取模块具体包括:
预加重单元,用于对语音信号进行预加重;
分帧加窗单元,用于将语音信号进行分帧、加窗操作;
频谱提取单元,用于对分帧加窗后的语音信号进行短时离散傅里叶变换并取对数提取对数频谱,得到对数短时离散傅里叶变换谱特征。
其中,卷积模块具体包括:
2D卷积神经网络,用于对语音的频谱特征进行降维并时域编码;
2D批归一化,用于加快模型训练速度;激活函数,用于提高模型的非线性表达能力。
其中,长短期记忆网络模块具体包括:
2个级联的双向LSTM,用与对语音这一时序信号的长度依赖关系进行建模。
其中,Transformer编码器模块具体包括:
标准的Transformer编码器,用于对语音的时序上进行注意力增强,减小情感无关语段对情感识别的影响。
其中,情感分类器模块具体包括:
池化单元,用于对所述语音样本的高层特征进行情感特征空间映射;
全连接层,用于对所述语音样本的情感特征进行分类预测。
- 一种基于增强式残差神经网络的多模态语音情感识别方法
- 一种基于多尺度时序建模的维度情感识别方法
- 一种基于多尺度时序建模的维度情感识别方法